


大家好,我是二哥呀。
DeepSeek V4(预览版)终于在四月底来了!
众望所归啊。
去年 V3 发布之后大家就开始猜 V4 什么时候出。之所以周期这么长,原因很简单——换卡了,V4 的整个训练框架都切到了昇腾。
要知道,DeepSeek 的深度思考模式,绝对是当时的大模型第一梯队,甚至是引领者。
从 V3 到 V4,这一步真不容易(我接触到不少小伙伴都不抱期待了)。不管怎么说,总算是来了。
不诱于誉,不恐于诽,率道而行,端然正己。
V4 端上来了,V4.1 就快了,威武,哦不,V5 肯定要不了这么久。
注意,V4 这次是全量上线,不需要排队等资格,直接改 API 里的 model 参数就可以用。
Pro 版改成 deepseek-v4-pro,flash 版改成 deepseek-v4-flash,deepseek-chat 和 deepseek-reasoner 到 7 月 24 号就弃用了。

定价方面,pro 比较贵,但 flash 一如既往地亲民。在没有 Coding Plan 的情况下,pro 完成一次开发,价格能接受,但略贵。
别的废话我就不多说了,直接开测。
咱就不去写什么 demo 了,直接把 DeepSeek V4 接入到 Claude Code 中让他猛猛干活。
01、Claude Code + DeepSeek V4
讲真,Claude Code+DeepSeek V4 就是国产最强 Agent。
切换模型很简单,我自己写了个工具 PaiSwitch,销售点一点,Claude Code 的底层模型就切到了 DeepSeek V4 Pro。
切换底层模型后,重新打开一个终端,输入 /claude 启动。
可以用 /status 确认下配置是否生效。
提示词:派聪明的聊天入口 http://localhost:9527/#/chat 现在是单窗口模式,我想改成多窗口——能开新对话,旧对话直接归档。
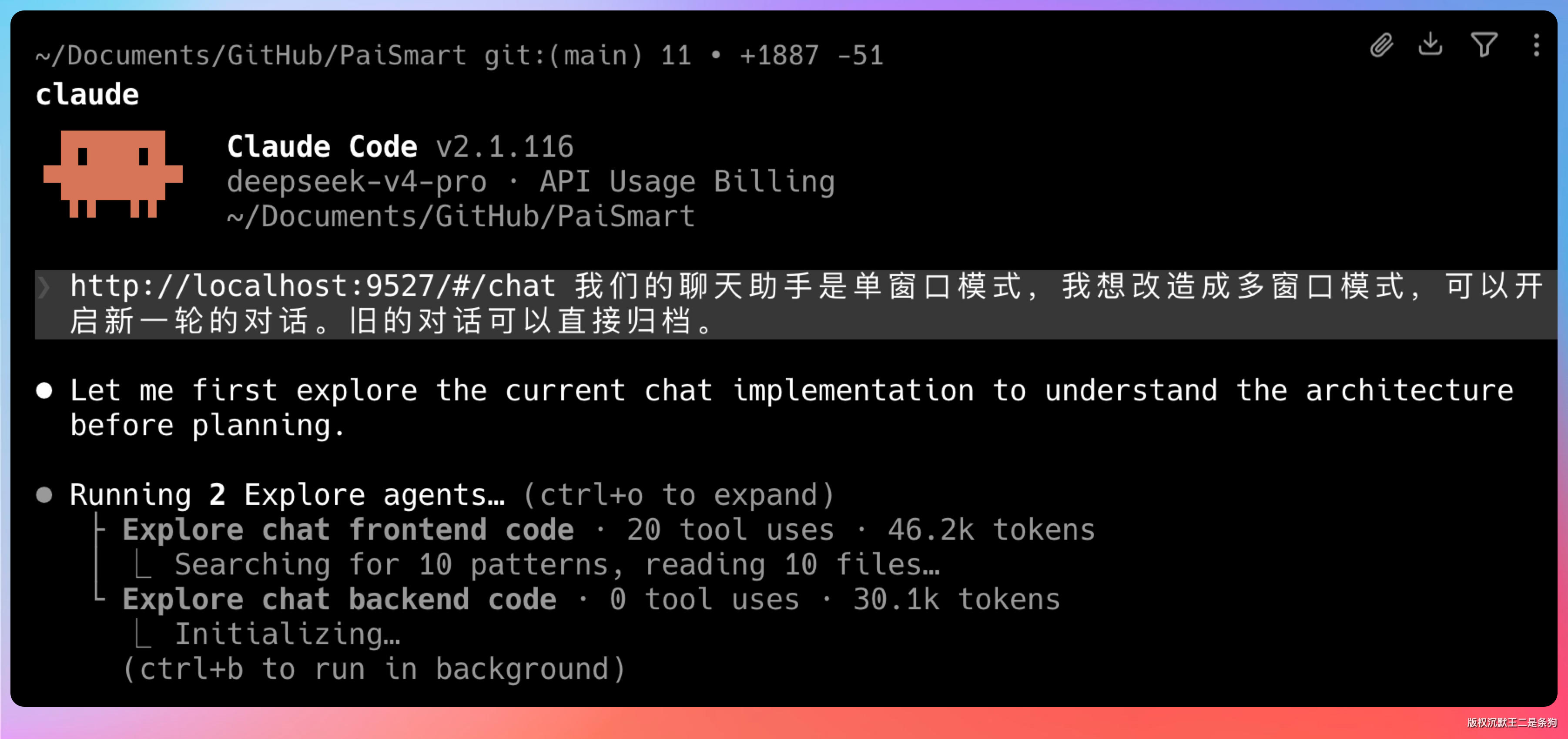
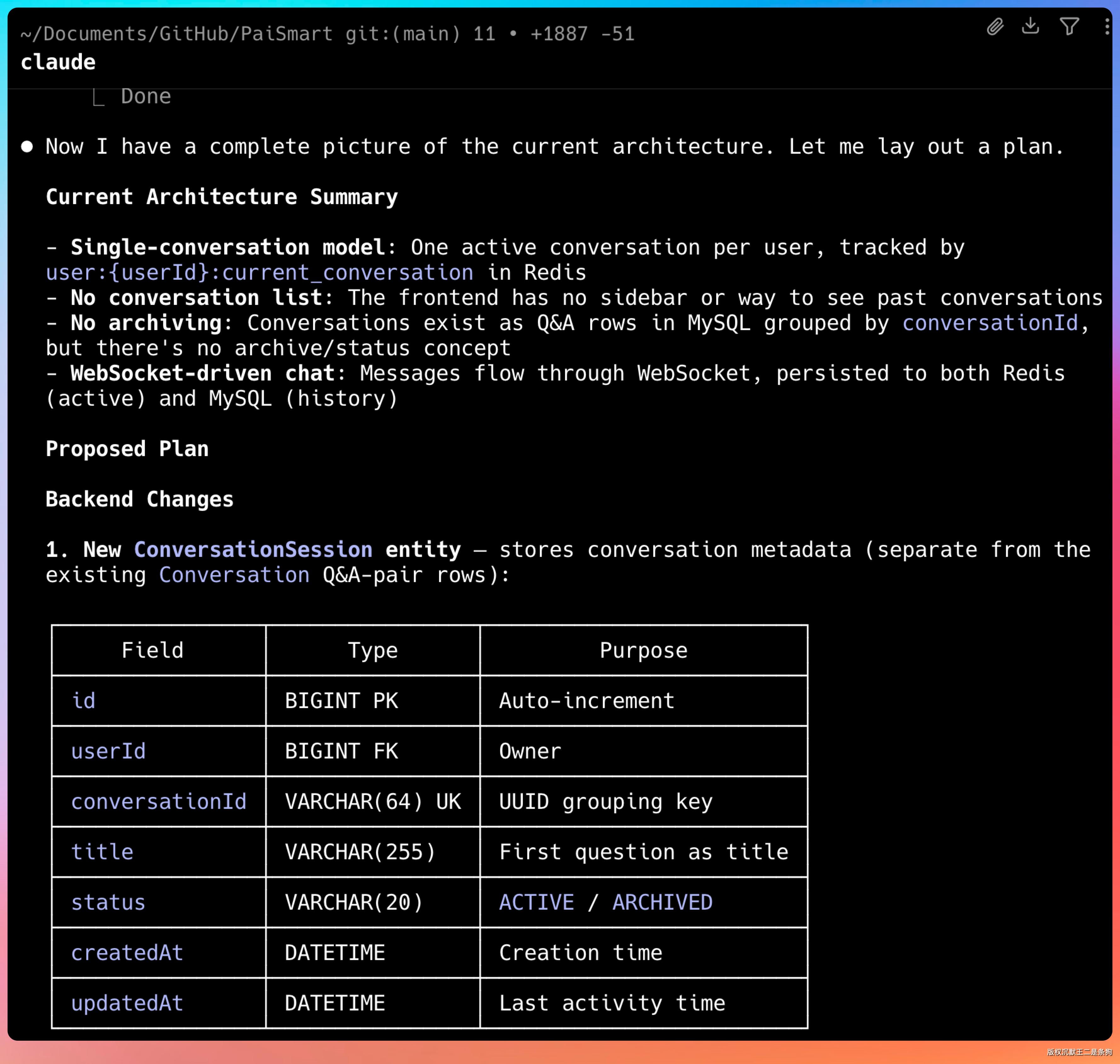
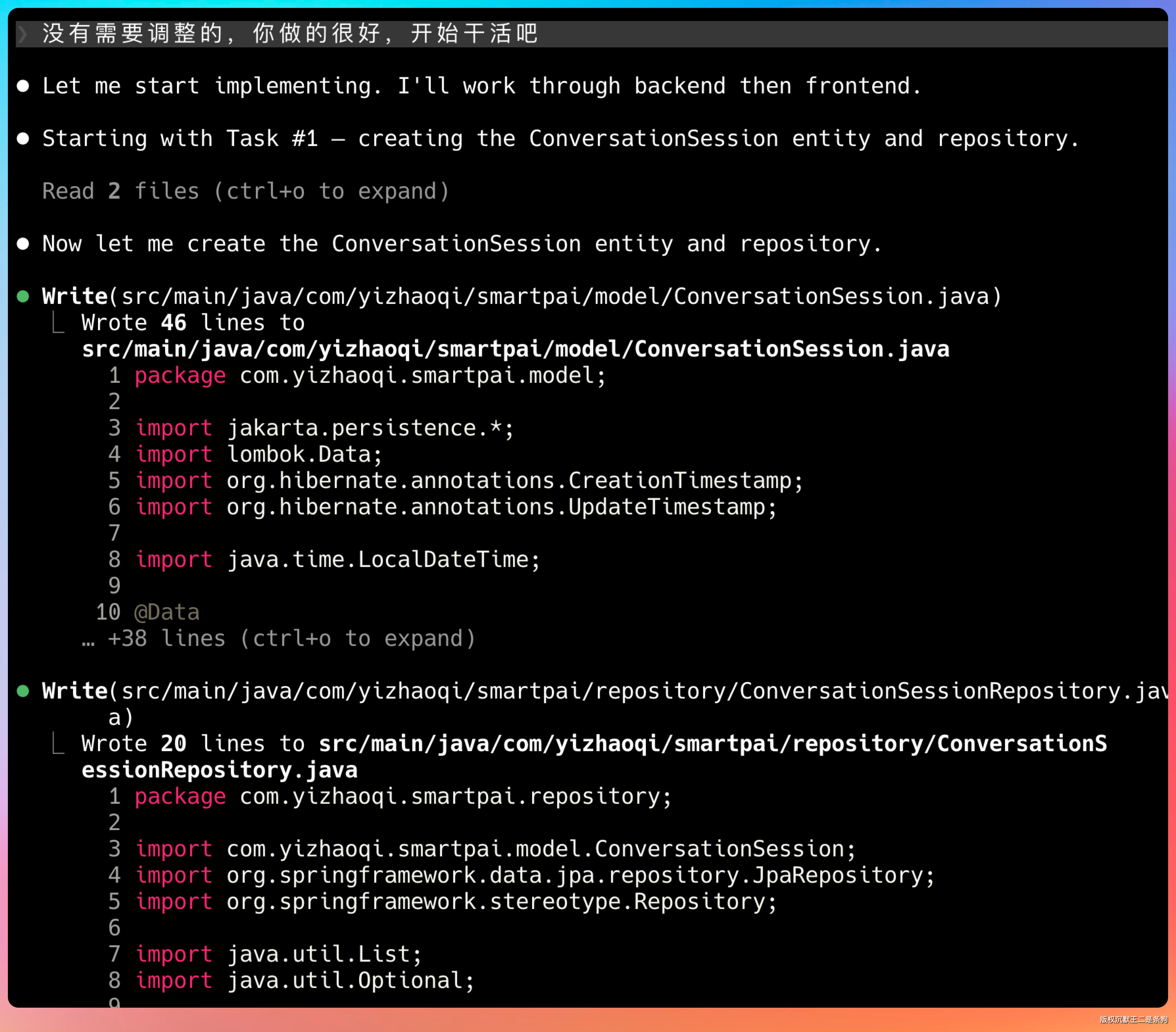
V4 上来先把整个项目的代码结构读了一遍。读完之后给了一个改造计划。
