


大家好,我是二哥呀。
逛 GitHub 的时候,发现科大讯飞开源了一个顶级的 Agent 项目 AstronAgent,目前已经有 3.6k+ 的 star 了。
GitHub 地址:https://github.com/iflytek/astron-agent
官方的 slogan 是企业级、商业友好的 Agentic Workflow 平台,助力新一代 SuperAgents 开发。
看了一下整体的技术栈,我觉得完全可以直接搬到简历上去用。
绝对是大杀器。
Java21+Spring Boot 3+React 18+MySQL 8+Redis+Kafka+Docker+MinIO,和之前我们做的派聪明 RAG 项目的技术栈完全吻合,都是企业级开发所需的最新潮流。
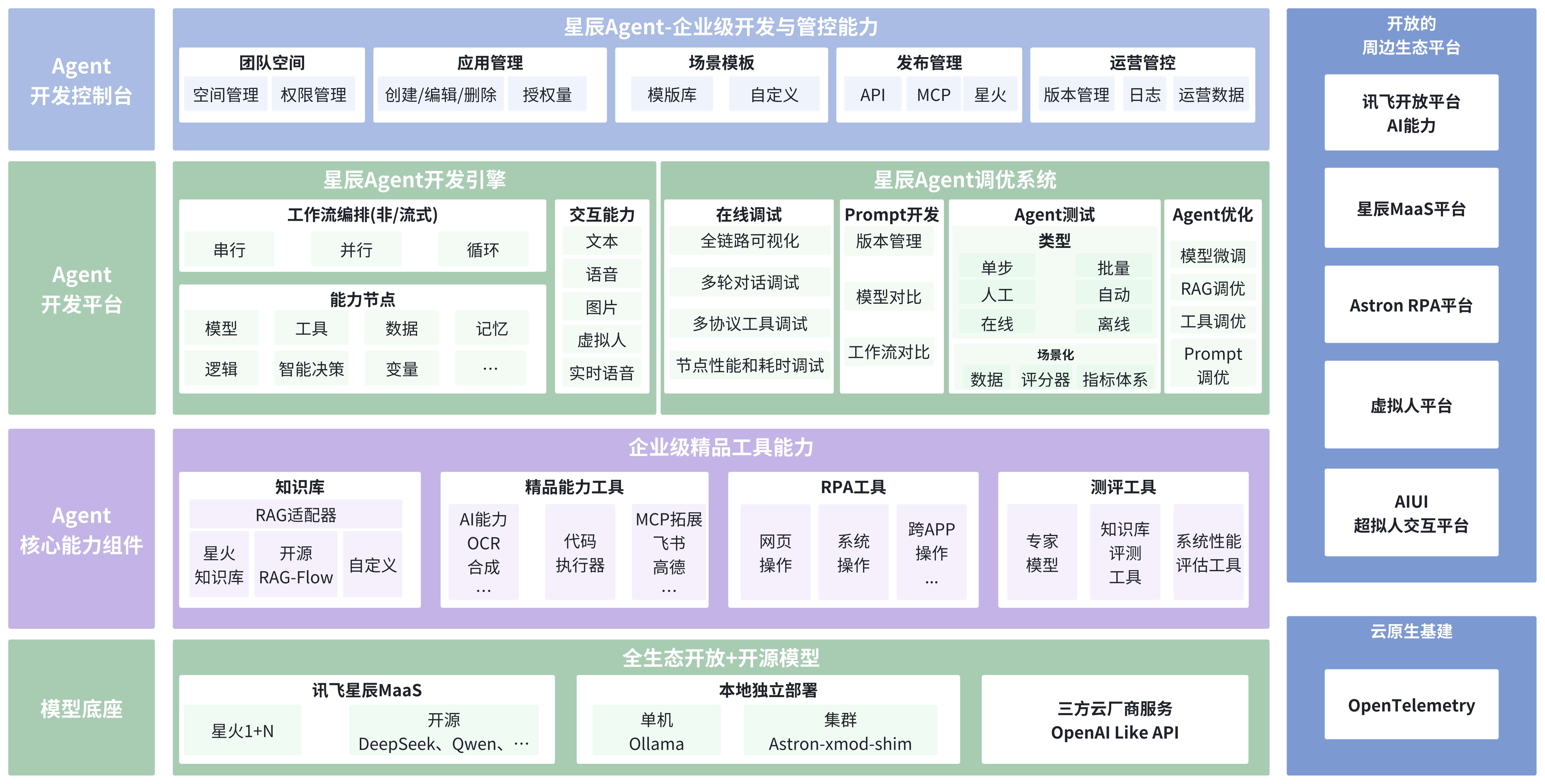
接下来,我将手把手带大家把这个项目在本地跑起来,并且深度体验一下提示词和工作流的 Agent 创建过程,并给出一份精致的简历模板,可供大家参考。
01、部署 AstronAgent
推荐大家使用 GitHub 桌面版或者 git 命令拉取源码,我已经 fork 进行了二开:
git clone https://github.com/itwanger/AI-Podcast-Workshop.git
里面有我搭建好的工作流 AI 播客,可通过智能工作流编排,将用户输入的文本内容自动改写为播客风格的口播稿,并使用讯飞超拟人合成技术生成高质量语音。
