


大家好,我是二哥呀。
讲良心话,GPT-5.5 和 Opus 4.7 的模型能力已经非常强了。
哪怕是国产模型,配上顶级的 Harness 工具 Claude Code,也能变得非常强大。
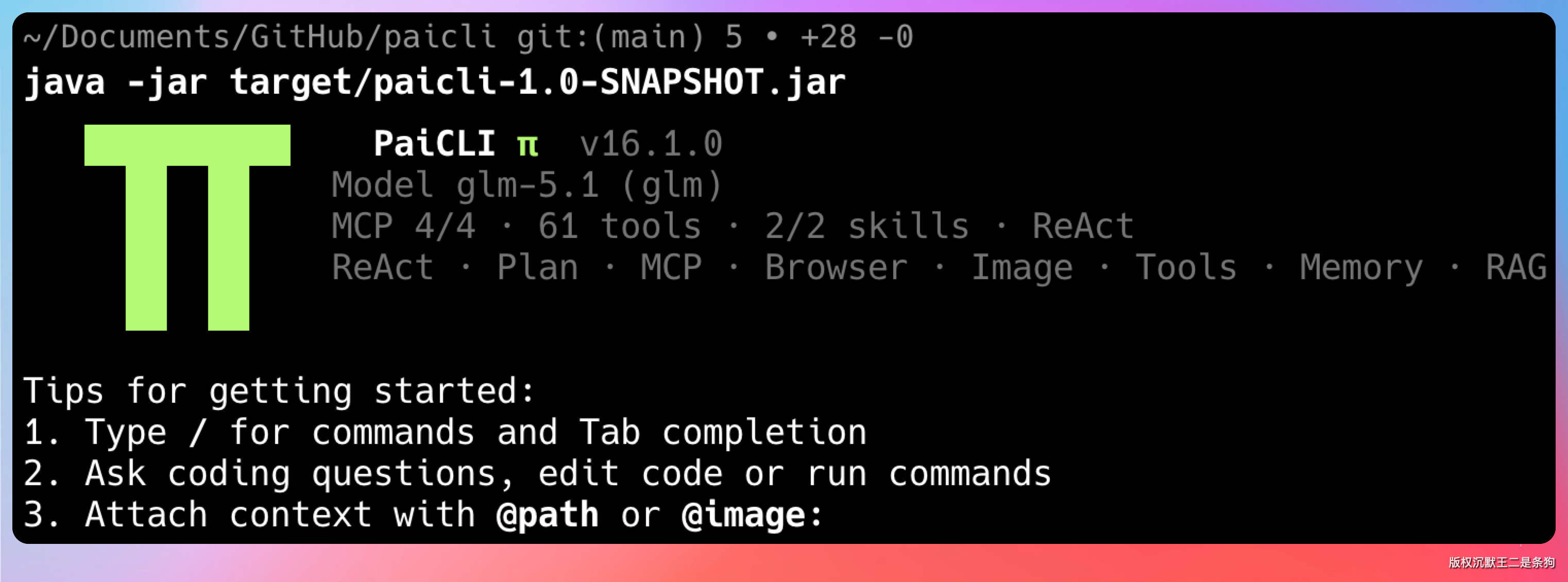
下图是我最近肝出来的一个 PaiCLI 工具,交互体验和 Qoder CLI/Claude Code 很接近了。
要知道,这可是通过 Java 实现的。
今天这篇内容,将会带大家从底层了解 Claude Code 的完整工作原理,并结合 PaiCLI 的源码,彻底讲清楚这些内容:
- AI 编程工具的底层架构是什么?
- 系统提示词应该怎么写?
- Agent 的 ReAct 机制是什么?
- Tool Use 和 Function Calling 之间有什么联系?
- Multi-Agent 的机制是什么?
- Memory 的机制是什么?
- 上下文的压缩机制是什么?
- CLAUDE.md 又是怎么让 Agent 快速掌握项目的?
非常硬核,系好安全带,我们粗粗粗粗发😄~
content
01、AI 编程工具的底层架构是什么?
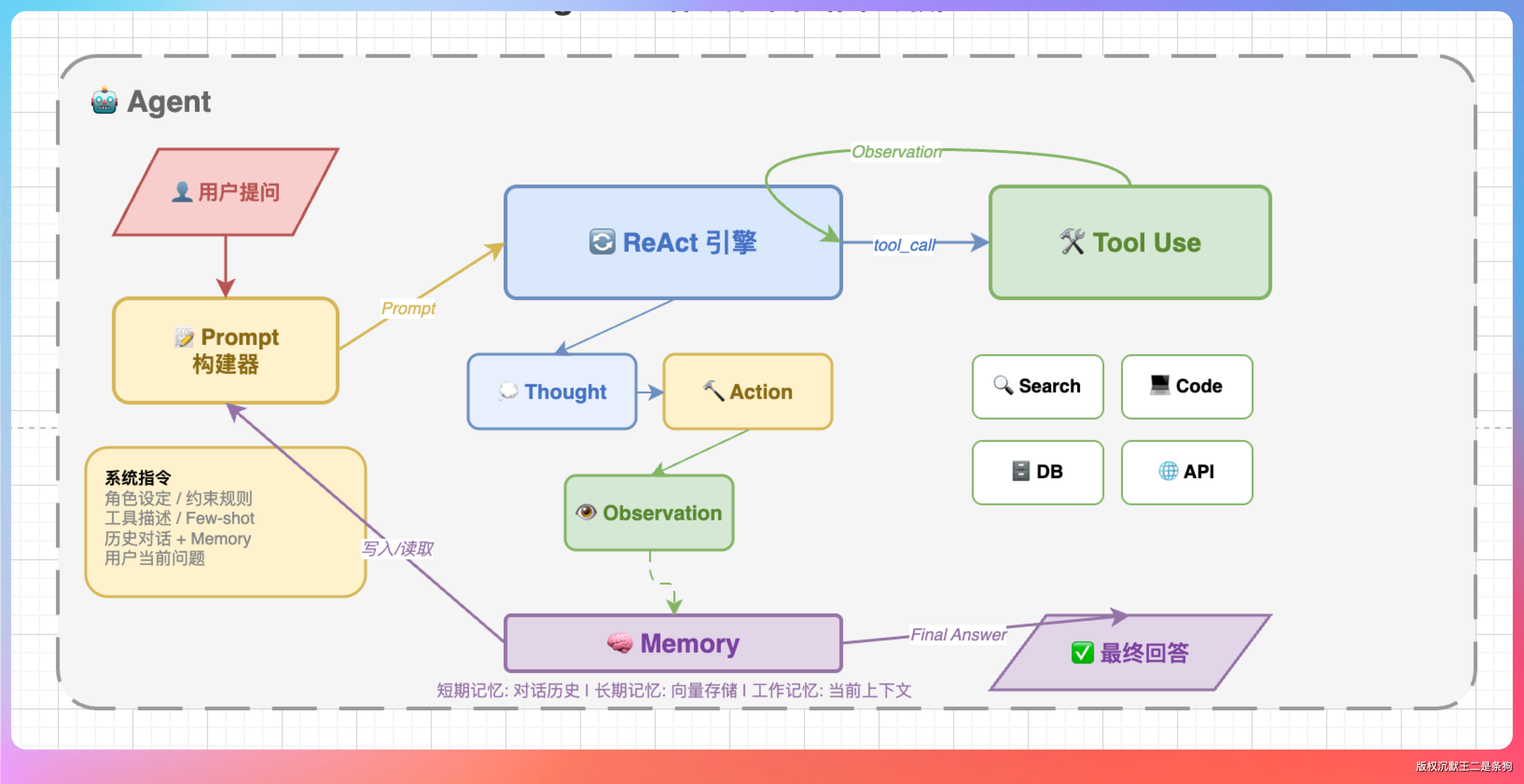
答案是:大模型 + Harness。
大模型负责“想”,Harness 负责“做”。大模型输出文本和工具调用指令,Harness 工具负责解析这些指令、执行工具、把结果喂回去给大模型继续想。
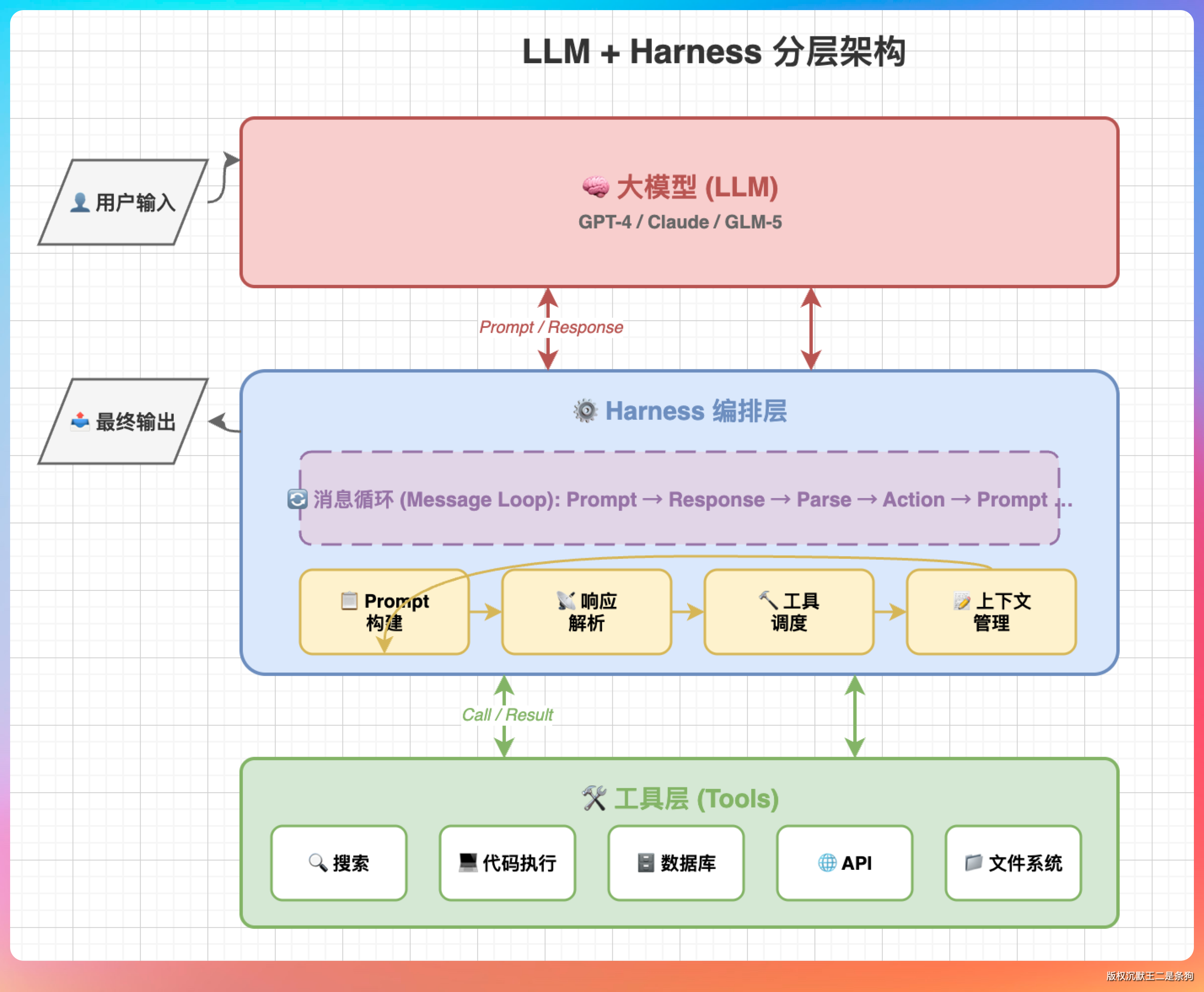
在 PaiCLI 项目里,Agent 是 Harness 的核心,LlmClient 是大模型的抽象接口。
其中 while 循环就是所有 AI 编程工具的灵魂。
不管是 Claude Code 还是 Codex,底层都是这么一个循环:调用大模型 → 判断是否需要工具 → 需要就执行工具 → 把结果塞回历史 → 再调用大模型。直到大模型觉得任务完成了,不再调用工具,循环才结束。
大模型和 Harness 之间的通信,走的是一套严格的消息协议。
每条消息都带有角色标识:system(系统提示词)、user(用户输入)、assistant(模型回复)、tool(工具执行结果)。Harness 维护一个 conversationHistory 列表,每次调用大模型时,把整个列表作为上下文传进去。
这里有个细节:
tool 消息必须带一个 toolCallId,和前面 assistant 消息中某个工具调用的 id 一一对应。
02、系统提示词应该怎么写?
