


大家好,我是二哥呀。
之前有读者在评论区安利了一款叫 CC GUI 的 IntelliJ IDEA 插件。
可以在idea中爽用Claude Code。
刚好 DeepSeek V4 pro 大降价,我就想着,能不能在 CC GUI 中配置上 DeepSeek V4 的 API key,然后爽用起来。
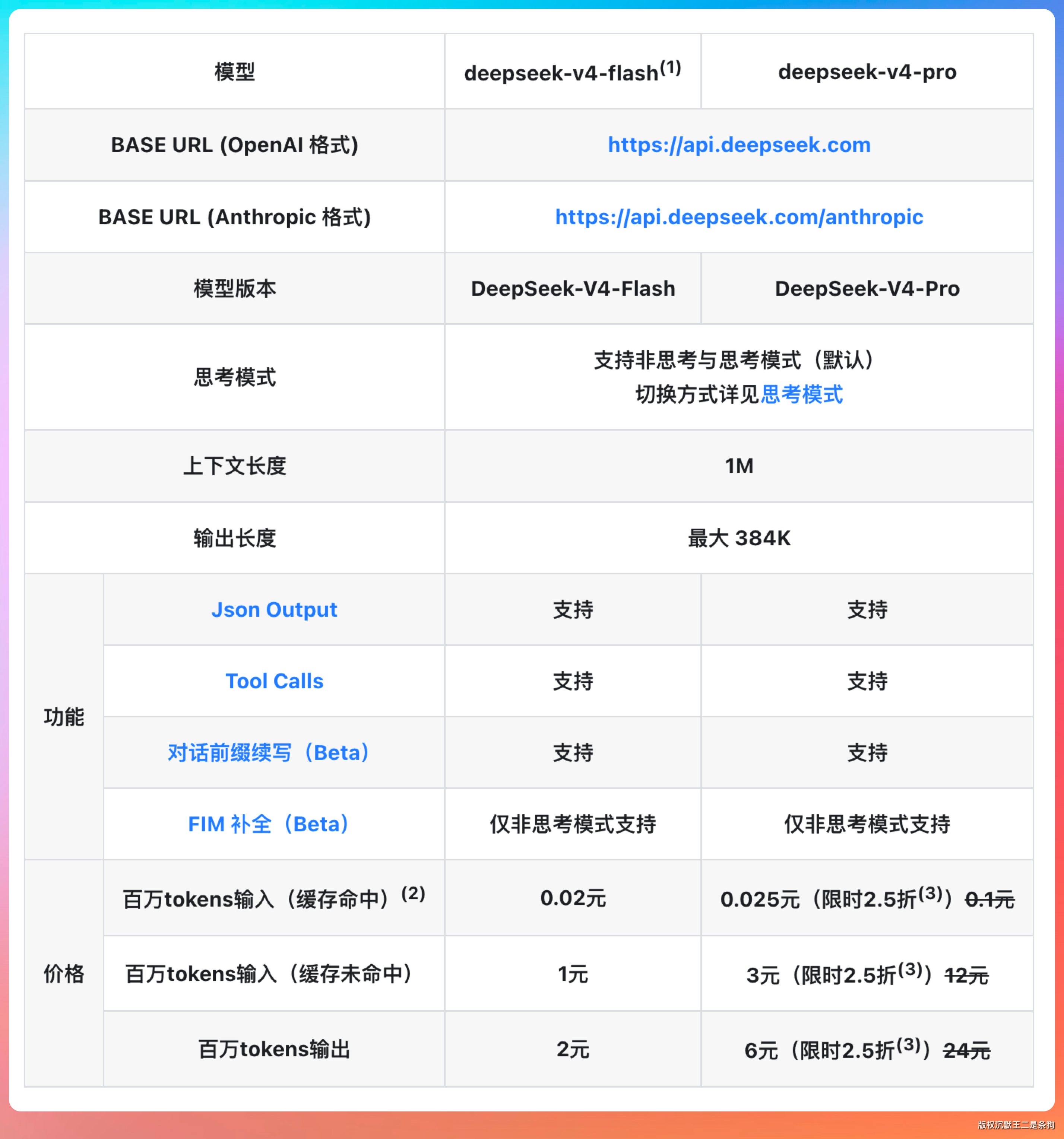
2.5折,比打10折确实优惠得多😄
从我之前发的内容来看,用 idea 的小伙伴还是非常多的,尤其是后端开发,离不开IntelliJ IDEA啊,查看代码、调试还是方便。
索性今天我们就来实践一把,手把手带大家体验。
插件地址:https://plugins.jetbrains.com/plugin/29342-cc-gui-claude-or-codex-
支持的功能也非常多,比如说图片解析、Skill命令、MCP服务器等等。

01、怎么装和怎么配?
装起来没什么门槛。
IDEA 里按 Cmd+Shift+A 调出搜索,输入 Plugins 进到插件市场,搜 “CC GUI” 就能看到结果。我这里已经安装过了。
装好以后 IDE 都不用重启。右侧边栏多出来一个 “CC GUI” 图标,戳一下就能打开操作面板。
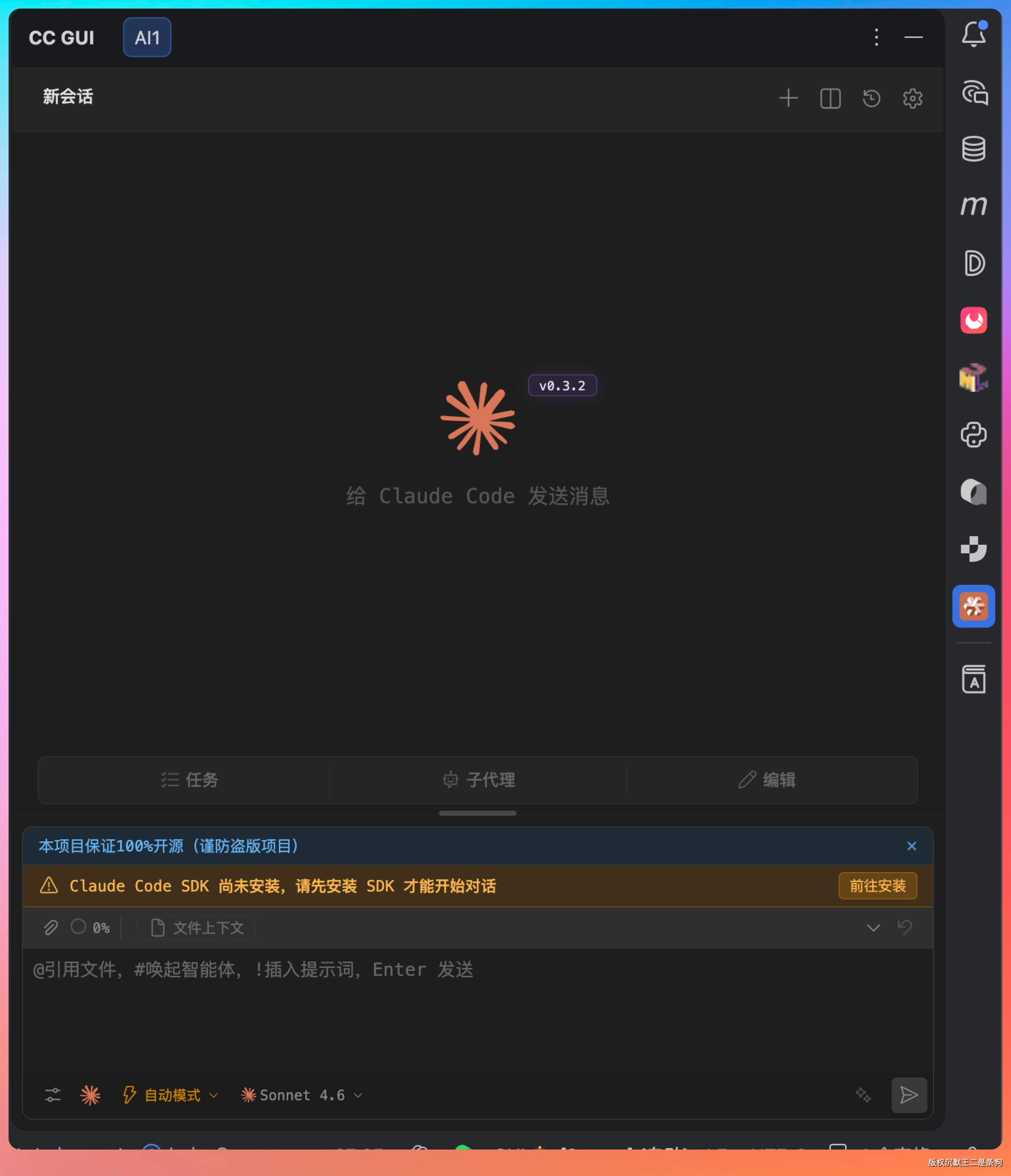
第一次打开的时候会弹出提示,让你先把 Claude Code SDK 装上,这是 Agent 跑起来的底层依赖,跟着引导,大概半分钟搞定。
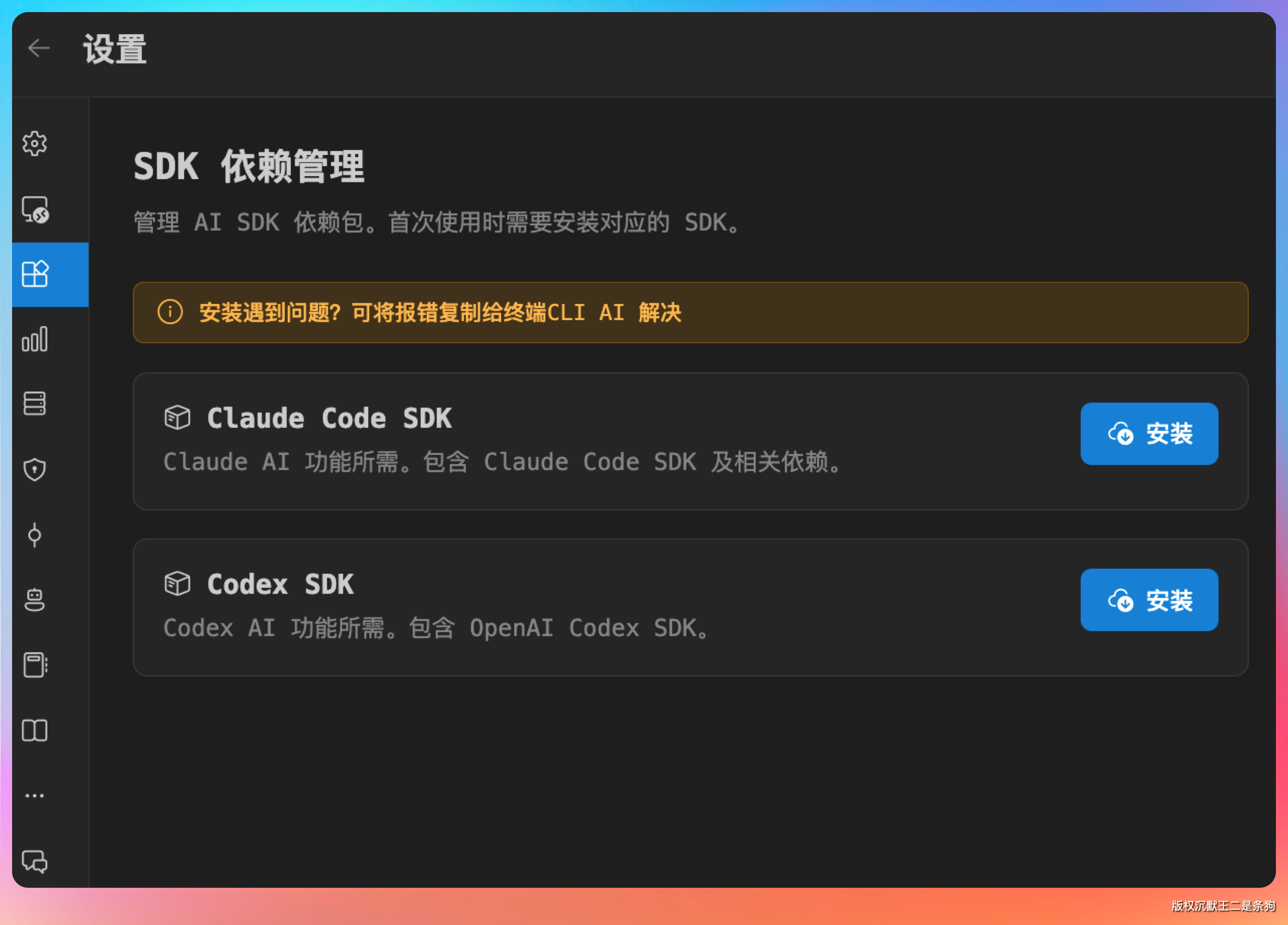
