


大家好,我是二哥呀。
用 Claude Code、Qoder CLI 或者 Codex 写代码的小伙伴,应该都有一个共同的痛点:Token 消耗太快了。
一个普通的开发任务跑下来,动不动就是几万甚至十几万的 Token。你看着那个数字蹭蹭往上涨,心里想的不是代码写得怎么样,而是钱包还撑不撑得住。
现在一个 Coding Plan 的费用真不便宜,我每个月至少在 token 上花费 4000 块。
不过最近发现了一个神器,叫 RTK,全称 Rust Token Killer。听名字就很直接,专门来干掉 Token 消耗的。
拿一个简单的 git status 命令来测试的话,差不多能省 30%的 token。
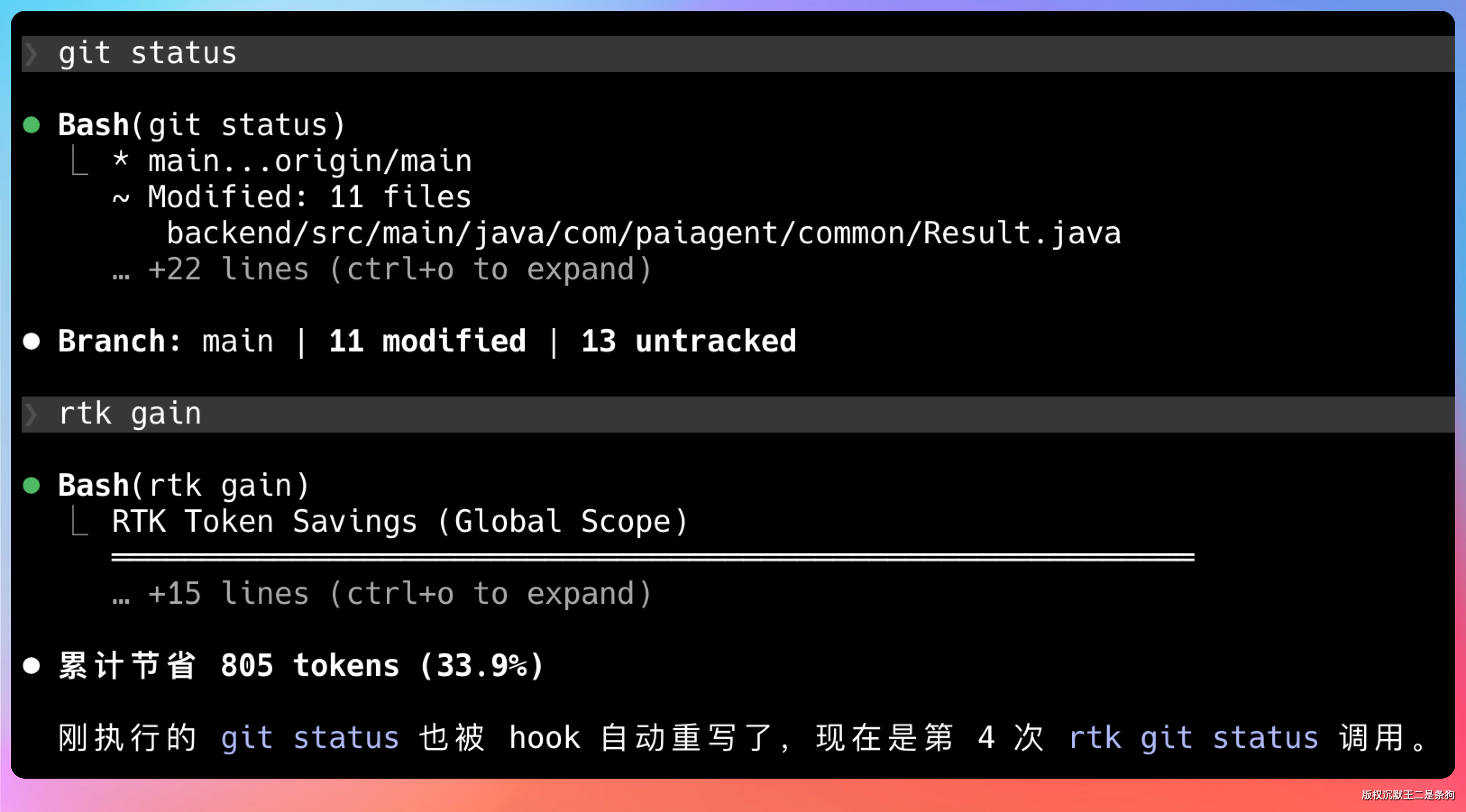
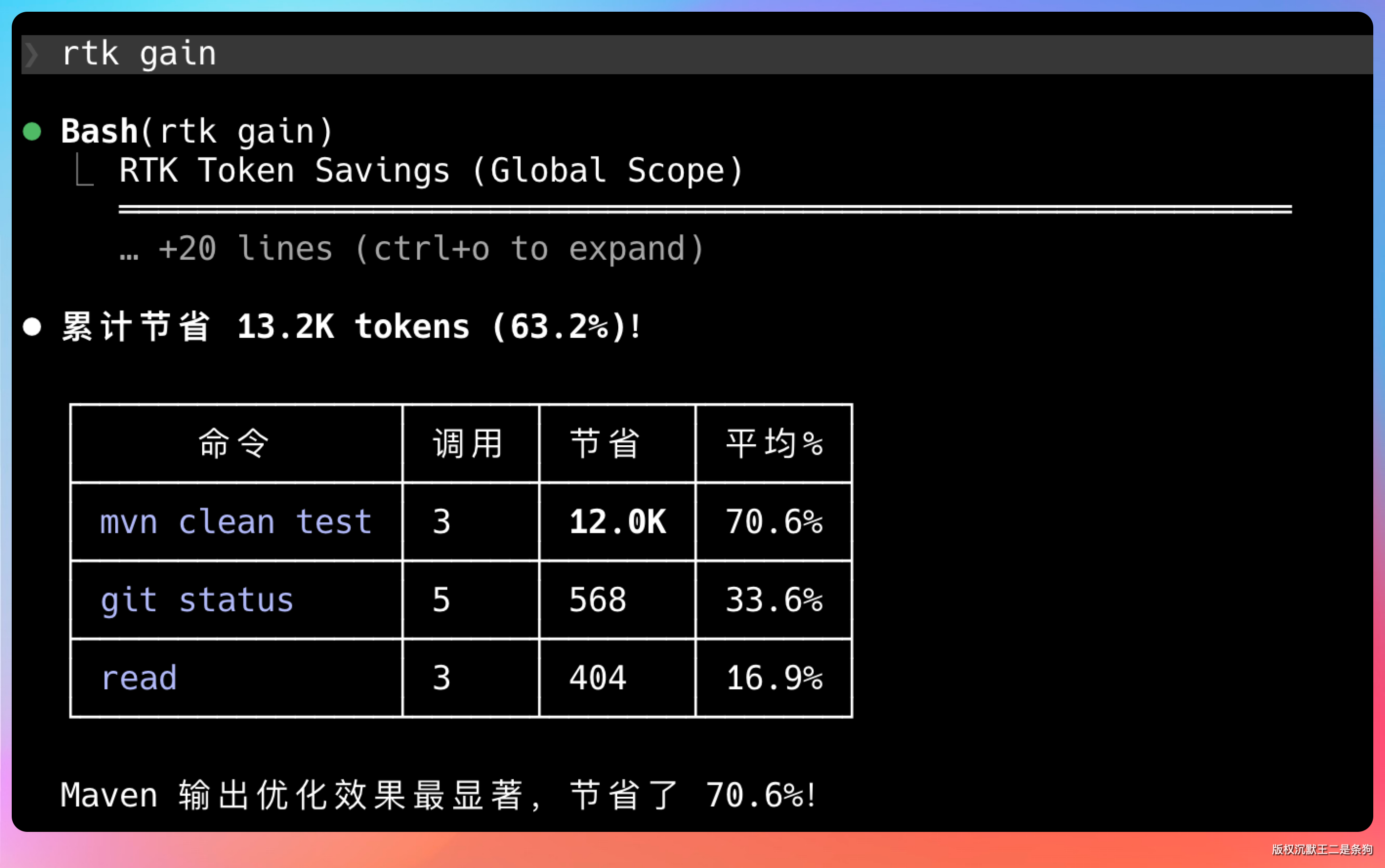
一个简单的 mvn test 能省 13.2k token。
这篇文章我就带大家实测一下这个工具,看看它到底香不香。
01、RTK 是个什么东西
说白了,RTK 就是一个 CLI 代理。它的工作原理很简单:在你的命令行输出到达 LLM 之前,先做一层智能压缩和过滤。
我们用 AI Coding 工具的时候,经常要跑各种命令:cargo test、pytest、git status、npm install。这些命令的输出动不动就是几百上千行。但 LLM 真正需要的信息可能就那么几行,比如测试是否通过、哪个文件改了、装了哪些包。
RTK 做的事情就是把噪音过滤掉。
用户命令 -> RTK代理 -> 压缩过滤 -> LLM
从技术实现上讲,RTK 支持这么几种压缩策略:
