


大家好,我是二哥呀。
这周技术圈被卡帕西的一条推文刷屏了。他说了这么一句:现在花在 LLM 上的 token,大部分不是在写代码,而是在整理知识库。
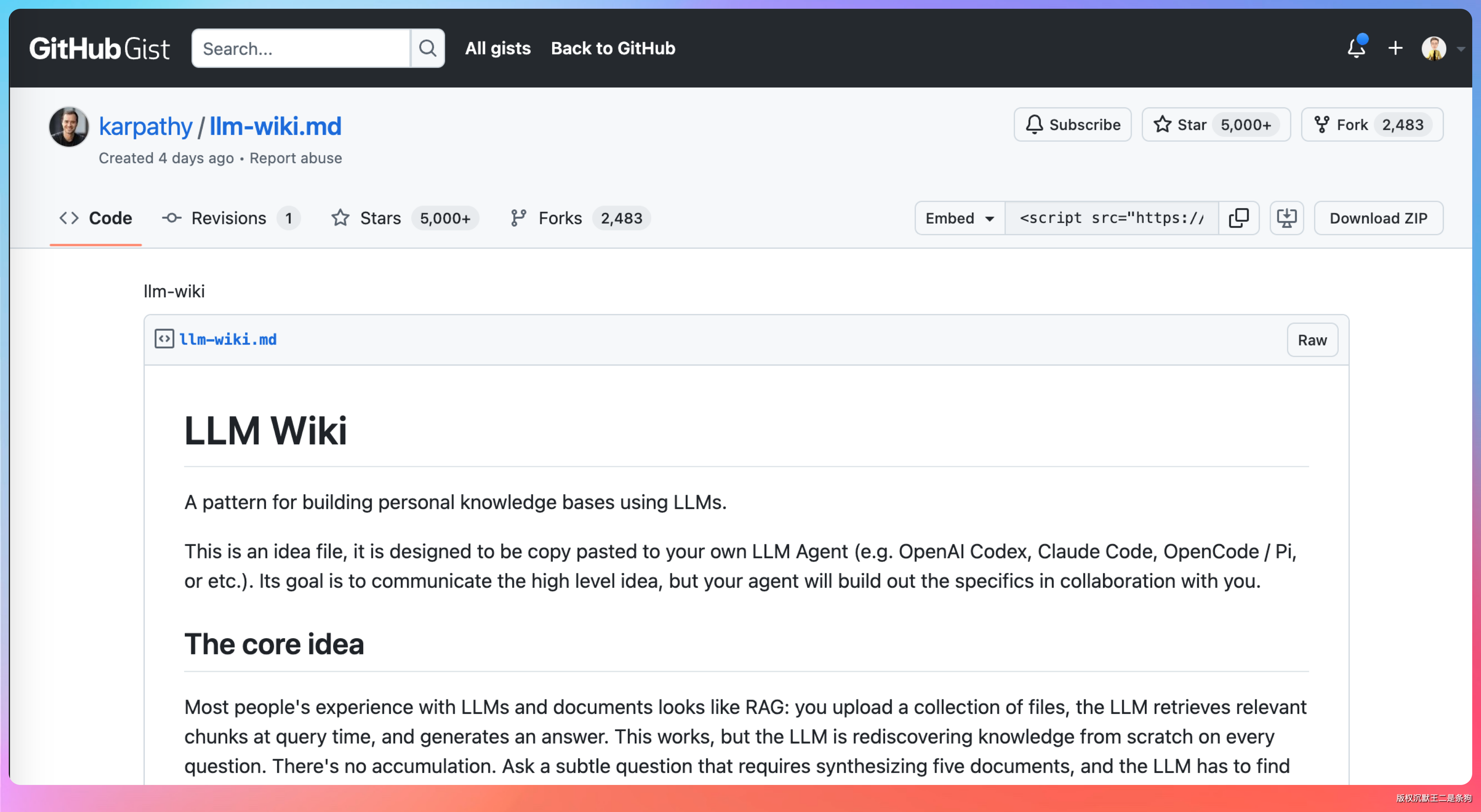
他给了一个叫「LLM Wiki」的方案,两个文件夹,一个 CLAUDE.md,没了。
没有向量数据库,没有 embedding 模型,没有混合检索 😄。
我看完的第一反应是:就这?
说真的,这个方案简单到让人怀疑人生。但我还是得亲自试试,才知道是不是真的好用,还是只是纸上谈兵。
01、LLM Wiki 到底是什么?
