


大家好,我是二哥呀。
说真的,这两天我被 OpenClaw 的 memory 机制干懵了一次。
一开始我以为,记忆就是 MEMORY.md 加上 memory/*.md 这些 Markdown 文件。

结果排查着排查着,突然又冒出来一个 ~/.openclaw/memory/paismart.sqlite。
我当时脑子里就一个问号:不是都已经有 md 了么,怎么又来一个 sqlite?难道是markdown升级到sqlite了,还是我理解错了?
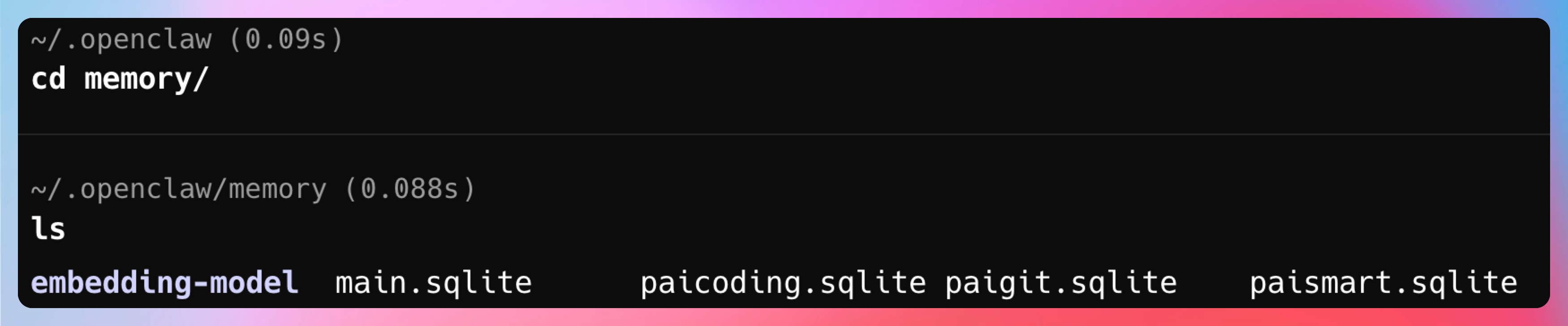
后来我一边查配置,一边看日志,终于把这个事弄明白了:
OpenClaw 不是把记忆从 Markdown 升级成 SQLite,而是把“记忆内容”和“记忆搜索”拆成了两层。Markdown 负责存,SQLite 负责找。
如果你最近也在折腾 OpenClaw,或者正准备给自己的 Agent 加一套“长期记忆 + 语义检索”的能力,那这篇文章一定要耐心看完。
我会把踩过的坑、最后跑通的方案,以及这套设计背后的思路,都给大家摊开讲明白。
01、我一开始到底搞混了什么
在很多人的直觉里(包括我),既然已经有 MEMORY.md 和 memory/YYYY-MM-DD.md 这些文件,那记忆系统不就应该只围绕这些文件转吗?
假如我们想让OpenClaw记住一件事,龙虾就应该写进 Markdown;下次我们问他,他再从 Markdown 里找出来。逻辑上完全闭环,看起来也没毛病。
但问题就出在这里。
“能存下来”和“能高效找到”,其实是两回事。
把内容写进 Markdown,确实完成了“存储”这一步。但后面要检索时,尤其是想用一种更像人说话的方式去问,比如“我之前是不是更喜欢美女”“我们上次关于向量索引讨论过什么”“那个跟 Ollama 配 embedding 的方案怎么配来着”,这时候如果只靠关键词匹配,命中率会很低。
因为真实的提问方式,往往不会和原文一模一样。
记下来的是“每完成一小步就汇报进度,不要等全部做完再反馈”,但搜索时可能问的是“沟通偏好”“反馈节奏”“是不是不要一次性做完才说”。这时候,纯文本匹配就开始吃力了。
也正因为这个原因,OpenClaw 才把 memory 设计成了两层:一层是你真正能看到、能编辑、能长期保存的 Markdown 文件;另一层是后台自动维护的 SQLite 索引,用来支持语义搜索。
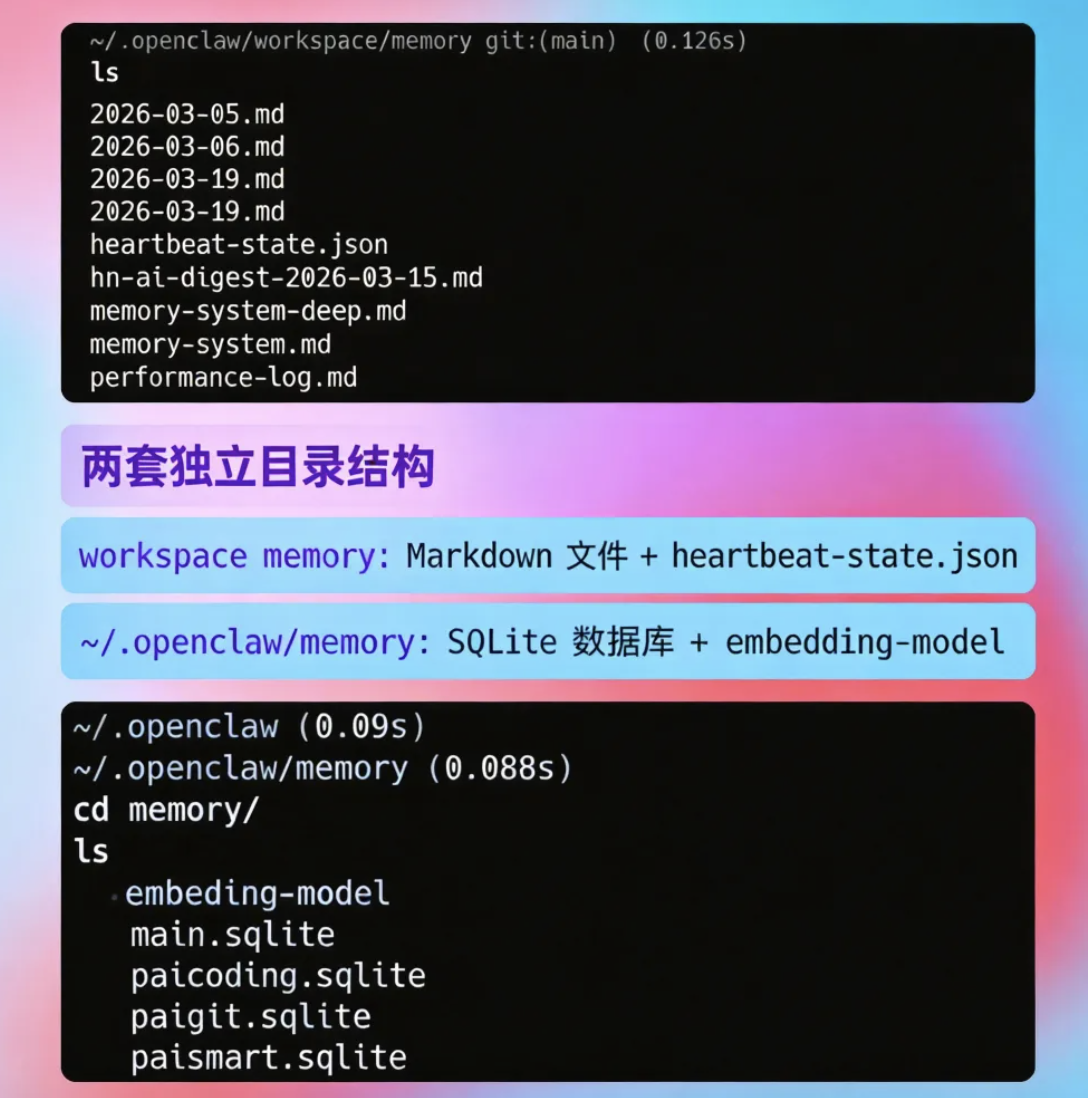
02、OpenClaw 的记忆分成哪两层
先把结论摆这:
~/.openclaw/workspace/MEMORY.md和~/.openclaw/workspace/memory/*.md,这是源数据层。~/.openclaw/memory/*.sqlite,这是索引层。
这两层不是替代关系,而是配合关系。
Markdown:真正的记忆内容
Markdown 文件是真正的“记忆本体”。
第一,它是纯文本,你能直接打开看,直接编辑,直接提交 Git。出了问题你也能肉眼检查,而不是对着一堆二进制结构发呆。

