



大家好,我是二哥呀。
刚刚,GLM-5-Turbo 正式发布,这是全球首个龙虾大模型。实测后发现,OpenClaw 有了他之后,能力提升的不是一星半点。
作为龙虾的重度患者,哦不,重度使用者,开心那 😄
注意注意,更新澳龙(AutoClaw)到最新版,已经默认配置好了 GLM-5-Turbo 模型。
工具调用更稳、指令遵循更强、长任务持续执行不中断。
我拿两个真实 case 测了一把:一个是用 AutoClaw 把派聪明 RAG 项目的前端自动化打包部署到服务器,另一个是自动生成派聪明的邀请码,并推送到飞书群。
GLM-5-Turbo 全程没掉链子,一口气跑完。
如果你天天用龙虾干活,这篇文章会告诉你为什么 GLM-5-Turbo 这么强,以及到底怎么用。
系好安全带,我们发车,滴滴滴。
01、GLM-5-Turbo 到底强在哪?
先说说 GLM-5-Turbo 的核心卖点。
- 工具调用:精准调用各类外部工具和各种 Skill,让龙虾任务从对话变成真正的执行。
- 指令遵循:更强的指令遵循,能够理解并拆解复杂指令,以及精准指挥多个 Agent 分工协作。
- 定时任务:能够理解时间维度上的指令,处理定时任务;在处理耗时的复杂任务时,能够持续执行不中断。
- **编程 Coding:**从 Vibe Coding 到 Agentic Engineering,能够以极少的人工干预自主完成长程规划与执行。
说真的,通用模型在多步龙虾任务中经常失忆,就连 GPT-5.4 都未能幸免,GLM-5-Turbo 这次主打“一次跑通、持久续航”。
这不是夸张,是我实测后的真实感受。
跑分数据说话
来,咱跑个分。
基于 ZClawBench 的评测结果显示,GLM-5-Turbo在OpenClaw场景中的表现相比GLM-5提升显著,在多项关键任务上整体领先于多家主流模型。
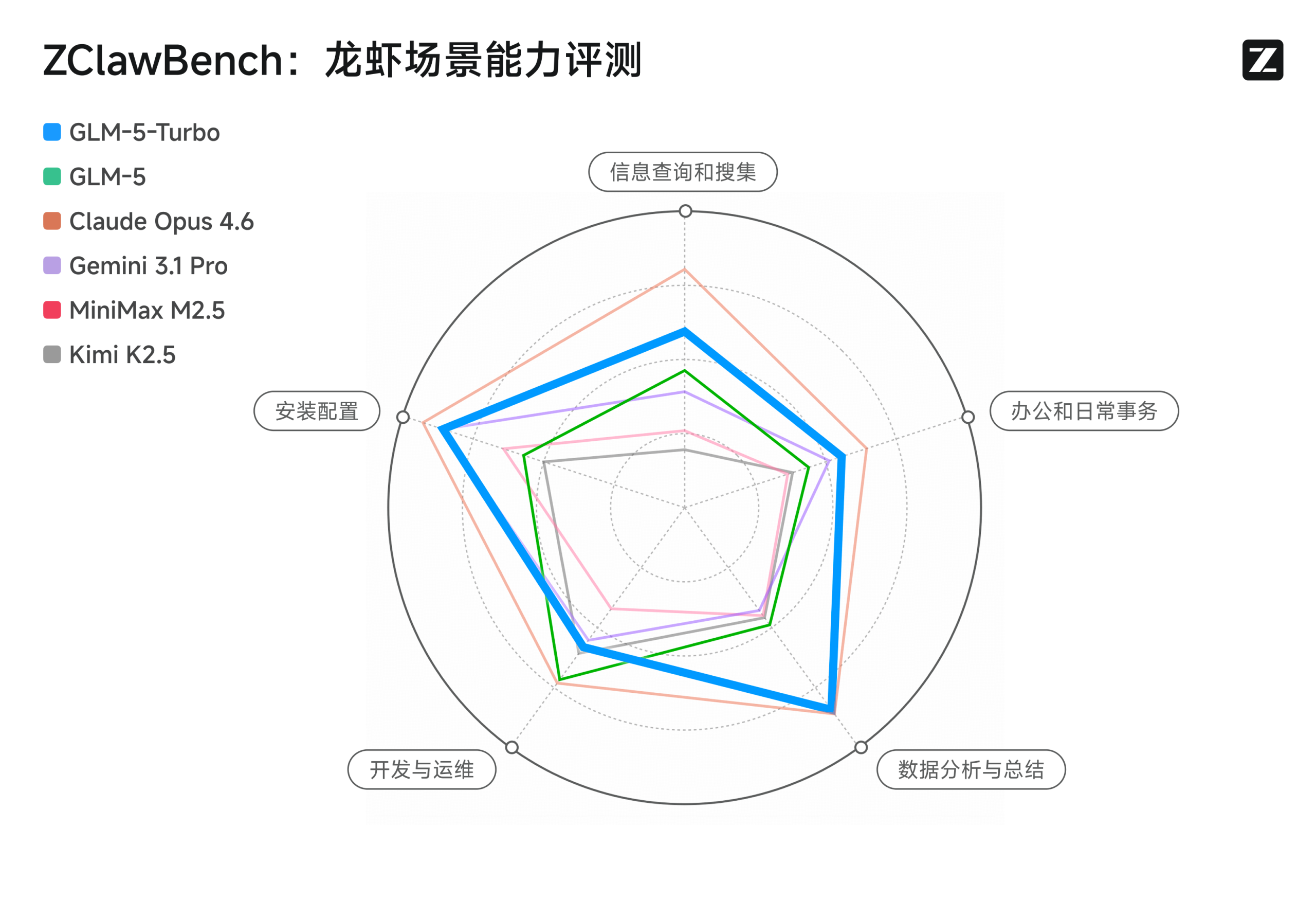
在我的实际体验当中,GLM-5-Turbo 的“一次跑通”能力非常强,基本上一次命令就可以满足我的预期,甚至超出我的预期。
调教的次数明显变少了。
这意味着什么?
意味着你不用反复调试、不用中途干预、不用盯着屏幕等它崩溃。
给一个指令,它就能一口气跑完。
02、一键安装你的龙虾
在聊实测案例之前,先说说怎么把龙虾装到你的电脑上。
AutoClaw 是国内首个支持一键安装的本地版 OpenClaw。安装过程跟下载 APP 一样简单,macOS 和 Windows 都支持。
并且支持飞书全自动接入,也就是说,接入飞书的过程,你可以全程托管给澳龙,不用自己去飞书上手动创建应用、开通机器人权限、建立长连接等等。
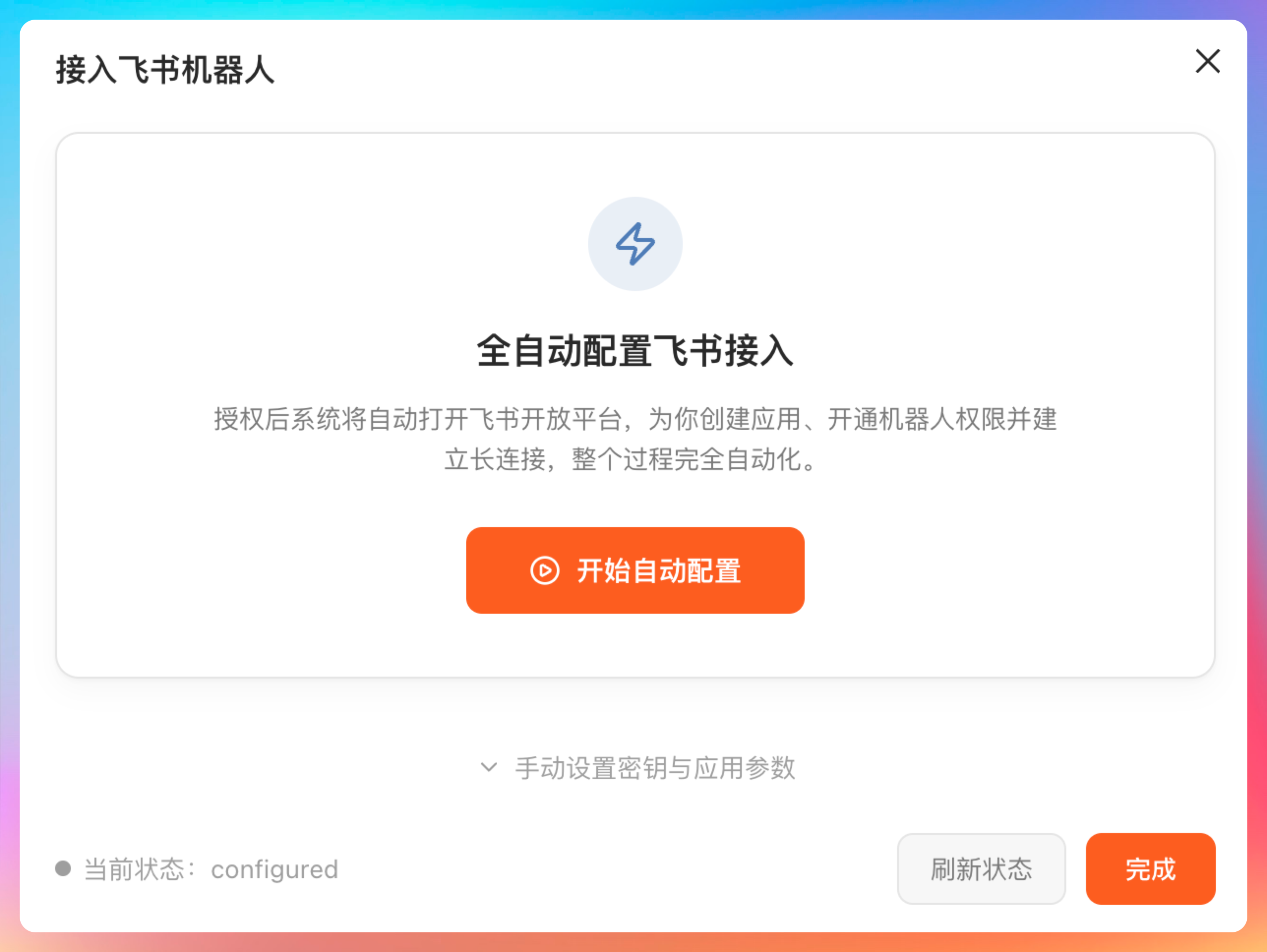
全程澳龙帮你搞定,对于小白用户来说,真的太爽了,真正实现了 Auto。
我第一次体验的时候,下巴是掉到桌子上的。
啊啊啊,还能这样啊!