卡帕西把这个方案发到了 GitHub Gist 上,核心就三层结构,简单明了。

raw/ —— 你的原始素材,可以是任何你想整理的内容。这是你的 curated collection,作为知识库的事实来源,LLM 只读不写。
wiki/ —— LLM 生成的知识库。它读取 raw/ 里的文章,编译成结构化的 wiki 页面:概念定义、实体页面、交叉引用、矛盾标注。里面还有一个 index.md,是内容目录,LLM 每次更新都会维护它。查询时好的答案也会存回这里,成为新页面。
CLAUDE.md —— 知识库的规则文件(schema)。告诉 LLM wiki 的结构、约定、工作流程。
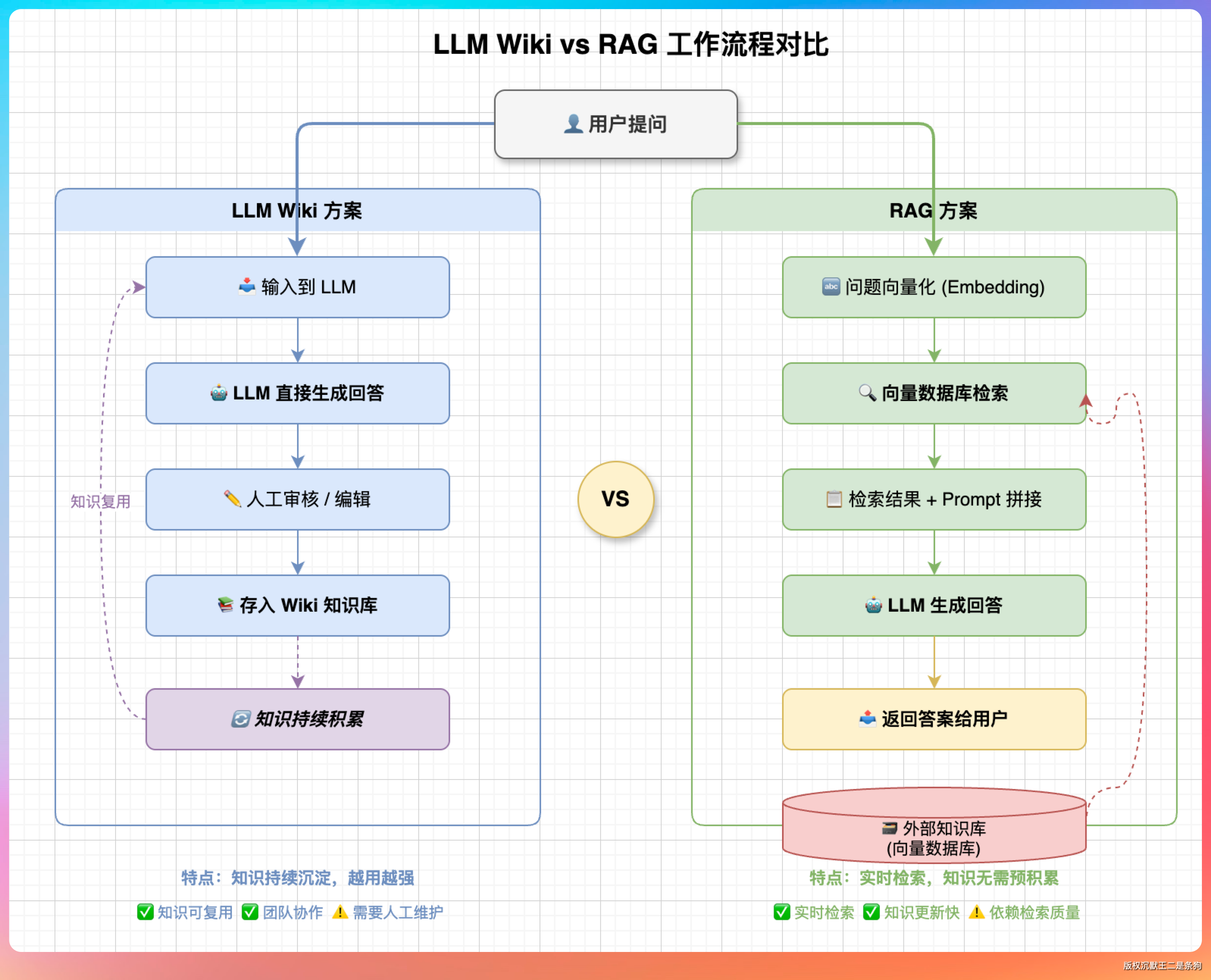
卡帕西这套方案,是让 LLM 先把书读完、理解完、做好笔记,考试时翻笔记、回顾自己的理解、不翻原书,和 RAG 不太一样。
除了「理解」,还有一个大区别——知识会积累。
你今天问了一个综合性的问题,LLM 的回答直接存回 wiki/ 成为新页面,明天再问相关问题时,它已经有了上次的分析结果。RAG 没有这一步。
卡帕西把这套流程叫做 Ingest-Query-Lint:
- Ingest:新素材放进 raw/,LLM 读取并更新 wiki/ 里的相关页面,同时更新 index.md
