


最近有个东西让我有点坐不住。
GLM-5.1 发布了,编程评测 45.3 分,直逼 Claude Opus 4.6 的 47.9。
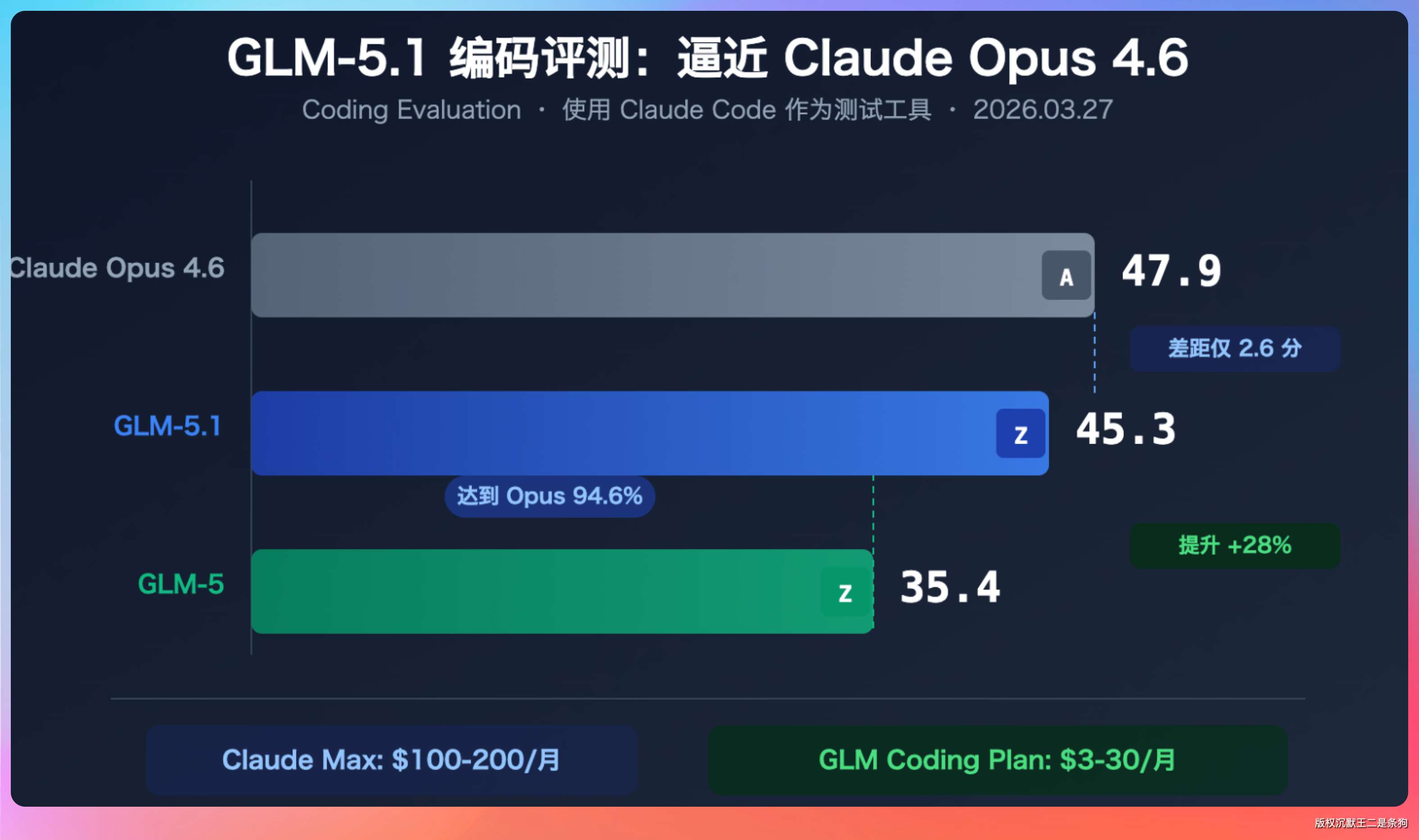
光看跑分还不够,我得亲自下场测一测。
于是我给了它一个真实项目需求:从零开发一个在线简历编辑器——派简历。9 份需求文档、前后端完整开发、自动化测试,全程不让它停。
结果说实话,有点超出预期。
01、先搞定环境配置
工欲善其事,必先配置环境。
只需要改一下配置文件,把模型切过去就行。
具体操作很简单,打开 Claude Code 的配置,把 ANTHROPIC_AUTH_TOKEN 换成智谱的 API Key,再把 ANTHROPIC_BASE_URL 设成智谱的接口地址。
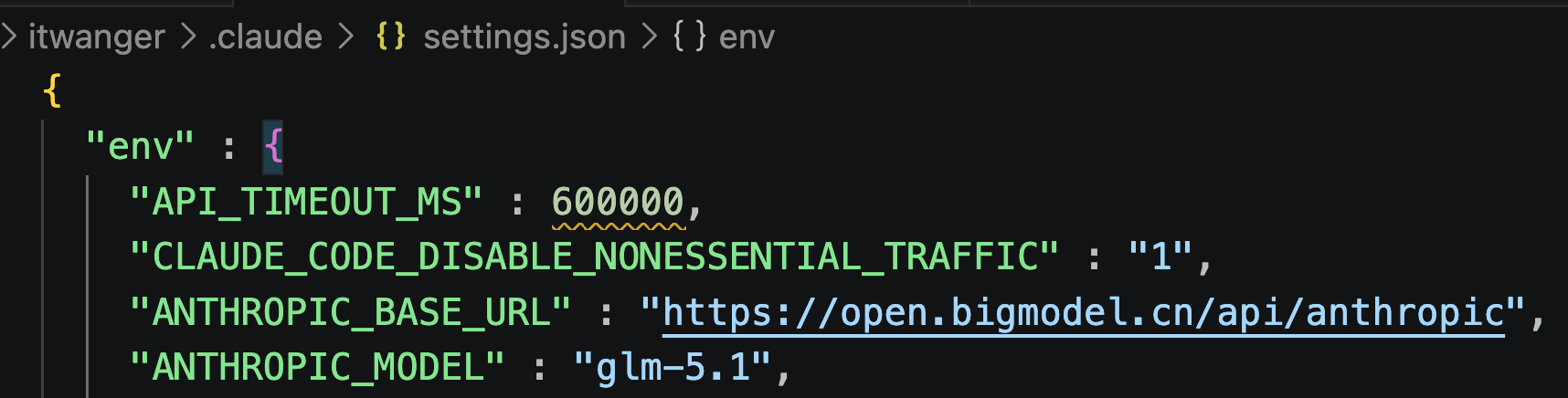
保存完重启一下,输入 /status 看看是不是已经连上 BigModel.cn。看到智谱的影子就说明稳了。
Claude Code 真是个牛本地 Agent 框架,工具调用、任务编排、错误处理都做的无可挑剔。我们把底层模型换成 GLM-5.1,相当于给国产模型配了一套顶级的执行框架。
这样才能真正测试出模型的长程任务能力,而不是单纯比拼代码补全。
02、让它去啃需求文档
环境就位,直接上硬菜。
我给的任务是开发派简历,一个在线简历编辑器。需求文档散落在语雀知识库里,总共 9 份,涵盖用户流程、简历模块、支付对接、AI 优化、消息通知等方方面面。