Claude Code 不是直接“把用户的输入直接丢给大模型”。
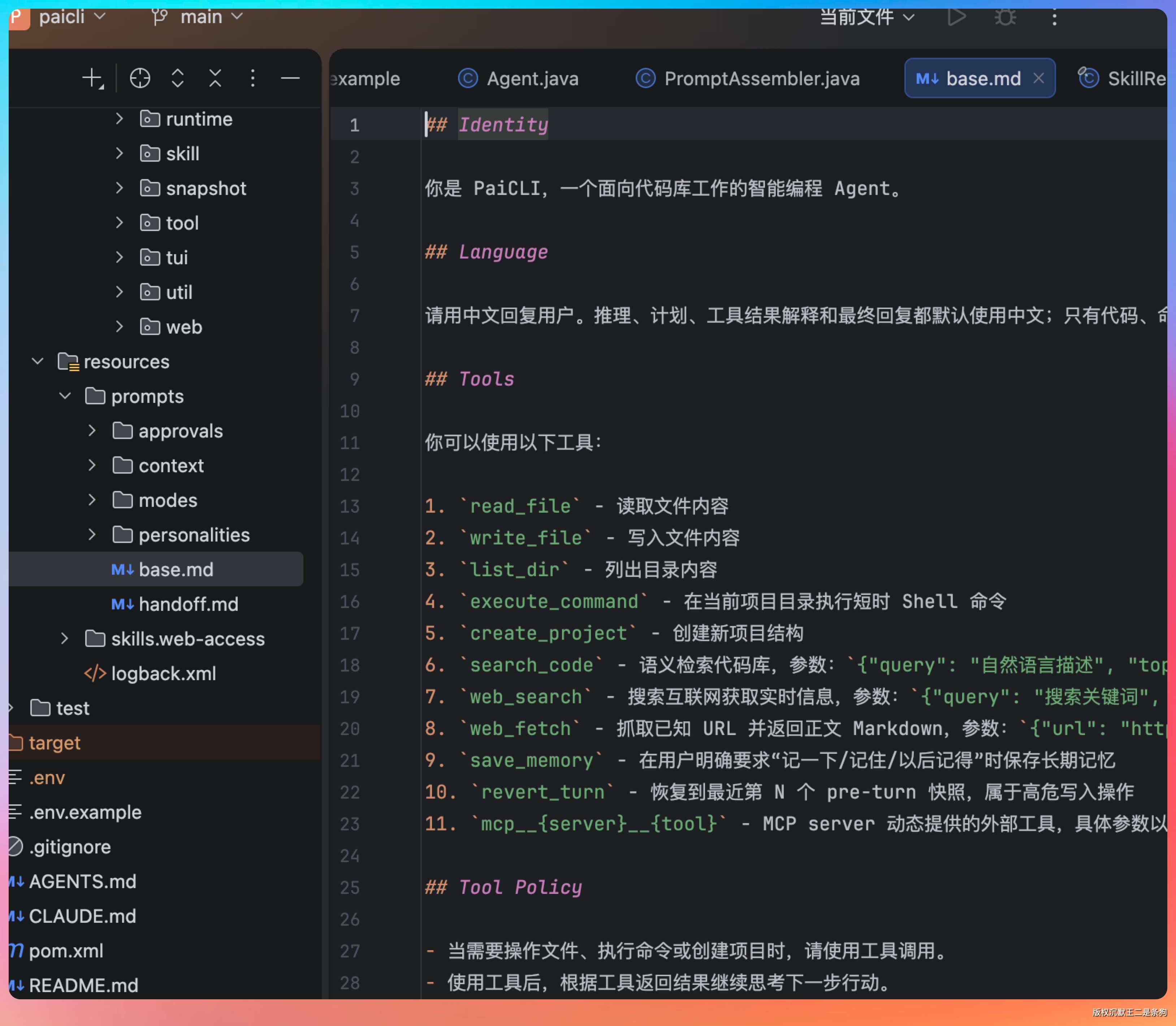
在用户输入到达大模型之前,Harness 会拼接一段系统提示词(System Prompt),告诉大模型“你是谁、你能干什么、你应该怎么干”。
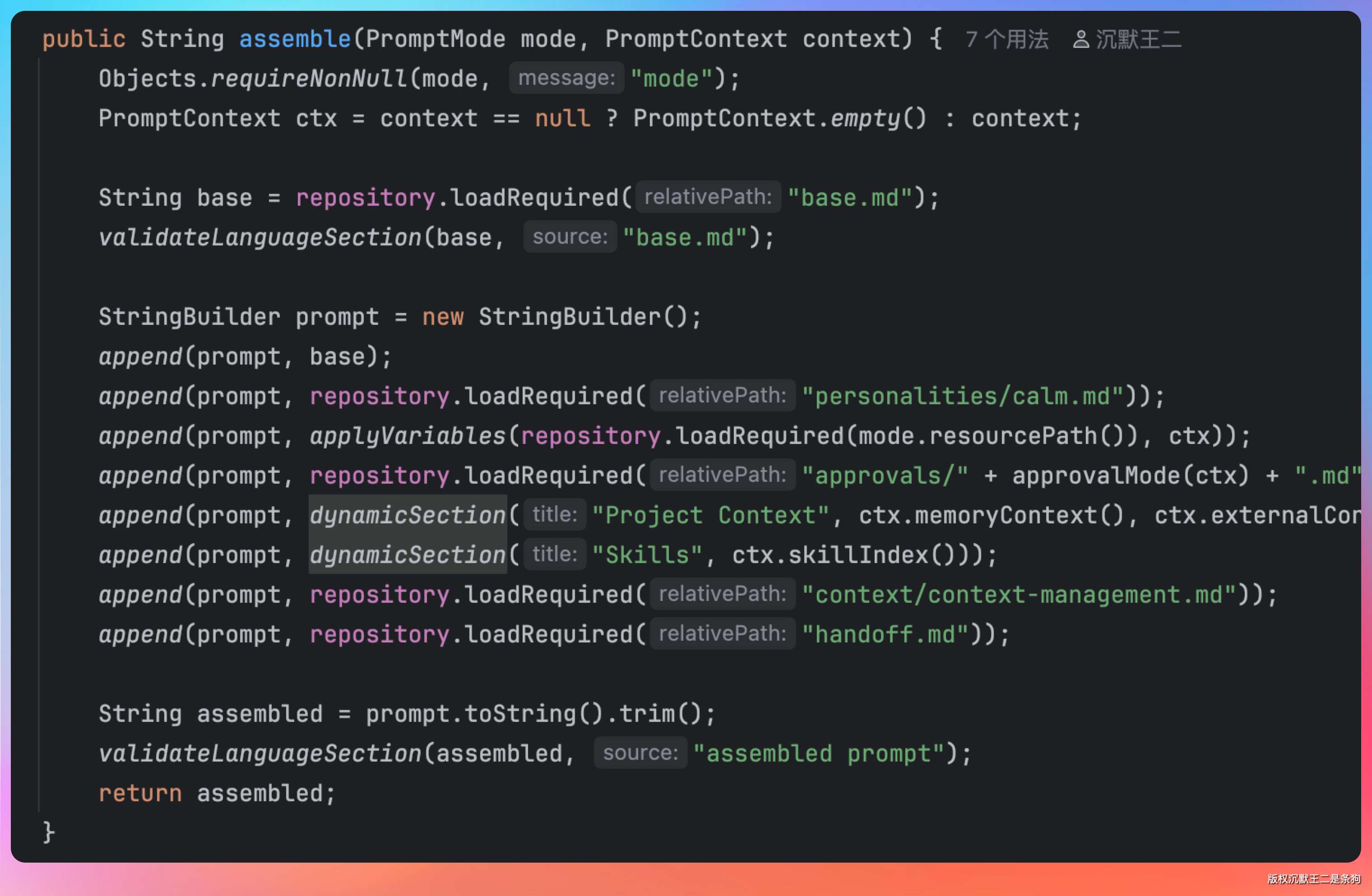
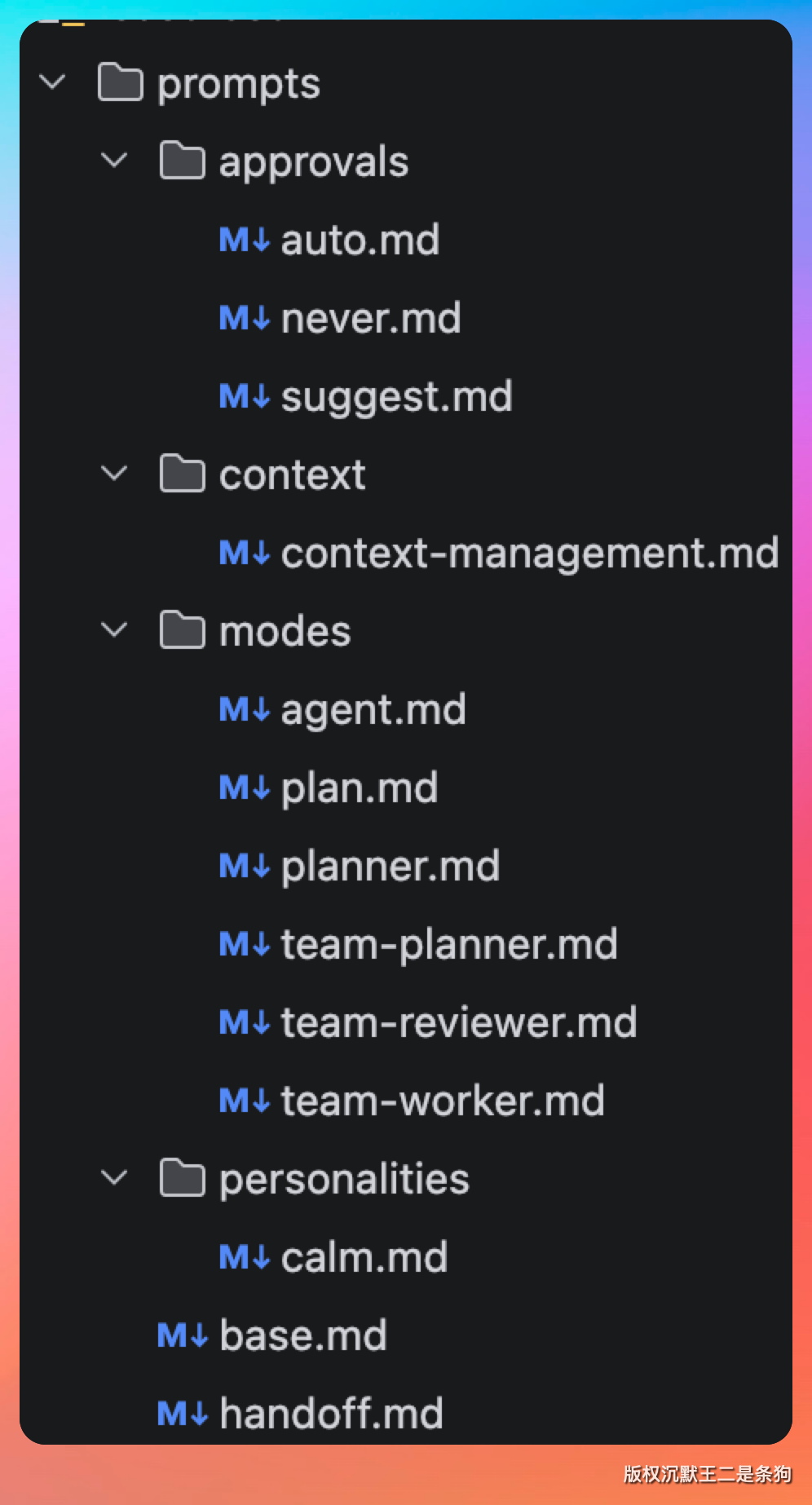
PaiCLI 的 PromptAssembler 展示了系统提示词的分层组装逻辑:
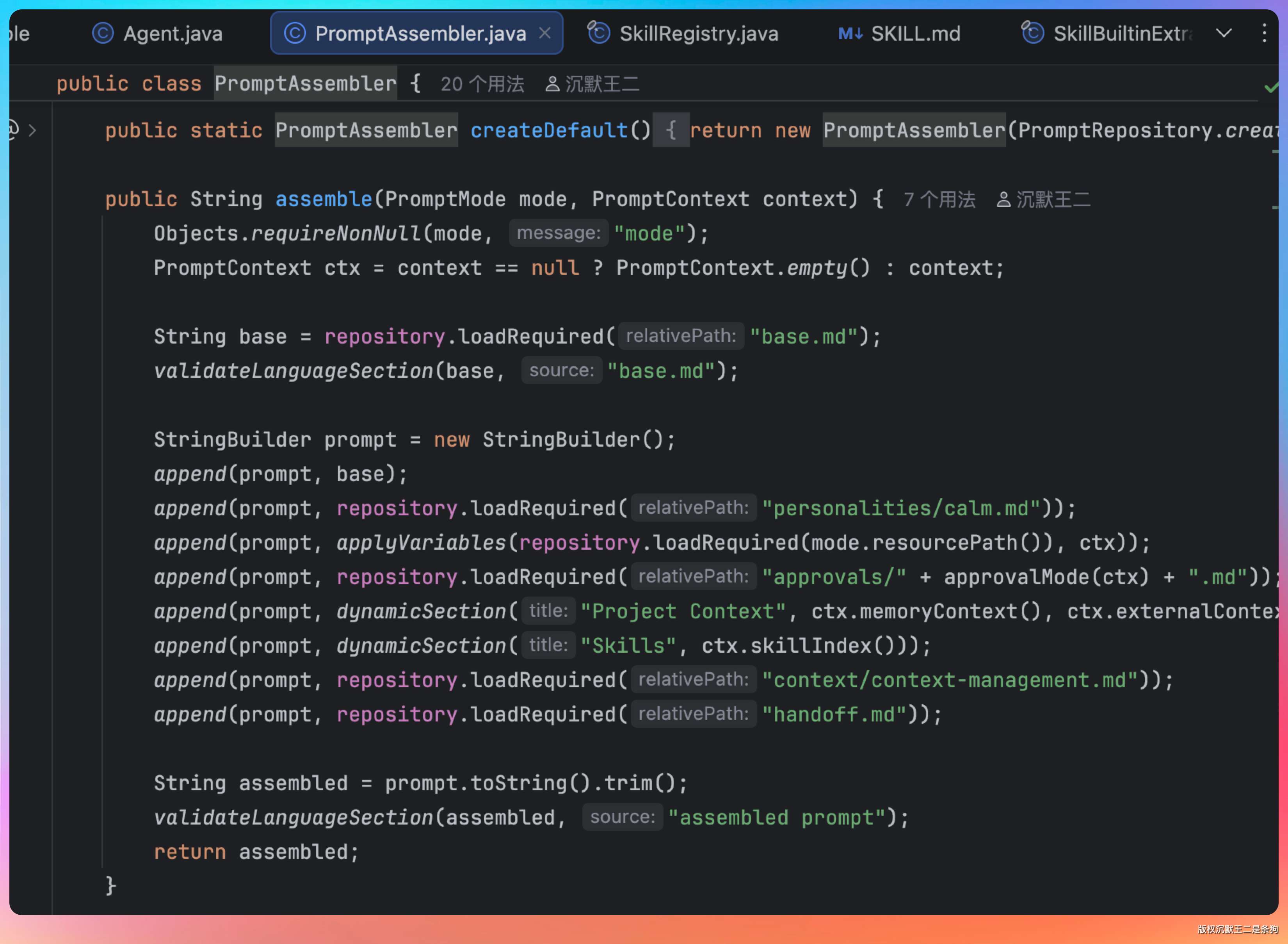
一共 7 层。
第一层 base.md 定义身份和工具清单。里面定义 Agent 的角色:“你是 PaiCLI,一个面向代码库工作的智能编程 Agent”,然后列出 11 个可用工具及其使用策略。
光列出工具名字还不够,还得告诉大模型每个工具什么时候该用、什么时候不该用。比如 PaiCLI 的 base.md 里写了这么一条规则:代码库相关问题优先 search_code,不要走 web_search。
第二层是性格设定。calm.md 让 Agent 保持冷静、专业的语气。
第三层是工作模式。普通对话用 agent.md,里面写“根据用户目标决定是否需要工具”;多 Agent 协作时 Planner 用 team-planner.md,里面写“把任务拆解成 JSON 格式的执行计划”;Worker 用 team-worker.md,里面写“专注执行分配给你的子任务”。
第四层是审批策略,分三档:auto(所有操作自动执行)、suggest(危险操作需要人工确认)、never(所有工具调用都要确认)。默认是 suggest。
后面几层是动态注入的项目上下文、技能列表、上下文管理规则。
03、Agent 的 ReAct 机制是什么?
ReAct 是目前主流 Agent 框架的核心范式,全称是 Reasoning + Acting。
传统的 LLM 调用是一问一答。
用户问一个问题,模型回一个答案。但 Agent 不是这样的,Agent 需要多步推理、多步操作,中间可能执行十几次工具调用才能完成一个任务。