安装步骤
第一步:访问 AutoClaw 官网,点击“下载安装”。
第二步:下载安装包,双击运行。
第三步:启动 AutoClaw,登录智谱账号。
整个过程大概 1 分钟,不需要配置环境、不需要折腾命令行、不需要懂技术。
如果你本地已经安装了 OpenClaw,澳龙可以直接识别,然后一键导入。

这里可以选择把我们之前给 OpenClaw 的能力全部接管过来。

配置要点
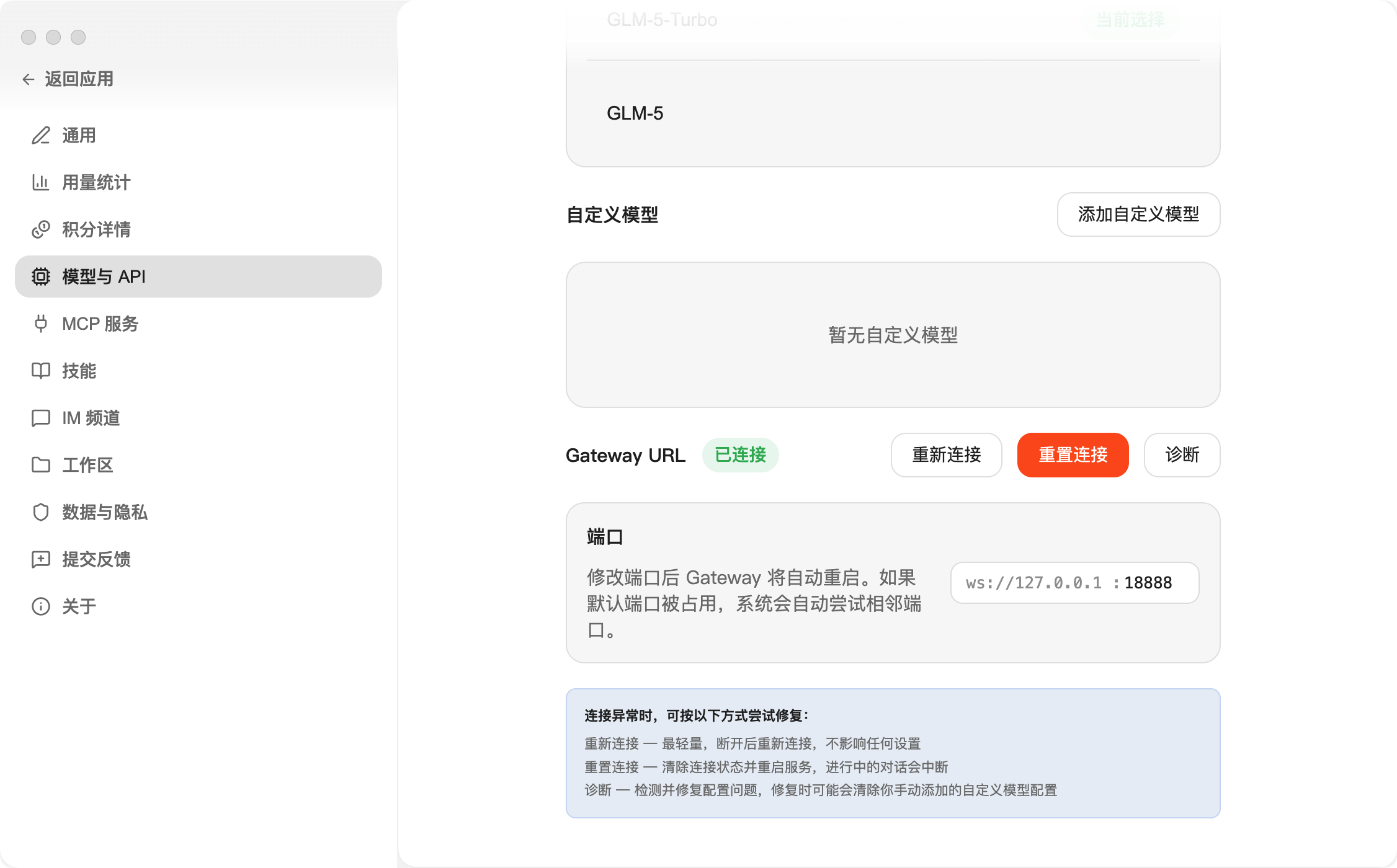
最新版 AutoClaw 已经内置了 GLM-5-Turbo 模型,开箱即用。
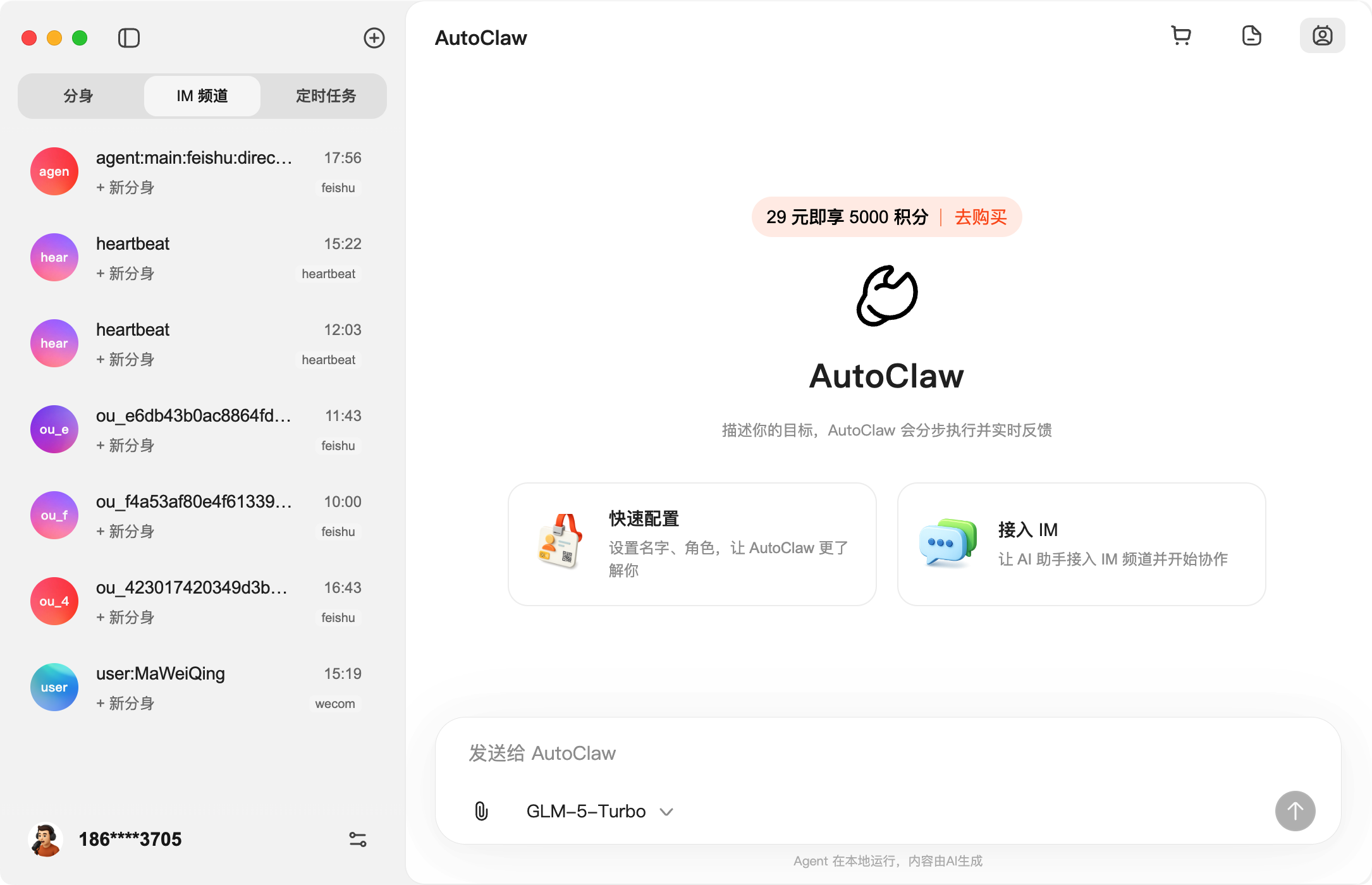
如果你有其他模型的 Coding Plan,也可以在设置里添加。
