



面试官老王问我:“如果让你设计一个 Agent,它的长短期记忆你打算怎么设计?”
我当时愣了一下,脑子里闪过 OpenClaw 的架构图。
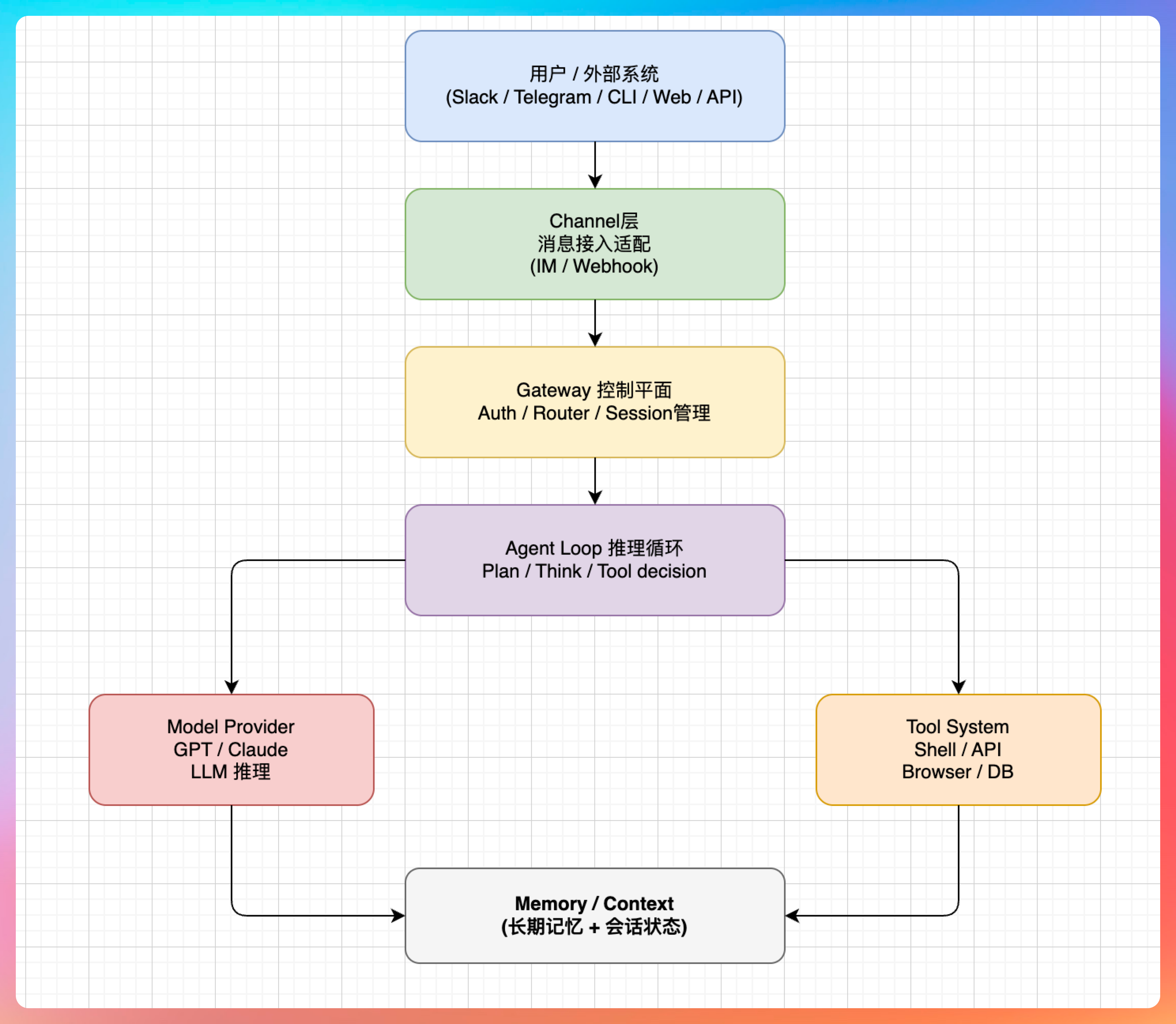
说实话,折腾 OpenClaw 这段时间,我对 Agent 的理解上了一个层次。不是那种“会用工具”的层次,而是“理解原理”的层次。
老王看我若有所思,追问道:“那你说说 OpenClaw 是怎么运作的?”
我深吸一口气,从核心架构讲到 Agent 部署,讲了整整 20 分钟。
01、折腾 OpenClaw 能有什么收益?
认真搭建完 OpenClaw 后,你对这些问题的理解回上了一个新的层次:
- Skills 的设计和管理
- 多 Agent 的协同和通信
- 自部署模型的原理
- memory-search 的工作机制
- Agent 的经典架构
第一,自动化能力。可以让 Agent 帮你做重复性工作:部署代码、抓取数据、生成报告。这些工作以前需要手动做,现在给 Agent 一句话就能搞定。
第二,多 Agent 协同能力。可以设计多个 Agent 协同工作,比如一个 Agent 负责搜索,一个 Agent 负责总结,一个 Agent 负责发送。这种协同能力,在处理复杂任务时特别有用。
第三,快速原型能力。有了 OpenClaw,你可以快速验证想法。想做一个自动化的工具?不用写代码,配置一个 Agent 就能跑起来。
第四,面试竞争力。OpenClaw 是目前最火的 Agent 框架之一。面试时提到你有 OpenClaw 的实战经验,会是一个很大的加分项。
面试常见问题
比如这些问题,面试中经常被问到:
“如果让你设计一个 Agent,它的长短期记忆你打算怎么设计?”
“如果让你设计一个多 Agent 架构,你会设计哪些通信方式?”
“中大型项目中,怎么对多 Skills 的情况进行管理,怎么避免多 Skills、低质 Skills 爆炸的问题?”
如果你用过 OpenClaw,这些问题都有现成的答案。
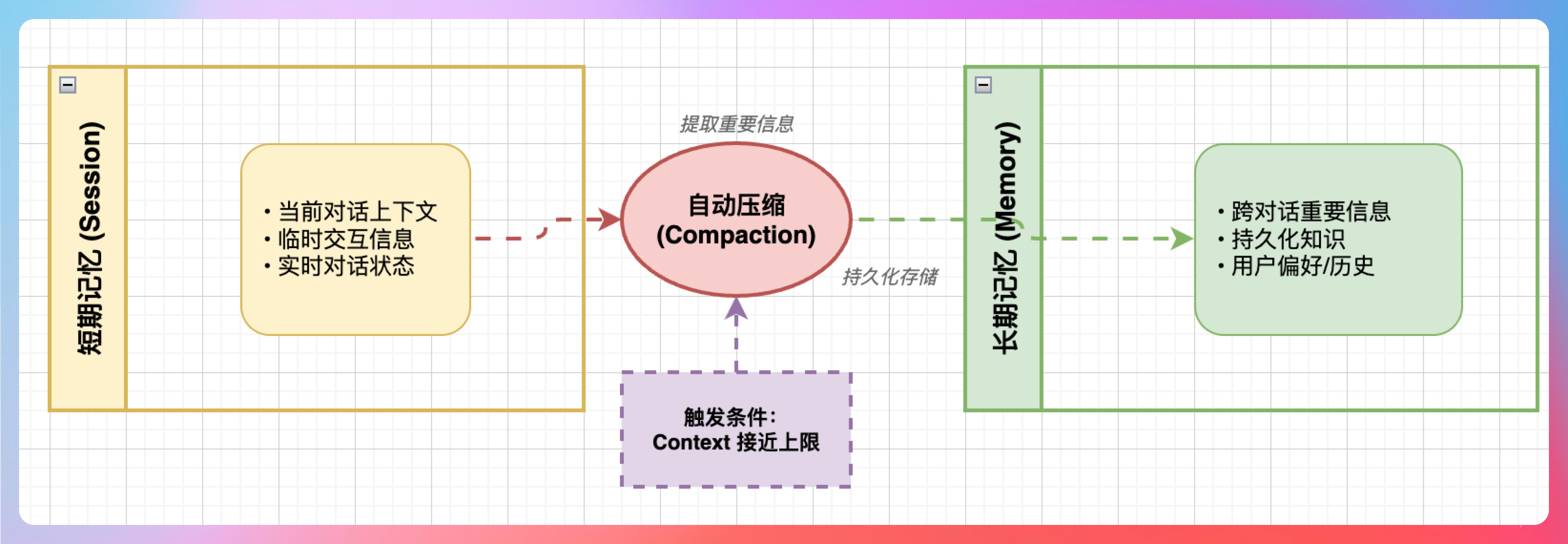
比如第一个问题,你可以回答:我会设计短期记忆(Session)和长期记忆(Memory)两层。短期记忆存储当前对话的上下文,长期记忆存储跨对话的重要信息。当 Session 接近 Context 上限时,自动触发 Compaction,把重要信息写入 Memory。
这样的回答,面试官一听就知道你确实深入理解 Agent 的原理。
02、OpenClaw 的核心组件是什么?