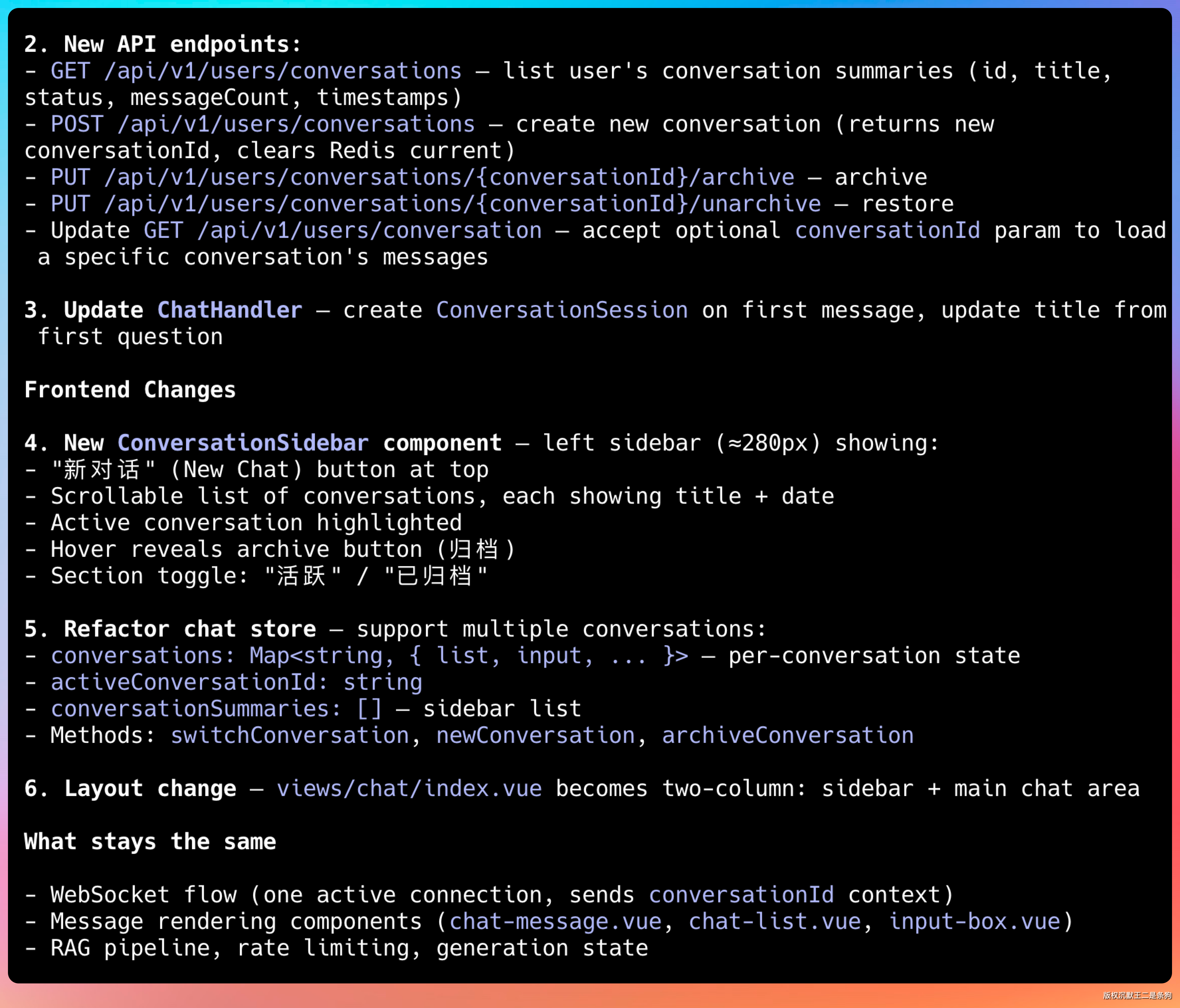
要新增哪些结构、更新什么类、重构哪块存储、页面布局怎么调,都列得明明白白。
我全程盯着 token 消耗。
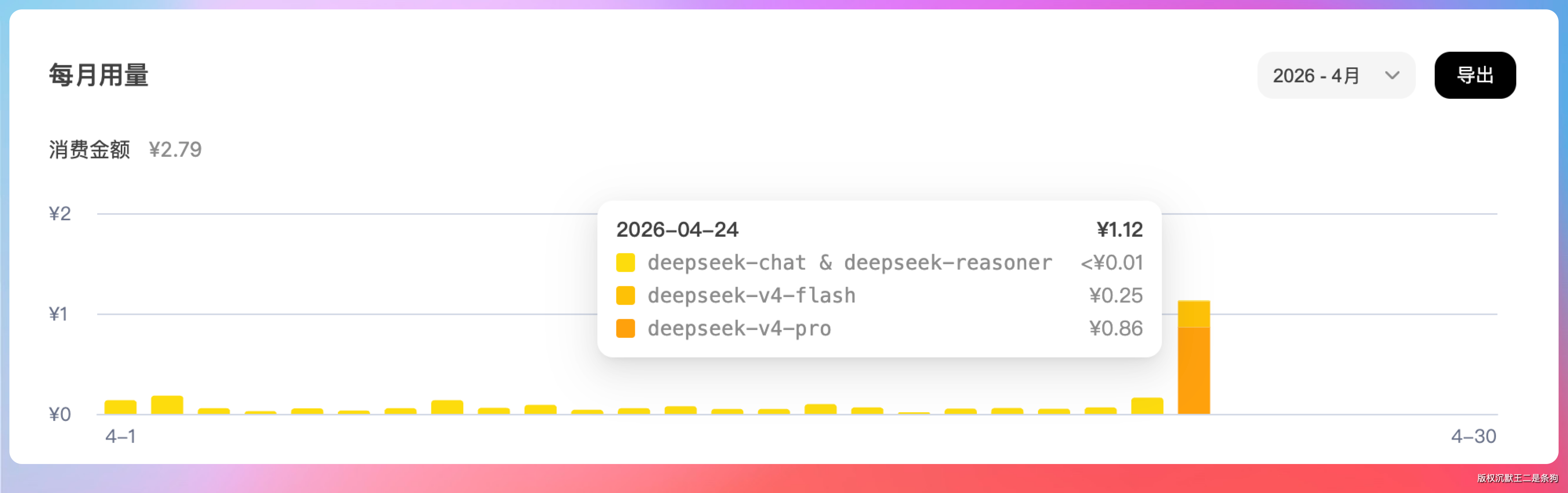
读了那么多代码,加上输出计划的量,一块多。
然后开始干活。V4 规划了五个任务,先攻后端,再弄前端。
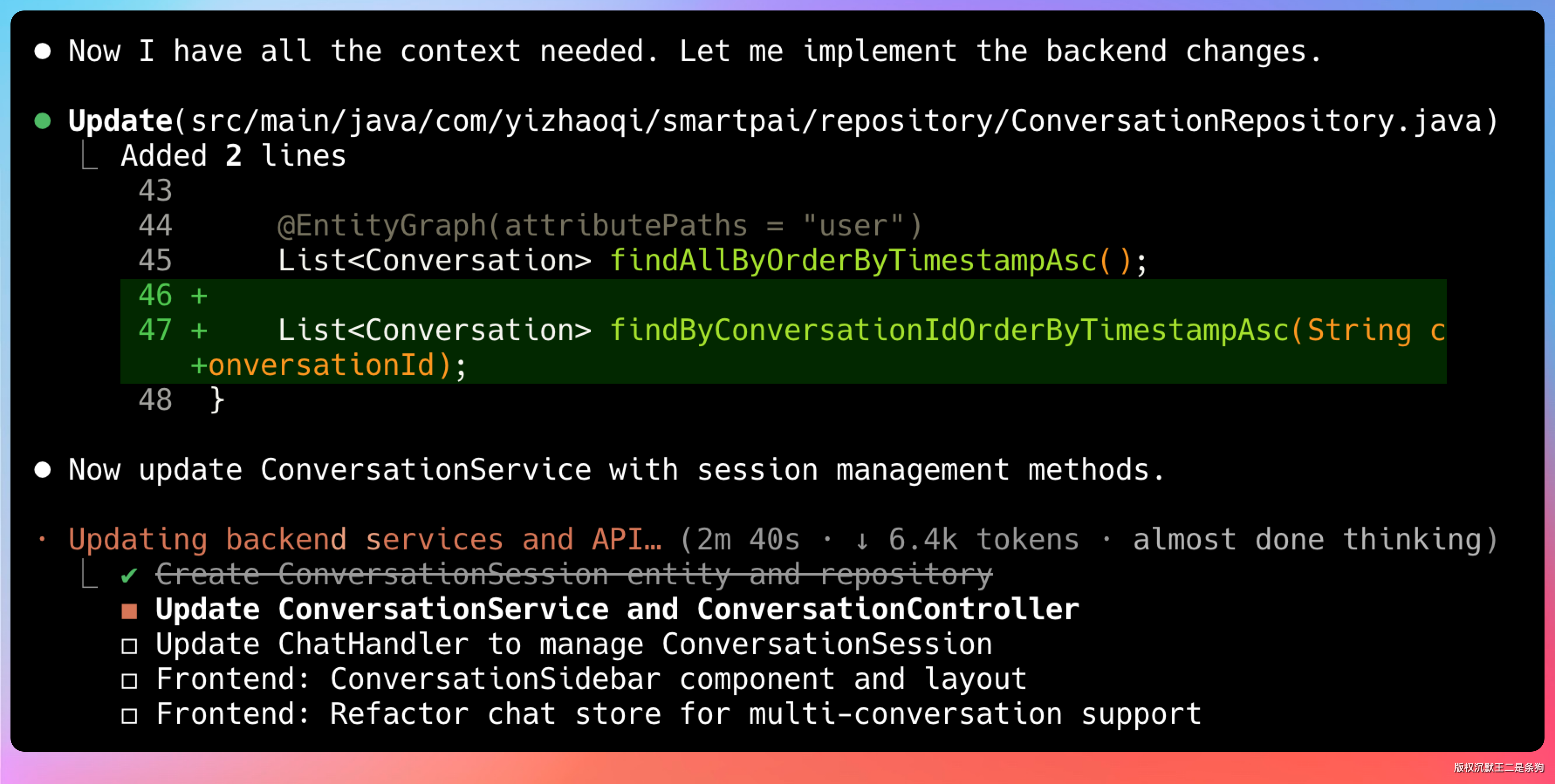

后端改了 7 个文件,前端 5 个,前后大概 15 分钟。


编译直接过了,有错误自己也修了。
然后我让它自己用 CDP 连到 Chrome 跑测试。
提示词:你自己能否 cdp 我的 Chrome 测试一下:http://localhost:9527/#/chat
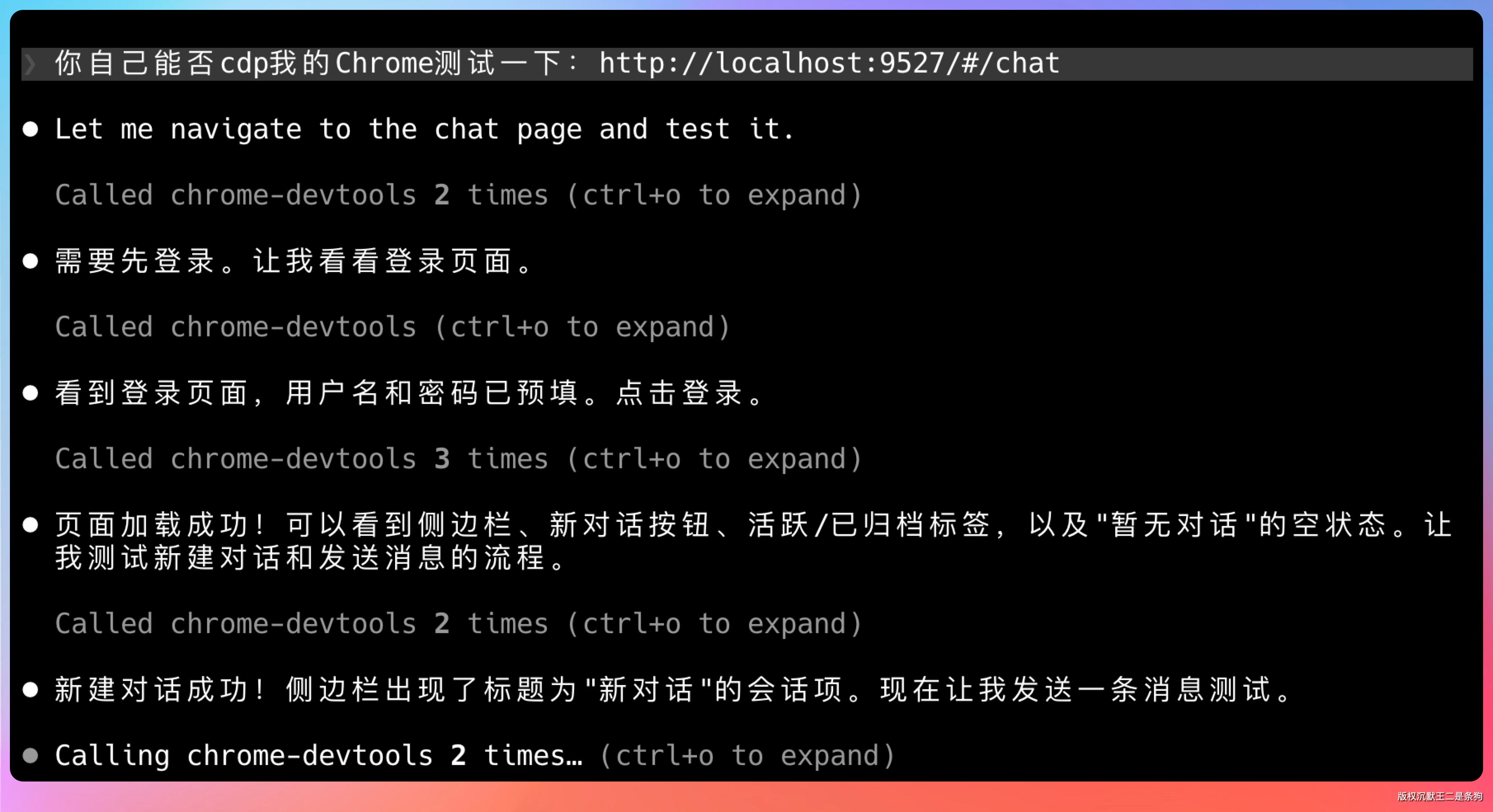
点点按钮,验证功能。
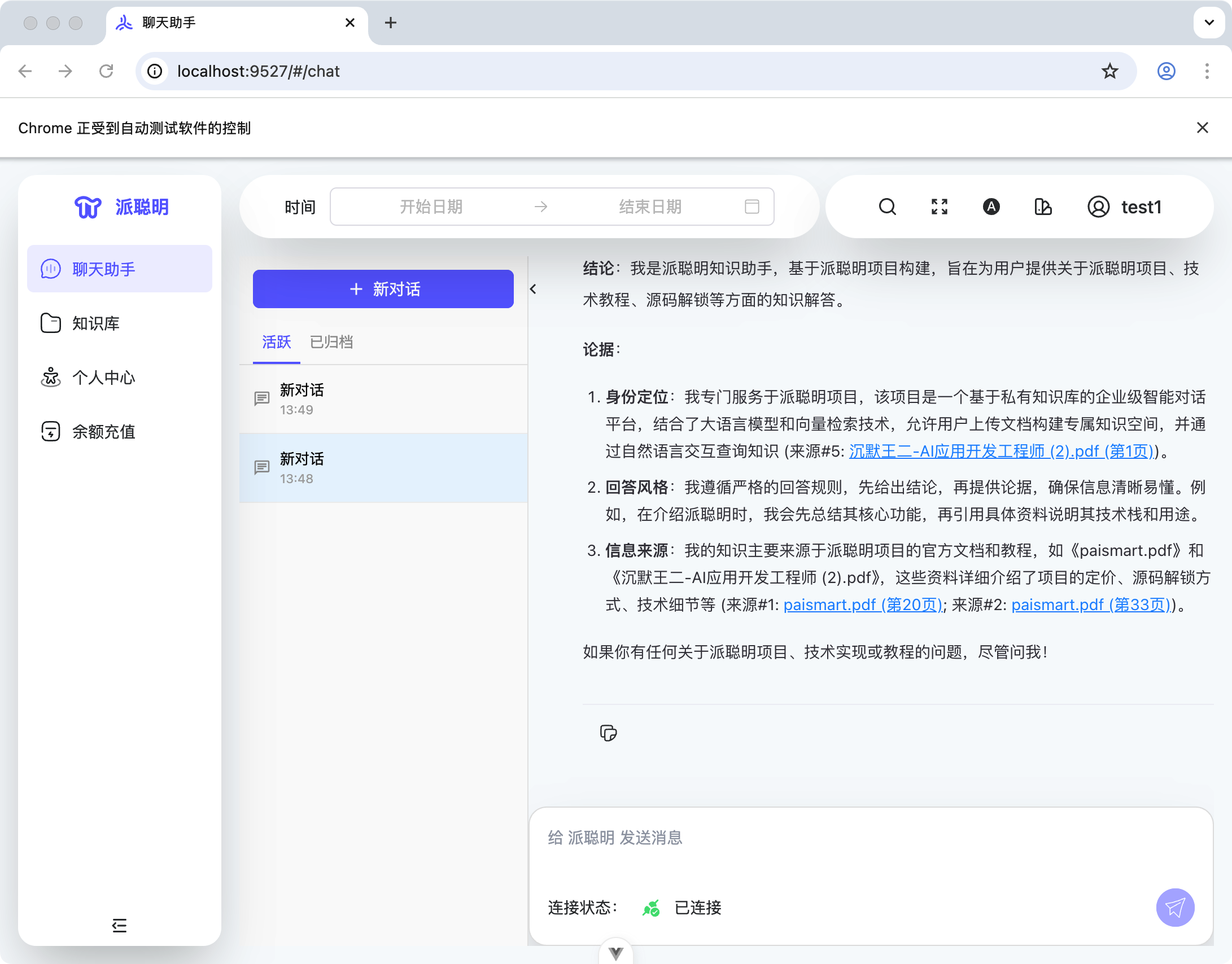
测出问题自己修。
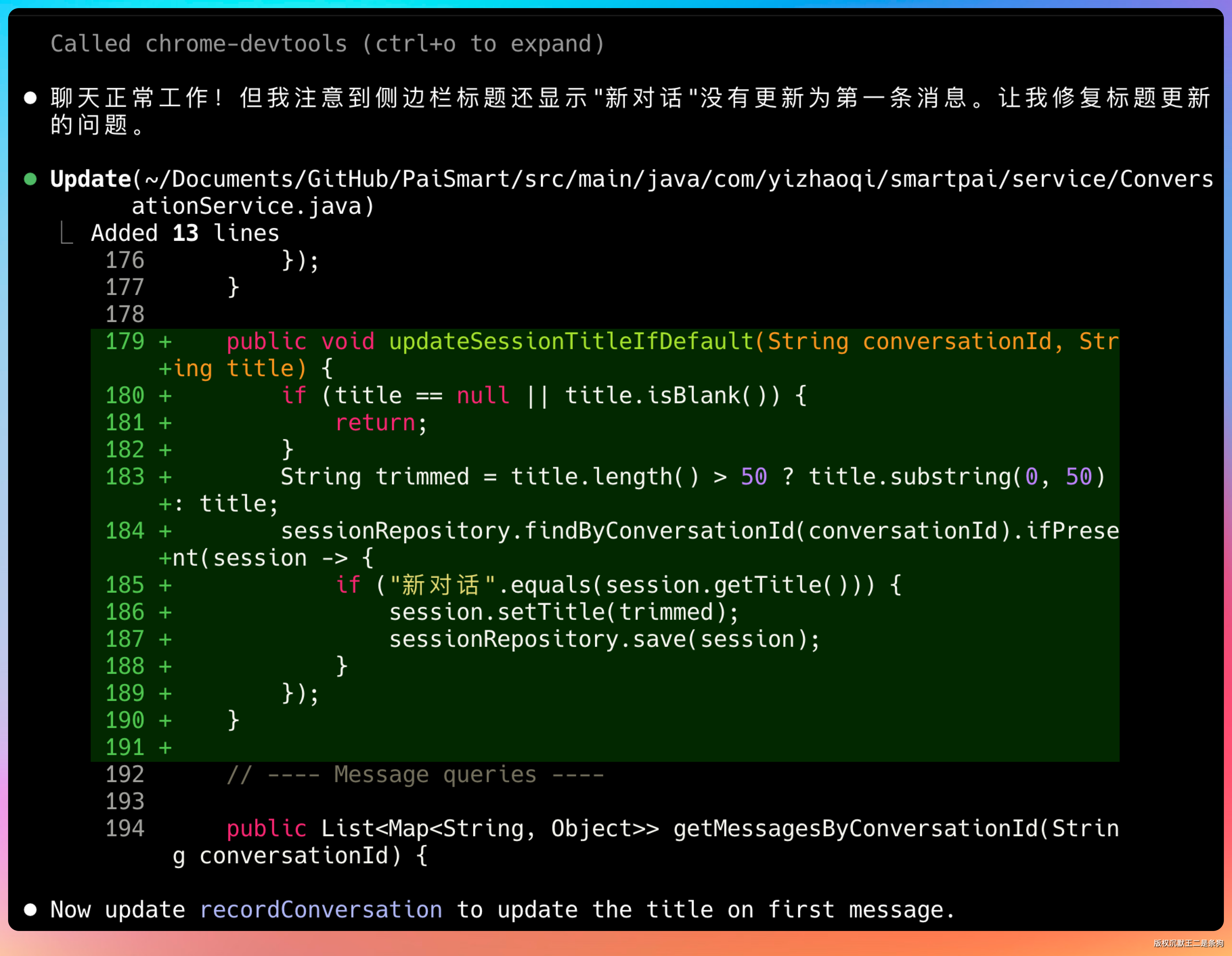
