


大家好,我是二哥呀。
最近一直在高强度调教 Claude Code 的 Skill,说实话,越用越觉得这东西设计得挺巧妙的。但作为一个程序员,光会用是不够的,总得搞清楚它背后是怎么运转的。
你说对吧?
今天咱们就来拆解一下 create-skill 这个 Skill,看看它从被触发到执行完毕,中间到底经历了什么。我直接把源码扒了个底朝天,连函数调用顺序都给你理清楚了。
看完这篇文章,你不仅能理解 Skill 系统的工作原理,还能自己动手写出一个高质量的 Skill。说真的,这技能写进简历里绝对加分。
01、Skill 到底是什么?
在深入源码之前,先简单科普一下 Skill 的基本概念。
Skill 是 Claude Code 的扩展机制,本质上是一个包含 SKILL.md 文件和可选资源(scripts、references、assets)的目录。它能把 Claude 从通用 AI 变成某个领域的专家。
比如说,你装一个 PDF 处理的 Skill,Claude 就能帮你合并 PDF、提取文字、填写表单。装一个前端开发的 Skill,它就能帮你生成符合你团队规范的 React 组件。
一个标准的 Skill 结构长这样:
skill-name/
├── SKILL.md # 必需,包含元数据和指令
├── scripts/ # 可选,可执行脚本
├── references/ # 可选,参考文档
└── assets/ # 可选,模板、图片等资源
create-skill 这个 Skill 比较特殊,它是一个“元 Skill”,专门用来帮你创建新 Skill 的 Skill。
套娃是吧?但确实好用。
如果每次写 Skill 都要从头开始,那得多麻烦。有了这个 Skill,你只需要告诉它你想做什么,它就能帮你生成一个完整的模板。

02、怎么知道该调用哪个 Skill?
这是 Skill 系统的核心机制,也是我觉得设计得最巧妙的地方。
当用户输入一句话时,Claude Code 会扫描所有 Skill 的 frontmatter,提取 name 和 description,然后判断哪个 Skill 最匹配用户意图。注意,这里不是简单的关键词匹配,而是通过 description 来理解用户的真实意图。
create-skill 的 frontmatter 长这样:
---
name: create-skill
description: Guide for creating effective skills. This skill should be used when
users want to create a new skill (or update an existing skill)...
---
关键函数调用链:
system_prompt_loader()
└── extract_skill_metadata(skill_dir) # 提取 name + description
└── 存入 available_skills 列表
match_skill(user_input, available_skills)
└── 基于 description 匹配用户意图
└── 返回匹配的 skill_name: "create-skill"
讲真,这个设计很巧妙。它不像传统的那种关键词匹配,而是通过 description 来理解用户意图。你写“帮我创建一个处理 PDF 的 Skill”,系统就能自动找到 create-skill,而不是傻乎乎地去匹配“create”这个单词。
触发关键词包括但不限于:
- “create a new skill”
- “write a skill”
- “skill structure”
- “how to make a skill”
这种基于语义的理解方式,让 Skill 的触发更加自然。你不需要记住特定的命令,只需要像平时说话一样描述你的需求,系统就能明白你想干什么。
03、SKILL.md 是怎么被读进去的?
一旦匹配成功,系统会读取对应 Skill 的 SKILL.md,解析 frontmatter 获取元数据,然后将 body 内容注入上下文。这个过程看起来简单,但里面有很多细节值得注意。
函数调用链:
load_skill(skill_name)
└── read_file(f"{skill_name}/SKILL.md")
└── parse_frontmatter(content)
├── extract_yaml_frontmatter() # 提取 --- 之间的内容
└── extract_markdown_body() # 提取 # 之后的内容
└── inject_to_context(body_content)
此时,Claude 的上下文里就有了 create-skill 的完整指令,包括那 6 个执行步骤。
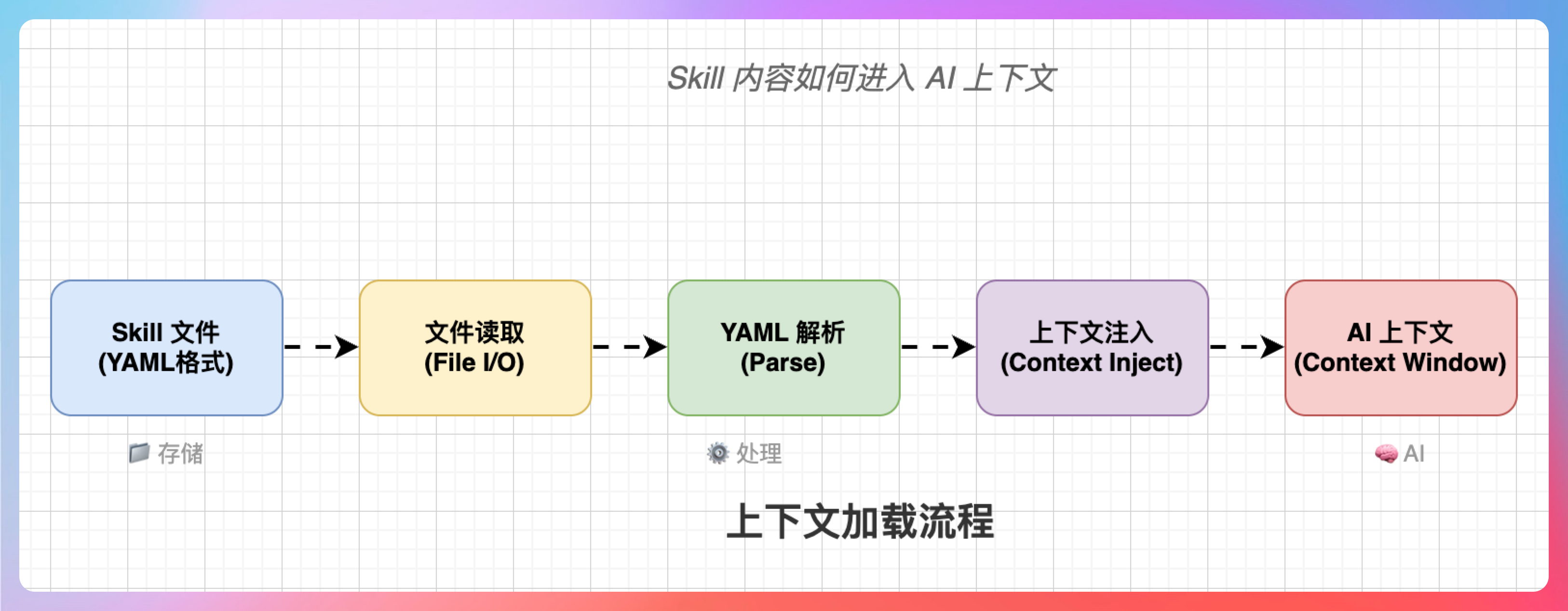
注意,这时候 references 和 scripts 里的内容还没有被加载,它们是按需加载的。这个设计叫“渐进式披露”,我们之前讲过了。
为什么要这样设计?
