


大家好,我是二哥呀。
Codex 最近的热度非常高,和 Claude Code 一起成为继 OpenClaw 之后,AI 圈又一个炙手可热的词。
反正我是文用 Claude Code,武用 Codex。
两个配合,天下我有。
上一篇我们分析了 Claude Code 的 CLAUDE.md,今天我们来分析分析 Codex 的 AGENTS.md。
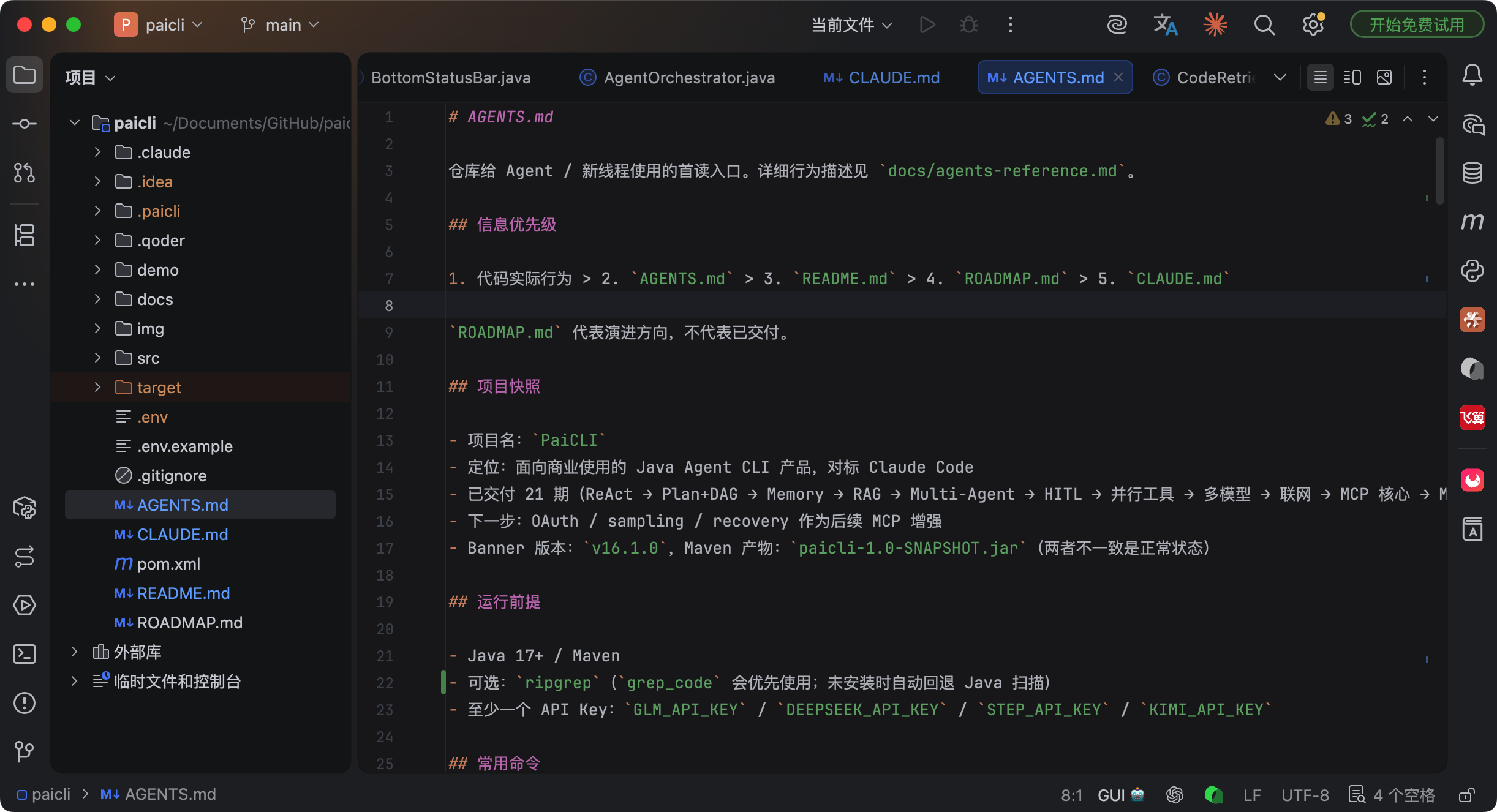
有一说一,第一次写 AGENTS.md,总觉得他就是个 README。
但随着对 Codex 的深入使用和理解,逐渐有了不一样的认知。确实都是 Markdown 文件,但写得好和写得烂,Codex 的工程能力差距能有天壤之别。
可能很多小伙伴没有时间去分析,今天这篇我花了很多 token 去调研分析,保管让大家看完就懂,也能和面试官掰扯,也能写出一份高质量的 AGENTS.md。
系好安全带,我们粗粗粗发~
01、AGENTS.md 到底是什么
先把最基本的概念搞清楚。
AGENTS.md 是一个面向 Codex 编程的指令文件,纯 Markdown 格式,没有强制字段,放在项目根目录下就行。

和 CLAUDE.md 最大的区别是什么?
CLAUDE.md 是 Claude Code 的私有指令文件,只有 Claude Code 认。
AGENTS.md 是一个开放标准,由 Linux 基金会下的 Agentic AI Foundation 管理,目前已经被 60,000+ 开源项目采用,支持 25+ 工具,包括 OpenAI Codex、Google Jules、GitHub Copilot、Cursor、Aider、Zed、JetBrains Junie 等等。
一份文件,多个 Agent 通用。
当然,Claude Code 也可以支持 AGENTS.md。我通常的做法是:CLAUDE.md 里加一行 @AGENTS.md,把 AGENTS.md 的内容导入进来。这样两边都不耽误。
那 AGENTS.md 和 README.md 有什么区别?