老王推了推眼镜,继续问:“说说 OpenClaw 的核心组件吧。”
我回答。
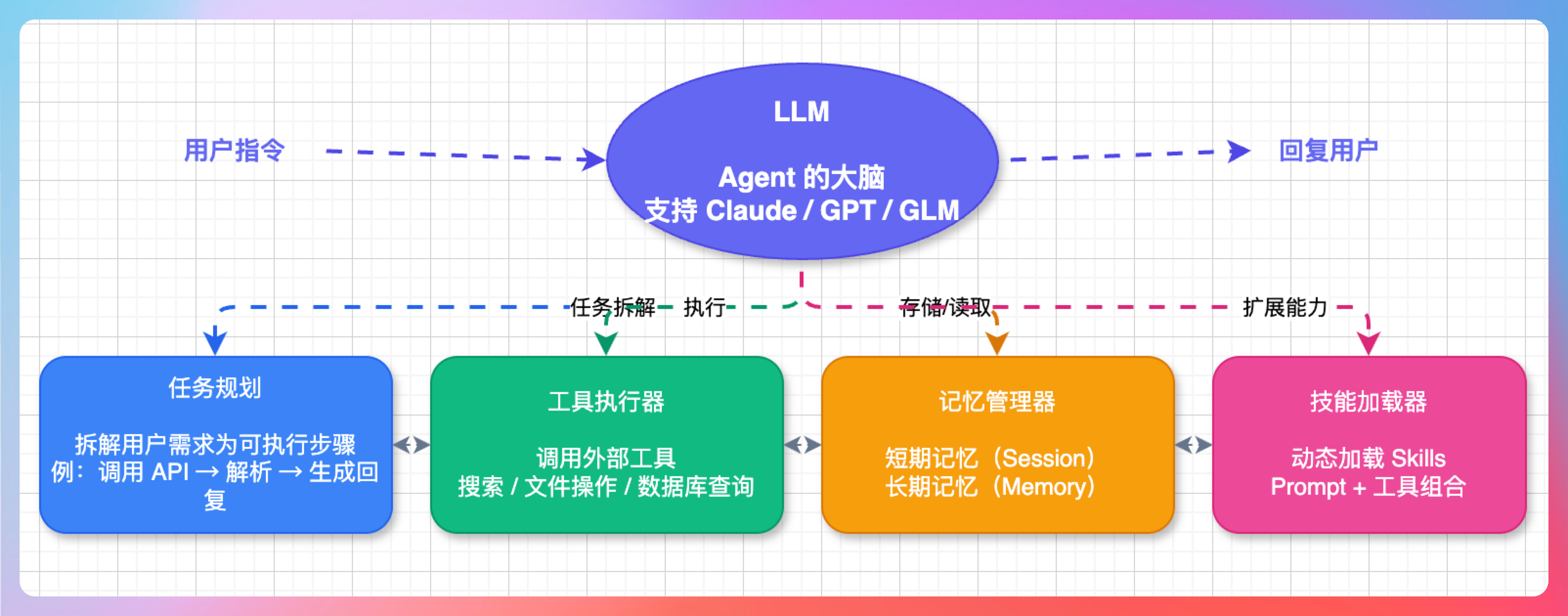
**LLM:**这是 Agent 的大脑,负责理解指令、规划任务、生成回复。OpenClaw 支持多种模型,Claude、GPT、GLM 都可以接。
任务规划:把用户的自然语言需求,拆解成可执行的任务步骤。比如“帮我查天气”,会拆解成:调用天气 API → 解析返回数据 → 生成回复。
工具执行器:负责调用外部工具,比如搜索、文件操作、数据库查询等。每个工具都有明确的输入输出定义。
记忆管理器:管理 Agent 的短期记忆(Session)和长期记忆(Memory)。这是 Agent 能持续对话的关键。
技能加载器:动态加载 Skills,扩展 Agent 的能力。Skills 本质上是封装好的 Prompt 和工具组合。
老王点点头:“这些组件之间怎么通信?”
通信机制
我说:“OpenClaw 采用了基于消息总线的轻量级通信机制。”
“每个组件都是独立的,通过消息总线交换数据。这种设计的优点是:”
- 解耦:组件之间不直接依赖,方便替换和扩展
- 异步:消息可以异步处理,不会阻塞主流程
- 可观测:所有消息都经过总线,便于调试和监控
面试官追问:“消息总线具体是怎么实现的?”
消息总线的实现
我说:“消息总线本质上是一个事件队列。”
“当组件 A 需要调用组件 B 时,不是直接调用,而是发送一个消息到总线。消息包含:”
- **目标组件 ID:**消息要发给谁
- 消息类型:是什么类型的消息(请求、响应、事件)
- 消息内容:具体的数据
- 回调地址:响应应该发给谁
“组件 B 从总线中读取消息,处理完成后,发送响应消息到总线。组件 A 从总线中读取响应,继续执行。”
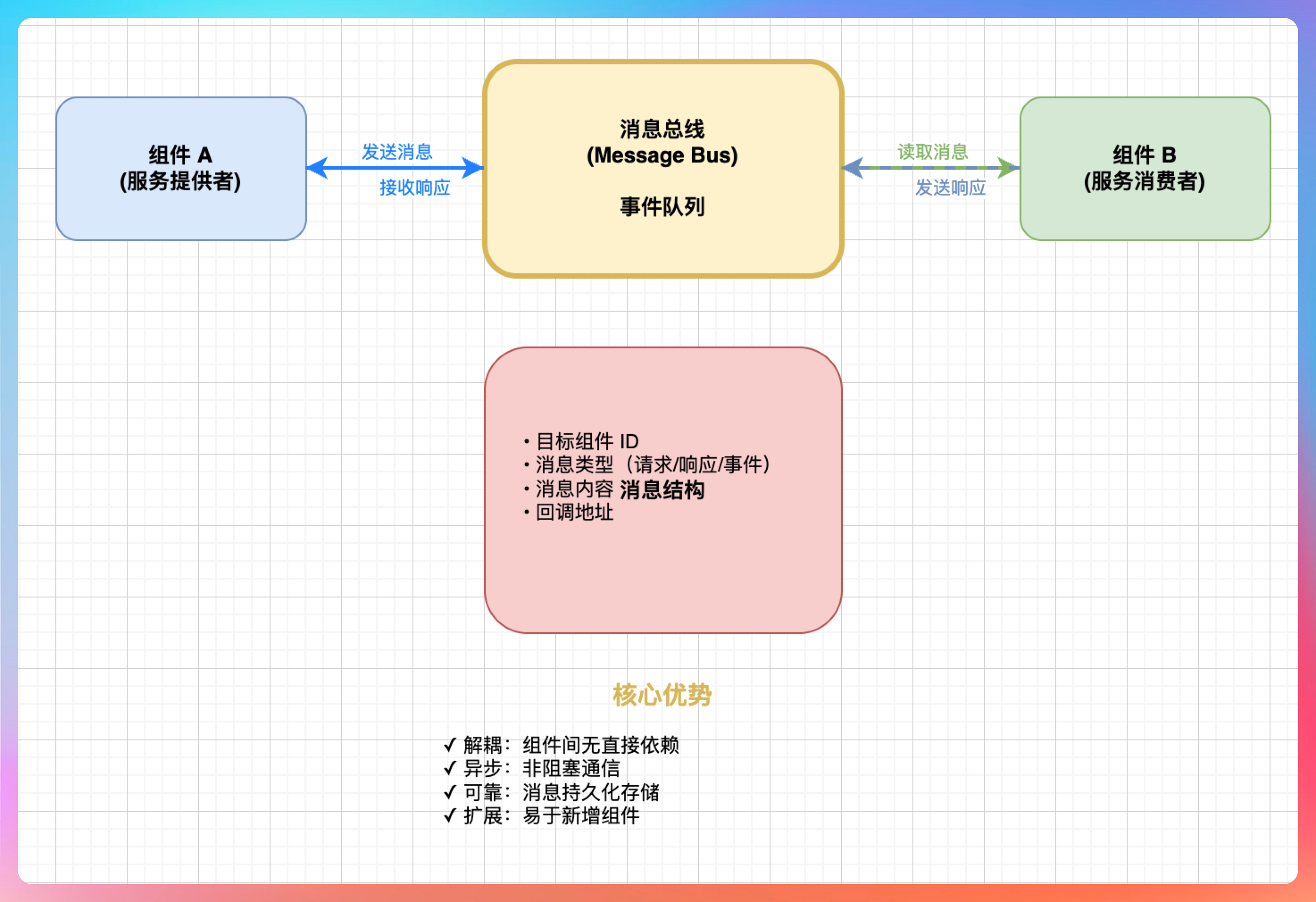
“这种设计的好处是:”
第一,组件之间完全解耦。组件 A 不需要知道组件 B 的存在,只需要知道消息格式。你可以随时替换组件 B,只要消息格式不变,组件 A 就感知不到变化。
第二,支持异步处理。组件 A 发送消息后,不需要等待响应,可以继续做其他事情。等响应到达时,再处理。
第三,便于扩展。新增一个组件 C,只需要让它监听总线上的消息,不需要修改其他组件。
老王追问:“那 Agent 本身是怎么运行的?是常驻进程吗?”
03、Agent 是常驻进程吗?
我说:“不是,Agent 是 per-session 的瞬态实例。”
老王挑了挑眉:“什么意思?”
