


大家好,我是二哥呀。
刚刚更新 Codex,发现了一个新的功能,插件。
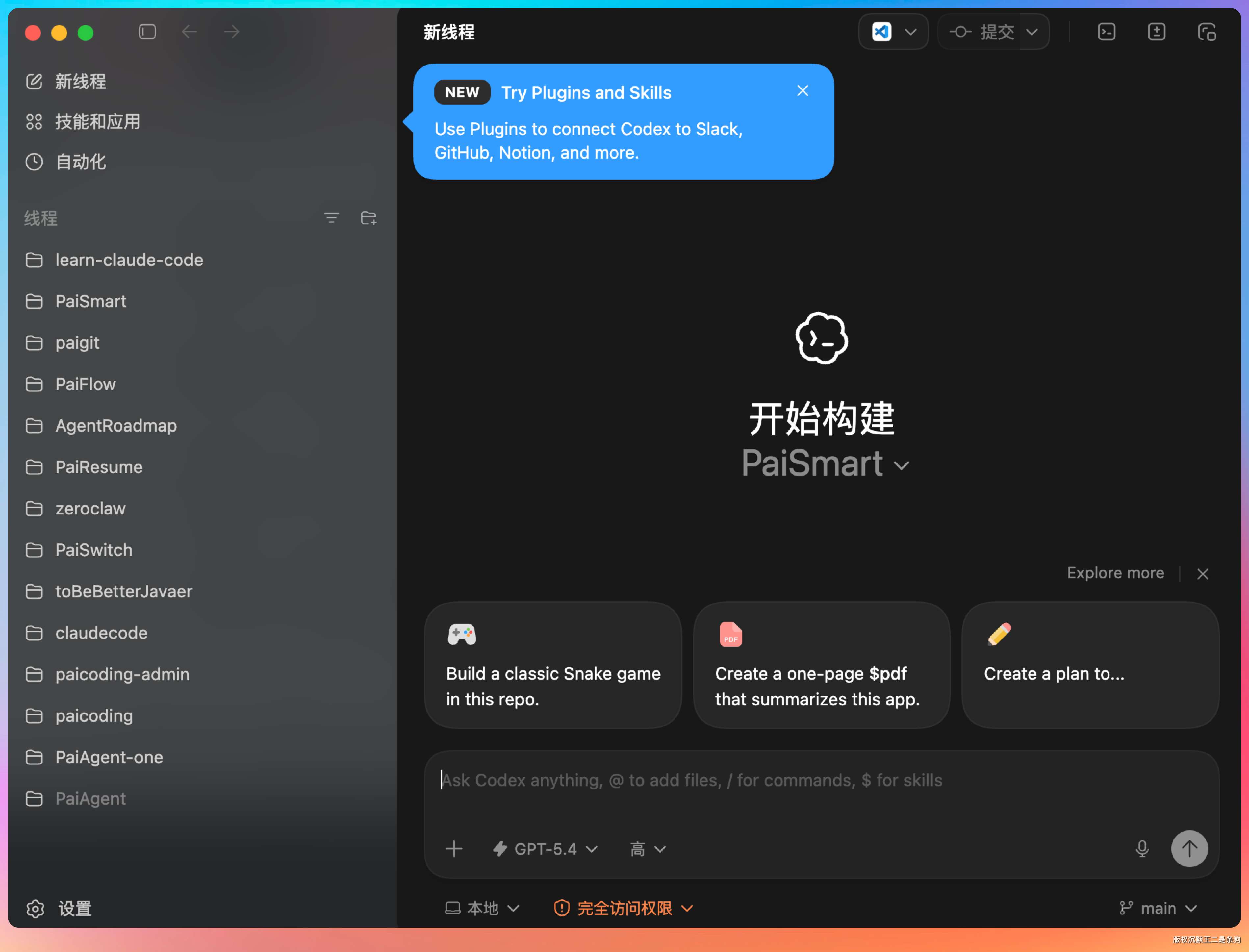
按理说,【技能和应用】应该叫“技能和插件”才对,但不知道为什么 Codex 翻译成了这个鬼样子,GPT-5.4 的文本能力是真的差劲啊,😄
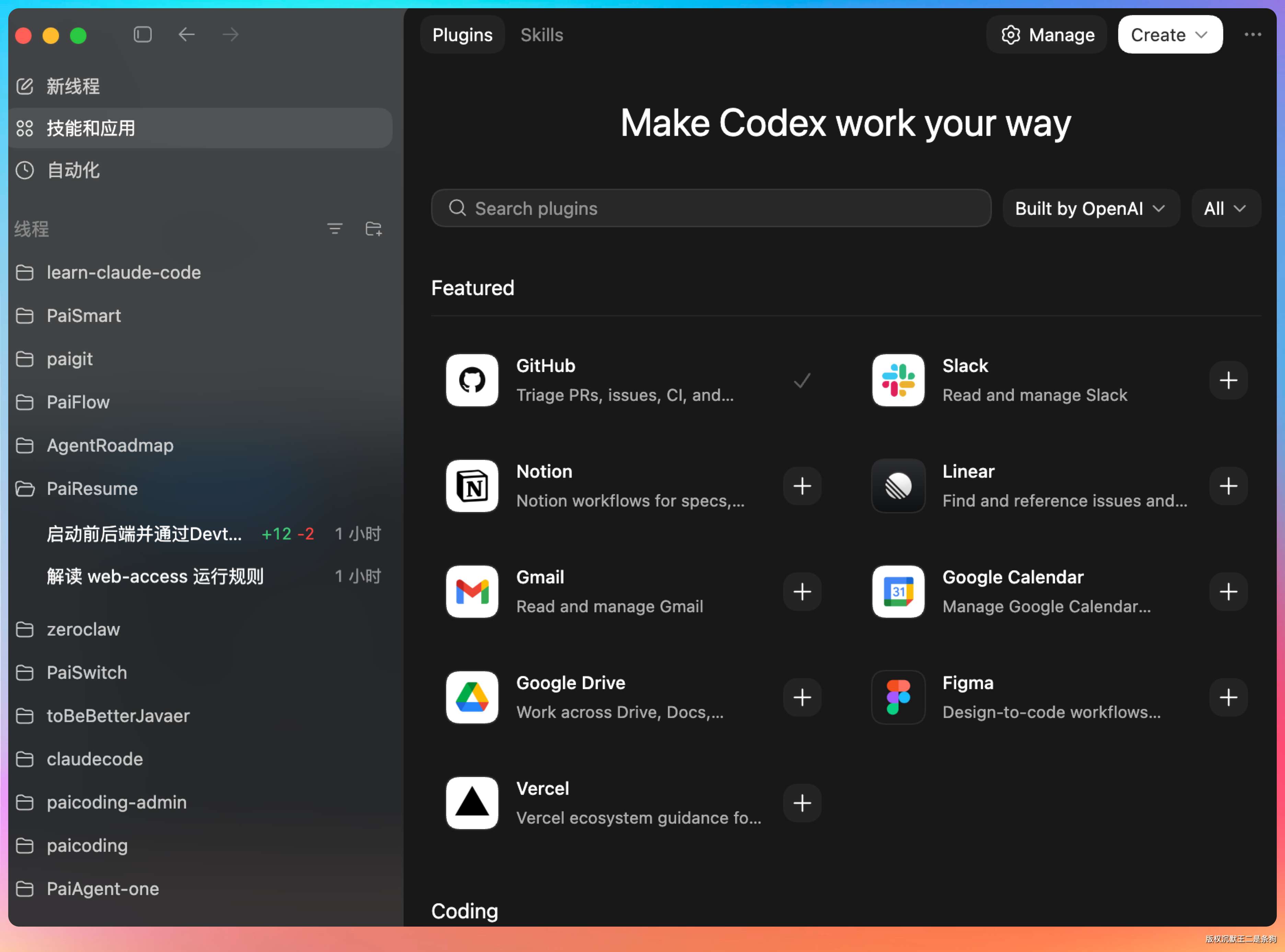
更新提醒上说,可以通过插件链接到 GitHub、Notion 这些应用,但我暂时没有这俩的应用场景。
但我确实有一个场景,可能插件体系能派上用场。
先说场景。
我经常需要把 Markdown 文档复制粘贴到飞书里,但飞书没有自动转换图片的功能,只能一张张手动上传,麻烦得要死。
这种痛苦,经历次数多了,你就会恶心。
尤其是像我这种图文并茂的博主,经常一篇内容包括几十张图片,手动复制粘贴真的很累。明明内容早就写好了,光是处理图片就能耗掉半小时,效率低到令人发指。
我想 Codex 的插件系统蛮适合这种场景的。
于是我就搞了一个飞书 Markdown 上传插件,直接把本地 Markdown 文档连图带文一键上传到飞书。现在几秒钟就能搞定,图片自动转换,格式完美保留,省心多了。

你看,现在就是一键直接上传的测试文档。如果大家也有类似 Markdown 转飞书的场景,这个插件就很香。