第二,它天然适合长期积累。比如 MEMORY.md 放长期偏好、重要结论、稳定上下文;memory/YYYY-MM-DD.md 放当天流水账、临时进展、排障记录。这种分层比把所有东西塞进一个数据库字段里要舒服太多了。
第三,它足够安全。就算后面的向量模型挂了,SQLite 崩了,embedding provider 换了,Markdown 还在,记忆就还在。不会因为某个索引重建失败,就把真正的历史内容搞丢。
SQLite:为了“搜得更像人”
SQLite 的任务不是“保存事实”,而是“把事实变得更容易被找回来”。
OpenClaw 会把 Markdown 内容切成若干 chunk,然后交给 embedding 模型做向量化,最后把这些向量和分块信息存到 sqlite 里。
等调用 memory_search 时,会把查询也转成向量,去和索引里的 chunk 做相似度匹配,再把最相关的片段返回。
和我们之前做的派聪明RAG是一个道理。
关键字匹配和语义向量匹配。
03、为什么只靠 Markdown 不够
如果只用 Markdown,那么检索方式基本就落在两类:
- 一种是你自己肉眼翻。
- 另一种是关键词搜索。
这两种都能用,但都有上限。
这时候,向量检索的价值就出来了。
它不是死盯某几个字,而是尽量去理解“你这句话大概在说什么”。也正因为这样,它才更适合拿来处理 Agent 的长期记忆,因为人和 Agent 的沟通,本来就不是写 SQL 条件,而是用自然语言在问。
更有意思的是,memory_search 返回的是 mode: hybrid。这意味着它不是只靠向量,也不是只靠关键词,而是两套一起上。
- 关键词擅长精确命中,比如人名、模型名、文件名。
- 向量擅长语义相近,比如“沟通偏好”和“汇报进度”。
两者组合起来,效果会更稳。

