



大家好,我是二哥。
相信大家也都发现了,今年和去年有很大的不同,不管是你面Java后端,还是其他岗位,AI 的浓度那是相当的高。
接下来就给大家分享一些真实的面经,冲大厂暑期实习的小伙伴可以拿来作为参考。

全文非常肝,系好安全带,我们粗粗粗发啦。
项目拷打
01、给你5分钟,介绍RAG项目整体流程,说出1-2个设计难点
派聪明的整体流程是这样的:用户上传文档后,系统会先对文档进行分片处理,把长文档切成若干个 chunk,每个 chunk 生成对应的向量(embedding),然后和原始文本一起存入 ElasticSearch。
用户提问时,系统对问题向量化,在 ES 中执行混合检索(向量检索 + BM25 关键词检索),把召回的相关 chunk 拼接进 prompt,交给大模型生成答案,最后通过 WebSocket 流式返回给前端。
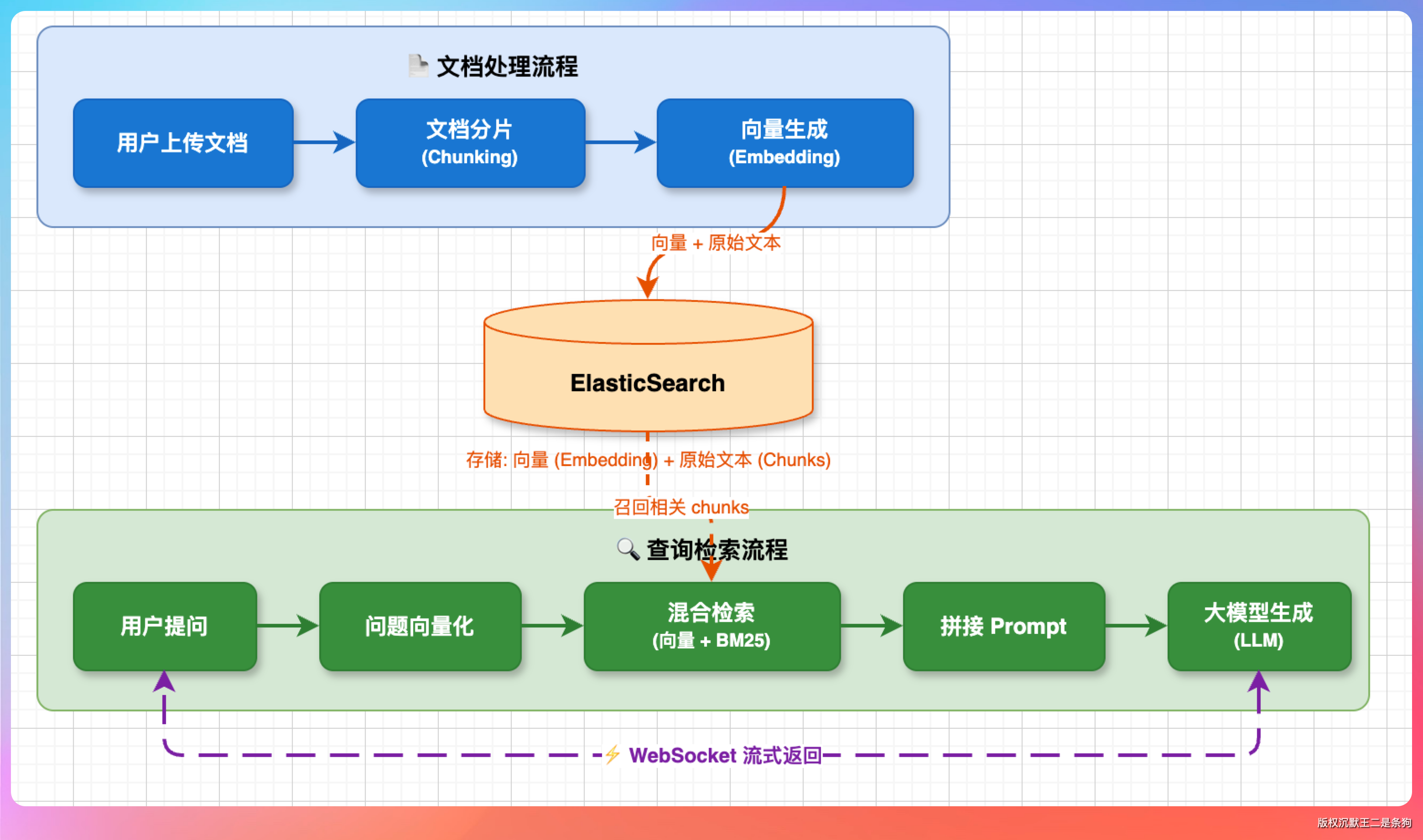
两个比较值得说的难点:
第一个是分片策略。文档分片不是随便切的,切太短会丢失上下文,切太长会超出 embedding 模型的 token 限制,而且会稀释语义。
派聪明采用的是固定大小分片加上 overlap(重叠),保证相邻 chunk 之间有一定内容重叠,避免关键信息刚好落在切割边界上。
第二个是对话上下文管理。多轮对话时需要把历史记录带入 prompt,但上下文越来越长会超出大模型的 context window。如何在保留足够上下文的前提下控制 token 数,是 RAG 项目里很实际的工程问题。
02、除了分片上传,有做断点续传吗?、
断点续传的核心思路是:把大文件切成多个分片(chunk),每个分片单独上传,上传成功后记录该分片的状态,如果上传中断,下次只上传还没完成的分片,最后在服务端把所有分片合并。
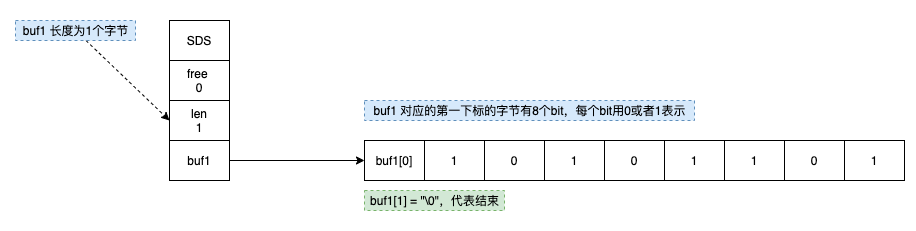
派聪明用 Redis 的 Bitmap 来存储分片的上传状态。每个分片对应 Bitmap 中的一个 bit,上传成功就设置为 1,没上传就是 0。
前端发起上传前先查一下 Bitmap,知道哪些分片已经上传过,哪些还没有,只传缺失的部分。
为什么要这样设计?