- README.md 是写给人看的,告诉开发者“这个项目是干嘛的、怎么跑起来、怎么贡献代码”。
- AGENTS.md 是写给 Agent 看的,告诉 AI“构建命令是什么、代码风格有哪些要求、哪些目录不能动、改了代码之后要同步哪些文件”。
02、Codex 的加载机制
搞懂加载机制,才能知道 AGENTS.md 应该放在哪、怎么组织。
Codex 每次启动时会构建一个指令链(instruction chain),这个过程只执行一次。
加载顺序分两层:
第一层:全局配置。 Codex 会先去 ~/.codex/ 目录下找。如果存在 AGENTS.override.md,就读它;不存在就读 AGENTS.md。注意,两者只取一个,不会叠加。
~/.codex/
├── AGENTS.md # 全局默认指令
├── AGENTS.override.md # 全局覆盖指令(存在时替代 AGENTS.md)
└── config.toml # Codex 配置文件
第二层:项目配置。 从项目根目录(通常是 Git 根目录)开始,一路走到你当前的工作目录。每到一个目录,按这个顺序查找:AGENTS.override.md → AGENTS.md → fallback 文件名。找到的文件会按顺序拼接在一起。
举个例子,假设你的项目结构是这样的:
my-project/
├── AGENTS.md # 项目根目录的规则
├── services/
│ └── payments/
│ └── AGENTS.override.md # payments 子目录的覆盖规则
└── frontend/
└── AGENTS.md # 前端子目录的规则
如果你在 services/payments/ 目录下启动 Codex,它的加载路径是:
~/.codex/AGENTS.md(全局默认)my-project/AGENTS.md(项目根目录)my-project/services/payments/AGENTS.override.md(当前目录覆盖)
三份文件的内容拼接在一起,后面的优先级高于前面的。
override 的妙用
AGENTS.override.md 是一个非常巧妙的设计。它的作用是“我不想改原文件,但需要临时覆盖某些规则”。
比如你的公司有一份统一的 ~/.codex/AGENTS.md,但你今天需要临时换一套规则做实验,就创建一个 AGENTS.override.md,实验完删掉,原来的文件完全不受影响。
对比 Claude Code
Claude Code 的加载体系是四层:系统级 → 用户级(~/.claude/CLAUDE.md)→ 项目级 → 本地覆盖(CLAUDE.local.md)。
Codex 的设计不同。它是在启动时就把当前路径上的所有 AGENTS.md 一次性拼接好,后续不会再动态加载。这意味着 Codex 的指令是“启动时确定,运行中不变”。
还有一个细节差异:Codex 有一个 project_doc_max_bytes 配置项,默认 32 KiB。
所有 AGENTS.md 文件拼接后的总大小不能超过这个值,超了就会被截断。Claude Code 没有这个硬性限制,但有指令预算的软限制(上一篇讲过,500 条指令密度下准确率只有 68%)。
在 ~/.codex/config.toml 里可以调大这个值:
project_doc_max_bytes = 65536
project_doc_fallback_filenames = ["TEAM_GUIDE.md", ".agents.md"]
project_doc_fallback_filenames 是另一个实用配置。如果你的项目历史原因用的是 TEAM_GUIDE.md 这样的文件名,不用改名,加到 fallback 列表里就行,Codex 会把它当 AGENTS.md 处理。
03、OpenAI 官方的 AGENTS.md
OpenAI 自己的 Codex 仓库(github.com/openai/codex)就有一份 AGENTS.md。
我把官方仓库根目录的 AGENTS.md 核心内容拆出来给大家看看:
Rust/codex-rs 的编码规范
- Prefix crate names with `codex-` (e.g., `codex-core`)
- Inline variables in format strings when possible
- Never modify code related to sandbox environment variables
- Apply Clippy linting rules
- Avoid ambiguous boolean/Option parameters; prefer enums or named methods
- Use exhaustive match statements and avoid wildcards
- Run `just fmt` automatically after making changes
这段规则有几个值得学习的地方。
第一,codex- 前缀。如果不写,Agent 新建 crate 的时候很可能就叫 core 或者 utils,和项目风格不统一。
第二,“Never modify code related to sandbox environment variables”。把红线明确写出来,Agent 在做代码变更时会绕开这些文件。
第三,“Run just fmt automatically after making changes”。改完代码自动格式化。如果不写这条,Agent 提交的代码可能格式不统一。
codex-core 的架构约束
Resist adding to the already-bloated codex-core crate.
Consider whether existing crates provide appropriate homes
or whether creating new workspace crates would better serve the architecture.
抵制向已经臃肿的 codex-core 添加新内容。
没有长篇大论解释什么是“单一职责”,没有画分层架构图,就是告诉 Agent:这个 crate 已经太大了,新功能别往里塞,考虑放到其他 crate 或者新建一个。
04、怎么写出高质量的 AGENTS.md
OpenAI 官方在最佳实践文档里有一句原话特别精辟:
A short, accurate AGENTS.md is more useful than a long file full of vague rules.
