


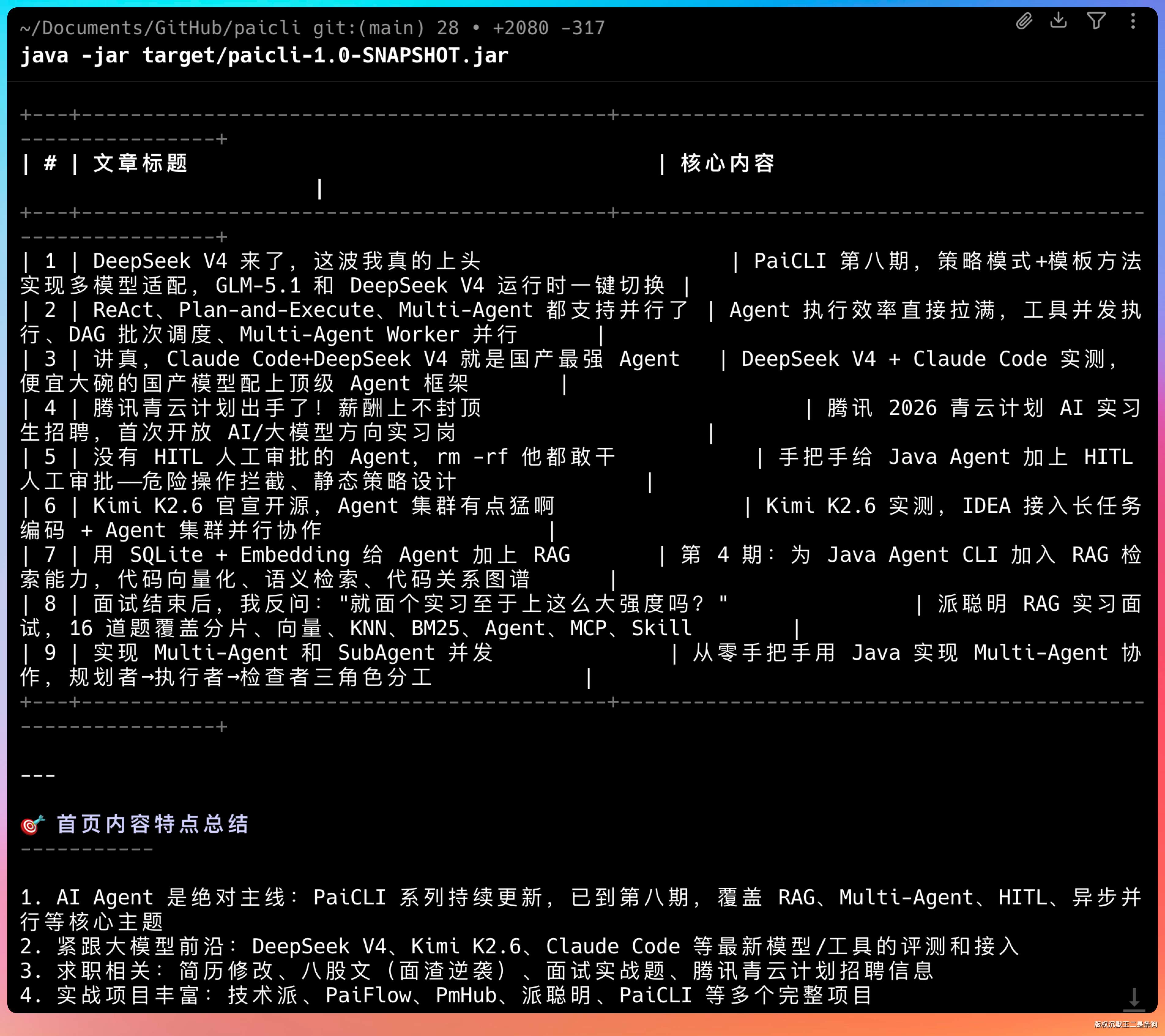
大家好,我是二哥呀。
大模型本身是没有联网能力的,他的知识库都是基于某一个时刻训练完成的。
像 GLM-5.1,通过 PaiCLI 去问的话,答案是基于 2024 年及之前的公开文本、代码、文档。
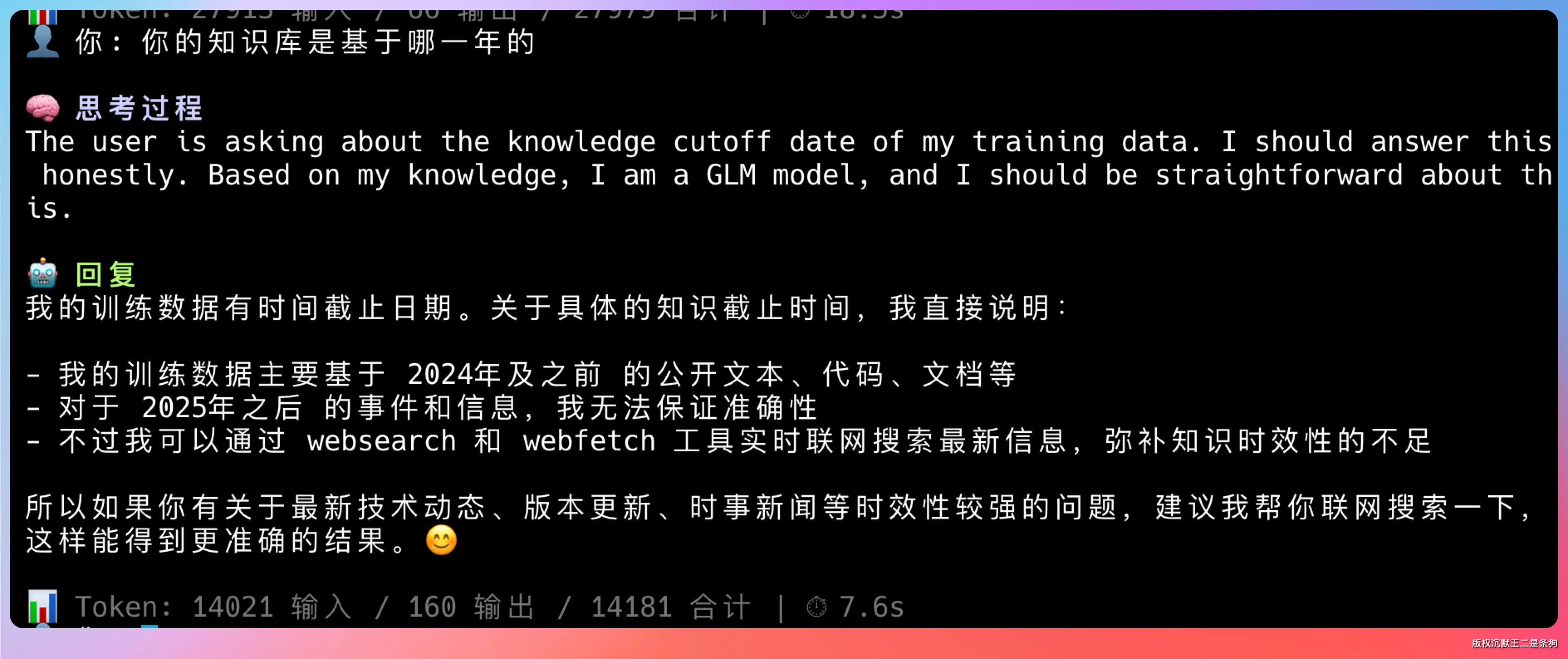
而现在已经是 2026 年 4 月 27 日了,这就意味着如果 Agent 没有联网能力的话,他对新事物是没有感知的。
那怎么给 Agent 加上联网能力呢?