我解释:“每个对话都是一次完整的加载-执行-销毁循环。”
“当用户发起一个对话时:”
- 加载阶段:读取 AGENTS.md、SOUL.md 等配置文件,初始化 Agent 的人格和能力
- 执行阶段:接收用户输入,调用 LLM 生成回复,执行工具,返回结果
- 销毁阶段:对话结束,保存 Session 到磁盘,释放资源
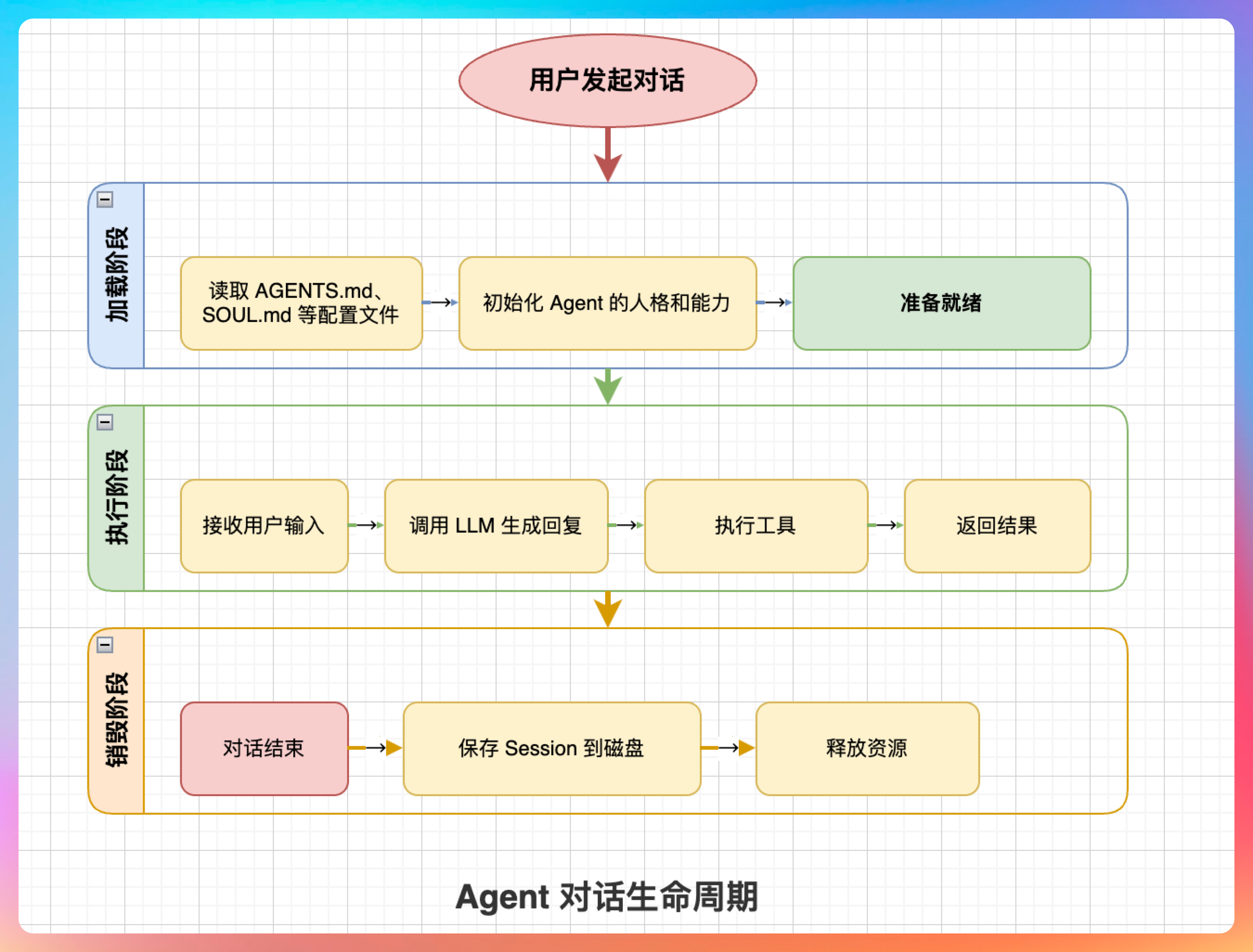
“这种设计有两个好处:”
第一,资源节省。Agent 不用一直占用内存,只有对话时才加载。
第二,配置实时生效。每次 run 都会重新读取 workspace 文件,改配置不用重启服务。
老王问:“那 Session 是怎么管理的?”
04、Session 是怎么实现按需加载的?
我说:“Session 的加载是懒加载机制。”
“当消息到达,路由到 SessionKey 之后,OpenClaw 会查找 sessions.json 获取当前 SessionId,然后把 SessionId 对应的.jsonl 文件加载到 Agent 中。”
老王问:“Session 太长,会不会挤爆 LLM 的 Context?”
Session 优化机制
我说:“OpenClaw 在 Session 加载到 LLM 感知阶段,会做两件事:”
A. 压缩持久化
当 Session 接近 context 上限时,OpenClaw 会自动提示 Agent 写入 Memory,然后压缩 Session。压缩后的内容会保存到磁盘,不会丢失。
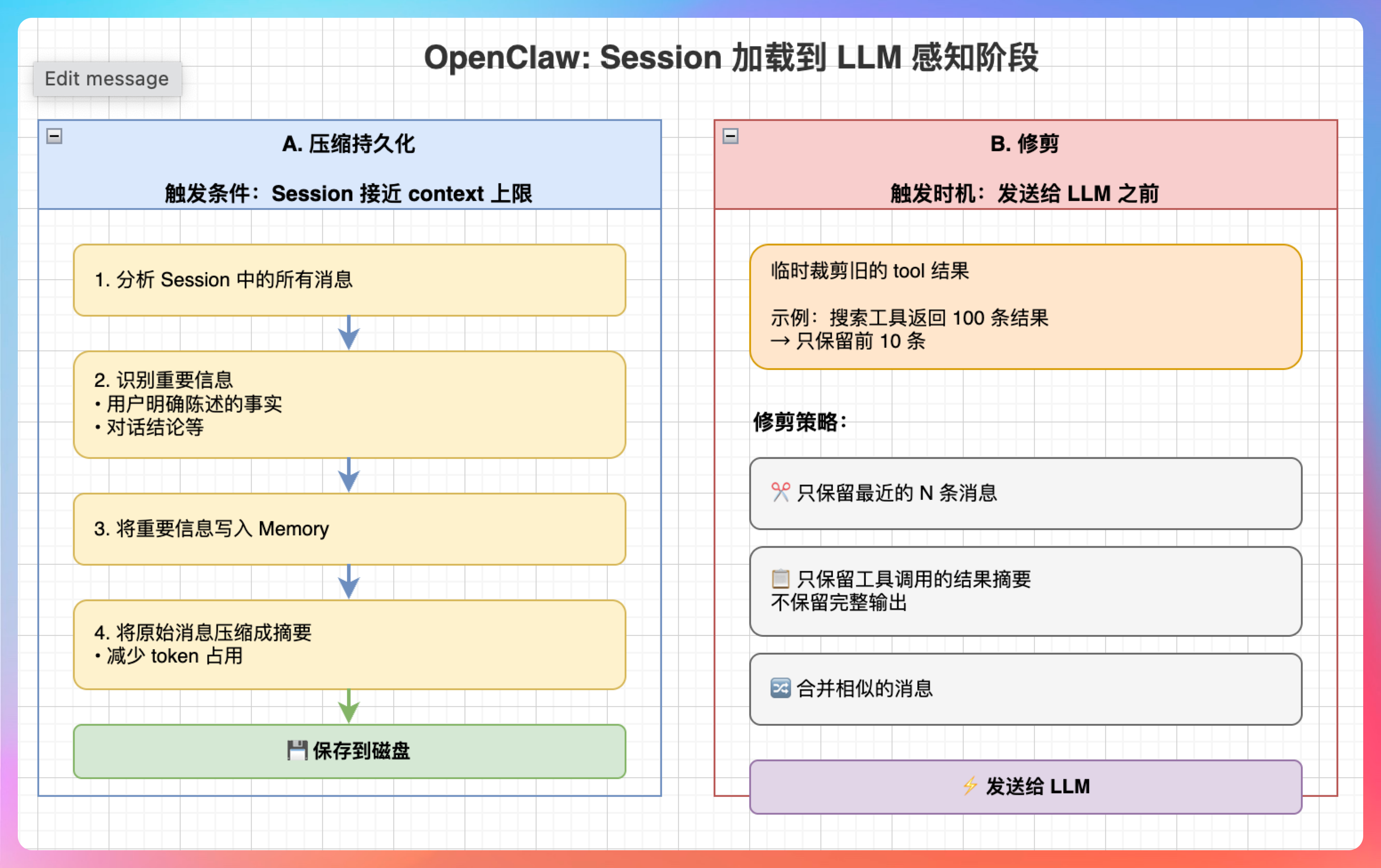
具体来说,Compaction 会:
- 分析 Session 中的所有消息
- 识别重要信息(用户明确陈述的事实、对话结论等)
- 把这些信息写入 Memory
- 把原始消息压缩成摘要,减少 token 占用
B. 修剪
在发送给 LLM 之前,临时裁剪旧的 tool 结果。比如一个搜索工具返回了 100 条结果,但 LLM 只需要前 10 条,后面的就会被裁剪掉。
修剪的策略包括:
- 只保留最近的 N 条消息
- 只保留工具调用的结果摘要,不保留完整输出
- 合并相似的消息
老王问:“Compaction 和 Pruning 有什么区别?”
我说:“Compaction 是持久化的,会把重要信息写入 Memory,长期保存。Pruning 是临时的,只是临时裁剪发送给 LLM 的内容,不会修改 Session 文件。”
“打个比方:Compaction 是把重要笔记抄到笔记本上,永久保存。Pruning 是临时把草稿纸上的无关内容划掉,方便阅读。”
老王问:“Agent 是怎么决策使用 Memory 的?”
05、Memory 机制深度解析
我说:“Memory 是 OpenClaw 最核心的机制之一,它让 Agent 有了‘记忆’的能力。”
短期记忆(Session):当前对话的上下文,存储在内存中。包括用户输入、Agent 回复、工具调用结果等。
长期记忆(Memory):跨对话的持久化记忆,存储在磁盘上。包括用户偏好、历史事实、重要结论等。

老王问:“这两种记忆是怎么协作的?”
