


前面我们讲了,为了提升 Java 运行时的性能,JVM 引入了 JIT,也就是即时编译(Just In Time)技术。
Java 代码首先被编译为字节码,JVM 在运行时通过解释器执行字节码。当某部分的代码被频繁执行时,JIT 会将这些热点代码编译为机器码,以此来提高程序的执行效率。
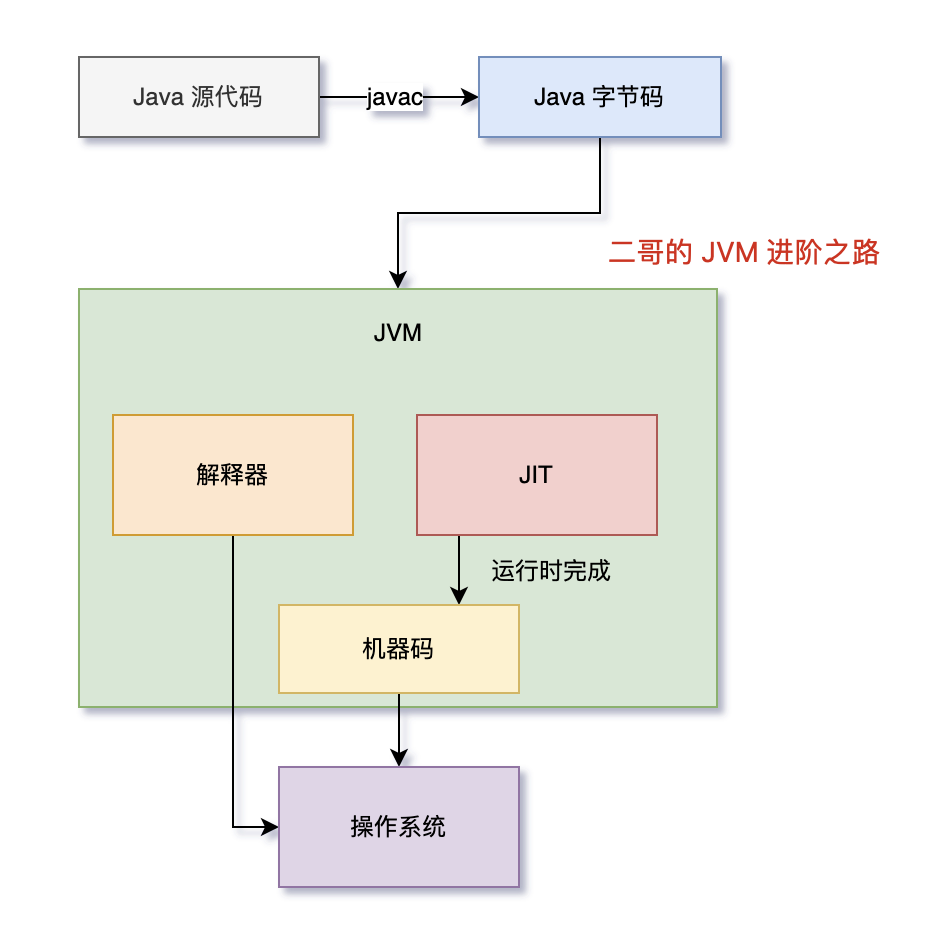
那为什么 JIT 就能提高程序的执行效率呢,解释器不也是将字节码翻译为机器码交给操作系统执行吗?
解释器在执行程序时,对于每一条字节码指令,都需要进行一次解释过程,然后执行相应的机器指令。这个过程在每次执行时都会重复进行,因为解释器不会记住之前的解释结果。
与此相对,JIT 会将频繁执行的字节码编译成机器码。这个过程只发生一次。一旦字节码被编译成机器码,之后每次执行这部分代码时,直接执行对应的机器码,无需再次解释。
除此之外,JIT 生成的机器码更接近底层,能够更有效地利用 CPU 和内存等资源,同时,JIT 能够在运行时根据实际情况对代码进行优化(如内联、循环展开、分支预测优化等),这些优化是在机器码级别上进行的,可以显著提升执行效率。
换句话说,解释器是一个循规蹈矩的人,每次都要按照规则来执行,而 JIT 是一个“偷奸耍滑”的人,他会根据实际情况来做出最优的选择。
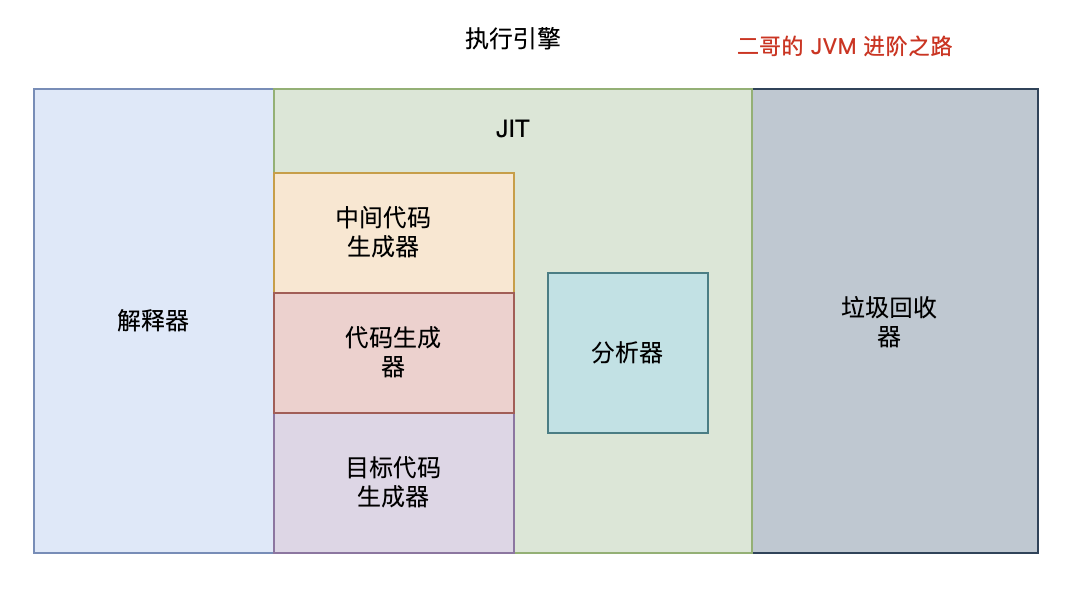
好,我们再来梳理一下。
Java 的执行过程分为两步,第一步由 javac 将源码编译成字节码,在这个过程中会进行词法分析、语法分析、语义分析。
第二步,解释器会逐行解释字节码并执行,在解释执行的过程中,JVM 会对程序运行时的信息进行收集,在这些信息的基础上,JIT 会逐渐发挥作用,它会把字节码编译成机器码,但不是所有的代码...
企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

1人已点赞
回复