智能过滤:把重复的、冗余的信息去掉。比如跑测试的时候,如果 100 个测试用例都通过了,RTK 不会把 100 行 PASSED 都发给 LLM,而是告诉它「100 个测试全部通过」。
分组聚合:把相似的输出归类。比如 git log 输出了 50 条 commit,RTK 会做个摘要,而不是全文搬运。
智能截断:输出太长的时候,保留关键部分。比如错误堆栈,一般只需要前几行就能定位问题,不需要把整个调用链都塞进去。
去重处理:相同的信息只保留一份。
官方给的数据是这样的:
| 命令类型 | Token 节省比例 |
|---|---|
| cargo test / pytest | 90% |
| git add/commit/push | 92% |
| ls / grep / git log | 80% |
| 综合场景 | 60-90% |
02、安装配置全流程
RTK 的安装非常简单,支持三种方式。
Homebrew 安装(macOS 推荐)
brew install rtk
一行命令搞定,这是 macOS 用户的首选方式。
Shell 脚本安装(Linux/macOS 通用)
curl -fsSL https://raw.githubusercontent.com/rtk-ai/rtk/master/install.sh | sh
我用的是这个安装的。
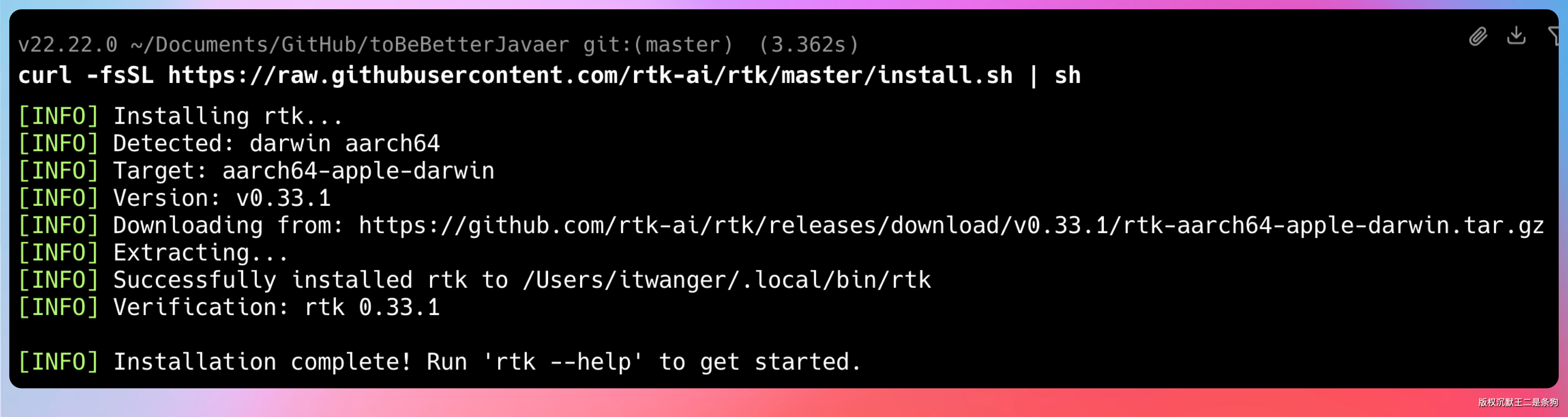
这种方式会自动检测你的系统架构,下载对应的二进制文件。
Cargo 安装(Rust 开发者)
cargo install --git https://github.com/rtk-ai/rtk