今天这篇内容我们就来完成他。
01、Agent 的联网搜索效果
先来看 PaiCLI Agent 加上联网能力之后能干什么。
在终端里输入提示词:“搜一下沉默王二是谁”。
PaiCLI Agent 会自动调用 web_search 工具,通过智谱搜索 API 获取相关信息。
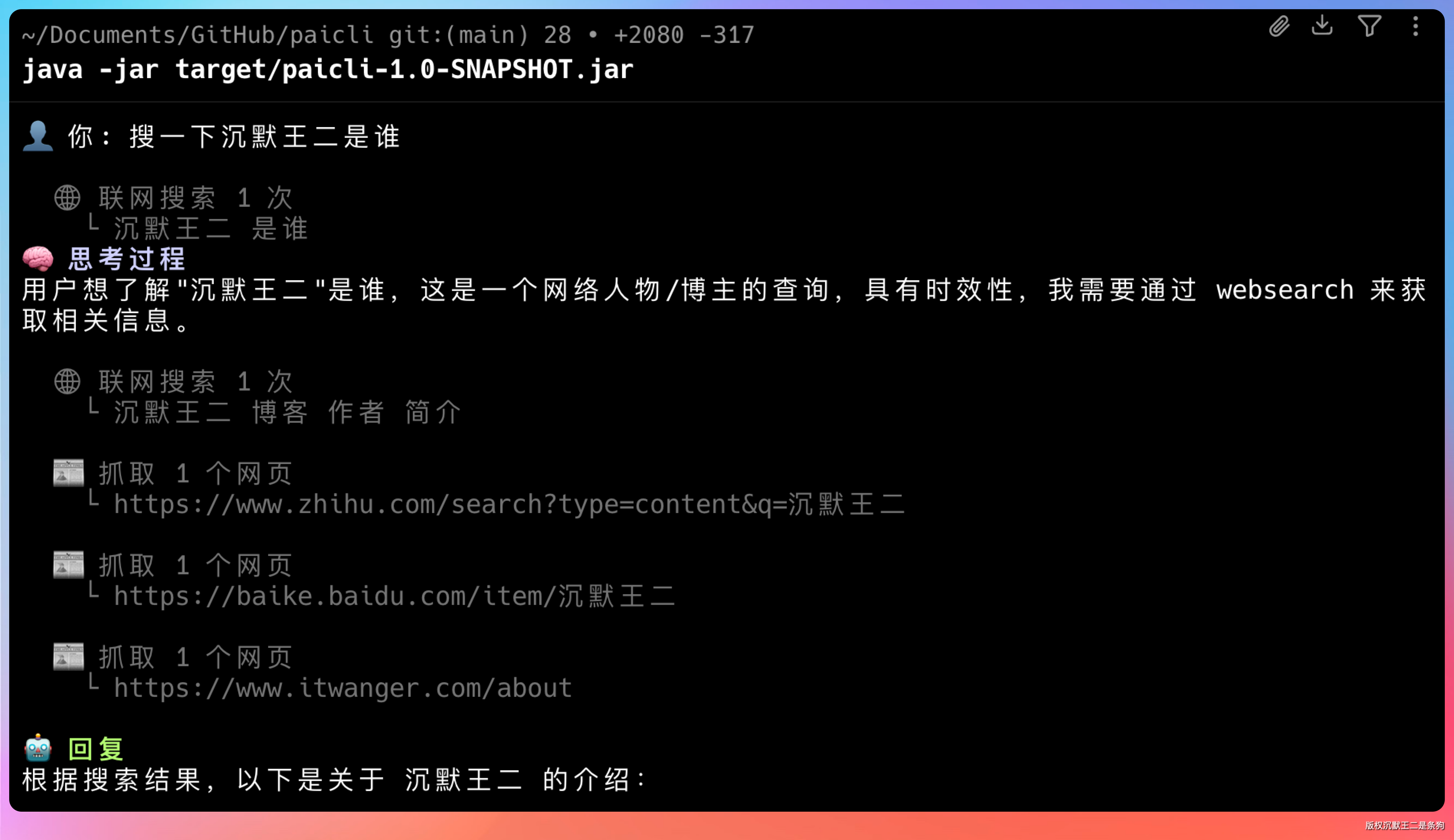
然后把搜索结果整理成一段非常准确的回复:
沉默王二 是一位知名的技术博主、程序员,真实身份与笔名一致,活跃于技术社区和自媒体领域。
就连我的座右铭都给出来了:没有什么可以使我停留,除了目的,纵然岸边有绿荫,有宁静的港湾,我是不系之舟。这回答我给满分。

再来一个。输入提示词:“paicoding.com 今天有没有更新啊”。
这次 PaiCLI Agent 调用的是 web_fetch 工具,直接去抓取网页内容。
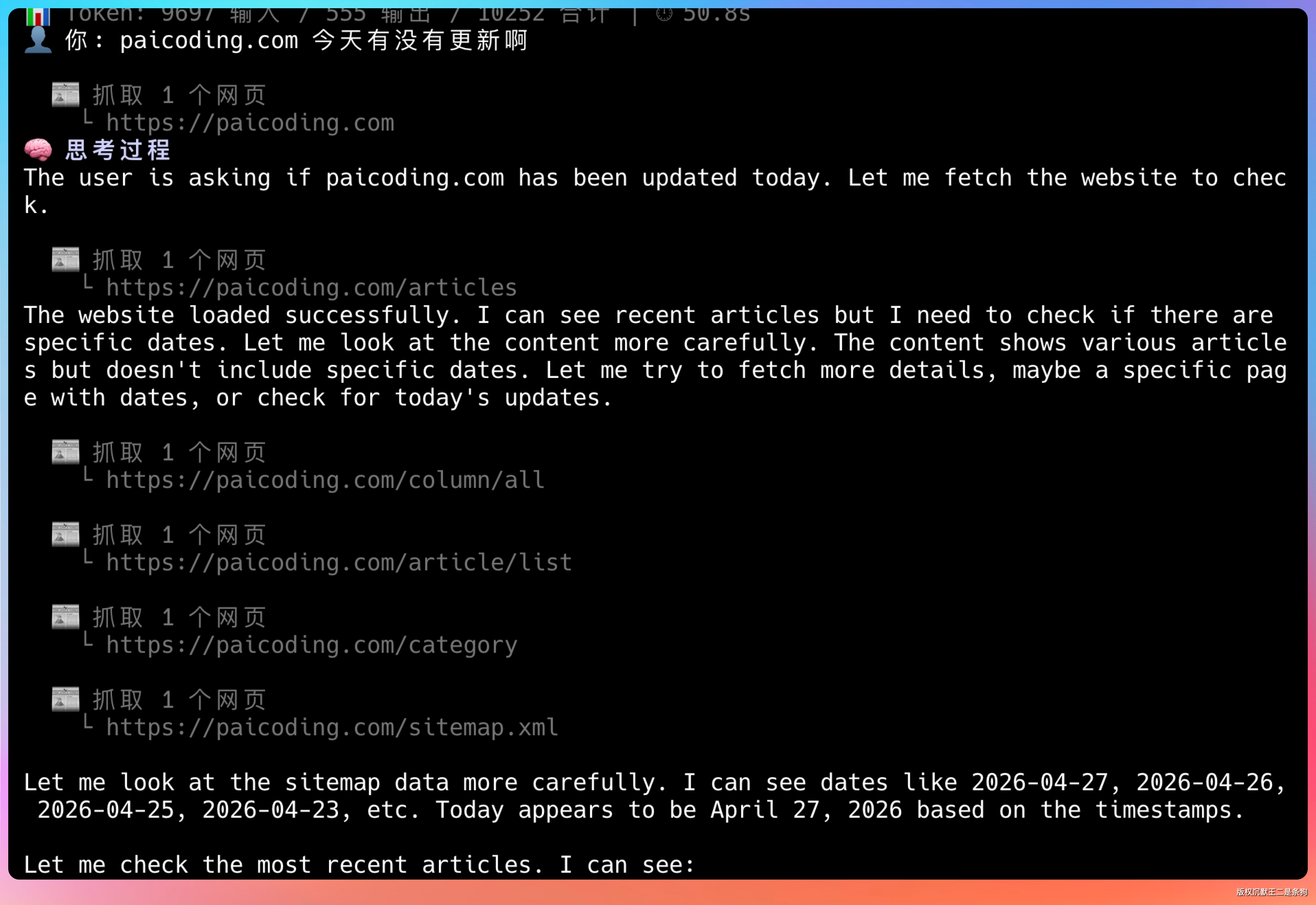
它把教程、文章、sitemap 都抓了一个遍。