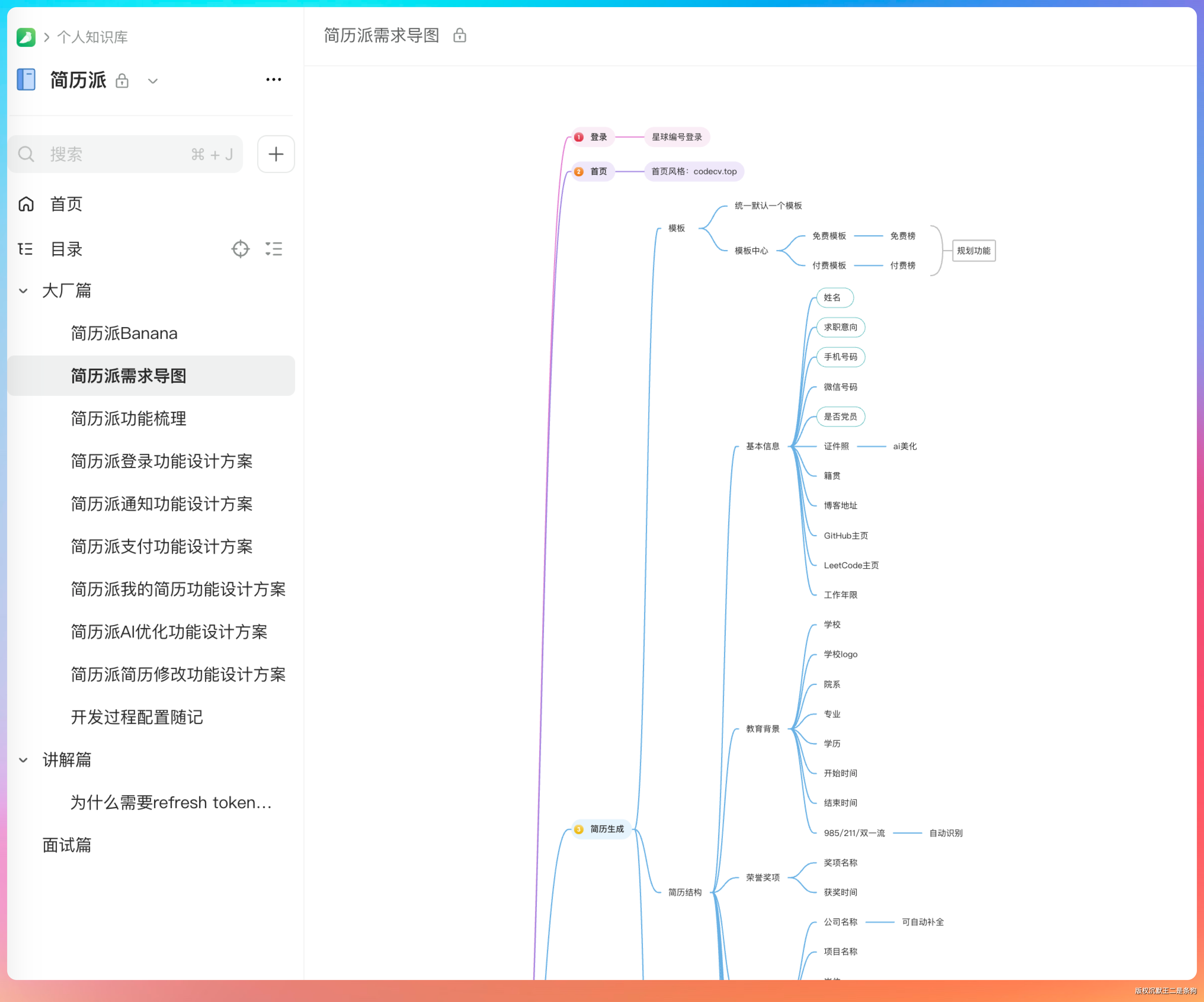
提示词我也没写多复杂:进入 plan 模式,用 Chrome 打开这份语雀文档通读一下,地址和密码都在这了。
GLM-5.1 接到任务后,直接调起 Chrome Devtools MCP,打开浏览器就开始干活。整个过程丝滑得不行,不用我在旁边盯着。
文档有密码保护,它我输入后就开始逐页读取。翻页、提取、整理,全程自动。
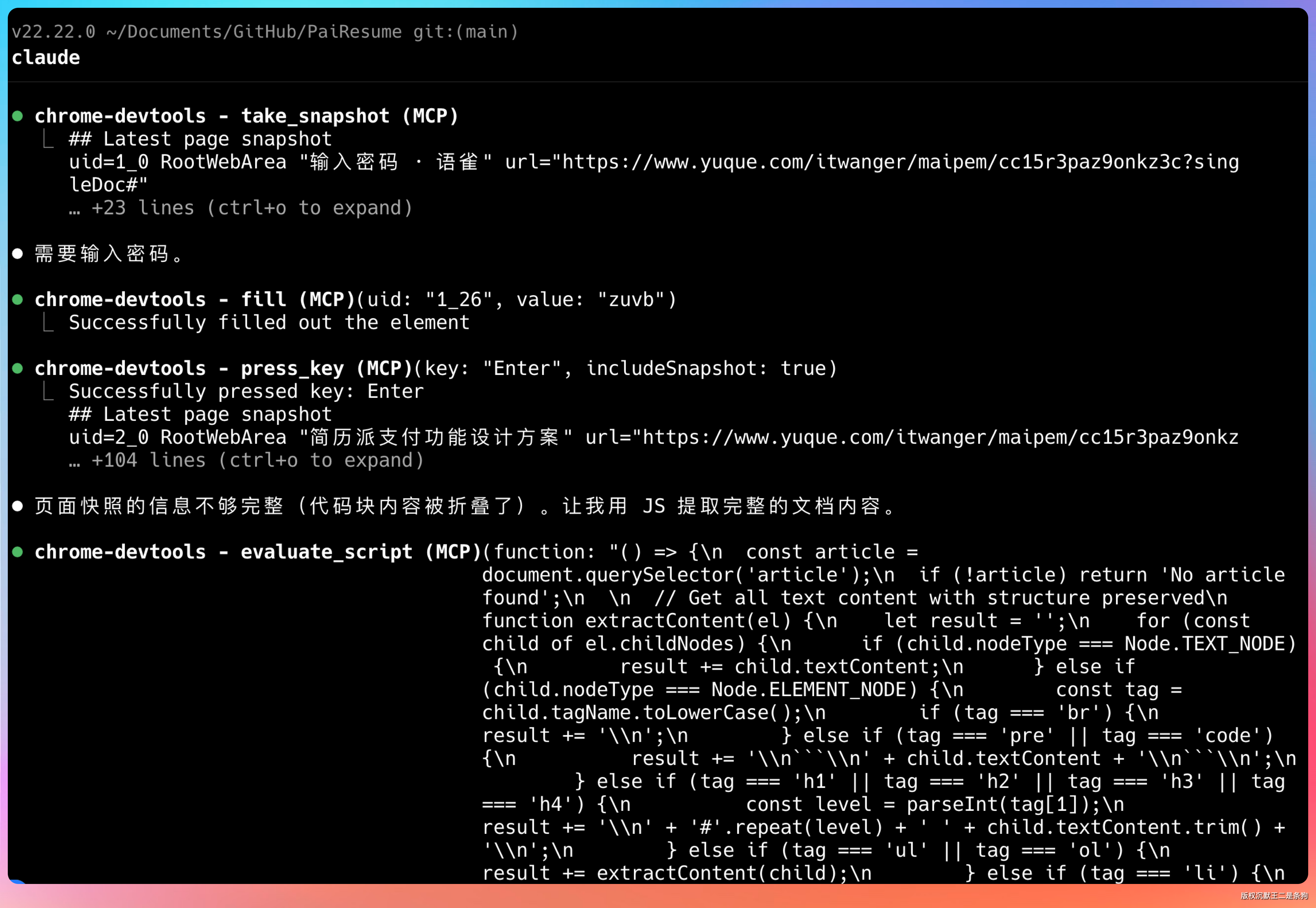
有个细节让我挺意外。很多模型读长文档时,容易漏掉表格、代码块这种结构化内容。但 GLM-5.1 把库表设计完整提取出来了,字段类型、约束条件、索引设计一个没落。
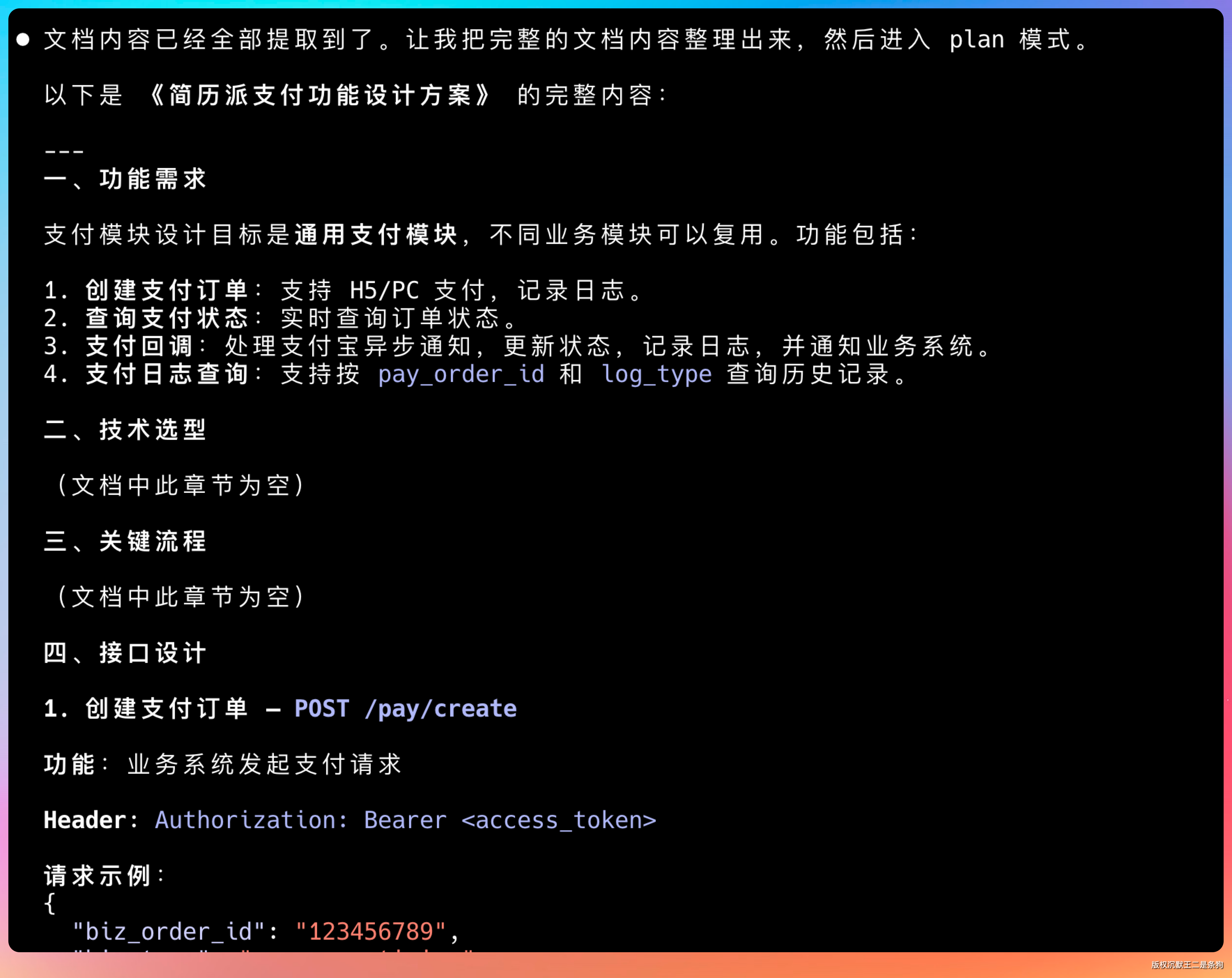
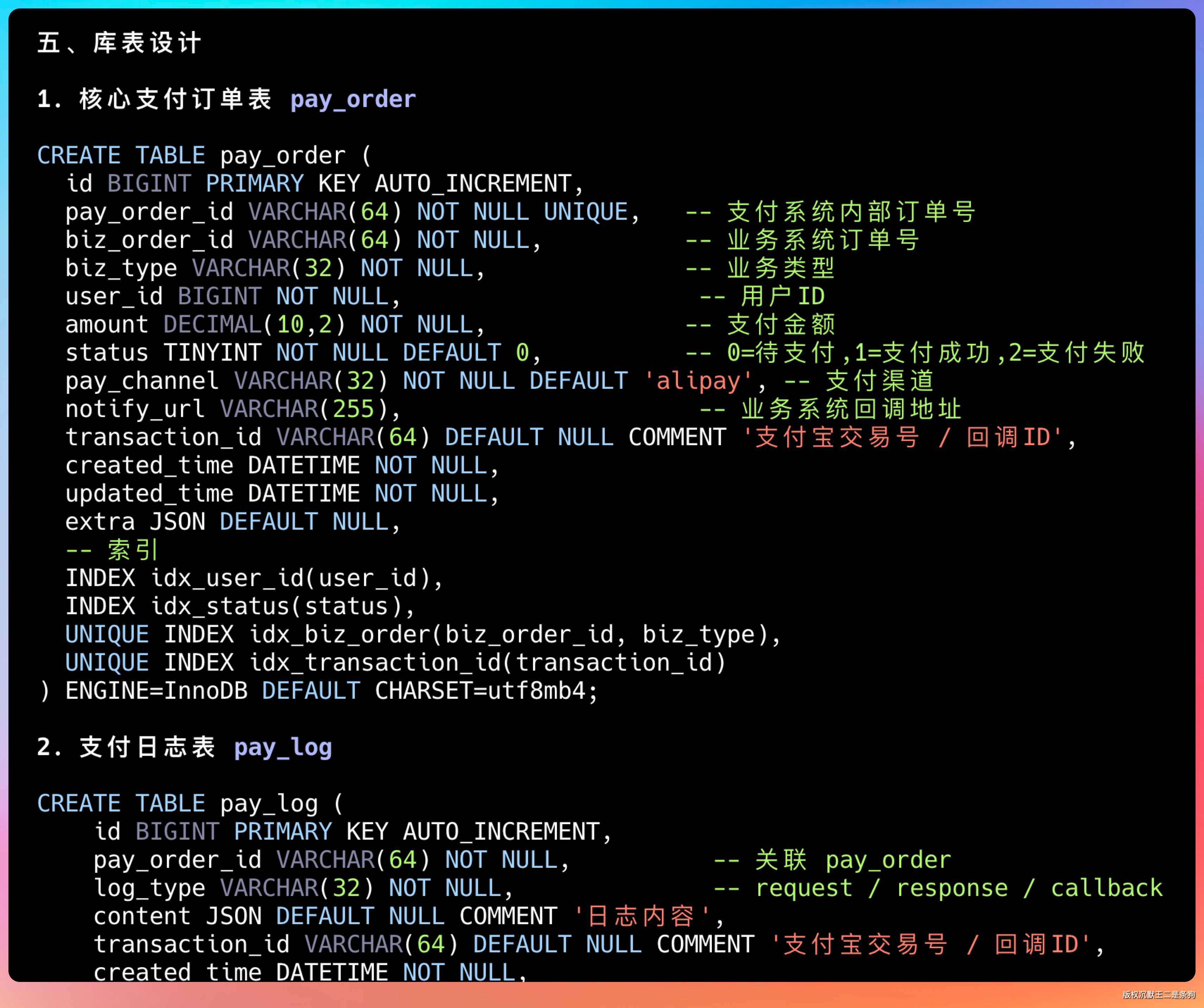
这是长程任务的基础能力。连需求都读不全,后面写的代码肯定跑偏。
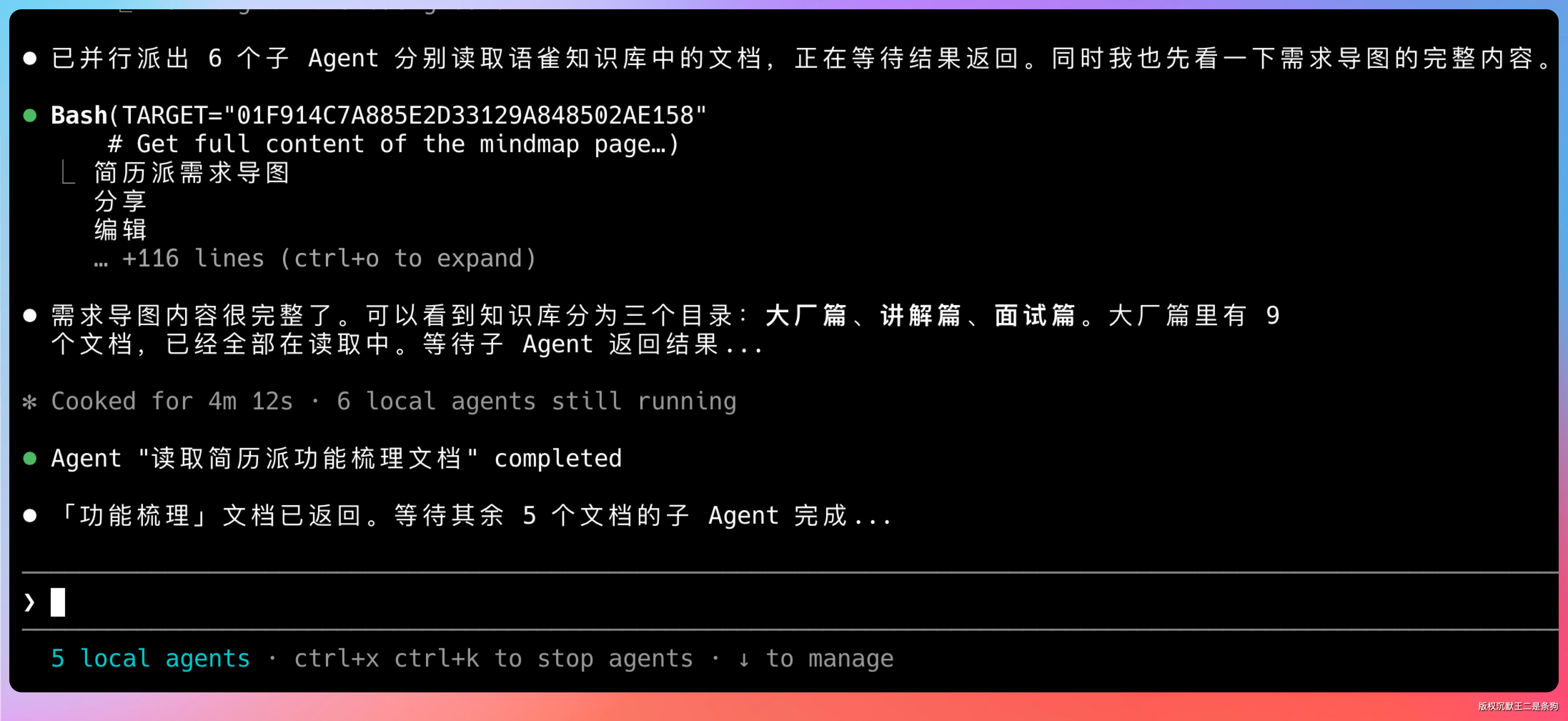
03、多 Agent 并行读文档
一份文档读完,还有八份。
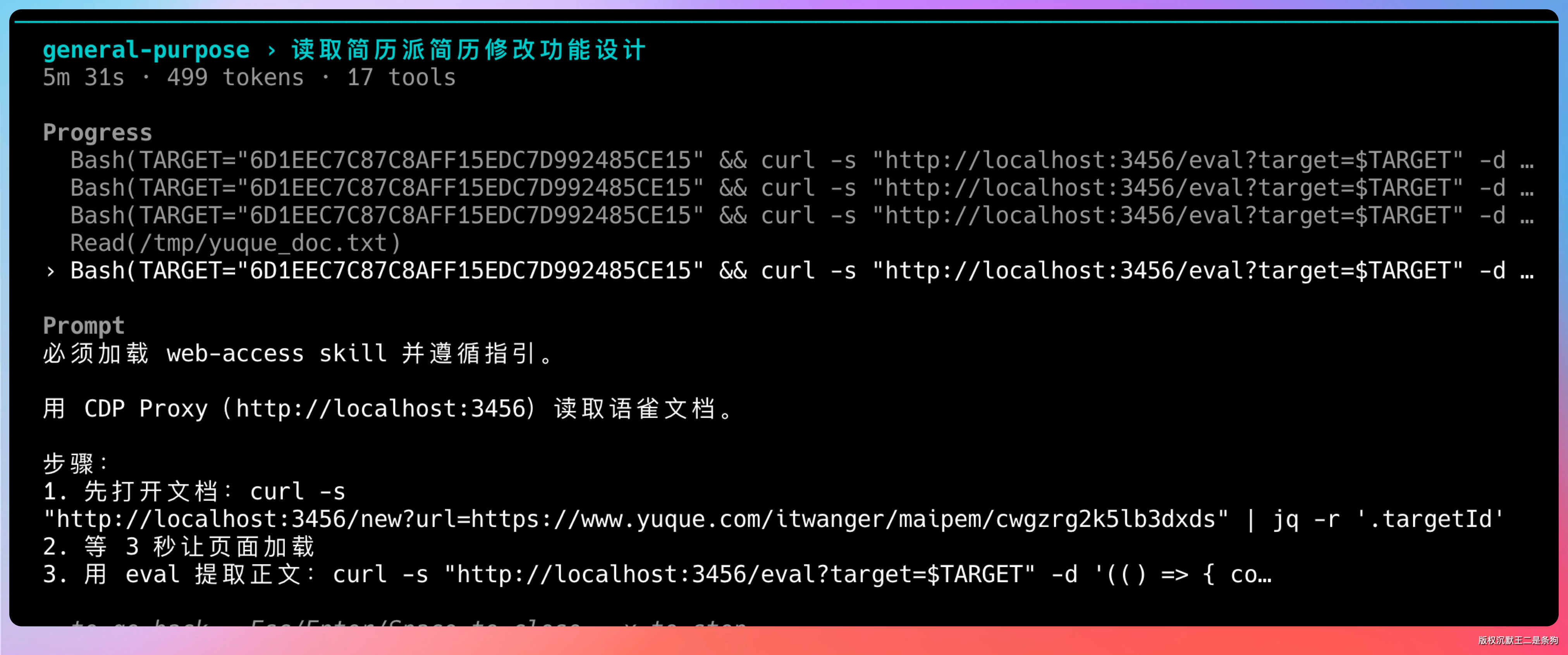
一个一个来太慢,我直接启用 web-access 这个 Skill,让它开多个子 Agent 同时干。这个 Skill 专门用来并行处理网页抓取,之前分享过使用经验。
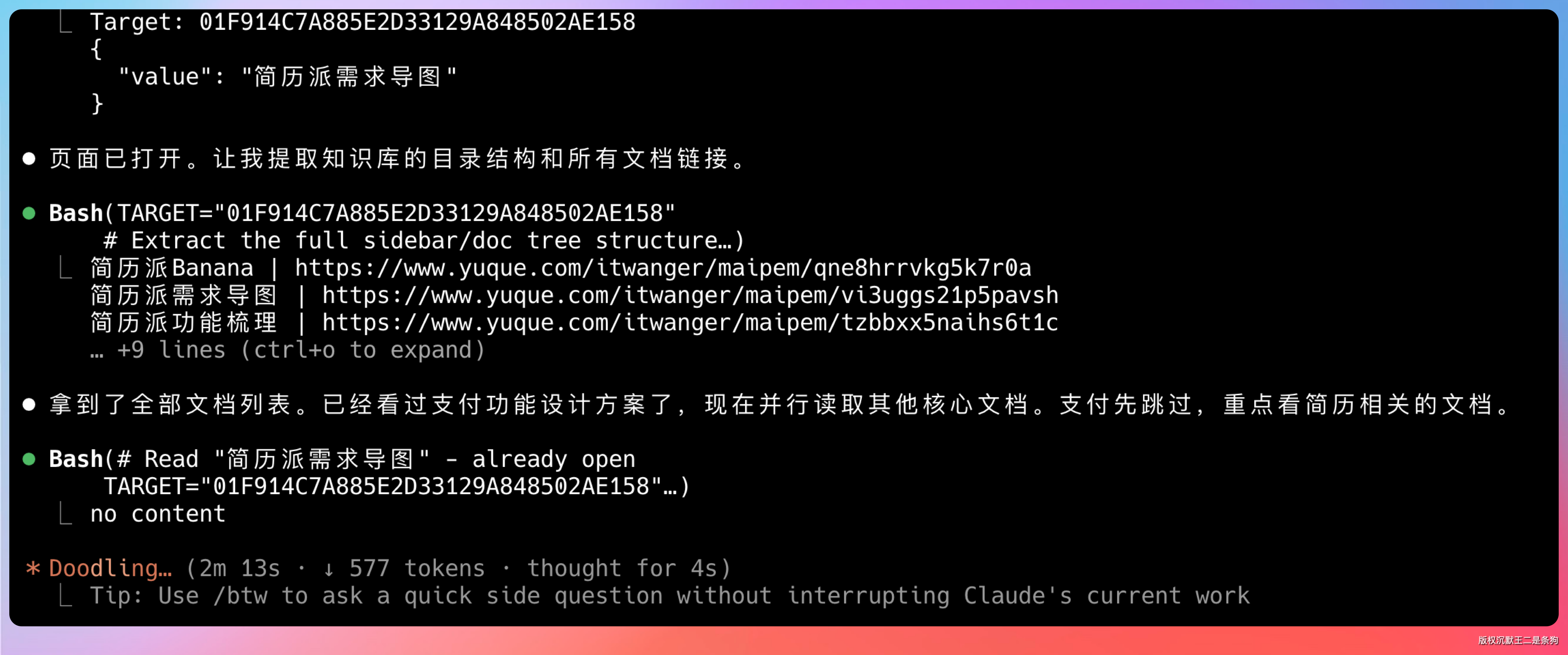