系好安全带,滴滴滴,我们发车。
要做这个插件,第一步是在飞书开放平台创建一个企业自建应用。
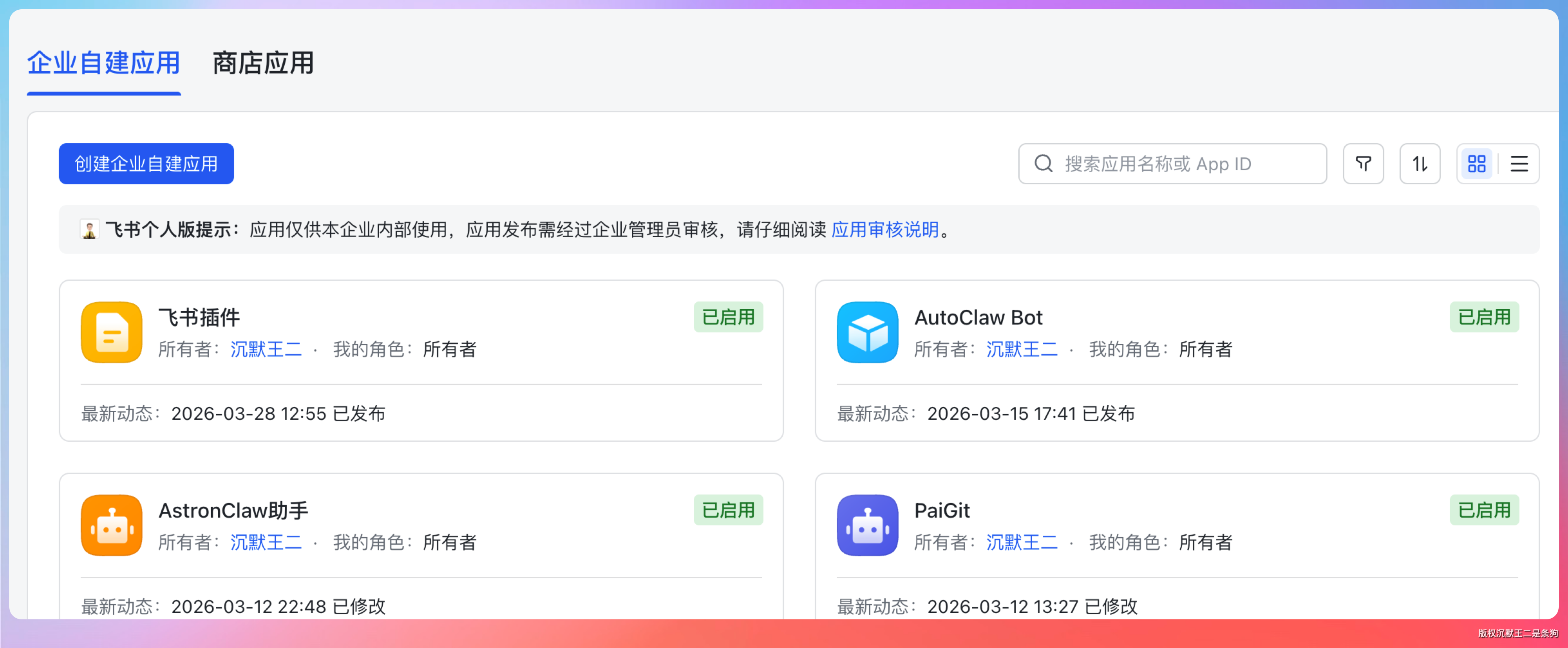
这次新建的就是一个飞书插件。
接下来是权限申请这块,需要申请云空间和云文档的相关权限,不然上传文档会报权限错误。
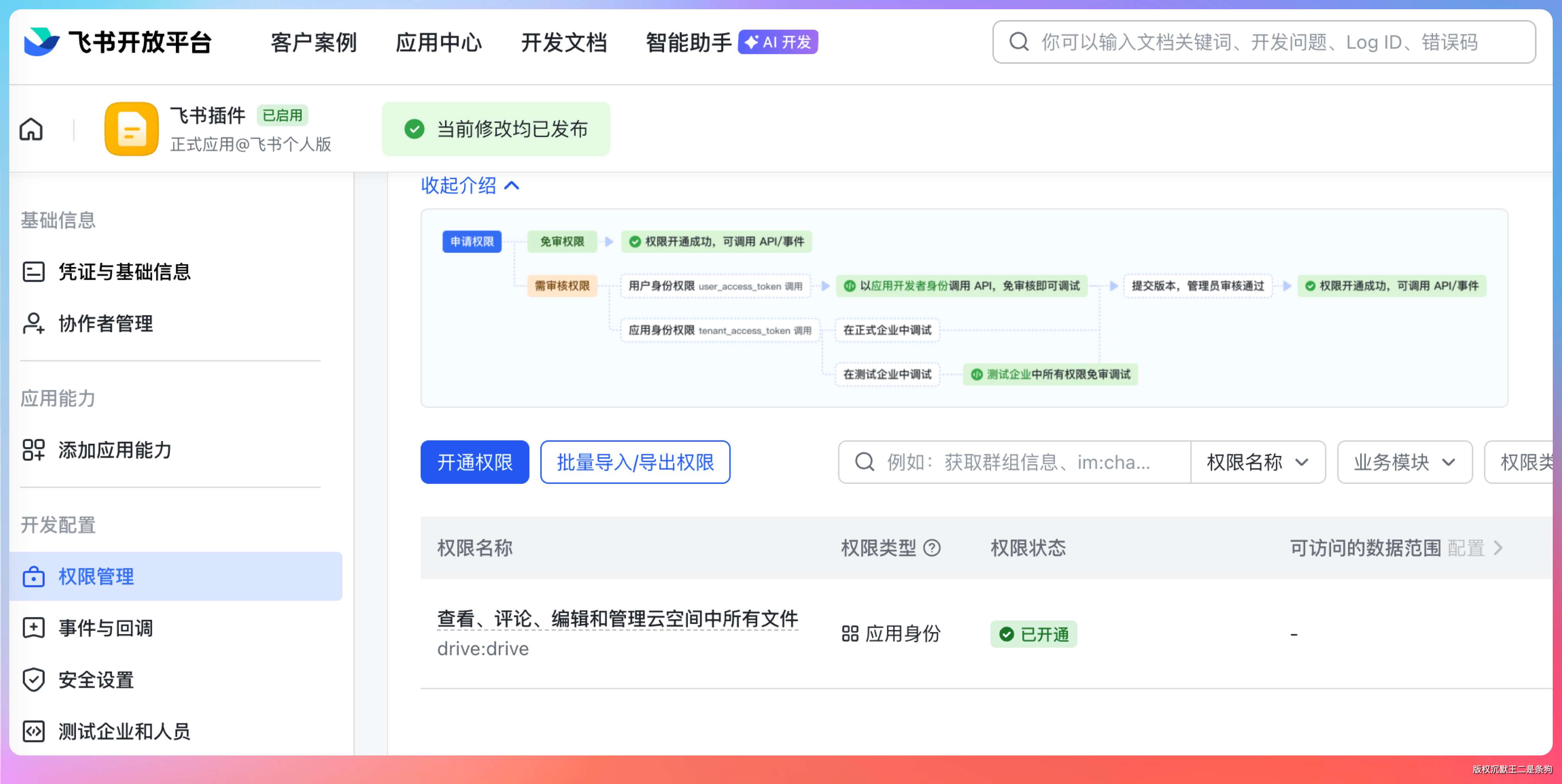
具体要申请的权限是【查看、评论、编辑和管理云空间中所有文件】,或者直接搜为【drive:drive】。
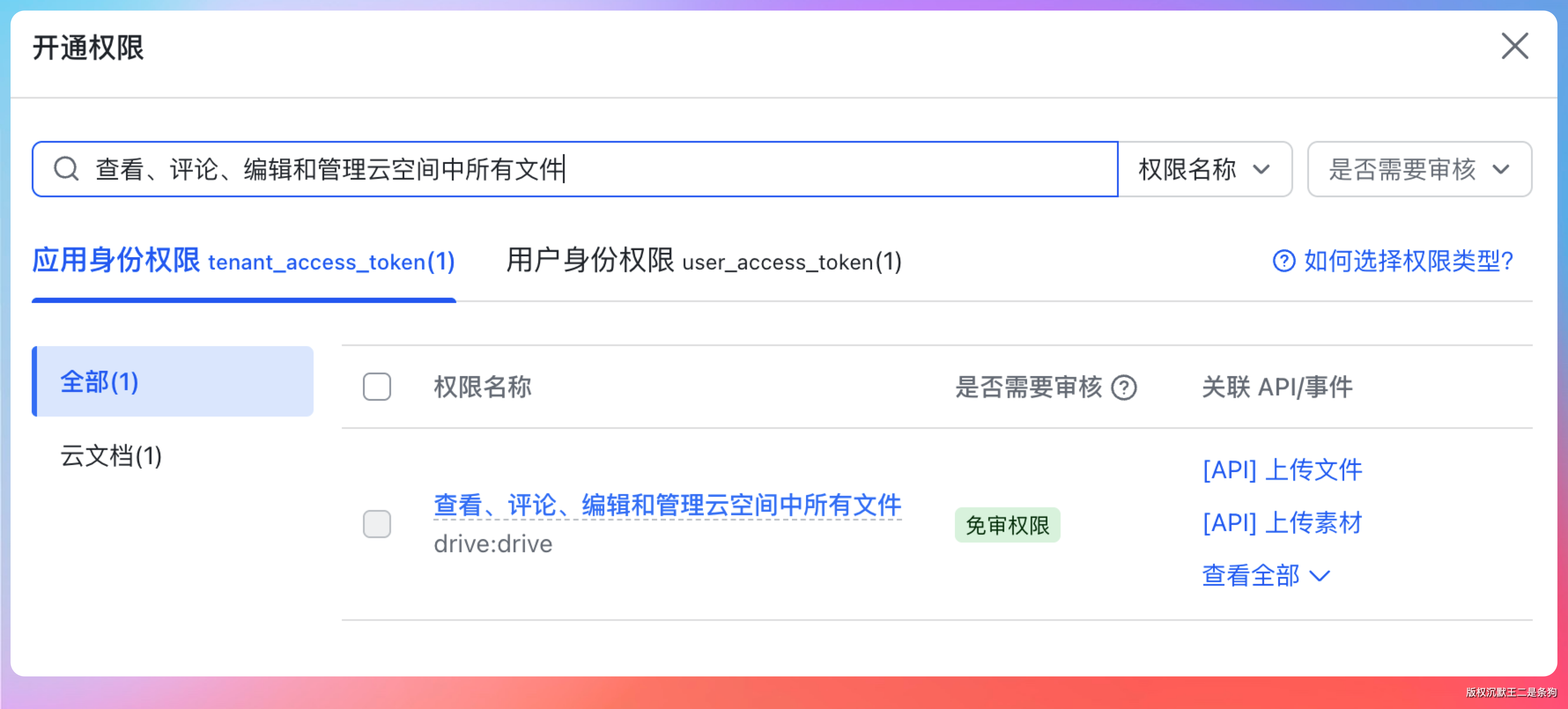
这里面就刚好有我们需要的写入图片功能。
申请完权限,拿到 App ID 和 App Secret,这两个是后续调用 API 的凭证。
等会我们要把 App ID 和 App Secret 放到环境变量里,插件启动时会自动读取。
插件的核心逻辑其实不复杂,主要是三步:
第一步:Markdown 转 DOCX
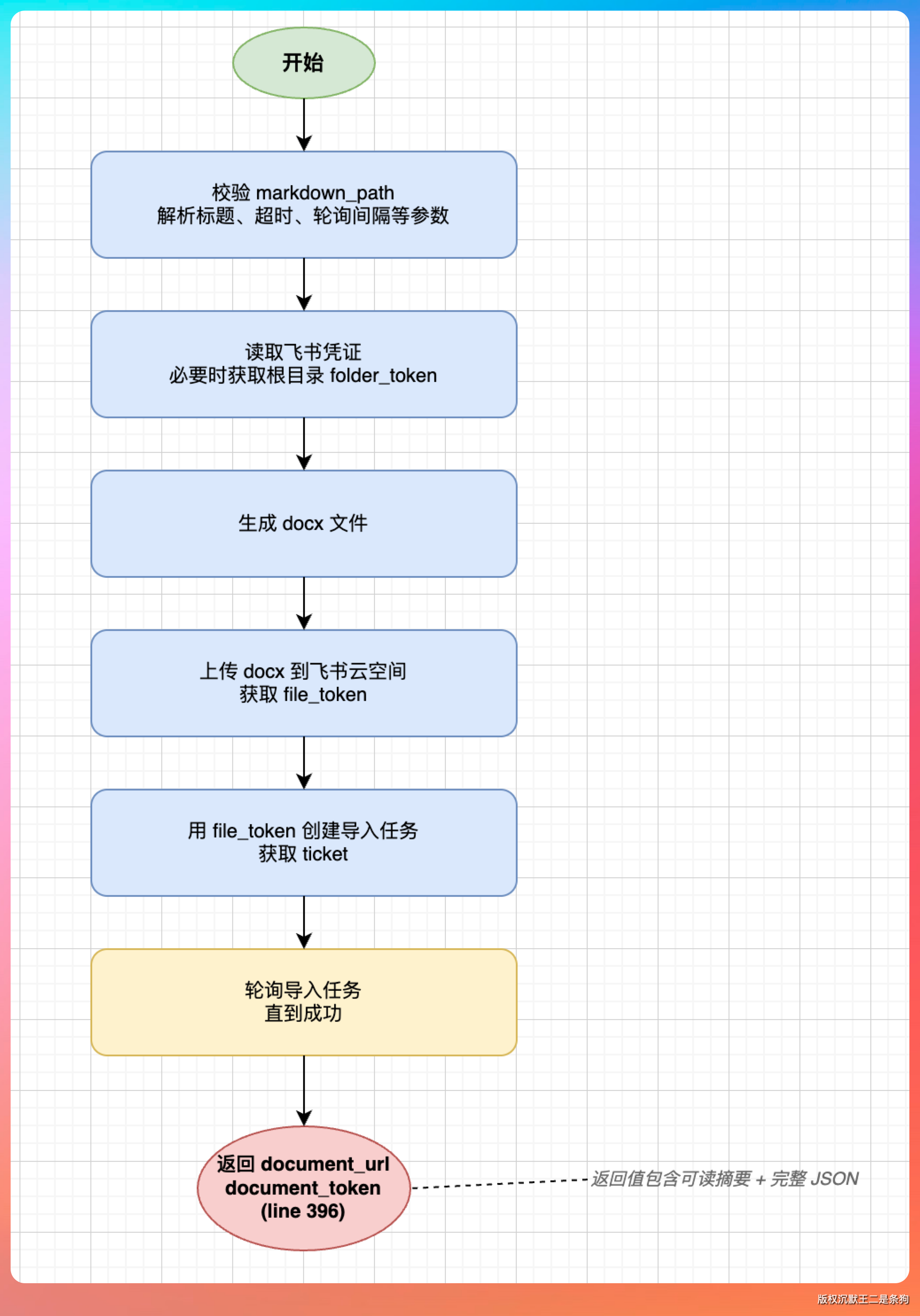
插件本质上是一个本地 MCP stdio server,作用是把本地 Markdown 转成 docx,再借助飞书云空间和导入任务接口,生成一篇飞书文档。
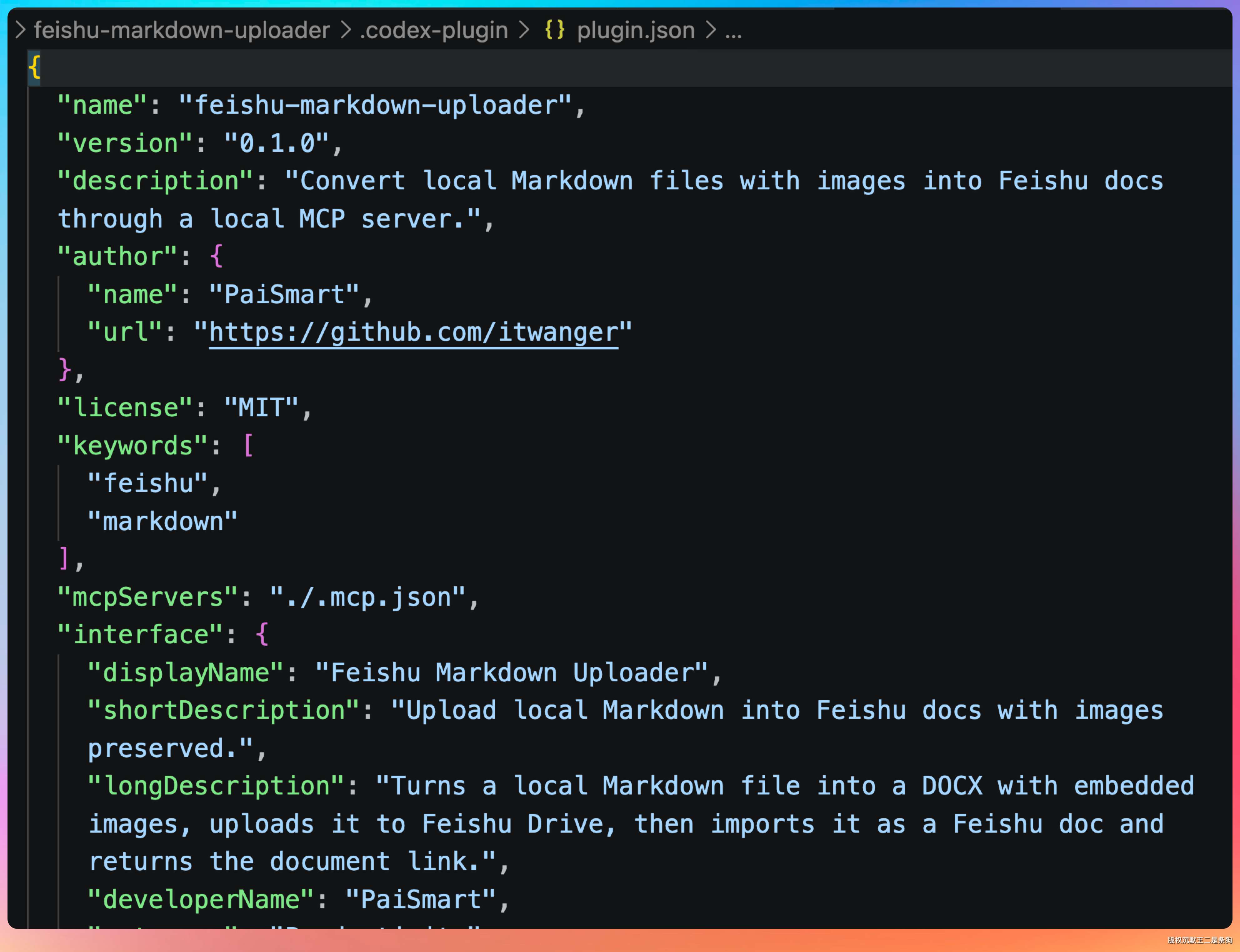