- Query:对 wiki 提问,LLM 查 index.md 定位页面,综合给出答案
- Lint:定期检查 wiki 里的过时内容、孤儿页面、缺失的交叉引用
02、搭建属于你的 Wiki
光说不练假把式,我花了一下午搭了一个自己的 LLM Wiki。
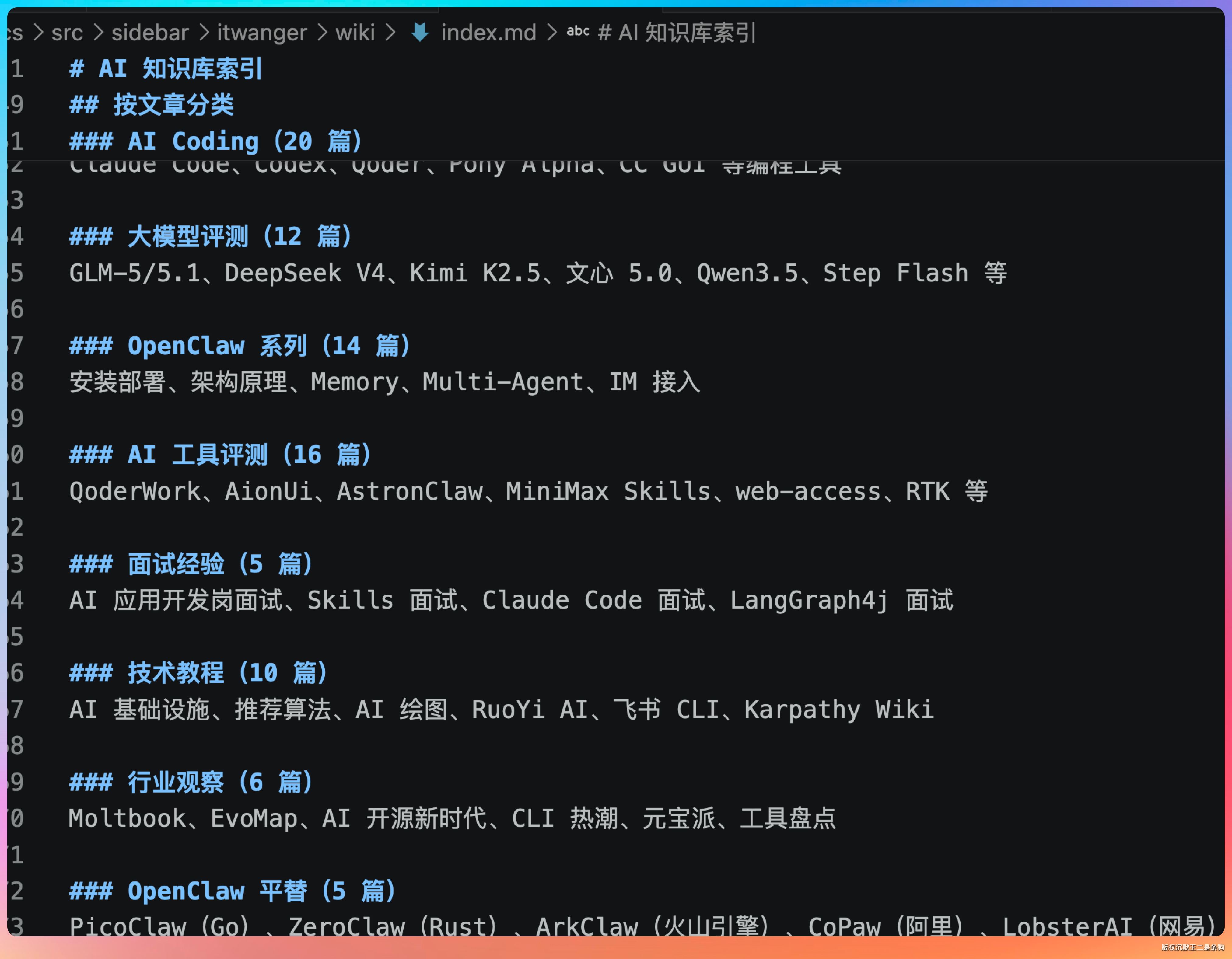
根目录是 docs/src/sidebar/itwanger/,里面建了两个文件夹:
- ai/ —— 我近期写的所有 AI 相关的文章,94 篇,涵盖 OpenClaw、Claude Code、Skills、Codex 等主题,都是 curated 过的
- wiki/ —— 空的,交给 LLM 来维护
然后写了一个 CLAUDE.md:
你是一个知识库维护助手。你的工作流程:
Ingest:
1. 读取 ai/ 文件夹里的所有文档
2. 在 wiki/ 文件夹里创建结构化的知识页面
3. 每个概念一个页面,包含定义、来源、相关概念链接
4. 更新 index.md,列出所有页面和一句话摘要
5. 发现矛盾时标注出来,不要强行统一
Query:
- 查 index.md 定位相关页面
- 综合信息给出答案
- 好的答案存回 wiki/ 成为新页面
Lint:
- 定期检查矛盾、过时内容、孤儿页面
- 补充缺失的交叉引用
把任务丢给 Claude Code,让它开始「编译」。
