


PaiCLI 已经更新到第7期了,ReAct、Plan-and-Execute、Memory、RAG、Multi-Agent、HITL,该有的都有了。
但有一个问题一直没解决——串行。
我们让 PaiCLI 帮忙读三个文件,它会老老实实读完第一个,再读第二个,再读第三个。三个文件之间没有任何依赖关系,完全可以同时读,但 Agent 偏偏要排队。
Plan-and-Execute 模式下更明显。五个任务拆出来,前两个互相不依赖,第三个依赖前两个的结果。按道理前两个应该同时跑,但现在是第一个跑完才轮到第二个。
Multi-Agent 也一样,两个 Worker 都闲着,但编排器只分配给其中一个,另一个干等。
今天,我们就把 PaiCLI 从串行改造成并行。改完之后,三条执行路径——ReAct、Plan-and-Execute、Multi-Agent——全部支持并行执行,效率直接拉满。
01、并行的切入点有哪些?
PaiCLI 里有三个可以并行的场景。
第一个是工具调用的并行。大模型在一次响应里返回多个 tool_calls,这几个工具之间没有依赖,可以同时执行。
比如 LLM 说“我要同时读 pom.xml 和 README.md”,返回两个 read_file 调用,那就没必要等第一个读完再读第二个。
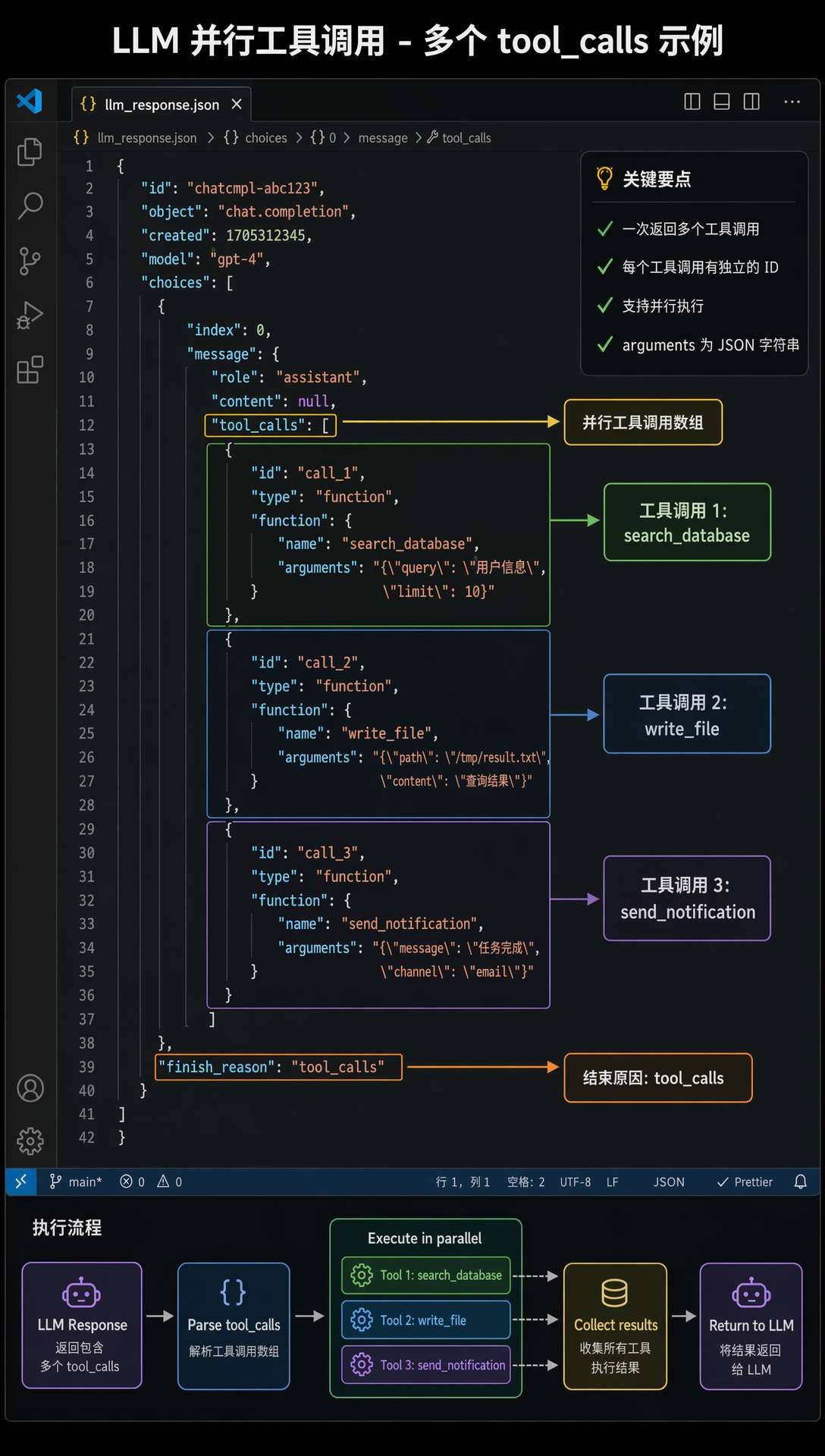
第二个是 Plan-and-Execute 模式下的任务并行。DAG 里同一批次的任务没有依赖关系,可以同时丢给 LLM 执行。
第三个是 Multi-Agent 模式下的 Worker 并行。编排器发现一批独立的步骤,可以同时分配给多个 Worker 跑。
02、工具并行执行
先看改造前的 ToolRegistry:
public String executeTool(String name, String argumentsJson) {
Tool tool = tools.get(name);
if (tool == null) {
return "未知工具: " + name;
}
// 解析参数,执行工具
JsonNode args = mapper.readTree(argumentsJson);
Map<String, String> argMap = new HashMap<>();
args.fields().forEachRemaining(entry ->
argMap.put(entry.getKey(), entry.getValue().asText()));
return tool.executor().execute(argMap);
}
一次调用执行一个工具,返回一个字符串。Agent 拿到多个 tool_calls 就循环调用这个方法,串行。
现在要加一个批量执行的方法 executeTools,接收一组工具调用,并行跑完再返回结果。
先定义数据结构。
ToolInvocation 表示一次工具调用请求,ToolExecutionResult 表示执行结果:
public record ToolInvocation(String id, String name, String argumentsJson) {}
public record ToolExecutionResult(String id, String name, String argumentsJson,
String result, long elapsedMillis, boolean timedOut) {
static ToolExecutionResult completed(ToolInvocation inv, String result, long elapsed) {
return new ToolExecutionResult(inv.id(), inv.name(), inv.argumentsJson(),
result, elapsed, false);
}
static ToolExecutionResult timedOut(ToolInvocation inv, long timeoutSeconds) {
return new ToolExecutionResult(inv.id(), inv.name(), inv.argumentsJson(),
"工具执行超时(" + timeoutSeconds + "秒),已取消",
timeoutSeconds * 1000, true);
}
static ToolExecutionResult failed(ToolInvocation inv, String message) {
return completed(inv, "工具执行失败: " + message, 0);
}
}
timedOut 字段标记是否超时,方便后续 LLM 根据超时结果决定是否重试。
核心的 executeTools 方法:
private static final int MAX_PARALLEL_TOOLS = 4;
private static final int DEFAULT_TOOL_BATCH_TIMEOUT_SECONDS = 90;
public List<ToolExecutionResult> executeTools(List<ToolInvocation> invocations) {
if (invocations == null || invocations.isEmpty()) {
return List.of();
}
// 只有一个工具时,不开线程池,直接执行
if (invocations.size() == 1) {
ToolInvocation invocation = invocations.get(0);
long startedAt = System.nanoTime();
String result = executeTool(invocation.name(), invocation.argumentsJson());
return List.of(ToolExecutionResult.completed(invocation, result,
elapsedMillis(startedAt)));
}
int parallelism = Math.min(invocations.size(), MAX_PARALLEL_TOOLS);
ExecutorService executor = Executors.newFixedThreadPool(parallelism, r -> {
Thread thread = new Thread(r, "paicli-tool-executor");
thread.setDaemon(true);
return thread;
});
try {
List<Callable<ToolExecutionResult>> tasks = invocations.stream()
.<Callable<ToolExecutionResult>>map(invocation -> () -> {
long startedAt = System.nanoTime();
String result = executeTool(invocation.name(),
invocation.argumentsJson());
return ToolExecutionResult.completed(invocation, result,
elapsedMillis(startedAt));
})
.toList();
List<Future<ToolExecutionResult>> futures =
executor.invokeAll(tasks, toolBatchTimeoutSeconds, TimeUnit.SECONDS);
List<ToolExecutionResult> results = new ArrayList<>();
for (int i = 0; i < futures.size(); i++) {
Future<ToolExecutionResult> future = futures.get(i);
ToolInvocation invocation = invocations.get(i);
if (future.isCancelled()) {
results.add(ToolExecutionResult.timedOut(invocation,
toolBatchTimeoutSeconds));
continue;
}
results.add(future.get());
}
return results;
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
return invocations.stream()
.map(inv -> ToolExecutionResult.failed(inv, "工具批次执行被中断"))
.toList();
} finally {
executor.shutdownNow();
}
}
单工具不开线程池
只有一个工具的时候,直接在当前线程执行,跳过线程池。
创建线程池本身就有开销——线程创建、任务调度、Future 包装,对于单个工具来说是资源浪费。
ReAct 模式下大部分时候 LLM 只返回一个 tool_call。
最大并行度限制
MAX_PARALLEL_TOOLS = 4,最多同时跑 4 个工具。
为什么不放开让工具调用有多少个就开多少个线程?