因为在实际场景里,用户上传大文档(比如 PDF、Word)时,网络抖动、页面刷新都可能中断上传,如果每次都要重头来,用户体验很差,而且服务端资源也浪费了。
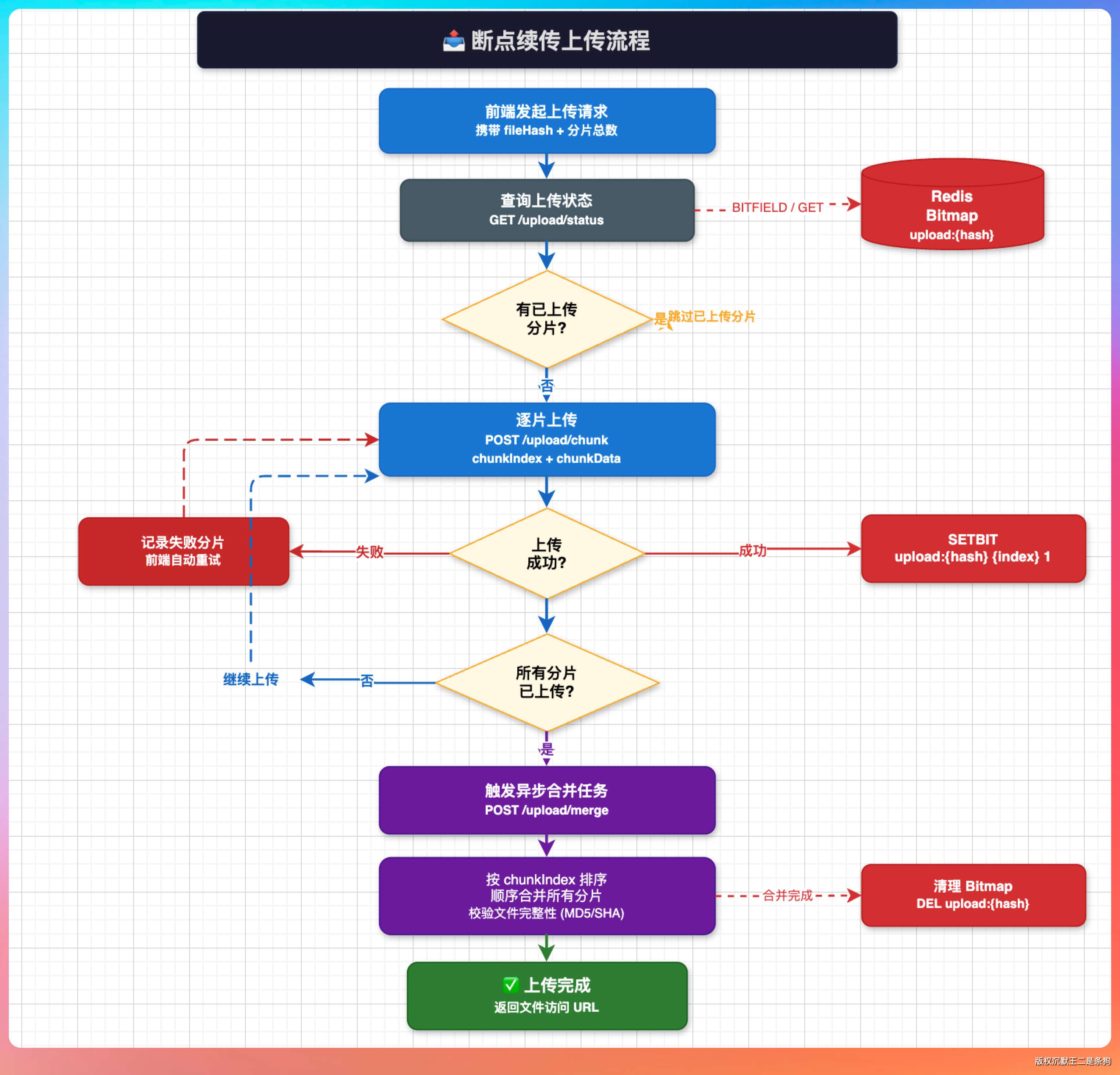
断点续传加上 Bitmap 记录进度,成本低、实现简单,效果很好。
值得一提的是,合并操作是在所有分片都上传完成后,由 MinIO 进行合并。
派聪明在合并完成后会立刻触发后续的文档解析和分片入库流程,整个链路是异步的。
03、既然用了Bitmap存储分片索引,Redis底层怎么实现的?还有哪些使用场景?
Redis 的 Bitmap 本质上是对 String 类型的封装。
String 在 Redis 中以字节数组存储,Bitmap 操作(SETBIT、GETBIT、BITCOUNT 等)实际上就是对这个字节数组进行位操作。每个字节有 8 个 bit,一个 512MB 的 String 可以存储 2^32 个 bit,也就是大约 42 亿个位,空间效率极高。
举个具体例子:执行 SETBIT mykey 7 1,Redis 会把 key 为 mykey 的字节数组的第 7 个 bit 设置为 1。底层就是一次简单的位运算。

Bitmap 的常见使用场景:
- 用户签到:userId 作为 offset,每天一个 key,签到就 SETBIT,统计月签到天数用 BITCOUNT。
- 活跃用户统计:每天记录哪些用户活跃,多天取交集(BITOP AND)就知道连续活跃的用户。
- 布隆过滤器:虽然 Redis 4.0 后有原生的 Bloom Filter,但用 Bitmap 自己实现也是常见方案。
- 分片上传进度:就是派聪明这种用法,记录哪些分片已上传,实现断点续传。
04、混合检索用了embedding模型+IK分词器,为什么这么设计?
