


大家好,我是二哥呀。
看到朋友 why 发表的一篇内容特别有意思,关于暗水印的,在职的小伙伴截图的时候一定要注意注意注意。
尽量不要发原图。
可以适当进行一些处理。
比如说用手机拍摄,然后转成单帧 GIF;截图给 AI,写个 HTML 页面复刻截图的内容,然后再截图 HTML。
那暗水印到底什么?
暗水印的工作原理是什么?
转成单帧 GIF 和 HTML 页面复刻截图内容为什么能去掉暗水印?
相信很多小伙伴都很好奇,包括我自己在内,也想一探究竟,那这篇我们就从面试的角度来盘一盘。同时,我也收集了一些网易的 AI 应用开发面经,附带答案一并分享给大家。
(全文比较肝,保证大家能学到很多,系好安全带,我们粗粗粗发了~)
content
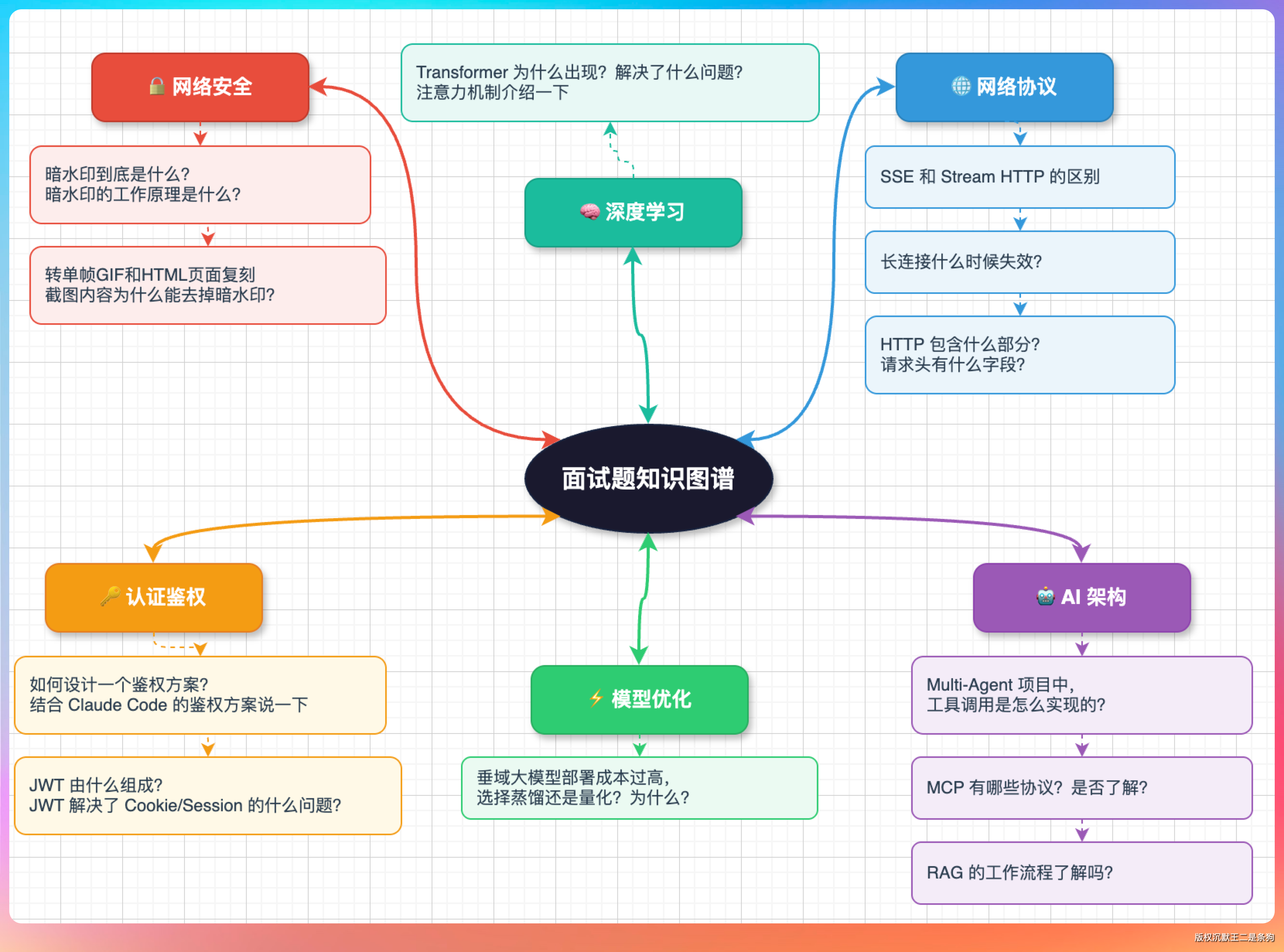
01、暗水印到底是什么?
老王的第一问就挺开门见山:“你知道暗水印吗?”
我回答:“暗水印,说白了就是在图片里藏一段人眼看不见的信息。”
“主要是为了截图溯源——在内部系统的页面(聊天工具)里给每个员工嵌入一个独一无二的标识,泄露了一查一个准。”
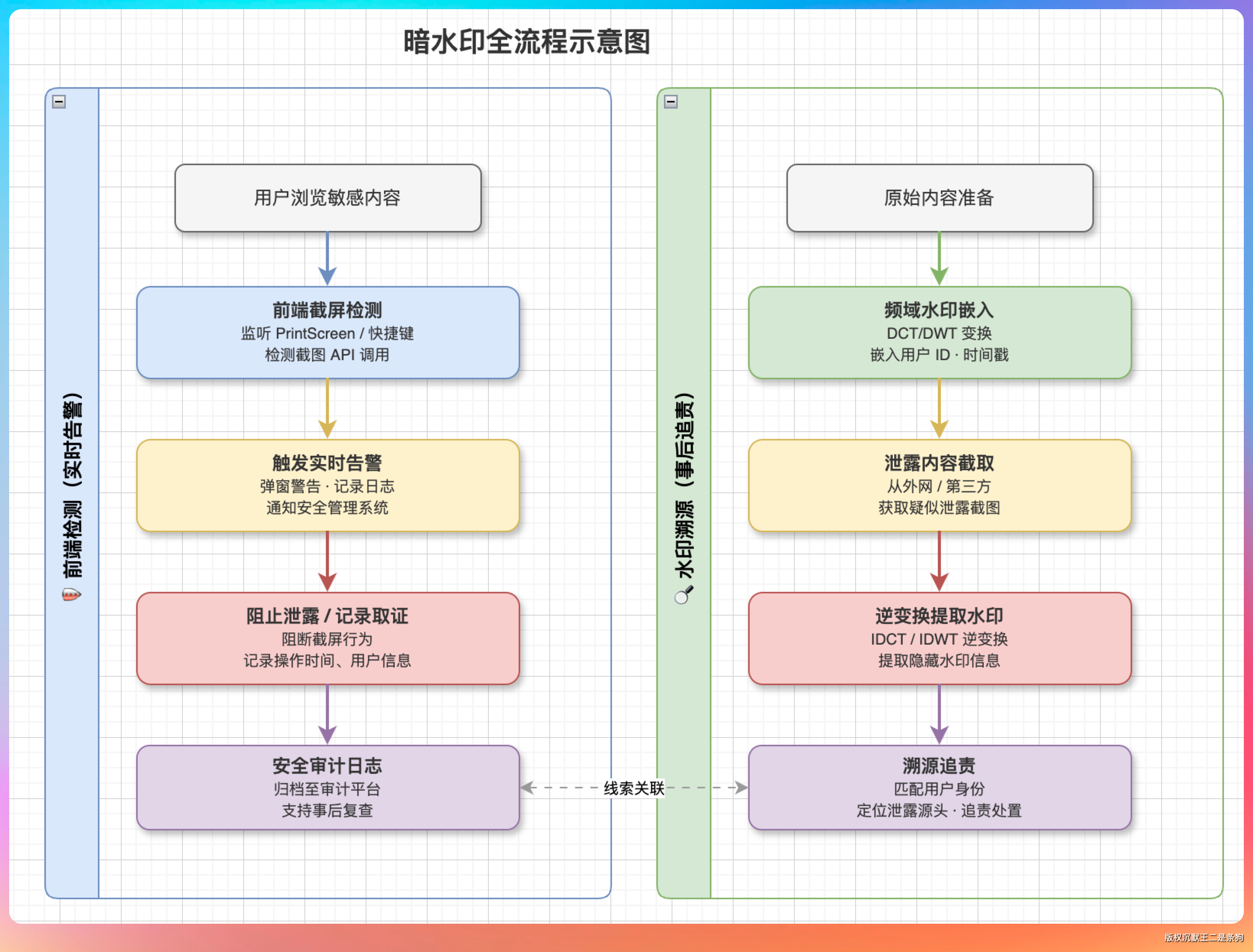
老王追问:“那老板是怎么知道有人截图了?”