SDK 就位之后,下一步是配模型。点开供应商设置界面:
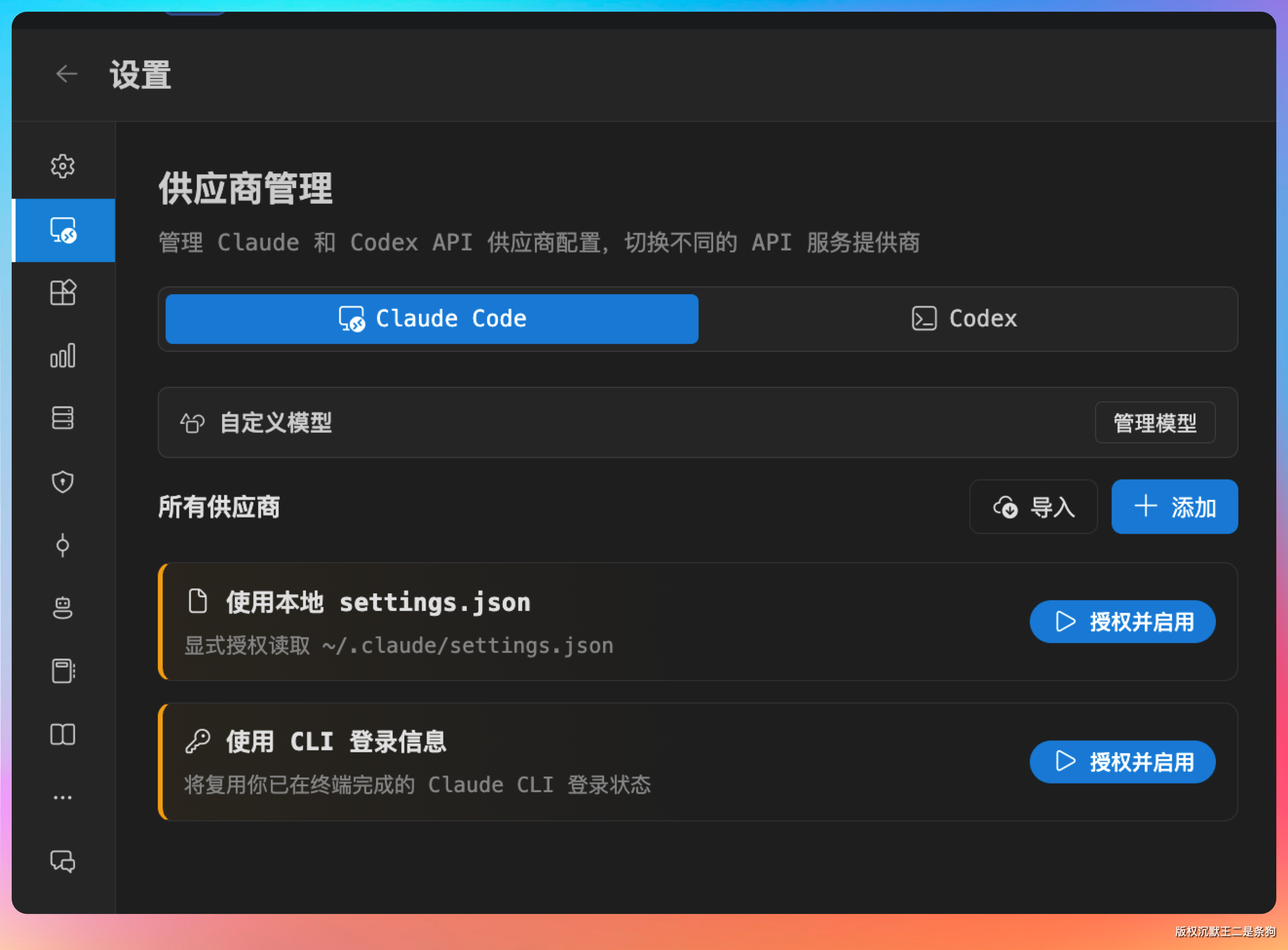
支持直接读取本地已有的 settings.json 来完成鉴权。
换句话说,如果你的 Claude Code 本来就已经跑通了,把配置路径指过来就完事。用国内的 Coding Plan(GLM-5.1、Kimi 2.6 什么的)都没问题,不用非得登录 Anthropic 账号。
除了通过 settings.json,还支持添加供应商。
点击【+添加】,选择DeepSeek。
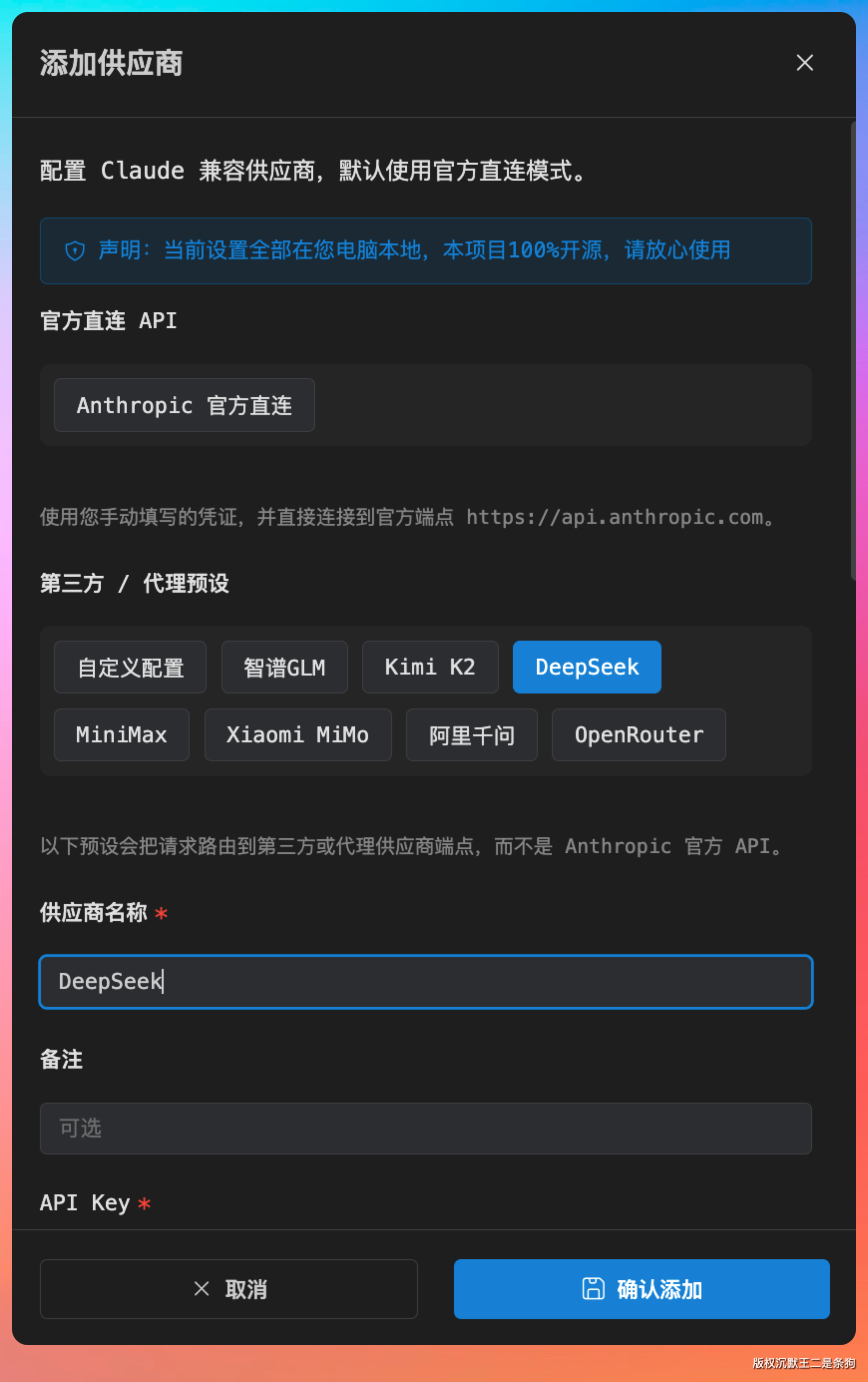
往下翻,把 deepseek-v4-pro 填入到 Sonnet 和 Opus 中,把 deepseek-v4-flash 填入到 haiku 中。
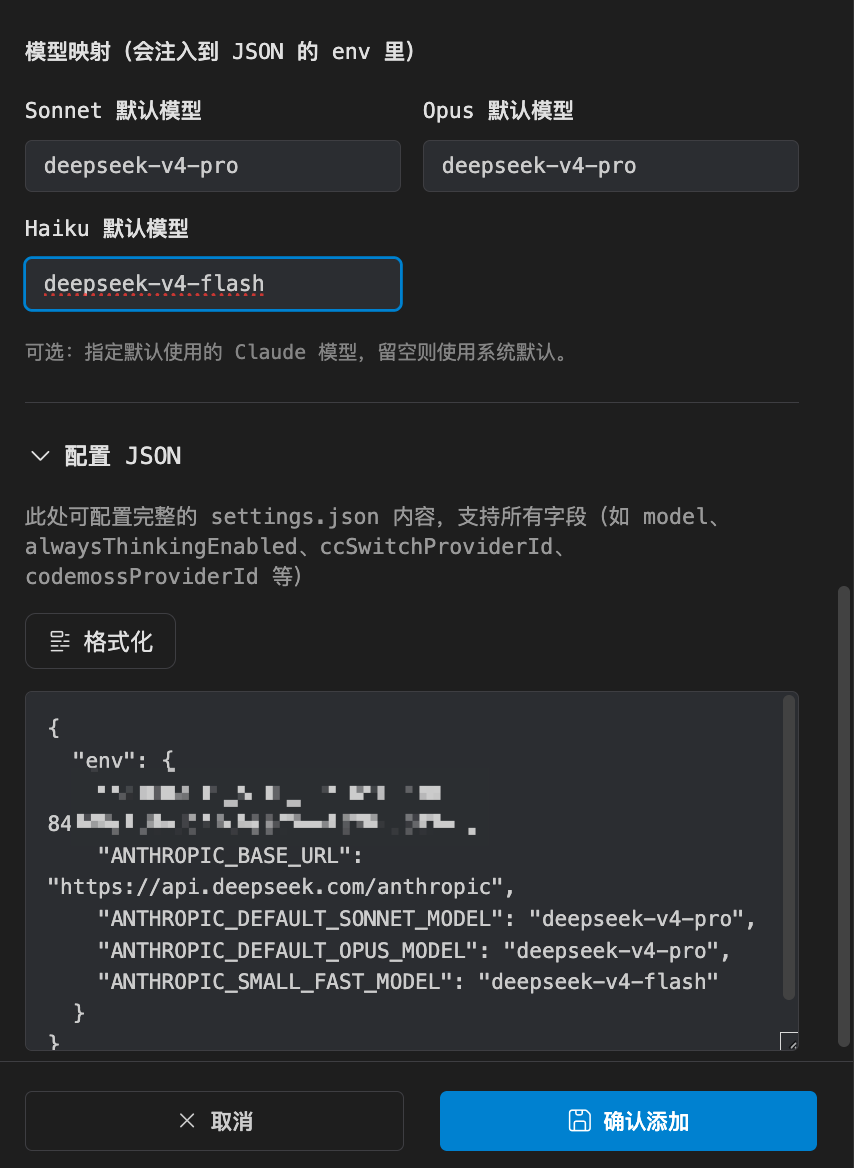
然后点击【确认添加】就OK了。
本质上,是帮你重写一下 setting.json 文件。
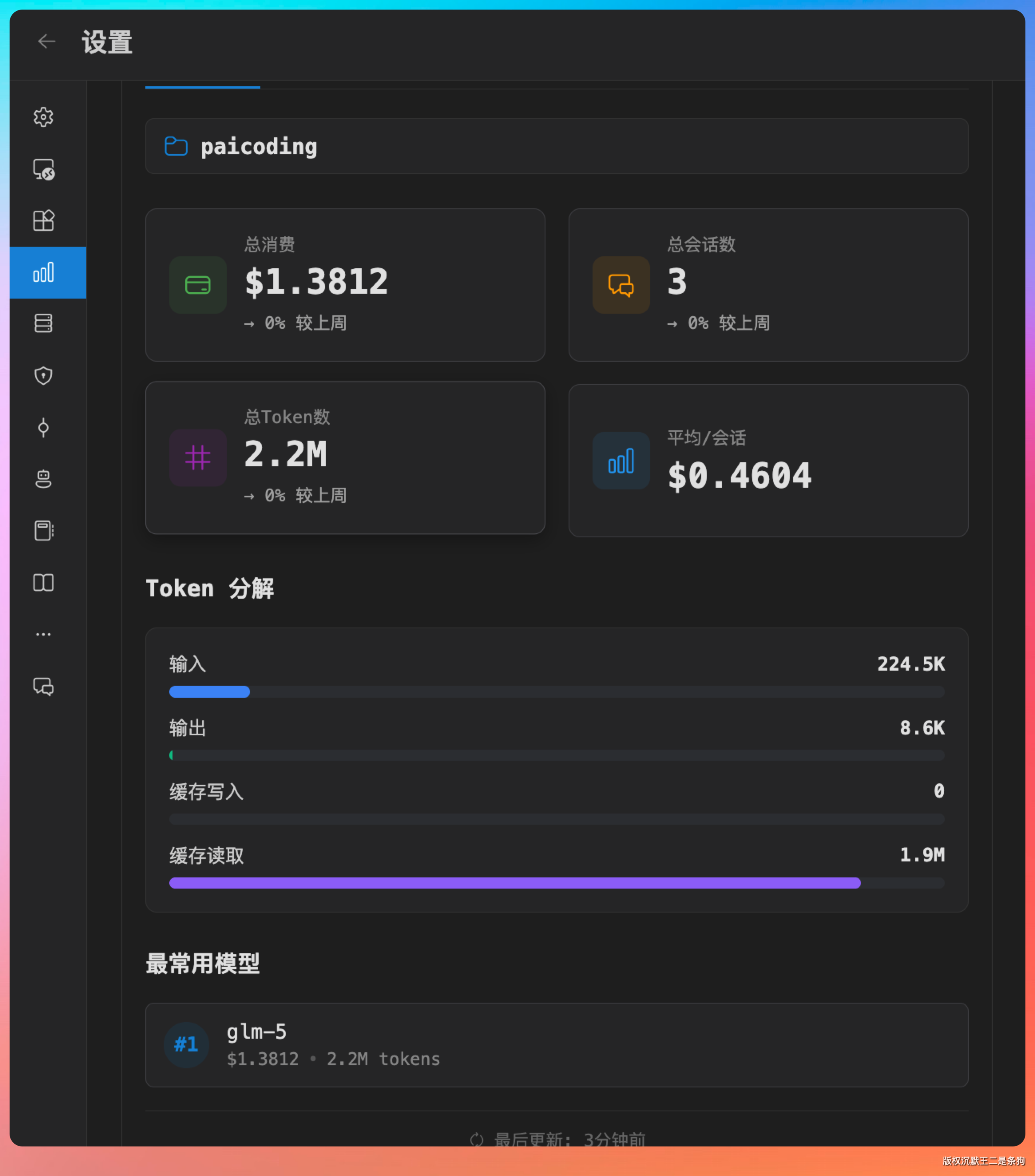
配完之后在统计面板能看到 token 消耗明细,每轮对话花了多少、累计烧了多少,一目了然。
MCP 可以给 Agent 挂载各种外部工具。
首先推荐 Chrome Devtools 这个 MCP,挂上之后 Agent 能直接操控浏览器,做前端页面的自动化测试和调试。特别是那些必须登录才能复现的 bug,或者需要特定浏览器环境才能触发的问题,有了它方便太多。
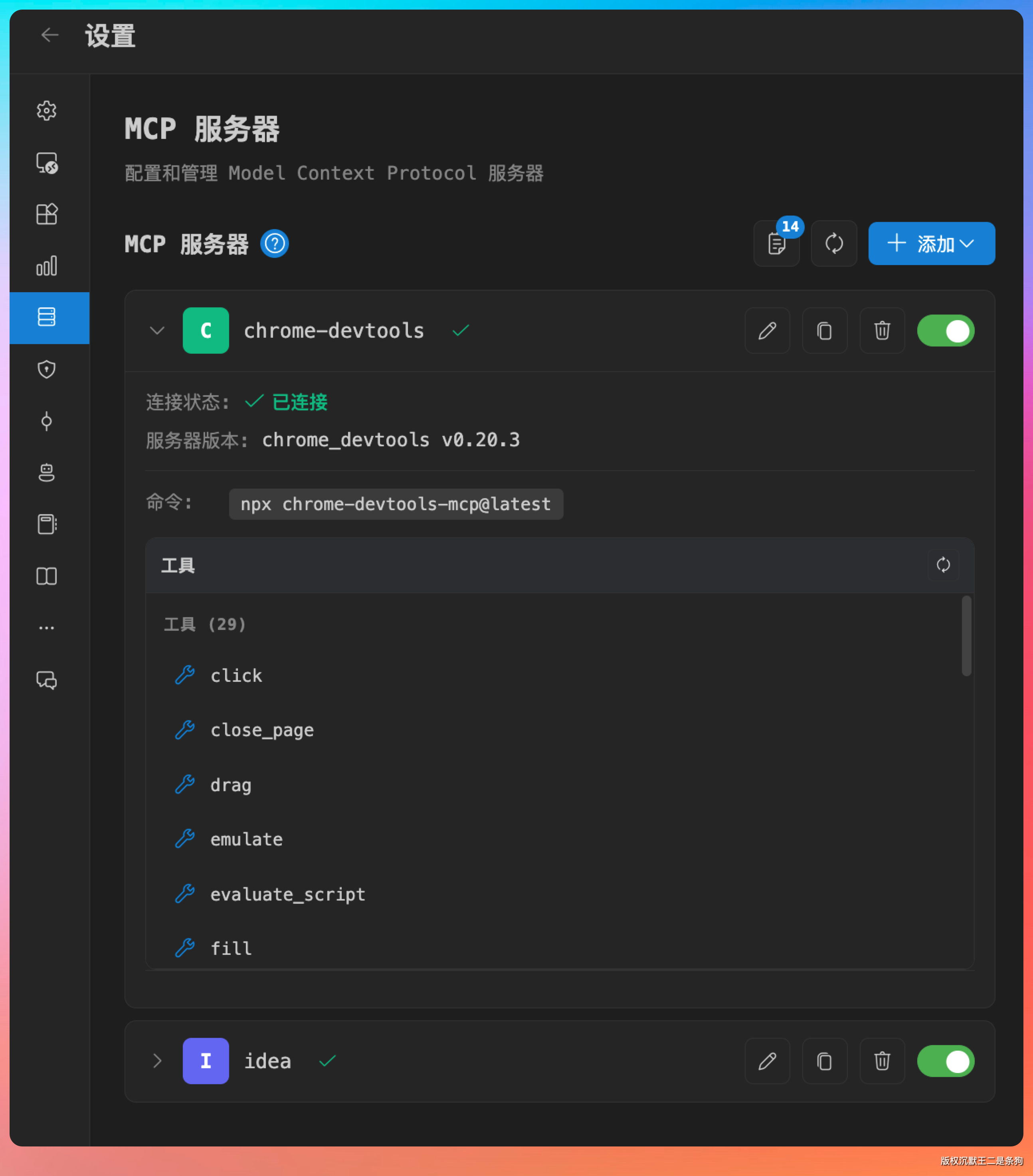