因为工具执行底层都是 IO 操作——读文件、跑命令、网络请求。同时开太多线程,操作系统层面的 IO 竞争反而会拖慢整体速度。
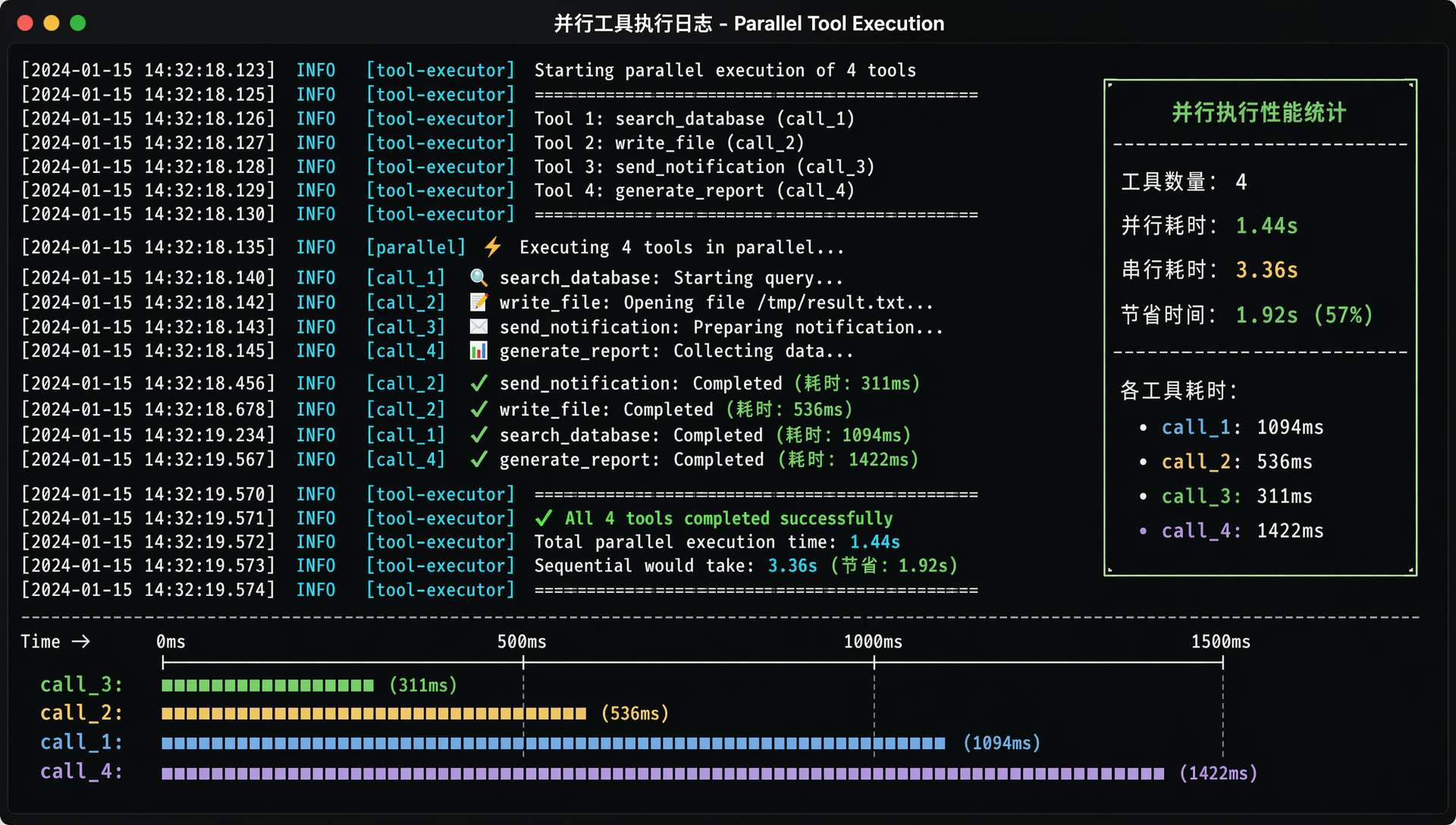
invokeAll 统一超时
用 executor.invokeAll(tasks, timeout, TimeUnit.SECONDS) 而不是给每个 Future 单独设超时。
invokeAll 的好处是一旦整个批次超时,还没完成的任务会被自动取消(future.isCancelled() 返回 true)。
已经完成的工具不受影响,结果照常拿。
批次超时设 90 秒,单个命令超时 60 秒。
这两个超时是独立的——execute_command 工具内部有自己的 60 秒限制,批次超时是兜底,防止某个工具完全卡死把整个 Agent 堵住。
结果顺序保持
返回结果的顺序和传入的 invocations 顺序要一致。这一点很重要。
LLM 返回 tool_calls 的时候是有顺序的,Agent 需要按照同样的顺序把工具结果返回到消息历史里。如果顺序乱了,大模型在下一轮推理时会混淆哪个结果对应哪个工具调用。
invokeAll 保证 futures 列表和 tasks 列表的顺序完全一致。
03、Agent.java 怎么接入并行
Agent.java 里的 ReAct 循环,改动很小。
之前是循环调用 executeTool:
for (GLMClient.ToolCall toolCall : response.toolCalls()) {
String result = toolRegistry.executeTool(
toolCall.function().name(),
toolCall.function().arguments());
conversationHistory.add(GLMClient.Message.tool(toolCall.id(), result));
}
现在改成批量调用:
private List<ToolExecutionResult> executeToolCalls(
List<GLMClient.ToolCall> toolCalls, int iteration) {
List<ToolInvocation> invocations = new ArrayList<>();
for (GLMClient.ToolCall toolCall : toolCalls) {
String toolName = toolCall.function().name();
String toolArgs = toolCall.function().arguments();
log.info("Scheduling tool: {} (iteration={})", toolName, iteration);
invocations.add(new ToolInvocation(toolCall.id(), toolName, toolArgs));
}
if (invocations.size() > 1) {
log.info("Executing {} tool calls in parallel (iteration={})",
invocations.size(), iteration);
}
return toolRegistry.executeTools(invocations);
}
调用方只需要把 toolCalls 列表转成 ToolInvocation 列表,扔给 executeTools,拿回结果按顺序返回就行。
List<ToolExecutionResult> toolResults = executeToolCalls(
response.toolCalls(), iteration);
for (ToolExecutionResult toolResult : toolResults) {
memoryManager.addToolResult(toolResult.name(), toolResult.result());
conversationHistory.add(GLMClient.Message.tool(
toolResult.id(), toolResult.result()));
}
改动量很少,因为并行的复杂全部封装在了 ToolRegistry.executeTools 里。
Agent 不需要知道工具是串行跑的还是并行跑的,它只关心“给一批调用,拿回一批结果”。
还有一个细节:系统提示词里加了一句话。
同一轮返回多个工具调用时,系统会并行执行这些工具;
如果工具之间有依赖关系,请分多轮调用。
告诉大模型“你可以一次返回多个工具调用,我们会并行跑”。同时也提醒它“有依赖的工具别放在同一轮”。大模型的指令遵循能力在这件事上还是靠谱的。
04、Plan-and-Execute 的 DAG 并行
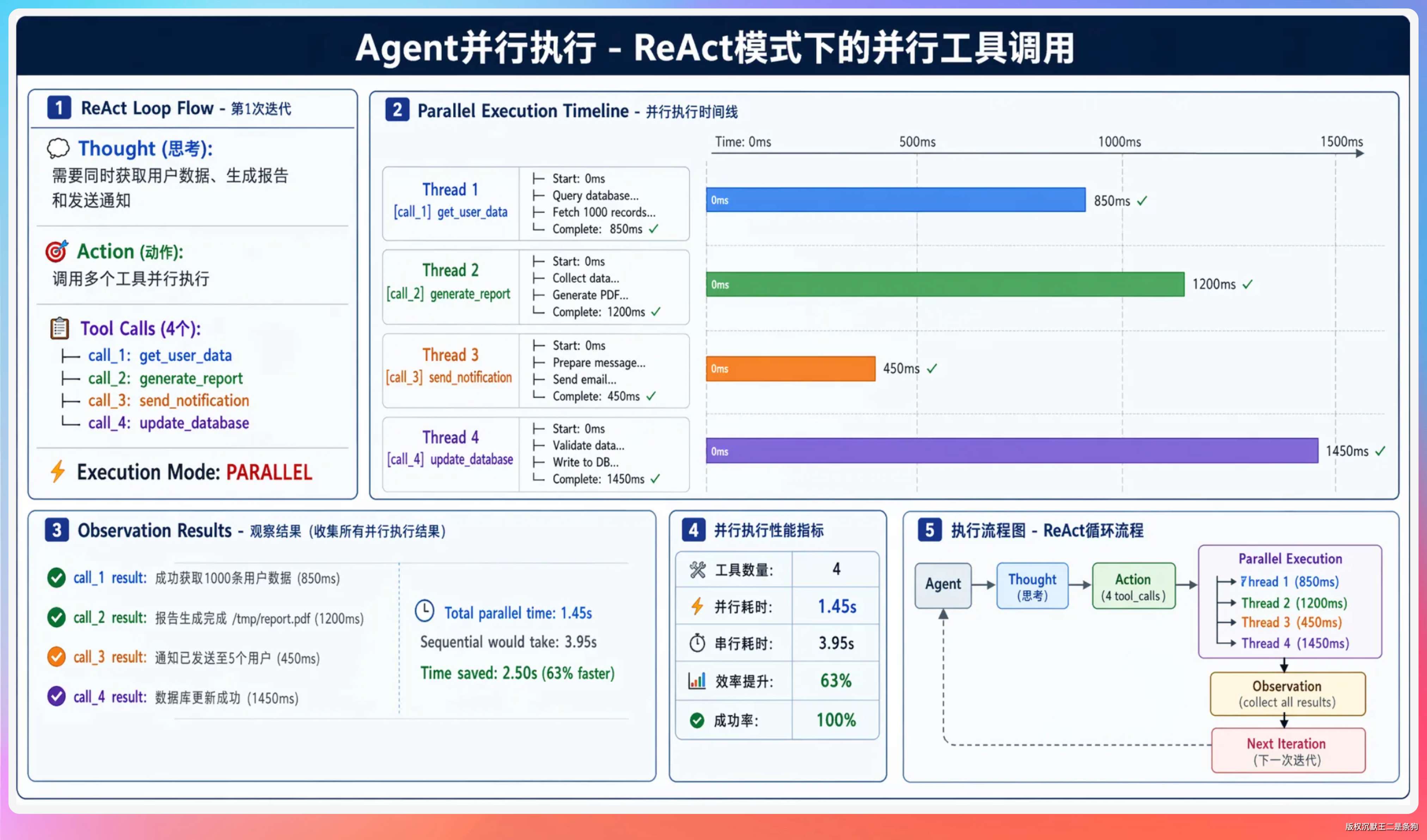
ReAct 的并行是工具级别的,粒度比较小。Plan-and-Execute 的并行是任务级别的,粒度更大。
回顾一下 ExecutionPlan 的结构。每个 Task 有依赖列表,整个计划形成一个 DAG。DAG 里没有相互依赖的任务可以同时执行。
getExecutionBatches() 方法把 DAG 按依赖层级拆成批次:
public List<List<Task>> getExecutionBatches() {
