


大家好,我是二哥呀。
4 月份的大模型圈子实在太热闹了。
先是 4月初发布的 GLM-5.1;
接着是 Claude Opus 4.7(虽然有点降智,但编码仍然比较强);
再接着是 GPT-5.5 发布,口碑直接逆转 Opus 4.7;
然后就是 4 月 24 号发布的 DeepSeek V4,再一次证明了国产开源模型的实力。
接下来,我将通过 7 个 case,同一套提示词,全方位地对比一下 GLM-5.1 和 DeepSeek V4,覆盖全栈开发、技术架构图、RAG 问答、数据可视化这些维度,尽可能把两个模型的底层能力展现得淋淋尽致。
先上两张图大家对比下,上面是用GLM-5.1,下面是用DeepSeek V4,载体都是draw.io,我个人还是非常喜欢的,平常文章的排版也都是用GLM或者DeepSeek来完成的,质量非常高。
这种技术风格的绘图水平,比起 GPT-Image2,我更喜欢这一类。
全文比较肝,系好安全带,我们粗粗粗发!!😄
01、有请两位选手上台
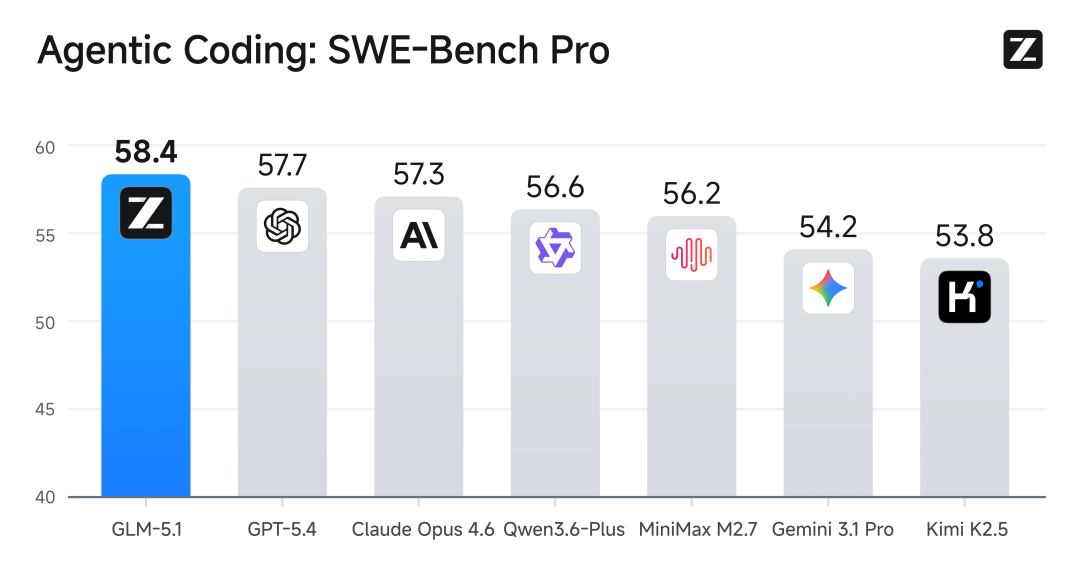
GLM-5.1,在长任务上表现突出,能连续工作8个小时不间断,中间遇到 bug 会自己调试、自己切换策略、自己修复错误,最后交付工程级的成果。在 SWE-bench Pro 上拿了全球最高分,代码能力确实是第一梯队。
我之前用 GLM-5.1 从 0 到 1 完成了一个 AI 智能简历生成 Agent,能力没得说。已开源在GitHub。
【录屏】
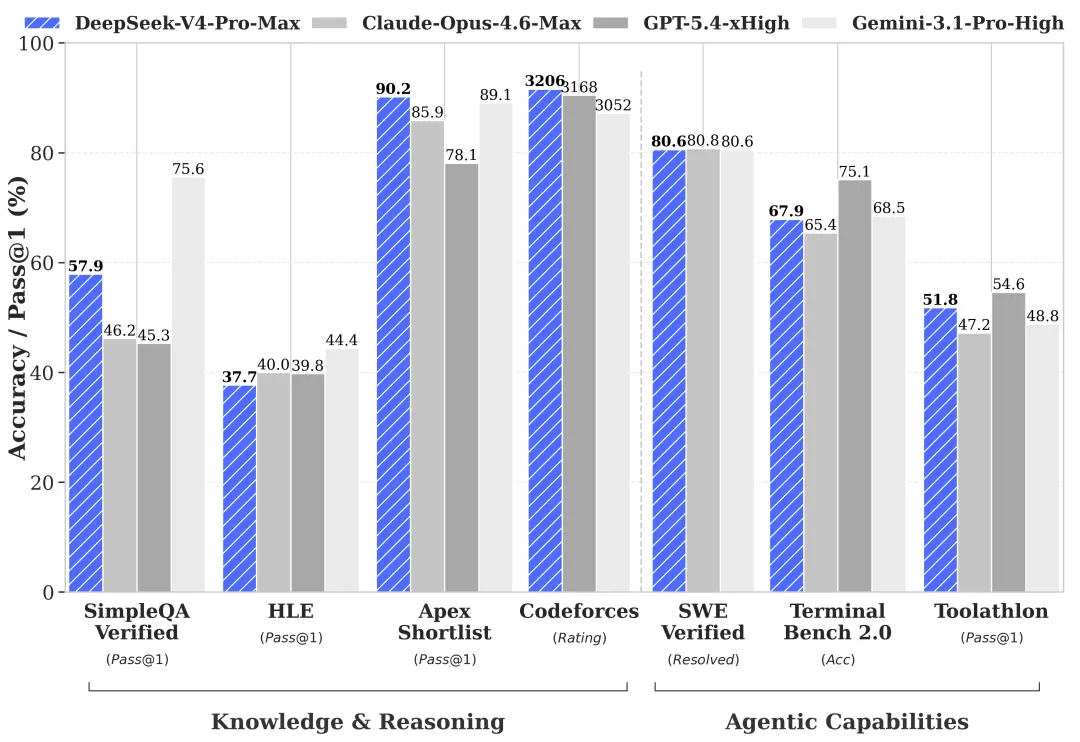
DeepSeek V4,Pro 版 1.6T 参数(49B 激活),支持 100 万 token 的上下文窗口,使用体验优于 Sonnet 4.5,交付质量接近 Opus 4.6 非思考模式。
我之前用 DeepSeek V4 给派聪明新增了一个多对话功能,后端没问题,但前端的能力有很大进步空间。
使用的Agent工具都是Claude Code,我是通过自己的PaiSwitch进行底层模型切换的。