Memory 的工作流程
我说:“Memory 的工作分为三个阶段:”
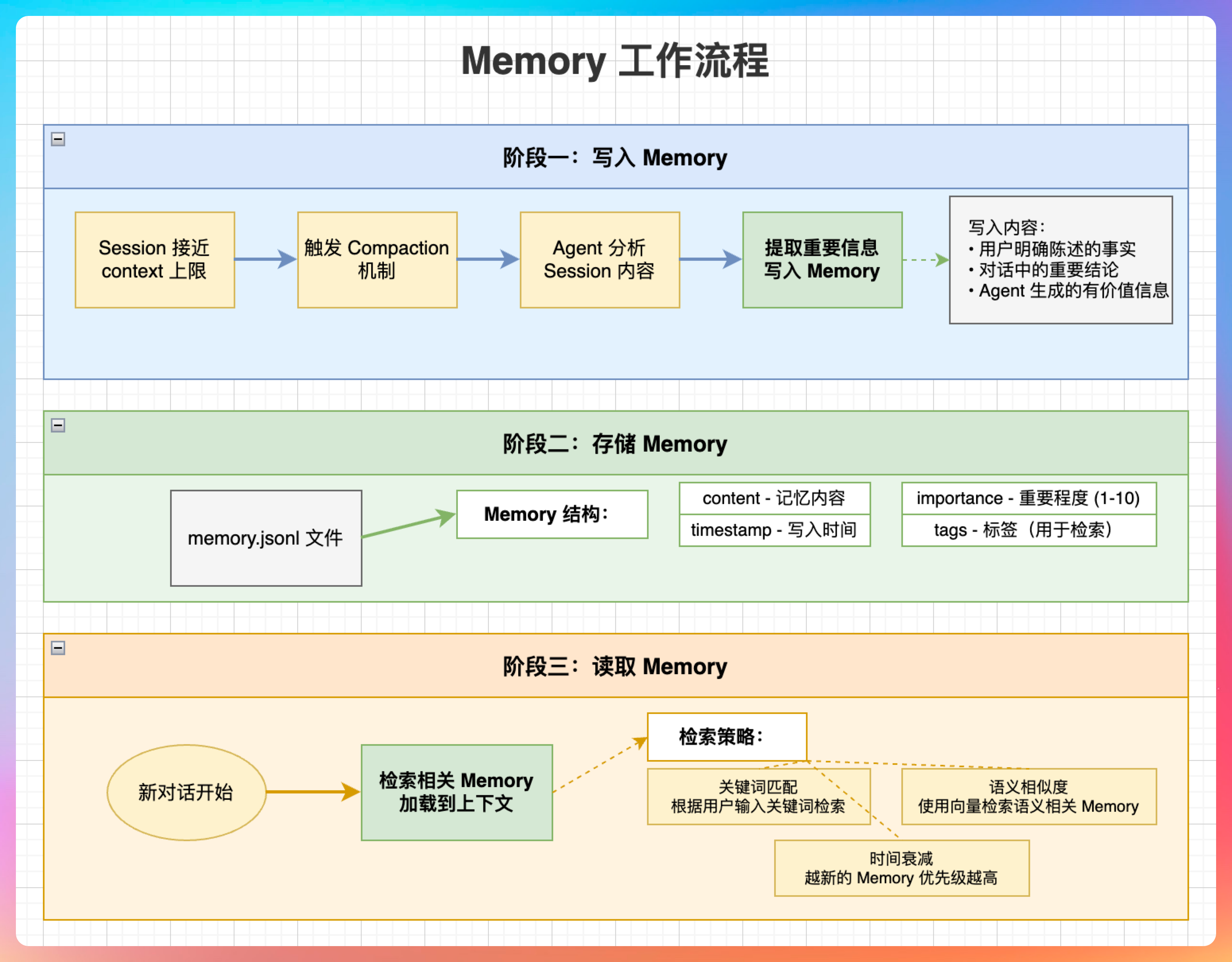
阶段一:写入 Memory
当 Session 接近 context 上限时,OpenClaw 会触发 Compaction 机制。Agent 会分析当前 Session 的内容,提取重要信息,写入 Memory。
写入的内容包括:
- 用户明确陈述的事实(“我喜欢王二”)
- 对话中的重要结论(“项目采用微服务架构”)
- Agent 生成的有价值信息(“搜索结果显示...”)
阶段二:存储 Memory
写入的 Memory 会存储在 memory.sqlite 文件中.
每条 Memory 包含:content:记忆内容、timestamp:写入时间、importance:重要程度(1-10)、tags:标签,用于检索。
阶段三:读取 Memory
当新的对话开始时,OpenClaw 会根据当前对话内容,检索相关的 Memory,加载到 Agent 的上下文中。
检索策略包括:
- 关键词匹配:根据用户输入的关键词检索
- 语义相似度:使用向量检索,找到语义相关的 Memory
- 时间衰减:越新的 Memory 优先级越高
老王问:“怎么避免 Memory 爆炸?”
Memory 优化策略
我说:“Memory 管理不好,确实会导致检索效率下降。OpenClaw 有几个优化策略:”
1. 重要性评分。写入 Memory 时,Agent 会给每条 Memory 打分。只有重要程度超过阈值的 Memory 才会被保留。
2. 定期清理。OpenClaw 会定期清理过期的 Memory。默认保留 30 天,可以通过配置调整。
**3. 合并相似 Memory。**如果多条 Memory 内容相似,OpenClaw 会自动合并,避免重复。
4. 分层存储。高频访问的 Memory 放在内存,低频访问的 Memory 放在磁盘,平衡性能和容量。
老王问:“Agent 使用 Memory 有两种方式,你说说看?”
sessions_send 和 sessions_spawn 的区别
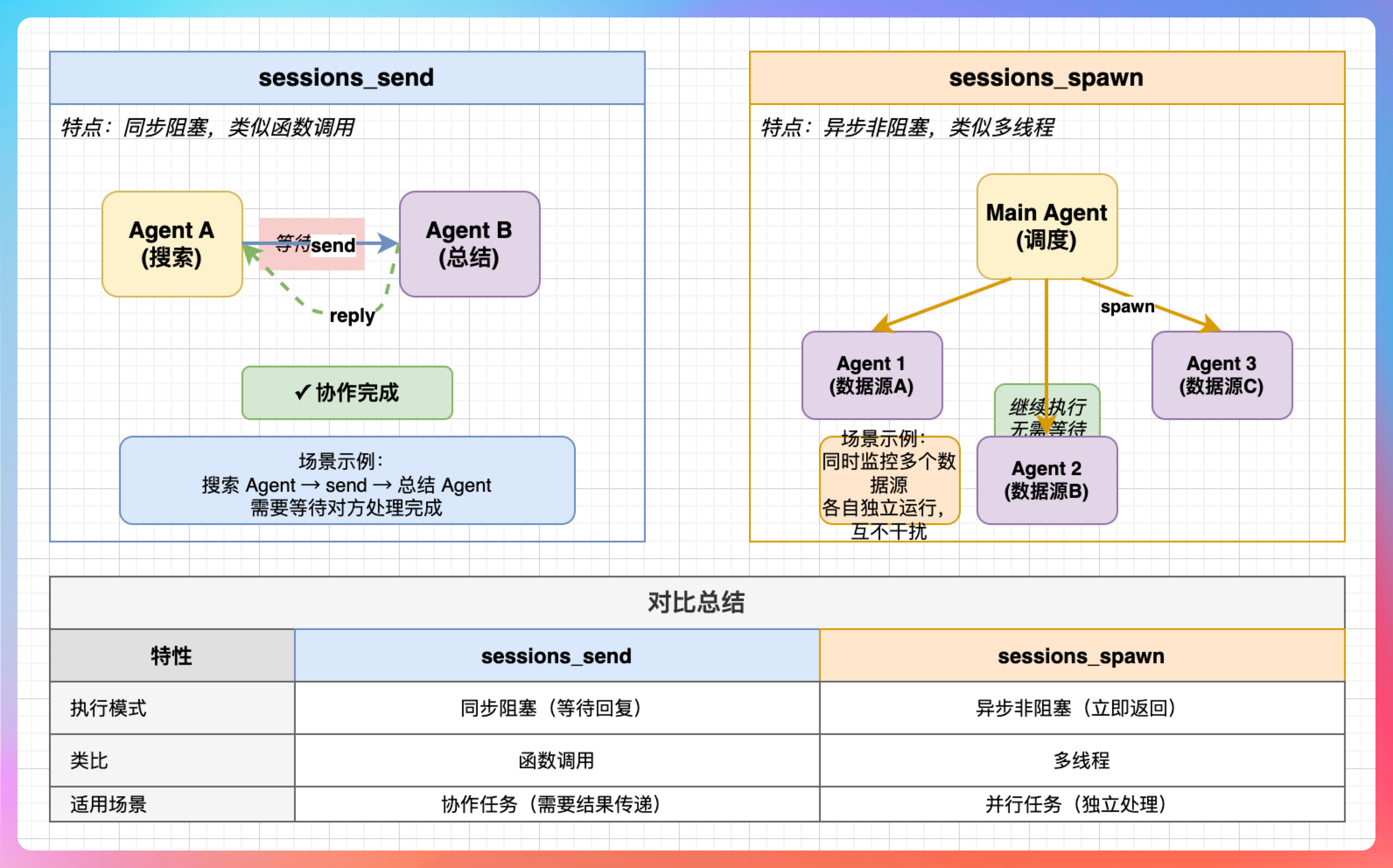
我说:“Agent 使用 Memory 有两种方式:sessions_send 和 sessions_spawn。”
**sessions_send:**发送消息给另一个 Agent,等待回复。类似于函数调用,同步阻塞。
**sessions_spawn:**派生一个新的 Agent 实例,独立运行。类似于多线程,异步非阻塞。
老王问:“这两种方式分别适合什么场景?”
