


大家好,我是二哥呀。
同样的工具,在每个人手里呈现出来的结果是完全不同的,就比如说 Codex,营销号说他就是神,但就我个人的感受来说,不至于。
但确实已经是最强的 Agent 工具了,日常编码、生图,都能用他来搞定。
有一点必须强调,人,也就是你,目前仍然要占主导地位。
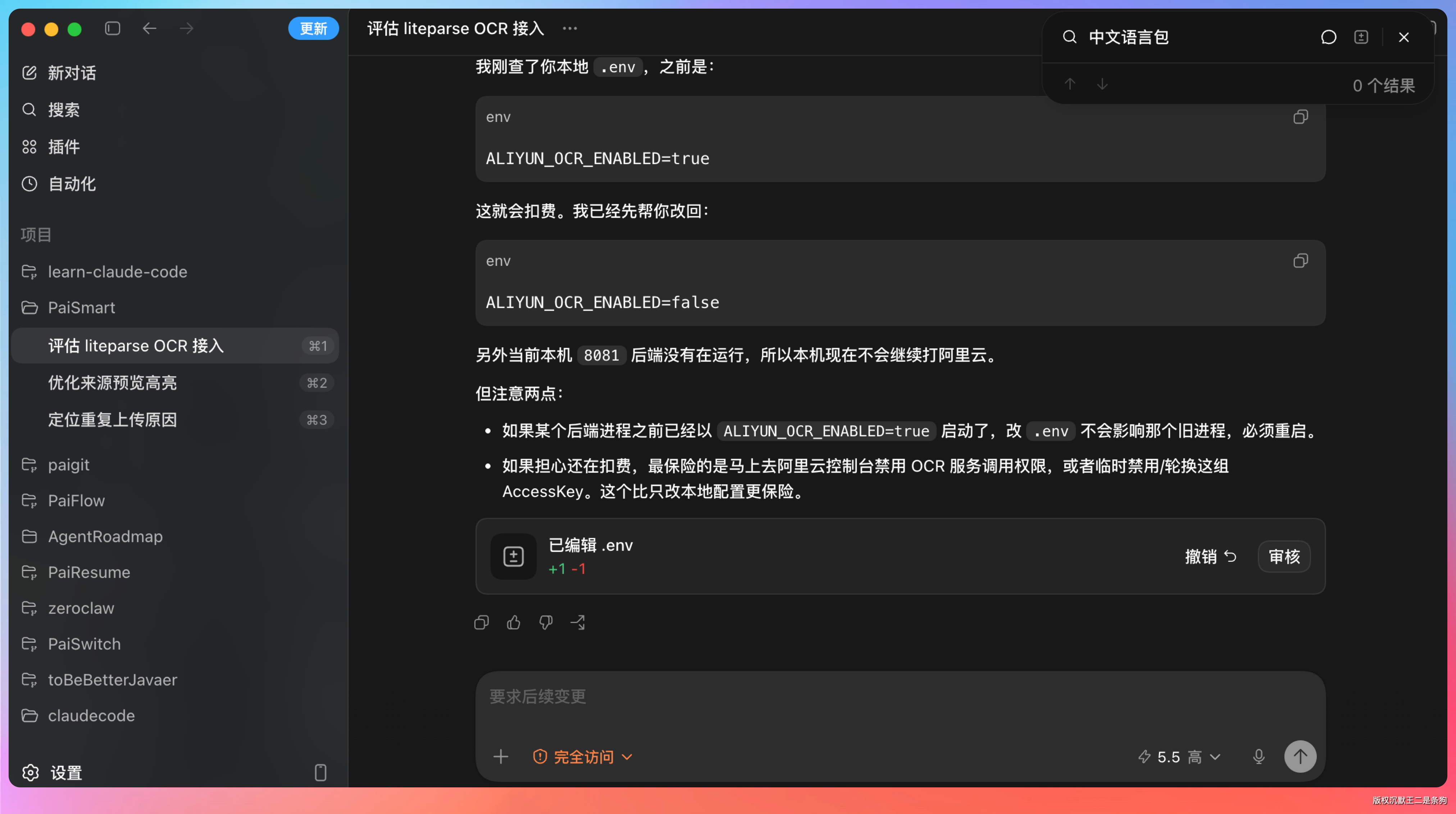
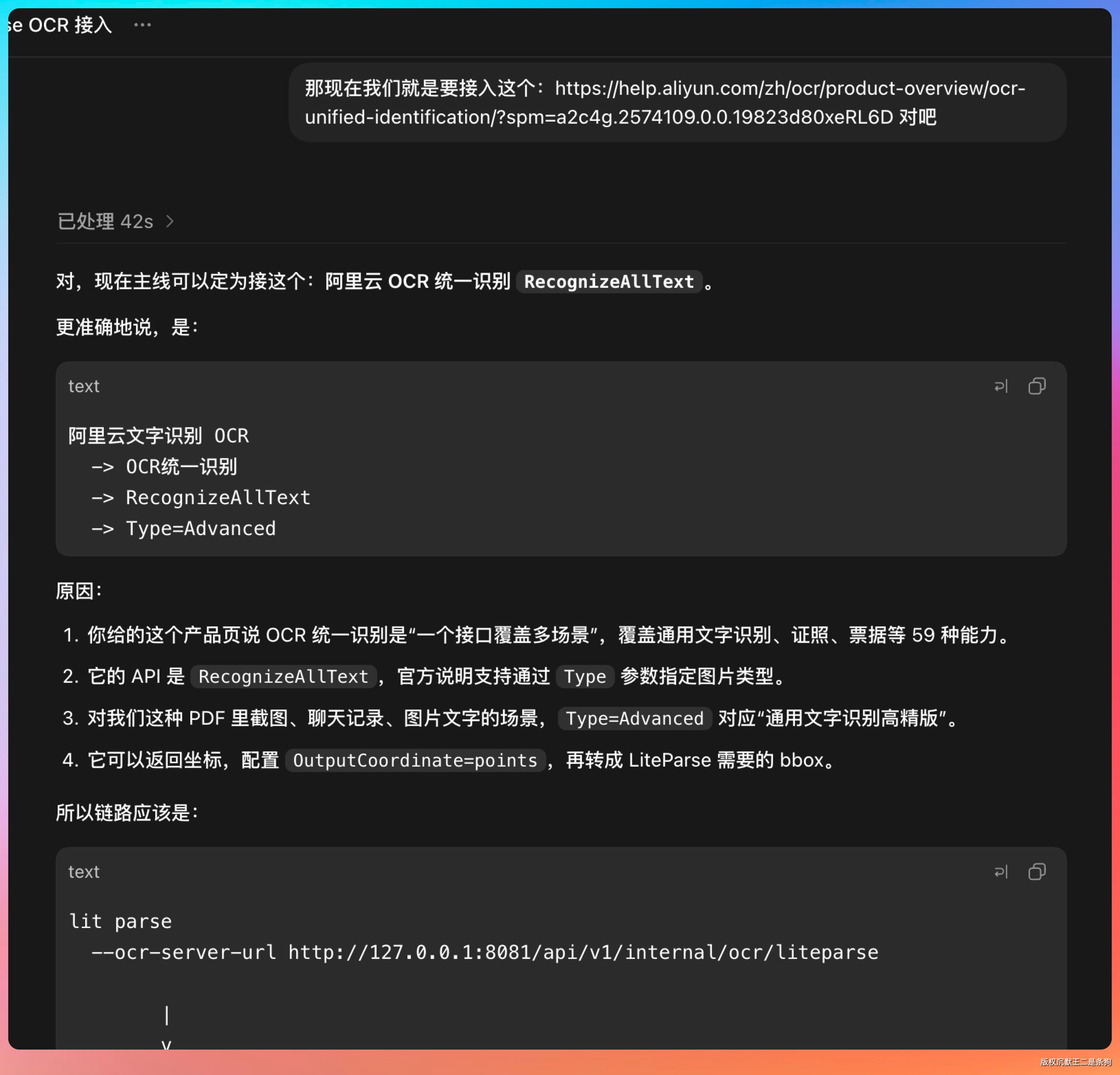
我昨天用 Codex 接了阿里云 OCR 到派聪明项目中,结果一天扣了我 700 多块钱。