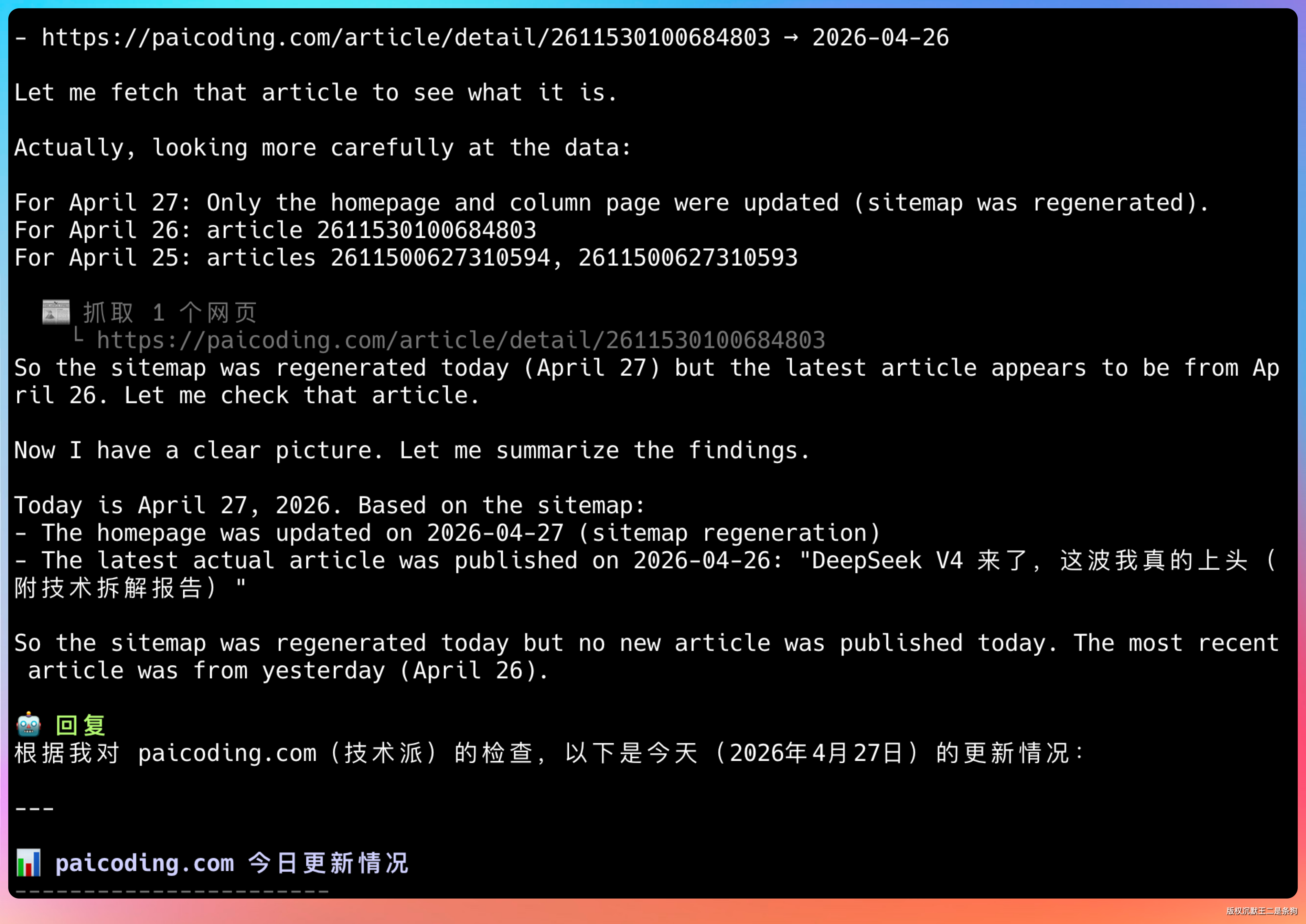
最终抓取到最新的文章是:《DeepSeek V4 来了,这波我真的上头(附技术拆解报告)》,昨天发布的。
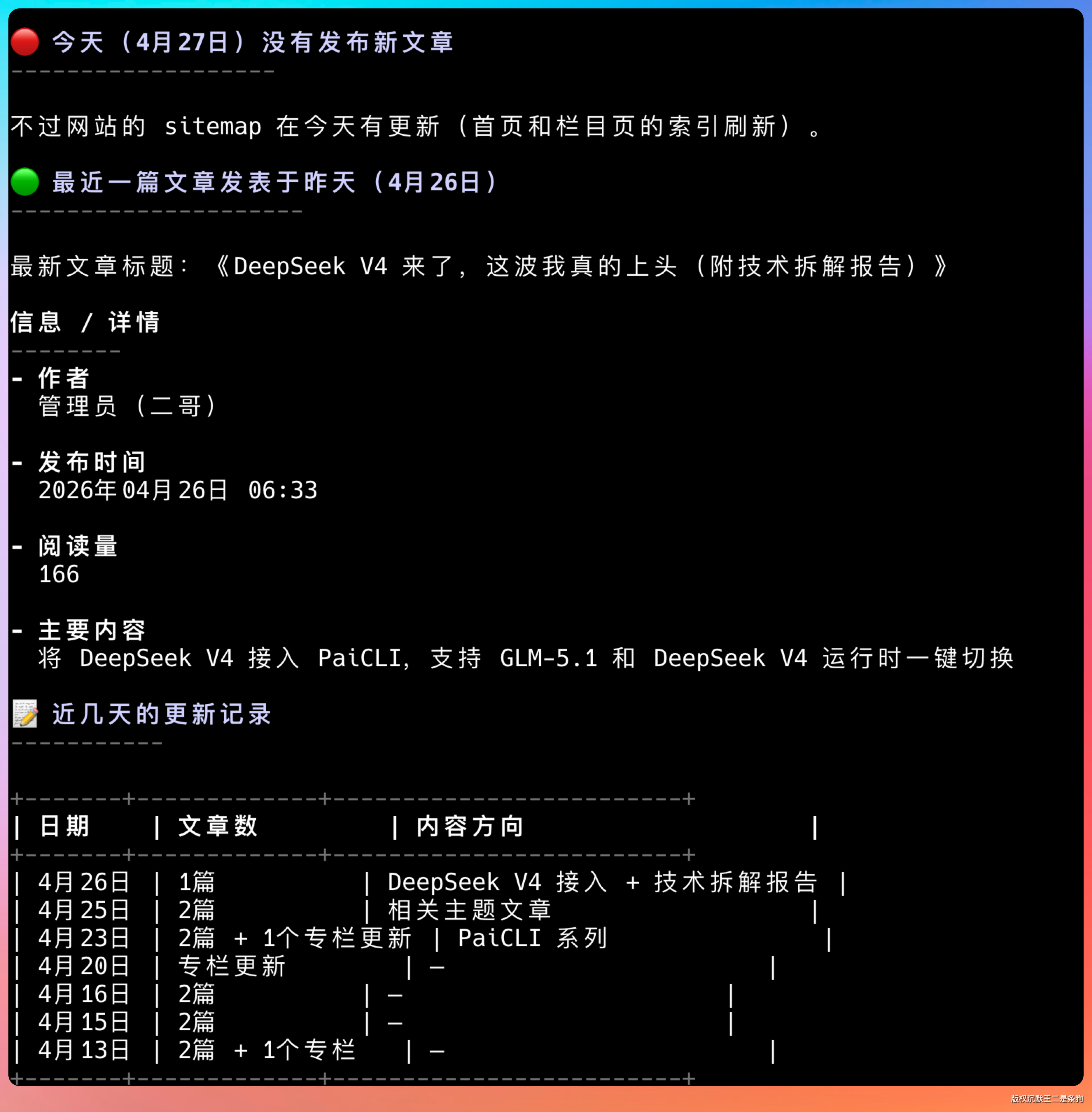
然后对网站整体做了一个非常细致的总结,包括最近的一些更新内容:
今天(4 月 27 日)暂无新文章发布,最近的一篇是昨天(4 月 26 日)关于 DeepSeek V4 的深度技术拆解文章。该站近期更新频率很高,几乎每隔 1-2 天就有新内容,主要集中在 PaiCLI、AI Agent、RAG、DeepSeek 等前沿 AI 技术方向。

这样 PaiCLI Agent 就具备了最基础的 WebSearch 和 WebFetch 能力,可以随时获取最新的网络信息。
不用手动打开浏览器搜索,不用复制粘帖网页内容,Agent 自己就能搞定。
接下来,我给大家详细讲讲是怎么实现的。
02、Agent 联网搜索的整体架构
