


大家好,我是二哥呀。
Kimi K2.6 发布了,代码能力、长任务能力和 Agent 集群能力都上了一个新台阶。
几乎可以媲美 GPT-5.4、Claude Opus 4.6 和 Gemini 3.1 Pro 等闭源模型。

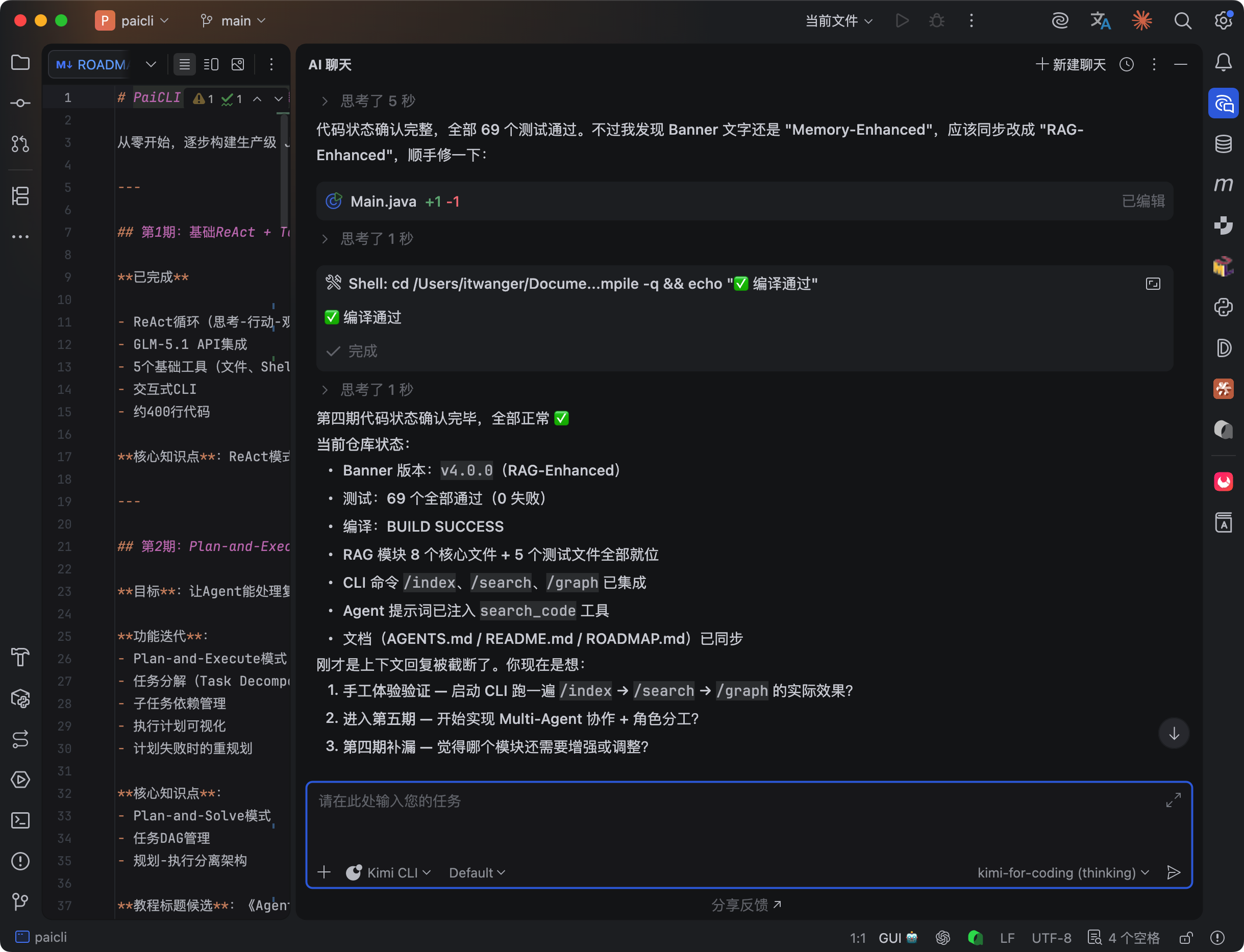
为了验证,我第一时间把 Kimi 2.6 接入到了 IntelliJ IDEA 中,并且让他完成了 PaiCLI Agent 实战项目的第四期 RAG 开发。
有一说一,我是 Claude Code 和 Codex 的重度用户,每天都在高强度使用这俩 Agent 工具编程,对背后模型的能力敏感度还是非常高的。
Kimi 2.6 这次主推的长任务编码和 Agent 集群是我最关心的两个方向。
所以我决定两个一起测。
第一个 case:在 IntelliJ IDEA 里接入 Kimi K2.6,让它开发 PaiCLI 的第四期功能(RAG 检索 + 代码库理解),这是一个包含 10 个子任务的长程编码场景。
第二个 case:趁着 Kimi 2.6 干活的空档,我让 Kimi 2.6 的 Agent 集群能力,帮我跑一个四款 AI 编程工具的竞品分析。
一手看编码能力,一手看集群协作。两手都要抓,两手都要硬,看看 K2.6 到底行不行。
全文比较肝,系好安全带,我们粗粗粗发~😄
01、K2.6 升级了什么
Kimi K2 系列用的是 MoE 架构,总参数量 1 万亿,每个 token 只激活 32B 参数,384 个专家里挑 8 个干活。
说人话就是,MoE 就像一个大公司里有 384 个专家,但每次开会只叫 8 个最相关的人来参加讨论。
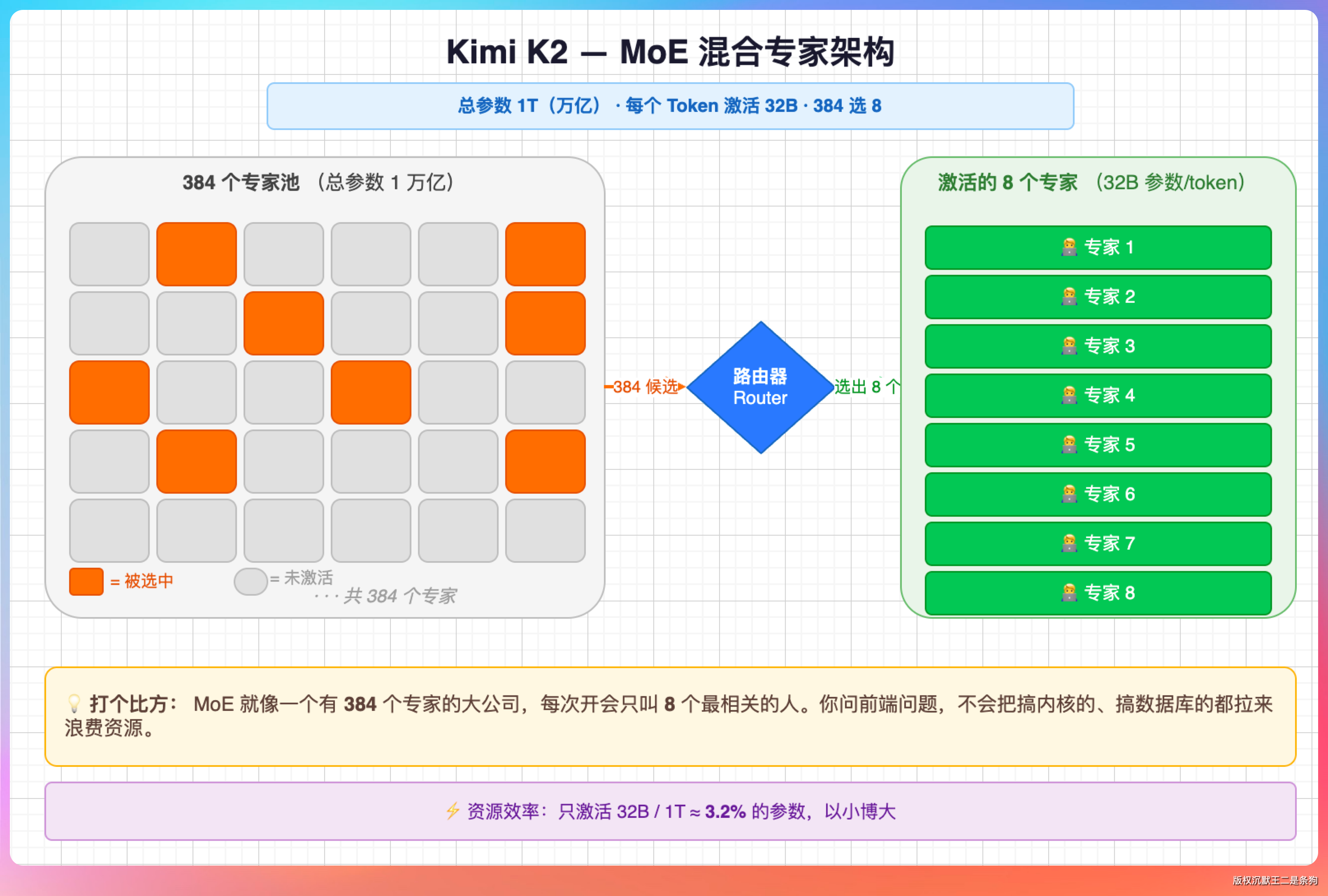
你问前端问题,它不会把搞内核的、搞数据库的都拉进来浪费资源。
从 K2.5 到 K2.6,核心升级集中在三个方面。
