


大家好,我是二哥。
还没养龙虾的小伙伴,可以不用养了。
现在又有新选手入场了——Hermes Agent,代号「爱马仕」。
GitHub 上已经 40.4k Star 了,Fork 也有 5.2k,涨得飞快。
不得不说,AI 圈是真的能卷,新玩意层出不穷,学是学不完的。
但人之所以为人,就在这一点,对创新充满了炽热。
可能有小伙伴会问,这玩意儿和 OpenClaw 啥区别?
Hermes 主打的是「自进化」——能用着用着把自己练强了,而不是每次都从零开始。
说真的,这个方向挺有意思。
传统的 Agent 框架,你让它干一件事,它干完了,下次再让它干类似的事,它还是从头学。但 Hermes 不一样,它有个内置的学习循环,会把你的偏好、常用工具、解决路径都记下来,越用越顺手。
今天这篇,我把 Hermes Agent 的安装、配置、和 OpenClaw 的协作方式全写清楚。跟着做就行,真的有手就行。
01、Hermes Agent 到底是个啥?
先搞清楚我们要装的是什么东西。
Hermes Agent 是 Nous Research 开源的自进化 AI Agent 框架,核心能力就一句话:用得越多越聪明。
它不是那种只会执行命令的 Agent,而是真正能学习的 Agent。
你让它帮你做浏览器自动化,它会记住你常用的操作顺序,下次自动优化流程。你让它整理文档,它会记住你的格式偏好,下次直接按你的风格来。

核心特点有这几个:
内置学习循环。Hermes 完成复杂任务后,会把整个解决过程沉淀成一个 Markdown 格式的 Skill。后续发现更好的路径,还会自动更新这个 Skill。这解决了一个超大痛点:不用手写 Rules 去规定不同工具的调用顺序。
三层记忆系统。用 SQLite 存对话历史,FTS5 做全文检索,大模型自动做摘要。所有历史对话都存下来,跨会话记住你的偏好和习惯。
