


大家好,我是二哥呀。
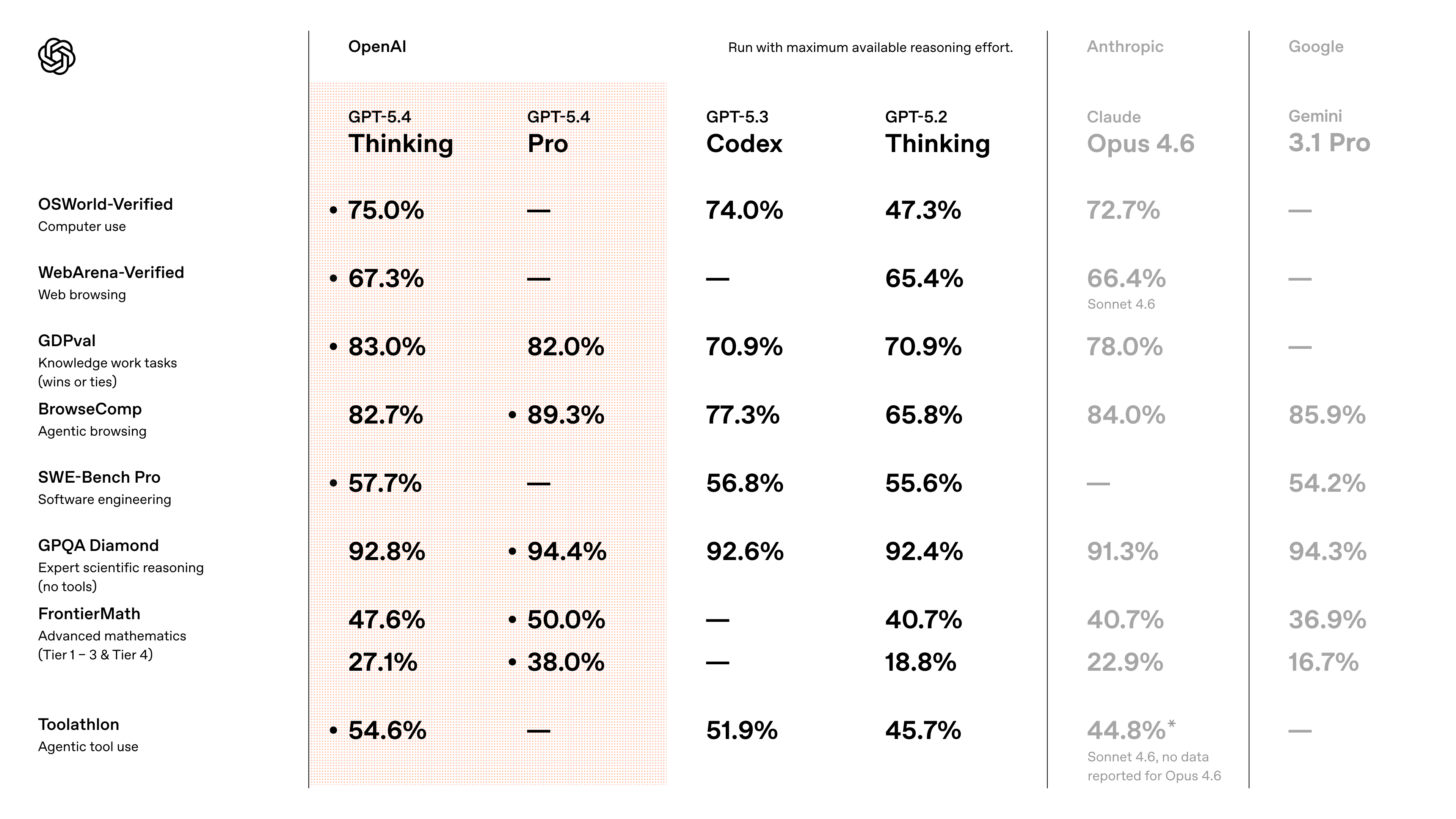
GPT-5.3-Codex 还没捂热,OpenAI 又正式发布了 GPT-5.4。
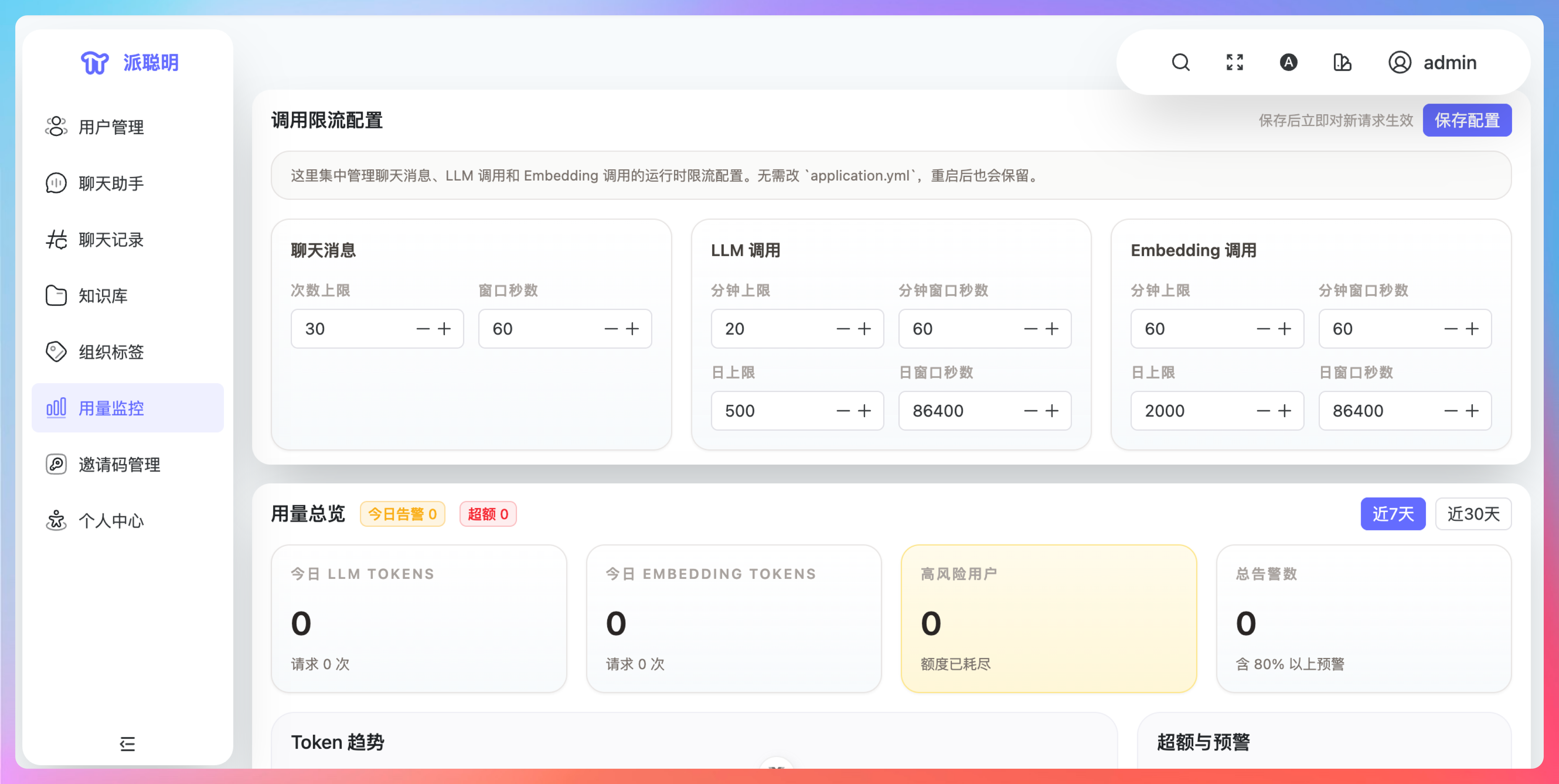
这不是一次普通的模型更新,而是被 OpenAI 定位为 AI 数字员工的首个大一统模型。它整合了推理、编程及百万级上下文能力,原生支持电脑操作,Agent 任务成本直接降低 47%。
基准测试成绩相当亮眼:SWE-Bench Pro 拿下 57.7%,MMMU-Pro 达到 81.2%,BrowseComp 更是飙到 82.7%。在内部投行建模测试中,GPT-5.4 的得分从 GPT-5 的 43.4% 直接干到了 87.3%。
X 上的开发者们已经炸开锅了。
有人说 GPT-5.4 等于GPT-5.3 Codex 的代码能力 + 比 GPT-5.2 还强的世界知识 + 更强的 Agent 执行,是真正意义上的六边形战士。也有人吐槽定价太贵,一句Hi就能烧掉 80 美元。