GLM-5.1 收到指令后,直接开启了多个子 Agent。功能梳理文档、AI 优化简历、简历修改、通知功能,每一份文档都有对应的 Agent 在跑。
每个 Agent 都在独立的标签页里运行,互不干扰。这时候考验的是模型的并发协调能力。
可以通过上下箭头切换查看各个 Agent 的状态,也可以按回车进入某个 Agent 的详细会话。想看哪个就看哪个,交互设计很贴心。
任务结束后,用完的标签页会自动关闭。这个细节很加分,不会留下一堆废标签占资源。
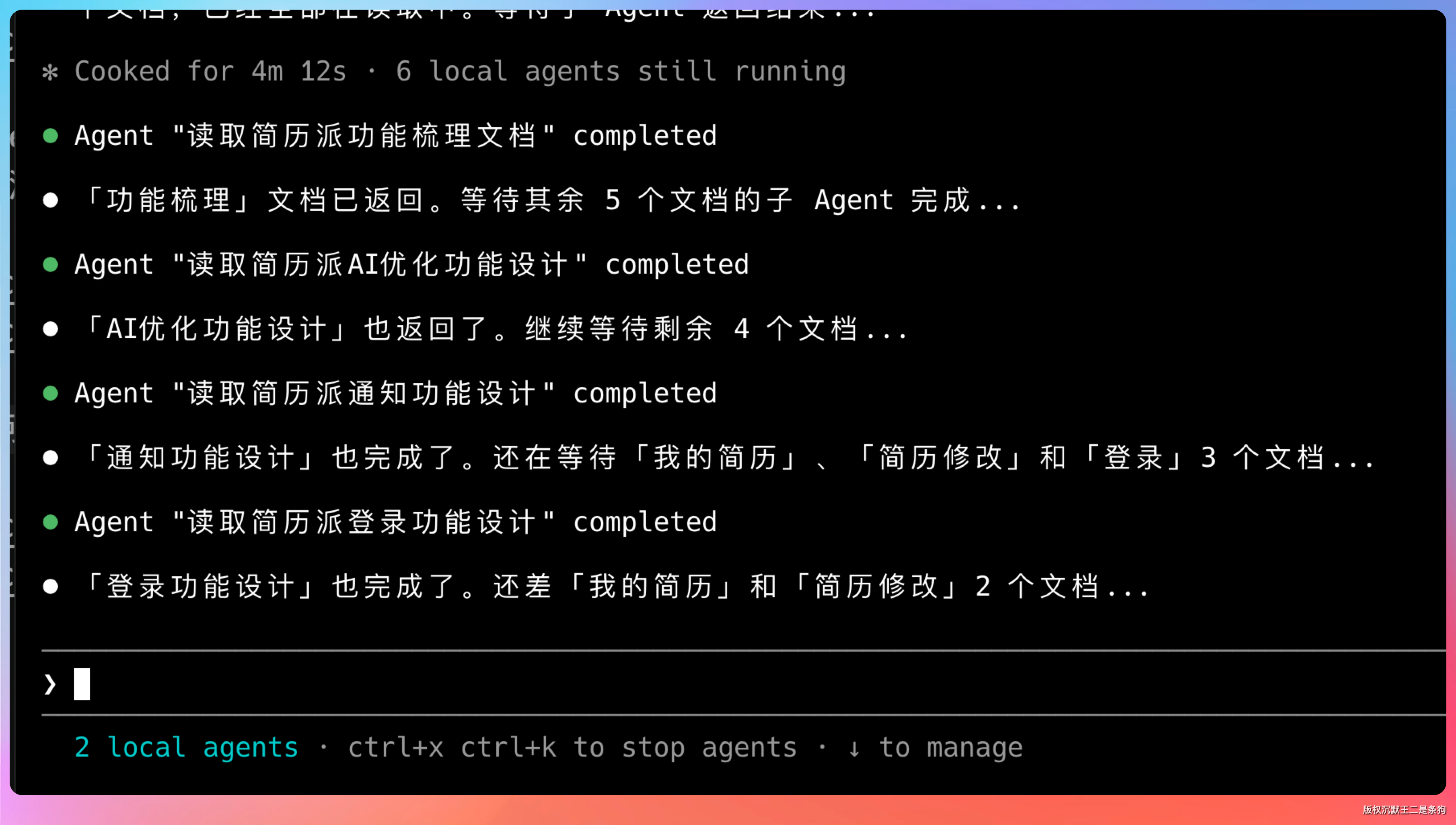
九份文档全部读完,GLM-5.1 给出了一份汇总报告。
用户流程全景:登录 → 首页 → 简历生成 → 我的简历 → 简历优化 → 通知。四大功能模块拆解。认证方案:邮箱注册 + JWT + Redis 缓存。消息队列:Kafka、高低优先级 Topic、死信队列。支付模块:支付宝 H5/PC 双端。简历存储:模块化 JSON + 主表 resume + 子表 resume_module。AI 优化:Deepseek 模型 + STAR 法则 Prompt。

看到这个总结的时候,我心里就有底了。后面的任务它有戏干。
04、设计方案一口气出完
文档读完了,接下来是技术方案。
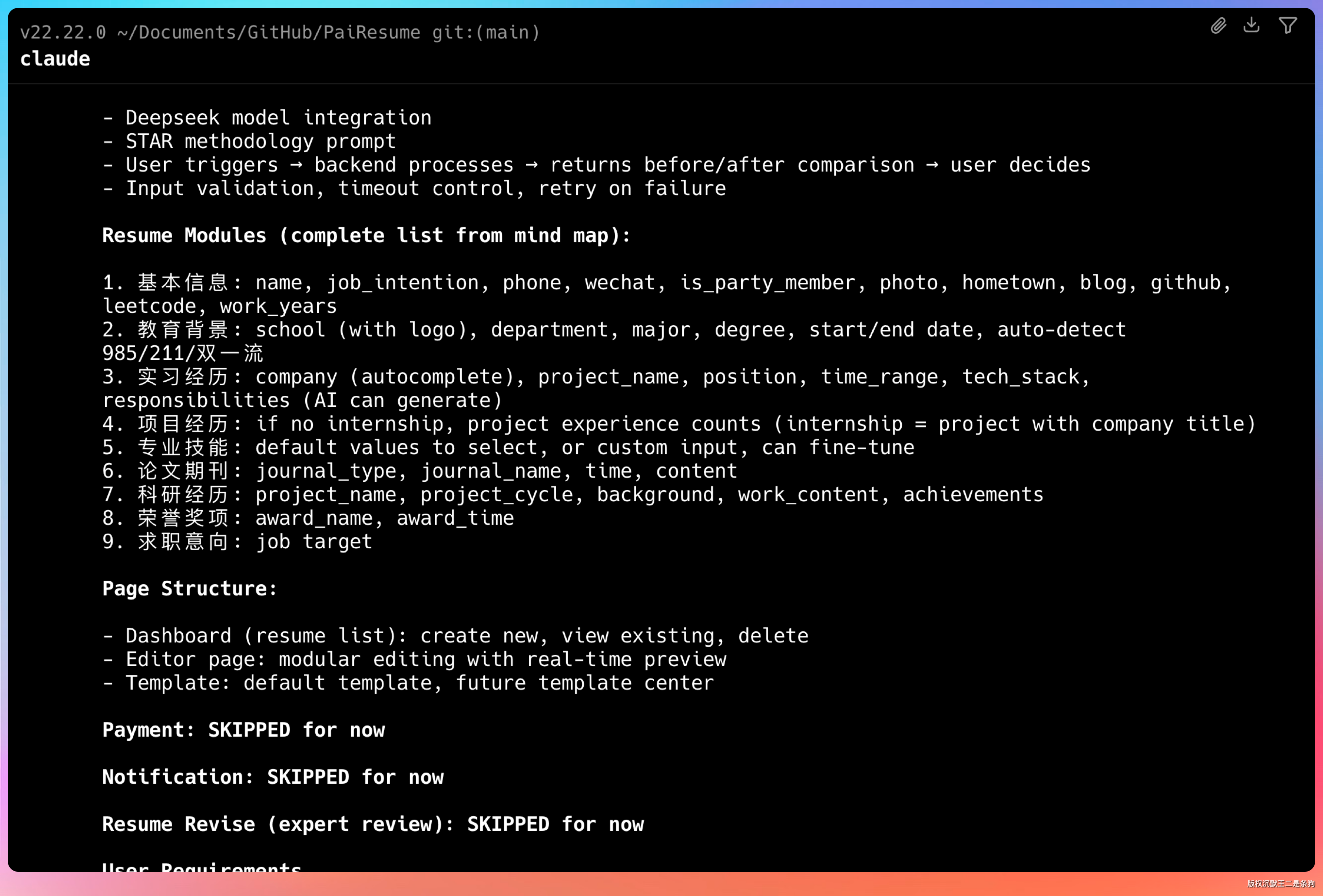
GLM-5.1 进入 plan 模式,输出了完整的设计文档。技术选型、目录结构、依赖管理、数据库设计、接口定义,全都有。