向量检索的优势是语义匹配,能找到「意思相近」的内容,但对于精确关键词匹配效果不稳定,特别是专有名词、产品名、缩写这类词,embedding 模型未必能很好地捕捉。
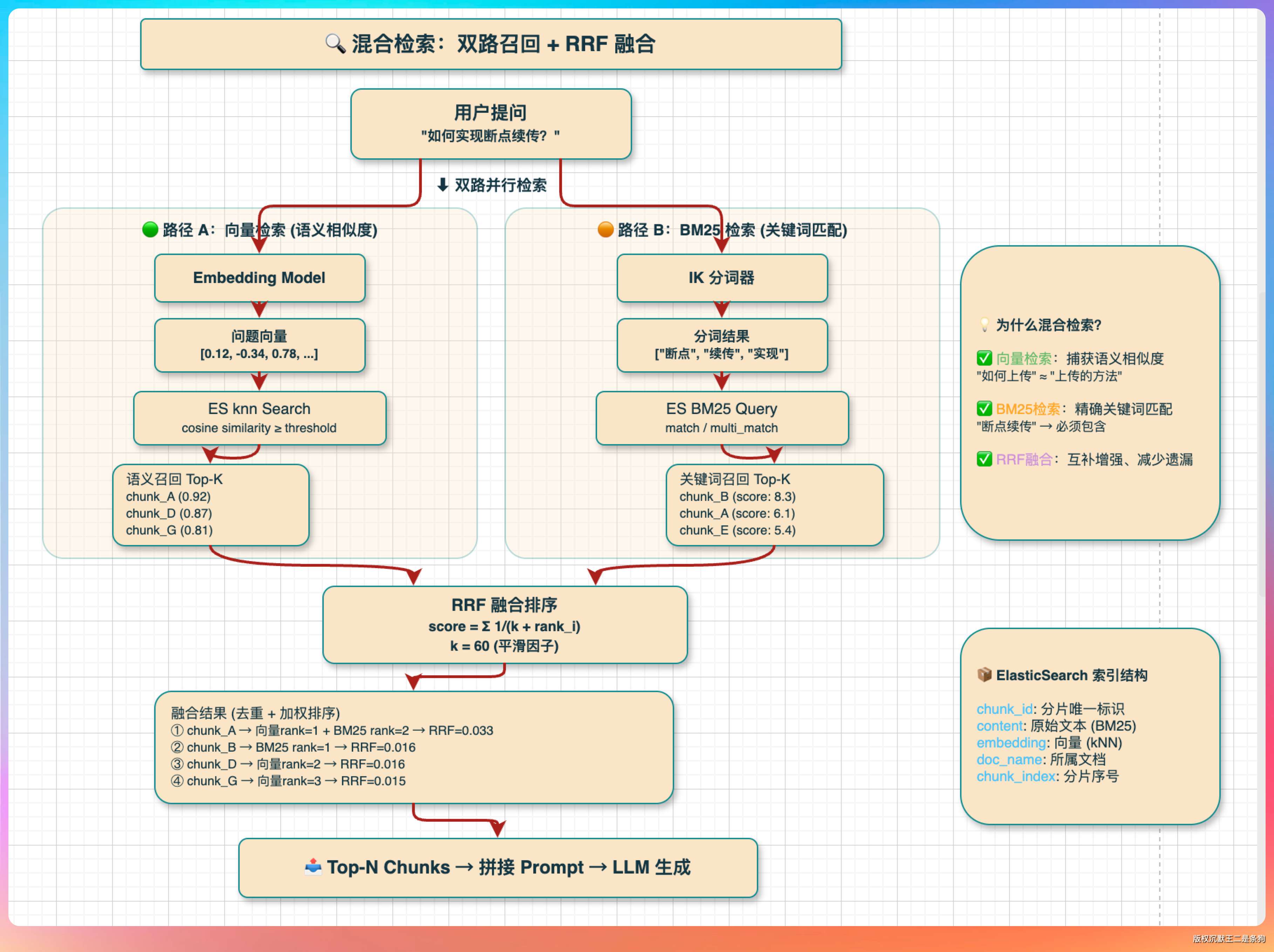
BM25 是词频统计模型,只看词是否出现、出现几次,完全不懂语义,问「怎么提升系统性能」和问「如何优化系统效率」,BM25 可能觉得这是两件完全不同的事。
两者结合,优劣互补。向量检索负责语义召回,IK 分词器配合 BM25 负责精确关键词匹配,最后用 RRF(Reciprocal Rank Fusion)或者加权的方式把两路结果融合,得到最终的排序。
IK 分词器是针对中文优化的分词工具,专门处理中文的分词问题(中文没有天然的空格分隔,直接按字切或者用英文分词器效果很差)。
用 IK 分词后,「检索增强生成」会被切成「检索」「增强」「生成」几个词,然后 BM25 就能正常工作了。
05、BM25算法和KNN算法分别是什么?具体怎么实现的?