因为上下文窗口是有限的。如果所有 Skill 的完整内容都一直放在上下文里,那很快就爆掉了。通过渐进式披露,系统只加载当前需要的内容,既保证了功能完整,又不会浪费上下文空间。
04、六个步骤的完整拆解
create-skill 的 SKILL.md 定义了 6 个标准步骤,咱们一个一个看。这 6 个步骤设计得非常合理,从需求理解到最终打包,形成了一个完整的闭环。
04-1、Understanding:先搞清楚你要做什么
这一步的目的是避免做出来一个没人用的 Skill。系统会问你:
- “What functionality should the skill support?”
- “Can you give some examples?”
- “What would trigger this skill?”
函数调用:
step1_understanding()
└── ask_user_questions([...])
└── 收集用户反馈
└── validate_examples(examples)
说实话,这个步骤很容易被跳过,但真的很重要。我见过太多人一上来就写代码,结果写出来的东西根本不符合实际需求。通过这个步骤,你能确保自己真正理解用户想要什么,而不是凭空想象。
举个例子,用户说“我想做一个处理 Excel 的 Skill”,这时候你需要追问:是处理什么类型的 Excel?是财务报表还是数据分析?需要支持哪些操作?是读取、写入还是格式转换?
只有把这些问题搞清楚,才能做出真正有用的 Skill。
04-2、Planning:规划 Skill 里要放什么
这一步是把用户的具体需求抽象成可复用的资源类型。这是整个流程中最考验经验的部分。
函数调用链:
step2_planning(user_examples)
└── analyze_example(example)
│ └── identify_reusable_resources(example)
│ ├── need_script? → 加入 scripts/ 列表
│ ├── need_reference? → 加入 references/ 列表
│ └── need_asset? → 加入 assets/ 列表
└── generate_resource_plan()
举个例子,如果你要做一个处理 PDF 的 Skill,分析下来可能需要:
scripts/rotate_pdf.py—— 旋转 PDF 的脚本references/pdf_lib_docs.md—— PDF 库的 API 文档assets/pdf_template/—— PDF 模板文件
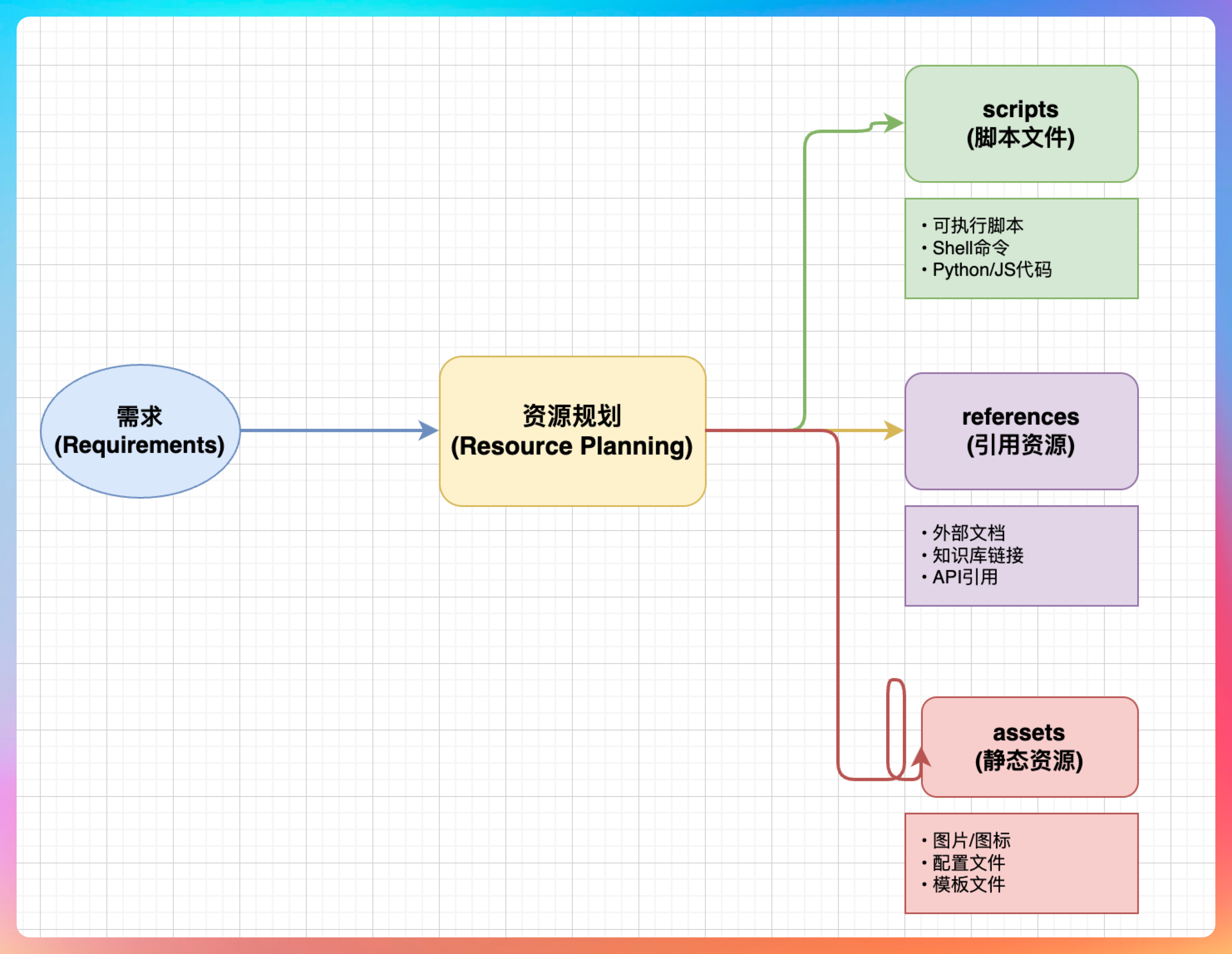
这个规划过程其实就是在做架构设计。你需要考虑哪些功能适合用脚本实现,哪些需要参考文档,哪些需要模板资源。一个好的规划能让后续的实现事半功倍。
04-3、Initializing:真正开始创建文件
这是第一个真正操作文件的步骤,会调用 init_skill.py 脚本。这个脚本会帮你生成一个完整的 Skill 模板。
函数调用链:
step3_initialize(skill_name, output_path)
└── run_script("scripts/init_skill.py", args=[...])
└── init_skill.main()
├── validate_skill_name(skill_name)
