


大家好,我是二哥。
最近看到小米大模型负责人罗福莉一段话,很有感触。
她说现在很多大模型的 Coding Plan 都是在亏钱抢用户。

以至于国内出现了一种非常奇怪的现象,就是便宜的 Coding Plan 抢都抢不到。
但同时,每个人手头又都需要一个 Coding Plan,因为这玩意接入到 Claude Code 中,就是最好的 Agent,不管是学习还是工作,效率都会大幅提升。
今天就给大家推荐一个让我眼前一亮的选项——阶跃星辰刚刚上线的 Step 3.5 Flash 2603。性价比还是挺高的。
01、Step 3.5 Flash 2603 有哪些提升
Step 3.5 Flash 这个系列我之前就用过,整体感受是快、稳,适合高频开发任务。
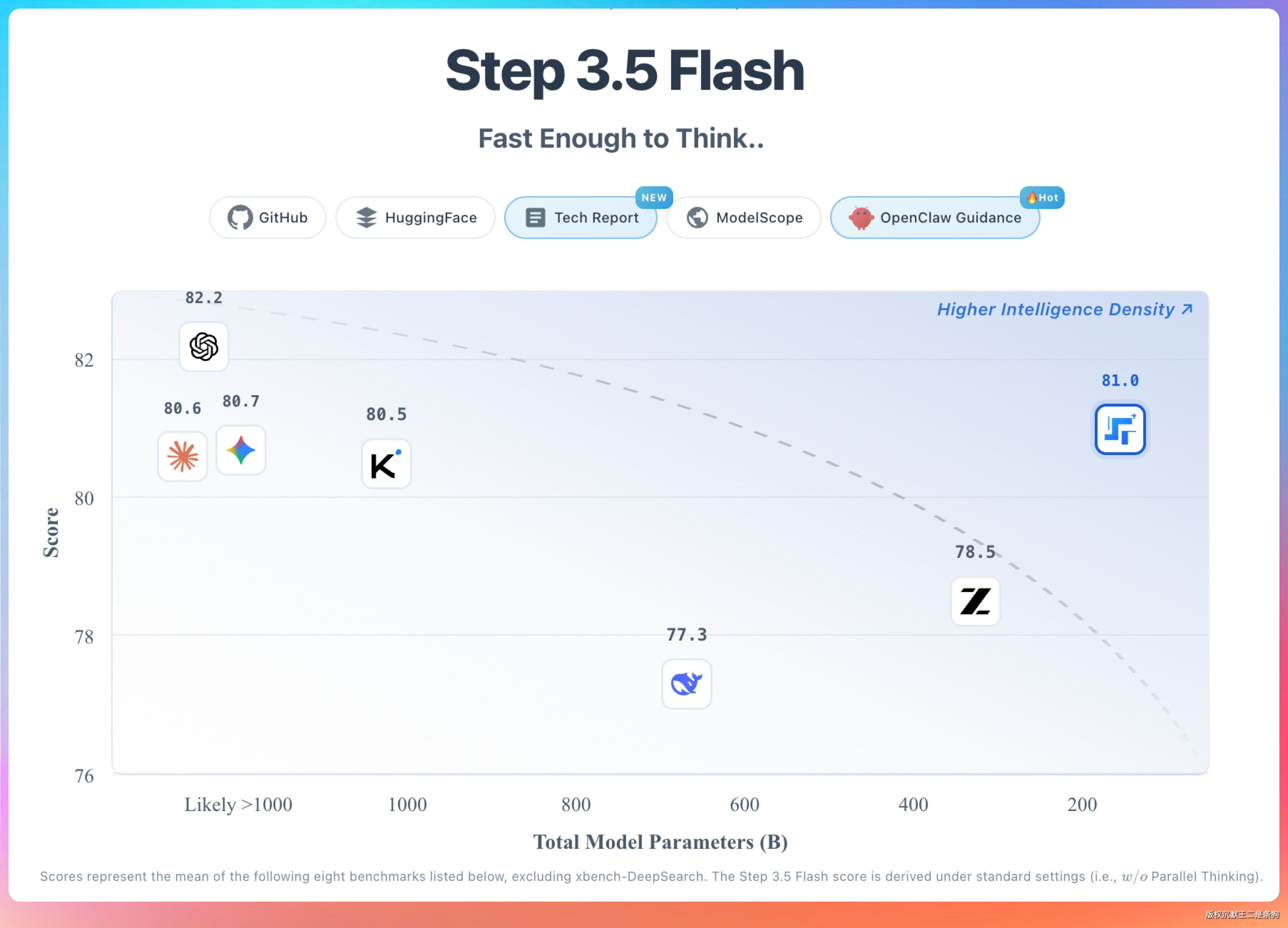
2603 最核心的变化是新增了一个低推理模式(low think mode):不是所有任务都需要深度推理,让简单问题快速过、复杂问题再深思,这才是合理的资源分配。
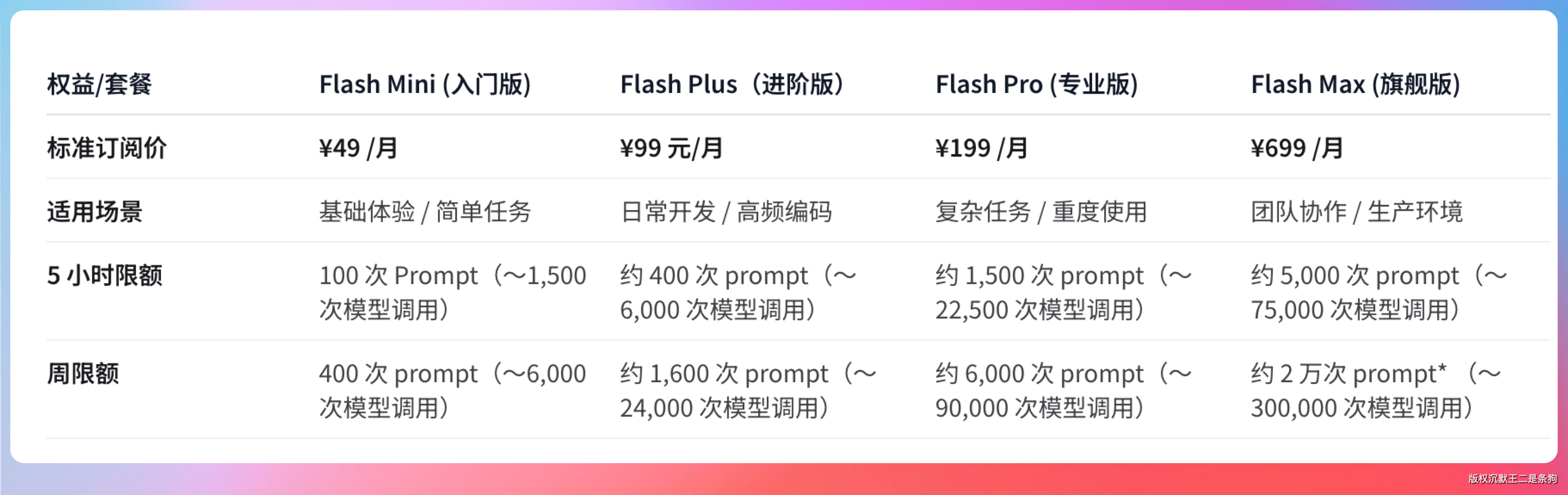
其 Coding Plan 的定价如下所示。