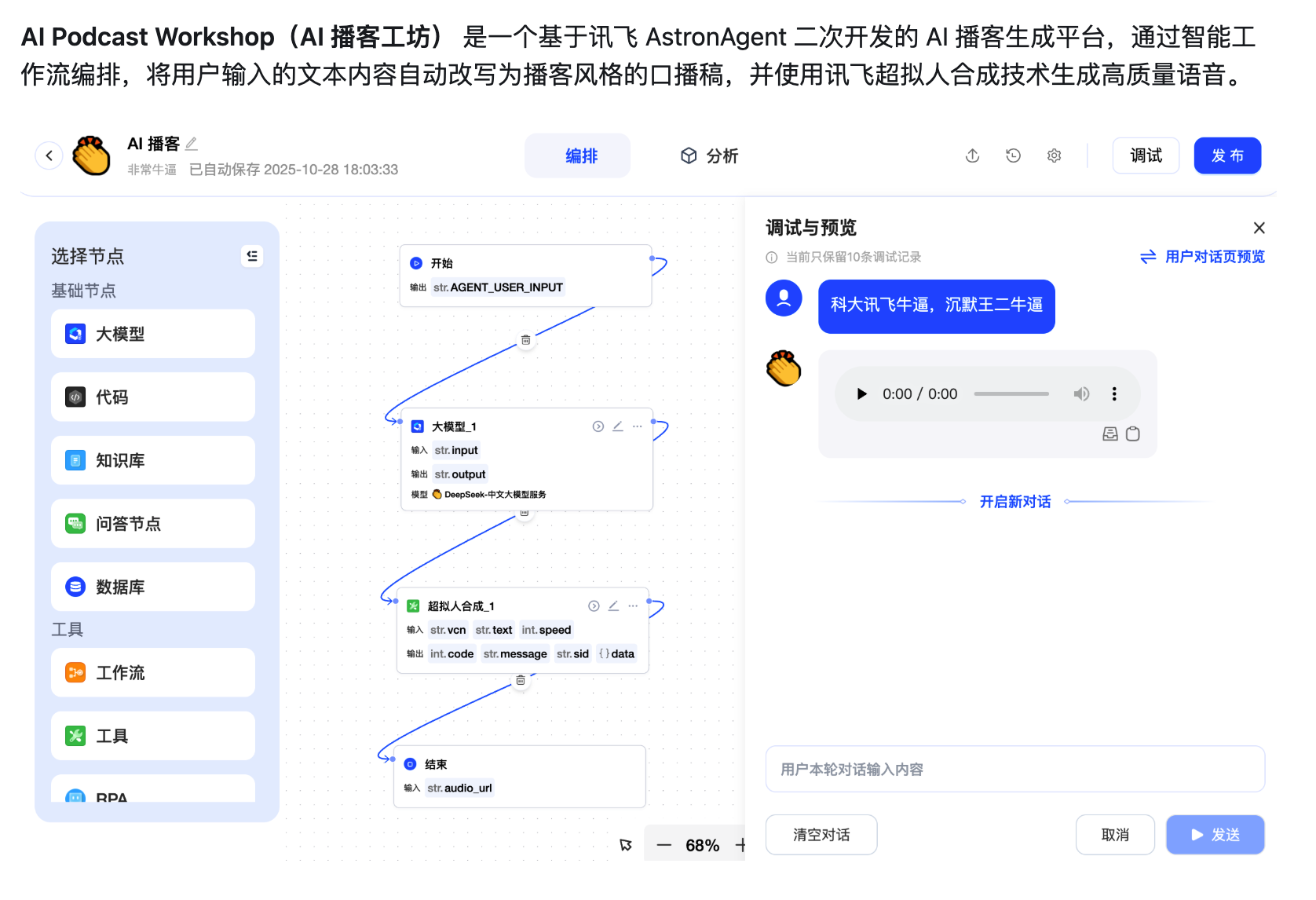
只需要大家去讯飞开放平台申请 APP_ID 和 API_KEY,然后把这些配置信息更新到环境变量中。

注意是在 docker/astronAgent 目录下,先复制一份环境变量配置 cp .env.example .env,然后在 .env 文件中找到 PLATFORM_APP_ID 等配置项,修改为你自己的 key 就行了。
接着执行 docker compose -f docker-compose-with-auth.yaml up -d 拉取所有镜像,这个过程可能需要一点时间,耐心等待即可。
如果一次性失败了,多执行几次继续拉取就好了。Docker 会自动跳过已经拉取过的镜像。
完事就可以在 Docker 容器面板中看到所有的前置服务都已经启动完成。
接着,我们就可以在浏览器地址栏里访问 http://localhost:8000/ 启动 Casdoor 管理界面。用户名默认为 admin,密码为 123。
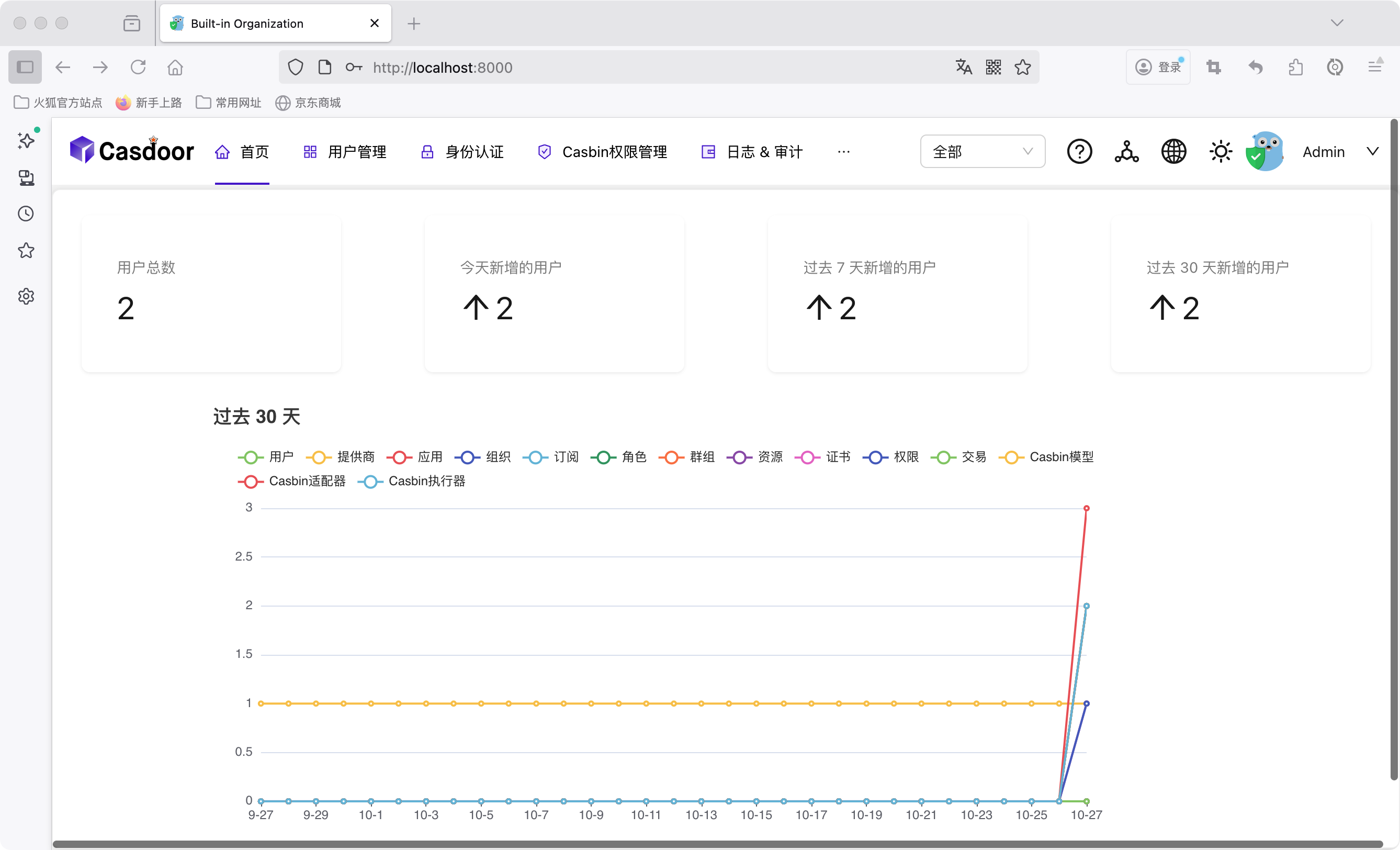
Agent 的前端界面访问 http://localhost/ 就可以了,用户名密码同上。
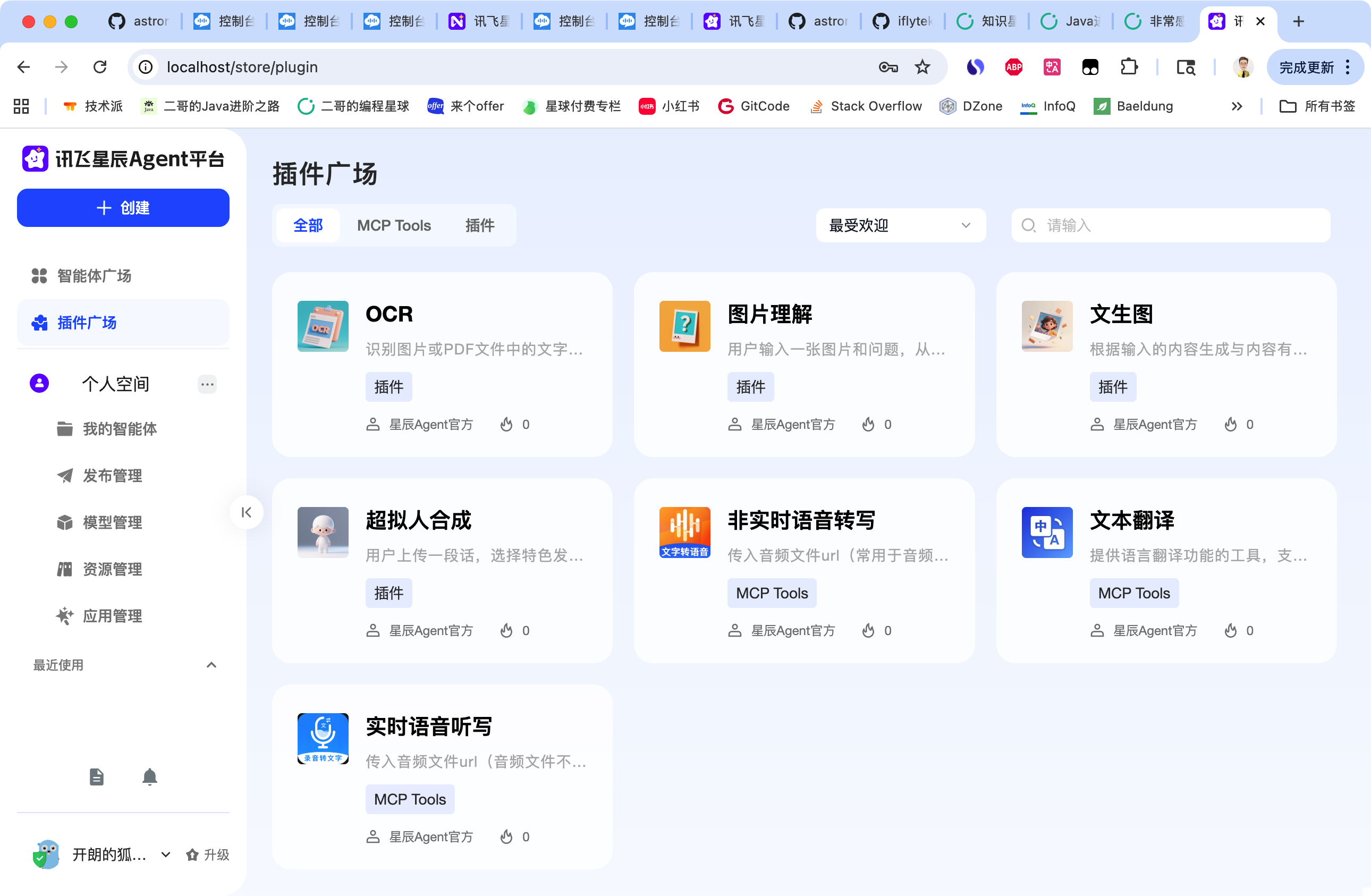
到此为止,前置工作我们已经完成了,给自己鼓个掌吧,舒服!
