


大家好,我是二哥呀。
虽然我一直强调,token 就是生产力,这年头要至少备一个 Coding Plan 套餐,否则你的生产力会严重拖后。
但 Coding Plan 现在也不好买,lite 版本基本上都抢不到。看看现在这个 token 消耗量吧。
2026 年 3 月份来到了 140 万亿。
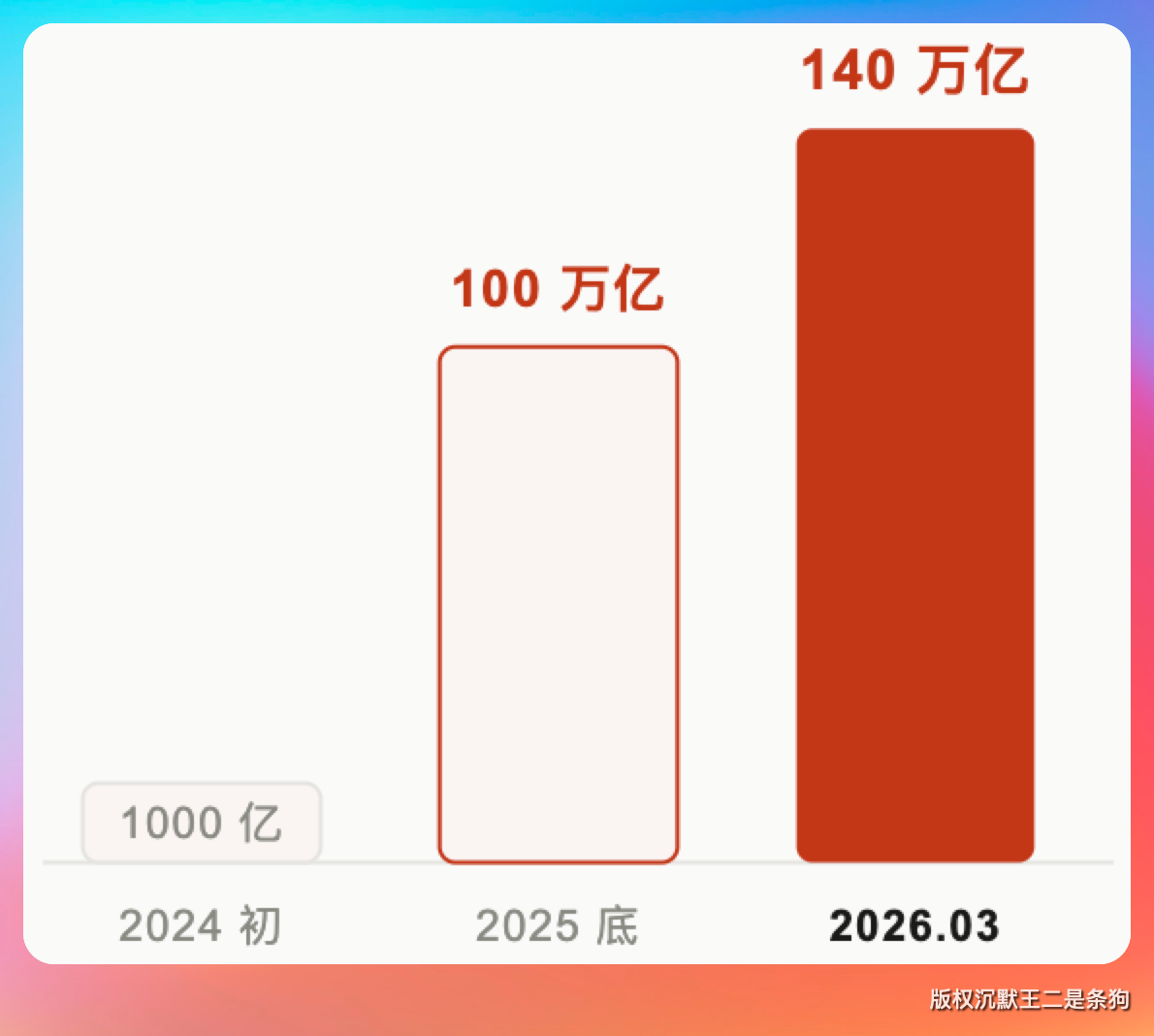
说真的,AI 时代最大的焦虑不是学不会,是用不起。Token 这东西就像手机流量,没有 Coding Plan,没有 pro和max,你不盯着它,一不留神就没了。
我花了整整两天时间,把能薅的羊毛全薅了一遍,国内 10 家、国外 12 家,哪些真香、哪些坑多,全部测完告诉你。
收藏这一篇就够了,建议先收藏再细看。
01、Token 到底是什么
聊免费额度之前,先把这个概念搞清楚。
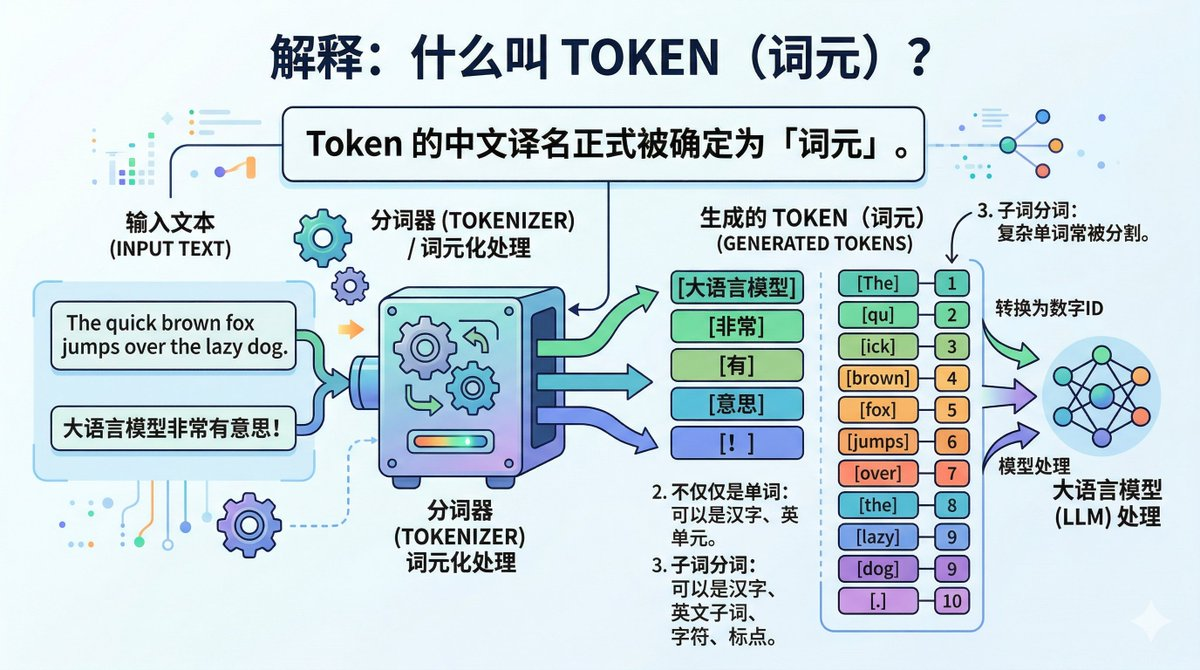
Token 不是字,不是词,也不是句子。它是大模型处理信息的最小单元。你可以把它理解成大模型的“像素”,就像图片由像素组成,大模型眼里的世界由 Token 组成。
中文 1 个汉字约等于 1.5-2 个 Token,英文 1 个单词约等于 1-1.5 个 Token。所以同样一段话,中文比英文更“费 Token”。
