


过去一周我做了一件事:把 shanraisshan/claude-code-best-practice 这个仓库从头翻到尾。
说实话,中间差点放弃。
这个项目在写这篇文章的时候,已经是 34.9k Star、3.3k Fork。README 里光 Beta 功能就列了 16 个。
还收录了 10 套主流开发工作流、152 个 subagent、194 个命令、352 个 skill。
再加上 69 条精选 tips,信息量大得吓人。
01、34.9k Star 背后的内容密度
一个开源项目能有这么多 star,本身就说明了 Claude Code 工程化这件事的需求有多刚。
整个 README 的结构大致分成四块。
CONCEPTS基础概念Hot前沿 Beta 功能DEVELOPMENT WORKFLOWS开发工作流横评- 然后是
tips、implementation、tutorial几个细分目录
粗略盘点一下,有 152 个 subagent、194 个斜杠命令、352 个 skill。
根目录下就有一个现成的 .claude/ 文件夹。agents、commands、skills 的配置,全都是可以直接 copy 的。

这一点对我这种懒人特别友好。
02、10 套工作流
这个仓库最有价值的部分,我觉得是 development-workflows 目录。作者把社区里最火的 10 套 Claude Code 工作流全部收集了一遍。
每套都拆成 agent、command、skill 三个维度做了统计。
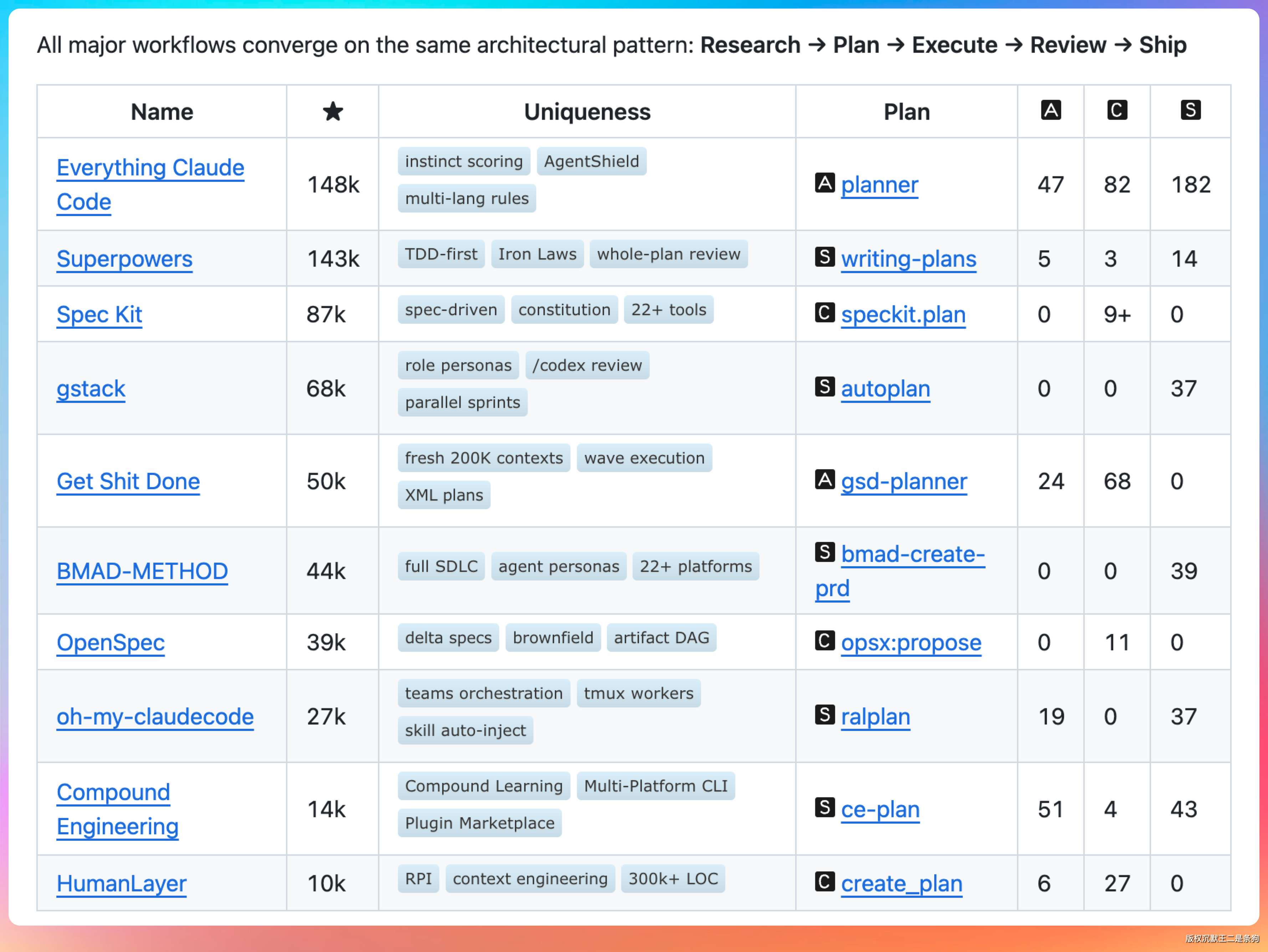
Everything Claude Code 排第一。148k Star。47 个 agent、82 个 command、182 个 skill。
走的是「我全都要」路线。
紧随其后的是 Superpowers。143k Star。反而极简。5 个 agent、3 个 command、14 个 skill。核心理念是 TDD-first 和所谓的 Iron Laws。简单来说,就是「测试没写完不准写实现」。是规则驱动派。
Spec Kit 87k Star。走的是 spec-driven constitution-based 路线。先写规格文档,再写代码。适合对一致性要求高的团队。