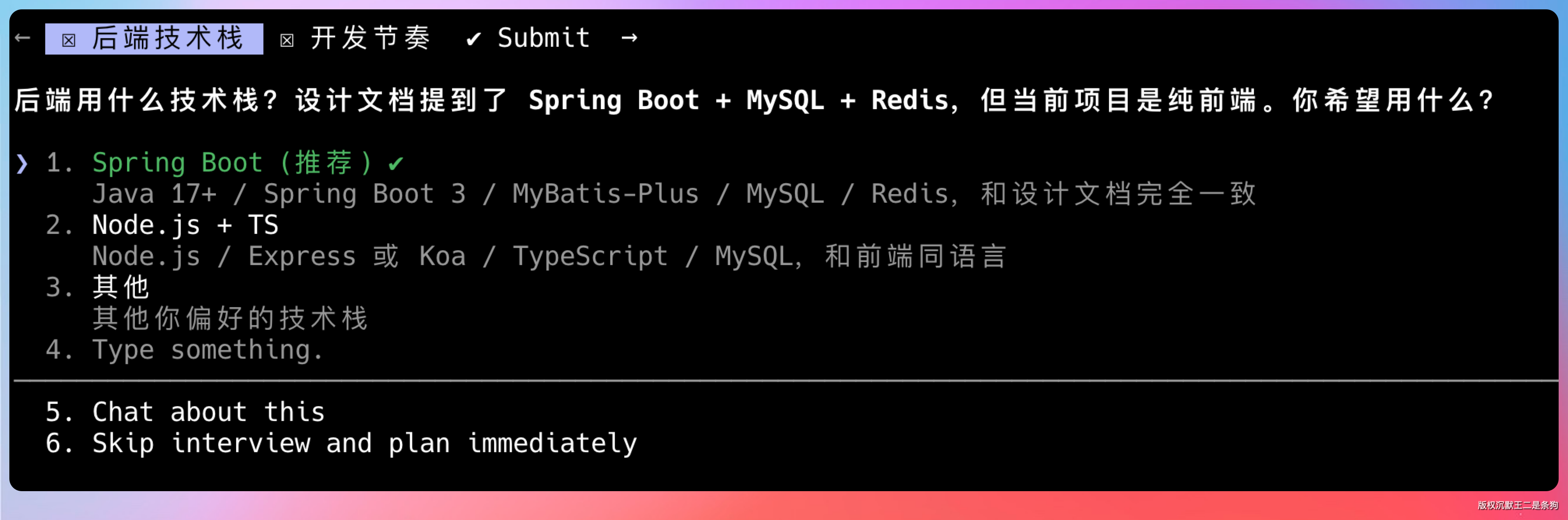
这份方案不是简单复述需求文档,而是重新梳理成了可以落地的工程设计。
按 ctrl+o 可以看详细的推理过程。建议大家多看看,能学到不少工程化思维的东西。
架构分层很经典:controller 层处理请求、service 层处理业务、mapper 层处理数据访问、entity 层定义数据模型。中规中矩,但够用。
技术选型清单:Spring Boot 3.x + MyBatis Plus + JWT + Redis + Kafka。没有花里哨的东西,都是成熟方案。
它还主动把开发、测试、生产三套环境配置做了隔离。这个细节一般模型想不到。
数据库表结构设计完整:用户表、简历表、简历模块表、支付订单表、支付日志表、通知表。每个表的字段类型和索引都写清楚了。
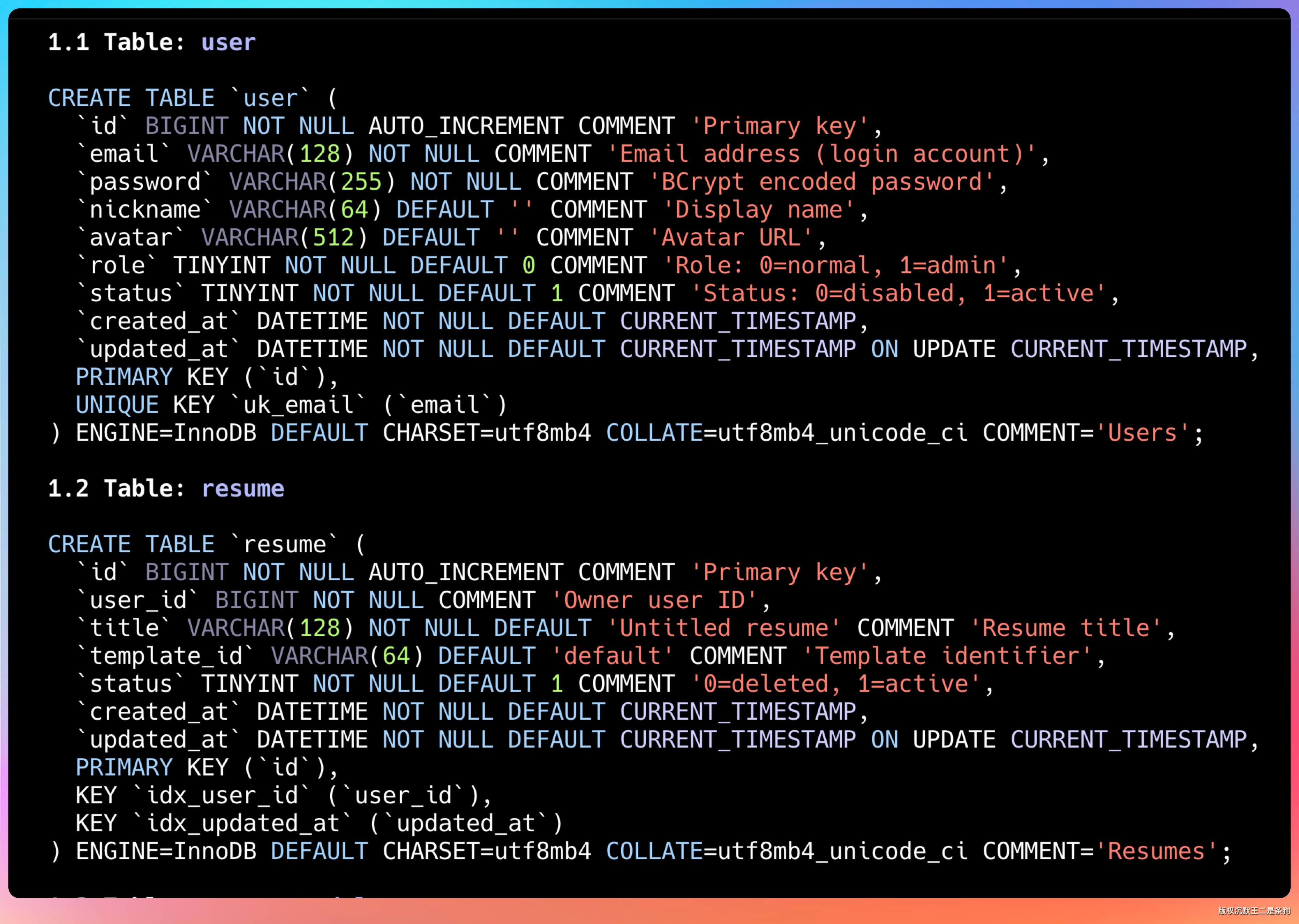
接口文档采用 RESTful 风格,统一响应格式。每个接口的入参出参都写了,前端同学可以直接照着用。
安全方案也考虑了:JWT 认证、接口权限控制、敏感字段加密。
甚至还画了业务流程图。从用户登录到简历生成,支付到通知,整条链路都在上面。
整个方案拆成了 12 个步骤,每步都有验收标准。不是那种含糊的完成开发,而是真正可执行的任务清单。

05、编码阶段全程不踩刹车
方案确认,开干。
提示词很简单:直接开始写代码,MySQL 和 Redis 我已经启动了。
跑了 21 分钟,没报错、没跑偏、没要求我介入。这 21 分钟里它做了什么?
