


大家好,我是二哥呀。
DeepSeek V4(预览版),1.6 万亿参数的 V4-Pro、284B 参数的 V4-Flash,原生 1M 上下文,Agentic Coding 评测直接对标 Opus 4.6。
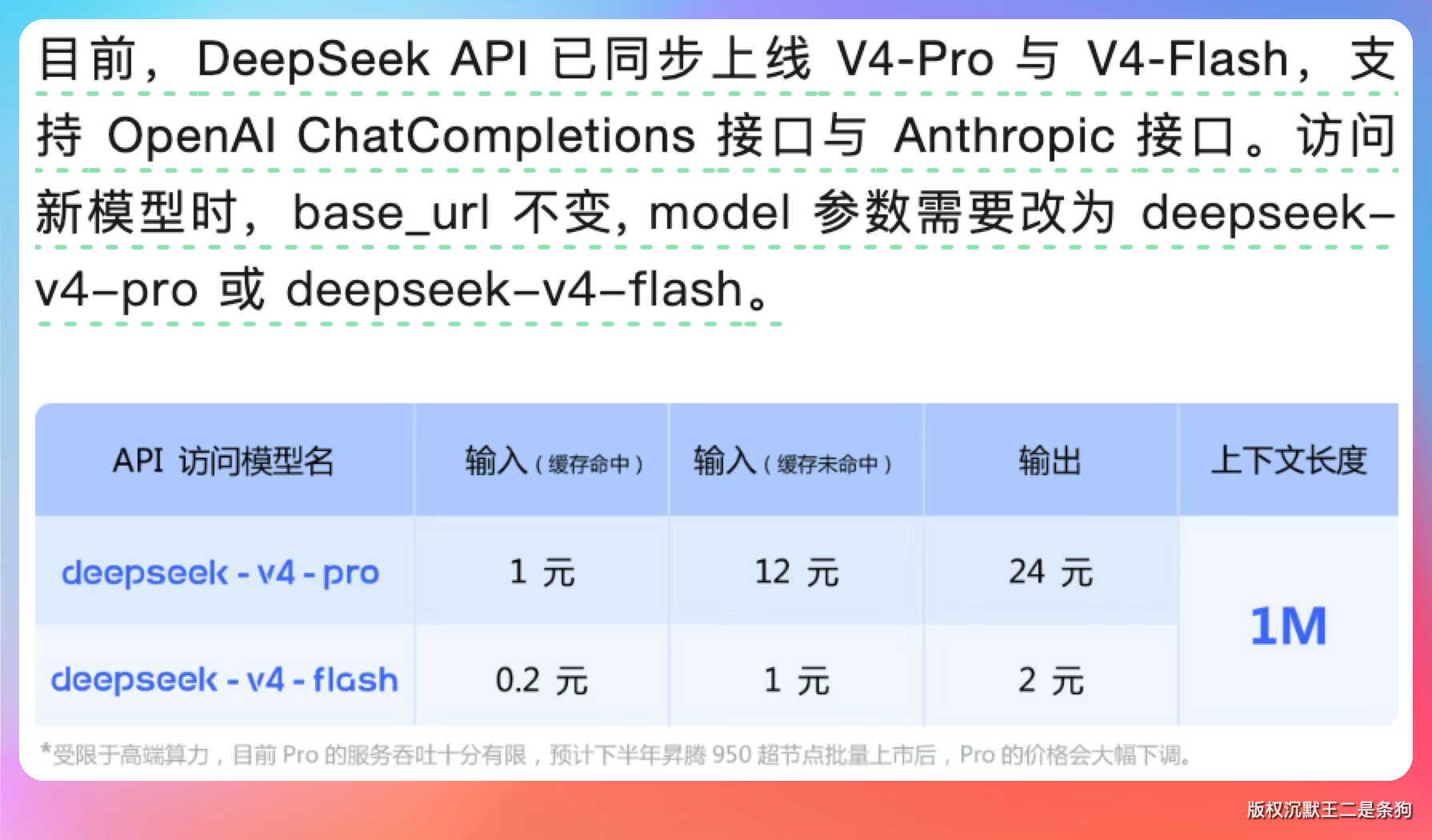
所以这一期我们来把 DeepSeek V4 接入到 PaiCLI。可以通过 /model deepseek 切到 DeepSeek V4,/model glm 切换到 GLM-5.1。
像 OpenClaw 那样。
01、DeepSeek V4 有哪些优化?
V4-Pro 在 Agentic Coding 评测里已经到了开源最佳水平,官方给的判断是“优于 Sonnet 4.5,交付质量接近 Opus 4.6 非思考模式”。
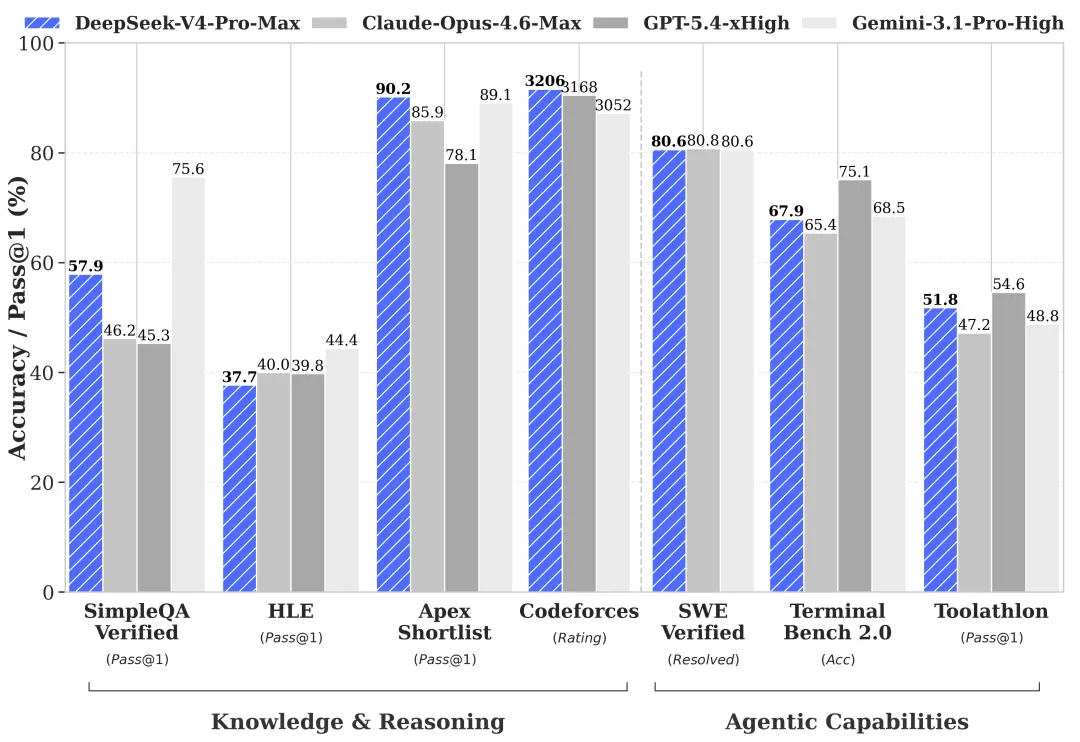
之前 DeepSeek V3.2 在每个新用户消息开始时会丢弃 thinking trace,等于模型每轮都重新想。V4 改成了在工具调用场景里完整保留全部 reasoning content,包括跨用户消息边界。
也就是说,V4 能在多轮调用之间维持累积的推理线索,连贯性好了一大截。
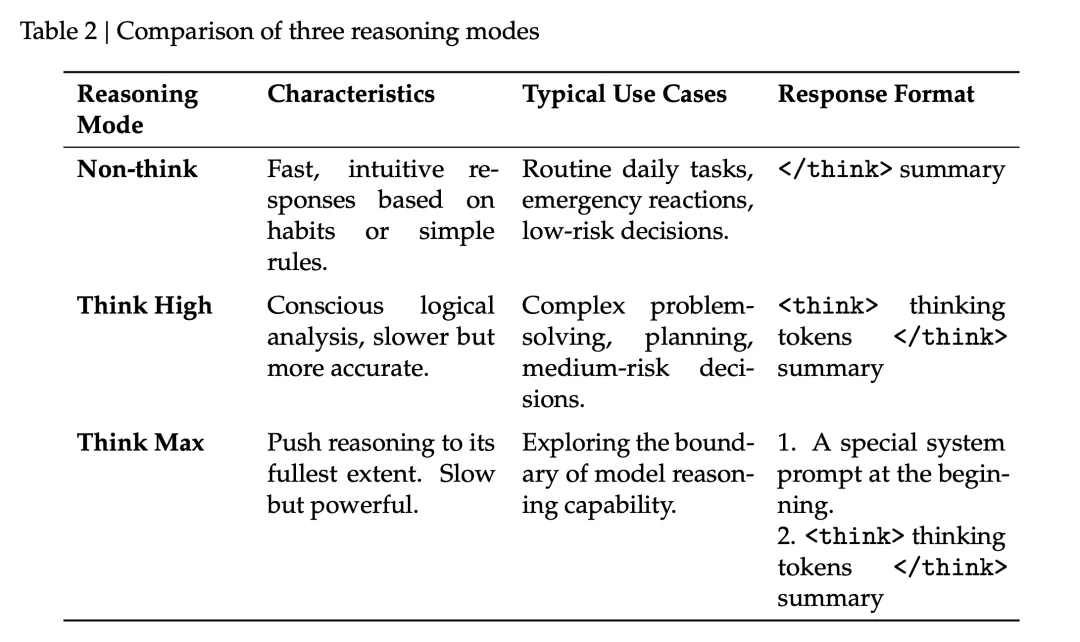
V4 支持 Non-think(直觉回应)、Think High(逻辑分析)、Think Max(推理极限)三个档位。简单工具调用走 Non-think,复杂的代码分析任务会切到 Think Max。
这意味着同一个模型可以在速度和深度之间灵活切换。
02、模型切换很简单
因为 GLM 和 DeepSeek 的 API 协议都是兼容 OpenAI 和 Anthropic 的。
意味着我们不需要给每个模型写一套完全独立的客户端。只需要提供 base_url、api_key 和 model 就行。