一份短小精准的 AGENTS.md,比一份充斥模糊规则的长文件有用得多。和上一篇讲 CLAUDE.md 时提到的“指令预算”是一个道理。
写得越多,Agent 遵循率越低。
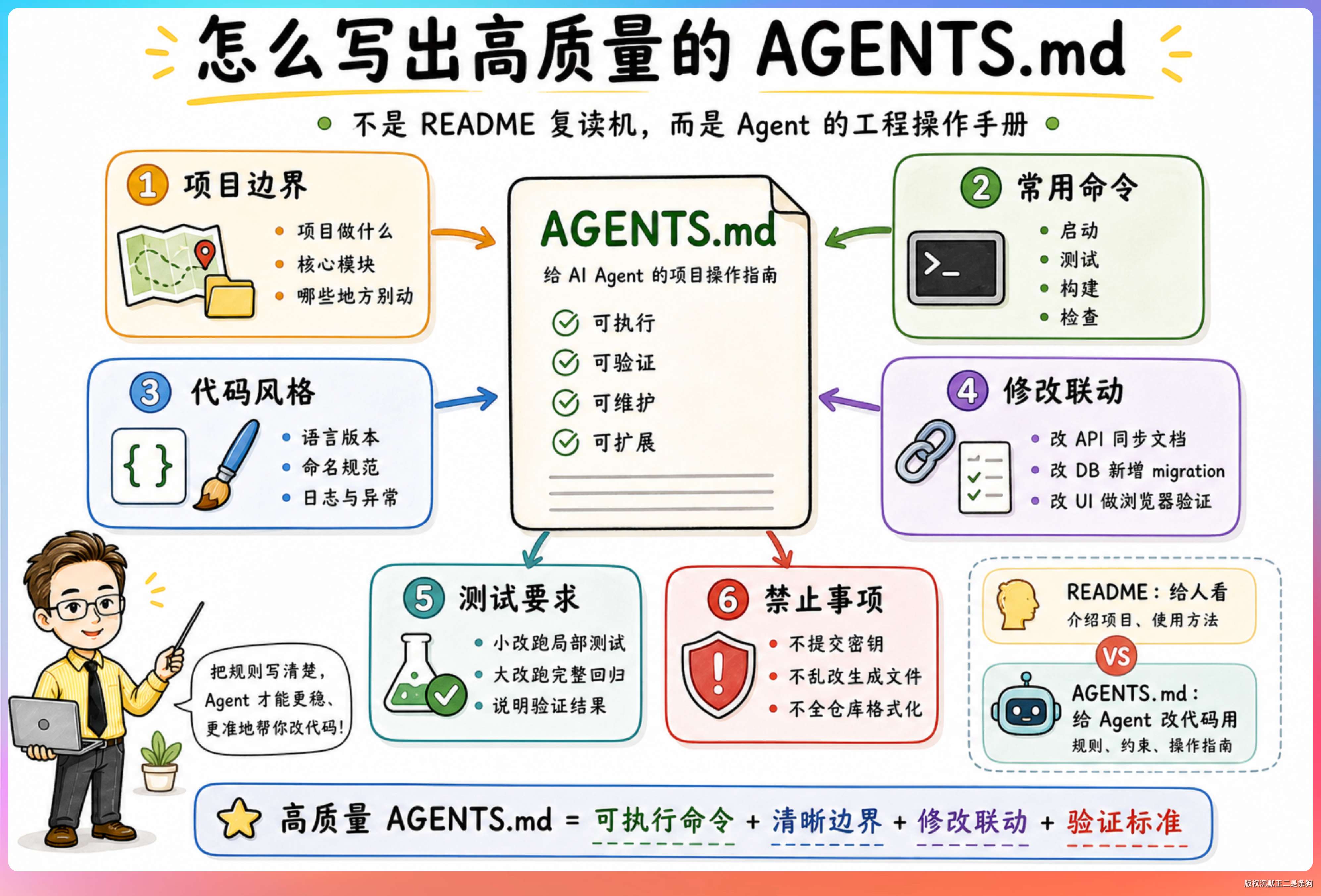
该写什么
①、构建和测试命令。 这是最基本的,也是 Agent 最常用的信息。
Agent 每次改完代码都需要知道怎么构建、怎么跑测试。写清楚了 Agent 就能自动完成“改代码 → 构建 → 测试 → 格式化”的完整流程。
如果你的项目有多种测试方式(快速回归、全量测试、单个测试),全部列出来,Agent 会根据场景选择最合适的。如果你的代码是热部署,这一条更重要,不然每次 build 会很烦人的。
②、项目特有的编码规范。 只写和行业默认不一样的部分。
如果你的团队约定请求对象用 *Params 后缀、响应用 *Response,这种信息不写的话,Agent 可能一会儿用 *Request,一会儿用 *Req,命名风格乱成一锅粥。
③、红线规则。 “禁止提交 .env 文件”“不要往 codex-core 添加新功能”。这些是 Agent 一旦违反就会造成严重后果的硬约束。
红线规则最好用明确的否定句式,如“禁止”“不要”“Never”,让 Agent 在处理相关文件时能第一时间触发警觉。
③、代码定位策略。 “search_code 是 RAG 辅助,优先用 glob → grep → read”。
告诉 Agent 用什么姿势找代码最高效。不同项目的代码搜索最优路径不一样,Agent 默认的搜索策略未必适合你的项目。明确告诉它优先级,能减少很多无效操作。

05、AGENTS.md 和 CLAUDE.md 的协同
很多小伙伴和我一样,Claude Code 和 Codex 都在用。那 AGENTS.md 和 CLAUDE.md 怎么共存?