“第一实时发现截图动作。企业内部系统可能会在前端检测截屏行为。一旦检测到截图动作,前端立刻上报给后端,后端直接通知管理员。”
“当然,如果不试用内部软件截图,用手机拍照,就检测不到。”
“第二是事后溯源。某个员工截了图,发到微信群、朋友圈、或者脉脉上。被舆情监控系统抓到了。安全部门拿到这张泄露的截图后,用对应的解码算法做逆变换——把图片做 DCT 或 DWT 变换,从频率系数中提取出嵌入的信息,解码出员工 ID。整个过程跟加密解密类似,有密钥才能提取。提取完一比对,谁截的图一目了然。”
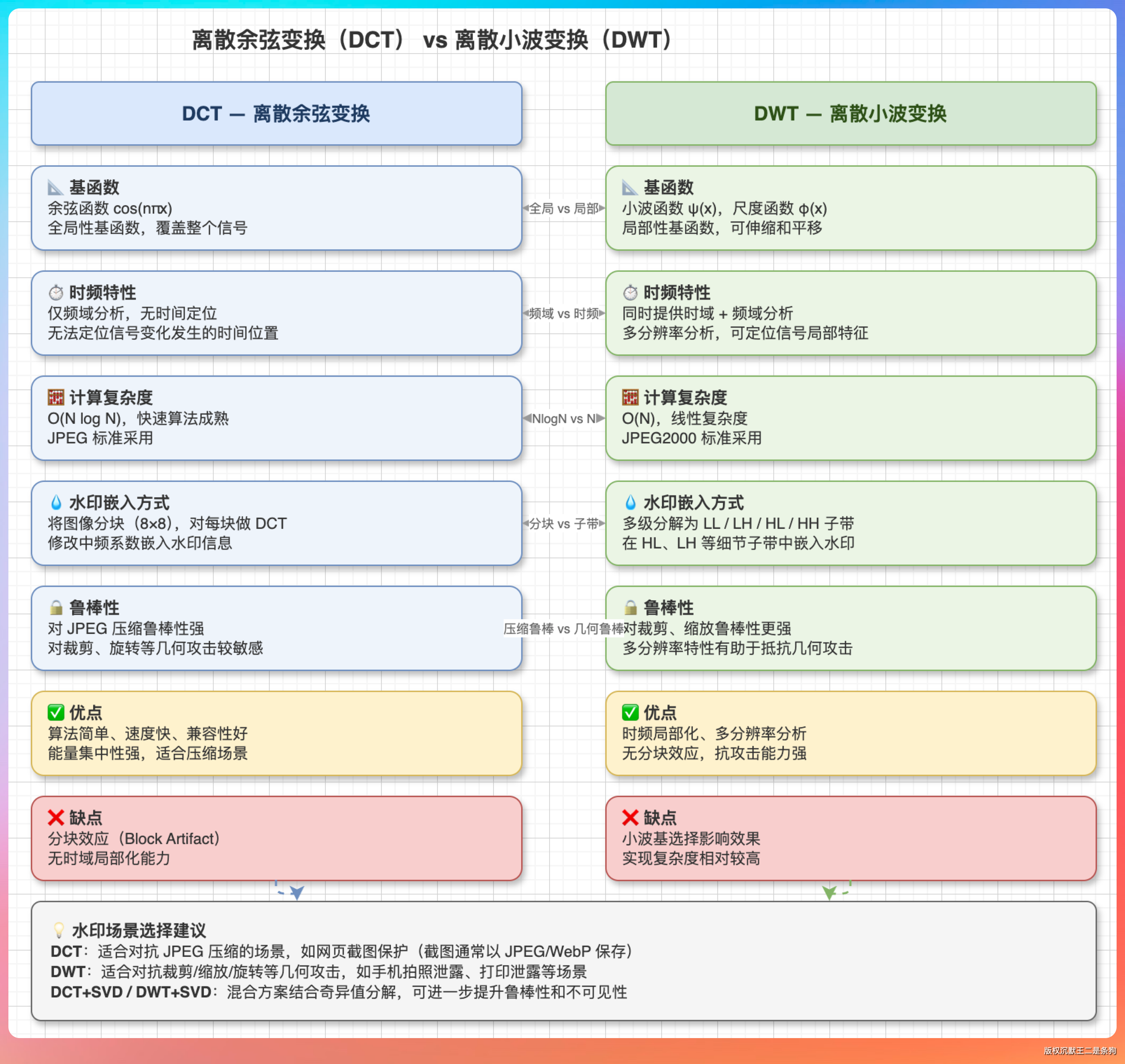
老王点点头:“暗水印的原理了解不?”
最经典的是基于频域变换的方法,比如离散余弦变换 DCT、离散小波变换 DWT。
原理是把图像从空间域转换到频域,在中频系数里嵌入水印信息。
因为低频承载了图像的主要视觉内容,改动会被肉眼察觉;高频容易在压缩、缩放等操作中丢失;中频既不影响视觉效果,又有一定的抗攻击能力。
还有一类是基于最低有效位 LSB 的方法。每个像素的 RGB 值最低位对视觉影响几乎为零,把水印信息编码进最低位,肉眼完全看不出来。但这种方法稍微压缩一下就没了。
“打个比方,LSB 就像在纸上用铅笔写了一行沉默王二是沙茶,橡皮一擦就没了。频域水印更像是往一杯水里滴了几滴墨,你没办法把墨从水里分出来。”
02、转成单帧 GIF 和 HTML 复刻为什么能去掉暗水印?
老王紧跟着追问:“转成单帧 GIF 和 HTML 复刻为什么能去掉暗水印?”
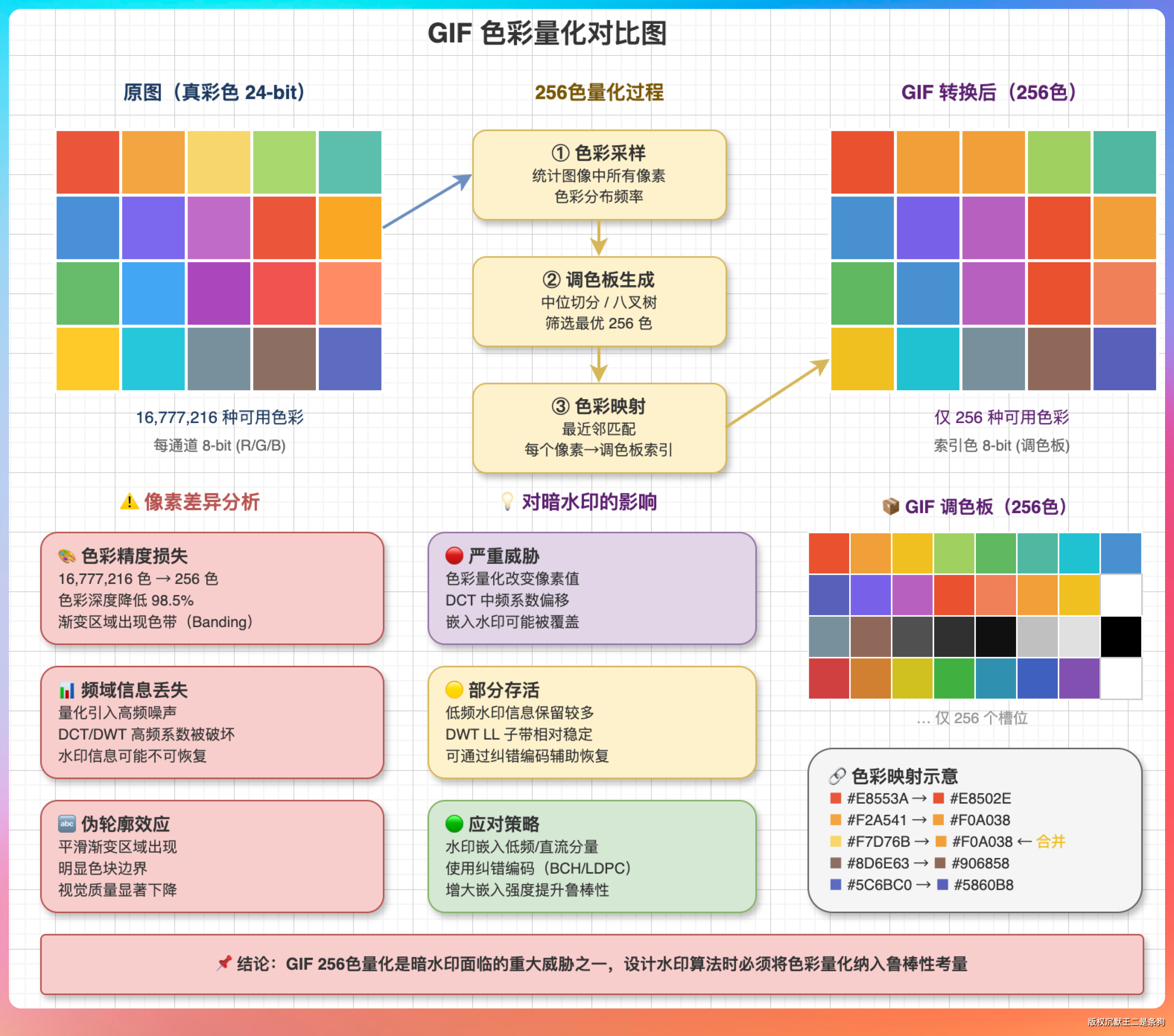
“先说 GIF。GIF 格式有一个致命限制——只支持 256 色。原始截图是 24 位真彩色,大概 1677 万种颜色。转成 GIF 的时候,系统必须把这 1677 万种颜色压缩到 256 种颜色。”

“这个过程叫色彩量化。频域水印之所以看不见,就是因为它修改的是频率系数的差异。色彩量化直接把这些差异给干掉了,水印自然就废了。”
老王若有所思:“那 HTML 复刻呢?”
我说:“HTML 复刻就更暴力了,压根不碰原图。”
“暗水印检测的前提是原始像素数据必须存在。不管算法多精妙,检测端总要拿到图像的像素矩阵或者字符流,然后在这些数据里查找水印特征。但 HTML 复刻把图像内容重新用 HTML/CSS 的方式描述了一遍,生成了一个看起来和原图一模一样、但底层完全不一样的新东西。”
“相当于赝品,跟真品里的暗水印没关系了。”
老王拍了一下桌子:“行,这块搞得挺清楚。换个方向问,SSE 和 Streamable HTTP 的区别知道吗?”
03、SSE 和 Streamable HTTP 有什么区别?