非常方便。
接下来,我就先跑 GLM-5.1,再切到 DeepSeek V4,把两家模型的实际表现展示给大家。有想看两家模型效果的小伙伴,这下可以大饱眼福了~~~~
模型我都已经配置好了,点点切换就可以了。
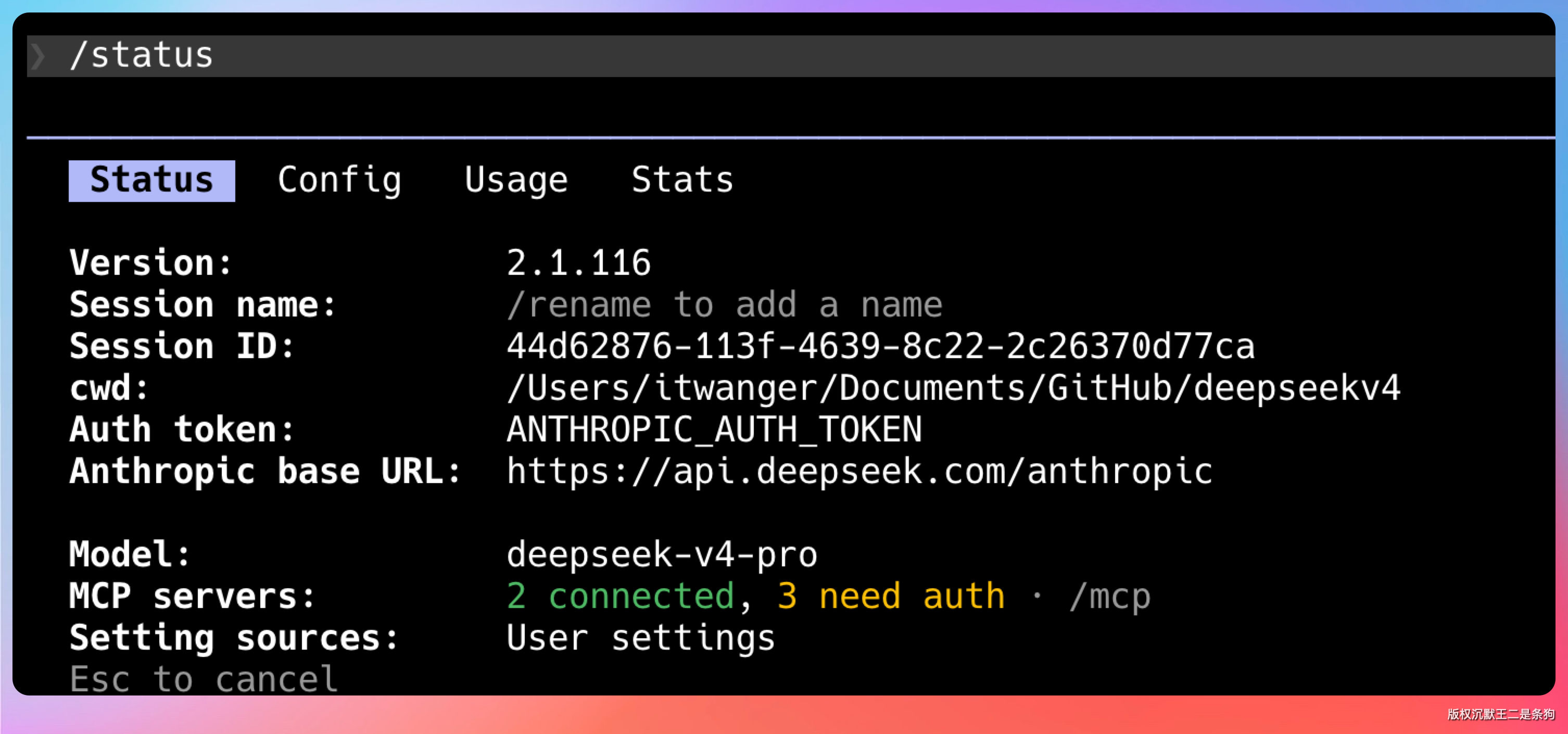
记得启动Claude Code后输入 /status 确认一下。
02、麻将教学网站
第一个 Case 来个有意思的,做一个麻将教学网站。
我参考了一个做得很漂亮的麻将视觉指南网站 themahjong.guide,设计很养眼,用卡片式布局展示各种牌型,配色清新,交互流畅。
来看看两个模型能不能也搞出这种水准的网站。
提示词是这样的:
请帮我做一个麻将教学网站,要求如下:
1. 整体风格:参考 themahjong.guide 的视觉设计,采用卡片式布局,配色要有中国风元素(朱红、墨绿、金色点缀),整体干净清爽
2. 页面结构:
- 顶部导航栏:logo + 四个板块(基础入门 / 牌型图鉴 / 番型速查 / 实战技巧)
- Hero 区域:大标题“麻将视觉指南”,配一句 slogan,背景用麻将牌的抽象纹理
- 牌型图鉴区:用 CSS 绘制麻将牌面(万、条、筒各 1-9,东南西北中发白),鼠标悬停显示牌名和读音
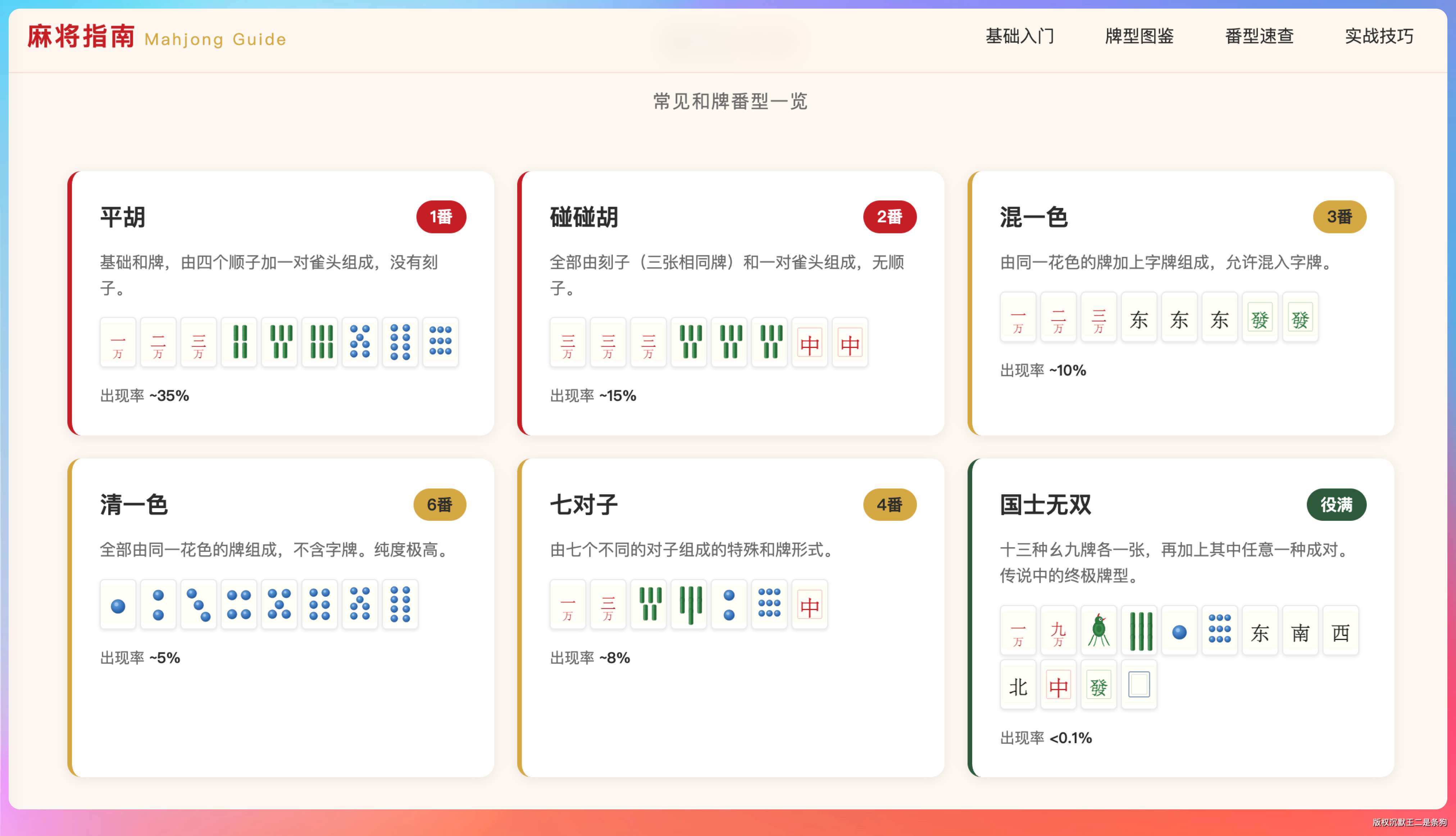
- 番型速查区:常见番型(平胡、碰碰胡、清一色、七对、国士无双等)用卡片展示,每张卡片包含番型名称、番数、示例牌组、胜率参考
- 底部:一个简单的“随机发牌”互动模块,点击按钮随机生成一手 13 张牌
3. 技术要求:纯 HTML + CSS + JavaScript,单文件实现,不依赖外部库
4. 交互细节:卡片 hover 有微动画,页面滚动有渐入效果,整体要有质感
涵盖了布局设计、视觉风格、数据展示、交互效果,非常考验模形的综合能力。
GLM-5.1 的表现
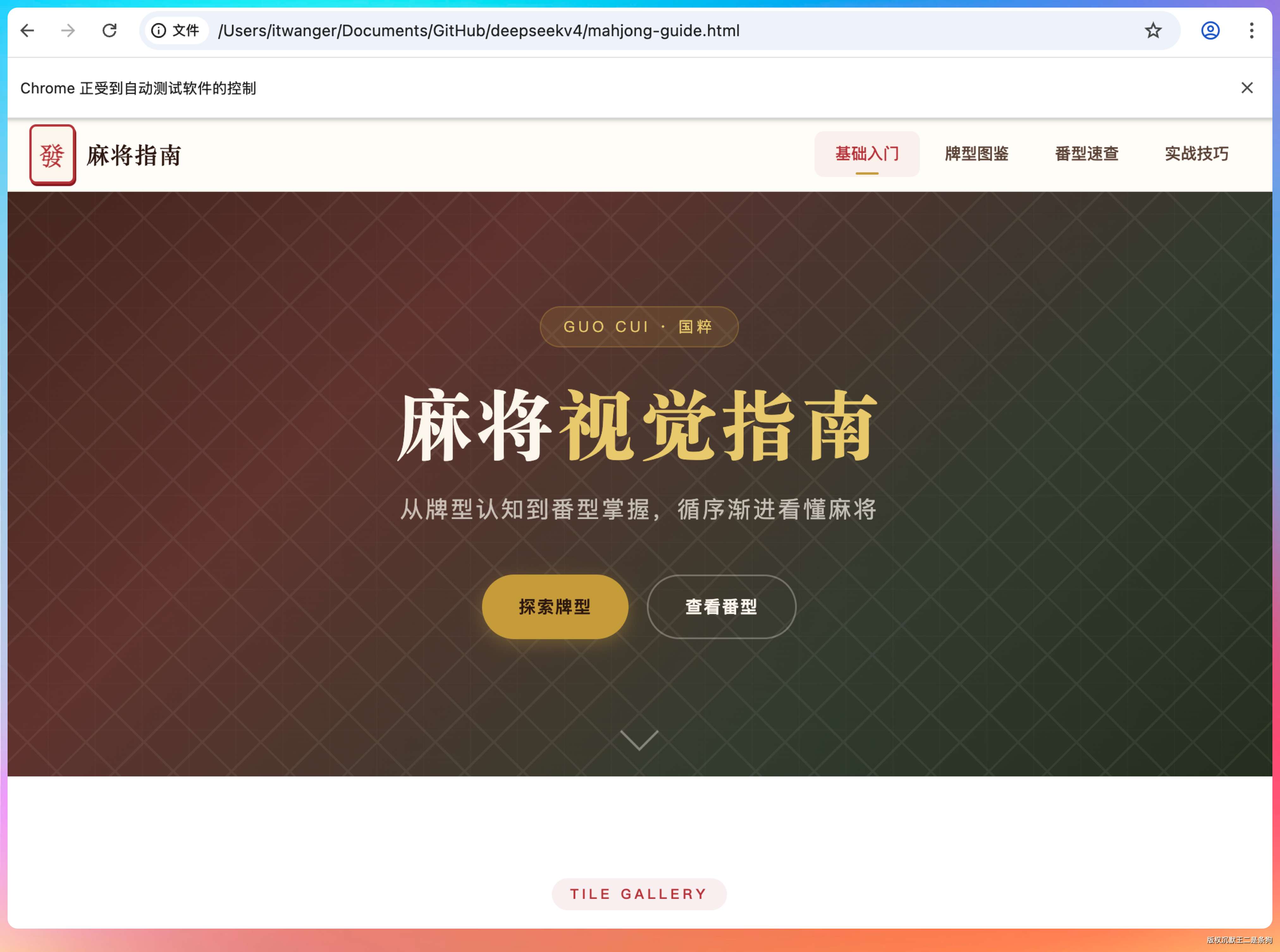