更恶心的是阿里云 OCR 启用后就没办法关闭,除非程序上做限制。幸好,我之前在 .env 中加了 ALIYUN_OCR_ENABLED=false/true 这么一个全局限制,不然麻烦的要死。
换句话说,我们在使用 AI 编程的过程中,一定要和 AI 形成默契,否则后果也会很严重。
接下来,我就把自己使用 Codex 的经验分享出来,系好安全带,我们粗粗发。
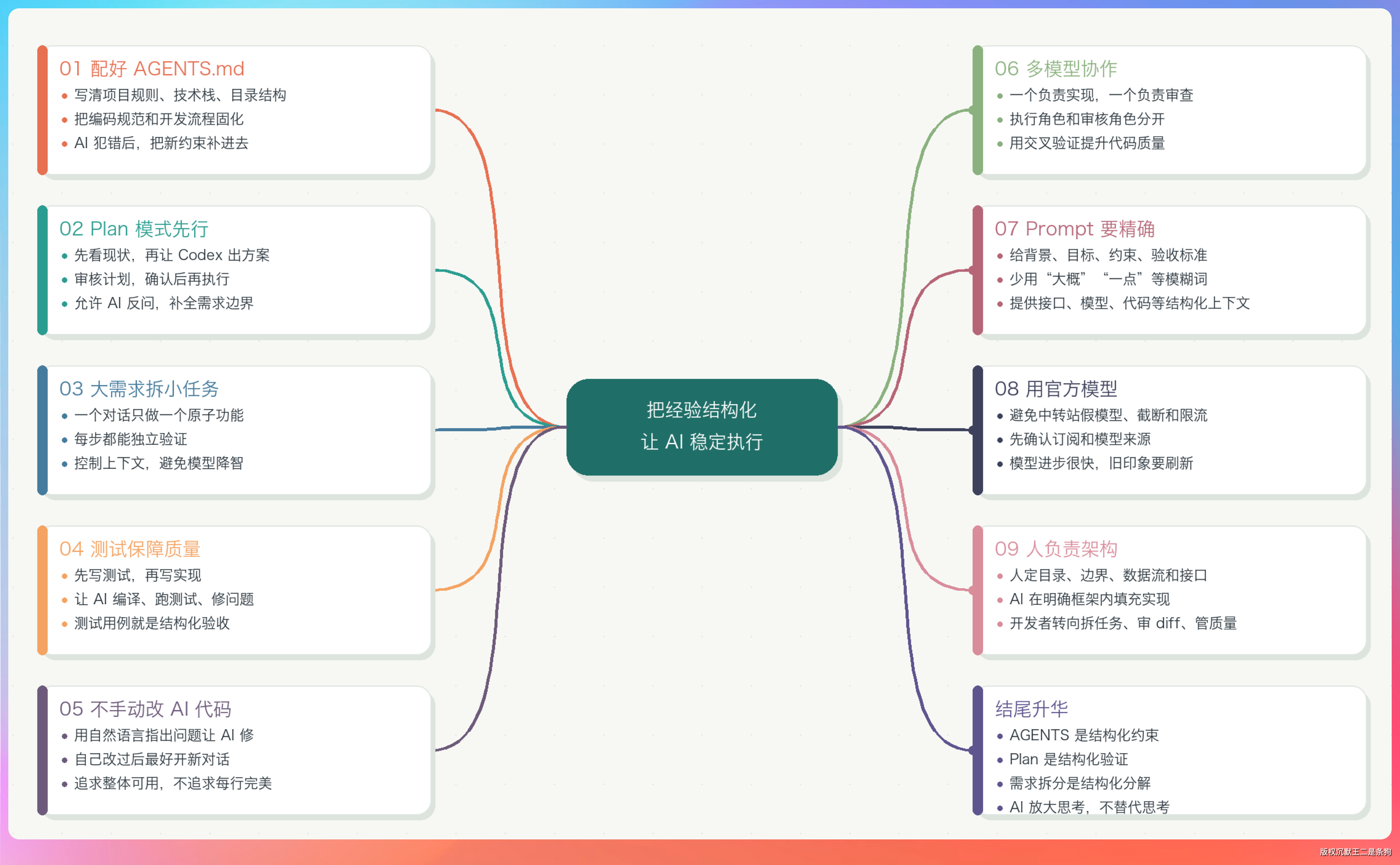
01、别上来就让 AI 写代码
进入工程文件夹,启动 Claude Code / Codex,先 /init 。然后开始改 CLAUDE.md / AGENTS.md。