Map<String, Task> remaining = new LinkedHashMap<>(tasks);
Set<String> completed = new HashSet<>();
List<List<Task>> batches = new ArrayList<>();
while (!remaining.isEmpty()) {
List<Task> batch = remaining.values().stream()
.filter(task -> completed.containsAll(task.getDependencies()))
.toList();
if (batch.isEmpty()) {
break; // 存在环或未满足依赖,退出
}
batches.add(batch);
for (Task task : batch) {
remaining.remove(task.getId());
completed.add(task.getId());
}
}
return batches;
}
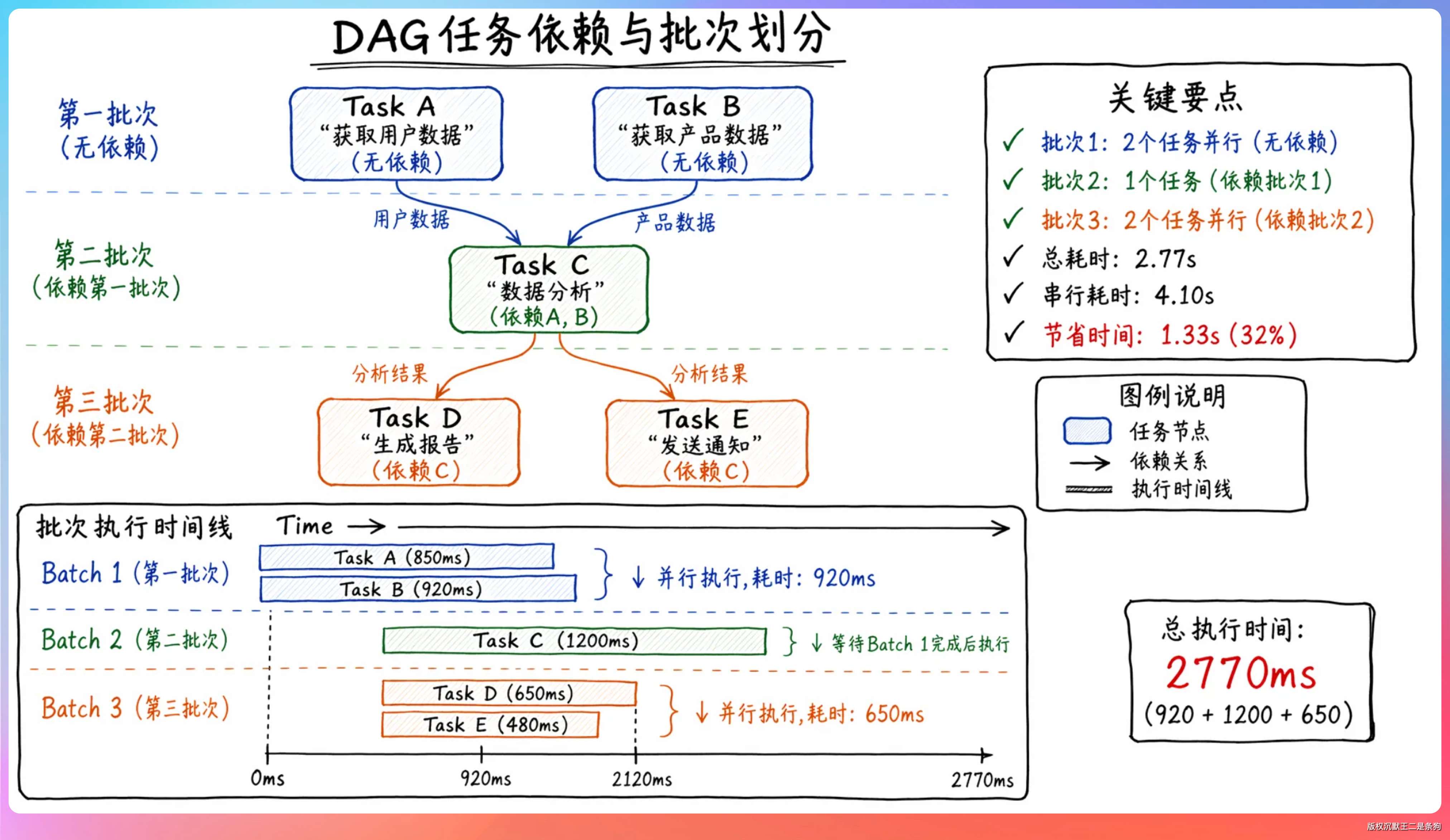
举个例子,五个任务的依赖关系是这样的:
task_1(无依赖)
task_2(无依赖)
task_3(依赖 task_1)
task_4(依赖 task_1, task_2)
task_5(依赖 task_3, task_4)
拆成三个批次:[task_1, task_2] → [task_3, task_4] → [task_5]。第一批两个任务同时跑,等都完成了再同时跑第二批,最后跑第三批。
PlanExecuteAgent 里的 executeTaskBatch 方法处理并行执行:
private List<TaskExecutionResult> executeTaskBatch(
ExecutionPlan plan, List<Task> executableTasks,
StreamState streamState) {
// 单任务批次:直接串行执行,不开线程池
if (executableTasks.size() == 1) {
Task task = executableTasks.get(0);
System.out.println("▶️ 执行任务 [" + task.getId() + "]: "
+ task.getDescription());
task.markStarted();
return List.of(TaskExecutionResult.success(task,
executeTask(plan.getGoal(), plan, task, streamState, System.out)));
}
// 多任务批次:并行执行
System.out.println("⚡ 本轮并行执行 " + executableTasks.size()
+ " 个任务: " + parallelTaskIds);
ExecutorService executor = Executors.newFixedThreadPool(
Math.min(executableTasks.size(), 4), r -> {
Thread t = new Thread(r, "paicli-plan-executor");
t.setDaemon(true);
return t;
});
Map<String, ByteArrayOutputStream> buffers = new LinkedHashMap<>();
List<Future<TaskExecutionResult>> futures = new ArrayList<>();
for (Task task : executableTasks) {
task.markStarted();
ByteArrayOutputStream baos = new ByteArrayOutputStream();
buffers.put(task.getId(), baos);
PrintStream taskOut = new PrintStream(baos, true, StandardCharsets.UTF_8);
futures.add(executor.submit(() -> {
return TaskExecutionResult.success(task,
executeTask(plan.getGoal(), plan, task, streamState, taskOut));
}));
}
// 等待所有任务完成,按顺序 flush 缓冲区
for (Task task : executableTasks) {
ByteArrayOutputStream buf = buffers.get(task.getId());
if (buf != null && buf.size() > 0) {
System.out.print(buf.toString(StandardCharsets.UTF_8));
System.out.flush();
}
}
return results;
}
这里有个很重要的设计——流式输出缓冲。
每个并行任务的输出不是直接写到 System.out,而是写到各自的 ByteArrayOutputStream 缓冲区。
所有任务完成后,再按任务 ID 的顺序把缓冲区 flush 到标准输出。
为什么要这么做?