还有一个 idea MCP,可以让 Claude Code 跟 IntelliJ IDEA 本身建立连接。
另外 git 提交相关的 MCP 也值得装,自动帮你写 commit message,省心。
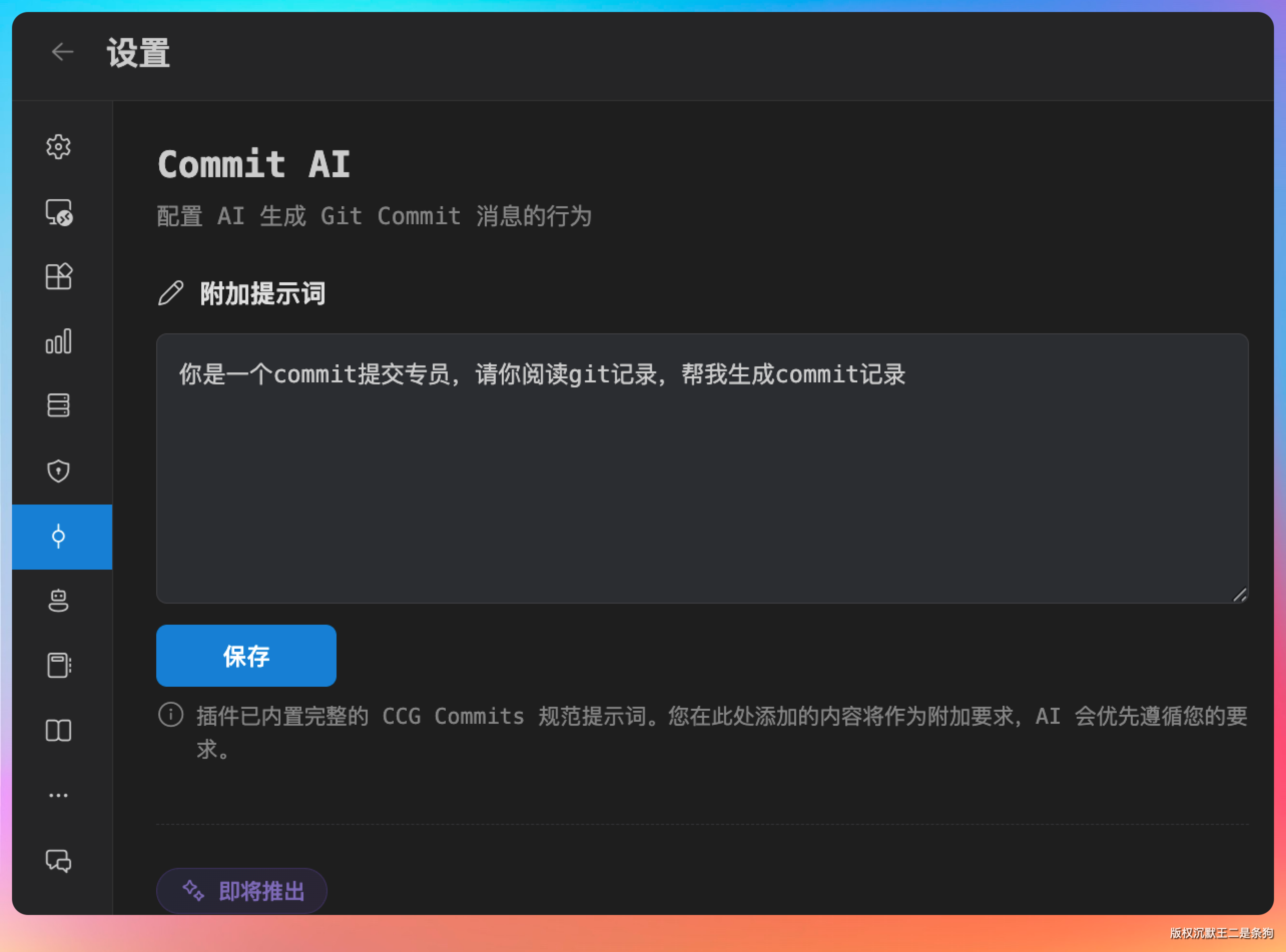
这个功能我之前是靠 GitHub Desktop 里内置的 Copilot 来做的。
然后要说的是 Skill,这块可以理解为 Claude Code 的能力扩展包,给 Agent 装上不同的 Skill 就能解锁对应领域的专项能力。
我个人认为必装的两个:web-access 和 frontend-design。
web-access 的作用是打通浏览器通道,碰到需要登录凭证的页面访问、或者要模拟真实用户行为的场景,用它特别顺手。
frontend-design 则是前端页面生成器,丢一段需求描述过去就能出 HTML/CSS,整体设计感比我预想的要好不少,至少比自己从零写快得多。
CC GUI 在 GitHub 上已经累积了 3.1k 的星标,社区活跃度很高。作者迭代节奏也快,差不多每个星期都推新版,修 bug 和加功能都很及时。
https://github.com/zhukunpenglinyutong/idea-claude-code-gui/blob/main/README.zh-CN.md
02、实战1:文章阅读统计功能优化
东西装好了,直接上手干活。第一个场景拿技术派的真实业务来试。
技术派是我们自己做的一个开源社区。
PaiAgent 这个开源项目的教程也会在上面同步。