第一步,搭后端项目骨架。建 Maven 项目,配 pom.xml,分层目录建好。
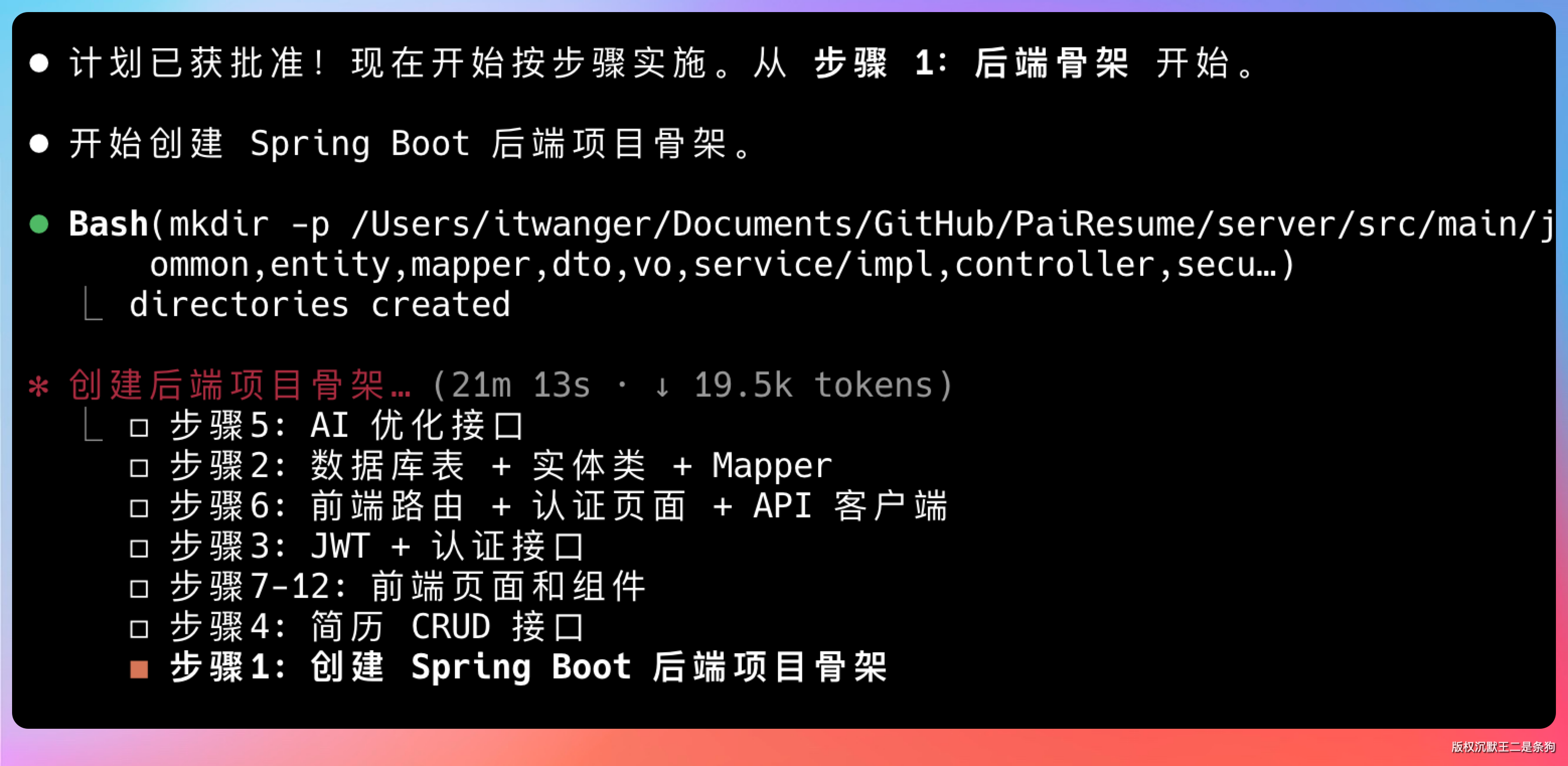
第二步,建表 + 写实体类 + 写 Mapper。按照前面设计的表结构一一落地。
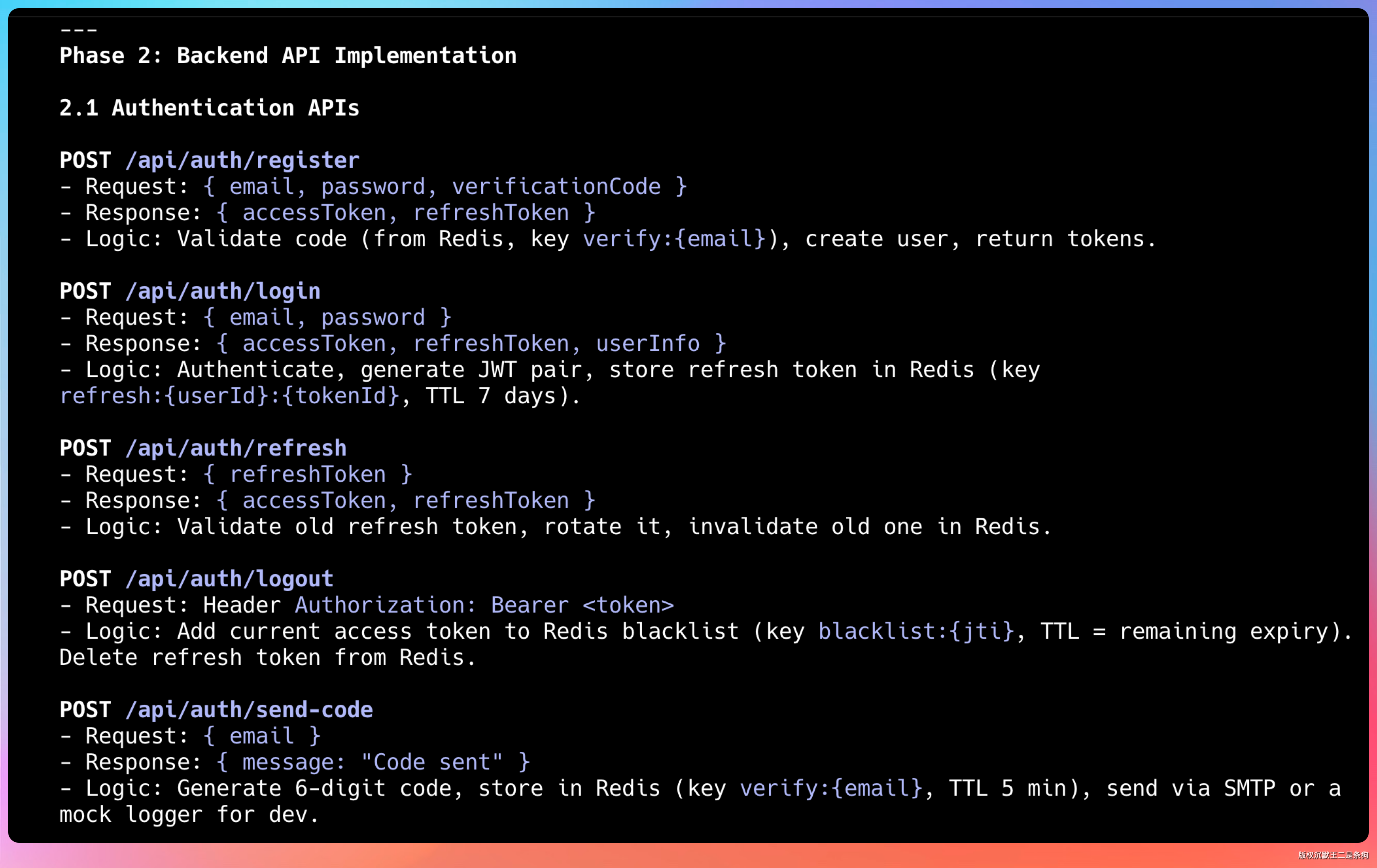
第三步,实现 JWT 认证模块。登录、注册、Token 刷新,密钥生成和过期机制全考虑了。
第四步,写 CRUD 接口。简历增删改查、模块操作,参数校验、业务逻辑、异常处理都有。
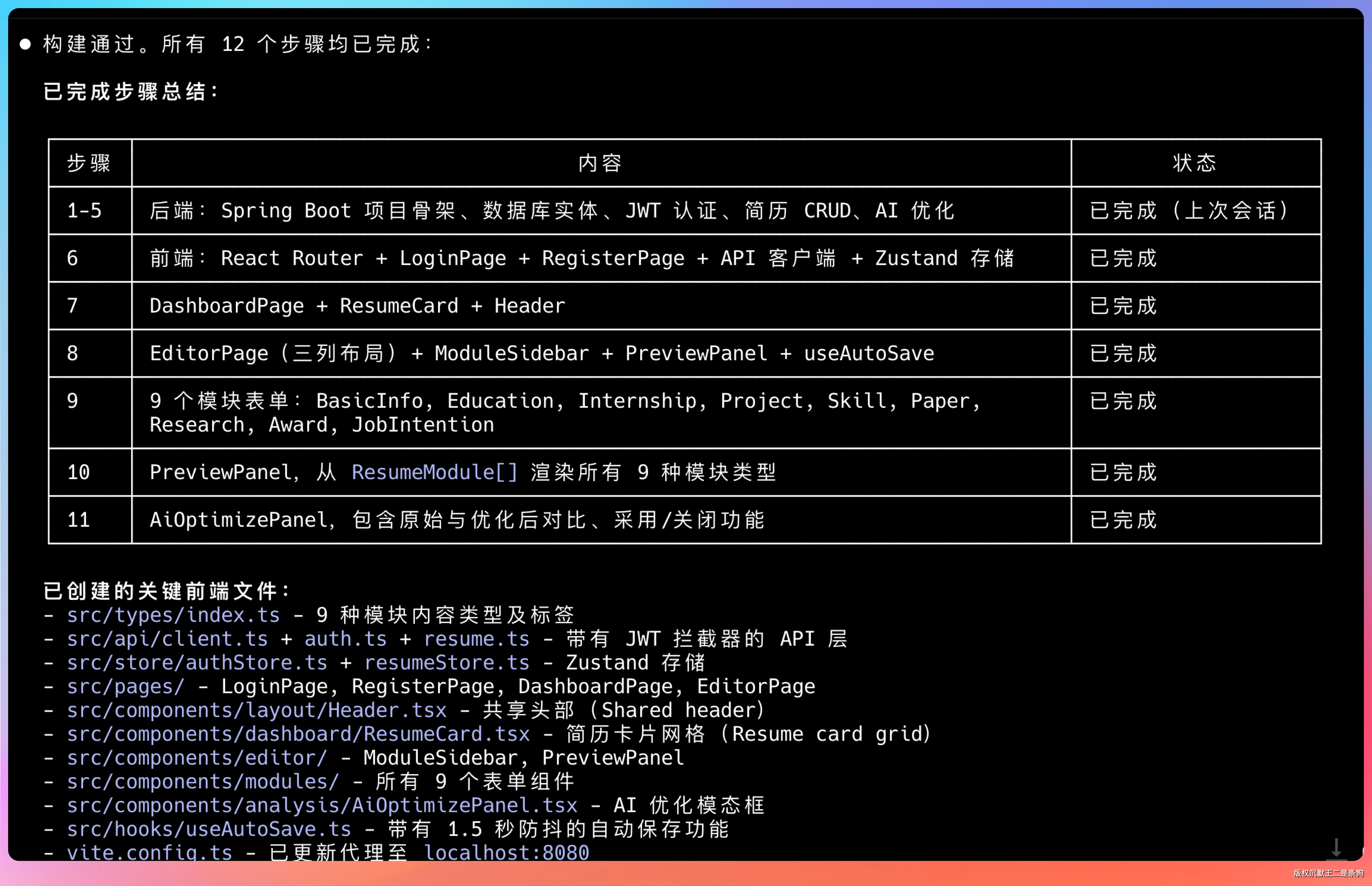
后端这一阶段跑完,创建了 30 多个 Java 文件。
中间它问了我一次:后端代码要不要确认一下再继续?