“SSE 是一一种服务端向客户端推送数据的机制。它的核心是长连接——客户端发一个 HTTP 请求,服务端保持住这个连接且不关闭,持续往客户端推送数据。数据格式用 data: 前缀,\n\n 分隔。浏览器用 EventSource API 来接收。”
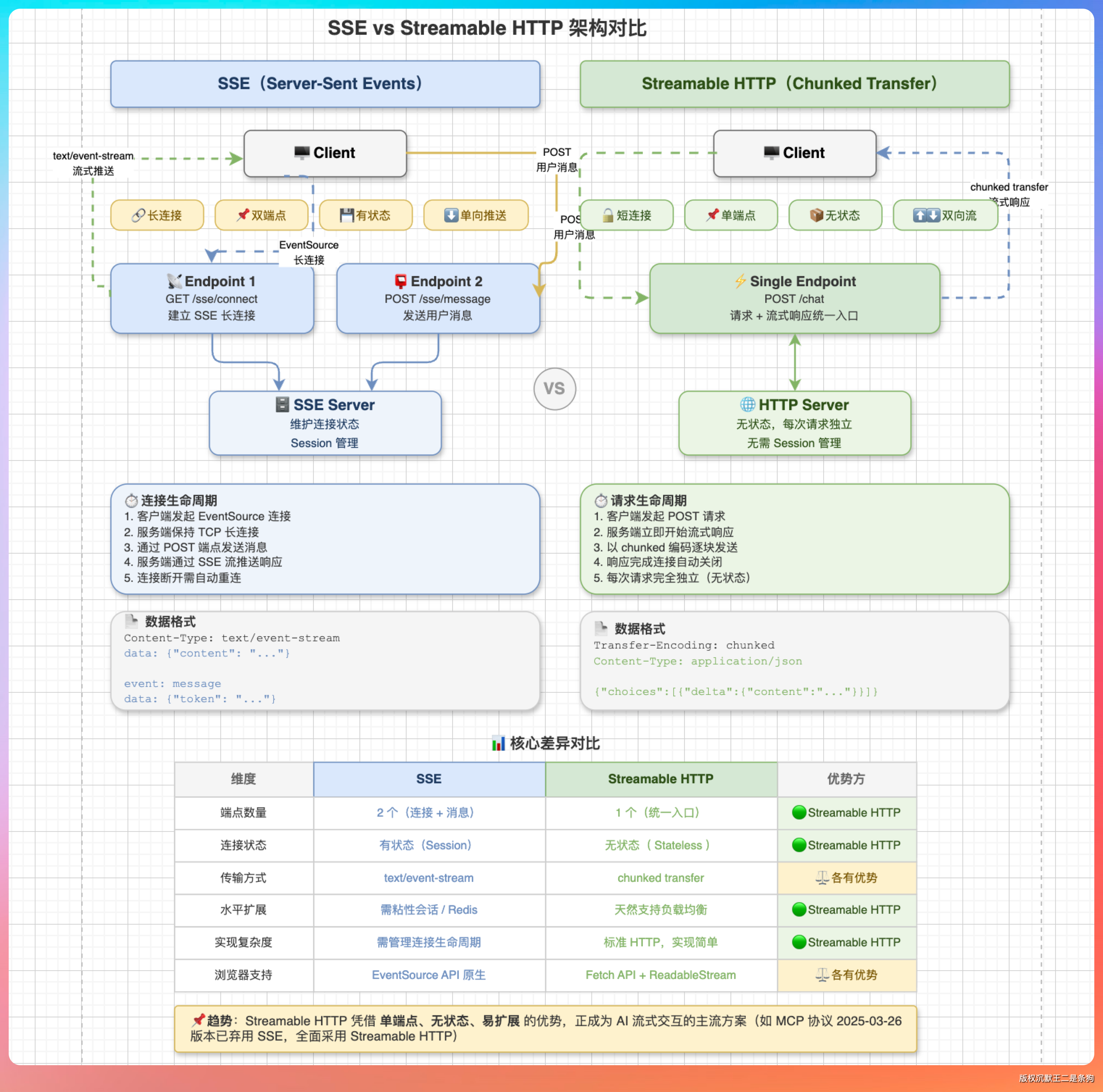
“Streamable HTTP 是 MCP 协议定义的一种传输方式,它跟 SSE 没有直接关系。它的核心特点是:”
“第一,单端点架构。一个 HTTP 端点同时支持 POST 和 GET。POST 用来发请求,GET 用来接收流式响应。”
“第二,流式响应用的是 HTTP chunked transfer encoding。响应头里设 Transfer-Encoding: chunked,服务端把数据分块发送,客户端边收边处理。”
“第三,支持无状态部署。每个请求都是独立的 HTTP 连接,服务端不需要维持长连接。”
04、长连接啥时候会失效?
老王顺着话题问:“长连接啥时候会失效?”
“第一种,Keep-Alive 限制。默认情况下,连接会在空闲 5 秒后失效,或者在处理完 100 个请求后强制关闭。”
Keep-Alive: timeout=5, max=100
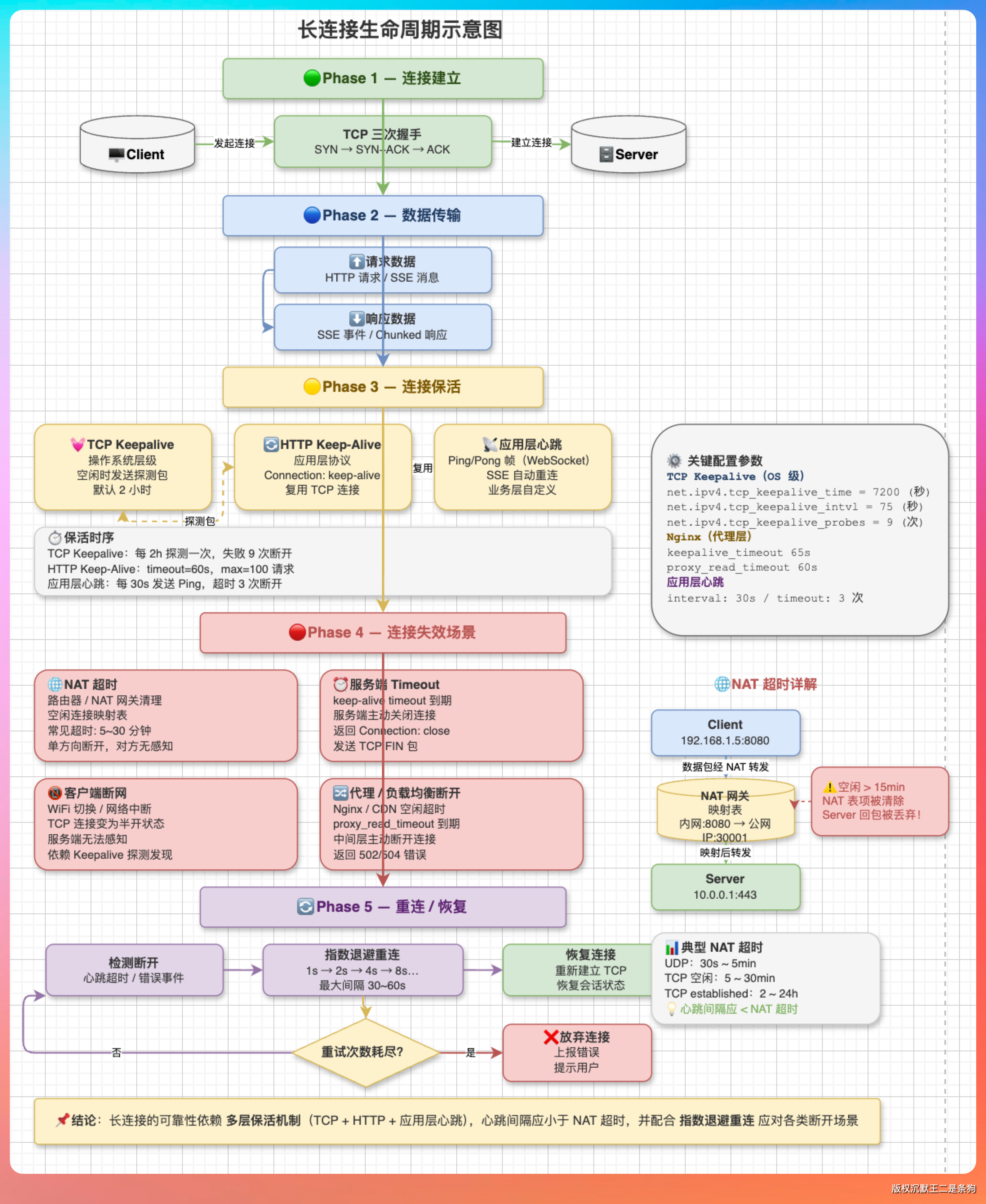
“第二种,服务端主动关闭。服务器资源紧张的时候,会主动清理空闲连接。比如在连接池管理中,LRU 策略会优先回收最久没用的连接。”
老王说:“不错,考虑得挺全面。那你做 AI 应用的时候,鉴权方案怎么设计的?”