BM25(Best Matching 25)是信息检索领域的经典算法,是 TF-IDF 的改进版。
它的核心思路是:一个词在文档中出现的次数越多(词频 TF),这个词对文档越重要;但这个词在所有文档中都很常见(逆文档频率 IDF 低),那它的权重就要打折扣。
BM25 在此基础上加入了文档长度归一化,避免长文档因为词出现次数多就天然占优。
BM25 的打分公式大概是这样的:
$$\text{score}(D, Q) = \sum_{i=1}^{n} \text{IDF}(q_i) \cdot \frac{f(q_i, D) \cdot (k_1 + 1)}{f(q_i, D) + k_1 \cdot (1 - b + b \cdot \frac{|D|}{\text{avgdl}})}$$
其中 $f(q_i, D)$ 是词 $q_i$ 在文档 $D$ 中的词频,$|D|$ 是文档长度,$\text{avgdl}$ 是平均文档长度,$k_1$ 和 $b$ 是可调参数。在 ElasticSearch 中,BM25 是默认的相似度算法,开箱即用。
KNN(K-Nearest Neighbors,K 近邻)在向量检索中指的是找到和查询向量最相近的 K 个向量。
文档被 embedding 模型转成高维向量后,存入向量索引,查询时把问题也转成向量,在索引中找余弦相似度最高的 K 个文档。
ElasticSearch 8.x 以后原生支持 dense_vector 类型和 knn 查询,可以直接在 ES 里做向量检索,不需要额外引入 Milvus 这样的向量数据库。
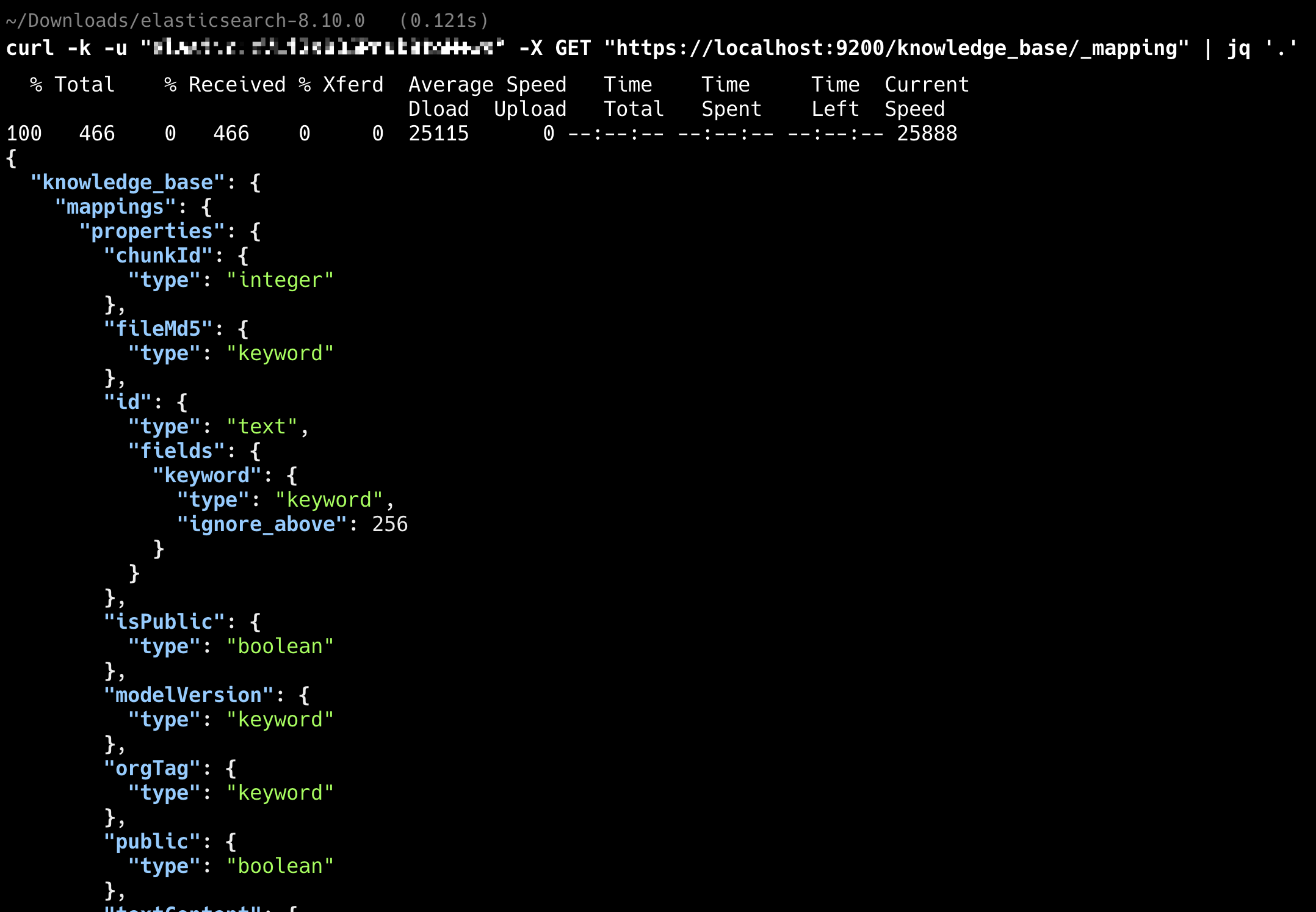
在 ES 的 mapping 里定义 dense_vector 字段,索引文档时把 embedding 结果写入该字段,查询时用 knn 查询指定 query_vector 和 k 值即可。
06、文档分片存储怎么考虑的?