如果你本身就是 Rust 开发者,这种方式可以从源码编译,能拿到最新的特性。
安装完成后,需要初始化配置。RTK 支持多种 AI Coding 工具,初始化命令略有不同。
Claude Code / GitHub Copilot
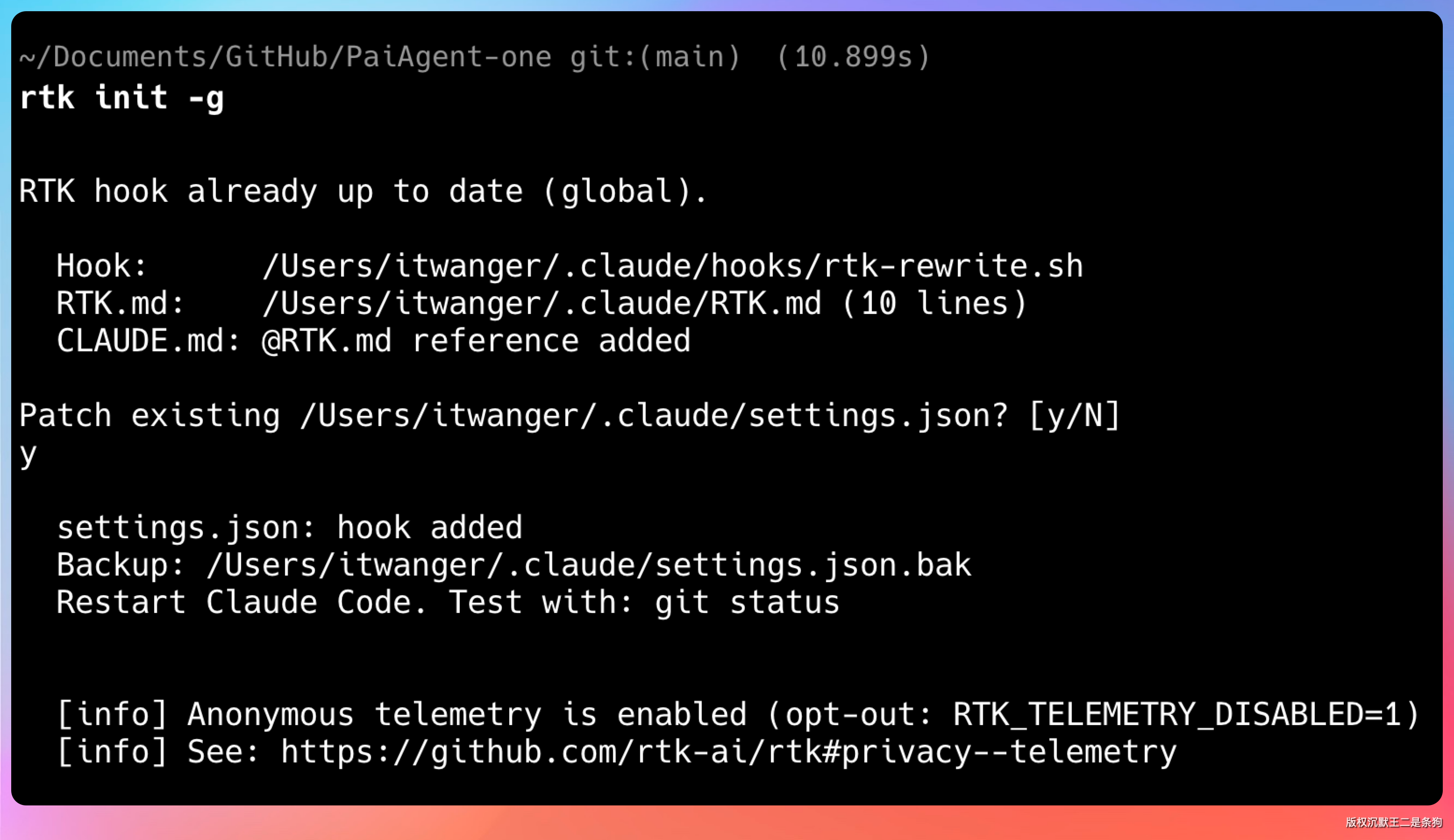
rtk init -g
Codex
rtk init -g --codex
Gemini CLI
rtk init -g --gemini
Cursor
rtk init --agent cursor
初始化完成后,RTK 会做这样一件事:在你的 Shell 配置文件里加一些 hook,让常用命令自动走 RTK 代理;
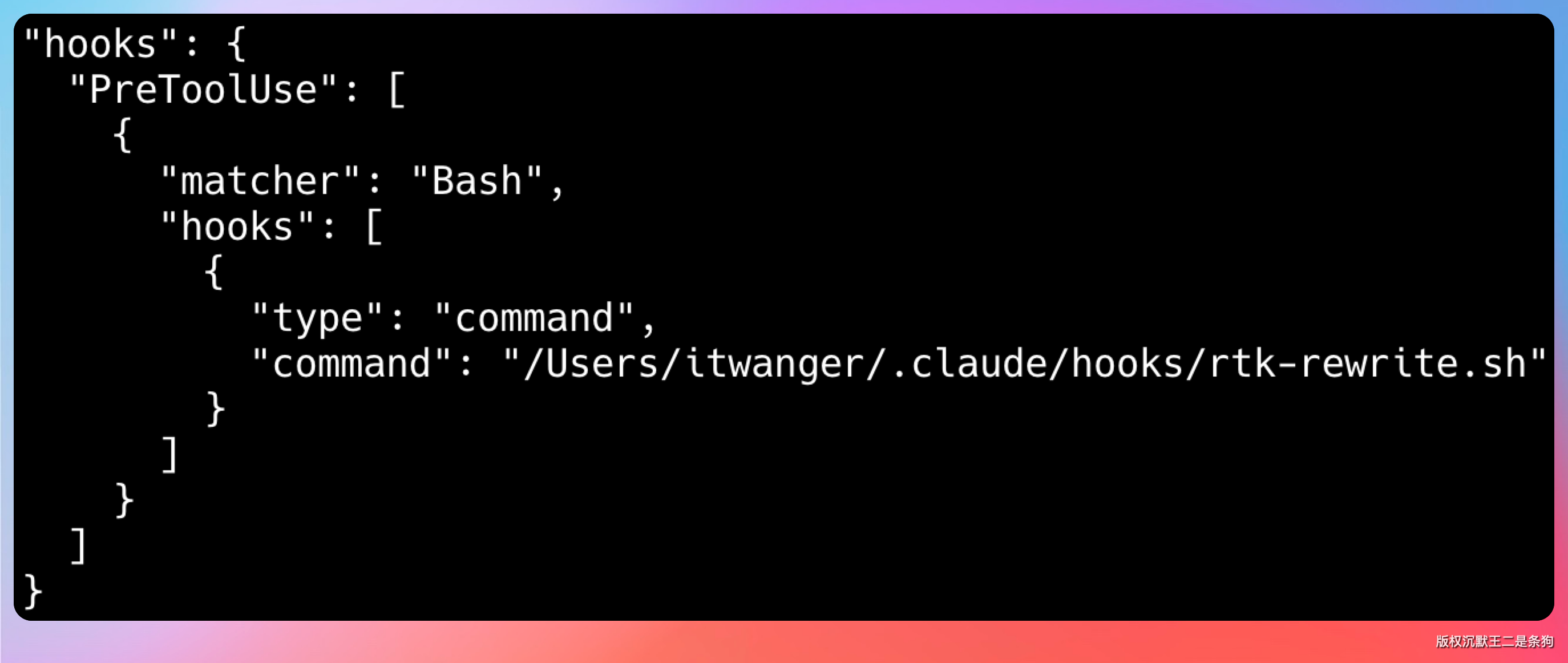
默认是不会生成配置文件的,但如果你想自定义,可以执行 rtk config --create,配置文件在 ~/.config/rtk/config.toml,你可以在里面自定义一些行为。
配置文件长这样:
[database]
path = "~/.local/share/rtk/history.db"
[commands]
exclude = ["vim", "nano", "less"]
[tee]
enabled = true
几个关键配置项说明一下。
database.path 是 RTK 用来存储命令历史和统计数据的数据库路径。默认放在用户目录下,一般不用改。
commands.exclude 是排除列表,里面的命令不会走 RTK 代理。像 vim、nano 这种交互式编辑器,本身就不需要压缩,也没法压缩。