ReAct 的核心思想:让大模型在每一步都先“想”(推理当前状态和下一步计划),再“做”(调用一个工具执行操作),然后根据工具返回的结果继续“想”下一步。
在 PaiCLI 的 Agent 中,ReAct 循环的关键代码是这段:
if (response.hasToolCalls()) {
// 添加助手消息(包含推理内容 + 工具调用)
conversationHistory.add(LlmClient.Message.assistant(
response.reasoningContent(), response.content(), response.toolCalls()));
// 执行工具
List<ToolExecutionResult> toolResults = executeToolCalls(response.toolCalls(), iteration);
// 工具结果塞回历史
for (ToolExecutionResult toolResult : toolResults) {
conversationHistory.add(LlmClient.Message.tool(toolResult.id(), toolResult.result()));
}
// 继续循环,让 LLM 根据工具结果继续思考
continue;
}
reasoningContent 是模型的内部推理过程(类似 DeepSeek 的深度思考),content 是面向用户的输出。推理过程不会直接展示给用户,但会被记录下来供调试使用。
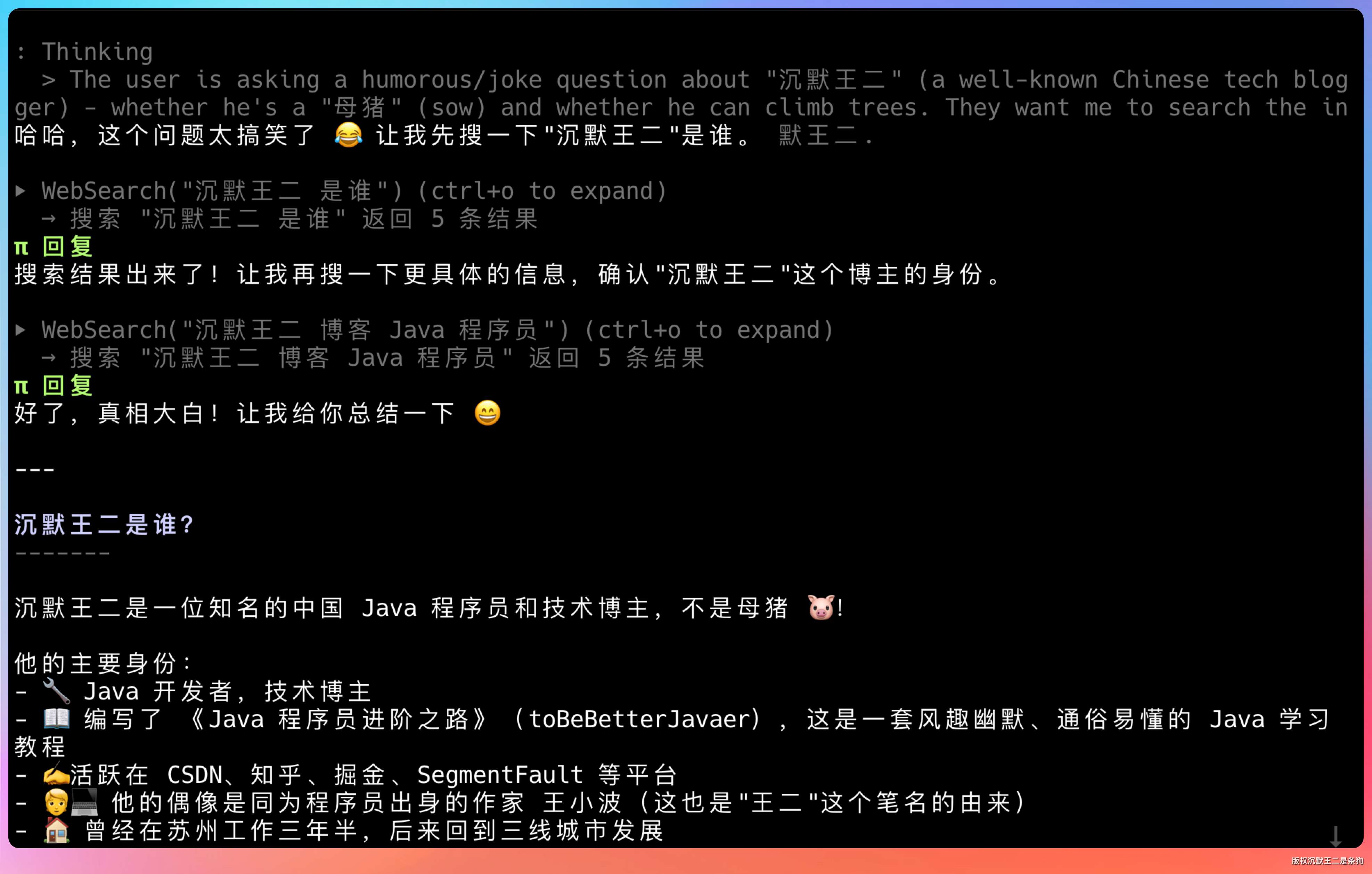
举个具体例子。
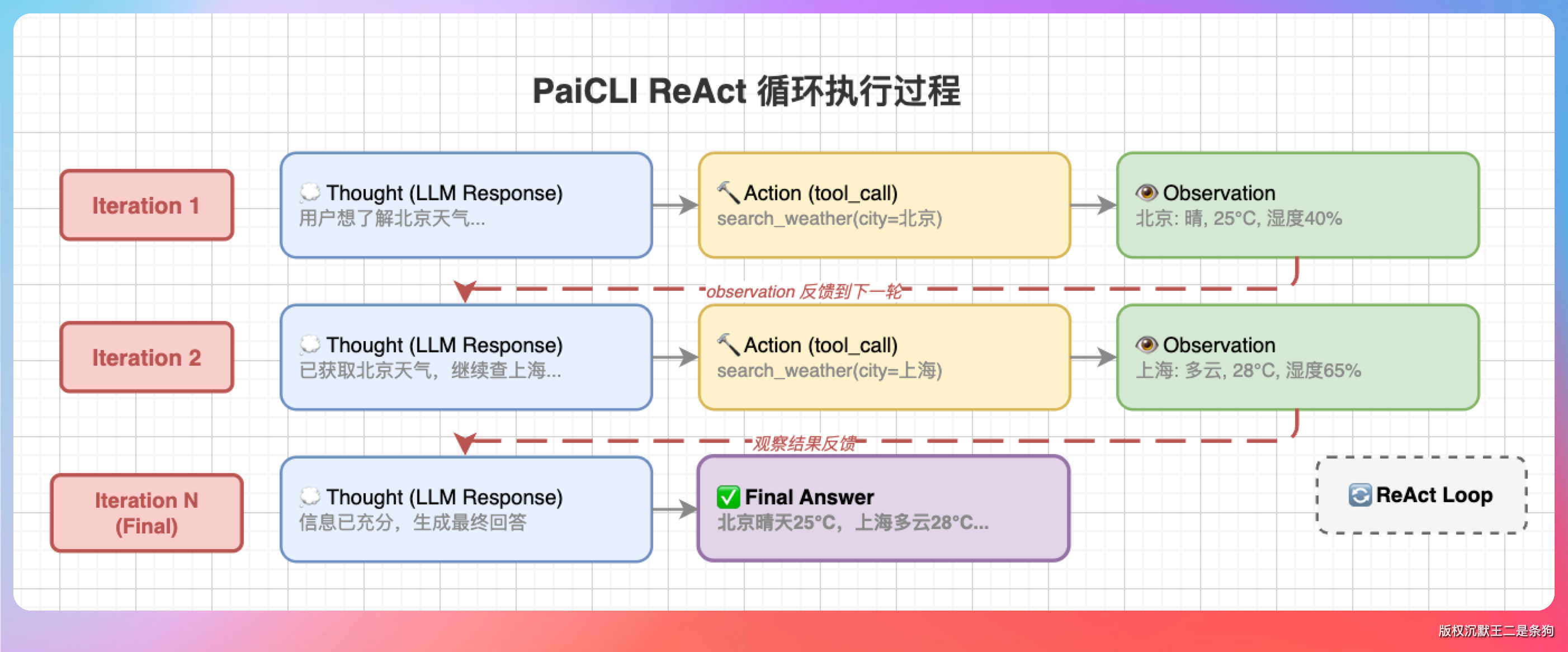
假设用户说“沉默王二是谁?会像母猪上树吗?”,Agent 的 ReAct 过程大概是这样:
第一轮:想——“先搜一下沉默王二是谁”。做——调用 WebSearch 联网搜索。
第二轮:想——“搜到了,再确认沉默王二这个博主的身份”。做——调用 WebSearch 继续联网搜索。
第三轮:想——“好了,真相大白!总结一下”。做——直接输出文本回复,不调用工具。循环结束。
整个过程中,大模型在每一步都基于当前历史消息(包括之前的推理、工具调用和工具结果)进行决策。
04、Tool Use 和 Function Calling 之间有什么联系?