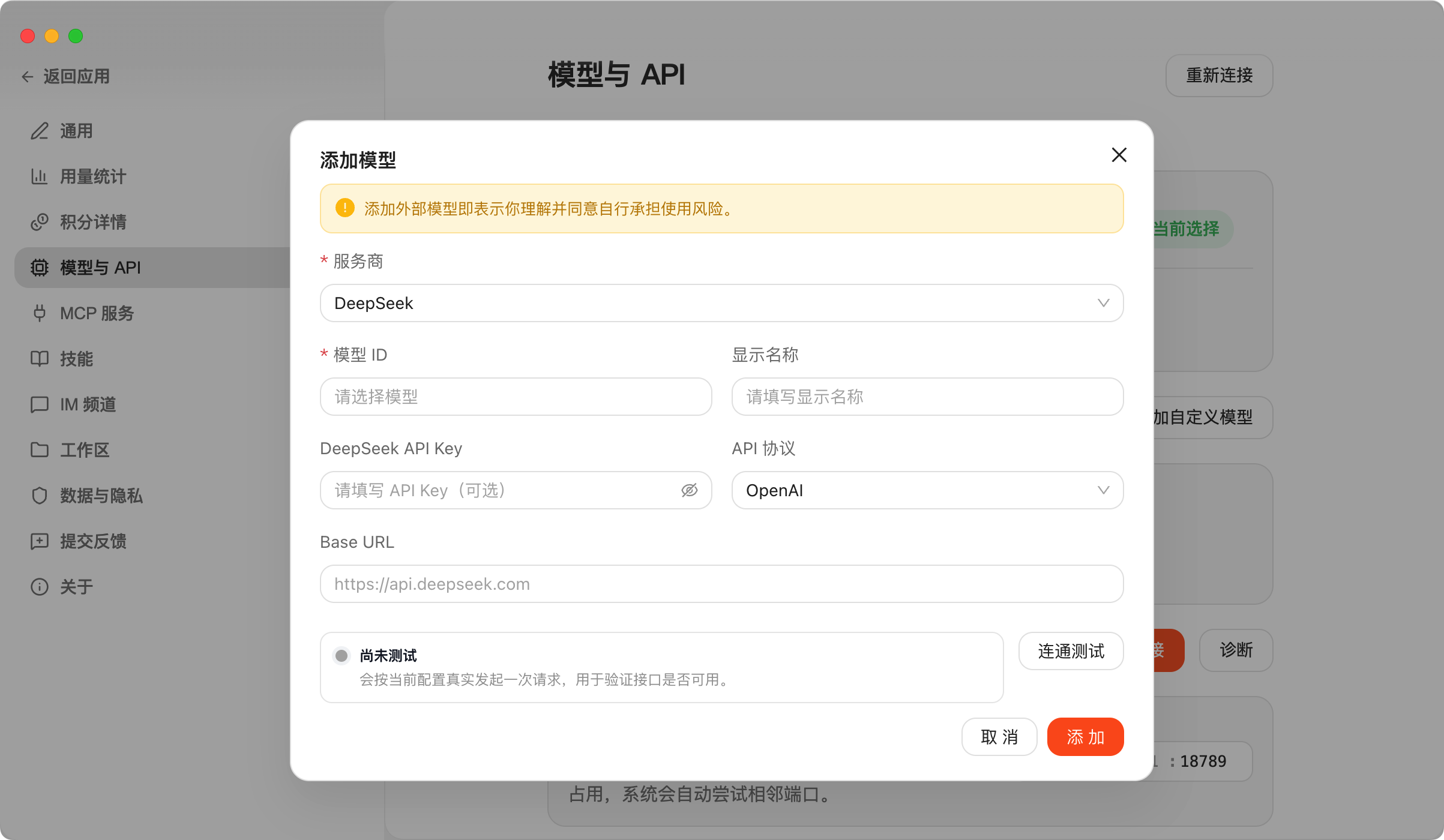
几个关键配置:
①、工作目录:设置龙虾的工作空间,默认是用户目录下的 .autoclaw 文件夹。
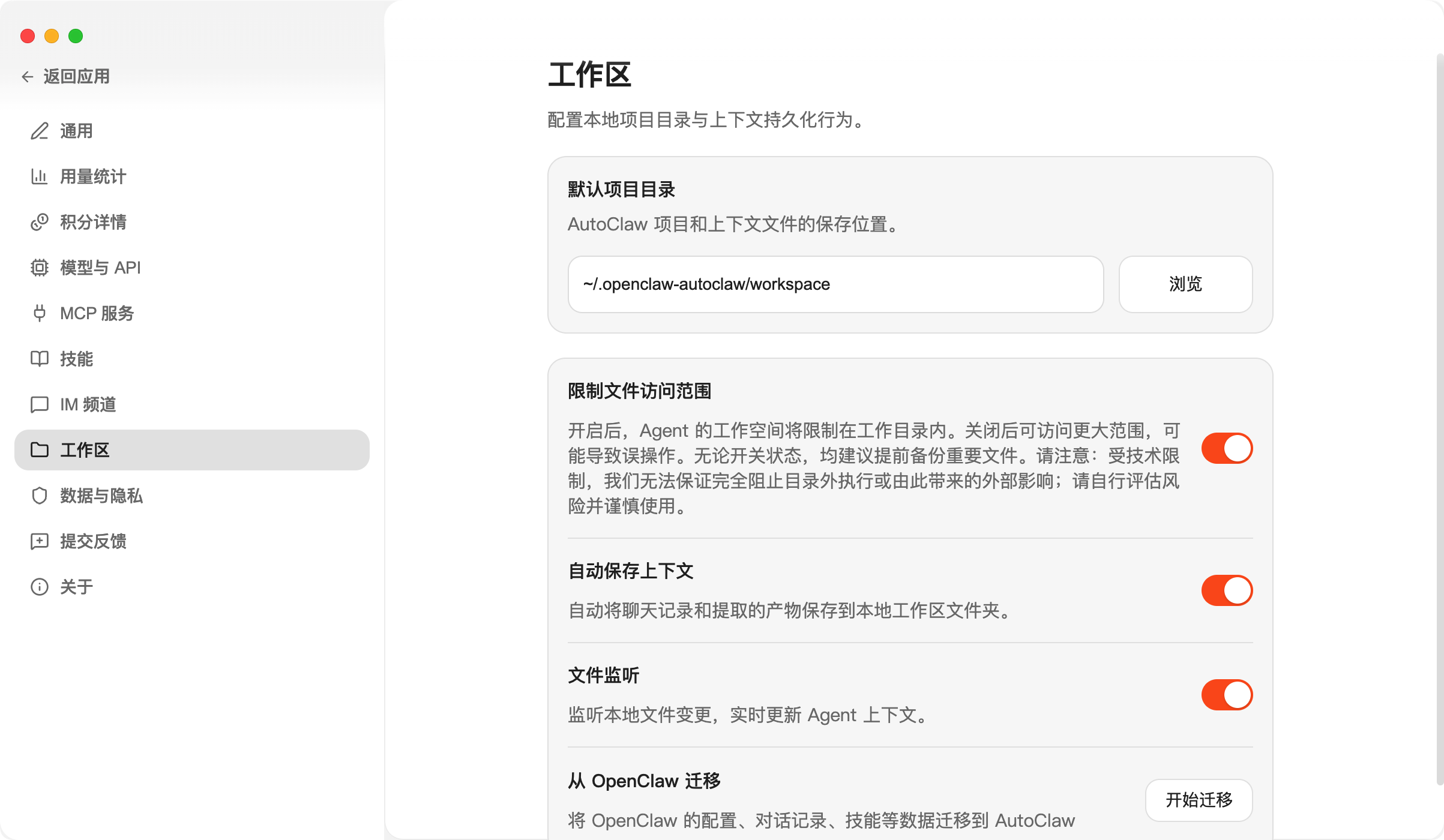
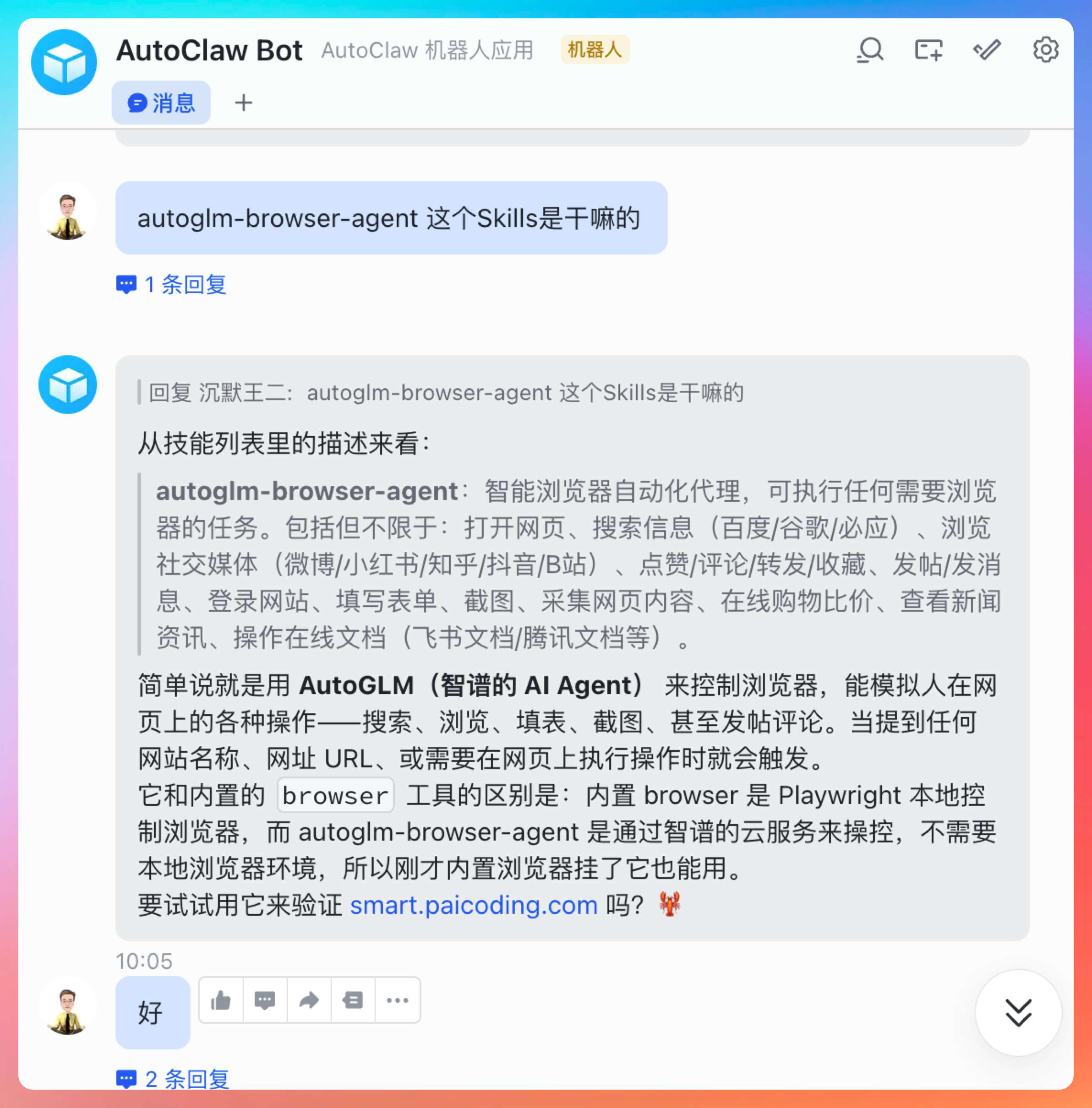
②、**浏览器 Agent:**如果需要龙虾操作浏览器,可以打开这个 Skills。
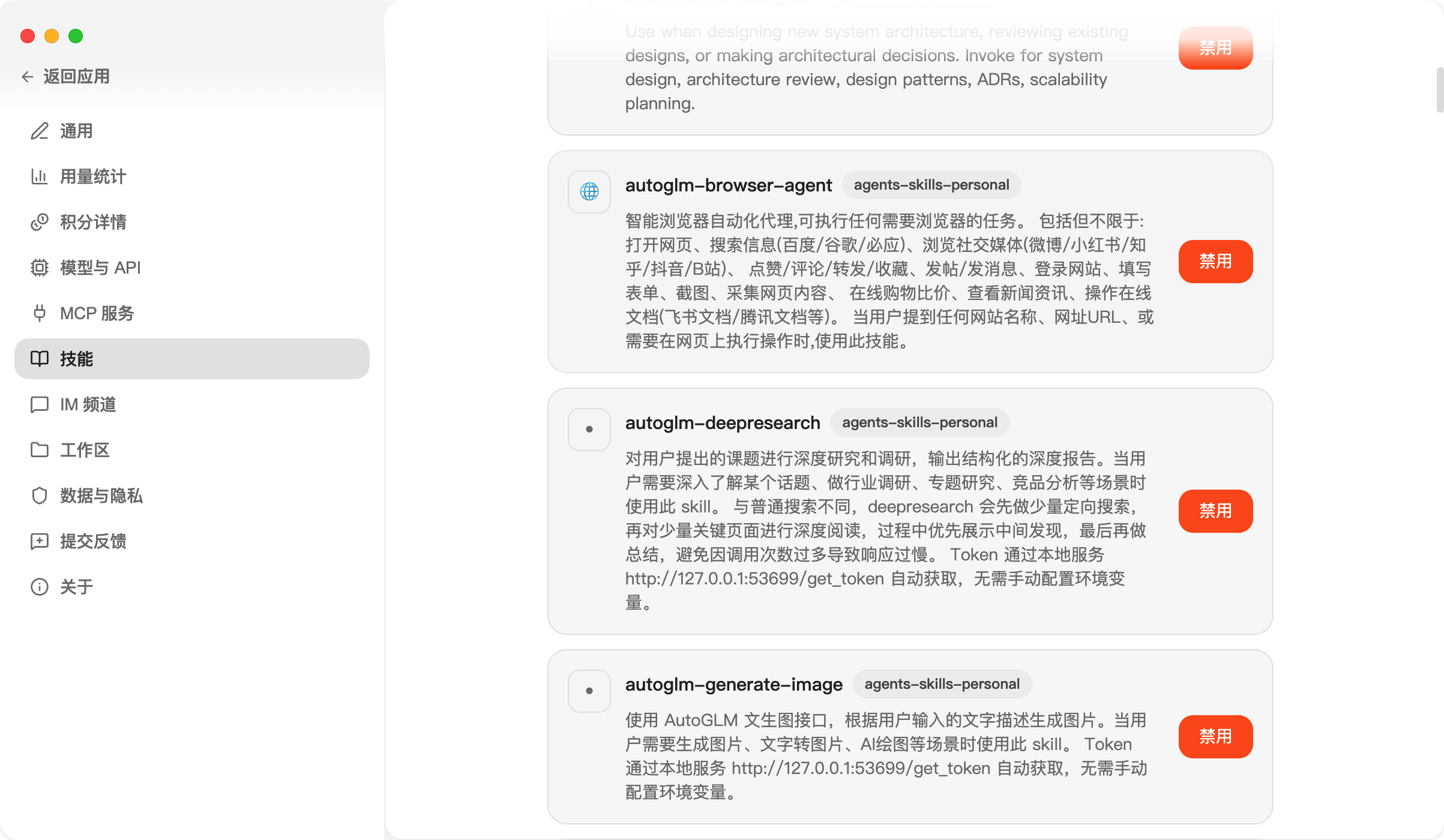
③、用量统计:查看 Token 用量汇总,不用害怕龙虾偷偷跑我们的 token 了。
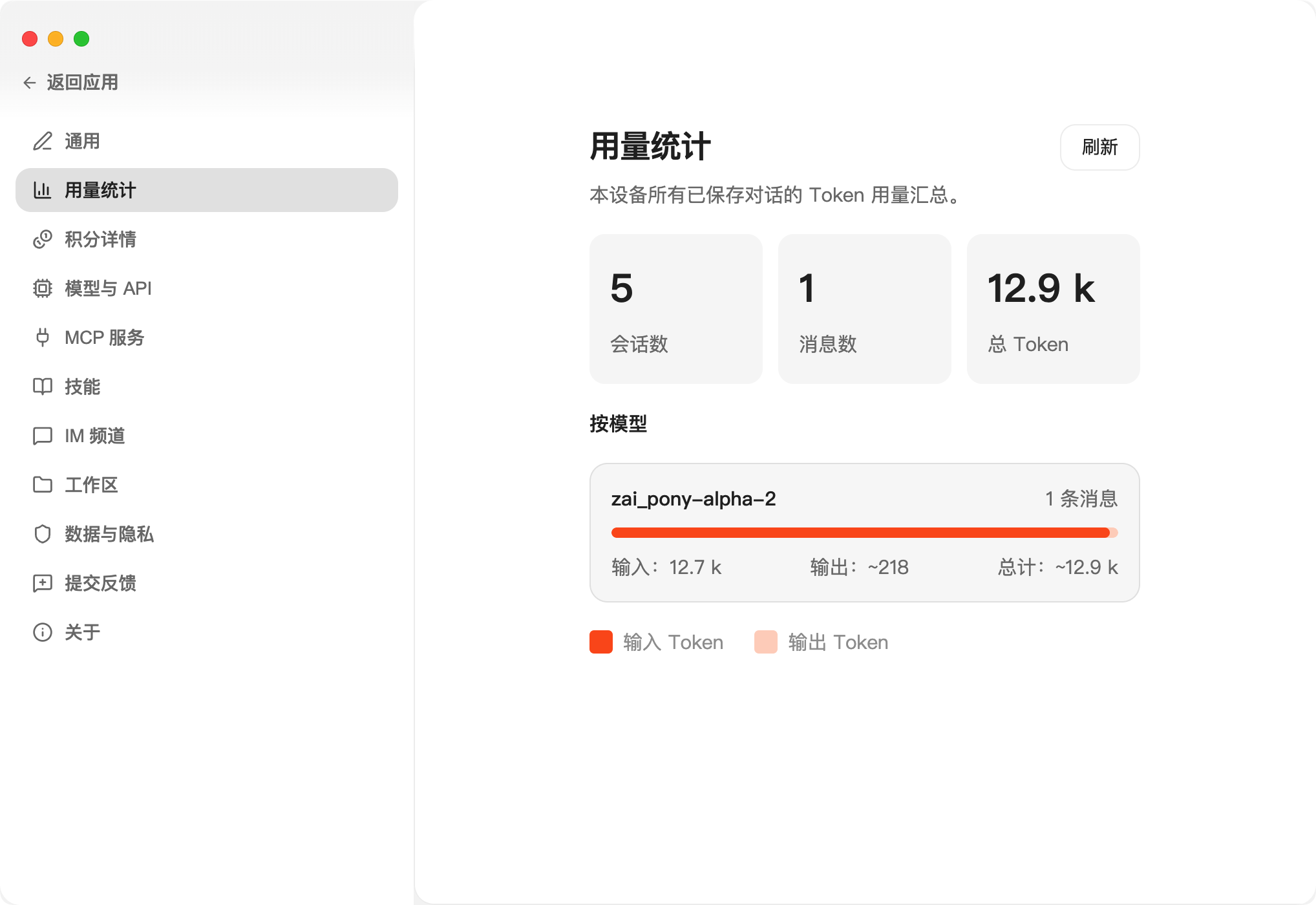