安全拉满。和 OpenClaw 依赖大模型自己判断风险不同,Hermes 在框架层面做了用户授权、危险命令审批、容器隔离和上下文扫描。就算用一般模型也够安全。
支持 200+ 大模型。无缝对接 OpenAI、Anthropic、OpenRouter 等主流模型。
多端消息互通。支持 Telegram、Discord、Slack 等多端接入,一个 Agent 多 IM 操控。
还有一点很关键:Hermes 能用 Claude 的额度。OpenClaw 现在用不了了,但 Hermes 可以。
02、前置环境准备
开始之前,先把该装的装好,免得中途报错一脸懵逼。
系统要求
Hermes Agent 支持以下系统:
- Linux(推荐 Ubuntu 20.04+)
- macOS(10.15+)
- Windows(必须启用 WSL2)
Windows 用户注意了,原生 Windows 环境不支持,必须用 WSL2。不熟悉 WSL2 的可以参考微软官方文档装一个 Ubuntu 子系统。
准备大模型的 API Key
Hermes 支持 200+ 大模型,我这里以智谱 GLM 为例,因为我是他们家的 Coding Plan 套餐用户。
访问智谱开放平台,登录后在 API Keys 页面创建一个 Key,复制保存好。
03、一键安装 Hermes Agent
启动 Claude Code,然后输入下面这段提示词:
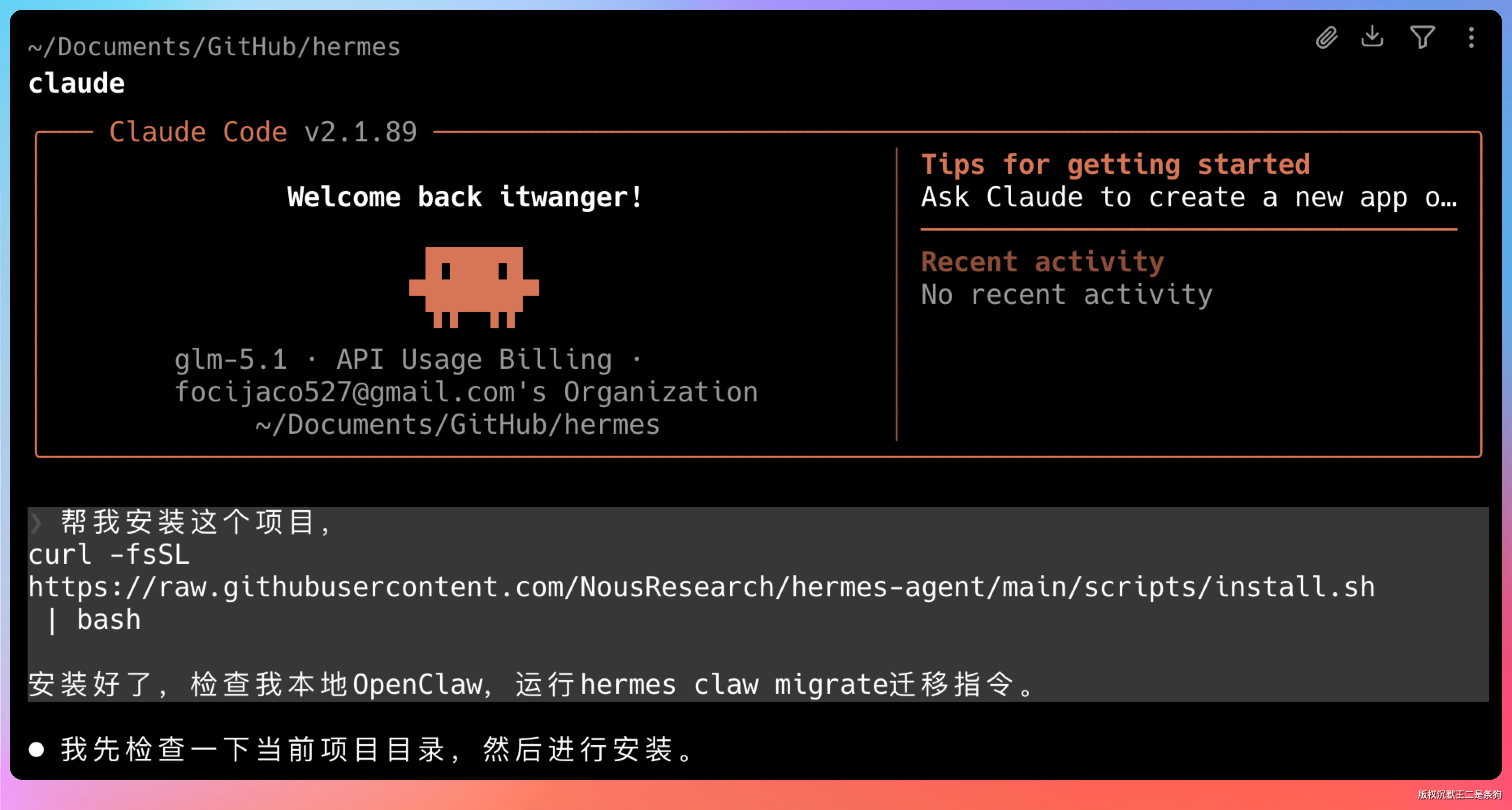
帮我安装这个项目,
curl -fsSL
https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash
安装好了,检查我本地OpenClaw,运行hermes claw migrate迁移指令。
这个脚本会自动检测系统环境,安装 Python 3.11、Node.js、Git 和所有依赖,基本不用你操心。
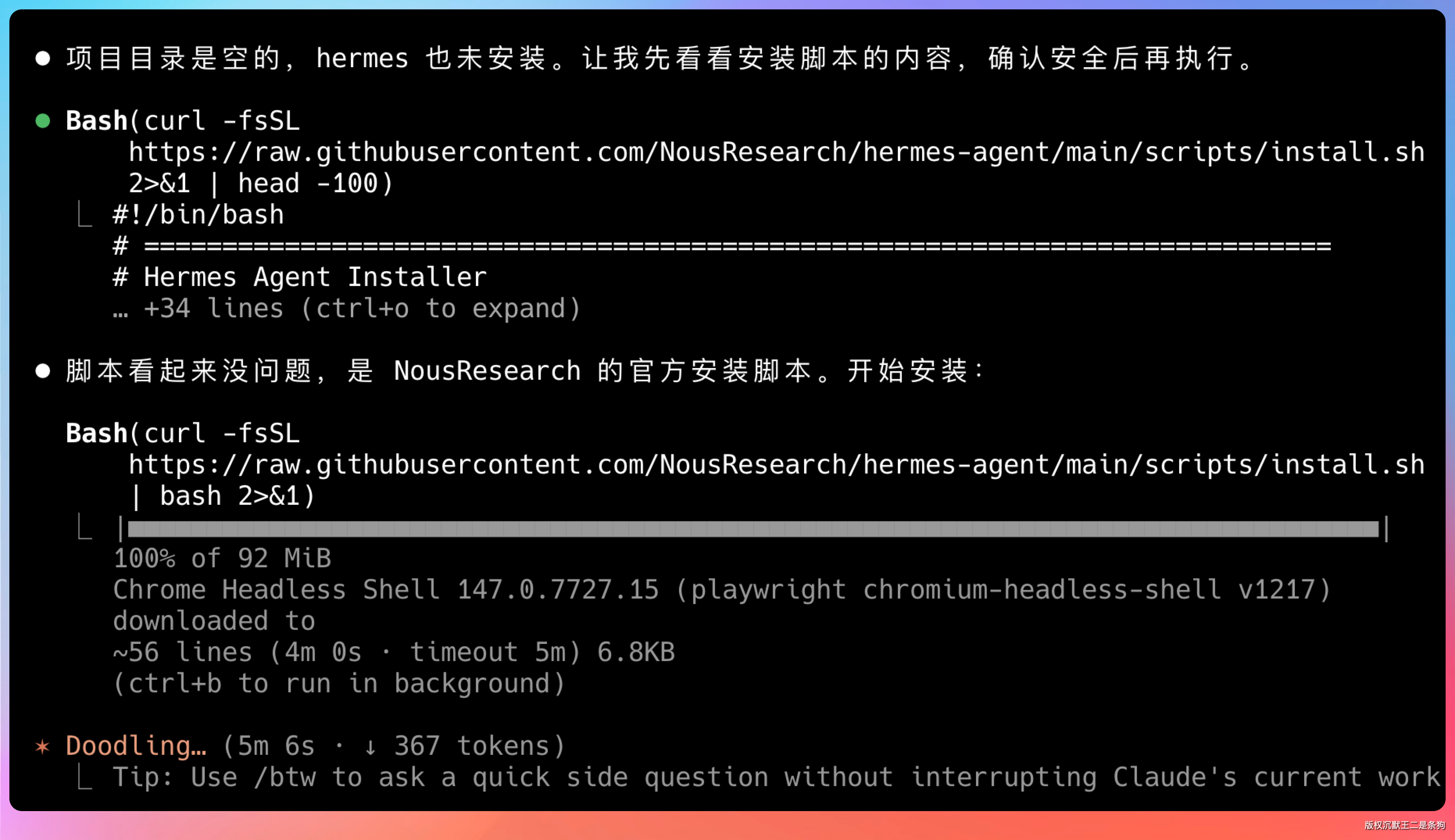
整个安装过程大概 3-5 分钟,取决于你的网速和电脑性能。
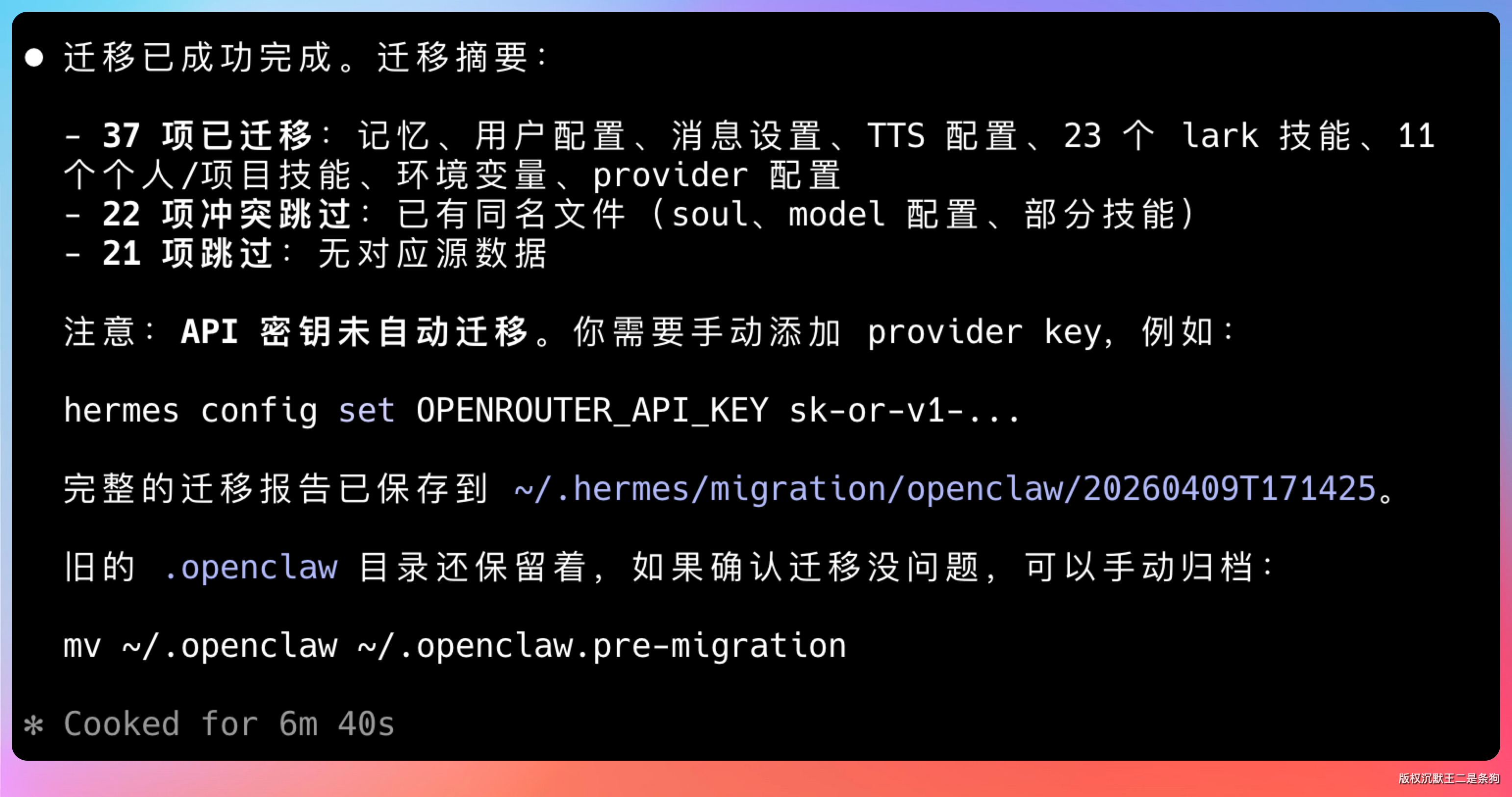
然后执行 hermes step 进行配置。
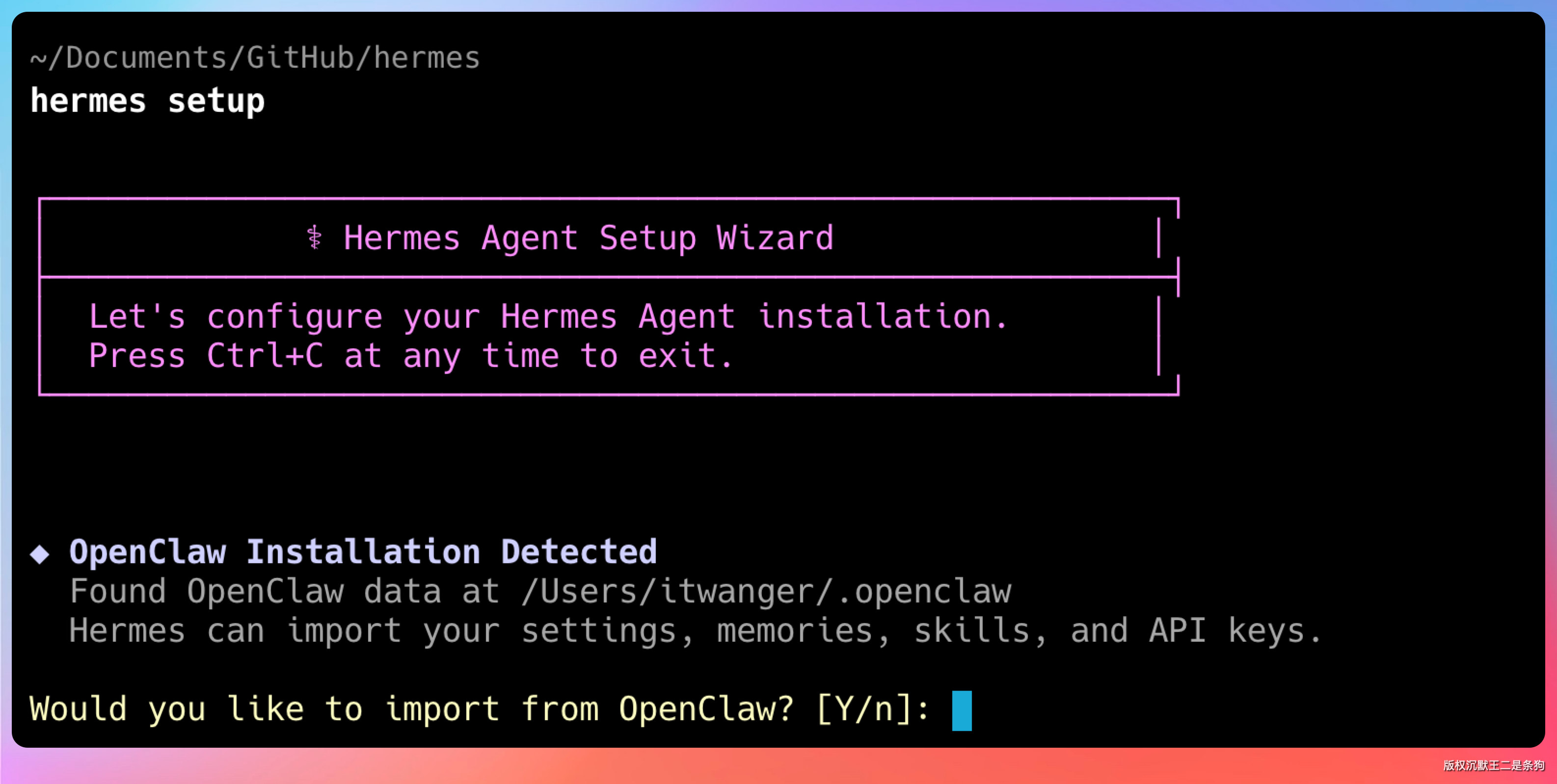
如果之前装了龙虾,很多配置可以直接迁移过来。
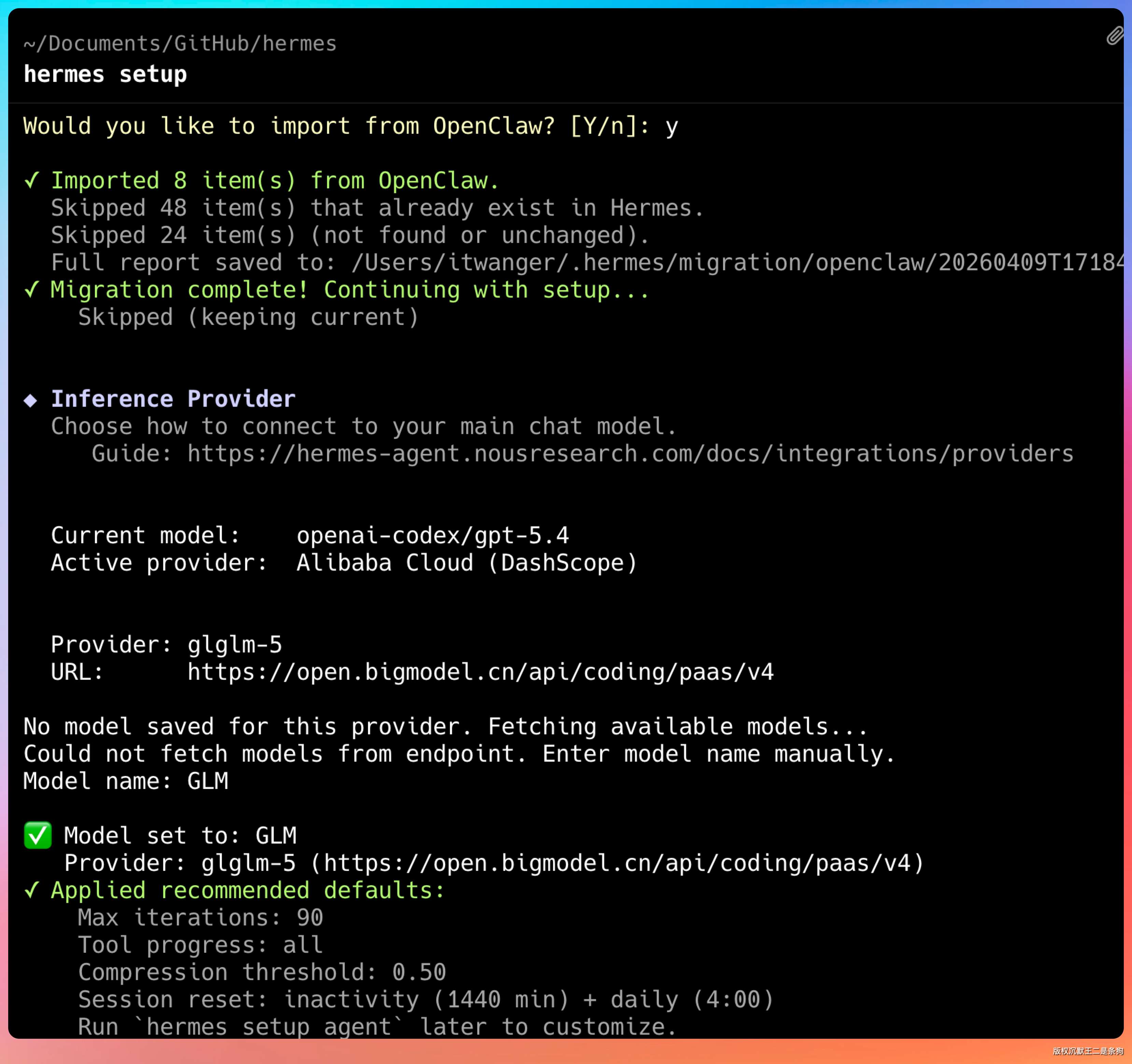
如果出现下面这个页面就说明配置成功了。
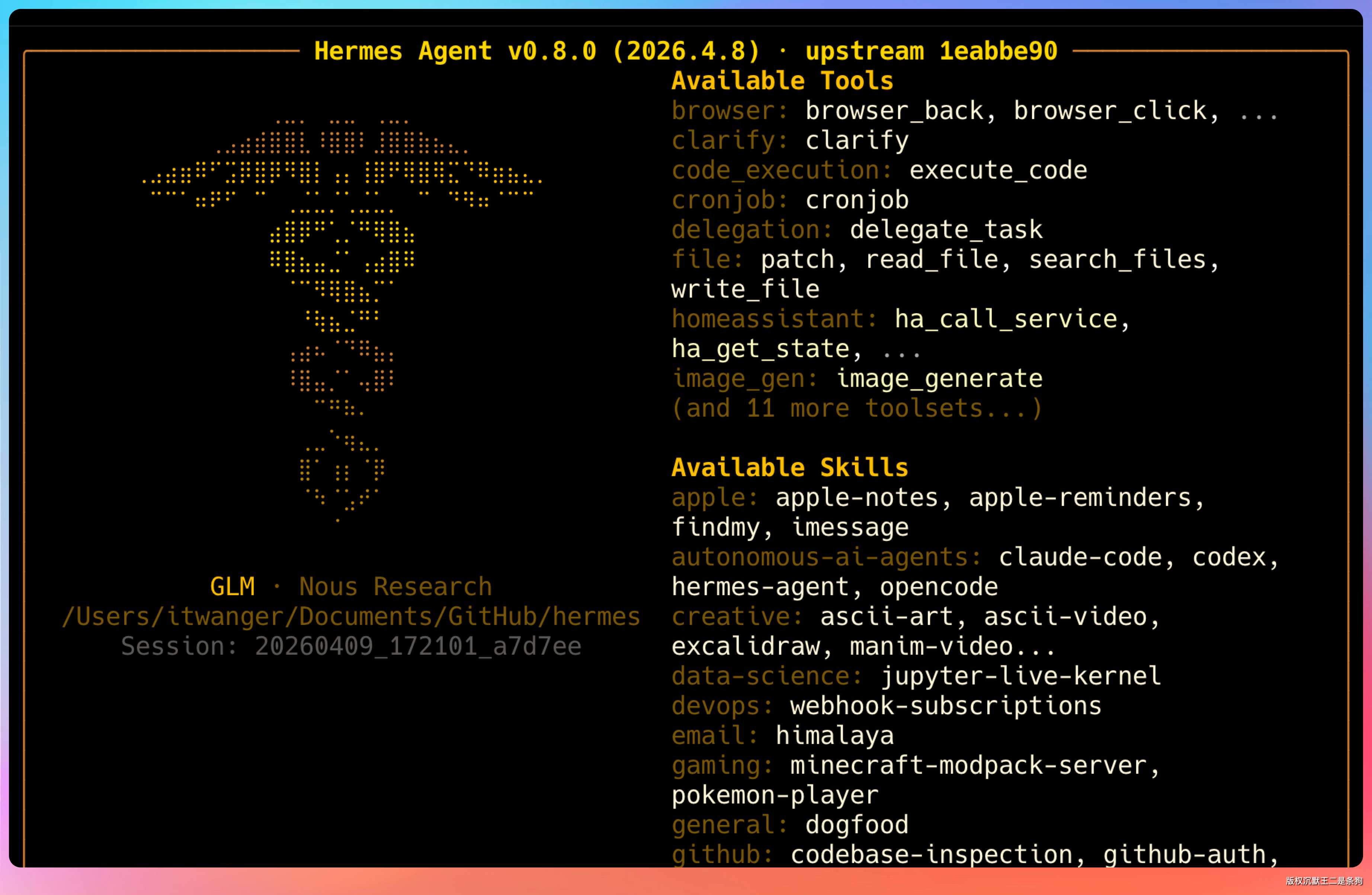
04、启动配置向导
Hermes 的配置文件在这个位置 ~/.hermes/,如果有想更改的配置,可以直接通过这个路径修改。

第一步:选择网关类型
Hermes 支持多种运行后端:
- local:本地运行(默认推荐)
- docker:Docker 容器
- ssh:远程服务器
- modal:Serverless 平台
可以在配置文件里加上 API_SERVER_ENABLED=true,这样就可以通过 http://127.0.0.1:8642/health 检查状态。
第二步:配置模型认证
比如说,我之前在 OpenClaw 里配置的 GLM-5.1 模型,可以在这里修改 API key。
如果出现 API key 不可用,最好检查一下,是不是之前的已经失效了。
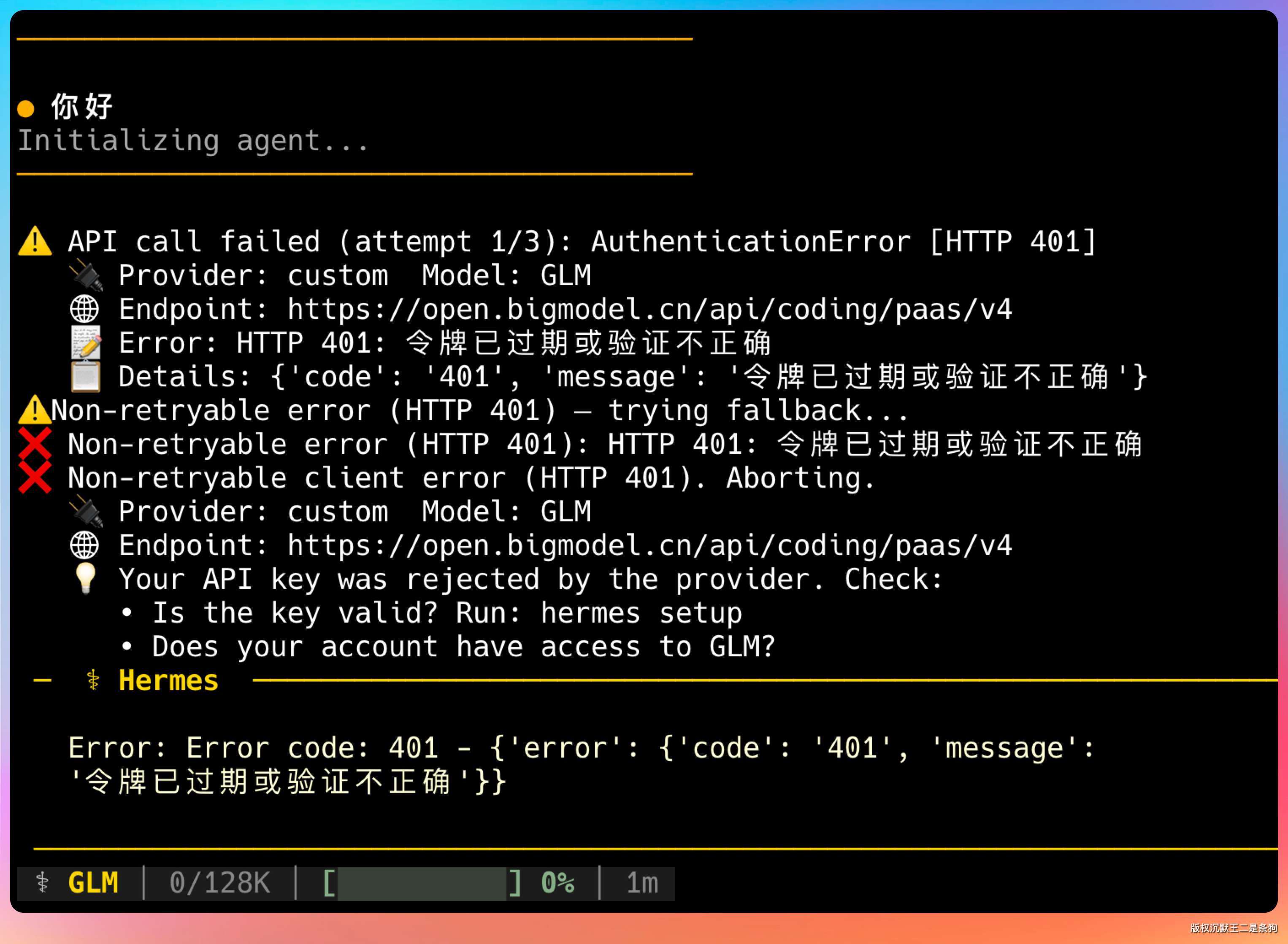
反正我就碰到这个坑了。