我第一时间把 Codex 的底层模型切到了 GPT-5.4。配合 Chrome DevTools MCP 升级了一波派聪明RAG项目,效果真的有点夸张。
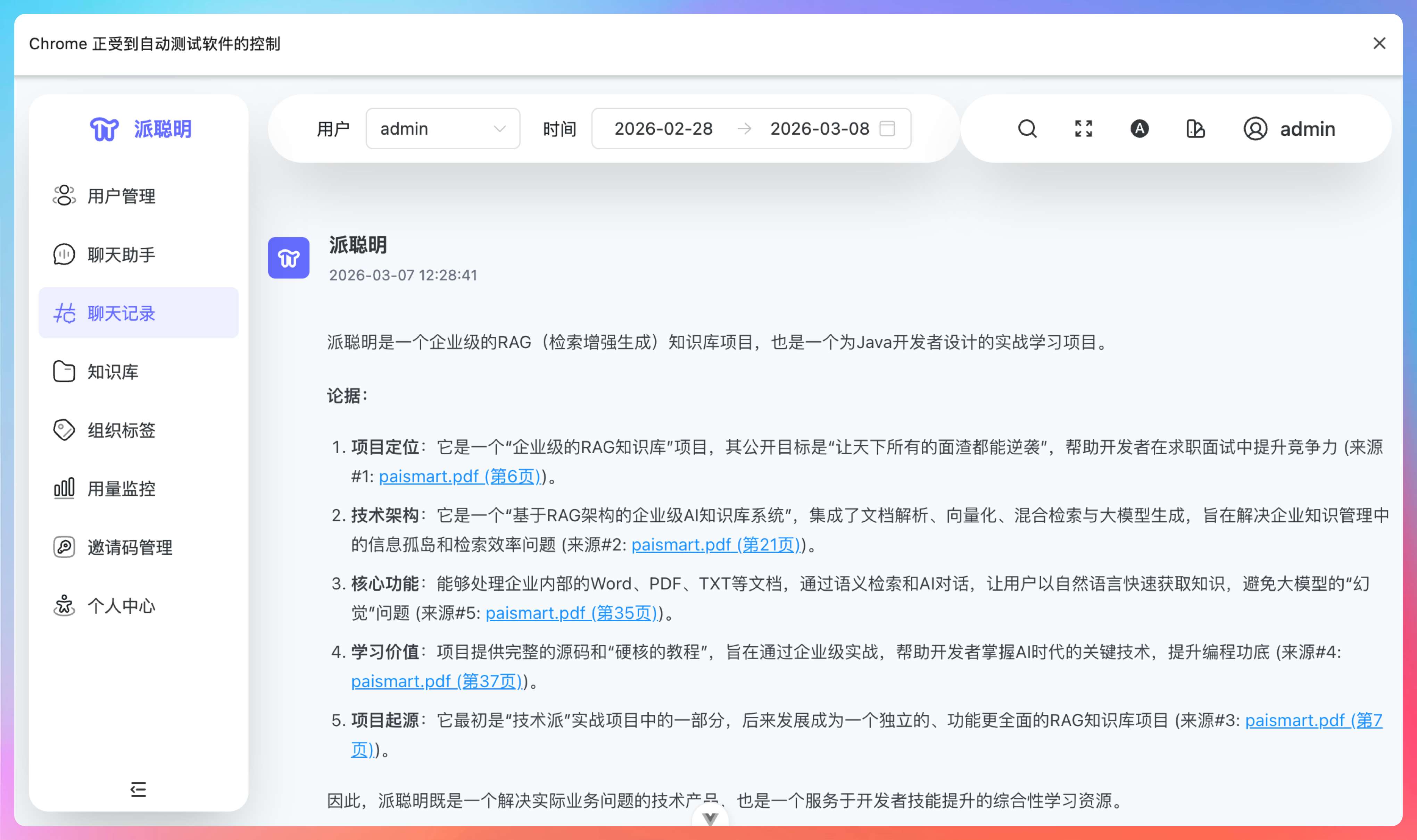
有些 Bug,截图、文字描述都不好使。索性让 Codex 自己控制浏览器去复现 Bug,这一招基本上所有难缠的 Bug 都能定位到。
我今天早上就遇到一个典型案例。在搞派聪明 RAG 知识库的 PDF 预览功能时,一个 Bug 把我折腾得够呛,最后靠 GPT-5.4 操控浏览器很快就搞定了。
今天这篇,我把完整过程记录下来,包括翻车现场和最终解决,供大家参考。
先交代背景。
我在做派聪明 RAG 知识库的 PDF 预览功能。功能是:用户在聊天窗口点击引用链接,能直接预览 PDF 中对应位置的原文。
但问题来了:PDF 预览的时候,内容死活不出来。
诡异的是,拖拽浏览器页面宽度的时候,内容突然又冒出来了。