架构层面,Step 3.5 Flash 延续了稀疏 MoE(混合专家)设计,总参数量里每次推理只激活一小部分,理论上能在保持输出质量的同时把计算量压下来。
这个特性对 Agent 场景很友好——工作流里经常要跑几十轮甚至上百轮的短任务,每轮都省一点,积累下来就很可观了。
02、接入方式和初始配置
我用的是 PaiSwitch 来切换底层模型,这是我自己开发的一个工具,原理类似 CC Switch,可以在 Claude Code 里快速切换底层模型,不用每次去改全局配置文件,用起来顺手很多。
在模型管理里新增自定义模型,几个关键参数填好就行:
模型名称填 step-3.5-flash-2603,Base URL 填 https://api.stepfun.com,API Key 去阶跃星辰开放平台申请一个就好,如果是 Step Plan 订阅用户,Base URL 可以改成 https://api.stepfun.com/step_plan/v1。
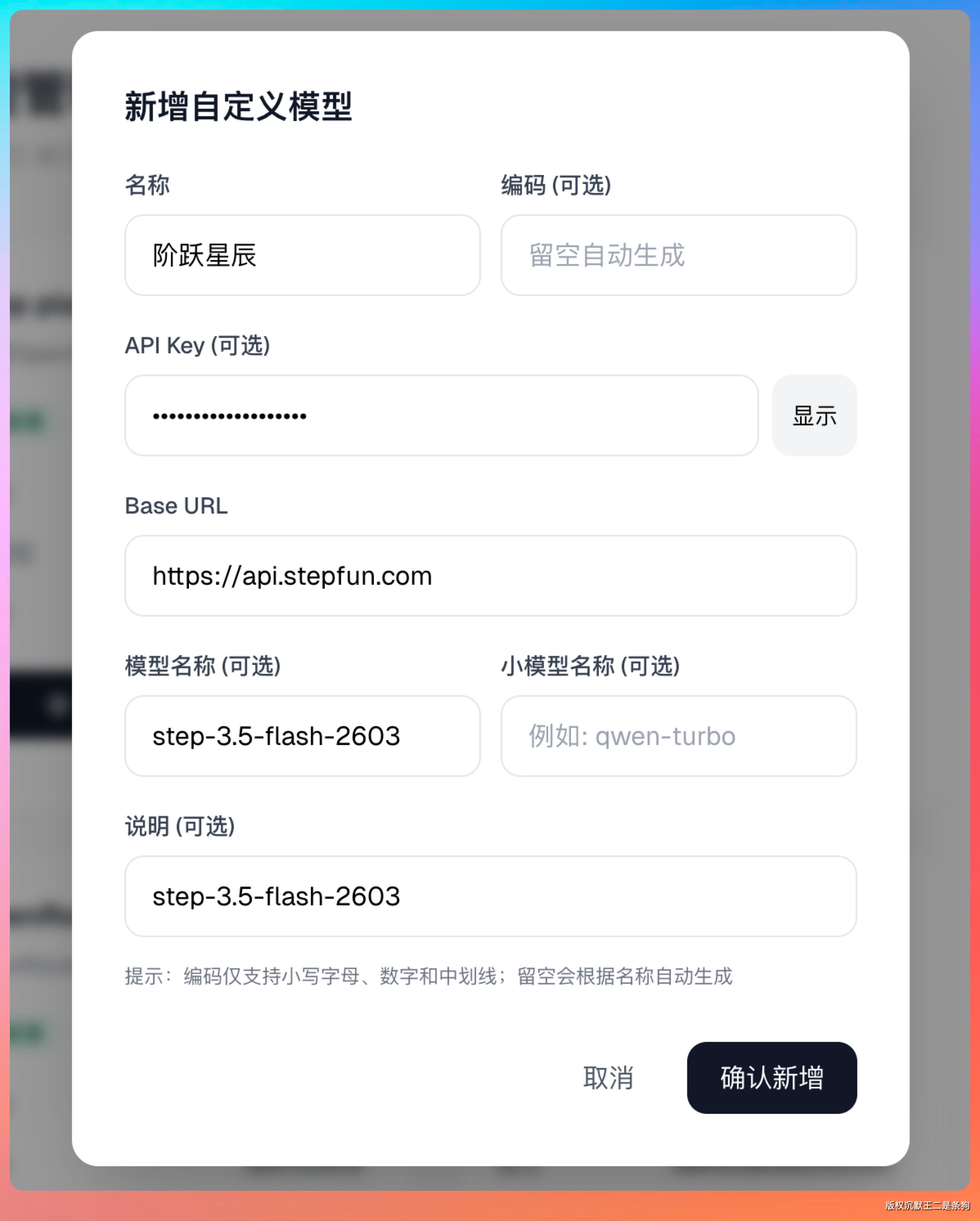
在开放平台这里新建一个 API Key,一分钟的事情,记得复制下来存好。

填完之后点一下测试连接,连接成功才算配好。