AGENTS.md(Codex 用的)和 CLAUDE.md(Claude Code 用的)本质上是一份“项目说明书”,告诉 AI 这个项目的边界在哪里。
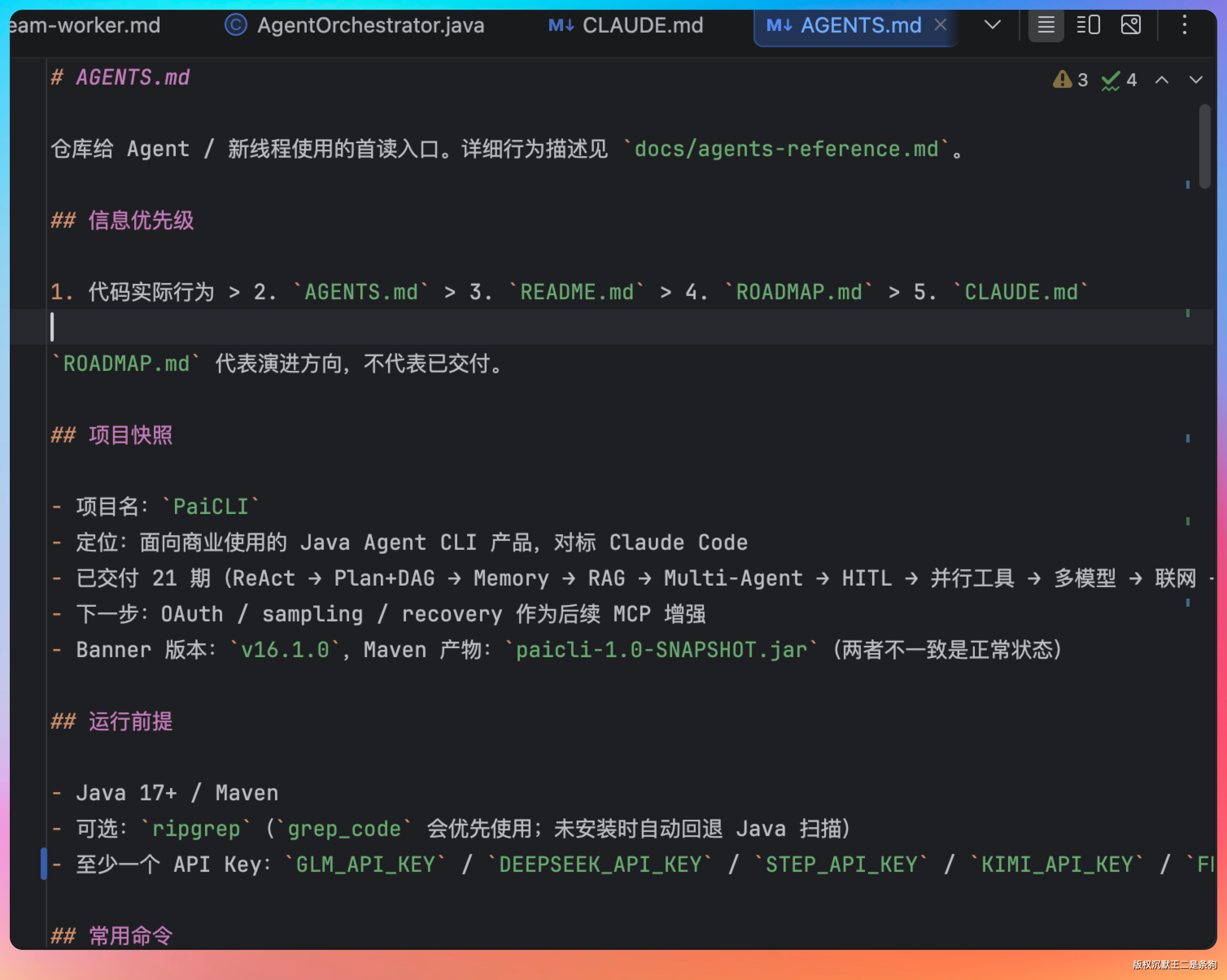
一份好的 AGENTS.md 至少要包含这些内容:
- 最高优先级的限制(比如不要每次改代码就 build,尤其是前端已经是热部署的项目)
- 项目的技术栈和目录结构
- 编码规范(命名、错误处理、测试要求)
- 开发流程(比如先写测试再写实现)
把架构约束、核心规则写成 AGENTS.md,每次对话都带进去,AI 健忘的问题基本能解决。
为什么?
因为 AI 没有长期记忆。
每次新会话它都是“失忆”状态,AGENTS.md 就是每次对话开始时自动加载的“记忆芯片”。你在里面写了不许过度封装,AI 就不会动不动给你搞个调度器出来。你在里面写了测试先行,AI 就会先跑测试再提交。
AGENTS.md 保持精简的同时规定好开发流程,例如测试文档先行,文档位于 xxx 目录。
别搞成长篇大论。
AGENTS.md 本身也占上下文,写太多反而适得其反。我的建议是控制在 200 行以内,只写最核心的约束。
多问一句,你有给项目编写 rule 和 Skill 吗?如果你发现 AI 写的代码有问题,你会让 AI 纠正并让 AI 更新规则和技能吗?