让 Claude Code 帮我们修。
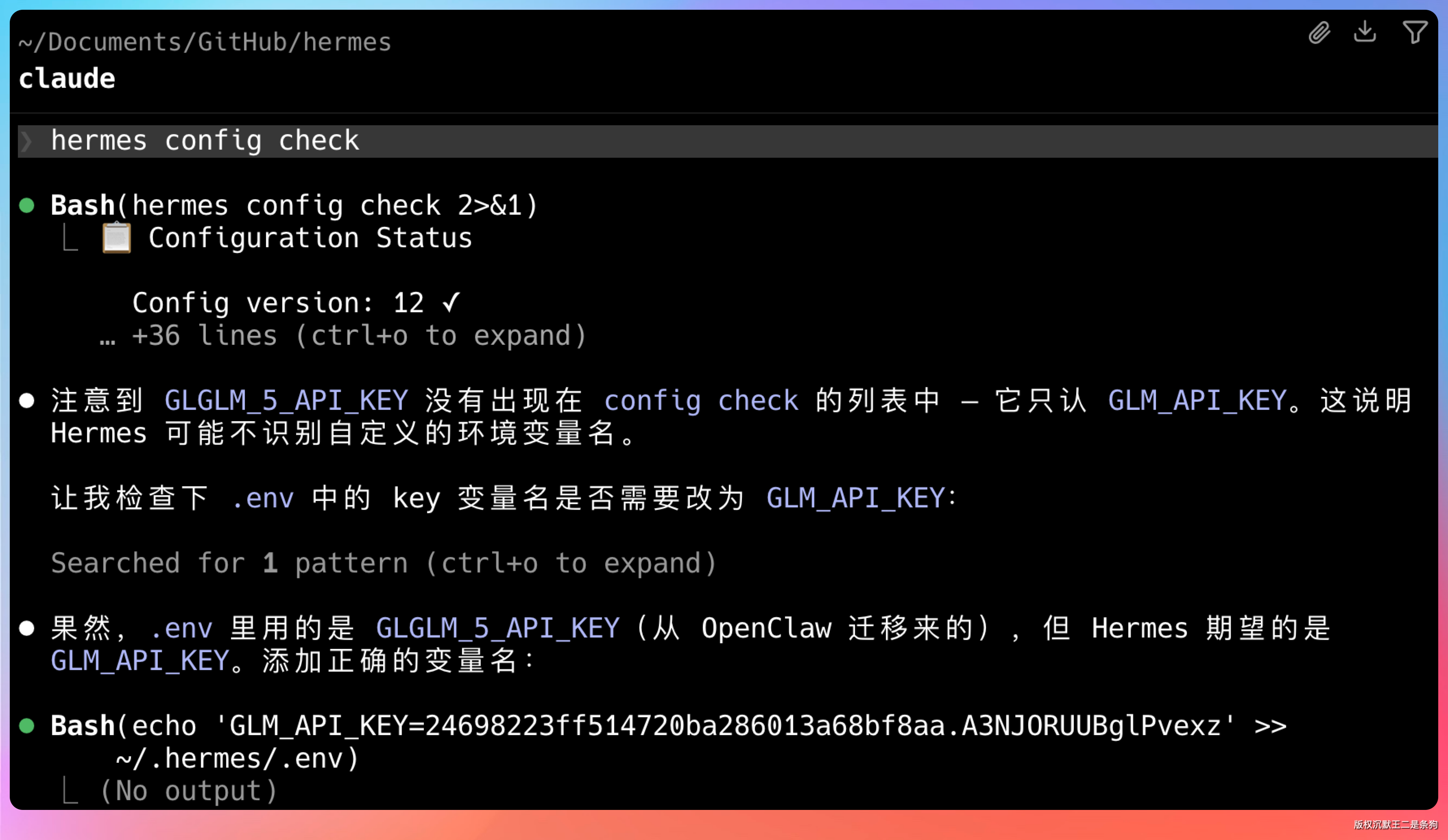
折腾了蛮久,说明这块做的还是不够友好。😄,也有可能是 GLM-5.1 的问题。
我把问题扔到了 Codex 里,这次算是问题解决了。
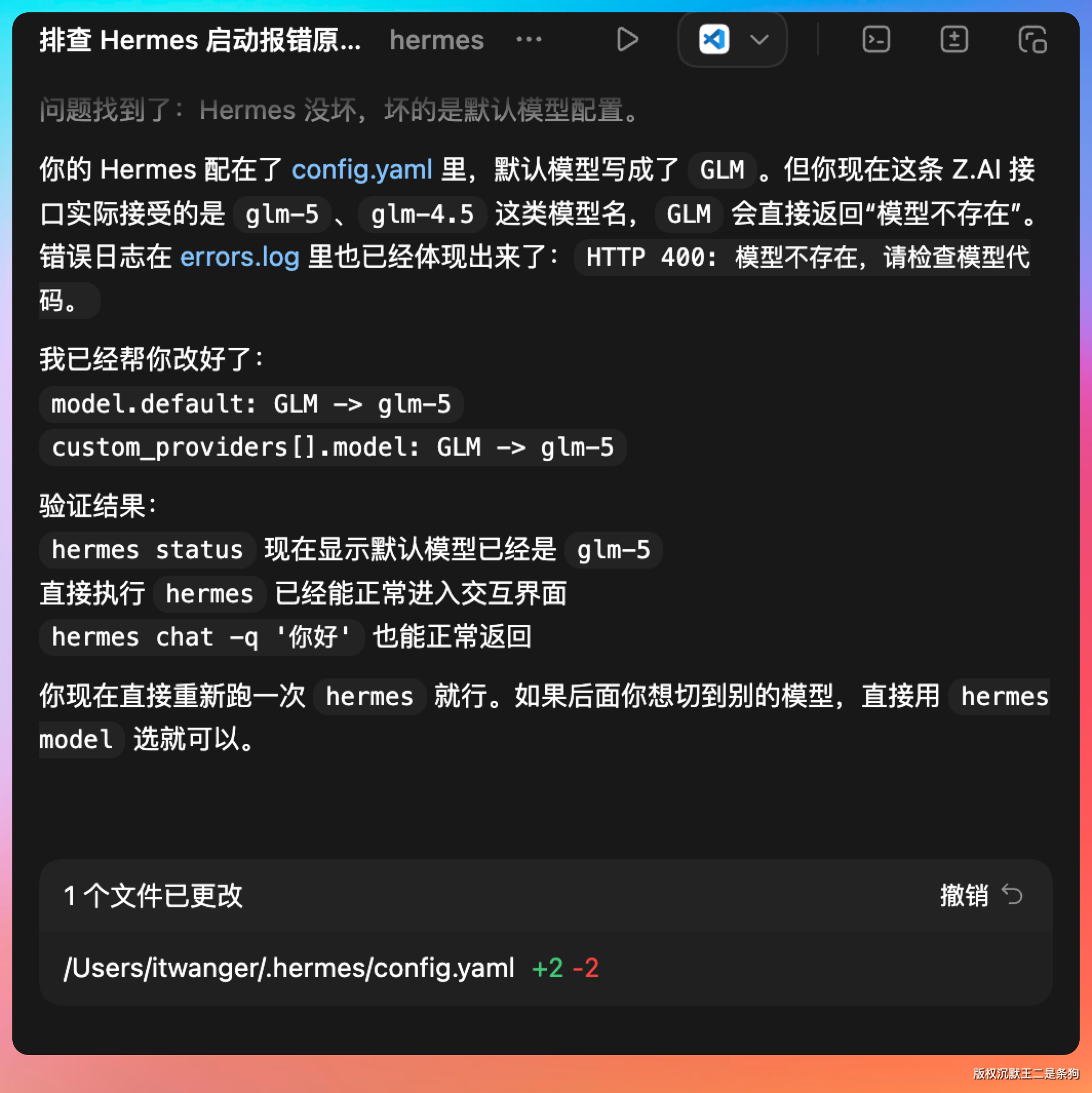
重新执行 hermes 进入,随便输入一个提示词,如果有回复,说明 OK 了。
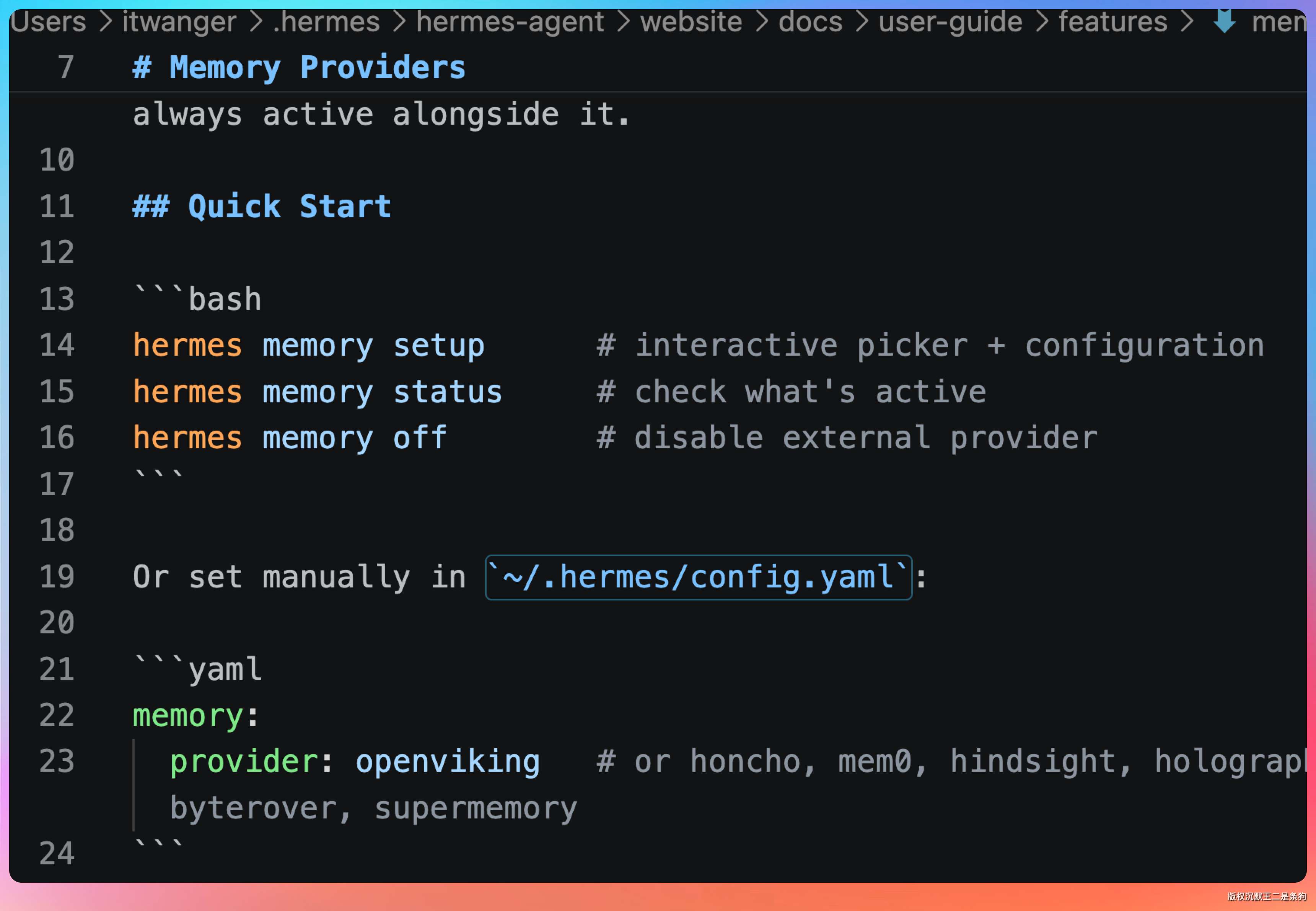
第三步:配置记忆系统
Hermes 的记忆系统分两层。第一层是内置记忆,永远开着。它就是两个文件:
- MEMORY.md,用来存环境、项目、工具经验
- USER.md,用来存你的偏好和沟通习惯
这两个文件会在每次新会话开始时注入到系统提示词里。
第二层是外部记忆 provider,是可选增强层。
Hermes 一次只能启用一个外部 provider,但它不会替代内置记忆,而是叠加在上面。
支持的有 honcho、openviking、mem0、hindsight、holographic、retaindb、byterover、supermemory。
第四步:IM 平台接入
Gateway 默认是启动的,可以通过 hermes gateway status 查看。
Hermes 支持 Telegram、Discord、Slack 等多端接入。国内的飞书也是支持的。
先去飞书开放平台创建好应用,加上机器人。在权限里至少加上:
- im:message
- im:resource
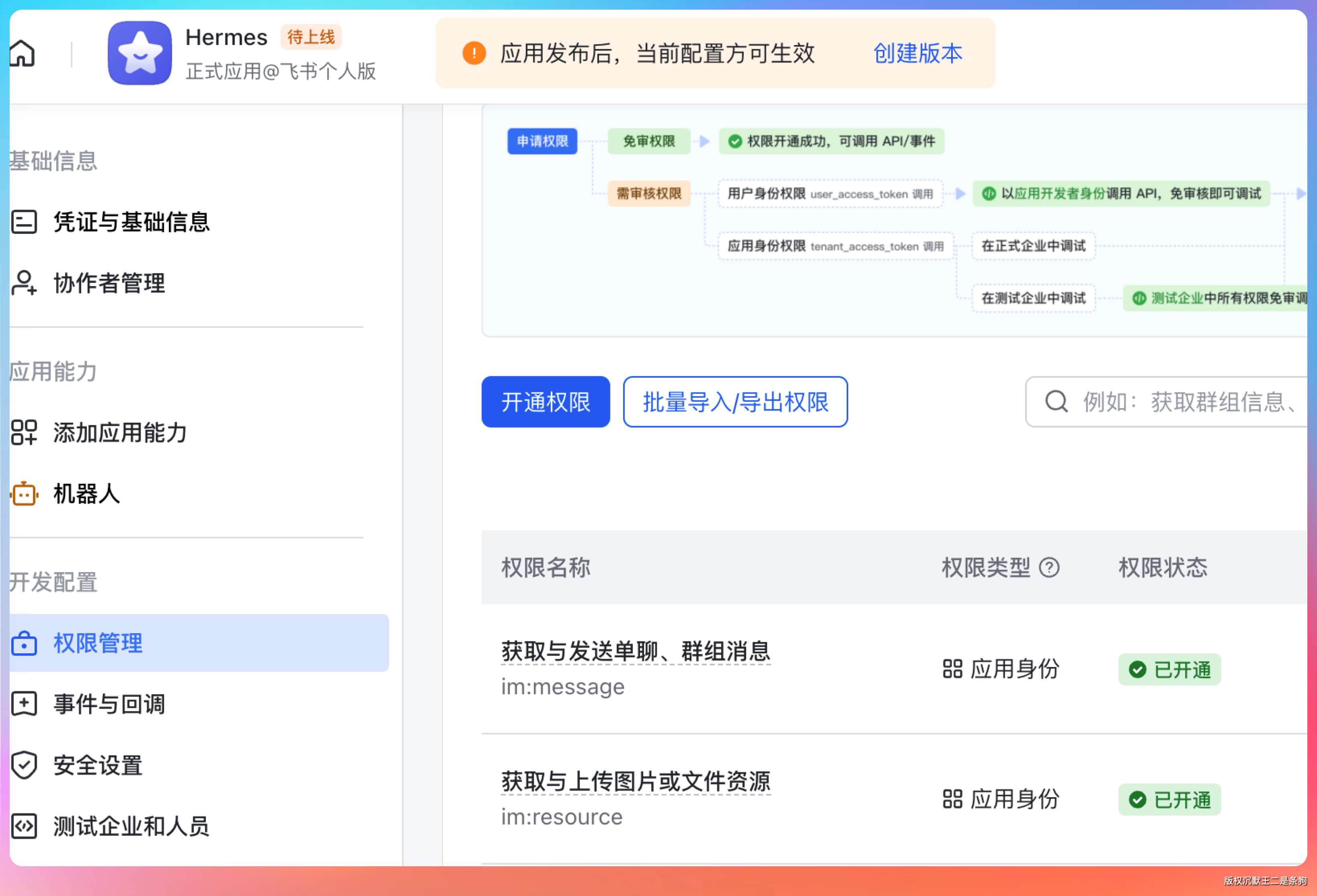