05、如何设计一个鉴权方案,结合 Claude Code 说一下
“一个完整的鉴权方案需要解决三个问题:你是谁(认证)、你能干什么(授权)、你的凭证怎么传递和刷新。”
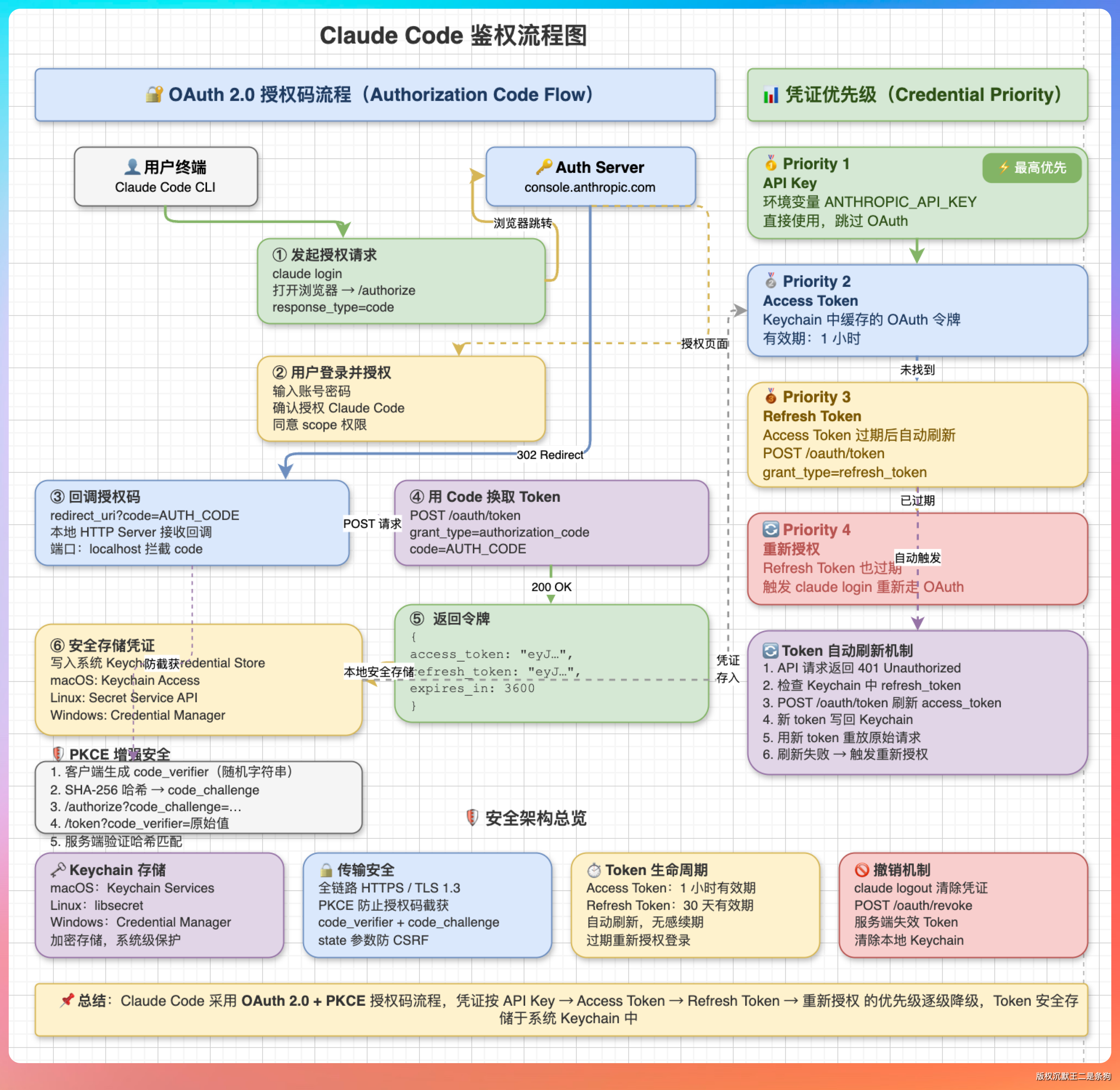
“具体到 Claude Code,它用的是 OAuth 2.0 授权码流程。首次运行 CLI 的时候,用户可以选择打开浏览器跳转到 Anthropic 的授权页面,点同意授权后,CLI 会拿到一个短期授权码,再用这个授权码换 access token 和 refresh token。”
“Claude Code 有两种凭证类型:OAuth Token 是以 sk-ant-oat01- 开头的,绑定 Claude.ai 的 Pro/Max 订阅账户,调用会计入订阅配额。API Key 是以 sk-ant-api03- 开头的,来自 Anthropic Console,按 token 用量计费。”
老王说:“说到 HTTP,那 HTTP 请求包含什么部分?”
06、HTTP 包含什么部分?请求头有什么字段?
我说:“HTTP 报文分请求报文和响应报文,结构都是三部分:起始行、头部、正文。”
“请求报文的起始行包含三个东西:请求方法(GET、POST、PUT、DELETE 这些)、请求 URL、HTTP 版本号。”
“头部是 key-value 的键值对,常见的请求头字段我说几个核心的:”

“Host 是必须有的,指定目标服务器的域名和端口。Content-Type 告诉服务端请求体的格式,比如 application/json、multipart/form-data。Authorization 携带认证信息,最常见的是 Bearer <token> 格式。”
“Accept 告诉服务端客户端能处理的响应格式。User-Agent 标识客户端类型。Cookie 携带之前服务端种下的 cookie。Cache-Control 控制缓存策略。”
“Connection 这个字段比较有意思,HTTP/1.1 默认是 keep-alive。”
“正文部分就是实际传输的数据了,GET 请求通常没有正文,POST/PUT 请求的正文是要提交的数据。”
老王又问:“那 JWT 你了解吗?”
07、JWT 由什么组成?解决了 Cookie 和 Session 的什么问题?
我说:“JWT 全称 JSON Web Token,由三部分组成,中间用点号分隔:Header.Payload.Signature。”
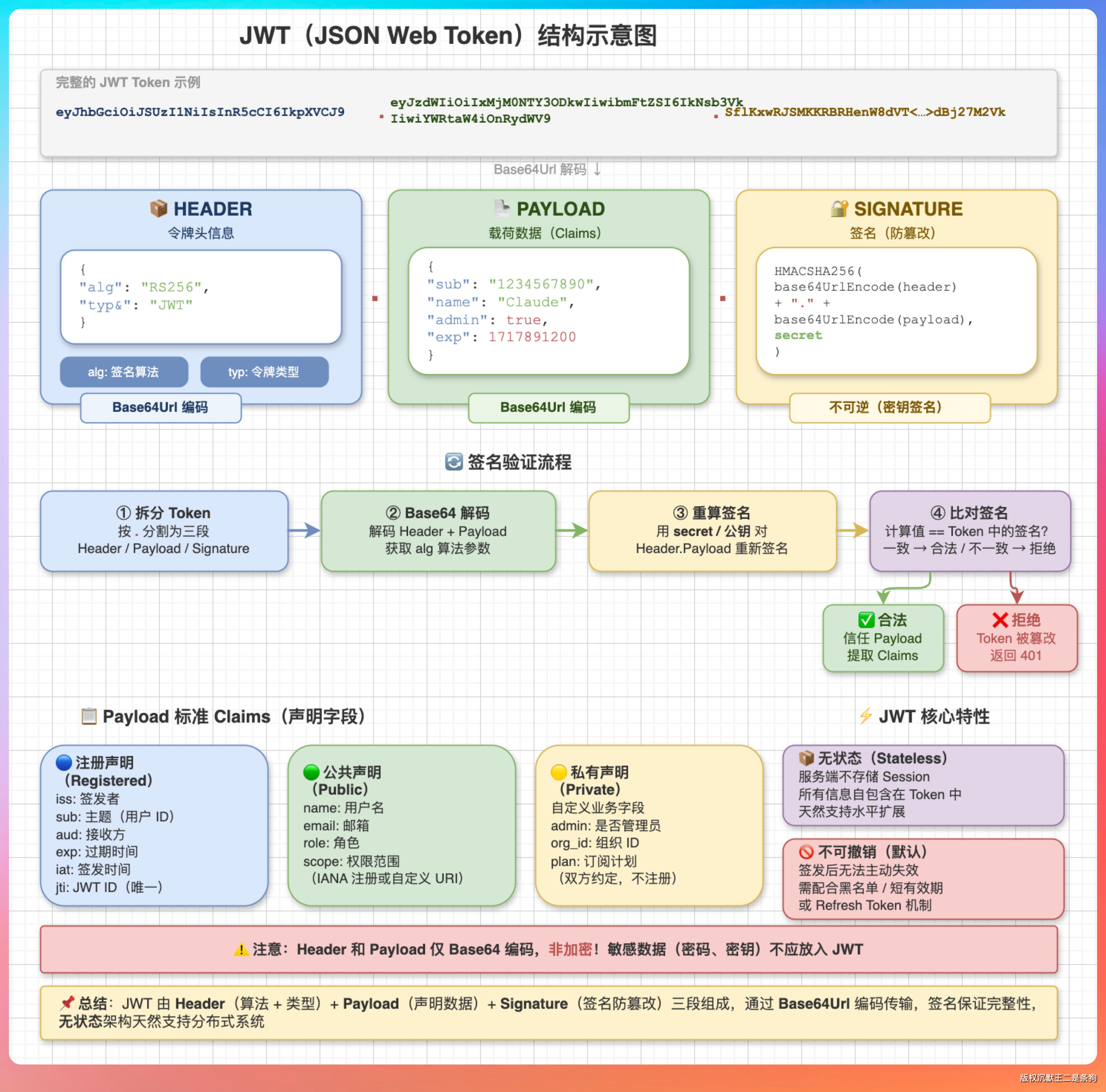
“Header 是头部,声明 token 类型(固定是 JWT)和签名算法(比如 HS256 或 RS256)。Payload 是载荷,存放实际的数据,比如用户 ID、过期时间、权限信息。Signature 是签名,用 Header 里声明的算法,对 Header 和 Payload 进行签名,防止被篡改。”
“Header 和 Payload 都是 Base64 编码的。安全靠的是 Signature——只要服务端的密钥不泄露,token 就没法被伪造。”
老王追问:“那 JWT 是为了解决什么问题?”
我说:“核心是解决 Session 在分布式场景下的痛点。”
“传统方案是 Cookie+Session:用户登录后,服务端创建一个 Session 对象存在内存里,把 Session ID 通过 Cookie 返回给浏览器。后续每次请求,浏览器自动带上 Cookie,服务端根据 Session ID 找到对应的 Session。”
“这个方案在单机环境下没问题,但到分布式就麻烦了。用户第一次请求到了 A 服务器,Session 存在 A 上;第二次请求到了 B 服务器,B 上没有这个 Session,用户就被踢出登录了。”
“解决办法有这么两种,比如 Session 共享,用 Redis 集中存储、比如 Nginx 把同一用户的请求固定到同一台服务器。”
“JWT 的思路完全不同——把用户信息直接编码进 token 里,服务端不需要存任何状态。每次请求过来,服务端只需要验证签名是否合法、token 是否过期就行了。天然支持分布式,不需要共享存储。”
“但 JWT 也有代价:一是 token 无法主动失效,除非引入黑名单机制;二是 Payload 里不能放敏感信息,因为任何人都能解码。”
08、Multi-Agent 项目中,工具调用是怎么实现的?
老王换了个方向:“Multi-Agent 项目中工具调用是怎么实现的?”