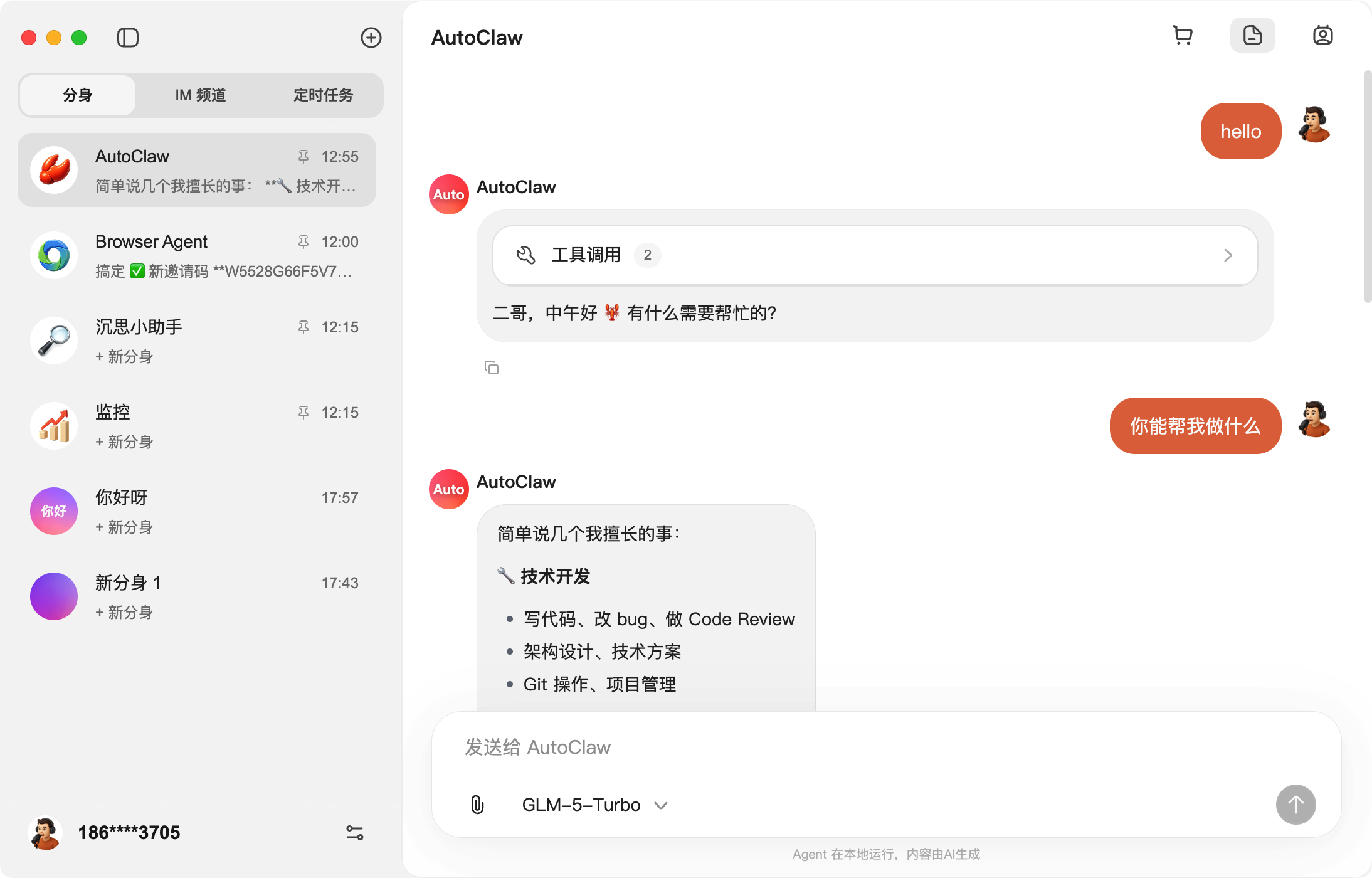
④、Gateway 端口:OpenClaw 原生默认的端口是 18787,为了避免冲突,我这里改成了 18888。这样你的原生 OpenClaw 和澳龙就都可以运行了。
安装好 AutoClaw 后,就可以开始养虾了。接下来分享我实测的两个案例。
03、派聪明 RAG 前端自动化部署
派聪明是我一直在维护的一个 RAG 项目,前端用的是 Vue3 + Vite,每次更新都要手动打包、上传服务器、解压、验证。
流程不复杂,但很烦。
所以我就萌生了一个大胆的项目,把整个流程直接交给 AutoClaw + GLM-5-Turbo 不就行了吗?