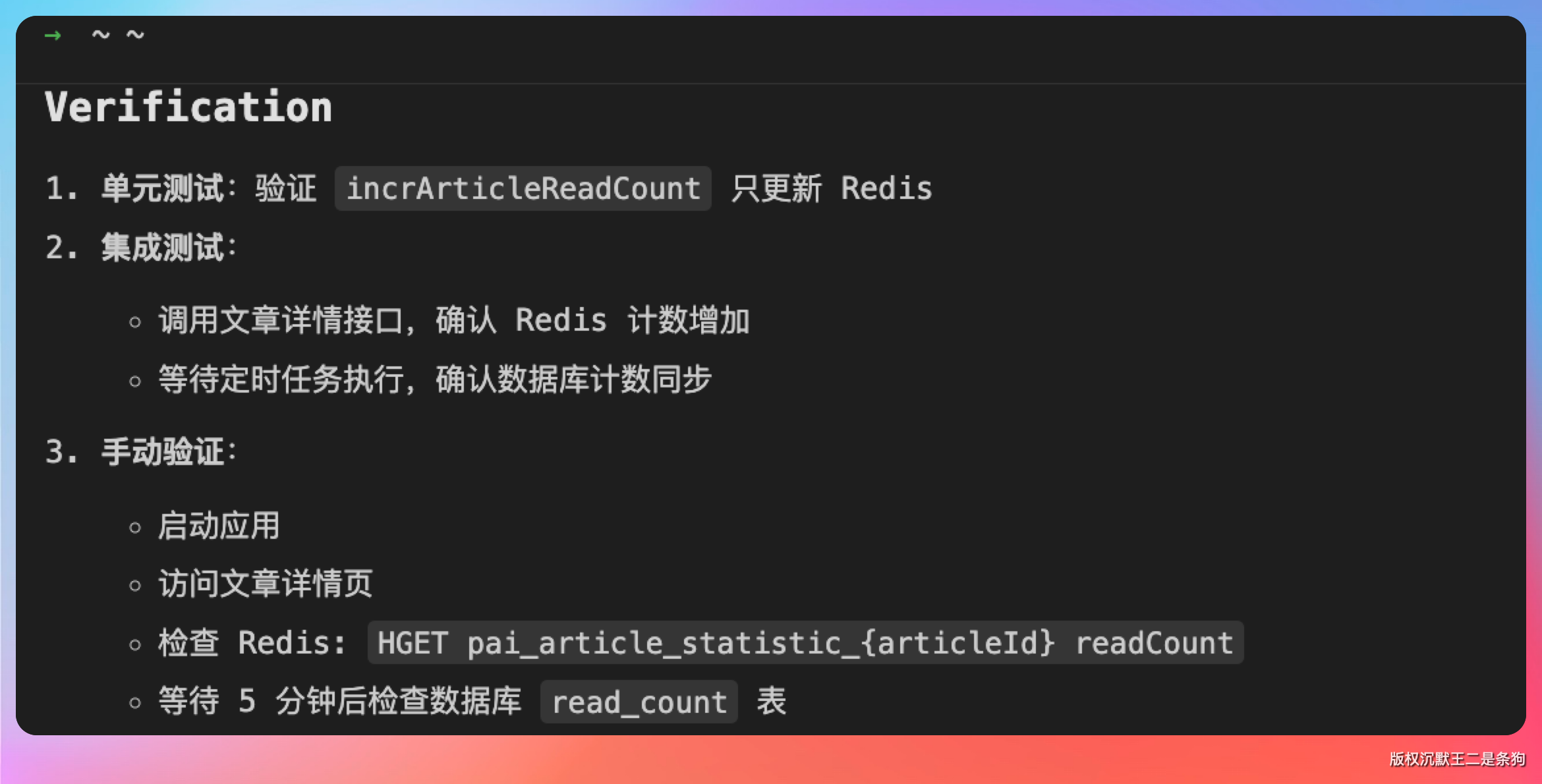
当前阅读数的更新逻辑写在 ArticleReadService.java 里面,每次有读者看文章就直接打一条 SQL 到数据库。我打算把它换成 Redis 先扛着、再定时刷回数据库的方案,改动会横跨 Service、Controller 和定时任务好几个文件。
在 CC GUI 的对话框里我输入:“帮我优化技术派项目的文章阅读统计功能,改成 Redis 缓存方案,先累加 Redis 计数,再定时同步到数据库”。
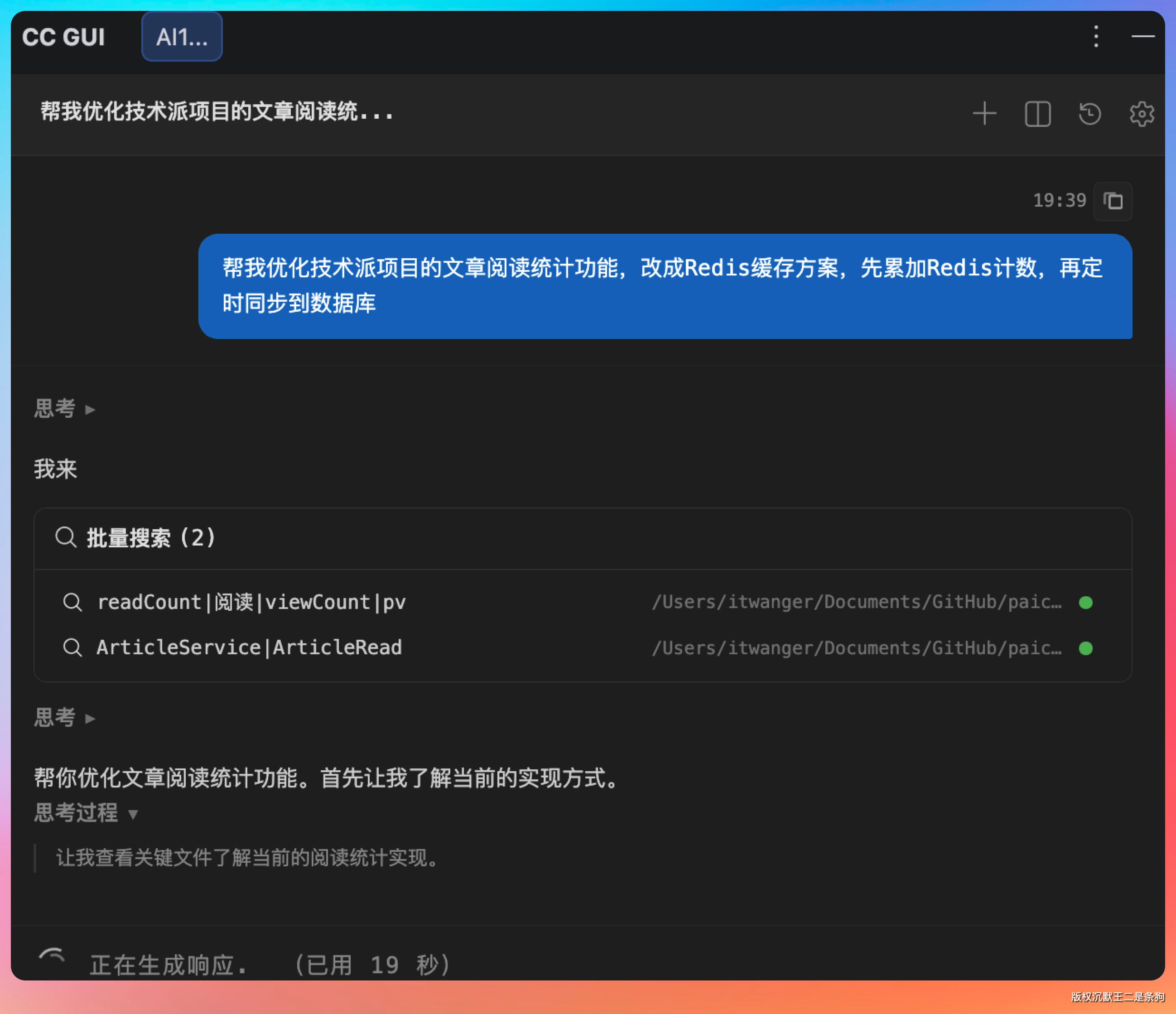
Agent 第一件事就是把现有代码结构过了一遍,顺便检查了项目依赖,确认 Redis 相关的配置早就到位了。
定位到了瓶颈所在,随即给出了整套改造思路。
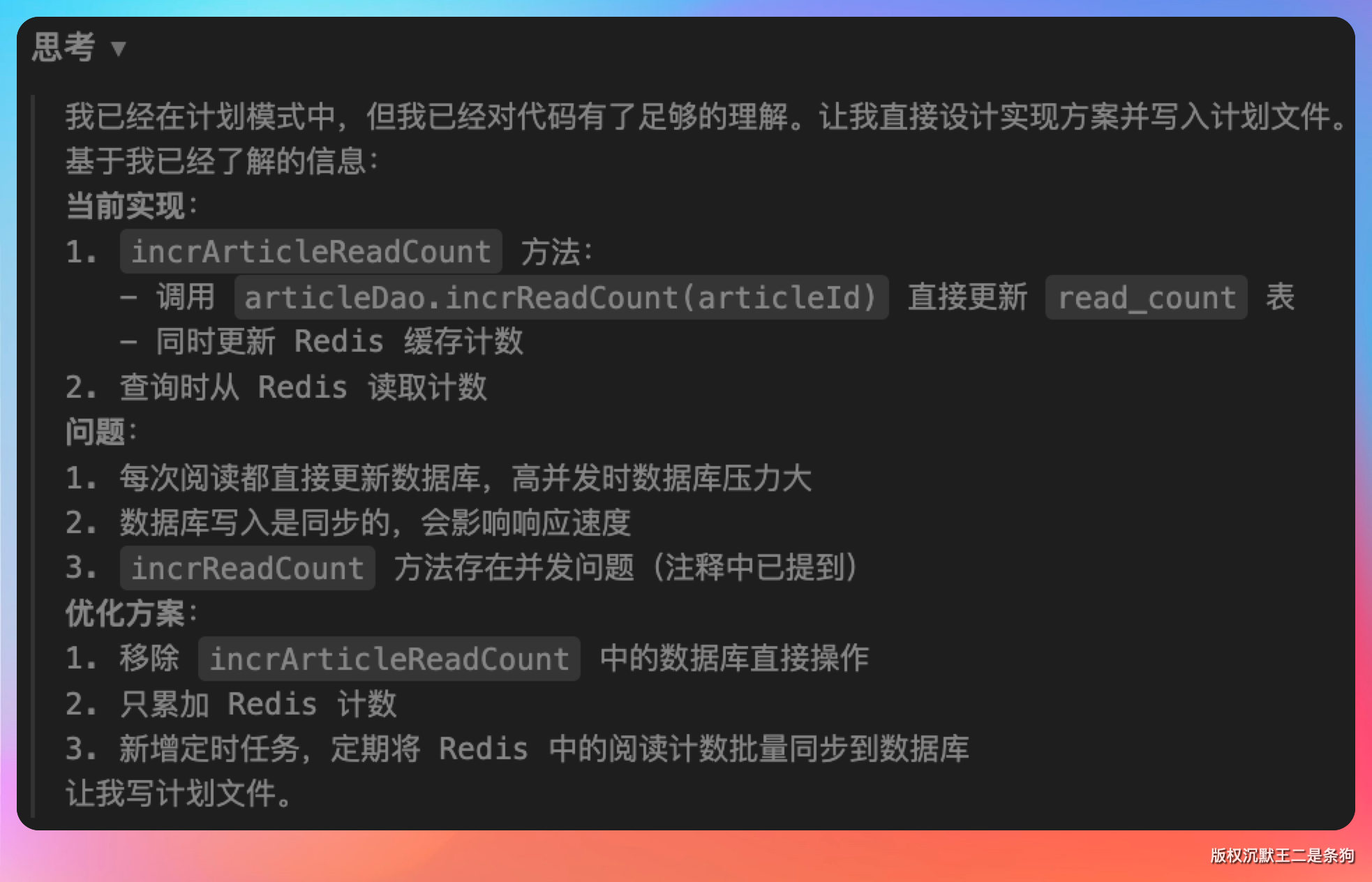
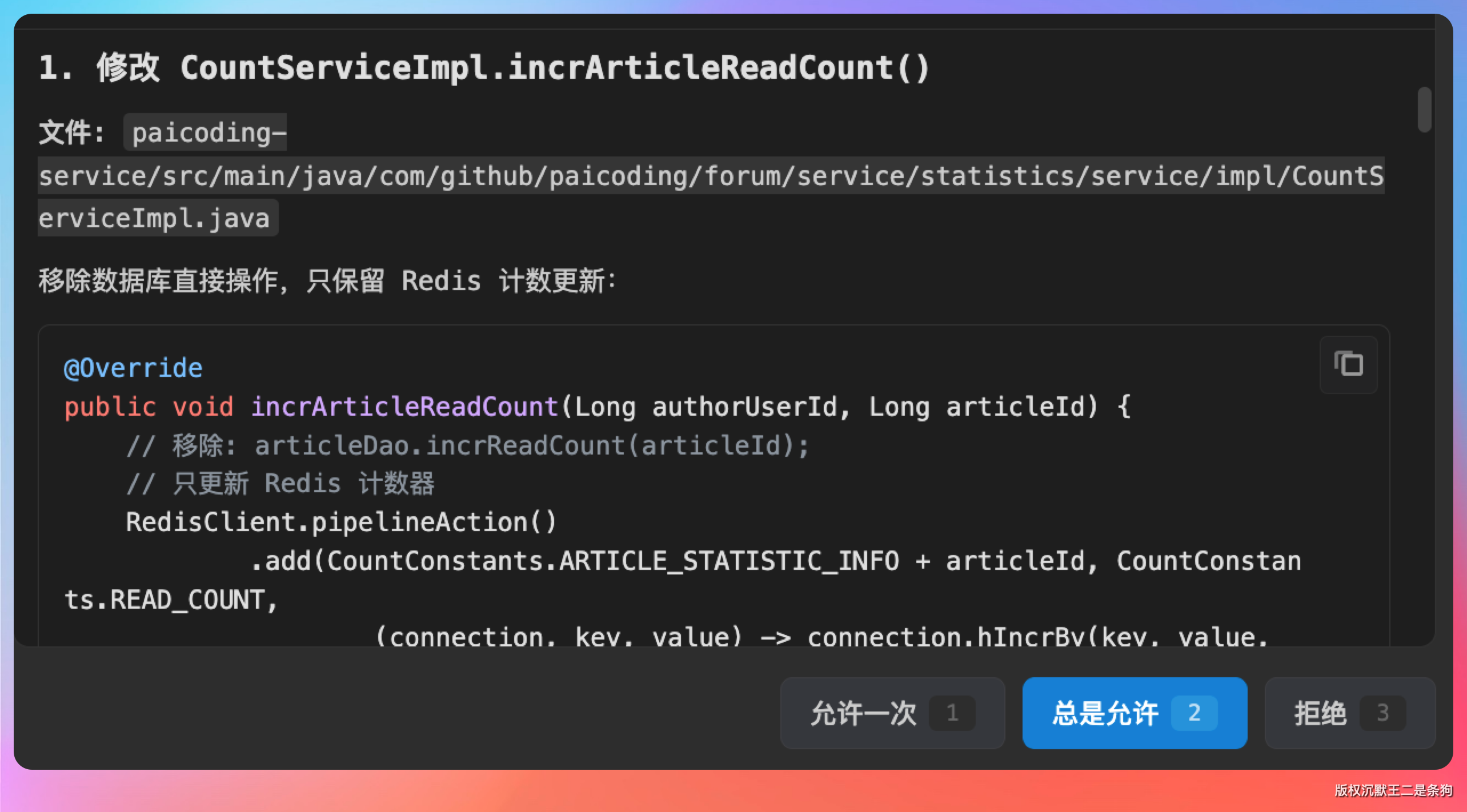
首先动刀 CountServiceImpl.incrArticleReadCount(),把直连数据库的代码干掉,只留 Redis 的计数累加逻辑:
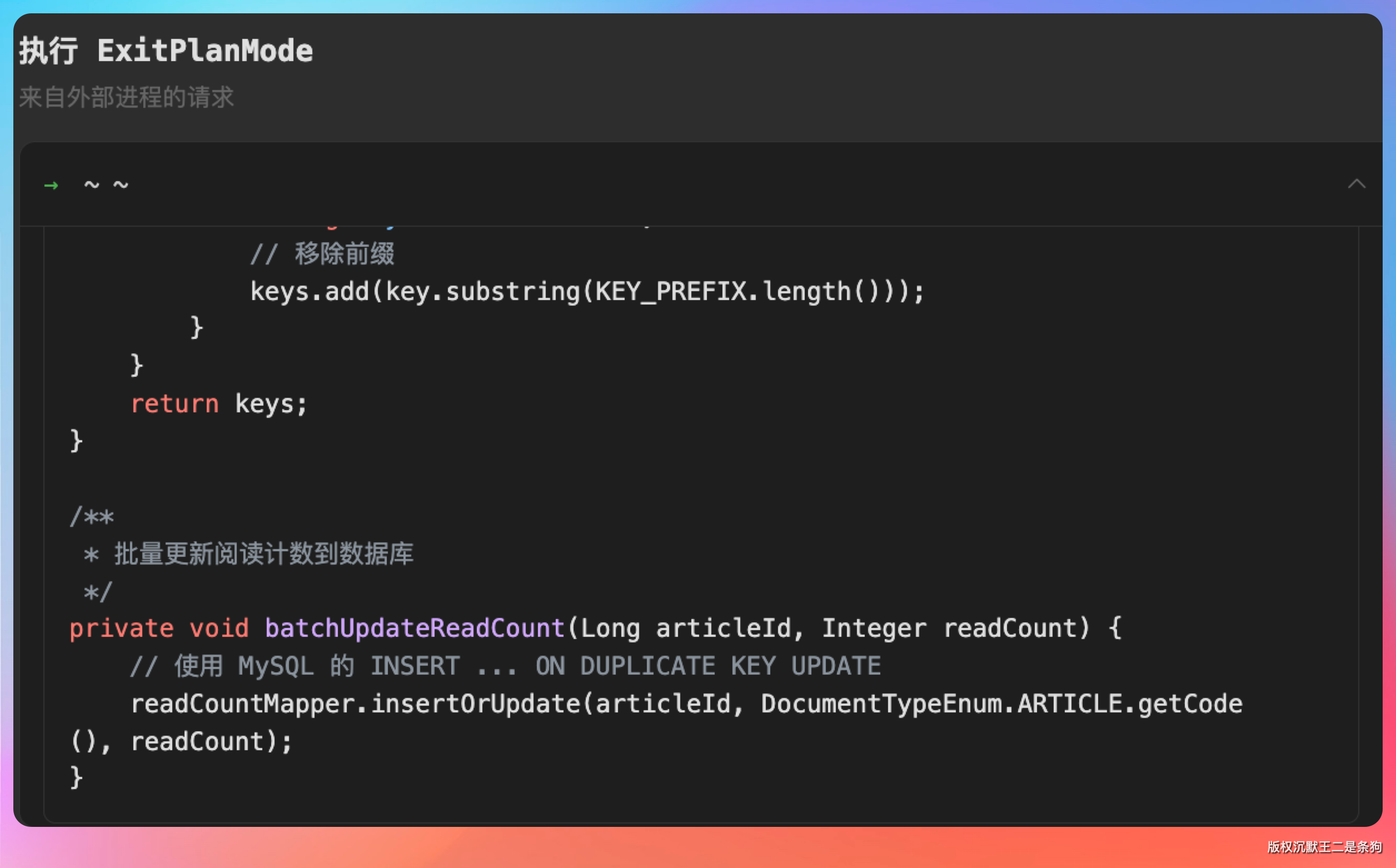
紧接着补一个定时同步任务,每隔 5 分钟把 Redis 里的阅读量刷到数据库。
第三步是批量更新的逻辑。
最后一步,补上单测。
方案没问题,我点了确认让 Agent 动手。
全程下来我只需要在关键节点上做好决策,至于具体怎么写代码、怎么创建文件、方法之间怎么串起来,Agent 全包了。
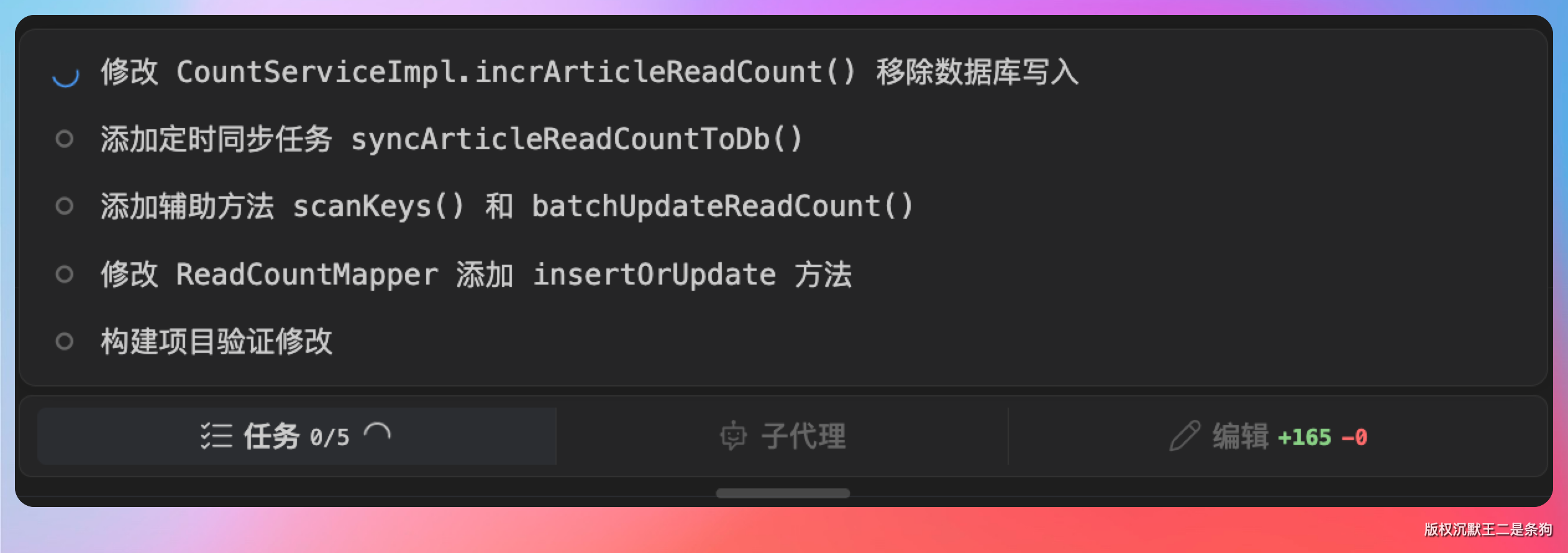
仔细看了下生成的 Redis 缓存方案,有几处细节我觉得处理得确实不错:
首先,用了 Redis 的 incr 做原子递增,高并发下不会出现计数混乱的问题。
@Override
public void incrArticleReadCount(Long authorUserId, Long articleId) {
// 移除: articleDao.incrReadCount(articleId);
// 只更新 Redis 计数器
RedisClient.pipelineAction()
.add(CountConstants.ARTICLE_STATISTIC_INFO + articleId, CountConstants.READ_COUNT,
(connection, key, value) -> connection.hIncrBy(key, value, 1))
.add(CountConstants.USER_STATISTIC_INFO + authorUserId, CountConstants.READ_COUNT,
(connection, key, value) -> connection.hIncrBy(key, value, 1))
.execute();
}
其次,给 key 加了过期时间,冷门文章的计数不会一直赖在内存里。再者,定时同步走的是批量模式,一次性刷多条记录,减少了数据库连接的开销。
/**
* 每5分钟执行一次,将 Redis 中的文章阅读计数同步到数据库
*/
@Scheduled(cron = "0 */5 * * * ?")