提示词:请编译 ai/ 文件夹里的所有文章,更新 wiki/ 和 index.md
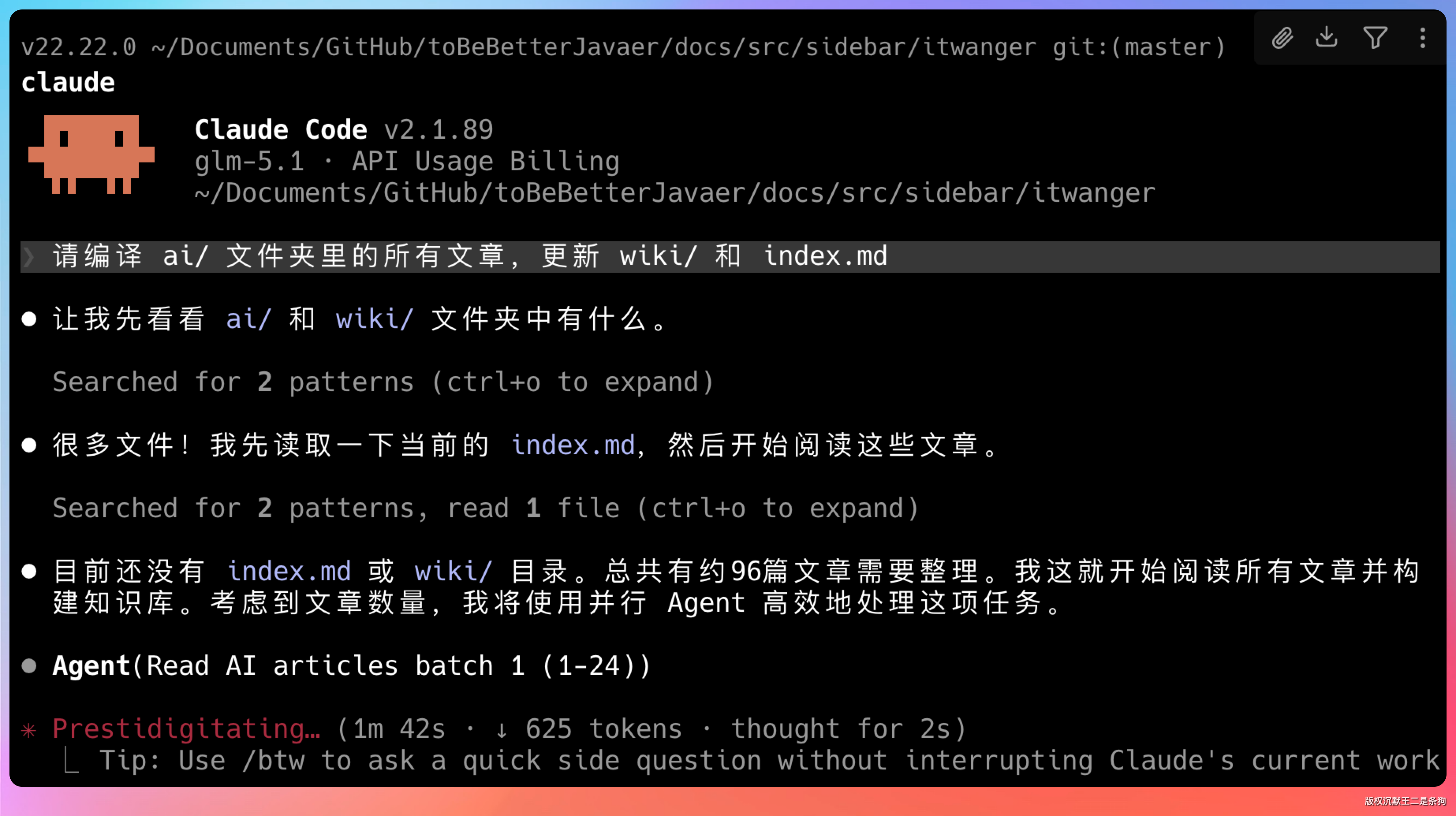
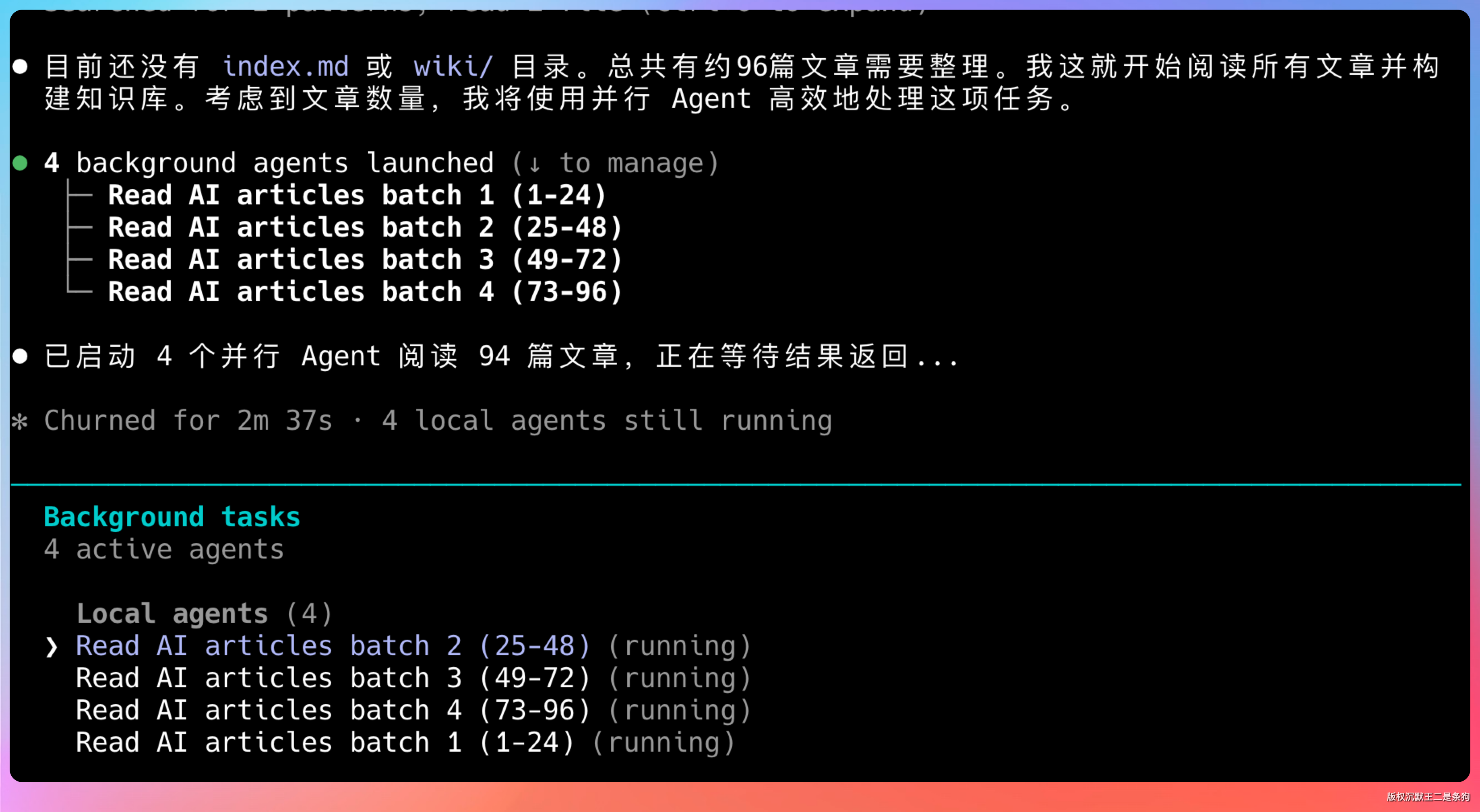
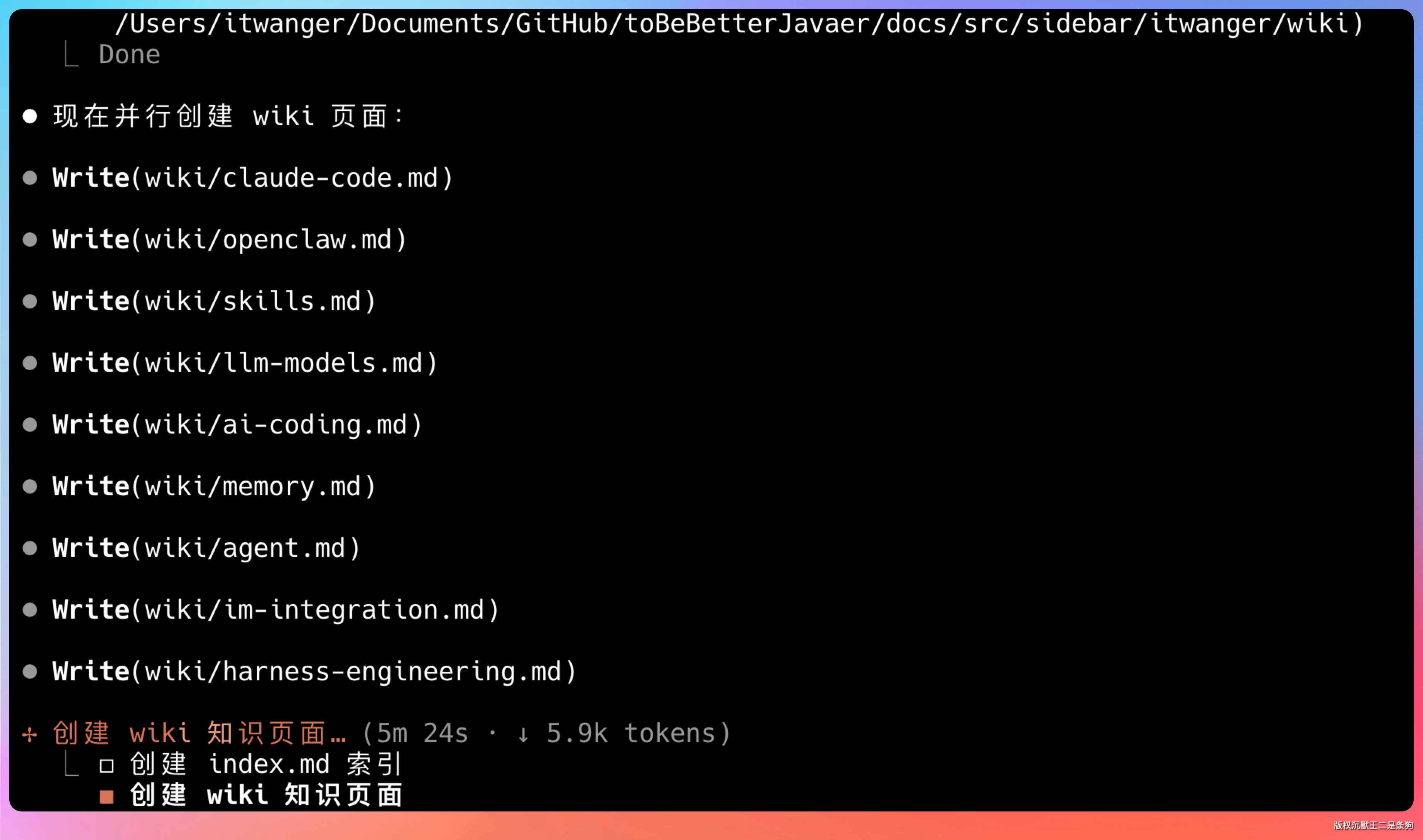
大约 10 分钟后,wiki 文件夹里多了十几个 markdown 文件。有「OpenClaw.md」、「Claude Code.md」、「Skills.md」、「Codex.md」、「Agent.md」……每个文件里都有清晰的定义、引用的原文链接、相关的其他概念。
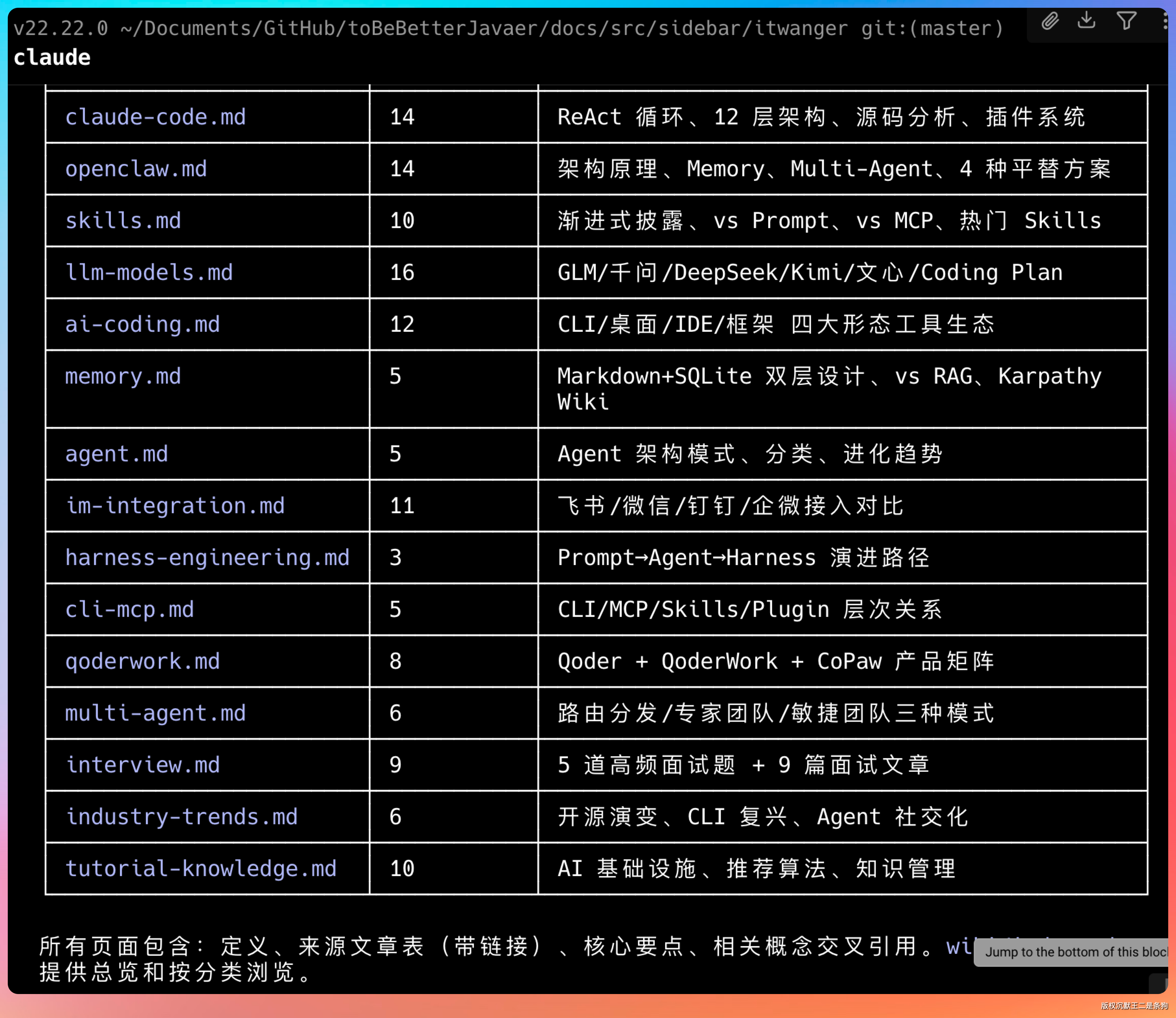
还有一个 index.md,是 LLM 自动维护的内容目录:
# Index
## OpenClaw 生态
- [OpenClaw 入门](OpenClaw 入门.md) - 龙虾生态的基础介绍
- [ArkClaw 评测](ArkClaw 评测.md) - 字节版 OpenClaw 的实测体验
- [AstronClaw 安装](AstronClaw 安装.md) - 科大讯飞版的部署指南
## Claude Code
- [Claude Code 深度解析](Claude Code 深度解析.md) - 从 Mythos 看 Agent 架构
