


老王和蔼可亲地问:“知道我们阿里新成立的 token 事业群吗?”
“那必须啊,我可是提前做好功课的,不信我背给你听。”我自信满满地说。
全名 Alibaba Token Hub,简称 ATH,下设五个部门,分别是:
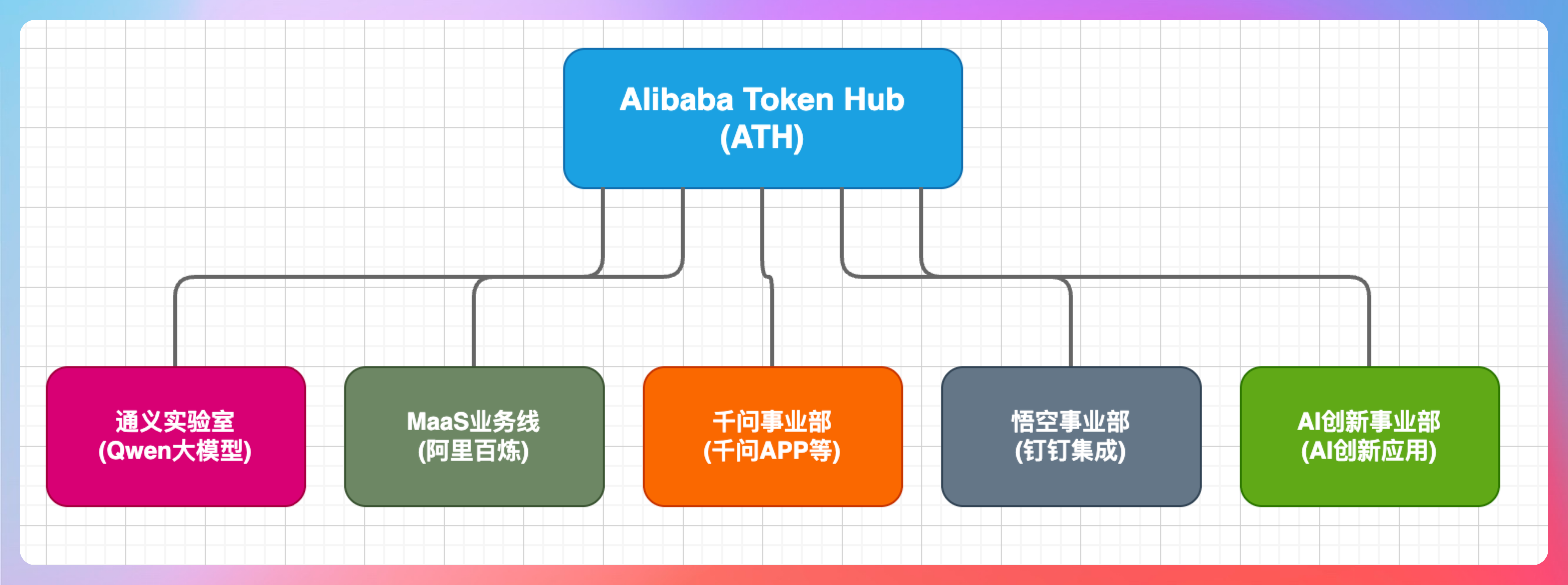
①、通义实验室:也就是 Qwen 大模型;②、MaaS 业务线:主要是阿里百炼那一套;③、千问事业部:包括千问 APP 等;④、悟空事业部:主要是钉钉那一套;⑤、AI 创新事业部:探索各类 AI 创新应用。
(内心 OS:你个糟老头子,想难倒我,没门,看我不狠狠吊打你 😄)
老王听完点点头:“背得挺熟。那我来问你几个实际的。”
content
01、你一天能烧多少 token?
老王开始压力了:“你一天能烧多少 token?”
我说:“王哥,就几十个吧。”
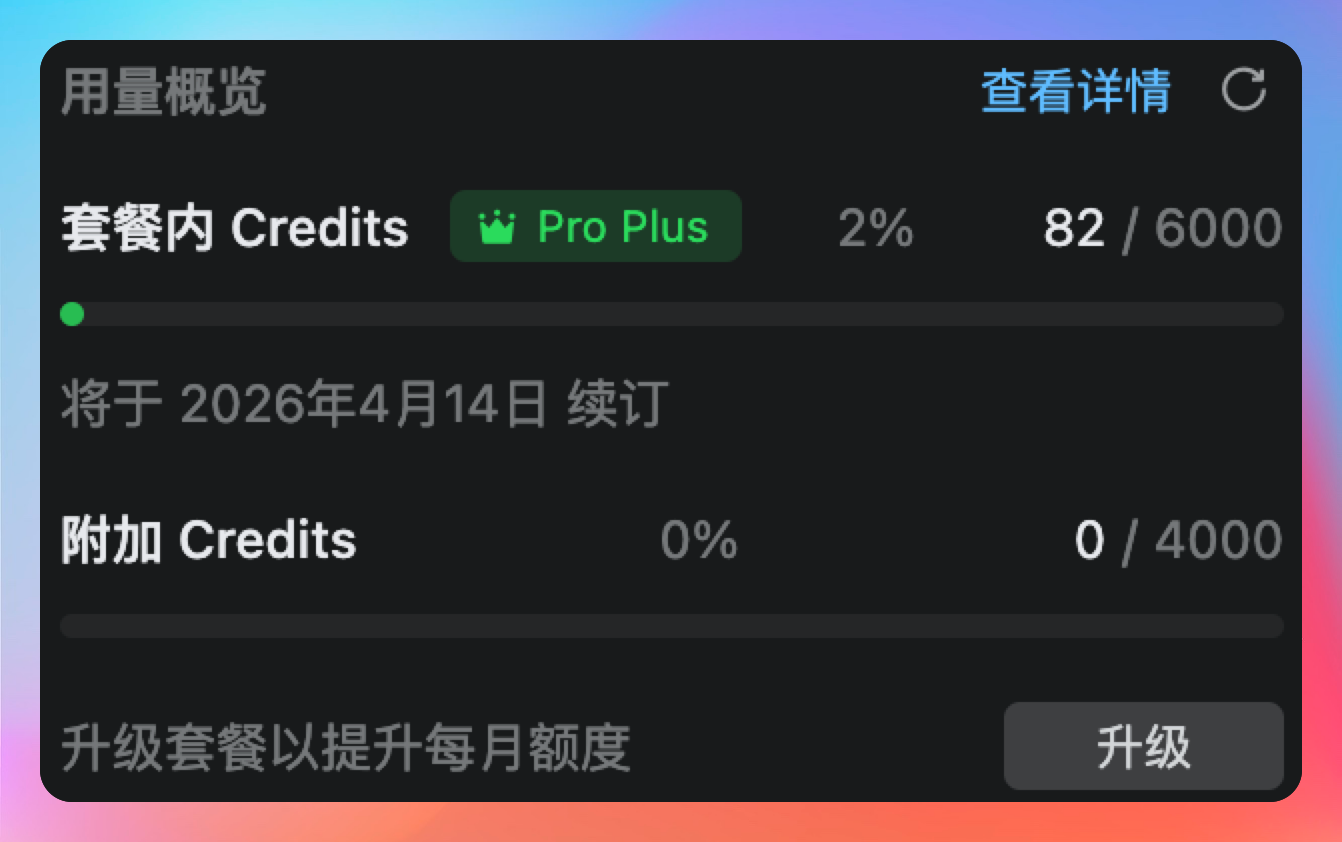
一看老王的脸色不太好看,我立马就改口了:“逗逗你的呀,王哥。我订阅了各种 Coding Plan,尤其是 Qoder,我订阅的是 6000 Credits 那个,一个月都不太够用。”
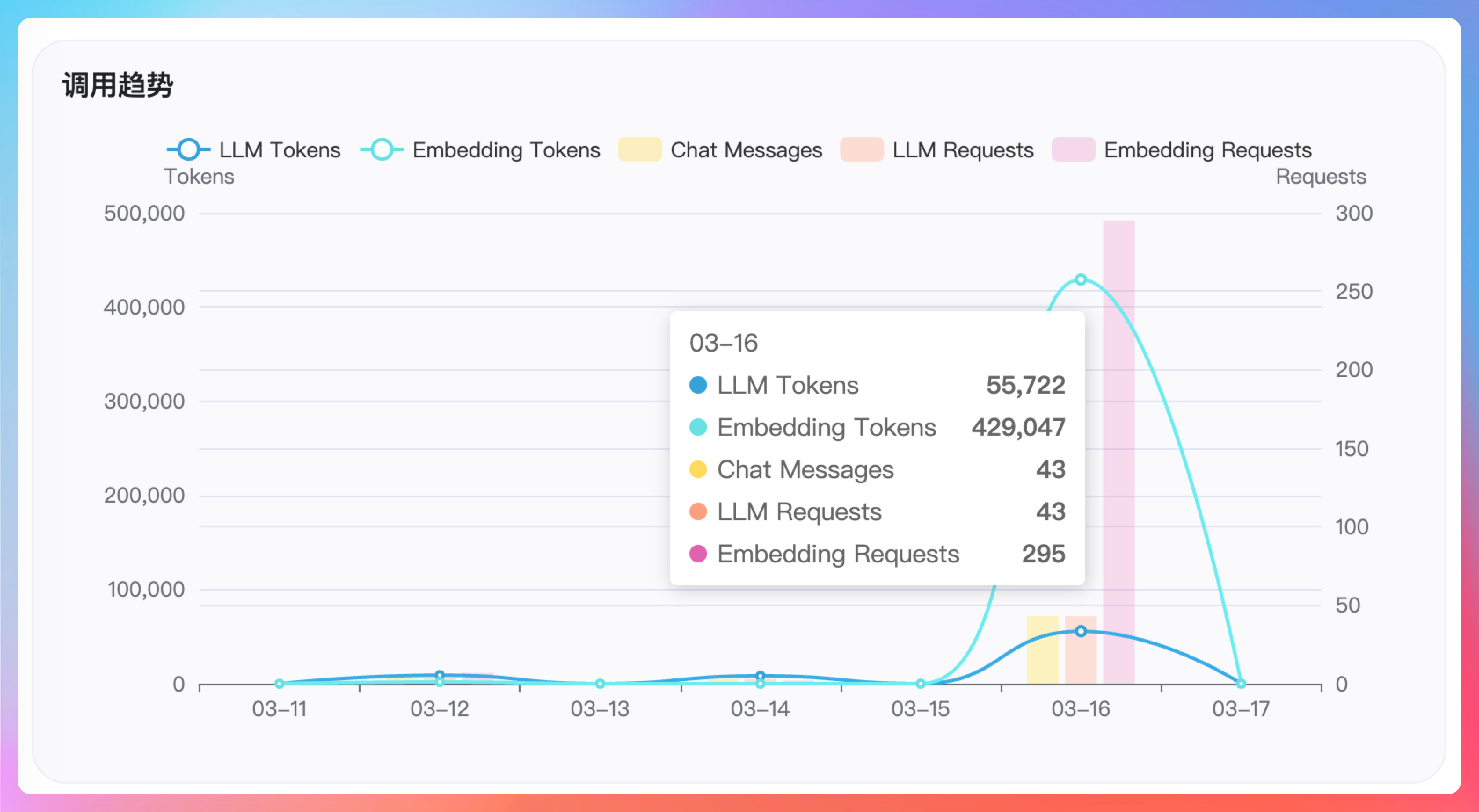
我接着说:“我昨天刚上架了派聪明 RAG 系统,发现 token 的消耗就有点顶不住。”
老王追问:“那你怎么优化 token 消耗?”