我的做法是这样的。
AGENTS.md 作为通用指令文件。 把构建命令、代码规范、架构约定、红线规则这些“不管用什么 Agent 都需要遵守的内容”写在 AGENTS.md 里。
CLAUDE.md 作为 Claude Code 的增强文件。 在 CLAUDE.md 里用 @AGENTS.md 导入通用规则,然后额外添加 Claude Code 特有的配置,比如 Skills 引用、memory 相关的规则、hooks 配置说明等。
这样做的好处是:通用规则只维护一份,改 AGENTS.md 就两边都生效了。
Codex 那边不需要做任何额外配置,它天然就读 AGENTS.md。
还有一个小技巧。
Codex 的 config.toml 里有一个 project_doc_fallback_filenames 配置,可以把 CLAUDE.md 加进去:
project_doc_fallback_filenames = ["CLAUDE.md", "TEAM_GUIDE.md"]
这样如果项目里没有 AGENTS.md 但有 CLAUDE.md,Codex 也会读取它。
06、Codex 的 Agent Loop 架构
AGENTS.md 只是 Codex 的指令入口。真正决定 Codex 工程能力的,是它背后的 Agent Loop。
OpenAI 今年发了一篇技术博客《Unrolling the Codex Agent Loop》,把 Codex 的核心引擎——harness 的内部架构公开了。这篇文章的技术密度非常高,我把核心要点拆出来。
一个 Turn 的完整生命周期
Codex 的 Agent Loop 遵循经典的 Agent 模式:用户输入 → 模型推理 → 工具执行 → 模型推理 → ... → 最终响应。
从用户发一条消息到 Codex 给出回复,这个过程叫做一个 Turn。一个 Turn 里面可能包含几十次“模型推理 → 工具调用”的循环。
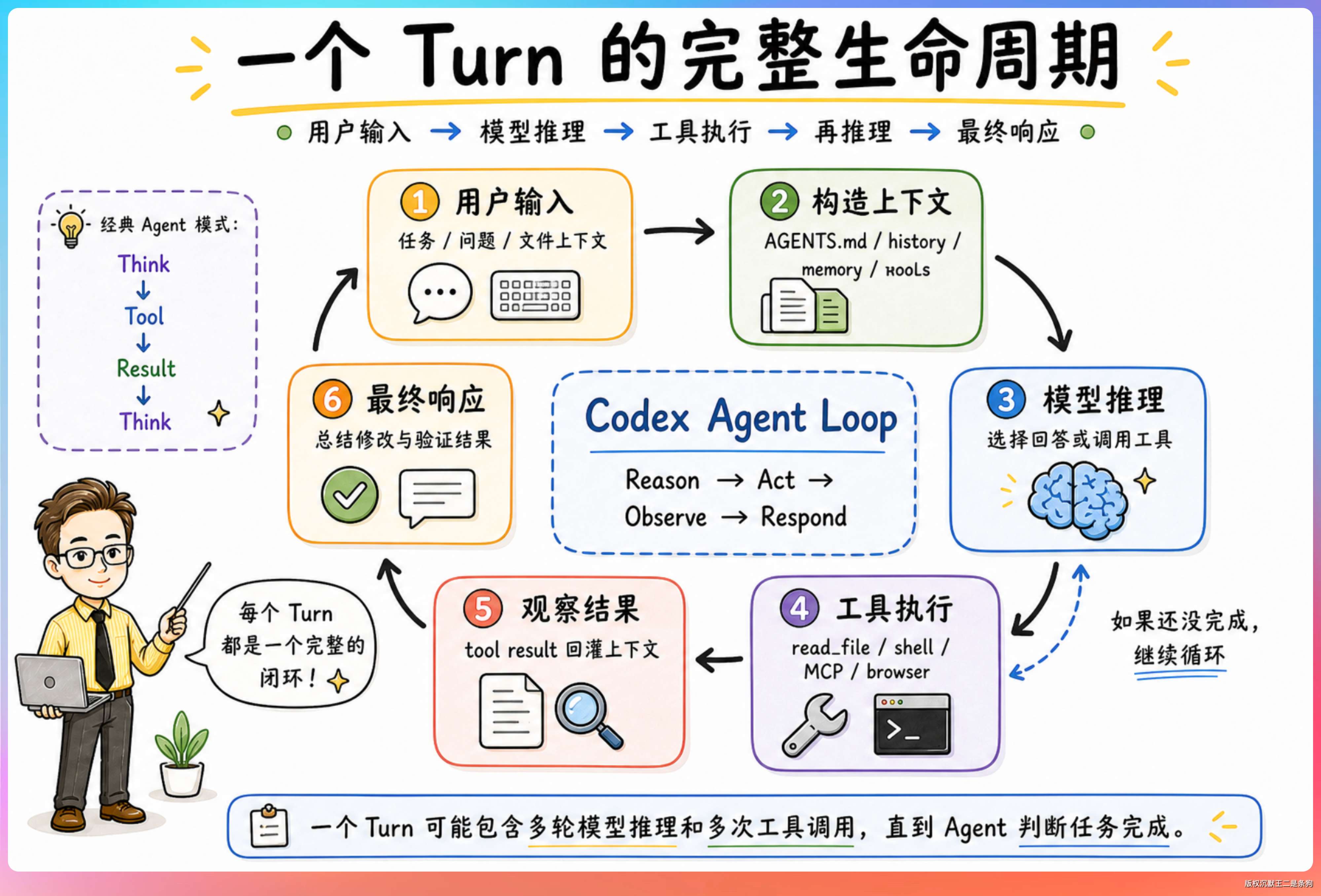
模型每次推理的输出只有两种形式:要么是给用户的最终回复,要么是一个工具调用请求。只要输出的是工具调用,循环就继续;输出了最终回复,循环就结束。
统一 Harness 与 App Server
还有一个架构层面的重要信息。
Codex 的 CLI、VS Code 扩展、Web 应用、macOS 桌面应用,底层跑的是同一套 harness。
连接它们的是 Codex App Server——一个双向的 JSON-RPC API。
为什么要做统一的 harness?
因为 Agent Loop 的逻辑非常复杂:Prompt 构建、工具调度、沙箱管理、Context 压缩、缓存优化,这些如果每个客户端自己实现一遍,维护成本极高,而且容易出现行为不一致。统一 harness 保证了不管你在终端、IDE 还是浏览器里用 Codex,Agent 的行为是一样的。
这个架构还有一个副产品:因为整个 Codex 都走 Open Responses API,理论上可以接任何兼容这个 API 的模型,包括本地部署的开源模型。
Codex 团队在博客里也明确说了这一点。
Prompt 的分层构建
AGENTS.md 在 Codex 的 Prompt 中处于什么位置?