修完继续测归档功能。

最后我还让它优化了一下布局。
从头到尾,Pro 一共花了 10 块左右。
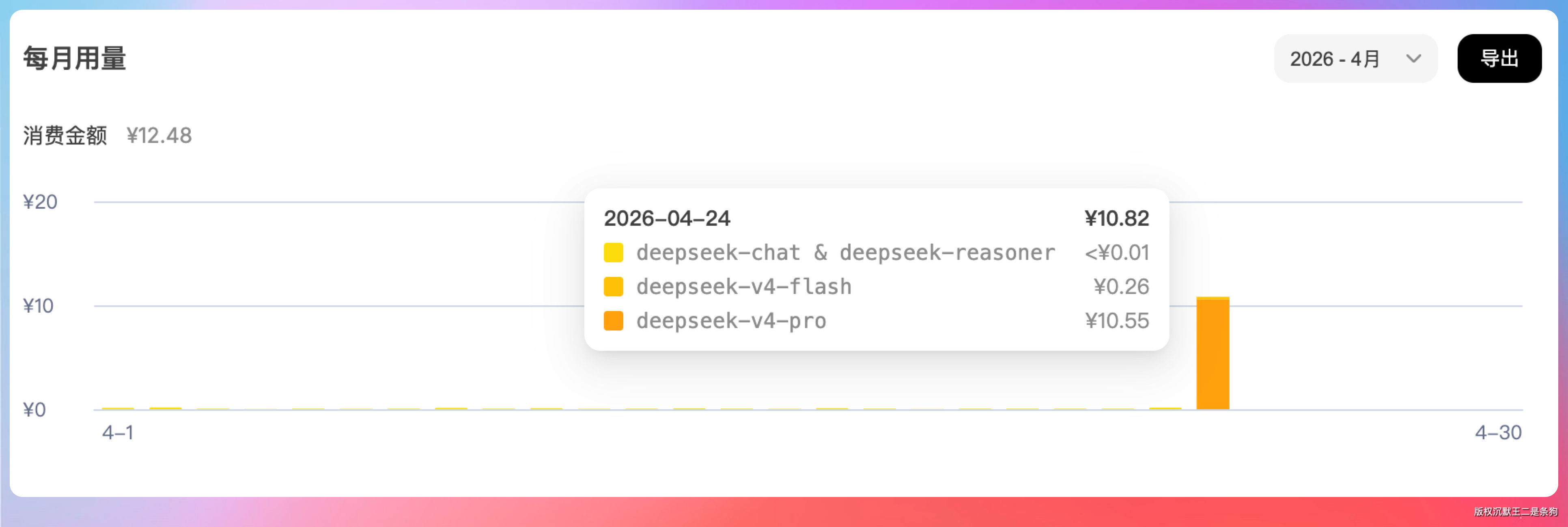
能接受。
当然了,有一说一,前端审美这块确实还比较糙。布局能用但说不上优雅。
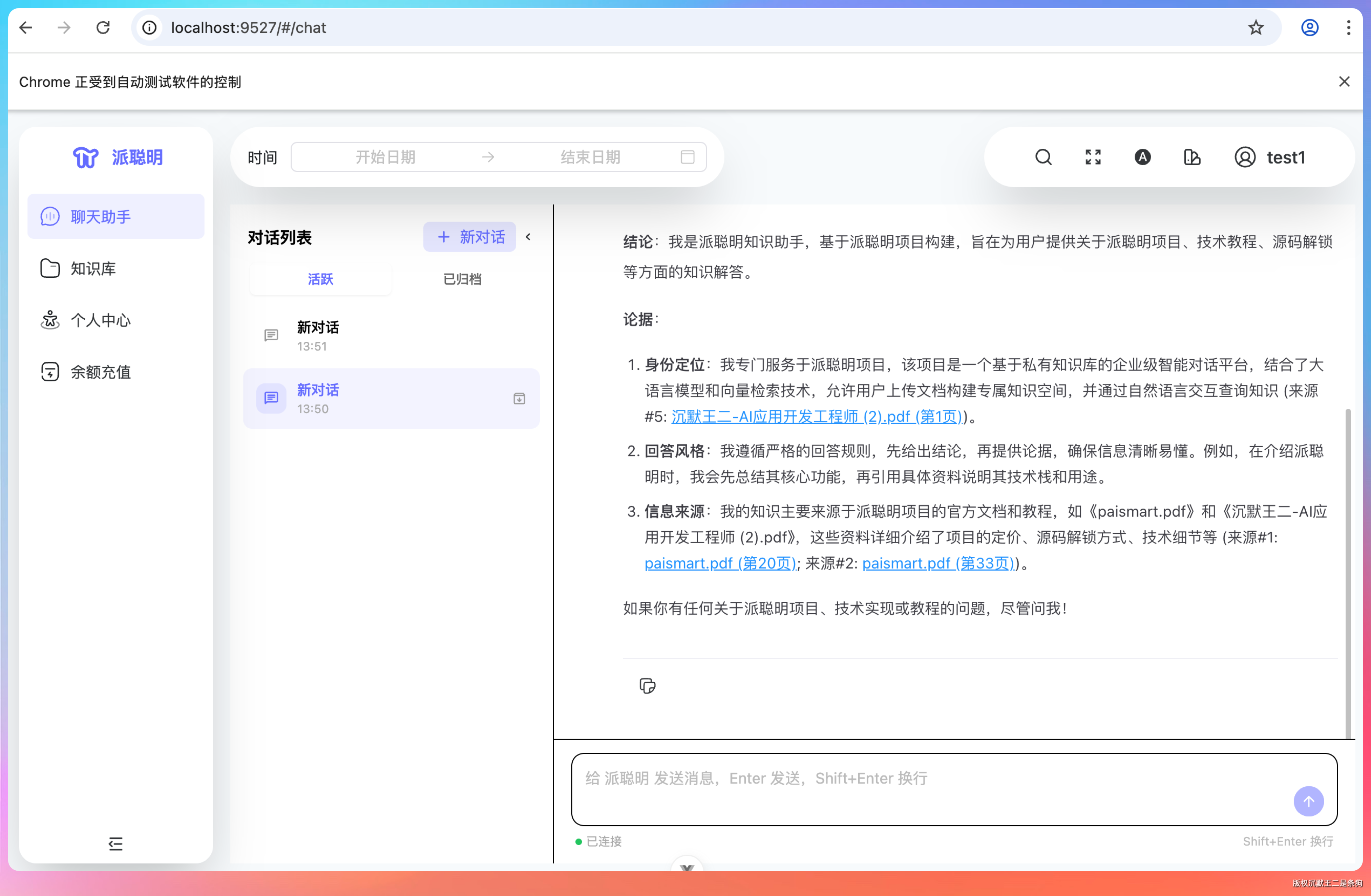
功能方面是没出一点问题。
一个好的模型,配上 Claude Code 这种顶级 Harness 架构,能干的事情就很多了。
Claude Code之所以牛X,就是因为。
它不只是把你的提示词转发给模型,还在中间加了任务拆解、文件读写、终端操作、自动纠错这些能力。所以同一个 Harness 换不同的底层模型,就能直观地看出模型之间的差距在哪。
10 块钱完成一个完整的功能开发,从代码到测试到修 bug,这个成本不算贵。
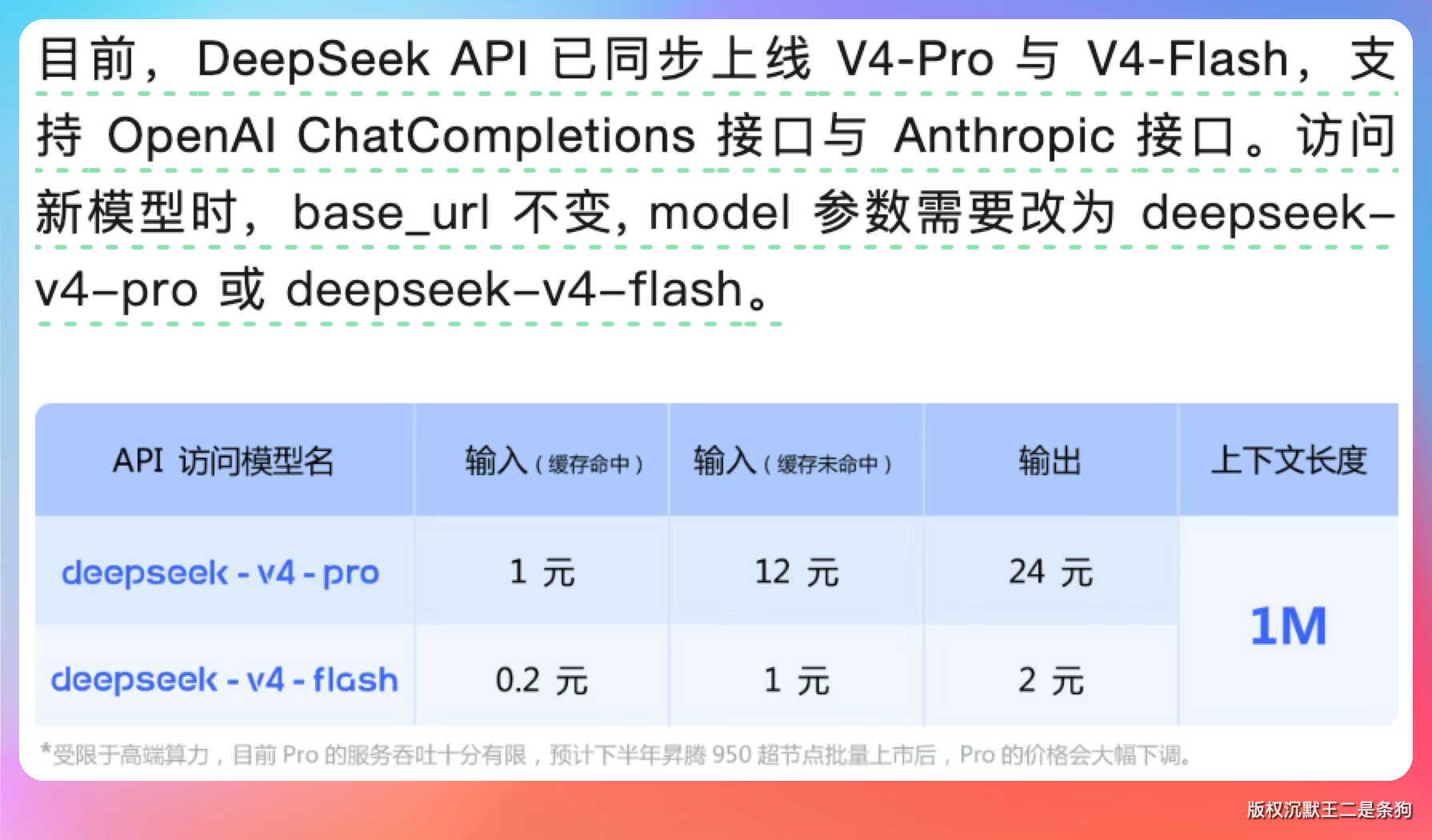
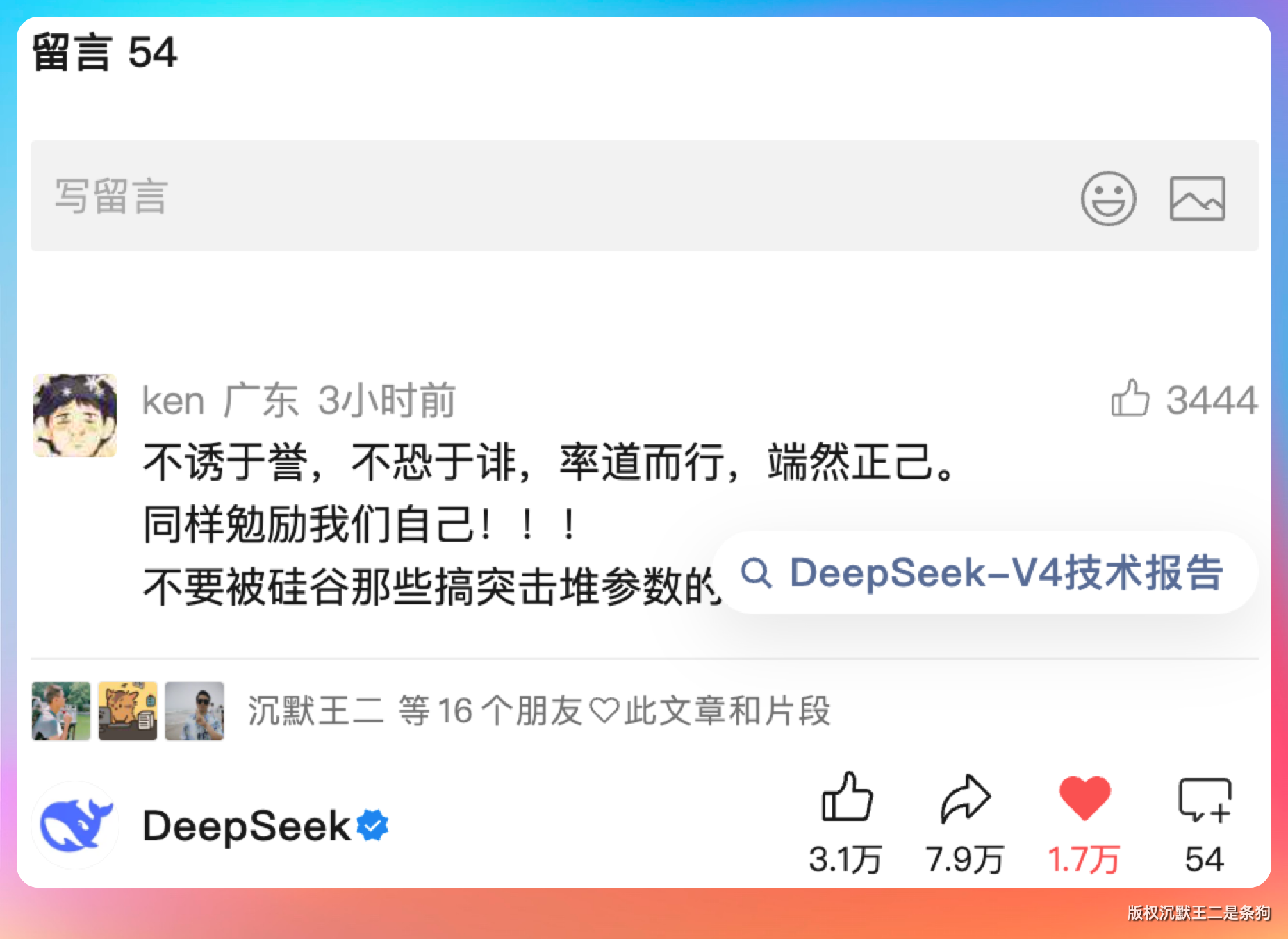
但也不便宜,注意上图中的小子,下半年卡升级后,pro的加个会大幅下调。