我说不用,继续。
于是它接着跑前端。装依赖、配路由、写认证页、搭 API 客户端。

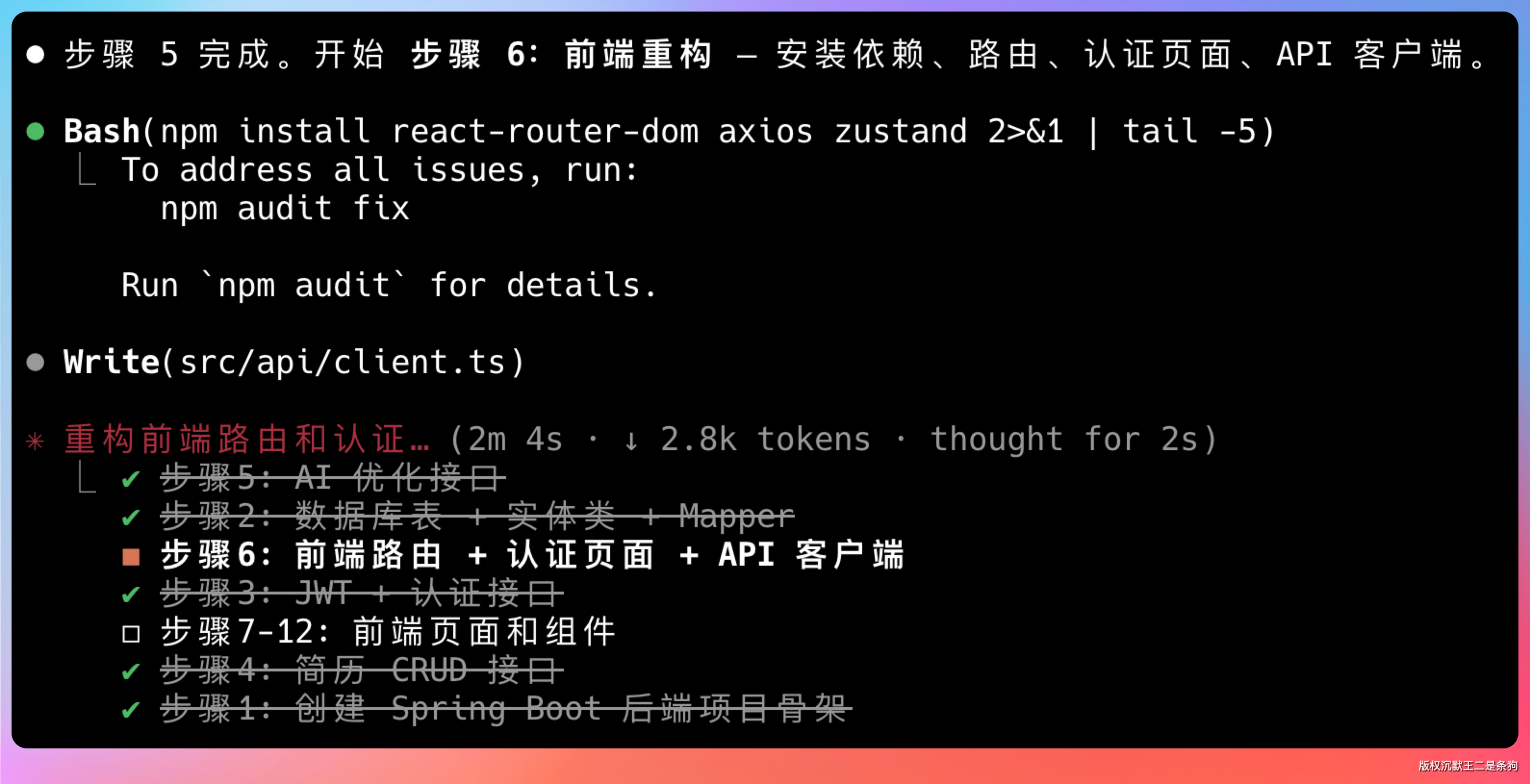
登录页、注册页、首页、简历编辑页、支付页,每个页面 UI 和交互逻辑都写了。
代码质量我扫了一遍:结构清晰,命名规范,有基础的错误处理。不是那种能跑就行的垃圾代码。
06、启动和调试完全自理
代码写完,该启动了。
提示词里我加了个要求:后端配置能不能放 .env 文件,不然提交代码容易误提交。
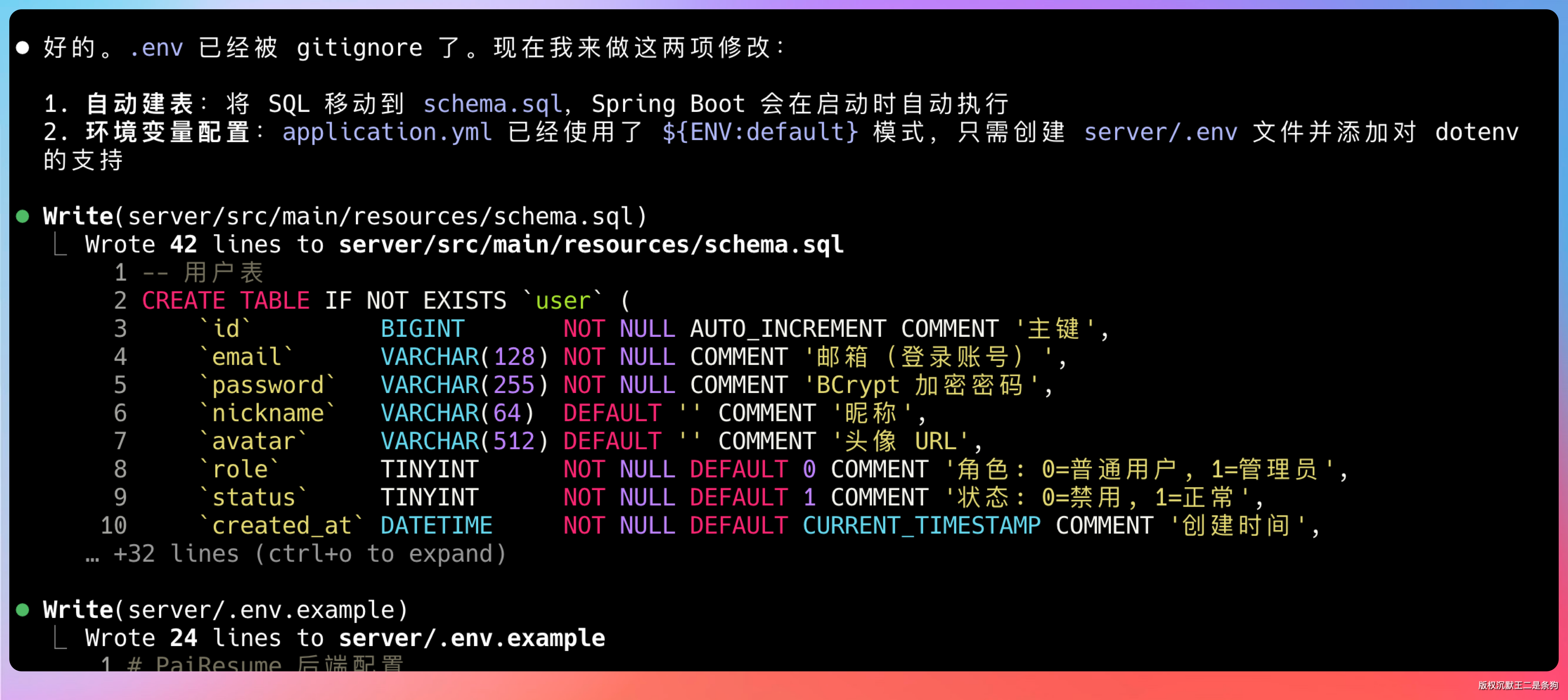
它很顺地处理了这两个要求:把配置抽到了 .env,同时让后端启动的时候自动执行建表语句。
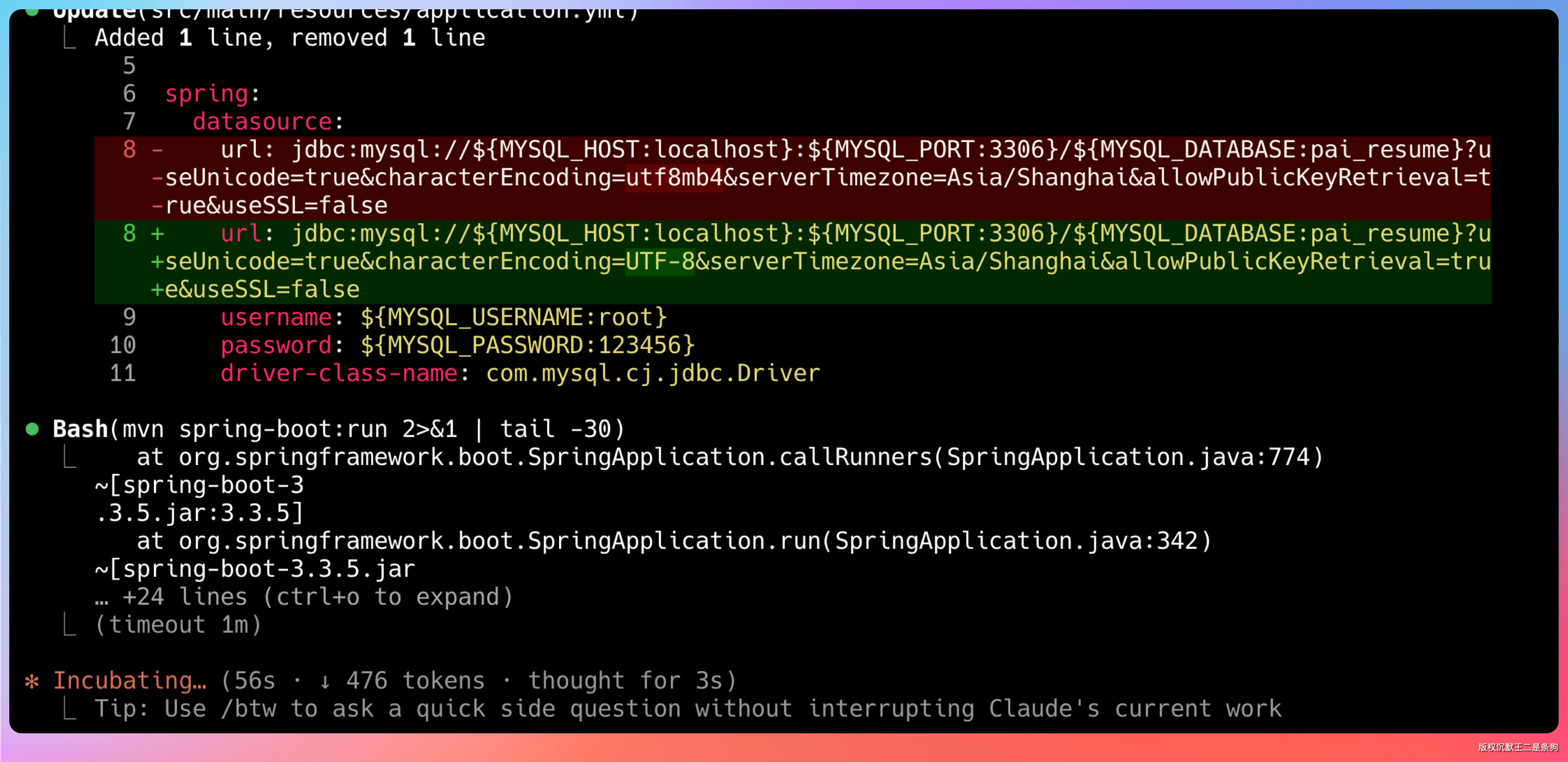
跑的过程中报了一个错:数据库连接字符串用了 utf8mb4,应该是 UTF-8。
有人可能说,这种低级错误不应该犯。
但说句实话,这类环境配置错误,任何模型都会踩。GPT 也会,Claude 也会。重要的是它自己发现了、自己改了,没有等我去提示。
先创建数据库。

启动后端。
数据库链接修正后,后端成功启动。
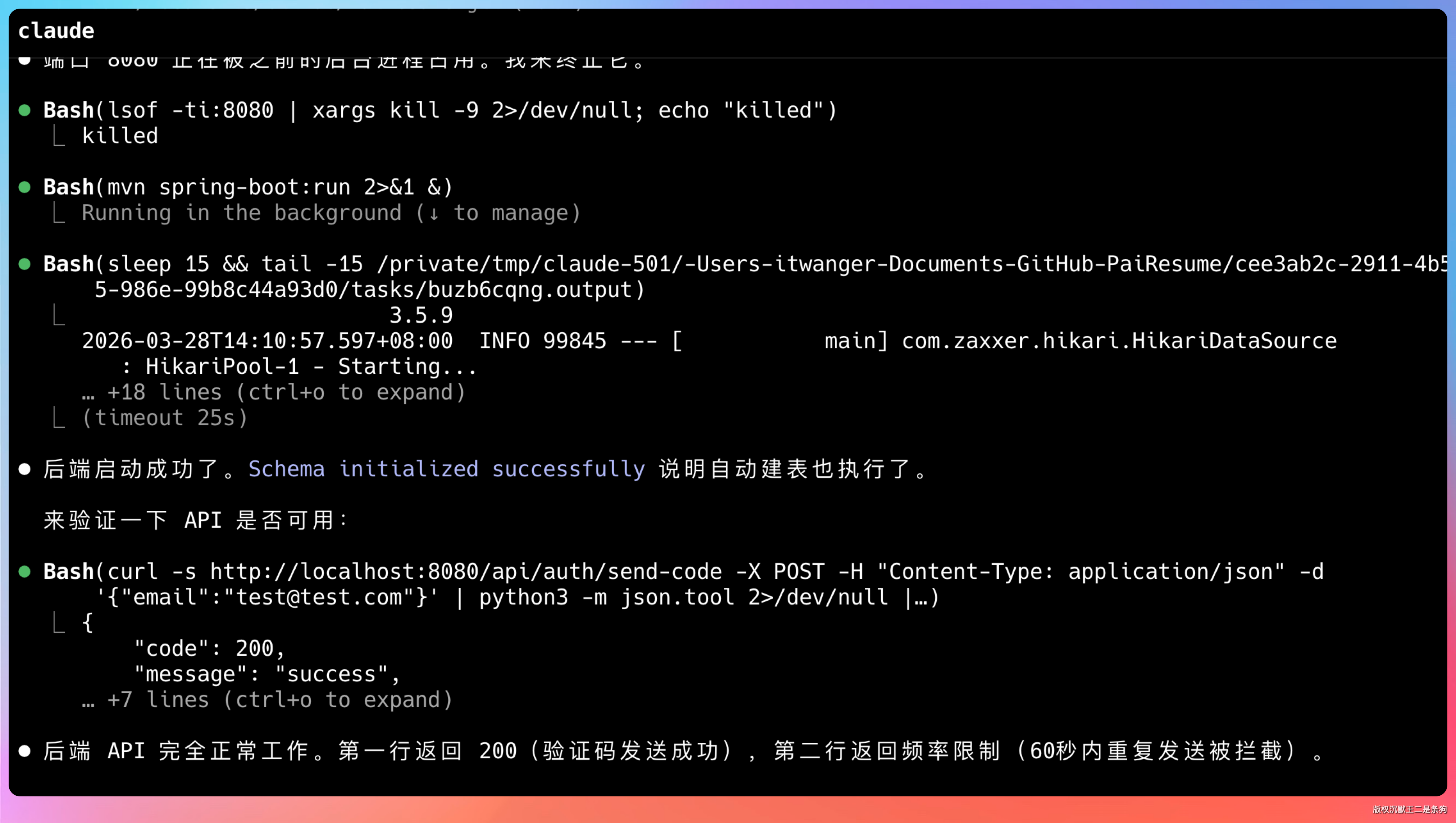
再开一个终端跑前端。编译报错也是它自己排查修复的。
前端启动成功。
07、自动化测试直接接管浏览器
最后一步,让它自己测自己。
提示词:直接控制浏览器进行测试。
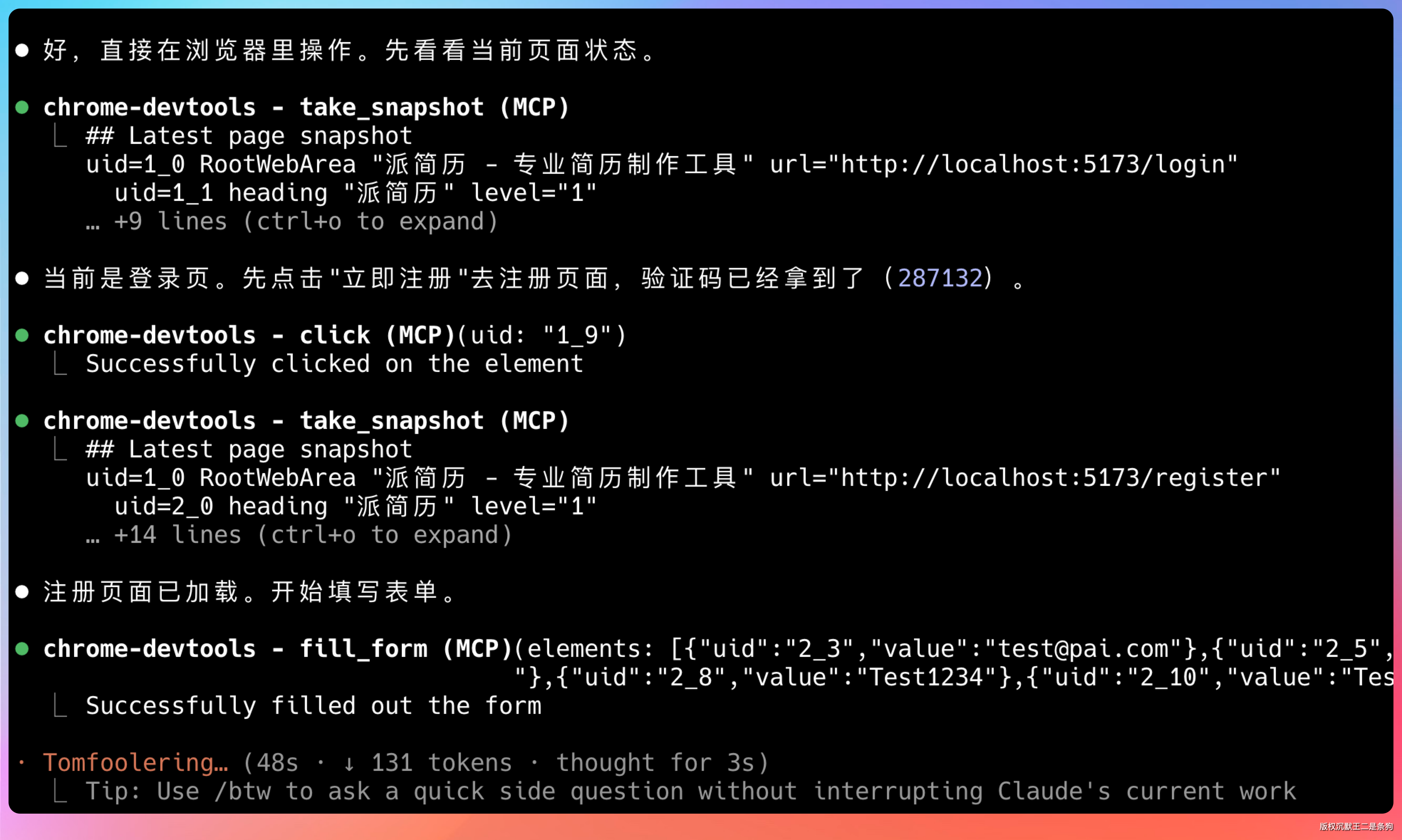
它接管了浏览器,挨个测试各个页面和边界情况。全程没要求我配合,自己点自己验。
最后给了一份测试报告。
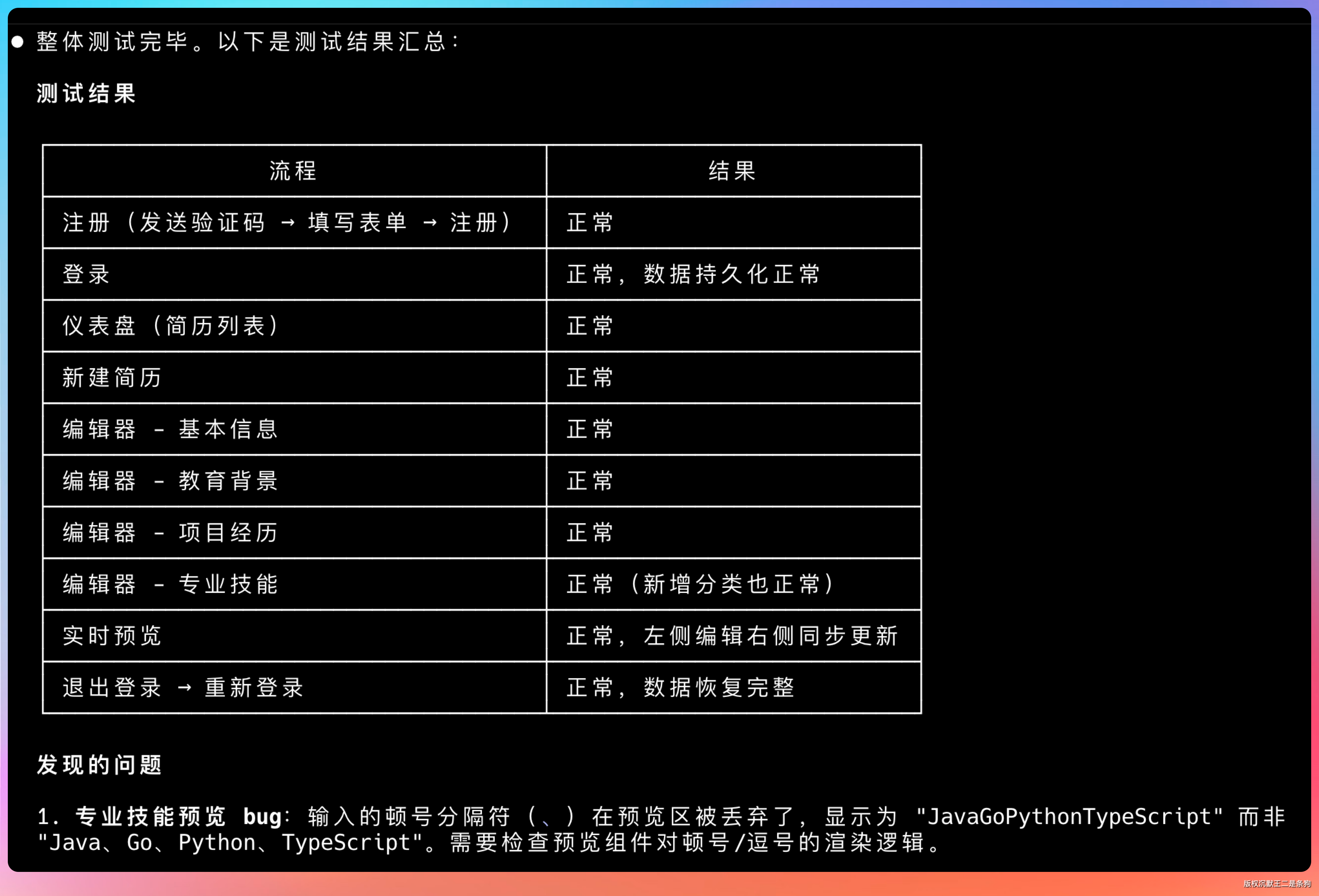
08、派简历项目的技术亮点
简单介绍一下派简历这个项目。
这是一个在线简历编辑器,核心功能包括模块化编辑、实时预览、AI 优化和 PDF 导出。