Codex 的 Prompt 构建是分层的,按优先级从高到低排列:
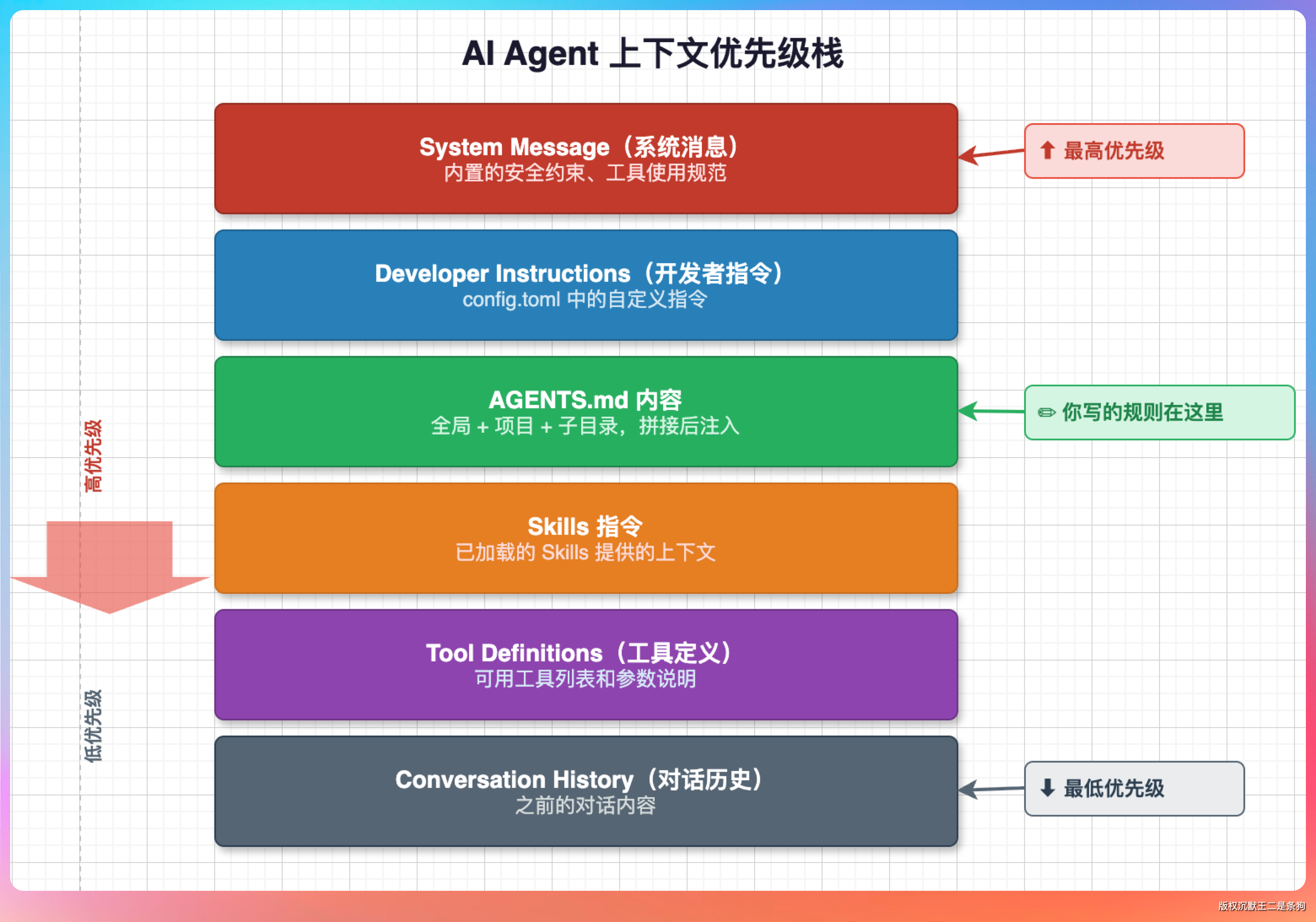
更准确地说,AGENTS.md 会被 Codex 发现、拼接后,作为项目级的 user instructions 放进初始上下文里。
它不是系统指令,也不是工具定义的一部分。系统/开发者级别的安全约束、沙箱策略、权限策略仍然优先;AGENTS.md 主要承担的是“项目约定”和“工作偏好”的持久上下文。
Prompt Cache 与线性复杂度
这是 Codex 性能优化的核心机制。
Agent Loop 每一轮都需要把指令、工具定义、对话历史等上下文一起交给模型。如果不做优化,随着对话越来越长,每轮推理的 token 消耗是 O(n²) 级别的——第 1 轮发 1000 token,第 2 轮发 2000,第 10 轮发 10000...累计消耗呈二次方增长。
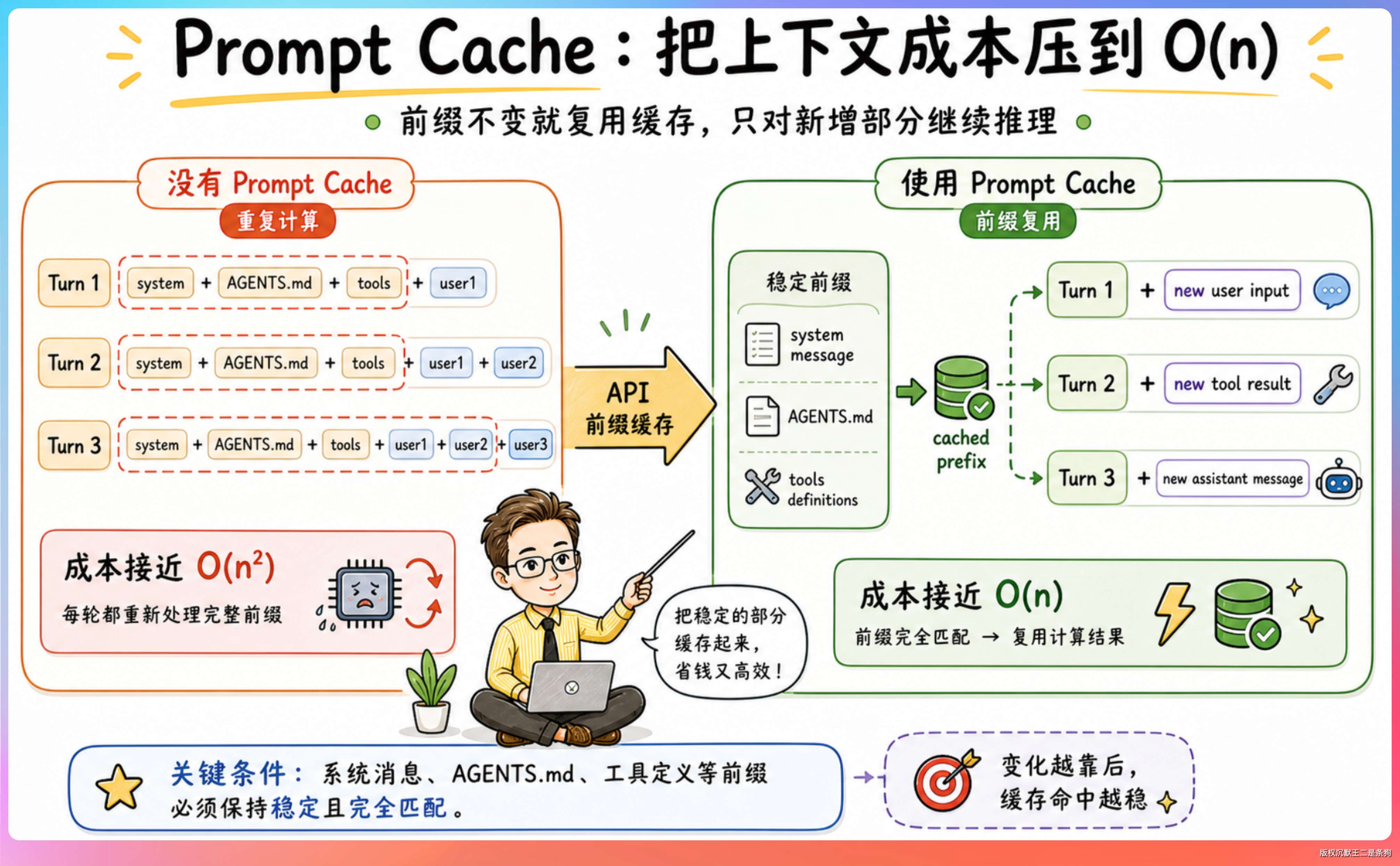