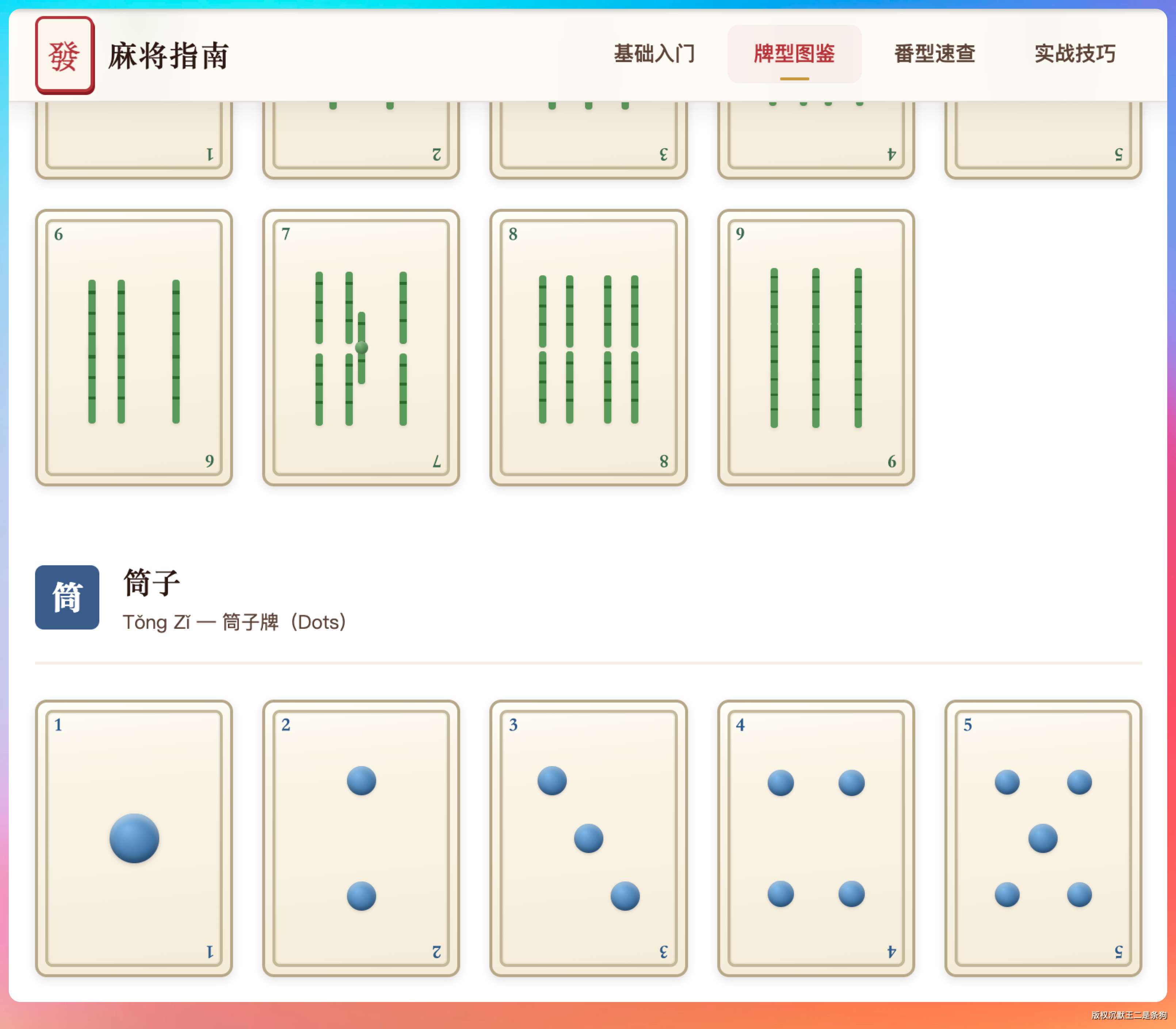
GLM-5.1 很快就搞定了。
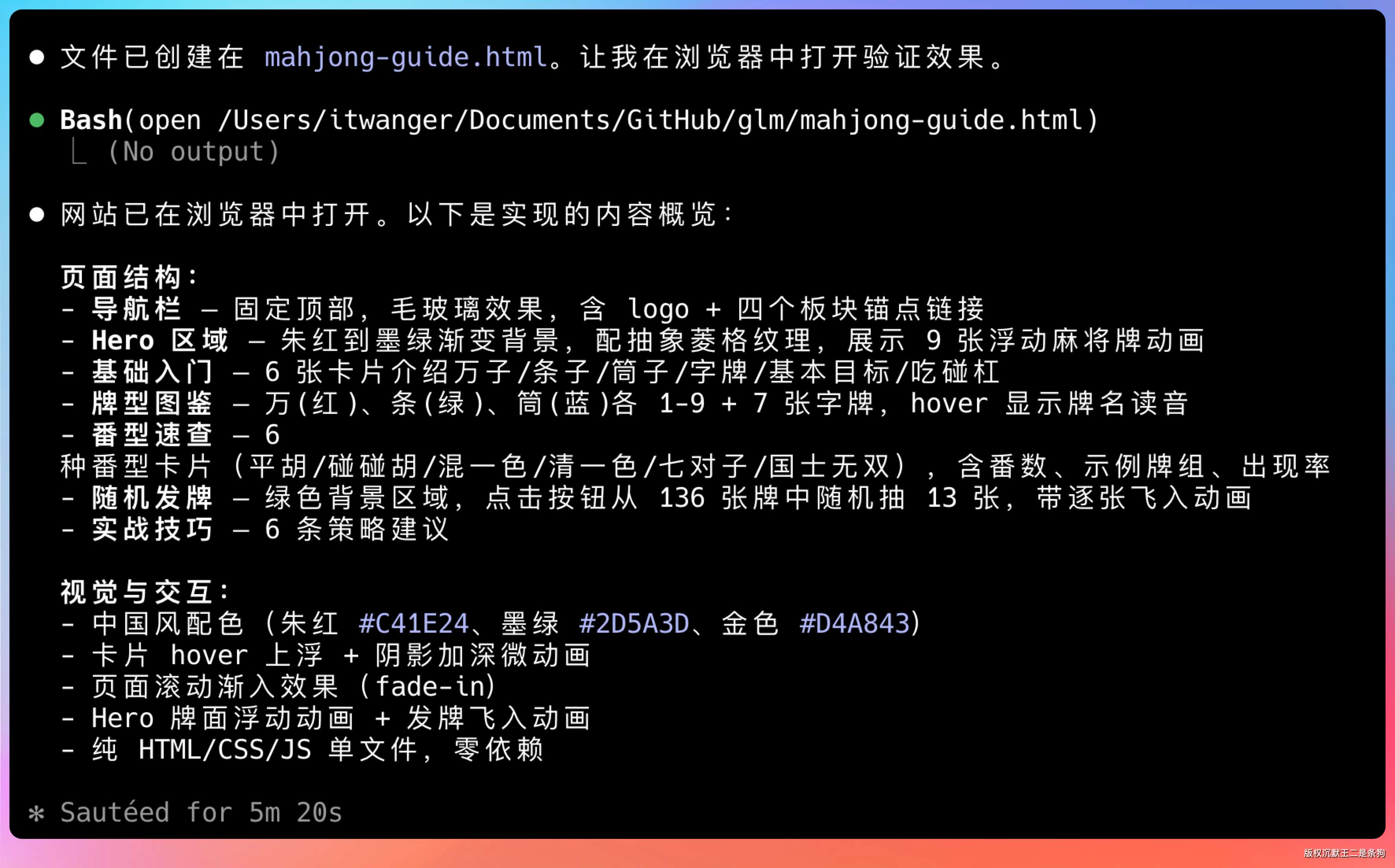
整体布局规整,中国风的配色拿捏得不错,朱红和墨绿的搭配看着很舒服。
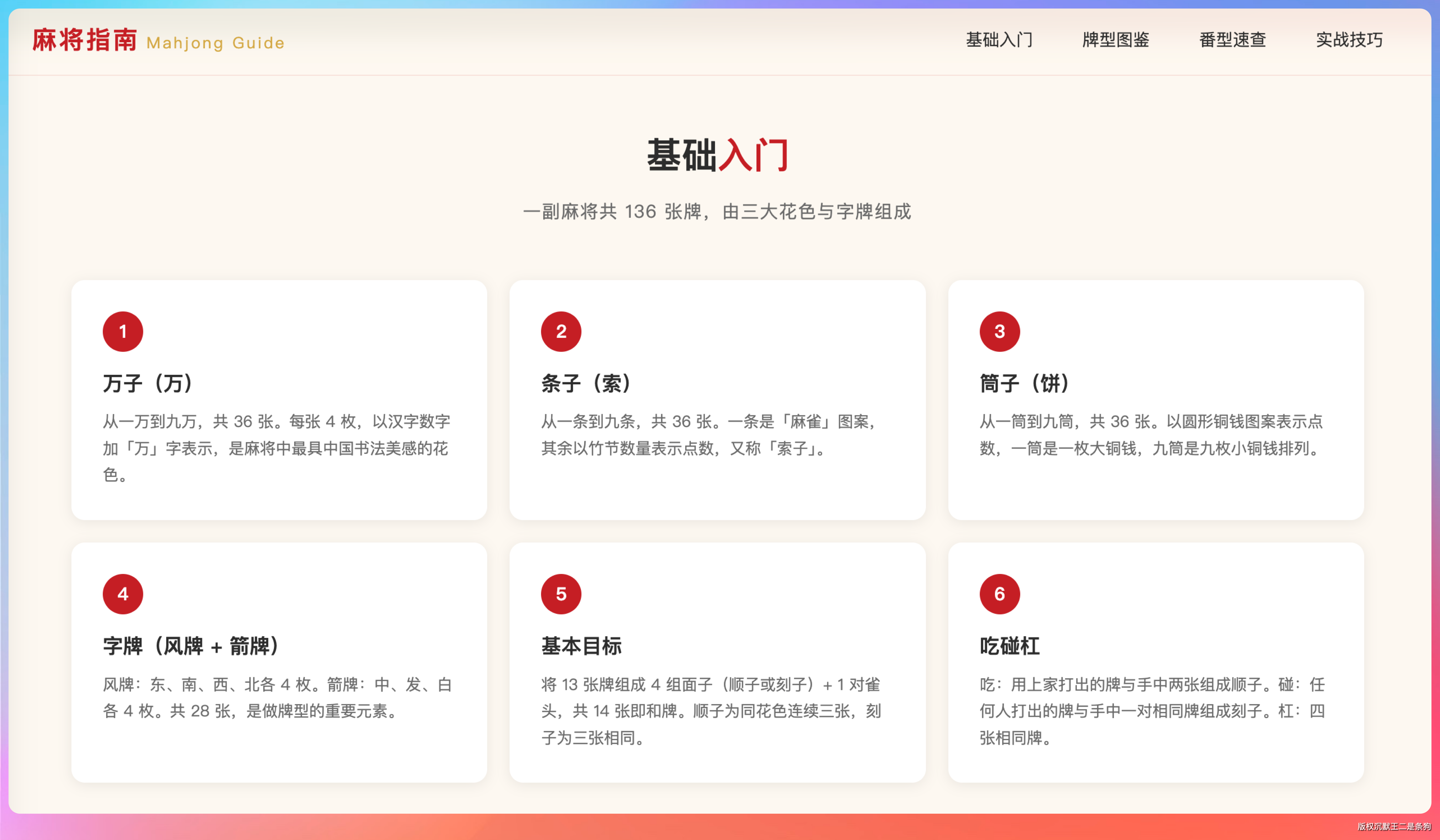
麻将牌面用 CSS 画的,万子牌上的汉字渲染得很清楚,条子牌用竹筒模拟,筒子牌用圆形模拟。hover 动画做了一个轻微上浮 + 阴影加深的效果,番型卡片的排版也挺紧凑。
在没有任何多余的提示词,以及矫正情况下(没有抽卡,一次性),这个效果,已经超出了我的预期。
随机发牌模块能正常工作,点一下确实能随机出 13 张牌,还带了一个简单的翻牌动画。

DeepSeek V4 的表现
好,我们把 Claude Code 的底层模型切到DeepSeek V4。
完全一样的提示词。
DeepSeek V4 走了一个不太一样的路线。它的配色偏向深色系,用了墨绿做底色,金色做点缀,整体看起来像一个棋牌室的感觉。

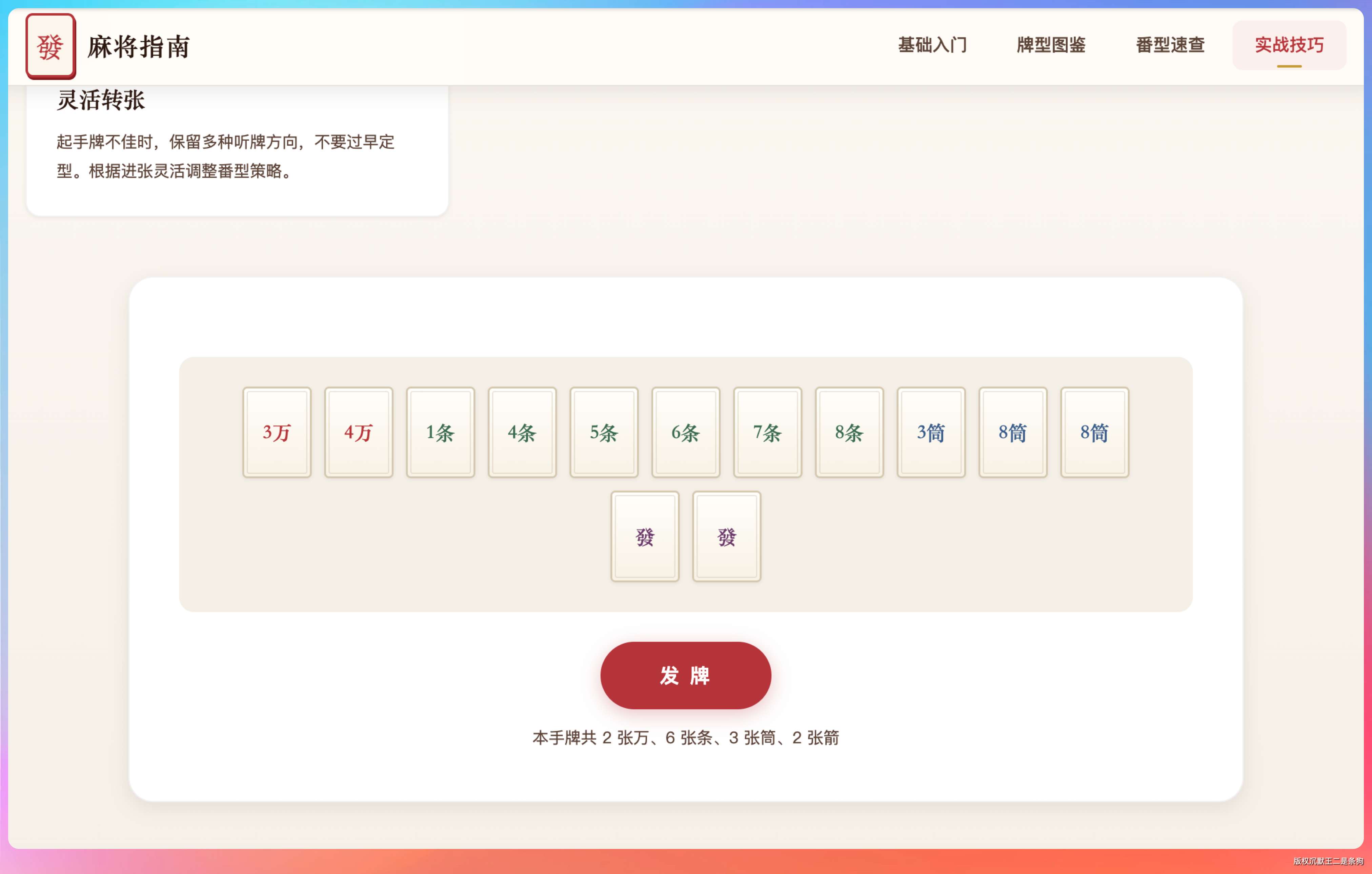
比较遗憾的是,牌的正面没有做拟物化,很多是用数字来代替的,需要二次调教。
03、draw.io 技术架构图
第二个 Case 测试两个模型生成 draw.io 的绘图能力。
平常我文章的配图基本上就是这么来的。
注意我这里已经配置好两个模型了。
我准备了四组提示词,都是和 AI 技术相关的架构图。
第一组:ReAct 原理流程图
画一张 ReAct(Reasoning + Acting)的原理流程图,要求:
1. 展示完整的 ReAct 循环:用户输入 → Thought(推理) → Action(调用工具) → Observation(观察结果) → 判断是否完成 → 完成则输出最终答案,未完成则回到 Thought
2. 用不同颜色区分:Thought 用蓝色系,Action 用橙色系,Observation 用绿色系
3. 在每个节点旁边加一个具体的例子