一次普通的 AI 对话,输入加输出大概消耗 1000-3000 个 Token。
如果是 Coding 场景,让 AI 帮你读一个中等规模的代码仓库再做修改,一次对话消耗 5 万到 20 万 Token 是常事。像 Claude Code 这种 Agent 模式,一个复杂任务跑下来,烧掉 50 万 Token 都不稀奇。
所以你就能理解,为什么很多人用 AI 写代码写到一半,突然收到“余额不足”的提示,不是你用得多,是 Coding 场景本身就是 Token 黑洞。
就在刚刚,一个挺有意思的事情发生了:国家数据局首次给了 Token 一个官方中文名,叫 词元。意思是“语言处理领域中,最小的、不可再分的基础信息单位”。这个命名延续了“像素”“字节”的构词逻辑,“词”锚定语言处理范畴,“元”代表最小基本单元。
清华大学的杨斌教授在两会期间曾提了个新方案:模元。理由是“模”直接对应大模型、多模态,锚定 AI 场景的核心属性。
在我看来,日常使用中,大家直接说 Token 就行。
但这个道理得明白,上一个时代的基础计量单位是 bit,这个时代的基础计量单位就是 Token。
搞明白了 Token 是什么,下面我们直接进入主题——哪些平台在送,送多少,值不值得薅。