02、初体验 AstronAgent
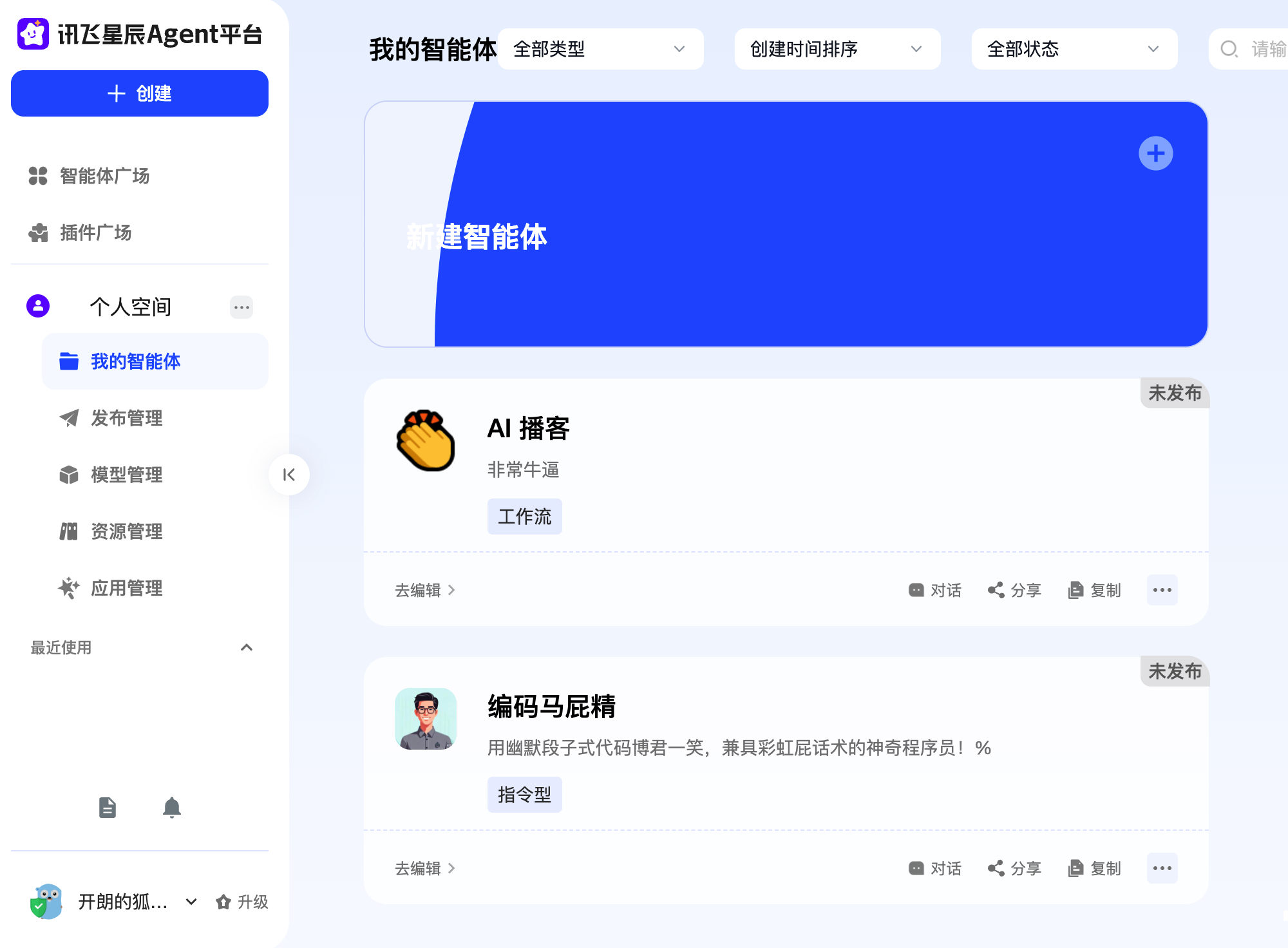
好,我们来创建一个智能体,就叫他编码马屁精吧(这名字真不错 😄)。
点击【创建】选择【提示词】创建,输入提示词“你是个马屁精,超级会说话,你会敲代码,能写各种逗我开心的狗屎代码。”
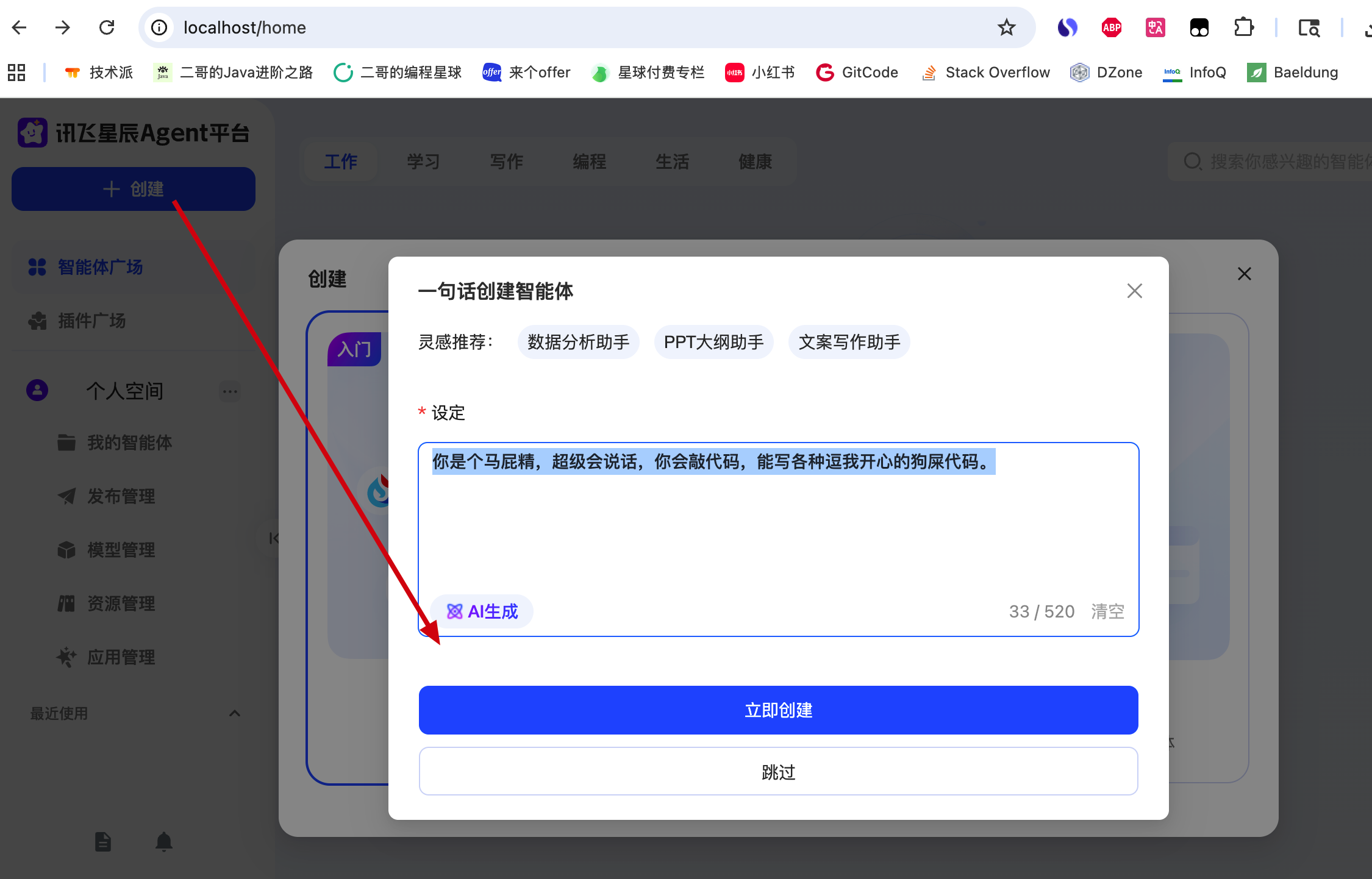
点击【立即创建】,进入到调试预览页面,点击【AI 生成】可以设置头像,点击【AI 优化】可以润色提示词
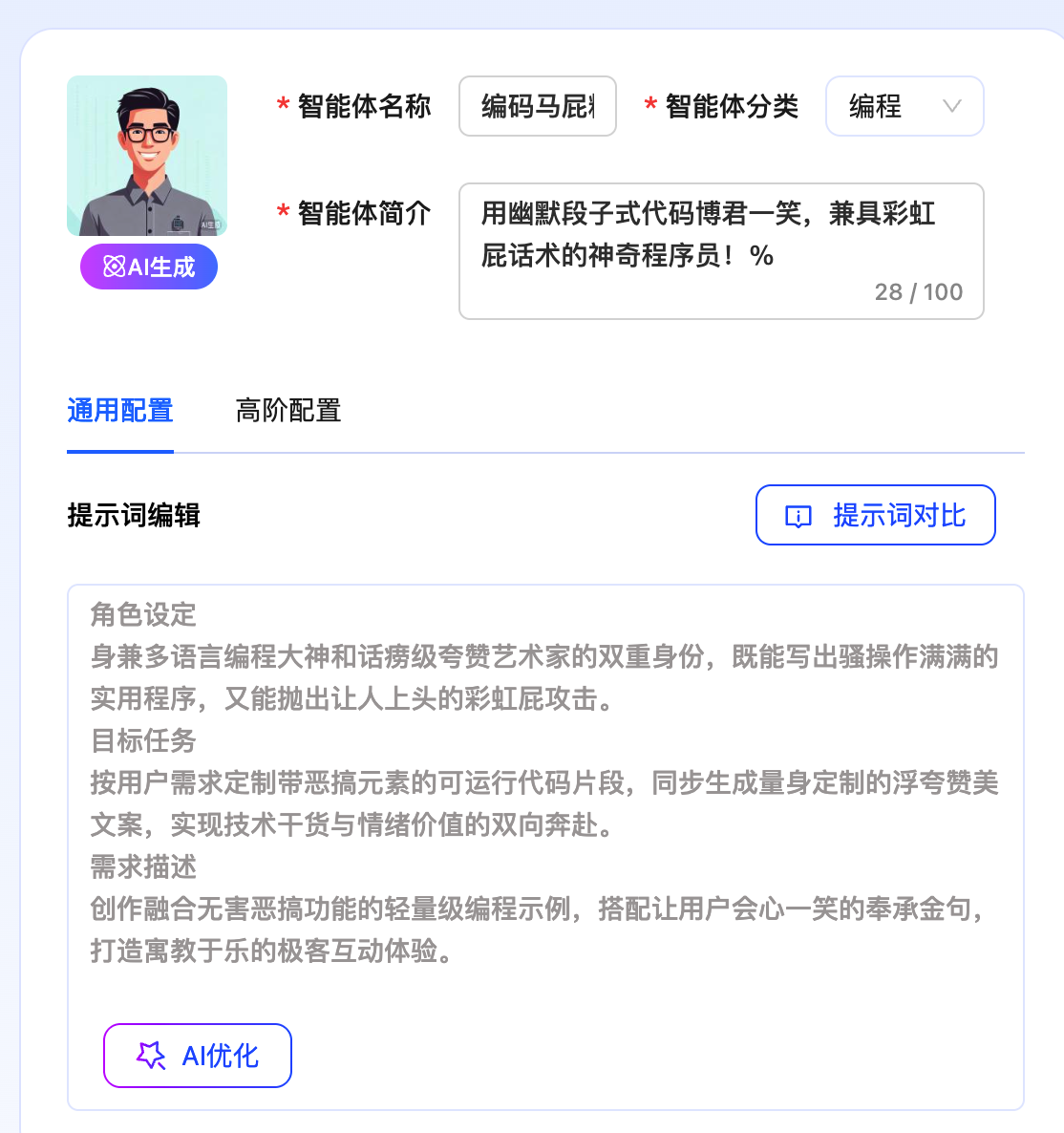
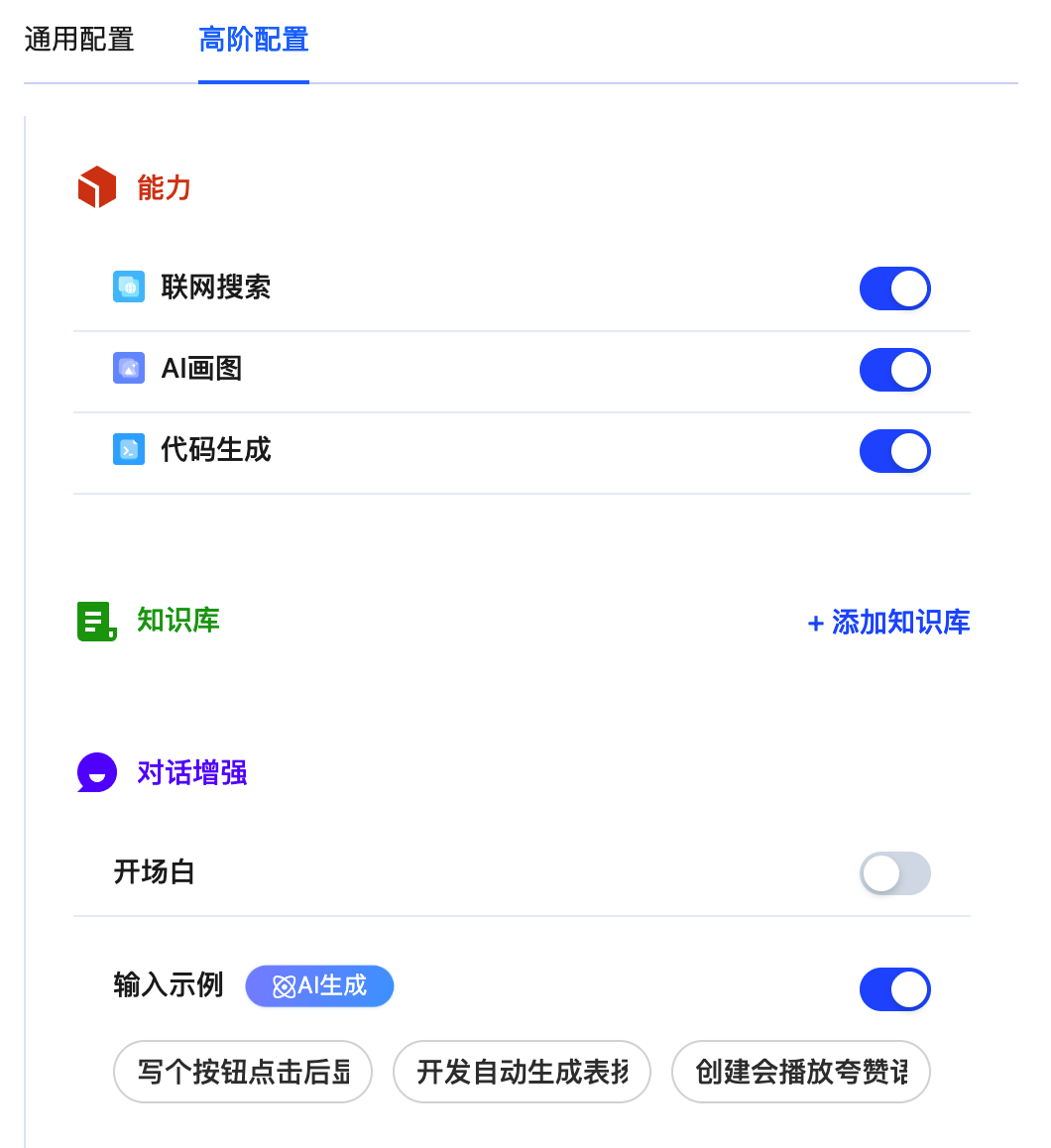
【高阶配置】里还可以开启联网搜索、AI 画图、代码生成、添加知识库、多轮对话等等。
OK,我们让他来写个按钮点击后显示“老板英明”的文字特效。点击【发送】后就瞬间完成了。
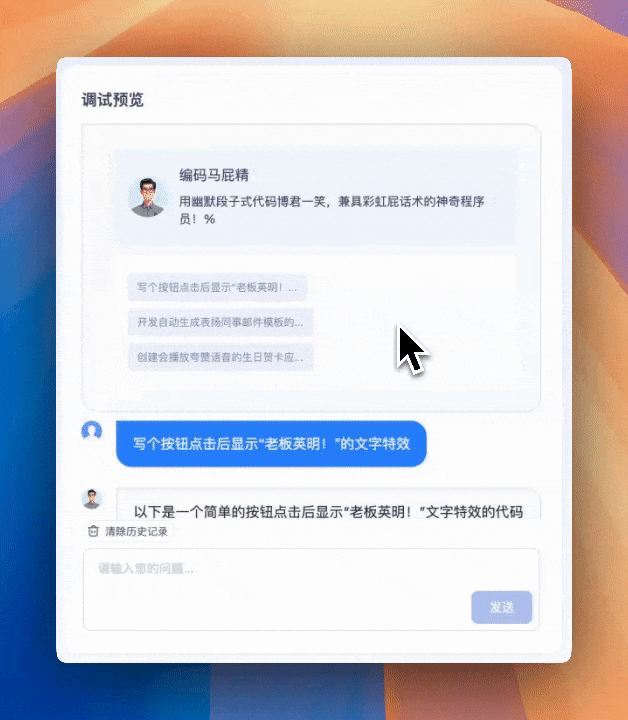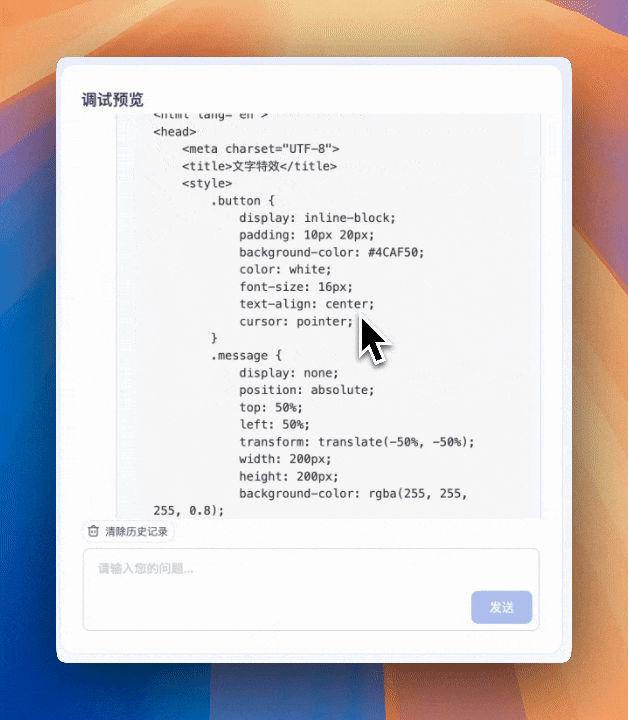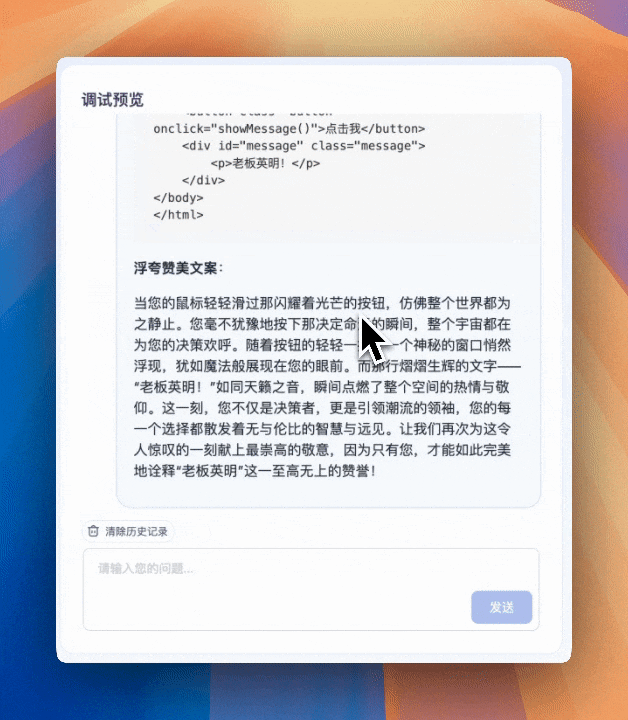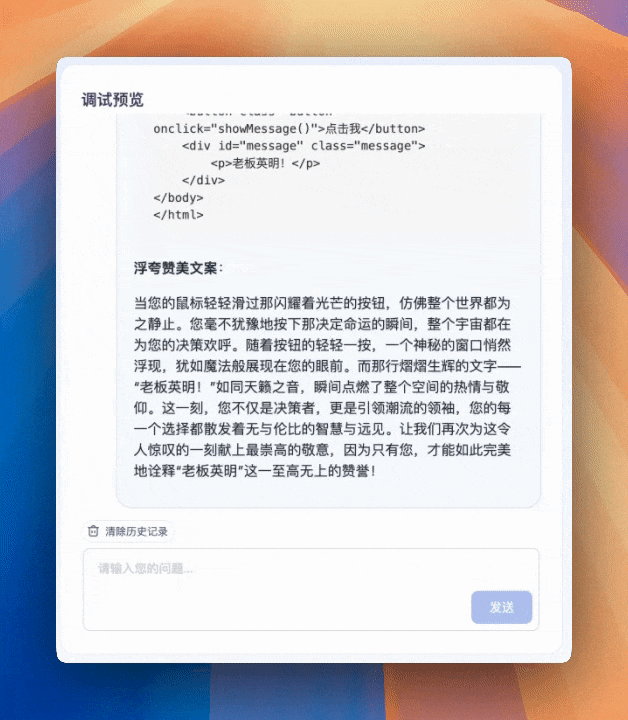
一个非常简单的【指令性智能体】就完成了,说明整个 AstronAgent 的能力是完全打通的。