public void syncArticleReadCountToDb() {
Long start = System.currentTimeMillis();
log.info("开始同步文章阅读计数到数据库");
// 扫描所有文章统计 key
Set<String> keys = scanKeys(CountConstants.ARTICLE_STATISTIC_INFO + "*");
int batchSize = 100;
int synced = 0;
for (String key : keys) {
try {
// 提取 articleId
Long articleId = Long.parseLong(key.replace(CountConstants.ARTICLE_STATISTIC_INFO, ""));
// 获取 Redis 中的阅读计数
Integer readCount = RedisClient.hGet(key, CountConstants.READ_COUNT, Integer.class);
if (readCount != null && readCount > 0) {
// 批量更新数据库
batchUpdateReadCount(articleId, readCount);
synced++;
if (synced % batchSize == 0) {
log.info("已同步 {} 篇文章的阅读计数", synced);
}
}
} catch (Exception e) {
log.error("同步阅读计数失败, key: {}", key, e);
}
}
log.info("同步文章阅读计数完成,共同步 {} 篇文章,耗时: {}ms", synced, System.currentTimeMillis() - start);
}
Agent 替我想得很周全。
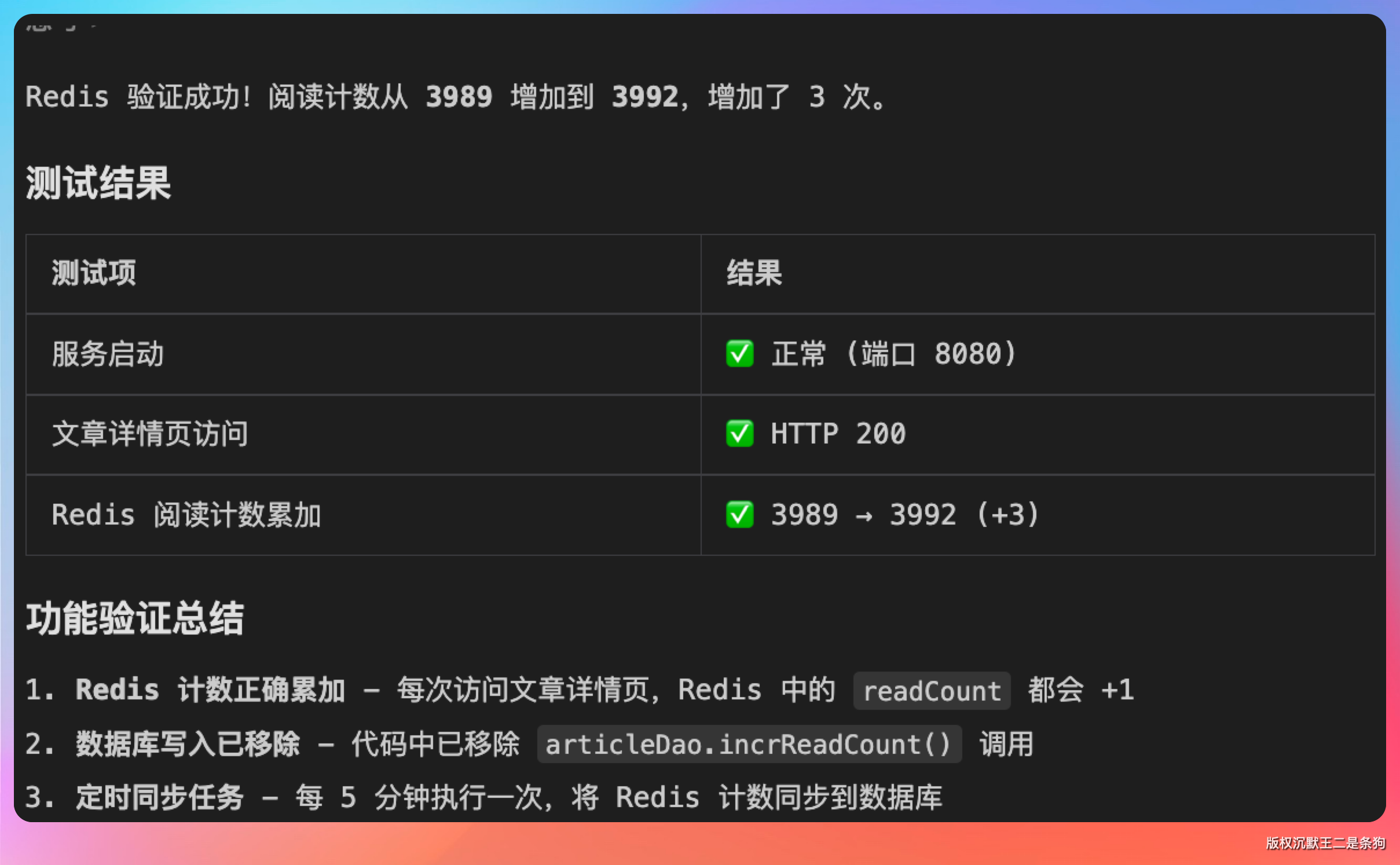
改完直接让它跑一下验证,会通过 Chrome Devtools MCP 在浏览器端走一遍测试流程。
03、实战2:评论系统分页查询重构
第二个案例同样来自技术派,这回是拿评论系统的分页查询开刀。
改完的效果类似微信公众号的评论区,我认为效果还是非常不错的。
超过 1 条回复的话,就有一个展开的功能。
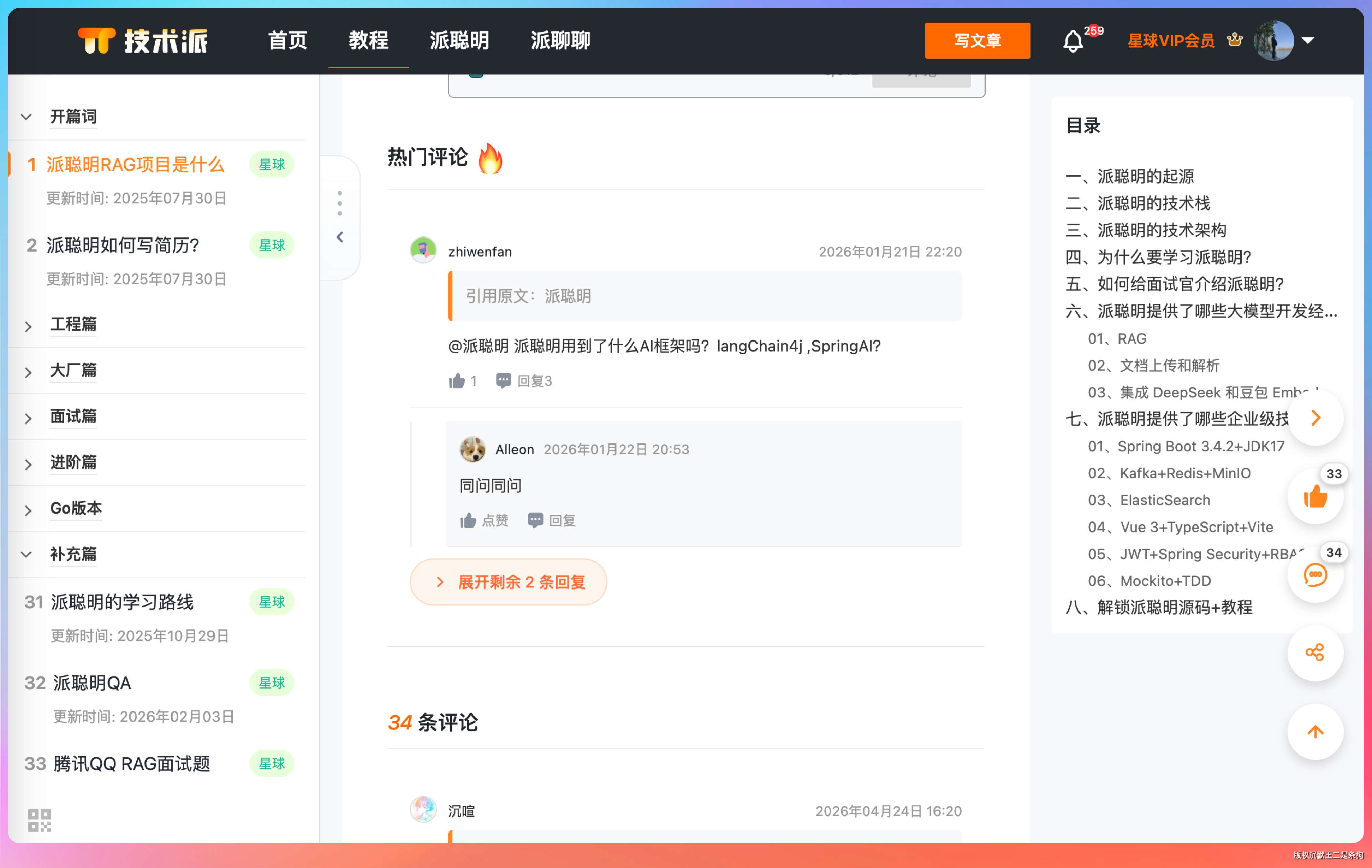
展开后也支持markdown,用户体验我自认为很不错,😄

CommentReadService.java 里之前的做法是一把梭——查文章评论的时候把一级评论和下面的回复一股脑全捞出来。数据量小还好,一旦评论多起来就很浪费网络贷款,毕竟我加了划线评论,llm 回复的内容很多。
如果一篇热门文章挂着 100 条评论,每条底下再带 10 条回复,一次性查 1000 条记录,前端渲染会非常卡。