├── skill_dir = Path(path) / skill_name
├── skill_dir.mkdir(parents=True)
├── generate_skill_md(skill_name)
├── generate_example_script()
├── generate_example_reference()
└── generate_example_asset()
看看 init_skill.py 的核心代码:
def init_skill(skill_name, path):
skill_dir = Path(path).resolve() / skill_name
# 检查目录是否已存在
if skill_dir.exists():
print(f"❌ Error: Skill directory already exists")
return None
# 创建目录结构
skill_dir.mkdir(parents=True, exist_ok=False)
# 从模板生成 SKILL.md
skill_content = SKILL_TEMPLATE.format(
skill_name=skill_name,
skill_title=title_case_skill_name(skill_name)
)
(skill_dir / 'SKILL.md').write_text(skill_content)
# 创建资源目录
(skill_dir / 'scripts').mkdir()
(skill_dir / 'references').mkdir()
(skill_dir / 'assets').mkdir()
脚本会帮你生成一个完整的模板,包括 TODO 标记,告诉你哪些地方需要填。这个体验真的很贴心。你不需要从零开始,只需要在模板的基础上修改就行了。
04-4、Editing:填充内容
这一步是交互式的,Claude 会引导你完成。这是整个流程中最耗时的部分,也是最能体现 Skill 质量的部分。
函数调用:
step4_edit_skill(skill_dir)
├── edit_scripts(skill_dir / "scripts")
├── edit_references(skill_dir / "references")
├── edit_assets(skill_dir / "assets")
└── update_skill_md(skill_dir / "SKILL.md")
有几个关键点需要注意:
- 使用不定式(imperative/infinitive form)
- description 必须包含触发条件
- 保持简洁,SKILL.md 不超过 500 行
写 SKILL.md 是一门艺术。
你要在有限的篇幅内,把 Skill 的功能、使用场景、触发条件都说清楚。description 尤其重要,因为它决定了 Skill 什么时候会被触发。
写得太宽泛,会被误触发;写得太狭窄,又可能错过真正的使用场景。
04-5、Packaging:打包成可分发格式
调用 package_skill.py 脚本,将 Skill 打包成 .skill 文件。这是 Skill 发布的最后一步。
函数调用链:
step5_package(skill_dir, output_dir=None)
└── run_script("scripts/package_skill.py", args=[...])