02、国内平台
2026 年这个卷法,几乎每家都在疯狂送。我把实测过的 10 家按“真香程度”排了个序。
第一梯队
硅基流动注册就送大额 Token,邀请好友还有额外奖励。更关键的是,它聚合了 100 多个开源模型,Qwen、DeepSeek、Llama 全都有。小模型(比如 Qwen/Qwen3.5-4B)直接永久免费调用。
如果你经常需要切换不同模型做对比测试,硅基流动一站式搞定。我在派聊聊中就接过硅基流动的 API。
智谱 AI 的 GLM-4.7-Flash 也是永久免费不限量。GLM 家族作为国产大模型的头部选手,Flash 版本虽然不如旗舰版强,但日常对话、文本处理、代码辅助完全够用。
新用户注册还送大额体验金,够你体验全系列模型了。更香的是,智谱还搞了个“龙虾体验卡”的计划,团队用户也能领到可观的 GLM-5-Tu 额度。
讯飞星火 的 Spark Lite。讯飞在语音识别领域的积累深厚,如果你的场景涉及语音转文字再接大模型处理,讯飞这套组合用起来不错。
第二梯队
火山引擎(豆包) 是字节系的。
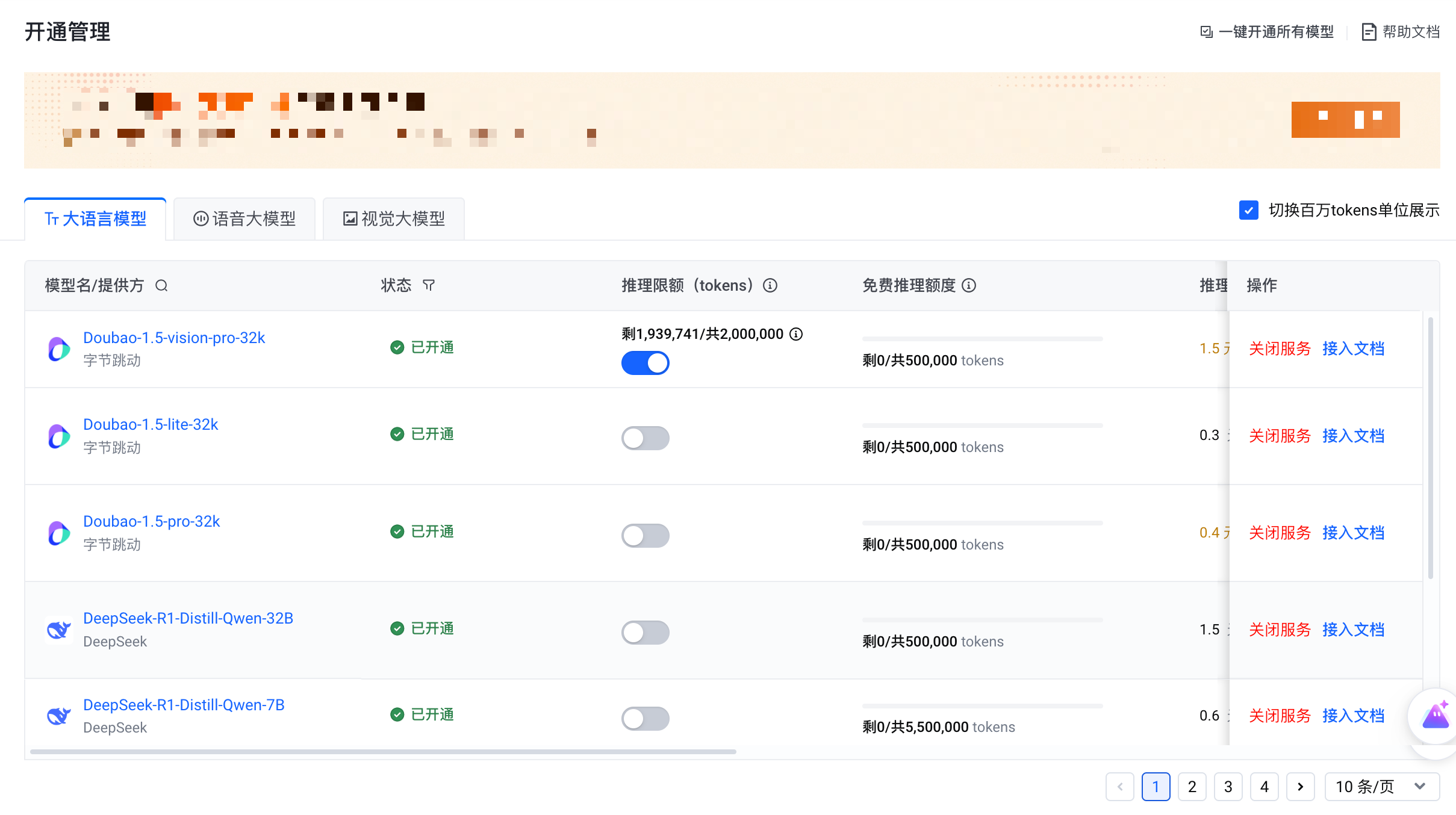