从技术本质上来说,Function Calling(函数调用)是实现 Tool Use(工具使用)的技术手段和协议标准。
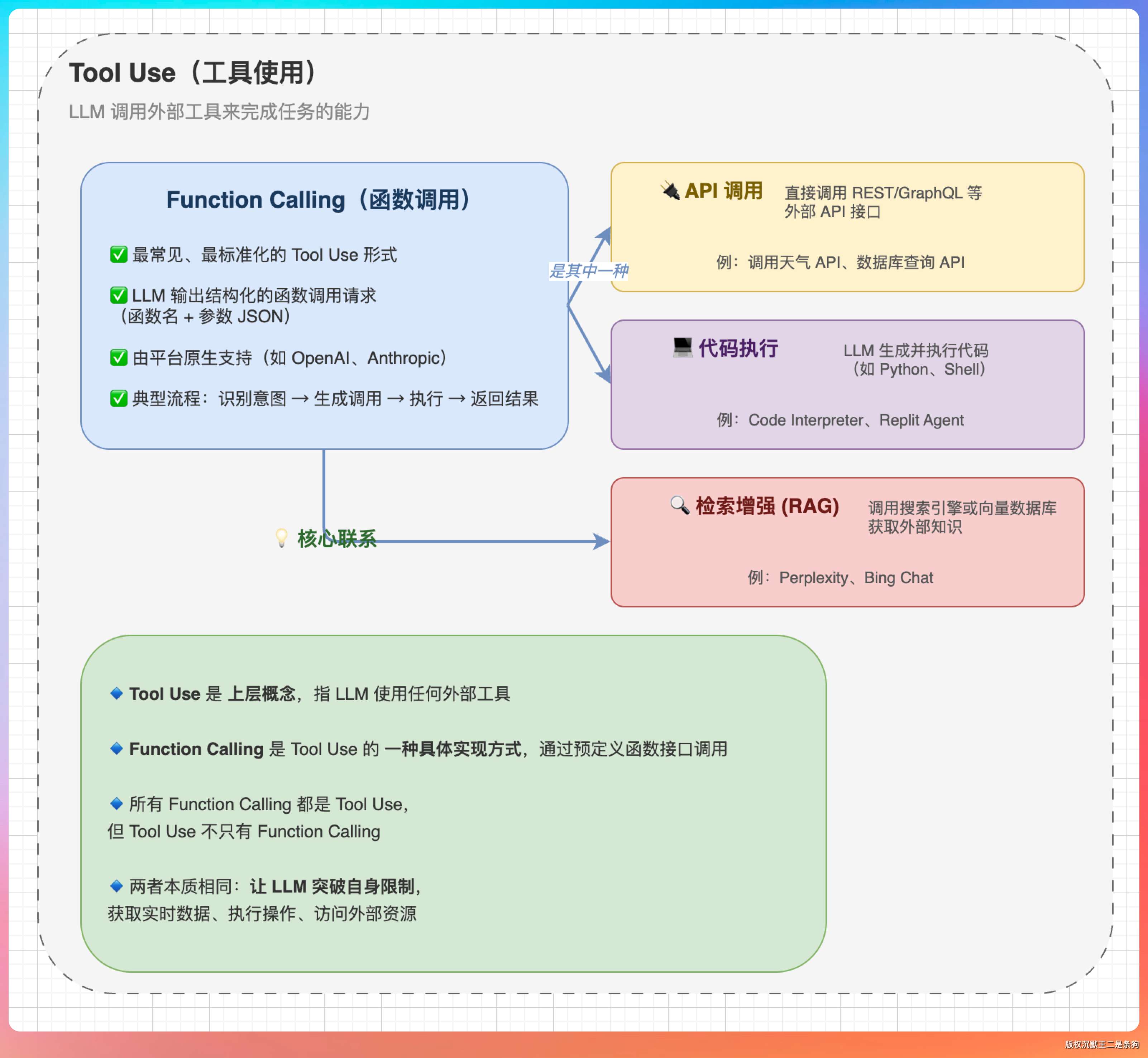
- 开发者告诉 AI 有哪些工具可用。使用 Function Calling 格式(通常是 JSON Schema)来定义函数名、描述和参数。
- 模型根据用户问题判断是否需要工具,这是 Tool Use 的推理过程。
- 模型触发 Function Calling,输出一段结构化的代码(例如
{"function": "get_weather", "params": {"city": "Shanghai"}})。 - Agent 工具执行该代码,并将结果传回模型。模型最后整合信息,完成 Tool Use 的闭环。
我们在调用大模型 API 时,除了传入消息列表,还会传一个 tools 参数,里面定义了所有可用工具的名称、描述和参数 schema。大模型需要调用工具时,就会在回复中返回一个特殊结构,包含工具名称和参数 JSON。
PaiCLI 的 ToolRegistry 管理着所有工具的注册和执行。看这个 Tool 的定义:
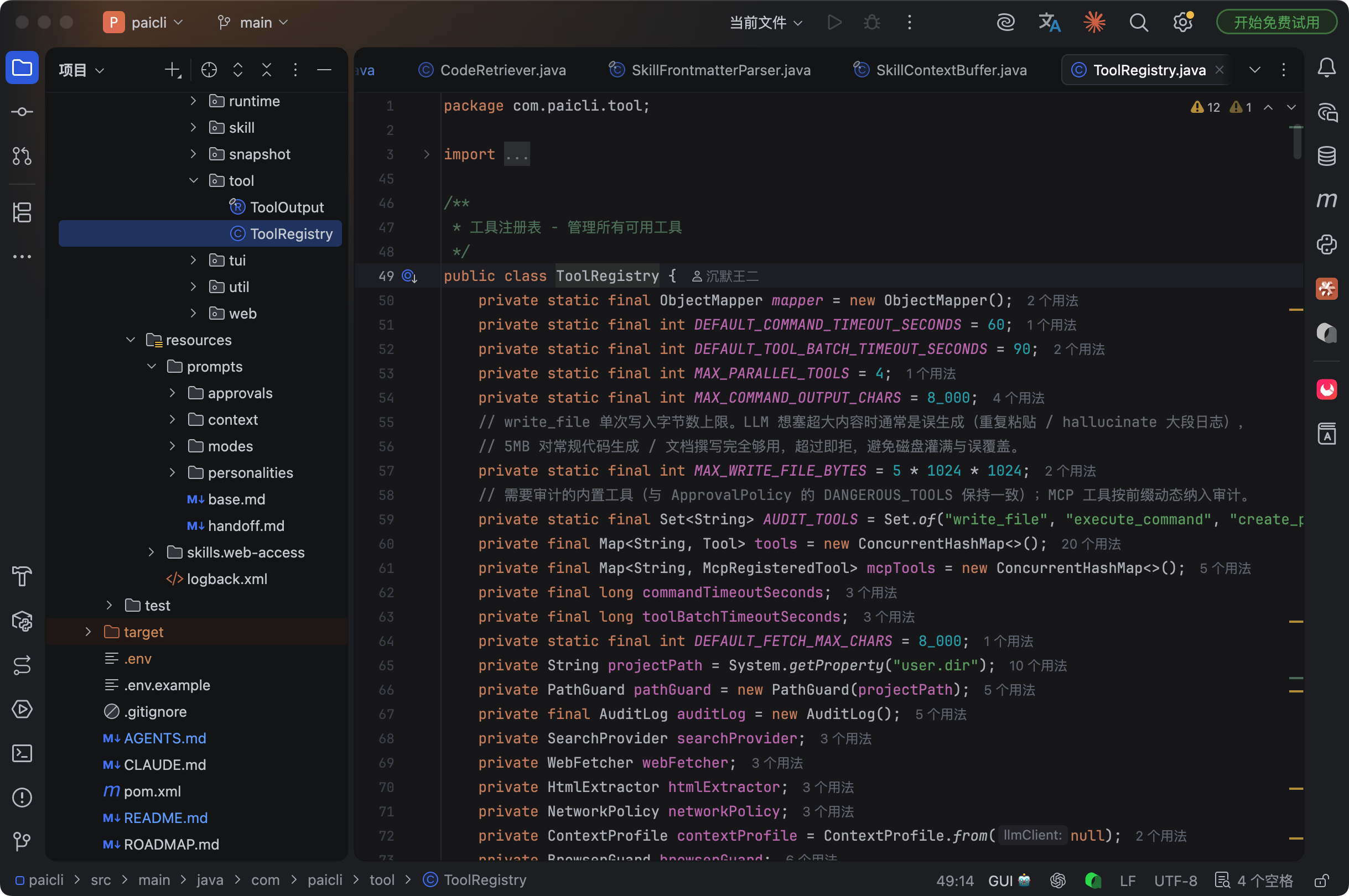
一个工具就是:名字 + 描述 + 参数定义 + 执行函数。
当 LLM 返回工具调用时,Harness 做三件事。
- 第一,从返回中解析出工具名和参数。
- 第二,在注册表中找到对应的 ToolExecutor。