└── package_skill.main()
├── validate_skill(skill_path)
│ └── quick_validate.validate_skill()
│ ├── check_skill_md_exists()
│ ├── parse_frontmatter()
│ ├── validate_name_format()
│ └── validate_description_length()
└── create_zip_file()
package_skill.py 的核心逻辑:
def package_skill(skill_path, output_dir=None):
# 先验证
valid, message = validate_skill(skill_path)
if not valid:
print(f"❌ Validation failed: {message}")
return None
# 打包为 zip(.skill 扩展名)
skill_filename = output_path / f"{skill_name}.skill"
with zipfile.ZipFile(skill_filename, 'w') as zipf:
for file_path in skill_path.rglob('*'):
if file_path.is_file():
arcname = file_path.relative_to(skill_path.parent)
zipf.write(file_path, arcname)
return skill_filename
注意,打包前必须先通过验证,避免分发损坏的 Skill。就像代码提交前的 CI 检查一样,能在最后一刻发现问题。
04-6、Iteration:持续优化
可选步骤,根据实际使用情况优化 Skill。一个好的 Skill 不是一次写成的,而是在使用中不断完善的。
step6_iterate(skill_dir)
└── observe_usage_patterns()
└── identify_improvements()
└── update_skill_md_or_resources()
你可能发现某些场景覆盖不到,或者某些描述不够清晰,这时候就需要迭代优化。Skill 的迭代成本很低,因为结构清晰,改起来很方便。
05、验证流程:三道关卡保质量
验证是贯穿整个流程的关键环节,主要由 quick_validate.py 负责。这个脚本就像 Skill 的守门员,确保只有合格的 Skill 才能被打包分发。
验证函数详解:
def validate_skill(skill_path):
# 1. 检查 SKILL.md 是否存在
skill_md = skill_path / 'SKILL.md'
if not skill_md.exists():
return False, "SKILL.md not found"
# 2. 提取 frontmatter
content = skill_md.read_text()
match = re.match(r'^---\n(.*?)\n---', content, re.DOTALL)
frontmatter_text = match.group(1)
# 3. 解析 YAML
frontmatter = yaml.safe_load(frontmatter_text)
# 4. 检查必填字段
if 'name' not in frontmatter:
return False, "Missing 'name' in frontmatter"
if 'description' not in frontmatter:
return False, "Missing 'description' in frontmatter"
# 5. 验证 name 格式(hyphen-case)
name = frontmatter.get('name', '')
if not re.match(r'^[a-z0-9-]+$', name):
return False, f"Name '{name}' should be hyphen-case"
# 6. 验证 description 长度
description = frontmatter.get('description', '')
if len(description) > 1024:
return False, f"Description too long"
return True, "Skill is valid!"
验证包括:
- SKILL.md 必须存在
- frontmatter 格式必须正确
- name 必须符合 hyphen-case 规范