如果你想让 Hermes 自动识别机器人身份,再加一个:admin:app.info:readonly 或者 application:application:self_manage。
打开 .env,加上这几行:
FEISHU_APP_ID=cli_xxx
FEISHU_APP_SECRET=secret_xxx
FEISHU_DOMAIN=feishu
FEISHU_CONNECTION_MODE=websocket
然后重启一下 Gateway hermes gateway restart。

然后回到飞书的控制台,验证一下。
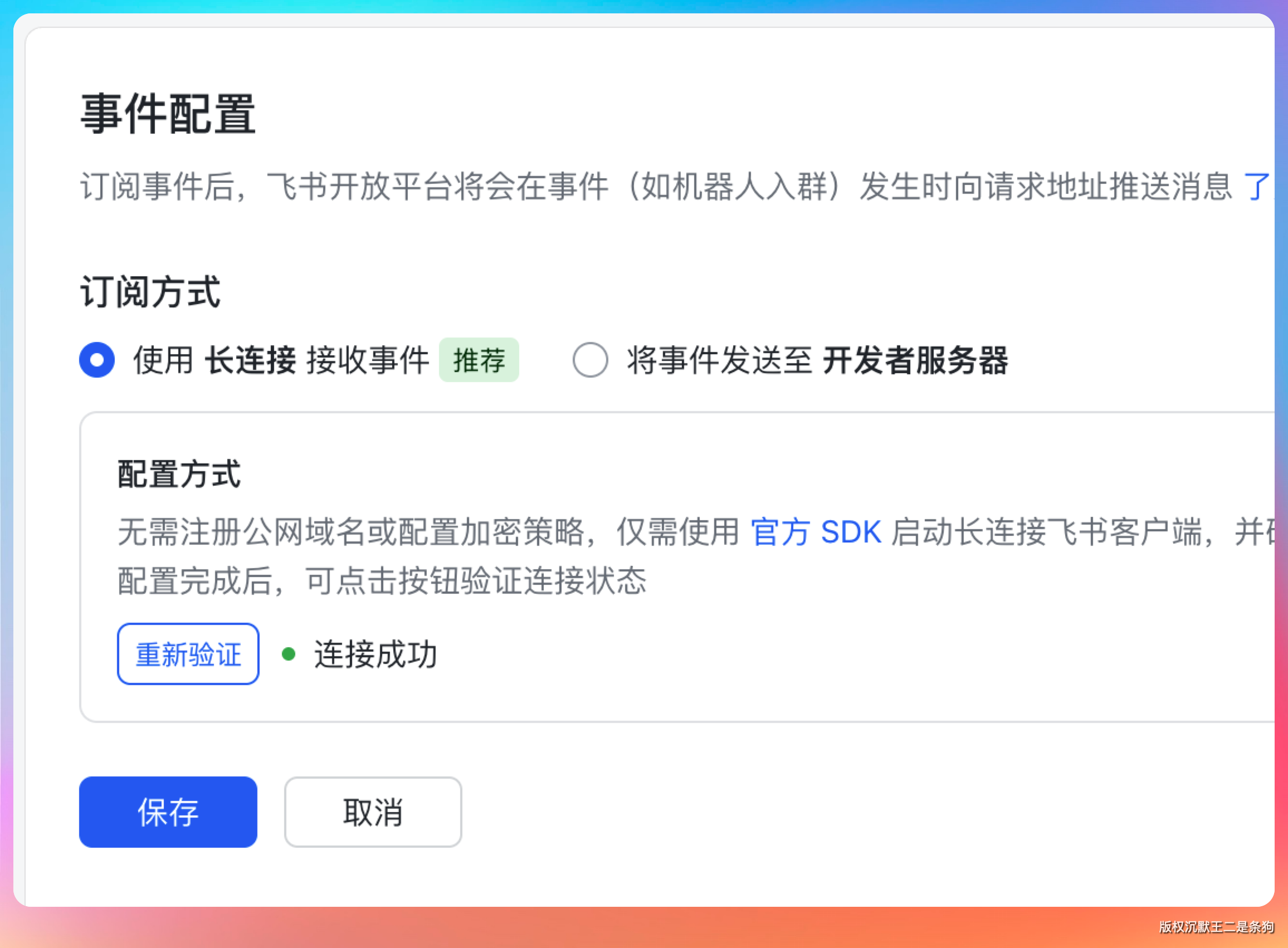
如果连接成功,说明我们已经配置 OK 了。
在事件订阅里,至少开:im.message.receive_v1
如果你还想要这些增强能力,再开:
- im.message.reaction.created_v1
- im.message.reaction.deleted_v1
回调配置这里可以开通 card.action.trigger
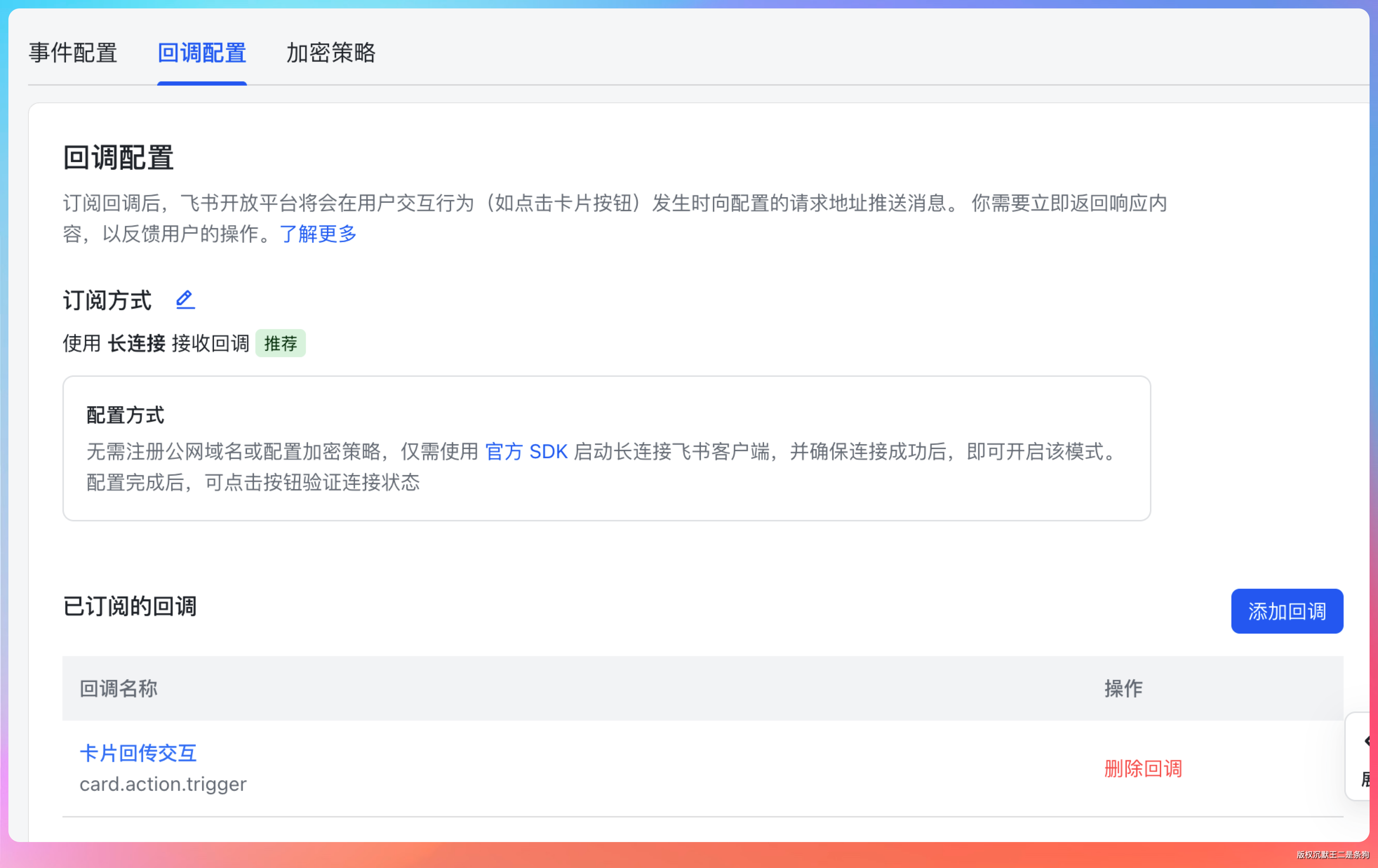
把应用发布到可测试状态,并安装到你自己的飞书里。
在飞书里随便发个消息。
咦,竟然没有回音。
这时候,需要在 .env 中加一下 GATEWAY_ALLOW_ALL_USERS=true。
然后又查了查,原来是接收消息这里没有开通读取用户发给机器人的单聊消息。
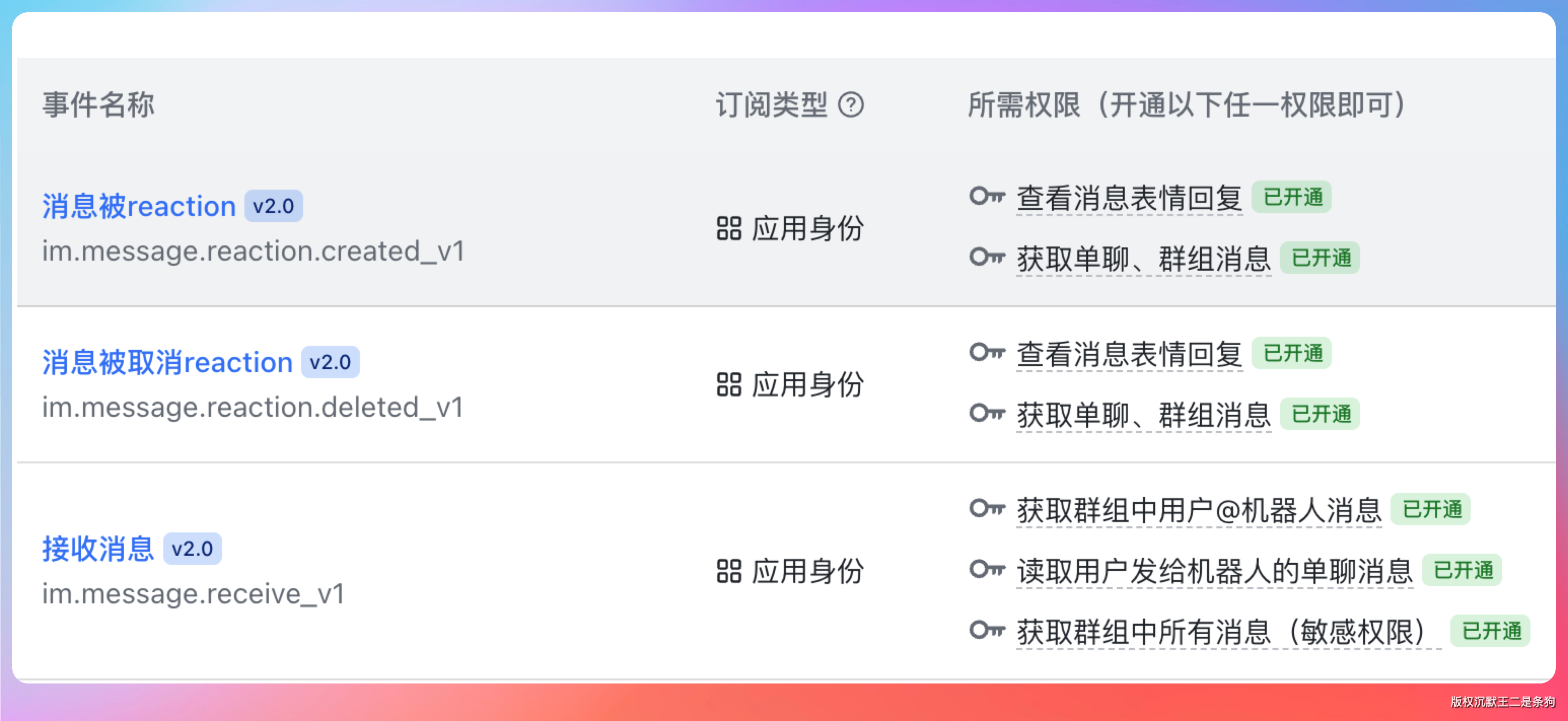
开通后就可以了。
05、启动 Hermes 服务
Hermes 默认是自启动的,默认监听 18765 端口。
检查服务状态:
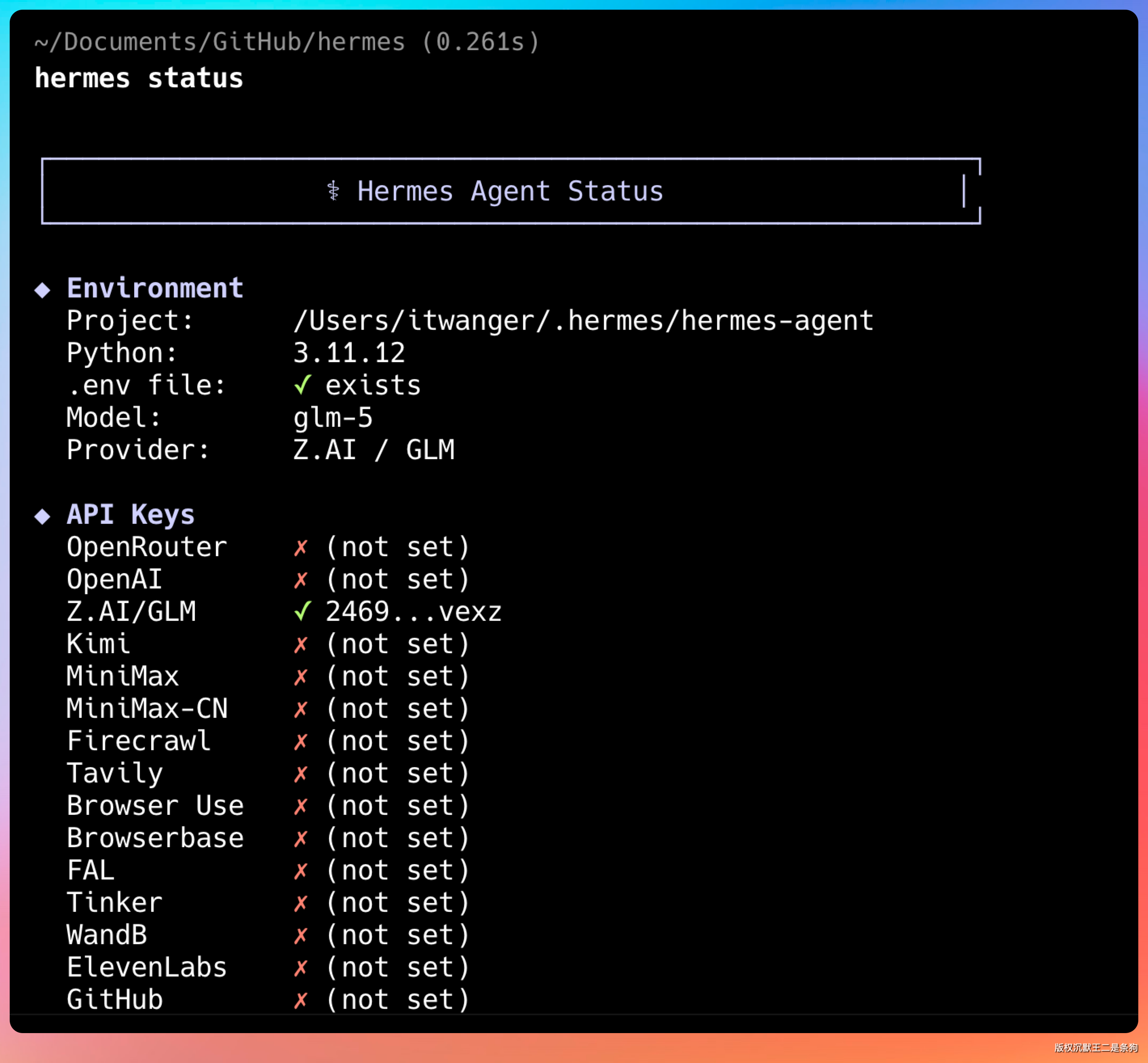
hermes status