插件入口和元信息在 plugin.json 和 .mcp.json,启动逻辑在 run_server.sh。
{
"mcpServers": {
"feishu-markdown-uploader": {
"type": "stdio",
"command": "/bin/bash",
"args": [
"./scripts/run_server.sh"
],
"cwd": ".",
"env": {
"PYTHONUTF8": "1"
}
}
}
}
run_server.sh 会先加载 .env.local/.env,再启动 Python 服务。
#!/bin/bash
set -euo pipefail
SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
PLUGIN_DIR="$(cd "${SCRIPT_DIR}/.." && pwd)"
if [[ -f "${PLUGIN_DIR}/.env.local" ]]; then
# shellcheck disable=SC1091
source "${PLUGIN_DIR}/.env.local"
fi
if [[ -f "${PLUGIN_DIR}/.env" ]]; then
# shellcheck disable=SC1091
source "${PLUGIN_DIR}/.env"
fi
cd "${PLUGIN_DIR}"
exec python3 "./scripts/feishu_markdown_uploader_server.py"
为什么要先转 docx?
因为这套实现走的是飞书“上传文件 + 导入文档”这条路线,不是直接把 Markdown 直接写进飞书文档。
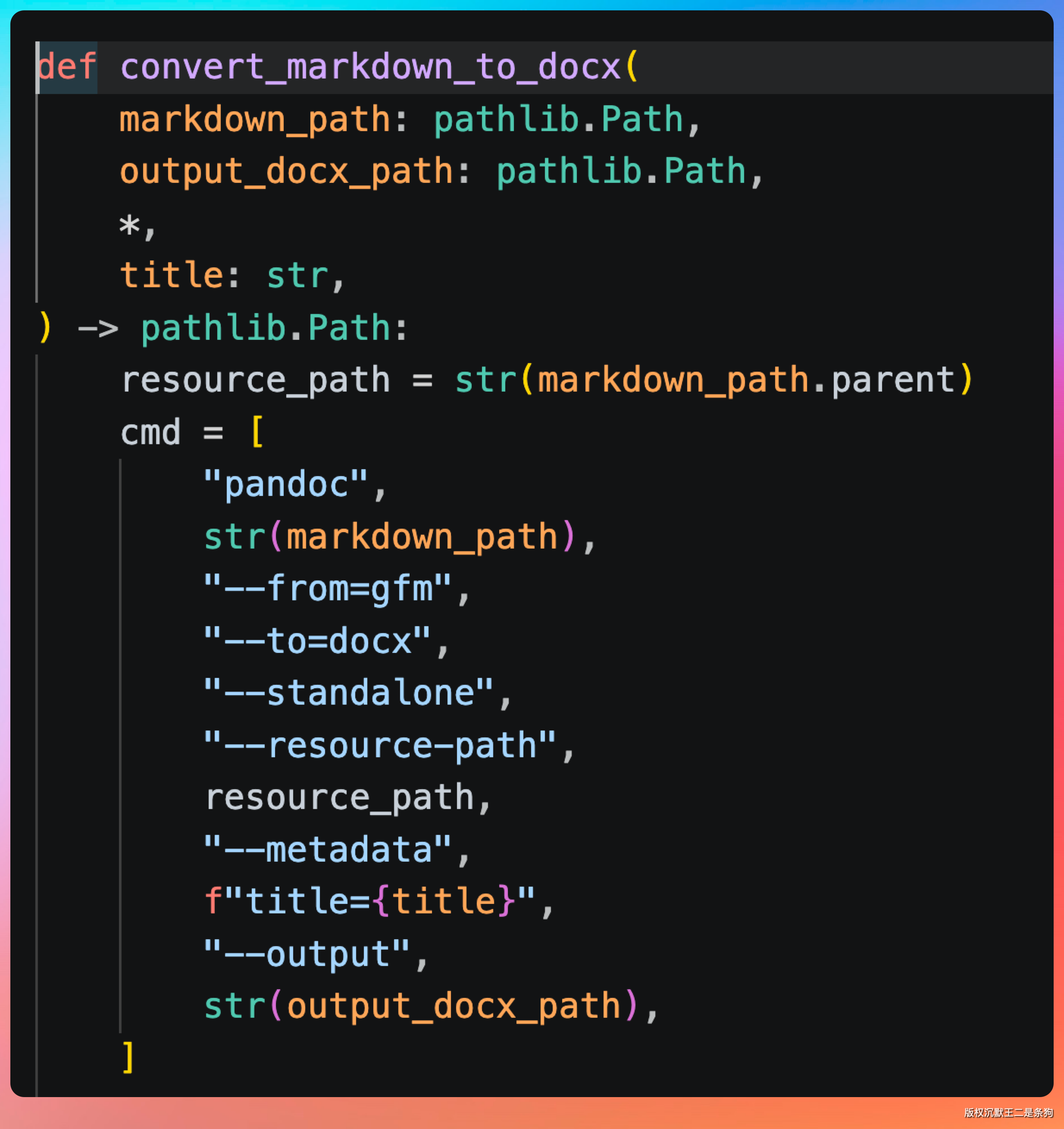
convert_markdown_to_docx 是用 pandoc 做的 Markdown 到 docx 的转换,关键参数是 --resource-path markdown 所在目录,这也是能把本地相对路径图片一起打进文档的原因。
第二步:上传到飞书云空间
调用飞书的文件上传接口,把生成的 DOCX 文件上传到云空间。
curl_upload_file 用 curl --form 上传二进制文件到飞书云空间。这里不用纯 Python multipart,而是直接交给 curl,实现简单,兼容性也高。
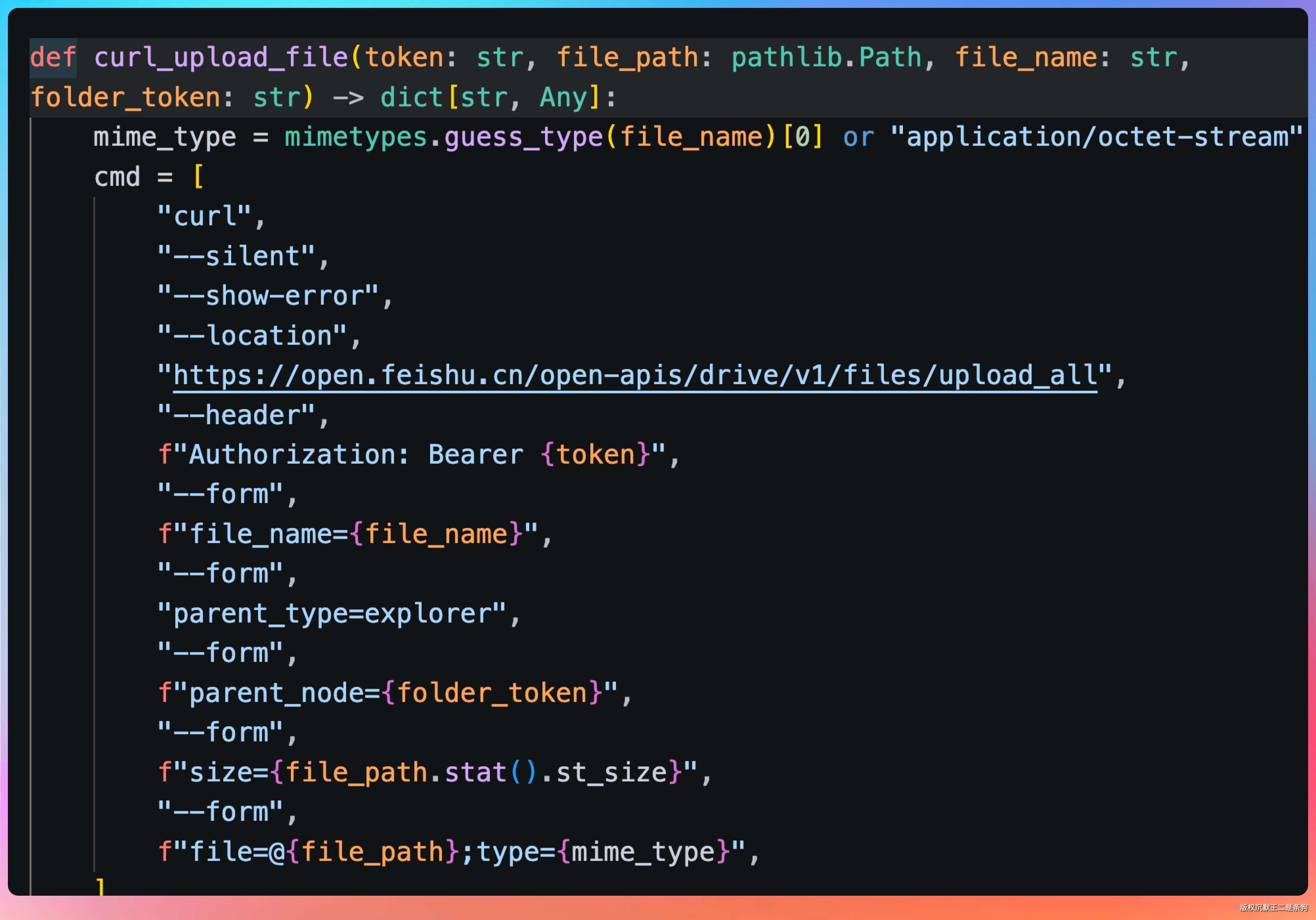
这里需要用到之前申请的 App ID 和 App Secret 获取访问令牌,然后用令牌调用上传接口。