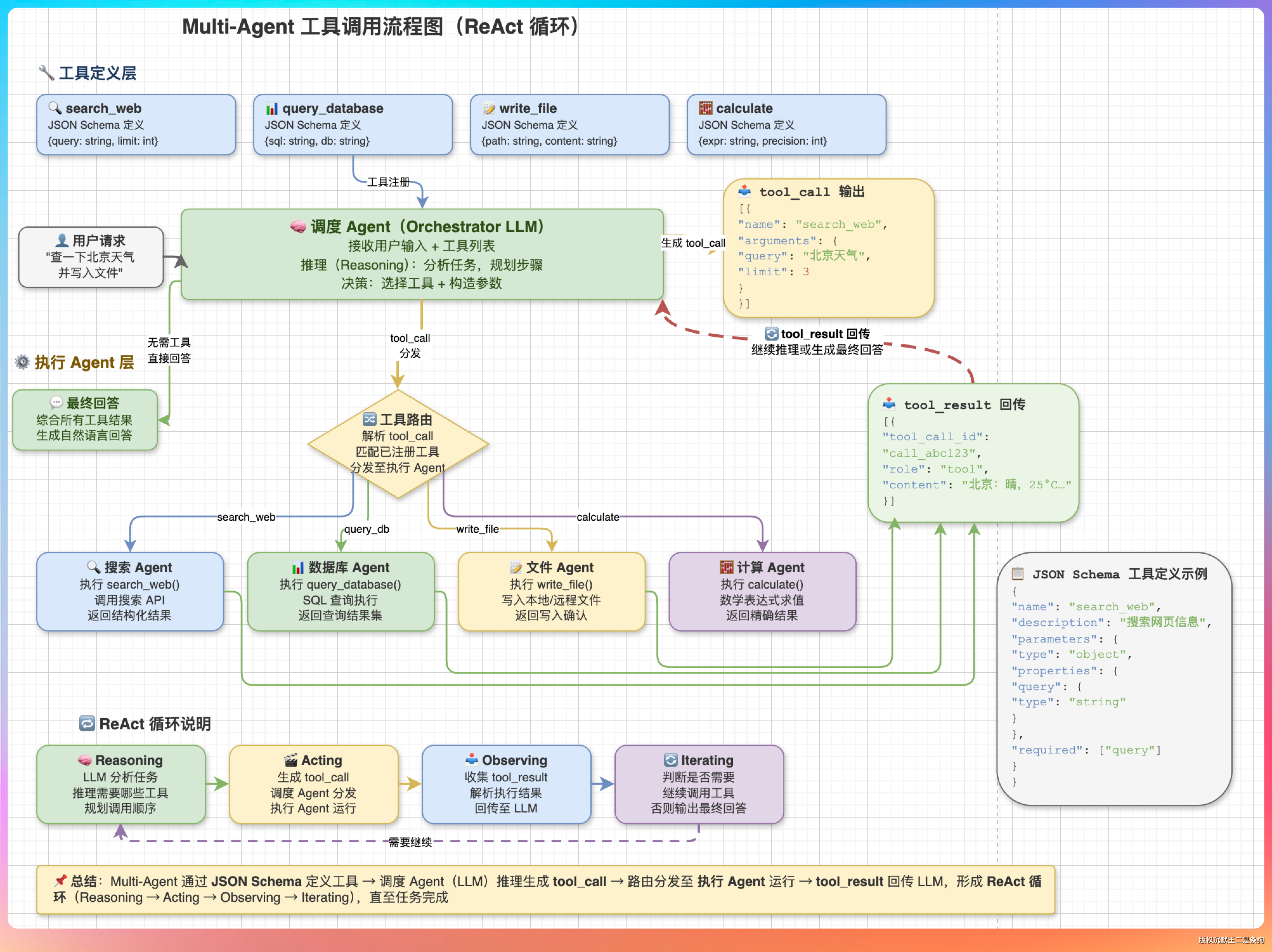
“核心流程分四步:定义工具 → LLM 决策 → 执行工具 → 结果回传。”
“第一步,定义工具。每个工具需要一个 JSON Schema,描述工具的名称、功能、入参类型。比如一个搜索工具,name 是 web_search,description 是‘搜索互联网信息’,inputSchema 定义一个 query 字段,类型是 string。”
“第二步,LLM 决策。把用户的问题和所有可用工具的描述一起发给 LLM,LLM 来判断需不需要调用工具、调哪个工具、参数是什么。LLM 返回的不是文本,而是一个 tool_call 结构体,包含工具名称和参数。”
“第三步,执行工具。Agent 框架拿到 tool_call 后,路由到对应的工具函数,执行实际操作——可能是发 HTTP 请求、查数据库、读文件,什么都有可能。”
“第四步,结果回传。把工具执行结果塞回对话上下文,再次调用 LLM,让它基于工具结果生成最终回答。如果一次不够,LLM 可能会连续调用多个工具,形成一个 ReAct 循环。”
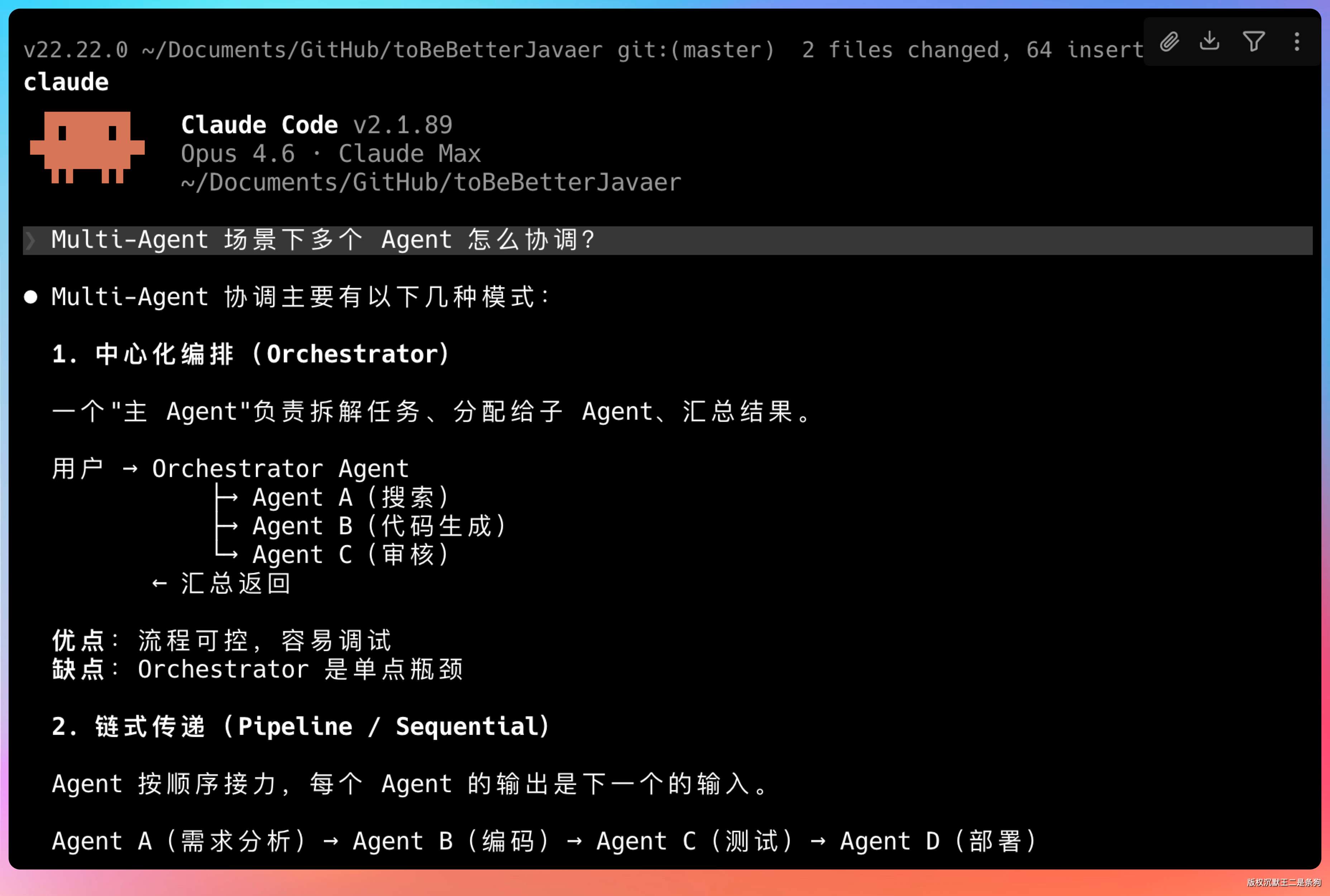
老王追问:“Multi-Agent 场景下多个 Agent 怎么协调?”
我说:“Multi-Agent 场景常见两种模式。一种是层级式——有一个调度 Agent 负责接收用户请求、拆解任务、分发给不同的执行 Agent。每个执行 Agent 有自己独立的工具集,比如一个负责搜索,一个负责代码执行,一个负责数据分析。”
“另一种是对等式——多个 Agent 之间通过消息总线通信,没有明确的上下级关系。每个 Agent 发布自己能做的事情,其他 Agent 按需调用。这种更灵活,但协调成本也更高。”
09、MCP 支持哪些协议?
老王问:“你刚才提到 MCP,那 MCP 支持哪些传输协议?”
我说:“MCP 当前规范定义了两种标准传输方式:stdio 和 Streamable HTTP。”
“stdio 是最简单也是最常见的,适合本地工具。Agent 和 MCP Server 跑在同一台机器上,通过标准输入/输出通信。优点是零配置、互动强;缺点是不支持远程调用,也不支持并发。”
“Streamable HTTP 是远程场景的推荐方案。”
老王满意地点了点头:“RAG 了解吗?”
10、RAG 的工作流程了解吗?