阿里百炼的策略是每个模型单独送,新用户每个模型首次开通就送。百炼上模型多——Qwen、DeepSeek、Kimi 系列都有,累计下来总额不算少。做 RAG 或者 Agent 应用开发的话,百炼的工具链比较完善。

第三梯队:特殊渠道
DeepSeek 我平常翻译会用。DeepSeek V3.2 和 R1 的推理能力在国产模型里属于顶尖水平。API 定价也便宜,续费也不心疼。
月之暗面(Kimi) Kimi K2.5 的长文本处理能力是一大卖点,128K 上下文窗口,处理长文档、论文解析这类场景很合适。
国家超算互联网前段时间搞了个大动作——面向 OpenClaw 用户免费发放 Token 额度。虽然是限时活动,但超算互联网的算力成本确实低,后续大概率还会有类似活动。
MiniMax 在多模态方面有特色,语音合成做得不错。
百度文心的 ERNIE 系列,新用户注册就送免费额度。我自己测了下,ERNIE 做文本摘要、翻译这类任务还是靠谱的,响应速度也不慢,基本一两秒就出结果。
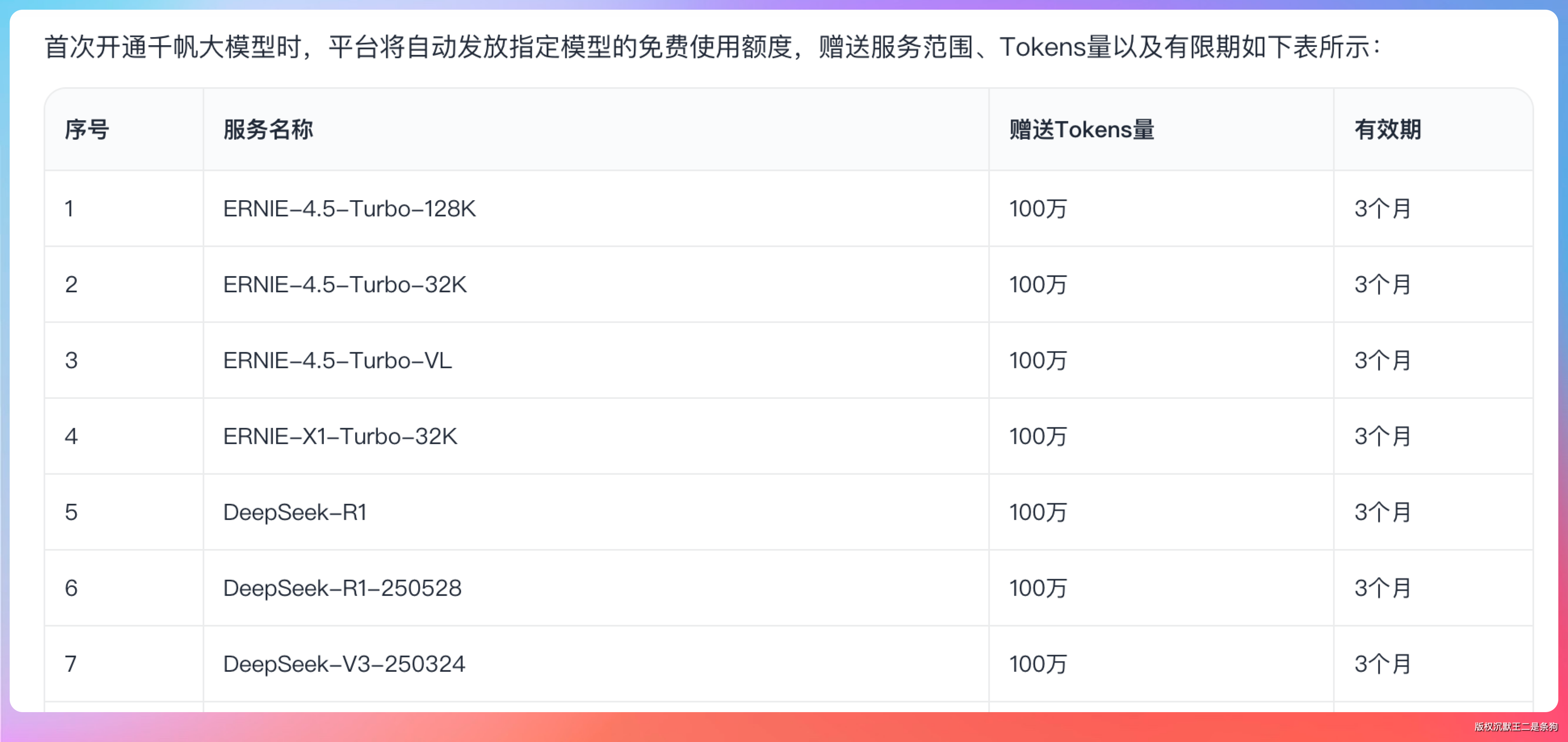
腾讯混元 新用户首次注册就送免费额度。混元的中文理解能力不错,做中文文本相关的任务表现稳定。
03、国外平台
Cerebras 是我比较推荐的国外免费平台。Cerebras 的特色是推理速度极快——它家的专用芯片 WSE-3 单芯片就有 4 万亿个晶体管,推理速度是 GPU 方案的几倍。免费薅到这种速度,真的赚到了。