这是一个动态优化的过程。
第一版 AGENTS.md 不可能完美,但每次 AI 犯错后你都应该把新的约束补进去。踩过一次坑,后面就不会再踩。
- 要先构建项目的知识库,有哪些基础库,有哪些基础接口,规范是什么。
- 要构建各种 skill 去适应项目的各种开发和流程。
- 要提前生成需求文档,和 AI 一步步对好需求。
- 生成代码后,你要 review,让 AI 一步步去改。
02、Plan 模式先行
先明确需求,使用 Codex 中的 plan 模式,plan 基本不会出错,但可能需要细节优化。
这是 Codex 用户最容易忽视的功能。
Plan 模式不写代码,只输出执行计划——准备改哪些文件、用什么方案、分几步完成。
我们要做的就是先审一下这个计划,不合理的地方直接让它重新规划。这比等它写完一堆代码再推翻重来要高效得多。
实际操作中,我一般是这样的流程:
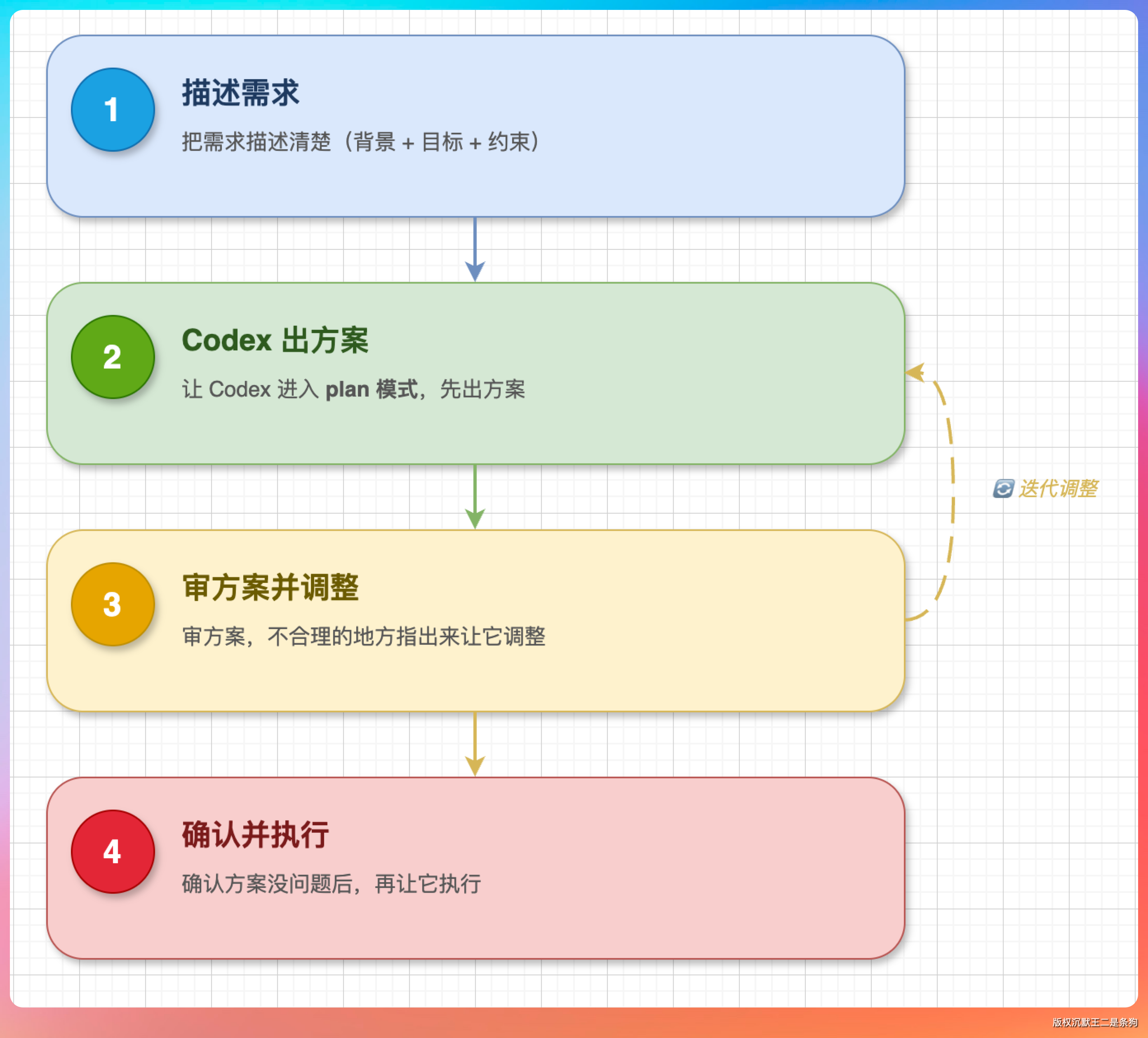
- 把需求描述清楚(背景 + 目标 + 约束)
- 让 Codex 进入 plan 模式先出方案
- 审方案,不合理的地方指出来让它调整
- 确认方案没问题后,再让它执行
建议 /init 后就不要加任何 skills,你要开发或者改 bug 就直接说比如“xxx 列表增加一个字段,你先看看现状,你准备怎么干,有问题可以问我”。
准确率几乎 99%。
03、把大需求拆成小任务
可以试着把一个复杂的需求拆成多个小需求让 AI 小步慢跑完成。完成一个原子功能任务后,新任务开启新的会话。
什么叫“原子功能”?