我说:“了解,RAG 就是检索增强生成。”
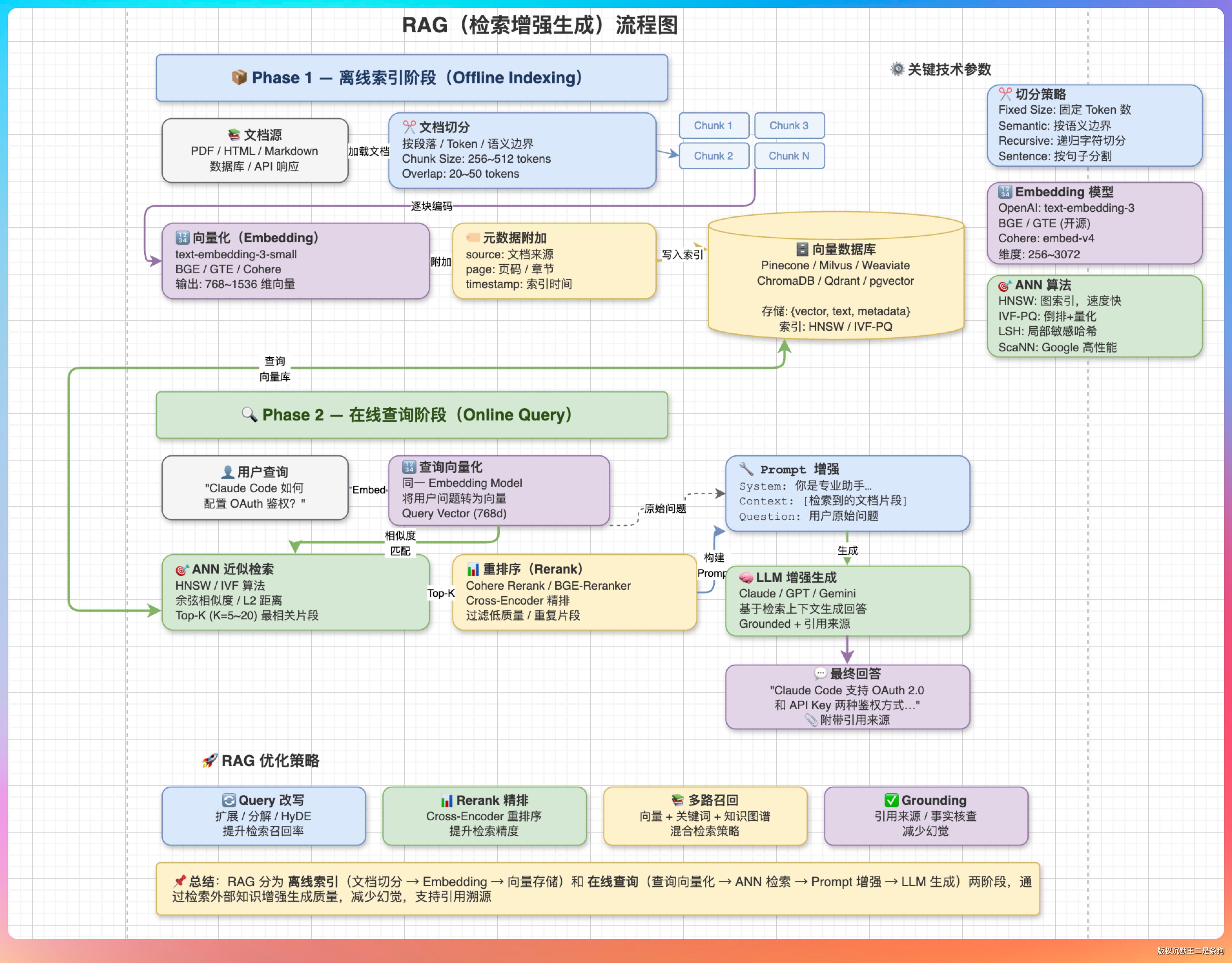
“工作流程分两个阶段:索引阶段和查询阶段。”
“离线阶段做三件事:文档收集 → 文本切分 → 向量化存储。把原始文档(PDF、Word、网页等)切分成合适大小的 chunk,用 Embedding 模型把每个 chunk 转成向量,存到向量数据库里。”
“查询阶段也是三步:查询向量化 → 相似度检索 → 增强生成。用户提问后,把问题也转成向量,在向量数据库里做 ANN(近似最近邻)检索,找到最相关的几个 chunk,把这些 chunk 作为上下文拼到 prompt 里,一起发给大模型生成回答。”
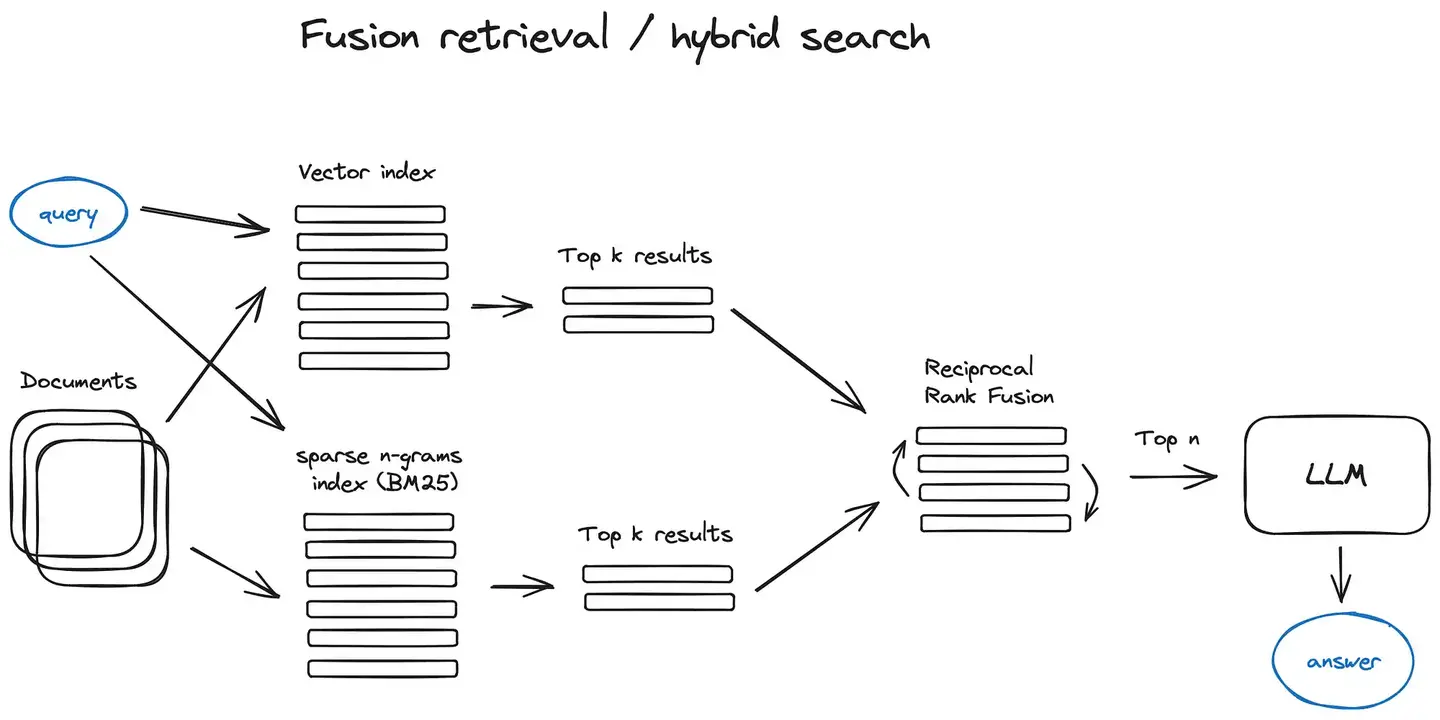
“实际工程中还有一些关键优化点。Chunk 切分策略很重要,切太大语义模糊、检索不准,切太小丢失上下文。一般按 512-1024 token 一个 chunk,带 20% 的重叠。”
“另外就是 Rerank。向量检索的结果不一定是最优的,因为语义相似不等于问题相关。加一个 Reranker 模型做二次排序,能有效提升召回质量。”
11、Transformer 为什么会出现?
老王说:“聊点底层的,Transformer 为什么会出现?”