冒出来后再拖拽,有时候还会出现【PDF 页面渲染失败,请稍后重试】的错误。
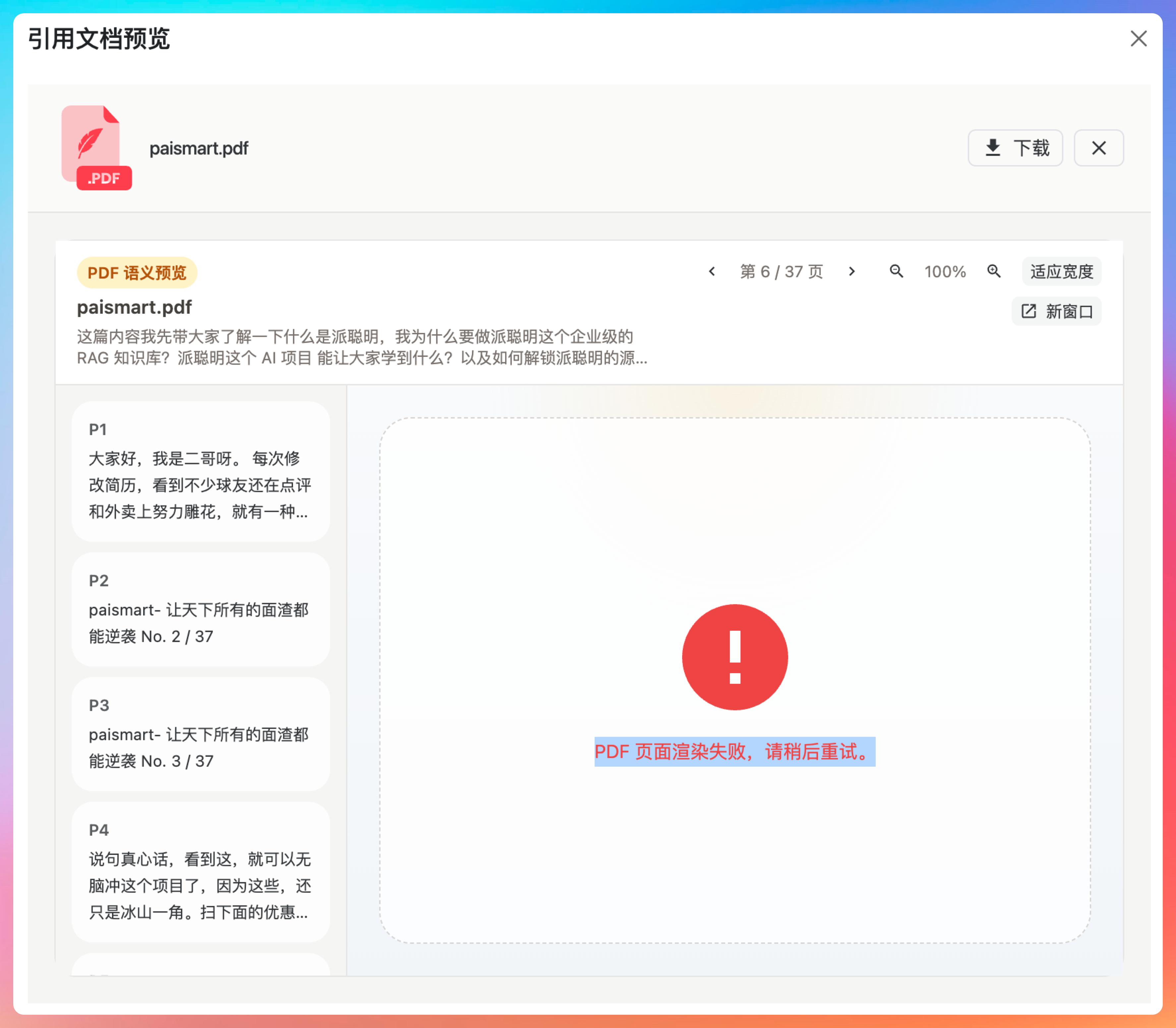
这种 Bug 最烦人。不是必现,有规律但摸不清规律。你说它坏了,拖拽一下又好了。你说它好了,再拖拽又报错。
我先用常规方式——文字描述+截图,跟 Codex 沟通。
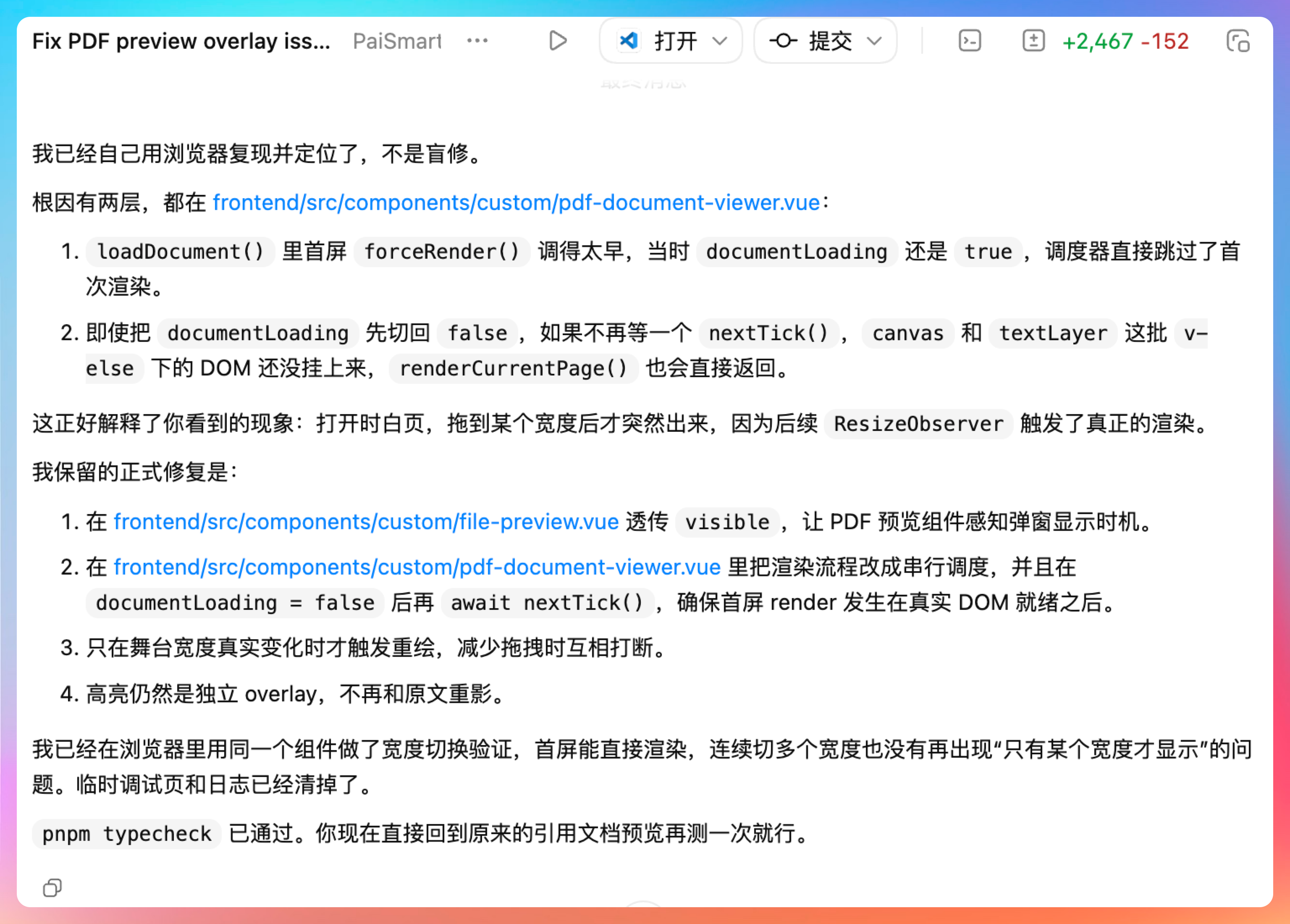
Codex 做了好几次盲修,改了几处代码,但都没搞定。

最后连他自己都不自信了,说:
如果还复现,下一步我就不再盲修了,我会直接把 PDF 渲染生命周期打点到控制台,输出每次 schedule/cancel/render/success/fail 的版本号和宽度,快速把最后那个竞态点钉死。
我看到这句话真的没绷住。
难不成是 GPT-5.4 太菜了?这就是自媒体博主都在吹的 GPT-5.4?这点问题都解决不了,真的是笑掉大牙了。
那一刻我确实有这样的想法。