Google Gemini 的免费层也很实在。不需要信用卡,直接用 Google 账号就能调。如果你做多模态应用(图片理解、视频分析),Gemini 的免费额度性价比很高。
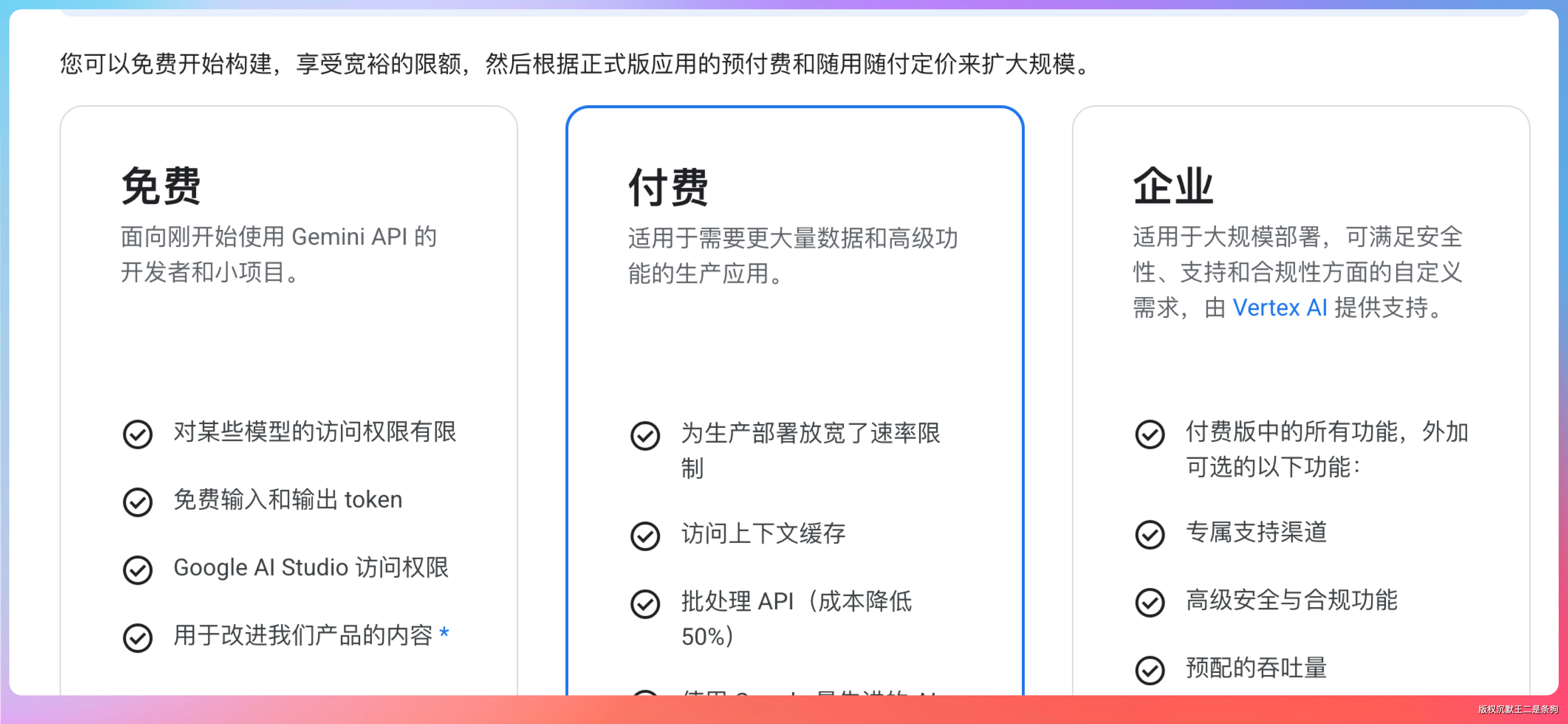
Mistral AI。
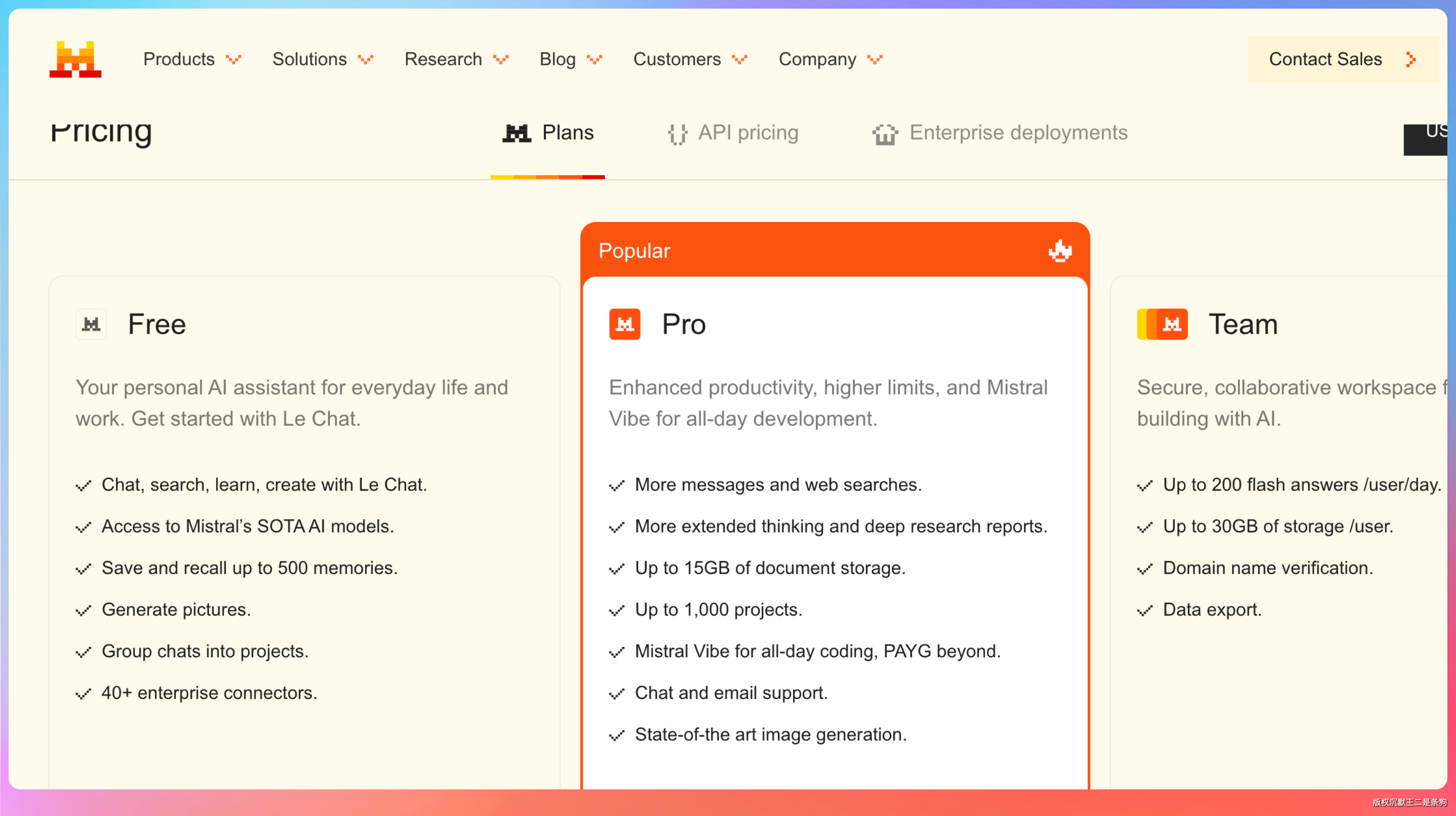
OpenRouter 是个聚合平台,目前有不少免费模型可用。好处是一个 API Key 调所有模型,做模型对比测试很方便。免费模型列表里包括 Llama、Qwen 等。
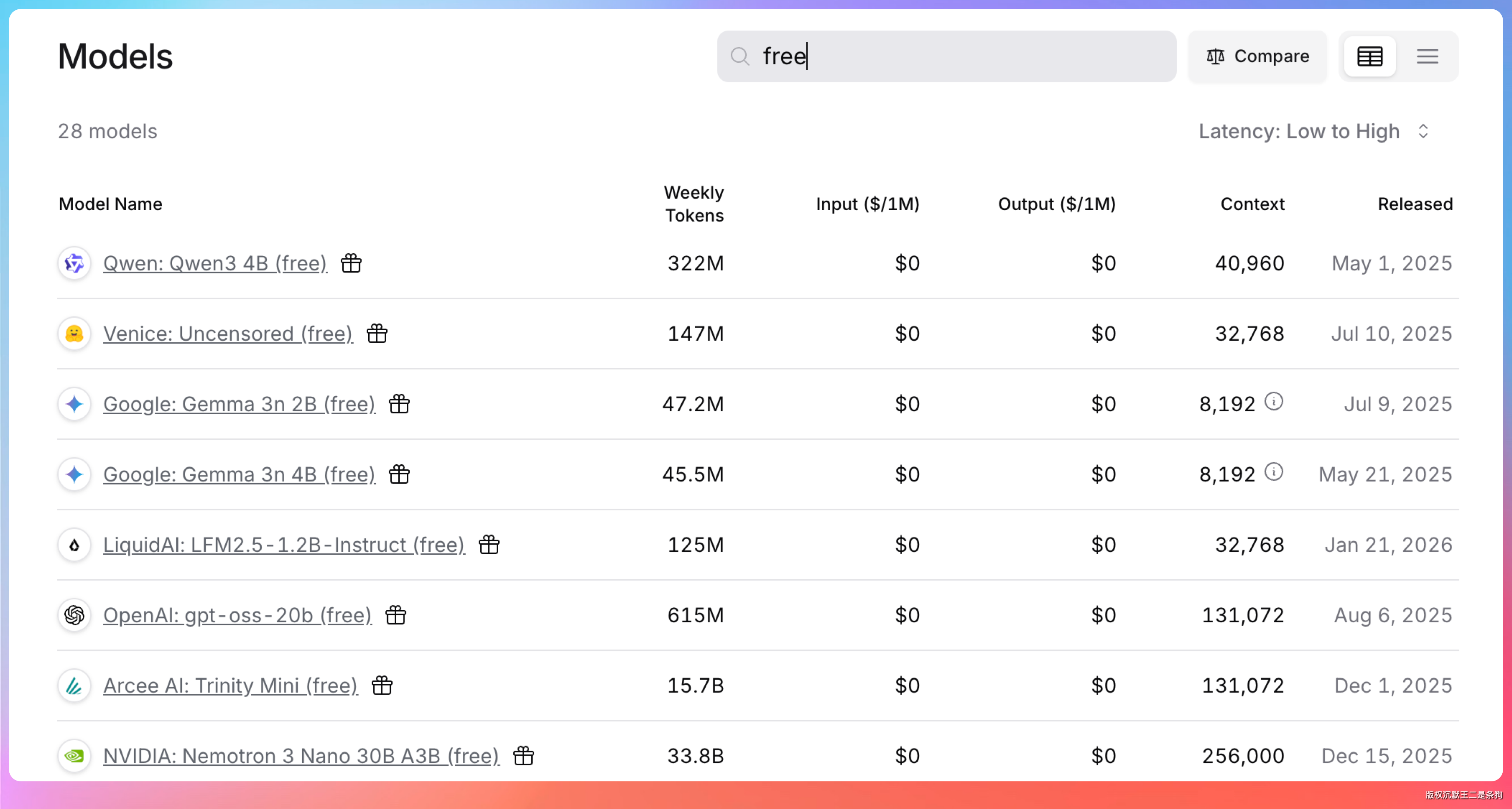
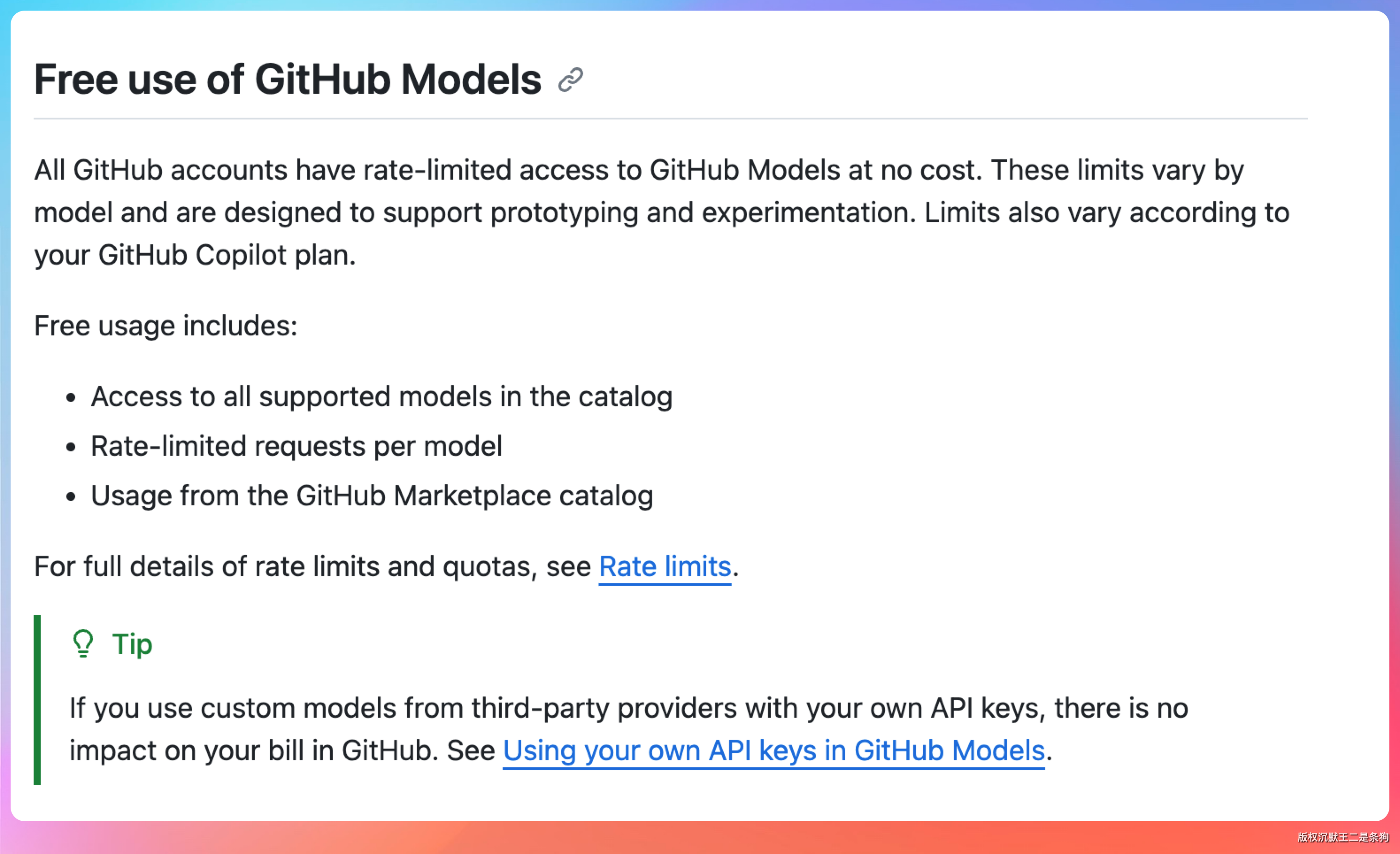
GitHub Models 对所有 GitHub 用户开放,如果你本来就是 GitHub 用户,这等于白捡的。对于想体验 OpenAI 模型但又不想绑海外信用卡的开发者来说,GitHub Models 目前是最便捷的入口。
04、强烈推荐
智谱 GLM-4.7-Flash(永久免费),一分钱不花,覆盖 90% 的日常场景。