4. 整体布局从上到下,循环部分用虚线箭头回连
5. 标题写“ReAct: Synergizing Reasoning and Acting in LLMs”
流程图的结构非常清晰,从上到下的布局一目了然。
颜色区分做到了,蓝色的 Thought 节点、橙色的 Action 节点、绿色的 Observation 节点,循环箭头也画对了。
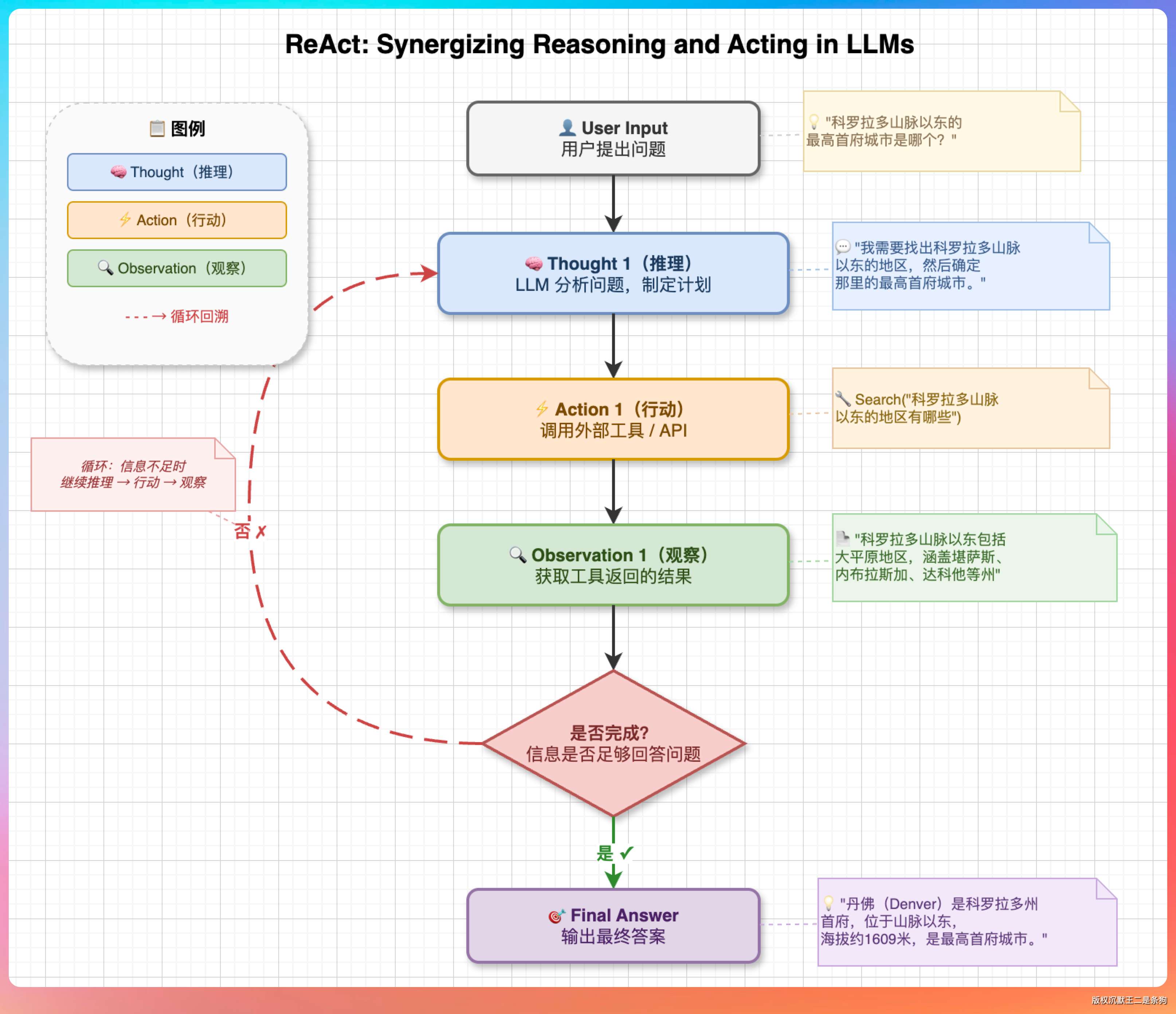
旁边的例子文本排版整齐,没有出现文字溢出的情况。
DeepSeek V4 这边,流程图的整体观感偏“轻量化”一些。
RAG 的整体思路是没问题的,但节点旁边的 case 丢了。思考的时间也比 GLM-5.1 更久一点。
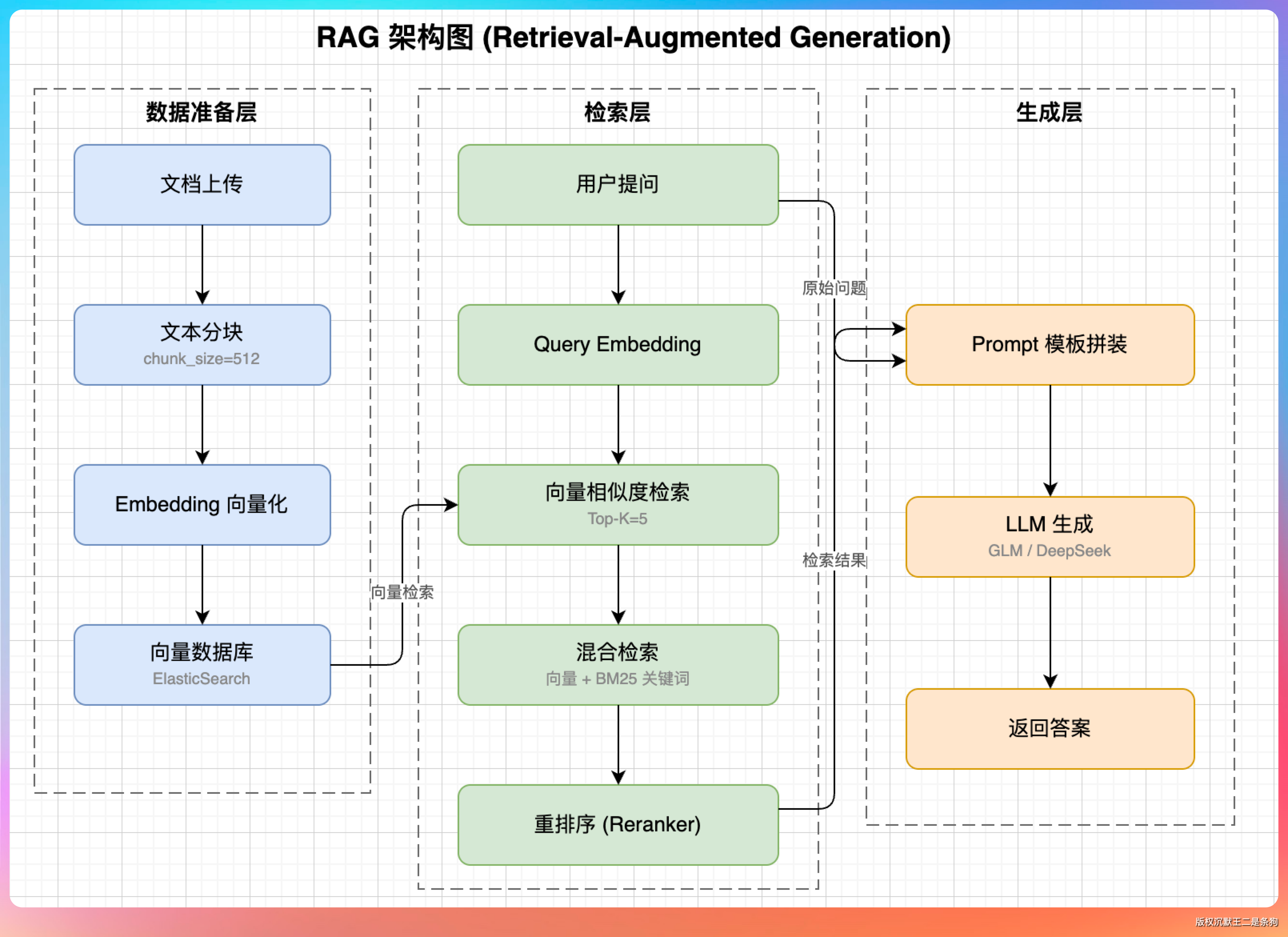
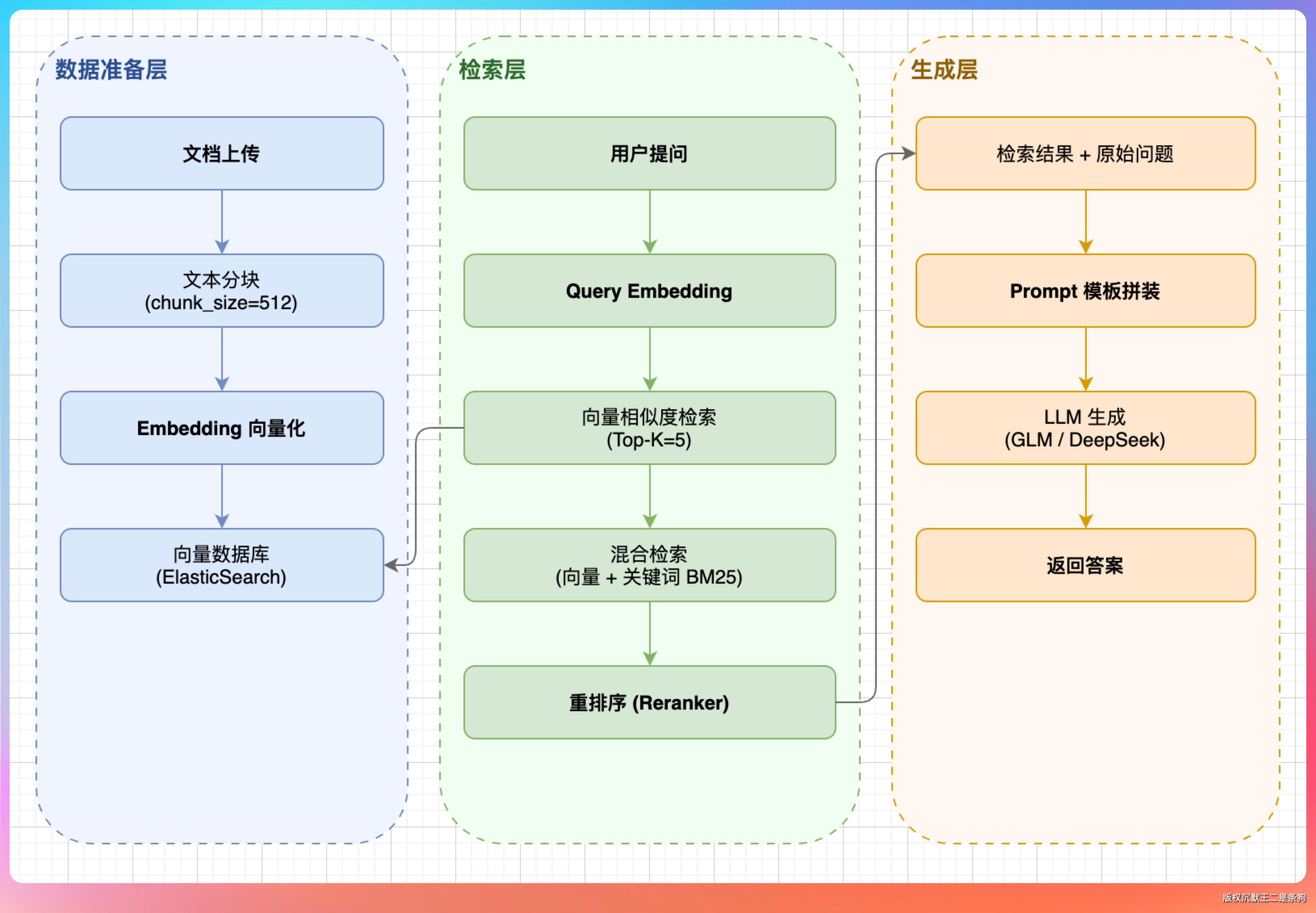
第二组:RAG 架构全景图
画一张 RAG(Retrieval-Augmented Generation)的完整架构图,要求:
1. 分三个大区域:数据准备层(左侧)、检索层(中间)、生成层(右侧)
2. 数据准备层包括:文档上传 → 文本分块(标注 chunk_size=512)→ Embedding 向量化 → 存入向量数据库(标注 ElasticSearch)
3. 检索层包括:用户提问 → Query Embedding → 向量相似度检索(标注 Top-K=5)→ 混合检索(向量 + 关键词 BM25)→ 重排序(Reranker)
4. 生成层包括:检索结果 + 原始问题 → Prompt 模板拼装 → LLM 生成(标注支持 GLM/DeepSeek)→ 返回答案
5. 用虚线框把三个区域框起来,每个区域标注名称
6. 数据流方向从左到右,用带箭头的实线连接
这个提示词信息量很大,考验模型能不能在一张图里把 RAG 的全流程画清楚。
GLM-5.1 的版本三个区域划分得很规整,虚线框的标注也都有。
数据流从左到右,从上到下,看一眼就能理解整个 RAG 的工作流程。