我说:“几个思路,我详细讲讲。”
“第一,prompt 压缩。很多 prompt 里都有冗余信息,比如重复的指令、不必要的示例。我在派聪明 RAG 中写了一个压缩算法,能自动识别并去除这些冗余。”
“第二,缓存机制。相同的问题,如果上下文没变,直接返回缓存结果,不再调用模型。”
“第三,模型分级。简单任务用轻量级模型,比如 Qwen-Turbo,速度快、成本低。复杂任务才用大模型,比如 GPT-5.4。”
“第四,批量处理。多个相似的问题,合并成一次调用,减少 API 请求次数。”
老王听完眼睛一亮:“批量处理这个思路不错,具体怎么实现的?”
我说:“用消息队列做缓冲。用户的问题先入队列,然后按时间窗口聚合,比如 100ms 内的相似问题合并成一次批量请求。这样 API 调用次数能减少 70%。”
老王点点头:“有成本意识,还懂工程优化,不错。”
02、简历上为什么都在写 AI 相关的内容?
老王翻着我的简历:“我看你简历上全是 AI 项目,有派聪明 RAG,有 PaiFlow Agent,传统开发经验怎么没写?”
我说:“王哥,不是我不写,是我觉得 AI 相关的内容更能体现我的竞争力。”
“传统开发我会,Java、Spring Boot、MyBatis 这些八股你随便问,没有我背不出来的,哦不,没有我回答不上来的。但现在是什么时代?AI 时代。HR 和你们这些面试官看简历,第一眼想看的不就是有没有 AI 开发经验?”
“再说了,AI 开发不是空中楼阁,底层还是传统开发。RAG 系统要用向量数据库,得懂 ElasticSearch;Agent 要调用 API,得懂 HTTP 或者 MCP 协议;工作流要编排任务,得懂并发编程、消息队列。”
老王追问:“那你觉得传统后端开发和 AI 应用开发最大的区别是什么?”
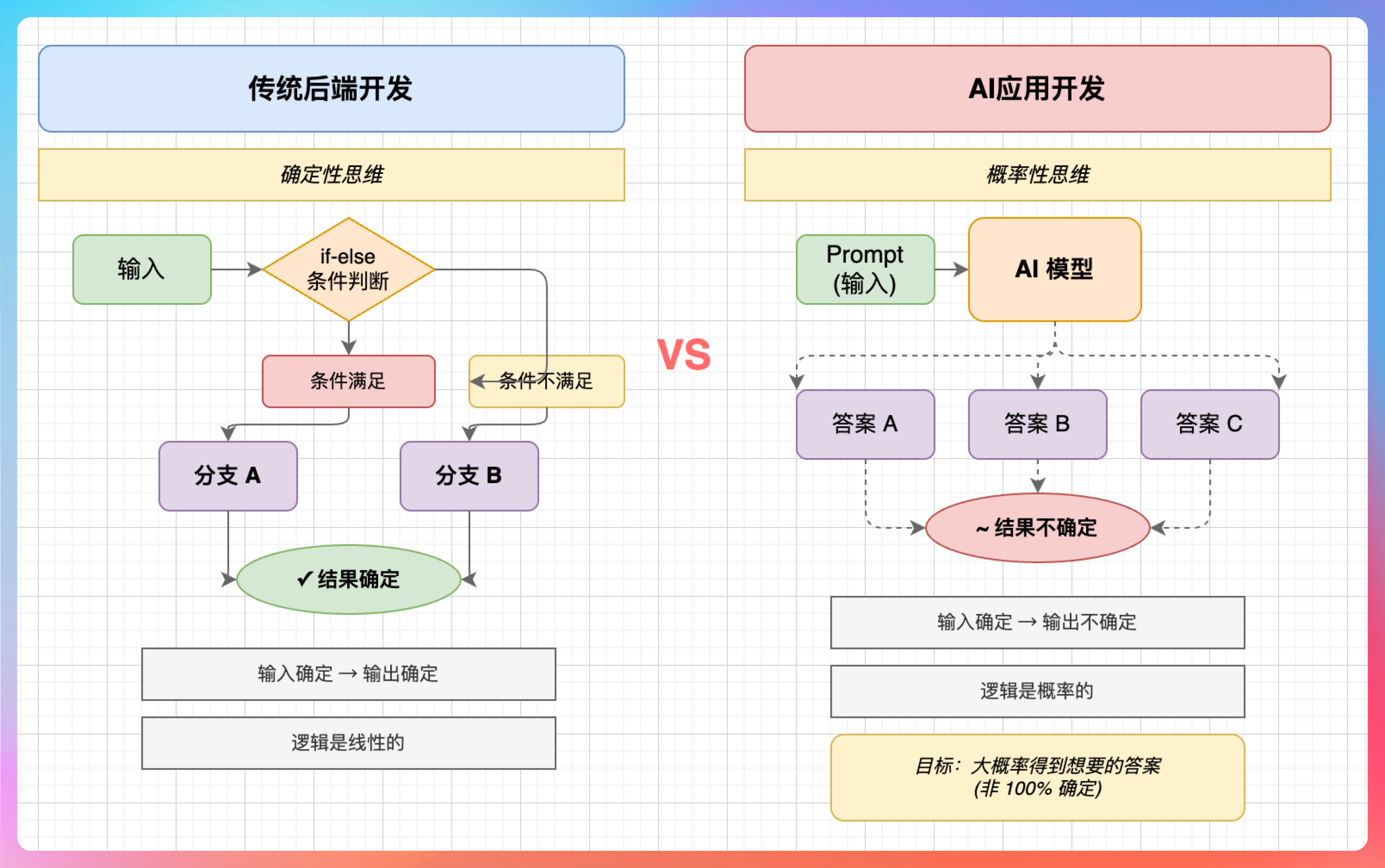
我说:“最大的区别是思维方式。”
“传统开发是确定性思维,输入确定,输出确定,逻辑是线性的。AI 开发是概率性思维,输入确定,输出不确定,逻辑是概率的。”
“比如传统开发,你写个 if-else,条件满足就走 A 分支,不满足就走 B 分支,结果是确定的。”
“AI 应用开发不一样,你给模型一个 prompt,它可能给你 A 答案,也可能给你 B 答案,甚至给你 C 答案。你要设计的是怎么让模型大概率给你想要的答案,而不是 100%确定。”
“这种思维方式的转变,是很多传统开发转 AI 开发最难适应的地方。”
老王点点头:“这个观察很深刻。那我问你,什么是 RAG?”
03、什么是 RAG?
我说:“RAG,是 Retrieval-Augmented Generation 的缩写,也就是检索增强生成。”
“简单说,就是让大模型在回答问题之前,先去知识库里检索相关信息,然后把检索结果作为上下文,一起送给大模型生成回答。”
“这样做有两个好处:
一是解决大模型的知识截止问题。大模型的训练数据有截止日期,之后发生的事情它不知道。RAG 通过实时检索,可以获取最新信息。
二是解决大模型的幻觉问题。大模型有时候会一本正经地胡说八道。RAG 通过检索真实文档,让回答有据可依。”
老王追问:“RAG 的核心流程是什么?”