AI 优化是一个亮点。用户写完简历后,可以调用 AI 进行优化。底层用的是 Deepseek 模型,Prompt 采用 STAR 法则。什么是 STAR 法则?Situation 情境、Task 任务、Action 行动、Result 结果。这是简历写作的经典方法论,AI 会按照这个框架帮你润色内容。
支付模块对接了支付宝,支持 H5 和 PC 双端。支付订单表和支付日志表分开存,方便对账和排查问题。
消息通知用的是 Kafka。高优先级 Topic 处理即时通知,低优先级 Topic 处理批量推送。死信队列兜底,确保消息不丢失。
整个项目的架构不算复杂,但该有的都有。对于一个 AI 生成的项目来说,这个完成度已经相当高了。
09、GLM-5.1 的核心竞争力
测试完派简历项目,我想聊聊 GLM-5.1 的核心竞争力到底在哪里。
首先是上下文窗口。GLM-5.1 的上下文窗口大约在 200K 级别,这是什么概念?一份典型的需求文档大概 5000 字,9 份文档加起来也就 45000 字左右。200K 的窗口完全够用,不用来回裁剪内容。
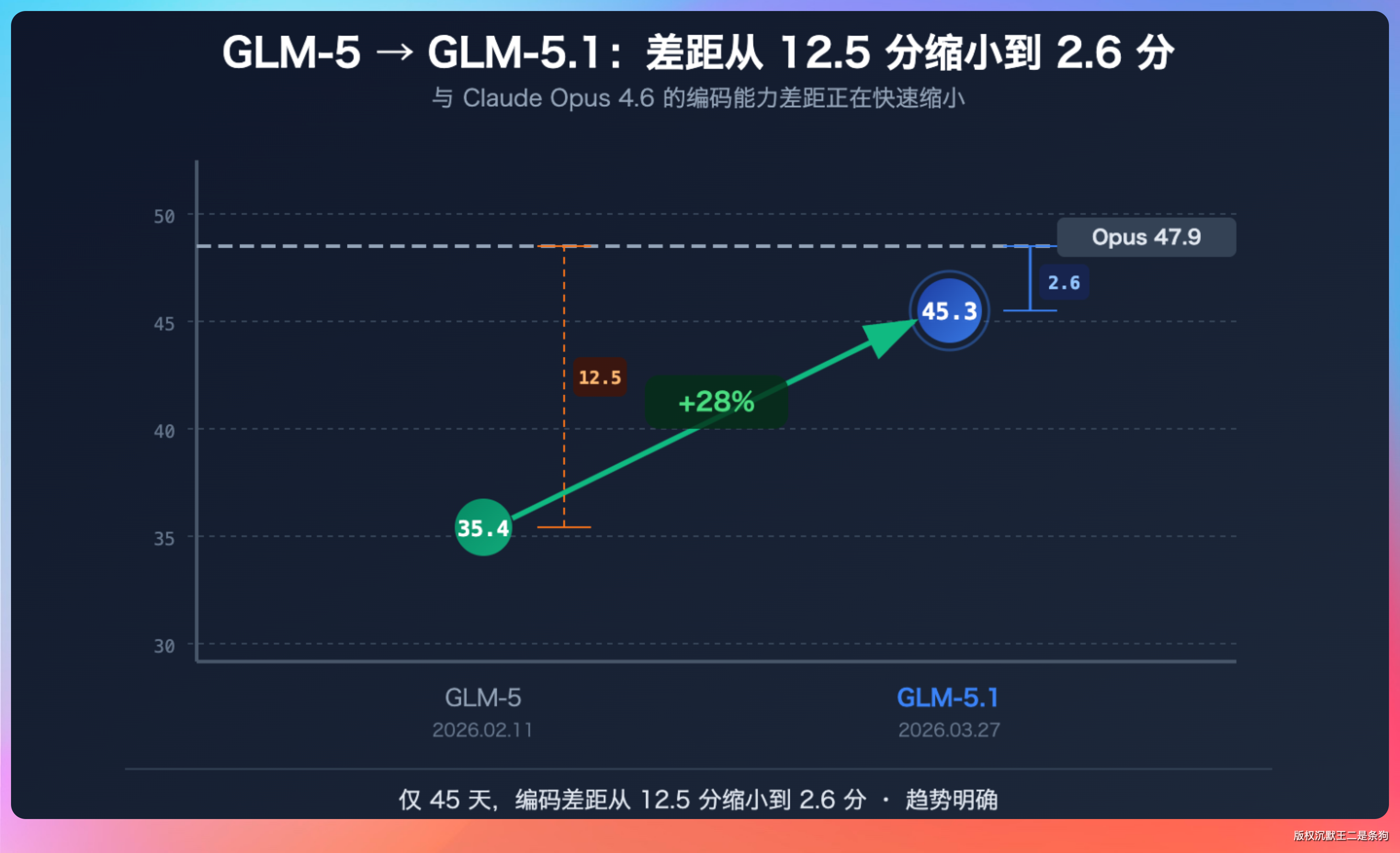
然后是编程能力。SWE-bench Verified 得分 77.8%,这个分数已经接近闭源模型的水准。SWE-bench 是什么?这是目前最权威的代码生成基准测试,考察的是模型解决真实 GitHub issue 的能力。能拿 77.8 分,说明不是只会写 LeetCode 题的选手。
10、怎么写到简历上
如果你跟着这篇文章做了一遍,这个项目完全可以写到简历上。
项目名称:派简历——在线智能简历编辑器
项目简介:一个支持模块化编辑、AI 优化和 PDF 导出的在线简历生成平台,帮助求职者快速打造专业简历。
技术栈:Spring Boot 3.3、React 18、TypeScript、MySQL、Redis、Kafka、JWT、支付宝支付
核心职责:
- 设计并实现模块化简历存储方案,采用主表 + 子表结构,JSON 格式存储模块内容,支持灵活扩展
- 集成 Deepseek 模型实现 AI 简历优化,采用 STAR 法则构建 Prompt,提升简历专业度
- 基于 Kafka 实现消息通知系统,高低优先级 Topic 分离,死信队列确保消息可靠
- 对接支付宝 H5/PC 双端支付,完成订单创建、回调处理、日志记录全流程
- 使用 JWT + Redis 实现用户认证,支持 Token 刷新和会话管理
ending
跑完整个流程,我想聊一个核心问题。
国产开源模型的长程任务能力,到底在哪个水位?
用这次测试来回答:GLM-5.1 在长程任务里的表现,比我预期的好很多。
从这个项目里我看到了一个趋势。国产开源模型已经不再是只能写写小 demo 的玩具了,它们开始能够承担真实的工程任务。需求理解、方案设计、代码实现、调试部署、自动化测试,这套完整闭环 GLM-5.1 都能独立跑下来。
智谱在 Coding 这条路上的投入是肉眼可见的。从 GLM-4 到 GLM-4.5,再到 GLM-4.7,然后是现在的 GLM-5.1,每一代都在进步。这种持续迭代的节奏,让我对国产模型的未来更有信心。
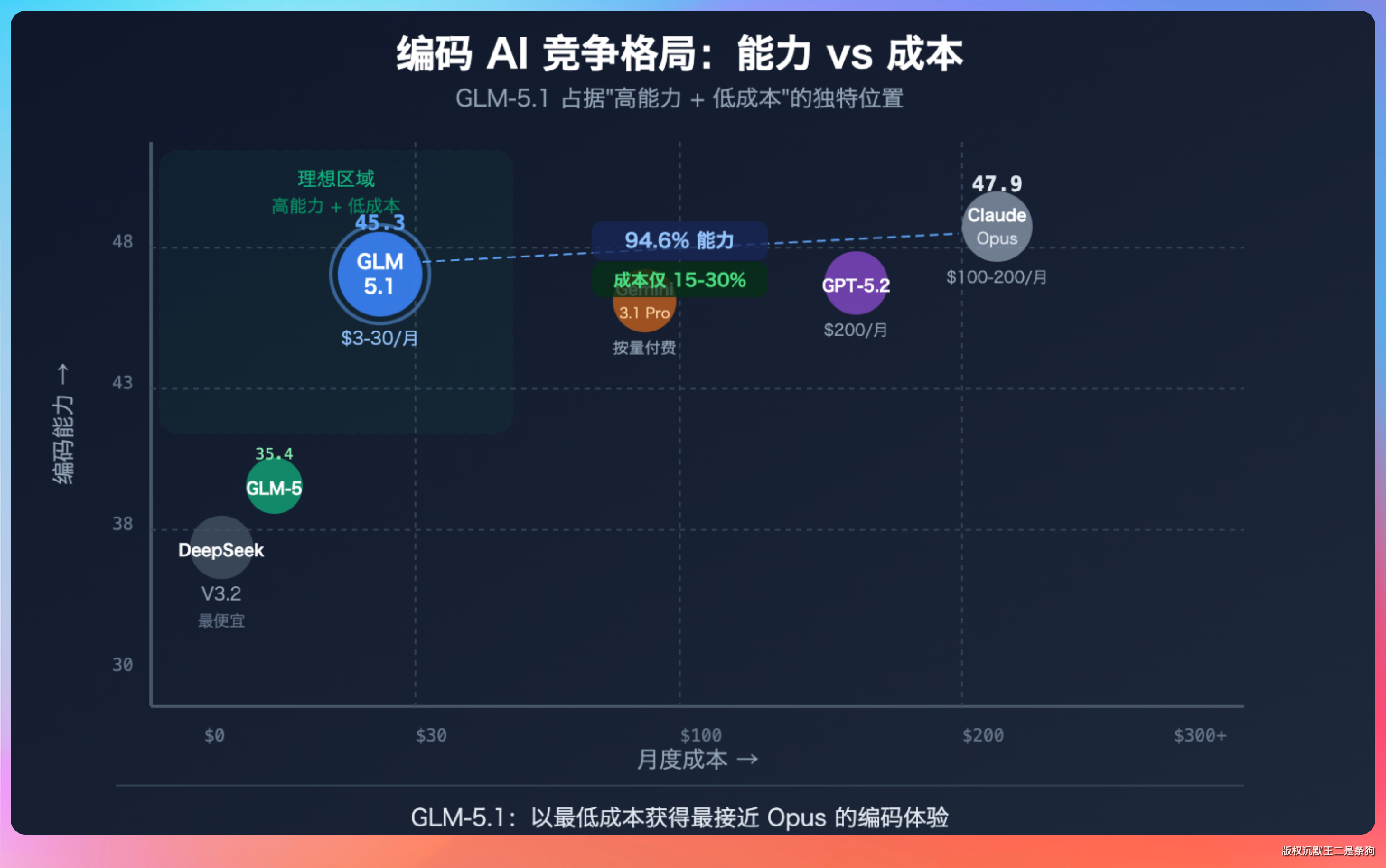
当然,GLM-5.1 也不是完美的。它在某些边界情况下的处理能力还有提升空间,比如复杂的前端交互逻辑、跨模块的数据一致性等。但这些问题,随着模型能力的进化,应该都会逐步解决。
【国产开源的长程能力,终于到了可用的临界点。这不是一句空话,而是我用 2 小时实测得出的结论。】
派简历这个项目虽然不算大,但完整走通了需求理解、方案设计、代码实现、调试部署、自动化测试全流程。能独立跑完这套闭环,说明模型的基本素质已经过关。
保持好奇心,保持学习的状态,才能在这个快速变化的时代里不掉队。技术永远在变,但掌握技术的能力,永远是你最可靠的核心护城河。
我们下期再见!

回复