就是一个可以独立验证的最小功能单元。比如“给用户列表加一个搜索功能”可以拆成:
- 添加搜索输入框的 UI 组件
- 实现后端搜索 API
- 前端对接搜索 API
- 添加搜索结果为空的兜底展示
每一步都是一个独立对话,做完验证通过后开新对话做下一步。
两个原因:
第一,AI 的上下文窗口是有限的。一次塞太多东西进去,AI 的注意力会分散,前面说的约束后面就忘了。
第二,AI 的“记忆”会随着对话变长而退化。对话越长,AI 越容易出现前后矛盾的问题。短对话做完一件事就结束,是最稳定的使用方式。
04、测试是最重要的质量保障
最重要的就是测试。
我一般会 Opus 4.8 写完代码让 GPT-5.5 验证,GPT-5.5 写完代码让 Opus 4.8 验证。
这样出来的代码质量就非常高。
如果你对 AI 写的代码质量不放心,与其花时间逐行 review,不如让另外一个 Agent 来验证。
尤其是遇到一些需要截图的测试,Codex会比Claude Code更好用,因为CC上传图片需要用 ctrl+v,并且我之前在测试的时候,还会有上下文长度限制,就是不能上传太多图片,Codex几乎没有这样限制。
具体到操作上:
- 在 AGENTS.md 里写明“实现任何功能前先写单元测试”
- 让 AI 先生成测试用例,你审完测试用例后再让它写实现
- 每次代码修改完成后自动跑全量测试
反正我在写PaiCLI这个项目的时候,每一个功能都会让Codex生成测试用例。
反正 200刀的 token 不用白不用,有测试用例,基本上AI就不会去犯错,并且假如编译出错,也会自己修复。
05、不要手动改 AI 的代码
不要手动改 AI 写的代码,不然你俩就会陷入改来改去的死循环。如果真要改,改完之后开新的对话。
为什么会陷入死循环?
因为 AI 在生成后续代码时会参考上下文中已有的代码。如果你手动改了一段,AI 不知道你改了什么、为什么改,它可能会在下一次修改中把你的改动覆盖掉。
正确的做法是:
- 发现问题后,用自然语言告诉 AI 哪里有问题、应该怎么改
- 如果 AI 反复改不对,开新对话重新描述需求
- 如果某个修改你确实比 AI 写得快,自己改完后一定开新对话,让 AI 基于改后的代码继续工作
不要有太强的洁癖,把 AI 当成多人协作项目中的其他贡献者就好。
AI 输出的产物没办法 100% 符合你的品味。
这个心态很重要。
AI 编程不是追求“每一行都完美”,而是追求“整体可用且可维护”。