tee.enabled 是一个很实用的功能。开启后,如果命令执行失败,RTK 会保存完整的原始输出。这样你在调试问题的时候,可以随时查看没被压缩过的完整信息。
03、一个开发会话的 Token 变化
说再多原理都不如实际跑一遍。我用 PaiAgent 项目来测试,这是一个基于 SpringAI 的工作流编排平台。
首先,我启动 Claude Code,开始一个开发任务。任务内容是给项目增加一个新的节点类型。
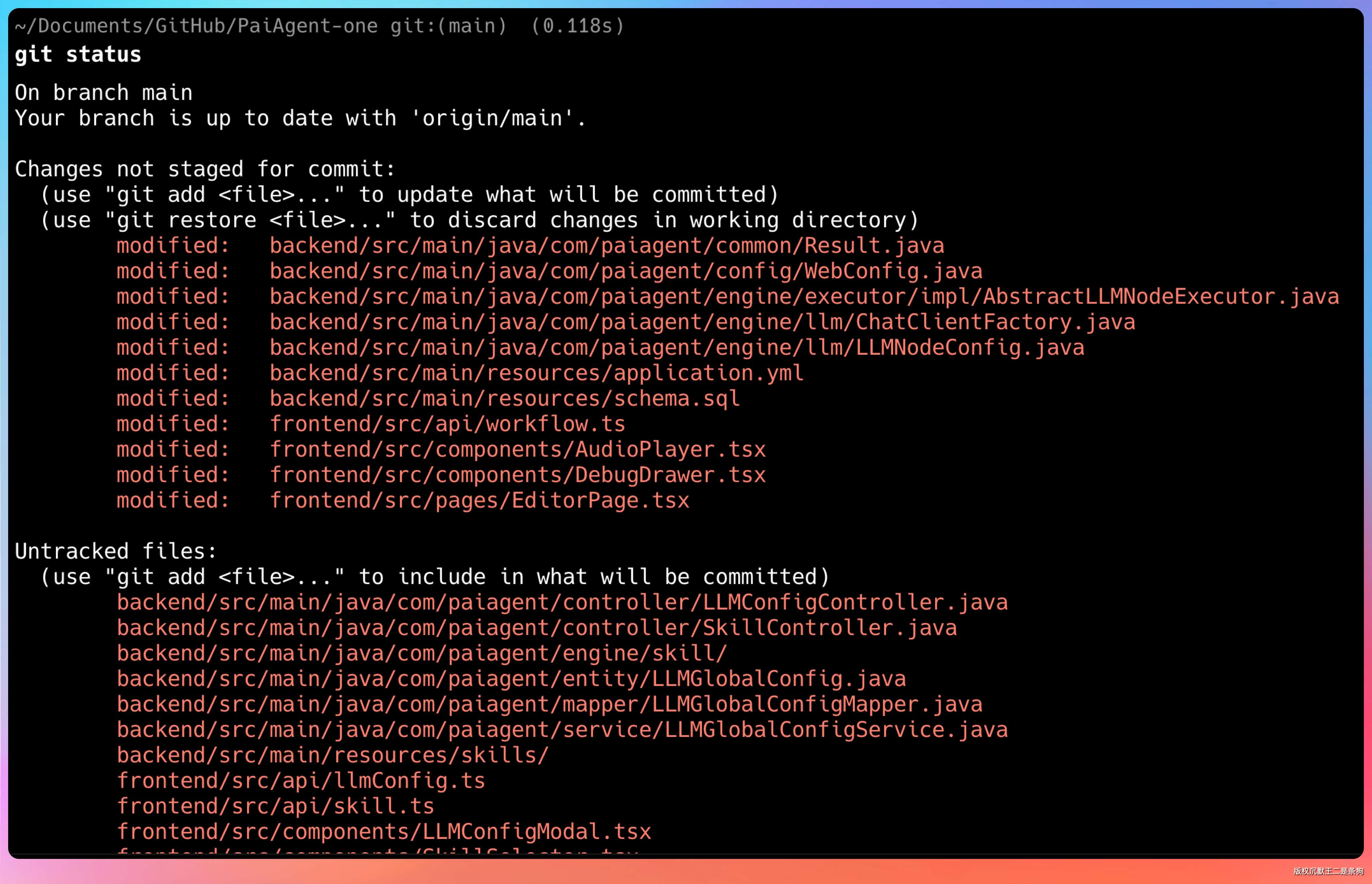
在没有 RTK 的情况下,我先跑了一遍 git status:
git status
然后我用 RTK 包装一下同样的命令:
rtk git status
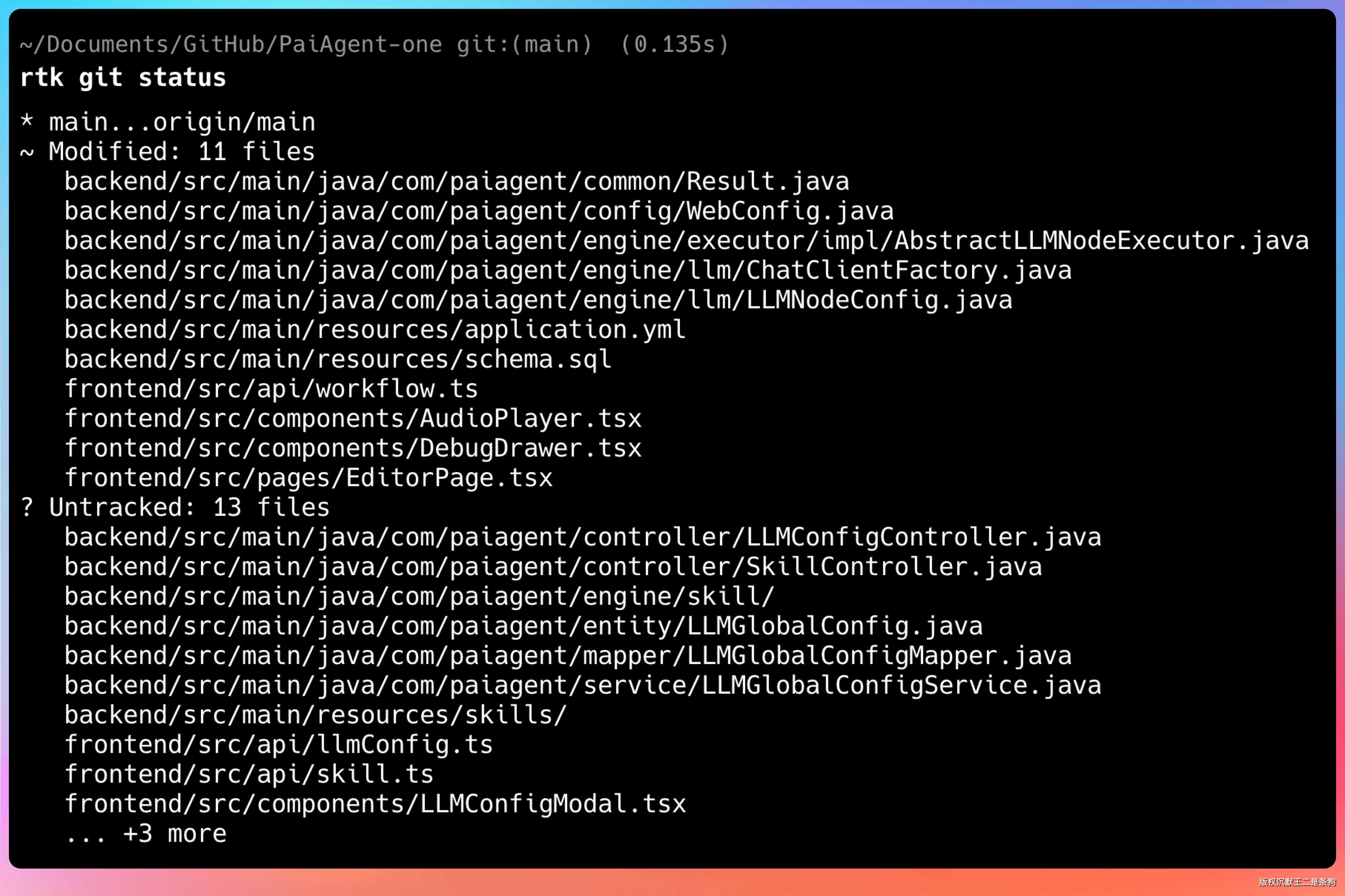
输出被压缩了很多行,但关键信息都在:当前分支、有哪些文件改了、有没有未提交的内容。
接下来跑测试。
mvn test
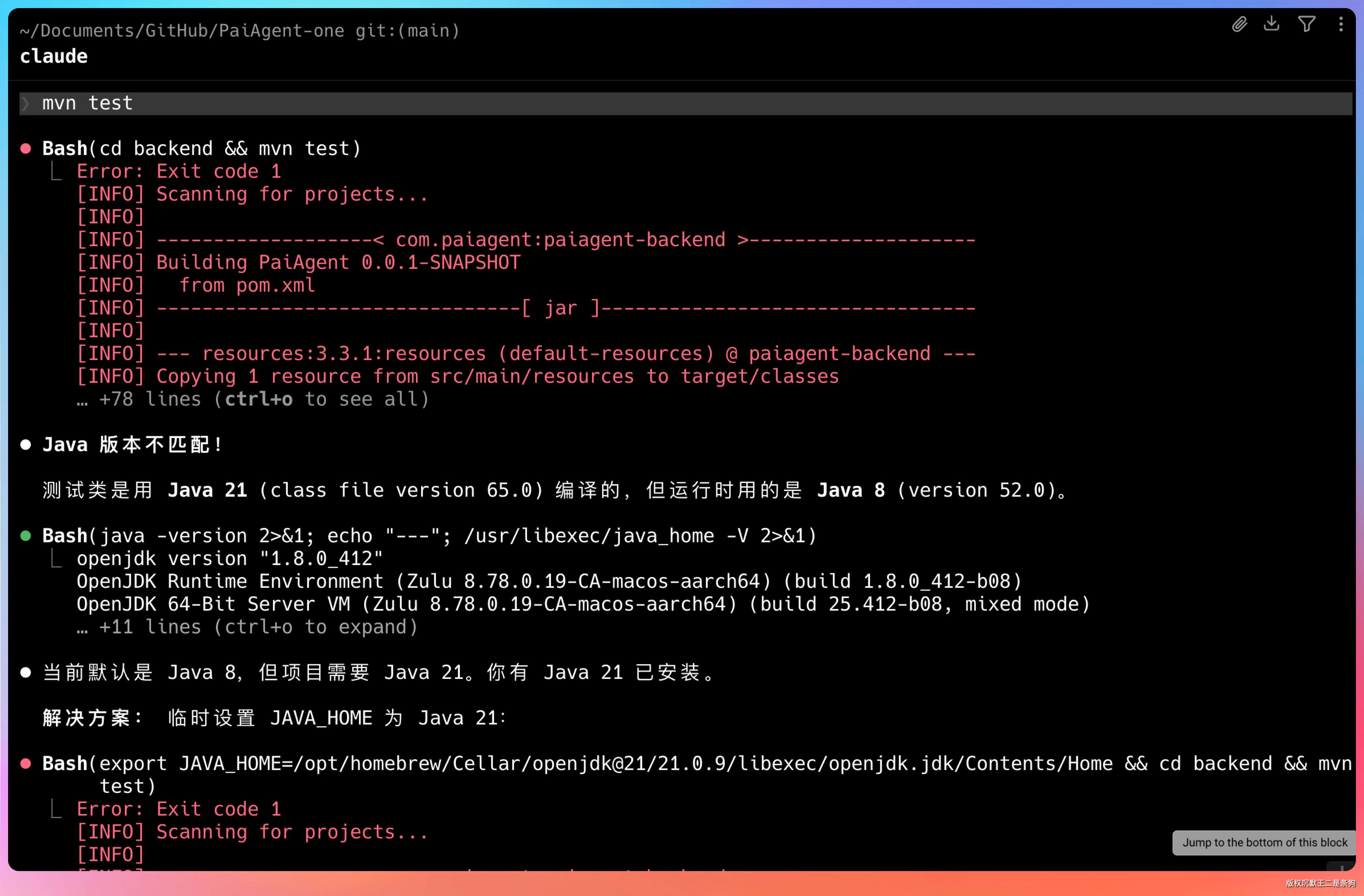
原始的 Maven 测试输出,你懂的,一堆 INFO 日志、下载依赖的信息、每个测试用例的执行详情。完整输出轻松超过 500 行。
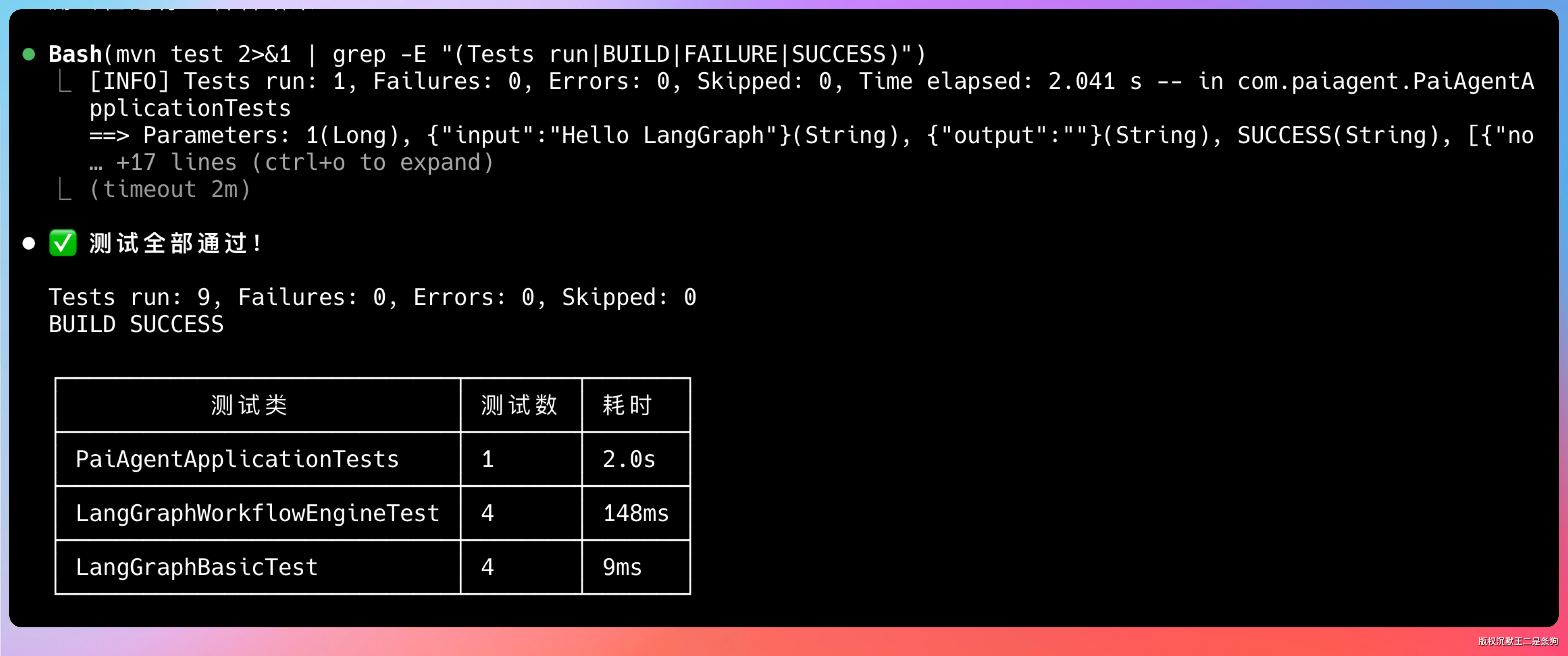
RTK 压缩后,输出变成了一个摘要:多少个测试、多少通过、多少失败、耗时多久。如果有失败的测试,会把失败的测试名和错误信息保留下来。
这一单就省了大概 70% 的 Token。