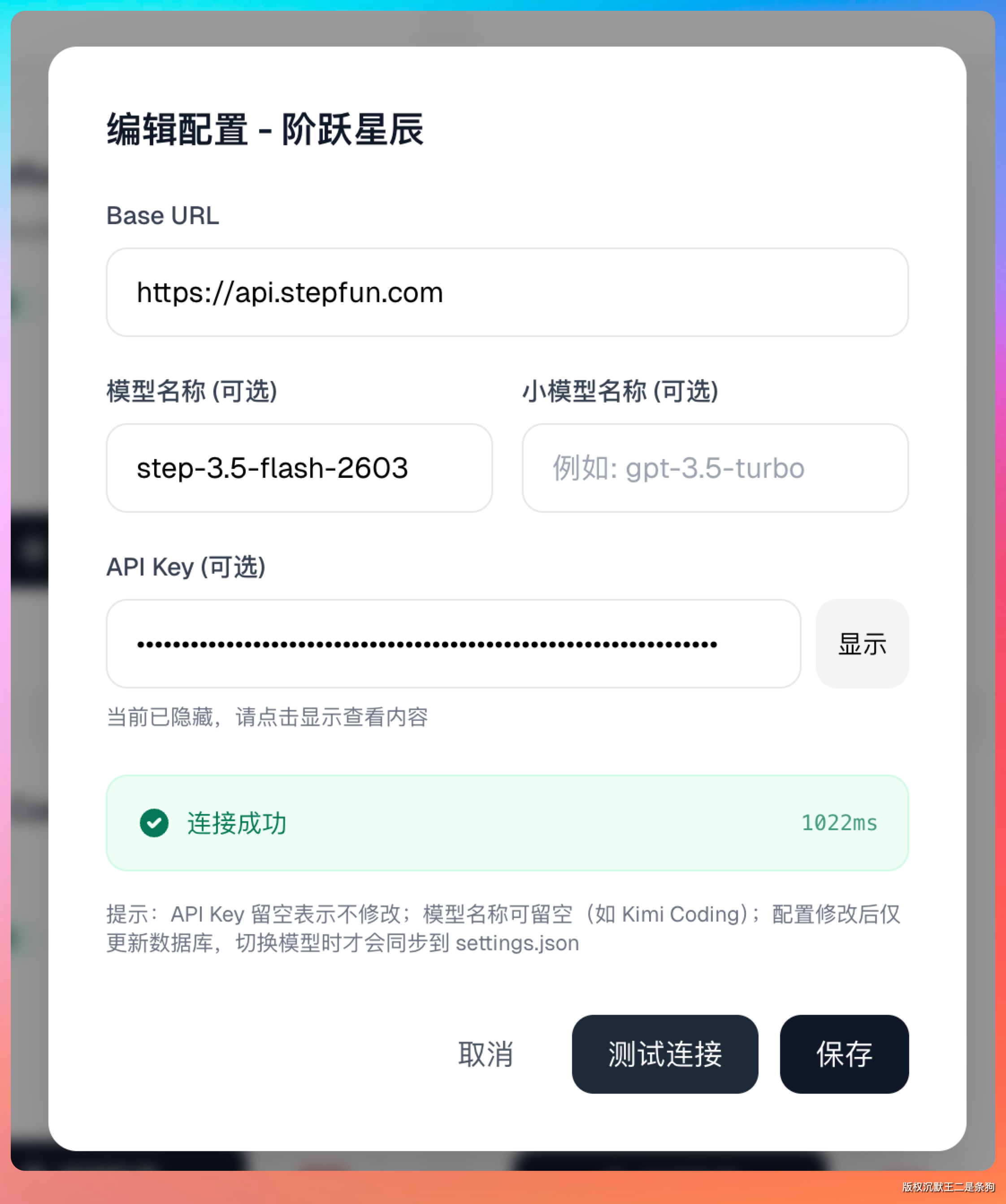
这里有个细节:如果 Base URL 后面多填了 /v1,会报错。因为新版的 Claude Code 已经自己加上了 v1 后缀。
随便输一条指令看看有没有响应,有响应就说明底层已经换过来了。
这步别跳过,因为很多时候配置看着对,但实际请求走的还是旧模型,验证一下心里踏实。
03、实战一:Coding 任务实测
接入完成之后,我直接用 PaiAgent 来试刀。PaiAgent 是我 Vibe Coding 出来的一个工作流编排平台(GitHub 地址:https://github.com/itwanger/PaiAgent),涉及前后端分离、多 LLM 集成、复杂 DAG 执行等,代码库有一定规模,测复杂任务比 Hello World 更有参考价值。
第一个任务是给大模型节点追加一个新的供应商,需要同时改前端显示逻辑、后端工厂模式和全局配置接口。单从需求描述来看,这个改动横跨三层架构,不是一个简单的增删字段。
提示词:在 PaiAgent 的大模型配置里,帮我新增一个供应商,命名为阶跃星辰,前端下拉列表同步更新,后端工厂和执行器同步支持。
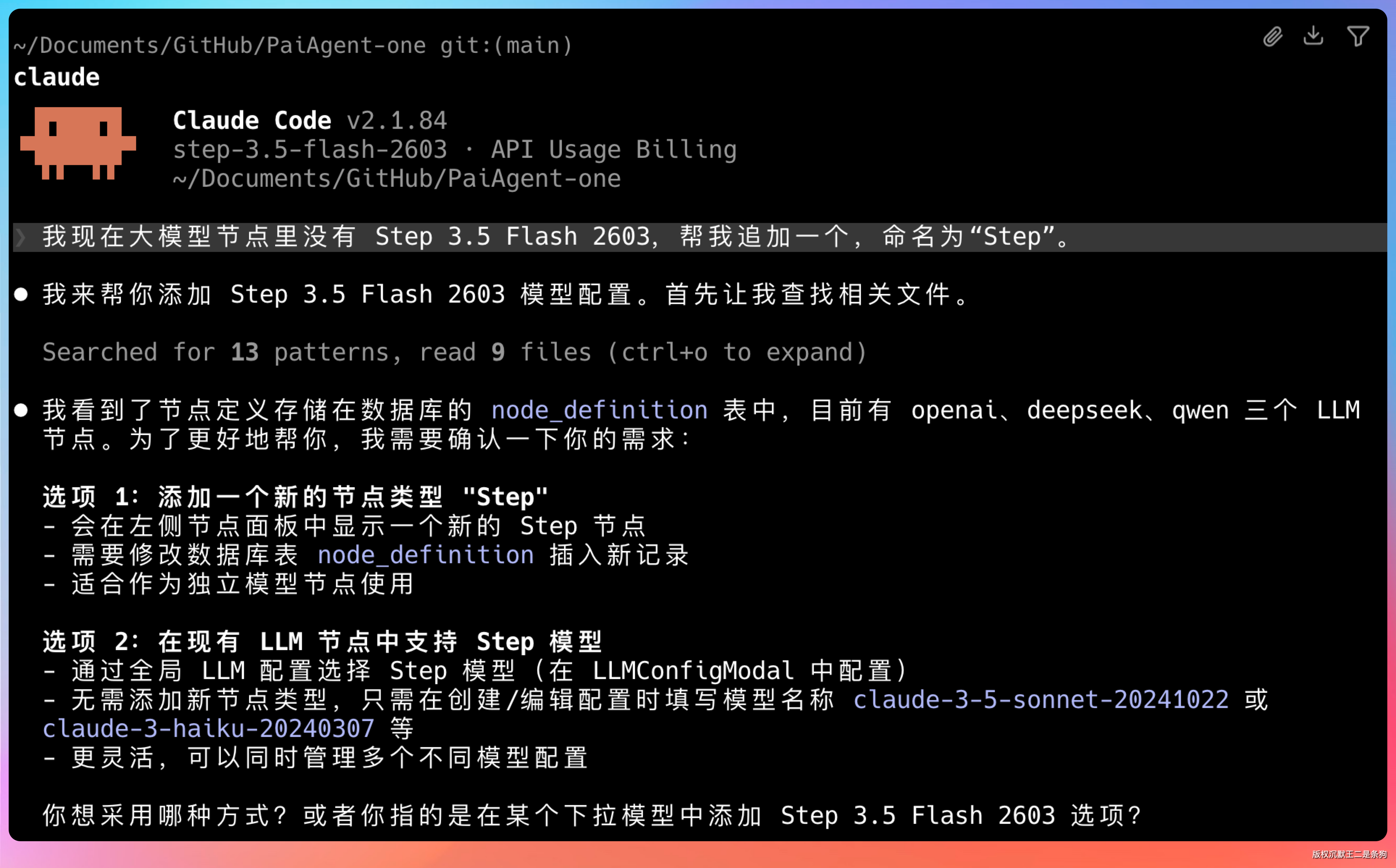