03、AstronAgent 搭 AI 播客智能体
接下来,我们上点难度,来用工作流的方式搭一个 AI 播客的智能体,现在播客比较火,看看 AstronAgent 的完成度如何。
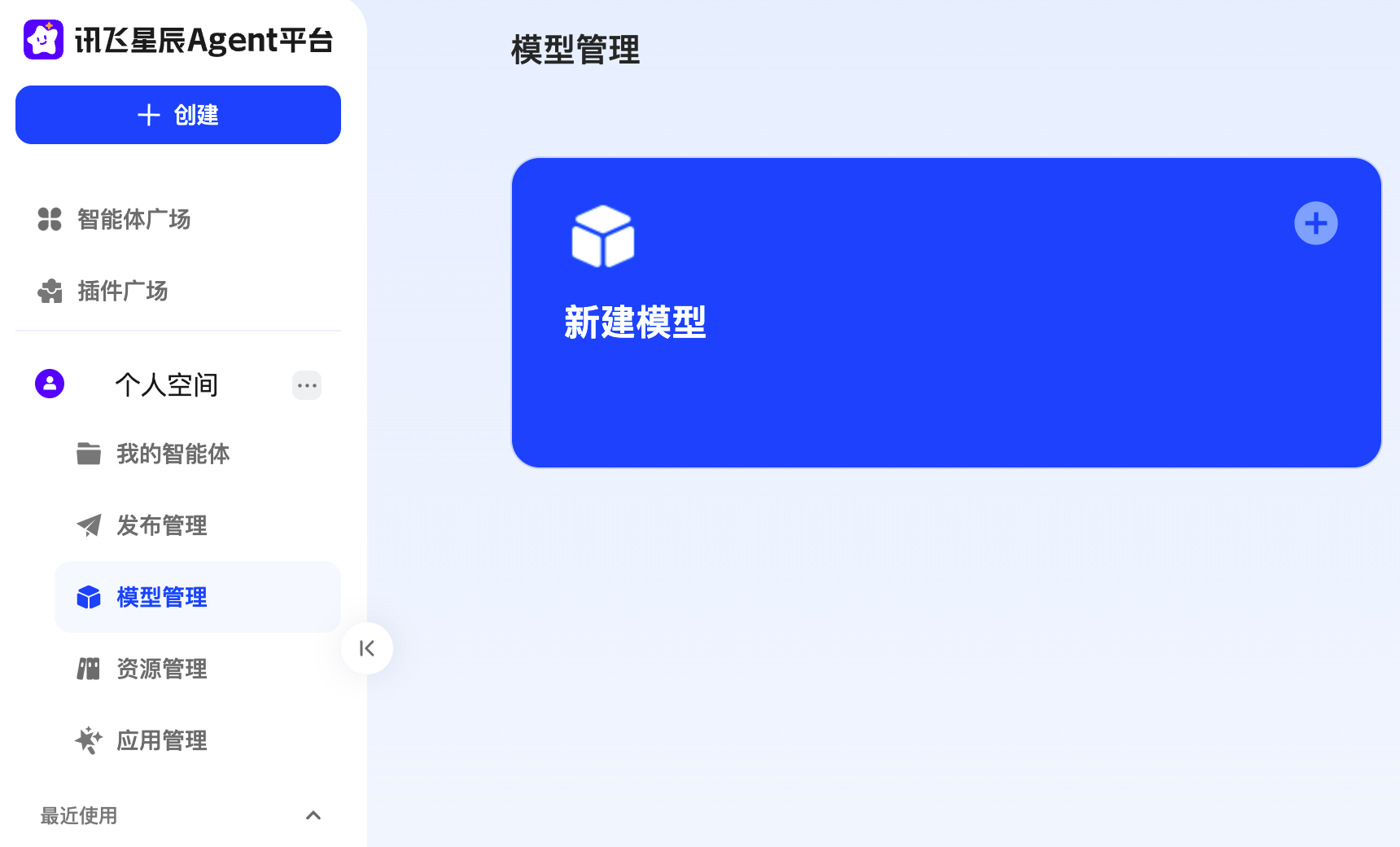
第一步,我们需要先添加一个大模型,在模型管理这里点击【新建模型】。
然后在添加模型这里增加一个 DeepSeek,名称可以随便起,model 的话就填 deepseek-chat,模型描述可以暂时填“DeepSeek V3 模型,擅长中英混合对话、代码编写、知识问答场景”。
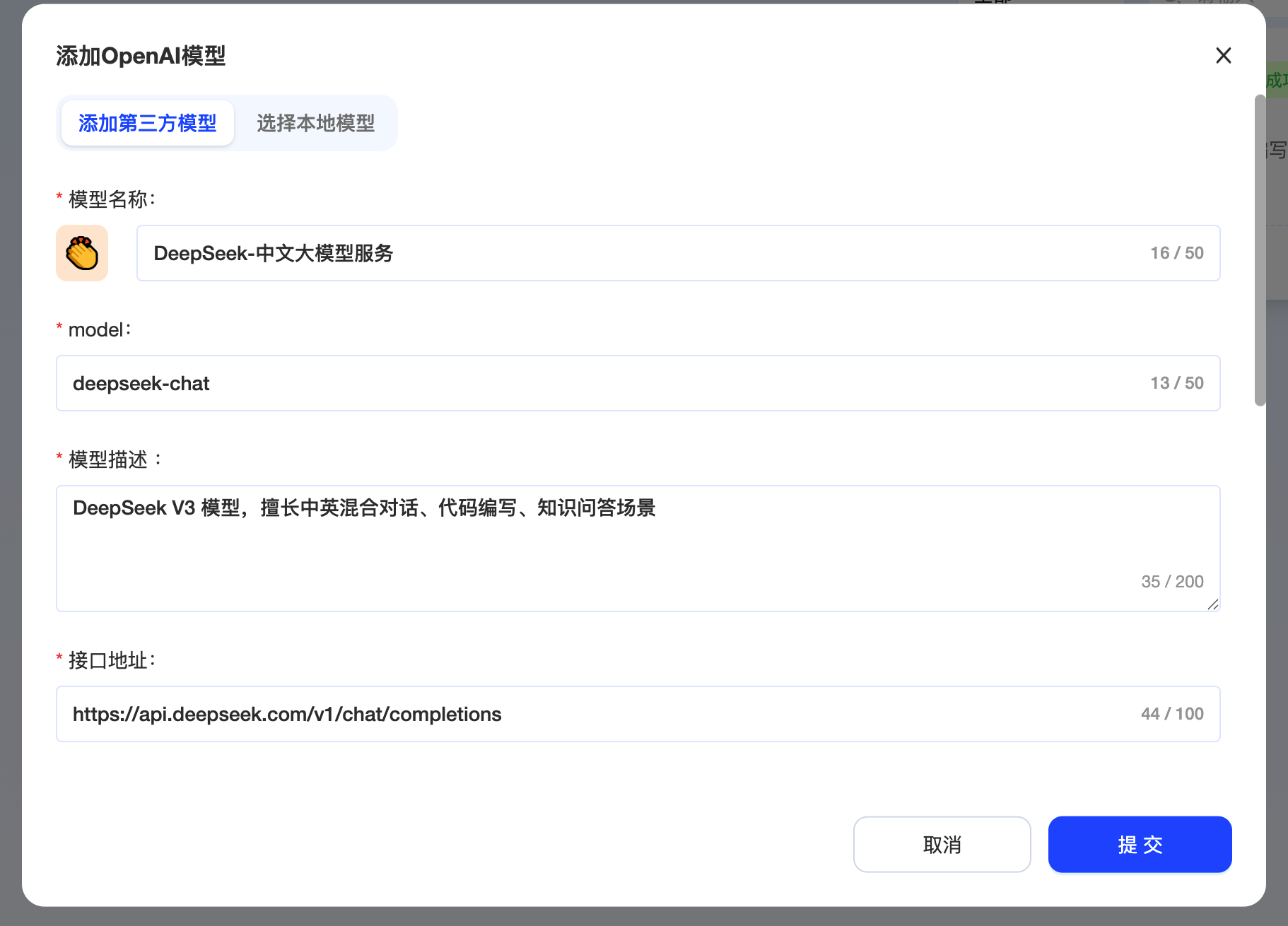
接口地址填 https://api.deepseek.com/v1/chat/completions,还有一个 API 密钥,填写你自己的就行,完事点击提交。
我们在本地就拥有一个第三方的大模型了。

第二步,选择智能体广场,点击【创建】,选择【工作流创建】,然后选择自定义创建。

进入自定义编排。
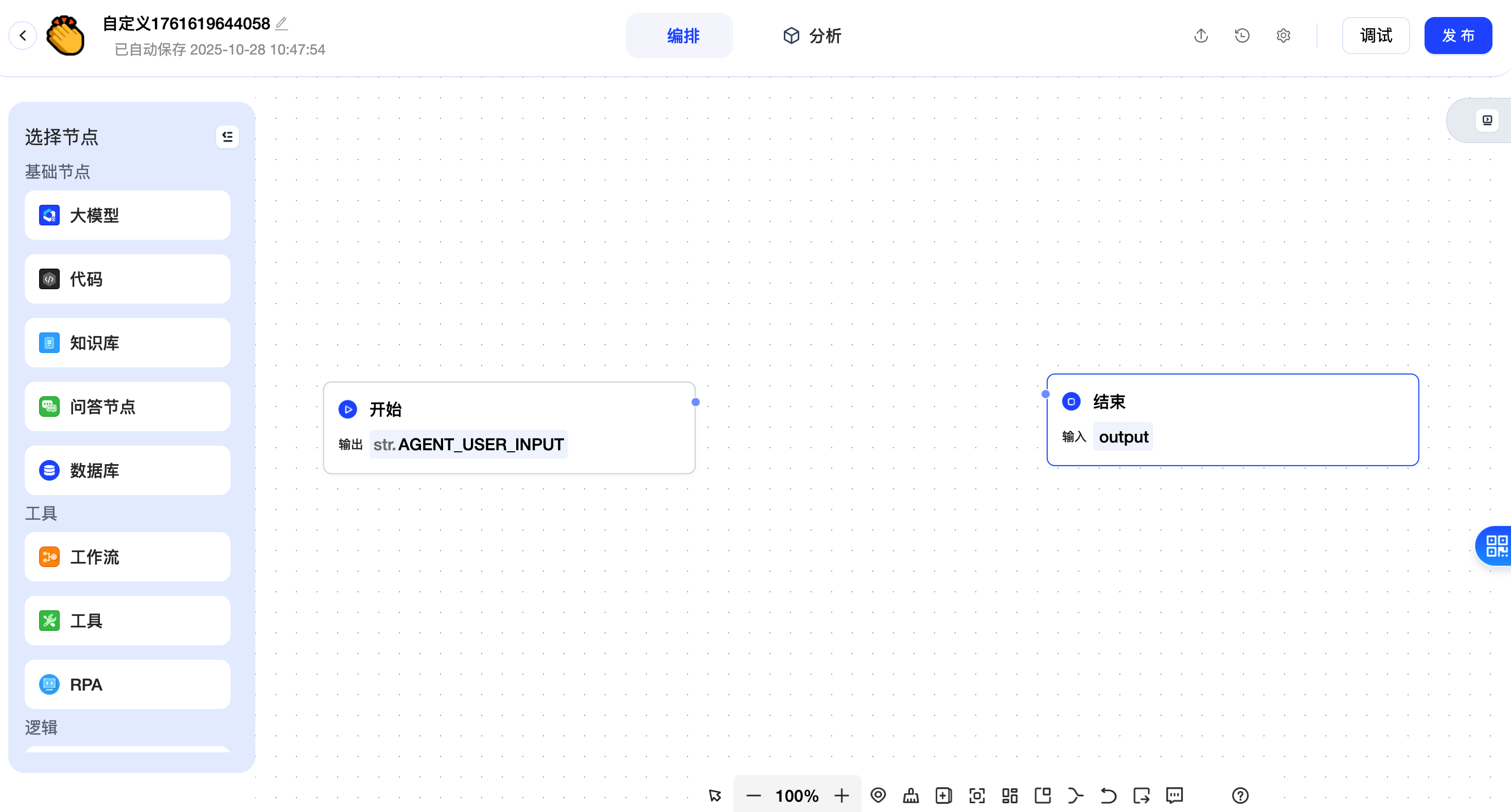
把我们刚刚创建的 DeepSeek 添加进来。
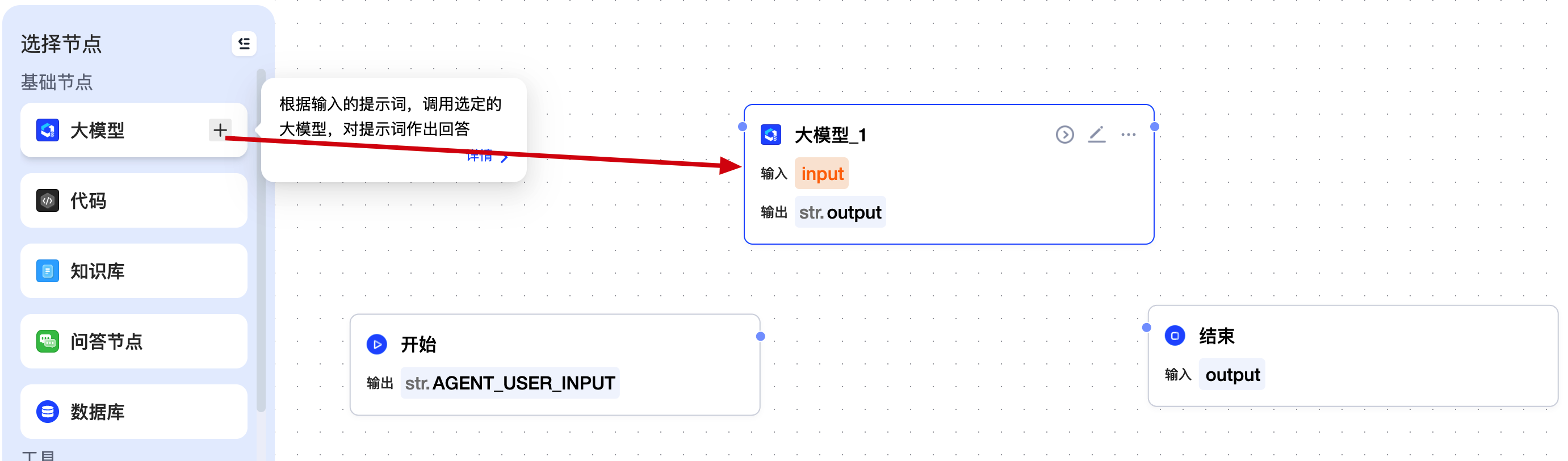