- description 不能超过 1024 字符
- 不能包含尖括号等特殊字符
这些规则看似繁琐,但都是为了保证 Skill 的质量和一致性。如果 Skill 的命名不规范,或者描述太长,都会影响触发效果。
06、设计亮点:渐进式披露
Skill 系统最精妙的设计是“渐进式披露”(Progressive Disclosure)。这个设计理念贯穿了整个 Skill 系统的架构。
| 层级 | 内容 | 大小 | 加载时机 |
|---|---|---|---|
| L1 | Metadata (name + description) | ~100 tokens | 始终加载 |
| L2 | SKILL.md body | <5k tokens | Skill 触发后 |
| L3 | Bundled resources | 无限制 | 按需加载 |
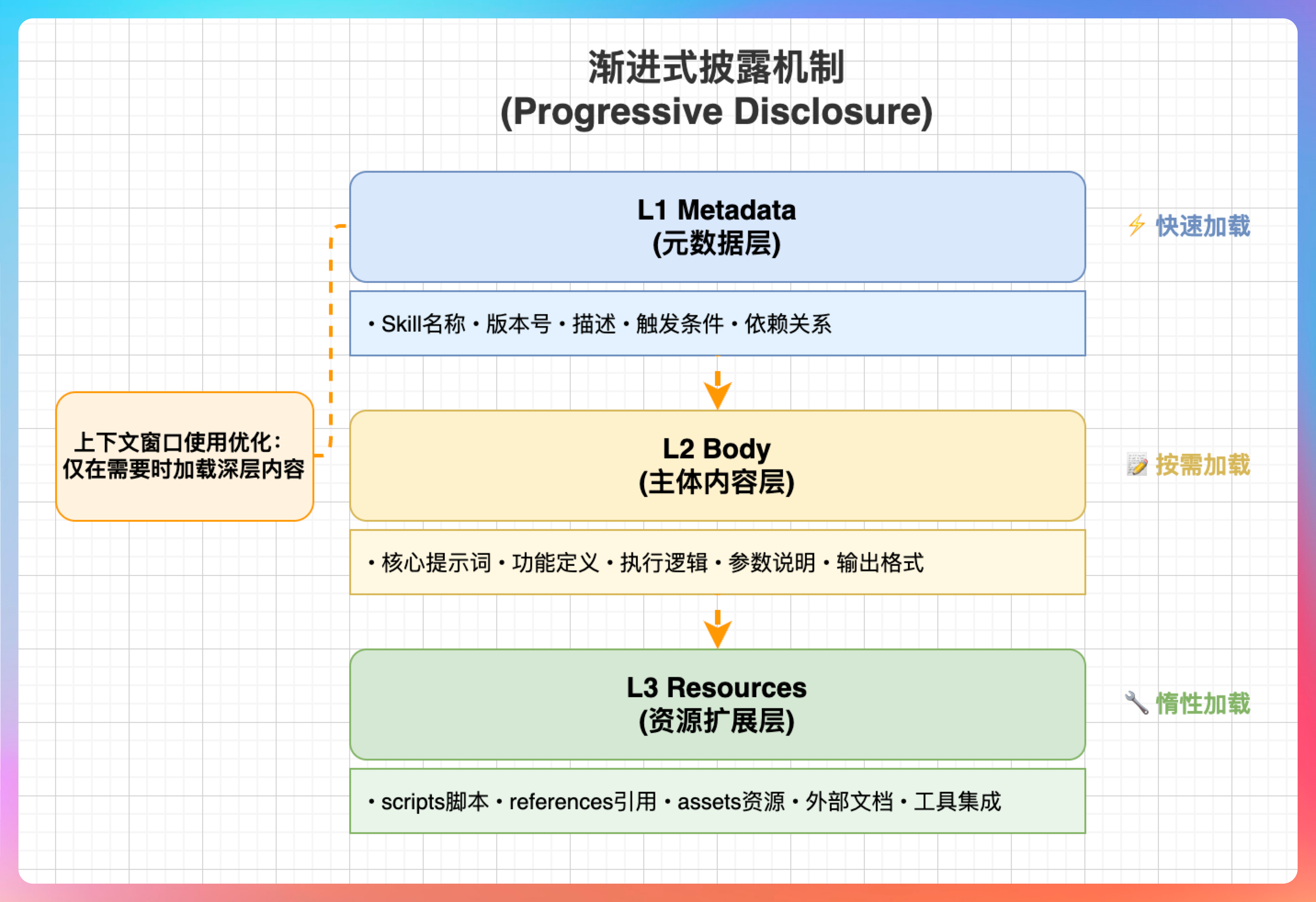
这种设计确保了上下文窗口的高效利用。如果所有 Skill 的完整内容都一直放在上下文里,那很快就爆掉了。通过渐进式披露,系统只加载当前需要的内容,既保证了功能完整,又不会浪费上下文空间。
还有一个设计是“自由度分级”:
- 高自由度:纯文本指令(适用于多种有效方法)
- 中自由度:伪代码或带参数的脚本(有推荐模式但允许变化)
- 低自由度:特定脚本,少量参数(操作脆弱,需要一致性)
这就像给 Claude 划定了一个活动范围,既不会管得太死,也不会完全放任自流。不同的任务需要不同的约束程度,这个设计让 Skill 可以灵活适应各种场景。
07、完整调用顺序图
用一张图总结整个执行流程:
用户输入 → 触发判断 → 加载 SKILL.md → 执行 6 个步骤 → 验证 → 打包 → 完成
│ │ │ │ │ │
│ │ │ │ │ └── .skill 文件
│ │ │ │ └── validate_skill()
│ │ │ └── step1() → step2() → ... → step6()
│ │ └── inject_to_context()
│ └── match_skill()
└── "帮我创建一个 Skill"
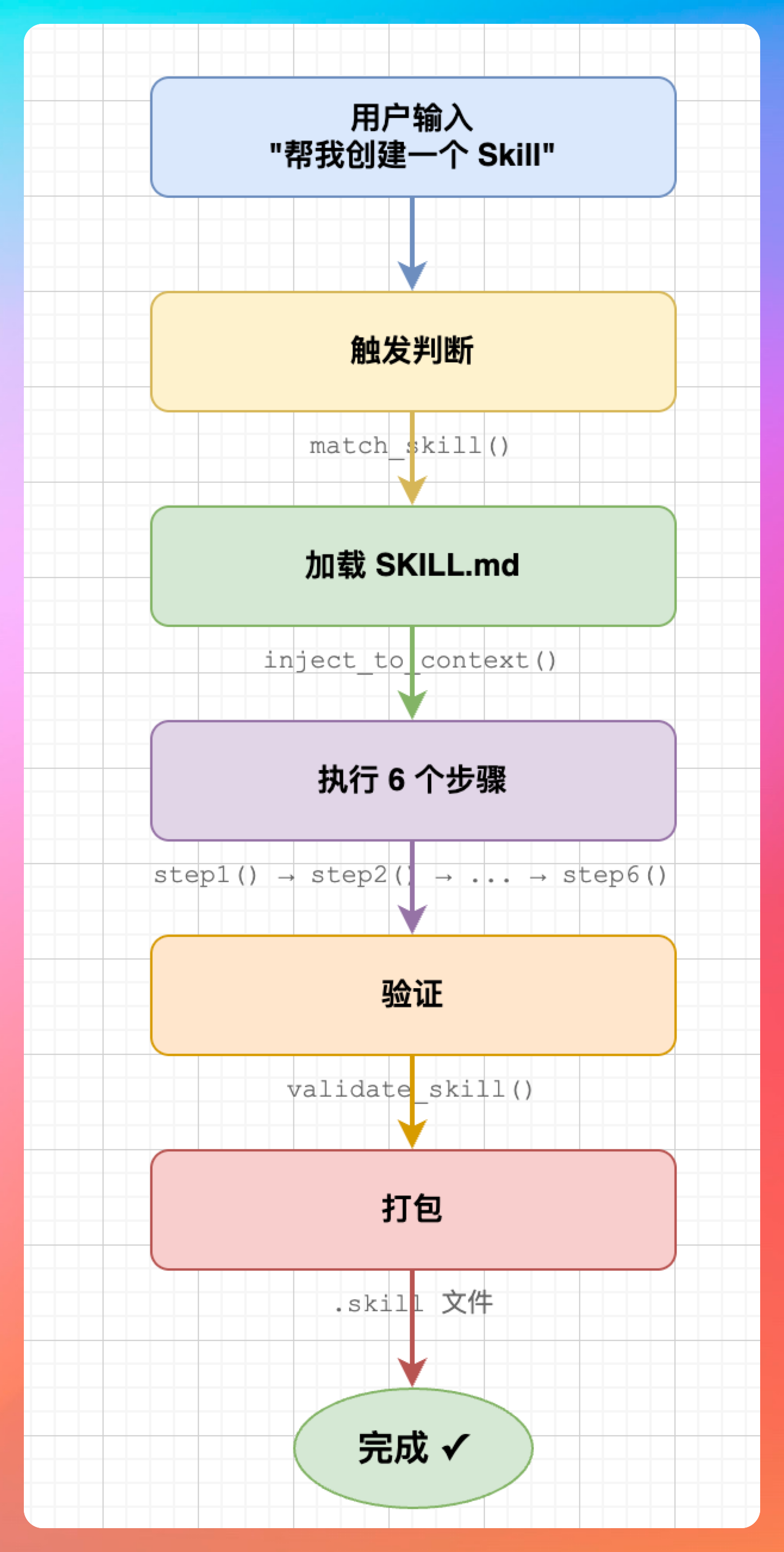
整个流程设计得非常流畅,从用户输入到最终输出,每一步都有明确的目的和产出。这种“显式复杂、隐式简单”的设计理念,让用户体验非常顺滑。
07-1、函数调用链的深层分析
让我们更深入地看看每个阶段的具体函数调用。这不仅能帮你理解系统如何工作,还能让你知道在出问题的时候该去哪里找原因。
触发阶段的完整调用链:
main_loop()
└── process_user_input(user_input)
└── load_all_skills_metadata()
│ └── for skill_dir in skills_directories:
│ └── extract_skill_metadata(skill_dir)
│ ├── read_file(f"{skill_dir}/SKILL.md", limit=50)
│ ├── parse_yaml_frontmatter(content)
│ └── return {name, description}
└── match_skill(user_input, available_skills)
└── semantic_match(user_input, skill.description)
└── calculate_similarity(user_input, description)
└── return best_match_skill_name
加载阶段的完整调用链:
execute_skill(skill_name)
└── load_skill_full(skill_name)
│ ├── skill_path = find_skill_directory(skill_name)
│ ├── skill_md = read_file(f"{skill_path}/SKILL.md")
│ ├── frontmatter = parse_frontmatter(skill_md)
│ ├── body = extract_markdown_body(skill_md)
│ └── inject_to_context(body, priority="high")
└── execute_skill_workflow(skill_name)
└── follow_skill_instructions(body)
这里有个细节:inject_to_context 的 priority 参数设置为 “high”,这意味着 Skill 的内容会优先于一般性的系统提示。这确保了 Skill 的指令能被充分重视。