Agent 集群扩展到了 300 个子 Agent。 更关键的是,K2.6 改进了编排器,让并行执行不会退化成顺序处理。
长程编码能力拉满。 支持不间断编码 13 小时,单次精准修改能超过 4000 行代码。
开源。 K2.6 是目前第一个在编程能力上追平第一梯队并且开源的模型。
02、IDEA 接入 Kimi K2.6
Kimi Code 支持 IntelliJ IDEA 集成,接入过程非常丝滑。
打开 IntelliJ IDEA,在【工具】→【AI Assistant】→【代理】中,找到 Kimi CLI,点击【安装】。
回到 AI 聊天窗口,随便输入一个提示词,第一次使用会提示登录 Kimi 账号。
点击【Login with Kimi account】,浏览器跳转到 Kimi Code 控制台,如果已经登录了 Kimi 账号会自动授权成功。
03、10 个子任务的 RAG 开发
接入完成后,我们来上点强度。
提示词:PaiCLI 第三期的代码已经完成了,接下来我想实现第四期的代码,主要是 RAG 检索和代码库理解。
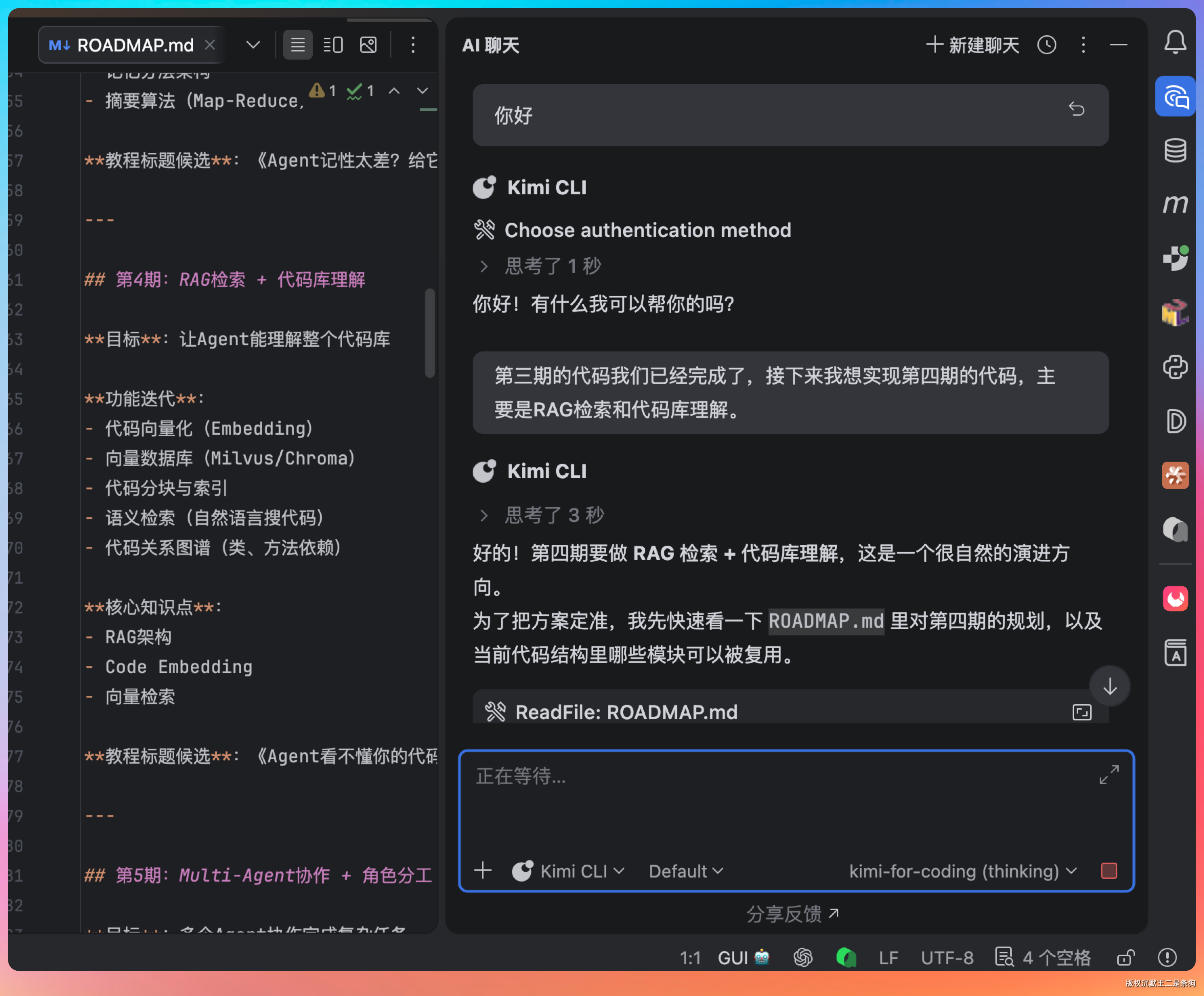
这个提示词我写得很简短,主要目的是想测试一下 Kimi 2.6 能不能自己去找上下文。
果然是有水平的。
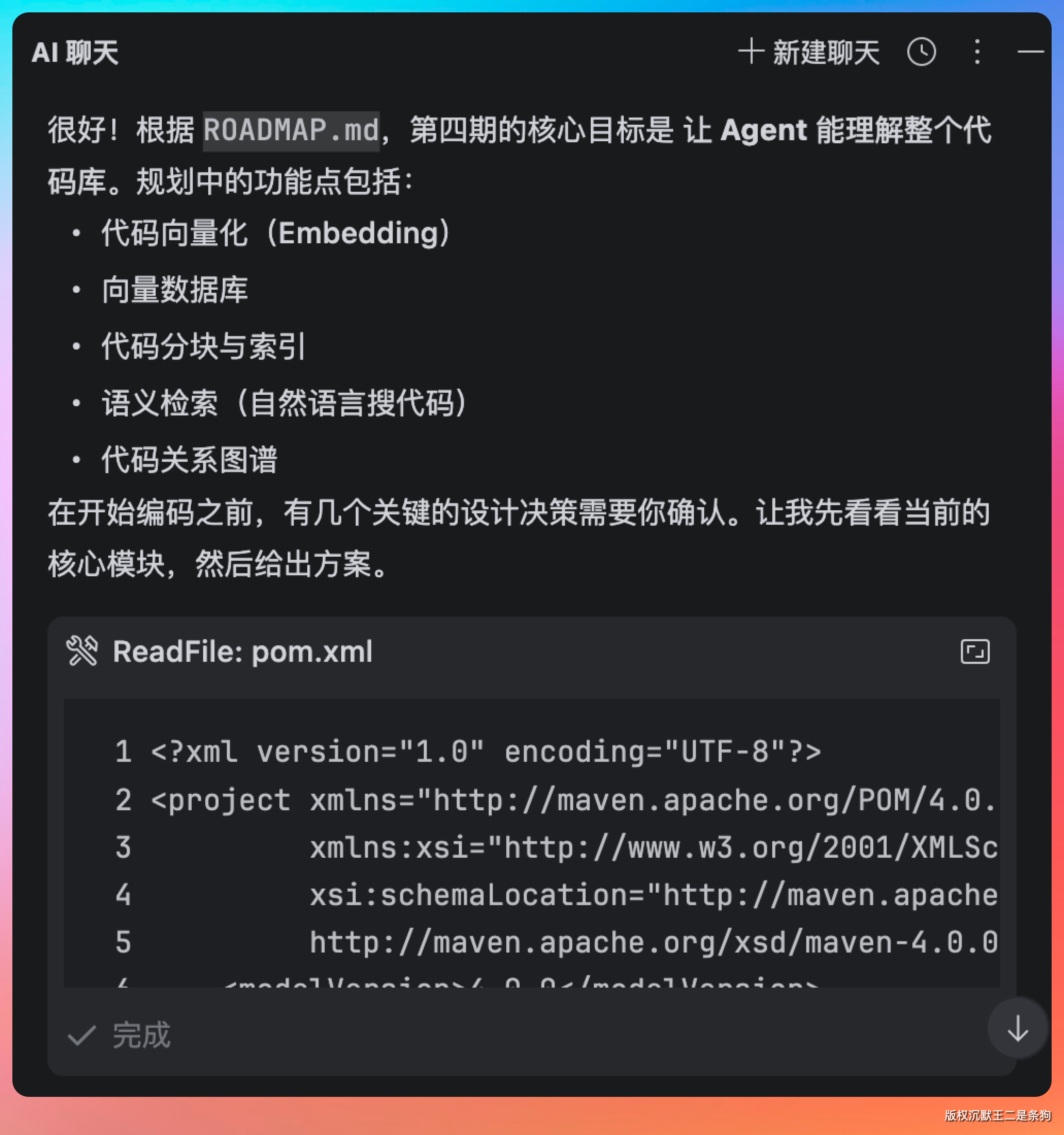
先去读了项目的 ROADMAP,了解第四期代码的完整规划,然后扫描了当前代码库的结构,看哪些模块可以复用。
好的 Agent 不应该上来就写代码,而是先理解项目的上下文和架构。接入 Kimi 2.6 后的 IntelliJ IDEA 干的不错,会先读 CLAUDE.md、扫描目录结构、理解依赖关系,然后才动手。
Kimi 分析完需求后主动问了我几个方案选型的问题:向量数据库用纯内存、SQLite 还是 Milvus?Embedding API 选哪家供应商?代码解析要不要引入 AST 解析?Embedding 模型是否需要可配置?