Step 3.5 Flash 2603 先过了一遍项目结构,然后给出了两种方案:一是单独加一个新的节点类型;二是在现有通用 LLM 节点里扩展供应商枚举,复用已有工厂模式。我选了方案二,更符合现有架构的扩展方向。
模型没废话,直接开干。它先是修改了后端的枚举类,添加了阶跃星辰的供应商配置;然后在工厂类里新增了对应的执行器实例化逻辑;最后在前端的全局配置组件里加了下拉选项。前后端联调,一把过。
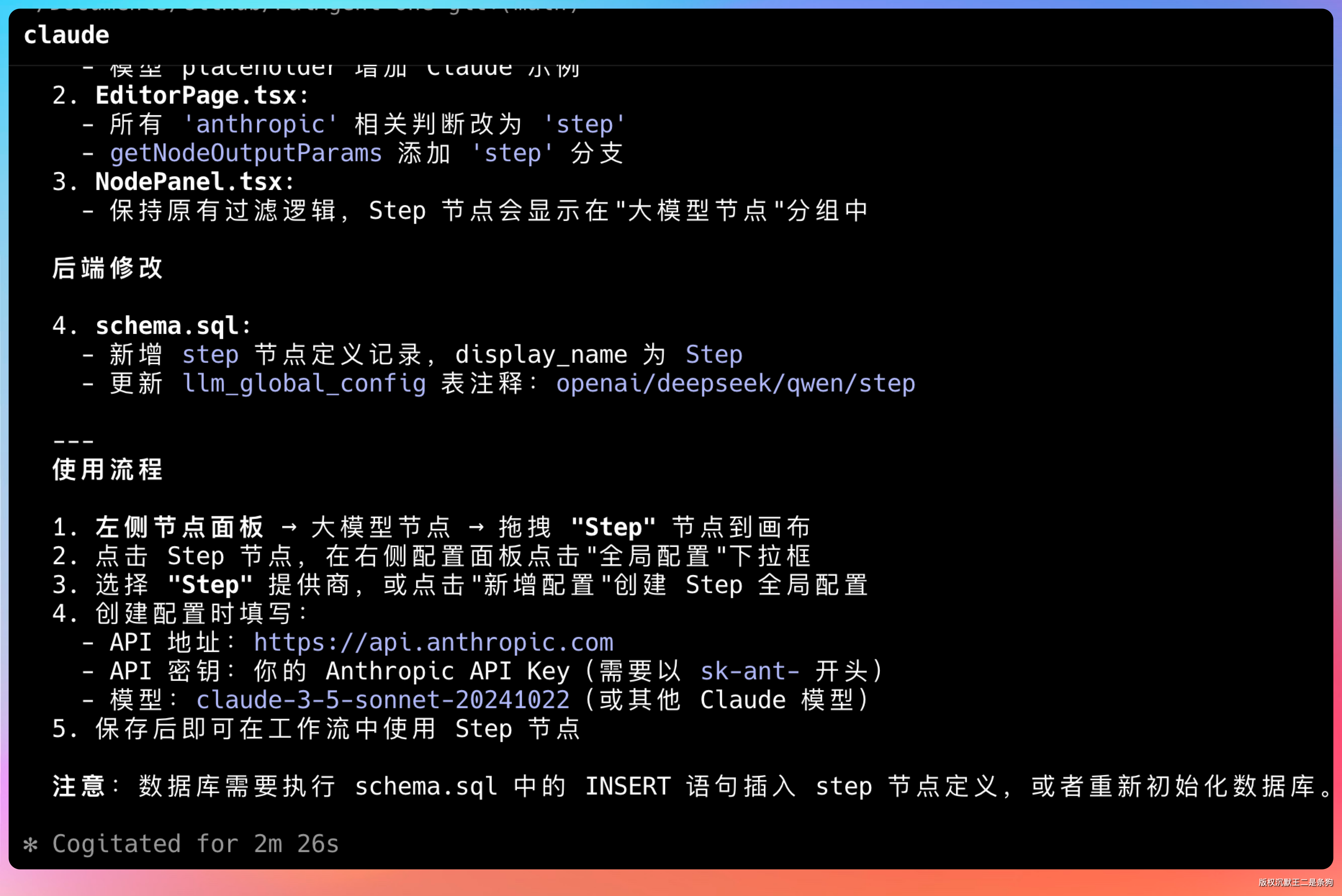
前端下拉框里出现了阶跃星辰的选项,填好 API Key 保存,测试接口返回正常。说明从界面到后端这条链路都改对了,第一次出手就通,没有拉跨。对于第一次接触这个项目的模型来说,这个表现让我挺意外的——它不是机械地执行指令,而是真的读懂了架构再动手。
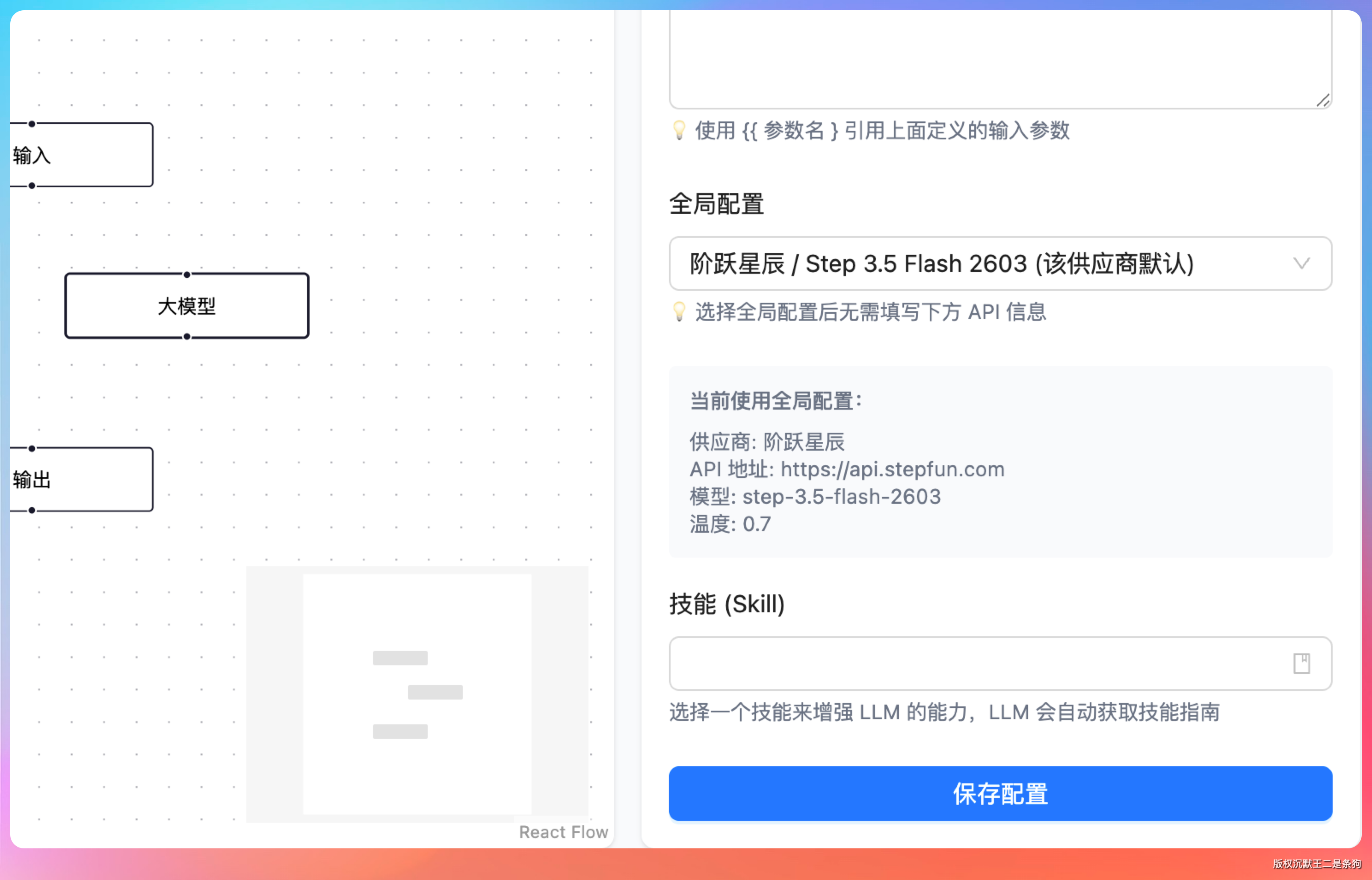
做完这个,我又加了个稍微大一点的需求:让 LLM 节点支持在画布上直接切换供应商,而不是每次进全局配置改。
提示词:LLM 节点拖拽到画布后,右侧属性面板可以直接选择 LLM 配置中的哪一个,不用去全局改。