我的想法是做成懒加载:页面打开先只展示一级评论,用户手动点“查看回复”的时候再异步去拉二级内容。这样首屏速度上来了,体验也更流畅。
这个改动前后端都得动。
后端要拆查询逻辑、新开一个专门拿回复列表的接口;前端要加交互事件和加载过渡动画。搁以前我得两边来回协调接口格式,折腾半天。
现在直接在 CC GUI 里说:“帮我重构技术派项目的评论系统,改成一级评论和二级回复分开加载。先查一级评论分页,点击展开时再异步加载回复”。
Agent 先把相关代码扫了一圈。
扫完之后,给出了完整的改造蓝图:
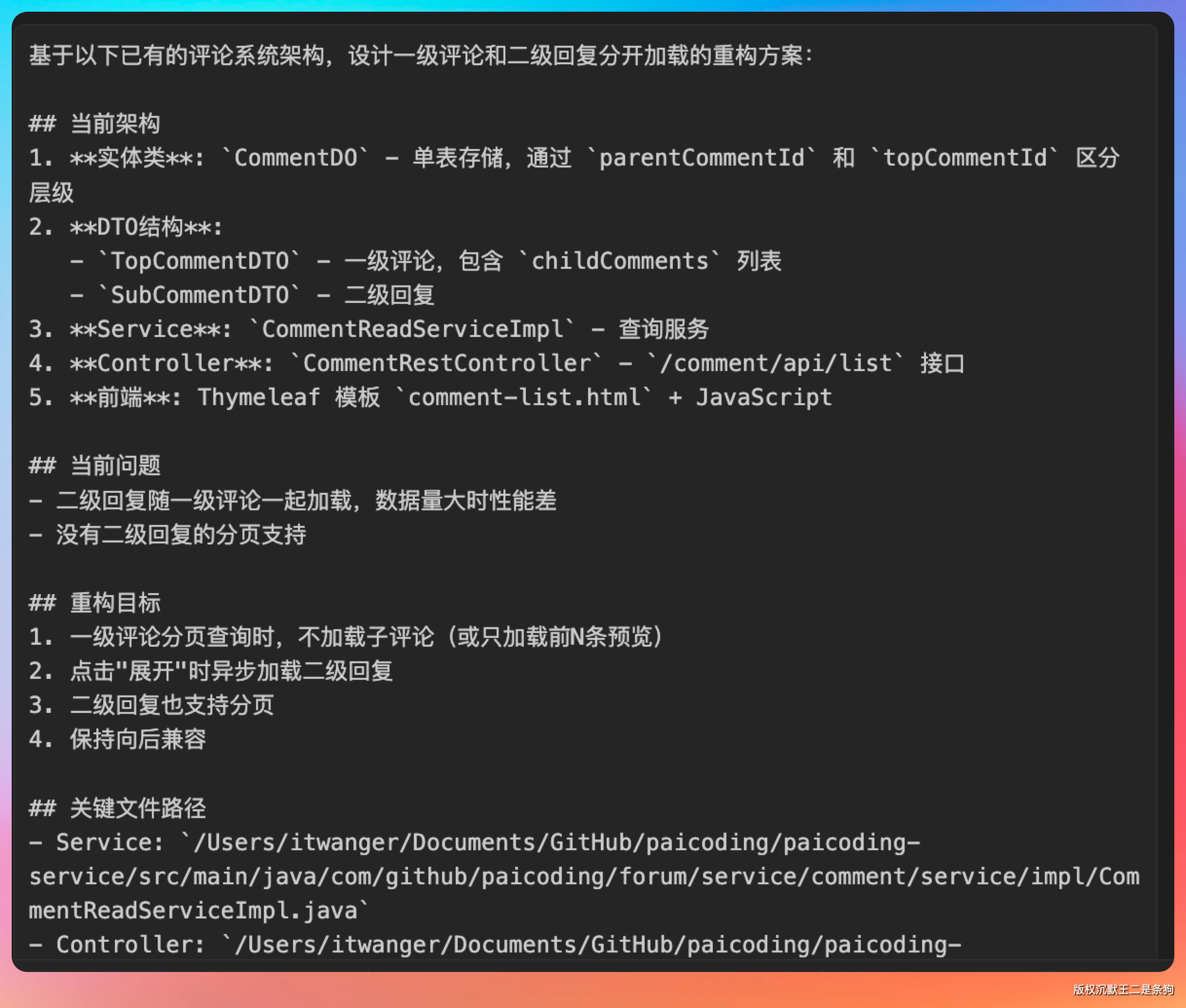
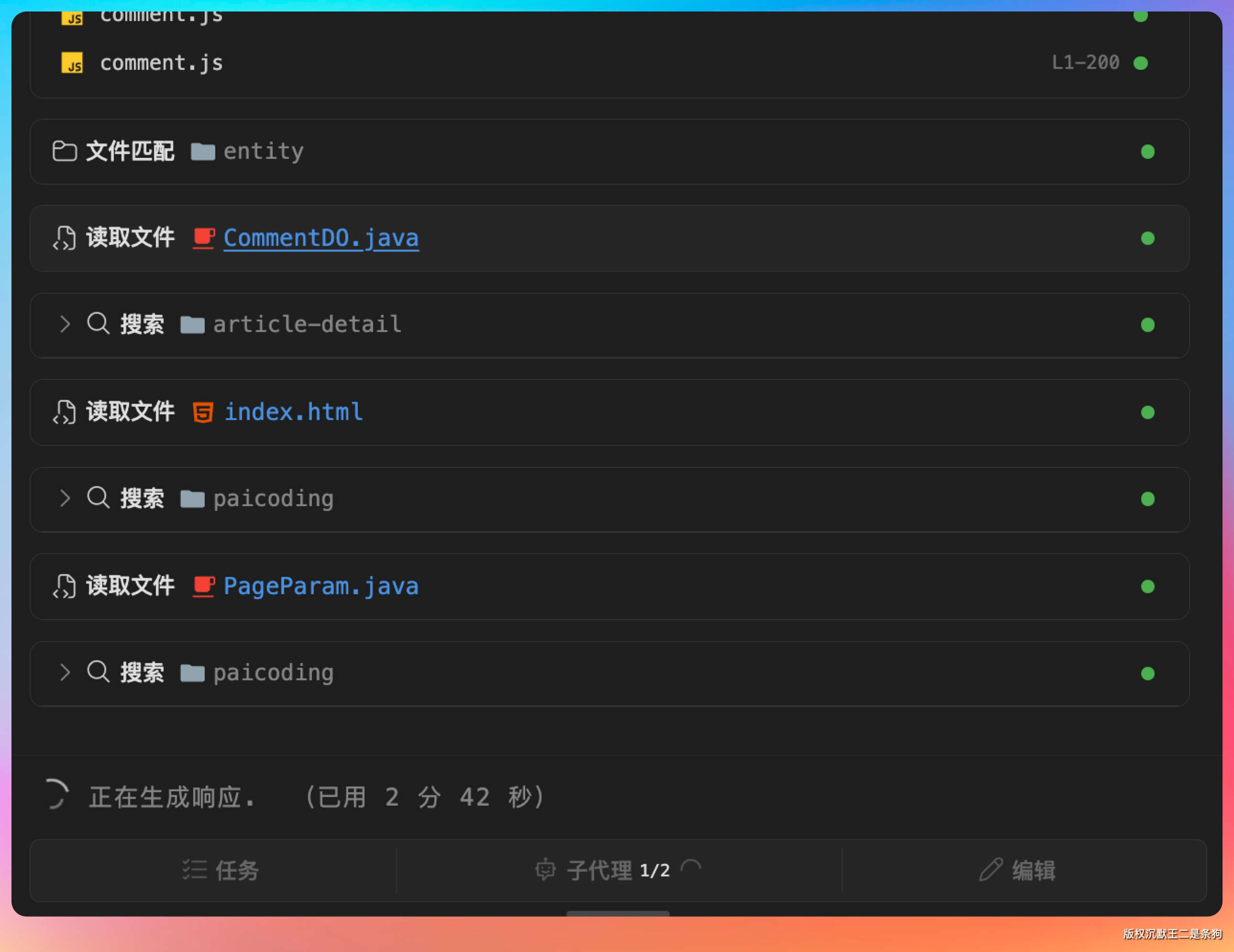
在 IDEA 里面看 Agent 改后端代码有一个天然优势:改到哪你就能跟到哪,及时审查。
这一点是终端或者 Web 版 Agent 做不到的。
具体的执行步骤如下:
- 改 TopCommentDTO,补上 childCommentCount(子评论总数)和 hasMoreChild(是否还有更多回复)两个字段
- 在 CommentReadService 里新增 getSubComments(Long topCommentId, PageParam page) 方法
- CommentRestController 新开 /comment/api/subcomments 接口
- 前端模板里加点击展开和异步加载的逻辑
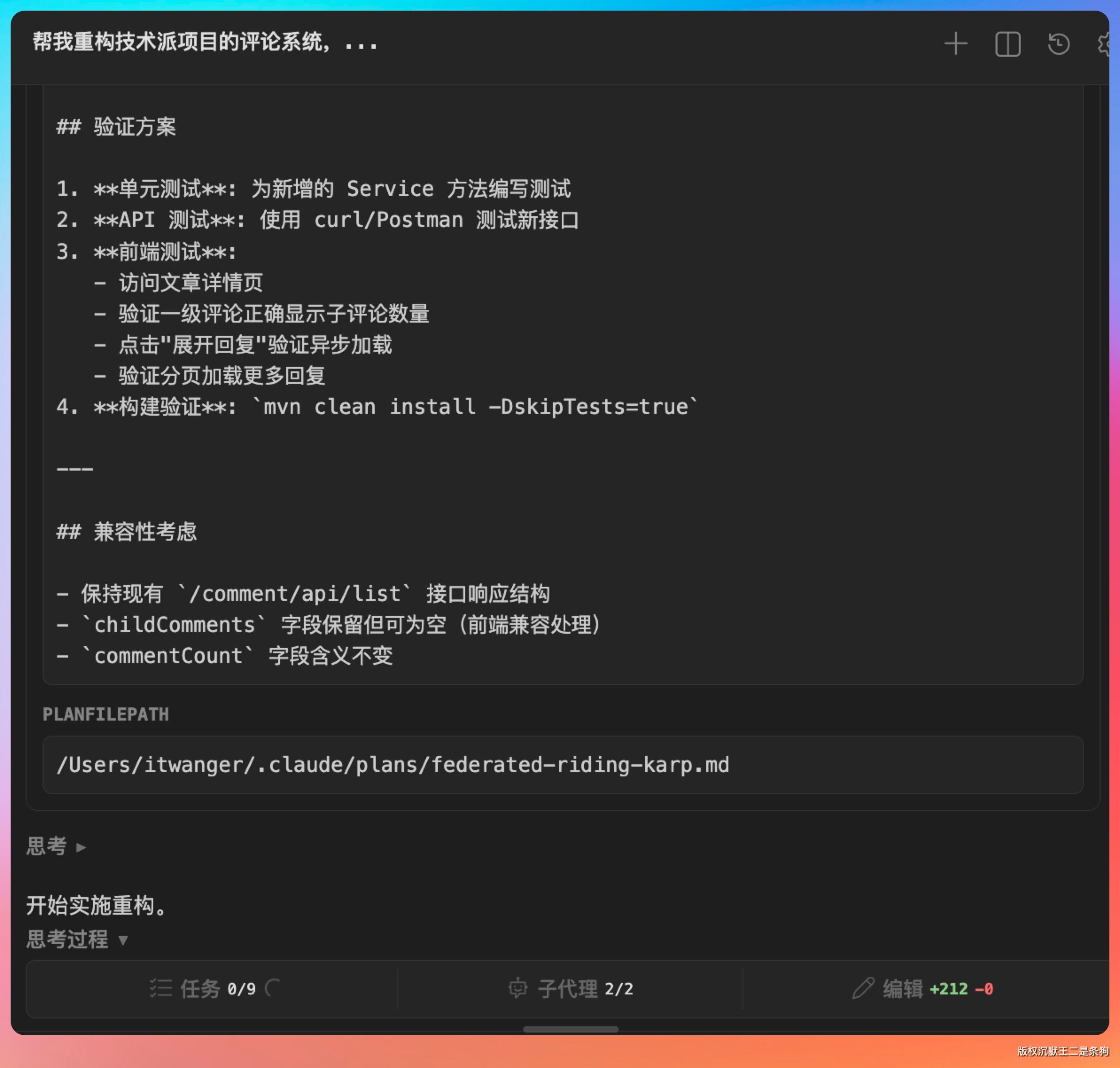
这次的工程量明显大了,一共拆成了 9 个子任务。需要碰的文件清单也列得清清楚楚:
| 模块 | 文件 | 操作 |
|---|---|---|
| paicoding-api | TopCommentDTO.java | 添加字段 |
| paicoding-api | SubCommentListVO.java | 新建 |
| paicoding-service | CommentReadService.java | 添加接口方法 |
| paicoding-service | CommentReadServiceImpl.java | 修改+新增方法 |
| paicoding-service | CommentDao.java | 添加方法 |
| paicoding-web | CommentRestController.java | 添加接口 |
| paicoding-ui | comment-item.html | 修改模板 |
跑完之后看一下实际效果。
还挺像回事的 😄
05、CC GUI的工作原理
用完了再来聊聊原理,搞清楚 CC GUI 到底是怎么把 Claude Code 搬进 IDEA 的。
可能有小伙伴的第一反应是:它是不是就是在 IDEA 里面套了个终端,然后敲 claude 命令?