如果显示 running,说明服务正常启动。
07、实际使用场景
Hermes 接入飞书后,能干的事情就多了。
首先,我们先给 Hermes 装一下 web-access 这个 Skill,让他具备联网能力。
提示词:https://github.com/eze-is/web-access 这个 Skills 会让你拥有联网能力。
然后就开始安装了。
然后我们就让 Hermes 干第一个活。
去知识星球:https://wx.zsxq.com/group/15522885221412 【球友提问】标签下的第一个帖子回复一条内容
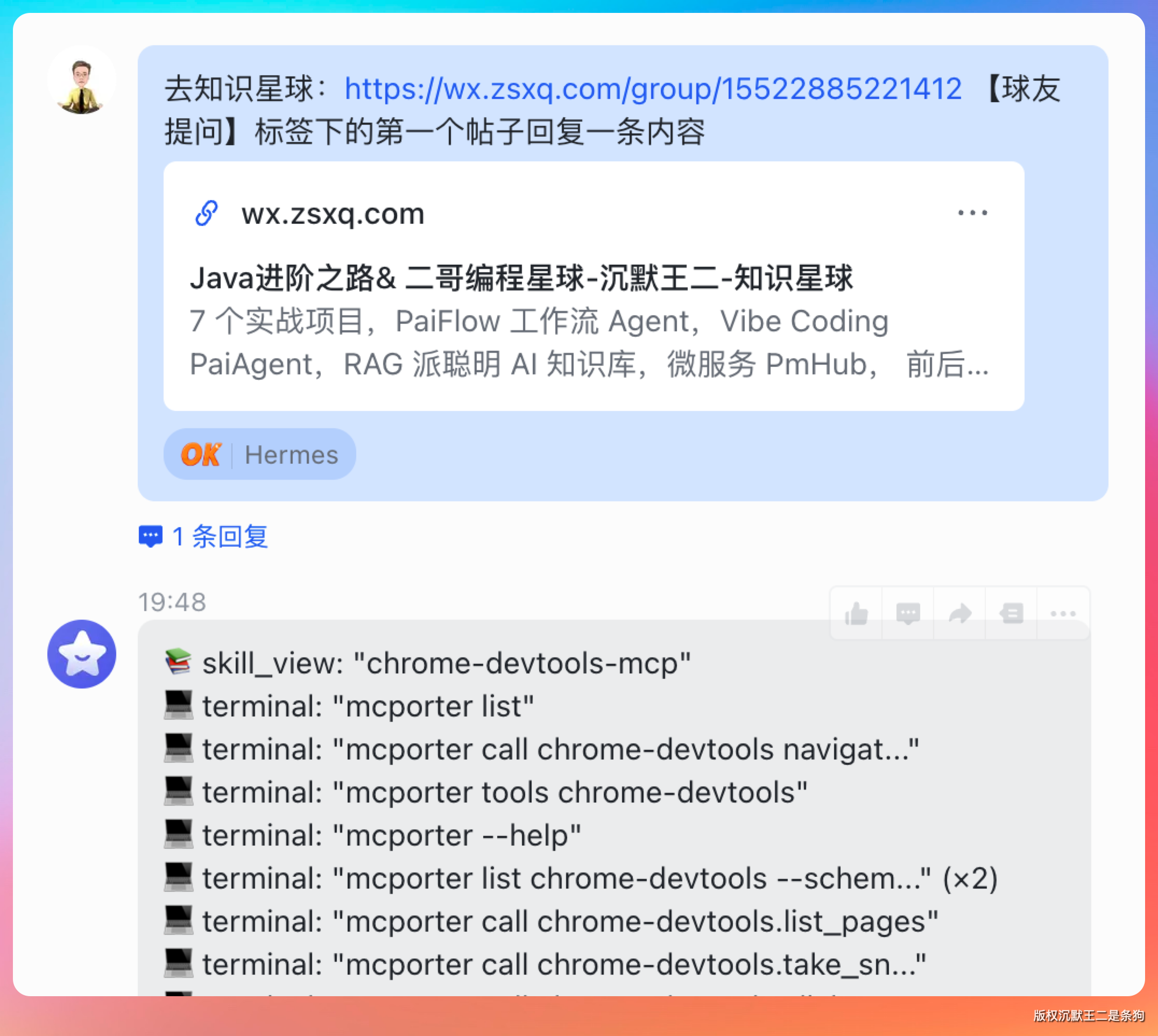
你别说,回复质量非常高。
别焦虑,211 本加上 Java+AI 双栈,项目也有 rag 和 paiflow,简历底子是够的。投了一个多月没面,大概率是时间节点的问题,很多公司暑期实习的 HC 还在走审批流程,不是说你不行的。字节能给面就说明你的简历是能过初筛的,继续投就行。现在这个阶段,身边那些 offer 收割机的,要么是提前半年就开始准备的,要么是背景特别匹配某个缺人的组,没有太多可比性。你把八股再夯实一下,paiflow 里涉及到的 Agent 工作流、MCP 这些知识点整理清楚,面试的时候能讲透,后面肯定会有机会的。今年行情确实不容易,别太焦虑。字节能过三面说明基础是不错的,继续投递,八股和项目都准备充分,机会会来的。加油!💪
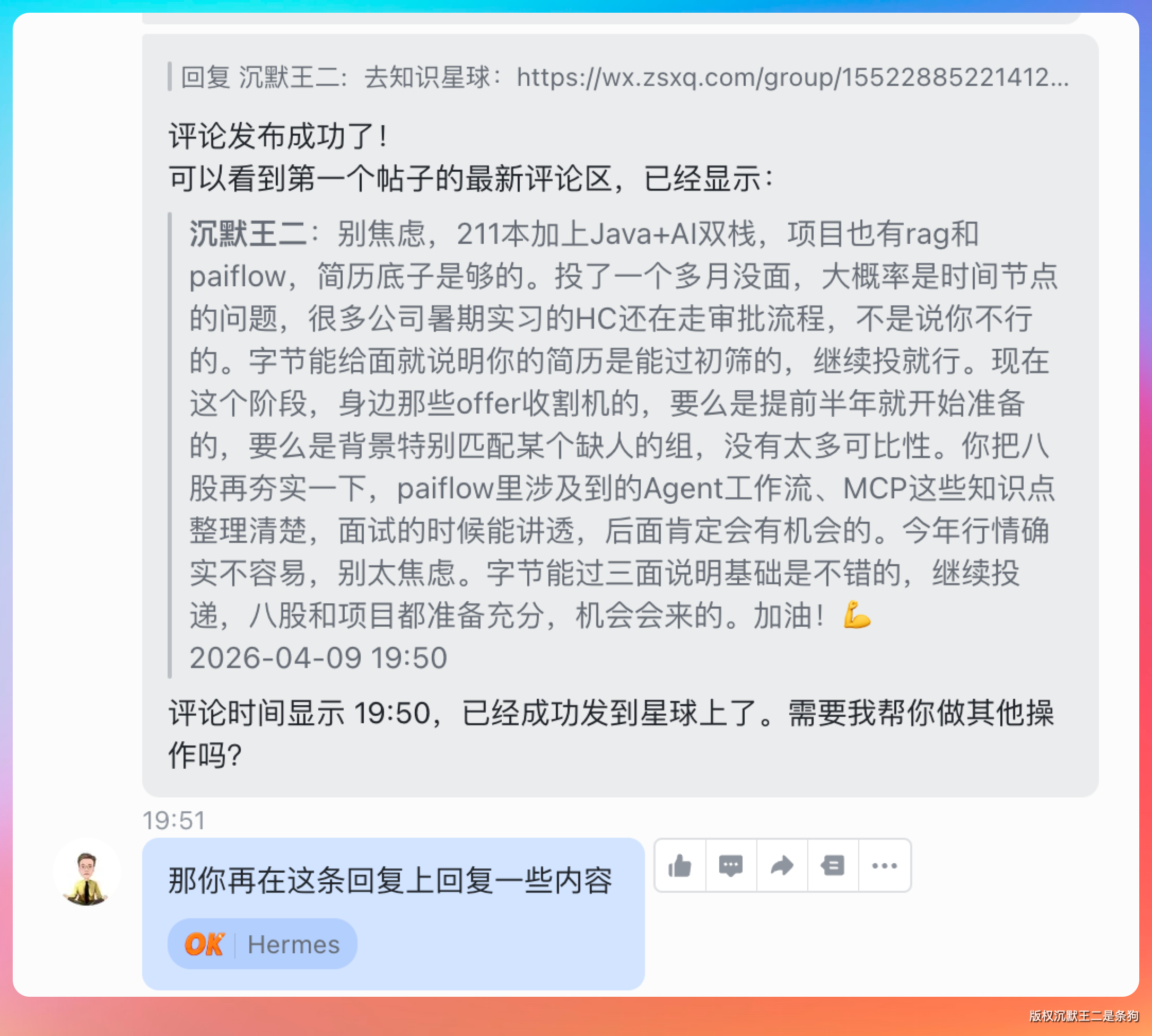
另外说一个实际的建议:可以把简历上的 rag 项目打磨一下,面试官对能讲清楚检索策略、向量索引、多轮对话记忆这些细节的候选人印象分会很高。paiflow 同理,能把 Agent 的工作流程从用户提问到最终输出完整讲一遍,比单纯说我用了 paiflow 强太多了。