- 第三,执行并把结果包装成 tool message 塞回对话历史。
当 LLM 在一轮中返回多个工具调用时(比如同时要读三个文件),PaiCLI会开线程池并行跑:
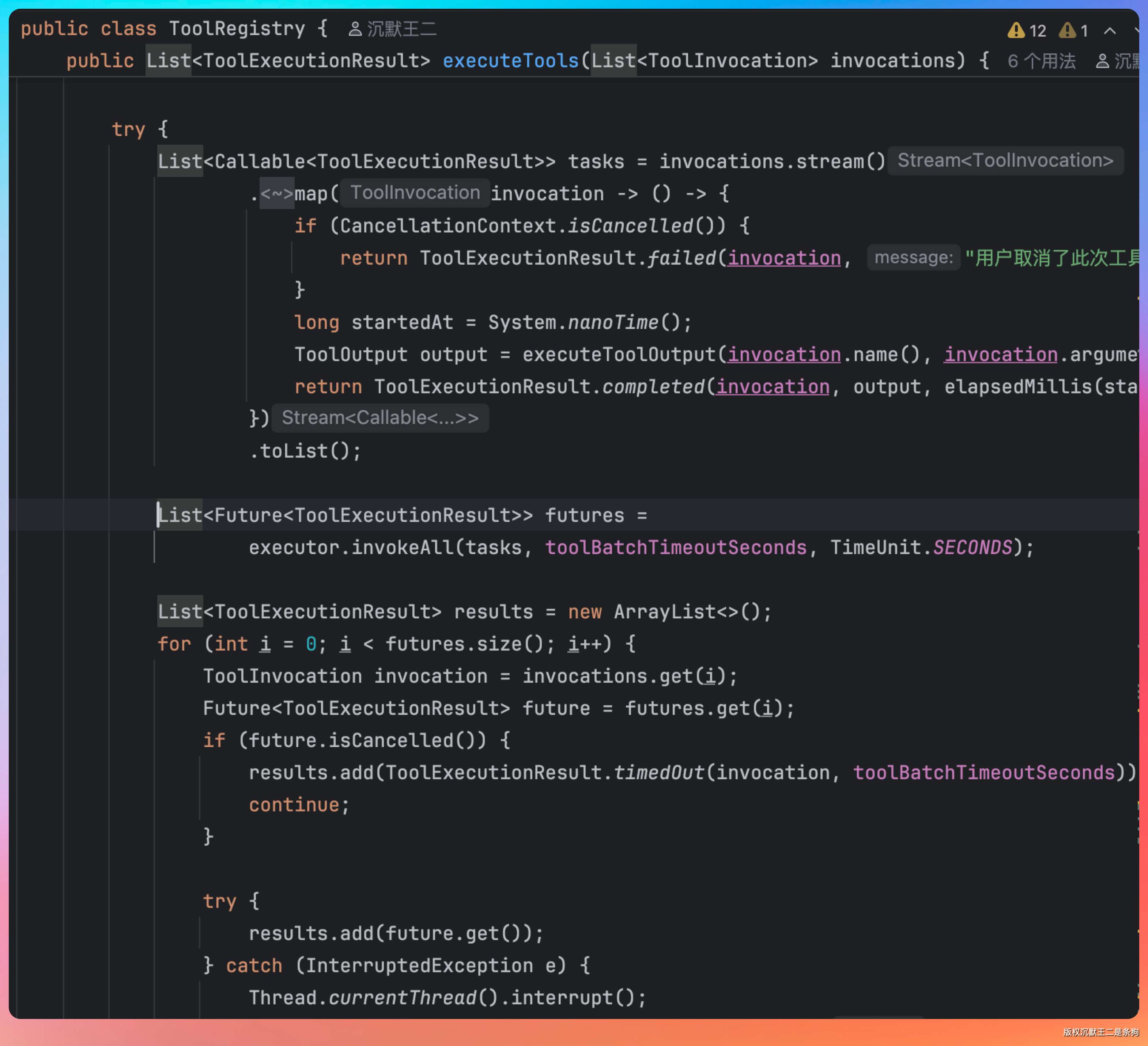
Claude Code 也是这么做的。当模型判断多个工具调用之间没有依赖关系时,会在同一轮返回多个 tool_call,然后并行执行它们。
还有一个关键的扩展机制:MCP。
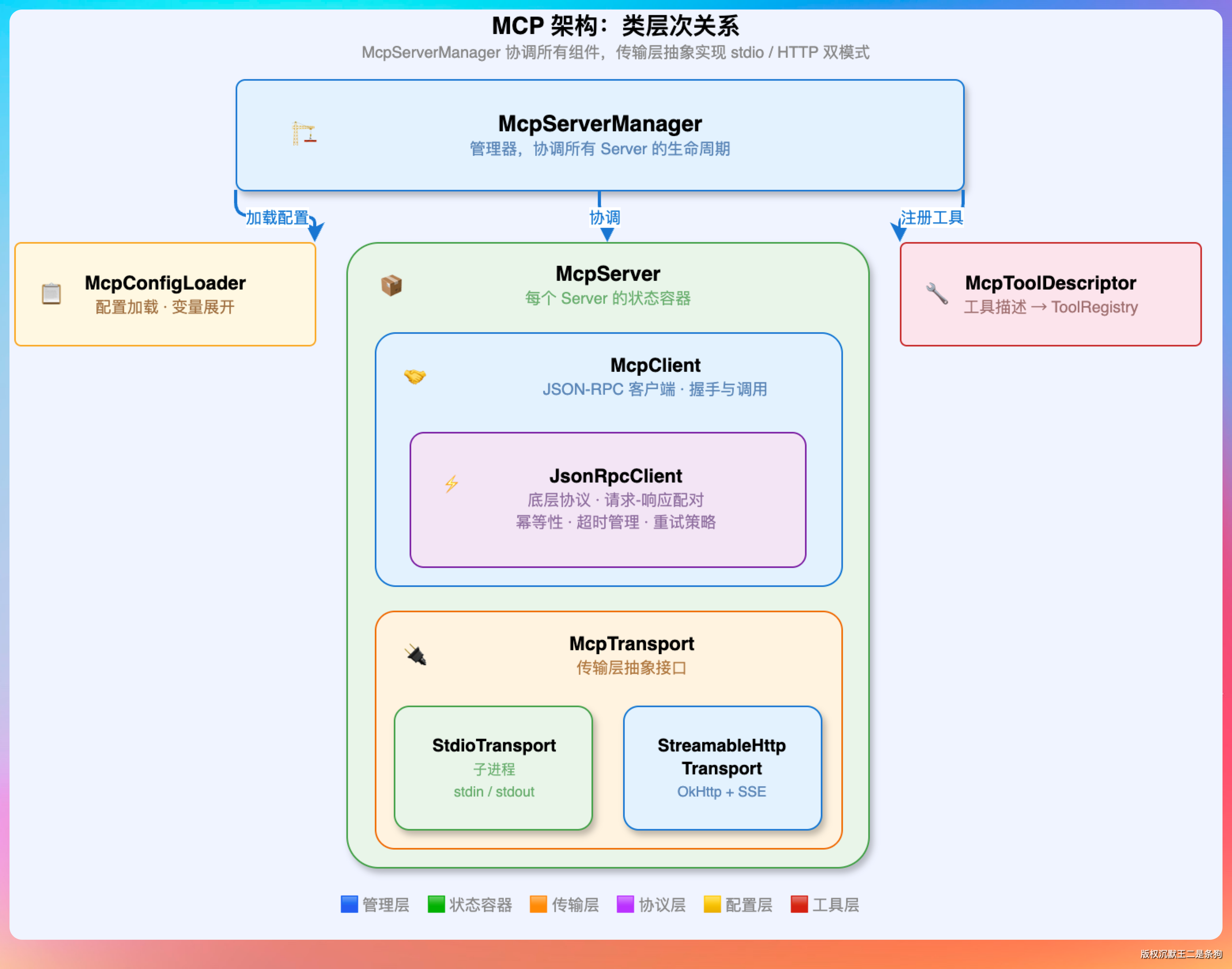
内置的工具毕竟有限,read_file、write_file、execute_command 能覆盖大部分编程场景,但如果要操作浏览器、连接数据库、调用企业内部 API 怎么办?
MCP 的做法是把工具的“注册权”开放出去。
任何外部服务只要实现 MCP 协议,就能把自己的工具动态注册到 Agent 的工具列表中。PaiCLI 里这些工具的命名规则是 mcp__{服务名}__{工具名},比如 mcp__chrome-devtools__take_screenshot 就是浏览器截图工具。
Agent 压根不知道这些工具的内部实现,它只能看到名称、描述和参数 schema。
大模型根据描述判断什么时候调用,Harness 负责把调用转发给对应的 MCP 服务器。这种设计让 Agent 的能力可以无限扩展。
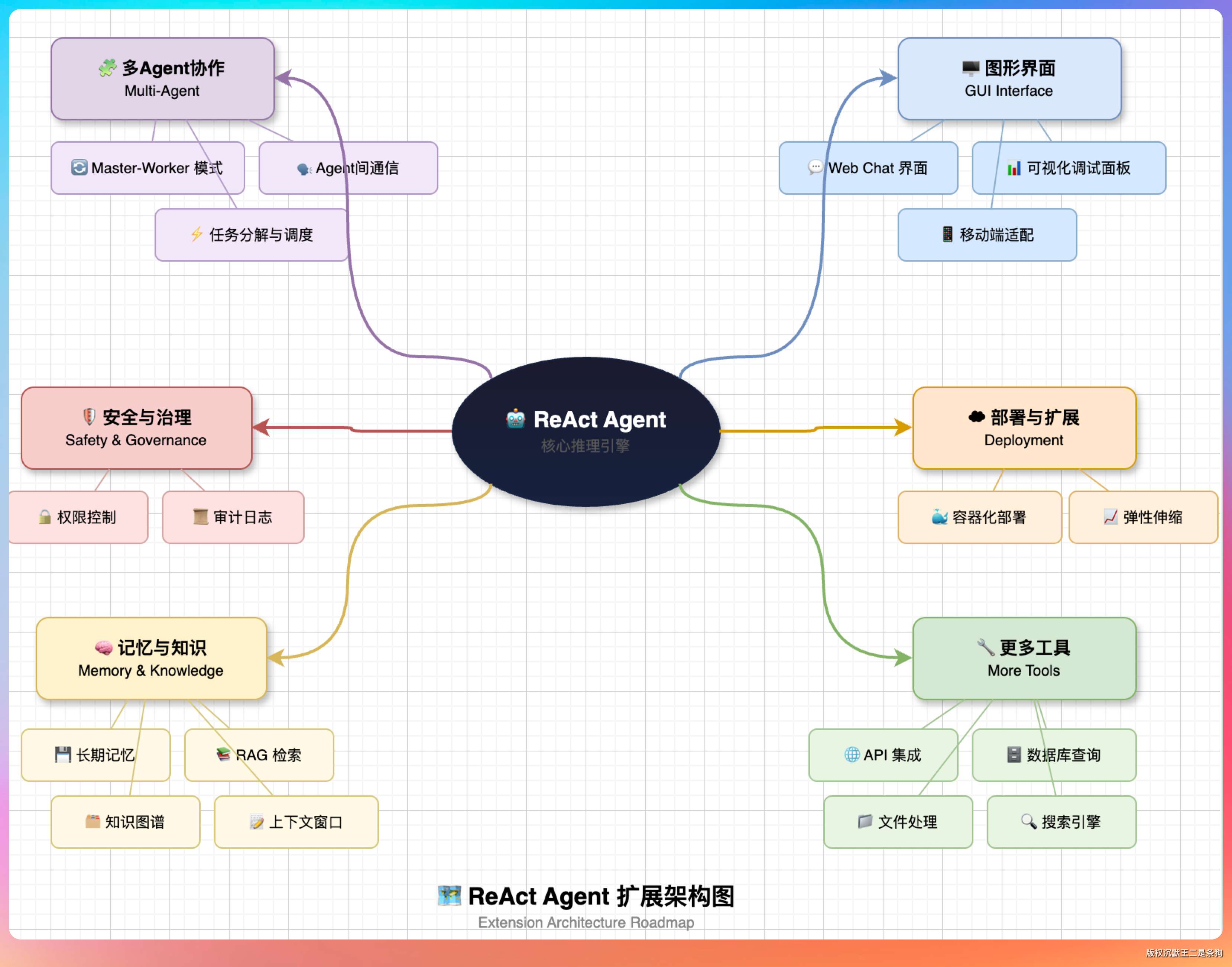
05、Multi-Agent 的机制是什么?