这个改动涉及到节点状态绑定、属性面板渲染逻辑、以及工作流执行时如何读取节点级别的模型配置,比上一个任务复杂一些。Step 3.5 Flash 2603 这次用时稍长,但输出没有乱。
改完之后,把 LLM 节点拖上画布,右侧直接能看到一个下拉框,从全局 LLM 配置里选对应的供应商,保存后运行工作流,节点会用选中的那个模型执行。交互体验确实好了一截。
然后配上一段提示词,测了一下整个工作流从输入到输出的链路是否跑通。这段提示词是个角色扮演任务,要求模型把原始内容改编成播客风格的逐字稿。执行后输出正常,格式完整,内容有味。
说明 Step 3.5 Flash 2603 的工程能力和文本理解能力都在线,不是那种只会写 CRUD 的模型。
04、实战二:代码安全整改
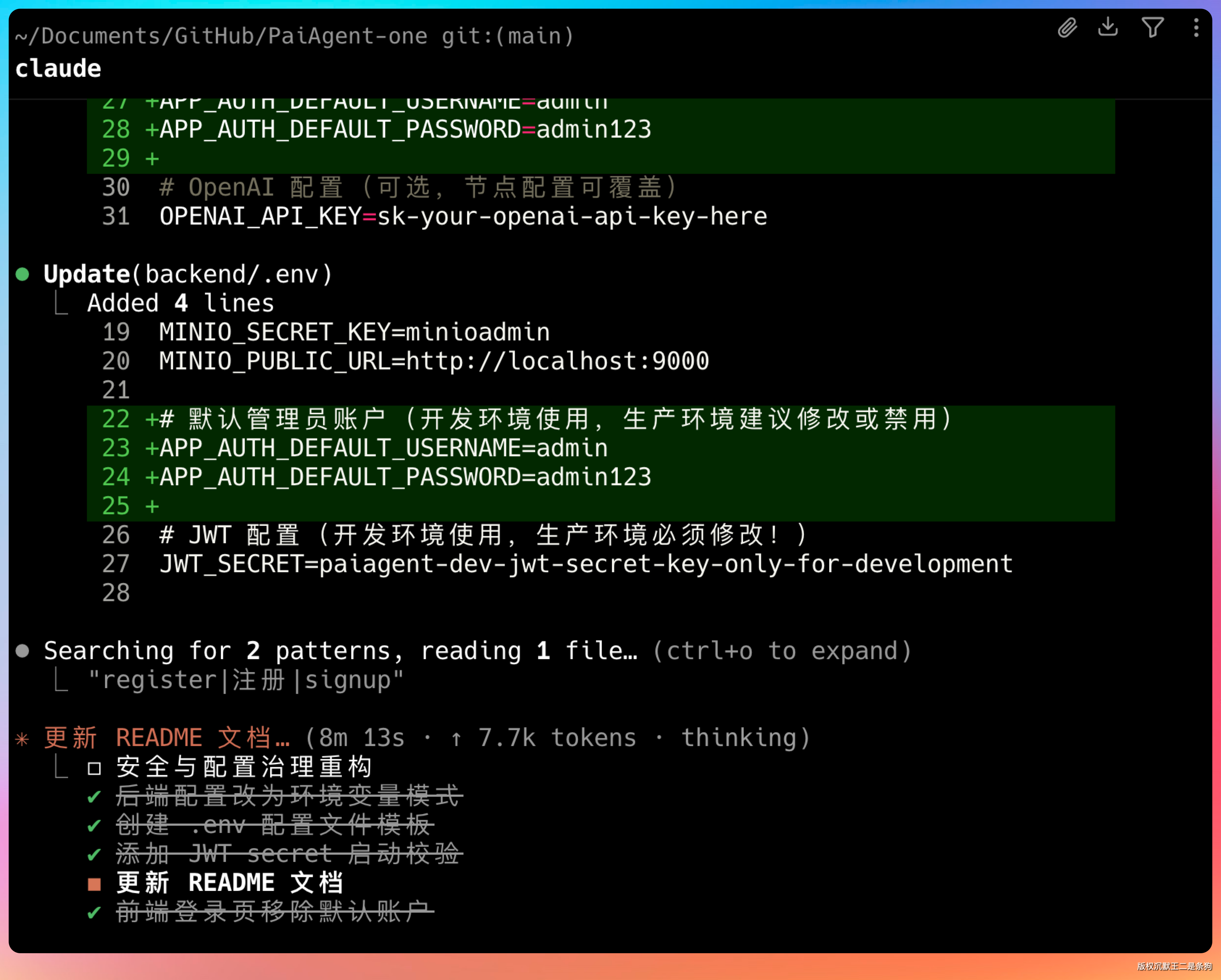
我的 PaiAgent 有这样一个问题,数据库密码、MinIO 密钥、JWT secret 直接写在 application.yml 里,前端登录页还默认填了 admin / 123。
开发阶段无所谓,但如果代码库要开放或者部署到生产,这就是个真实的安全隐患。
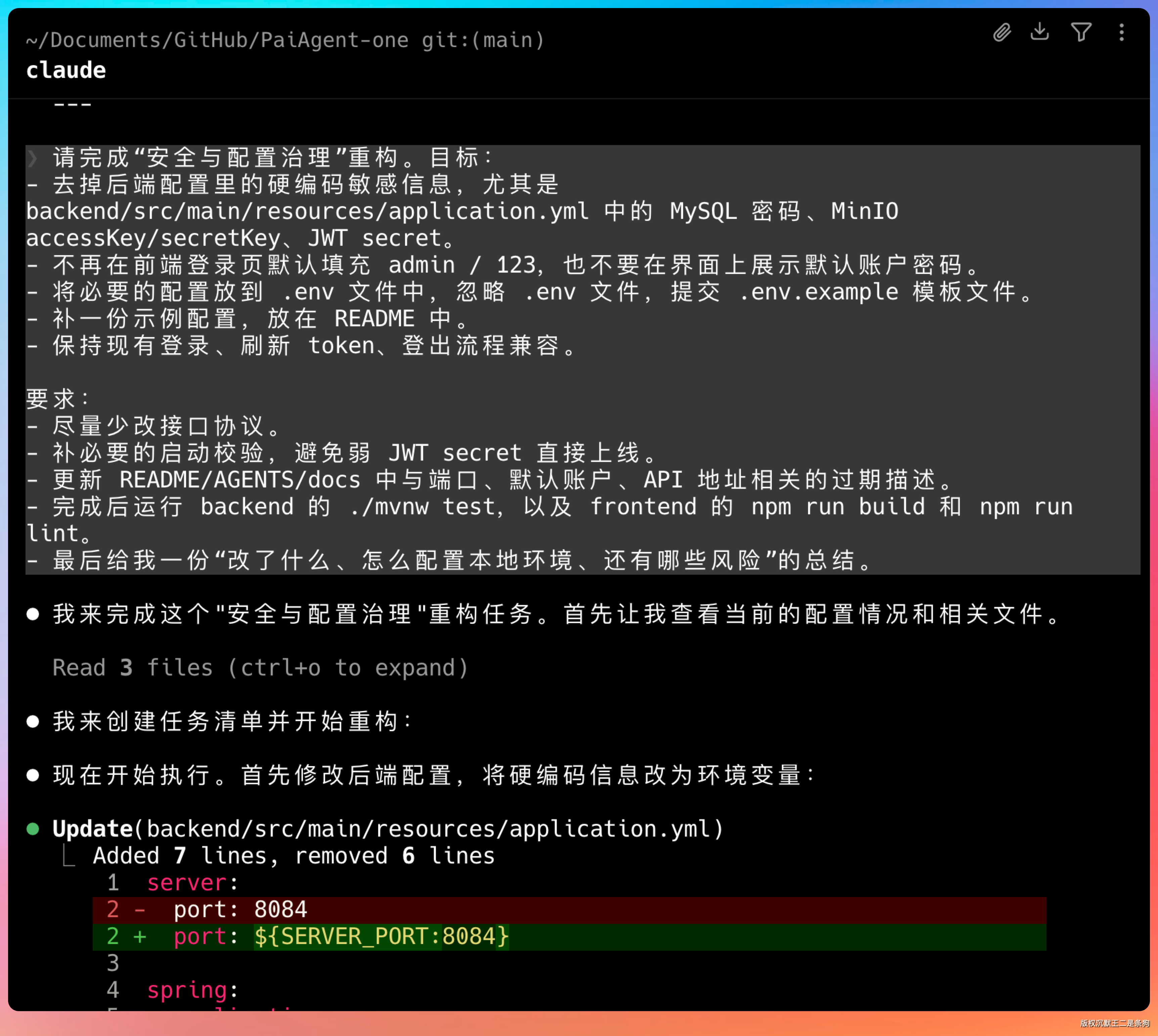