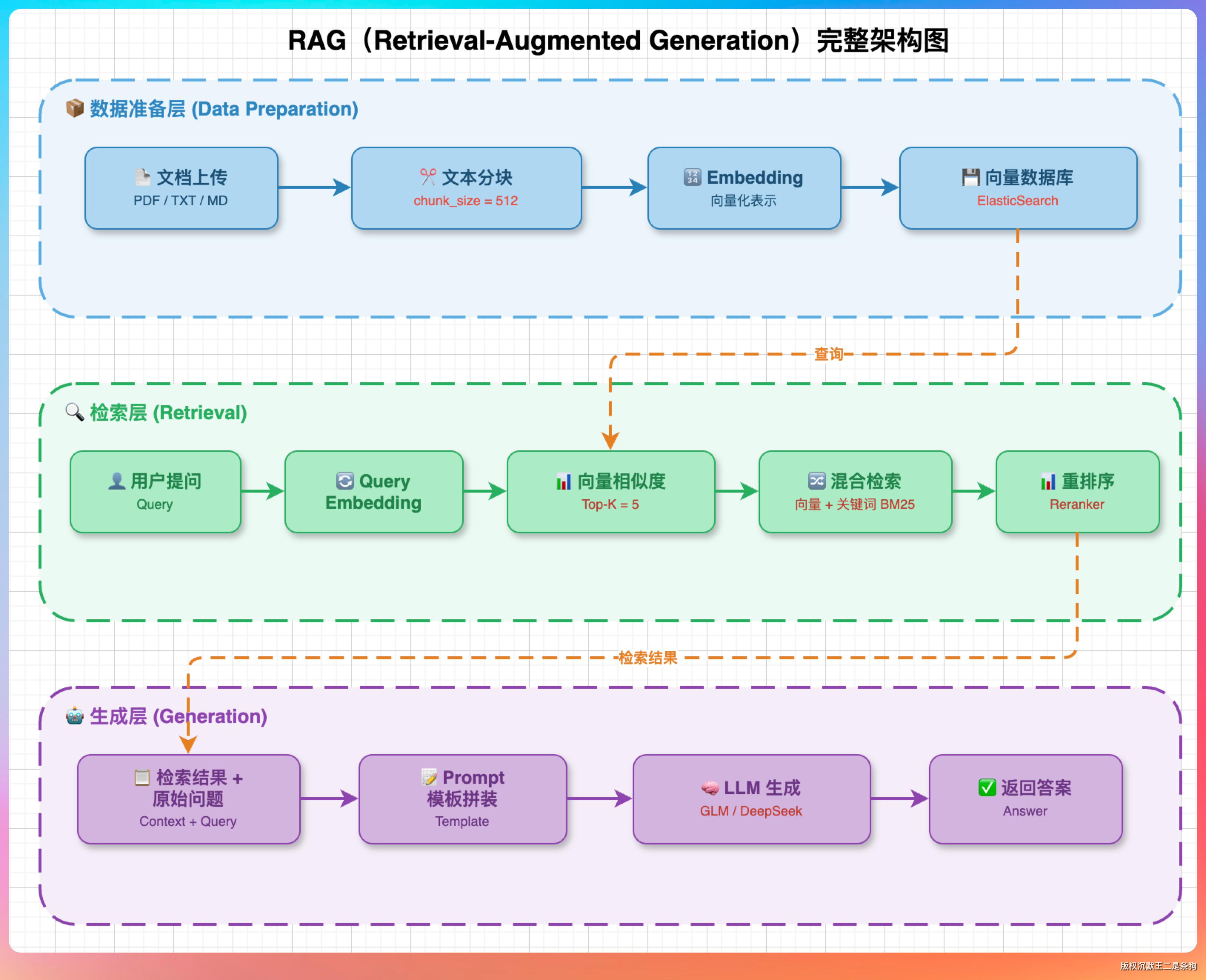
DeepSeek V4 仍然是简洁风,排版更喜欢从左到右一次排列,细节没丢。
第三组:MoE 混合专家架构图
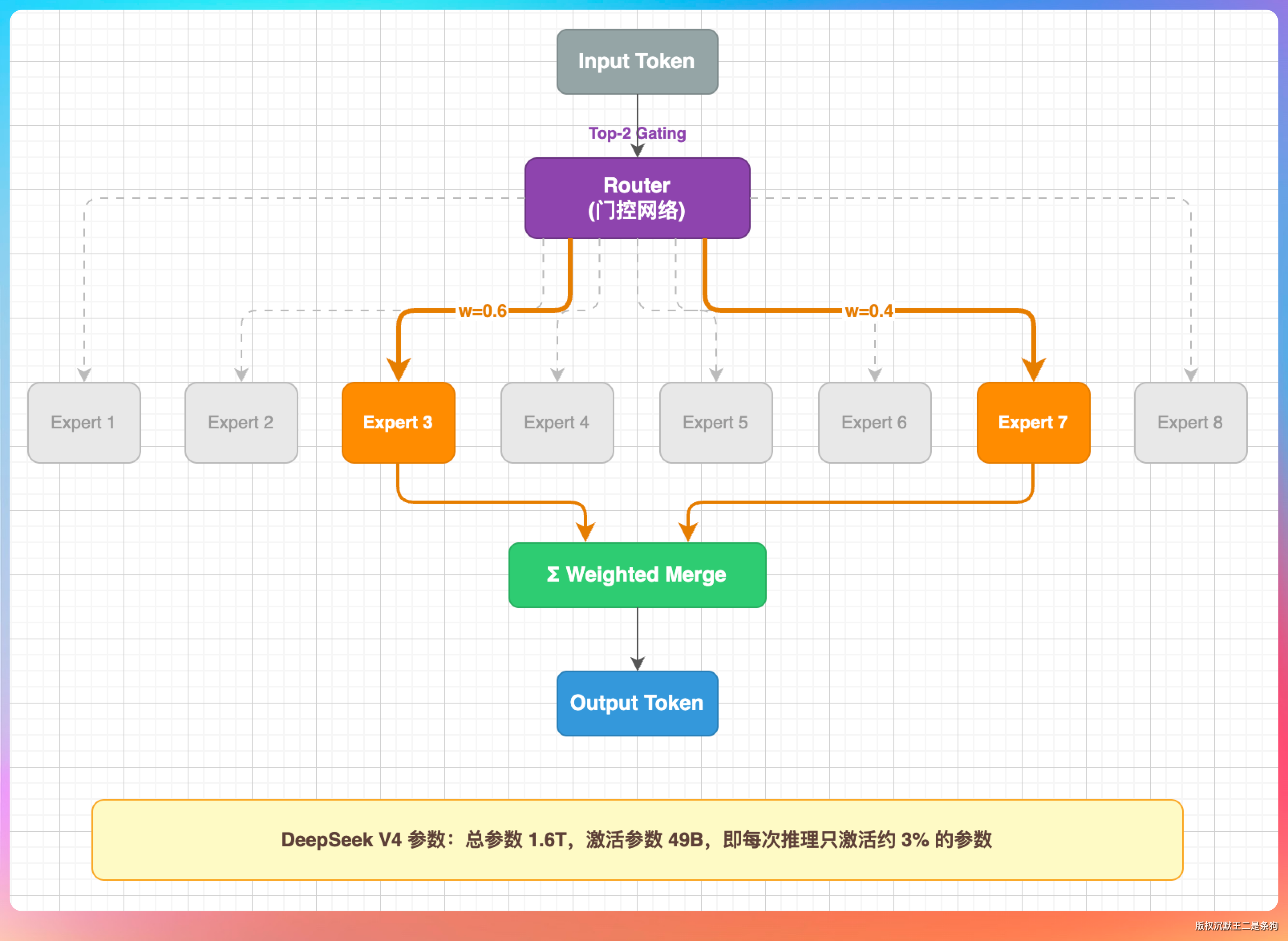
画一张 Mixture of Experts(MoE)架构的原理图,要求:
1. 展示一个完整的 MoE 层结构:输入 Token → Router(门控网络)→ 选择 Top-2 专家 → 两个被选中的专家并行计算 → 加权合并 → 输出
2. 画 8 个 Expert 方块排成一排,其中 Expert 3 和 Expert 7 高亮表示被选中,其余灰色
3. Router 到每个 Expert 之间画连线,被选中的用粗实线 + 权重标注(如 w=0.6 和 w=0.4),未被选中的用细虚线
4. 在图的下方加一个注释框,写明“DeepSeek V4 参数:总参数 1.6T,激活参数 49B,即每次推理只激活约 3% 的参数”
5. 配色方案:Router 用紫色,被选中的 Expert 用橙色,未选中的用浅灰色
这张图对排版的要求比较高,8 个 Expert 要排成一排还要区分状态,考验模型对空间布局的理解。
GLM-5.1 画出来的 MoE 图排版很规范。8 个 Expert 均匀排列,高亮的 Expert 3 和 Expert 7 确实是橙色的,权重标注 w=0.6 和 w=0.4 也放在了连线上。Router 的紫色节点在正上方居中,整体对称感很好。底部的注释框信息准确。
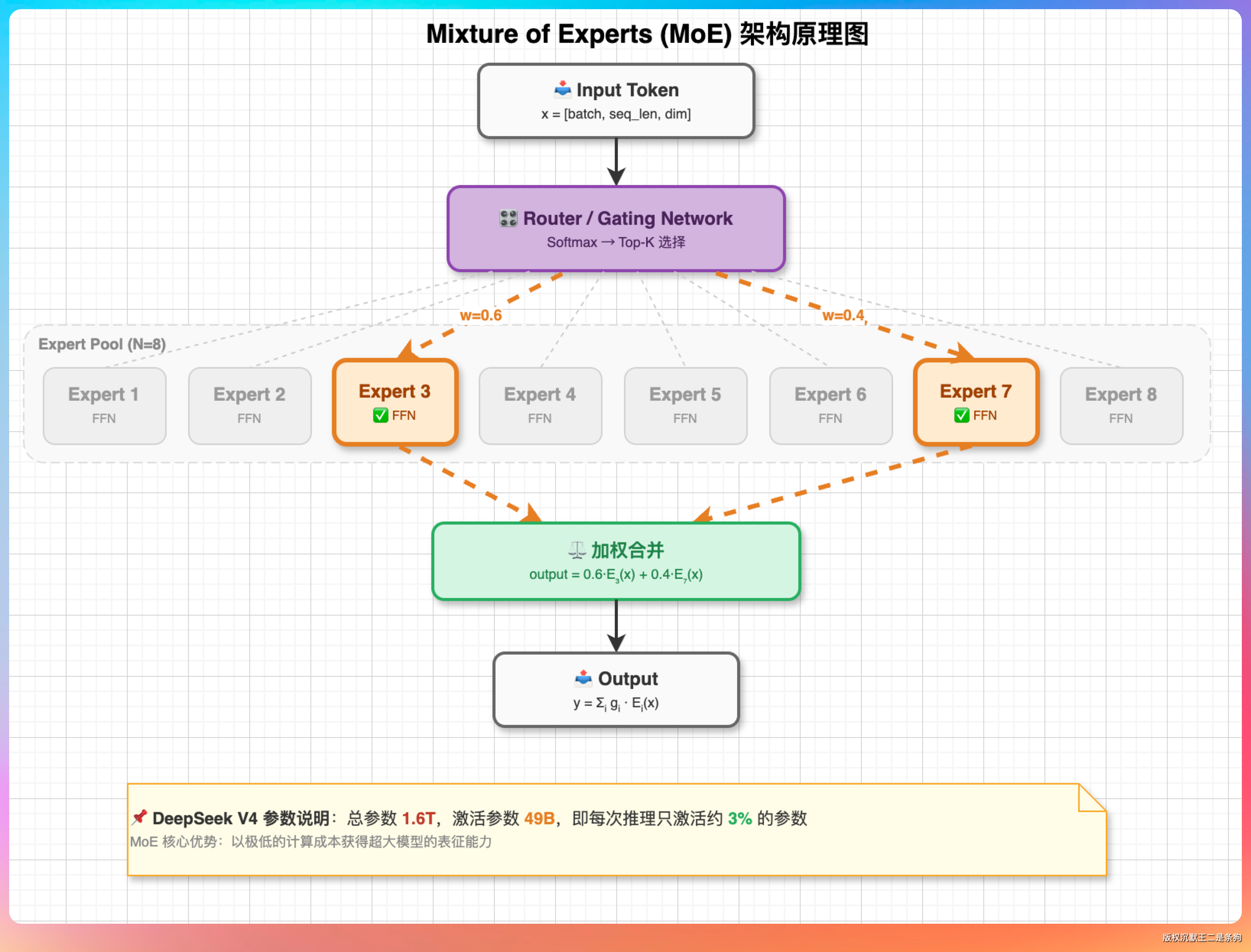
DeepSeek V4 的输出要素和GLM-5.1差不多,色彩搭配我认为也比较合理。
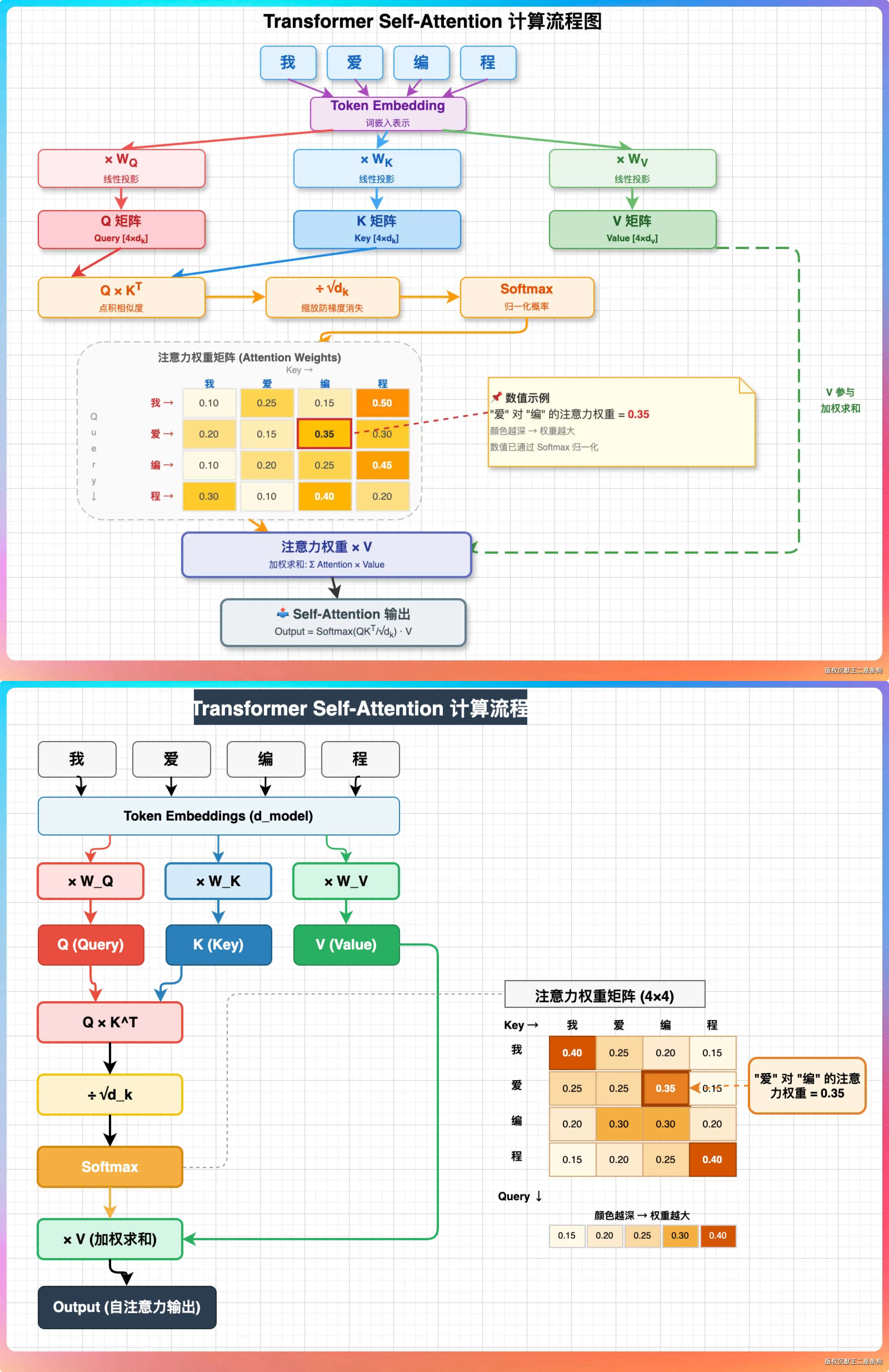
第四组:Transformer 自注意力机制图
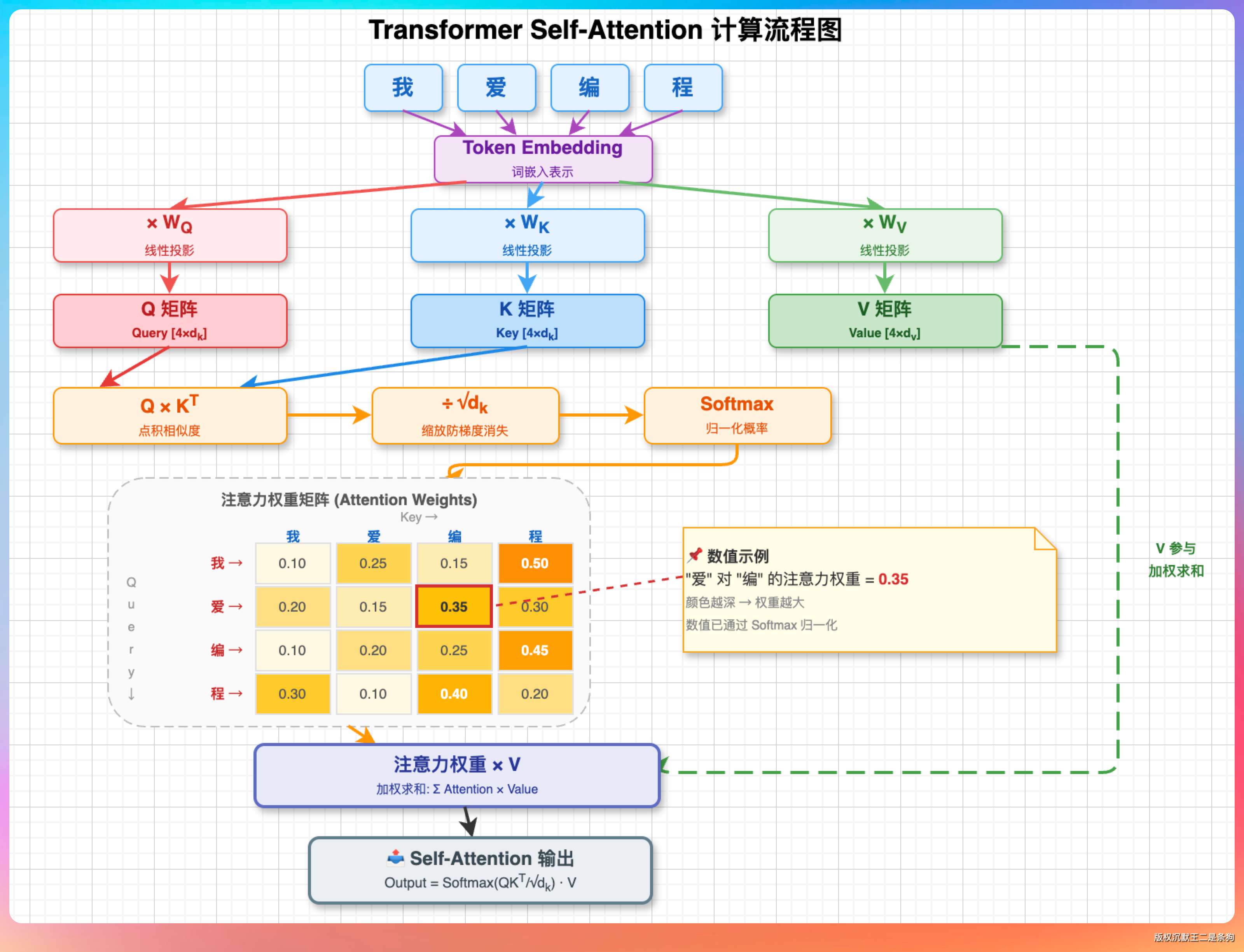