因为多个线程同时往 System.out 写,输出会乱掉。用户在终端看到的就是一坨混在一起的东西,task_1 的思考过程夹带着 task_2 的工具结果,完全没法看。
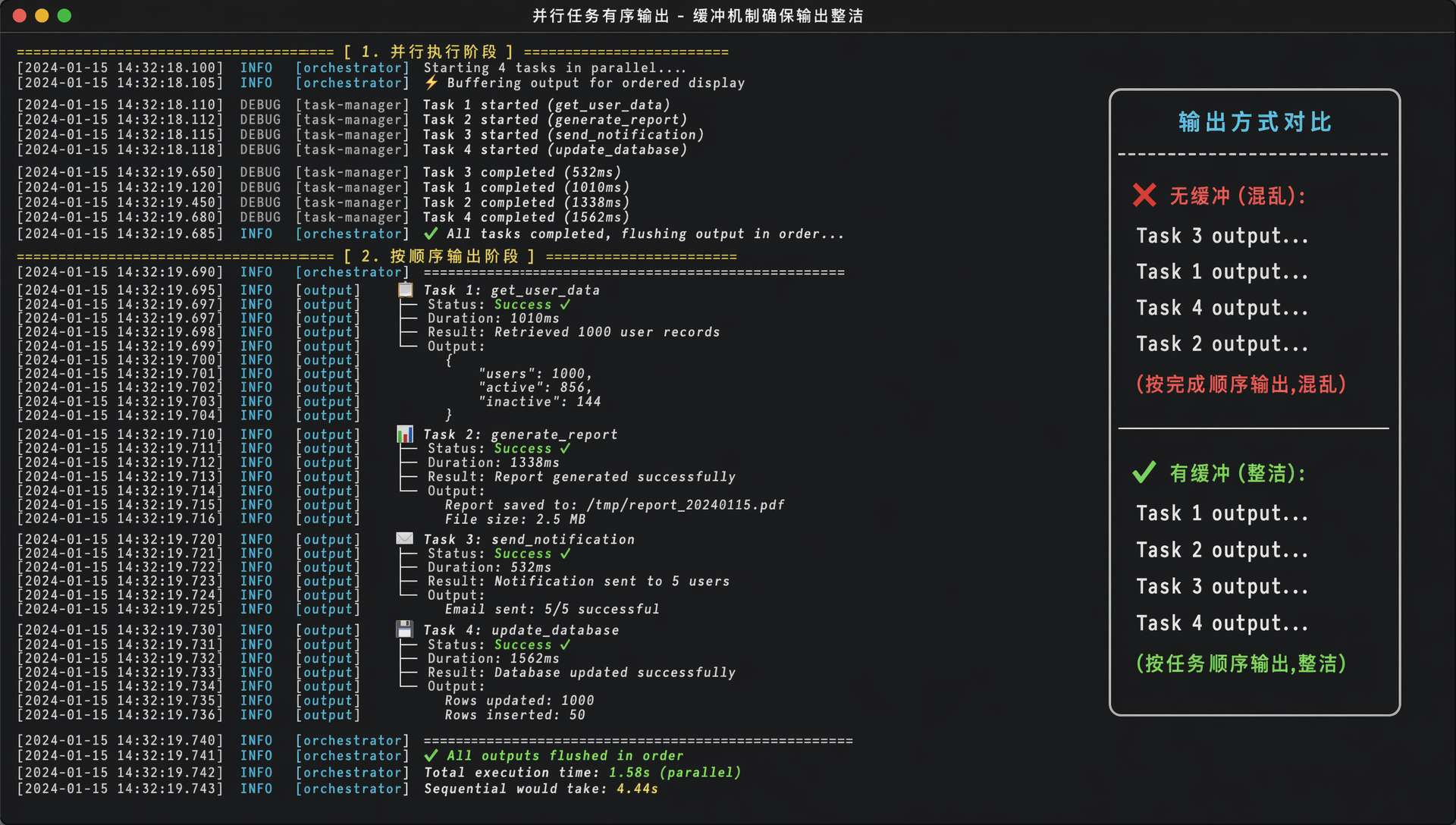
缓冲之后,用户看到的输出顺序是固定的——先是 task_1 的完整执行过程,再是 task_2 的,清楚明白。
单任务批次的时候直接走 System.out,保持实时打字的观感。
只有真正多任务并行时才启用缓冲。
05、Multi-Agent 的 Worker 并行
Multi-Agent 的并行和 Plan-and-Execute 的思路一致,但多了一个额外的复杂度——Worker 池化。
AgentOrchestrator 里有两个 Worker:worker-1 和 worker-2。
同一个 Worker 不能被两个步骤并发占用,因为 Worker 内部有对话历史,并发写会导致数据竟争。
用 BlockingQueue 做 Worker 池:
BlockingQueue<SubAgent> workerPool = new LinkedBlockingQueue<>(workers);
for (ExecutionStep step : batch) {
futures.add(executor.submit(() -> {
SubAgent worker = null;
SubAgent localReviewer = new SubAgent(
"reviewer-" + step.id(), AgentRole.REVIEWER,
llmClient, toolRegistry);
try {
worker = workerPool.take(); // 从池中借一个 Worker
runStep(step, steps, retryCount, worker, localReviewer,
context, stepOut);
} finally {
if (worker != null) {
worker.clearHistory();
workerPool.offer(worker); // 用完还回池
}
}
}));
}
workerPool.take() 会阻塞,直到池里有空闲 Worker。如果三个步骤同时要执行但只有两个 Worker,第三个步骤会等前面某个 Worker 完成后才能开始。
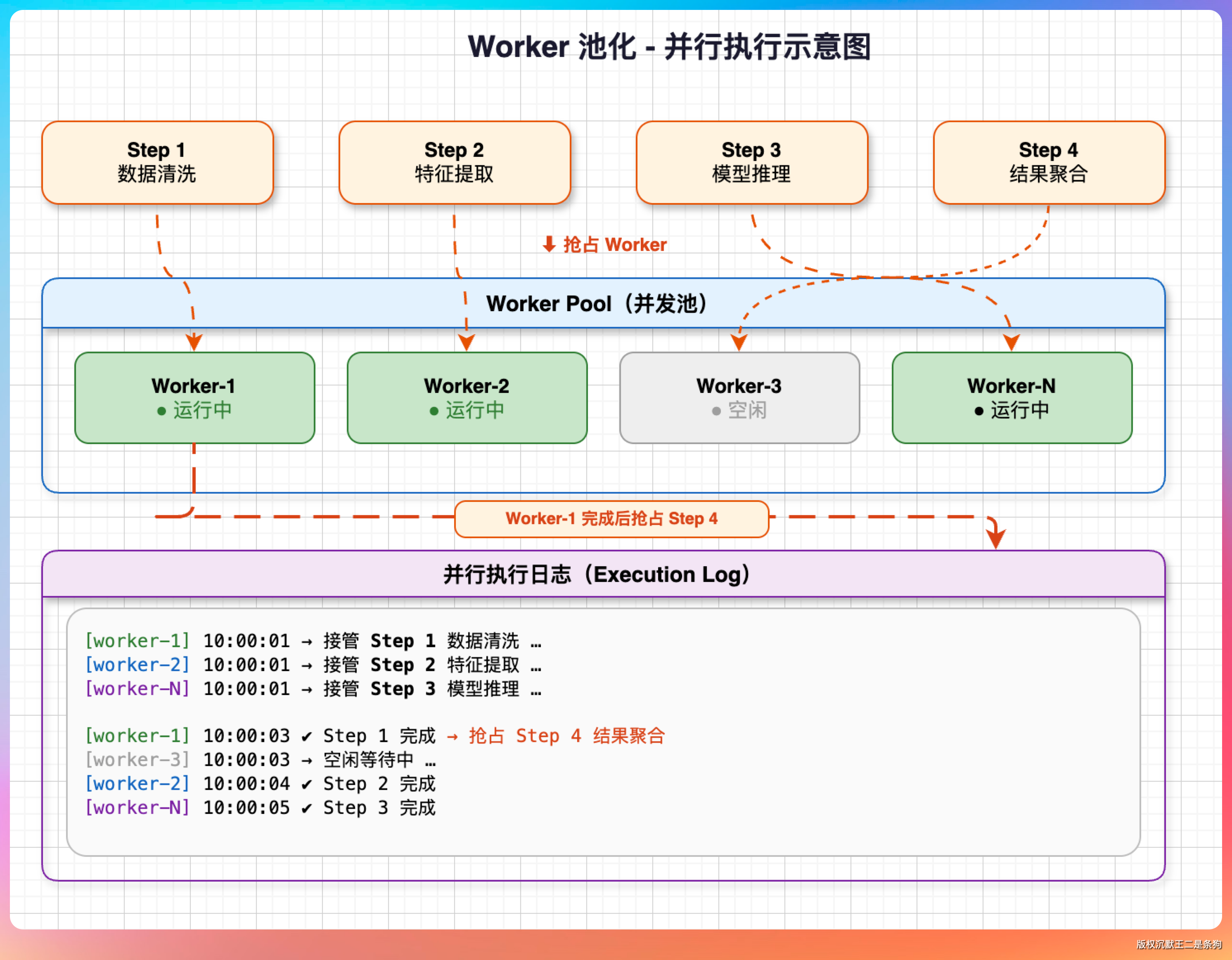
Reviewer 的处理方式不一样。每个并行步骤创建独立的 Reviewer 实例,不走池化。
为什么 Worker 用池,Reviewer 不用?