第一步,定义统一接口 LlmClient。
我们把GLMClient.Message、GLMClient.ToolCall、GLMClient.ChatResponse全部放到接口级别:
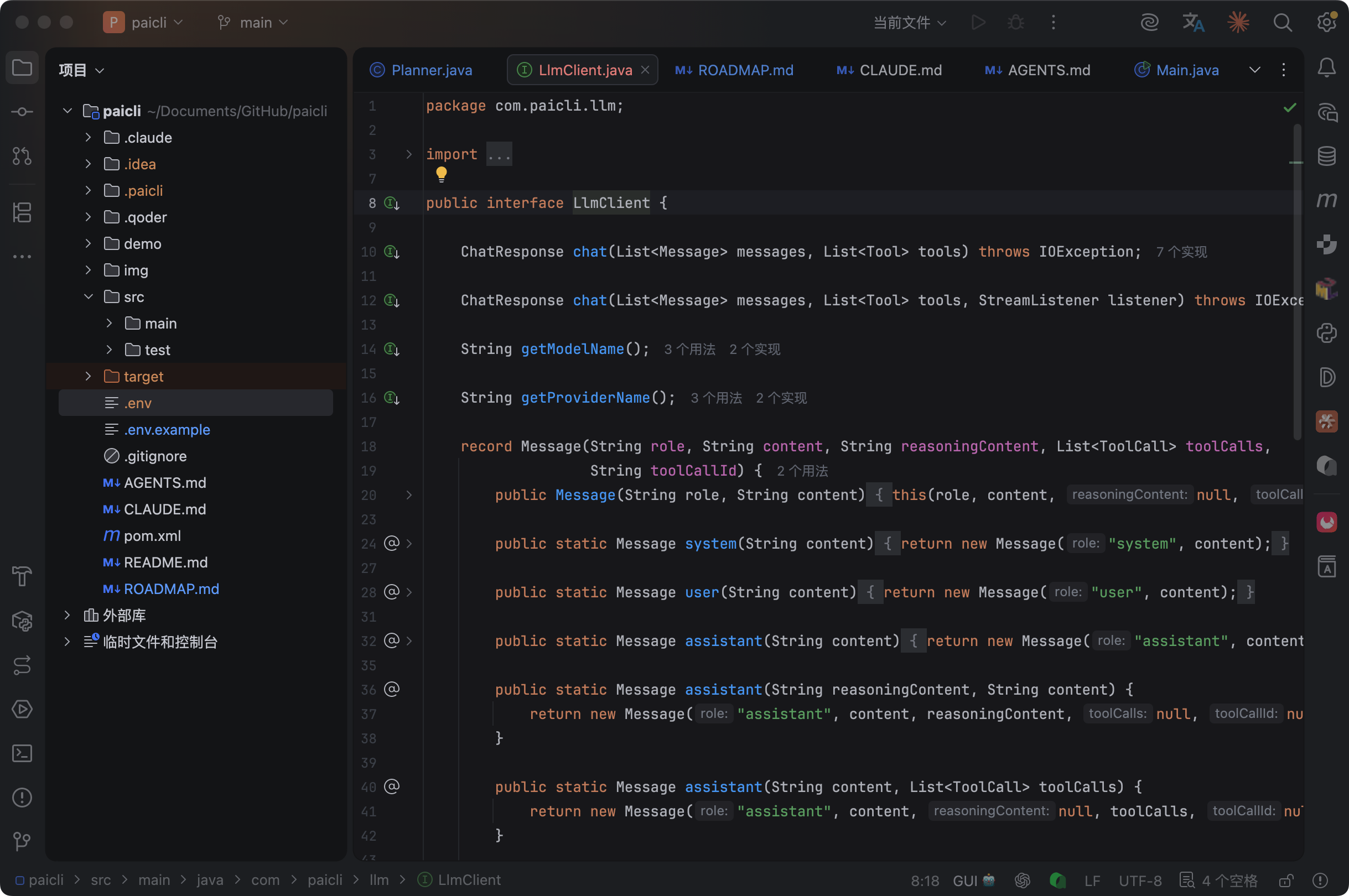
两个 chat 方法,一个带流式监听器,一个不带。
getModelName() 返回当前模型名(比如 glm-5.1),getProviderName() 返回供应商名(比如 deepseek)。
reasoningContent 是给支持思维链输出的模型准备的,GLM-5.1 和 DeepSeek V4 都支持。
// 改造前
public Agent(String apiKey) {
this.llmClient = new GLMClient(apiKey);
// ...
}
// 改造后
public Agent(LlmClient llmClient) {
this.llmClient = llmClient;
// ...
}
接口定义好了,下一步是实现。
所以我们用模板方法模式,把共享逻辑抽到基类 AbstractOpenAiCompatibleClient 里:
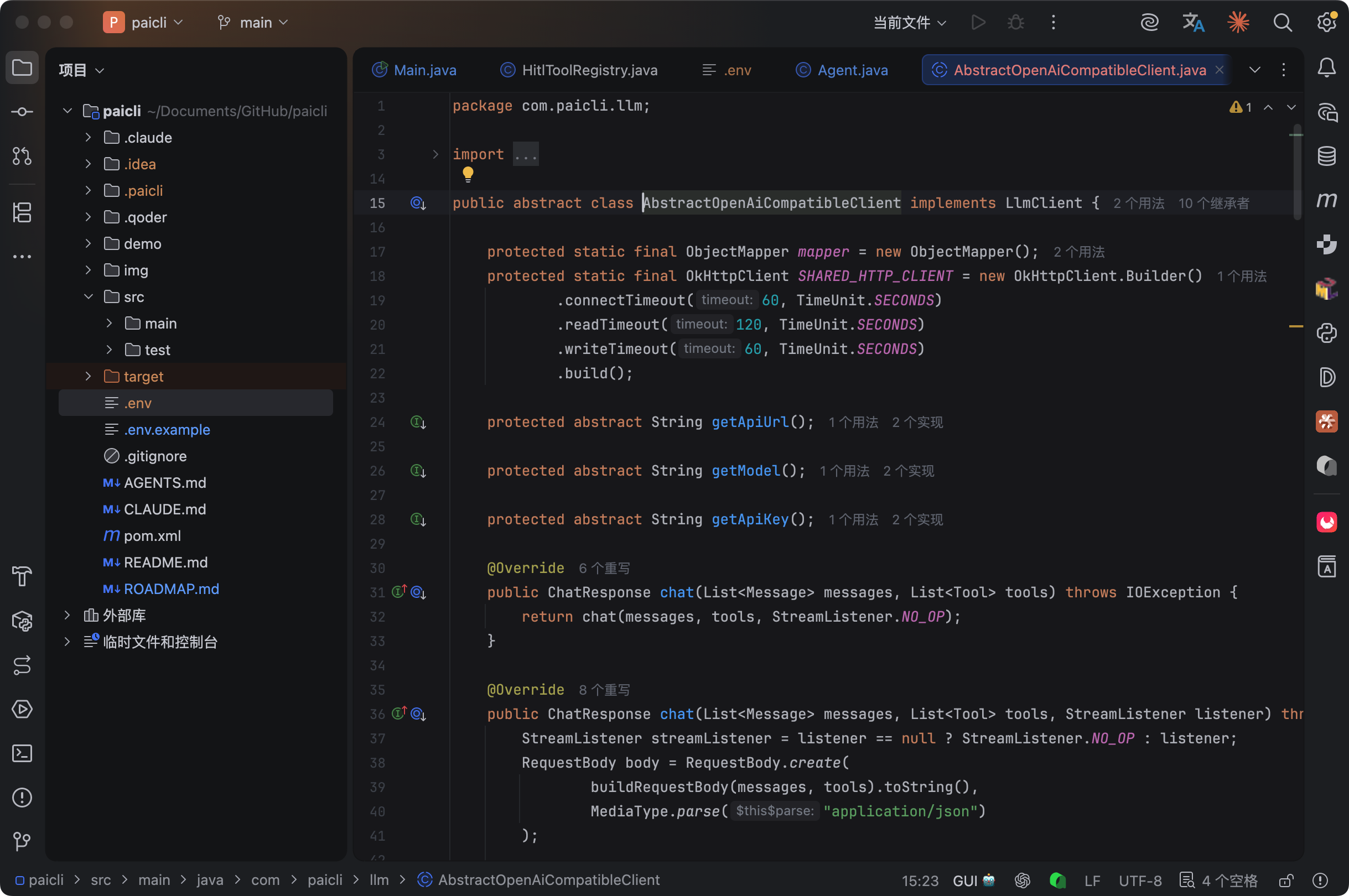
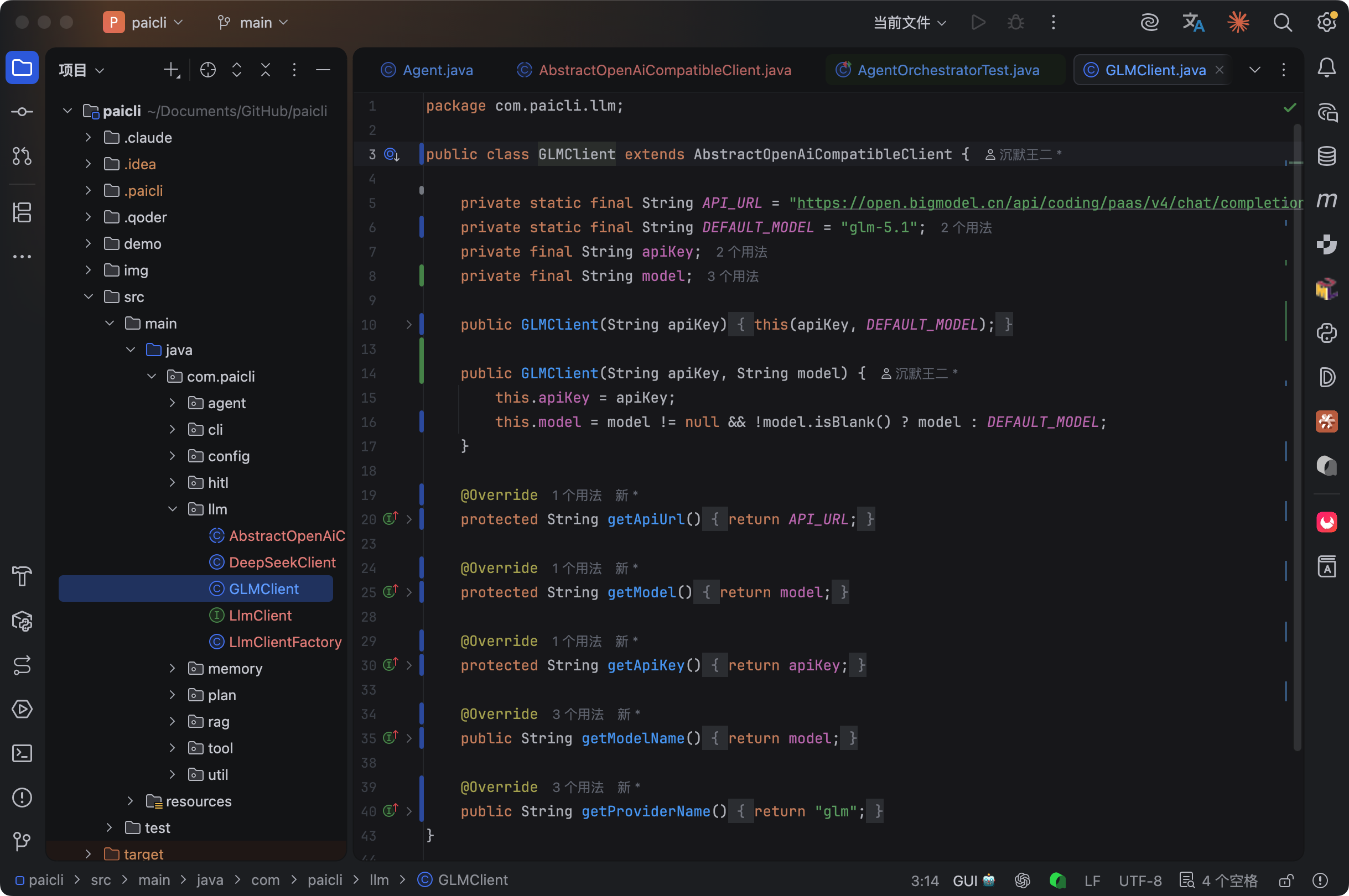
三个抽象方法——getApiUrl()、getModel()、getApiKey()。
基类负责组装 HTTP 请求、解析 SSE 等,子类只需要告诉基类“我的 API 地址是什么、我用哪个模型、我的密钥是什么”就可以了。
流式读取也非常简单。
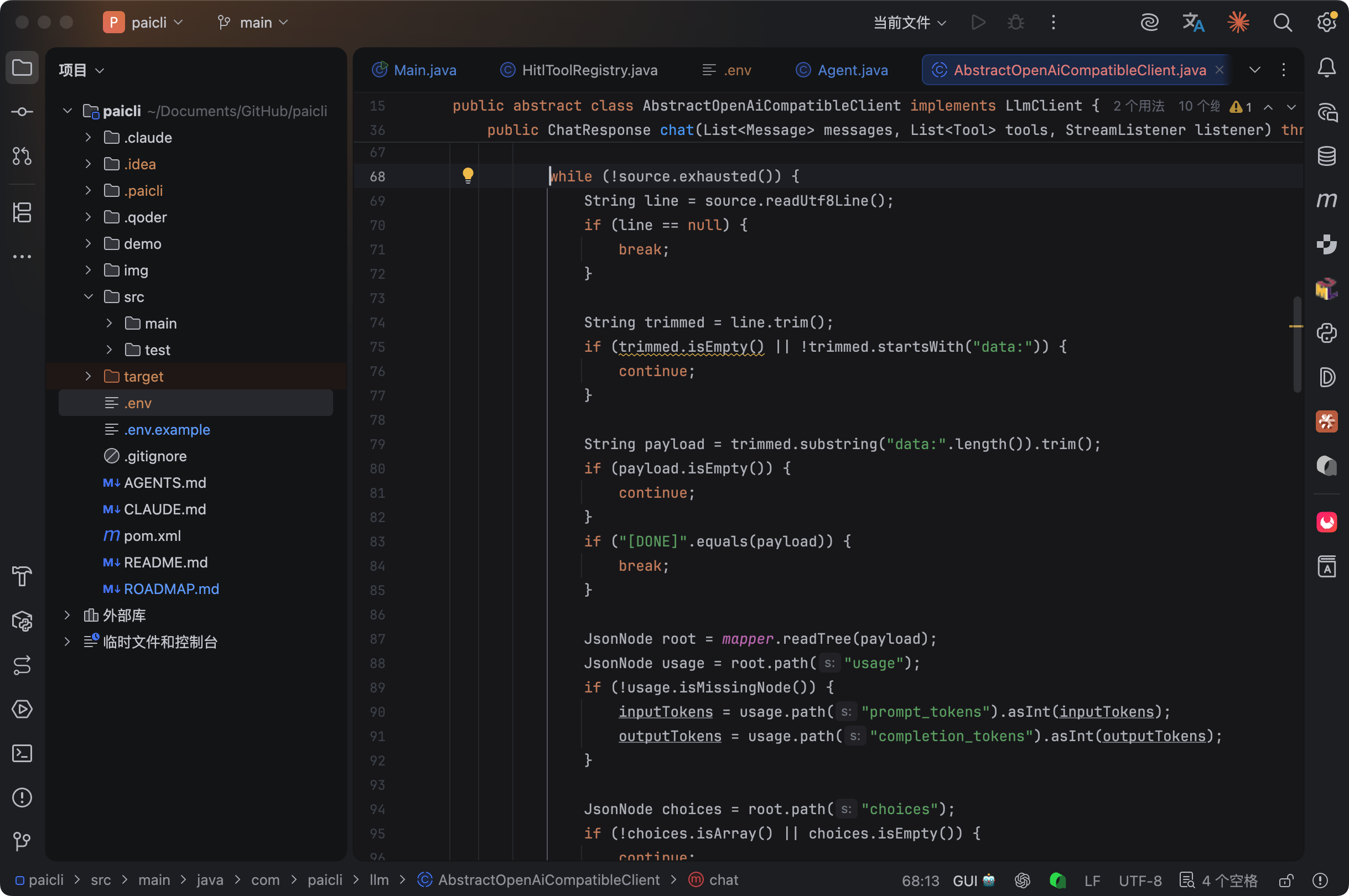
大模型返回 tool_calls 的时候不是一次性给完整 JSON 的,而是把参数拆成很多小的片段,一块一块返回。