gstack 68k Star。主打 role personas 和 parallel sprints。给 Claude 分配「产品经理」「架构师」「前端开发」这种角色。让它在不同角色之间切换。
03、16 个 Beta 功能实测
然后是这个仓库最让我上头的一部分,Hot 栏目。

这里整理了 Claude Code 当前所有处于 Beta 阶段的功能。总共 16 个。
封神三件套:Auto Mode、Git Worktrees、Agent Teams。
实用但有门槛:Claude Code Web、Scheduled Tasks、Agent SDK。
鸡肋:Voice Dictation、Computer Use。
Computer Use 让 Claude 控制我们的屏幕,自动开应用、点按钮、打字、截图。理念很炫酷。实际体验下来非常尴尬。Claude 的操作比人慢五倍。而且一旦界面稍微变化就迷路。
离日常生产力还有距离。
04、Auto Mode+Worktrees
Auto Mode。用过 Claude Code 的小伙伴都懂。每执行一个命令,都要点「同意/取消」。每写一个文件,都要确认。一段长任务下来,光点按钮就能让手指抽筋。

这种设计初衷是安全。但体验上确实反人类。
尤其是在 agent 模式下跑长任务。中间弹出十几次确认框,和手动干活没啥区别。
Auto Mode 的做法,是引入一个安全分类器。它会实时判断每个动作的风险等级。
低风险动作,比如读文件、跑测试、改业务代码,直接放行。高风险动作,比如删文件、改 CI 配置、推远程仓库,才弹框确认。
然后是 Git Worktrees。
这个功能严格来说不算新东西。Git 本身支持 worktree 很多年了。但 Claude Code 把它集成进来之后,完全是另一回事。
场景是这样的。我经常同时改两个相关但独立的 feature。 传统做法是,一个 feature 做完,切分支到另一个 feature。中间要 stash、commit、pull。非常打断心流。
而且很多时候,Claude 正在分支 A 上跑长任务。我又想在分支 B 上做点小修改。这两件事会互相阻塞。
Git Worktrees 让我可以在一个仓库下,同时存在多个工作副本。每个副本对应一个独立的分支。互不干扰。
更爽的是,仓库里给了一套配套脚本。能让多个 Claude 实例分别在不同 worktree 里干活。