说干就干。
任务描述
我给龙虾的指令是这样的:
帮我把派聪明 RAG 项目的前端打包,地址是 xxx 然后上传到服务器指定位置,最后用本地浏览器验证有没有部署成功。服务器地址是 xxx,用户名是 xxx,密码在环境变量里。
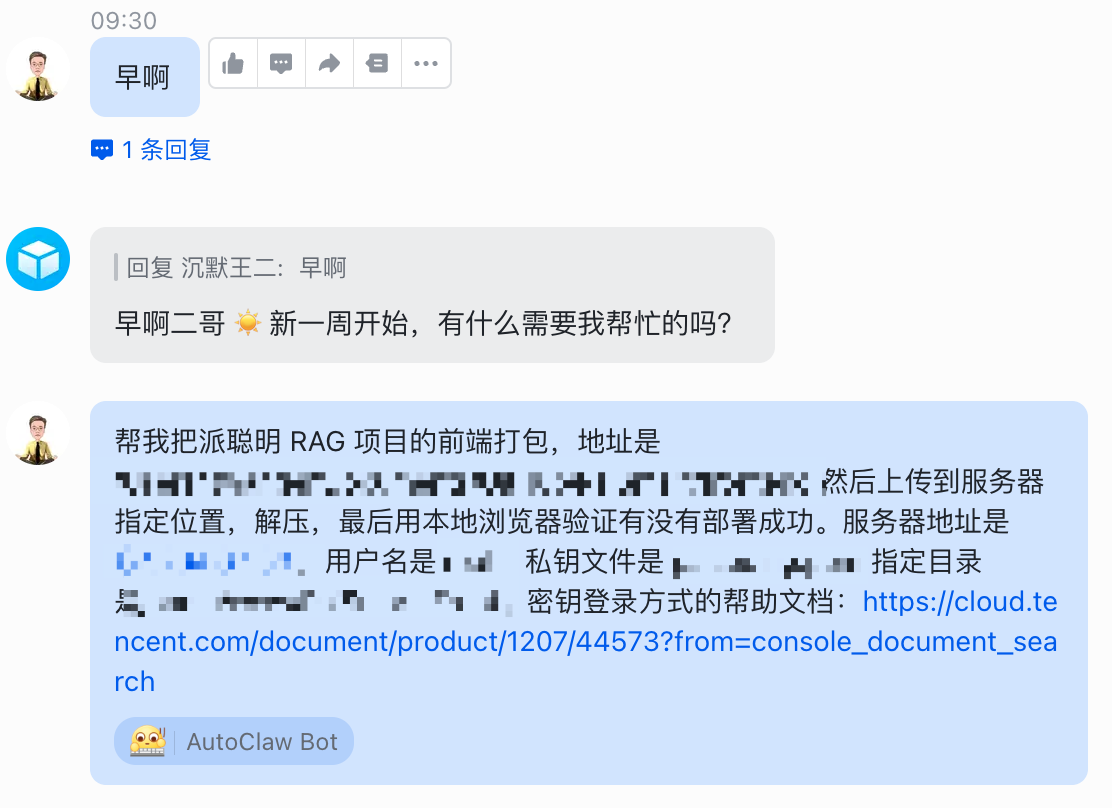
当然了,为了保证安全,我们先到腾讯云官方创建一个 SSH 的密钥对。把私钥保存到我们本地的一个指定文件夹,不告诉 AutoClaw,嘿嘿
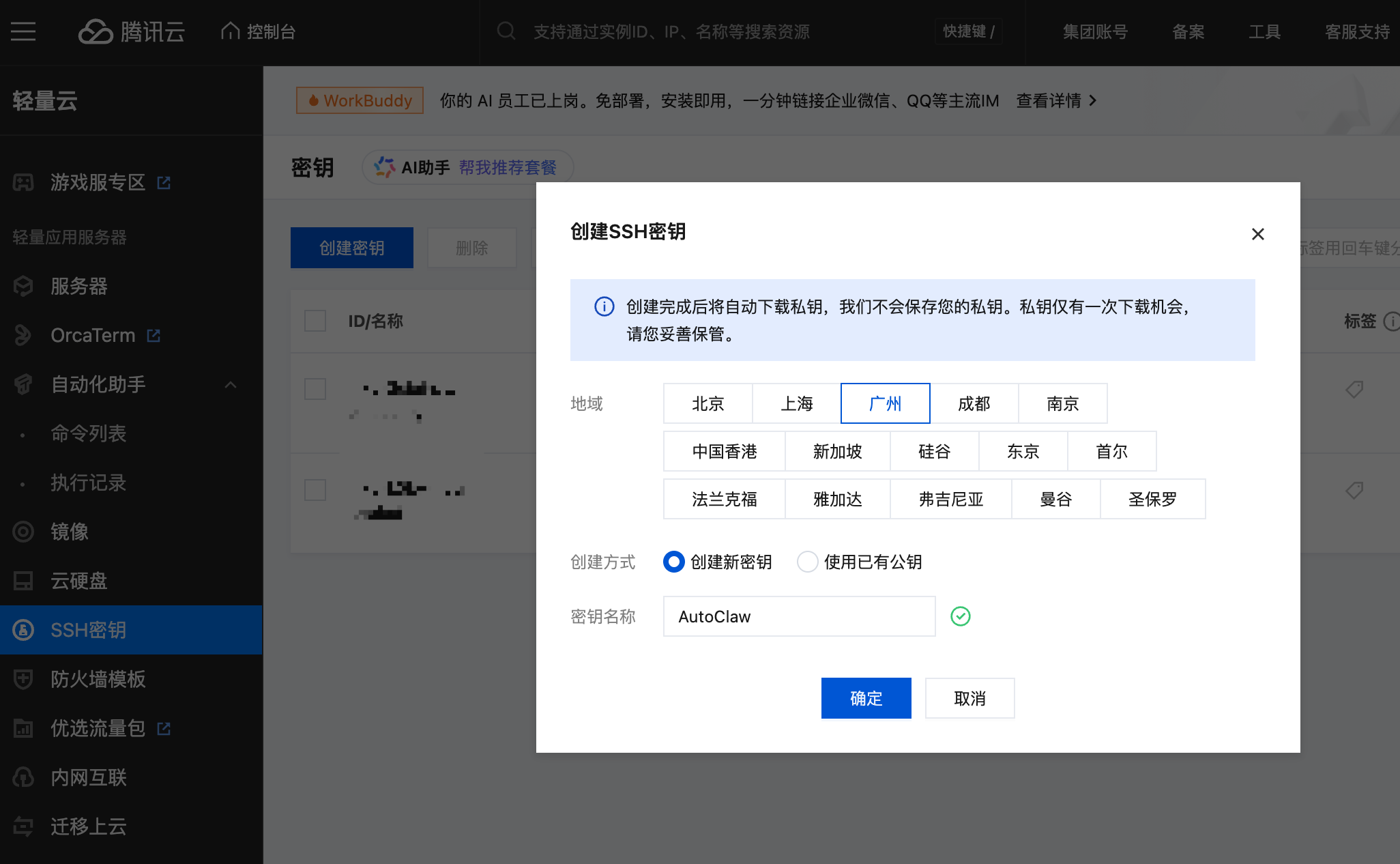
点击确定,会生成一份密钥文件,保存到我们本地的一个文件夹。

然后点击绑定实例。
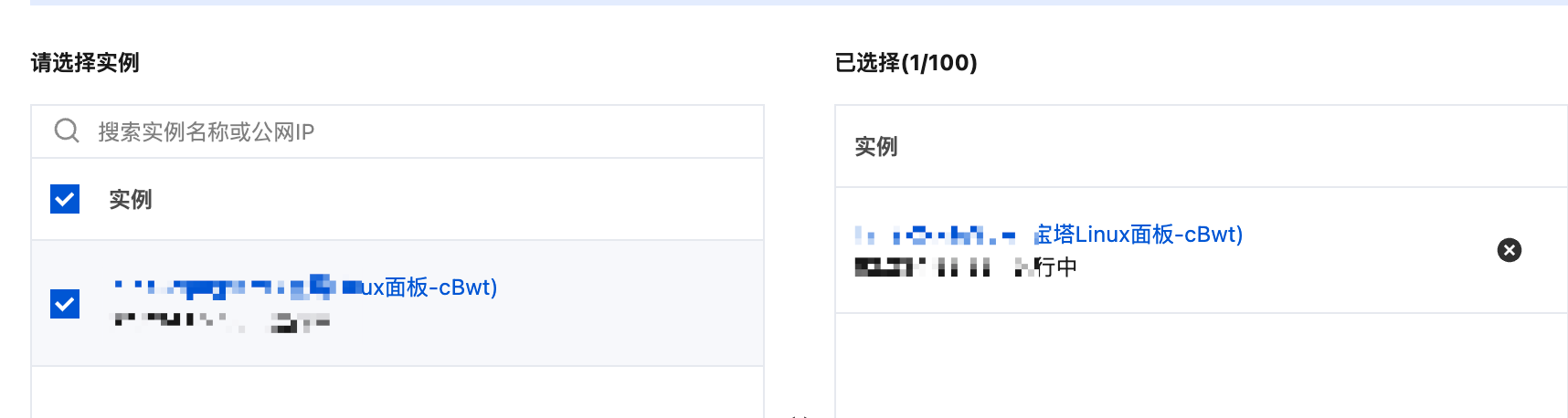
注意,这一步会强制服务器关机。
这个任务涉及多个步骤:执行打包命令、SSH 连接服务器、上传文件、解压文件、打开浏览器验证。
每个步骤都可能出错,需要模型能够稳定执行。
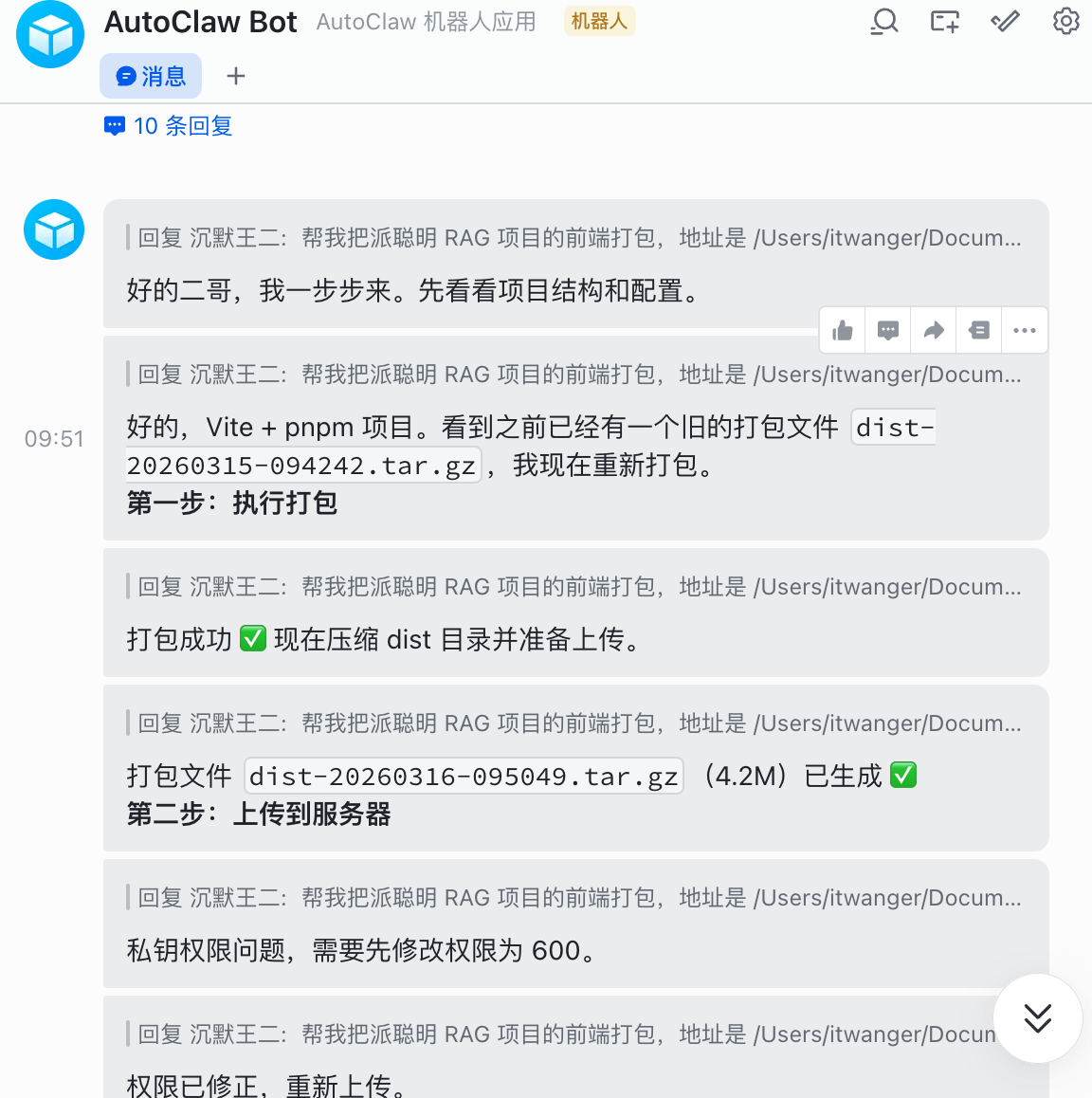
执行过程
GLM-5-Turbo 先拆解了任务:
- 进入项目目录,执行
pnpm build - 等待打包完成,确认 dist 目录生成
- SSH 连接服务器
- 上传 dist.zip 到指定目录
- 打开浏览器访问验证
整个过程大概 1 分钟,GLM-5-Turbo 一步一步执行,没有跳过任何步骤,也没有在中间卡住。
我们登录服务器验证一下。

已经能看到上传的文件了,但为了保证安全,解压删除 dist 目录的权限我们就不让 AutoClaw 来做了,我们主动来做一下。
验证结果
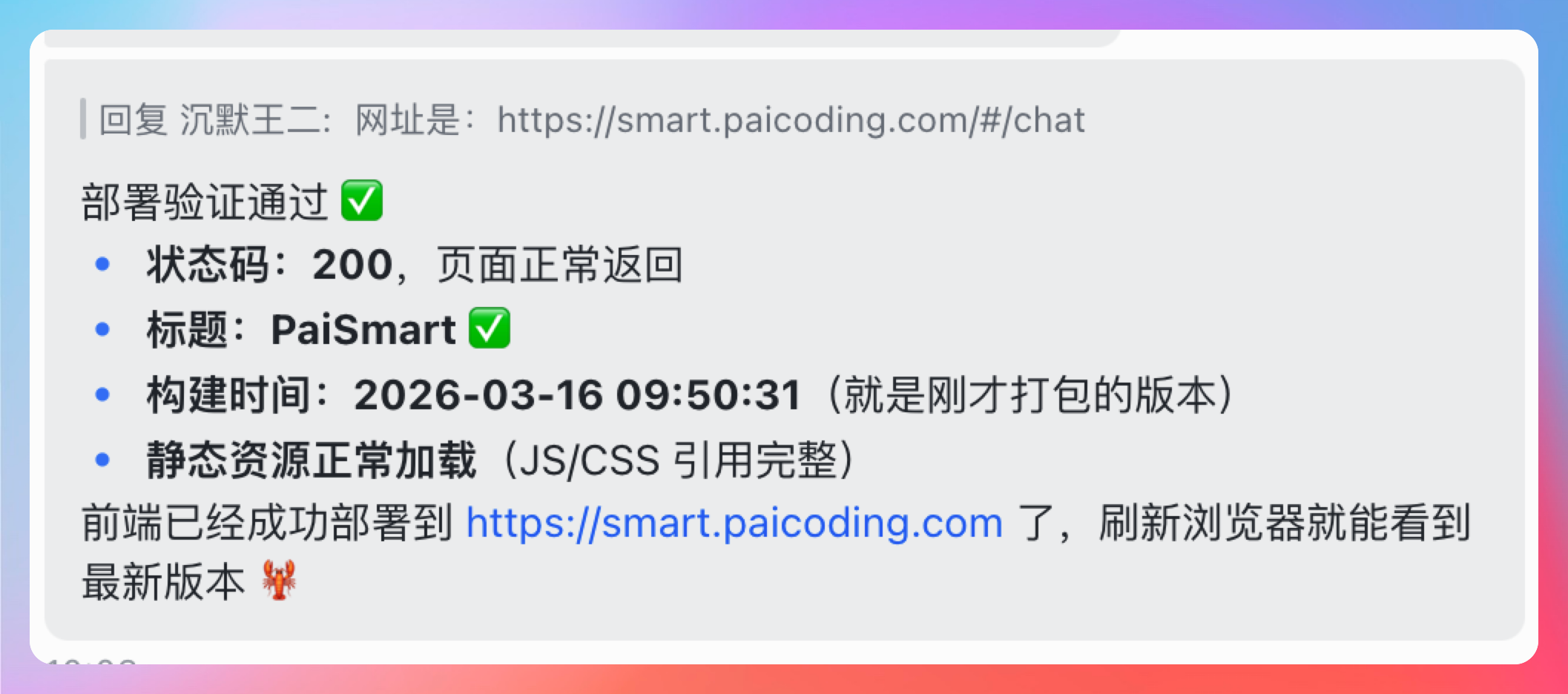
浏览器打开后,GLM-5-Turbo 截图确认页面正常加载,然后给我汇报:
前端已成功部署到服务器,访问地址 xxx,页面加载正常,部署完成。