更让我满意的是,整个过程中,AI 的理解和执行能力没有受到影响。该改的代码改对了,该跑的测试跑通了。说明 RTK 的压缩策略确实是「去噪音留信号」,没有把关键信息给滤掉。
04、哪些场景最省 Token
测试输出
这是 Token 消耗的大户。不管是 Java 的 Maven/Gradle、Python 的 pytest、JavaScript 的 Jest,还是 Rust 的 cargo test,测试框架的输出都很啰嗦。100 个测试用例,每个都打一行 PASSED,对 LLM 来说完全是冗余信息。
RTK 把这类输出压缩得最狠,能到 90% 以上(官方的说法,我自己的测试是70%,也很不错了)。而且很聪明的是,它会把失败的测试用例单独拎出来,完整保留错误信息。这样 AI 在分析问题的时候,能拿到足够的上下文。
Git 操作
git log、git diff、git status 这些命令,原始输出往往很长。特别是 git diff,改动一个大文件,输出可能有几百行。
RTK 会对 diff 做摘要:哪些文件改了、改了多少行、关键的改动内容是什么。对于 git log,它会压缩成「最近 N 次提交」的摘要,而不是把每条 commit 的完整信息都列出来。
依赖安装
npm install、pip install、cargo build 这些命令,大部分输出都是下载进度和编译信息。对 AI 来说,它只需要知道「安装成功了」或者「安装失败了,报错信息是什么」。
RTK 把这类输出压缩到只剩关键信息,节省比例通常在 85% 以上。
目录列表和文件搜索
ls、find、grep 这些命令,输出经常是一大串文件名或者搜索结果。RTK 会做适当的截断和聚合,保留最相关的部分。
05、一些使用技巧