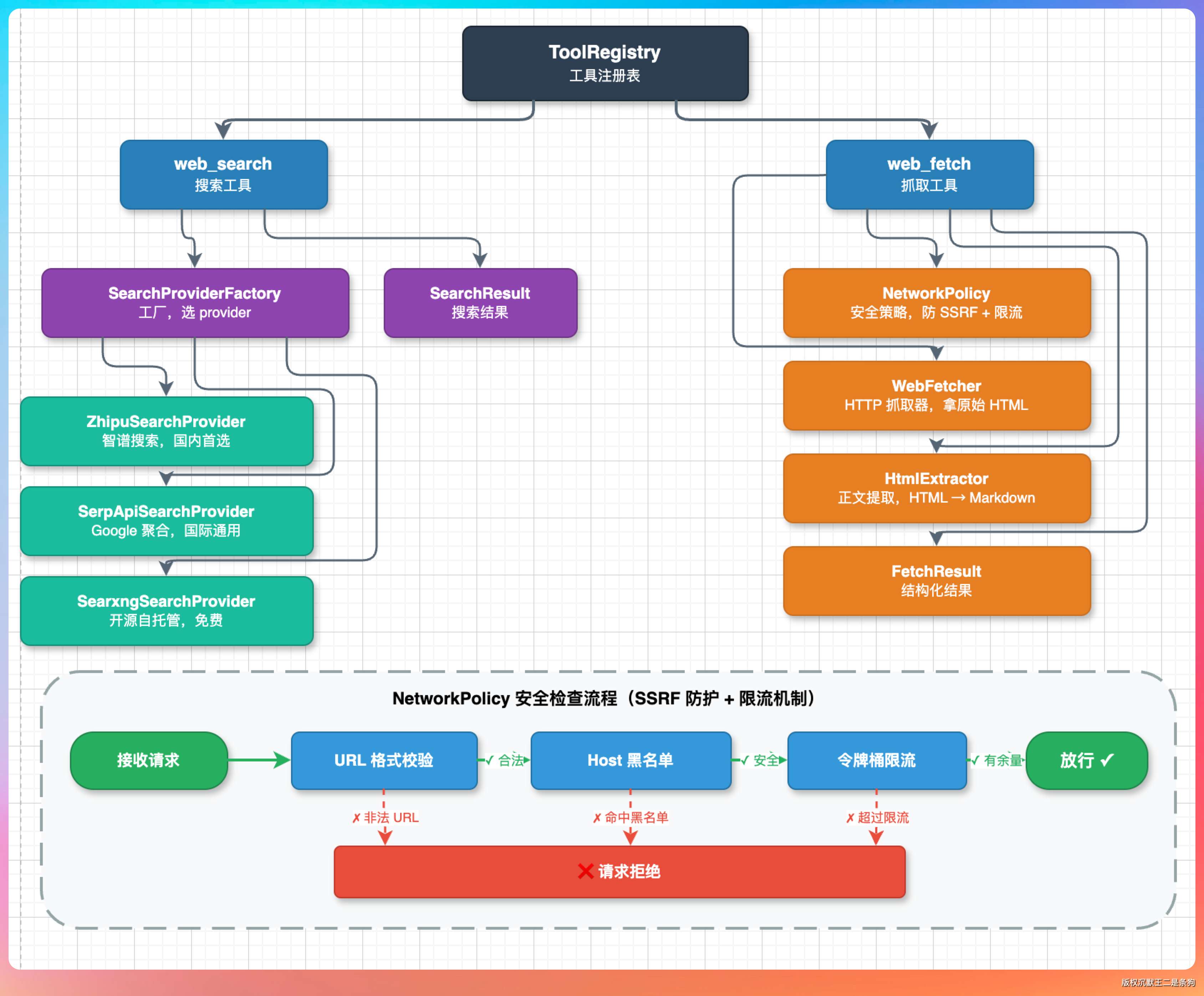
PaiCLI 的联网模块放在 com.paicli.web 包下,一共 8 个类,分工明确。
我画了一张依赖关系图,大家感受一下这个架构:
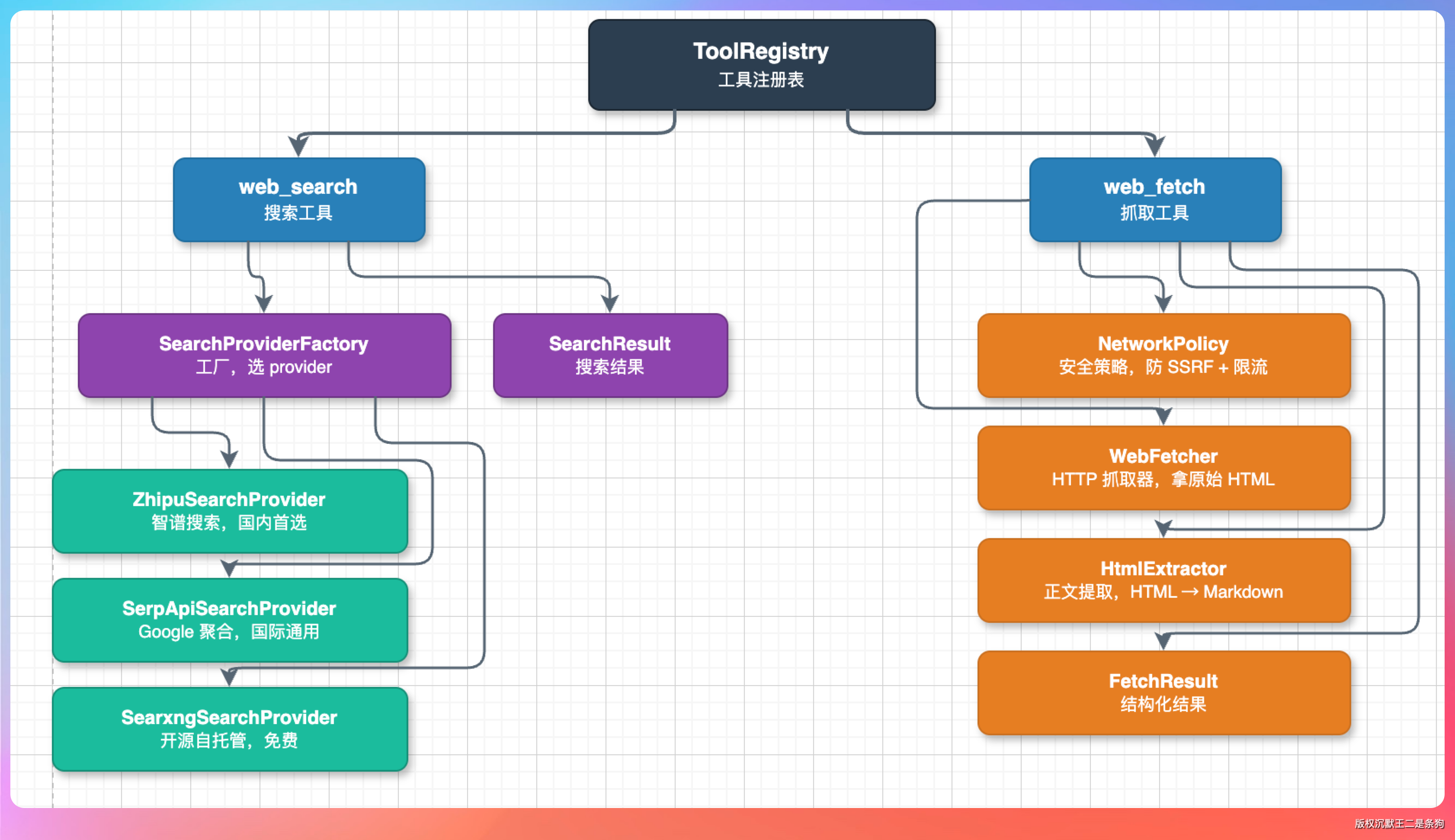
这里有两个设计决策值得说一下。
第一个,搜索和抓取是两个独立的工具,不是一个“联网工具”。
为什么?
因为它们的使用场景完全不同。
搜索是“我不知道去哪找”,抓取是“我知道 URL,帮我把内容拿回来”。
分成两个工具,Agent 可以根据用户意图自己选择用哪个,也可以先搜再抓(搜到 URL 后再 fetch 详情)。
第二个,搜索引擎做了 Provider 抽象。
三个实现类各有特点:智谱的联网搜索可以和 LLM 共用 API Key 零额外配置,SerpAPI 付费但开箱即用,SearXNG 开源免费但需要自己部署。
通过工厂模式自动选择。
为什么不直接在代码里写死用智谱?