这些问题问得好啊。
每一个都直接影响后续的架构设计——选 SQLite 还是 Milvus,意味着你这个项目是单机部署还是分布式部署,后面的代码实现完全不一样。
我的回复是:选 SQLite、本地用 ollama 的 nomic-embed-text 作为向量模型、引入 AST 解析、Embedding 模型可配置。

调研结束,Kimi 进入编码阶段。它先生成了一个整体的编码计划,分成 4 个阶段、10 个任务:
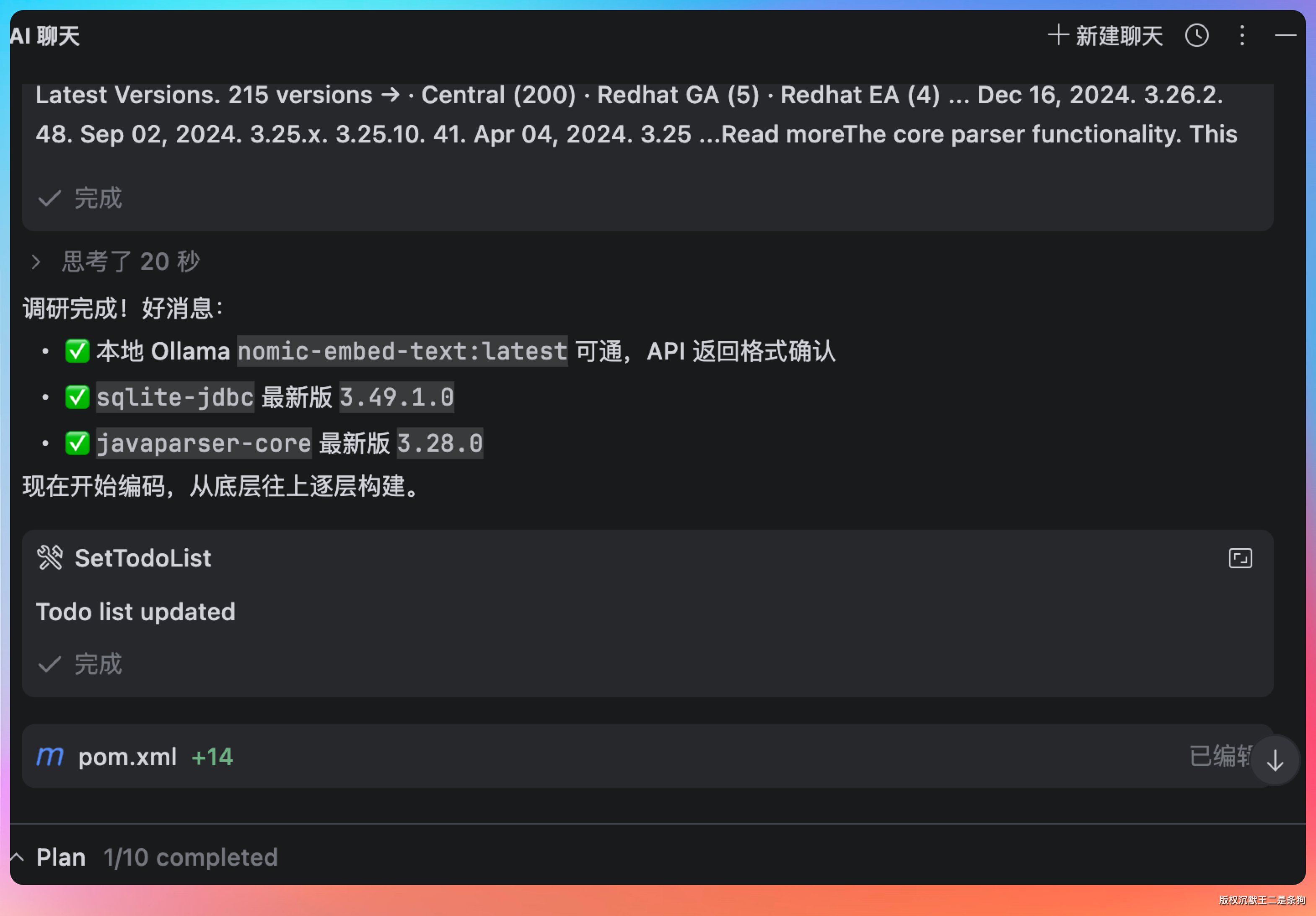
第一阶段完成基础设施——Embedding 客户端的实现和 SQLite 向量存储。
第二阶段是代码理解层——AST 解析器、索引管理和语义检索。
第三阶段是用户界面——给 Agent CLI 添加 /index、/search、/graph 等斜杠命令,以及把 RAG 能力集成进 Agent。
第四阶段是质量保证——编写单元测试和集成测试。
不是那种一口气堆 2000 行然后跑不起来的莽夫式写法。
10 个任务,工作量不小啊。这种复杂度的长任务,正好能验证 K2.6 在长时间持续编码上的能力和稳定性。
等待 Kimi CLI 干活的同时,我们同时测测 K2.6 的另一个重头戏——Agent 集群。
04、Agent 集群实测
浏览器地址栏输入 kimi.com,进入 Agent 集群页面。
输入提示词:
帮我做一个完整的竞品分析报告:对比分析 Claude Code、Cursor、Windsurf、Kimi Code 四款 AI 编程工具的 Agent 能力、代码生成质量、定价策略,输出专业 Markdown 研究报告,包含数据表格。
为什么选这个任务?