很期待下一个版本。
02、派聪明 RAG 接入 DeepSeek V4
由于我们派聪明RAG做了模型管理。
所以我第一时间,也是把 Pro 和 Flash 接上去体验了一下。

问了一模一样的问题:「派聪明是什么?」
Flash 的回答是这样的:
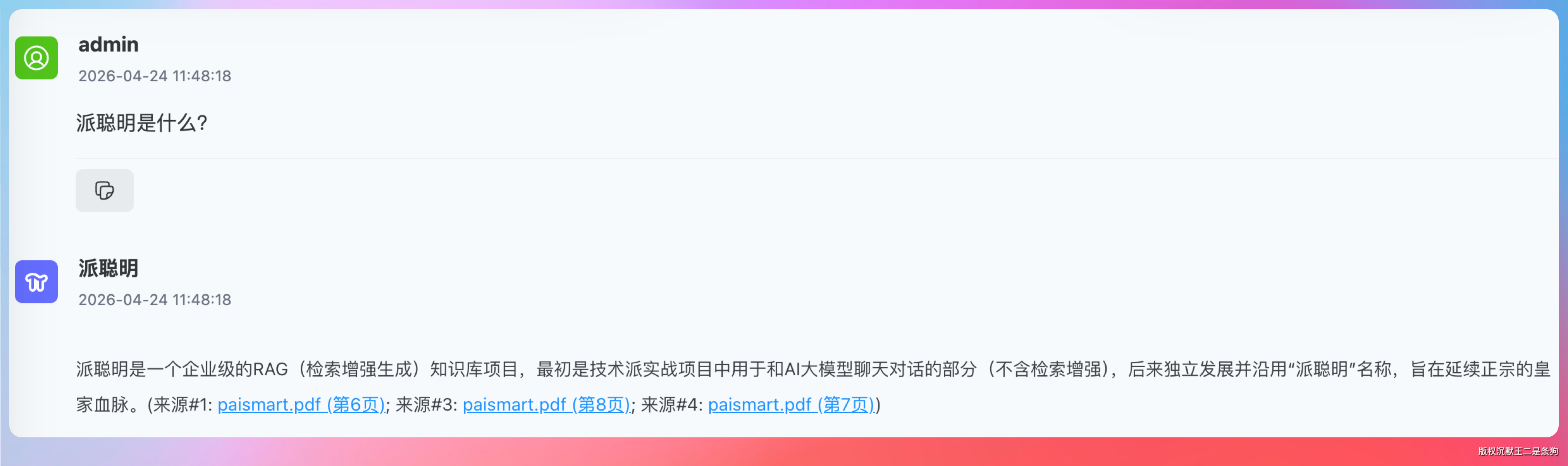
派聪明是一个企业级的 RAG(检索增强生成)知识库项目,最初是技术派实战项目中用于和 AI 大模型聊天对话的部分(不含检索增强),后来独立发展并沿用“派聪明”名称,旨在延续正宗的皇家血脉。
Pro 的回答是这样的:
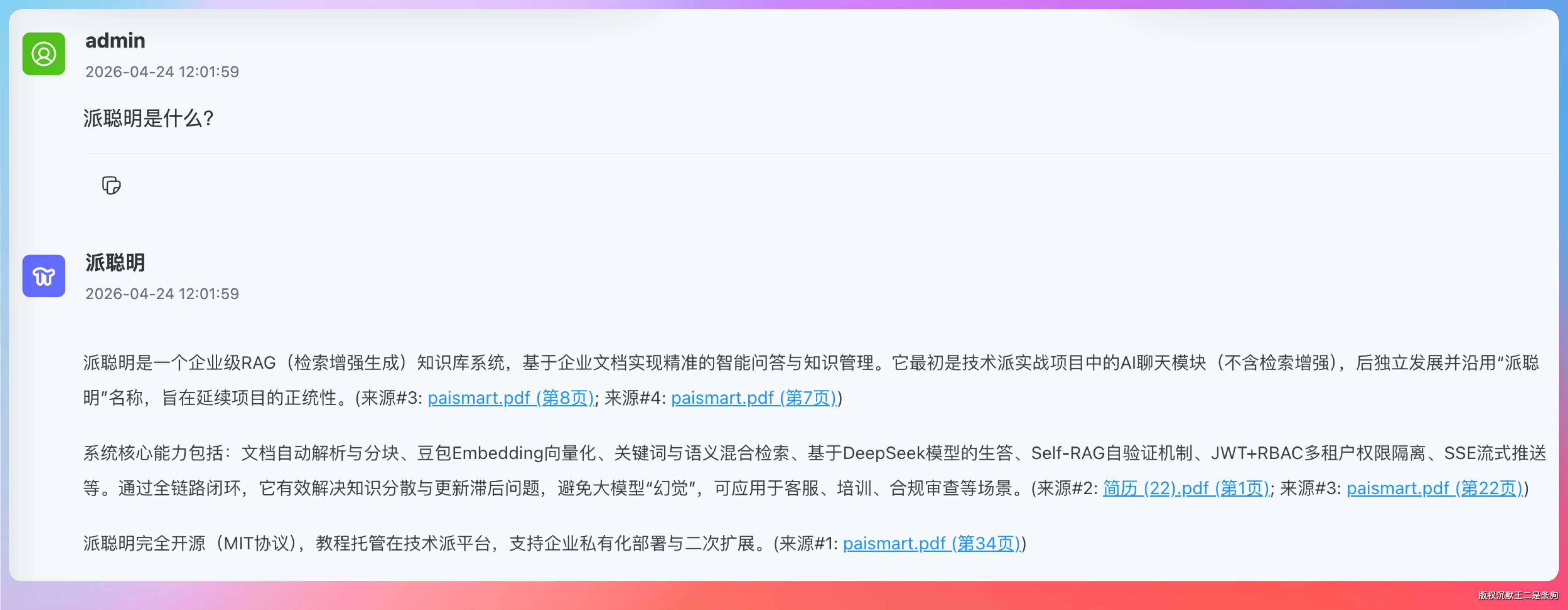
派聪明是一个企业级 RAG(检索增强生成)知识库系统,基于企业文档实现精准的智能问答与知识管理。它最初是技术派实战项目中的 AI 聊天模块(不含检索增强),后独立发展并沿用“派聪明”名称,旨在延续项目的正统性。系统核心能力包括:文档自动解析与分块、豆包 Embedding 向量化、关键词与语义混合检索、基于 DeepSeek 模型的生答、Self-RAG 自验证机制、JWT+RBAC 多租户权限隔离、SSE 流式推送等。