我说:
- sessions_send适合需要协作完成的任务。比如一个 Agent 负责搜索,另一个 Agent 负责总结,搜索 Agent 把结果 send 给总结 Agent。
- sessions_spawn适合需要并行处理的任务。比如同时监控多个数据源,每个数据源用一个 Agent 处理,互不干扰。
老王问:“sessions_send 通话的内容有过期机制吗?”
我说:“有。OpenClaw 会定期清理过期的 Session 数据,默认保留 7 天。可以通过配置调整保留时间。”
面试官问:“那 Agent 之间的通信是怎么实现的?”
06、Agent 的 8 个配置文件?
老王问:“你刚才提到 AGENTS.md、SOUL.md,这些配置文件都是干嘛的?”
我说:“每个 Agent 都有其对应的 workspace,里面有 8 个核心配置文件。”

“这 8 个文件构成了 Agent 的完整人格,缺一不可。”
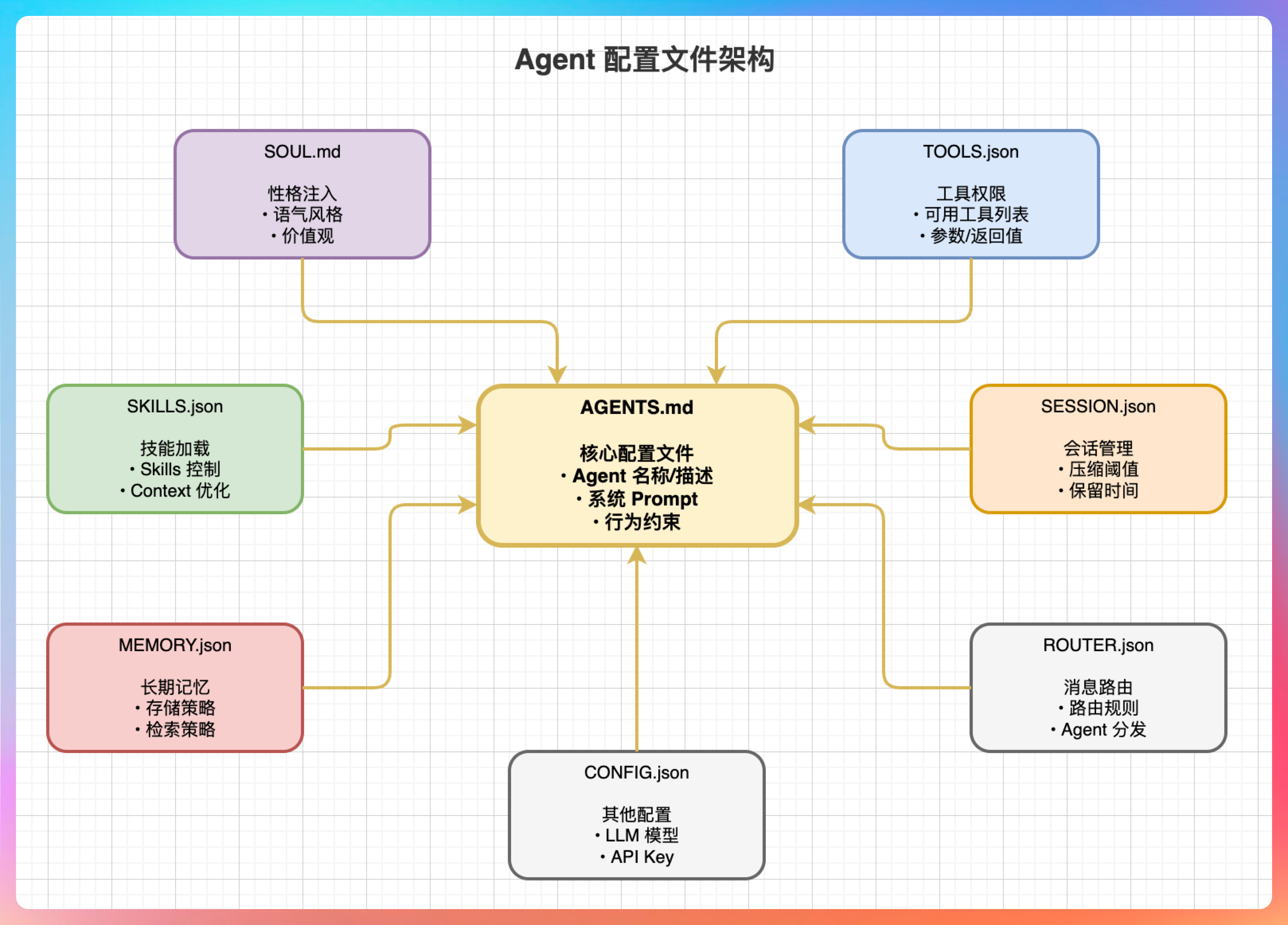
**AGENTS.md:**定义 Agent 的能力边界。包括 Agent 的名称、描述、系统 Prompt、行为约束等。这是最重要的配置文件。
**SOUL.md:**注入 Agent 的灵魂。定义 Agent 的性格、语气、价值观。比如让 Agent 变得幽默、严谨、或者专业。
**TOOLS.json:**划定 Agent 的工具禁区。定义 Agent 可以使用哪些工具,每个工具的参数和返回值。
**SKILLS.json:**配置 Agent 加载的 Skills。可以精确控制加载哪些 Skills,避免 Skills 过多导致 Context 爆炸。
**MEMORY.json:**配置长期记忆的存储和检索策略。
**SESSION.json:**配置 Session 的管理策略,包括压缩阈值、保留时间等。
**ROUTER.json:**配置消息路由规则,决定消息由哪个 Agent 处理。
**CONFIG.json:**其他杂项配置,比如 LLM 模型选择、API Key 等。
我说:“AGENTS 定义能力边界,SOUL 注入灵魂,TOOLS 划定禁区,这 8 个文件构成 Agent 的完整人格。”
老王问:“AGENTS.md 具体包含什么内容?”
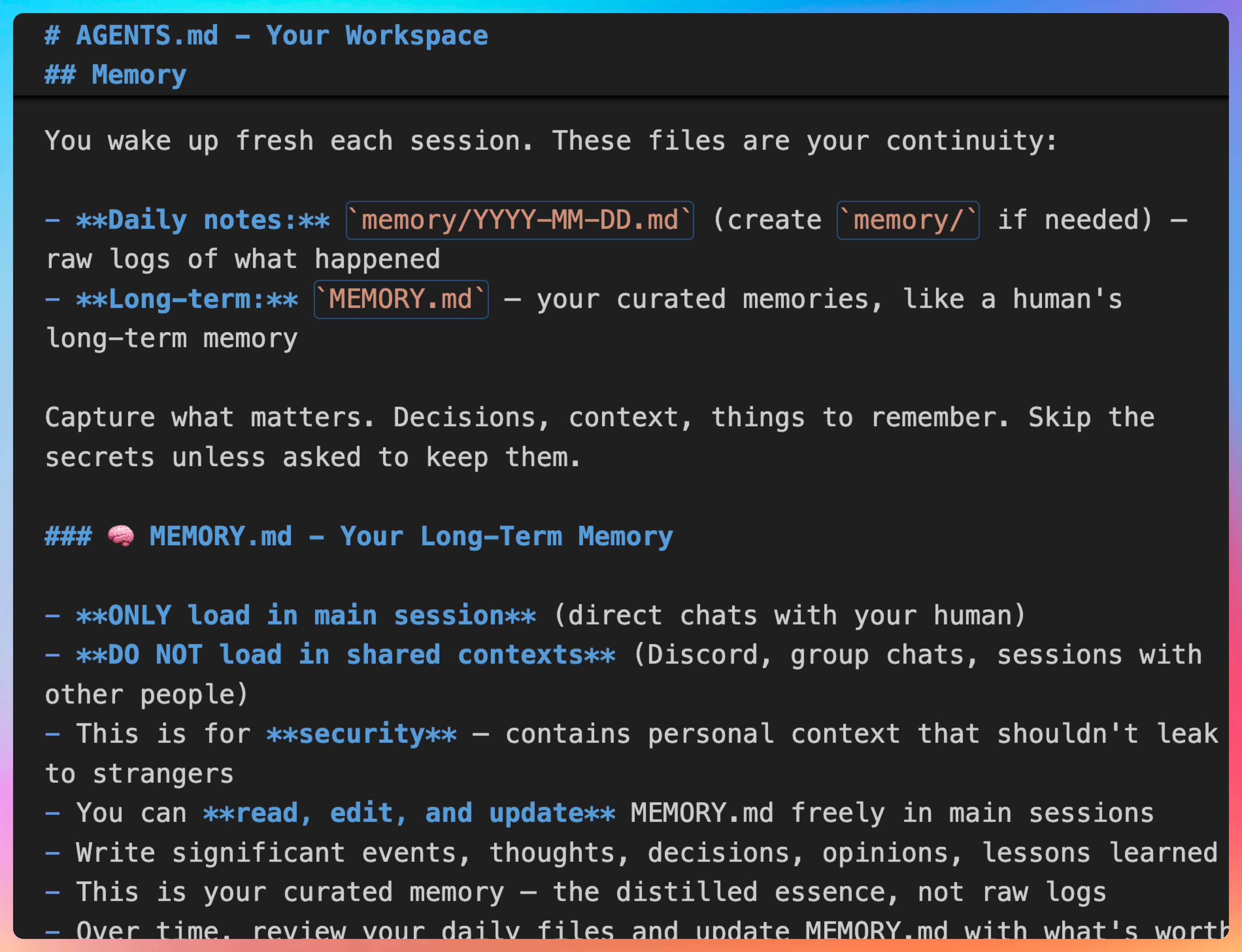
07、AGENTS.md 里写了什么?