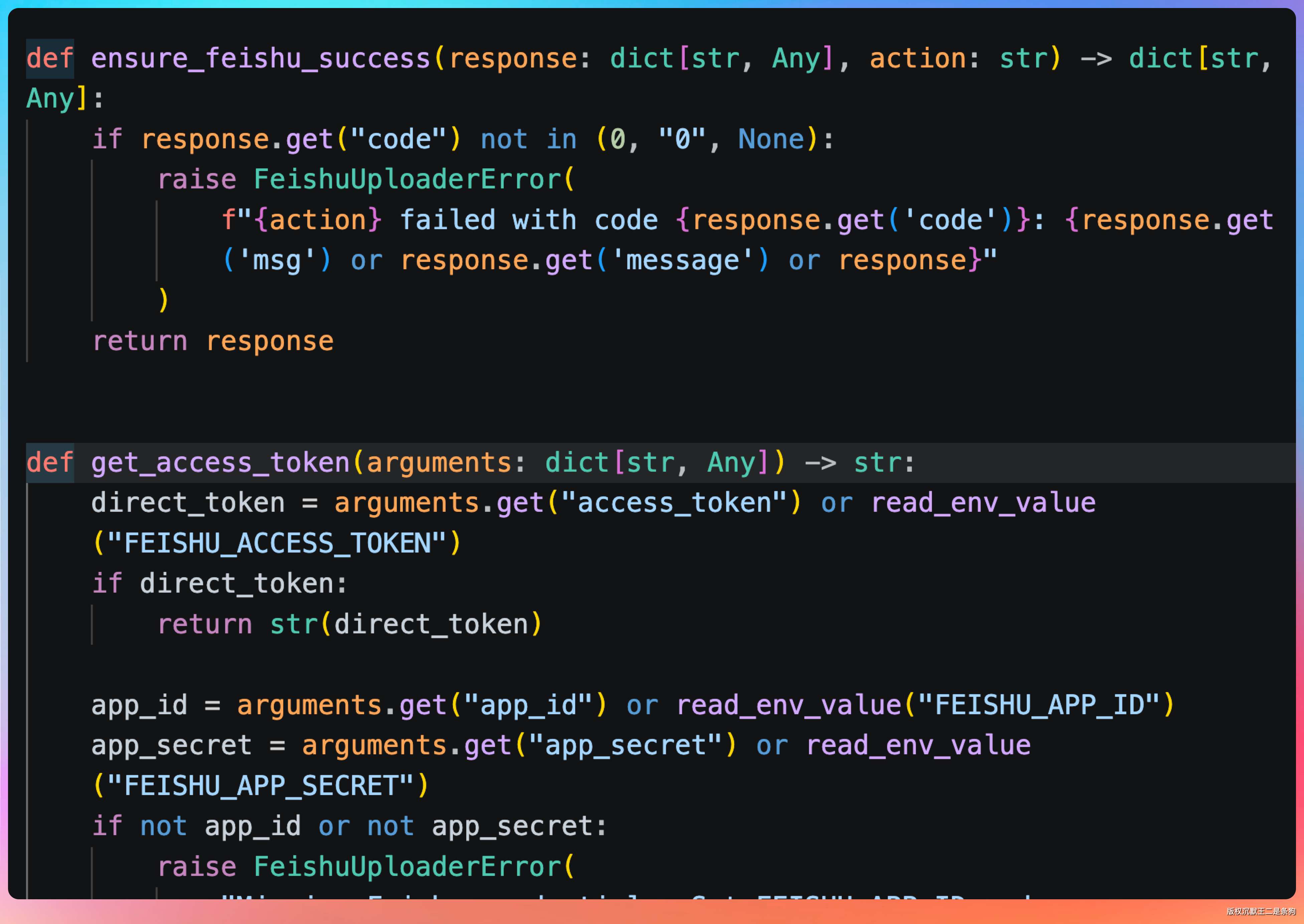
get_access_token 用 FEISHU_APP_ID/FEISHU_APP_SECRET 换 tenant_access_token,这是所有飞书调用的前置条件。
第三步:导入为飞书文档
拿到文件 token 后,调用飞书的文档导入接口,把云空间里的 DOCX 文件导入为飞书新版文档。这个接口是异步的,需要轮询导入状态,直到导入完成。
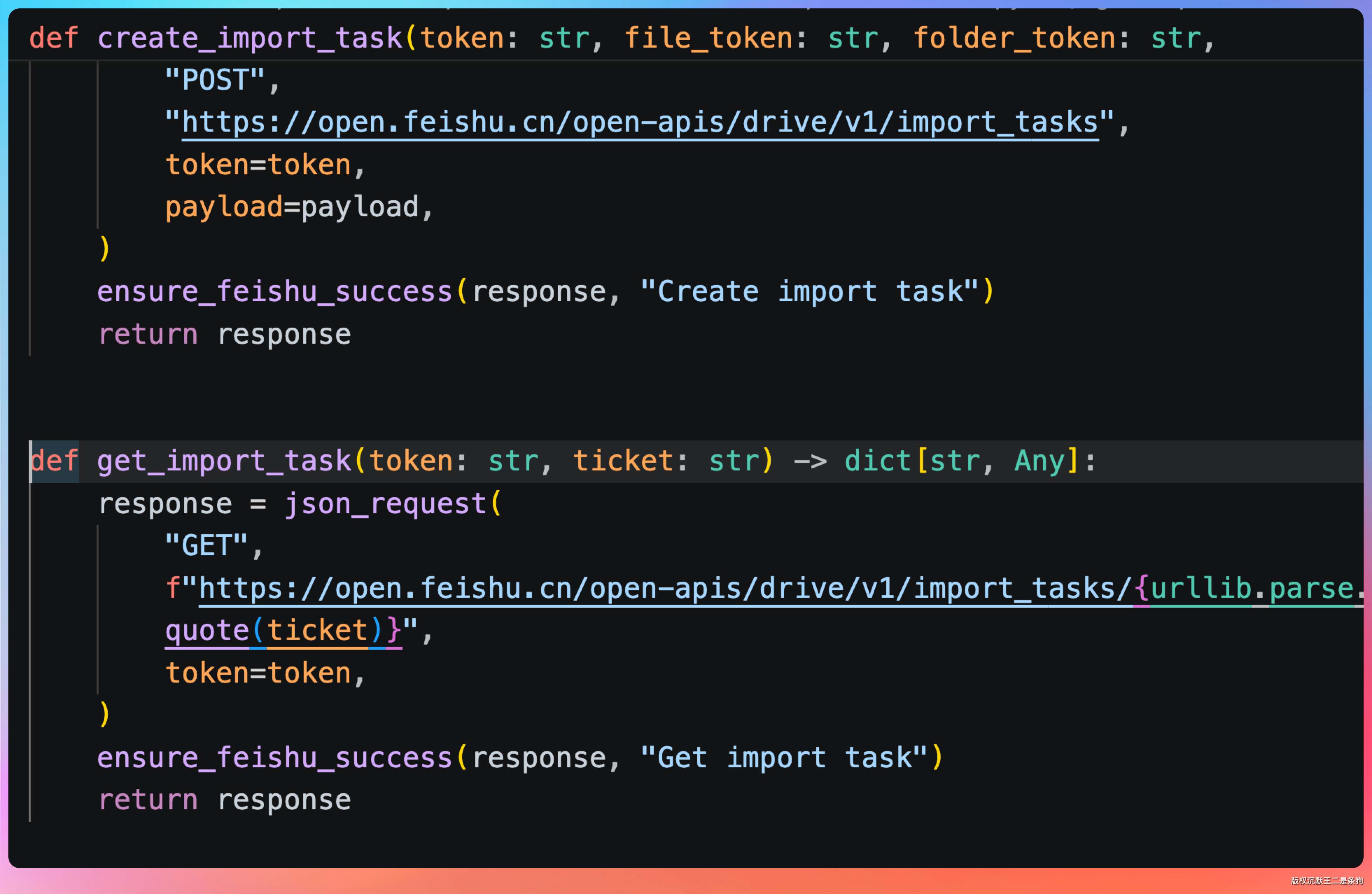
导入成功后,飞书会返回文档的 URL,这个 URL 就是最终可以在浏览器中打开的飞书文档链接。
整个流程跑通后,我把它封装成了一个 MCP 服务器,提供了三个工具函数:
import_markdown_to_feishu:完整的 Markdown 到飞书文档流程convert_markdown_to_docx:只做本地转换,方便调试get_feishu_root_folder:获取根目录 folder token
当然了,这样的插件完全不用我自己来实现。
因为 Codex 已经帮我们提供了插件创建的方法,我们直接写提示词就好了。