因为 PaiCLI 虽然主要面向国内用户,但不排除二哥装逼给海外用户用。
最重要的是,能教大家学到东西,比如策略模式 😄
做了 Provider 抽象之后,以后哪怕再加一个 Bing Search 或者 Tavily,也只需要加一个实现类和工厂里加一行判断就行了,不用动任何现有逻辑。
这就是策略模式的好处,开闭原则玩得很到位。
03、搜索引擎 Provider 抽象
先看接口定义,SearchProvider 只有四个方法:
public interface SearchProvider {
String name(); // provider 名称
boolean isReady(); // 是否可用
String unavailableHint(); // 不可用时的提示
List<SearchResult> search(String query, int topK) throws IOException;
}
为什么要有 isReady() 和 unavailableHint()?
因为用户可能还没配置 API Key 就开始用了。
这时候不是抛异常让程序崩掉,而是友好地提示“请配置 XXX”。
这种防御式设计在 CLI 工具里特别重要,用户的环境千其百怪,你不能假设所有配置都是完美的。
智谱搜索
智谱搜索是我给 PaiCLI 选的默认 Provider,原因很简单:PaiCLI 主要面向国内 GLM 用户,智谱的搜索 API 和 LLM 推理共用同一个 GLM_API_KEY,不需要额外注册、额外付费、额外配置。
调用方式是 POST 请求到 https://open.bigmodel.cn/api/paas/v4/tools/web_search,请求体长这样:
ObjectNode payload = MAPPER.createObjectNode();
payload.put("search_engine", searchEngine); // search_std / search_pro
payload.put("search_query", query);
payload.put("count", count);
payload.put("content_size", "medium");
智谱提供了四种搜索引擎可选:
search_std标准版 0.01 元/次,search_pro增强版 0.03 元/次,- 还有搜狗和夸克的 Pro 版各 0.05 元/次。
默认用 search_std 就够了,一次搜索一分钱,比 SerpAPI 便宜 5 到 10 倍。
返回结果的解析从 search_result 数组里提取 title、link、content 三个字段,封装成 SearchResult 返回。
SerpAPI
SerpAPI 是一个搜索聚合服务,帮我们绕过 Google 的反爬。它需要单独注册账号和 API Key,每月有免费额度。
调用方式是 GET 请求,把关键词和 API Key 拼到 URL 参数里:
HttpUrl url = HttpUrl.parse(ENDPOINT).newBuilder()
.addQueryParameter("q", query)
.addQueryParameter("api_key", apiKey)
.addQueryParameter("num", String.valueOf(maxResults))
.addQueryParameter("hl", "zh-cn")
.build();
解析结果从 organic_results 数组取。如果没有自然搜索结果(比如搜的是计算题),会降级到 answer_box(Google 精选摘要)兜底。
SearXNG
SearXNG 是开源的元搜索引擎,自己不爬互联网,而是把请求转发到 Google、Bing、DuckDuckGo 等几十个引擎再聚合返回。
最大的优点是完全免费,不需要任何 API Key。但需要自己部署,Docker 一行命令就够:
docker run --rm -p 8888:8888 searxng/searxng
然后在 .env 里配置:
SEARCH_PROVIDER=searxng
SEARXNG_URL=http://localhost:8888
工厂自动选择
SearchProviderFactory 负责根据环境变量自动选择最合适的 Provider。选择逻辑很简单:
static String pickProvider(String explicit, String glmKey,
String serpKey, String searxngUrl) {
if (explicit != null && !explicit.isBlank()) {
return explicit.trim().toLowerCase(Locale.ROOT);
}
if (glmKey != null && !glmKey.isBlank()) return "zhipu";
if (serpKey != null && !serpKey.isBlank()) return "serpapi";
if (searxngUrl != null && !searxngUrl.isBlank()) return "searxng";
return "zhipu"; // 默认占位
}
优先看有没有显式指定 SEARCH_PROVIDER,没有的话按 GLM → SerpAPI → SearXNG 的顺序检测哪个的 Key 已经配好。
因为 PaiCLI 用户大概率已经配了 GLM_API_KEY(用来调模型的),所以智谱搜索是零额外配置就能用的。
工厂还会从三个地方读环境变量:系统环境变量、Java 系统属性、.env 文件(当前目录和 home 目录各找一次)。这样不管你是直接 export、还是写在 .env 里、还是用 IDE 的 VM Options,都能读到。
04、WebFetch 抓取器
搜索引擎找到了链接,但很多时候还需要看完整内容。web_fetch 工具就是干这个的。
整个抓取流程分三步:HTTP 请求拿原始 HTML → 安全检查 → 正文提取转 Markdown。
HTTP 抓取
WebFetcher 负责第一步,用 OkHttp 发 GET 请求,拿回原始 HTML 字符串。几个关键参数:
响应体上限 5MB,超出会被截断。30 秒整体超时。字符集优先从 Content-Type 的 charset 参数获取,全失败用 UTF-8 兜底。
public RawResponse fetch(String url) throws IOException {
Request request = new Request.Builder()
.url(url)
.header("User-Agent", "Mozilla/5.0 (compatible; paicli-web-fetch/1.0)")
.get()
.build();
// ... 发请求,读响应,截断大体
}
这里有一个细节:readBounded 方法是流式读取的,每次读 8KB,累计到 5MB 就停。不是先把整个响应体读进内存再截断,那样碰到几百 MB 的文件会直接 OOM。
网络安全策略
在 HTTP 请求发出之前,NetworkPolicy 会先做两件事。
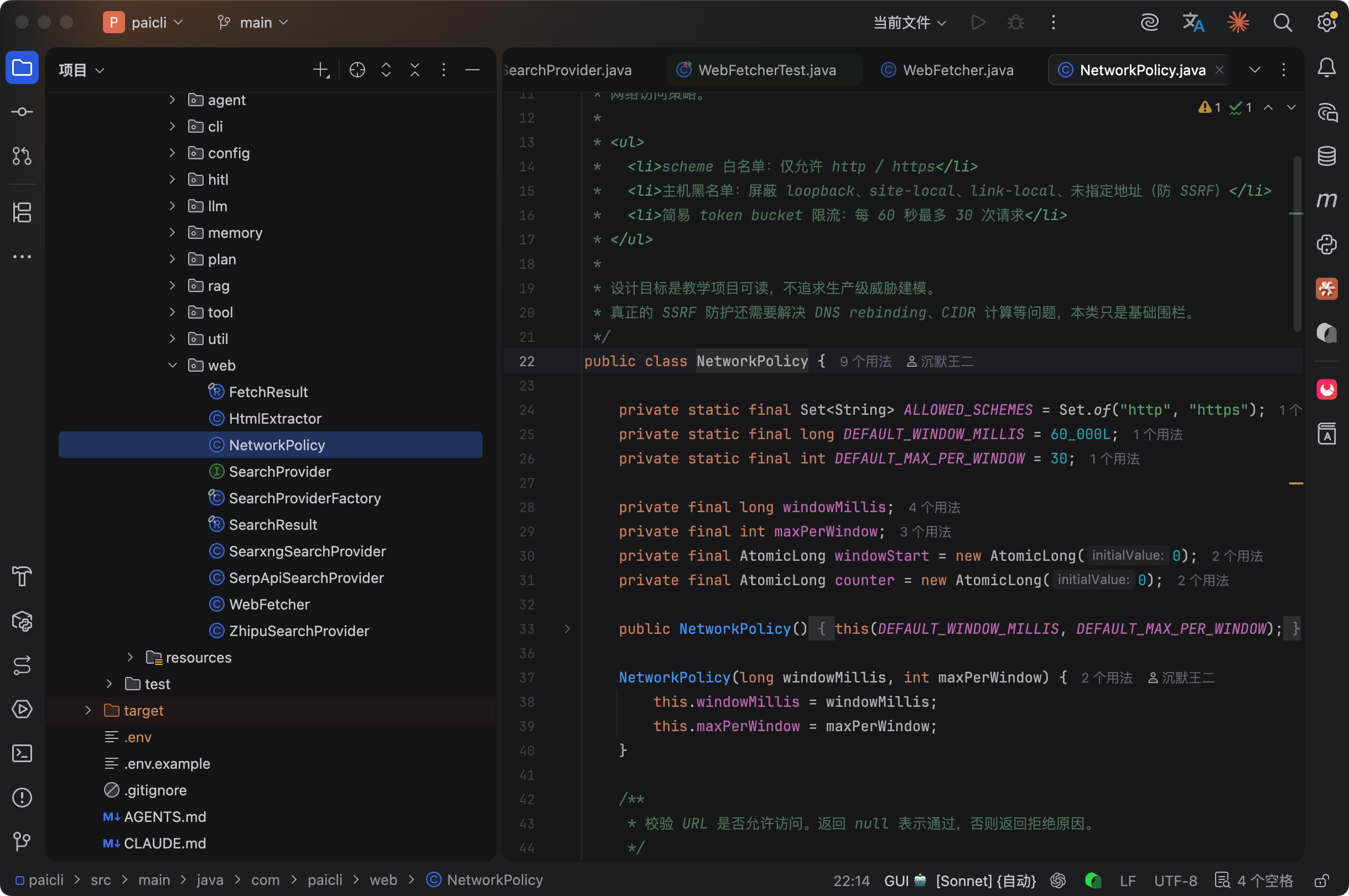
第一件是 URL 安全检查。只允许 http 和 https 协议,不允许 file:// 和 ftp:// 这些。屏蔽 localhost、127.0.0.1、内网地址(192.168.x.x、10.x.x.x),防止 SSRF 攻击。
什么是 SSRF?