我摸索出的一些实用的技巧也毫无保留的分享给大家。
手动包装 vs 自动 Hook
RTK 初始化的时候会自动 hook 一些常用命令。但有些场景下,你可能想手动控制。比如调试一个复杂的问题时,你希望保留完整输出,就可以直接用原始命令,不加 rtk 前缀。
或者不在 Claude Code 中执行。
如果想临时禁用 RTK 对某个命令的 hook,可以用完整路径调用:
/usr/bin/git status
查看被过滤掉的信息
开启 Tee 模式后,RTK 会保存失败命令的完整输出。你可以用这个功能来「复盘」:
rtk tee show
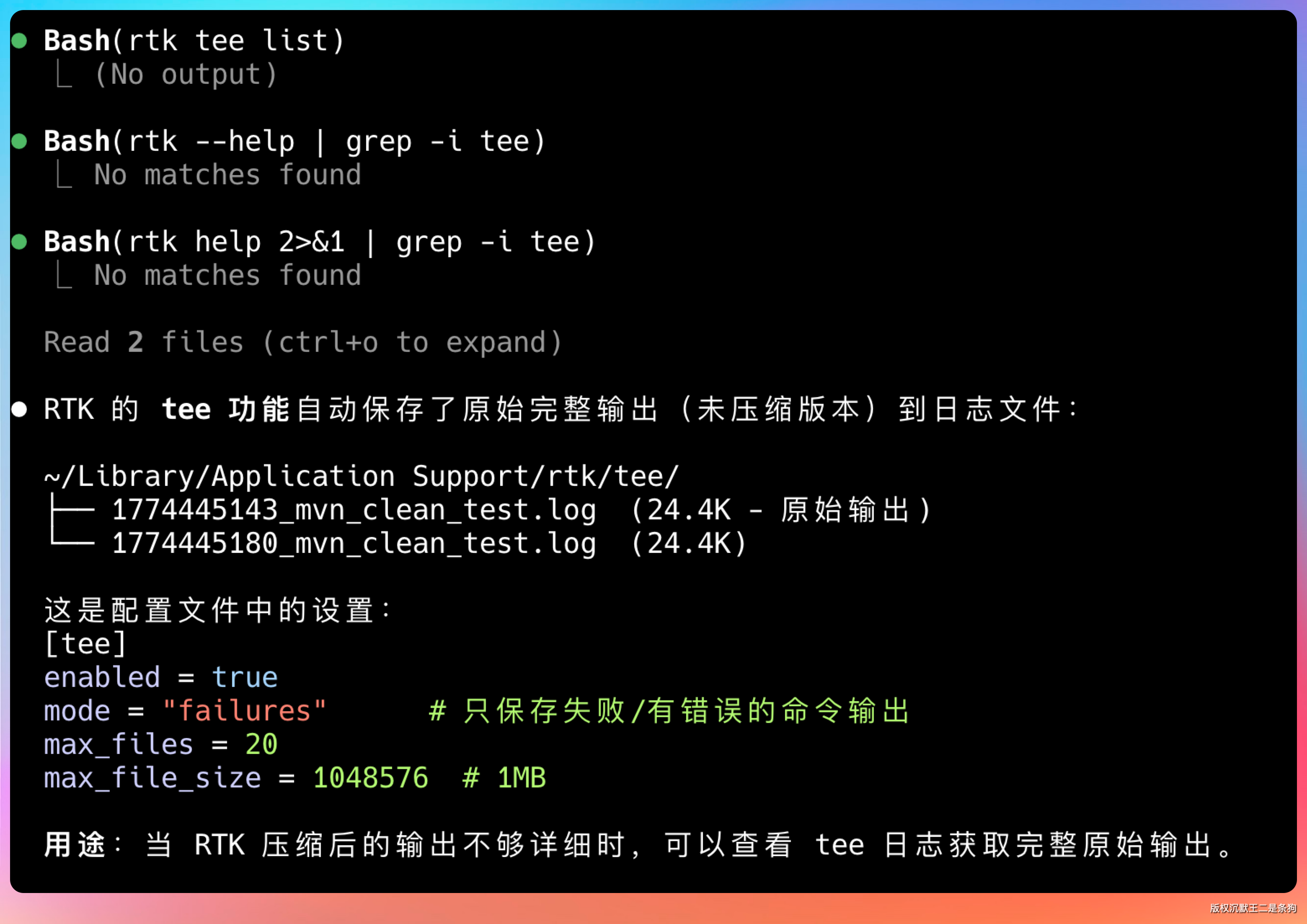
这在调试疑难问题的时候特别有用。有时候 AI 根据压缩后的信息给出的方案不对,你需要回头看看完整输出,手动定位问题。
分析历史统计
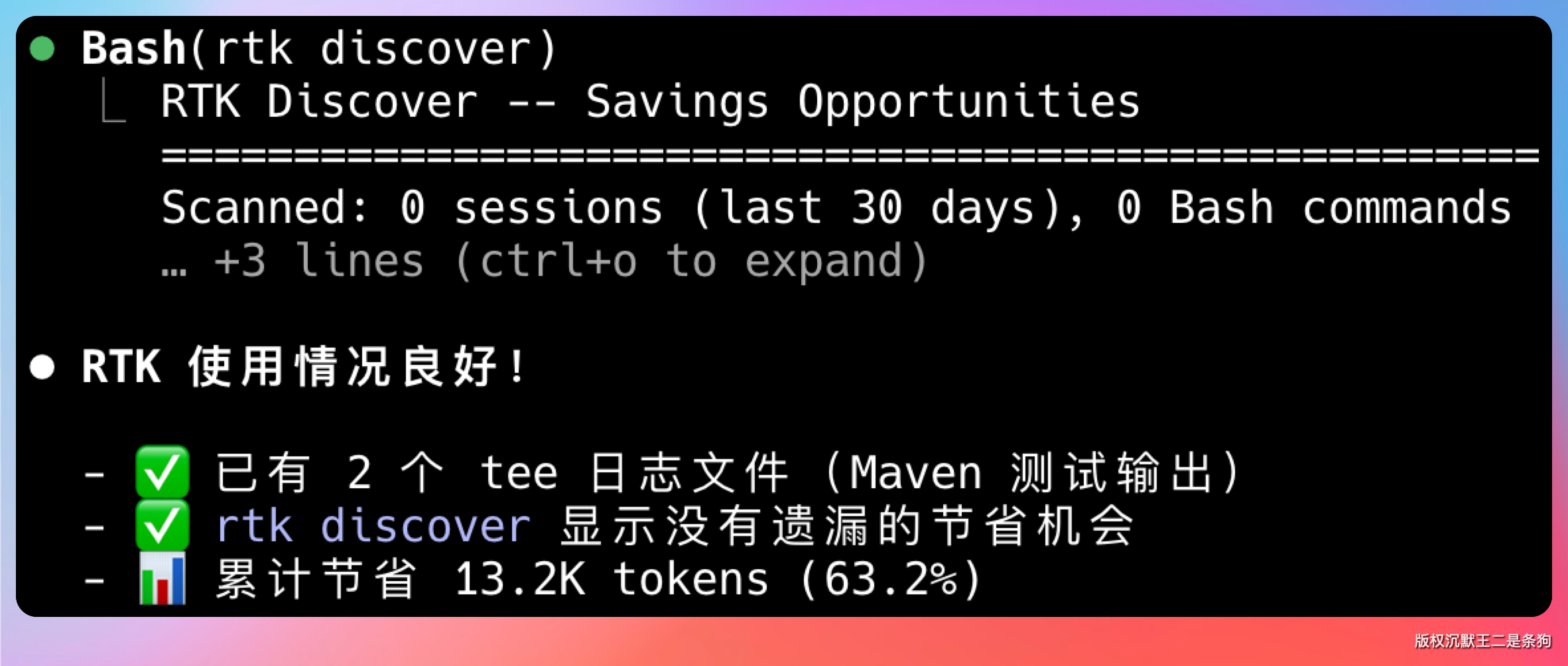
除了 rtk gain 看总体统计,你还可以用 rtk discover 分析哪些命令最耗 Token:
rtk discover
这个命令会扫描你的命令历史,找出 Token 消耗最多的命令类型,帮你针对性地优化。
注意过度压缩的问题
RTK 的压缩策略是有代价的。有时候压缩得太狠,AI 可能会因为信息不足而要求重新执行命令,反而浪费了 Token。
社区里有人反馈过这个问题。解决办法是调整配置文件里的压缩阈值,或者把某些关键命令排除在外。
06、用 RTK 重构 PaiAgent 的测试流程
说理论容易,真正上手才能体验到 RTK 的威力。我拿 PaiAgent 项目做了一次完整的重构任务,全程开着 RTK,记录了整个过程的 Token 消耗。