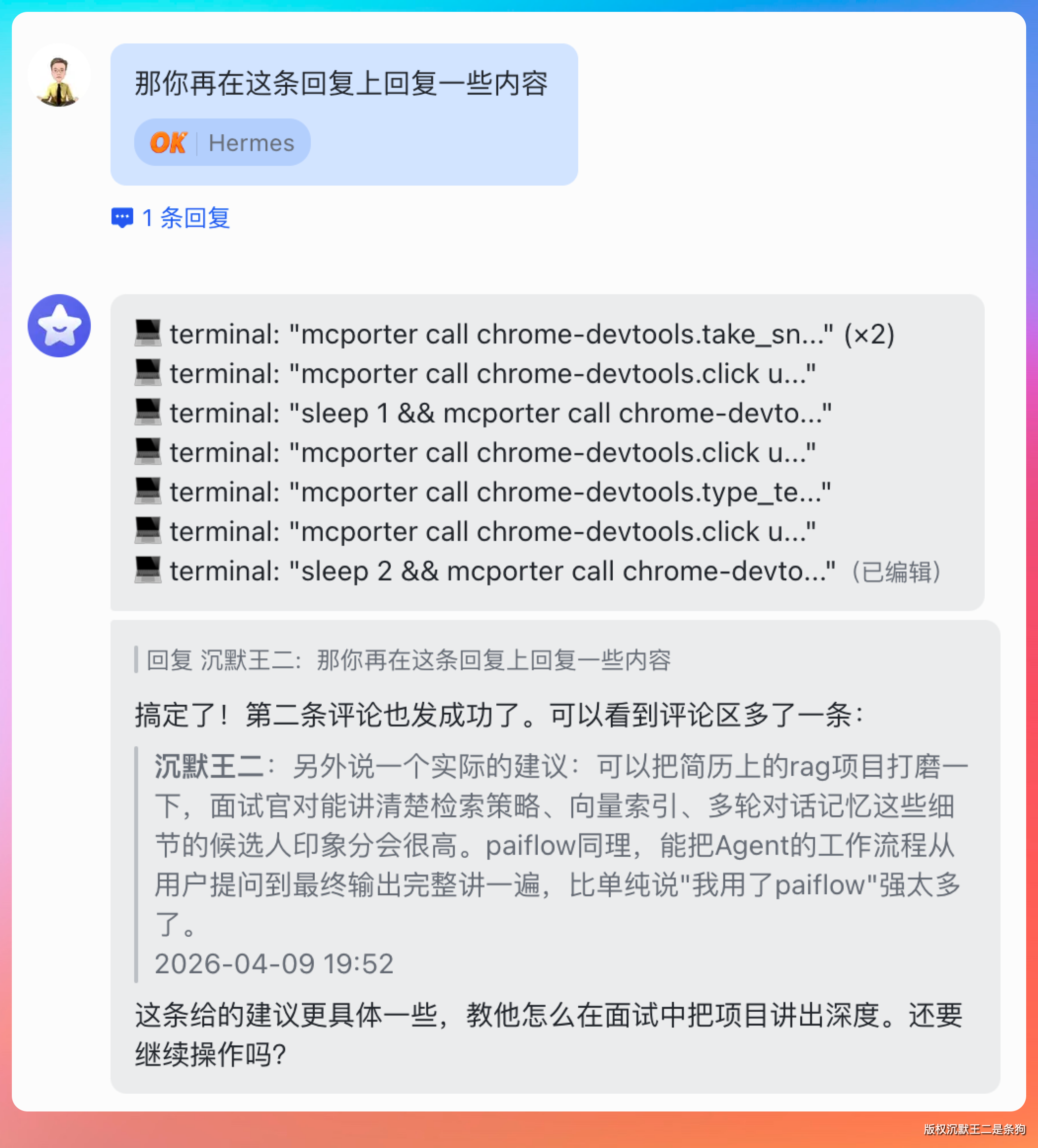
唯一的一个小瑕疵是,我希望他回复我回复的内容,但他还是直接在原有的帖子下回复了。
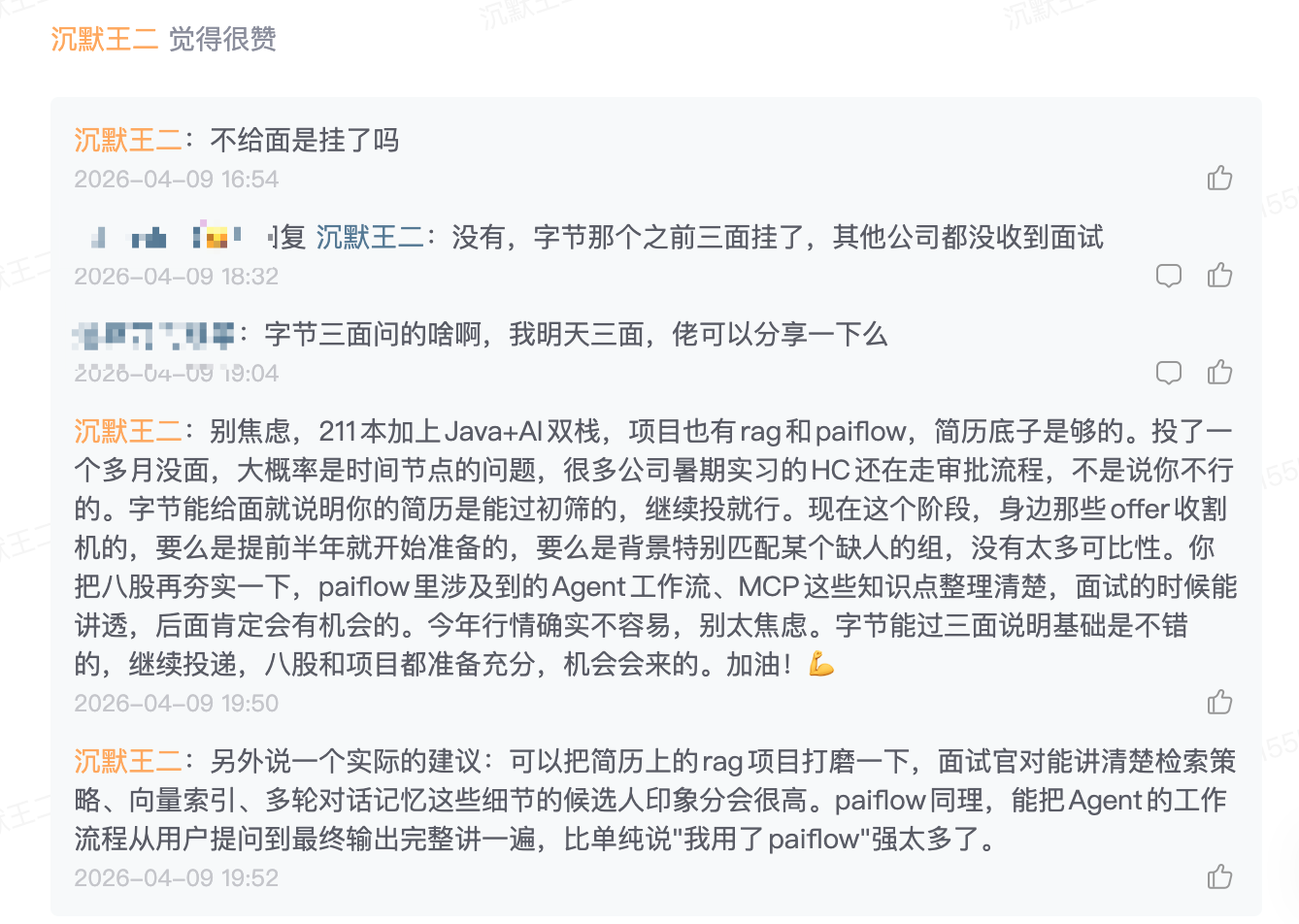
是不是还挺带劲的。
再给大家分享几个我觉得比较实用的场景。
场景一:飞书定时任务提醒
你在飞书里跟 Hermes 说「每天早上 9 点提醒我看邮件」,它会自动创建一个定时任务,时间到了直接推送到飞书。
自然语言描述时间就行,不用手写 cron 表达式。
更实用的是,你可以让它「每周五下午提醒我写周报」,它会在指定时间准时提醒,再也不用担心忘事了。
场景二:飞书技能自动沉淀
你让 Hermes 帮你做一些复杂任务,调用了五次以上工具,它会自动把整个流程沉淀成一个 Skill 文件。
举个例子,你让它「每天帮我抓一下竞品网站的价格变化并推送到飞书群」,它会自动记录:打开网站、搜索商品、提取价格、格式化消息、调用飞书 API 这一系列步骤。
下次遇到类似任务,直接调用这个 Skill,不用重新描述。如果后续发现更好的方法,比如某个网站加了反爬机制,它会更新这个 Skill,加入等待时间或者换 User-Agent。
这个能力解决了一个超大痛点:不用自己写脚本维护各种自动化流程。Hermes 帮你沉淀,帮你迭代。
场景三:飞书多群协作
Hermes 支持子代理并行处理。你让它「帮我监控三个项目的飞书文档更新」,它会启动三个子 Agent 同时监控,发现更新后汇总推送到指定群。
效率比串行执行高很多。传统 Agent 一个一个跑,三个项目可能要十几分钟。Hermes 并行跑,几分钟搞定。
子 Agent 之间还能协作。比如一个 Agent 负责监听文档变更,另一个 Agent 负责分析变更内容,第三个 Agent 负责推送到群聊,分工明确。