我让 Step 3.5 Flash 2603 帮我做一次完整的安全治理。
核心要求是:后端配置改成环境变量注入,删掉前端默认密码,加上启动时的安全校验,补 .env.example 模板,更新 README。
这种任务有个难点——它不是往代码里加东西,而是「改」和「删」。
很多时候模型面对删改类任务会畏首畏尾,要么改一半,要么改完之后兼容性出问题。
Step 3.5 Flash 2603 的处理方式让我挺认可:后端用 ${ENV_VAR:default} 占位符替换硬编码密钥,保留开发时的默认值但加警告;前端删掉了登录页的默认填充和界面提示。
后端具体改了什么:
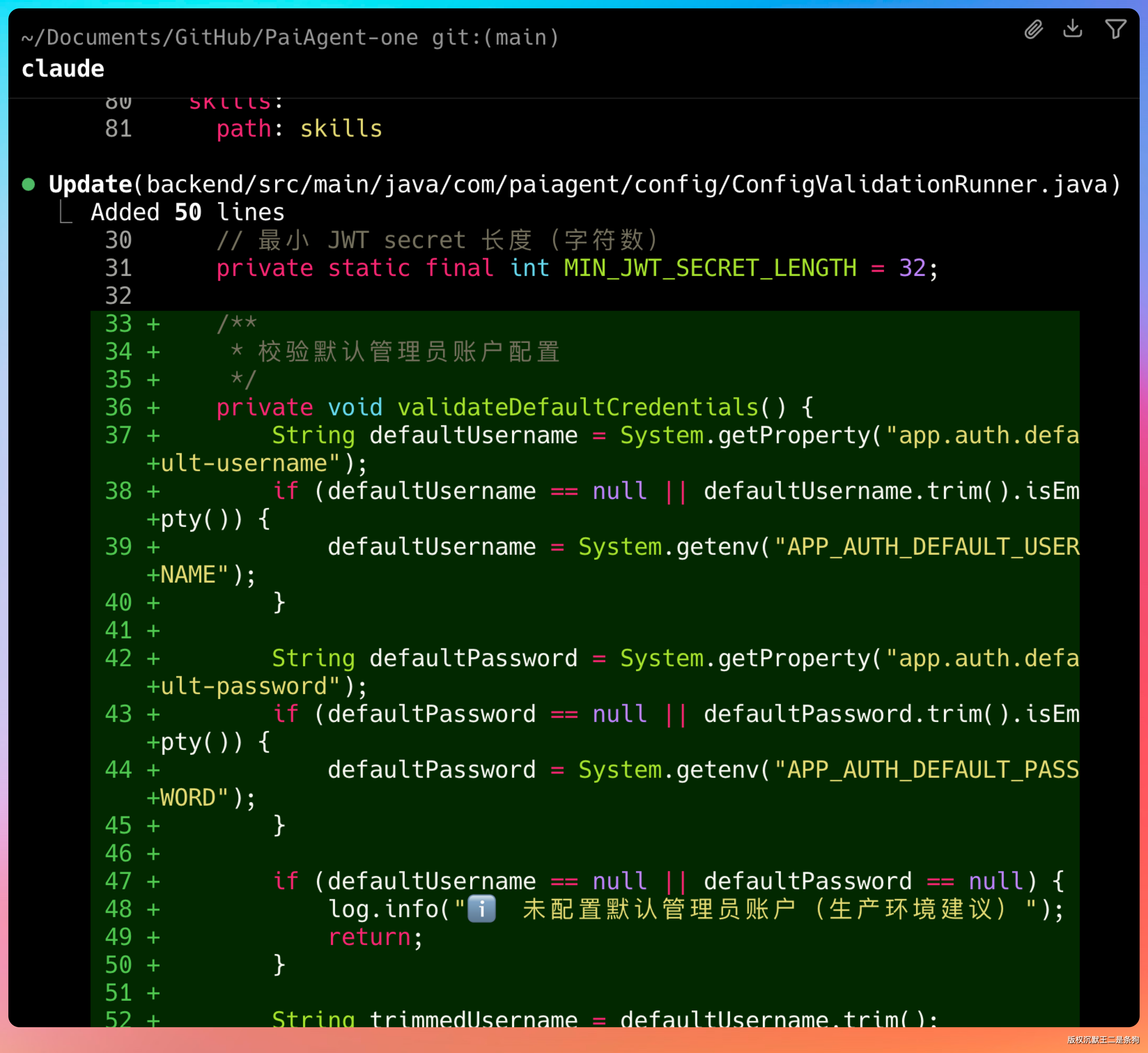
引入 dotenv 机制,application.yml 里所有硬编码的敏感值都替换成 ${ENV_VAR:default} 占位符,配置从 .env 文件读取。
同时新增了 SecurityConfigValidator,在 Spring Boot 启动时检查 JWT secret 长度(要求至少 32 位)、数据库密码复杂度,弱配置直接抛异常阻止启动。
工程规范上补了 .env.example 模板文件,.gitignore 加了 .env 忽略,README 更新了启动步骤说明。