分片存储要考虑几个维度:
分片大小。太小(比如 100 token)会导致每个 chunk 上下文不完整,检索回来的内容片段无法独立成句,大模型很难基于它给出好答案。
太大(比如 2000 token)会超出 embedding 模型的输入限制,而且会稀释语义,导致检索精度下降。
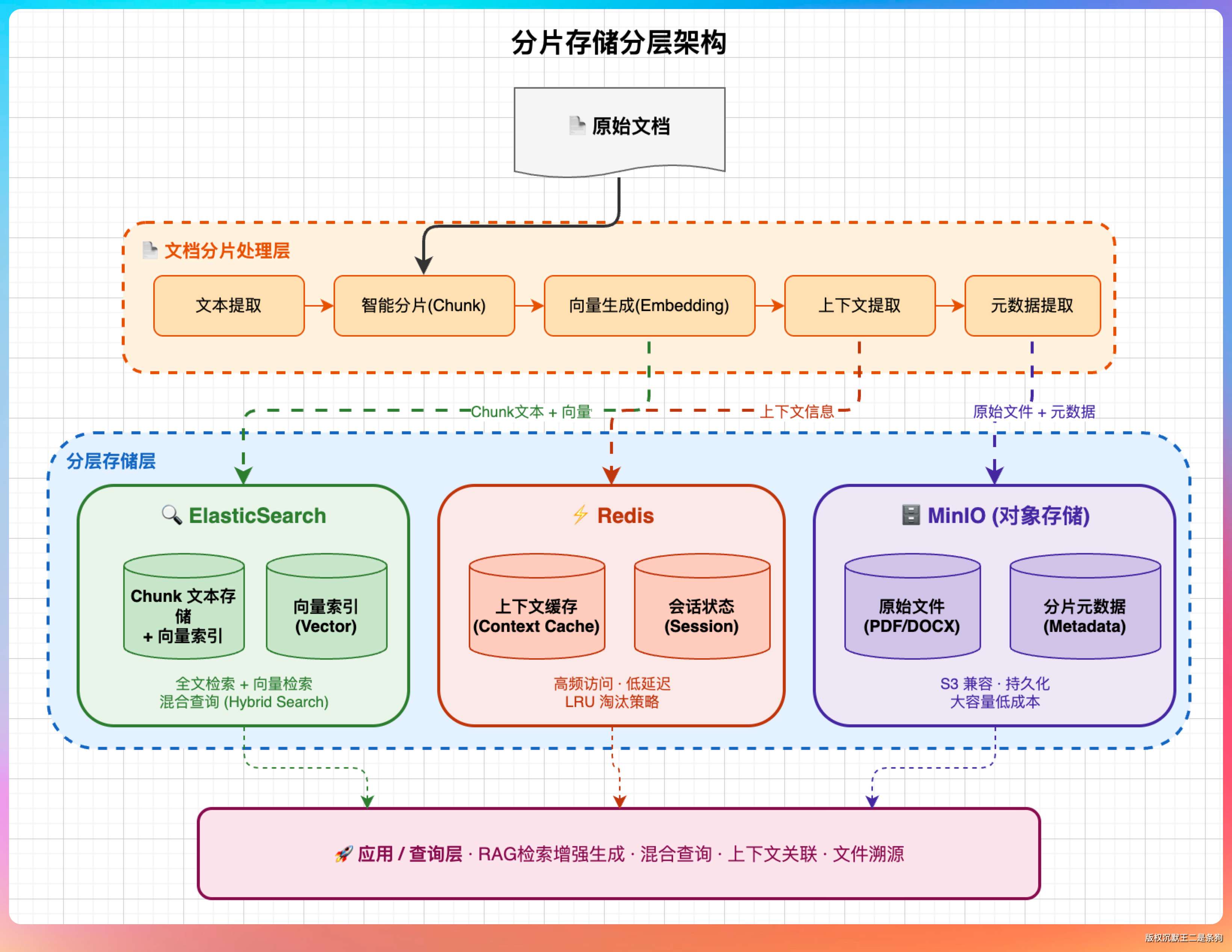
派聪明采用的是 512 token 左右的分片大小,是一个经过实测的合理值。
overlap(重叠)。前后两个 chunk 之间保留一定重叠(比如 50 token),避免关键信息刚好被切断。
一段话「……因此,这个方案的核心优势是……」,如果「因此」在第一个 chunk 的结尾,「核心优势」在第二个 chunk 的开头,没有 overlap 的话两个 chunk 都不完整。
元数据。每个 chunk 存储时要带上来源文档的 ID、分片序号、原始文件名等元数据,一方面方便溯源(告诉用户答案来自哪里),另一方面在某些场景下还需要按顺序把相邻 chunk 一起返回(滑动窗口召回)。