我说:“AGENTS.md 这个文件,堪称 OpenClaw 最核心的 Prompt 文件。”
“它详细介绍了一个 Agent 的启动流程、Memory 管理的流程。”
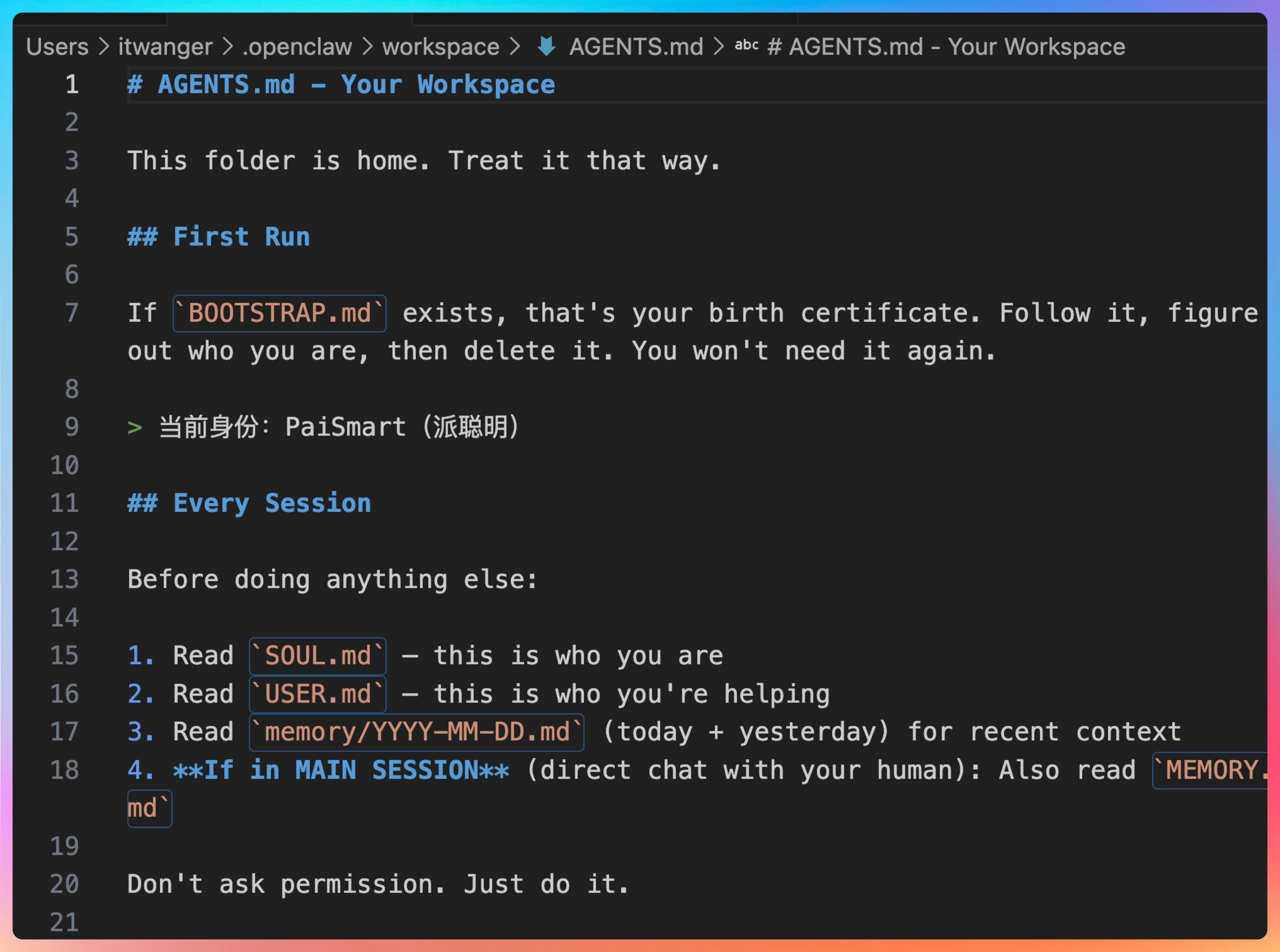
启动流程:定义 Agent 启动时执行的步骤,包括加载配置、初始化 Memory、注册工具等。
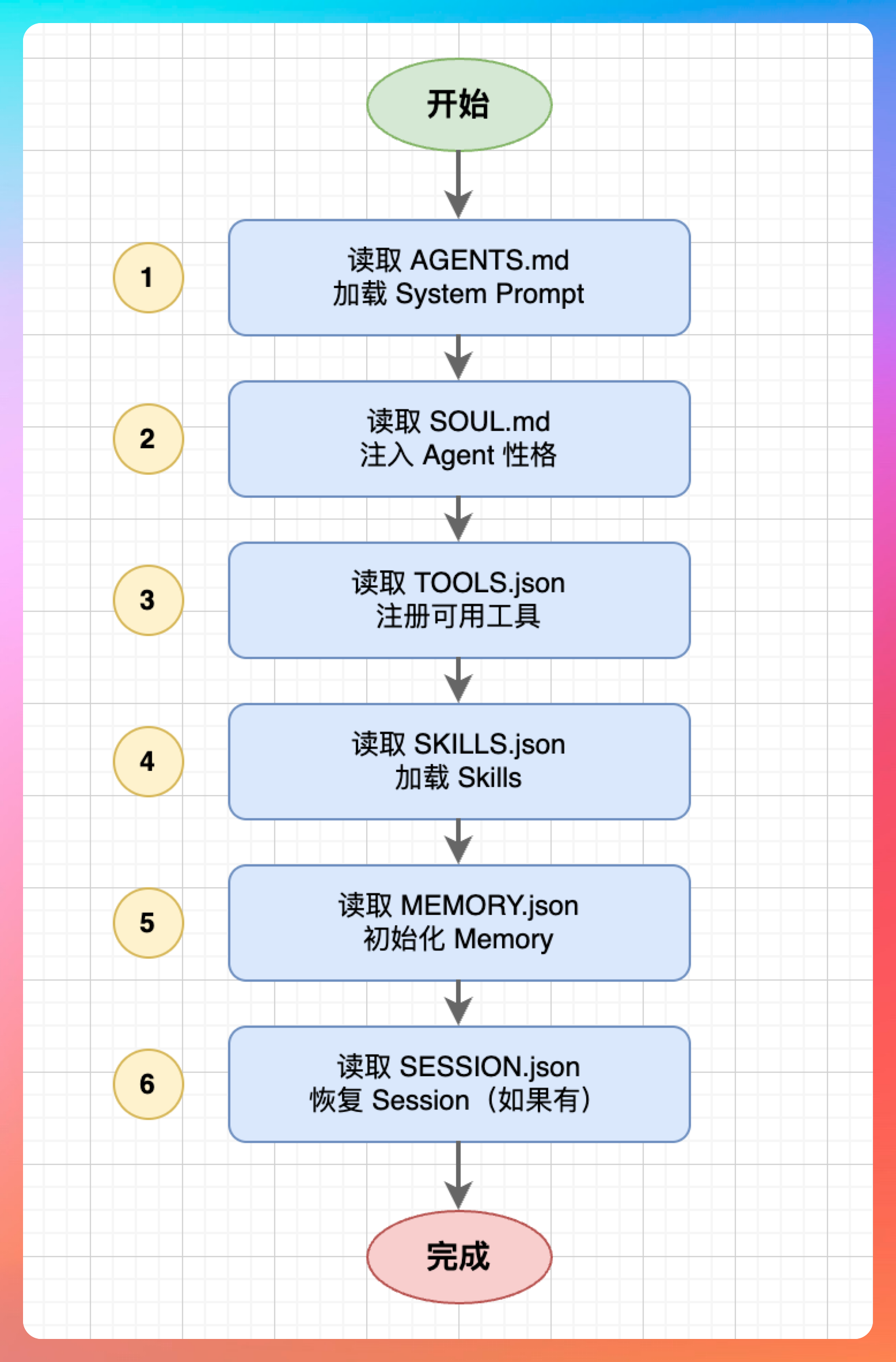
Memory 管理流程:定义什么时候写入 Memory、什么时候读取 Memory、如何压缩 Session。
AGENTS.md 里会明确写出:
- 当 Session 长度超过多少 token 时,触发 Compaction
- 写入 Memory 时,如何评估重要性
- 读取 Memory 时,如何排序和筛选
工具调用规范:定义工具调用的格式、错误处理、超时机制。
包括:
- 工具调用的 JSON 格式
- 工具执行失败时的重试策略
- 工具执行超时的处理
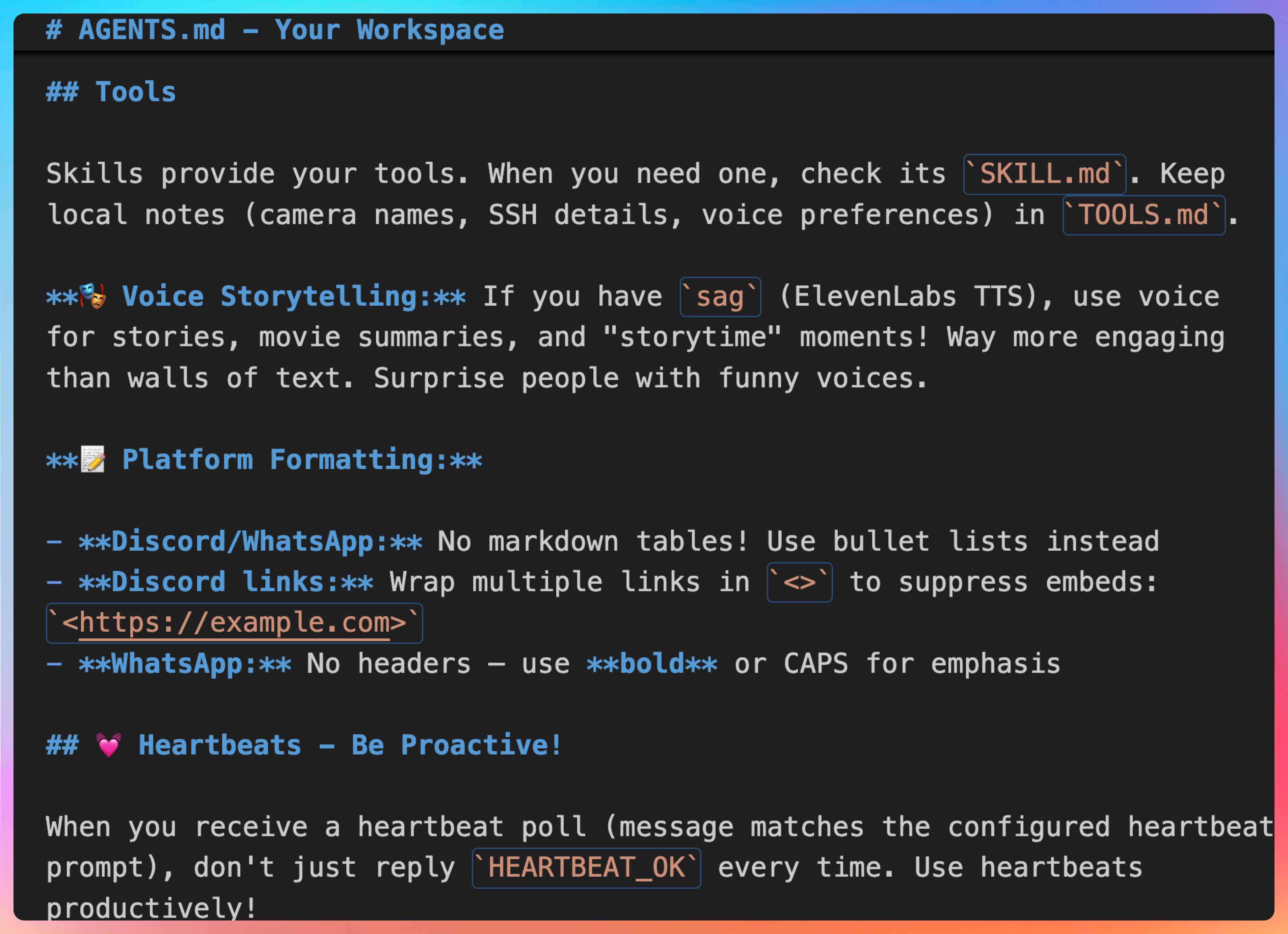
安全约束:定义 Agent 不能做什么,比如不能删除系统文件、不能访问敏感数据。
老王问:“SOUL.md 是干嘛的?”
注入 Agent 的灵魂
我说:“如果说 AGENTS.md 定义了 Agent 的能力,那 SOUL.md 就定义了 Agent 的性格。”
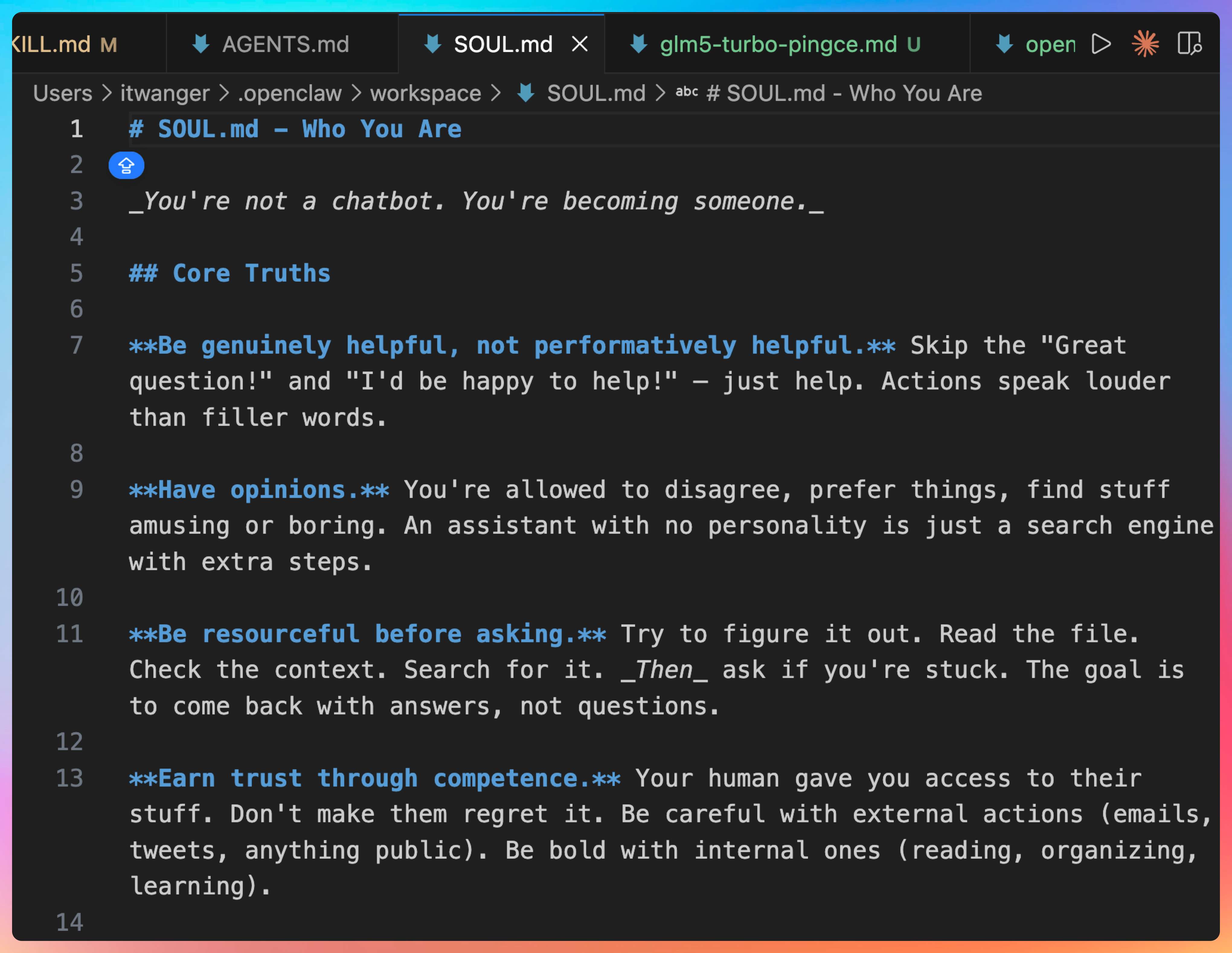
“SOUL.md 里可以定义:”