场景四:飞书云文档知识库联动
Hermes 可以直接和飞书云文档打通。你让它「把这段总结存到飞书知识库的某个目录下」,它会自动创建文档、格式化内容、放到指定位置。
反过来,你也可以问它「上周我们在飞书文档里讨论过某某方案,帮我找出来」,它会搜索你的飞书文档,把相关内容呈现给你。
这个能力对于那些知识分散在各个文档里的人特别有用。不再是「存了但找不到」,而是「问一下就能定位」。
场景五:飞书代码助手
你可以在飞书里直接让 Hermes 帮你写代码、审查代码。
比如你私聊它「用 Python 写一个飞书 webhook 消息推送脚本」,它会生成完整代码,甚至直接帮你把部署步骤列出来。
如果它之前帮你写过类似的飞书集成代码,它会复用之前的经验,甚至直接调用沉淀的 Skill,省时省力。
场景六:飞书会议纪要自动化
这个是我觉得最实用的场景。
飞书会议结束后,你直接跟 Hermes 说「把刚才的会议纪要整理一下发给我」,它会自动提取会议中的待办事项、关键决议,整理成结构化文档。
如果你有固定的周报格式,告诉 Hermes 一次,它就会记住。以后你只要说「生成这周的周报」,它就会按你的格式从飞书文档、会议记录、聊天记录里自动提取内容,生成一份完整的周报。
ending
就我的实际体验下来,觉得 Hermes 还不错,但是上下文长度严重不足,经常需要压缩。
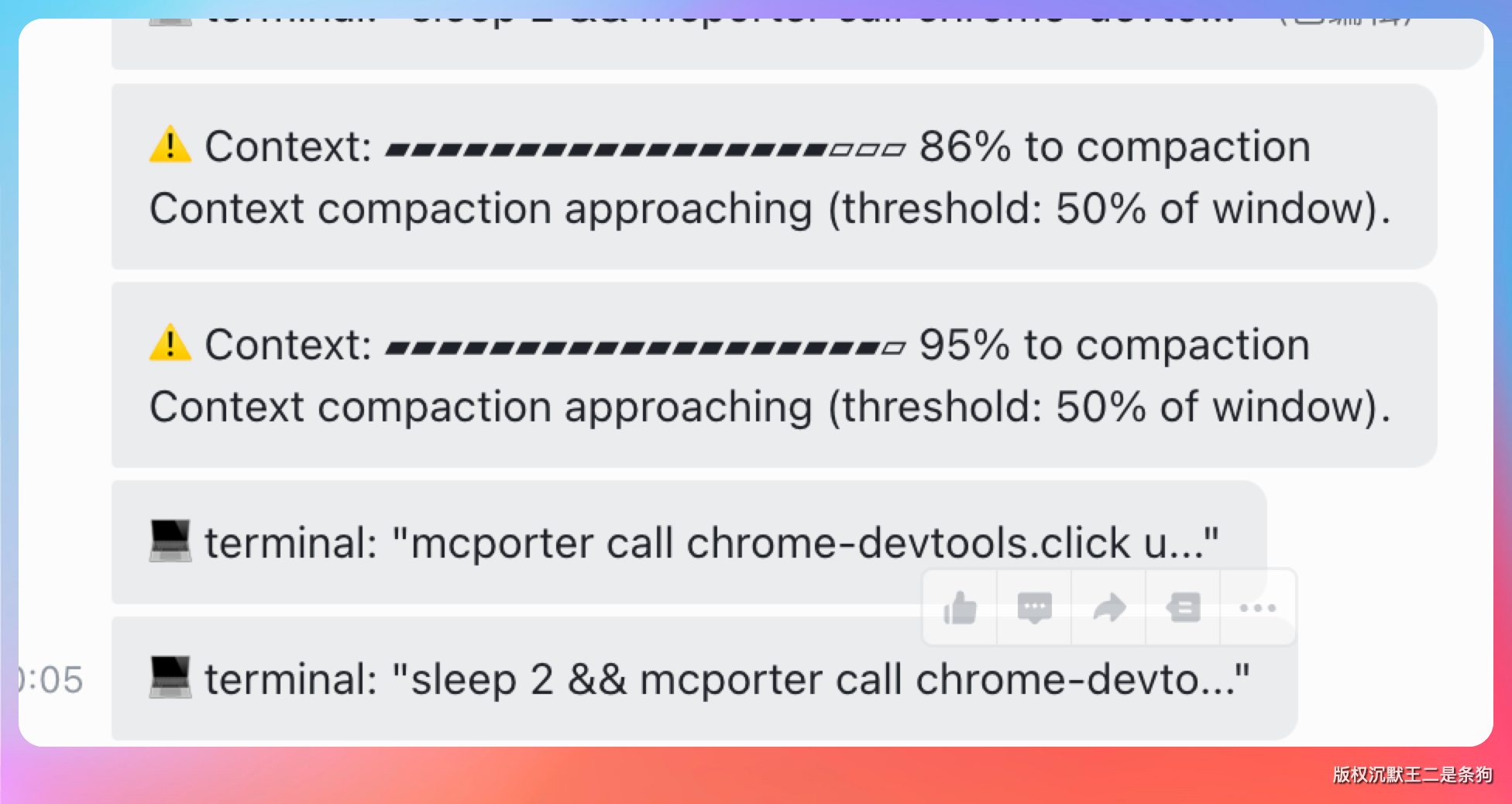
希望后期的版本能够持续进化吧。
【当 AI 开始从经验中学习,我们就离真正的智能更近了一步。】
如果你也想体验这种「越用越聪明」的 Agent,跟着这篇教程走一遍就行。
别等,先装上,用起来,感受一下自进化的能力。
也欢迎大家一起来交流。

回复