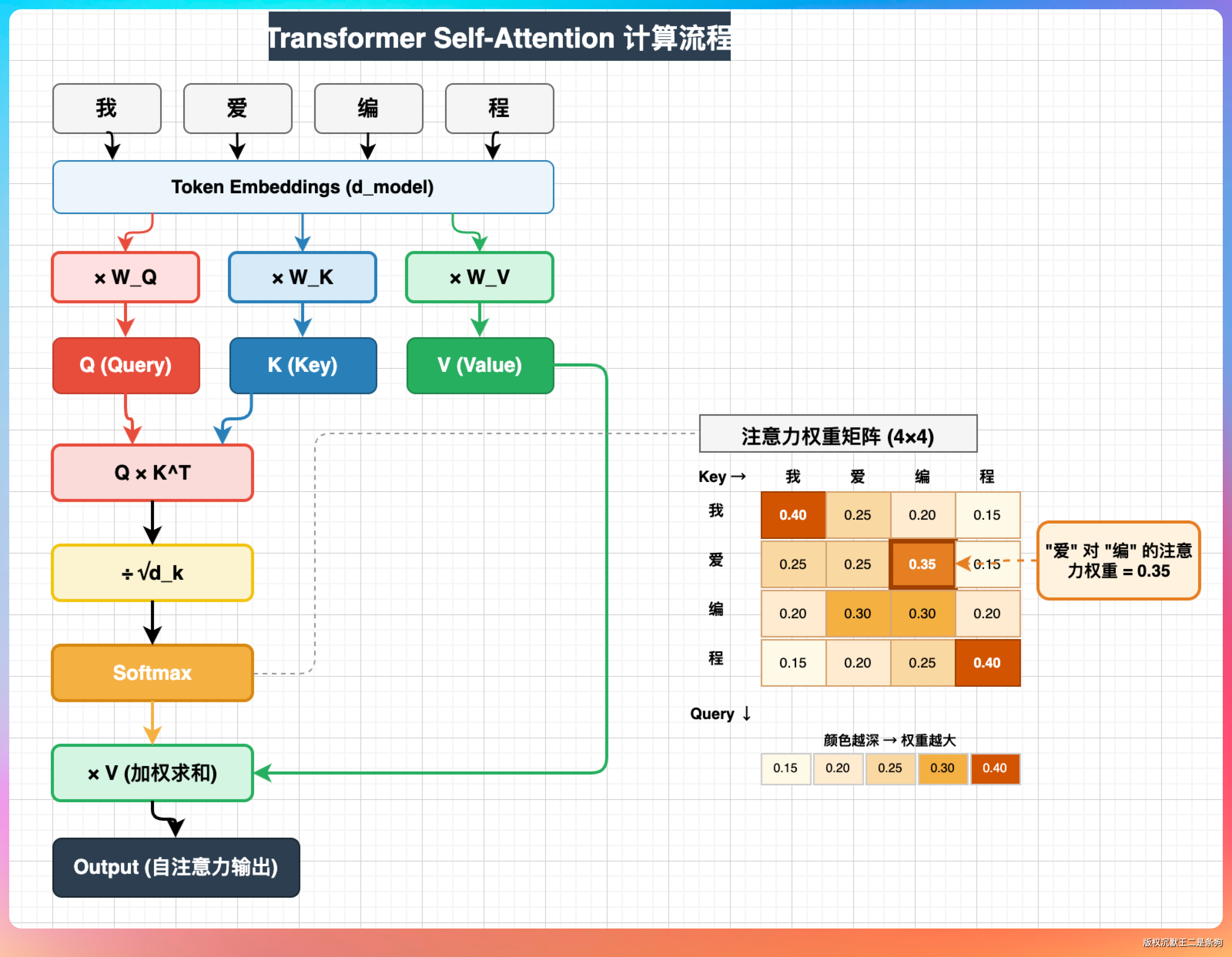
画一张 Transformer Self-Attention 的计算流程图,要求:
1. 输入序列“我 爱 编 程”四个 token
2. 展示 Q、K、V 三个矩阵的生成过程:每个 token 的 embedding → 乘以 W_Q、W_K、W_V → 得到 q、k、v 向量
3. 展示注意力分数的计算:Q × K^T → 除以 √d_k → Softmax → 注意力权重矩阵(画成 4×4 的热力图格式,颜色深浅表示权重大小)
4. 展示加权求和:注意力权重 × V → 输出
5. Q 用红色系,K 用蓝色系,V 用绿色系
6. 在热力图旁标注一个具体的数值示例,比如“爱”对“编”的注意力权重为 0.35
两个模型在这个 Case 上表现都挺好。
GLM-5.1 的流程图偏教科书风格,从上到下一步步来,每一步的矩阵运算都标注了维度信息,适合教学用。热力图部分用了 4 个不同深度的绿色来表示权重大小,直观。
DeepSeek V4 的版本我也很喜欢,色彩更重一点。热力图部分画了一个 4×4 的色块矩阵,每个格子里也标了数值,一清二楚。
04、派聪明 RAG 问答
第三个 Case 我们直接放到实际的 RAG 应用场景里。
派聪明是我做的一个企业级RAG知识库。文档上传后经过语义分块、向量化存到向量数据库里,用户提问时走混合检索(向量相似度 + Elasticsearch 关键词匹配),检索结果经过 Reranker 重排序后喂给大模型生成回答。
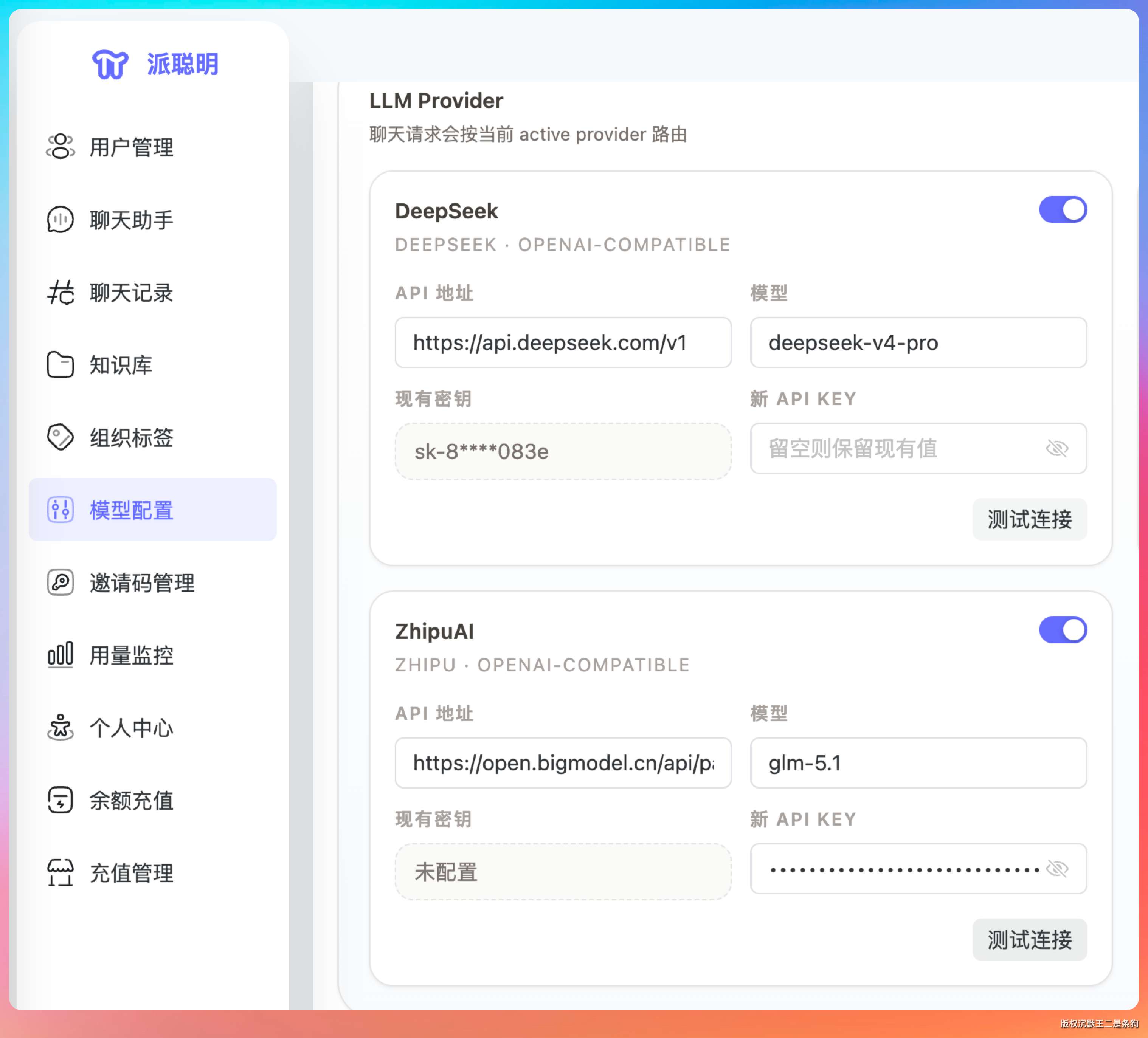
模型配置这里我们也都做了DeepSeek V4和GLM-5.1的配置。
我往知识库里上传了一份派聪明的介绍文档(大概 200 页),然后用同样的三个问题分别测试 GLM-5.1 和 DeepSeek V4 作为生成模型时的回答质量。
问题一
Spring Boot 3 的 GraalVM Native Image 支持是怎么回事?和传统的 JVM 部署相比有什么优劣?