因为竞品分析是典型的“广度优先”场景——需要搜集大量分散在不同平台的信息,然后交叉对比、归纳总结。
这种任务让一个人去做,光搜集资料就要半天。让一群 Agent 并行搜集,效率就完全不一样了。
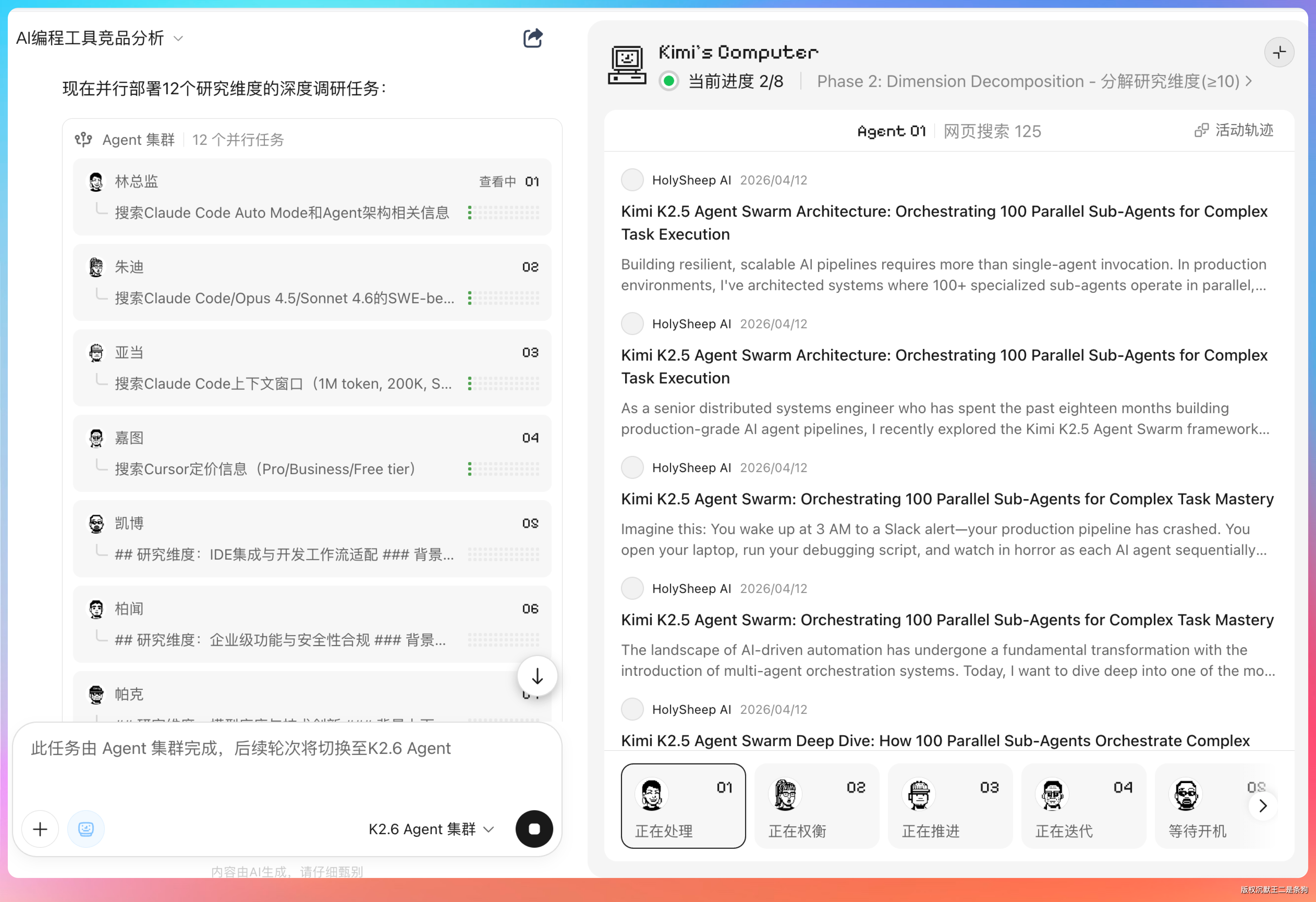
Kimi 先是自动拆解了一个执行计划——制定研究框架、深度研究、交叉验证,一直到报告组装和格式转换。然后就开始召唤 Agent 了。
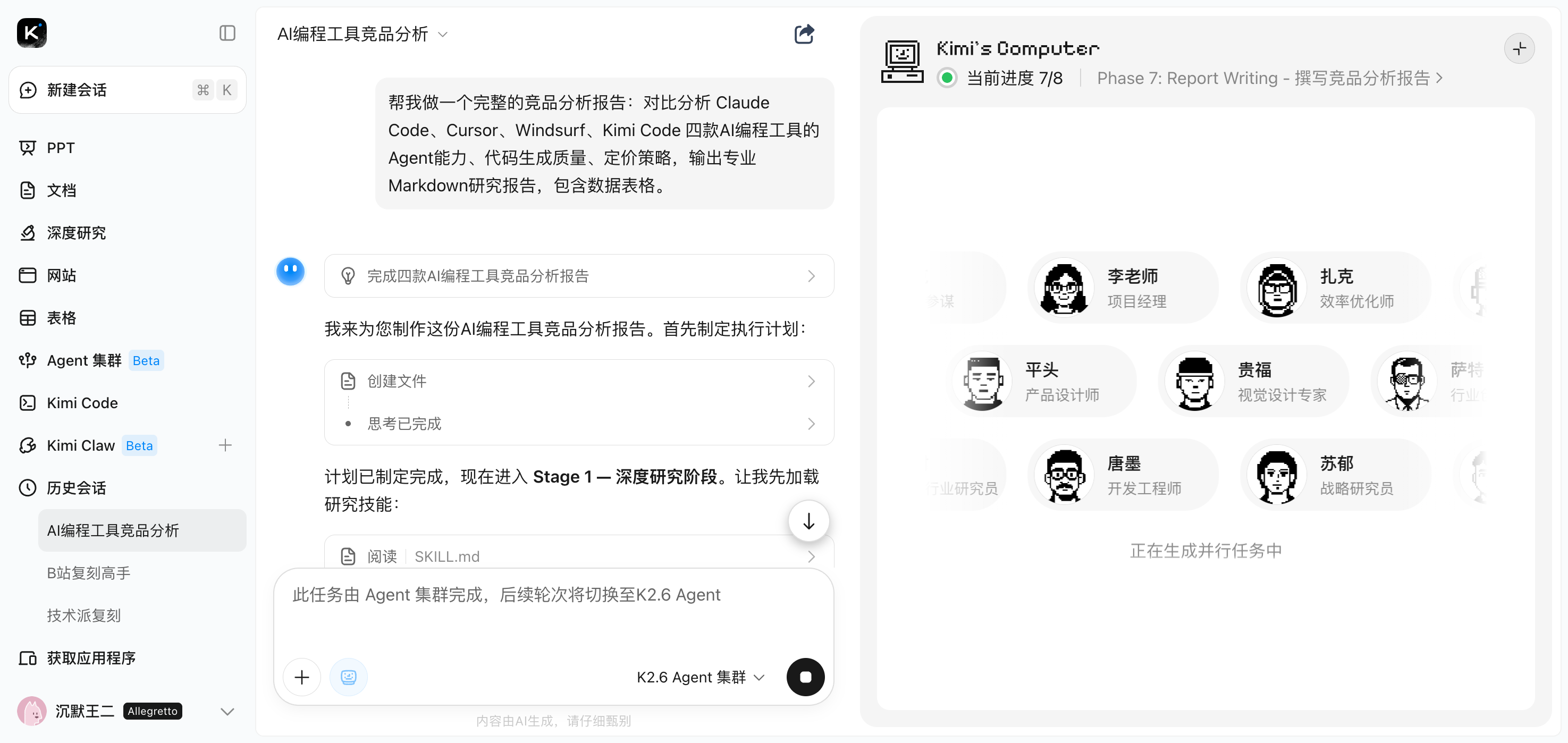
8 个子 Agent,每个都有名字、头像和职责分工:李老师负责路径规划、扎克负责效率优化、平头负责产品设计、贵福负责设计专家、唐墨负责开发工程、苏郁负责战略研究……
一群 Agent 同时干活,每个人只负责一个细分维度。
而且分工还挺讲究的。
不是简单地把任务切成 9 份随机分配,而是按照研究维度来划分:有人专门看技术架构,有人跑 benchmark 数据,有人盯定价策略,有人做生态对比。
在 Phase 2 推进过程中,右侧面板还会实时刷新新一批 Agent——帕克、李老师、贵福、萨特——像流水线一样,前一批搜完了,后面立刻接上。
我看了一下右侧面板的实时状态,发现每个 Agent 都在独立开浏览器标签页搜索。有的在查 SWE-bench 排行榜,有的在对比各家的定价页面,甚至主动开了一个 Ubuntu 沙箱终端,用 mkdir -p 创建研究输出目录,这说明 Agent 集群不只是在聊天框里搜搜写写,背后有一个真实的执行环境在跑。
整个过程中有几个细节让我没绷住。
Phase 1 搜集完基础信息后,Kimi 没有直接跳到写报告,而是进了一个交叉验证阶段——让不同 Agent 互相检查彼此搜集到的数据。比如扎克搜到的 Cursor 定价和嘉田搜到的不一样,系统自动标记出来,再派一个 Agent 去核实。这个设计挺聪明的,信息搜集最怕的就是张冠李戴。
还有一个更离谱的。到了报告撰写阶段,Agent 01 居然自己写了一段 Python 代码来画图。右侧 Kimi's Computer 面板里直接出现了 matplotlib 的代码,给四款工具在 Agent 能力、代码质量、定价竞争力、企业合规、生态体验、用户体验六个维度打分,然后画雷达图。
搜着搜着自己开始写代码画图了,我当时的表情大概是这样的:😳
执行效率也很夸张。从提交任务到 56 页报告交付,前后大概 20 分钟。300+ 次独立搜索、500+ 引用来源、12 个维度的深度研究。同样的活儿让一个分析师手工做,保守估计两到三天。