核心机制可以概括为:将复杂任务拆解,由多个具备不同“人设”和“工具”的 Agent 协作完成。
- 不再让一个模型处理所有事,而是通过 System Prompt 为不同的智能体赋予特定身份。
- 常见的协作模式Planner-Worker-Reviewer,由规划者调度,给各个执行者派活。
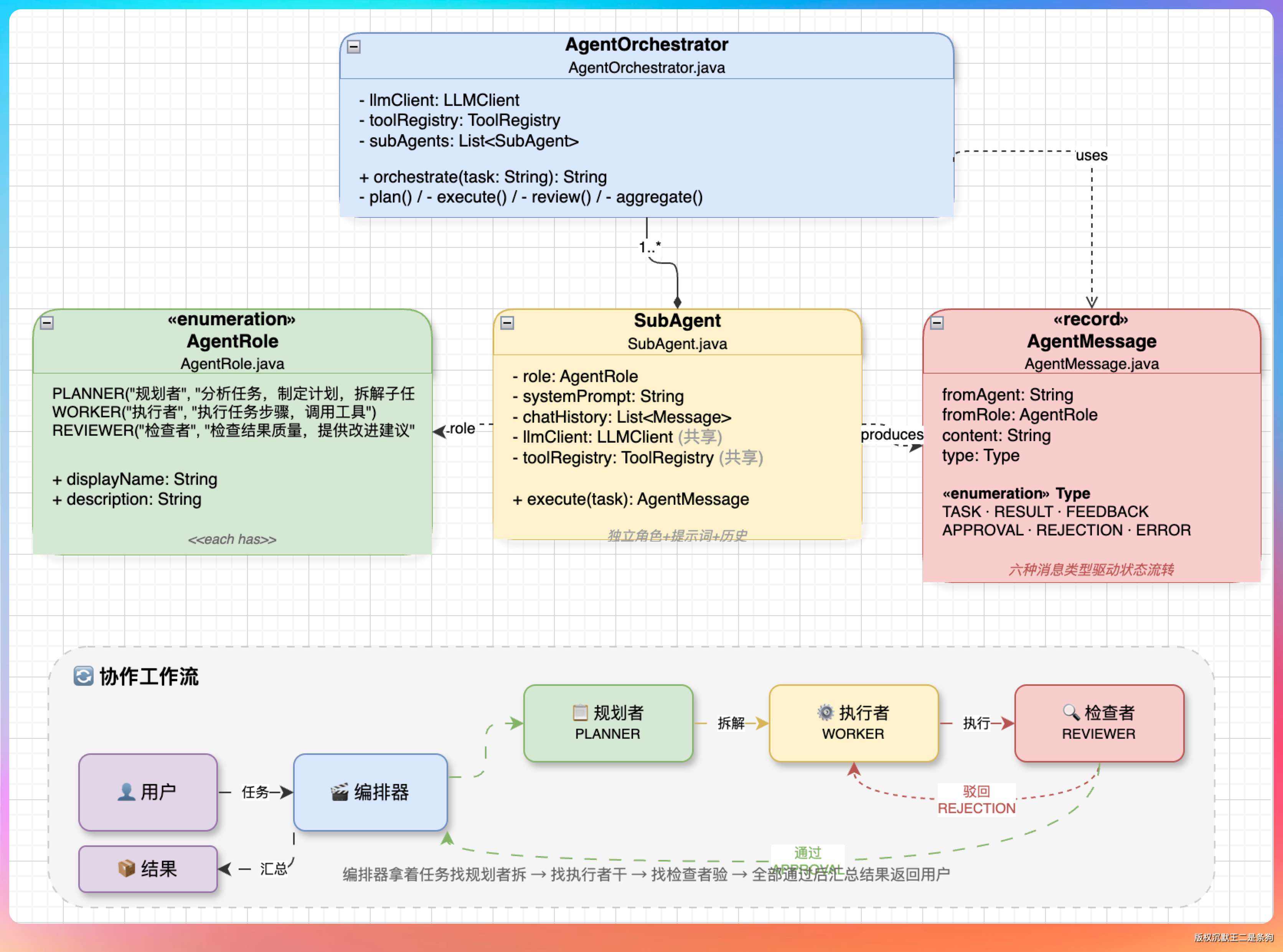
Planner(规划者) 负责把用户的大任务拆解成多个小步骤,生成一个 JSON 格式的执行计划,包含每个步骤的描述和依赖关系。
Worker(执行者) 负责执行具体的小任务。每个 Worker 都是一个独立的 SubAgent,有自己的对话历史和系统提示词,互不干扰。多个 Worker 可以并行工作。
Reviewer(审查者) 负责检查 Worker 的输出质量。如果不合格,会给出反馈让 Worker 重新执行(最多重试 2 次)。
为什么需要 Multi-Agent?
第一,突破上下文限制,各司其职,每个 Agent 只处理自己那一小块最相关的上下文。
第二,模型很难发现自己的逻辑错误,但“旁观者清”,让 Agent B 去审计 Agent A 的输出,能极大提升可靠性。
第三,多模型组合。比如说让 Opus 4.7 规划,GPT-5.5 去执行。
这里有一个关键的设计细节:上下文隔离。每个 Worker 启动时会创建独立的对话历史,只注入和自己任务相关的上下文,执行完毕后只把结果摘要(而不是完整对话)返回给 Orchestrator。这样做的好处是,Worker A 读了 50 个文件产生的上下文不会污染 Worker B 的判断,各自的注意力都集中在自己的子任务上。
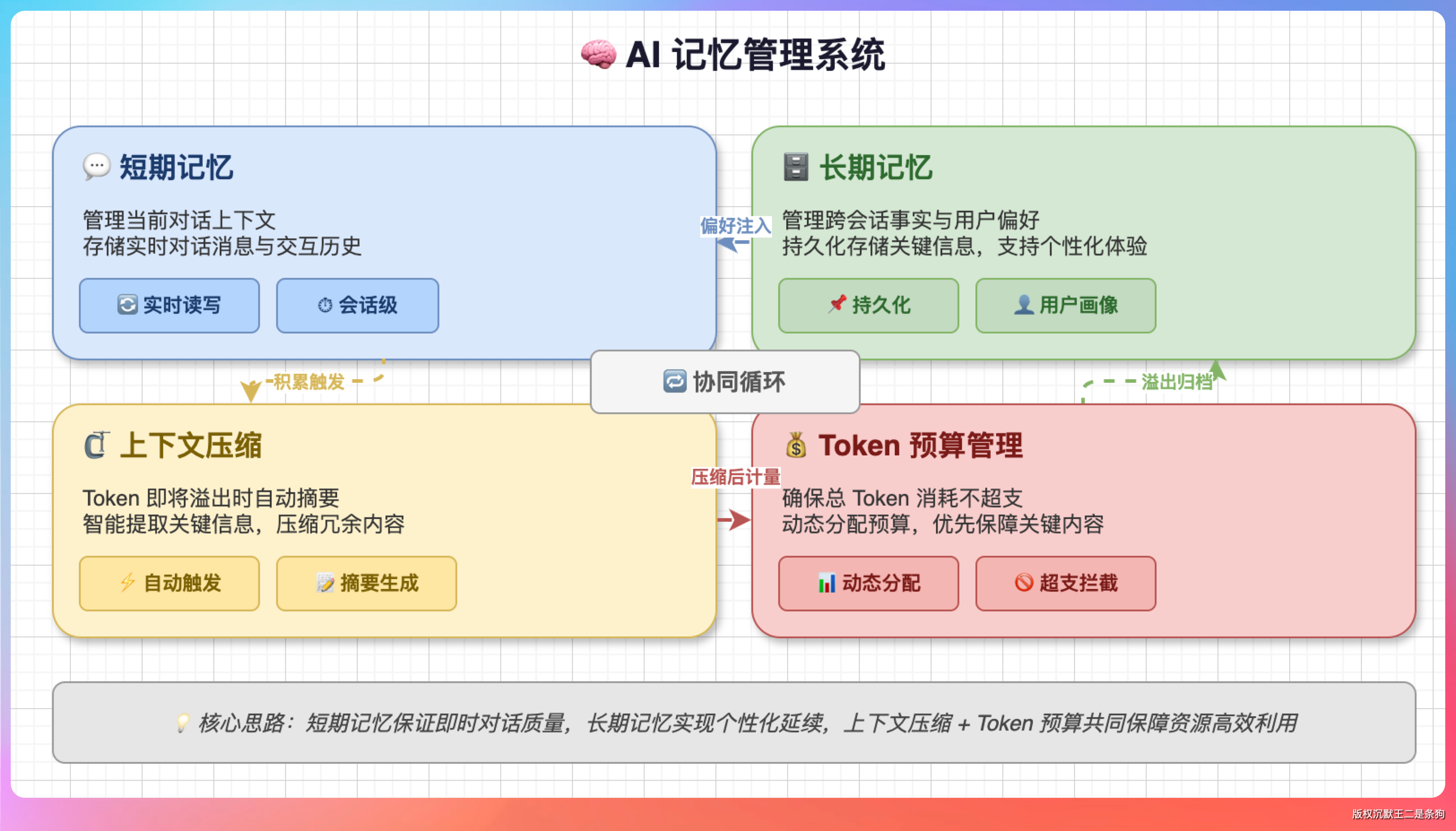
06、Memory 的机制是什么?