Worker 数量是有意限制的——两个 Worker 已经够了,太多 Worker 同时调用 LLM 会把 API 打爆。Reviewer 的对话历史很短(就一轮审查),创建新实例的成本极低,而且并行步骤的 Reviewer 如果共享实例,对话历史会被并发写乱掉。
runStep 方法被串行和并行两条路径共享,通过 PrintStream out 参数控制输出目的地:
private void runStep(ExecutionStep step, List<ExecutionStep> steps,
Map<String, Integer> retryCount,
SubAgent worker, SubAgent reviewer,
String context, PrintStream out) {
out.println("🛠️ " + worker.getName() + " 执行步骤 ["
+ step.id() + "]: " + step.description());
// Worker 执行 → Reviewer 审查 → 最多 2 次重试
}
串行路径传 System.out,并行路径传 ByteArrayOutputStream 包装的 PrintStream。
06、超时和取消机制
并行执行带来了一个新问题:如果某个工具或任务卡住了怎么办?
之前串行的时候,execute_command 有 60 秒超时,超时就强制杀进程。但并行场景下,一个工具超时不应该影响其他工具。
executeTools 用 invokeAll 的超时参数解决这个问题。批次超时到了,还没完成的 Future 会被 cancel:
List<Future<ToolExecutionResult>> futures =
executor.invokeAll(tasks, toolBatchTimeoutSeconds, TimeUnit.SECONDS);
for (int i = 0; i < futures.size(); i++) {
Future<ToolExecutionResult> future = futures.get(i);
if (future.isCancelled()) {
results.add(ToolExecutionResult.timedOut(invocation,
toolBatchTimeoutSeconds));
continue;
}
results.add(future.get());
}
超时的工具返回一个 timedOut 结果,LLM 在下一轮推理时可以看到“这个工具超时了”,然后决定是重试还是换个方案。

execute_command 工具内部的超时处理也值得一提:
private String executeCommand(String command) {
Process process = pb.start();
boolean finished = process.waitFor(commandTimeoutSeconds, TimeUnit.SECONDS);
if (!finished) {
process.destroyForcibly();