存储选择。原始 chunk 文本和向量存在 ES,对话上下文存在 Redis,文件本身存在对象存储(比如 MinIO 或者云存储),各司其职。
07、为什么选WebSocket?
RAG 项目用 WebSocket 主要是为了实现流式输出(Streaming)。
大模型生成回答不是一次性返回的,而是一个 token 一个 token 地输出,如果等全部生成完再返回,用户要等很久,体验很差。
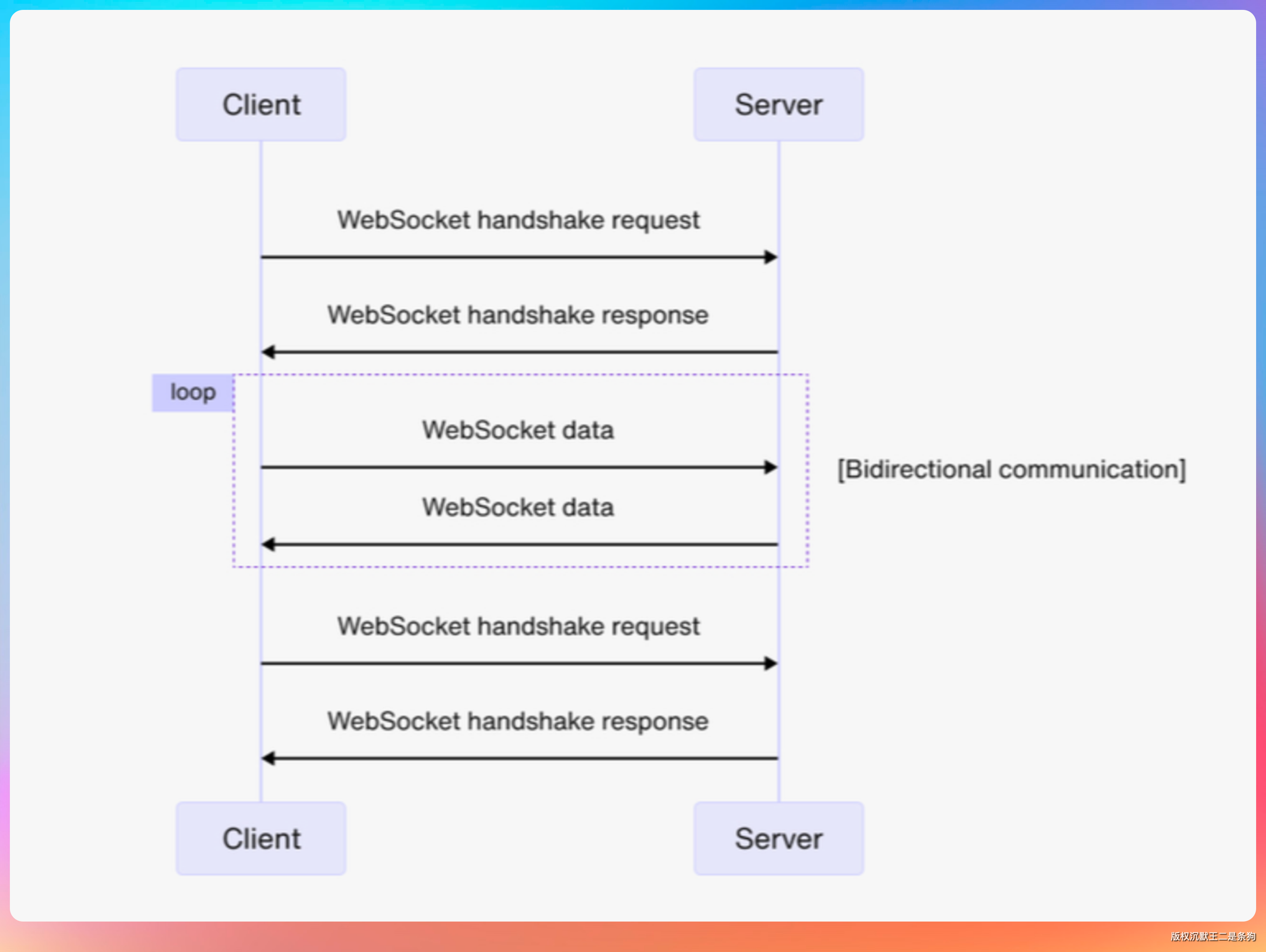
WebSocket 支持服务端主动推送,可以把大模型生成的每个 token 实时推给前端,用户看到的效果就是文字一个个地「打」出来,这是目前主流的 AI 对话产品的标准交互方式。
相比 HTTP 的 SSE(Server-Sent Events),WebSocket 是全双工的,前端也可以随时发消息给服务端(比如中断生成),更灵活。
当然,如果只需要单向推送,SSE 也是不错的选择,实现更简单。
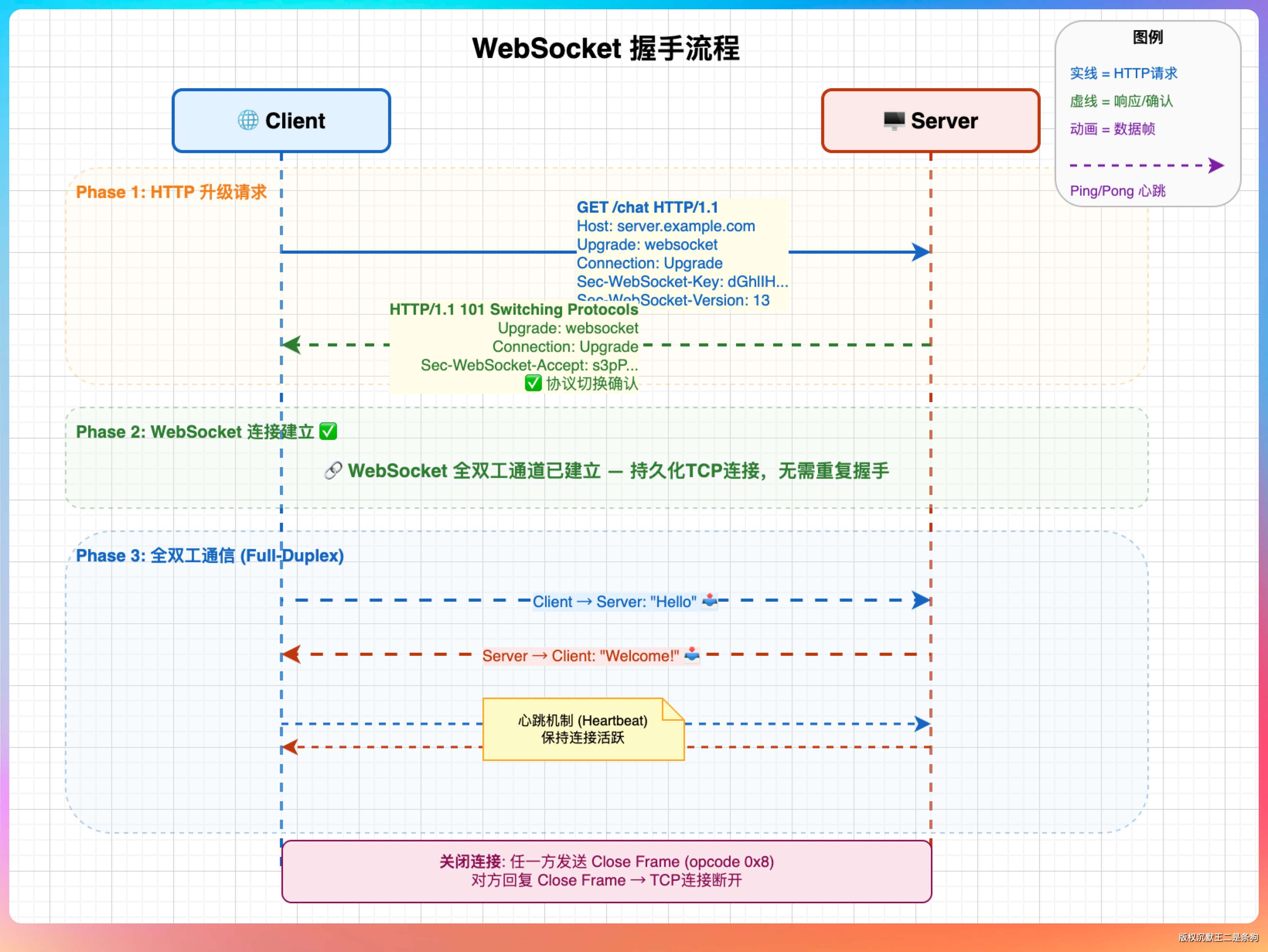
WebSocket 基于什么协议?