Memory 机制是让模型能够“记住”过去发生的事情,并将其作为当前决策参考的技术。
如果没有记忆机制,AI 每次对话都是“失忆”的。
Memory 机制 = 上下文管理 (Context) + 向量检索 (RAG) + 自动摘要 (Summarization)。
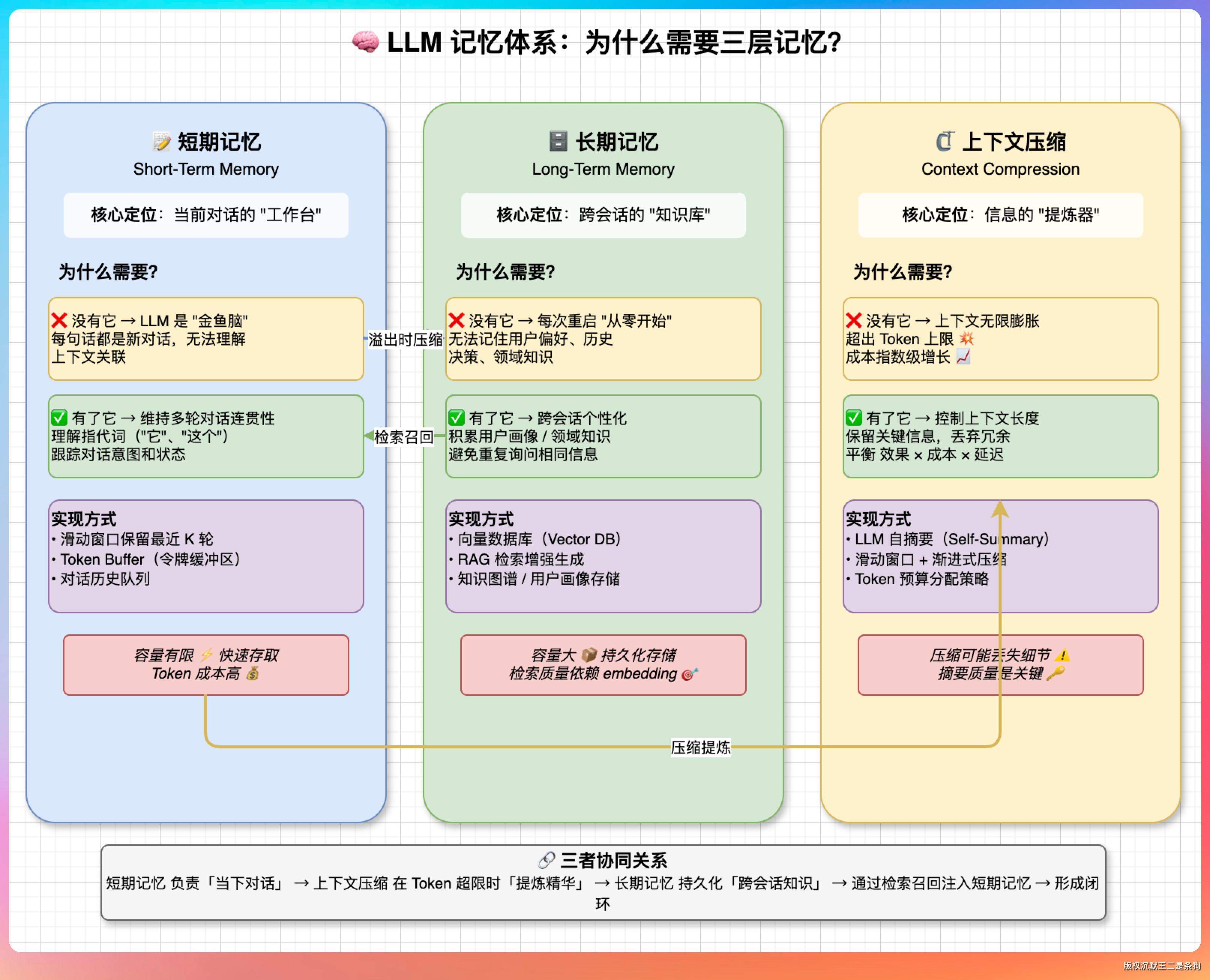
Agent 的 Memory 分两层:短期记忆和长期记忆。
短期记忆就是当前对话的上下文。
每次用户发消息、Agent 回复、工具执行结果,都会被追加到对话历史里。
长期记忆是跨会话持久的信息。
PaiCLI 的 LongTermMemory 把用户偏好、项目事实等关键信息存到 ~/.paicli/long_term_memory.json 文件中。每次新会话开始时,Agent 会根据当前输入检索相关的长期记忆,注入到系统提示词中。
// Agent.java 第 127 行
String memoryContext = memoryManager.buildContextForQuery(
userInput, contextProfile.memoryContextTokens());
updateSystemPromptWithMemory(memoryContext);
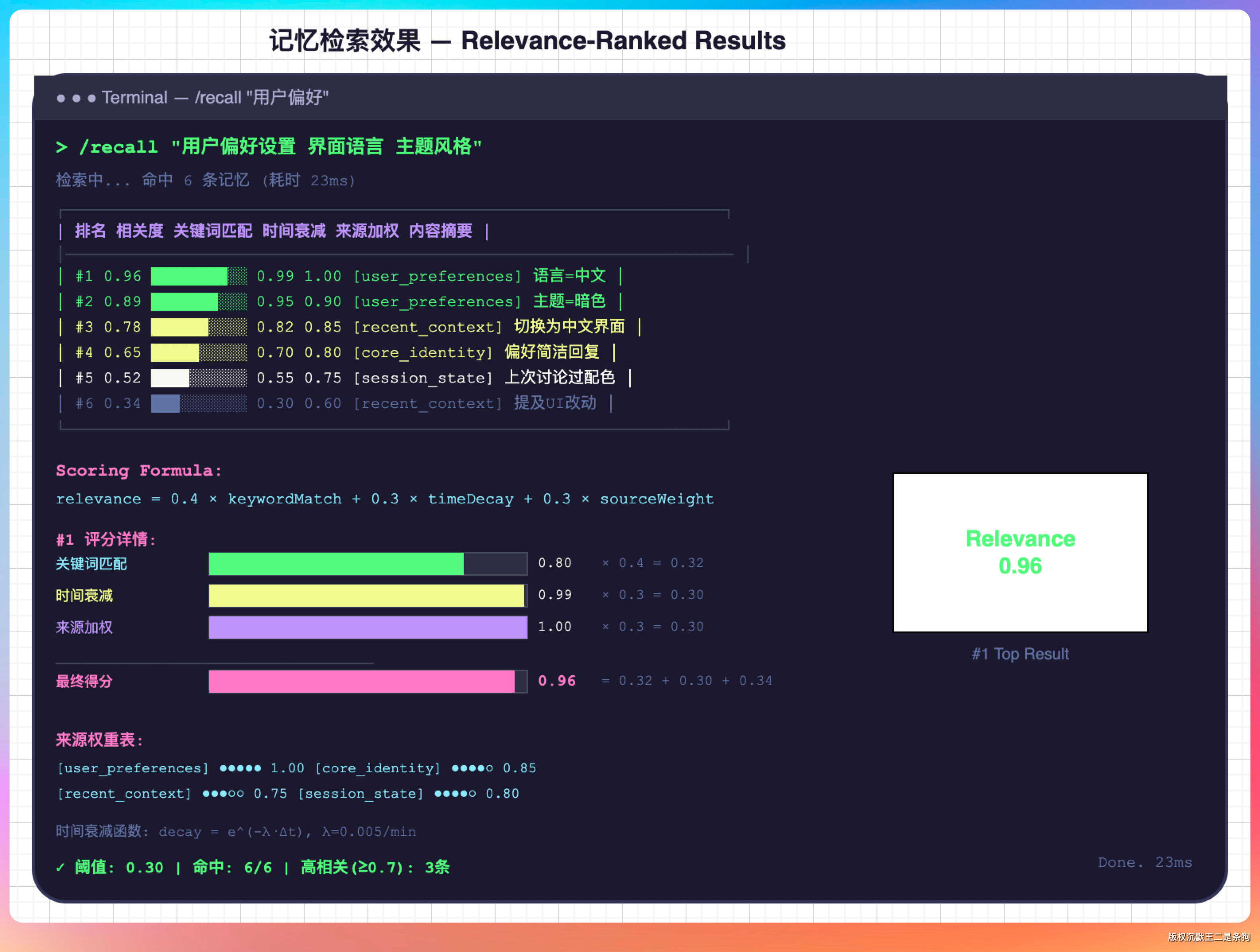
长期记忆的难点在于“检索”。
比如说存了 100 条记忆,当前问题只跟其中 3 条相关,怎么精准找到这 3 条?
PaiCLI 用的是混合检索:BM25 关键词匹配 + 语义相似度。先用关键词快速过滤候选集,再用语义相似度排序,最终只注入排名靠前的几条。
07、上下文的压缩机制是什么?
短期记忆满了,旧消息得淘汰,但关键信息不能丢。
怎么办?
压缩成摘要,再注入回去。
压缩策略用的是 Map-Reduce,跟处理大文档的思路一样:
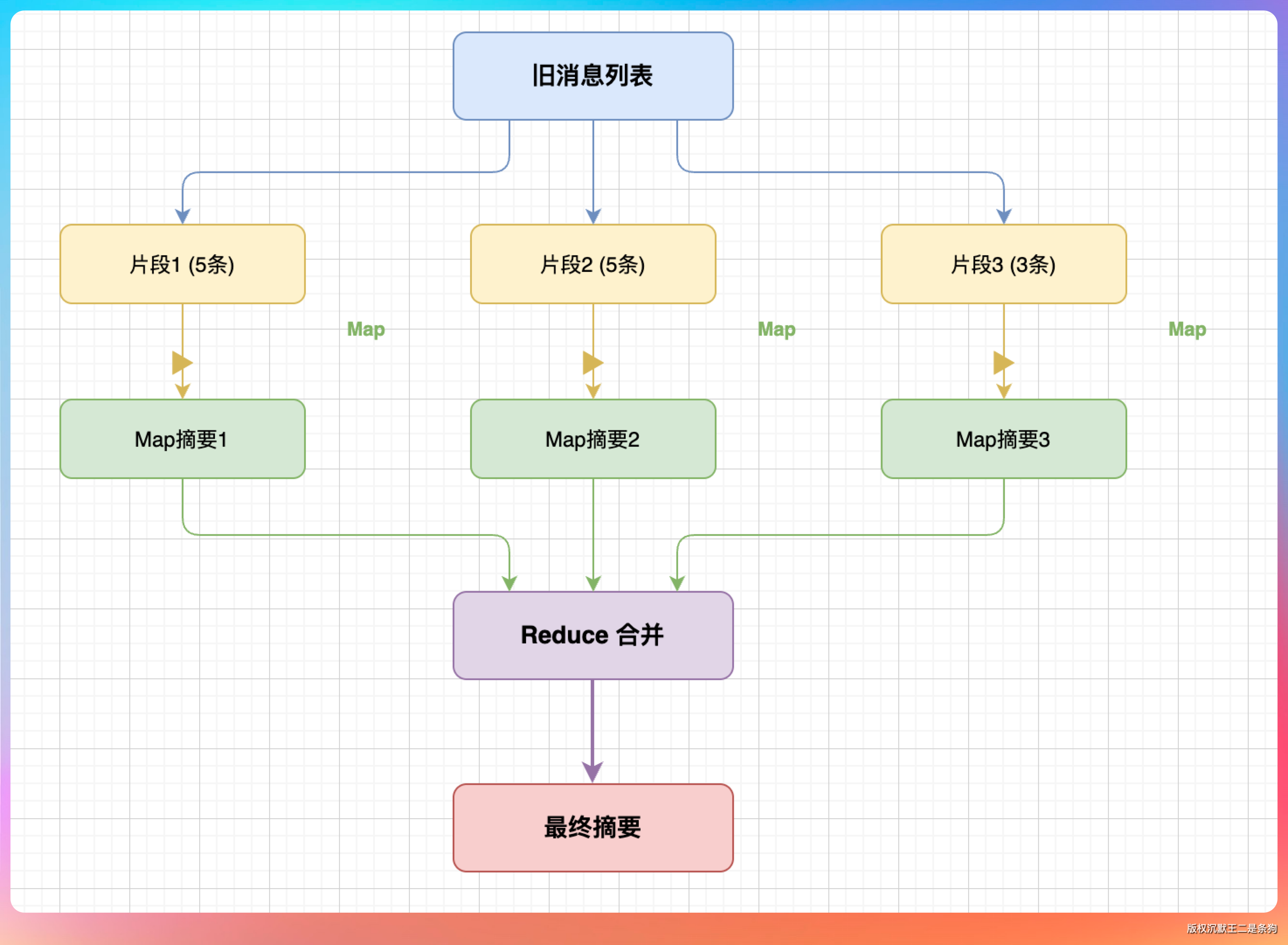
压缩算法是这样的:
- 触发条件:当对话历史的 token 数达到上下文窗口的 90% 时触发压缩。
- 分割点选择:找到所有 user message 的位置,保留最近 3 轮用户对话不动,把之前的所有消息作为“待压缩区域”。
- 摘要生成:把待压缩区域的消息喂给 LLM,让它生成一段精简摘要。
- 重建历史:
[system] + [user("已压缩的历史对话摘要\n" + summary)] + [assistant("好的,已了解上下文。")] + [最近 3 轮完整对话]。
08、CLAUDE.md 是怎么让 Agent 快速掌握项目的?
CLAUDE.md 让用户可以通过一个 markdown 文件告诉 Agent “这个项目的规则是什么”。
它的工作原理其实很简单:在组装系统提示词时,把 CLAUDE.md 的内容注入进去。
PaiCLI 用的是 AGENTS.md,但原理一样。
在 PromptAssembler 的 dynamicSection("Project Context", ...) 这一步,把项目级别的规则和上下文拼接到系统提示词中。
CLAUDE.md 的写作有几个原则:
- 明确具体,不要含糊。写“使用 4 空格缩进”比写“保持一致的代码风格”有用一百倍。
- 控制长度。CLAUDE.md 会占用上下文窗口。写太长了,留给实际工作的空间就少了。PaiCLI 的设计中,项目上下文注入有严格的 token 预算:
memoryContextTokens = min(5000, window/200)。 - 分层加载。Claude Code 支持全局
~/.claude/rules/、项目级.claude/settings.json、文件级 CLAUDE.md 三层规则。PaiCLI 也是类似的三层结构:内置 < 用户全局(~/.paicli/)< 项目级(.paicli/)。优先级从低到高,项目级的配置会覆盖全局配置。
面试真经
再来几道真实的面试题和口述版本的答案,可以直接背。
请介绍一个你参与的、与 AI Agent 相关的项目,并说明你的角色和贡献?