我说:“这得从大模型的前身说起。”
“在 Transformer 出现之前,处理文本的主流方法是 RNN(循环神经网络)。它的思路是:一句话要一个词一个词地读,读完前一个才能读后一个,像人读书一样。”
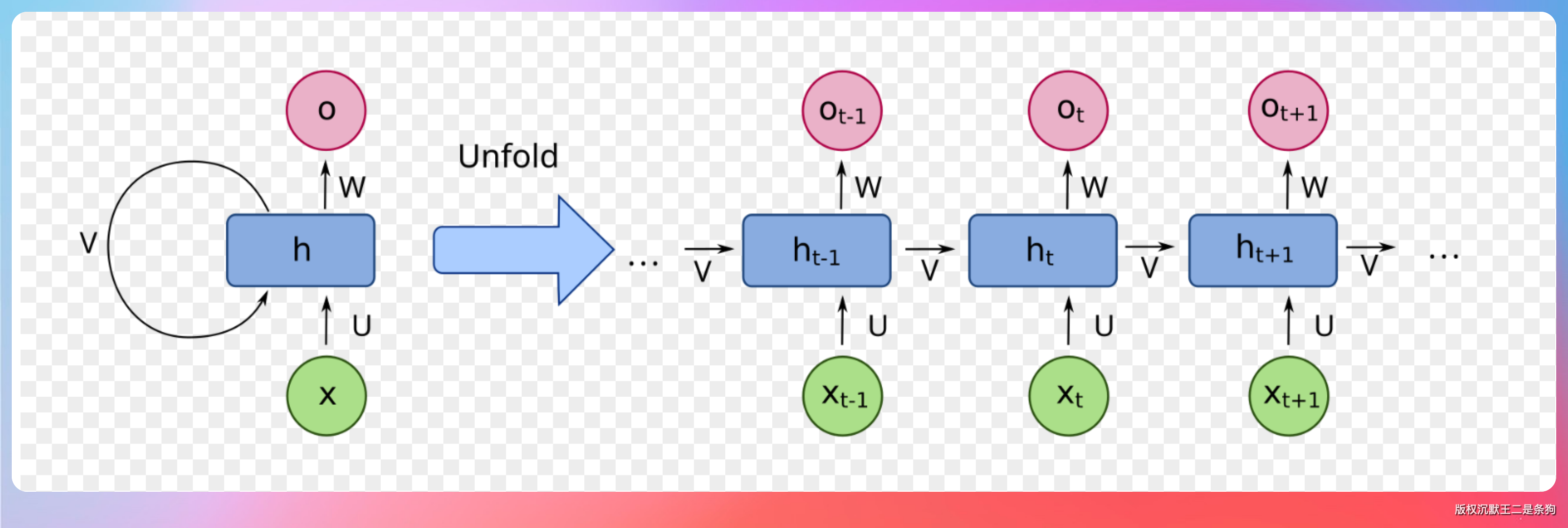
“这个思路有个致命问题——太慢了。因为必须按顺序来,没法并行处理。GPU 最擅长的是并行计算,RNN 完全没法利用这个优势。”
“还有个更大的麻烦:读到后面,前面的内容就忘得差不多了。比如一篇几千字的文章,读到最后一句话的时候,第一句话的信息早就在传递过程中被稀释没了。这就是所谓的‘长距离依赖问题’。”
“后来有人提出了 LSTM(长短期记忆网络),加了‘门控机制’——简单说就是给模型装了记忆开关,重要的信息多留一会,不重要的可以趁早忘掉。在一定程度上缓解了长距离依赖,但本质还是顺序处理,速度问题没解决。”
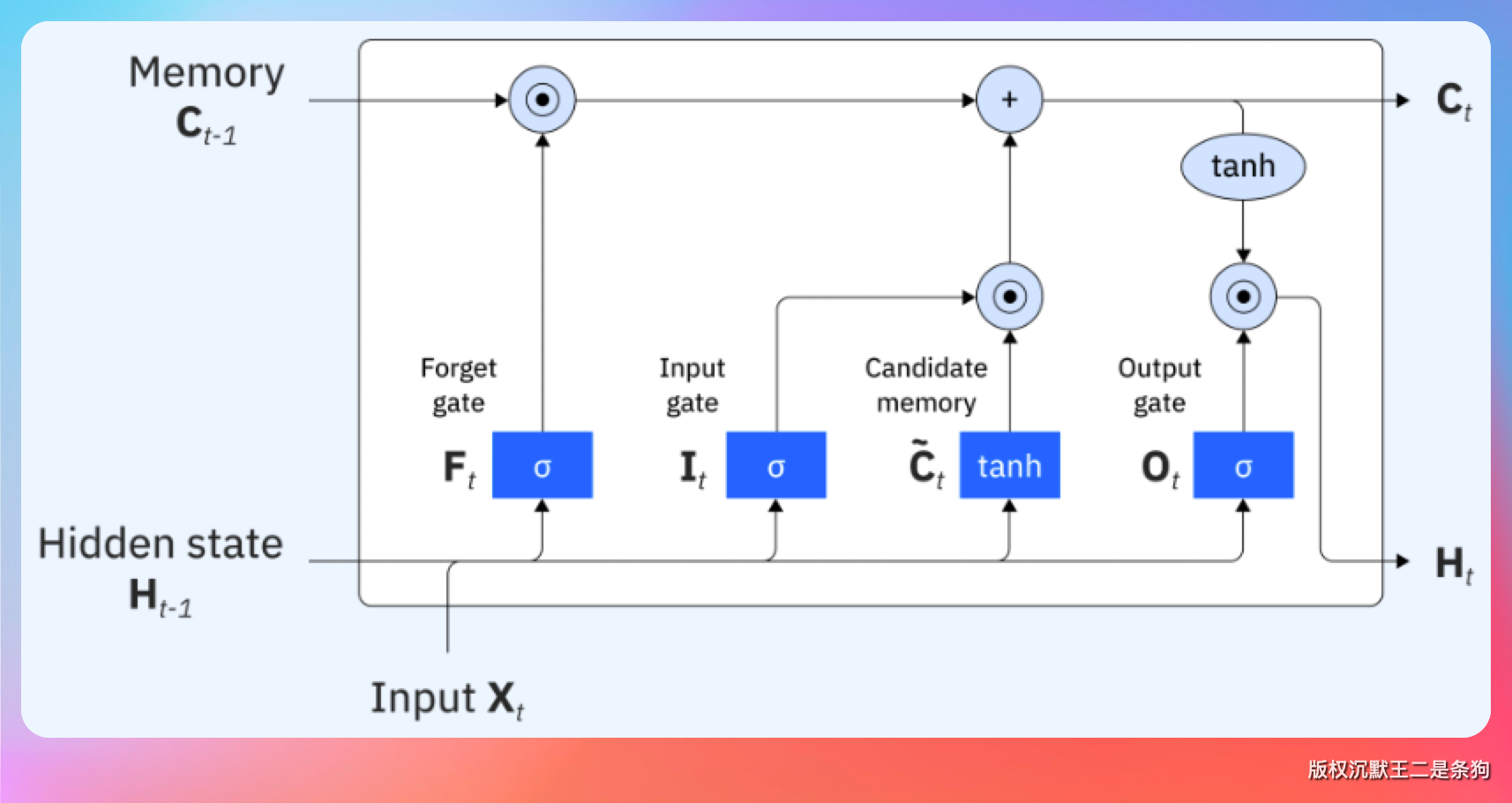
“2017 年,Google 发了一篇论文叫《Attention is All You Need》,提出了 Transformer 架构。核心就一句话:把循环结构扔了吧,只在乎注意力机制。”
老王说:“那注意力机制到底是怎么回事?”
我说:“打个比方,RNN 像学生记笔记,老师说什么记什么,记到后面前面的就忘了。注意力机制像学霸划重点,看完一整篇文章后,知道哪些句子是关键,重点关注那些地方。”
具体怎么实现的?
“每个词会生成三个向量:”
“- Query(查询向量):我要找什么信息”
“- Key(键向量):我有什么信息可以匹配”
“- Value(值向量):我携带的实际内容”
“然后每个词的 Query 和所有词的 Key 做匹配,算出相关性分数,分数高的就多关注一点。最后用这些分数对所有 Value 做加权求和。”
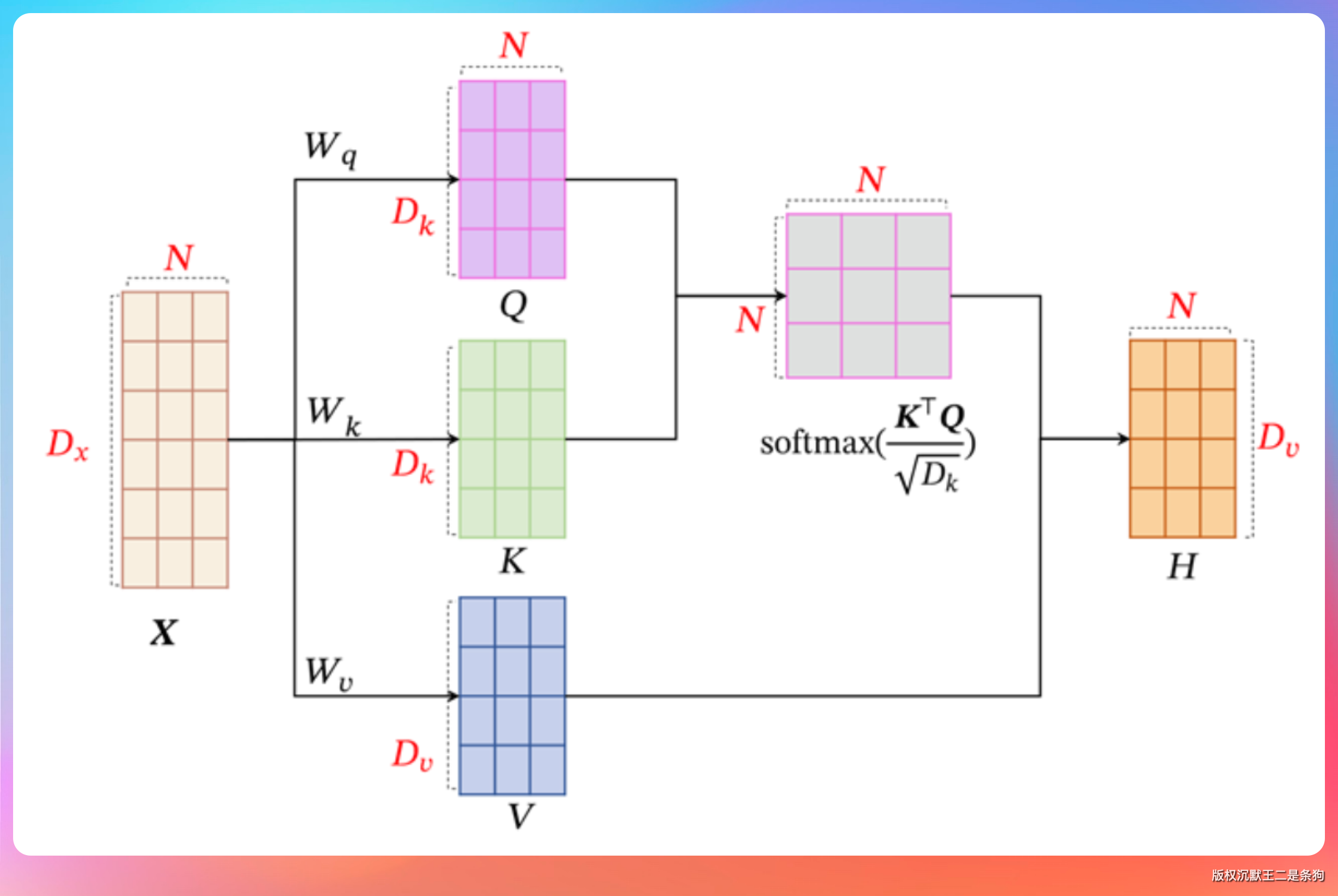
“这么做的好处有三点:第一,所有词可以同时处理,GPU 并行能力拉满,训练速度起飞。第二,不管句子有多长,任意两个词之间的距离都是一步,不存在‘传着传着就忘了’的问题。第三,注意力权重可视化之后,能看出模型在关注哪些词,调试起来很直观。”
“现在所有的大模型,都是基于 Transformer 架构的。”
12、垂域大模型部署成本高,选蒸馏还是量化?