假如有人让 Agent 去抓 http://localhost:8080/admin/delete-all,Agent 就会用自己的身份去访问你本机的服务,可能造成严重后果。
NetworkPolicy 就是防这个的。
private String checkHost(String host) {
if (lower.equals("localhost")) return "禁止访问 localhost";
InetAddress[] addrs = InetAddress.getAllByName(host);
for (InetAddress addr : addrs) {
if (addr.isLoopbackAddress()) return "禁止访问环回地址";
if (addr.isSiteLocalAddress()) return "禁止访问站内地址";
// ...
}
return null; // 通过
}
第二件是请求频率限制。60 秒内最多 30 次请求,超出会返回“请求过于频繁”。这个限制是为了防止 Agent 陷入重试循环,疯狂抓同一个网站被封 IP。
HTML 正文提取
HTML 里充斥着导航栏、广告、评论区、页脚这些噪声。直接把整个 HTML 丢给 LLM 既浪费 token 又影响理解。HtmlExtractor 的工作就是把噪声去掉,只留正文,再转成 Markdown。
提取流程分四步:
第一步,清理噪声标签。script、style、nav、aside、footer、header、form、iframe 这些标签直接删掉。class 或 id 里包含 ads、banner、sidebar、comment 等关键词的元素也一并清掉。
第二步,找主语义容器。优先找 <article>、<main>、[role=main] 这些语义化标签。大部分博客和文档站都有这些标签,找到就能直接定位到正文区域。
第三步,打分兜底。如果页面没有语义化标签(很多老网站就是一堆 div 嵌套),就给所有 block 元素打分。打分公式很简洁:文本长度 × (1 - 链接密度惩罚)。文本越多、链接占比越低的元素,越可能是正文。
第四步,转 Markdown。把选中的正文容器递归遍历,h1-h6 转标题、p 转段落、strong 转粗体、a 转链接、pre/code 转代码块、table 转 Markdown 表格。
private double score(Element el) {
String text = el.text();
int textLen = text.length();
if (textLen < 80) return 0;
int linkLen = 0;
for (Element a : el.select("a")) {
linkLen += a.text().length();
}
double linkRatio = (double) linkLen / textLen;
double penalty = Math.min(linkRatio * 2.0, 1.0);
return textLen * (1.0 - penalty);
}
这个打分公式的思路是:导航栏和侧边栏的特征是“链接密度高”,正文的特征是“文字多、链接少”。用链接密度做惩罚,就能比较准确地区分二者。

HtmlExtractor 有一个已知的边界:JS 渲染的 SPA 页面(比如 React/Vue 单页应用)抓回来可能是空白的,因为正文要靠 JavaScript 执行才能生成。
另外一些网站有反爬机制,比如 Cloudflare 的人机验证页面,抓回来也是一堆验证脚本而不是真正的内容。
这个问题会在接入 Chrome DevTools MCP 后解决,到时候会用真正的浏览器去渲染页面,JS 该跑跑、验证码该过过。