比如参数 {"path": "/src/main/java"} 可能被拆成三个 delta:{"pa、th": "/src/m、ain/java"}。
ToolCallAccumulator 负责把这些碎片拼起来:
private static final class ToolCallAccumulator {
private String id;
private final StringBuilder name = new StringBuilder();
private final StringBuilder arguments = new StringBuilder();
}
每来一个 delta,就往对应的 StringBuilder 追加。全部接收完之后,用 buildToolCalls 方法把累加器转成最终的 ToolCall 列表。
HTTP 客户端是共享的:
protected static final OkHttpClient SHARED_HTTP_CLIENT = new OkHttpClient.Builder()
.connectTimeout(60, TimeUnit.SECONDS)
.readTimeout(120, TimeUnit.SECONDS)
.writeTimeout(60, TimeUnit.SECONDS)
.build();
用 static final 保证整个 JVM 里只有一个 OkHttpClient 实例。因为 OkHttp 内部维护了连接池和线程池,多个实例会导致资源浪费。而且切换模型也不需要重建 HTTP 客户端,切换的只是 URL 和密钥。
有了基类,GLMClient 和 DeepSeekClient 就变得非常简单:
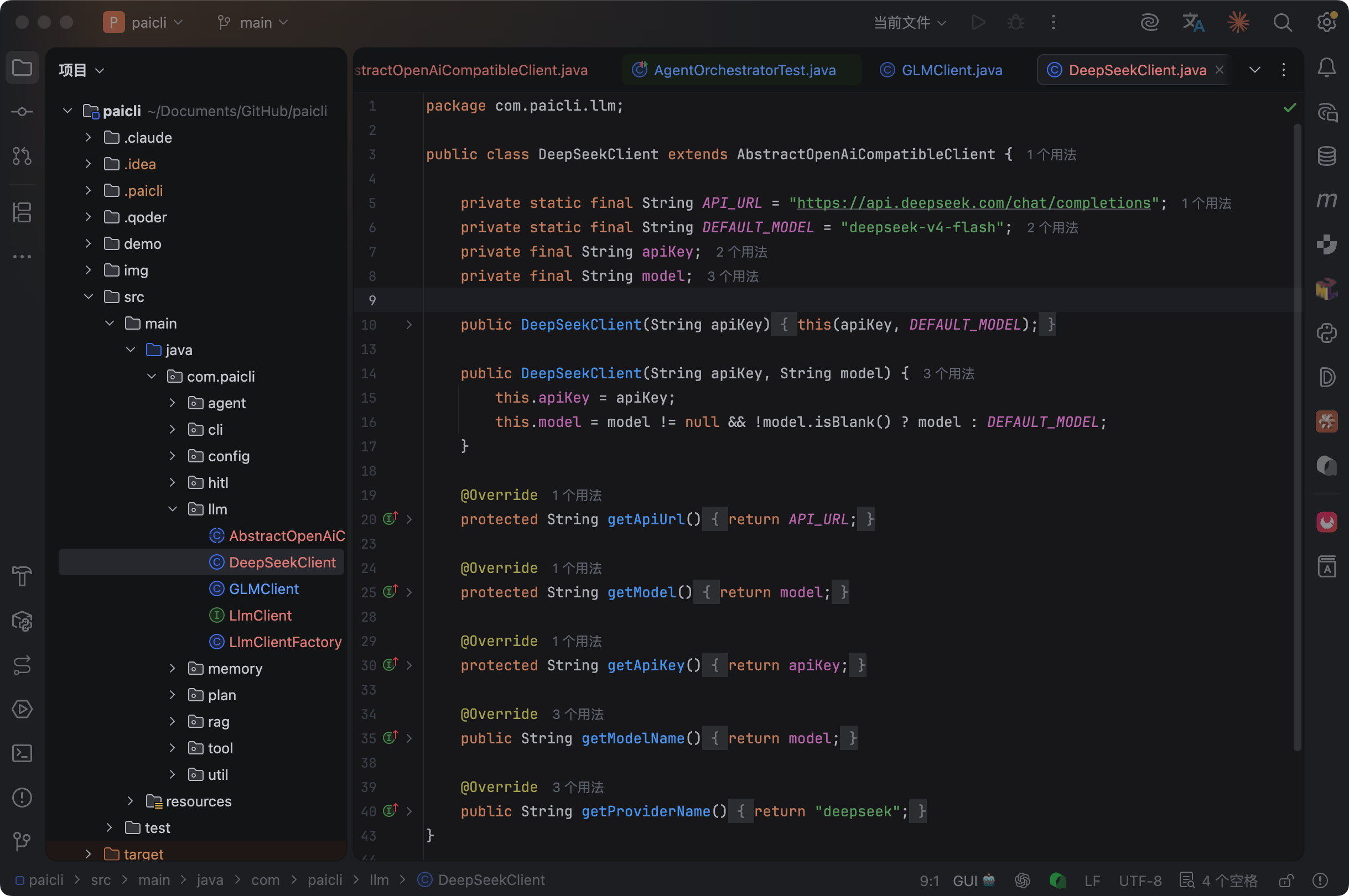
DeepSeekClient 几乎一模一样,就是 URL 和默认模型不同:
子类有了,谁来决定创建子类呢?