大概 20 分钟后,Agent 集群这边就交卷了,56 页的 doc 文档,内容扎实详细。
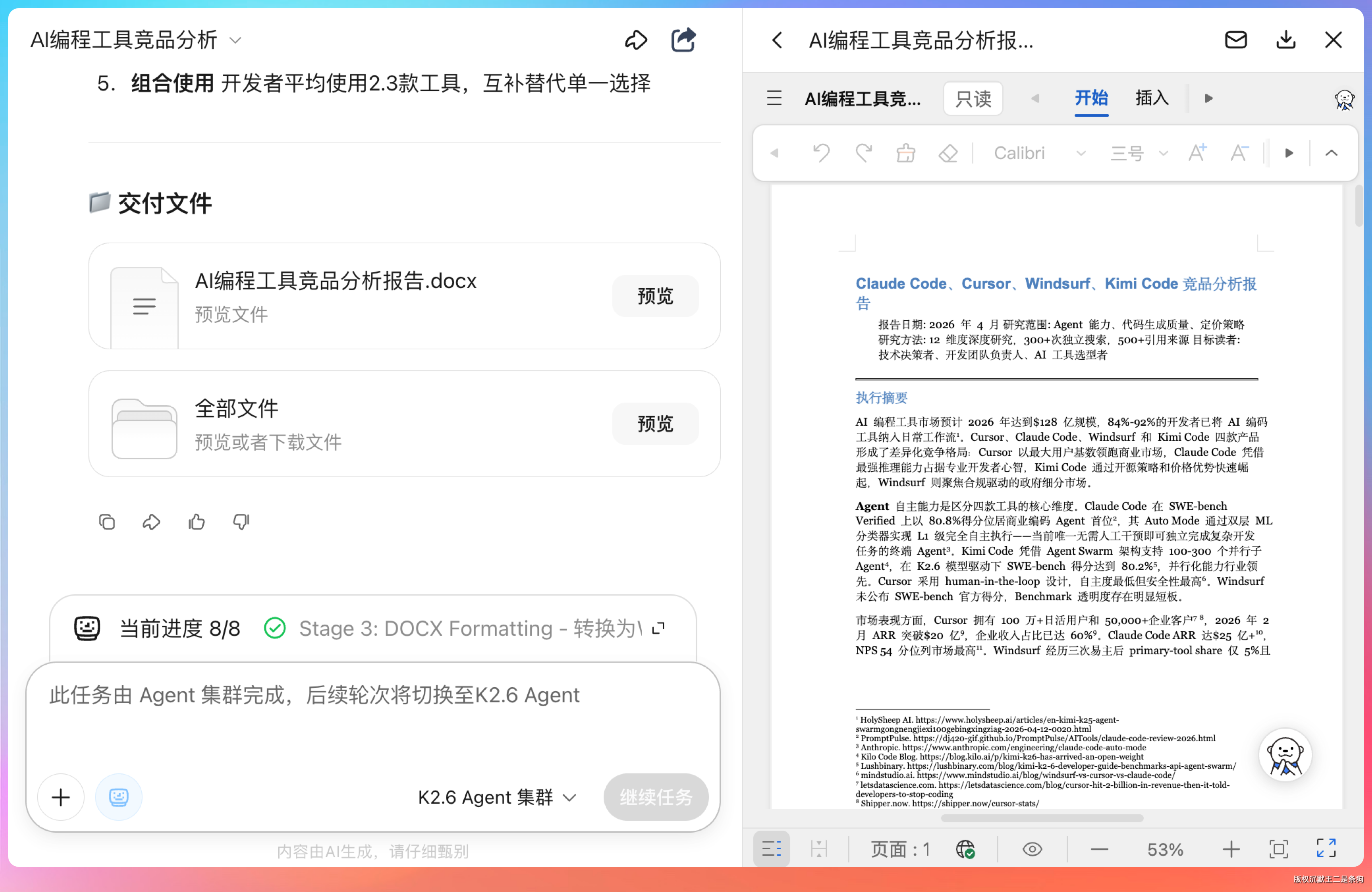
各种图表,数据表格,分析结果一应俱全。
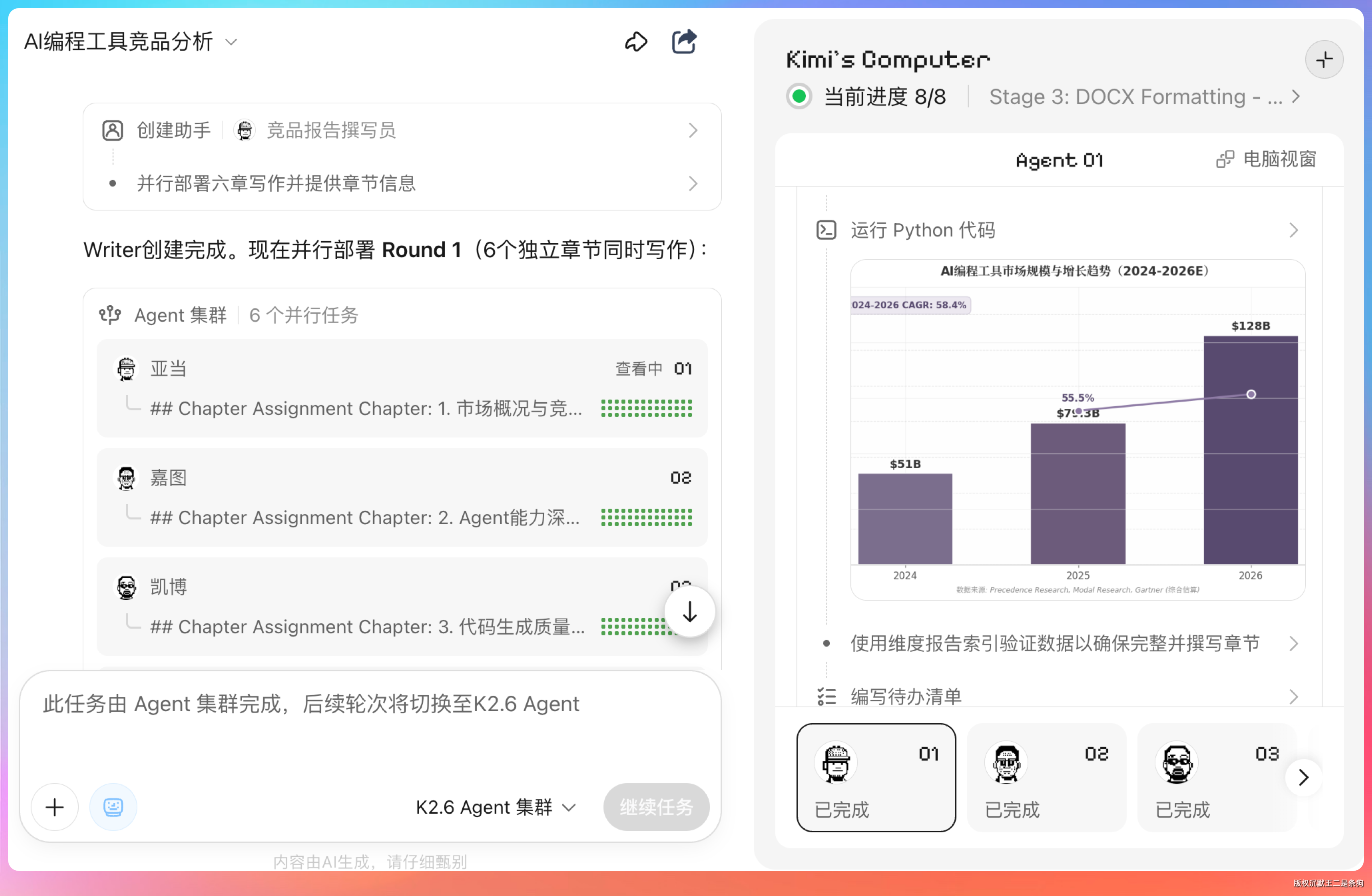
翻了一下最终报告,内容大致分这么几块:四款工具的 Agent 架构对比、代码生成质量的 benchmark 数据、定价策略横向对比表、IDE 集成完整度评估、企业级功能支持情况。
数据搜集得很全,引用也标注了来源。
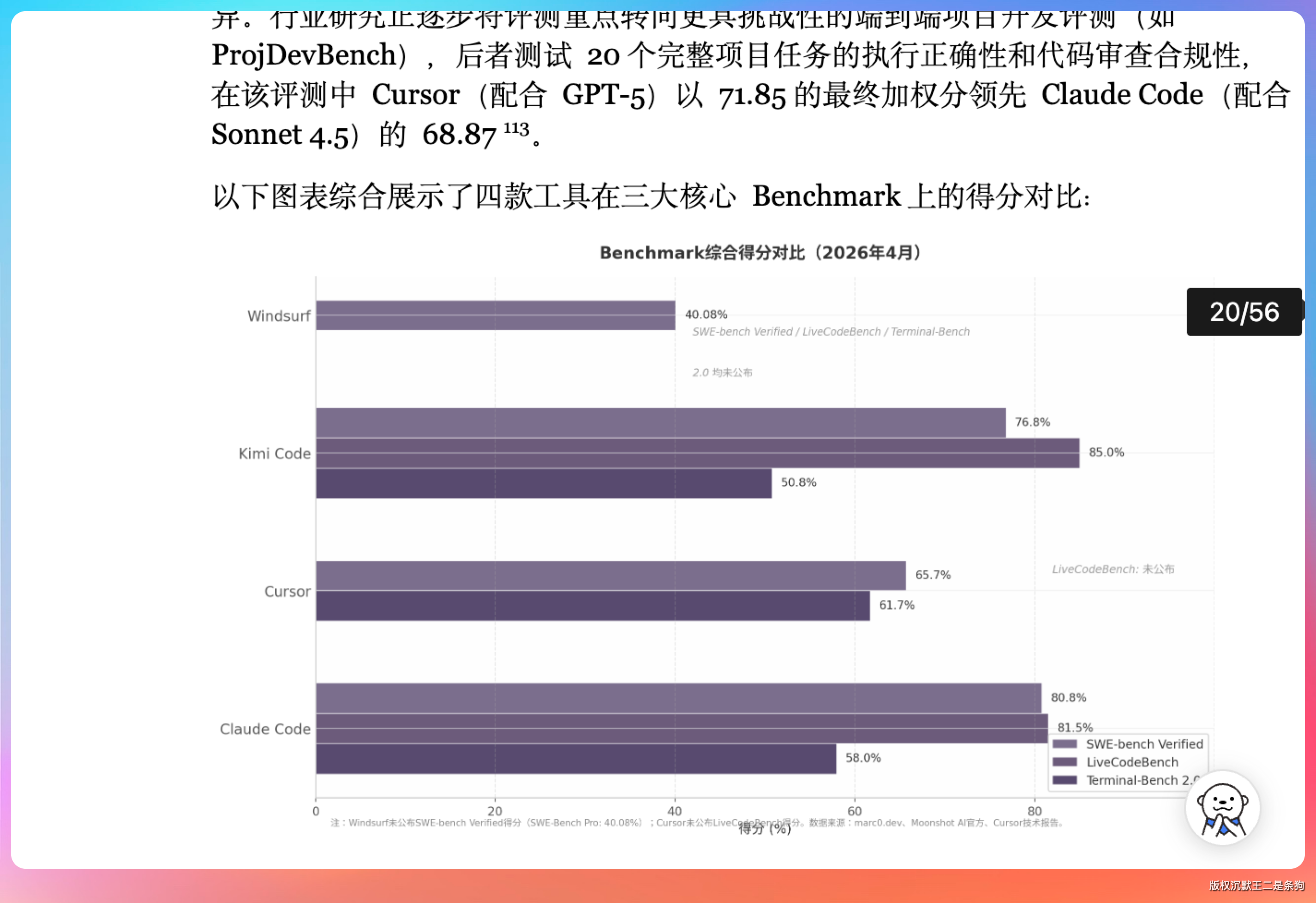
12 个维度的深度研究(300+ 次独立搜索、500+ 引用来源)→ 交叉验证 → 洞察提取 → 8 个章节的专业撰写 → 56 页的 Word 文档,太顶了。
05、长任务编码的交付质量也很顶
没过一会,IntelliJ IDEA那边的任务也结束了。
为了验证交付质量,我还特意开了 Qoder的专家团模式。
提示词:第四期代码已经交付了,测试一下吧,主要是SQLite、本地向量、代码ast分析、Embedding可以配置等
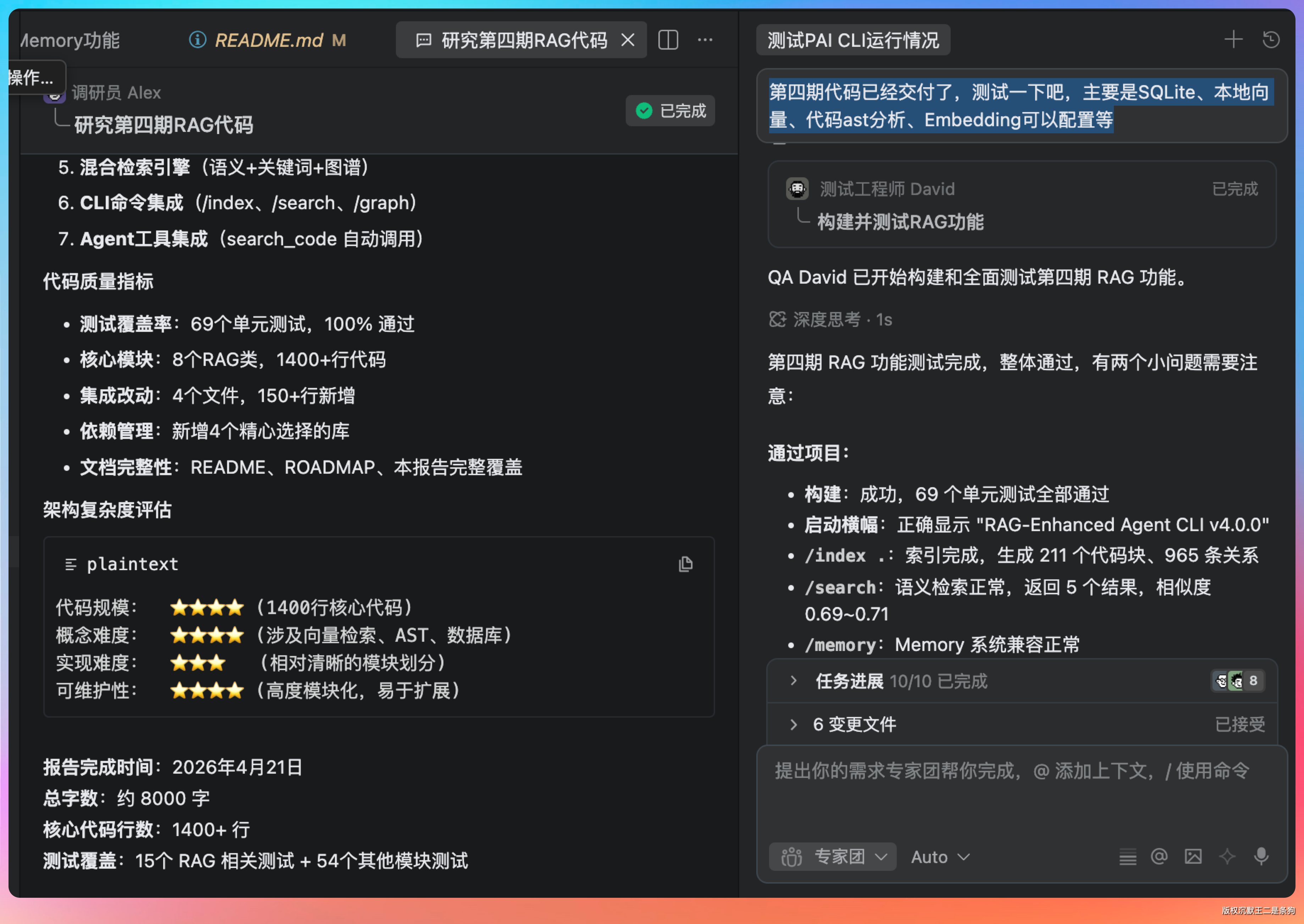
Kimi 2.6 这次提交的核心代码行数有 1400+ 行,包括:
- Embedding 可配置系统(3个provider)
- JavaParser AST 分析(5种关系类型)
- SQLite 向量存储(内存余弦检索)
- 三级代码分块(文件/类/方法)
- 混合检索引擎(语义+关键词+图谱)
- CLI命令集成(/index、/search、/graph)
- Agent工具集成(search_code 自动调用)
69 个单元测试,100% 通过。
我滴怪怪,Kimi 2.6 这个交付质量确实没得说。
说几个让我比较惊喜的点,直接上代码。
Embedding 可插拔设计。 看这段 EmbeddingClient.java 的核心逻辑:
public float[] embed(String text) throws IOException {
// 截断过长文本,防止 API 报错
String input = text.length() > MAX_INPUT_CHARS
? text.substring(0, MAX_INPUT_CHARS) : text;