- [Claude Code 插件开发](Claude Code 插件开发.md) - CC GUI 和 Skills 开发
## AI 工具评测
- [Skills 体系](Skills 体系.md) - 6 个核心 Skills 推荐与评测
- [Codex 评测](Codex 评测.md) - OpenAI Codex 的桌面端体验
这个 index.md 是查询时的入口。LLM 先读它,快速定位到相关页面,而不是遍历整个 wiki。
好家伙,我自己都没注意,小号已经写了这么多内容。
然后我试着问了一个问题:「我想选一个 AI 编程工具,该用 Claude Code 还是 Codex?」
Agent 没有直接给答案,而是先查了 wiki 里的相关页面,然后给了我一个结构化的对比:

再比如说,我问:
我写过哪些关于 Skills 的文章?核心观点是什么?

03、和 RAG 比,真的更好吗?
现在我来说说大家最关心的问题:卡帕西这套方案,真的比 RAG 好吗?
先说结论:至少不用接 Embedding 模型和向量数据库,比较轻量级。但如果你的文档量是十万级,那还是得上 RAG。
RAG 有这么一个问题。
没有知识积累。你今天问了一个复杂问题,LLM 花了很多 token 分析了一堆文档,给出答案。明天你问一个相关的问题,它又要重新分析一遍。上次的思考过程,没有沉淀下来。这就像你每次做数学题都要重新推导一遍公式,而不是直接套用已经证明过的定理。