Codex 通过 Prompt Cache 把这个问题压到了 O(n)。原理是:Prompt 里稳定的前缀内容可以被缓存,只要前缀精确匹配,就可以复用之前的计算结果,只需要对新增的部分做推理。
但有个前提:前缀必须精确匹配。工具列表变化、模型变化、沙箱配置变化、approval mode 变化、工作目录变化,都可能导致缓存失效。
AGENTS.md 作为启动时加载的稳定项目上下文,也有利于提高缓存命中率。但不要把它理解成“为了缓存才这样设计”。更准确的说法是:AGENTS.md 提供稳定的项目规则,Prompt Cache 则利用这种稳定性做性能优化。
Context Window 压缩
当 token 计数超过阈值时,Codex 会调用一个专门的 /responses/compact 端点。
这个端点返回一个压缩后的消息列表,替代原来的完整对话历史。压缩后的内容包含一个加密的 compaction 项,保留了模型对原始对话的“潜在理解”。
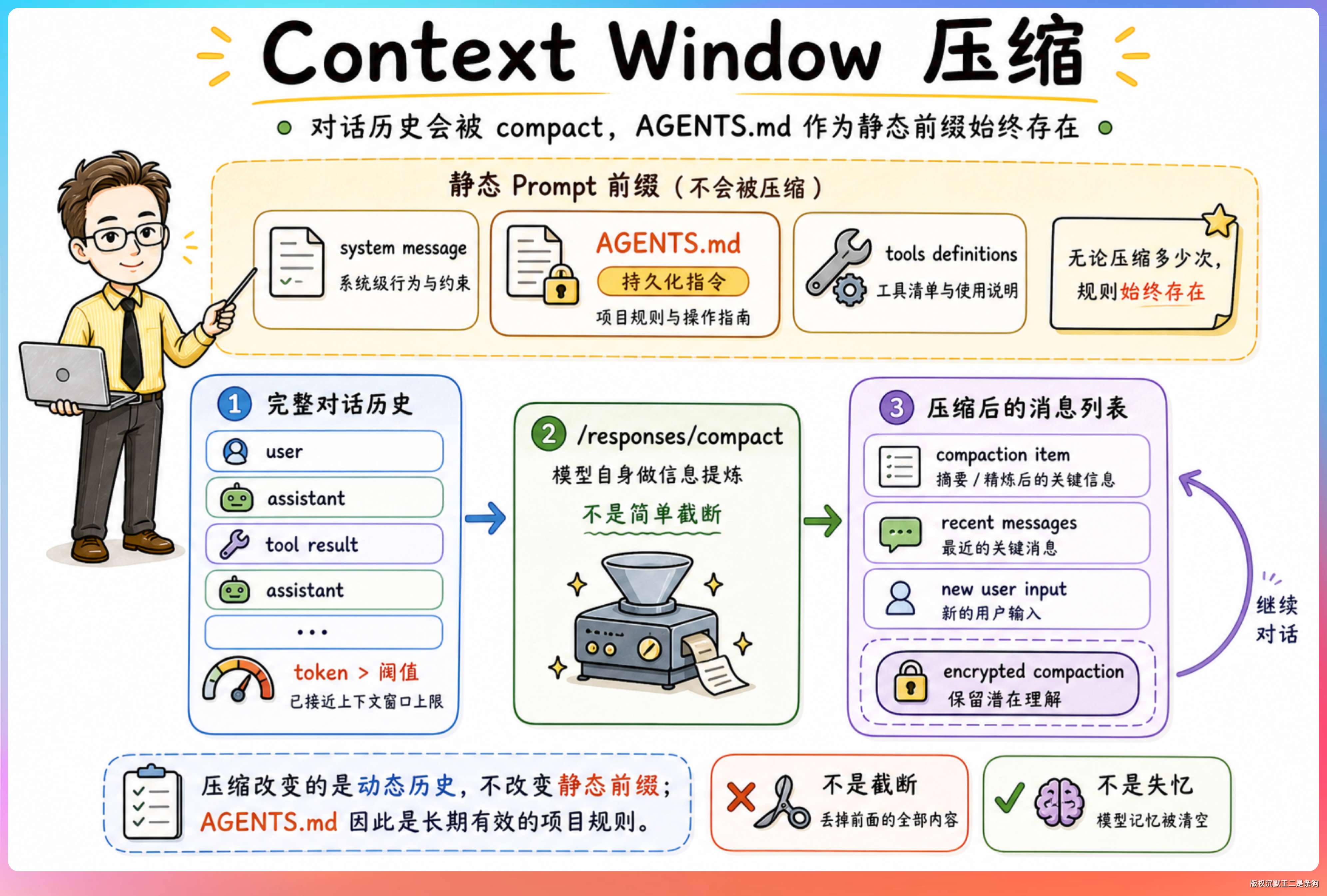
不是简单的截断或摘要,而是用模型自身来做信息提炼和压缩。被压缩的对话内容虽然消失了,但模型对项目上下文的理解还在,不会因为压缩而“失忆”。