目前遇到空正文会返回一条提示:"未提取到正文。可能是 JS 渲染或防爬墙;本期范围内不再重试。",让 Agent 知道这是已知边界,不要反复重试浪费 token。
05、工具注册和 Agent 集成
工具实现好了,还需要注册到 ToolRegistry 里,Agent 才能发现和使用它们。
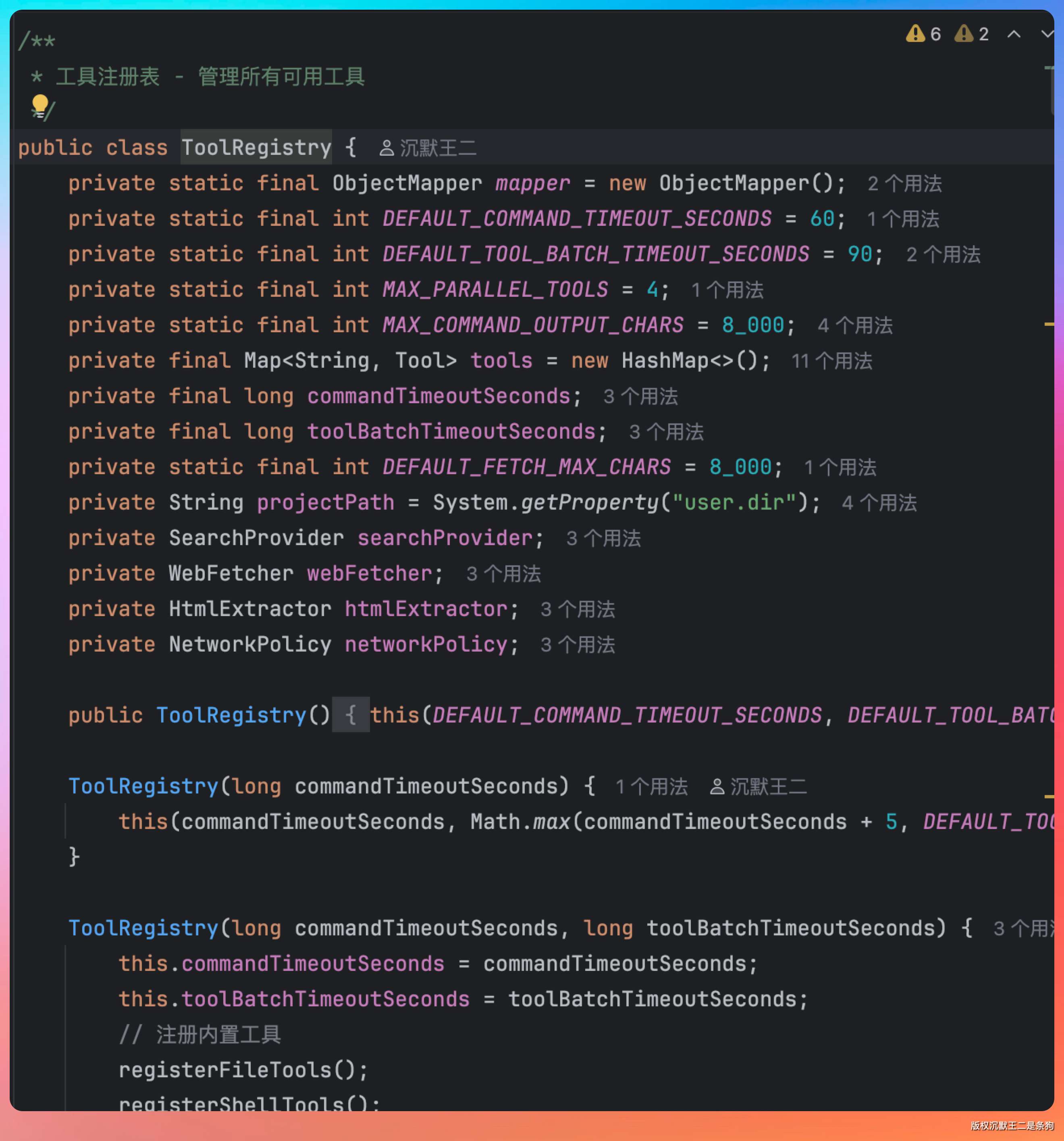
ToolRegistry 是 PaiCLI 的工具中心,所有工具(文件操作、Shell 命令、RAG 检索、联网工具)都在这里注册。注册一个工具需要四样东西:名称、描述、参数定义、执行函数。
private void registerWebTools() {
tools.put("web_search", new Tool(
"web_search",
"搜索互联网,获取实时信息...",
createParameters(
new Param("query", "string", "搜索关键词", true),
new Param("top_k", "integer", "返回结果数量(默认5)", false)
),
args -> webSearch(args.get("query"), parseInt(args.get("top_k"), 5))
));
tools.put("web_fetch", new Tool(
"web_fetch",
"抓取指定 URL,提取正文转 Markdown...",
createParameters(
new Param("url", "string", "完整 URL", true),
new Param("max_chars", "integer", "最大字符数(默认 8000)", false)
),
args -> webFetch(args.get("url"), parseInt(args.get("max_chars"), 8000))
));
}
这里的描述文本很重要,是给 LLM 看的。
LLM 根据工具描述来决定什么时候用什么工具。所以 web_search 的描述里写了“获取实时信息(最新版本、官方文档、技术资讯等)”,给 LLM 明确的使用场景提示。
web_fetch 的描述里写了“适用静态/SSR 页面”和“JS 渲染或防爬站会返回空正文”,让 LLM 知道边界在哪。
SearchProvider 和 WebFetcher 这些组件都是懒加载的——第一次用到的时候才创建实例。因为不是每次对话都需要联网,没必要一起动就初始化网络组件。
private synchronized SearchProvider searchProvider() {
if (searchProvider == null) {
searchProvider = SearchProviderFactory.create();
}
return searchProvider;
}
加了 synchronized 是因为 PaiCLI 支持并行工具调用,多个工具可能同时执行,需要保证只初始化一次。
不加这个关键字的话,两个线程同时进来可能会创建两个 SearchProvider 实例,虽然不会报错但浪费资源,而且状态可能不一致。这是 Java 并发编程里面非常经典的双重检查锁定场景。
06、配置和使用
说完了实现原理,讲讲怎么配置和使用。
最简配置(推荐)
如果你已经有 GLM_API_KEY(用来跑 GLM-5.1 模型的),恭喜你,不需要任何额外配置。
PaiCLI 会自动检测到 GLM_API_KEY,用智谱搜索作为默认搜索引擎。
在项目根目录的 .env 文件里确认一下有这行就行:
GLM_API_KEY=你的智谱API密钥

切换搜索引擎