直接在 Main.java 里写一堆 if-else?
用工厂模式:
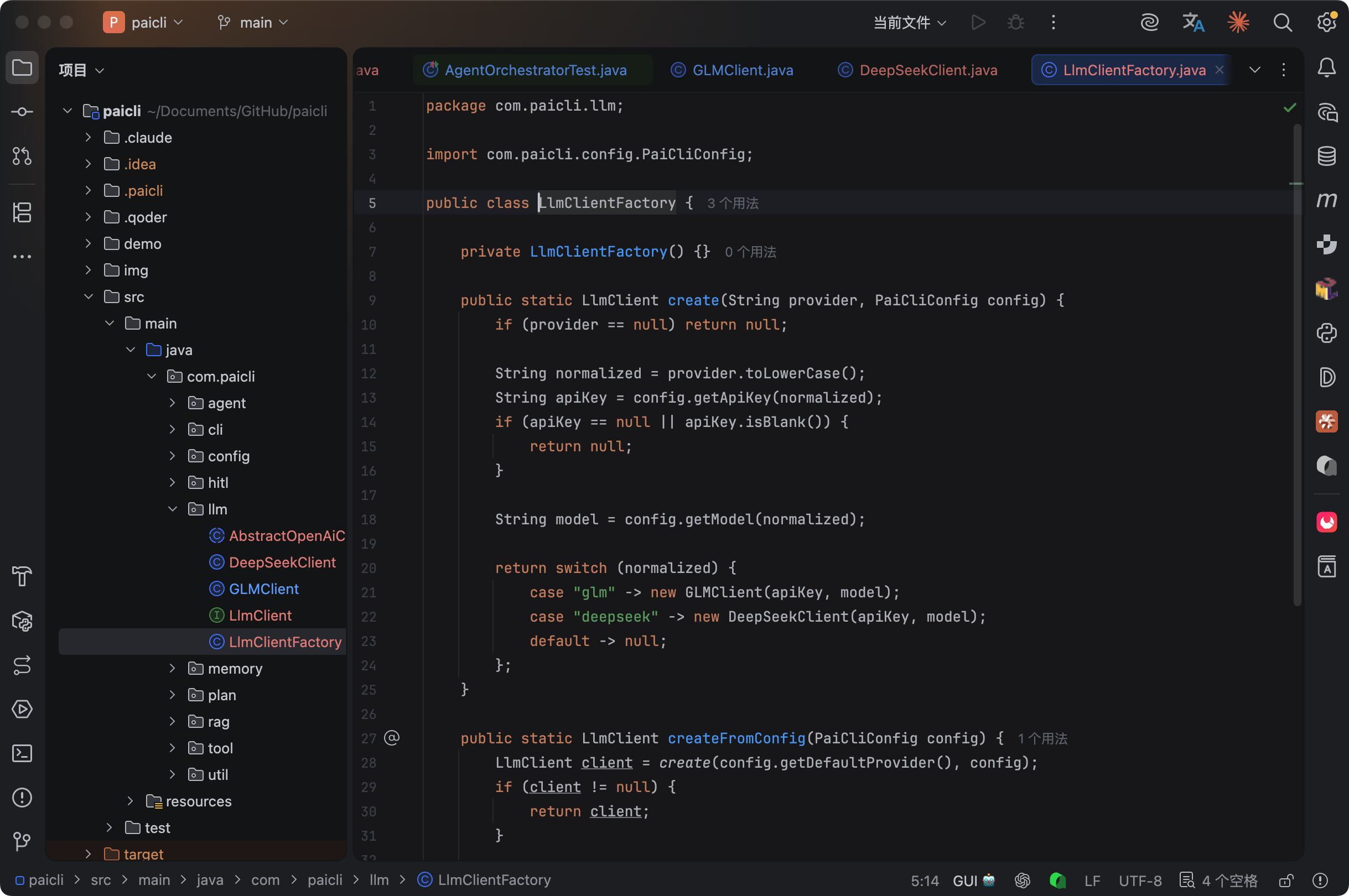
create 方法根据 provider 名称创建对应的客户端。createFromConfig 方法先尝试用户配置的默认 provider,如果没配置或者 API Key 缺失,就按优先级依次尝试。
03、/model 命令切换模型
配置和工厂都准备好了,最后一步是在 CLI 里加上运行时切换的能力。
CliCommandParser 新增了 SWITCH_MODEL 命令类型:
if (trimmed.equalsIgnoreCase("/model")) {
return new ParsedCommand(CommandType.SWITCH_MODEL, null);
}
if (trimmed.regionMatches(true, 0, "/model ", 0, 7)) {
return new ParsedCommand(CommandType.SWITCH_MODEL,
trimmed.substring(7).trim());
}
/model 不带参数显示当前模型信息,/model glm 或 /model deepseek 切换模型。
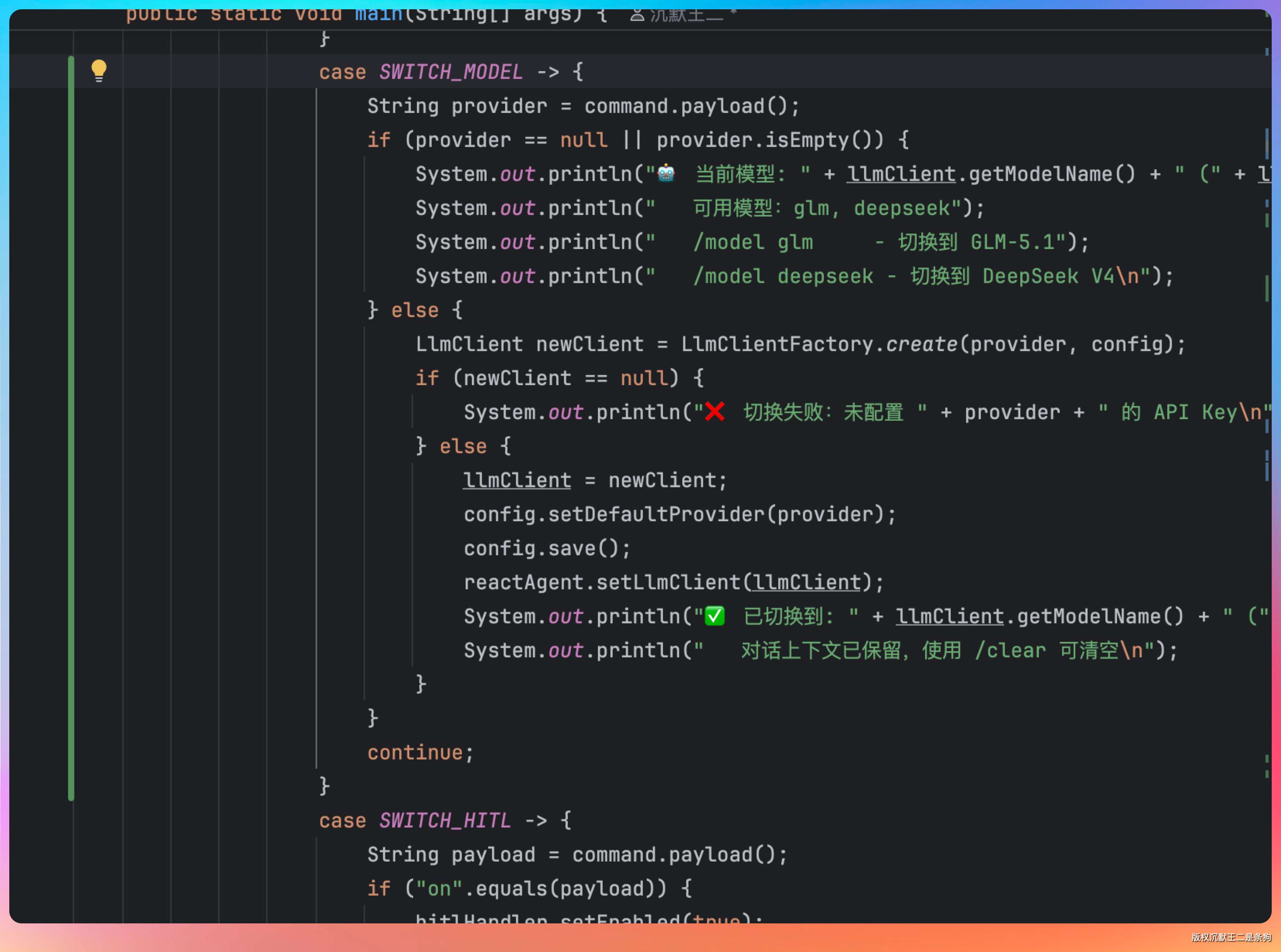
切换的时候做三件事:
第一,通过工厂创建新的 LlmClient。如果目标 provider 没有配置 API Key,直接报错,不会把当前可用的模型搞丢。
第二,更新默认 provider 并持久化到 config.json。下次启动 PaiCLI 的时候会自动用上次选择的模型。
第三,通过 setLlmClient() 热替换 Agent 内部的模型客户端。注意这里不是重建 Agent,而是原地替换——对话历史、工具注册表、记忆管理器全部保留。这样大家在用 GLM 跑到一半觉得不够好,可以直接切到 DeepSeek 继续,新模型能看到之前的对话上下文。想要干净的对比,手动 /clear 一下就行。
Agent 里的实现很简单,llmClient 字段从 final 改为可变,setLlmClient 同时更新 MemoryManager 内部的引用:
public void setLlmClient(LlmClient llmClient) {
this.llmClient = llmClient;
this.memoryManager.setLlmClient(llmClient);
}
用到的设计模式有三个:
策略模式:LlmClient 接口就是策略。Agent 不知道自己在用 GLM 还是 DeepSeek,它只依赖 LlmClient 接口。运行时通过 /model 命令切换策略实现。
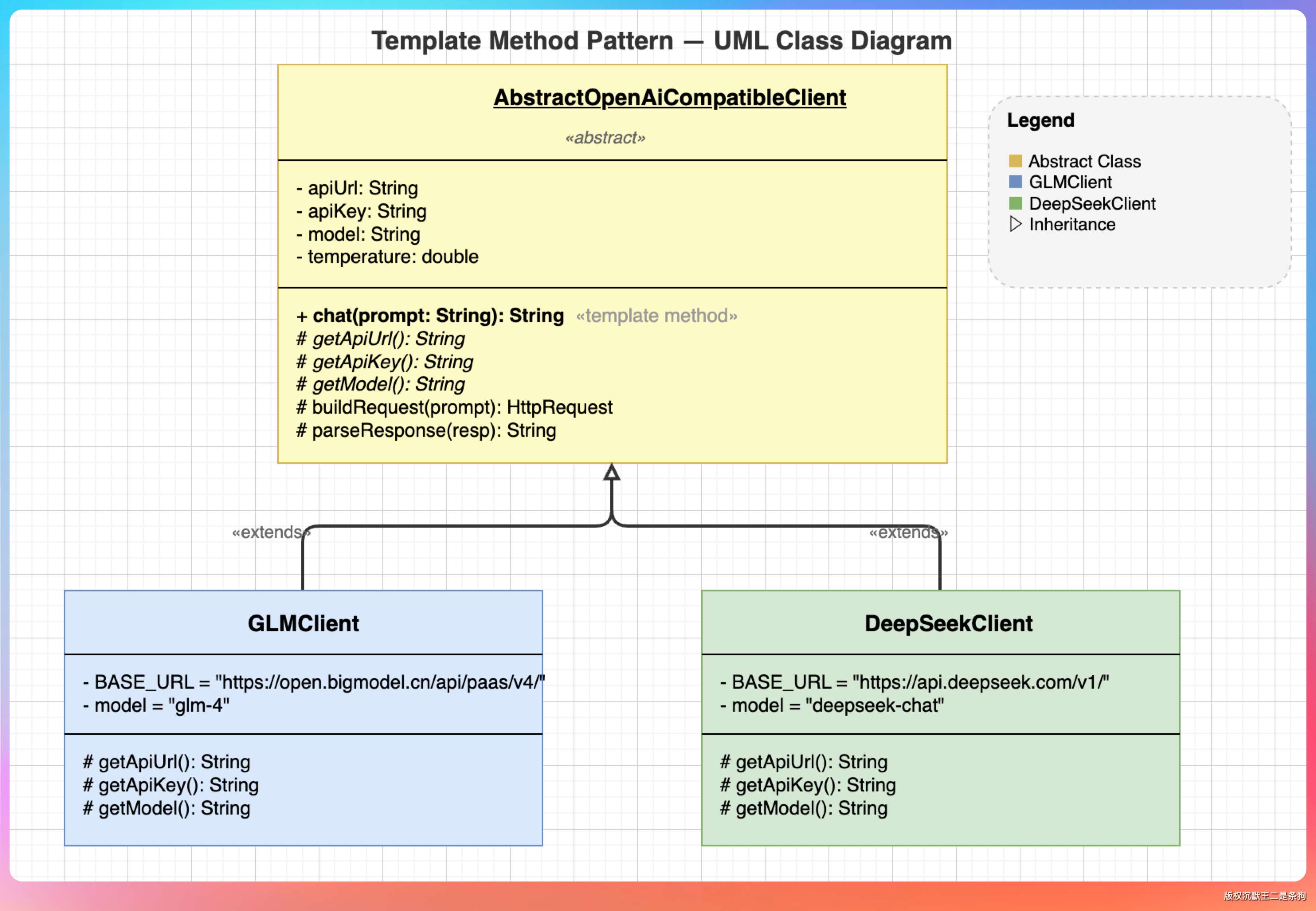
模板方法模式:AbstractOpenAiCompatibleClient 是模板。骨架逻辑(HTTP 请求、SSE 解析)在基类里写死,子类只需要填 getApiUrl()、getModel()、getApiKey() 三个方法。
工厂模式:LlmClientFactory 封装了客户端的创建逻辑。
策略模式管“面向谁编程”,模板方法管“公共逻辑怎么复用”,工厂模式管“对象怎么创建”。
04、保证两个模型是公平的
接了两个模型之后,第一个想法肯定是——让它们跑同一个任务比一比。
但这里有个容易踩的坑:如果两个模型收到的上下文不一样,比出来的结果就没意义。
第一,system prompt 完全一致。 两个模型拿到的系统提示词是同一份 SYSTEM_PROMPT,不随模型切换而变化。Memory 检索注入的上下文也走同一条路径。
private void updateSystemPromptWithMemory(String memoryContext) {
if (memoryContext == null || memoryContext.isEmpty()) {
conversationHistory.set(0, LlmClient.Message.system(SYSTEM_PROMPT));
} else {
String enrichedPrompt = SYSTEM_PROMPT + "\n" + memoryContext;
conversationHistory.set(0, LlmClient.Message.system(enrichedPrompt));
}
}