对 AGENTS.md 来说有一个关键影响:AGENTS.md 的内容不会被压缩。
它属于 Codex 会反复带入的初始项目上下文,无论对话多长、压缩多少次,AGENTS.md 里的核心规则通常都会继续存在。这就是“持久化指令”这个名字的真正含义。
Codex 的工具体系
Agent Loop 里调用的“工具”分三类。
第一类是 Codex 内置工具:文件读写、Shell 执行、代码搜索。这些工具运行在沙箱内,受沙箱策略约束。
第二类是 API 提供的工具,由 Responses API 暴露。
第三类是用户通过 MCP 接入的外部工具。这类工具不受 Codex 沙箱保护,需要自己实现安全边界。
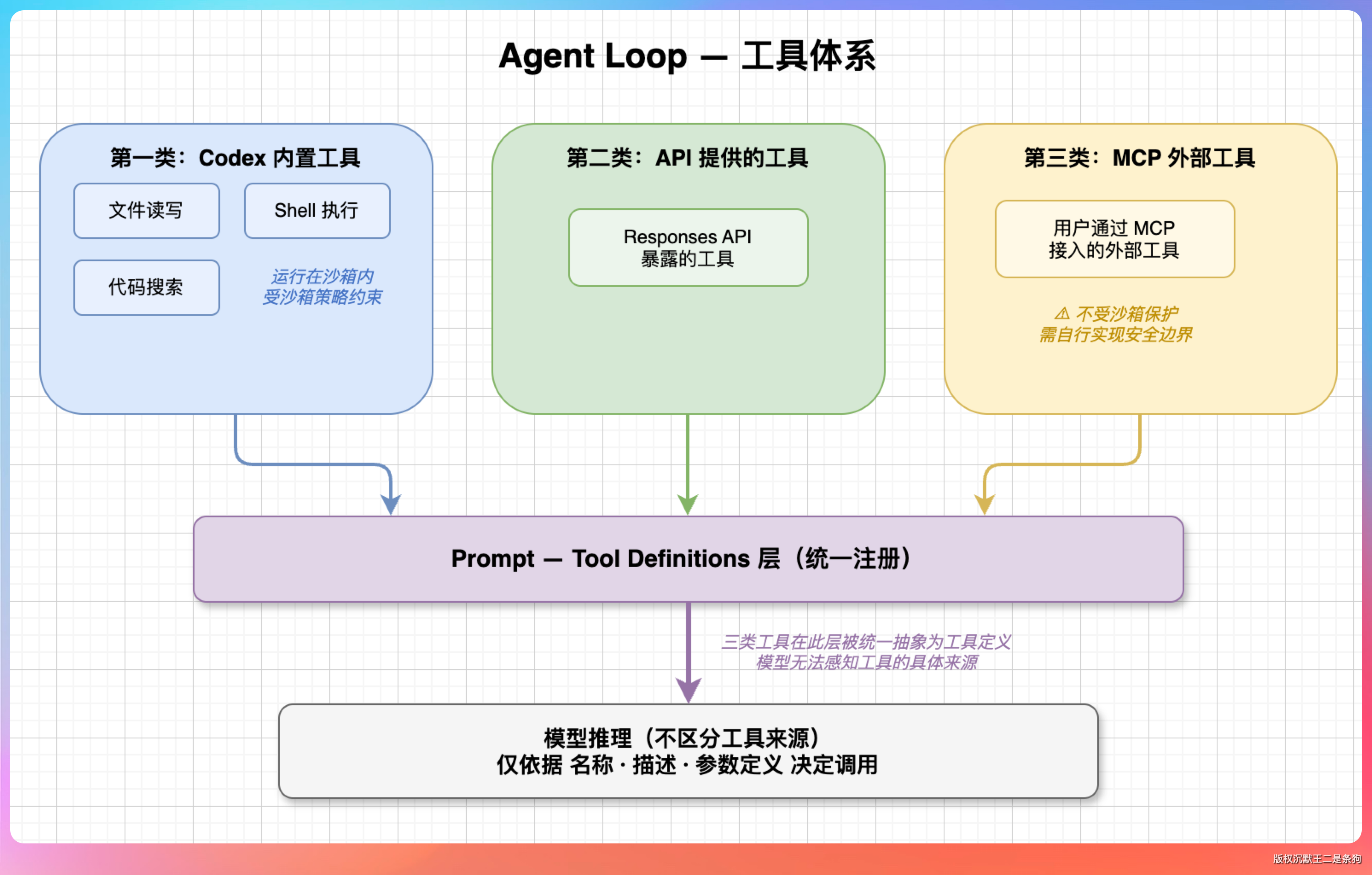
这三类工具在 Prompt 的 Tool Definitions 层被一起注册。模型在推理时不区分工具来源,它只看工具的名称、描述和参数定义来决定调用哪个。
AGENTS.md 可以在这里发挥作用——告诉模型优先用哪些工具、避免用哪些工具,相当于给工具调度加了一层人为偏好。