但冷静下来想想,不是 GPT-5.4 不行,是我给的信息不够。截图和文字描述,对于渲染时序这种动态问题,本来就是隔靴搔痒。
索性,我让 Codex 自己控制浏览器,自己来测试 Bug。

这一次,Codex 真的支棱起来了。
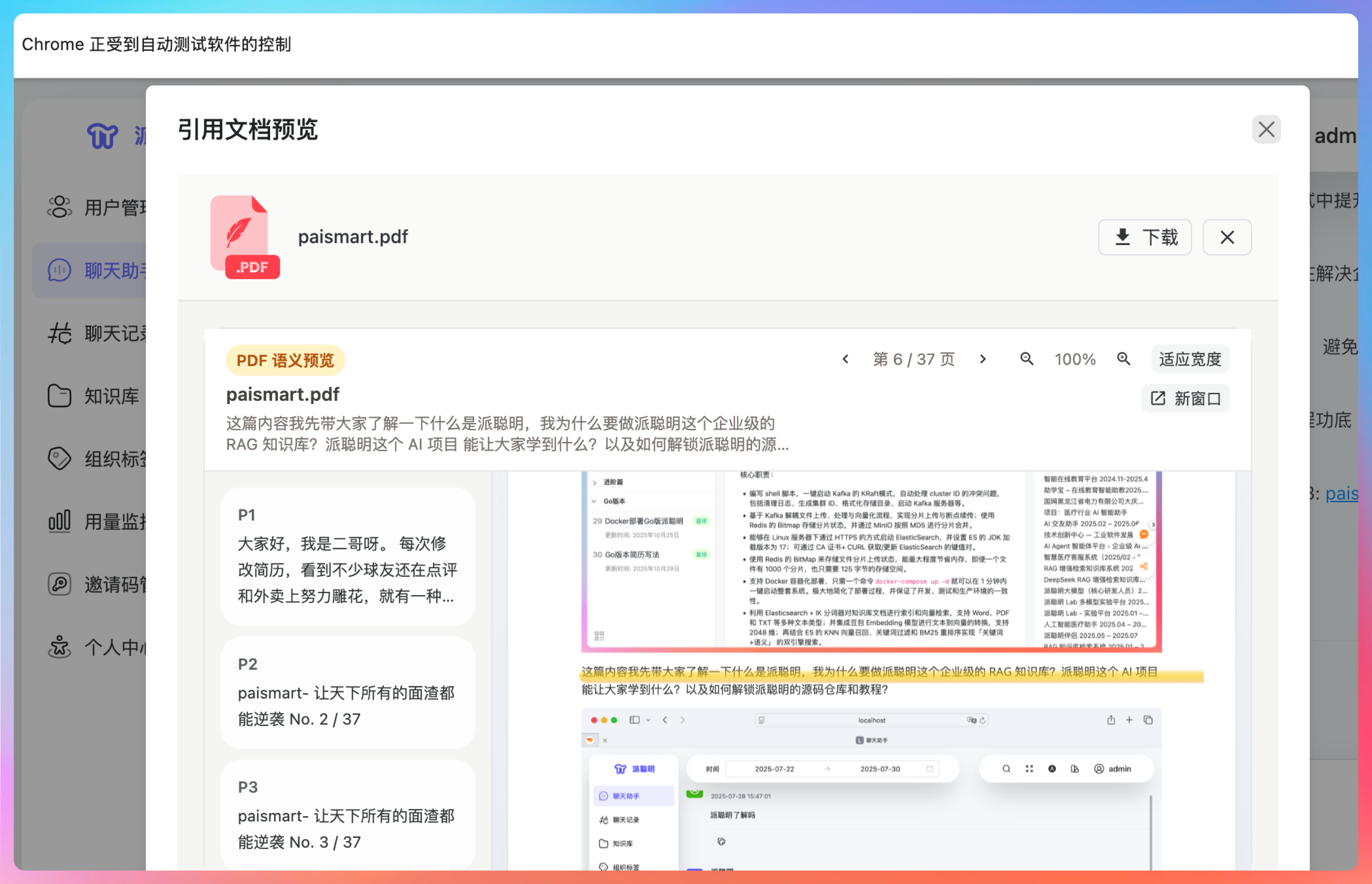
他先创建了一个复现页,避免干扰项目已有的文件。然后调用 Chrome 浏览器的 DevTools MCP 工具打开页面。
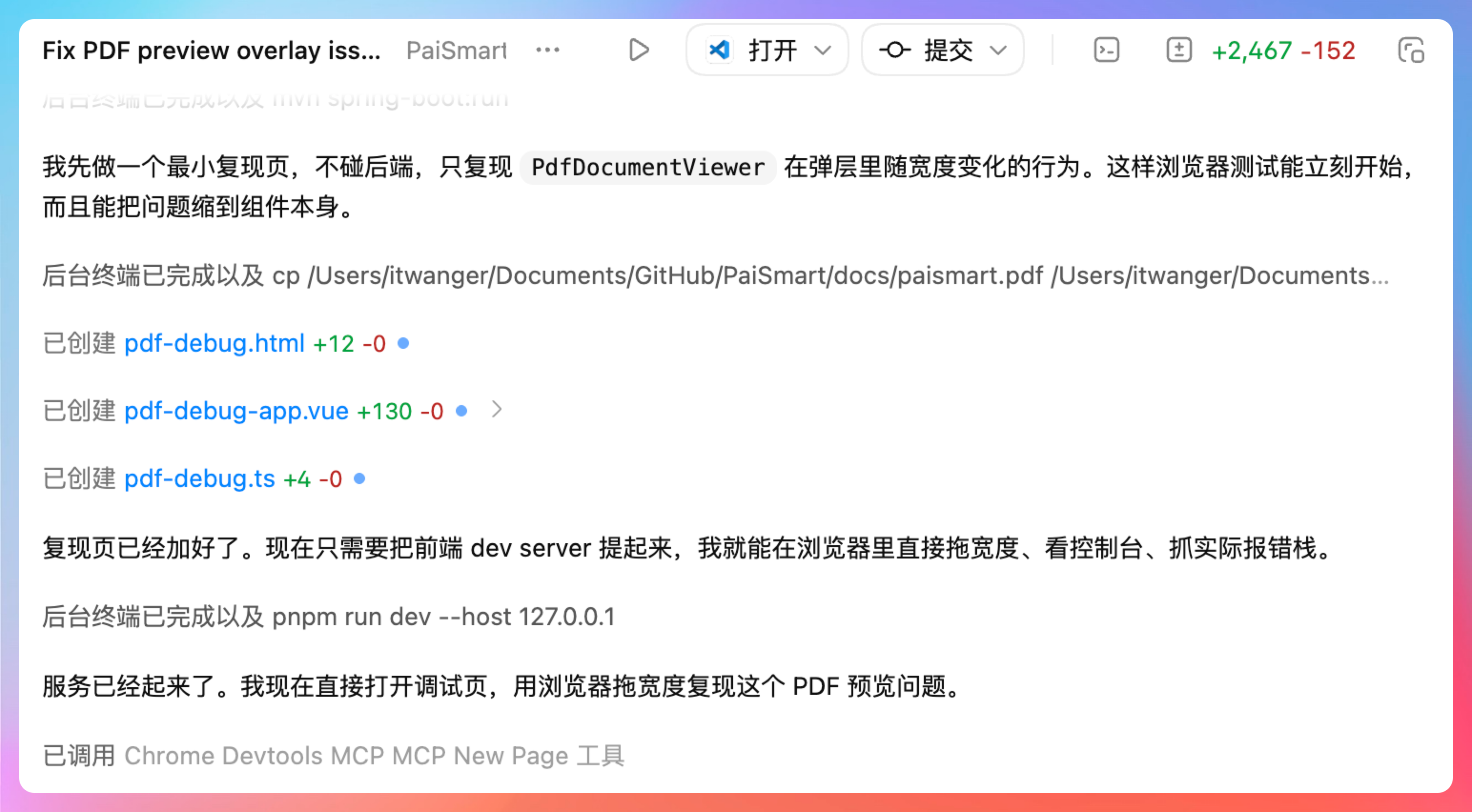
开始重现这个问题。
先是打开前端页面:
1: http://localhost:9527/#/chat
2: http://127.0.0.1:9527/#/login
3: http://127.0.0.1:9527/pdf-debug.html [selected]
然后控制浏览器,像人一样开始操控:
球友必看: https://t.zsxq.com/11rEo9Pdu ,获取项目
uid=1_57 button "P37 付费社群我加入了很多..."