通过全链路闭环,它有效解决知识分散与更新滞后问题,避免大模型“幻觉”,可应用于客服、培训、合规审查等场景。派聪明完全开源(MIT 协议),教程托管在技术派平台,支持企业私有化部署与二次扩展。
一个简略,一个详细。
毕竟 Pro 激活参数 49B,Flash 只有 13B,差了将近 4 倍。
但重点不在谁答得长。
RAG 场景里,检索质量才是天花板,模型能力决定的是在这个天花板下能发挥几成。Flash 的回答虽然短,但核心信息都抓到了——项目来源、名称由来、定位。Pro 多出来的那些内容(Self-RAG、JWT+RBAC、SSE 流式推送),其实全都是从知识库里检索出来的原始文档内容,它只是组织得更完整。
换句话说,如果你的知识库文档质量高、分块合理,Flash 完全够用。
03、DeepSeek V4 值得聊的一点
传统 Transformer 的注意力机制,每个 token 要和前面所有 token 都算一遍相似度。
上下文能从 10 万拉到 100 万,这是长上下文一直跑不起来的根本原因。
DeepSeek 的解法是把注意力拆成两种,交替堆叠起来用。
第一种叫 CSA,全名 Compressed Sparse Attention,压缩稀疏注意力。
它的逻辑是先把每 4 个 token 的 KV 缓存合并成一条摘要,然后用 Lightning Indexer 快速估算相关性,让每个 query 只从这些摘要里挑出最相关的 top-1024 个去算。
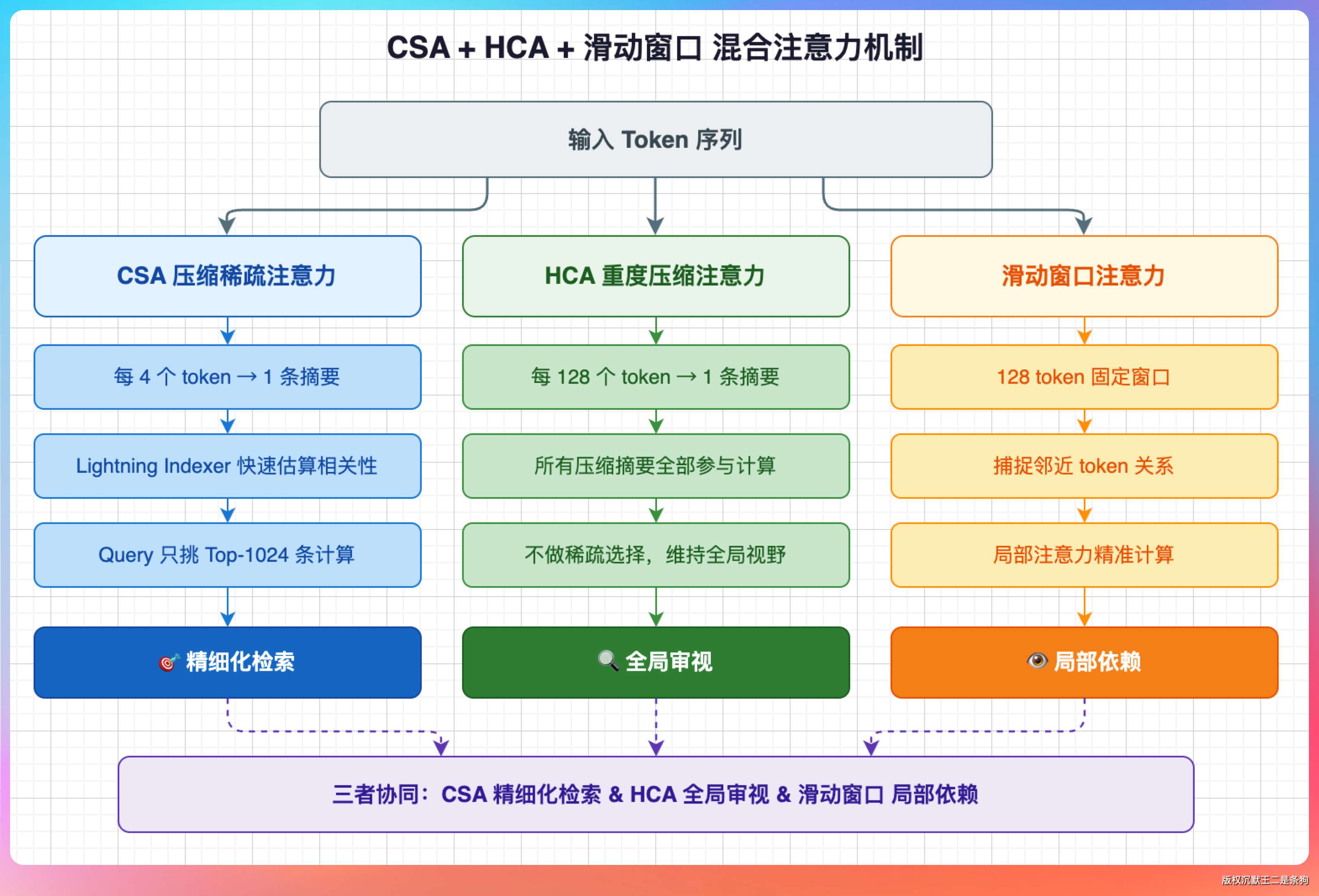
第二种叫 HCA,全名 Heavily Compressed Attention,重度压缩注意力。
每 128 个 token 才合并成一条,但不做稀疏选择,所有压缩后的摘要全部参与计算。HCA 的定位是维持全局视野,保证模型不会丢了对整段文本的把控。
再加一个 128 token 的滑动窗口管局部依赖。
也就是说,CSA 负责精细化检索,HCA 负责全局审视,滑动窗口管好眼前。
可以这样理解这个设计:
读一本 1000 页的书,传统注意力是把每一页和前面所有页都对比一遍,翻到第 1000 页的时候要同时记住前 999 页的细节,脑容量直接爆炸。