04、为什么选 Ollama 做向量模型
最开始其实不是这么配的。
我一开始走的是 OpenClaw 文档里更“标准”的思路:memorySearch.provider = local,然后让 node-llama-cpp 去吃本地 GGUF 模型。
这条路没毛病,但实际折腾起来,有点绕。
实际上,我本地已经有 Ollama 了。
这就让我想到一个更顺手的方案:既然 Ollama 已经在跑模型了,那 embedding 这件事,能不能也让 Ollama 来干?
结果一试,还真行。
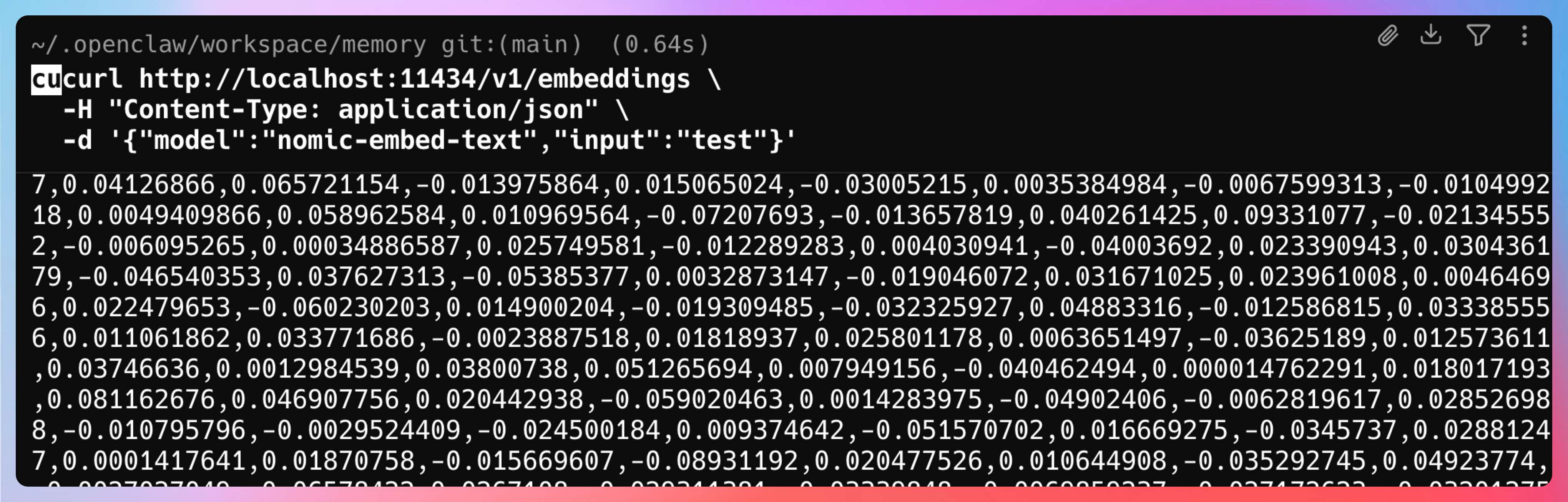
我最后 pull 了 nomic-embed-text,然后测了 Ollama 的两个接口:
- 原生接口:
/api/embeddings - OpenAI 兼容接口:
/v1/embeddings