如果你想用 SerpAPI(国际搜索能力更强),在 .env 里加两行:
SEARCH_PROVIDER=serpapi
SERPAPI_KEY=你的SerpAPI密钥
如果你想用免费的 SearXNG,先启动 Docker 实例,再配置:
docker run --rm -p 8888:8888 searxng/searxng
SEARCH_PROVIDER=searxng
SEARXNG_URL=http://localhost:8888
实际使用
启动 PaiCLI 后,Agent 会自动识别哪些问题需要联网。你不需要手动指定“用搜索工具”,Agent 自己会判断。
几个典型的使用场景:
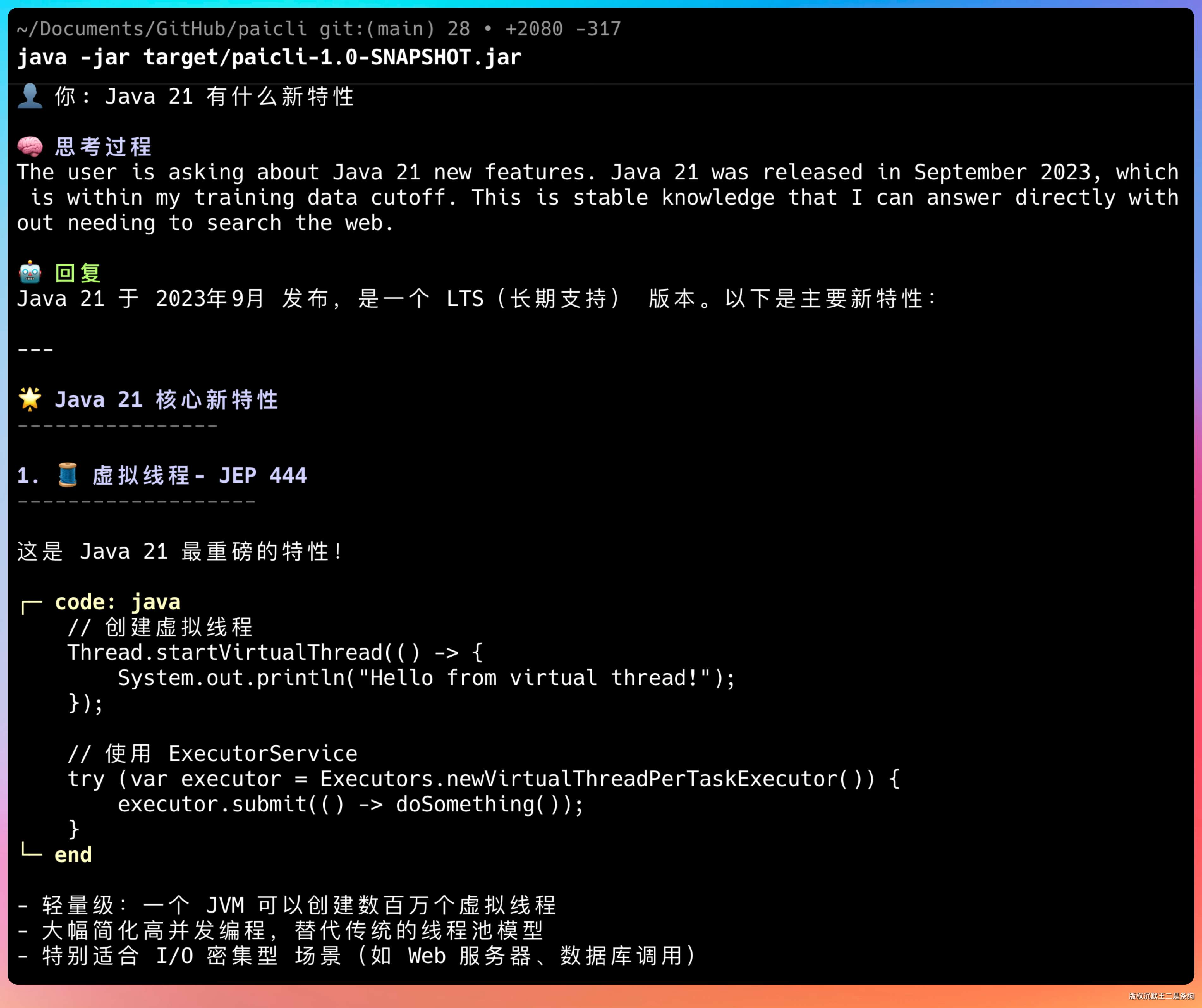
问“Java 21 有什么新特性”,Agent 会调用 web_search 去搜索最新信息。
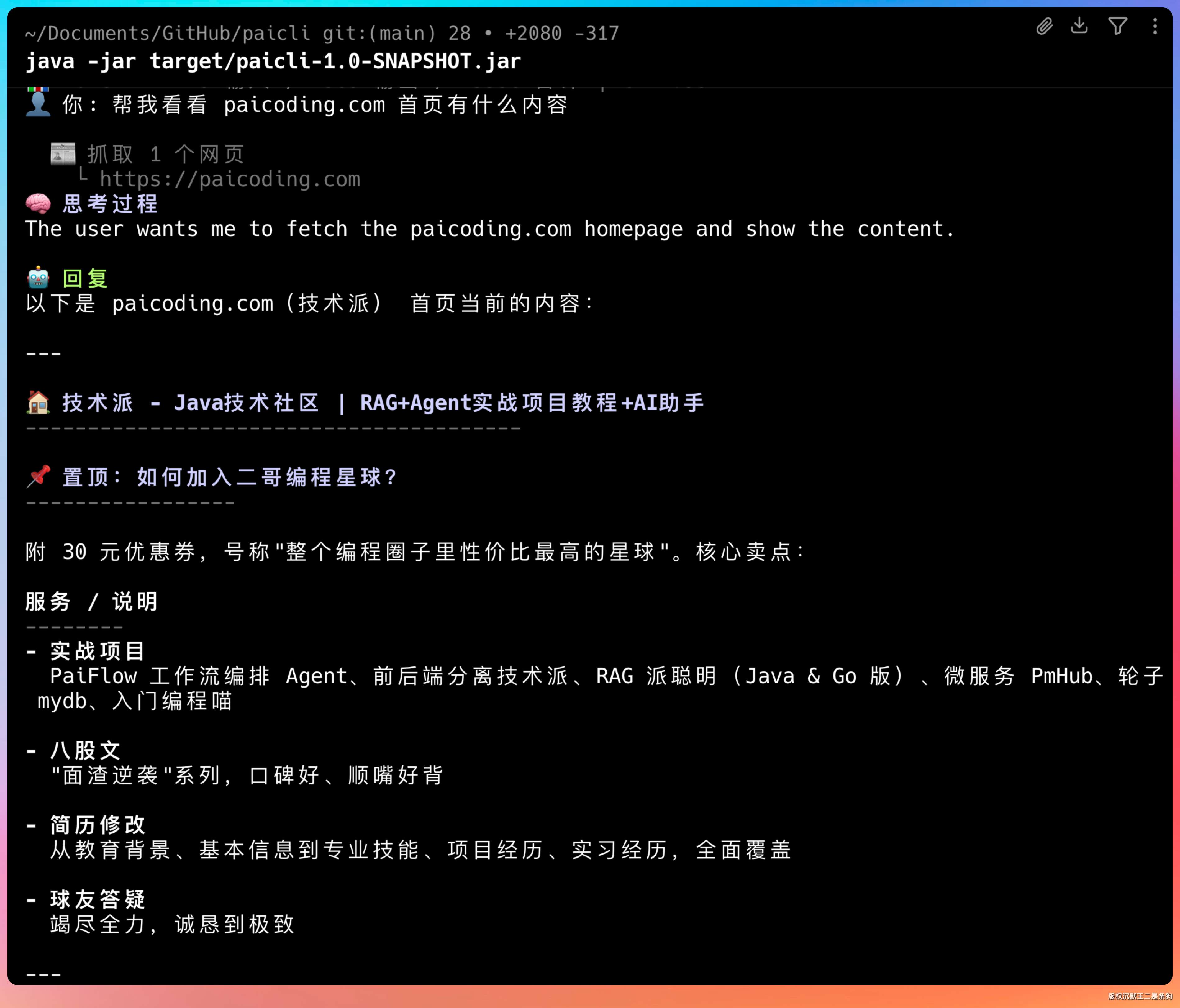
问“帮我看看 paicoding.com 首页有什么内容”,Agent 会调用 web_fetch 去抓取页面。
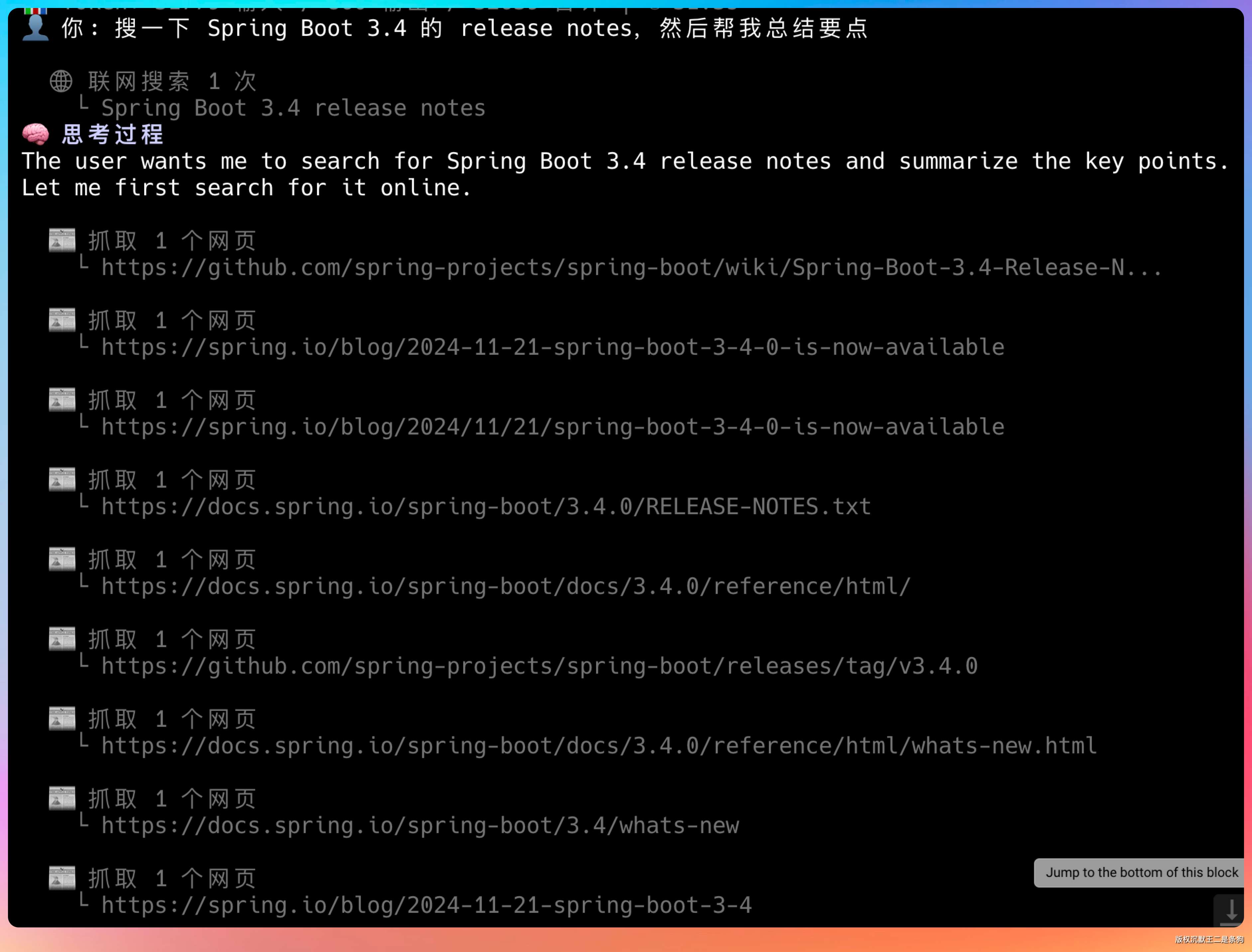
问“搜一下 Spring Boot 3.4 的 release notes,然后帮我总结要点”,Agent 会先搜再抓,组合使用两个工具。
这里有个小技巧:如果你觉得搜索结果不够详细,可以追问一句“帮我打开第一条链接看看详细内容”,Agent 就会自动用 web_fetch 去抓取搜索结果里的 URL。搜索 + 抓取的组合拳打法,基本上能覆盖百分之 80 的联网需求了。
07、如何把 PaiCLI 写到简历上?
学完这一期,大家可以在简历上这样写:
- 项目名称:PaiCLI - Java Agent CLI
- 项目简介:从零构建的生产级 Java Agent 命令行工具,支持联网搜索、网页抓取、RAG 检索、多 Agent 协作等能力
- 技术栈:Java 21、OkHttp、Jsoup、GLM-5.1/DeepSeek V4、策略模式、工厂模式
- 核心职责:
- 基于策略模式设计了 SearchProvider 搜索引擎抽象层,支持智谱/SerpAPI/SearXNG,可在运行时自动选择和热切换
- 实现了基于 Jsoup 的 Readability 正文提取算法,通过语义标签优先+链接密度评分的两阶段策略准确提取网页正文
- 设计 NetworkPolicy 网络安全策略,包括 SSRF 防护(scheme 白名单+host 黑名单+DNS 解析校验)和令牌桶限流
- 基于工厂模式实现了 SearchProviderFactory,支持从环境变量、系统属性、.env 文件三级回退读取配置,实现零额外配置的开箱即用体验
- 将 web_search 和 web_fetch 作为 Function Calling 工具注册到 Agent 的工具链中,实现了 LLM 自主判断联网时机的智能工具选择
项目源码地址:https://github.com/itwanger/paicli,第 9 期的代码已经全部提交。
欢迎大家 star、fork、提 issue,一起把这个项目做得更好。
ending
从第 1 期的 400 行 ReAct 循环,到现在第 9 期加上联网能力,PaiCLI 已经不再是一个“只会操作本地文件”的 Agent 了。
搜索让它知道世界上正在发生什么,
抓取让它能真正读懂一个网页在说什么,
安全策略让它不会乱来。
如果你也想从零开始理解 Agent 是怎么一步步搭建起来的,
跟着 PaiCLI 的路线图走就对了。
每一期都有完整代码、有真实 case、有可以写进简厉的亮点。
【最好的学习方式不是看别人怎么用,而是自己从零造一个。】
我们下期见。

回复