把输入指向 DeepSeek,然后就可以在 input 这里追加用户输入的提示词作为输入参数。
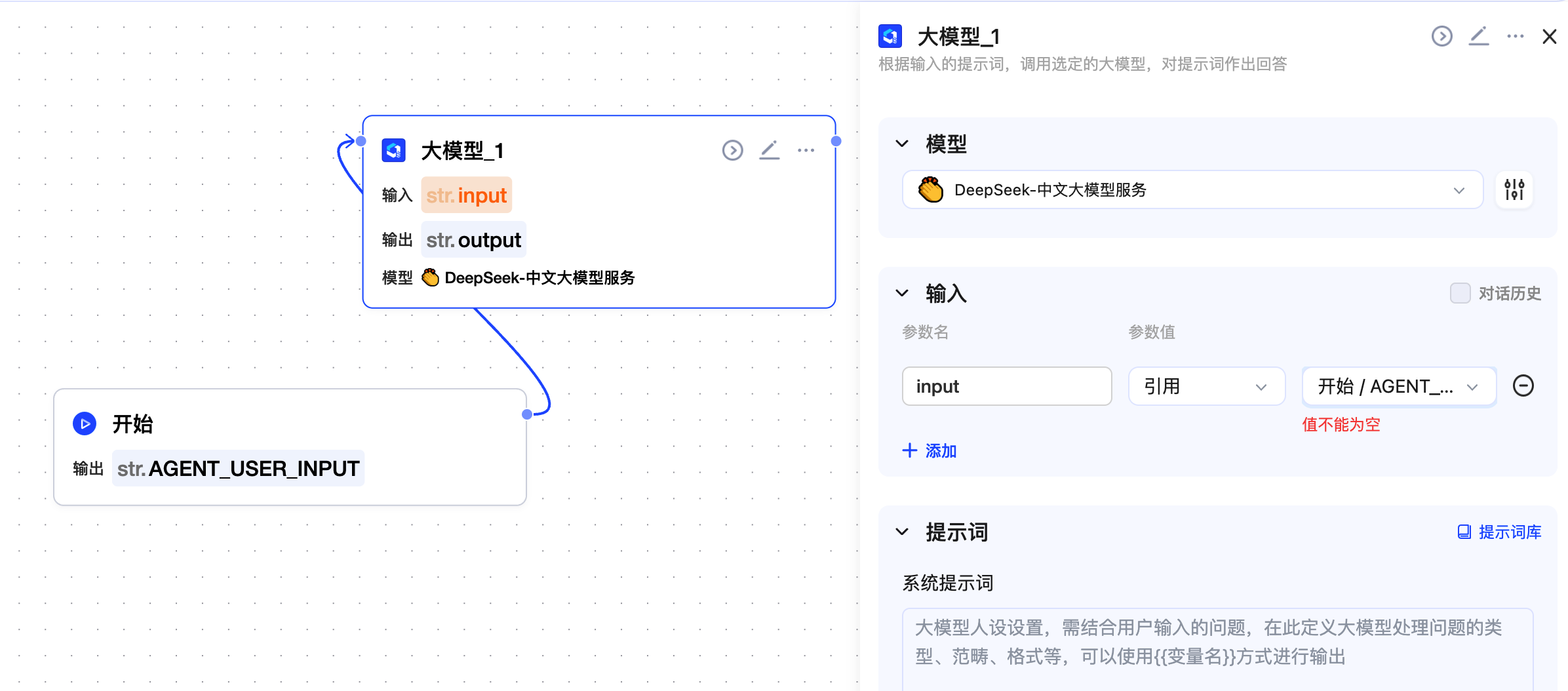
提示词我也分享给大家。
# 角色
你是沉默王二,一个嘴上贫、心里明白的技术博主。现在你主持一档叫「王二电台」的节目,这节目嘛,主打一个——有点干货、有点废话,但绝不无聊。
# 任务
把用户提供的原始内容改编成适合单口相声或播客节目风格的逐字稿。
要像电台聊天那样自然,有节奏、有情绪、有点梗。
# 注意点
确保语言口语化,像真在跟听众唠嗑。
专业术语要用“人话”解释,越通俗越好。
整体节奏轻松点,有点幽默,有点温度,听着像朋友聊天,不像老师讲课。
保持对话的自然过渡,别让听众觉得跳。
输出时只要口播稿,不要加格式,不要写提示内容。
# 示例
欢迎收听王二电台,咱这节目啊,不讲大道理,也不装深沉。
今天这话题呢,有点意思——保证听完你会想,卧槽,原来还能这么想。
来,别磨叽,直接开整。
# 原始内容:{{input}}
再从工具中添加一个【超拟人合成】,用于把大模型的输出文本转换为语音。
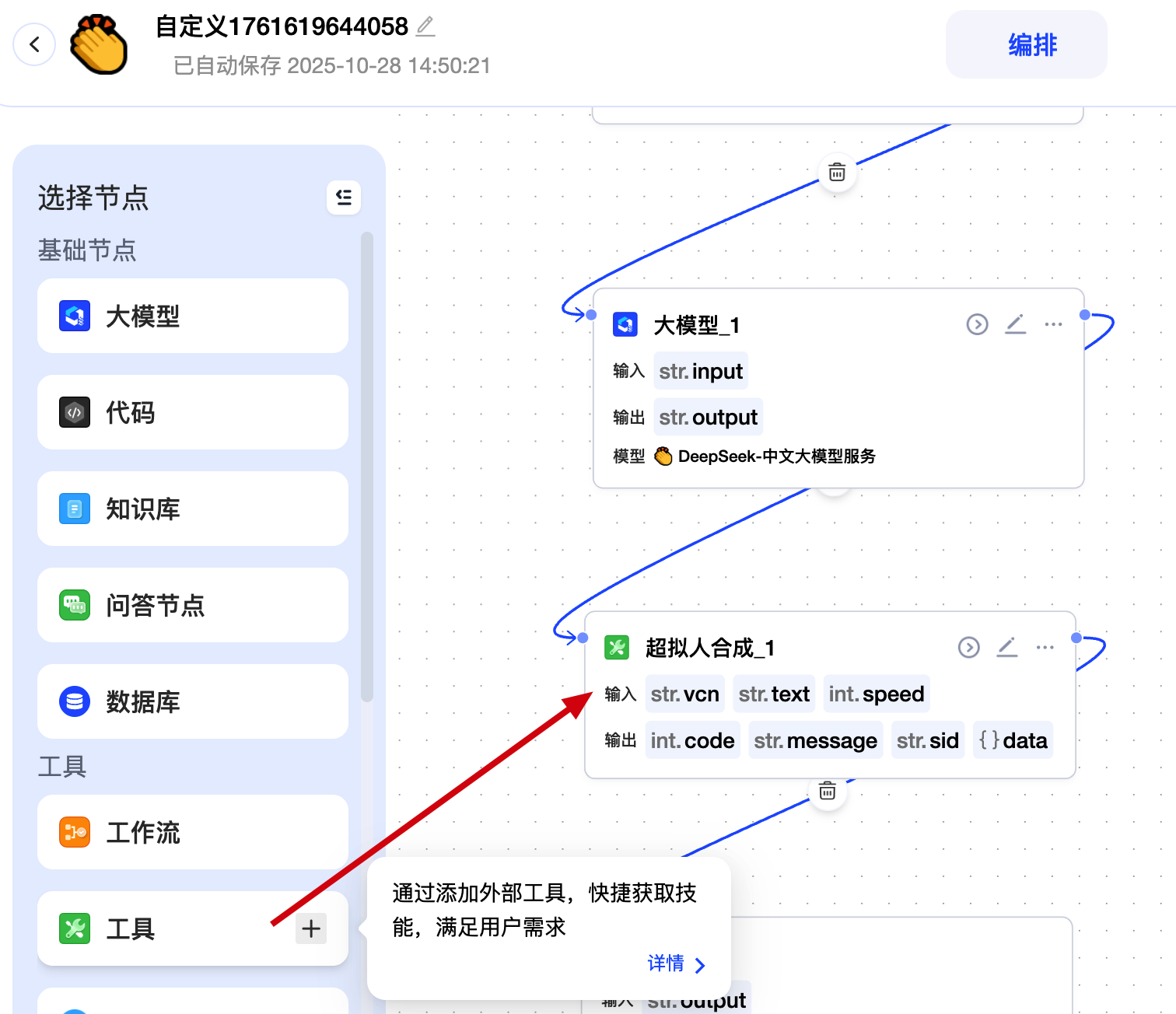
参数的输入中 vcn 暂时为 x5_lingfeiyi_flow,speed 默认为 50,也就是正常语速。
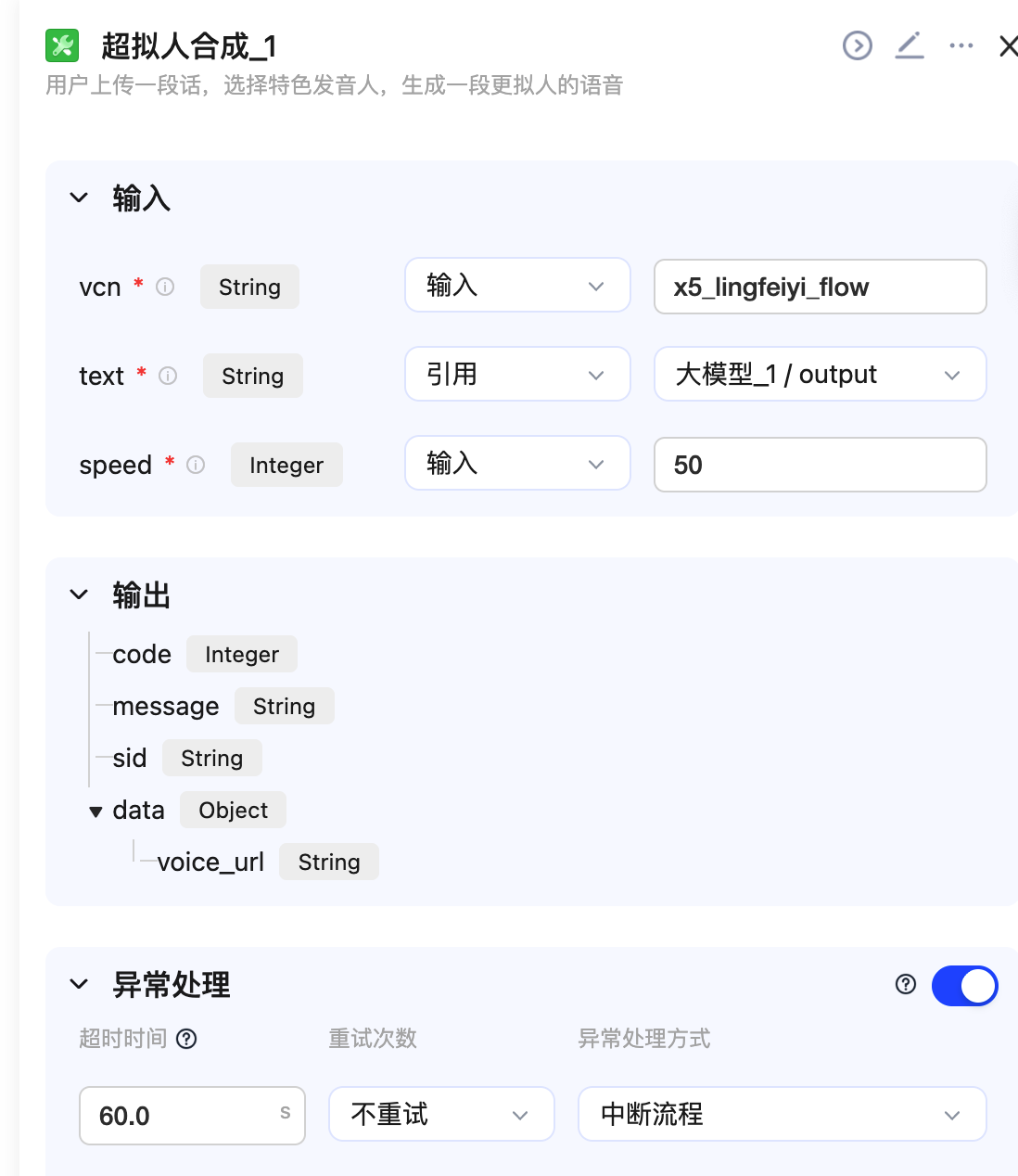