WebSocket 协议基于 TCP,但建立连接的握手过程借用了 HTTP/1.1。具体来说:
- 客户端发送一个 HTTP 请求,带上
Upgrade: websocket和Connection: Upgrade头。 - 服务端返回 101 Switching Protocols,表示同意升级。
- 之后这个 TCP 连接就不再走 HTTP 协议,而是走 WebSocket 帧协议,实现全双工通信。
WebSocket 的默认端口是 80(ws://)和 443(wss://,加密版),和 HTTP/HTTPS 一样,方便穿透防火墙。
08、用Redis存储对话上下文,具体用的哪种类型?
对话上下文是一个有序的消息列表,每条消息有角色(user/assistant)和内容(content)两个字段。
基于这个特点,Redis 的 List 类型是最合适的选择。
具体做法:以用户 ID + 会话 ID 作为 key,每条消息序列化成 JSON 字符串后,用 RPUSH 追加到 List 末尾。
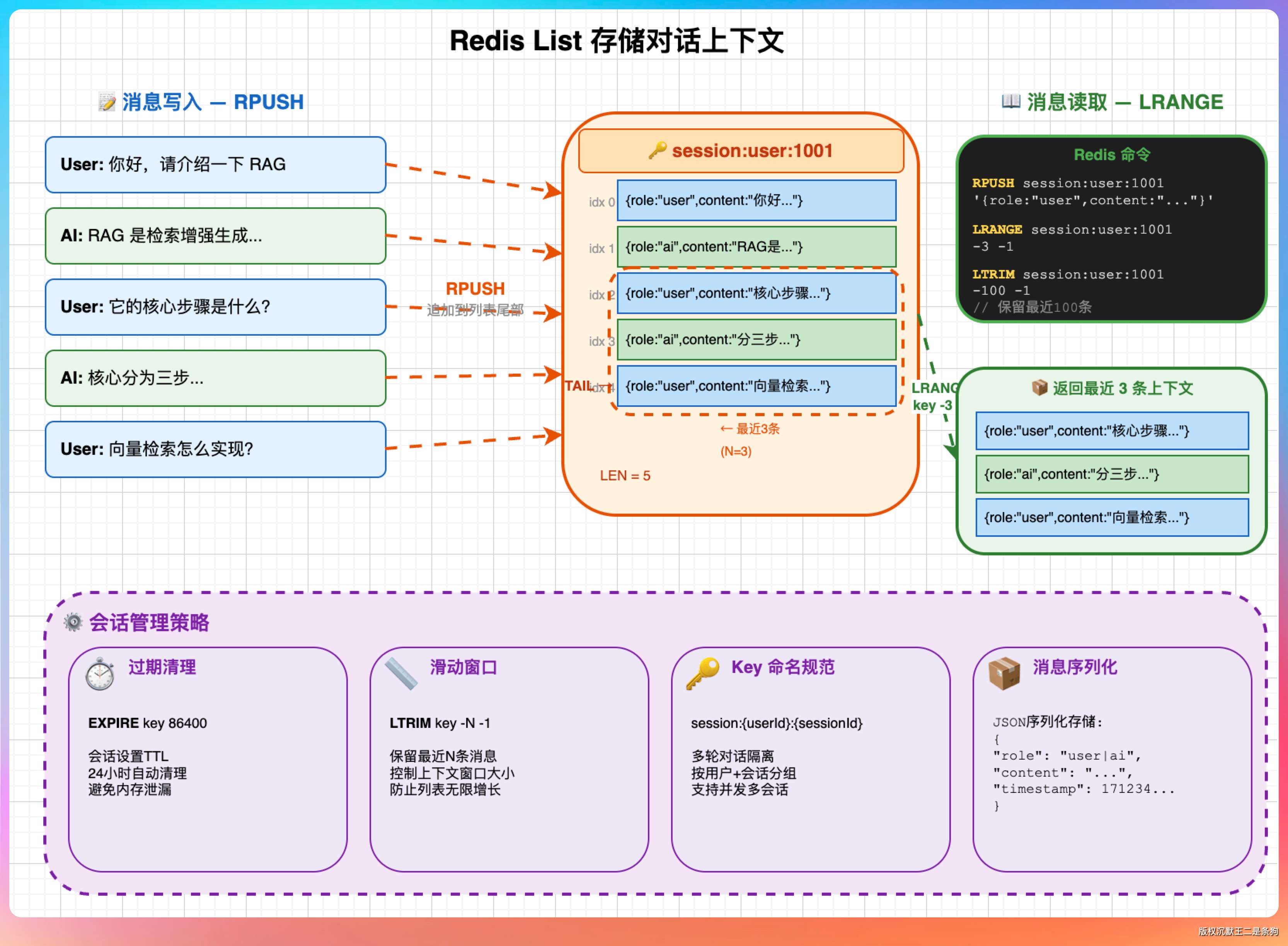
读取时用 LRANGE key 0 -1 取出所有消息,或者 LRANGE key -20 -1 取最近 10 轮(20 条,因为一轮包含 user 和 assistant 各一条)。
为什么不用 String?
因为 String 存的话每次要读出来反序列化、修改、再序列化写回去,麻烦,而且有并发风险。
为什么不用 Hash?
Hash 适合存结构化的键值对,但消息列表是有序的,Hash 不保证顺序。
为什么不用 ZSet?
ZSet 是有序集合,可以用时间戳做 score 来保证顺序,功能上也能实现,但比 List 复杂,对这个场景来说有点大材小用。
所以 List 是最自然的选择:有序、支持两端操作(方便截断最旧的消息)、操作简单。
09、对话上下文过长怎么办?除了取最近10轮,还有别的方法吗?