process.waitFor(2, TimeUnit.SECONDS);
return "命令执行超时(" + commandTimeoutSeconds + "秒),已强制终止";
}
// ...
}
两层超时是独立的。
命令级 60 秒超时保证单个命令不会无限跑,批次级 90 秒超时保证整个并行批次有一个兜底。正常情况下命令级超时先触发,批次级超时是 fallback。
07、三条路径统一入口
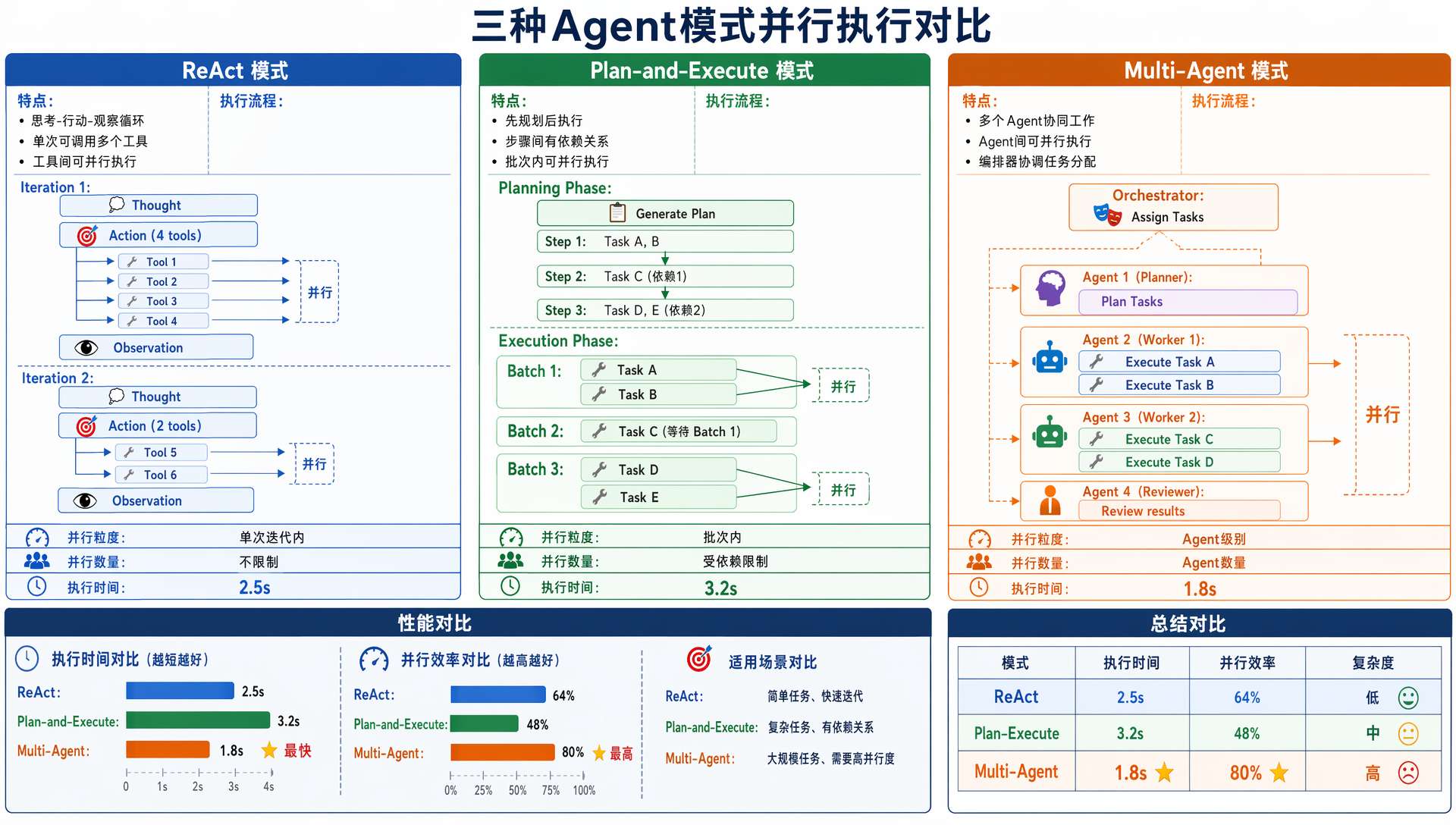
改造完之后,ReAct、Plan-and-Execute、Multi-Agent 三条执行路径都走同一个 ToolRegistry.executeTools 方法。
| 执行路径 | 并行级别 | 调用方式 |
|---|---|---|
| ReAct(Agent.java) | 工具级别 | LLM 单轮返回多个 tool_calls,并行执行 |
| Plan-and-Execute | 任务级别 | DAG 同一批次任务并行,每个任务内部工具也并行 |
| Multi-Agent | Worker级别 | 同一依赖批次步骤并行分配给 Worker 池 |
Plan-and-Execute 和 Multi-Agent 是双层并行:外层是任务/步骤级别的并行(executeTaskBatch / runBatchParallel),内层是工具级别的并行(executeTools)。
一个并行任务在执行过程中,LLM 可能返回多个工具调用,这些工具调用也会被 executeTools 并行处理。两层嵌套,但互不干扰,因为每一层都有各自的线程池。
08、守护线程和资源清理
并行执行引入了线程池,线程池的生命周期管理必须处理干净。
所有线程池创建的线程都设成了 daemon 线程:
Executors.newFixedThreadPool(parallelism, r -> {
Thread thread = new Thread(r, "paicli-tool-executor");
thread.setDaemon(true);
return thread;
});
daemon 线程在所有非 daemon 线程退出后会自动终止。这意味着用户按 Ctrl+C 退出 PaiCLI 的时候,工具执行线程不会阻止 JVM 关闭。
每个方法结束时都有 executor.shutdownNow(),在 finally 块里调用:
try {
// 并行执行逻辑
} finally {
executor.shutdownNow();
}
shutdownNow 会中断所有正在执行的任务,然后销毁线程池。不能用 shutdown()——那只是“停止接收新任务”,已提交的任务还会继续跑。我们需要的是“立即停掉所有东西”。
daemon 线程 + shutdownNow,双重保险,确保线程池不会泄漏。
09、命令输出截断
并行执行还有一个之前不太明显的问题:命令输出太长会撑爆内存。
串行时一次只有一个命令在跑,一个命令的输出再长也有限。但并行时四个命令同时输出,如果每个命令都输出几十 MB 的日志,内存直接爆了。