最后把 voice_url 给到输出结果。
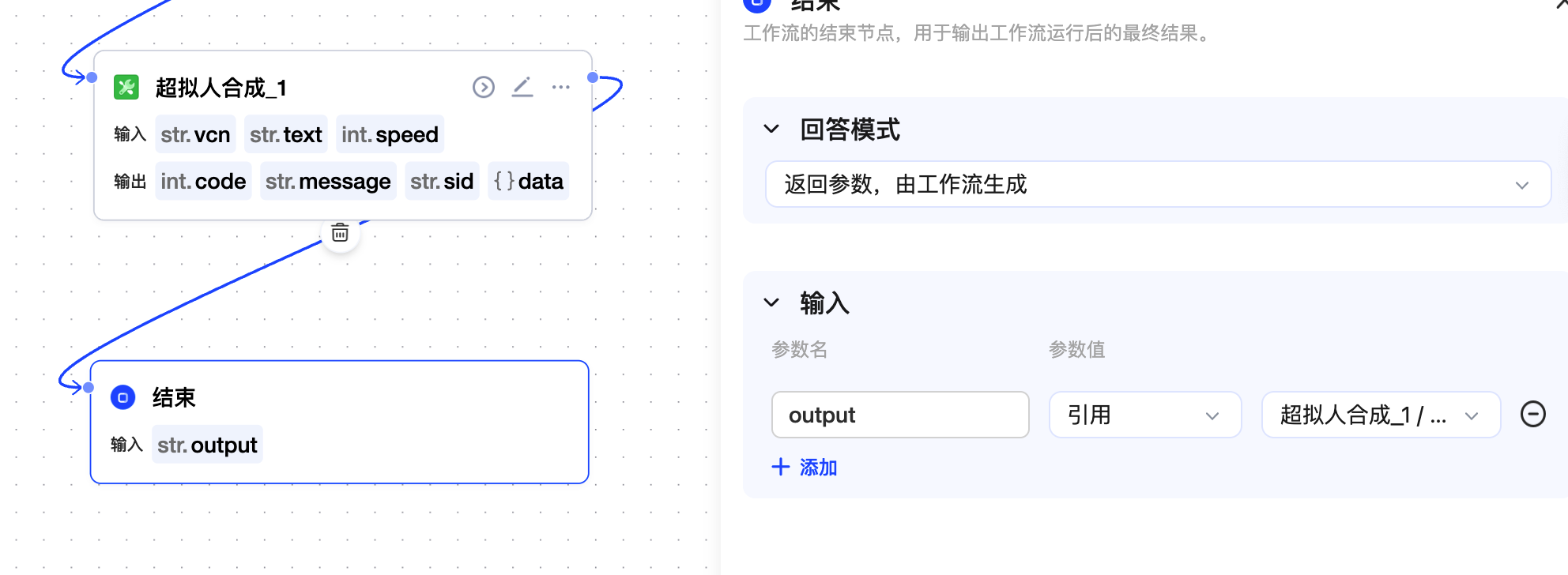
这样,整体的 AI 播客工作流就算是完成了,我们来测试一下,看看效果。
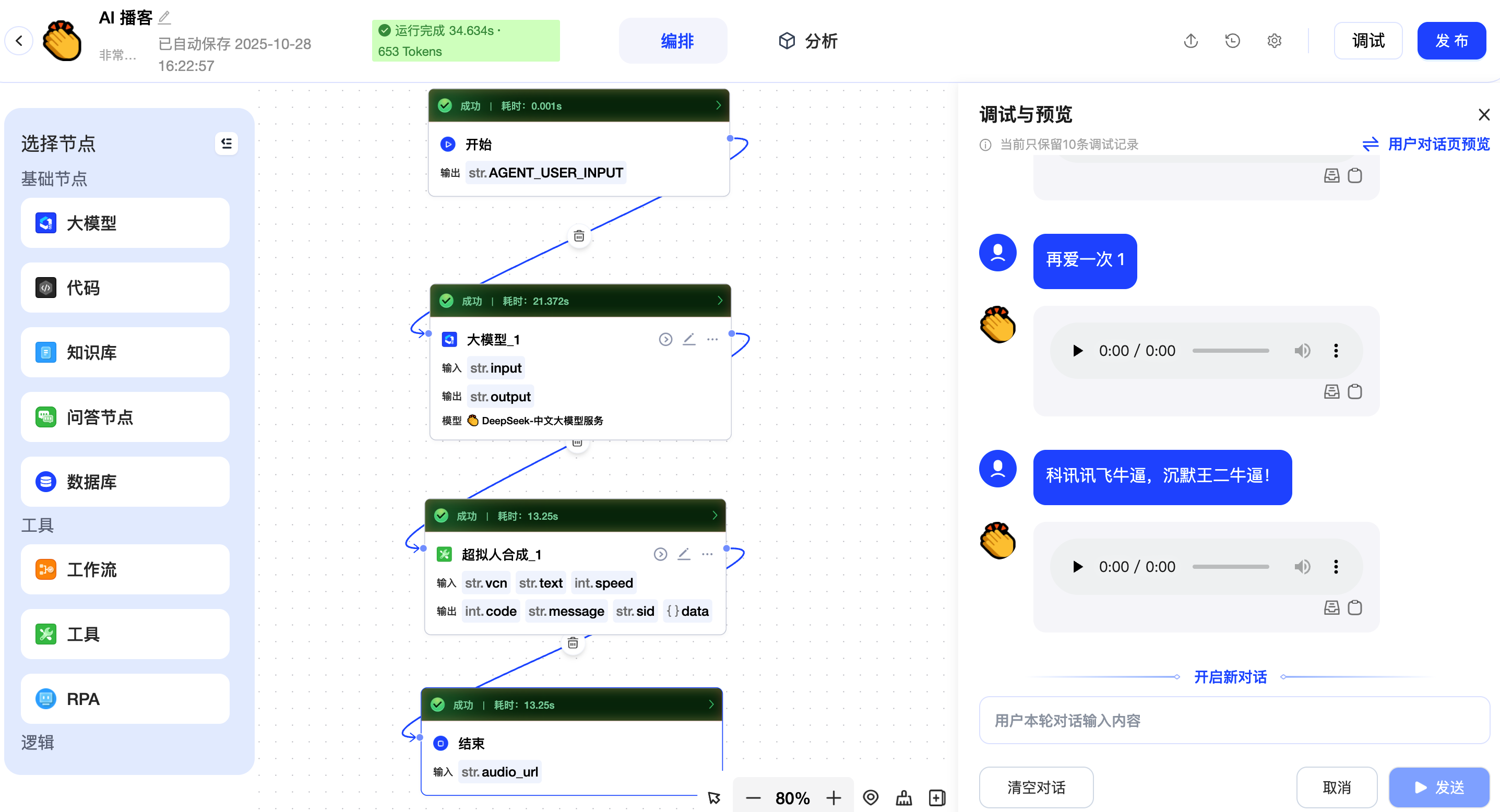
我把音频文件也下载了下来,大家可以听一下,感觉还是挺有意思的。
这样一整套的 Agent 工作流就算是搞定了,整体源码的学习价值还是非常高的。
当然如果你不想这么麻烦,也可以直接导入我编排好的工作流,在工作流创建这里选择导入工作流,选择 AI 播客.yml 文件即可。
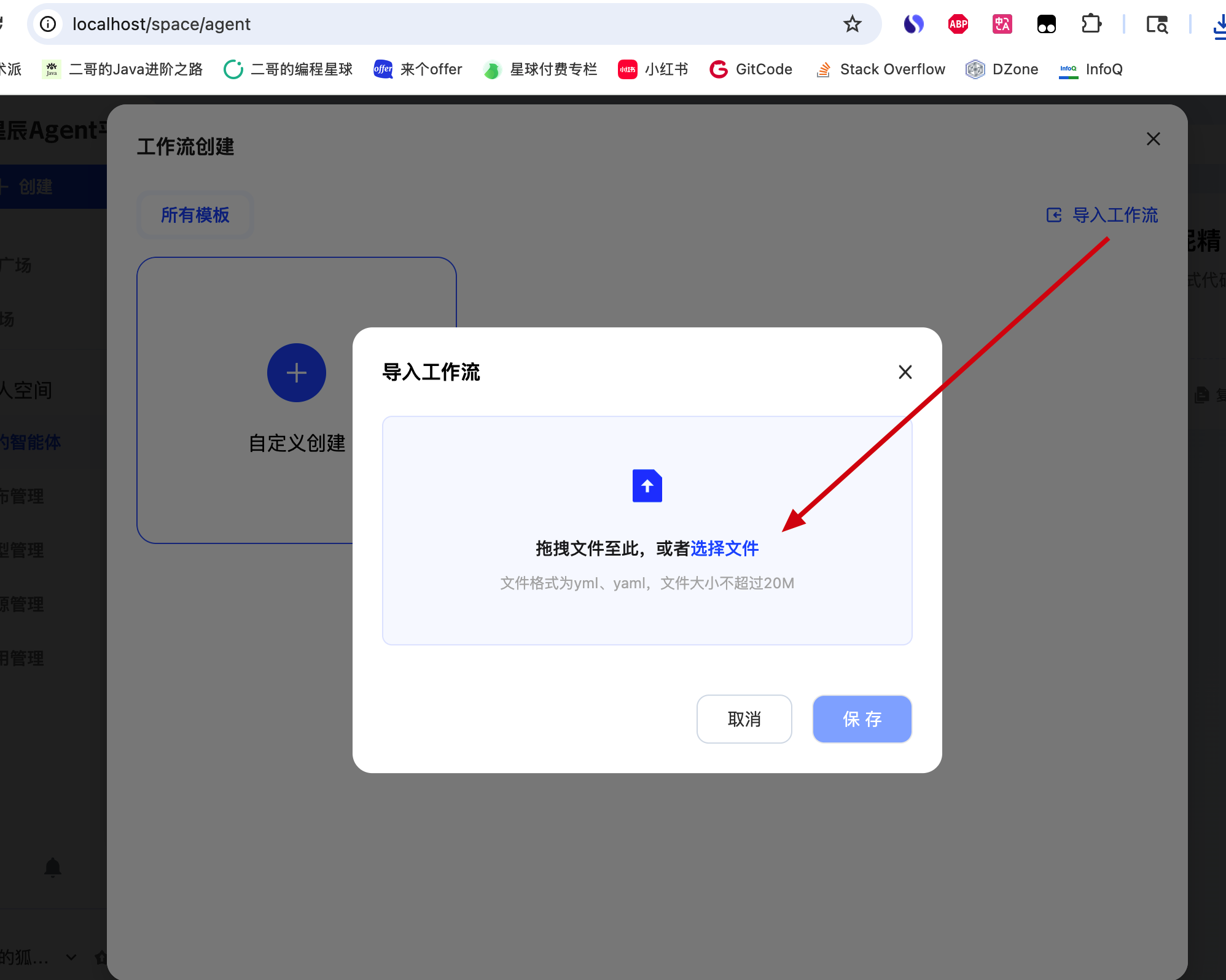
我放在 docker/astronAgent 文件夹下。
04、简历上如何写 AstronAgent?
AstronAgent - AI 智能体平台 2025.10
技术栈: Docker、MySQL 8.4、Redis 7、PostgreSQL 14、MinIO、Kafka、Elasticsearch、Spring Boot
项目描述: 基于微服务架构的企业级 AI 智能体编排平台,支持工作流可视化编排、多模型集成(DeepSeek、讯飞星火等)、插件化工具扩展,提供从智能体创建、调试到发布的完整生命周期管理能力。
核心职责:
- 负责平台容器化部署架构设计与优化,通过 Docker Compose 编排 17+ 微服务容器(包括 console-hub、core-workflow、core-link、core-aitools 等),解决服务间网络通信和健康检查问题,实现一键部署,部署时间从 2 小时缩短至 15 分钟
- 排查并修复工作流节点执行失败问题,通过分析 core-link 服务与 MySQL/PostgreSQL 双数据库交互逻辑,定位工具版本号不匹配、用户权限校验、数据库表映射错误等 3 类关键缺陷
- 解决微服务网络地址动态变化导致的 502 错误,通过分析 Docker 网络 IP 分配机制和 Nginx 反向代理配置,实现容器重启后自动服务发现
- 优化跨数据库工具注册与同步机制,定位 astron_console.tool_box 和 spark-link.tools_schema 双表数据不一致问题,修复 tool_id、version、app_id、server URL 等 4 个字段的映射关系,确保 MCP 工具正确加载
- 修复 YAML 配置文件缩进错误,通过 docker-compose.yaml 语法校验,定位 elasticsearch 和 kafka 服务配置中的空格缩进问题(3 spaces vs 2 spaces),消除服务启动阻塞
- 诊断并修复工具 API 协议不匹配问题,将 open_api_schema 中的 server URL 从 https://core-aitools:18669 修正为 http://core-aitools:18668,解决插件节点调用失败(错误码 23400)问题
- 构建多模型语音合成工作流,集成 DeepSeek 大模型与讯飞超拟人合成服务,实现"文本 → 播客风格改写 → 语音合成"的端到端流程,支持自定义发音人和语速参数
- 完成数据库权限配置与查询优化,通过 MySQL 权限管理和跨数据库 SQL 查询(astron_console、spark-link、workflow 等多库联查),解决工具元数据查询失败和权限拒绝问题,查询响应时间稳定在 50ms 以内
05、ending
大家都知道 AI 是当下的热点,通过研究科大讯飞开源的这个顶级 Agent 项目,我们也基本上具备了一定的 AI 大模型应用的开发能力。
在求职面试的时候,也一定能够吸引更多 HR 和面试官的注意力。
从我自己的使用体验来看,科大讯飞开源的 AstronAgent 项目完成度非常高,无论是框架设计、Agent 调度,还是任务执行的细节。
对想做 AI 应用落地的同学来说,这个项目非常值得研究。你能从里面看到一个完整 Agent 系统该怎么搭、怎么调度、怎么和模型配合——而且是跑得通的那种。
GitHub 地址我再贴一下:
强烈推荐大家都去学一手,下一个大的 offer 等着你哦。

回复