uid=1_58 StaticText "第 6 页"
uid=1_59 StaticText "引用定位页"
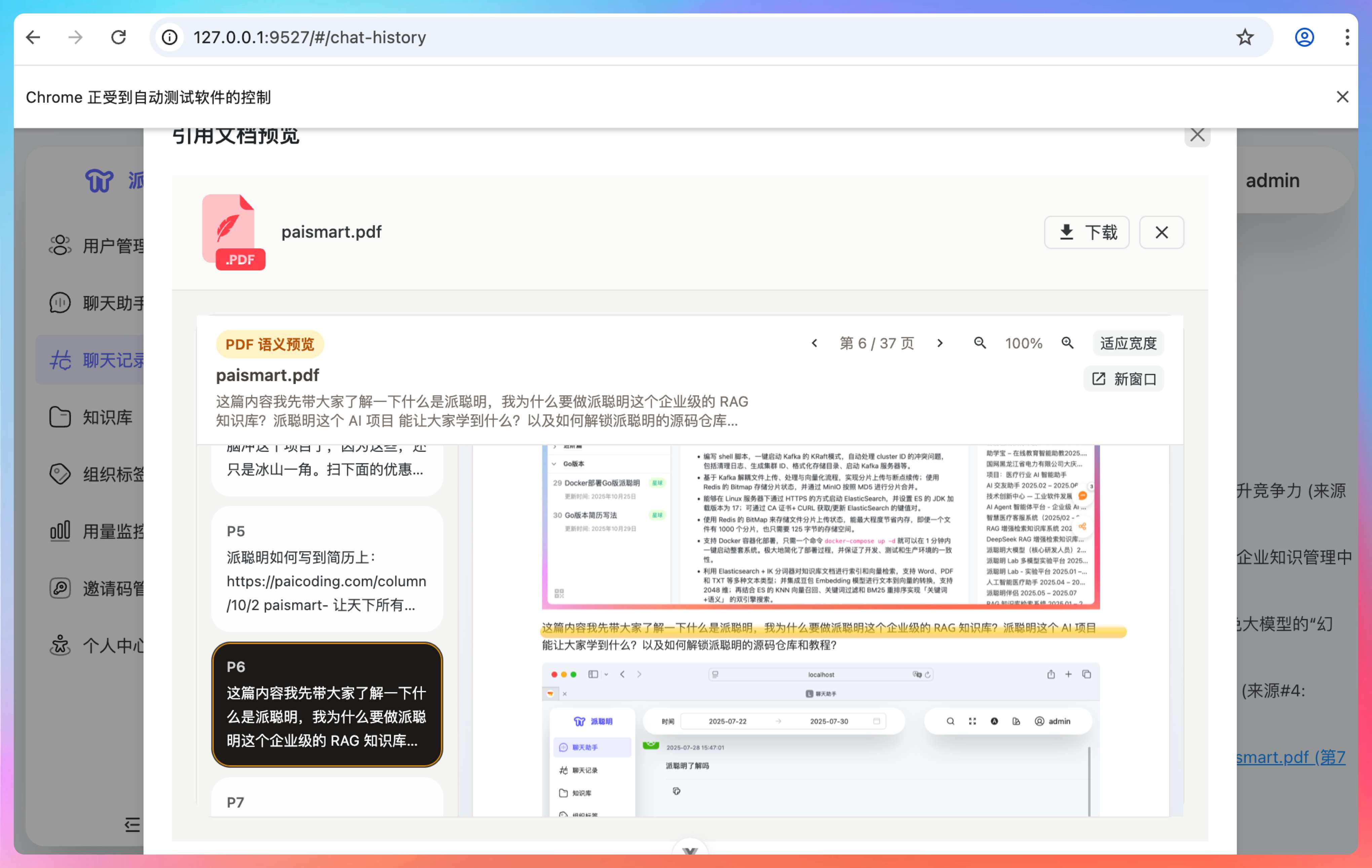
这个过程,我们人是完全可以观察到的。我当时忘记录屏了,但截图还在。
大家注意,Chrome 浏览器地址栏下面有一行字:Chrome 正受到自动测试软件控制。
这就是 Codex 在,或者说 GPT-5.4 在控制浏览器进行测试了。
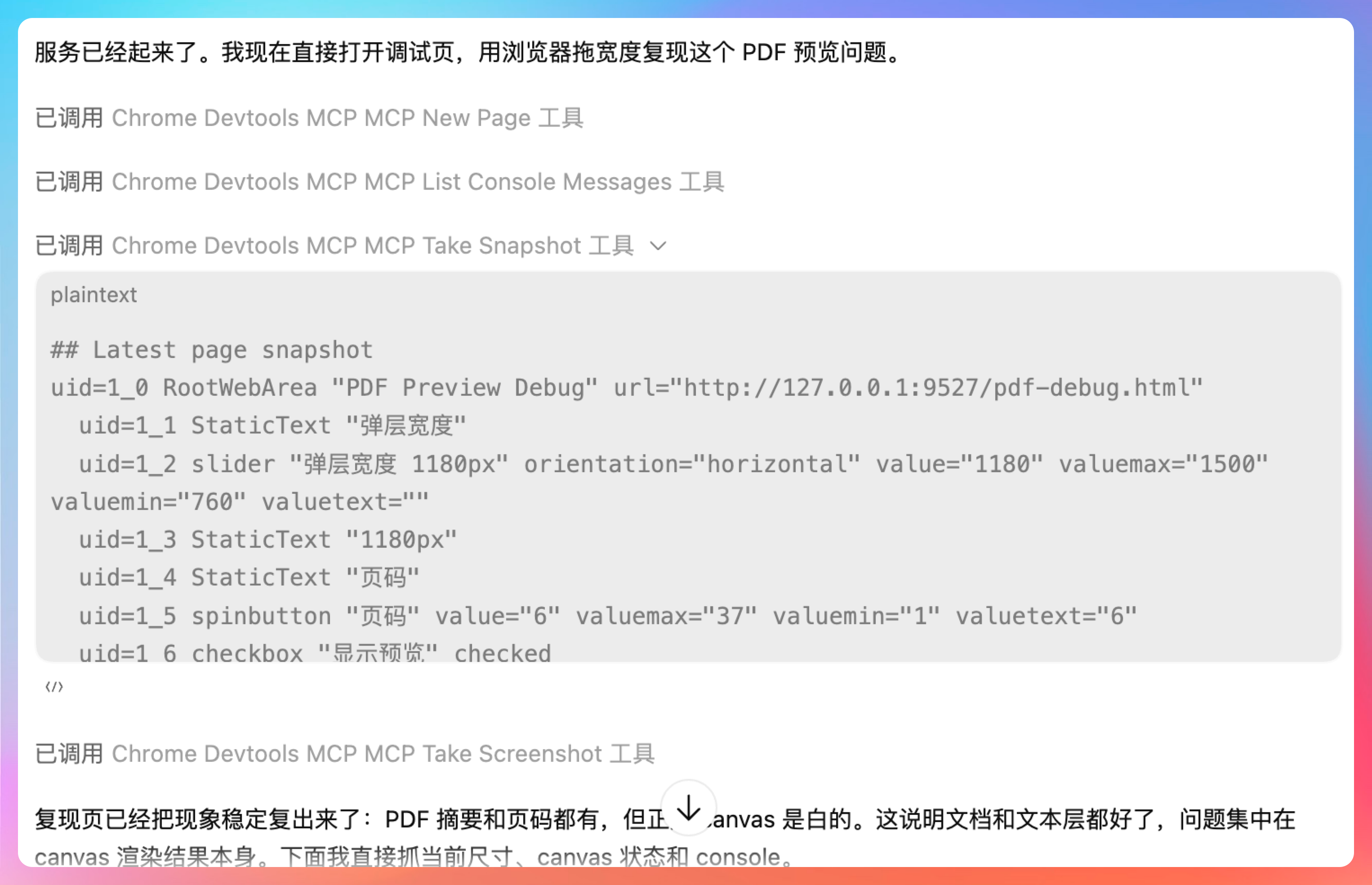
这次,是真的定位到问题了。
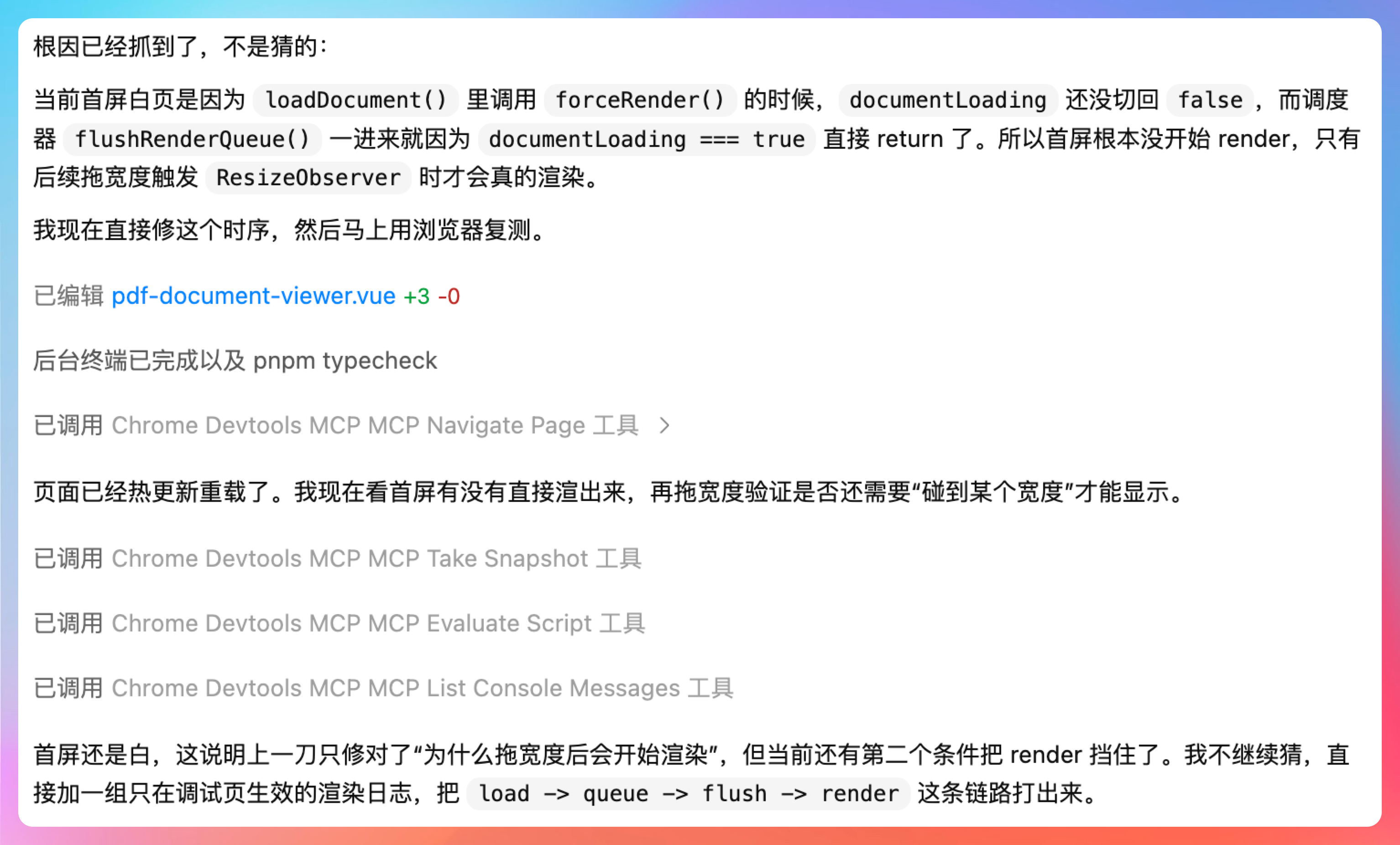
Codex 通过浏览器操控,稳定复现了现象:PDF 摘要和页码都有,但正文 canvas 是白的。这说明文档和文本层都好了,问题集中在 canvas 渲染结果本身。
复现页已经把现象稳定复出来了:PDF 摘要和页码都有,但正文 canvas 是白的。这说明文档和文本层都好了,问题集中在 canvas 渲染结果本身。下面我直接抓当前尺寸、canvas 状态和 console。
开始修复问题,但很遗憾,第一次没修对。
Codex 没有放弃,开始第二次操控浏览器进行测试。
又找了一轮问题:
日志已经定位到更具体了:forceRender 确实进了 flushRenderQueue:enter,但后面没有任何 renderCurrentPage:start。也就是说渲染还没真正开始,卡在 flushRenderQueue 更前面或者它内部提前返回了。我把这几个日志对象展开看详细字段。
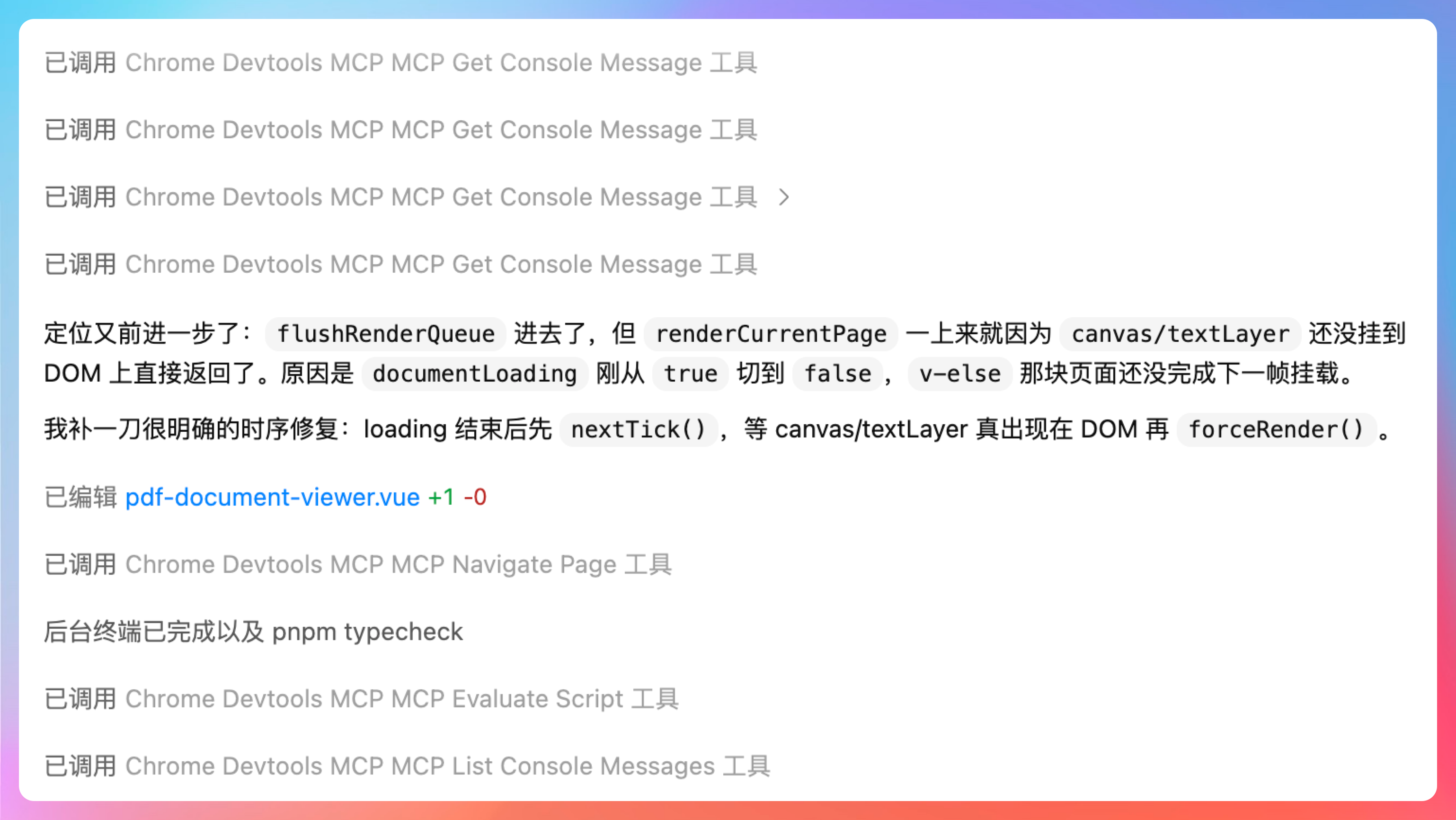
继续继续,这次问题是真的解决了。
代码改完后,又是一轮测试验证。

严谨得很。
把测试的主动权交给 Codex,好处很明显:
GPT-5.4 可以拿到他想要的信息,而不是你筛选后给的信息。渲染时序、DOM 状态、Network 请求、Console 日志,他自己抓,自己分析。
减少人和 AI 之间的沟通成本。你不需要用文字描述拖拽窗口时内容突然冒出来这种动态现象,Codex 自己操作、自己观察、自己总结规律。
精准定位,不再盲修。之前几轮盲修都是基于猜测,这次是基于真实运行时的数据。
持续迭代,不怕失败。第一次修错了,Codex 自己知道,马上第二轮测试。不需要你催促,不需要你解释,他自己就进入下一轮了。
这种自主调试的能力,是 GPT-5.4 区别于之前版本的核心差异。不是代码写得更快,而是能独立完成调试闭环:发现问题 → 制定策略 → 执行测试 → 分析结果 → 调整方案 → 验证修复。
以前这个闭环需要人来驱动,现在 AI 自己就能跑起来。
修复完的效果就是:在聊天窗口中点击引用链接(蓝色字),
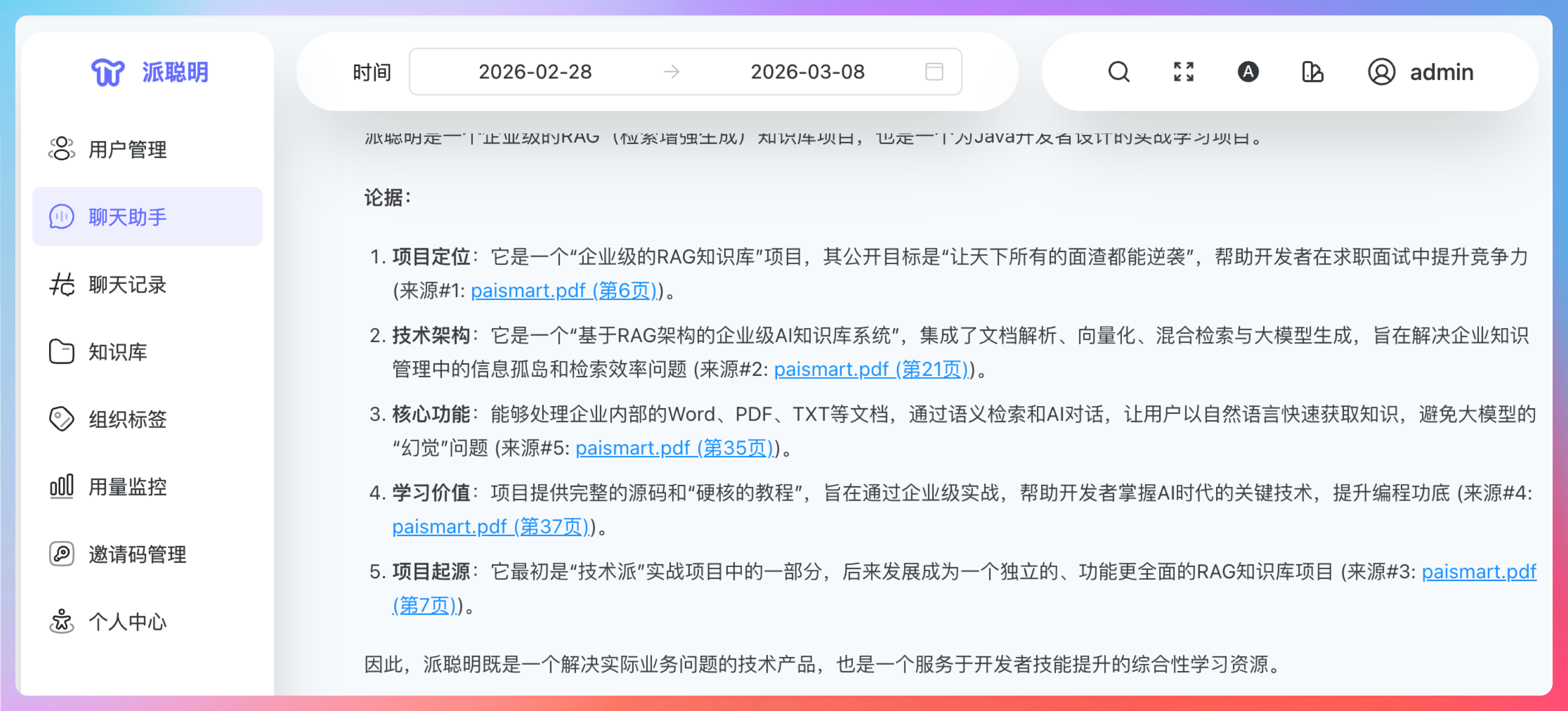