第二,对话历史默认保留,手动清空。 /model deepseek 切换模型的时候,PaiCLI 不会重建 Agent,而是通过 setLlmClient() 原地替换模型客户端,对话历史保留。想做干净的对比,切完模型后手动 /clear 清空对话历史就行。
reactAgent.setLlmClient(llmClient);
// 对话上下文已保留,使用 /clear 可清空
第三,工具定义一模一样。 toolRegistry.getToolDefinitions() 返回的工具列表不依赖模型,GLM 和 DeepSeek 拿到的工具描述、参数定义完全相同。两个模型面对的是同一套“工具箱”。
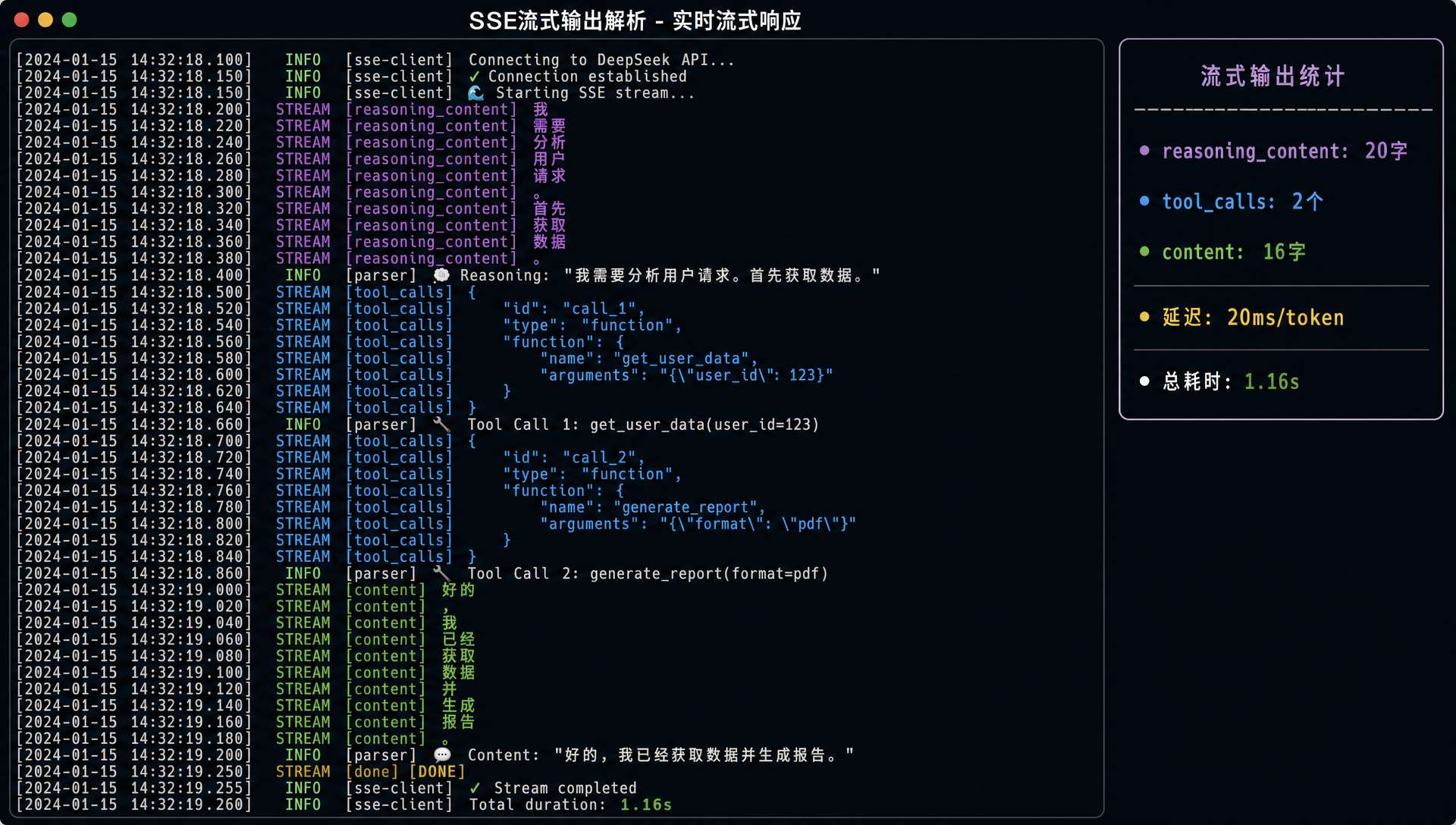
第四,reasoningContent 的处理差异。 这是唯一一个两个模型表现不同的地方。DeepSeek V4 在工具调用场景中会保留完整的 reasoning_content,而 GLM-5.1 的思维链行为不太一样。但 LlmClient.Message 的 reasoningContent 字段是统一的——两个模型的思考内容都走同一个字段存储和传递,不会因为模型不同就丢失或格式不同。
// 两个模型的响应都走同一个 record 结构
record ChatResponse(String role, String content, String reasoningContent,
List<ToolCall> toolCalls, int inputTokens, int outputTokens)
05、同一个任务,两个模型跑出来什么样
说了这么多,直接跑一个真实场景看看。
任务是让 PaiCLI 分析项目的 pom.xml,找出核心依赖并给出简要说明。这个任务刚好能覆盖工具调用(read_file)和文本生成两个环节,可以同时对比工具使用策略和回答质量。
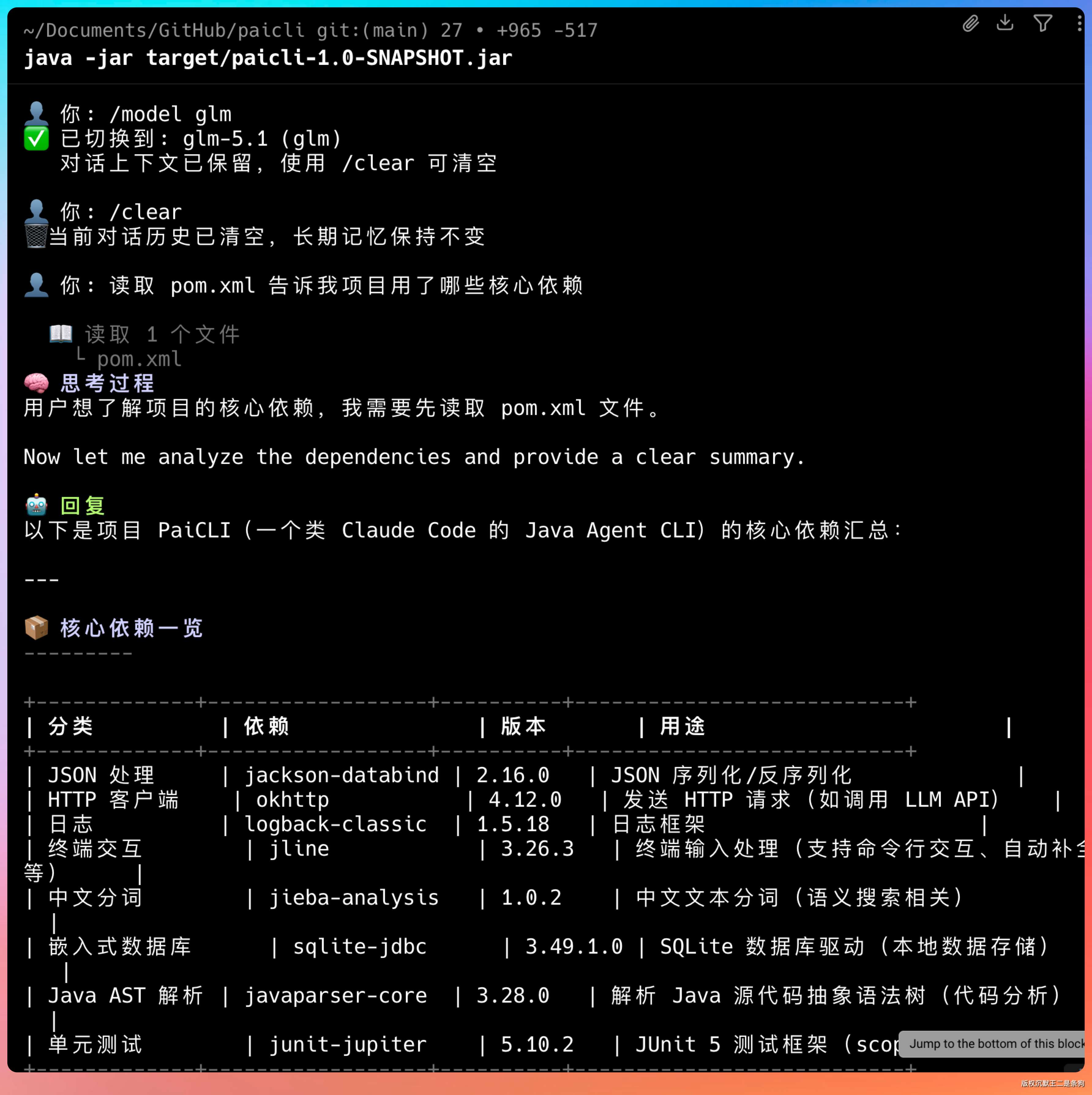
先用 GLM-5.1:
✅ 已加载模型: glm-5.1 (glm)
🔄 使用 ReAct 模式
👤 你: 读取 pom.xml 告诉我项目用了哪些核心依赖
切到 DeepSeek V4:
👤 你: /model deepseek
✅ 已切换到: deepseek-v4-flash (deepseek)
👤 你: 读取 pom.xml 告诉我项目用了哪些核心依赖