取最近 N 轮是最简单的滑动窗口方案,实现成本低,但缺点明显:如果用户在第 1 轮提到了关键信息,第 11 轮再问相关问题时,已经把第 1 轮的内容丢掉了,模型不知道之前说过什么。
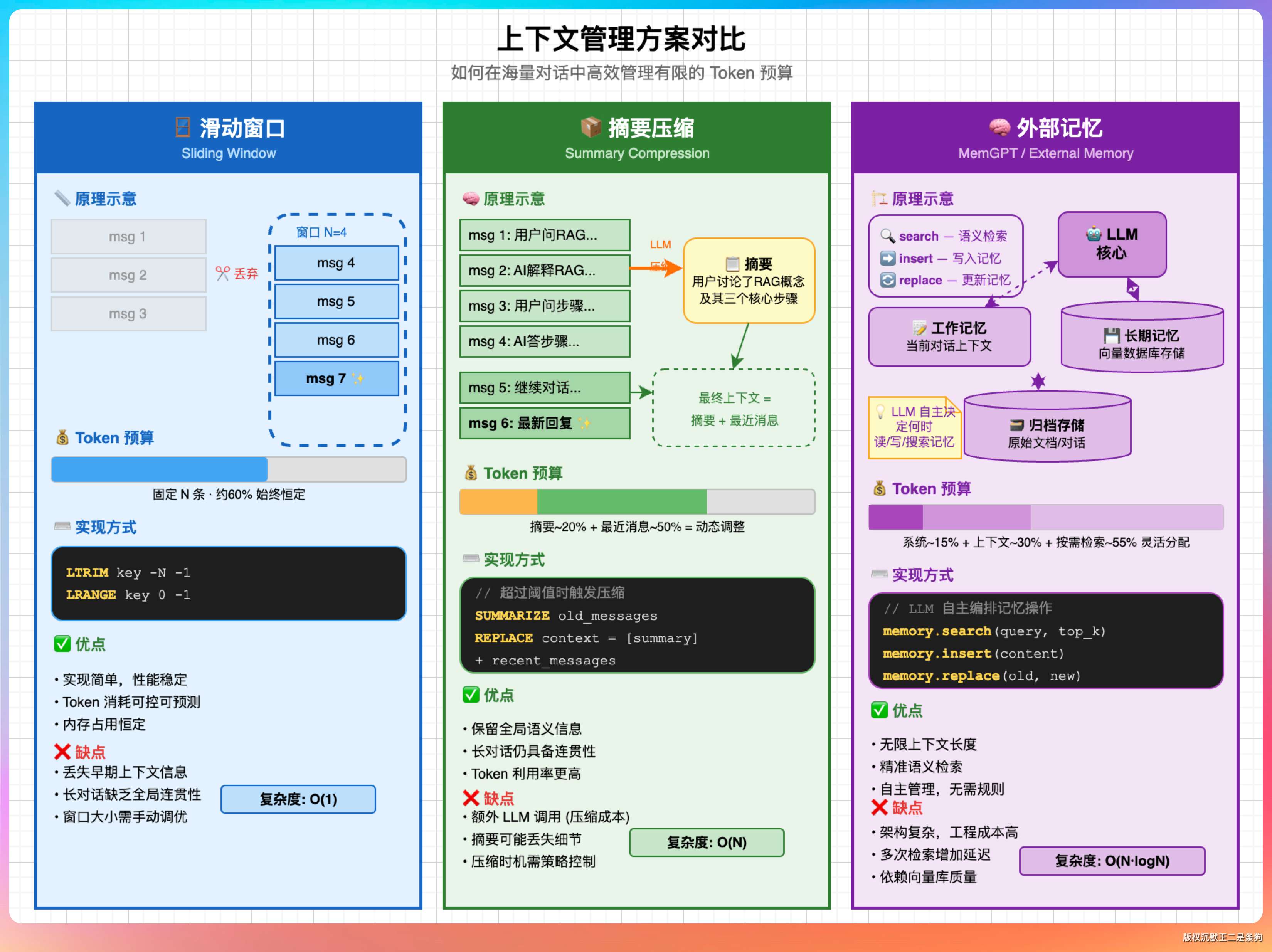
更进阶的方案有这几种:
方案一:摘要压缩(Summarization)。当上下文超过阈值时,不是简单丢掉旧消息,而是用大模型把前面的对话总结成一段摘要,摘要 + 最近几轮完整对话一起作为上下文。这样既保留了历史信息的精华,又控制了 token 数量。缺点是多了一次大模型调用,增加了延迟和成本。
方案二:重要性打分(Importance Scoring)。对历史消息按重要性打分,优先保留重要的消息,而不是简单地按时间顺序截断。比如用户明确说「记住我叫王二」这种话,就应该比一般的闲聊更重要。
方案三:外部记忆(External Memory)。把重要信息(比如用户偏好、关键事实)单独存到一个「记忆库」里,每次对话时先从记忆库里检索相关信息拼入 prompt,类似于 RAG 的思路。MemGPT、LangChain 的 Memory 模块都有这种实现。
方案四:动态 token 预算。根据问题复杂度动态分配上下文长度。简单的问题少给上下文、快速响应;复杂的问题多给上下文、允许更长的推理链。
ending
我一直说,简历上写的项目,要能「经得起拷打」。
不是说每道题都要答得完美,而是要能展示你的技术思考路径——你为什么这样设计,有没有考虑过别的方案,遇到问题是怎么排查的。
【项目背后是思路,思路背后是积累。】
这也是为什么我一直推荐大家把 RAG 项目做深、做透,而不是只会跑通流程就罢手。
对了,还有一件事想说:面试结束后,不管过没过,都值得把被问到的题目复盘一遍。
面试就是这样,一次面经能逼着你把一个技术方向从头到尾捋一遍,这比自己闷头看书有效得多。
冲,加油。


回复