GLM-4.7-Flash 在前后端任务上表现出色。在编程场景之外,也推荐大家在中文写作、翻译、长文本、情感/角色扮演等通用场景中体验 GLM-4.7-Flash。
OpenRouter 和 GitHub Models 也是强烈推荐,可能你买的那些非官方的 token,用的也许就是这些。😄
05、ending
说实话,免费的东西最容易让人忽略一件事——时间才是最贵的。
以前我也会图便宜,用一些免费的模型,但经常是返工又返工。但自从开了Codex pro版,感觉开发效率就像坐火箭一样。
我这两天用 Codex 高强度编码了很多很多技术派和派聪明的内容。简单给大家总结一下。
首先是派聪明新增功能的简历写法。
项目名:派聪明 RAG 企业级知识库系统
技术栈:Spring Boot 3、Spring Security、JWT、MySQL、Redis、Elasticsearch、Kafka、MinIO、WebSocket、Docker
项目描述:面向企业知识管理场景搭建 RAG 智能知识库平台,支持文档解析、向量检索、组织级权限隔离、AI 问答、邀请码注册和 Token 余额计费。
核心职责:
- 1、主导 RAG 平台 Token 计费架构升级,采用 Redis 保存实时余额、MySQL 保存按天账本与统计明细,支持 LLM/Embedding 双 Token 的充值、扣减、排行榜和趋势分析。