return switch (provider.toLowerCase()) {
case "ollama" -> embedOllama(input);
case "openai", "zhipu", "glm" -> embedOpenAICompatible(input);
default -> embedOllama(input);
};
}
一个 switch 搞定多 provider 路由,Ollama 本地、OpenAI 兼容接口都支持。想切模型?改一下环境变量 EMBEDDING_PROVIDER 就行,代码不用动。
还做了 2000 字符的安全截断,防止长文本把 API 打挂——这种防御性编码的细节,不是说“帮我写个 Embedding 客户端”就能写出来的,得真正理解生产环境会遇到什么坑。
AST 关系提取。 CodeAnalyzer.java 用 JavaParser 做 AST 解析,提取了 5 种代码关系:
// extends 关系
clazz.getExtendedTypes().forEach(ext -> {
relations.add(new CodeRelation(
filePath, className, null, ext.getNameAsString(), "extends"));
});
// implements 关系
clazz.getImplementedTypes().forEach(impl -> {
relations.add(new CodeRelation(
filePath, className, null, impl.getNameAsString(), "implements"));
});
// calls 关系:方法调用
clazz.findAll(MethodCallExpr.class).forEach(call -> {
String callee = call.getNameAsString();
Optional<MethodDeclaration> parentMethod = findParentMethod(call);
if (parentMethod.isPresent()) {
String caller = className + "." + parentMethod.get().getNameAsString();
relations.add(new CodeRelation(