CSA 的做法是把每 4 页贴一张便签纸,只写摘要,然后看到某一页时只去翻最相关的 1024 张便签纸。
HCA 的做法更绝——每 128 页才贴一张便签纸,但所有便签纸都看一眼。再加上手里的那一页(滑动窗口),局部细节、中程逻辑、全局脉络都有了,但脑容量得消耗只有原来的十分之一。
04、DeepSeek 真的很克制
最让我意外的是 DeepSeek 官方这次的措辞。
公告里是这样写的:
使用体验优于 Sonnet 4.5,交付质量接近 Opus 4.6 非思考模式,但仍与 Opus 4.6 思考模式存在一定差距。
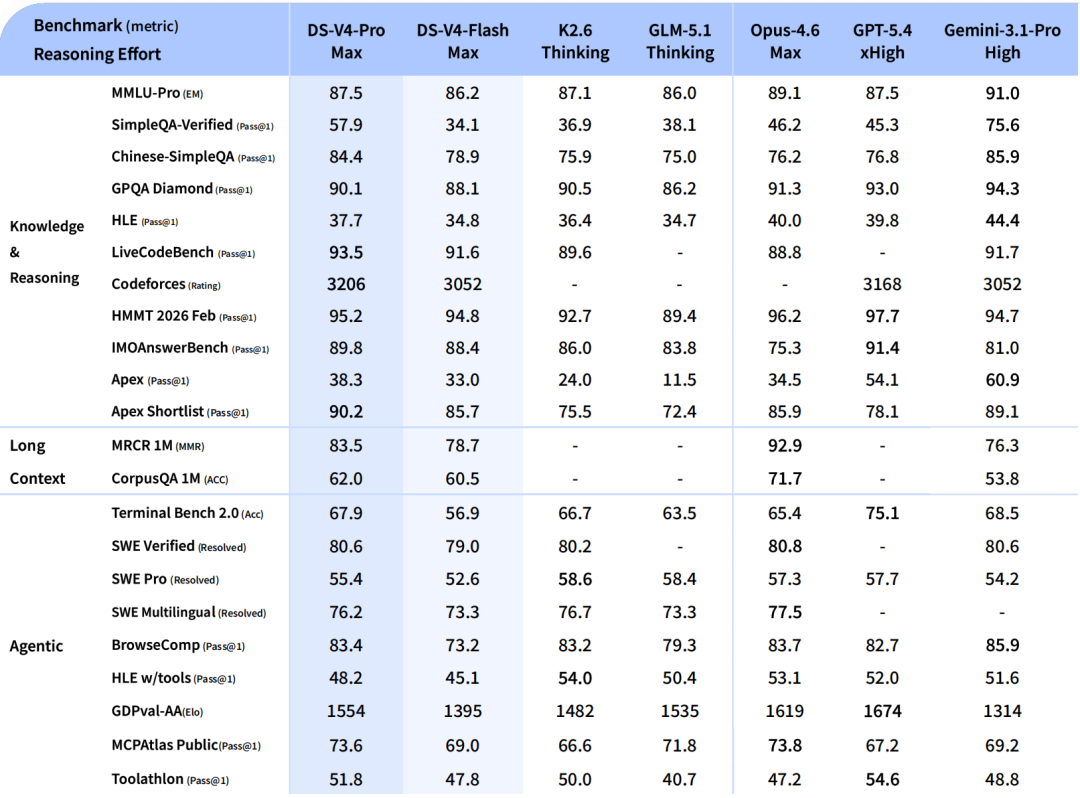
没有「吊打」,没有「碾压」,没有「遥遥领先」。
在充斥着「超越 GPT」「全球最强」「里程碑式突破」的当下,这种「我们确实还差一截」的表态真的很真诚。
「不诱于誉,不恐于诽,率道而行,端然正己。」
V4 不是一个完美的模型。
就我自己的使用体感下来看,前端这块的处理我认为还是有很大进步空间的。
这种实心的线条来布局,有点回到返璞归真的。😄
下一版不急,按你的节奏来。

1 条评论
回复