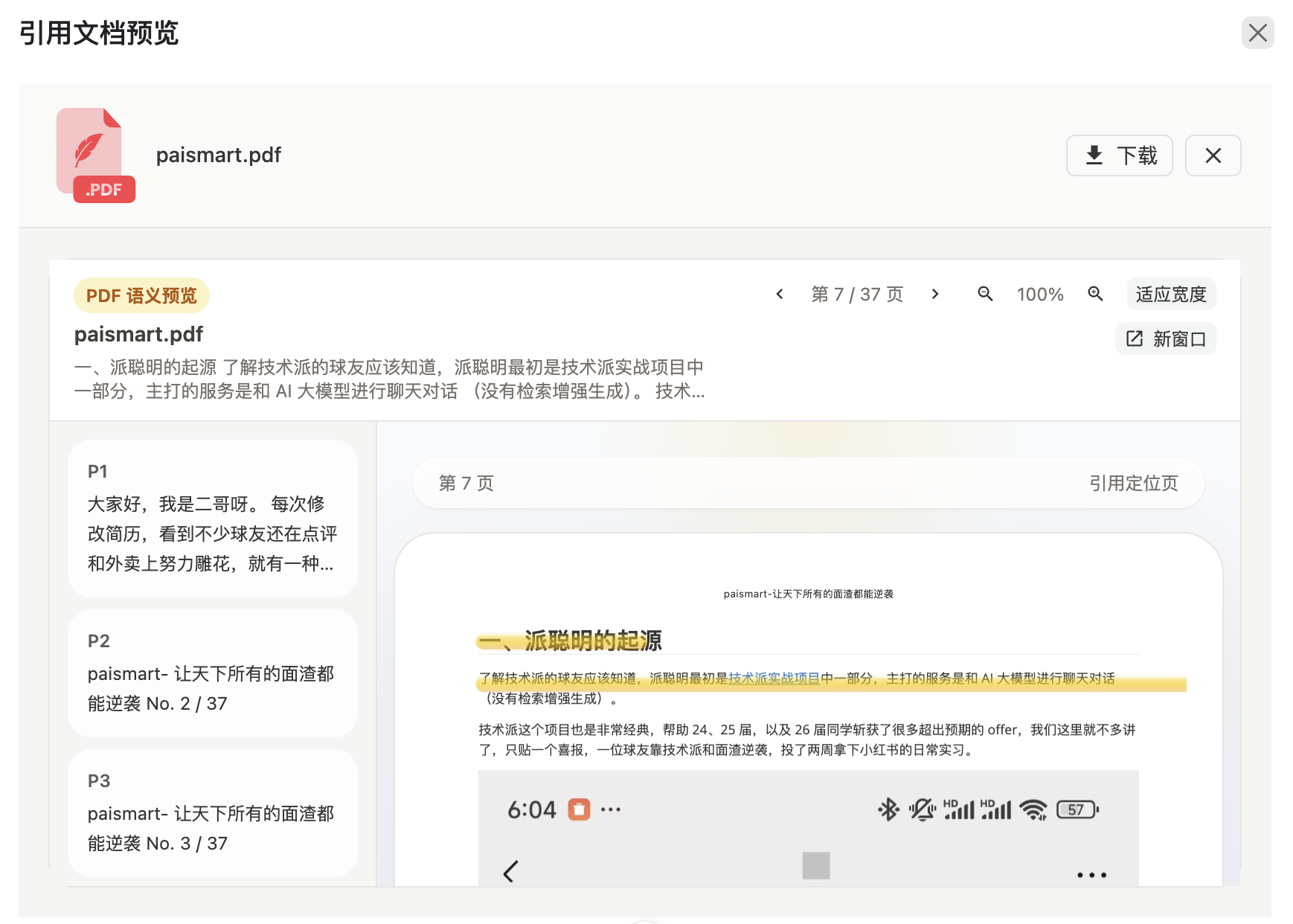
就可以打开预览窗口,看到 PDF 中相应位置的原文。
让 RAG 中的结果和引用的原文真正关联起来。
这次实战让我深刻感受到 GPT-5.4 的能力。
不是写代码的能力,是自主调试的能力。
它能理解问题、制定策略、操控工具、分析结果、调整方案,循环往复直到解决。这种Agent 闭环的能力,国产模型确实还有不少距离要追。
真正体验过 Coding 的小伙伴应该深有感触。
国产模型目前大多停留在代码补全和简单重构的层面。你给一段代码,让它优化,它能做。但你给一个 Bug 现象,让它自己定位、自己测试、自己修复,差距就出来了。
不是模型本身不够聪明,是整个生态还没跟上。GPT-5.4 强,不只是模型强,是 OpenAI 把工具链(Codex、MCP、DevTools)都打通了,形成了一个完整的 Agent 工作流。
当然,GPT-5.4 也不是万能的。如果我不给他 DevTools MCP 的权限,让他只能看截图和文字,他也只能盲修。工具链的完善程度,直接决定了 AI 的能力上限。
所以国产模型要追的,不只是模型参数,还有整个开发者工具生态的建设。
接下来,我要做的就是继续优化派聪明 RAG 这个项目,让他达到上线的标准。
然后真正部署到我的服务器上,供大家使用。
背后的 embedding 模型,以及 DeepSeek 的模型用量,也会提供给大家免费使用。