这个问题是关于Spring Boot的,但实际上我们的知识库里并没有这份文档,来看看两个模型的回答。

都是暂无相关信息,说明提示词约束都做到位了,模型没有一本正经地回复。
GLM-5.1 给的原因是:提供的参考文档中主要介绍了派聪明知识库的架构与功能、Java开发常见技术栈(如Spring Boot、Redis、MySQL、Spring Cloud等)以及AI应用开发的相关经验,并未包含关于“Spring Boot 3 的 GraalVM Native Image 支持原理”以及“其与传统 JVM 部署优劣对比”的任何信息。

DeepSeek V4 给的原因是:参考材料中均未提及 Spring Boot 3 对 GraalVM Native Image 的支持机制或与传统 JVM 部署的对比。若需了解该特性,建议查阅 Spring Boot 官方文档或 GraalVM 相关资料。
问题二
派聪明RAG了解吗,介绍一下,如果你是求职者,面试官问你这个问题,你该如何回答,要求尽量符合口述方式。
这个问题很考察模型对内容的检索能力,已经文本功能,先来看看GLM-5.1的回复。
其次,从技术架构和实现原理上来说,它构建了一套非常完整的智能知识处理流水线。具体来说分为几个关键步骤:第一步是利用 Apache Tika 来自动解析 Word、PDF、TXT 等各种格式的文档;第二步是引入豆包 Embedding 向量模型,把解析出来的非结构化信息转化为可检索的知识资产;第三步是检索层,它结合了 Elasticsearch 的混合检索技术,利用基于语义理解的向量检索,突破了传统关键词匹配的局限性

DeepSeek V4 的回答相对简约一点。
从技术实现上看,它用 Apache Tika 做多格式文档解析,再通过豆包的 Embedding 向量模型把文本语义向量化,结合 Elasticsearch 做混合检索,最后对接 DeepSeek 等大模型 API 生成准确答案,整个流程形成了一套完整的智能知识处理流水线。相比纯关键词匹配,它的语义理解能力更强,回答也更精准。

05、一镜到底写一个 CLI 工具
我之前用GLM-5.1 和DeepSeek V4 开发过Java后端+前端的全栈项目,比如说派简历是用GLM-5.1完成的,派聪明的多聊天窗口是用 DeepSeek V4 完成的。
实力我认为都是非常顶的,前面也都通过录屏和图片的形式给大家展示了。
接下来,我打算给一个相对复杂的需求,这次不用 Java 了,咱直接上 Python,看谁能“一镜到底”不出错。
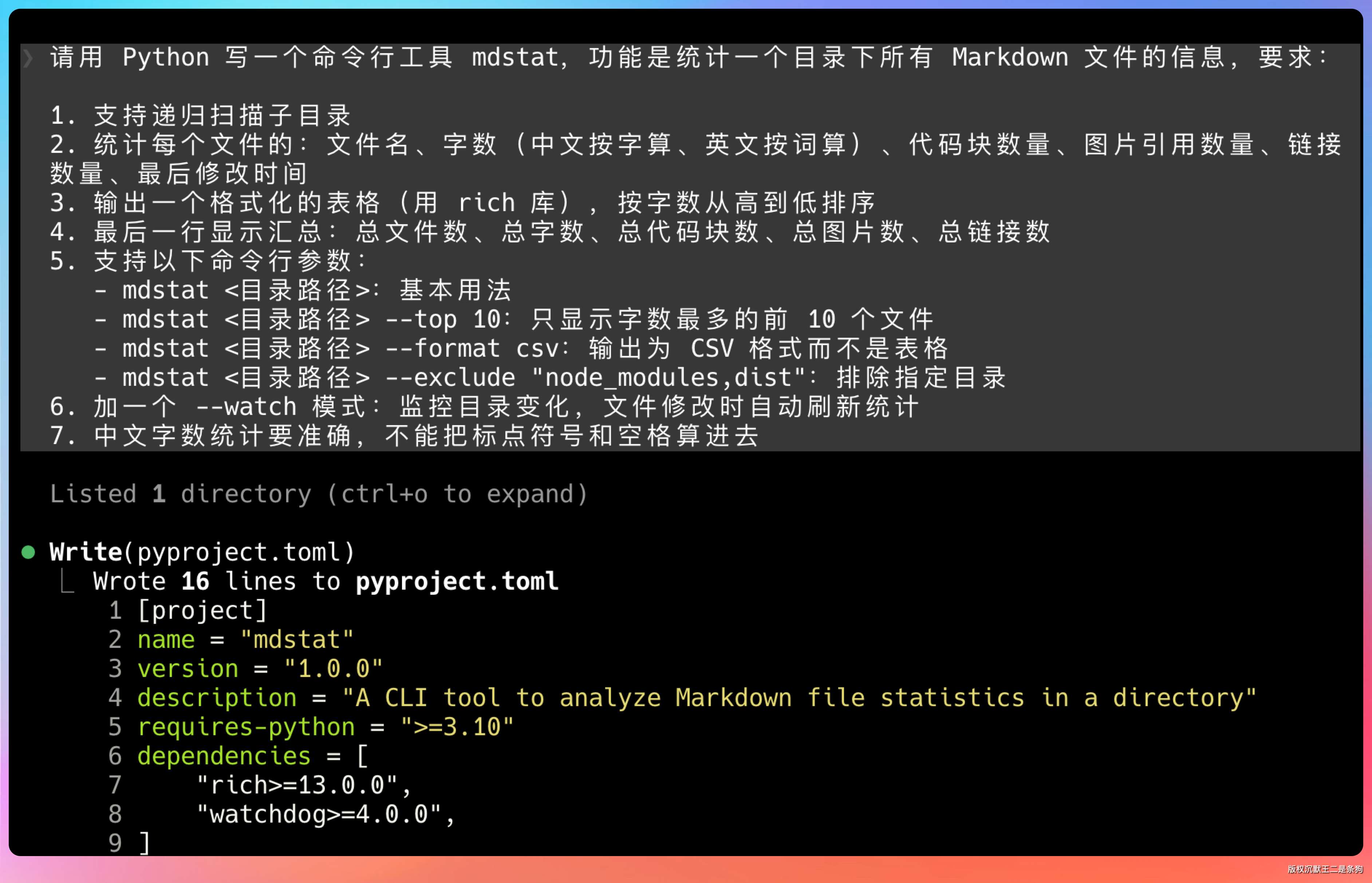
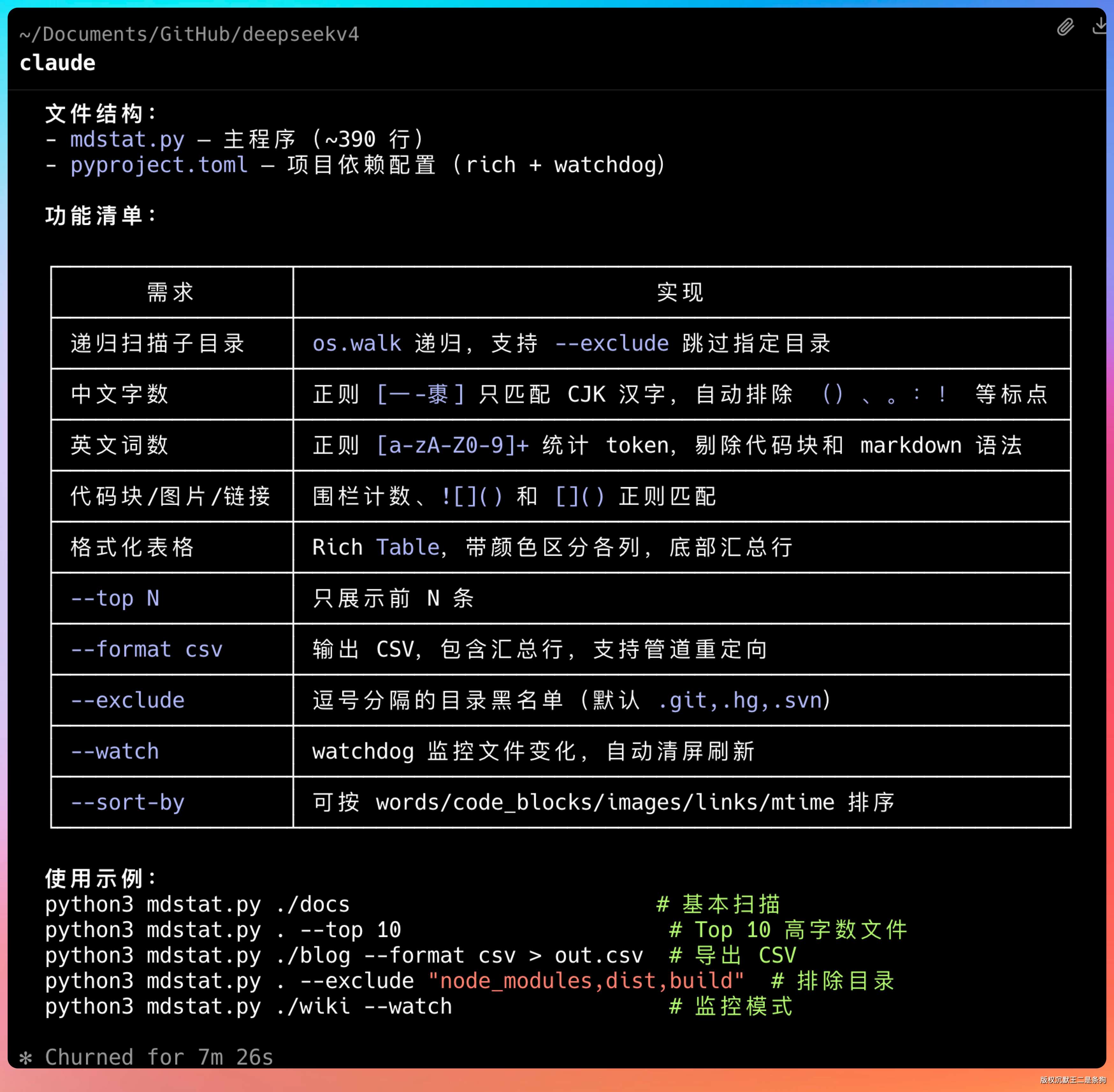