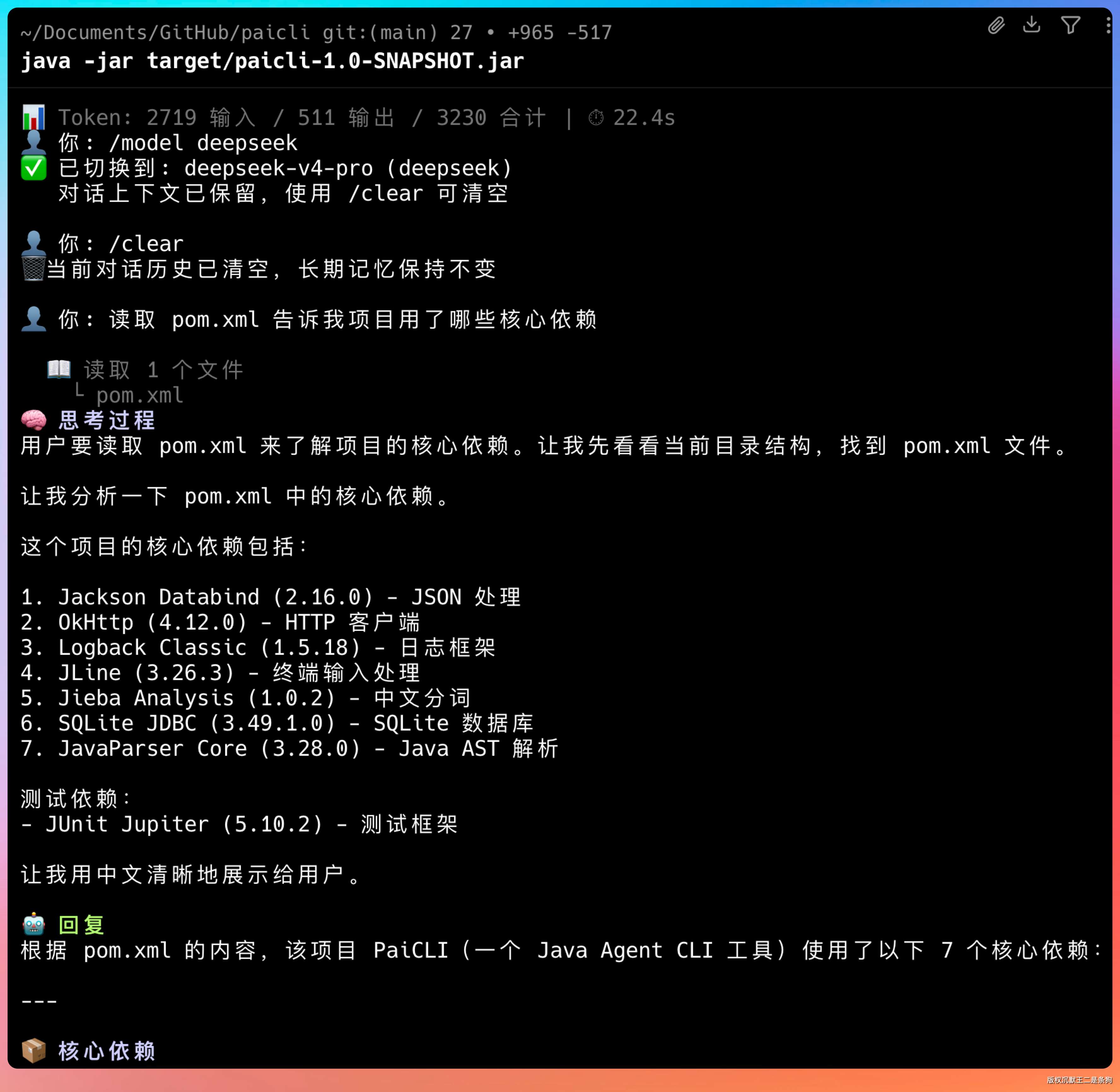
Token 消耗对比:
- GLM-5.1: 2719 输入 / 511 输出 / 3230 合计 | ⏱ 22.4s
- DeepSeek V4: 3028 输入 / 648 输出 / 3676 合计 | ⏱ 19.2s
06、拆一拆 DeepSeek V4 的技术报告
这块我是让 Claude Opus 4.6 帮我啃的 DeepSeek 官方技术报告,加上我自己的学习能力,有错误大家可以指出,共同学习下(装逼。
Hybrid Attention
V4 把上下文拉到原生 1M,核心靠的是一套混合注意力设计。
我们都知道标准 Transformer 的注意力计算量是 O(n²),100 万 token 硬算根本扛不住。V4 的解法很巧妙——既然全量关注做不到,那就换个思路。
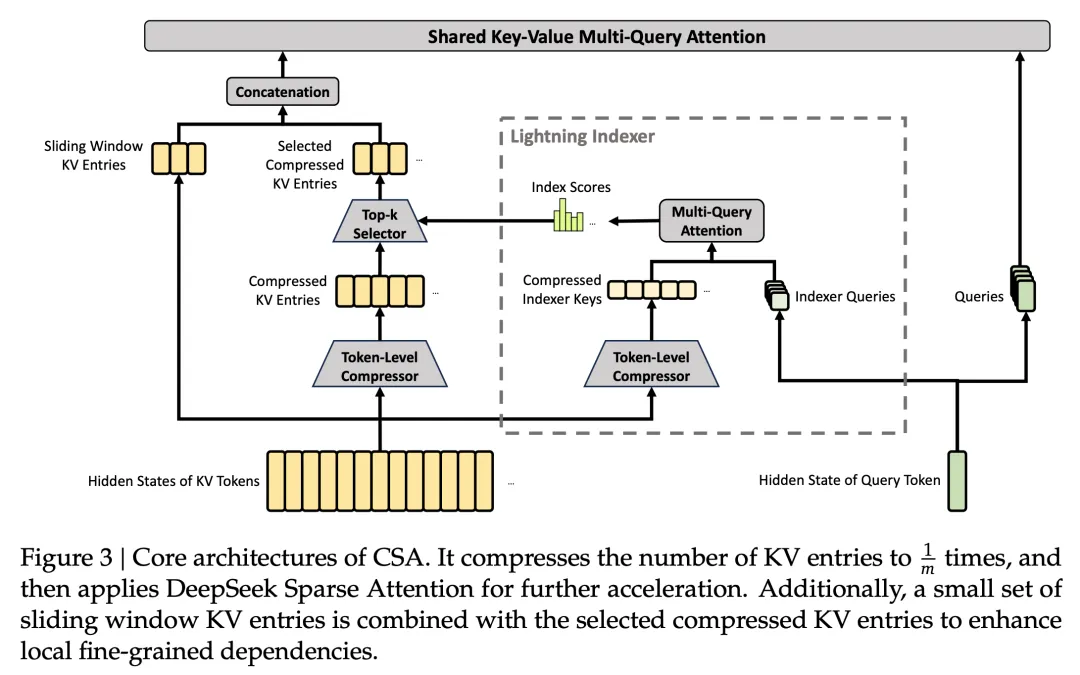
第一个是CSA(Compressed Sparse Attention)。它先把相邻的几个 token 压缩在一起(Flash 版本里每 4 个 token 压一块),然后每个 query 只挑最相关的几百个压缩块来看。打个比方,100 万 token 先压成 25 万块,再从中只挑 512 块做注意力计算,相当于只看了原文的千分之二,计算量断崖式下降。
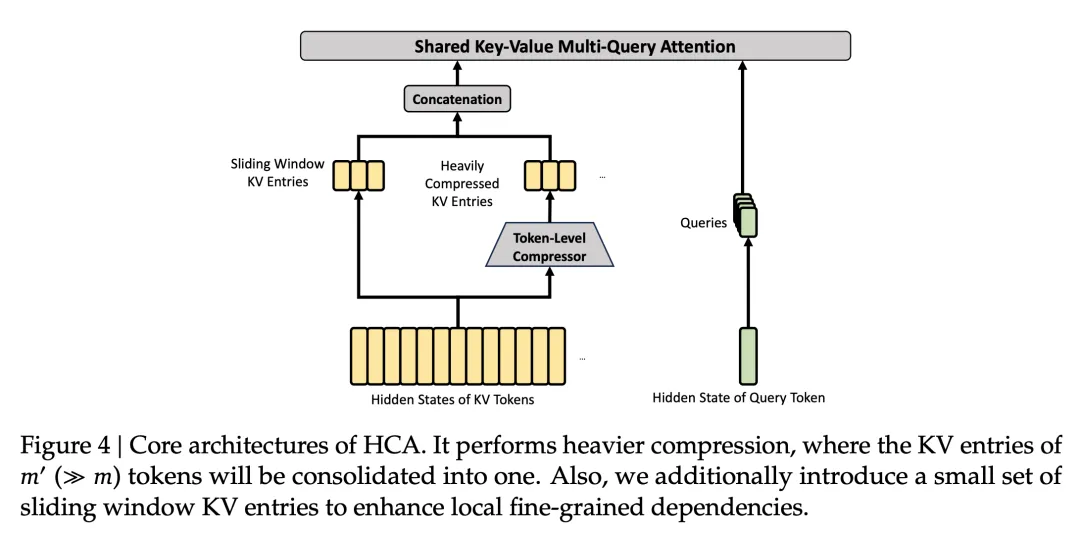
第二个是 HCA(Heavily Compressed Attention)。压缩粒度比 CSA 大得多(Flash 版本每 128 个 token 压一块),换来的好处是能用全量注意力——不挑不拣,每个 query 都看所有压缩块。好比用一个超低分辨率的摄像头做全景监控,细节模糊但不会漏掉大的趋势变化。
CSA 负责精确检索远处的信息,HCA 负责维持对全局的大致把握。另外每层还带了一个滑动窗口分支专门处理附近的 token,防止压缩把局部的前后文关系搞丢。
省了多少呢?
根据技术报告的数据,在 1M 长度下,V4-Pro 的推理算力开销降到了 V3.2 的不到三成,显存里的 KV 缓存更是不到十分之一。Flash 版本更狠,算力降到一成,缓存降到不足一成。
意味着什么?