LLM Wiki 解决了这个问题。
「编译」阶段,LLM 已经把文档读完了、理解完了、做好笔记了。提问时,它翻的是自己的笔记,不是原书。笔记是结构化的,有索引、有链接、有交叉引用,检索效率比向量相似度高。
更重要的是,知识会积累。好的回答可以存回 wiki,变成新的知识节点。这个知识库会越来越厚,越来越聪明。
04、卡帕西 Wiki 的底层设计
用久了你会发现,这套三层结构不是随便设计的,它暗合了计算机系统的一个经典架构——缓存层级。
CLAUDE.md 是 L1 缓存,最小、最快、最常被访问。每次 Query 都要读它,就像 CPU 每次运算都要访问寄存器。index.md 是 L2 缓存,比 CLAUDE.md 大,比遍历整个 wiki 快,先查索引再定位具体页面。wiki 页面本身是 L3 缓存,容量最大,访问最慢,只有必要时才读取。

这和 CPU 缓存的访问延迟数量级对应:CLAUDE.md(几个 token)< index.md(几百 token)< wiki 页面(几千 token)。卡帕西没明说,但他设计的 Ingest-Query-Lint 流程,本质上是在优化缓存命中率和更新策略——用空间换时间,用预计算换查询速度。
另一个底层问题是:知识是否是有损的?