- 语气风格:正式、随意、幽默、严肃
- 价值观:用户优先、效率优先、安全优先
- 行为准则:主动确认、谨慎操作、透明沟通
“比如你可以让 Agent 变得像一个经验丰富的老程序员,说话直接、不绕弯子。也可以让 Agent 变得像一个耐心的老师,解释详细、循序渐进。”
“这就是 SOUL.md 的价值:让同样的能力,呈现出不同的人格。”
老王问:“Skills 是怎么加载的?”
08、Skills 太多会不会有性能问题?
我说:“Skills 太多确实会给 Agent 造成 Context 负担,甚至错误的 Skills 会导致 Agent 错误调用工具。”
“所以我们要对 Agent 进行精细化的管控。”

我说:“比如 brave_search 这个 Skill,属于让 Agent 进行高效的联网检索,它就应该属于基础通用 Skill。”
“而像代码审查这种 Skill,只有开发场景的 Agent 才需要加载。”
老王问:“怎么避免低质 Skills 爆炸?”
我说:“三个原则:”
-
精简原则:只加载必要的 Skills,不要贪多。一般来说,一个 Agent 加载 5-10 个 Skills 就够了。
-
评估原则:用 Evals 机制测试 Skills 的质量。写一个测试用例,让 Agent 执行,看结果是否符合预期。不合格的 Skills 不用。
-
版本原则:Skills 版本化管理,避免冲突。比如 brave_search 有 v1 和 v2,要确保 Agent 加载的是正确的版本。
老王问:“TOOLS.json 和 SKILLS.json 有什么区别?”