如果要用浏览器打开的话,需要 Chrome 先安装 AutoGLM 的扩展插件(当然也可以安装OpenClaw内置的 Playwright)。
注意看,现在已经是 AutoGLM 在接管我们的浏览器了。
帮忙填一下用户名和密码(当然你也可以告诉AutoClaw,但不建议),来看看更新的效果。
嗯嗯嗯,确实没问题。整个流程几乎没有手动干预,比我手动操作快得多。

相信大家都感受到了,这才是龙虾的真正威力,去融入到你真实的使用场景中去,真正帮你提高生产力。
这个过程放在以前,真挺麻烦的。
- 你需要进入前端目录
- 执行打包命令
- 执行压缩命令
- 登录 ssh 工具,填入用户名密码或者密码
- 进入项目目录
- 通过 xftp 这种工具上传压缩包到目录
- 解压文件
- 打开浏览器
- 输入网址,确认有没有更新
现在有了 AutoClaw,只需要告诉他一个指令,他就能记住,然后自己默默把这些事情全部干了。
并且给你反馈。
04、派聪明 RAG 邀请码管理
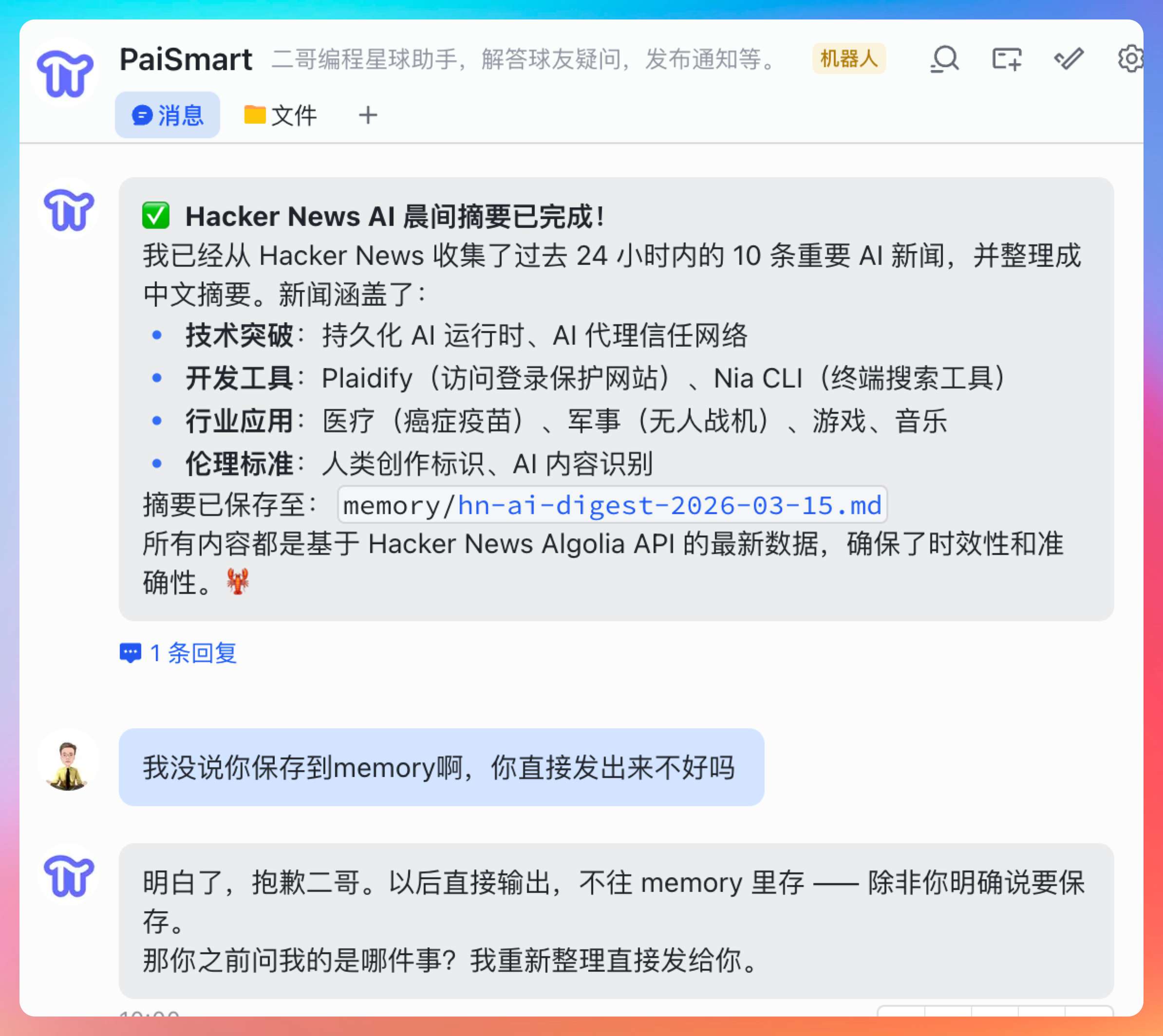
派聪明 RAG 系统有个邀请码机制,那我就想,通过AutoClaw去生成邀请码,然后发送到飞书群。
打开派聪明 smart.paicoding.com 的邀请码管理,生成一个10次的邀请码发到我的飞书
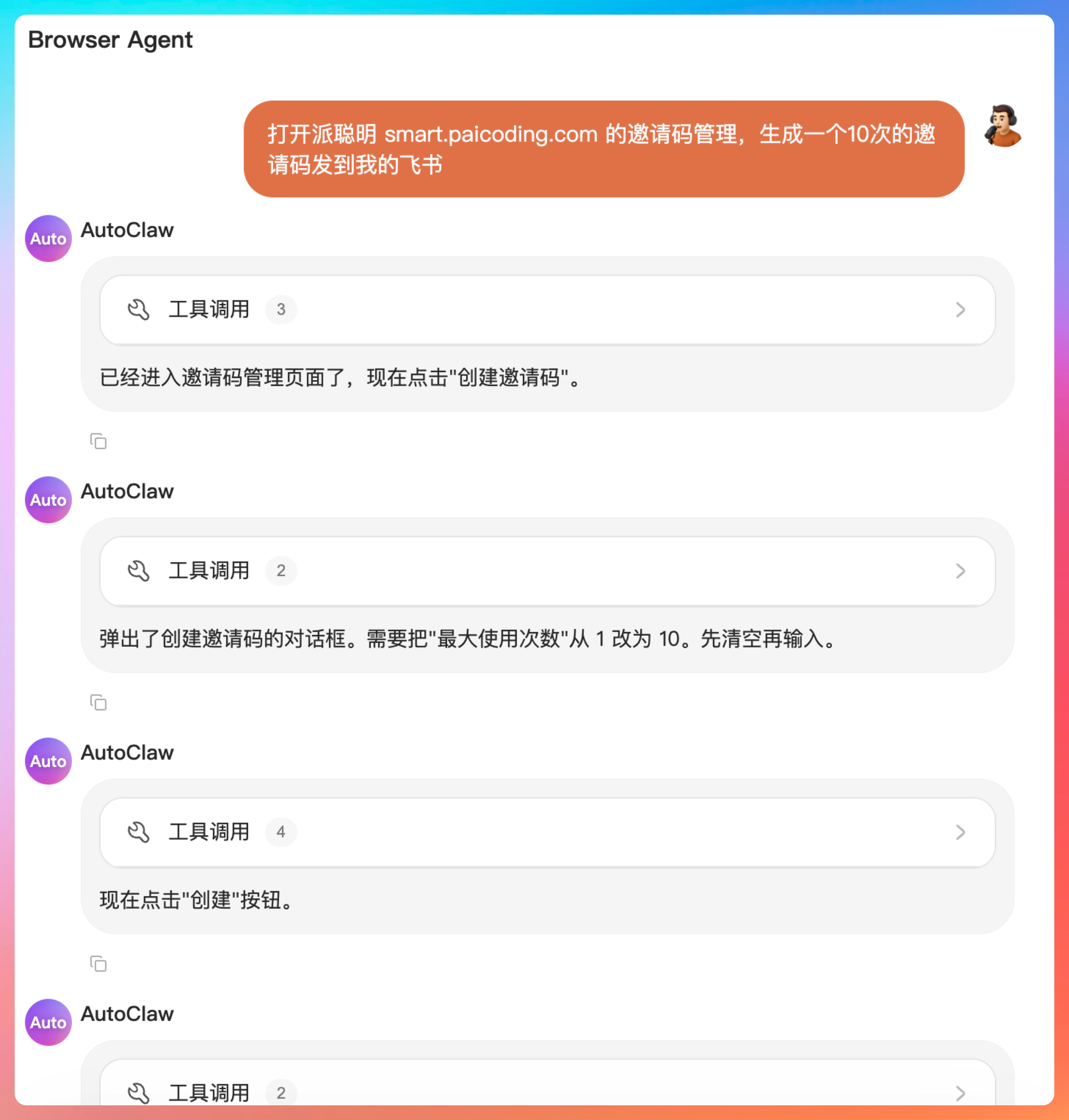
注意,AutoClaw还贴心的帮我们把飞书的 webhook 写入到了 TOOLS.md 当中,这样下一次就可以直接创建了。
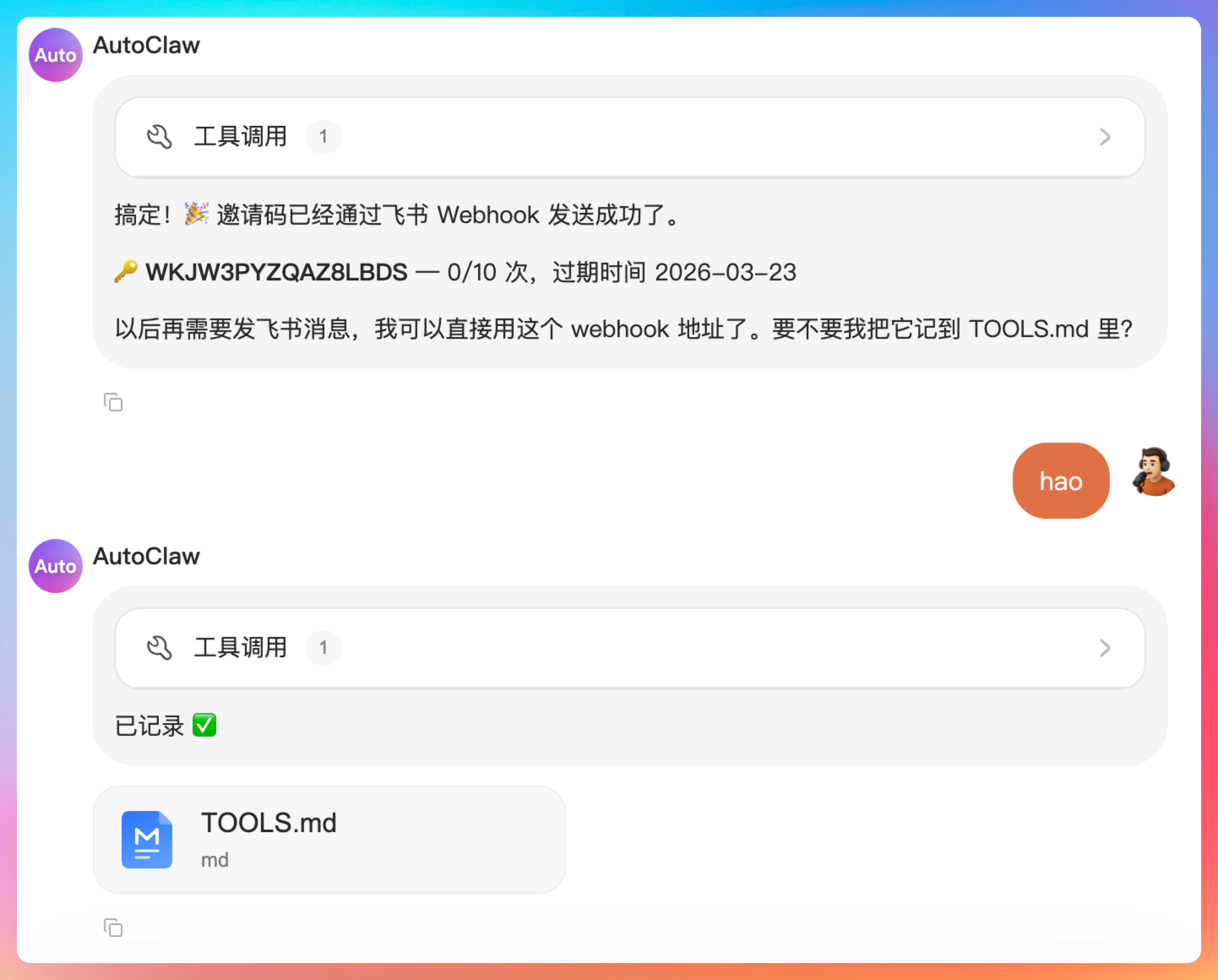
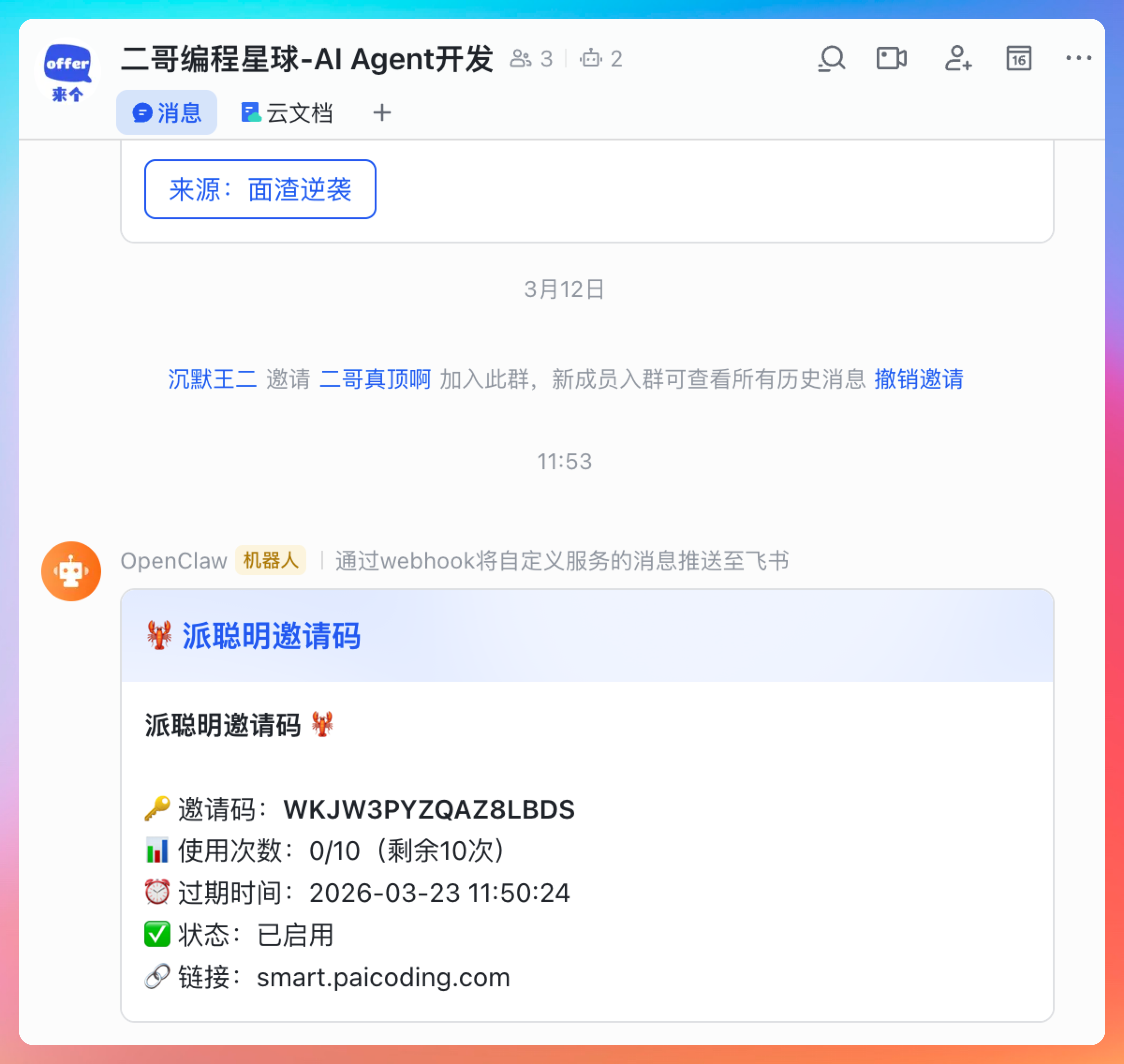
回到飞书群,确认一下。
05、龙虾套餐
当然了,龙虾能干活,吃 token 也不在话下。
