


雪崩之下,没有一片雪花是无辜的 ~~
大家好,我是楼仔!
今天写的这个主题内容,其实非常基础,但是作为高并发非常重要的几个场景,绝对绕不开,估计大家面试时,也经常会遇到。
这个主题的文章,网上非常多,本来想直接转载一篇,但是感觉没有合适的,要么文章不够精炼,要么就是精简过头,所以还是自己写一篇吧。
内容虽然基础,但我还是秉承以往的写作风格,参考众多优秀的博客后,打算写一篇能通俗易懂,又不失全面的文章。
前言
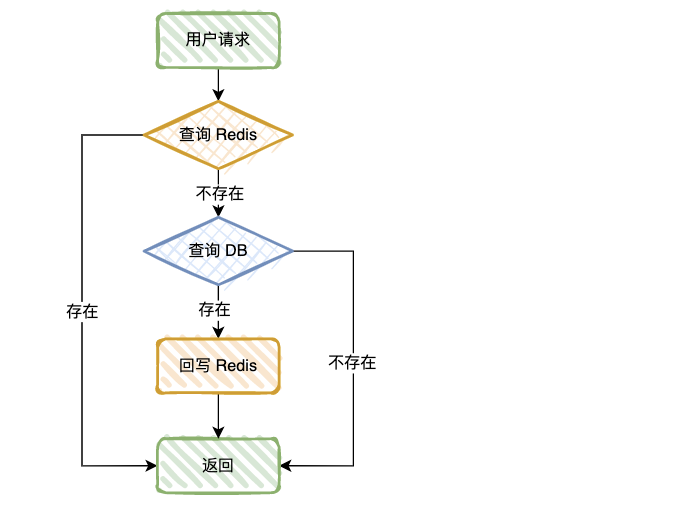
我们先看一下正常情况的查询过程:
- 先查询 Redis,如果查询成功,直接返回,查询不存在,去查询 DB;
- 如果 DB 查询成功,数据回写 Redis,查询不存在,直接返回。
缓存穿透
定义:当查询数据库和缓存都无数据时,因为数据库查询无数据,出于容错考虑,不会将结果保存到缓存中,因此每次请求都会去查询数据库,这种情况就叫做缓存穿透。
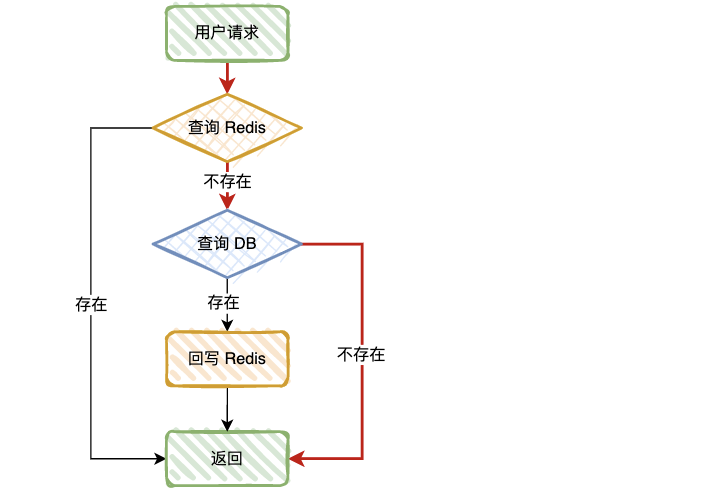
红色的线条,就是缓存穿透的场景,当查询的 Key 在缓存和 DB 中都不存在时,就会出现这种情况。
可以想象一下,比如有个接口需要查询商品信息,如果有恶意用户模拟不存在的商品 ID 发起请求,瞬间并发量很高,估计你的 DB 会直接挂掉。
可能大家第一反应就是对入参进行正则...
4人已点赞
回复