94 篇原始文章编译成 wiki,信息熵必然减少。
这触及一个深层问题:我们人类理解一本书,其实也是「压缩」——记住核心观点,忘记具体措辞。LLM Wiki 的压缩,某种程度上模仿了人类的学习过程。但代价是:那些「不可压缩」的东西——风格、个性、情绪——在 wiki 结构里没有位置。
卡帕西的方案假设「知识是可结构化的」,但你的原始素材里,可能有些东西是反结构化的。这是 LLM Wiki 的理论边界,也是它和最原始的文本之间,永远无法弥合的鸿沟。
05、这套方案适合谁?
说了这么多,这套方案到底适合什么人用?
第一类:个人知识管理
如果你平时会读很多技术文章、论文、博客,但读完就忘,想找的时候找不到,那 LLM Wiki 是个神器。
把 curated 过的素材放进 raw/,让 LLM 帮你整理成结构化的 wiki,以后想问什么直接问,不用自己翻。
第二类:小型团队的知识库
团队里有一些内部文档、技术规范、项目笔记,分散在各地。用 LLM Wiki 统一整理,新人入职时直接问 wiki,不用追着老人问。
第三类:研究和学习
你在研究一个新领域,读了一堆论文和资料,想建立一个系统的认知。LLM Wiki 可以帮你梳理概念关系、发现矛盾、建立知识图谱。
比如你想系统了解「AI 编程工具生态」,收集了十几篇关于 Claude Code、OpenClaw、Codex、Cursor 的文章。传统的做法是读一遍,自己做笔记,画思维导图。用 LLM Wiki,你把 curated 过的素材放进 ai/,让 LLM 帮你整理出核心概念(Agent 架构、Skills 体系、Gateway 设计)、每种工具的优缺点、不同方案之间的适用场景。相当于请了一个研究助理,帮你做了第一轮的梳理工作。
用目录的方式,根据知识结构生成的多层级文件夹,并且每个文件夹都有摘要和索引,然后还有一个总索引,整个文件夹版本的知识库完全可以按照脑图的架构无限扩展,遇到标签和其他可以多分类的信息点,会在摘要文件和索引文件中注明。
效率非常高。毕竟个人知识库数据肯定不会打到百万条那么多。如果只是几万条,完全够用。和向量数据库比起来太轻便了。