执行阶段的完整调用链:
follow_skill_instructions(skill_body)
└── parse_workflow_steps(skill_body)
│ └── extract_numbered_steps(body)
│ └── return [step1, step2, step3, step4, step5, step6]
└── for step in steps:
└── execute_step(step)
├── identify_step_type(step)
├── load_required_resources(step)
└── execute_step_logic(step)
├── if step.has_script:
│ └── run_script(step.script_path, step.args)
└── if step.requires_user_input:
└── ask_user(step.question)
这种分层设计的好处是,每一层只关心自己的职责,层与层之间通过清晰的接口交互。如果某一层出了问题,你可以快速定位到具体的位置。
07-2、错误处理机制
create-skill 的错误处理也设计得很周到。每个步骤都有相应的错误处理:
Step 3 (Initializing) 的错误处理:
def step3_initialize(skill_name, output_path):
try:
result = run_script("scripts/init_skill.py", args=[skill_name, "--path", output_path])
if result.returncode != 0:
print(f"❌ 初始化失败: {result.stderr}")
return False
return True
except FileNotFoundError:
print(f"❌ 找不到 init_skill.py 脚本")
return False
except PermissionError:
print(f"❌ 没有权限执行脚本")
return False
这种细粒度的错误处理,能让用户清楚地知道问题出在哪里,而不是看到一个模糊的“执行失败”。
07-3、资源加载策略
Skill 系统的资源加载采用了“懒加载”策略。只有当真正需要某个资源时,才会把它加载到上下文中。
load_resource_on_demand(resource_path)
├── if resource_path in loaded_resources:
│ └── return cached_content
├── content = read_file(resource_path)
├── validate_content(content)
├── loaded_resources[resource_path] = content
└── inject_to_context(content, priority="medium")
这种策略有两个好处:一是节省上下文空间,二是提高加载速度。如果一次性加载所有资源,不仅占用空间大,而且很多资源可能根本用不到。
08、深入源码:三个核心脚本的实现细节
前面讲了流程,现在咱们深入看看三个核心脚本的具体实现。这些代码都是我从 Claude Code 的安装目录里扒出来的,绝对一手资料。
08-1、init_skill.py:模板生成的艺术
这个脚本的核心任务是生成一个标准的 Skill 目录结构。它不只创建文件夹,还生成了一系列模板文件。
让我给你看看 SKILL_TEMPLATE 的完整内容:
SKILL_TEMPLATE = """---
name: {skill_name}
description: [TODO: Complete and informative explanation of what the skill does and when to use it. Include WHEN to use this skill - specific scenarios, file types, or tasks that trigger it.]
---
# {skill_title}
## Overview
[TODO: 1-2 sentences explaining what this skill enables]
## Structuring This Skill
[TODO: Choose the structure that best fits this skill's purpose...]
## Resources
This skill includes example resource directories...