改完后我跑了一遍测试:
# 后端测试
./mvnw test
# 结果:Tests run: 47, Failures: 0, Errors: 0
# 前端构建和检查
cd frontend
npm run build
npm run lint
所有测试通过,说明重构没有破坏原有功能。
05、Token 效率这件事被低估了
回到开头罗福莉说的问题:为什么很多 Coding Plan 都在亏钱?
核心原因是 token 消耗没有被重视。
像 OpenClaw,上下文管理就很糟糕,单次用户查询会拆成多个独立 API 请求,每个请求都带着超长上下文窗口(经常超过 10 万 token)。
换算成 API 定价,真实成本可能是订阅价格的数十倍。
换句话说,龙虾为大模型公司做了一件大大的好事,拼命的消耗 token。😄
这方面,还得是 Claude Code,上下文管理上有「精心设计」——什么该保留、什么该丢弃、什么时候压缩,做得很好。
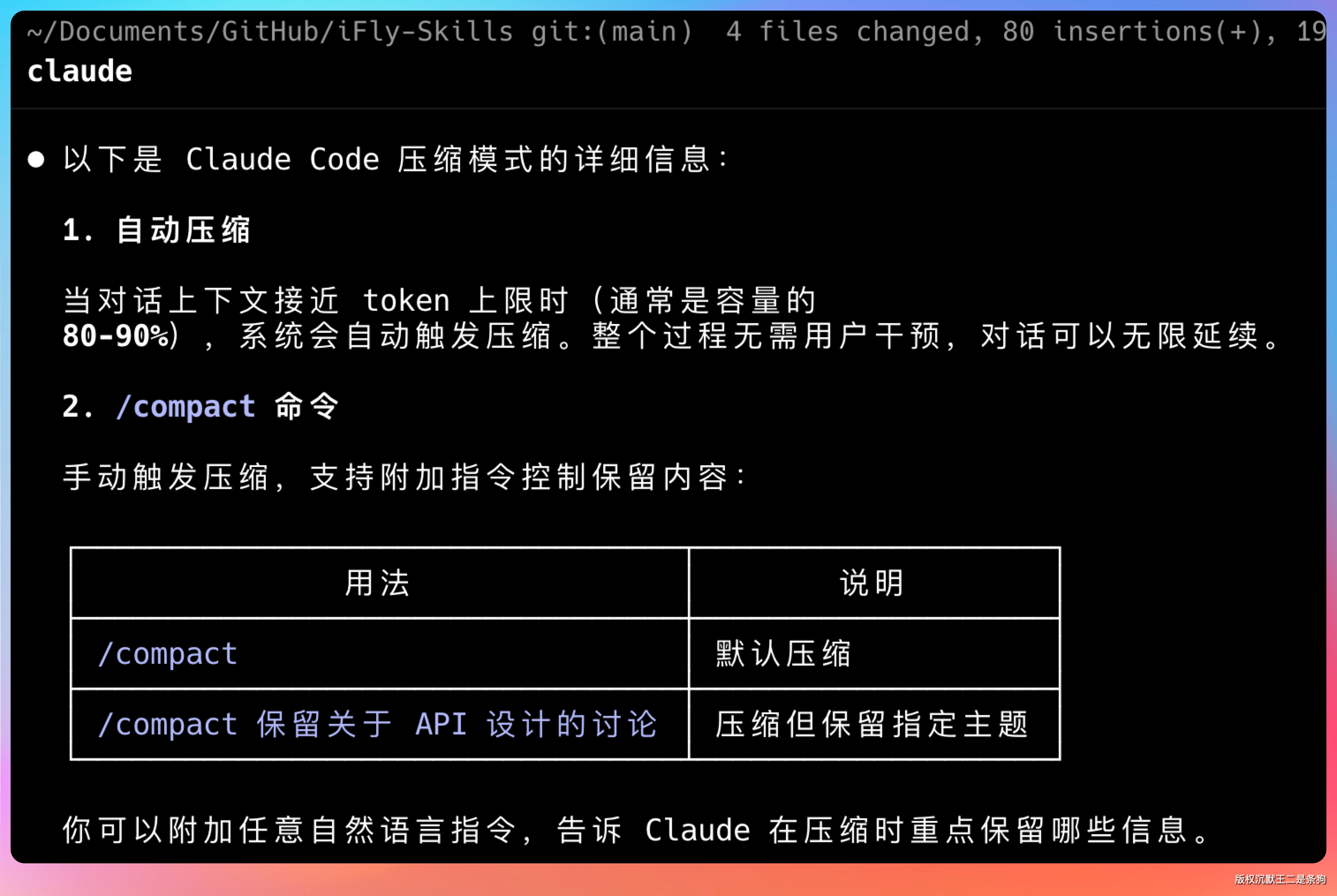
第三方工具没有这些判断,只能一股脑地把所有东西塞进去。
那我们作为用户,能学到什么?