Plugin Creator 我有这么一个场景,我希望能够把我本地的markdown文档上传到飞书,我现在是复制粘贴过去的,但粘贴过去的时候,图片没办法直接用,需要我手动一张一张粘贴过去,我希望有这么一个插件,能够连上我的飞书,然后创建文档,把markdown的内容复制粘贴过去,并自动化上传我的图片。
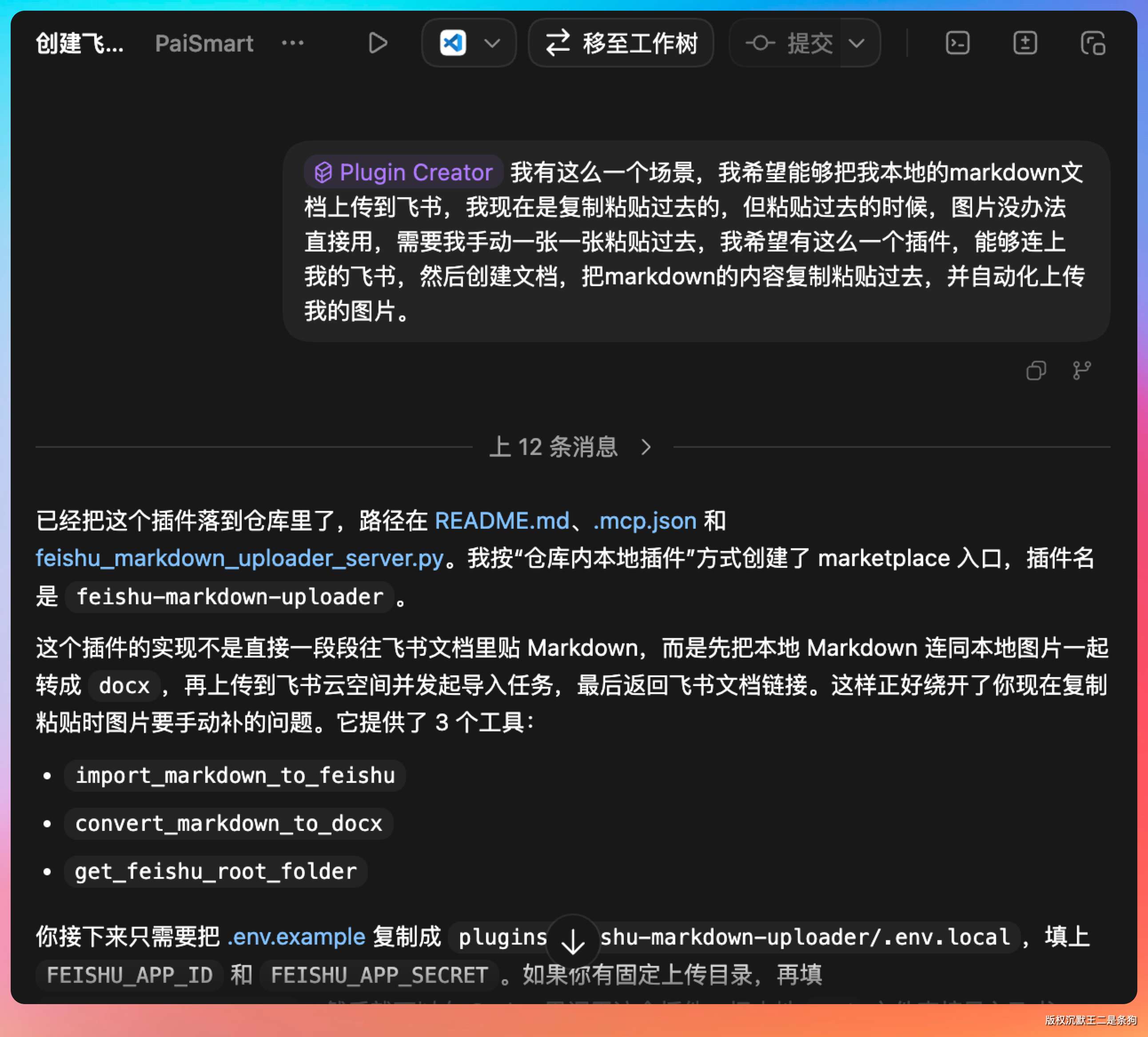
plugin-creator 会帮我们一键生成插件。

完事后就可以让 Codex 再帮我们做一遍测试。
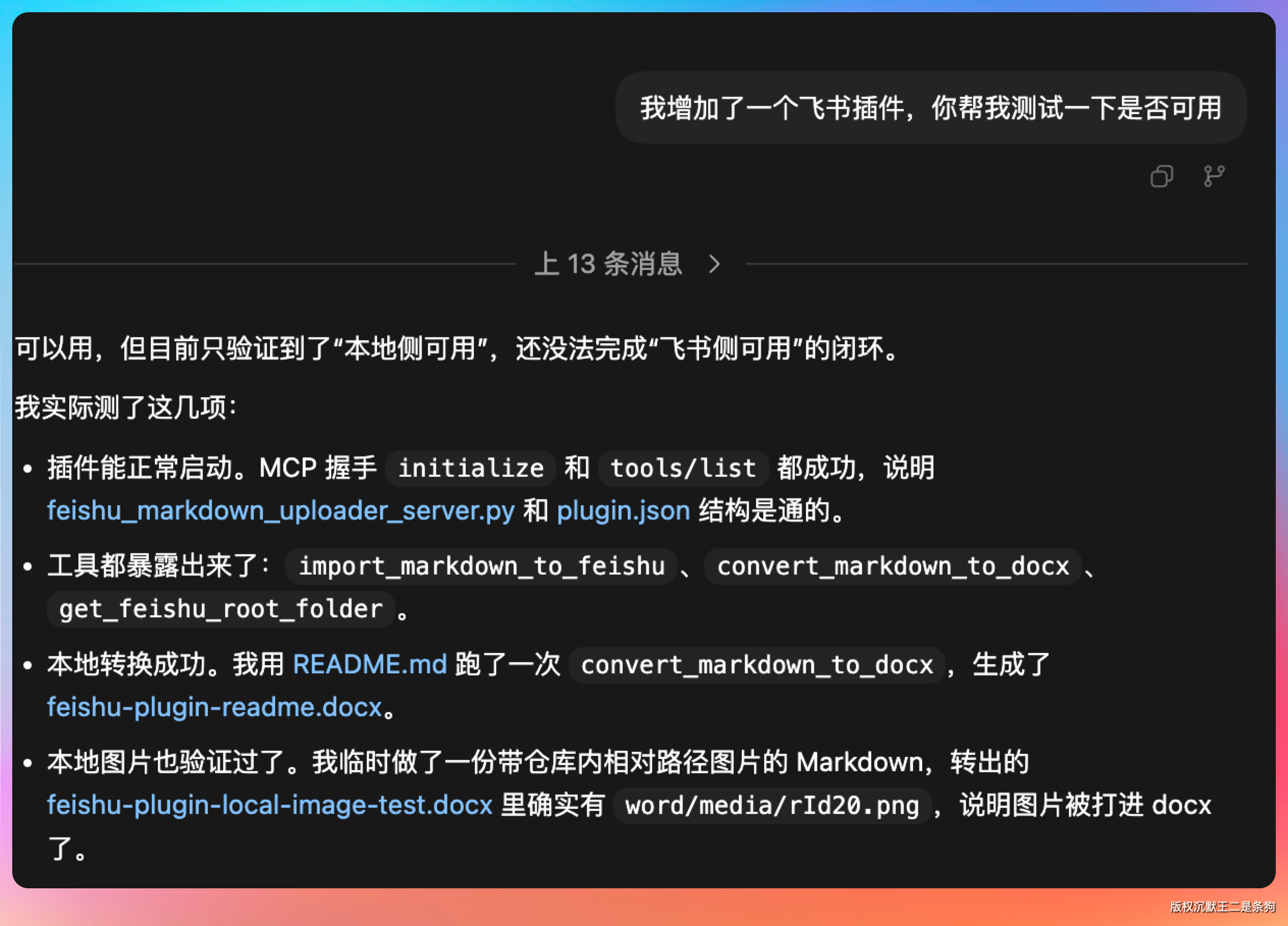
有任何不满意的地方也都可以调整。
我画一张流程图,还挺简单的。
插件写完了,但真正让我惊喜的是 Codex 的插件体系设计。
Codex 采用的是 MCP(Model Context Protocol)协议,这是 Anthropic 推出的一种开放标准,用于 AI 模型与外部工具的通信。
简单来说,MCP 定义了一套标准的接口规范,只要你的工具实现了这套接口,Codex 就能调用它。
这种设计有几个好处:
第一,语言无关。
MCP 服务器可以用任何语言编写,只要支持标准输入输出就行。我的插件是用 Python 写的,但你也可以用 Node.js、Go、Rust 甚至 Java 来写。
第二,进程隔离。
每个 MCP 服务器运行在独立的进程中,通过标准输入输出与 Codex 通信。
第三,声明式配置。