请用 Python 写一个命令行工具 mdstat,功能是统计一个目录下所有 Markdown 文件的信息,要求:
1. 支持递归扫描子目录
2. 统计每个文件的:文件名、字数(中文按字算、英文按词算)、代码块数量、图片引用数量、链接数量、最后修改时间
3. 输出一个格式化的表格(用 rich 库),按字数从高到低排序
4. 最后一行显示汇总:总文件数、总字数、总代码块数、总图片数、总链接数
5. 支持以下命令行参数:
- mdstat <目录路径>:基本用法
- mdstat <目录路径> --top 10:只显示字数最多的前 10 个文件
- mdstat <目录路径> --format csv:输出为 CSV 格式而不是表格
- mdstat <目录路径> --exclude "node_modules,dist":排除指定目录
6. 加一个 --watch 模式:监控目录变化,文件修改时自动刷新统计
7. 中文字数统计要准确,不能把标点符号和空格算进去

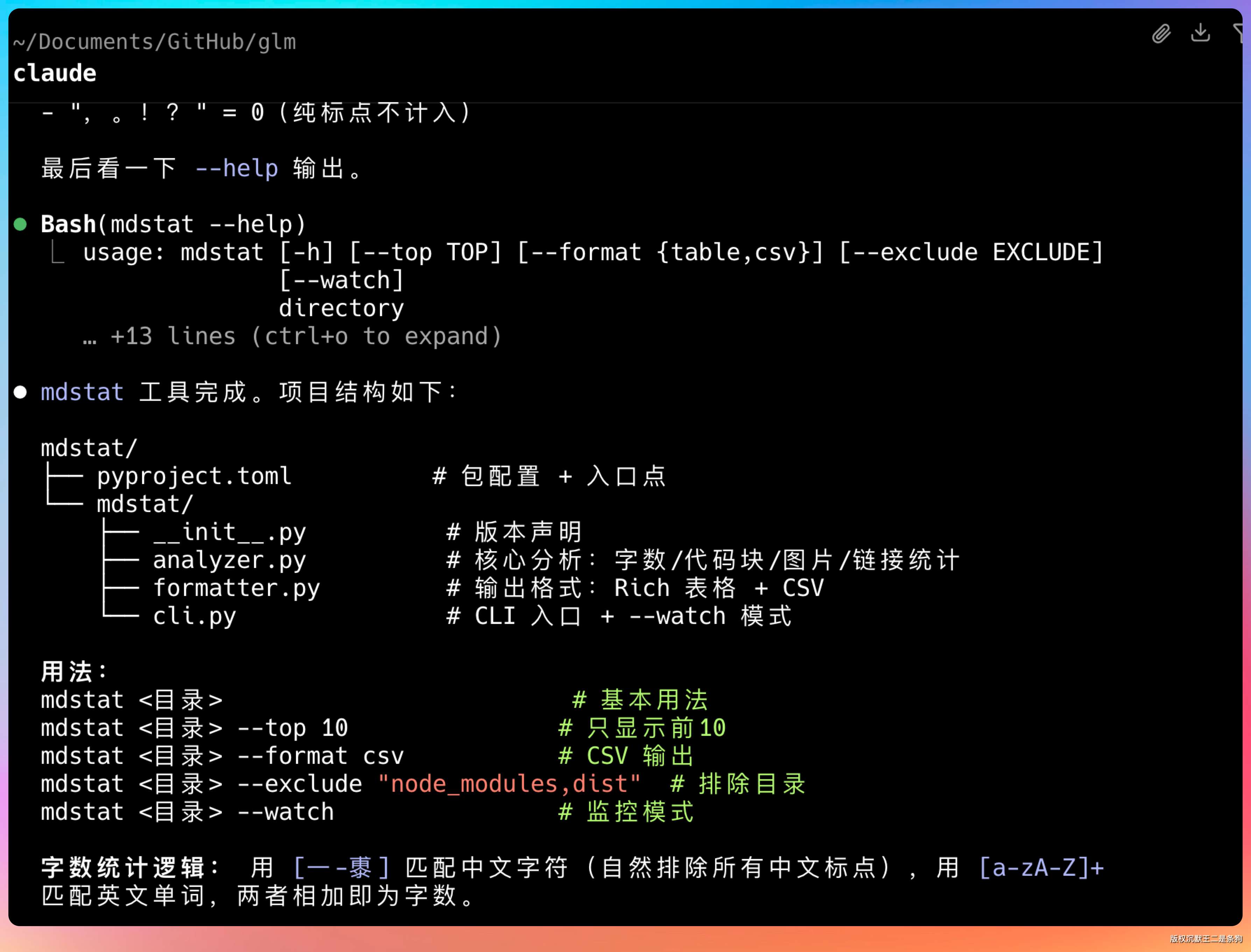
GLM-5.1 给出的代码大约 270 行,结构很清晰。

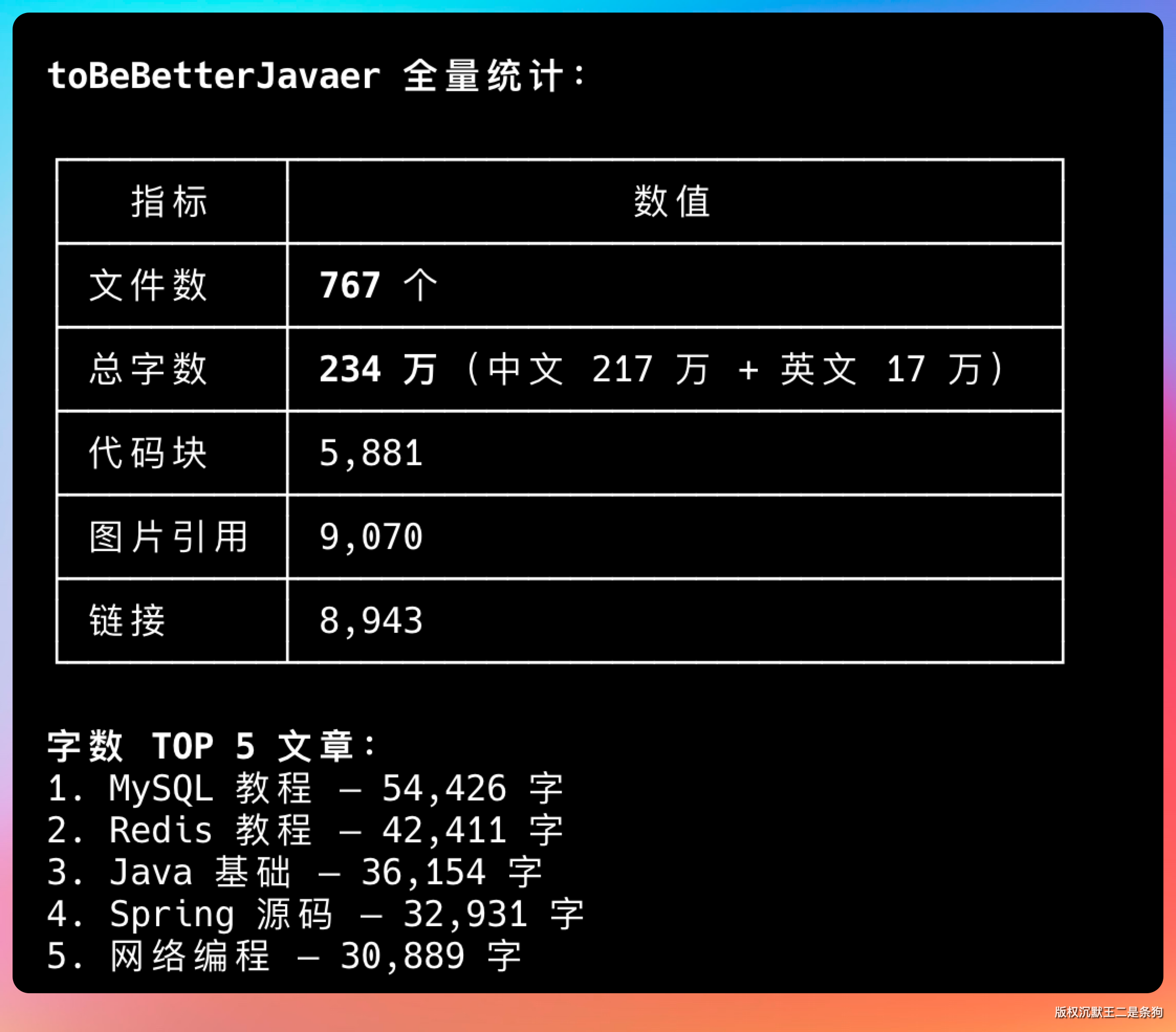
我拿这个代码跑了一下 toBeBetterJavaer 的文档目录,统计结果看起来合理。其中字数最多的是MySQL的面渣逆袭文档,7万多字,图片足足 330张,这也印证了为什么面渣逆袭受欢迎的原因,硬啊,核啊。
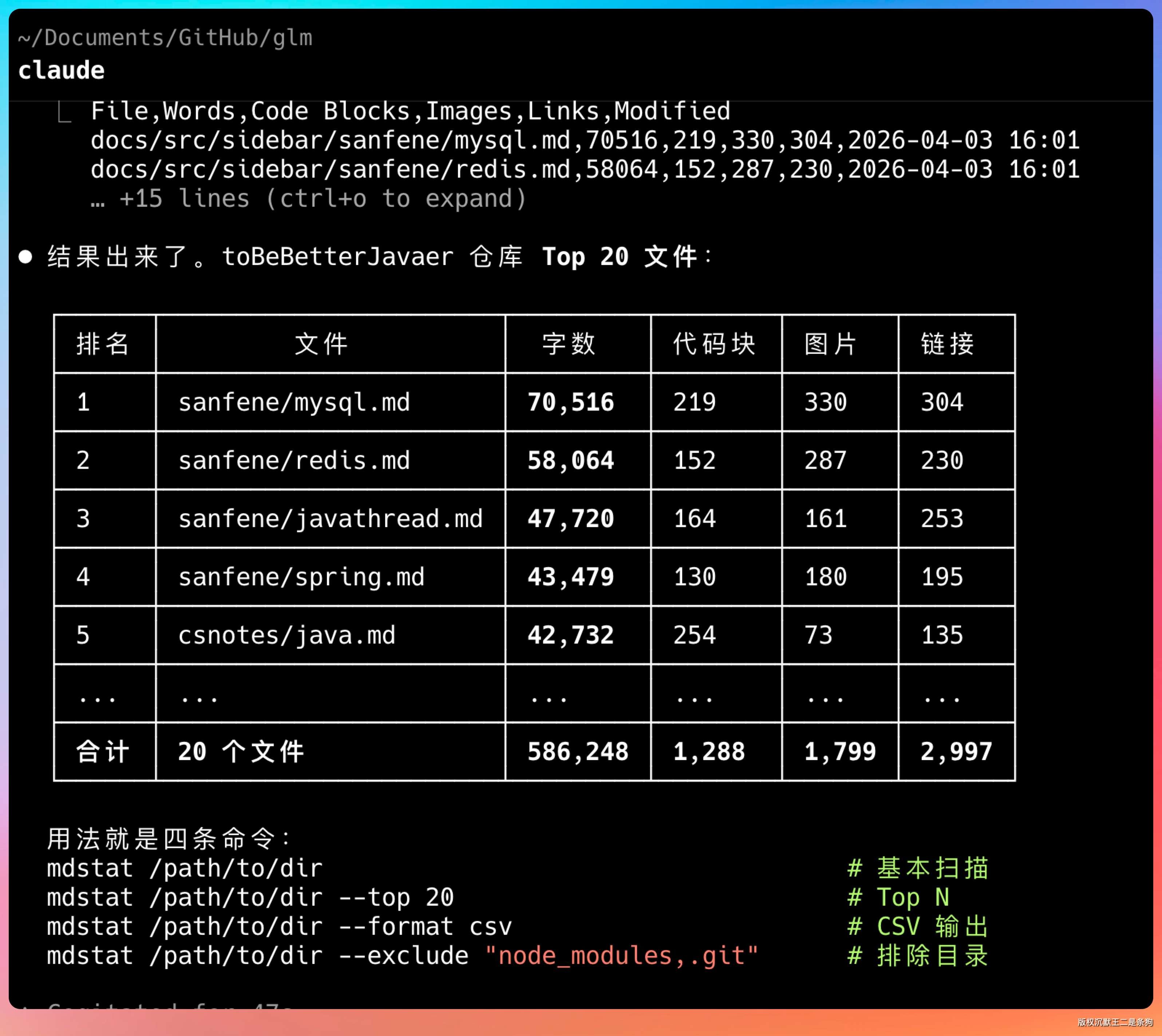
DeepSeek V4 也是同样的提示词,来一波。
跑一下结果,比GLM-5.1的简略一点,字数统计上好像也有一些偏差。
ending
2026 年的大模型赛道,真的越来越精彩了。
GLM-5.1 在 SWE-bench Pro 上跑出全球最高分的那一刻,
DeepSeek V4 用国产卡跑出接近 Opus 4.6 非思考模式的编程能力那一刻,
我相信很多小伙伴和我一样,心里都有一种说不上来的激动。
说实话,DeepSeek V4 这次发布的意义,可能不仅仅在于模型能力本身。更重要的是,它在国产芯片和基础架构上实现了大幅提升——用国产卡就能跑出这样的成绩,这对整个国产 AI 生态的底座建设来说,是一个非常积极的信号。
而 GLM-5.1 确实在编程能力上表现更突出一些,从我们前面的实测也能看出来,无论是代码生成的完整度还是细节的把控,都非常顶。
这两家也是目前开源大模型阵营里最顶尖的两个。更重要的是,正是他们不懈的努力,我们才有了更多的选择,这对我们来说非常重要。
不过说到底,不用纠结选哪个。百家争鸣、百花齐放,让工具为我们所用,才是拥抱这个时代的最好办法。
我们下期见。

回复