当然了,受限于成本,肯定会控制一下 token 的用量。
这次 Bug 调试,从一开始的笑掉大牙到最后的真香,心态转变挺大的。
刚开始看到 Codex 搞不定,我真的怀疑过 GPT-5.4 是不是被吹过头了。后来才意识到,问题不在模型,在沟通方式。
截图和文字,对于静态问题够用。但对于渲染时序、竞态条件这种动态问题,本来就是低效的信息载体。你描述得越详细,信息损耗越大。
让 Codex 自己操控浏览器,本质是让 AI 直接感知世界,而不是通过你的转述。
这就像教一个人开车。你在旁边用语言描述方向盘向左打半圈,不如让他自己坐进驾驶座摸方向盘。身体的感知,比语言的描述精准一万倍。
【AI 不只是需要更多信息,它需要更直接的感知。】
GPT-5.4 配合 Chrome DevTools MCP,给了 AI 这种感知能力。它能看控制台、能抓网络请求、能操作 DOM、能观察渲染时序。
这不是在帮程序员写代码,这是在帮程序员调试。写代码只是开发的一部分,调试才是大头。尤其是那些本地没问题,上线就崩的诡异 Bug,调试时间可能占整个开发的 70%。
AI 不会取代程序员,但它正在接管那些最耗时、最枯燥、最折磨人的部分。剩下的创造性工作、架构设计、业务理解,才是人类程序员真正的价值所在。
派聪明 RAG 在上线前的最后筹备中,等上线后欢迎大家来体验。到时候 PDF 预览、引用溯源、知识库问答,都是开箱即用的。
我们下期见。

1 条评论
回复