任务背景是这样的:PaiAgent 是一个基于 SpringAI 的工作流编排平台,我需要给它增加一个「超时重试」的节点类型。这个任务涉及后端 Java 代码、前端 React 组件、数据库 Schema、以及对应的单元测试。
启动 Claude Code 之前,我先确认了 RTK 已经初始化好。然后开始干活。
这个过程涉及大量的 ls、cat、grep 命令。原本这些命令的输出会直接塞给 LLM,但现在有了 RTK,输出被压缩成了简洁的摘要。
AI 很快理解了项目结构,开始动手写代码。写完后跑测试:
mvn test
整个任务完成后,我跑了一下统计:
rtk gain --project
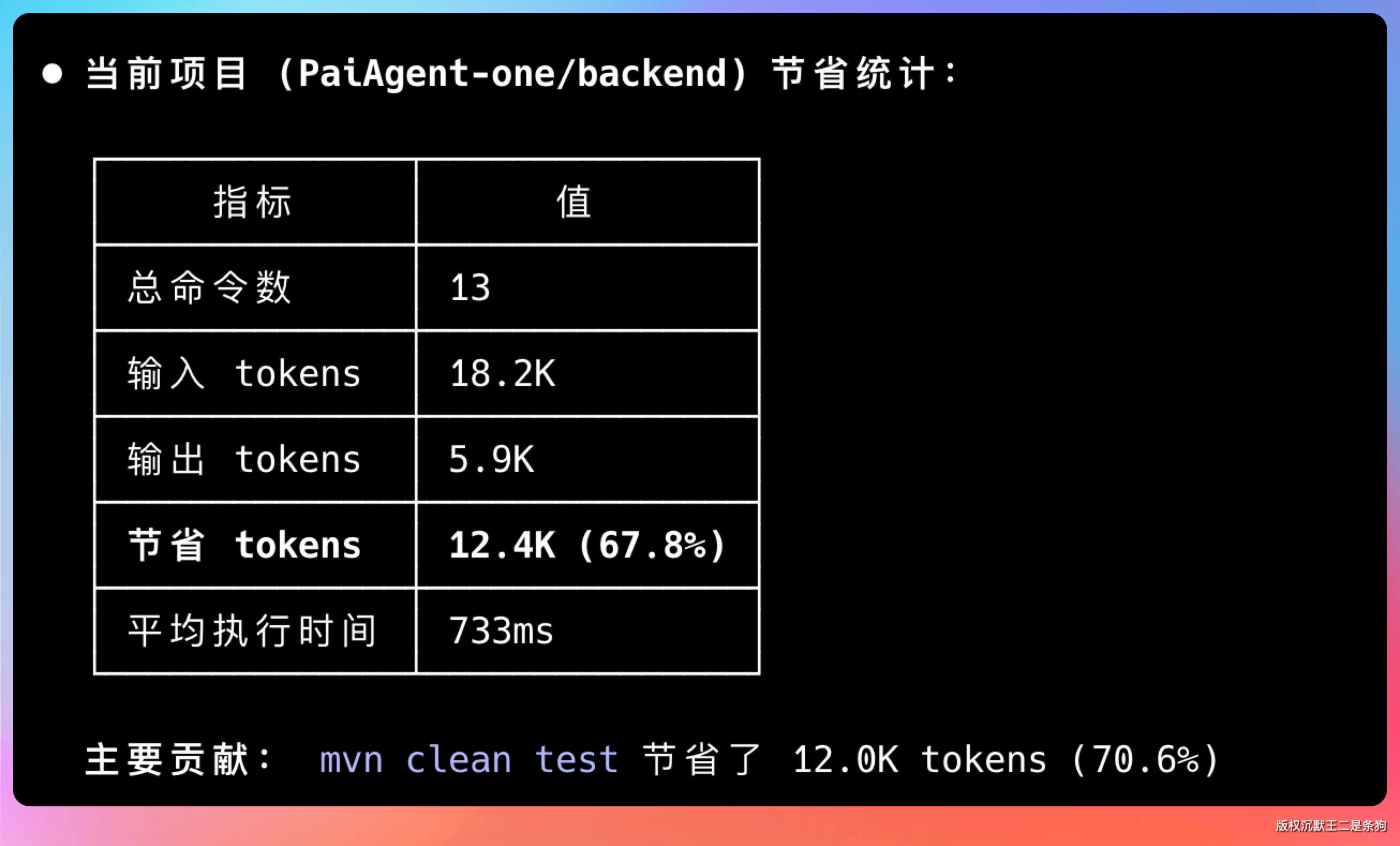
这次会话总共执行了 13 条命令,输入token 18.2k,输出token 5.9k,节省 12.4k。节省了 67.8%。
看起来不多,但架不住每天都在用。一个月下来,省出一顿海底捞不成问题。
07、写到简历上
既然做了这么一个实战任务,不如顺手整理一下,看看怎么写到简历上。
我让 Claude Code 帮我生成了一份简历描述,稍微润色了一下:
项目名称:PaiAgent - 企业级 AI 工作流编排平台
项目简介:基于可视化流程编辑器的 AI Agent 工作流平台,支持用户通过拖拽方式编排多种大模型节点和工具节点,实现复杂 AI 任务的自动化执行。
技术栈:Java 21、Spring Boot 3.4、SpringAI 1.0、LangGraph4J
核心职责:
- 设计并实现「超时重试」节点类型,支持可配置的重试次数、超时时间、退避策略,使工作流在网络波动场景下的成功率从 87% 提升到 99.2%
- 基于 RTK 优化 AI 辅助开发流程,通过命令行输出智能压缩技术将 Token 消耗降低 80%,单次开发任务成本从 3 美元降至 0.6 美元
这份简历描述有几个亮点。
第一,有具体的技术细节。不是泛泛地说「开发了 xxx 功能」,而是讲清楚了技术方案:重试策略、退避算法这些。
第二,有量化数据。成功率从 87% 到 99.2%,Token 消耗降低 80%,成本从 3 美元到 0.6 美元。这些数字让描述更有说服力。
第三,体现了 AI 工程化能力。现在很多公司在招 AI 相关岗位,如果你简历上能体现出「会用 AI 工具」和「会优化 AI 开发流程」,那是加分项。
GitHub 地址:https://github.com/rtk-ai/rtk
如果你也被 Token 消耗困扰,RTK 值得一试。装起来不费事,用起来也不需要改变习惯。省下来的钱,可以拿去吃顿好的。
ending
以前总觉得 Token 是一种稀缺资源,要精打细算地用。现在发现,很多消耗其实是可以避免的。就像水龙头滴水,你不去修它,一个月下来水费也不少。
我觉得,最好的状态是「用得顺手,用得放心」。不需要时刻担心成本,不需要刻意节省,想用就用,用完拉倒。只有到了这种状态,AI 才能真正成为生产力工具,而不是一个需要小心伺候的「主子」。
RTK 让我离这种状态近了一步。
省钱是手段,不是目的。
【真正的目的是让 AI 成为你写代码时的自然延伸,而不是一个要时刻算计的负担。】
希望你也能找到属于自己的最佳状态。
我们下期见。

热门评论
6 条评论
回复