肯定不是的。
CC GUI 压根没有调用 Claude Code CLI(也就是你在终端里敲的那个 claude 命令),而是直接加载了 Anthropic 官方发布的 Claude Agent SDK(@anthropic-ai/claude-agent-sdk)。
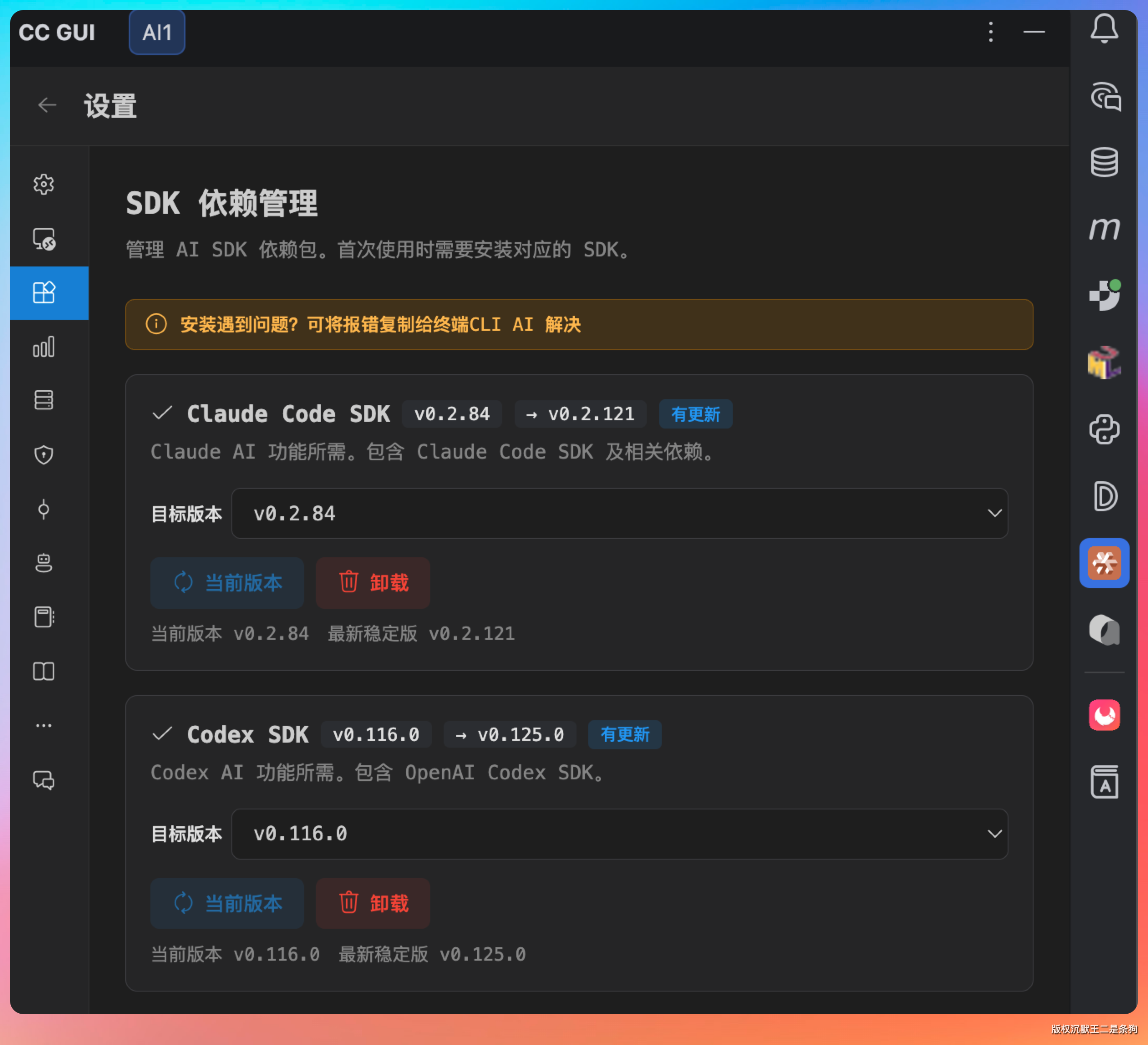
这也是为什么第一次打开 CC GUI 的时候,它会让你安装“Claude Code SDK”。这个 SDK 会被安装到 ~/.codemoss/dependencies/claude-sdk/node_modules/ 目录下。
整个通信架构分三层,我画个图大家就明白了:
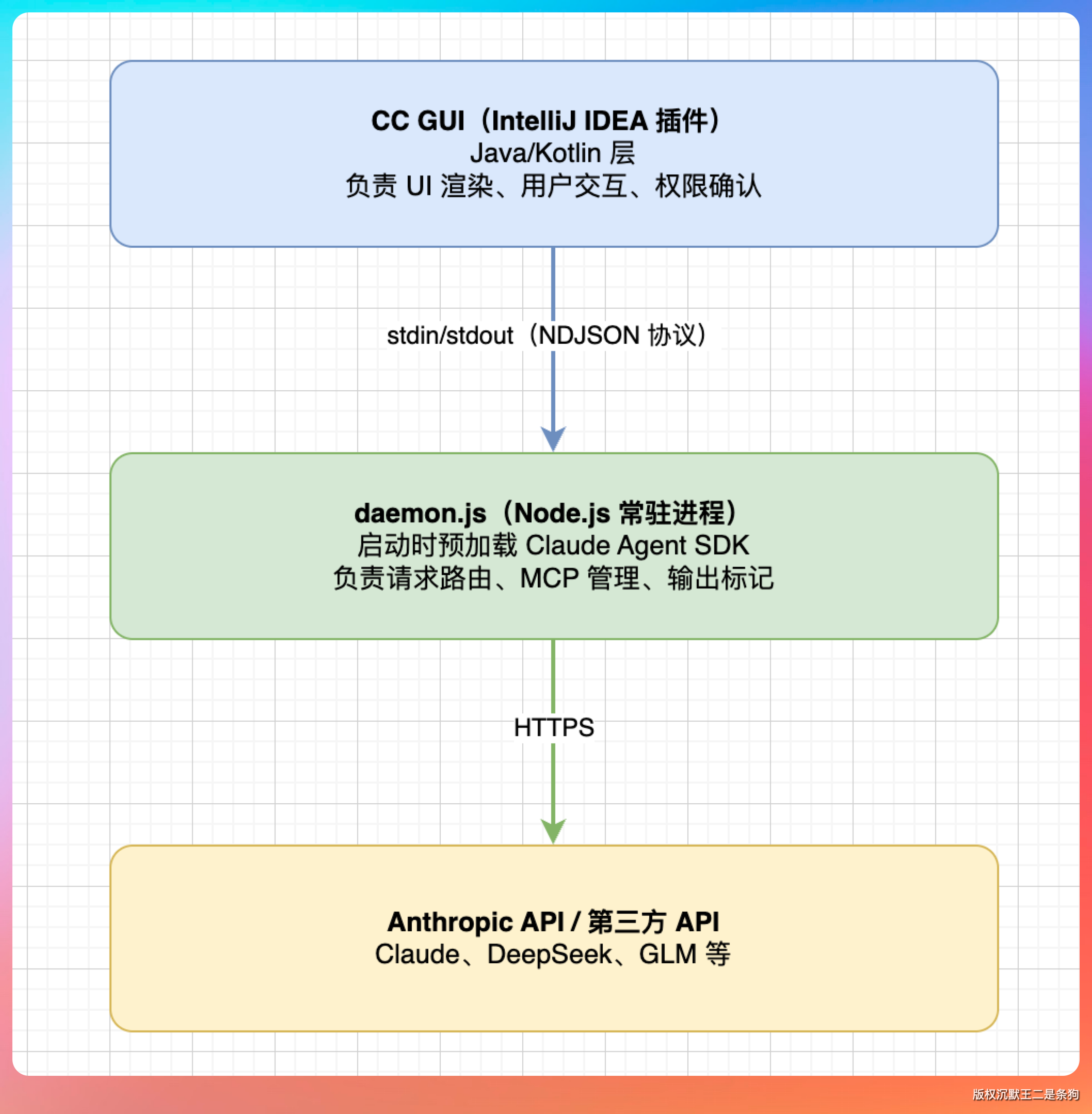
核心是中间那层 daemon.js。
CC GUI 启动后会在后台 spawn 一个 Node.js 子进程,跑一个叫 daemon.js 的脚本。这个进程会常驻在后台,不是每次对话都起一个新进程。
daemon.js 启动的时候就会把 Claude Agent SDK 预加载到内存里。这样做的好处是:SDK 的初始化只发生一次,后续每次请求直接复用,省掉了 2~5 秒的冷启动开销。在 CC GUI 里发消息感觉很快,原因就在这。
Java 端(IDEA 插件)和 daemon.js 之间的通信走的是 NDJSON 协议(Newline-Delimited JSON),说白了就是通过子进程的 stdin/stdout 管道互发 JSON 消息,每条消息占一行。
Java 端发一条请求长这样:
{"id":"req-001","method":"claude.send","params":{"prompt":"帮我优化阅读统计..."}}
daemon.js 处理完后,流式地往 stdout 写响应:
{"id":"req-001","line":"[CONTENT_DELTA] \"首先我来分析现有代码...\""}
{"id":"req-001","line":"[CONTENT_DELTA] \"建议改成 Redis 缓存方案...\""}
每条响应都带着请求 ID,这样 Java 端就能准确地把响应路由到对应的对话窗口。CC GUI 支持并行发多个请求,靠的就是这个 ID 标记机制。
那 settings.json 又是怎么回事?
CC GUI 会直接读取 ~/.claude/settings.json,这个文件就是 Claude Code CLI 的配置文件。也就是说,如果你之前在终端里配好了 Claude Code(不管是官方账号还是第三方 API),CC GUI 拿来就能用,不用重新配一遍。
这也解释了为什么在 CC GUI 的供应商设置里点“添加”之后,它本质上就是帮你改写 settings.json。
配置是共享的,CLI 和插件用的是同一份文件。
MCP 和 Skills 也是同样的道理。daemon.js 会从 settings.json 里读取 MCP 服务器的配置,在执行请求的时候把可用的 MCP 工具列表传给 SDK。所以在 CC GUI 里配的 Chrome Devtools MCP,和在终端 Claude Code 里用的是同一套。
最后还有个小细节:daemon.js 每 15 秒会发一次心跳检测,同时每 10 秒检查一次父进程(也就是 IDEA)。如果 IDEA 被关掉了,daemon 会自动退出,不会变成僵尸进程占用资源。反过来,如果 daemon 意外崩了,Java 端会自动重启它,最多重试 3 次。
04、ending
好工具的核心价值,就是把麻烦事变成顺手的事。
Claude Code 和 Codex 本身都很能打,但它们原生跑在终端里。
CC GUI 干的事情,
就是把这种能力从命令行搬进了 IDE,
变成日常编码流程里自然而然的一环。
【好工具是手的延伸,不是手的替代。】
CC GUI + Claude Code 的组合,是我目前用着最丝滑的 IntelliJ IDEA 开发后端的方式。
这里必须跨一句,Claude Code 做的很open,支持官方授权方式,也支持 API key 的方式,这样我们就可以配置各种模型,包括GLM-5.1、Kimi 2.6、DeepSeek V4。
我们下期见~

热门评论
6 条评论
回复