老王抛出最后一题:“假设你有一个垂域大模型,部署成本非常高,要降低成本的话,选蒸馏还是量化?”
我说:“这两个东西解决的问题不一样。”
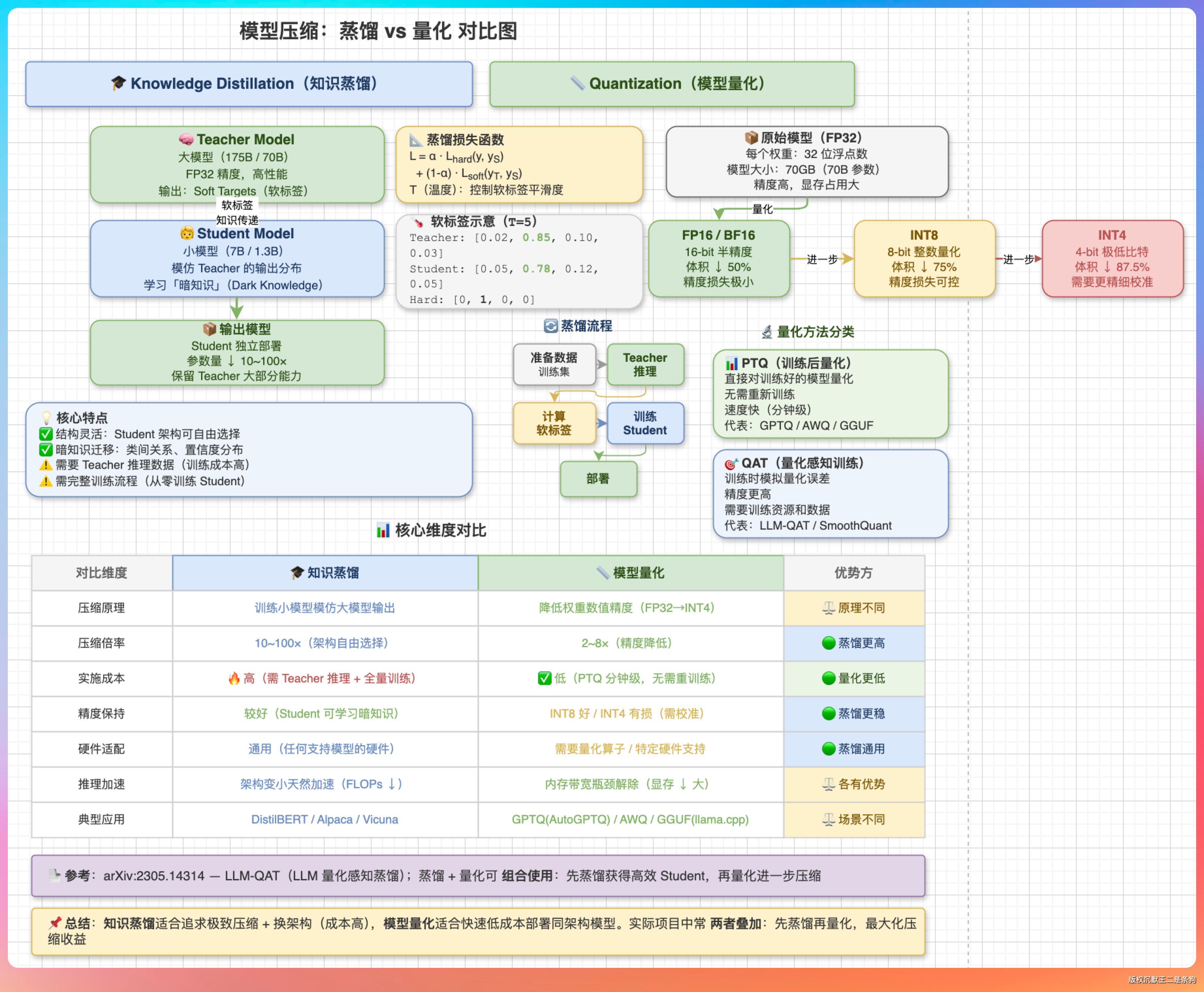
“蒸馏,就是用大模型‘教’小模型。大模型(叫 Teacher)不仅告诉小模型(叫 Student)正确答案是什么,还告诉它‘我觉得 A 选项 80% 可能是对的,B 选项 15%,C 选项 5%’。这个概率分布叫‘软标签’,包含了大模型的推理思路。”
“打个比方,大模型像老师,不光告诉学生答案是 A,还讲了一通为什么选 A 不选 B。学生听懂了思路,下次遇到类似题目也能做对。”
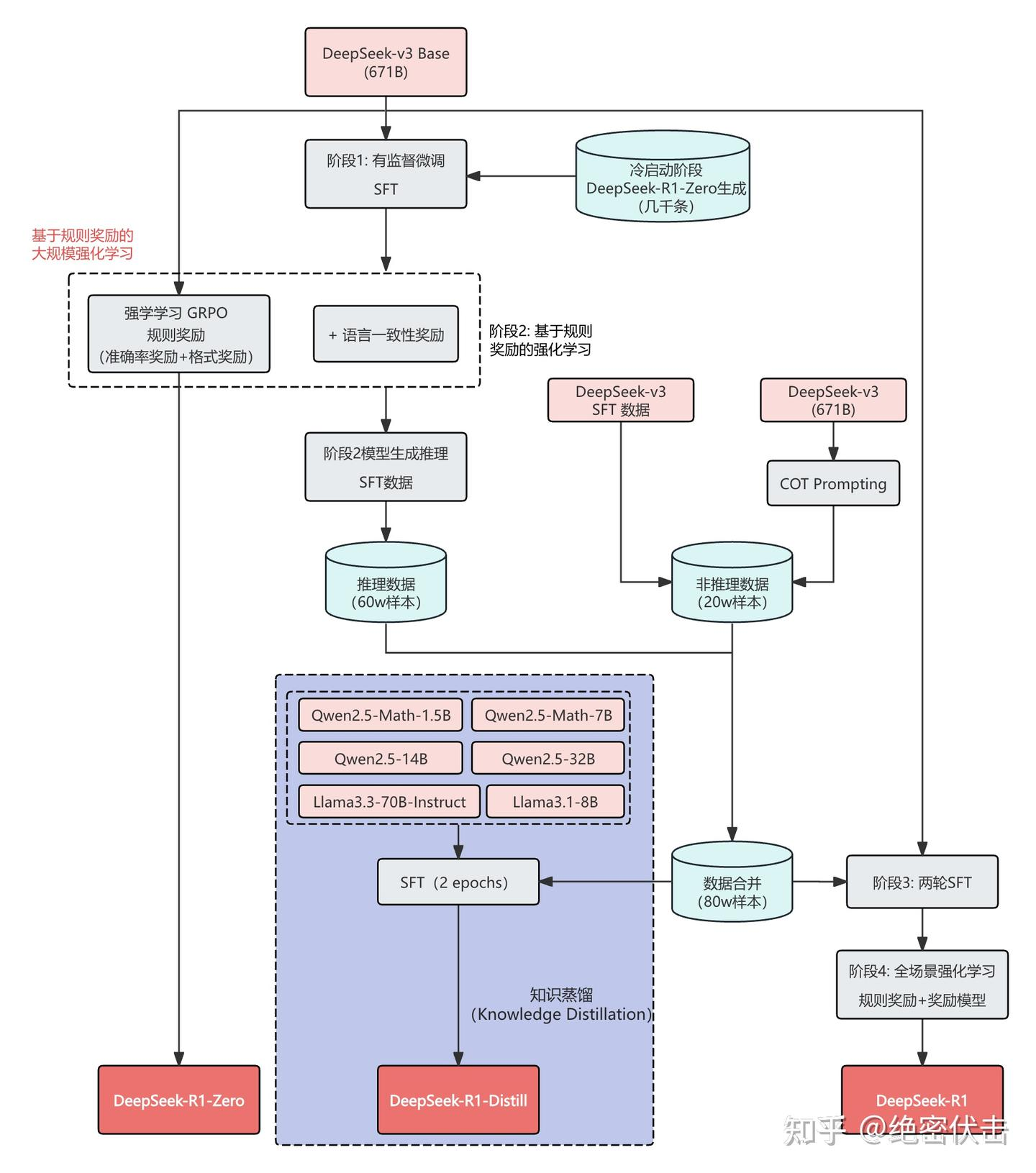
“蒸馏的压缩效果很好——可以从 700 亿参数压到 70 亿,规模直接缩一个数量级。代价是需要重新训练,要有数据、有算力、有时间。DeepSeek 的蒸馏版就是这样来的,用 DeepSeek-R1 当 Teacher 训练小模型。”
“量化,简单说就是‘降低精度’。模型参数本来用 32 位浮点数存,改成 8 位整数甚至 4 位整数。数值精度降了,存储和计算开销就降低了。”
“举个例子,Llama 3 8B 这个模型:”
“- FP32(32 位浮点):需要约 32GB 显存”
“- Int8(8 位整数):只需要约 8GB”
“- Int4(4 位整数):只需要约 4GB”
“压缩比能达到 75%-90%,而且不需要重新训练,拿现成的模型直接转就行。缺点是精度会掉,位数越低掉得越厉害。”
老王追问:“那怎么选?”
我说:“看三个维度。”
“时间维度:急着上线选量化,快。”
“精度维度:医疗、法律这种必须准确无误的,蒸馏更稳。通用问答、客服这种,Int8 量化的精度损失基本能接受。”
“资源维度:有 GPU 集群、有标注数据,蒸馏的投入产出比高。只有推理服务器,量化是唯一选择。”
“最优解是组合使用:先蒸馏得到合适尺寸的模型,再量化进一步压缩。”
ending
以前我们写 CRUD,现在我们需要懂协议、懂模型、懂 Agent、懂工程化。
【要学的东西越来越多,但只要保持对这个世界的好奇心,求知欲,我们就会从畏惧变成享受。】
我们有机会站在 AI 发展的风口浪尖,见证并参与这个时代最激动人心的技术革命。虽然挑战不少,但也充满了无限可能。
加油吧,兄弟姐妹们。
下期见。

回复