所以 readProcessOutput 方法加了 8000 字符的限制:
private static final int MAX_COMMAND_OUTPUT_CHARS = 8_000;
private String readProcessOutput(Process process) throws Exception {
StringBuilder output = new StringBuilder();
try (BufferedReader reader = new BufferedReader(
new InputStreamReader(process.getInputStream()))) {
String line;
while ((line = reader.readLine()) != null) {
if (output.length() < MAX_COMMAND_OUTPUT_CHARS) {
output.append(line).append("\n");
}
}
}
if (output.length() >= MAX_COMMAND_OUTPUT_CHARS) {
return output.substring(0, MAX_COMMAND_OUTPUT_CHARS) + "\n...(输出已截断)";
}
return output.toString();
}
超过 8000 字符的部分会被截掉,末尾加一个“输出已截断”的提示。LLM 看到这个提示知道输出不完整,可以决定是否需要更精确的命令来获取需要的信息。
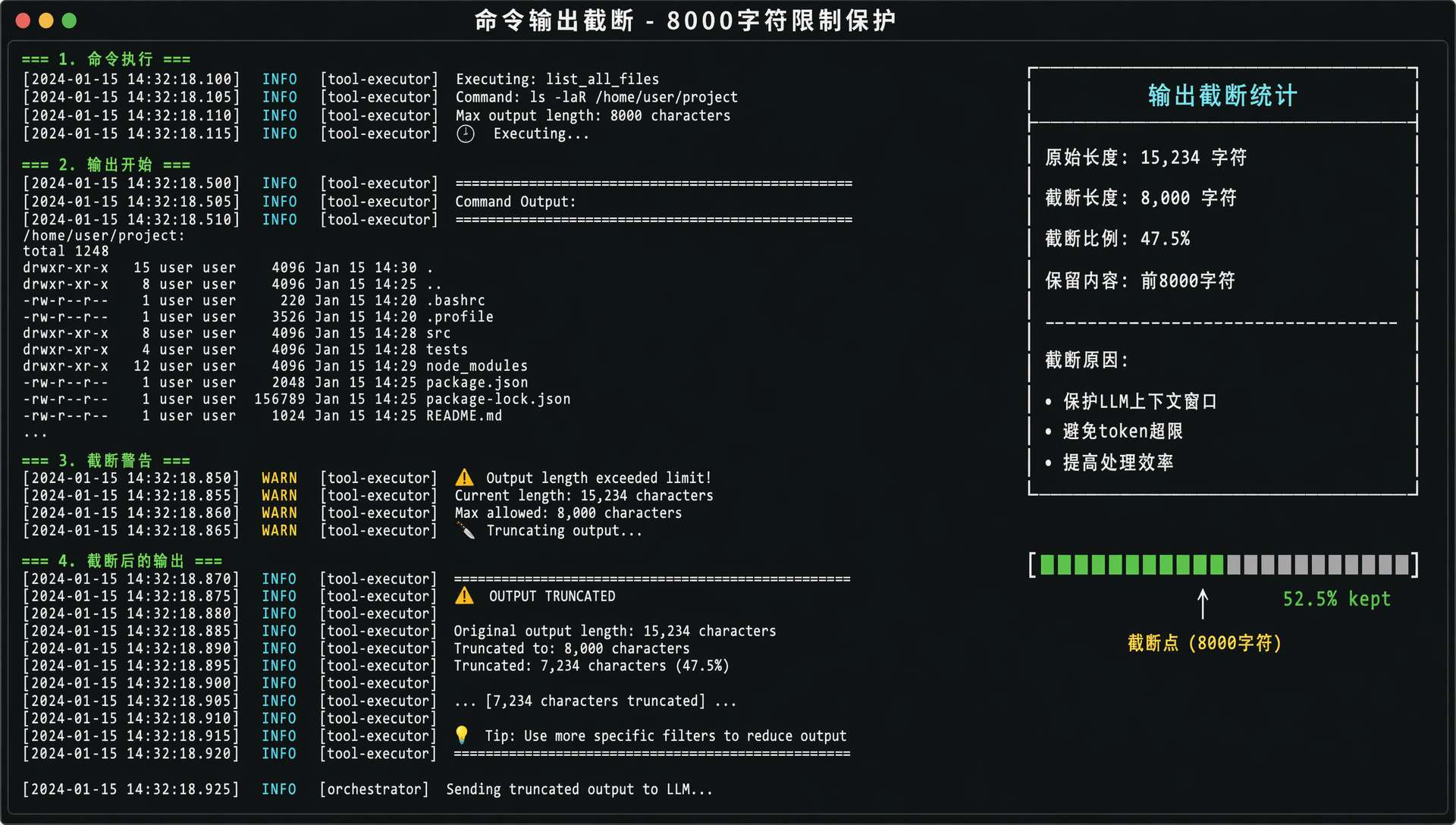
8000 字符是权衡的结果。太短了 LLM 拿不到足够信息,太长了 token 消耗会飙升(LLM 的 context 是收费的)。大多数命令的有效信息在前面几千字符就够了。
10、禁止全盘扫描
还有一个安全相关的改动。并行执行让 Agent 的速度变快了,但速度快意味着如果做了蠢事,后果也更严重。
execute_command 加了一个黑名单检查:
private boolean isDisallowedBroadScan(String command) {
String normalized = command.replaceAll("\\s+", " ")
.trim().toLowerCase(Locale.ROOT);
return normalized.contains("find /")
|| normalized.contains("find ~")
|| normalized.contains("find $home");
}
禁止 find /、find ~、find $HOME 这类扫描整个文件系统的命令。
LLM 有时候为了“全面了解项目”会试图扫描整个磁盘,这在串行时就很烦(一个 find / 能跑好几分钟),并行时更不能忍。四个线程同时 find /,IO 直接打满,系统卡成狗。
被拦截的命令会返回一个友好的错误信息,引导 LLM 用 read_file、list_dir、search_code 这些工具替代。
11、跑一遍看效果
启动 PaiCLI,用 /plan 模式执行一个有多步骤的任务:
> /plan 分析 PaiCLI 项目:读取 pom.xml 了解依赖,读取 README.md 了解功能,读取 ROADMAP.md 了解规划
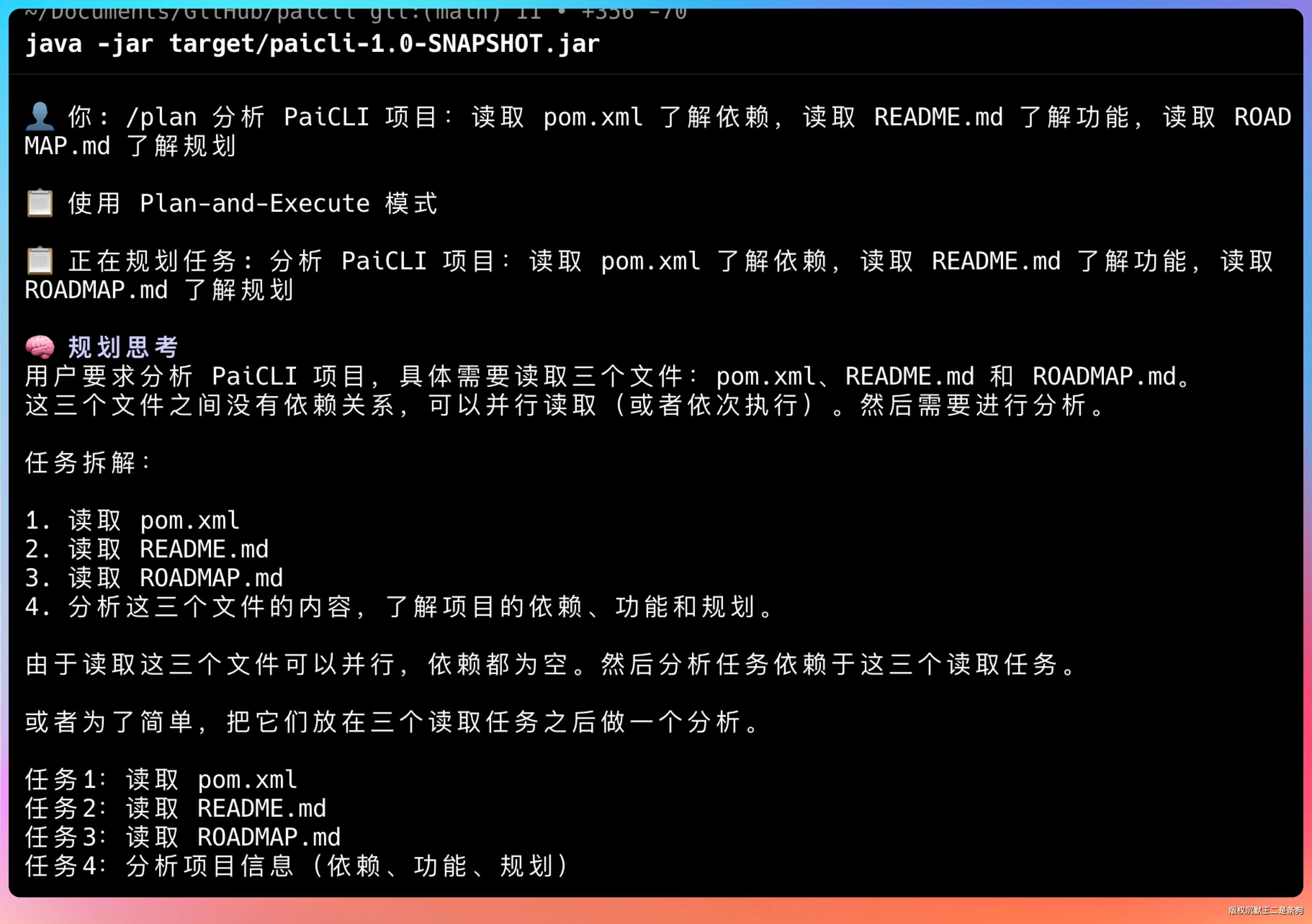
规划器拆成三个任务,三个都没有依赖关系。
之前的版本会串行执行:读 pom.xml → 读 README.md → 读 ROADMAP.md,总耗时大约是三次 LLM 调用的叠加。
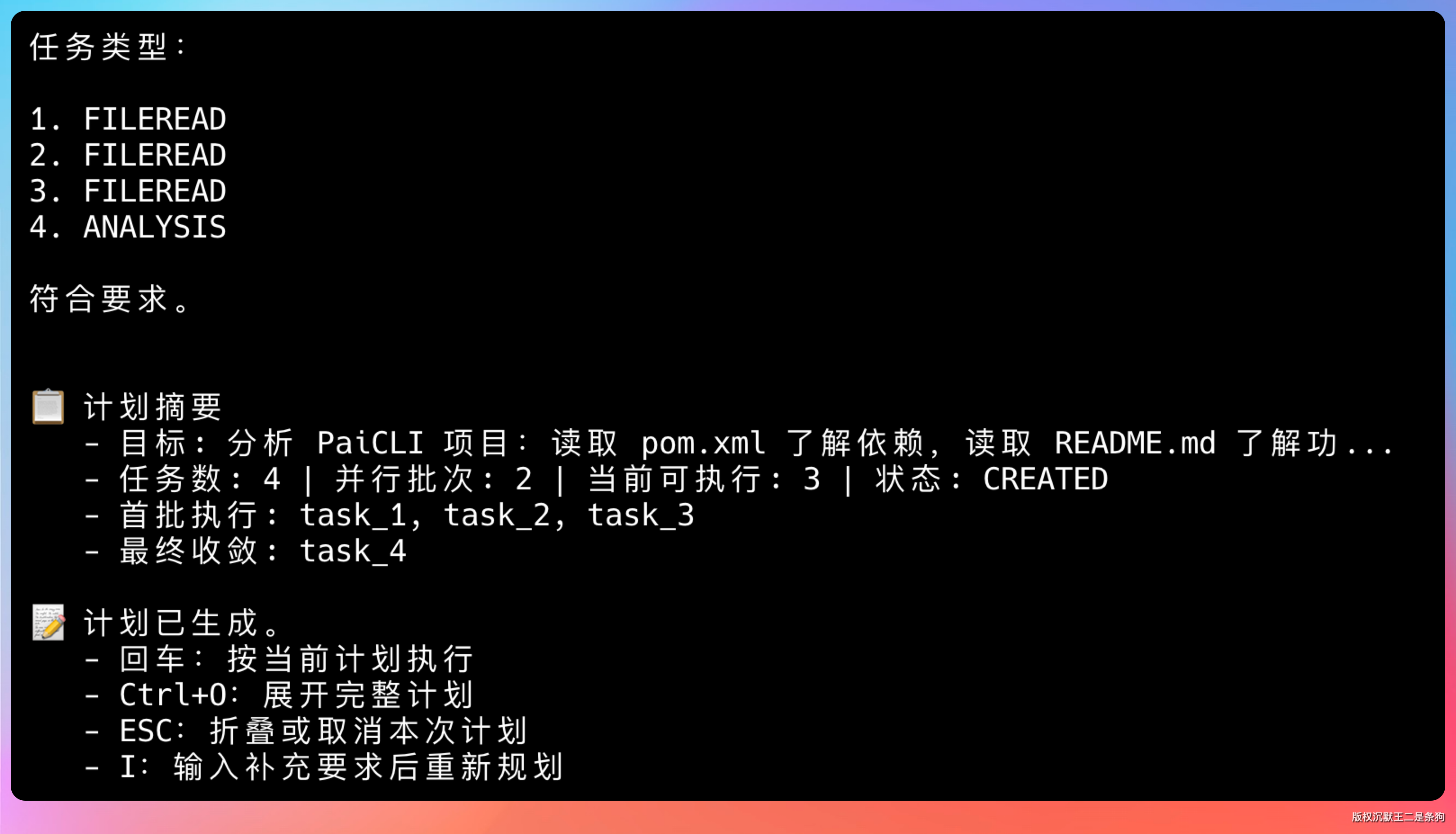
现在三个任务同时开始跑:
⚡ 本轮并行执行 3 个任务: task_1, task_2, task_3
▶️ 并行任务 [task_1]: 读取 pom.xml 分析项目依赖
▶️ 并行任务 [task_2]: 读取 README.md 了解功能特性
▶️ 并行任务 [task_3]: 读取 ROADMAP.md 了解规划
三个任务的执行时间重叠,总耗时约等于最慢那个任务的时间。


ReAct 模式下也能看到效果。让 Agent 帮忙看看项目结构:
> 请同时列出 src/main/java、src/test/java、src/main/resources 这三个目录下有哪些文件
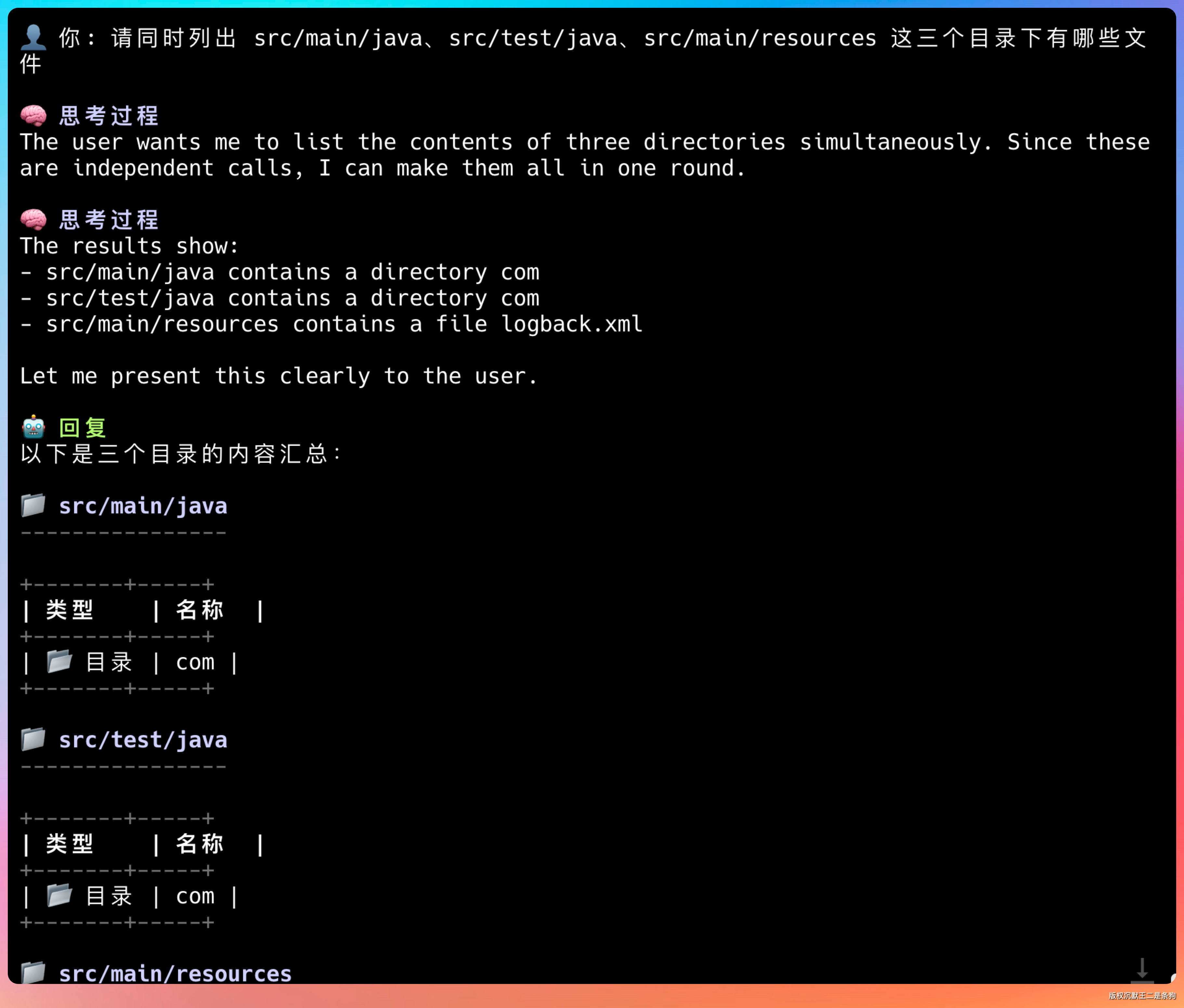
LLM 会返回多个 list_dir 调用,这些调用会被并行执行。
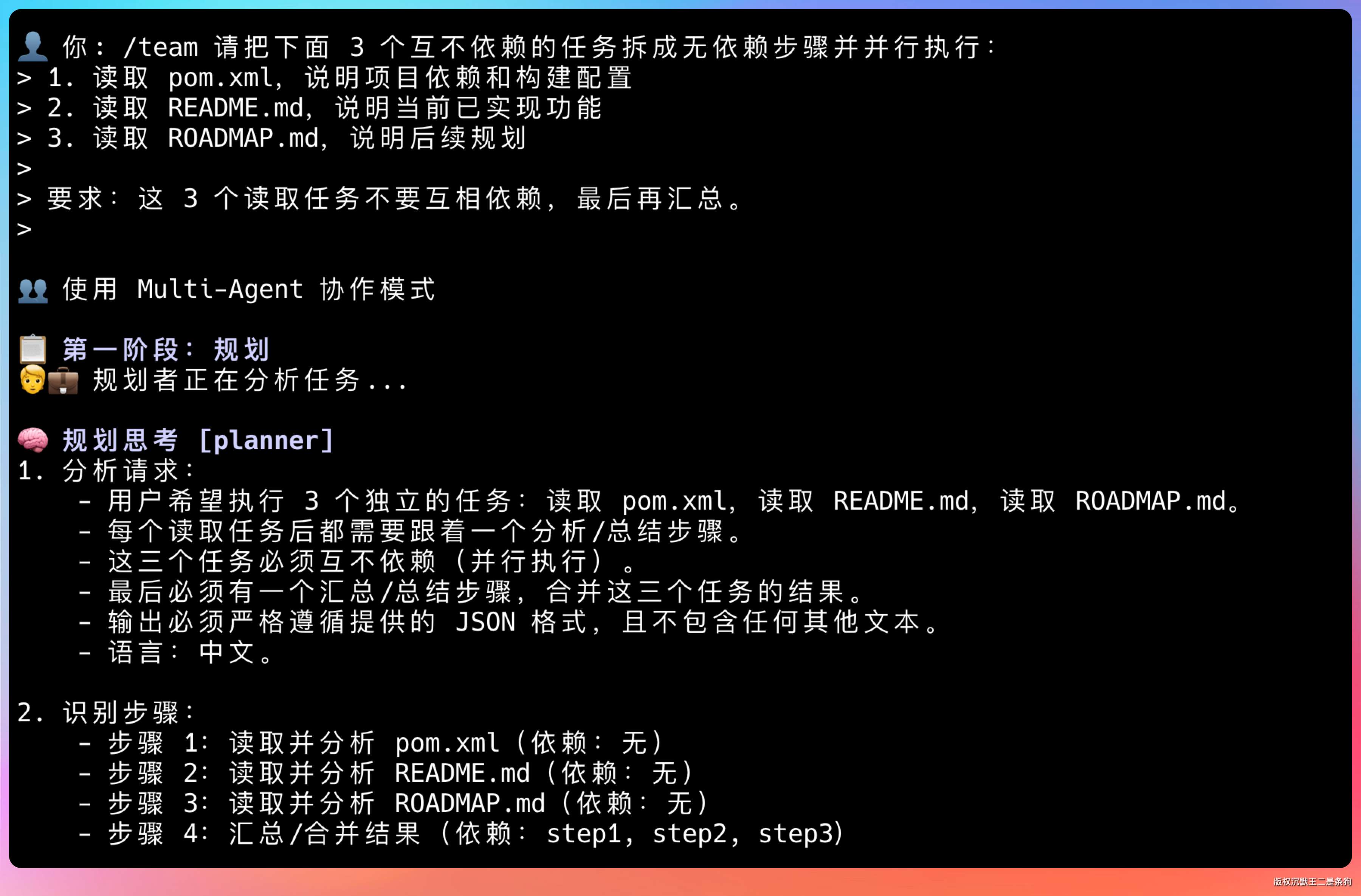
Multi-Agent 模式更明显。/team 模式下,编排器发现两个独立步骤,同时分给 worker-1 和 worker-2:
/team 请把下面 3 个互不依赖的任务拆成无依赖步骤并并行执行:
1. 读取 pom.xml,说明项目依赖和构建配置
2. 读取 README.md,说明当前已实现功能
3. 读取 ROADMAP.md,说明后续规划
要求:这 3 个读取任务不要互相依赖,最后再汇总。
两个 Worker 同时干活,效率翻倍。
PaiCLI如何写到简历上?
项目名称:PaiCLI — Java Agent CLI
项目简介:基于 ReAct 范式从零实现的 Java Agent 命令行工具,集成 Plan-and-Execute、Memory、RAG、Multi-Agent、HITL 人工审批和异步并行执行,完整覆盖 AI Agent 核心技术栈。
核心职责:
- 设计并实现统一的并行工具执行引擎,使用
ExecutorService+ 批次超时实现最多 4 路并发,超时工具自动取消并返回可返回结果供 LLM 重新决策 - 将 ReAct、Plan-and-Execute、Multi-Agent 三条执行路径的工具调用统一接入并行引擎
- 在 Plan-and-Execute 模式中实现 DAG 批次调度,按依赖层级将独立任务并行执行,通过
ByteArrayOutputStream缓冲实现并行输出的有序展示 - 使用
BlockingQueue实现 Multi-Agent Worker 池化分配,保证同一 Worker 不被并发占用,Reviewer 按步骤独立创建避免对话历史竞争

回复