也就是说,我们可以让 Claude A 在 feature-login 分支上写认证逻辑。同时让 Claude B 在 feature-notification 分支上写通知模块。
两个进程并行。最后各自出 PR。
05、Agent Teams
第三个封神功能是 Agent Teams。
这个功能,是让多个 agent 在同一个代码库上并行协作。 自带任务协调机制。听起来和我们平时说的 multi-agent 差不多。
仓库里的 agent-teams 目录,给了完整的编排范例。 核心思路是把一个大任务拆解成一个 DAG,也就是有向无环图。
每个节点分配给一个专职 agent。节点之间用文件系统作为消息总线。比如做一个完整的功能,编排大致是这样:
需求分析 agent -> 架构设计 agent -> [前端 agent + 后端 agent + 数据库 agent] -> 集成测试 agent -> 文档生成 agent
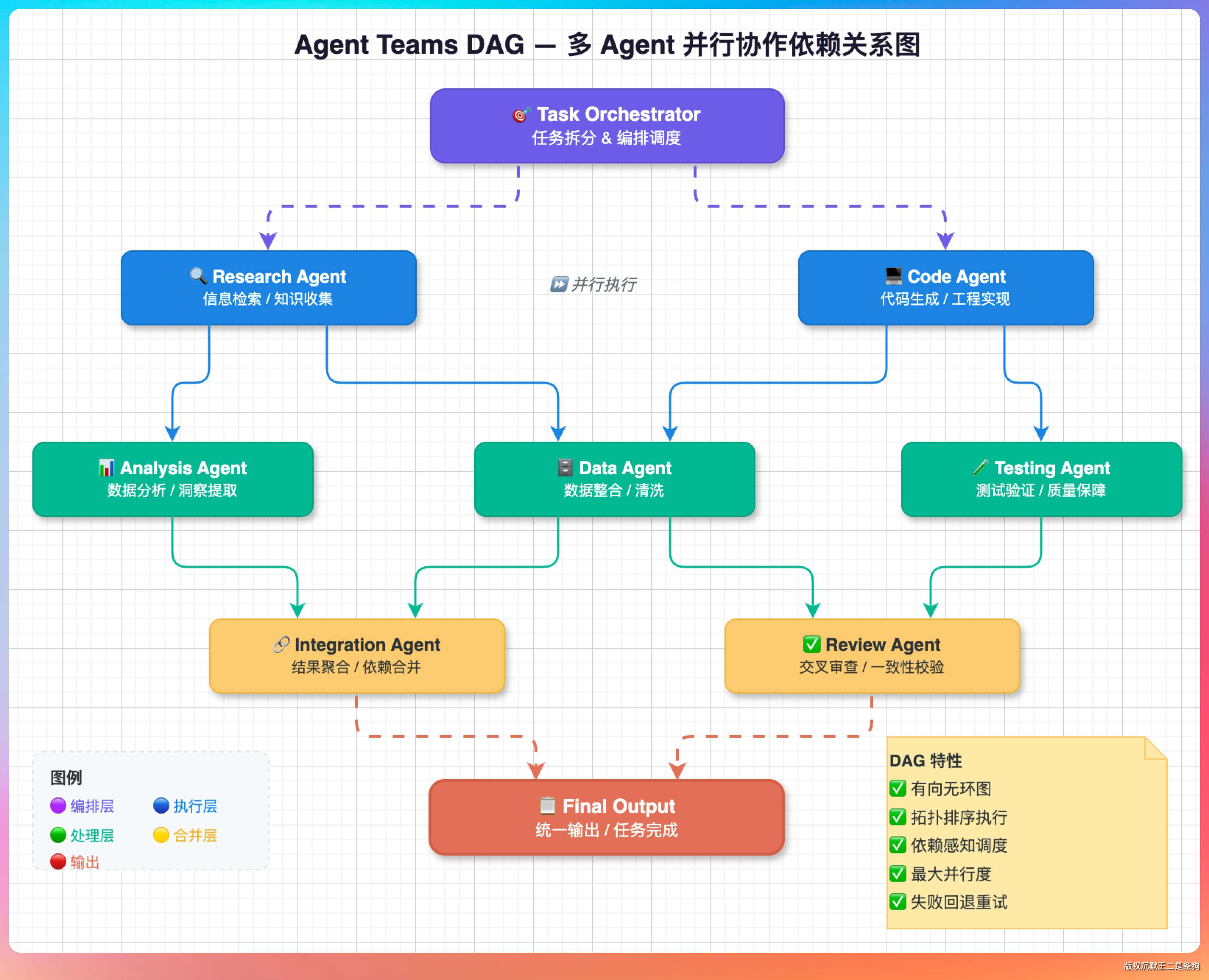
每个 agent 都有自己独立的上下文窗口。专注做自己那一块事情。互不干扰。
这个仓库里整理的 152 个 subagent 配置,很多都是这种专职 agent 的定义文件。照着搬,基本能少走半年弯路。
有一点要提醒大家。
Agent Teams 对上下文 token 的消耗是线性增长的。 5 个 agent 并行,基本就是 5 倍消耗。
06、69 条 tips 里最颠覆认知的 5 条
最后聊聊 tips 目录。作者在这里整理了 69 条精选 tips,分成 13 个类别。我挑 4 条自己印象最深的,分享给大家。
第一个是 CLAUDE.md 尽量小于200行
在项目根目录放一个 CLAUDE.md 文件,Claude Code 会自动读取并记住里面的内容。
这是什么概念?
以前你每次打开 Claude Code,都要手动交代:「这是一个 Spring Boot 项目,使用 MyBatis 作为 ORM 框架,代码规范要求驼峰命名,测试用 JUnit 5……」
现在把这些全部写进 CLAUDE.md,Claude Code 一上来就知道项目的整体架构、技术栈、编码规范、测试要求。不需要每次都重新介绍,它会像记住老朋友的喜好一样,记住你项目的「性格」。