多轮 ReAct 循环里,模型能记住的对话历史和工具返回结果多了好几倍。
三挡思考模式是怎么训出来的
前面提到 V4 支持 Non-think、Think High、Think Max 三档。
训练方法上 V4 做了一个大胆的范式切换:后训练阶段不再用之前 V3.2 那套混合强化学习,改成了一种叫 On-Policy Distillation(OPD) 的方法。
第一步,按领域(数学、代码、Agent、指令跟随等)各练一个专精模型,每个领域还分三种推理预算:快速直觉版给短窗口,中等思考版给 128K 窗口,深度推理版直接给 384K 窗口让模型想个够。
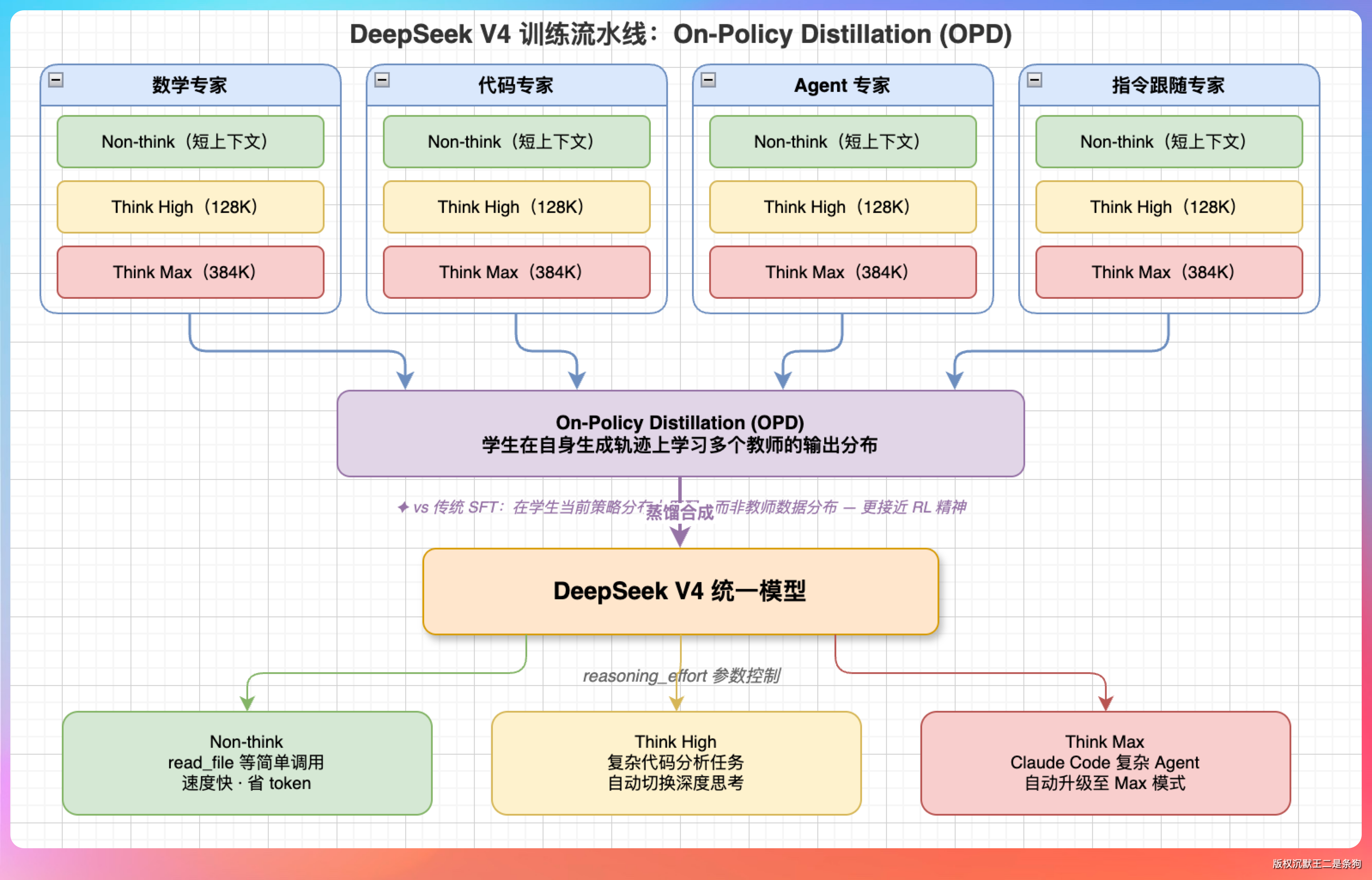
第二步才是关键。用 OPD 把所有领域的专精模型合体到一个统一的学生模型里。和传统蒸馏不同的是,学生不是在老师的数据上学,而是一边自己生成内容、一边向多个老师的输出分布对齐。本质上更接近一种在线策略优化。
简单的 read_file 调用走 Non-think 就够了,速度快、省 token。遇到复杂的代码分析任务,模型会自动加深度思考。API 层面通过 reasoning_effort 参数控制,对 Claude Code 这类复杂 Agent 请求还会自动升到 Max。
基础设施这次份量很足
V4 的技术报告给基础设施单独写了一整章,这在大模型报告里挺少见的,说明 DeepSeek 这次在工程侧下了很大的功夫。

挑几个我觉得有意思的聊聊:
推理加速内核 MegaMoE。 MoE 架构最头疼的就是专家间的通信开销,DeepSeek 在自家 DeepGEMM 基础上做了一个大粒度融合内核,把 dispatch、计算、combine 合成一步走。实测下来日常推理提速五到七成,强化学习阶段那种小批量长尾请求甚至能快一倍。而且这个内核同时适配了 N 卡和华为昇腾。
可复现的计算。 报告里花了不少篇幅讲确定性:同一批数据换个排列顺序、或者同样的输入跑两遍,结果都必须比特级一致。从预训练到后训练到推理,三个阶段的数值完全对齐。这事听起来简单,实际在分布式 GPU 上做到很费工夫,但对排查训练 bug 和保证模型一致性非常关键。
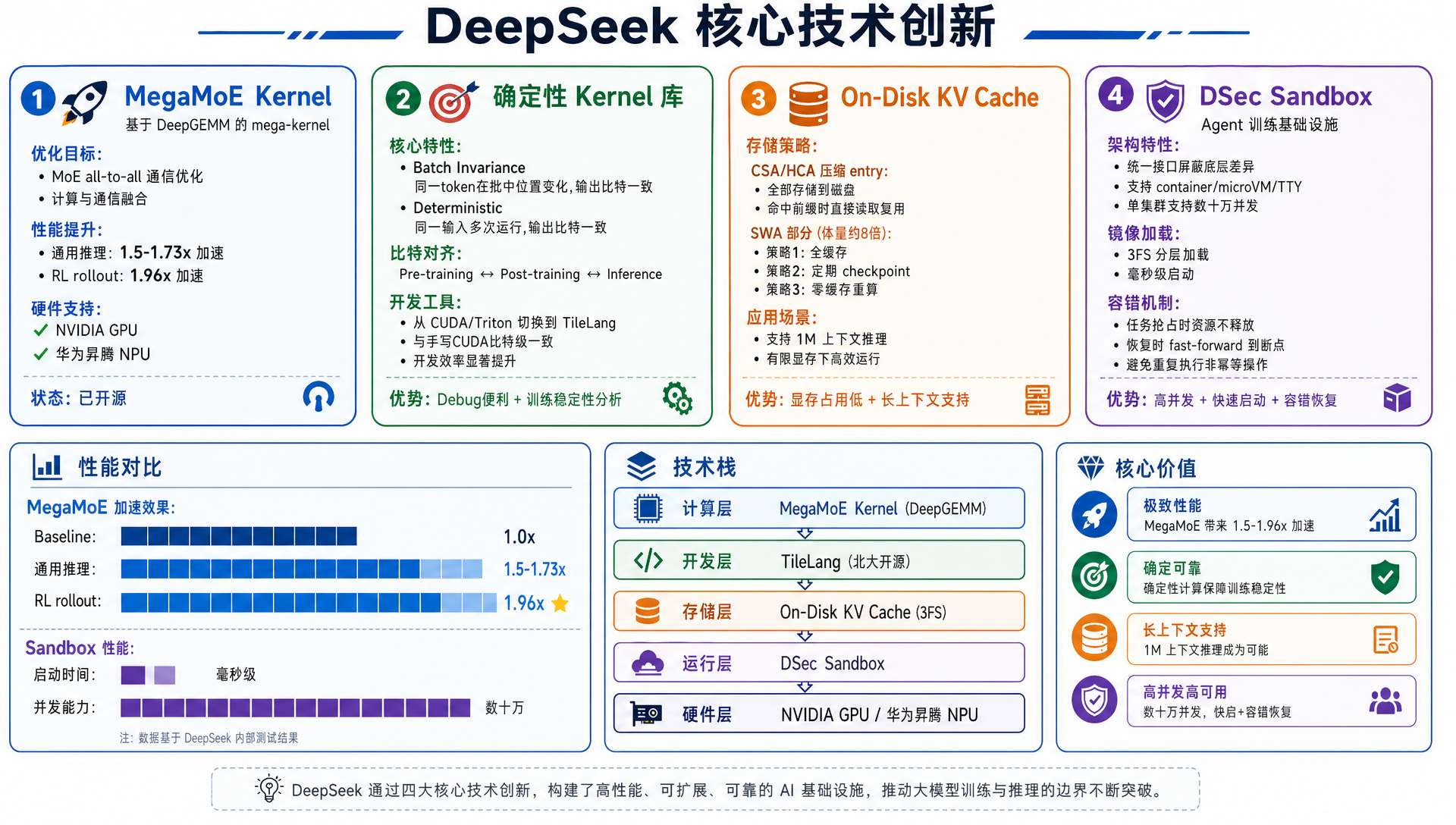
KV 缓存落盘。 既然前面两种注意力已经把 KV 压得很小了,那干脆把压缩后的缓存直接存磁盘。下次请求如果命中了相同的前缀,直接从磁盘读,省掉重复计算。滑动窗口那部分因为体量大得多,给了全缓存、定期打快照、不存直接重算三种可选方案。这套设计让 1M 上下文在有限显存下也能跑得动。
Agent 训练沙箱 DSec。 这个最让我意外。DeepSeek 为了训练 Agent 搭了一套专用的沙箱系统,一个集群能同时跑几十万个隔离环境。最妙的是训练中断恢复的设计——任务被抢占时沙箱不主动销毁,恢复后直接从断点继续,不会重复执行那些不能幂等的操作(比如已经写入数据库的命令)。
PaiCLI 如何写到简历上?
项目名称:PaiCLI — Java Agent CLI
项目简介:基于 ReAct 范式从零实现的 Java Agent 命令行工具,集成 Plan-and-Execute、Memory、RAG、Multi-Agent、HITL 人工审批、异步并行和多模型运行时切换,完整覆盖 AI Agent 核心技术栈。
核心职责:
- 基于策略模式设计
LlmClient统一接口,将GLMClient的内部类型(Message、ToolCall、ChatResponse)提升为接口级公共类型,实现 Agent 层与模型实现层的完全解耦 - 使用模板方法模式实现
AbstractOpenAiCompatibleClient基类,共享 SSE 流式解析、请求构建和工具调用增量合并逻辑,新增模型适配只需 20 行子类代码 - 通过工厂模式
LlmClientFactory封装客户端创建,结合三层配置回退(config.json → 环境变量 → .env 文件),支持运行时/model命令一键切换 GLM-5.1 和 DeepSeek V4 - 在 Agent 执行循环中集成 Token 消耗统计,累计每轮 LLM 调用的输入/输出 token 数和耗时,方便不同模型间的成本和性能对比

1 条评论
回复