06、多模型协作
每隔一段时间让 Codex 设计功能,然后让 Claude Code 去挑刺和审查,再让 Codex 去评估修改,反复几回合生成接下来的任务列表,再照着做就行了。
这个思路本质上是利用不同模型的能力差异做交叉验证。
我在开发PaiCLI的时候就严格践行了这个约定,每一个功能都会让Claude Code和Codex进行多次校验,最终会由Claude Code做出需求拆解生成一份标准的markdown开发计划,然后再交给Codex去执行。
高质量 vibe coding 最核心就两个原则。
- 至少有两个 session,一个是审核 role 一个是执行 role。
- 上下文占用低于 30%。
当然了,不一定非得用两个不同的模型。
你可以在同一个 Agent 里开两个会话——一个负责写代码,另一个负责审代码。审核会话不需要了解实现细节,只需要看最终的代码 diff 和测试结果,判断是否合理。
记住这一点。
当 AI 开始“打补丁”式地修 bug,说明当前架构已经不对劲了。这时候不要让它继续打补丁了,立刻马上让另一个模型重新审视架构,给出重构方案。
07、Prompt 要精确
Prompt 要用专业词汇,别说“一点”“一些”“大概”这类模糊词汇。一个对话不要穿插不同的需求,多开新对话。
不要给 AI 太多的文档(任何 LLM 都有上下文限制),也不要给 AI 太少的描述(任何 LLM 都不是你肚子里的蛔虫)。
我总结了一个 Prompt 的基本结构:
- 背景:当前项目的状态、涉及的模块
- 目标:这次要做什么(用具体的技术语言描述)
- 约束:不能动什么、必须兼容什么、性能要求是什么
- 验收标准:什么情况算完成
别只用自然语言描述需求。
如果你改的是一个 API,把现有的接口定义贴进去;如果你加的是一个数据库字段,把表结构贴进去。AI 看代码比看自然语言准确得多。
我平常在开发新的功能的时候,都会先去找官方的文档,然后把官方的最新文档丢给 Codex,让Codex先去理解官方文档的内容。
有时候,模型会偷偷去用比较旧的版本。
因为模型本身的训练数据是有时间戳的,习惯用自己已有的经验来解决问题。
哪怕你给了Skills等等。
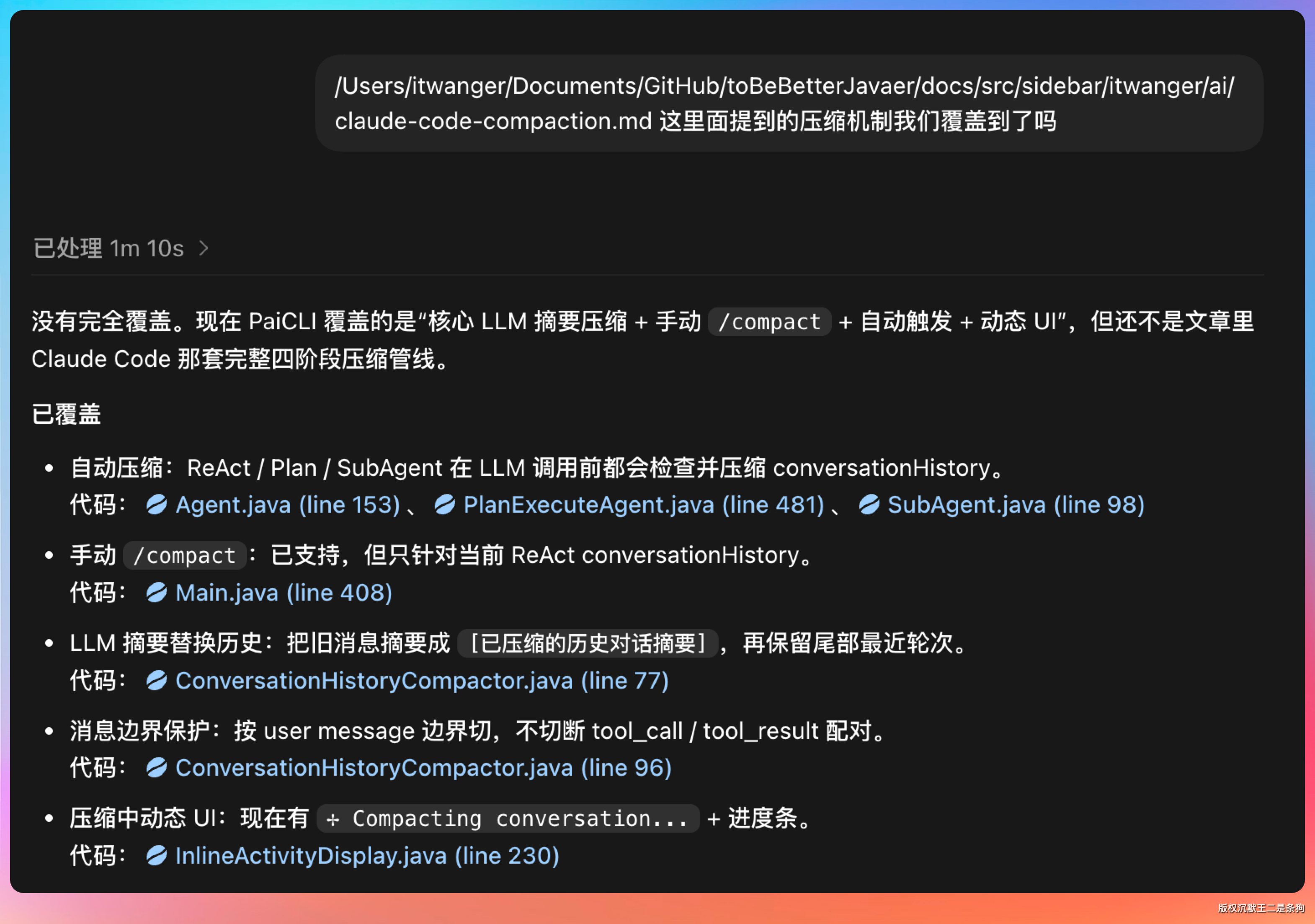
必要的时候,我们必须把我们自己总结的经验丢给Codex。
08、尽量用官方模型,别用中转站