当然了,你不需要手动编辑这个文件,只需要执行 /init 命令即可。
一个好的 CLAUDE.md 应该包含哪些内容?
项目概述:一句话描述项目是做什么的,核心功能是什么,目标用户是谁。
技术栈清单:前端用什么框架,后端用什么语言,数据库选哪个,中间件有哪些。让 Claude 对技术边界有清晰认知。
代码规范:命名约定、目录结构、注释要求、异常处理方式。这些细节决定了生成代码的质量。
测试策略:单元测试用什么框架,覆盖率要求多少,集成测试怎么跑。Claude 写代码时会自动考虑可测试性。
常见陷阱:项目里有哪些容易踩的坑,比如某个第三方库的版本兼容问题,某个配置项的默认值不符合预期。
第二条是必须 squash merge
很多团队爱用 merge commit 保留完整历史。
作者的论点是:个人分支上的中间 commit,对主分支没意义。
squash 之后,主分支的 git log 每一条都对应一个可回滚的业务单元。远比一堆 WIP commit 有价值。
第三条是小时级提交。
作者要求一旦某个小任务完成,立刻提交。不要攒到晚上一起。
第四条是 skill 的 description 要写成「触发器」,而不是「摘要」。
这条非常反直觉。
我以前写 skill 的 description,都是「这个 skill 是用来做 X 的」。
作者说,正确的写法是「什么时候应该触发这个 skill」。 比如「当用户提到生成 README 时,使用此 skill」。
原因是 Claude Code 在决定是否调用某个 skill 时,匹配的是触发条件,而不是功能描述。 换了写法之后,我的自定义 skill 命中率从不到 50% 提升到了 90% 以上。
ending
以前我以为,用好 Claude Code 的关键是提示词写得好。
现在我知道,真正的关键是工程化。
- 写好的 CLAUDE.md。
- 合适的 skill 触发器。
- worktree 里的并行分身。
- 配合 Auto Mode 放手让它跑。
【工具的上限,从来不是工具本身决定的。】
很多人用 Claude Code 一个月,就觉得「不过如此」。 换个模型,还是「差不多」。
但真正用好它的人,会花时间打磨自己的工作流。 把重复的事情封装成 skill。 把危险的事情交给 hook。 把并行的任务交给 worktree。 把编排的事情交给 agent team。

回复