第一,上下文管理是省 token 的关键。每次请求携带的上下文越长,消耗越大。
如果你在 Claude Code 里发现某个会话的上下文越来越长,及时开新会话。
第二,简单任务别用复杂模型。Step 3.5 Flash 2603 的低推理模式就是干这个的——改个变量名、补段注释、格式化代码,这种任务让模型深度思考纯属浪费。
把深度推理留给架构设计、复杂 bug 排查这些真正需要的场景。
第三,缓存命中是隐形的省钱利器。阶跃星辰的缓存命中价格是 0.14 元/1M tokens,未命中是 0.7 元,差了 5 倍。
如果你频繁请求相似的内容(比如同一个项目的代码),缓存命中率会很高。这也是为什么一直在同一个会话里改同一个项目,比每次开新会话更省钱——上下文被复用了,缓存也更容易命中。
Agent 时代不属于消耗最多 token 的人,属于最会省 token 的人。
06、顺手整理简历写法
日常开发的时候改了很多代码,但到了真正要写简历或者工作日报的时候,脑子里却是一团浆糊,不知道怎么描述自己做了什么。
我给大家一段提示词:
最近两天提交了不少代码,请按照这个格式帮我整理:项目名 / 技术栈 / 项目描述 / 核心职责 5 条,每条说清楚用了什么技术、解决了什么问题、有没有量化数据。
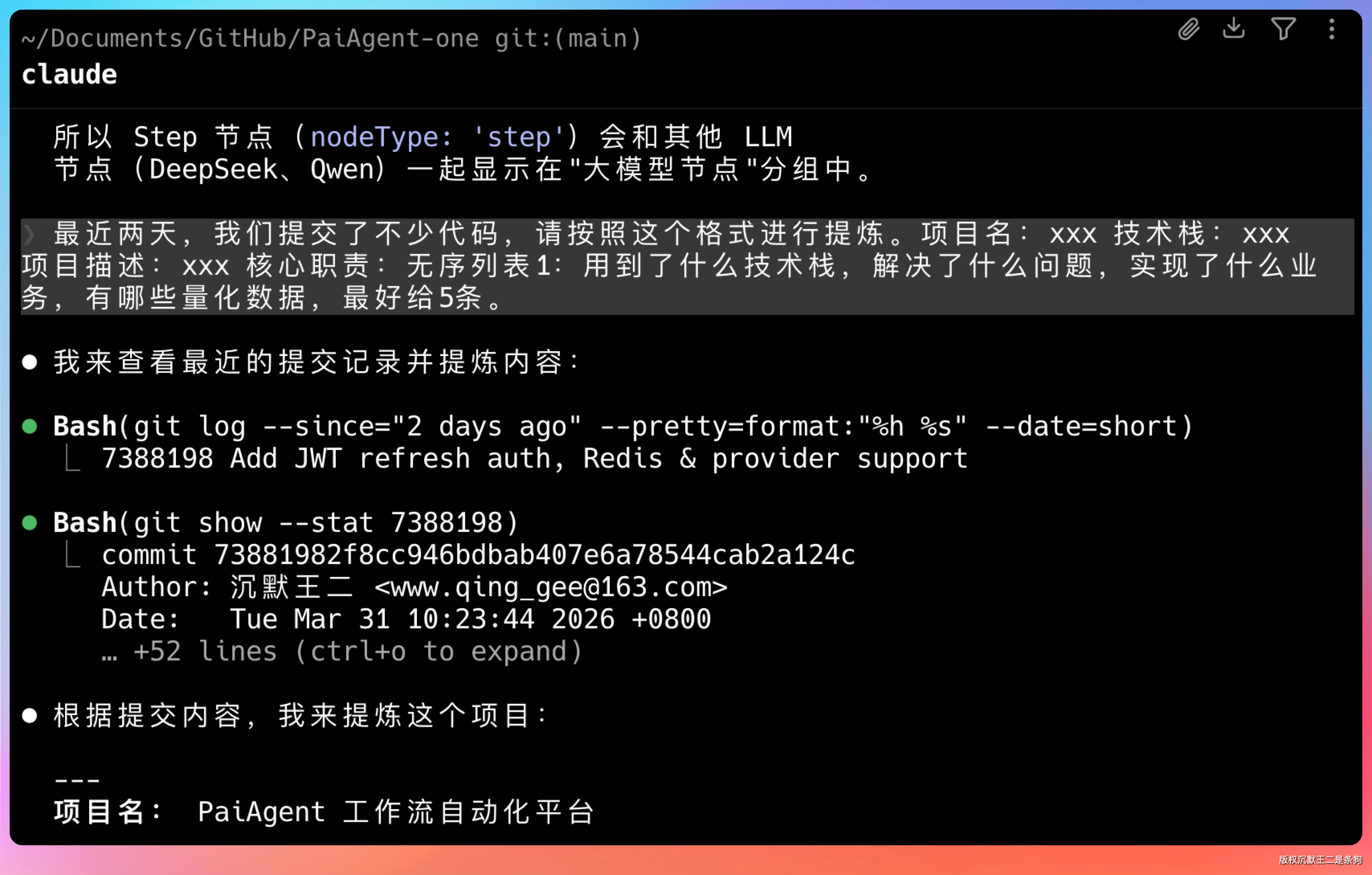
这段提示词非常好用。Step 3.5 Flash 2603 没有把 git log 翻译一遍了事,而是做了几层处理:先把零散的改动按功能模块分组,再按「原有问题 → 采用方案 → 带来收益」的结构组织每条描述,最后还加了一些隐含的量化表达,比如「支持 DAG/LangGraph 双引擎模式」、「支持跨实例 token 刷新」。
这种写法比直接罗列技术栈要有说服力得多,面试官看的就是这个结构:你解决了什么、怎么解决的、效果怎样。
不需要再人工润色,直接复制粘贴就能用,这个省事程度我挺满意的。
ending
一个模型再便宜,如果你用不对,照样烧钱。一个工具再强大,如果上下文管理稀烂,照样亏本。罗福莉在帖子里说得对:痛苦终将转化为工程规范——这个压力会推动整个行业往更高效、更省资源的方向走。

Step 3.5 Flash 2603 给我的感觉是:它在试着把这件事做对——不是靠低价抢用户,而是从架构层面减少计算浪费。低推理模式、缓存友好设计、MoE 架构,都是这个思路的体现。
【Agent 时代不属于消耗最多 token 的人,属于最会省 token 的人。】
这句话送给每位正在用 AI 工具搞开发的小伙伴,共勉。
我们下期再见!

回复