插件的能力通过 JSON 文件声明,包括提供的工具函数、参数定义、返回值结构等。Codex 在启动时会读取这些配置,自动理解插件能做什么。这种声明式的设计让插件的接入成本很低,不需要修改 Codex 的代码,只需要把配置文件放到指定目录就行。
第四,生态开放。
MCP 是一个开放协议,不仅 Codex 支持,Claude Code、Claude Desktop 等工具也都支持。
具体来说,一个 Codex 插件包含以下几个部分:
plugin.json:插件的元信息,包括名称、版本、描述、作者、关键词等。这部分主要是面向插件市场的展示信息。
.mcp.json:MCP 服务器的配置,包括启动命令、参数、环境变量等。Codex 通过读取这个文件知道如何启动插件。
MCP 服务器:实际提供功能的程序,需要实现 MCP 协议,处理 Codex 发来的请求并返回结果。
以我的飞书插件为例,目录结构是这样的:
plugins/feishu-markdown-uploader/
├── .codex-plugin/
│ └── plugin.json # 插件元信息
├── .mcp.json # MCP 配置
├── scripts/
│ ├── run_server.sh # 启动脚本
│ └── feishu_markdown_uploader_server.py # MCP 服务器
├── .env.example # 环境变量示例
└── README.md # 使用说明
MCP 采用 JSON-RPC 2.0 作为通信协议,这是一种轻量级的远程调用协议。
Codex 和插件之间通过标准输入输出交换消息,每个消息包含请求 ID、方法名、参数等信息。插件收到请求后执行相应操作,然后通过标准输出返回结果。
这种通信方式简单可靠。因为是在本地进程间通信,不存在网络延迟问题,响应速度很快。
插件开发完成后,我在 Codex 里测试了一下,体验确实不错。
直接在对话里告诉 Codex:把这篇内容上传到飞书。
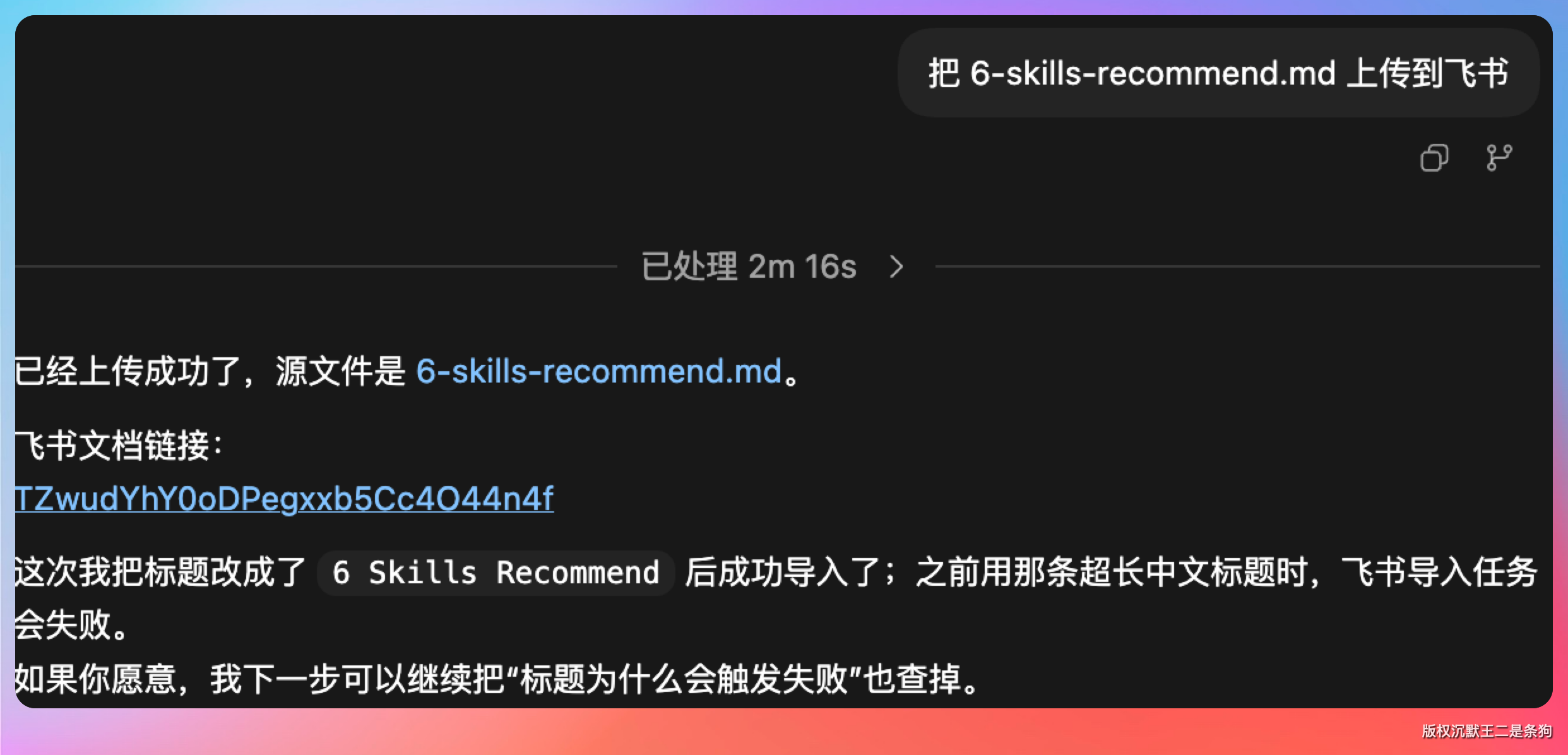
Codex 会自动识别到我的飞书插件,调用 import_markdown_to_feishu 函数,传入 Markdown 文件路径。
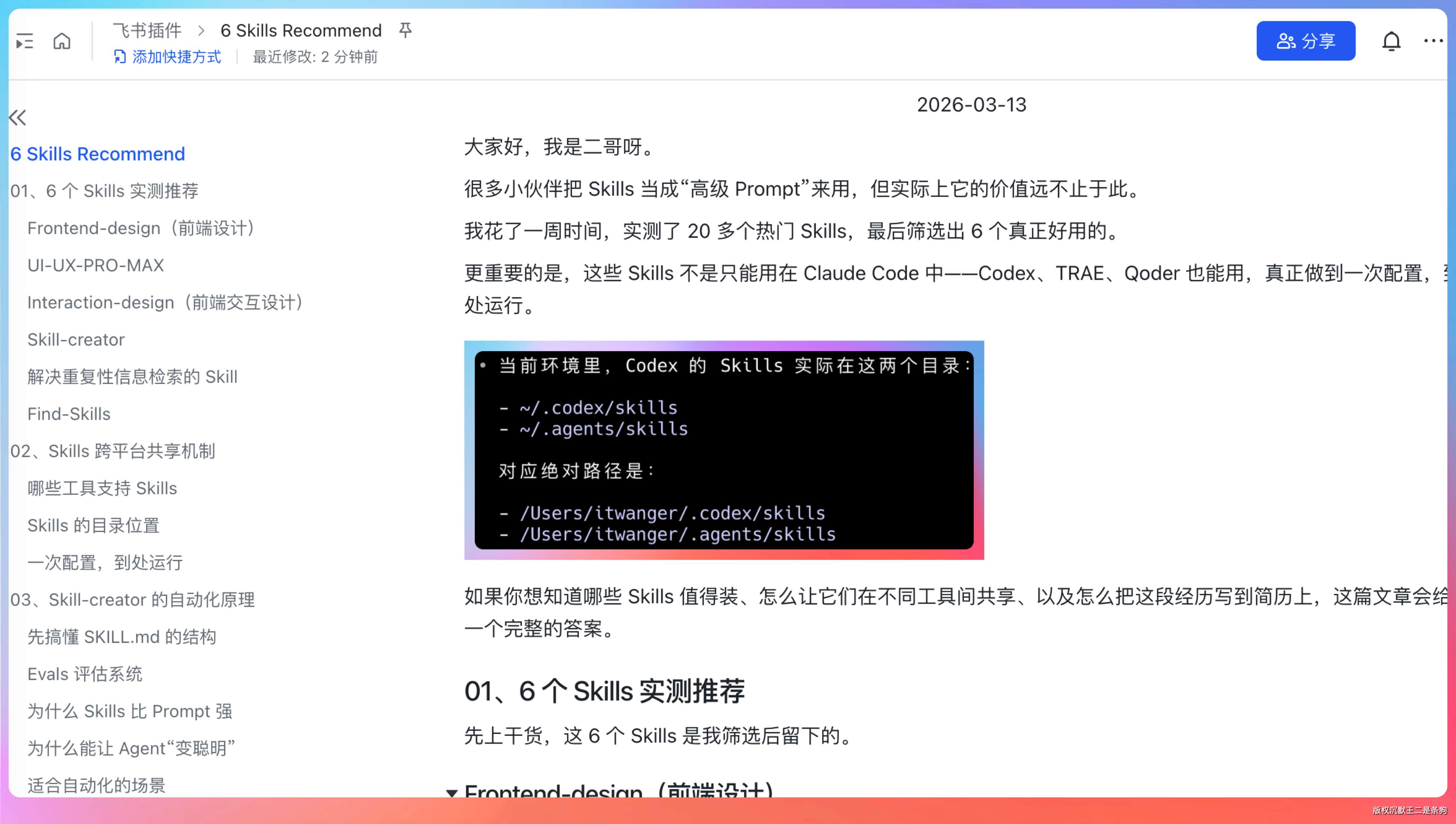
整个流程全自动:转换格式、上传文件、导入文档、返回链接。我只需要等着拿最终的飞书文档 URL 就行。
之前手动操作需要半小时的事,现在几秒钟就搞定了。而且图片全部自动处理,顺序也不会乱,省心多了。
AI 时代的开发,不再是单打独斗。我们可以借助 AI 的能力,快速构建解决实际问题的工具。这种效率提升,是传统开发方式没法比的。
我们下期见!

回复