filePath, caller, null, callee, "calls"));
}
});
继承、实现、调用、依赖、包含,五种关系全部建模。/graph Agent 能画出调用关系图,靠的就是这些 AST 关系数据。
混合检索引擎。 CodeRetriever.java 的 hybridSearch 方法是整个 RAG 模块最有技术含量的部分:
public List<VectorStore.SearchResult> hybridSearch(String query, int topK) throws Exception {
// 1. 语义检索
for (VectorStore.SearchResult result : semanticSearch(query, semanticLimit)) {
mergeResult(merged, result, dualMatchBonused);
}
// 2. 关键词检索
Set<String> keywords = RagQueryTokenizer.tokenize(query);
for (String keyword : keywords) {
for (VectorStore.SearchResult result : keywordSearch(keyword)) {
mergeResult(merged, boostKeywordMatch(result, keyword), dualMatchBonused);
}
}
// 3. 代码类型加分:method/class 比 file 更直接回答"怎么实现"
double typeBoost = switch (r.chunkType()) {
case "method" -> 0.15;
case "class" -> 0.10;
default -> 0.0;
};
}
语义检索 + 关键词检索 + 类型加权,三路并行后合并去重。双重命中的结果还有额外 0.1 的奖励分,method 类型比 file 类型多 0.15——因为你问“怎么实现”的时候,方法级别的代码块比文件级别的肯定更直接嘛。
这种排序策略的细节,不是随便写写就能想到的。
当然了,不能只看 Qoder 的测试结果,还得自己实际用一下。
打开终端,执行 mvn clean package 先编译一下。
build 没问题后,我们执行 java -jar target/paicli-1.0-SNAPSHOT.jar 进入 PaiCLI。