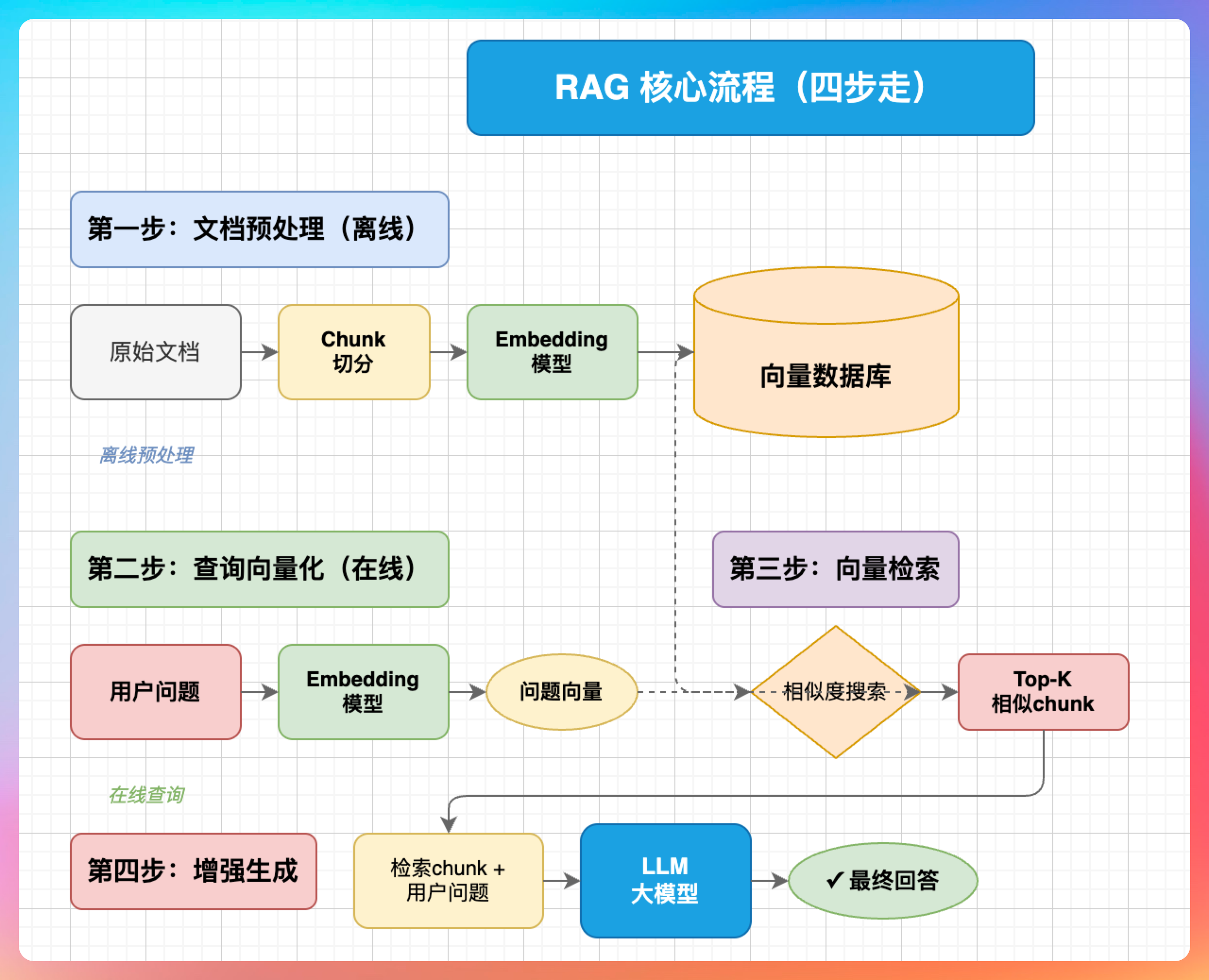
我说:“四步走:
第一步,文档预处理。把原始文档切分成 chunk,用 embedding 模型转成向量,存入向量数据库。
第二步,查询向量化。用户提问时,把问题也转成向量。
第三步,向量检索。在向量数据库里找最相似的 chunk。
第四步,增强生成。把检索到的 chunk 作为上下文,和问题一起送给大模型,生成最终回答。”
老王追问:“RAG 和微调有什么区别?什么时候用 RAG,什么时候用微调?”
我说:“这是个好问题,很多人搞混。”
“RAG 是检索增强,不改变模型本身,只是给模型提供额外的上下文。适合知识频繁更新、需要实时性的场景。”
“微调是改变模型参数,让模型学会新的知识。适合知识相对稳定、需要深度理解的场景。”
“我的判断标准是:如果知识更新频率高于一周,用 RAG;如果低于一周,可以考虑微调。”
“另外,RAG 成本低,不需要训练;微调成本高,需要标注数据和算力。”
老王点点头:“判断标准清晰。那你做的 RAG 智能报价系统是在哪个公司?”
04、RAG 智能报价系统是在哪个公司做的?
我说:“是在上一家公司,一家做 B2B 供应链的企业。”
“他们的业务场景是:采购商在平台上传需求文档,系统需要根据文档内容,自动生成报价方案。”
“传统做法是人工看文档、人工写报价,一个单子平均要 2 小时。用 RAG 之后,系统自动解析文档、匹配历史报价、生成报价方案,平均 5 分钟搞定。”
老王追问:“技术上有哪些难点?”
我说:“三个难点。”
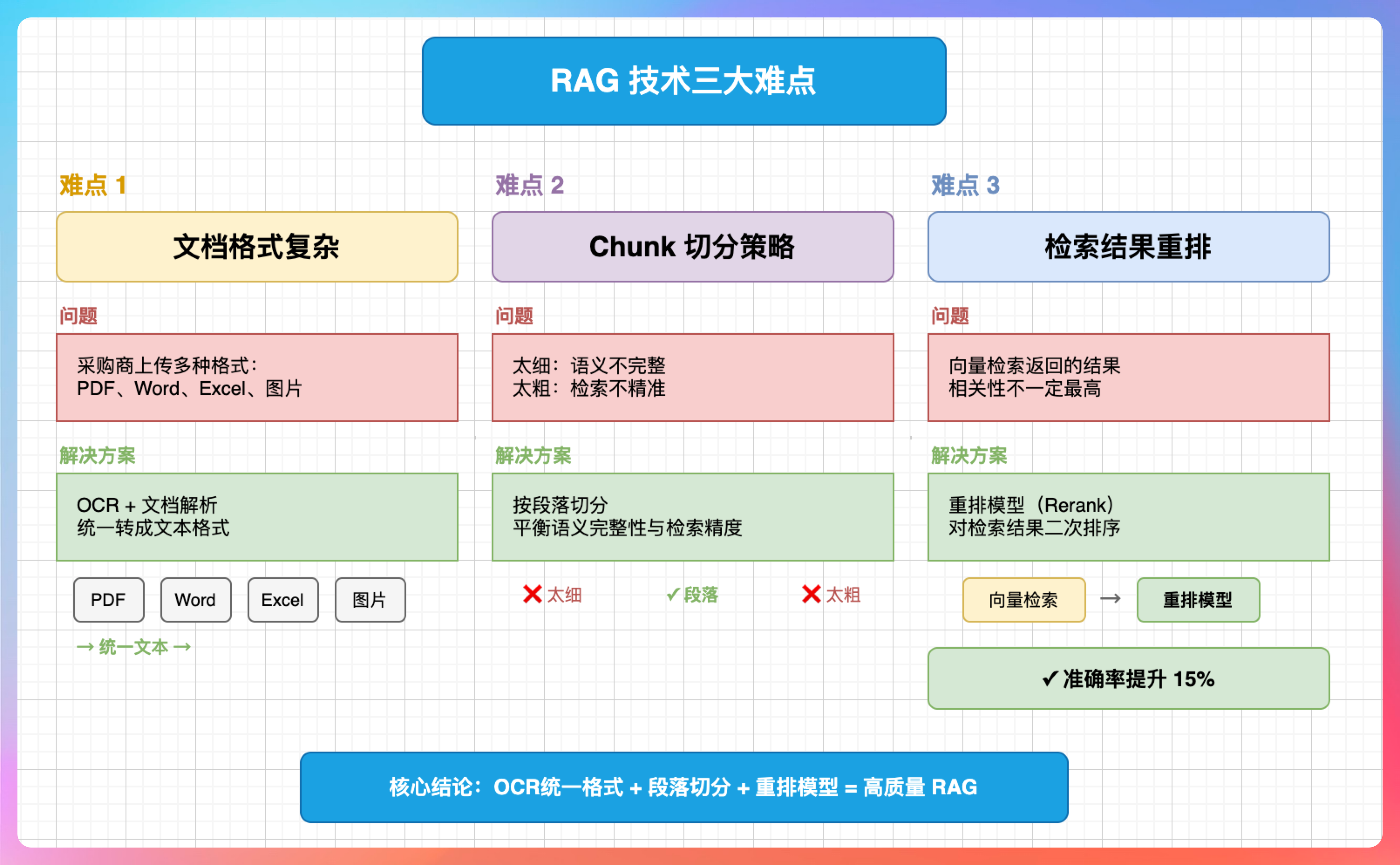
“第一,文档格式复杂。采购商上传的文档有 PDF、Word、Excel,还有图片。我们用了 OCR+文档解析,先把各种格式转成文本,再做后续处理。”
“第二,chunk 切分策略。切得太细,语义不完整;切得太粗,检索不精准。我们试了多种策略,最终按段落切分,效果比较好。”
“第三,检索结果重排。向量检索返回的结果,相关性不一定是最高的。我们加了重排模型,对检索结果二次排序,准确率提升了 15%。”
老王眼睛一亮:“不错,技术细节也讲清楚了。那你在这个项目里担任什么角色?”
05、你在 RAG 项目中担任什么角色?