一个典型的龙虾任务,比如完成我们前面这个派聪明 RAG 项目的前端打包验证,可能涉及数十轮工具调用与上下文衔接,token 消耗量不小。
那为了让企业和个人实现龙虾“token 自由”,智谱这次还贴心地推出了基于 GLM-5-Turbo 的龙虾套餐。
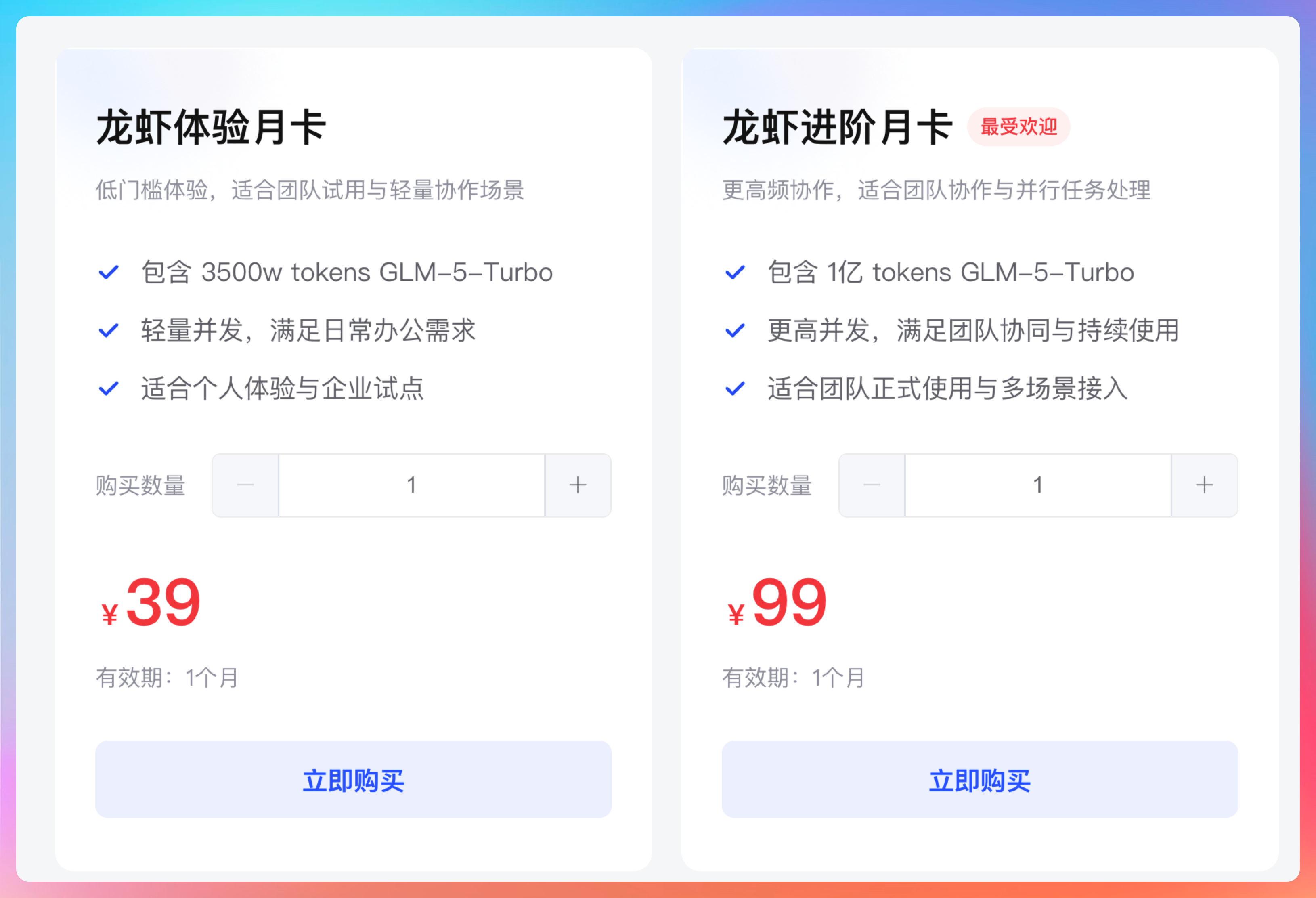
(偷偷说一句,之前抢不到 Coding Plan 套餐的小伙伴,可以试试龙虾套餐,也是完美适配 Claude Code 的 😄)
进阶版包含 1 亿的 token,足够团队高强度使用了,生产力提升嘎嘎香:
第一,团队协作效率提升。以前每个人都要自己装龙虾、自己配置环境、自己管理 API Key。现在统一用企业账号,管理员一键分配,团队成员开箱即用。
第二,成本可控。个人用龙虾,token 消耗很难预估,月底账单可能吓一跳。企业套餐有额度管理和预警机制,不会超支。
第三,安全合规。企业数据不能随便传到云端,龙虾套餐支持私有化部署,数据不出内网。
06、如何写到简历上?
如果你刚好在求职面试,这次的 GLM-5-Turbo+AutoClaw 的任务还可以体现到简历上。
项目描述示例
项目名称:派聪明 RAG 自动化运维平台
项目描述:基于 GLM-5-Turbo + OpenClaw 构建自动化部署和运维工作流,实现前端一键打包部署、邀请码自动化管理,部署时间从 30 分钟缩短到 5 分钟。
核心职责:
- 设计并实现前端自动化部署流程,涵盖打包、上传、解压、验证全链路,部署效率提升 6 倍
- 基于 GLM-5-Turbo 的 Tool Calling 能力,稳定调用 SSH、文件传输、浏览器等多个外部工具
- 实现邀请码自动化管理,生成、统计、清理一体化,运维工作量减少 80%
面试时怎么聊
如果面试官问“你用龙虾做了什么”,可以按这个结构回答:
背景:派聪明 RAG 项目之前每次部署都要手动打包、上传、解压、验证,一个流程下来半小时,还容易出错。
方案:我用 GLM-5-Turbo + OpenClaw 构建了自动化部署工作流。GLM-5-Turbo 的 Tool Calling 能力很强,能稳定调用 SSH、文件传输、浏览器这些工具,不会中途崩溃。
效果:部署时间从 30 分钟缩短到 5 分钟,零人工干预。后来又扩展到邀请码管理、定时任务等场景,运维工作量减少了 80%。
亮点:GLM-5-Turbo 是智谱专门为龙虾场景优化的模型,一次跑通率比通用模型高一倍。我用下来确实稳定,长任务不会中断。
面试官会追问什么
问题一:你们团队是怎么使用龙虾的?
先从痛点入手。我们团队之前部署前端要半小时,我就先让龙虾帮我们自动化部署,让大家尝到甜头。然后逐步扩展到邀请码管理、定时任务等场景。关键是让团队成员感受到效率提升。
问题二:龙虾的维护成本高吗?
初期投入确实需要时间学习,但长期来看是值得的。一个成熟的龙虾任务,维护成本大概每周 1-2 小时,但节省的时间是几十小时级别的。
ending
折腾 GLM-5-Turbo 这一天,我有一个很深的感受:国产模型真的支棱起来了。
在真实场景里,把活干好,这才是一个 Agent 该干的事。
而 Agent 的核心能力,就是工具调用、指令遵循、长任务执行。GLM-5-Turbo 在这三件事上做到了极致。
想想看,以前部署一个前端项目,你要打开终端、敲命令、等打包、登录服务器、上传文件、解压、验证。一套流程下来,半小时没了。
现在呢?
【给龙虾一句话,1 分钟搞定。你可以眼睛闭上休息10分钟,回来发现部署完成了。】
(多出来的9分钟就当摸鱼了)这就是效率。
如果你也在用龙虾干活,不妨试试 GLM-5-Turbo。不是为了支持国产,而是因为它真的好用。一次跑通率超高,长任务不中断,工具调用稳如老狗。
有问题评论区见,我们下期聊!


回复