输入 /index 命令,看看能不能正确地把当前代码库的结构和内容索引到向量数据库里。
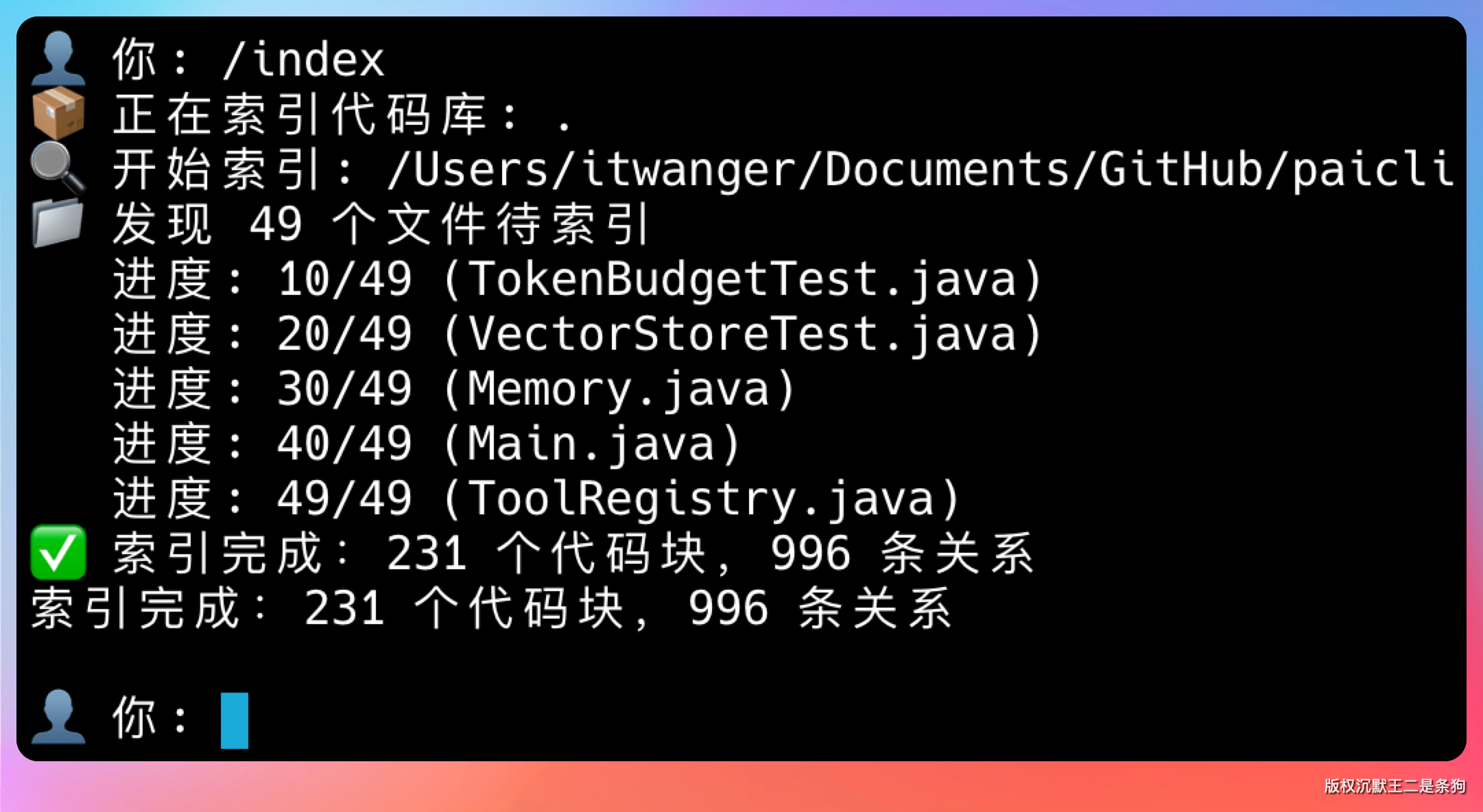
全部索引成功,太牛 x 了。索引过程中会自动做 AST 解析,把每个 Java 文件拆成文件级、类级、方法级三层 chunk,然后通过 Ollama 的 nomic-embed-text 模型转成向量,存进 SQLite。整个流程是自动化的,不需要手动配置任何东西。
再验证一下边界情况:/index /non/existent/path。

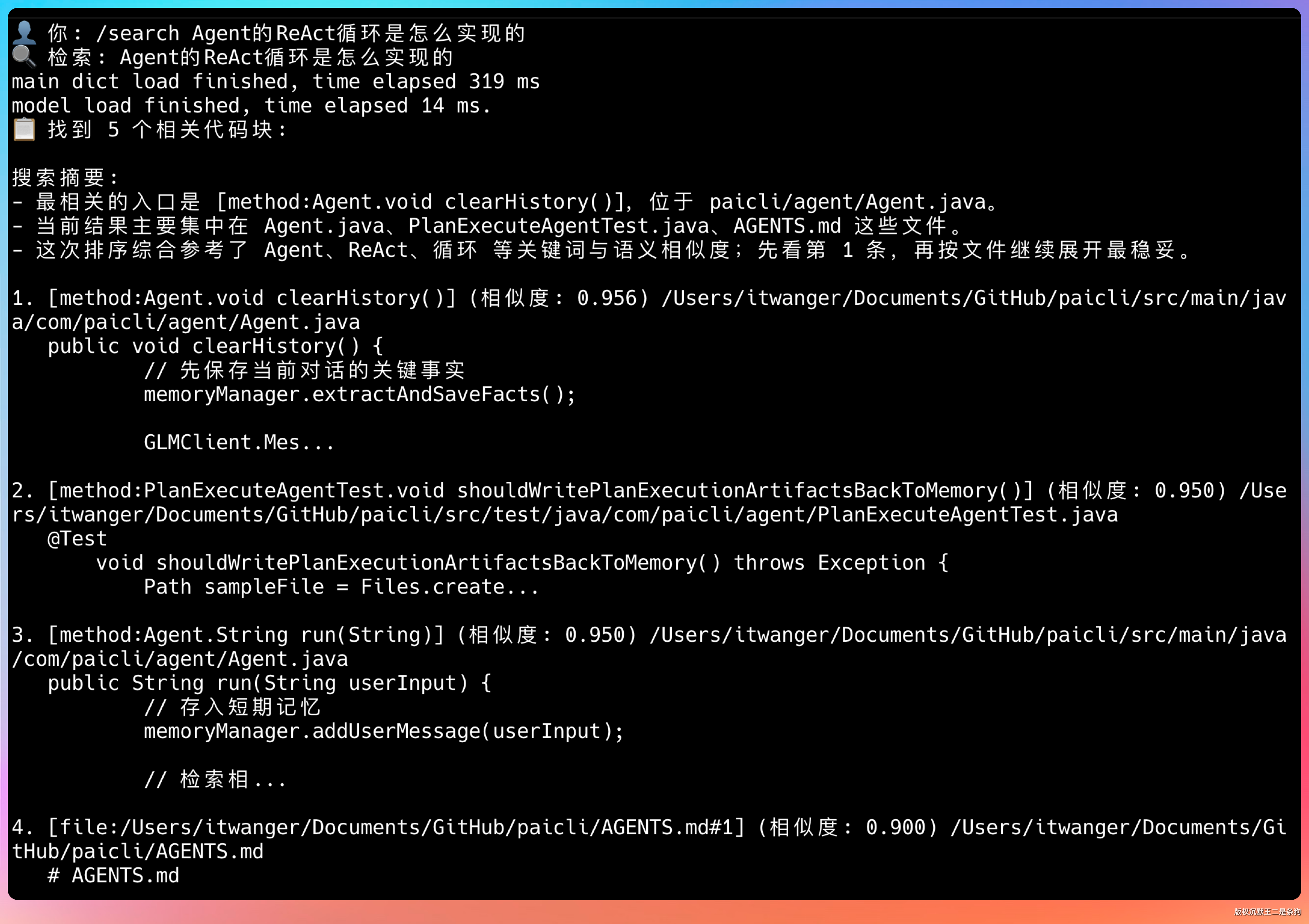
接下来输入 /search 命令,看看能不能正确地检索到相关代码片段。
/search Agent的ReAct循环是怎么实现的 能直接定位到 Agent.java 里的核心代码片段,而不是把所有带“Agent”这个词的文件都丢给你。
这就是混合检索的价值——语义理解知道你问的是“ReAct 循环的实现”。
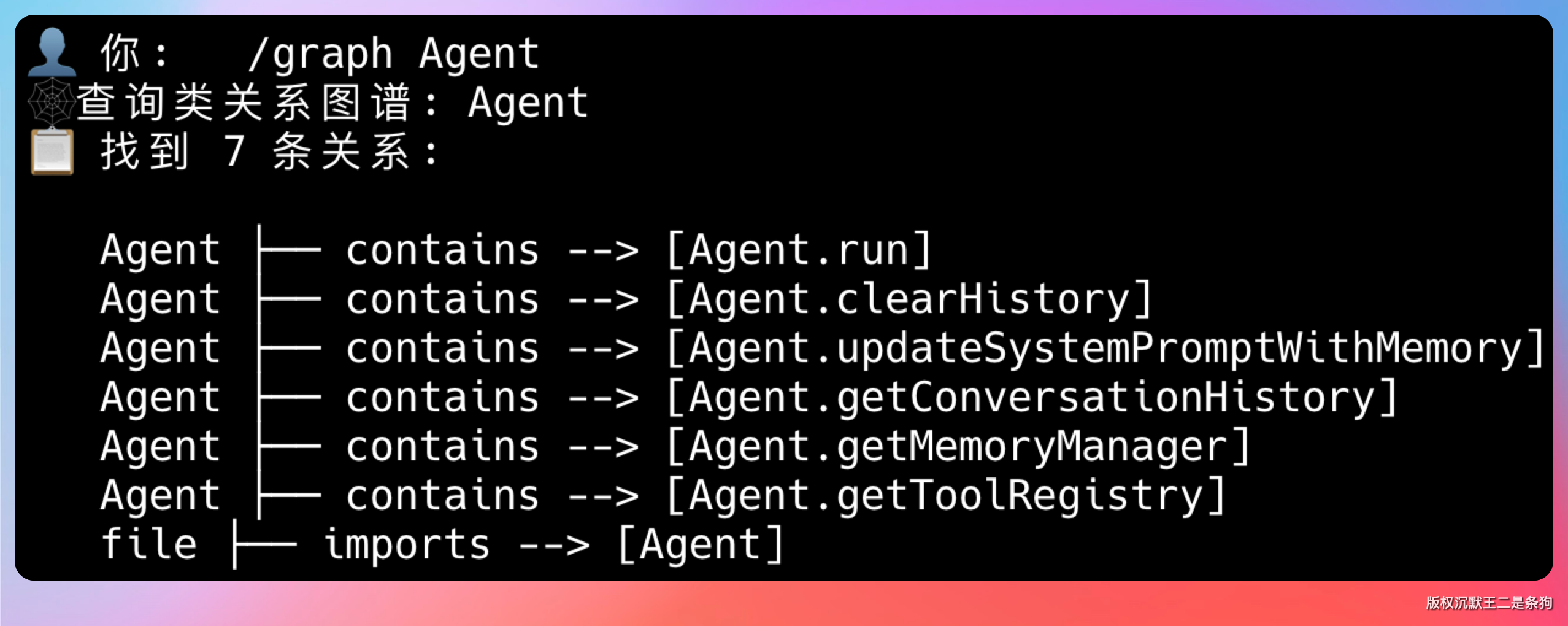
/graph Agent 也能正确地展示 Agent 相关类的调用关系图。这个功能依赖的就是前面 AST 解析器建立的五种关系模型。
/plan 分析一下这个项目的记忆系统是怎么实现的,有哪些核心类 验证 Plan 模式下 Agent 自动调用 search_code 工具检索记忆相关代码,然后基于检索结果给出分析。
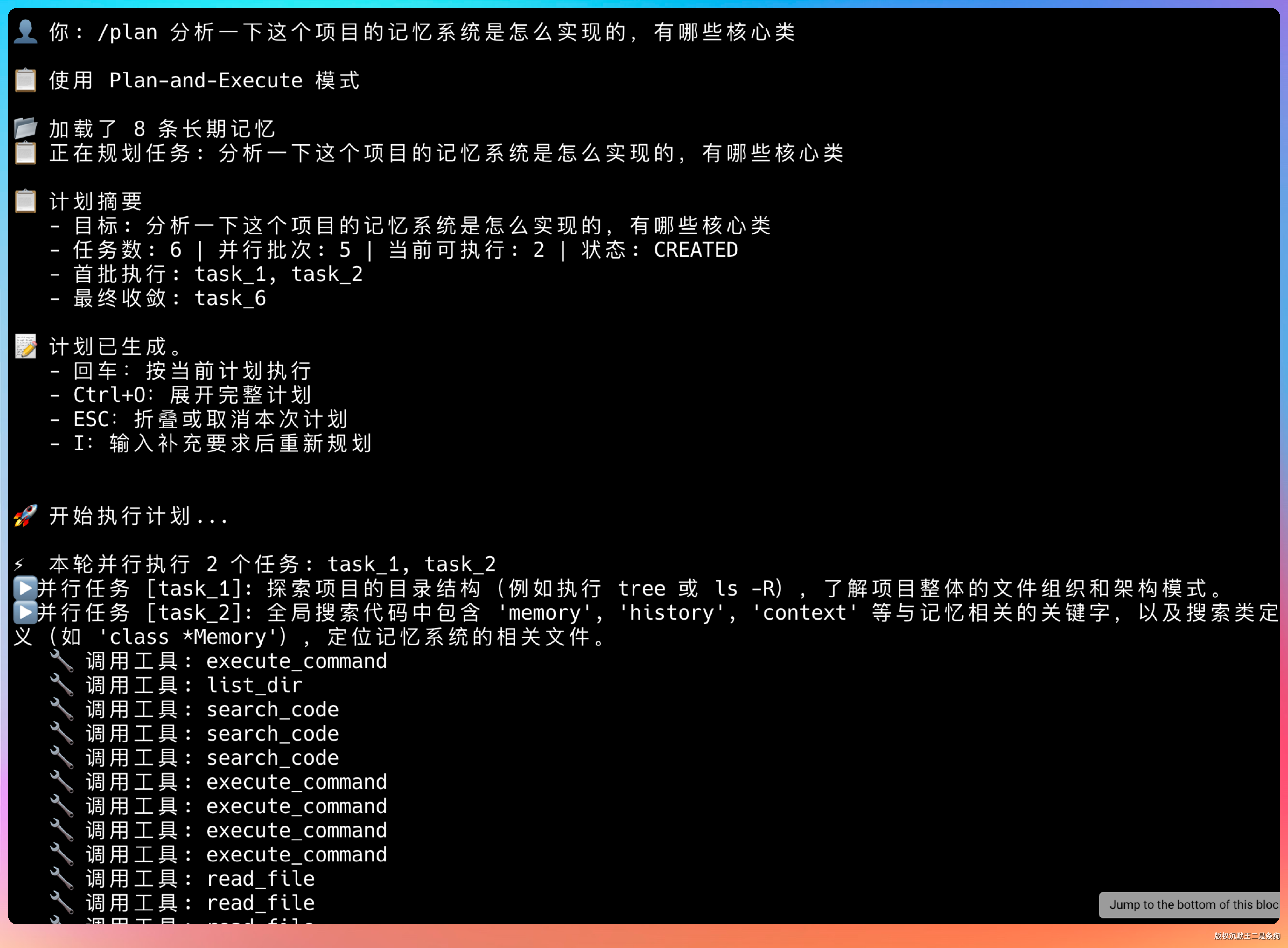
这几个验证跑下来,我心里基本有数了。
这不是那种“看着能跑但经不起折腾”的 demo 代码。边界情况有处理,异常路径有兜底,模块之间的依赖关系理得清清楚楚。
1400 多行核心代码、69 个测试用例、编译通过、实测可用。
这个交付质量放在真实的开发团队里,也算是一次合格的 Sprint 交付了。
ending
测完这两个 case,我对国产大模型的能力有了更直观的感受。
以前觉得模型强不强,看跑分就行了。SWE-bench 多少分、HumanEval 多少分,数字摆在那里。
但跑分高,不一定干活能力就强。
Kimi 2.6 这次不仅跑分高,真正干起活来也是恰到好处、不仅效率高,交付质量也是没得说。
如果非要让我有两字来形容,那就是:靠谱。
继续进化吧,就等 K3 了!
我们下期见。

回复