我说:“我是技术负责人,带了一个 5 人的小团队。”
“具体工作包括:
技术选型:调研了 Milvus、Pinecone、Weaviate、ElasticSearch 等向量数据库,最终选了 ElasticSearch,因为性能好、社区活跃。
架构设计:设计了文档预处理服务、向量检索服务、报价生成服务三个核心模块。
模型调优:针对报价场景,微调了 embedding 模型,让检索准确率从 75%提升到 92%。
工程落地:解决了文档格式兼容、chunk 切分策略、检索结果重排等工程问题。”
老王追问:“安装包这些东西都是你整理的还是协助的?”
06、安装包这些东西都是你整理的还是协助的?
我说:“安装包是我主导整理的。”
“因为 RAG 系统涉及多个组件:向量数据库、embedding 服务、大模型 API、业务后端。部署起来很麻烦,我整理了一键安装包,把 Docker Compose 配置、环境变量模板、初始化脚本都打包进去。”
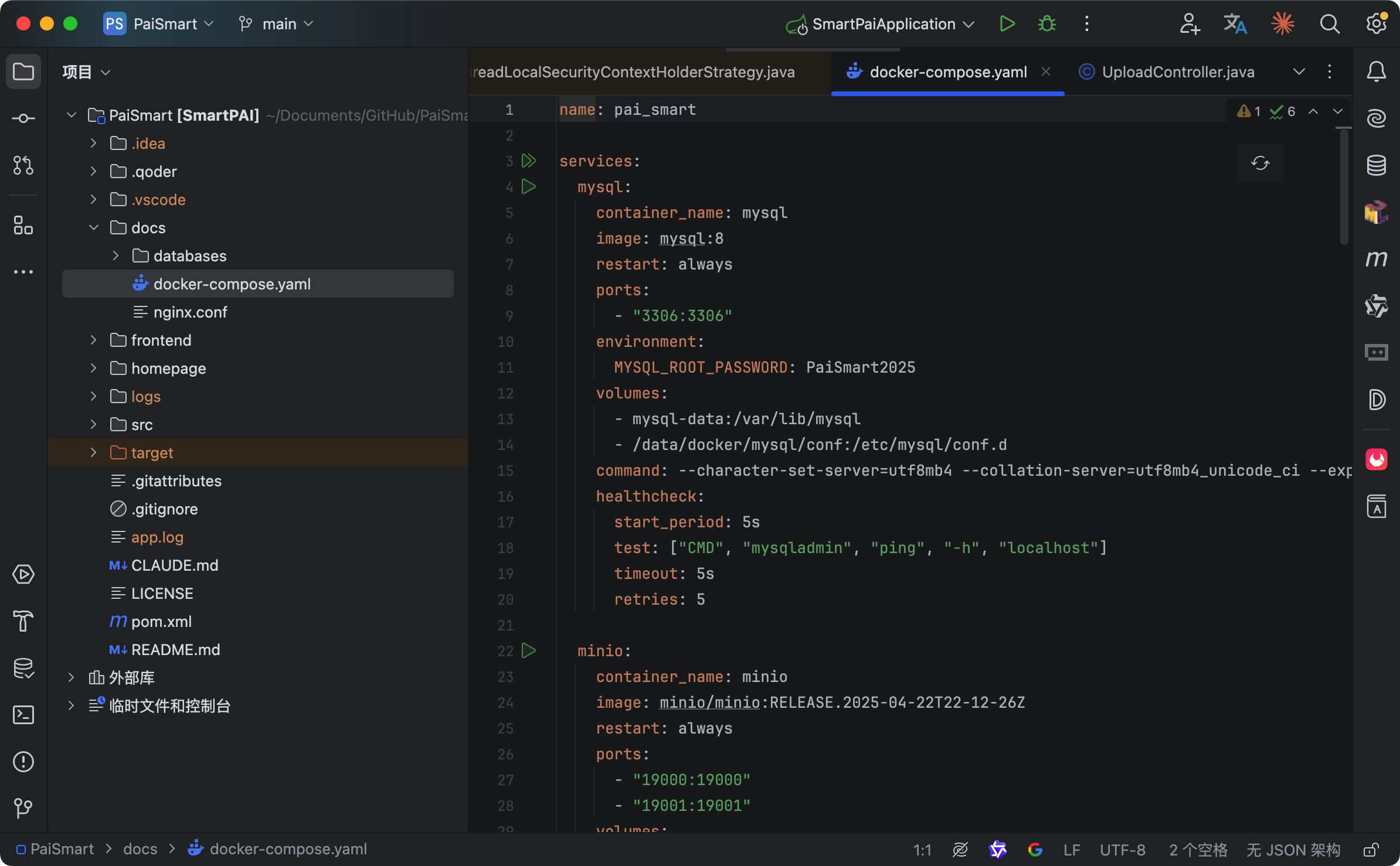
“新环境部署,原来需要一天,现在半小时搞定。”
老王问:“镜像打包是开发打包还是你负责?”
07、镜像打包是开发打包还是你负责?
我说:“CI/CD 流程是我搭建的,但镜像打包是自动化的。”
“我用 GitLab CI 做了流水线:代码提交 → 自动测试 → 构建镜像 → 推送仓库 → 触发部署。开发人员只需要写代码,打包部署全是自动的。”
“镜像分层也做了优化,基础镜像和业务镜像分开,构建时间从 10 分钟降到 3 分钟。”
“另外,镜像安全扫描也做了。用 Trivy 扫描镜像漏洞,高危漏洞自动阻断发布。”
老王追问:“如果镜像构建失败,怎么排查?”
我说:“先看构建日志,定位失败步骤。常见原因有:依赖下载失败、单元测试不通过、Dockerfile 语法错误。”
“如果是依赖下载失败,检查网络或者换国内镜像源。如果是测试不通过,本地先跑通再提交。如果是 Dockerfile 错误,用 docker build --progress=plain 看详细日志。”
老王点点头:“工程化能力不错。那 AI 运维智能管理平台是一个什么平台?”
08、AI 运维智能管理平台是一个什么平台?
我说:“这是我最近做的一个项目,用 AI 来辅助运维工作。”
“平台核心功能包括:
日志分析:自动分析系统日志,识别异常模式,提前预警。
故障诊断:出现故障时,自动收集相关信息,给出可能的原因和解决方案。
资源优化:分析服务器资源使用情况,给出优化建议,比如哪些服务可以缩容、哪些需要扩容。
知识库问答:把运维文档、历史 case 都录入知识库,运维同学可以直接问 AI,不用翻文档。”
老王问:“这个平台用了什么技术?”
我说:“底层是 RAG+Agent 的技术栈,上层用 LangGraph4j 做了工作流编排。”
老王追问:“工作流是什么?”
09、工作流是什么?(LangGraph4j)
我说:“工作流,就是把一系列任务按照一定的逻辑顺序编排起来,自动执行。”
“LangGraph4j 是一个 Java 的工作流编排框架,特别适合做 AI 任务的工作流。”
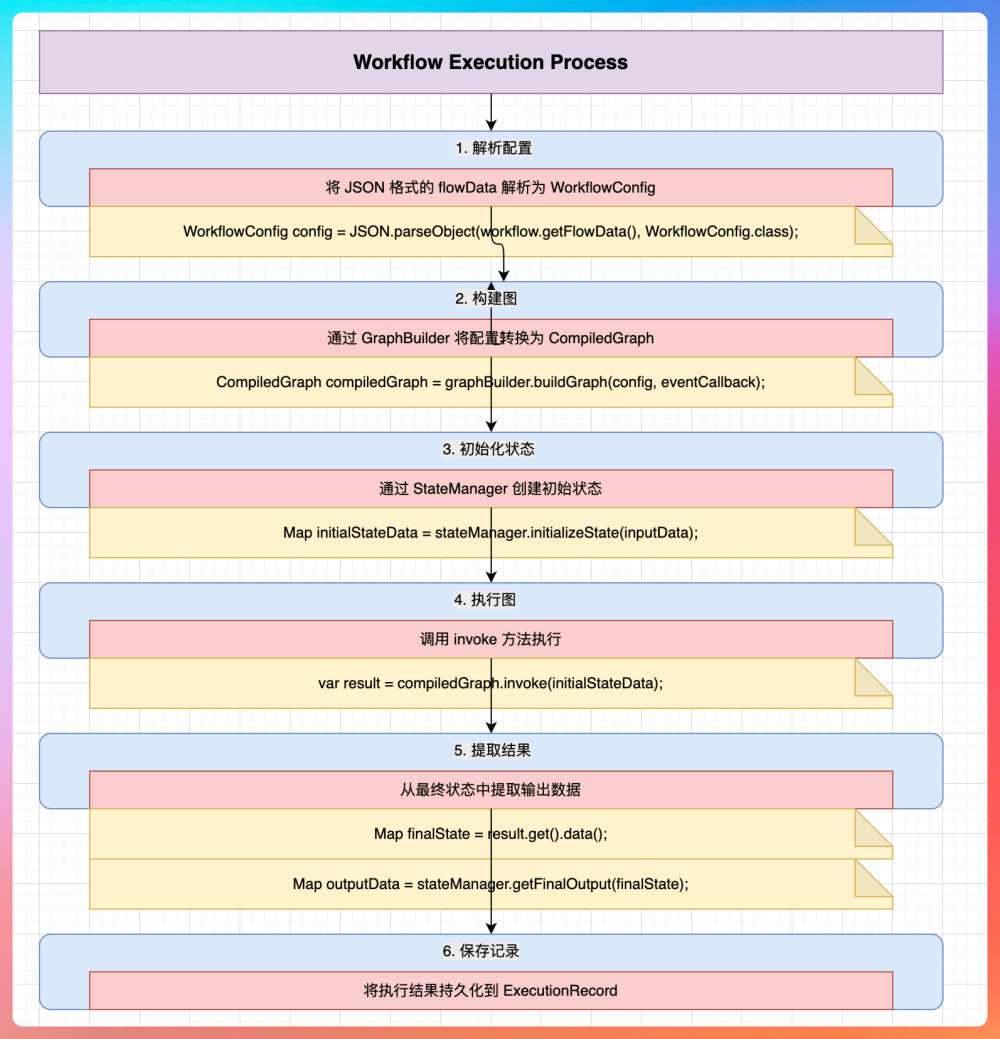
“比如故障诊断这个场景,工作流可以这么设计:
第一步,接收告警通知;第二步,查询相关日志;第三步,分析日志内容;第四步,查询知识库;第五步,生成诊断报告;第六步,通知运维人员。”
“每个步骤都是一个节点,节点之间可以设置条件分支。比如如果日志分析发现是磁盘满了,直接走磁盘清理分支;如果是内存溢出,走服务重启分支。”
老王问:“这个工作流不是 AI 的那个工作流是吧?”