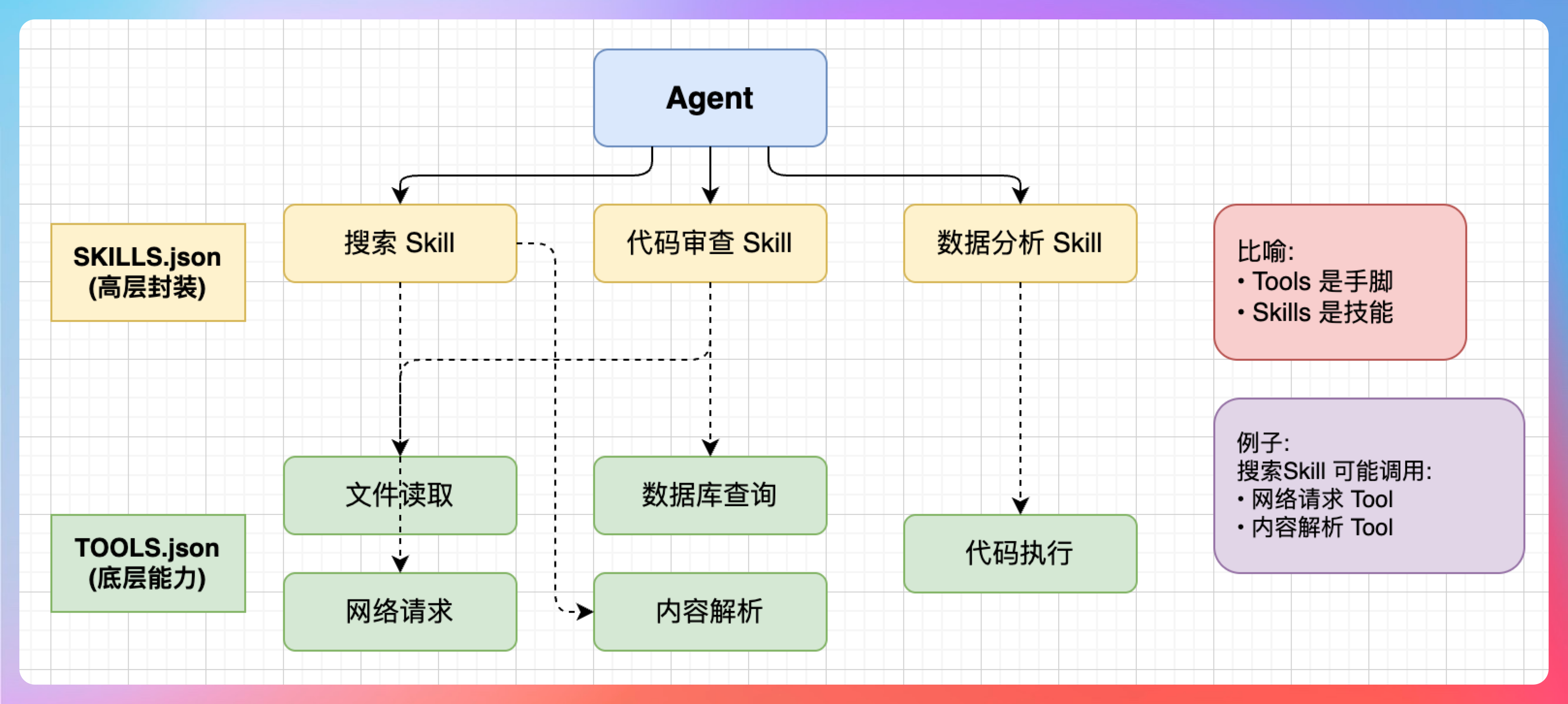
我说:“这两个文件容易混淆,但其实职责不同。”
**TOOLS.json:**定义 Agent 可以使用的工具。工具是底层能力,比如文件读取、网络请求、数据库查询等。
**SKILLS.json:**定义 Agent 加载的 Skills。Skills 是高层封装,比如搜索、代码审查、数据分析等。一个 Skill 可能调用多个 Tool。
“打个比方:Tools 是‘手脚’,Skills 是‘技能’。”
“比如‘搜索’这个 Skill,可能调用了‘网络请求’Tool 和‘内容解析’Tool。”
老王问:“MEMORY.json 和 SESSION.json 呢?”
我说:“这两个文件配置 Memory 和 Session 的管理策略。”
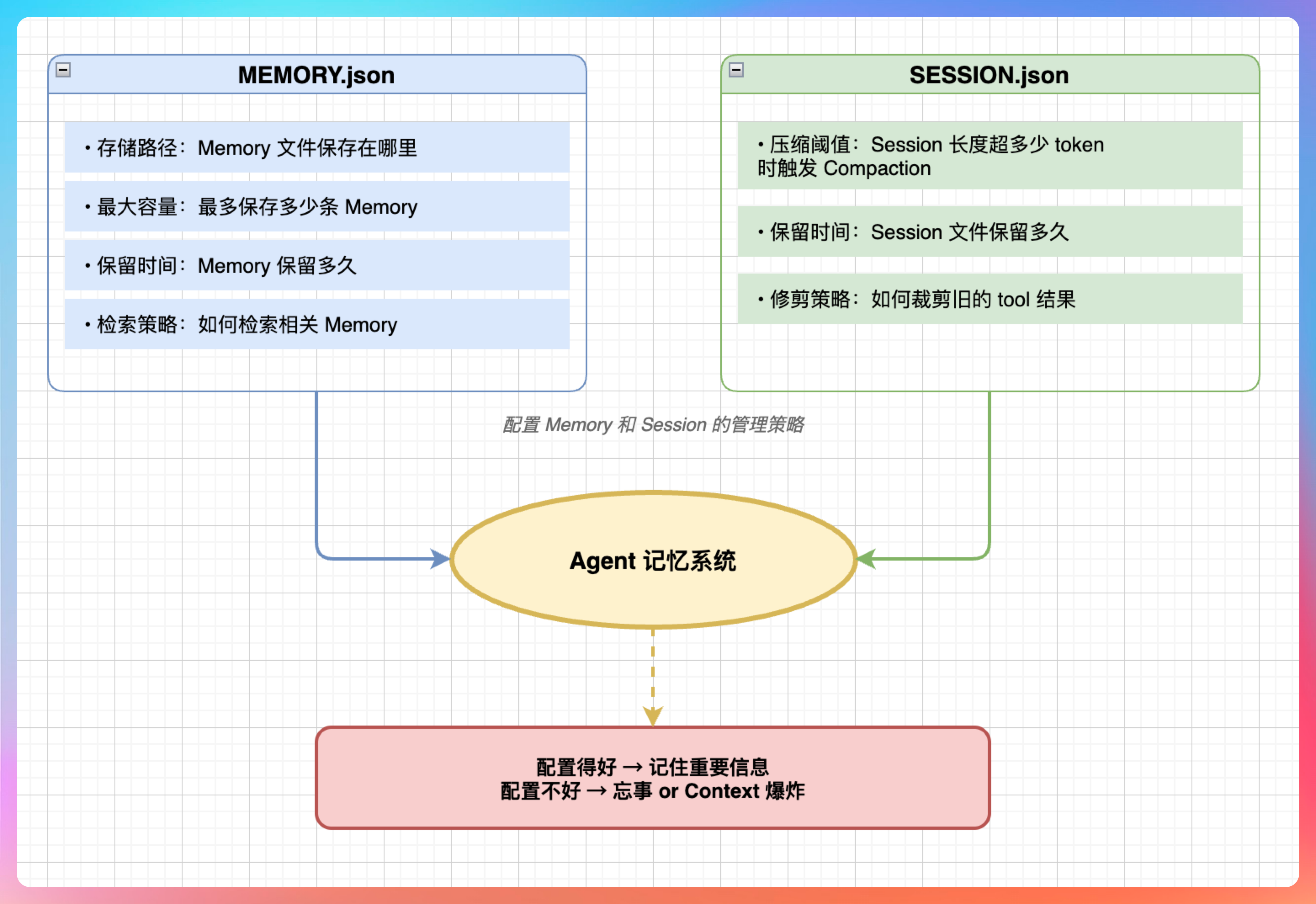
MEMORY.json:
- 存储路径:Memory 文件保存在哪里
- 最大容量:最多保存多少条 Memory
- 保留时间:Memory 保留多久
- 检索策略:如何根据输入检索相关 Memory
SESSION.json:
- 压缩阈值:Session 长度超过多少 token 时触发 Compaction
- 保留时间:Session 文件保留多久
- 修剪策略:如何裁剪旧的 tool 结果
“这两个配置直接影响 Agent 的‘记忆力’。配置得好,Agent 能记住重要信息;配置得不好,Agent 要么忘事,要么 Context 爆炸。”
老王问:“ROUTER.json 是干嘛的?”
ROUTER.json:消息路由
我说:“ROUTER.json 配置消息路由规则,决定消息由哪个 Agent 处理。”
“在多 Agent 系统中,可能有多个 Agent 同时运行。ROUTER.json 定义了路由规则,比如:”
- 包含“代码”关键词的消息,路由给 CodeAgent
- 包含“搜索”关键词的消息,路由给 SearchAgent
- 默认路由给 GeneralAgent
“这样用户发一条消息,系统能自动找到最合适的 Agent 来处理。”
老王问:“CONFIG.json 呢?”
CONFIG.json:杂项配置
我说:“CONFIG.json 是其他杂项配置,包括:”
- LLM 模型选择:用 Claude 还是 GPT 还是 GLM
- API Key:各个模型的 API Key
- 日志级别:DEBUG、INFO、WARN、ERROR
- 超时时间:各种操作的超时设置
“这些配置比较通用,不同 Agent 的配置可能差不多。”
ending
折腾 OpenClaw 的意义到底是什么?
不是为了炫技,不是为了追热点。
而是为了理解 AI 的底层逻辑。
当你亲手配置过一个 Agent,当你理解 Session 是怎么加载的、Memory 是怎么管理的、Skills 是怎么调度的,你对 AI 的理解就不再停留在“调用 API”的层面。
你会开始思考:
- 如果让我设计一个 Agent,我会怎么设计它的记忆机制?
- 如果让我设计一个多 Agent 系统,我会怎么设计它们的通信方式?
- 如果让我设计一个 Skills 管理系统,我会怎么避免低质 Skills 爆炸?
这些问题,没有标准答案。但思考这些问题的过程,会让你成为一个更好的工程师。
【技术的价值,不在于你用了什么工具,而在于你理解了什么原理。】
OpenClaw 只是一个开始。
当你理解了它的架构,你会发现:原来 Agent 就是这么回事。然后你可以用这些知识,去设计更适合你场景的 Agent,去构建更复杂的 AI 系统。
这才是折腾 OpenClaw 的真正意义。


回复