05、开源复刻版本
卡帕西发布 Gist 后,GitHub 很快出现了好几个开源复刻,我挑几个试过还不错的推荐给大家。
第一个是 llm-wiki-compiler(Python),把手动流程自动化了:监控 xx/ 文件夹变化,自动触发 LLM 编译,增量更新 wiki。
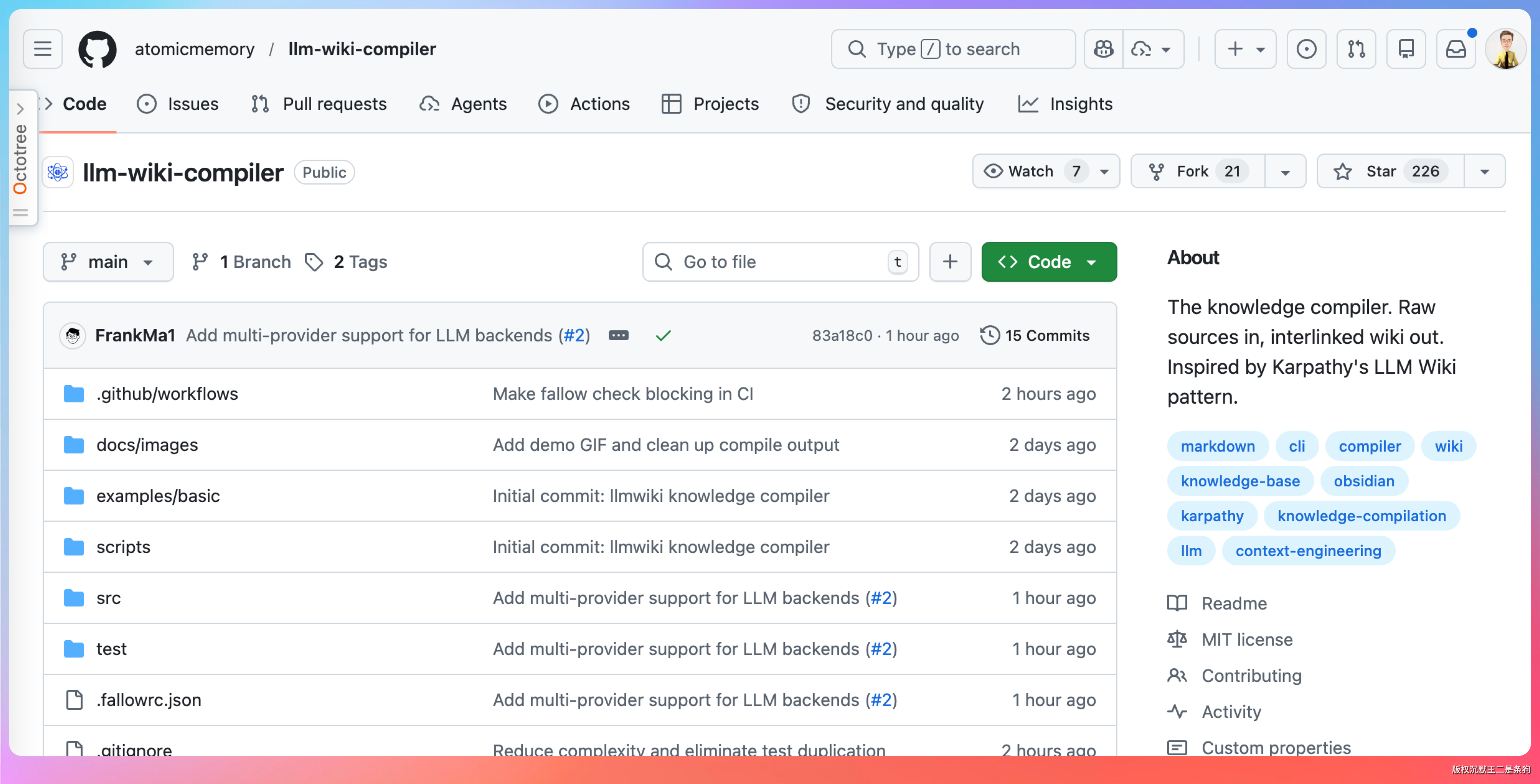
第二个是 obsidian-llm-wiki(Obsidian 插件),直接把 LLM Wiki 集成到 Obsidian 里。如果你本来就是 Obsidian 用户,这个体验最无缝。
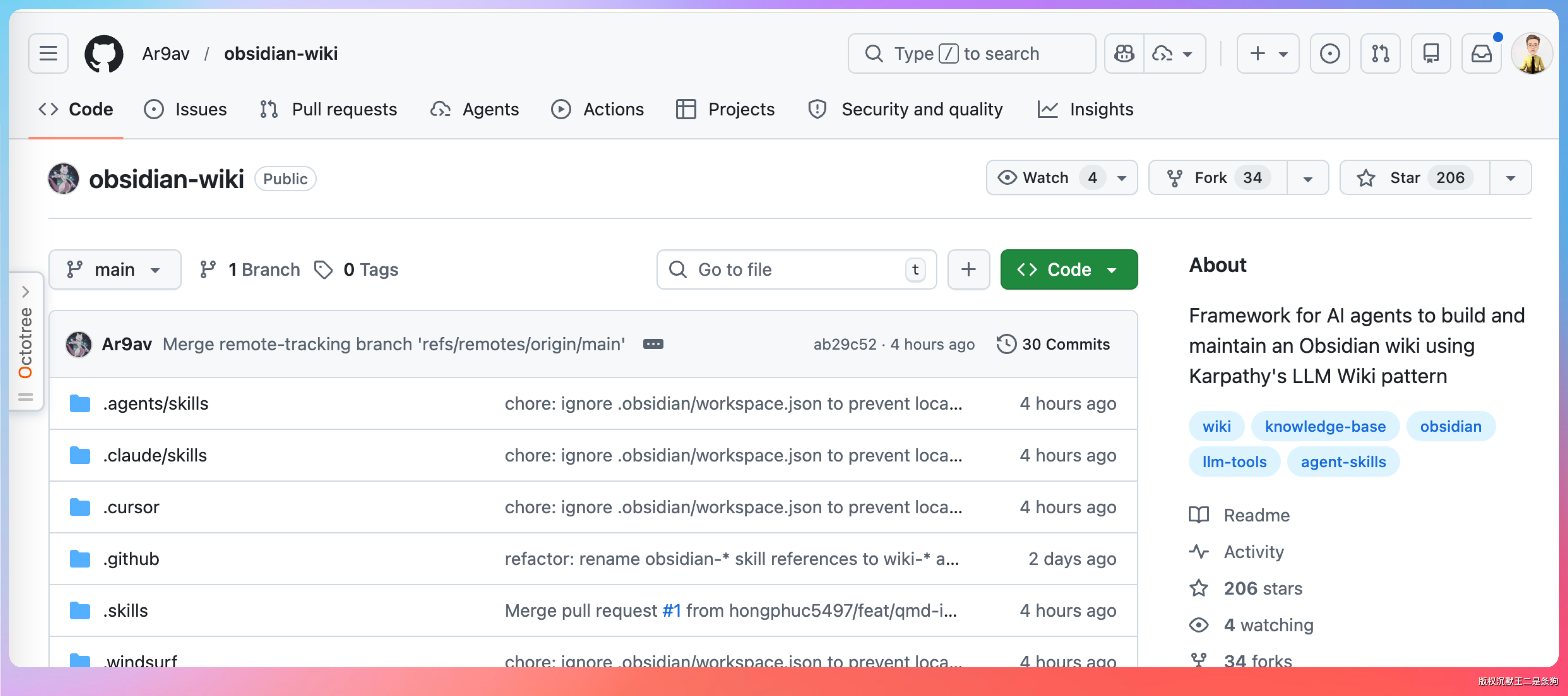
我平常的文字稿就是放在 Obsidian 里的。
第三个是 Benboerba620/karpathy-claude-wiki,基于投资视角写了一个 Karpathy 的个人 wiki。

GitHub 上搜「karpathy llm-wiki」能找到更多,有的是 VS Code 插件,有的是完整的 Web 应用。本质上都是基于卡帕西的核心思想做的封装,两个文件夹加一个配置文件,理解了底层原理用哪个都行。
ending
卡帕西的 LLM Wiki 方案,给我的最大启发不是技术,而是思维方式。
我们总想把 AI 当成一个「更聪明的搜索引擎」,问什么就检索什么、答什么。但卡帕西告诉我们,AI 可以是一个「知识整理者」,帮你读书、做笔记、建立理解。
这个转变,从「检索」到「理解」,从「拼答案」到「用知识」,可能是 AI 应用的一个新方向。
【有时候,简单的方法比复杂的方法更有力量。】
不是说 RAG 没用了,而是对于大多数人、大多数场景,我们可能根本不需要那么重的技术栈。两个文件夹,一个配置文件,就能搭起一个个人知识库。
如果你还没试过,建议搭一个。把手里那些「收藏了但从来没看」的文章丢进去,让 LLM 帮你整理一遍。你会发现,原来自己已经积累了这么多知识。
我们下期再见,冲啊!

回复