10、这个工作流不是 AI 的那个工作流是吧?
我说:“王哥,这个问题问得好。”
“传统的工作流,比如 BPMN,是给人执行的流程,强调流程的规范性和可追溯性。”
“AI 的工作流,比如 LangGraph,是给 AI 执行的流程,强调任务的自动化和智能化。”
“LangGraph4j 是两者的结合:用工作流的结构来保证任务的完整性,用 AI 的能力来完成具体的任务。”
“比如故障诊断工作流,流程结构是固定的,但具体的日志分析、原因推断,都是 AI 来完成的。”
老王点点头:“区分清楚了。平常开发用 AI 工具多吗?”
11、平常开发用 AI 工具多吗?
我说:“多,现在基本离不开 AI 工具了。”
“搭项目骨架的时候,我会用 Qoder 的 Quest 模式;读源码我会用 TRAE 的 Gemini;开发任务我会交给 Codex。”
“但用得最多的还是 Claude Code。”
老王追问:“请讲一下你在 AI 编程中的使用经验,比如 Claude Code。”
12、请讲一下你在 AI 编程中的使用经验,比如 Claude Code。
我说:“Claude Code 是我目前的主力开发工具。”
“我用它做过几件事:
一是代码重构。给一个指令,它能自动理解代码逻辑,给出重构方案,甚至直接生成重构后的代码。
二是 Bug 修复。把报错信息丢给它,它能分析可能的原因,给出修复建议。有时候甚至能直接定位到问题代码。
三是代码生成。写重复性的代码特别快,比如 CRUD 接口、单元测试,几分钟就能生成一套。
四是技术调研。遇到不熟悉的技术,直接问它,比查文档快多了。”
老王问:“Claude Code 和传统的 IDE 插件有什么区别?”
我说:“传统插件是辅助,Claude Code 是协作。”
“传统插件只能做代码补全、语法检查这些基础功能。Claude Code 能理解你的意图,参与整个开发流程。”
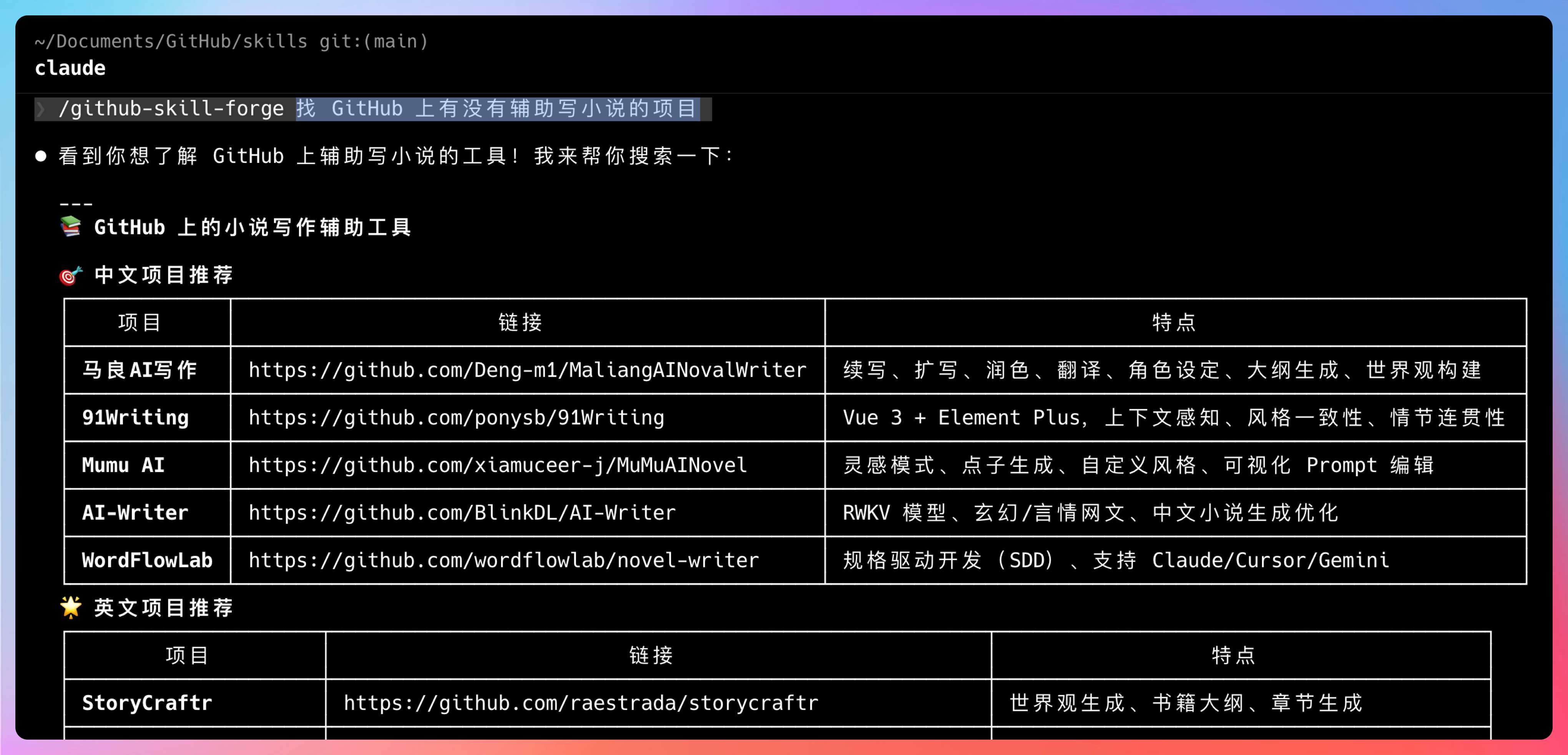
“比如你说‘/github-skill-forge 找 GitHub 上有没有辅助写小说的项目’,它能按照某个 Skills 帮我找出来我想要的源码,然后下载到本地后进行快速的二次开发。”
老王点点头:“最近很火的 OpenClaw 了解过吗?”
13、最近很火的 OpenClaw 了解过吗?
我说:“太了解了,我自己部署了好几个 Agent。”
“OpenClaw 是一个 Agent 框架,让你可以用自然语言指挥 AI 完成复杂任务。”
“我自己部署了三个 Agent:一个是 gitcode 账号审核助手,一个是技术文档生成助手,还有一个是定时任务监控助手。”
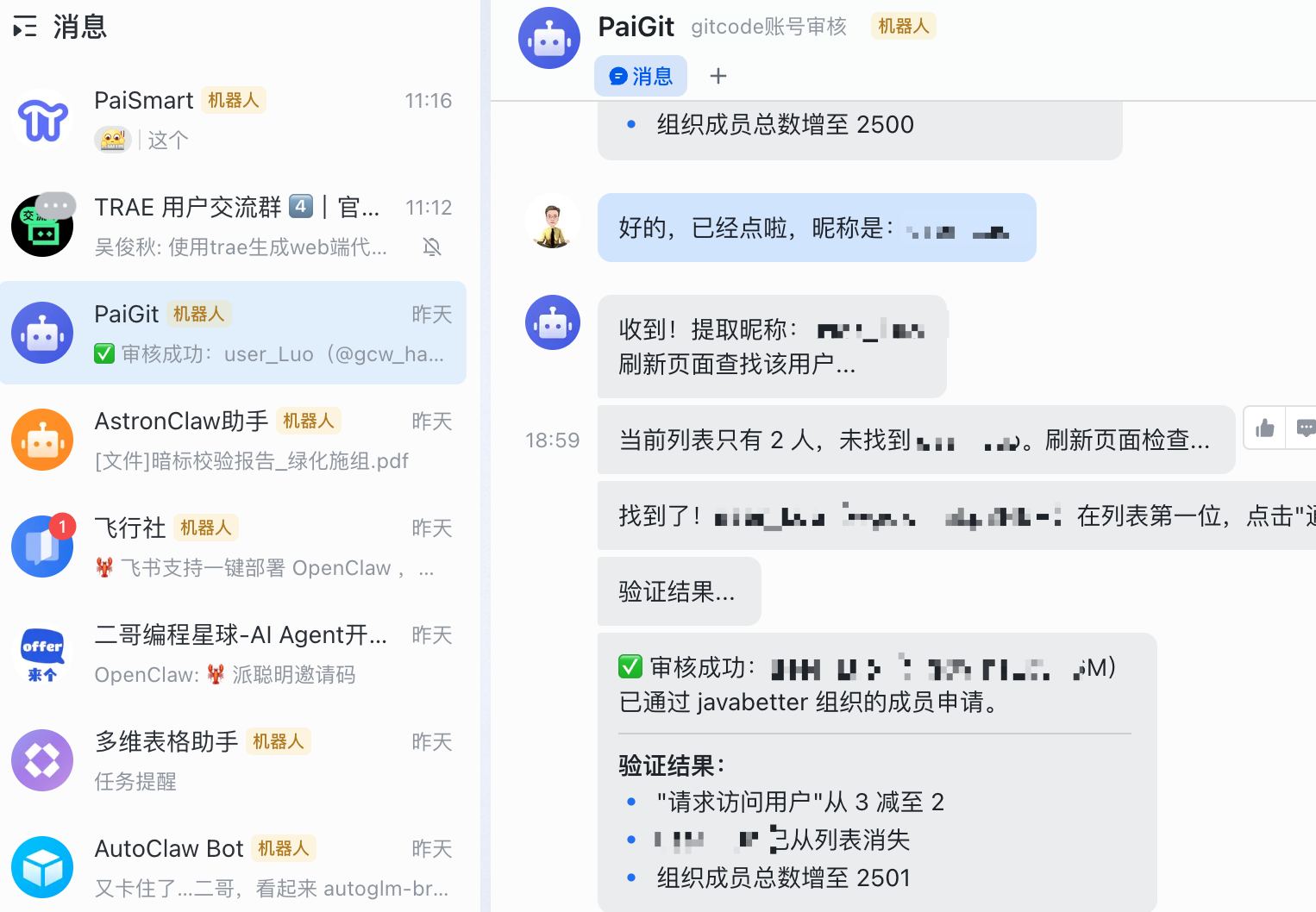
“比如 gitcode 审核这个场景,以前我要手动登录后台、搜索用户、添加权限,一个账号要 2 分钟。现在我把流程教给 Agent,它在后台自动执行,20 个账号 1 分钟搞定。”
老王眼睛一亮:“效率提升很明显啊。那如果让你设计一个 Agent,它的长短期记忆你打算怎么设计?”