"""
这个模板设计的很用心。它不仅包含了必需的 frontmatter,还在每个需要填写的地方加了 TODO 标记。这样用户在创建 Skill 后,能清楚地知道哪些地方需要修改。
08-2、package_skill.py:打包与验证的一体化
这个脚本的设计哲学是“先验证,后打包”。它调用了 quick_validate.py 来确保 Skill 的质量,只有验证通过的 Skill 才会被打包。
这里有个细节值得注意:打包时使用的是 zipfile.ZIP_DEFLATED 压缩方式。这意味着 .skill 文件实际上是一个压缩过的 zip 文件,只是换了扩展名。这种设计既保证了文件体积小巧,又方便了传输和存储。
with zipfile.ZipFile(skill_filename, 'w', zipfile.ZIP_DEFLATED) as zipf:
for file_path in skill_path.rglob('*'):
if file_path.is_file():
arcname = file_path.relative_to(skill_path.parent)
zipf.write(file_path, arcname)
08-3、quick_validate.py:六重验证机制
验证脚本采用了六重验证机制,每一重都有明确的目的:
- 文件存在性验证:确保 SKILL.md 存在
- Frontmatter 格式验证:确保有正确的 YAML 分隔符
- YAML 解析验证:确保 frontmatter 是合法的 YAML
- 必填字段验证:确保 name 和 description 存在
- 命名规范验证:确保 name 符合 hyphen-case
- 长度限制验证:确保 description 不超过 1024 字符
这种层层递进的验证方式,能在早期就发现各种问题,避免把有问题的 Skill 打包出去。
09、与其他 AI 工具的对比
讲真,Skill 系统是 Claude Code 的一大杀器。GPT 有 GPTs,Cursor 有 Rules,但 Claude Code 的 Skill 系统有几个独特之处:
1. 渐进式披露:只有被触发后才加载完整内容,节省上下文 2. 自由度分级:可以根据任务复杂度选择不同的约束程度 3. 验证机制:打包前强制验证,保证质量 4. 可执行脚本:支持 bundled scripts,可以执行确定性操作
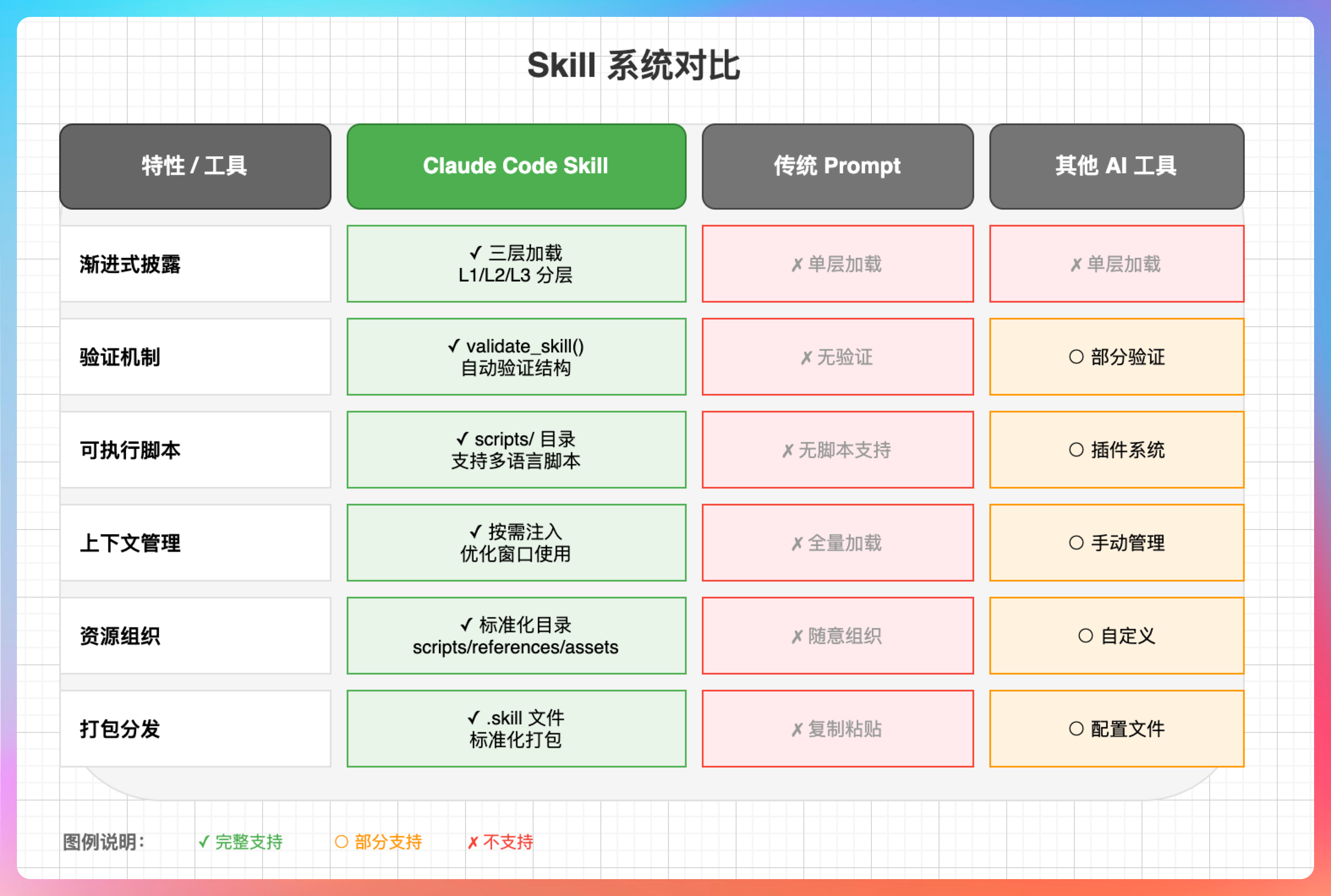
相比之下,GPT 的 GPTs 更侧重于知识库和对话定制,Cursor 的 Rules 更侧重于编码规范约束,而 Claude Code 的 Skill 则是把上下文管理、领域知识和可执行能力三者结合在了一起。
这也是为什么很多用 Claude Code 的开发者都在说,Skill 是真正改变工作流的功能。
10、实战建议:如何写出一个高质量的 Skill
说了这么多理论,最后给几个实战建议:
1. description 要写清楚触发条件
这是 Skill 被正确触发的关键。不要写得太宽泛,也不要太狭窄。要准确描述 Skill 能解决什么问题,什么场景下应该使用。
举个例子,好的 description 应该是这样: “Use when working with PDF documents for: (1) Extracting text and tables, (2) Merging or splitting PDFs, (3) Filling form fields, (4) Converting to other formats”
2. 保持 SKILL.md 简洁
不要超过 500 行。如果内容太多,把详细内容放到 references 里,SKILL.md 只保留核心流程。记住,SKILL.md 是指南,不是百科全书。
3. 多写示例
示例比说明更有用。在 SKILL.md 里多放一些具体的例子,让 Claude 知道怎么处理各种情况。比如你可以写:“When user says 'merge these PDFs', use scripts/merge_pdf.py”
4. 测试你的 Skill
在发布之前,多测试几次。看看触发是否准确,执行是否符合预期。一个好的 Skill 需要反复打磨。建议至少测试 5 个不同的场景,确保覆盖各种边界情况。
5. 善用 references
如果 Skill 涉及复杂的领域知识,比如数据库 schema、API 文档、业务规则,把这些放到 references 目录下。这样 SKILL.md 保持简洁,详细内容按需加载。
11、性能优化:Skill 系统的幕后功臣
很多人可能没注意到,Skill 系统在性能优化上也下了不少功夫。这些优化让 Skill 的执行既快速又高效。
11-1、Metadata 缓存机制
系统不会每次都重新读取所有 Skill 的 metadata,而是会缓存起来:
# 伪代码展示缓存机制
class SkillMetadataCache:
def __init__(self):
self.cache = {}
self.last_update = None
def get_metadata(self, skill_name):
if skill_name in self.cache:
if not self.is_expired(skill_name):
return self.cache[skill_name]
# 缓存未命中或已过期,重新读取
metadata = self.load_from_disk(skill_name)
self.cache[skill_name] = metadata