- 2、基于微信支付 v3 Native Pay 封装订单创建、支付二维码生成、订单状态查询、支付回调验签解密和到账后 Token 增发流程。
- 3、补充部署脚本 deploy-front.sh,实现前端构建产物打包、远程上传、服务器解压替换和健康检查自动化,减少手工发布步骤。
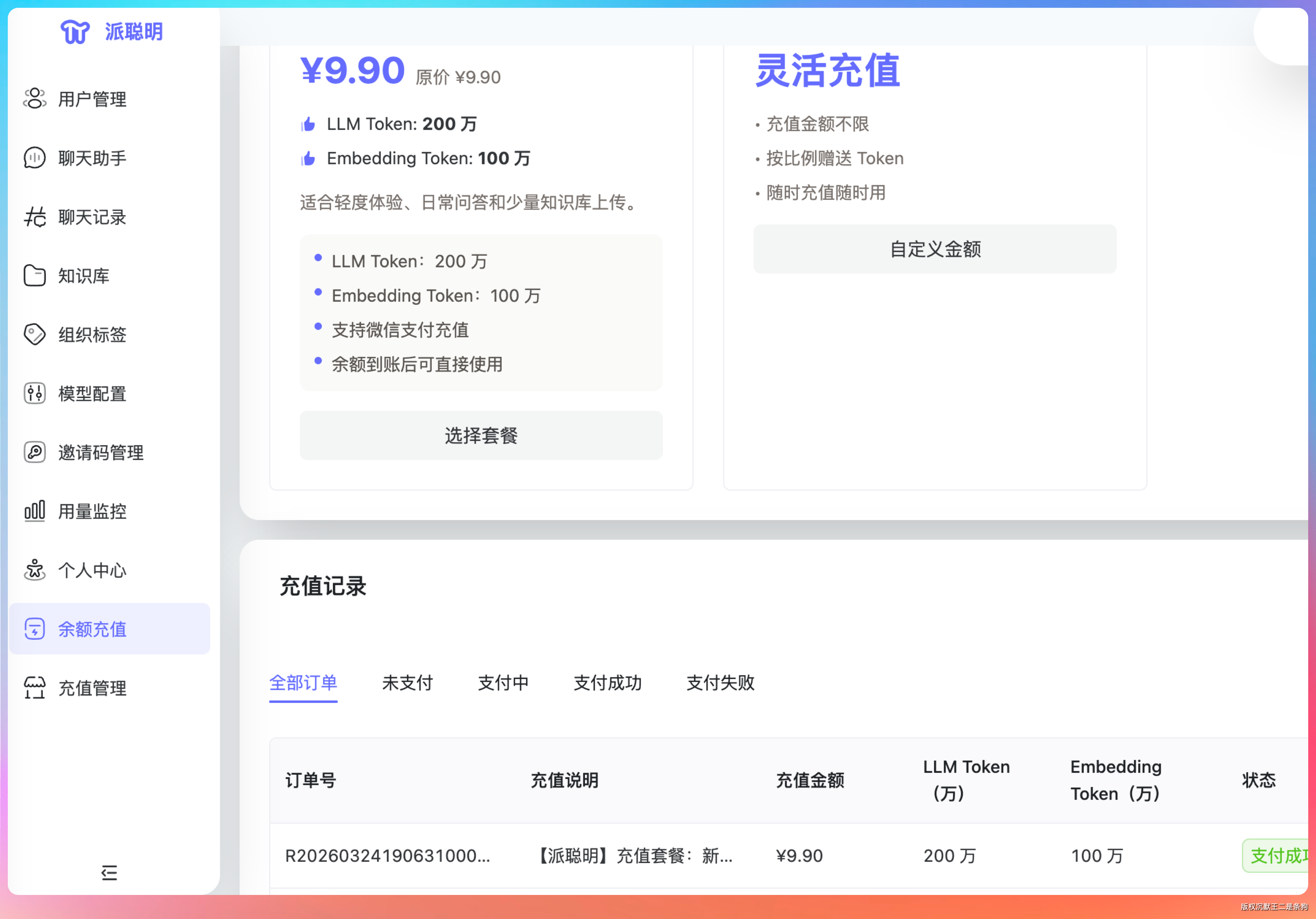
这种开发强度,换做以前,没有一周是搞不定的。
这是技术派的简历写法。
项目名:技术派社区
技术栈:Spring Boot 2.7、MyBatis-Plus、MySQL、Redis、RabbitMQ、ElasticSearch、MongoDB、Liquibase、WebSocket、微信公众号、LLM
项目描述:采用 5 模块分层架构,覆盖文章发布、搜索、评论、活跃排行、AI 问答、微信扫码登录、公众号消息回复等核心场景。重点负责 AI 平台能力建设与微信公众号智能运营升级。
核心职责:
- 1、基于 Redis + 动态配置实现 AI 配置管理后台,打通智谱、讯飞、DeepSeek、豆包、阿里等 9 类模型的统一配置。