14、如果让你设计一个 Agent,它的长短期记忆你打算怎么设计?
我说:“我会设计两层记忆:短期记忆和长期记忆。”
“短期记忆,Session,存储当前对话的上下文。包括用户输入、Agent 回复、工具调用结果。短期记忆在内存中,对话结束就清空。”
“长期记忆,Memory,存储跨对话的重要信息。比如用户偏好、历史结论、关键事实。长期记忆持久化到磁盘,下次对话可以读取。”
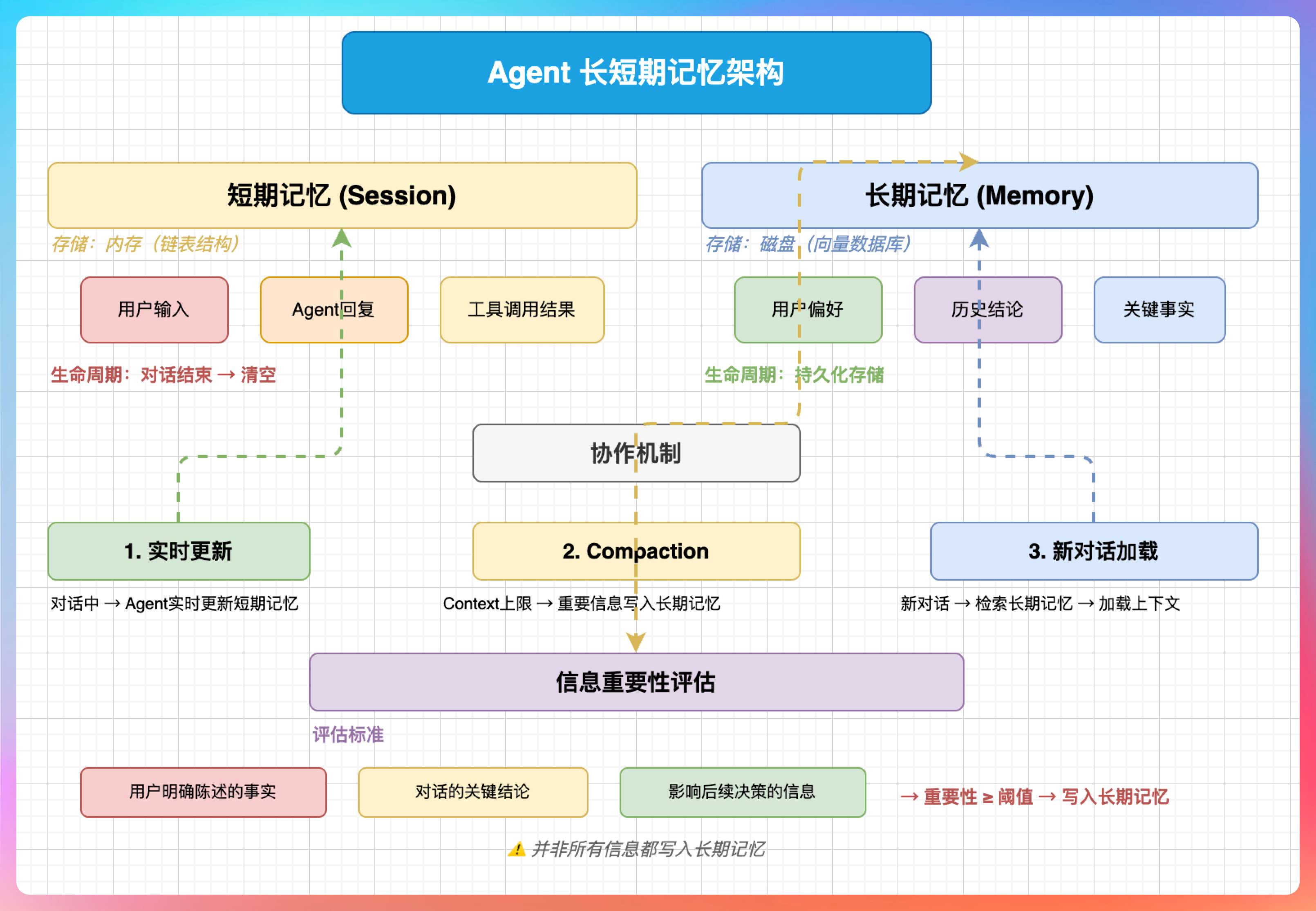
“两者的协作方式是:对话过程中,Agent 实时更新短期记忆;当短期记忆接近 Context 上限时,触发 Compaction,把重要信息写入长期记忆;新对话开始时,从长期记忆中检索相关信息,加载到上下文中。”
“具体实现上,短期记忆存在内存里,用链表结构,方便快速插入和删除。长期记忆存在磁盘上,用向量数据库,方便语义检索。”
“还有一个细节:不是所有信息都值得写入长期记忆。Agent 会评估信息的重要性,只有重要程度超过阈值的才会写入。评估标准包括:用户明确陈述的事实、对话的关键结论、可能影响后续决策的信息。”
老王追问:“OpenClaw 的核心组件有哪些?”
15、OpenClaw 的核心组件有哪些?
我说:“五个核心组件:”
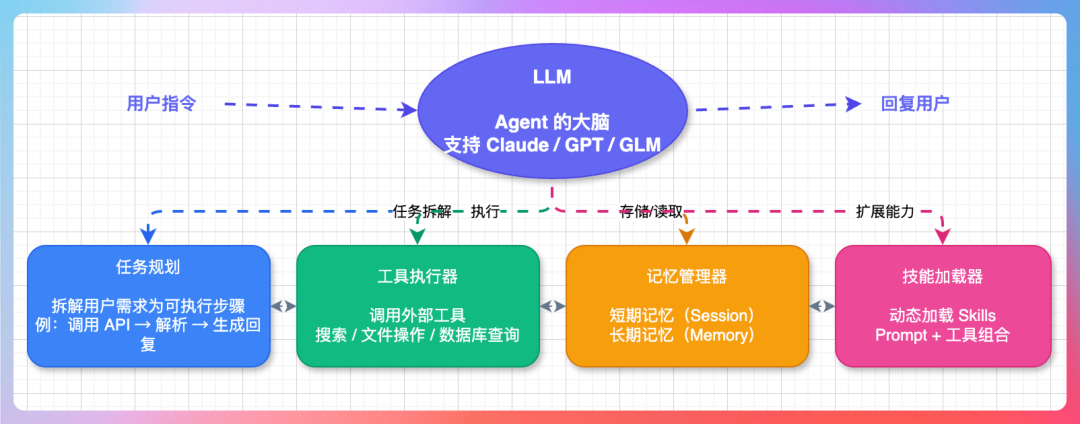
“LLM,大语言模型,Agent 的大脑,负责理解指令、规划任务、生成回复。”
“Task Planner,任务规划器,把用户需求拆解成可执行的任务步骤。”
“Tool Executor,工具执行器,负责调用外部工具,比如搜索、文件操作。”
“Memory Manager,记忆管理器,管理短期记忆和长期记忆。”
“Skill Loader,技能加载器,动态加载 Skills,扩展 Agent 能力。”
“这五个组件之间通过消息总线通信,互相解耦。比如你可以把 LLM 从 Claude 换成 GPT,其他组件感知不到变化。”
“另外,OpenClaw 还有 8 个配置文件,定义 Agent 的完整人格。AGENTS.md 定义能力边界,SOUL.md 注入灵魂,TOOLS.json 划定禁区,SKILLS.json 配置技能,MEMORY.json 管理记忆,SESSION.json 管理会话,ROUTER.json 配置路由,CONFIG.json 其他配置。”
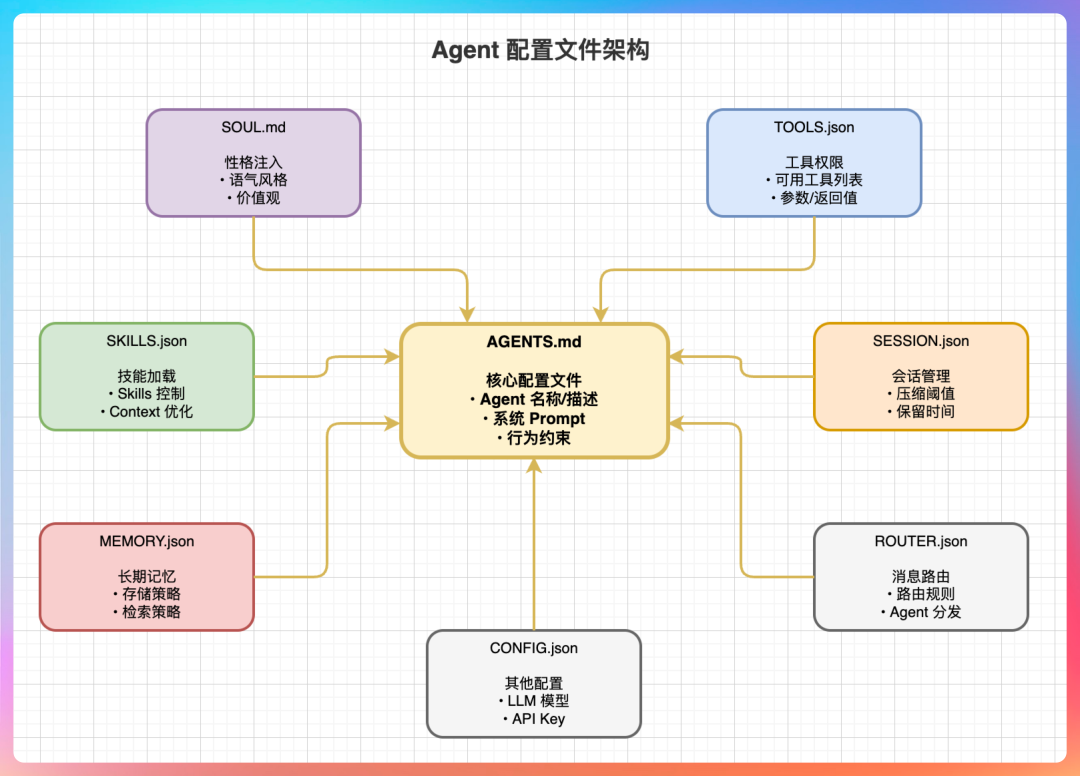
老王问:“Agent 是常驻进程吗?”