Codex 已经很顶了,我现在基本上所有的代码都是交给他来搞定。
原厂的大模型可能会在高峰期出现降智或者其他情况,但是总体上还是比较稳定,智力水平很在线的。
中转站的问题不只是模型可能被偷换,还有请求限流、上下文被截断、响应延迟等一系列问题。如果你用 Codex 觉得效果很差,第一步应该确认你用的是不是官方订阅。
不同模型在不同任务上表现不同。
写业务代码 GPT 5.5 xhigh 已经很强了,如果是架构设计类的任务可以切到 Claude Opus。
模型能力也在快速进步。
如果你一两个月前试过觉得不行,现在可以重新试试。GPT 5.5 和半年前的 GPT 5 完全不是一个量级。
09、架构由你来,实现交给 AI
虽然 AI 本身的能力已经非常强了,但有些工程上架构能力,还得我们自己来。
我在做PaiCLI的JLine 交互时,就遇到过这个问题,当时弄了快一天时间,交互总是有问题。
最后没办法我直接去读官方的doc,然后再告诉Codex应该这样设计,这样设计,最后才搞定。
AI 经常会将两个业务共同的点封装成一个 xxx 调度器,实际上很多时候是过度封装的,要是以后要调整其中一个业务,如果没有注意修改了调度器会影响另一个业务。
正确的分工是:
- 你负责:目录结构、模块边界、数据流向、接口设计
- AI 负责:在你定好的框架内填充具体实现
让它先读代码、复述理解、列计划,然后盯着它慢慢改。

Codex 有一个引导功能,当你发现 Codex 在执行过程中和你的预期有偏差,一定要及时引导。
及时的中断,也是非常有必要的。
否则 Codex 也很有可能误入歧途,我上周在对接 OCR 的时候就遇到了,直接快把我的CPU干报废了。
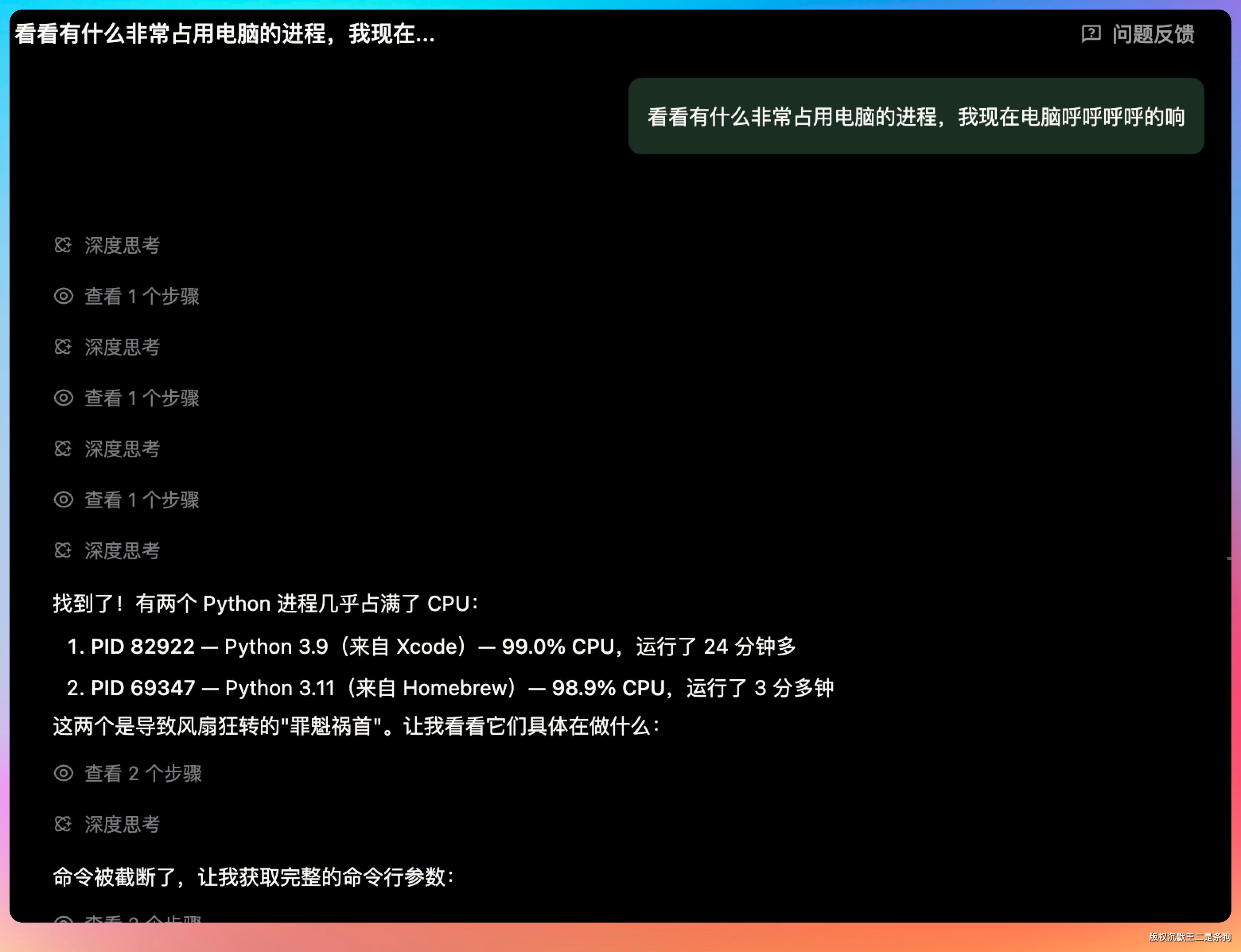
有个Python进程直接占用了99% 的CPU,并且不会停止,风扇呼呼呼呼的转,我还以为是电脑配置跟不上导致呢。
AI 目前还没办法完全自主,虽然有一些营销号疯狂吹,但实际上 AI 的发展远没有到 AGI 的水平。
我们需要及时干预。
ending
AI 编程不是“把需求丢过去就完事了”。
那些用得好的人,无一例外都在做同一件事——把自己的工程经验告诉给 AI。
【技术从来不是用来取代思考的,而是用来放大思考的。】
你还是那个架构师、那个决策者、那个兜底的人。
只不过现在,你的手速变成了 AI 的手速。
你的瓶颈不再是“写代码慢”,而是“想清楚,看清楚”。
你,仍然是那个主宰。

回复