- 2、搭建微信菜单管理能力,支持菜单草稿保存、规则校验、远程同步、正式发布、关键词匹配、订阅回复与 AI 兜底回复,解决公众号强依赖研发的问题。
- 3、基于 Redis + Async 异步任务 + 微信客服消息接口重构微信回调,实现 300ms 内快速 ACK、异步补发 AI 回复,并增加 30 秒回调去重锁和 600 秒响应缓存,解决大模型响应慢导致微信超时重试、消息重复处理的问题。
- 4、基于 ChatService 抽象层 + Prompt 注入机制增强多模型对话能力,支持 system prompt、多消息上下文和统一对话协议适配,解决不同模型请求结构不一致、上下文利用不充分的问题,支持最近 10 条历史上下文参与多轮对话。
- 5、补充 .env 配置注入、mock 登录、敏感词 AI 优化、异常兜底与日志增强能力;最近两天累计完成 104 个文件改动,新增 5190 行代码。
就我这种高强度,两天 Codex 的 pro 额度也就用了不到一周的 30%。
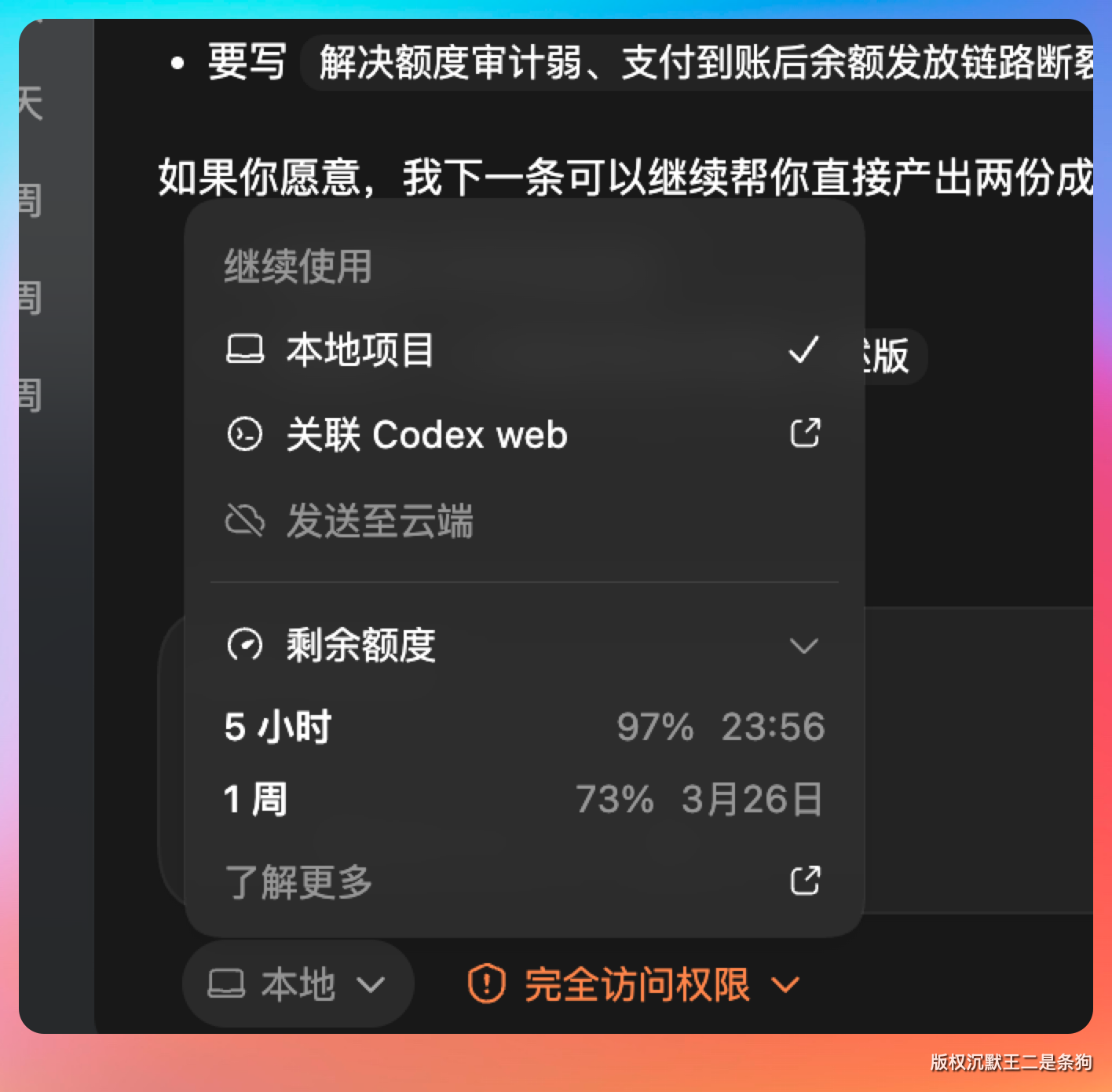
所以不管是薅免费的 token,还是付费买 Coding Plan 套餐,我觉得最重要的是,AI 到底帮助了你多少。😄
而不是 token 消耗了多少。

回复