16、Agent 是常驻进程吗?
我说:“不是,Agent 是 per-session 的瞬态实例。”
“每个对话都是一次完整的加载-执行-销毁循环。用户发起对话时,Agent 加载配置、初始化记忆;对话过程中,Agent 执行任务;对话结束,Agent 保存状态、释放资源。”
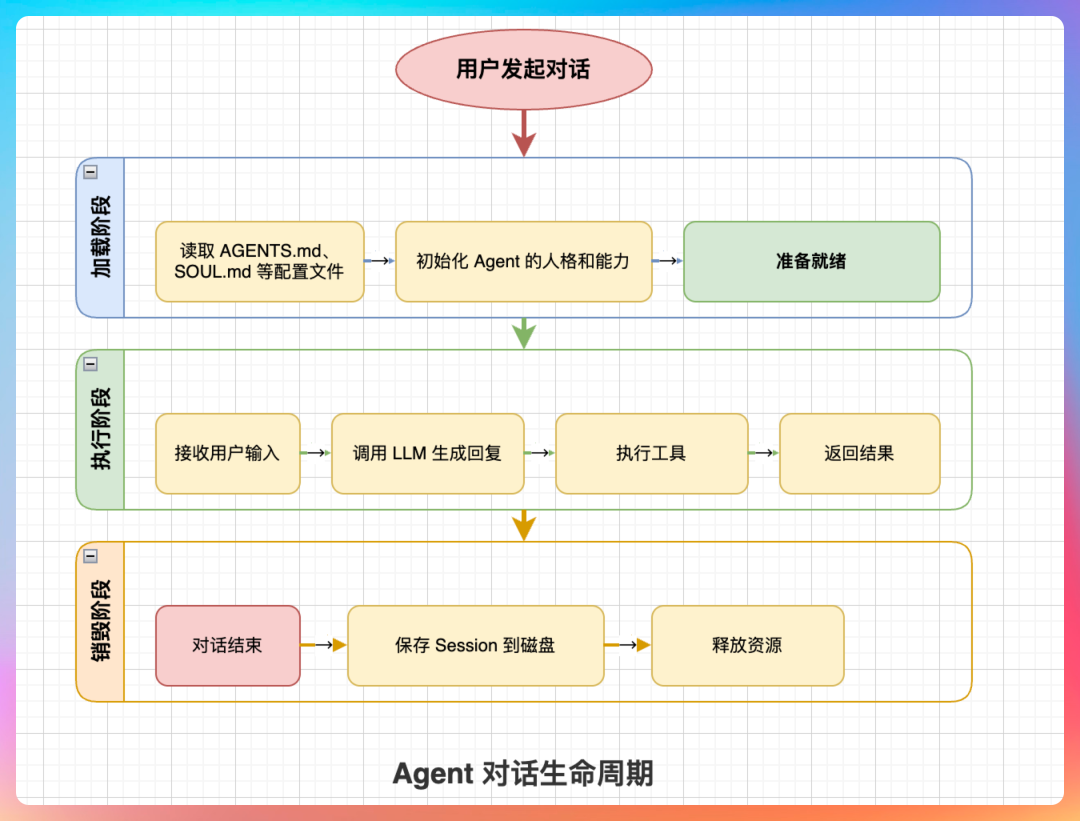
“这种设计的好处是资源节省,Agent 不用一直占用内存;配置实时生效,每次 run 都会重新读取配置文件。”
“还有一个好处是隔离性。每个对话都是独立的 Agent 实例,一个对话出问题不会影响其他对话。”
老王追问:“Session 太长,会不会挤爆 LLM 的 Context?”
17、Session 太长,会不会挤爆 LLM 的 Context?
我说:“会,所以 OpenClaw 做了优化。”
“两个机制:Compaction 和 Pruning。”
“Compaction,压缩,当 Session 接近 Context 上限时,Agent 把重要信息写入 Memory,然后压缩 Session 内容。”
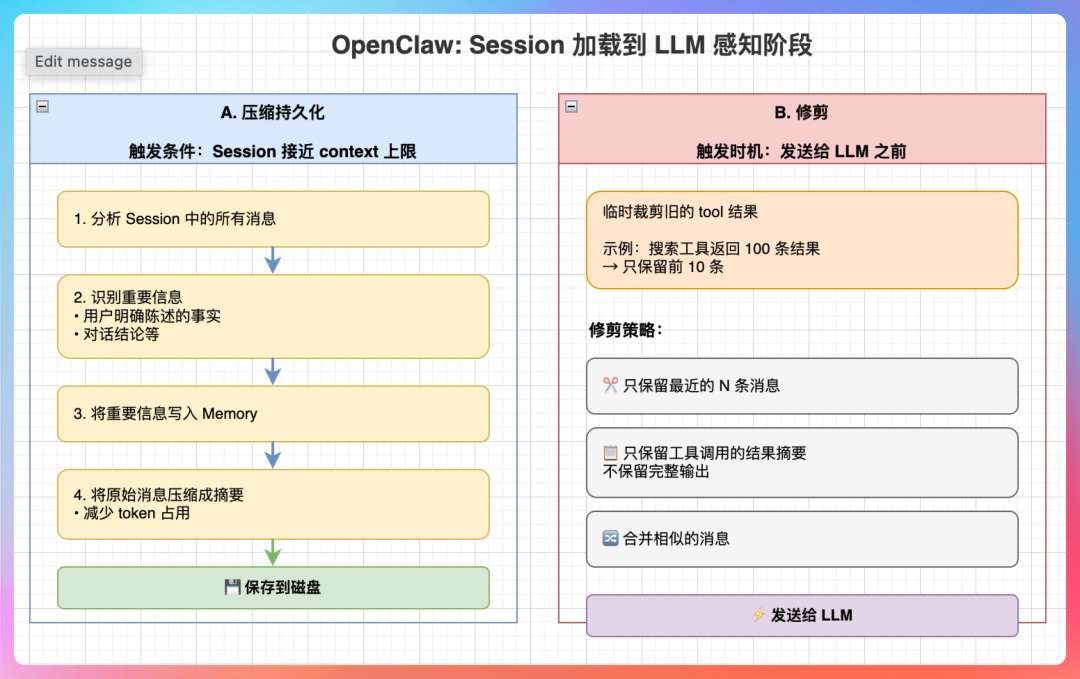
“Pruning,修剪,在发送给 LLM 之前,临时裁剪旧的 tool 结果。比如搜索返回 100 条结果,但 LLM 只需要前 10 条,后面的就剪掉。”
“Compaction 是持久化的,重要信息会长期保存。Pruning 是临时的,只影响当前请求。”
“具体数值上,当 Session 长度超过 4000 个 token 时,触发 Compaction。Pruning 会保留最近 2000 个 token,裁剪更早的内容。”
“还有一个优化:如果某个 tool 调用结果特别大,比如搜索返回了 1000 条结果,Pruning 会直接取前 10 条,其他的全部丢弃。”
老王点点头:“Memory 机制是怎么设计的?”
18、Memory 机制是怎么设计的?