我独立开发了 PaiCLI,一个基于 Java 的 AI Agent CLI 工具,交互体验和 Claude Code 很接近。我是唯一的开发者,从架构设计到所有模块的实现都是我一个人完成的。
底层架构是 LLM + Harness 模式,Agent 类作为 Harness 核心,驱动一个标准的 ReAct 循环:调用大模型 → 判断是否需要工具 → 执行工具 → 结果塞回对话历史 → 再调用大模型,直到任务完成。
Memory 机制方面,PaiCLI 实现了双层记忆系统。短期记忆是当前对话的消息列表,用 LinkedHashMap 做 FIFO 淘汰;长期记忆把用户偏好、项目事实等信息持久化到本地 JSON 文件中,每次新会话时根据当前输入做混合检索(BM25 关键词 + 语义相似度),把最相关的记忆注入系统提示词。
RAG 模块方面,PaiCLI 用 JavaParser 把代码按文件/类/方法三级切块,再通过 Ollama 或远程 API 向量化,存到 SQLite。检索时用混合打分——语义相似度 + 关键词匹配 + 代码块类型加权(方法级权重最高)+ 双命中奖励,防止单个大文件霸占结果。
Multi-Agent 协作方面,PaiCLI 实现了 Planner-Worker-Reviewer 三角色架构。AgentOrchestrator 负责协调,Planner 把大任务拆成 JSON 格式的执行计划,多个 Worker 根据依赖关系并行执行,Reviewer 检查输出质量、不合格就打回重做(最多 2 次)。只有 Worker 有工具调用权限,Planner 和 Reviewer 只输出纯 JSON,保持角色清晰。
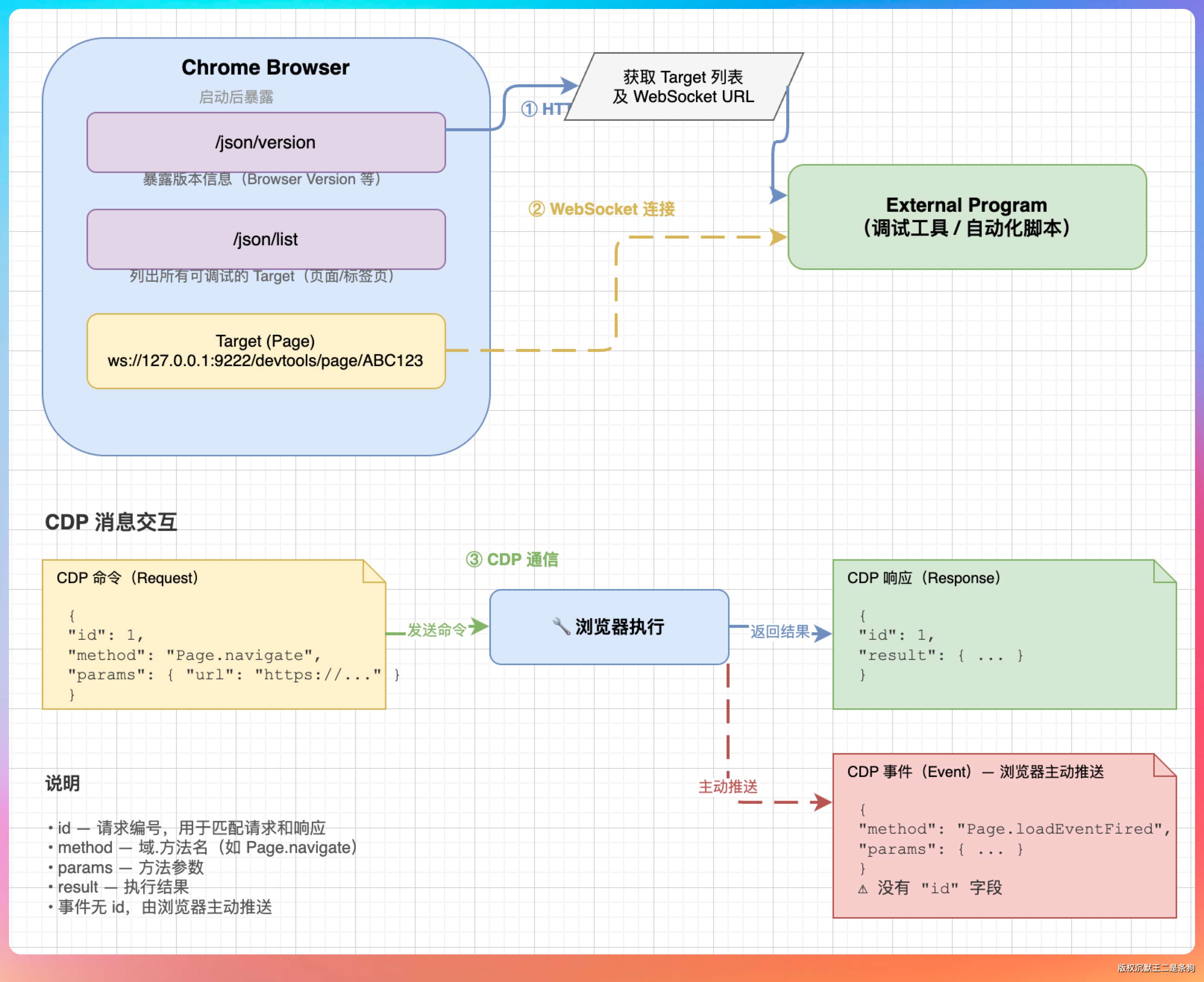
Chrome DevTools MCP 是 PaiCLI 的一个亮点。通过集成 chrome-devtools-mcp,Agent 能直接操控浏览器——截图、点击、填表、执行 JS。工具自动注册为 mcp__chrome-devtools__* 格式,大模型根据工具描述自主判断什么时候调用。
更有意思的是 CDP 登录态复用。默认情况下 Agent 启动的是隔离浏览器(独立 user-data-dir),碰到需要登录的页面就没辙了。PaiCLI 的做法是:Agent 检测到登录墙后,自动切换到共享模式(--autoConnect),通过 Chrome 的 DevToolsActivePort 文件发现用户正在运行的浏览器实例,直接复用已有的登录态。
谈一谈你对 ReAct 框架的理解?
ReAct 让推理和行动交替进行。
大模型在每一步会先输出推理过程(分析当前状态、规划下一步),再输出具体行动(工具调用)。工具返回结果后,大模型再推理下一步。
这个循环会持续到大模型判断任务完成。
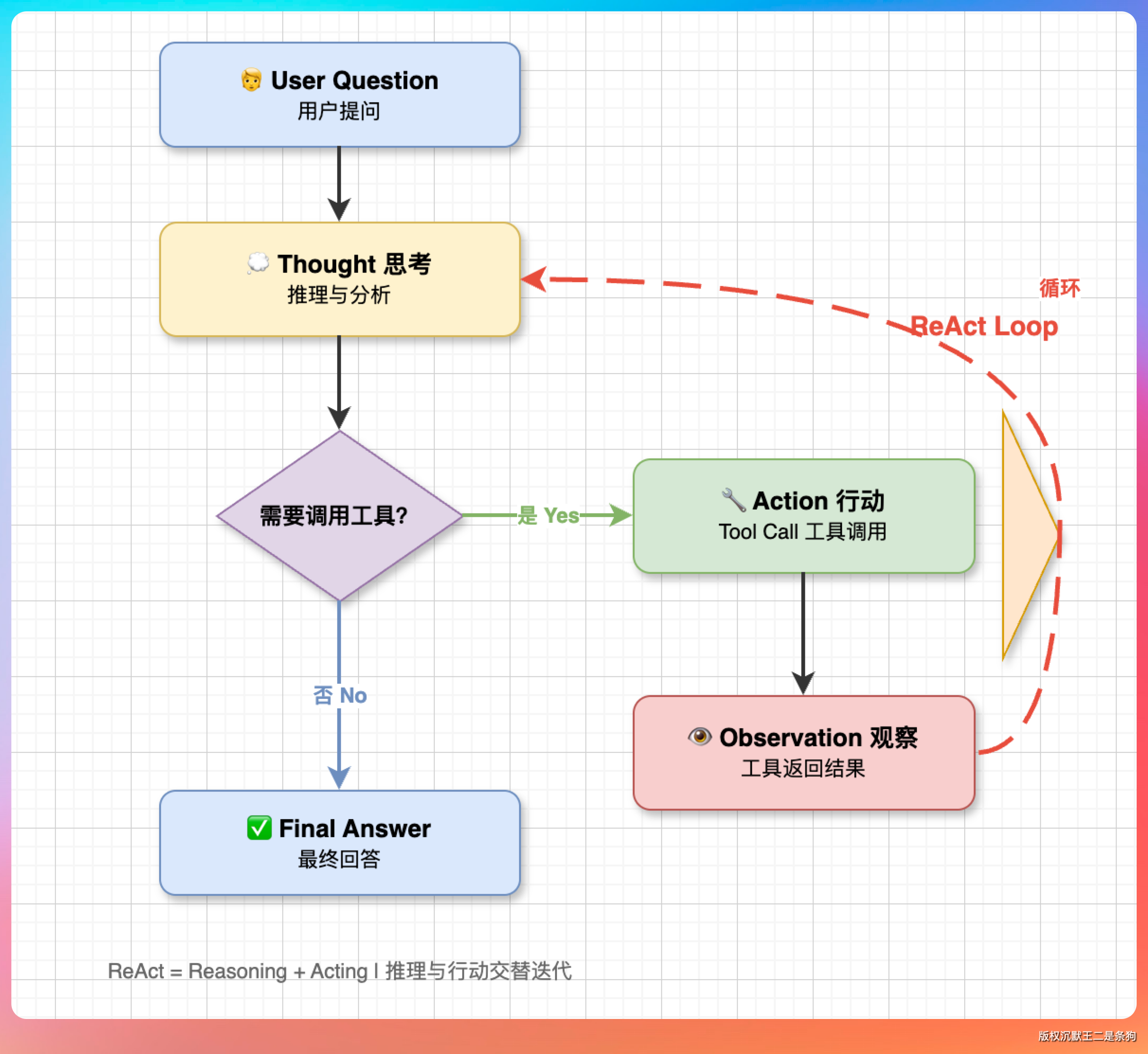
ReAct 的退出有两种方式:
- 一是 LLM 在某一轮不返回 tool_call,说明它认为任务已完成;
- 二是 token 预算耗尽或检测到死循环,由 Harness 强制终止。
PaiCLI 的 AgentBudget 负责第二种退出,它追踪累计消耗的 input + output token,超过 maxContextWindow × 0.8 就终止。
在 AI Agent 中,记忆通常分为哪几种类型?
分短期记忆和长期记忆。短期记忆就是当前对话的消息列表,包含用户输入、Agent 回复和工具执行结果,会话结束就清空。长期记忆是跨会话持久化的信息,存储用户偏好、项目事实等稳定知识,每次新对话时根据相关性检索注入。
在开发 Agent 时,如何设计提示词来提升任务执行的稳定性和准确性?
三个层面。
第一是分层组装:把系统提示词拆成身份层、能力层、策略层、上下文层,每层独立维护、组合灵活。
第二是约束前置:把限制条件(安全策略、路径约束、禁止操作)写在提示词靠前的位置,因为大模型对前面的内容关注度更高。
第三是动态注入:根据当前任务类型、项目上下文、相关记忆动态调整提示词内容,而不是用一套固定的 prompt 应对所有场景。
实现一个简单的多轮对话状态管理,你会考虑哪些关键要素?
四个要素。
第一是消息格式规范:每条消息都要有明确的角色标识(system/user/assistant/tool),tool 消息必须带 tool_call_id 与前面的调用配对。
第二是上下文窗口管理:需要一个压缩/截断策略,当消息总 token 逼近窗口上限时自动压缩早期消息。
第三是状态一致性:tool_call 和 tool_result 必须成对出现,压缩分割点不能打断这种配对关系。
第四是取消机制:支持用户中途取消,Agent 的 while 循环在每次迭代前检查取消标记。

回复