我实际用到的配置
{
agents: {
defaults: {
model: {
primary: "openai-codex/gpt-5.4"
},
memorySearch: {
provider: "openai",
model: "nomic-embed-text",
remote: {
baseUrl: "http://localhost:11434/v1",
apiKey: "ollama"
},
sync: {
watch: true
}
}
}
}
}
这段配置最容易让人误解的,就是 provider: "openai"。
很多人一看到这里,就会本能觉得:哦,原来还是在用 OpenAI。
其实不是。
这里的 openai 说的是协议兼容方式,不是说请求真的发去 OpenAI。真正干活的,是本地 Ollama 跑着的 nomic-embed-text。
05、这次我踩过的几个坑
坑一:Gateway 看起来重启了,其实旧进程还活着
这是我这次踩得最烦的坑。
我明明改了 openclaw.json,日志里也出现了 config change detected,但 memory_search 返回的还是:
provider: nonemode: fts-only
这就很邪门。
后来一查,发现 Gateway 的旧进程还在占着端口。所以每次,重启Gateway要先等一会。或者用stop或者kill掉进程。
坑二:SQLite 里保留着旧索引元数据
我把 provider 从 none 改成了 Ollama 方案,按理说应该重新索引了吧?
结果 sqlite 里还是旧的元数据:
provider: nonemodel: fts-only
也就是说,配置虽然改了,但索引库还是旧状态。
这个时候,不是内容有问题,而是索引没有重建。
解决思路也很直接:
- 清掉旧索引元数据
- 必要时重建 sqlite
- 再触发一次
memory_search

06、如果你刚开始用 OpenClaw
如果你现在还没开始配 memory,我给你的建议是:先别把自己卷进最复杂的方案里。
第一阶段:只用 Markdown
刚开始,先把这两个文件用起来:
MEMORY.mdmemory/YYYY-MM-DD.md
养成“有结论就写进去”的习惯,不然你的龙虾用着用着就失忆了。
第二阶段:记忆多了,再开向量索引
等你开始遇到这些问题:
- 记忆文件越来越多
- 你开始记不住东西写在哪了
- 你希望
memory_search更像“问人”而不是“搜文件”
这时候再上向量索引。
如果你本地已经有 Ollama,可以直接走 nomic-embed-text。
第三阶段:把“写记忆”和“搜记忆”变成工作流的一部分
我觉得最理想的状态,不是把 memory 当成一个“高级功能”,而是把它当成 Agent 日常工作流的一部分。
第四阶段:学会判断自己到底有没有配对
具体怎么判断?
第一,看 memory_search 返回的 provider 和 model。如果还是 provider: none、mode: fts-only,那说明你现在只是关键词搜索,还没有真正进到向量模式。
如果返回的是 provider: openai、model: nomic-embed-text、mode: hybrid,那就说明 embedding 已经通了。

第二,看 sqlite 里是不是开始出现 chunk。因为真正的向量索引,不是“配置文件里写了就算成”,而是 sqlite 里真的有内容了,搜索也真的能命中相关片段。
第三,看搜一句自然语言能不能命中语义相近的内容。比如你记的是“每完成一小步就汇报进度”,搜“沟通偏好”“反馈节奏”也能中,说明这套东西正常了。

比如:
- 配完一项重要配置,就顺手写进
MEMORY.md - 排完一次典型故障,就顺手写进
memory/YYYY-MM-DD.md - 下一次问问题时,先
memory_search - 命中后再决定要不要
memory_get或直接读原文
这样慢慢积累下来,Agent 的记忆才会真的开始有“连续性”,而不是每次都像临时工一样重新上岗。
ending
我这次折腾 OpenClaw 的 memory,最深的感受其实不是“终于把向量索引跑通了”,而是我突然更能理解,为什么一个 Agent 要把“存”和“找”拆开。

真正重要的东西,往往不是你脑子里有没有,而是你在需要的时候,能不能把它快速找回来。
记忆本身,决定了你有没有积累。
检索能力,决定了这些积累能不能在关键时刻变成判断、变成动作、变成效率。
Markdown 像是在认真做笔记。
SQLite 像是在帮你建立索引。
一个负责记下来,一个负责找回来。
【真正有用的记忆,不是“我保存过”,而是“我下次还能用得上”。】
一旦想明白了,后面不管是配 OpenClaw、做 Agent、还是给自己的系统加长期记忆,思路都会清楚很多。
好,今天这篇就先聊到这,先写到这里。
如果你也在折腾 OpenClaw,或者也被 memory 这套机制绕晕过,评论区告诉我,我后面可以继续把另外几个坑也拆开讲,继续聊。🦞

回复