我说:“Memory 机制分三个阶段:写入、存储、读取。”
“写入阶段,Agent 分析 Session 内容,提取重要信息,包括用户明确陈述的事实、对话中的重要结论、Agent 生成的有价值信息。”
“存储阶段,写入的 Memory 存到 memory.jsonl 文件,每条 Memory 包含 content、timestamp、importance、tags。”
“读取阶段,新对话开始时,根据当前对话内容,检索相关的 Memory。检索策略包括关键词匹配、语义相似度、时间衰减。”
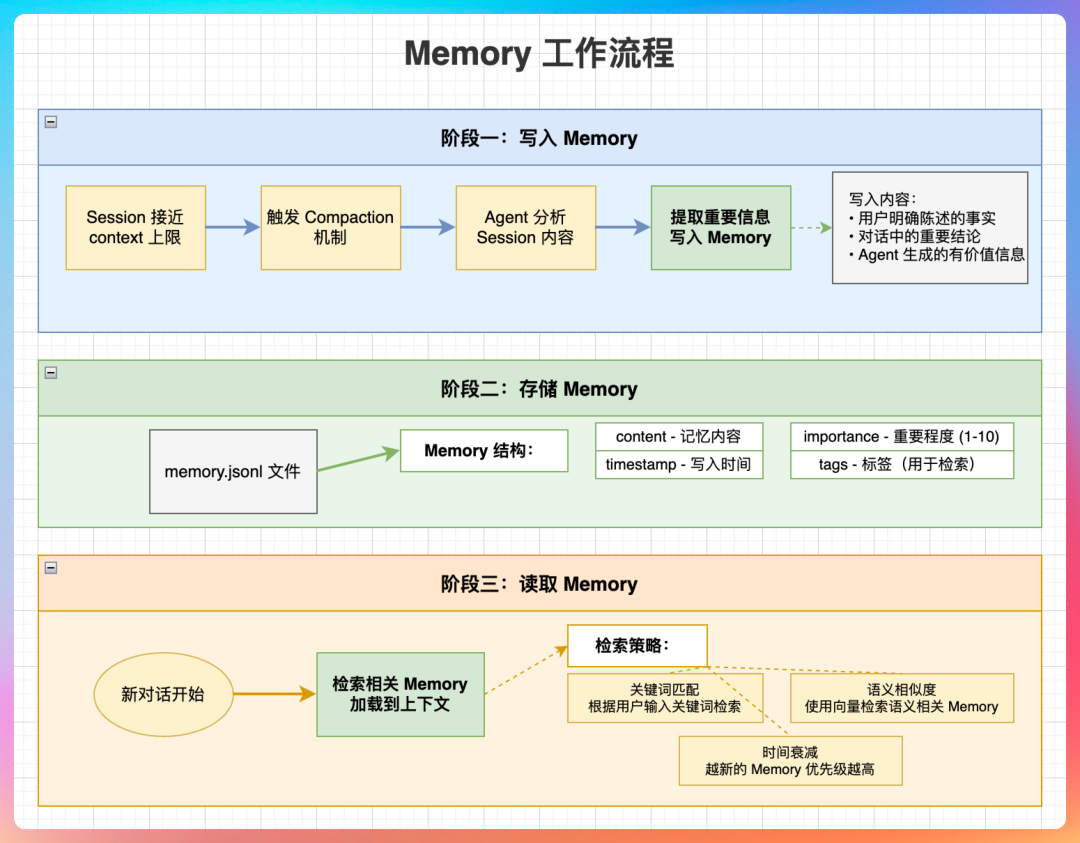
“关键词匹配就是简单的字符串匹配,适合检索明确的实体,比如用户名、项目名称。”
“语义相似度用向量检索,把查询和 Memory 都转成向量,计算相似度。这个适合检索概念相关的内容,比如‘分布式事务’和‘分布式一致性’,虽然关键词不同,但语义相关。”
“时间衰减是给 Memory 加时间权重,越新的 Memory 优先级越高。但也不是简单的线性衰减,而是指数衰减,保证最新的几条 Memory 权重明显高于旧的。”
“为了避免 Memory 爆炸,还有几个优化策略:重要性评分,只保留高重要性的 Memory;定期清理,默认保留 30 天;合并相似 Memory,避免重复;分层存储,高频放内存,低频放磁盘。”
“重要性评分是 Agent 在写入 Memory 时自动评估的,评估标准包括:信息的新颖性、对后续决策的影响程度、用户的明确强调。”
老王追问:“如果让你优化 OpenClaw 的 Memory 机制,你会怎么做?”
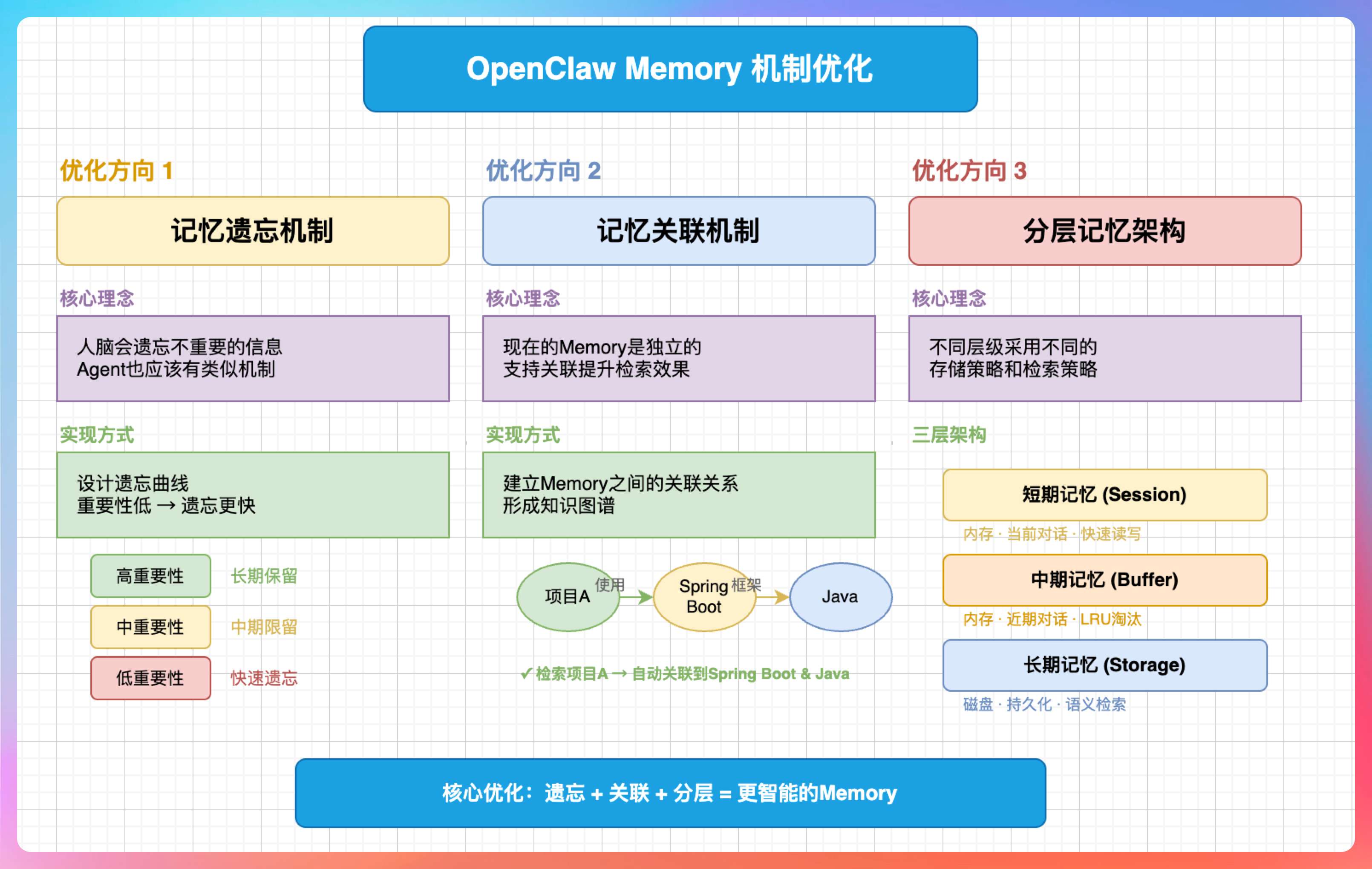
我说:“有几个优化方向。”
“第一,引入记忆遗忘机制。人脑会遗忘不重要的信息,Agent 也应该有类似机制。可以设计一个遗忘曲线,重要性低的信息遗忘得更快。”
“第二,支持记忆关联。现在的 Memory 是独立的,如果能支持 Memory 之间的关联,比如‘这个项目用了 Spring Boot’和‘Spring Boot 是 Java 框架’关联起来,检索效果会更好。”
“第三,分层记忆。短期记忆、中期记忆、长期记忆三层,每层有不同的存储策略和检索策略。”
老王听完沉默了两秒,然后说:“明天下午 14.04 来二面!”
ending
走出阿里大楼,我来到星巴克点了一杯冰美式。
明明我一个破做 Java 的,竟然问了这么多 AI 的,还有 OpenClaw 原理?
在AI的挟持下,时代变化太快了。
快到应接不暇,快到身边不少人开始抵触 OpenClaw,抵触 AI。
但同时,我也看到另外一批人,他们去看 OpenClaw 的源码,开始理解 Agent 不只是一个套壳 ChatGPT,开始用 LangGraph4j 编排真正的业务流程。
【人生有很多活法,你变与不变,世界都在变化;与其恐惧、怀疑,不如尝试、行动,这个过程也许会挣扎、彷徨,但结果一定是充实的。】
打开IntelliJ IDEA,继续看研究。
二面加油,我一定要拿下。
下期见。

回复