return metadata
def is_expired(self, skill_name):
# 检查文件修改时间
file_mtime = os.path.getmtime(skill_path)
return file_mtime > self.cache[skill_name].loaded_time
这种缓存机制避免了重复的文件读取,大大提高了响应速度。特别是在 Skill 数量较多时,效果更加明显。
11-2、增量加载策略
对于大型 reference 文件,系统采用了增量加载策略。不会一次性把整个文件都加载到上下文中,而是只加载需要的部分。
def load_reference_incremental(ref_path, section=None):
if section:
# 只加载指定章节
content = extract_section(ref_path, section)
else:
# 先加载目录和概述
content = extract_toc_and_summary(ref_path)
inject_to_context(content)
这种策略对于几百行的 reference 文档特别有用。你可以先加载目录,让 Claude 知道文档的结构,然后根据需要再加载具体内容。
11-3、脚本预编译
对于 Python 脚本,系统会检查是否有预编译的字节码(.pyc 文件)。如果有且没有过期,就直接使用字节码,省去了编译时间。
run_script("scripts/init_skill.py")
├── check_pyc_exists("scripts/init_skill.py")
│ └── if exists and not expired:
│ └── execute_pyc("scripts/__pycache__/init_skill.cpython-311.pyc")
│ └── else:
│ ├── compile_to_pyc("scripts/init_skill.py")
│ └── execute_pyc(compiled_path)
这些性能优化虽然用户感知不明显,但它们确保了 Skill 系统的流畅运行。一个好的系统,就应该让用户感觉不到它的存在。
12、安全机制:Skill 系统的防护网
Skill 系统在执行外部脚本时,有一套完善的安全机制。这确保了即使 Skill 来自不可信的来源,也不会对系统造成危害。
12-1、沙箱执行环境
脚本在沙箱环境中执行,限制了它们的权限:
def run_script_in_sandbox(script_path, args):
sandbox = Sandbox()
sandbox.restrict_network_access() # 限制网络访问
sandbox.restrict_file_access(allowed_dirs=["./temp"]) # 限制文件访问
sandbox.restrict_system_calls() # 限制系统调用
result = sandbox.execute(script_path, args)
return result
这种沙箱机制防止了恶意脚本对系统的破坏。即使脚本有问题,也只能在受限的环境中运行,无法访问敏感资源。
12-2、输入验证
所有传入脚本的用户输入都会经过严格验证:
def validate_user_input(user_input):
# 检查是否包含危险字符
dangerous_patterns = [';', '&&', '||', '`', '$(']
for pattern in dangerous_patterns:
if pattern in user_input:
raise SecurityError(f"Input contains dangerous pattern: {pattern}")
# 检查长度
if len(user_input) > 1000:
raise SecurityError("Input too long")
return sanitize_input(user_input)
这种验证防止了命令注入等攻击。用户的输入会被清理,确保不会被执行或解析为命令。
12-3、资源使用限制
脚本执行时有资源使用限制,防止资源耗尽攻击:
script_limits = {
"max_execution_time": 30, # 最多执行30秒
"max_memory_mb": 512, # 最多使用512MB内存
"max_file_size_mb": 100, # 最多读写100MB文件
"max_network_requests": 10 # 最多10次网络请求
}
这些安全机制让 Skill 系统既能提供强大的功能,又能保证系统的安全稳定。用户可以放心地使用各种 Skill,不用担心安全问题。
ending
拆解完 create-skill 的执行流程,我有一个很深的感触。
好的工具设计,不是把功能堆叠得越多越好,而是把复杂性留给系统,把简单性留给用户。
create-skill 涉及 3 个 Python 脚本、6 个主要步骤、数十个函数调用,但用户体验是流畅的、引导式的。你不需要知道背后发生了什么,只需要按照提示一步步走,就能创建出一个合格的 Skill。
这种“显式复杂、隐式简单”的设计理念,值得我们每个开发者学习。
AI 编程工具的竞争,最终比拼的不是谁的功能更多,而是谁能让用户更省心。Claude Code 的 Skill 系统,在这方面确实下了功夫。
【技术的价值,不在于它有多复杂,而在于它能让多少人的生活变得更简单。】
如果这篇内容对你有用,记得点赞,转发给需要的人。
我们下期见!

回复