08、面试怎么回答
讲完底层原理,回到面试场景。
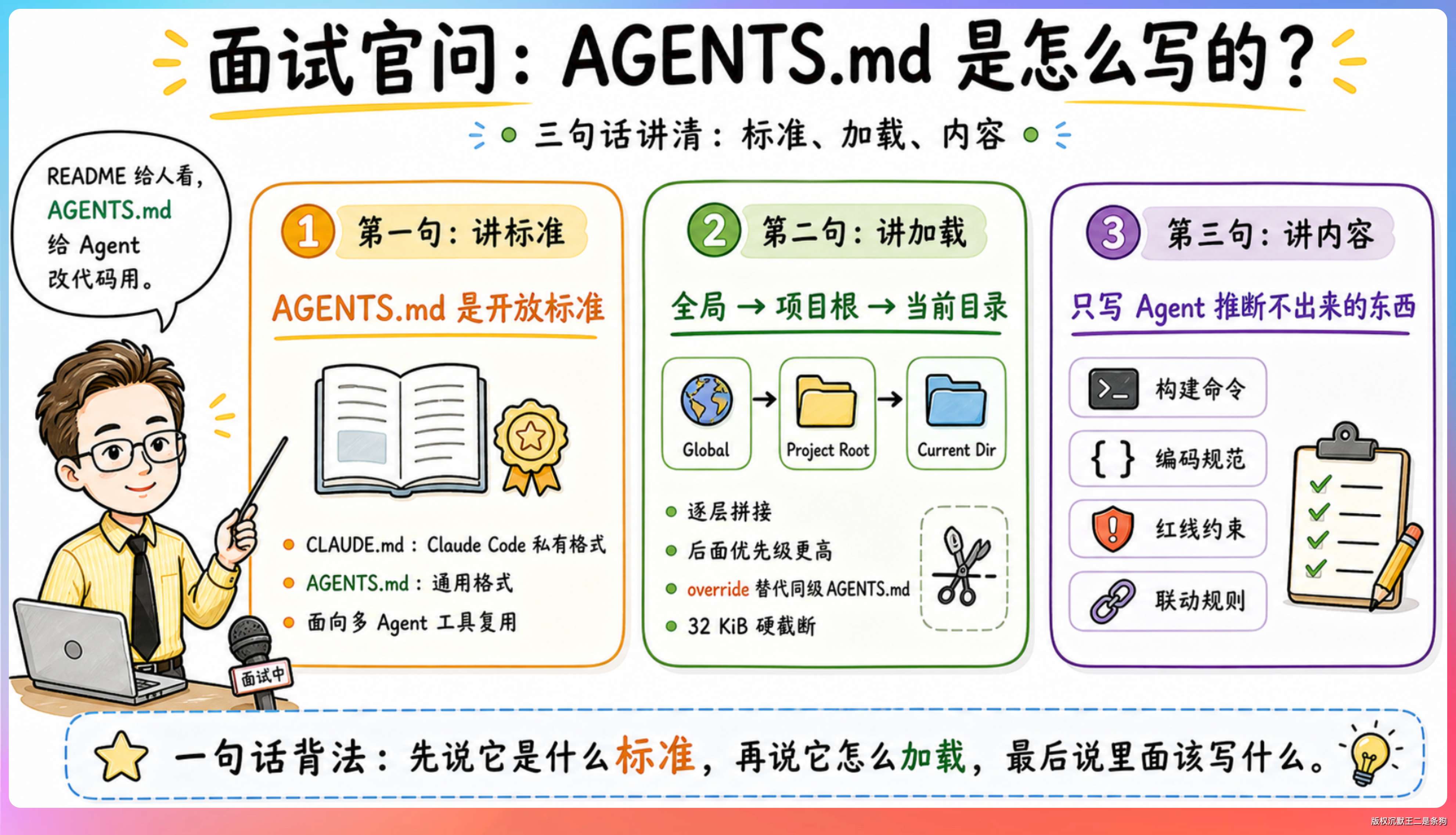
如果面试官问:“你用 Codex 的时候,AGENTS.md 是怎么写的?”
第一句讲标准。 AGENTS.md 是 Linux 基金会管理的开放标准。和 CLAUDE.md 的区别是:CLAUDE.md 是 Claude Code 的私有格式,AGENTS.md 是通用格式。
第二句讲加载。 Codex 启动时构建指令链,全局 → 项目根目录 → 当前目录,逐层拼接,后面优先级高。override 文件替代同级 AGENTS.md。32 KiB 硬截断。
第三句讲内容。 只写 Agent 推断不出来的东西:构建命令、编码规范、红线约束、联动规则。
如果面试官追问更深——“AGENTS.md 在 Codex 的 Prompt 里处于什么位置?”
AGENTS.md 会被 Codex 聚合进初始上下文里的项目级 user instructions。
这个位置意味着两件事:
- 第一,它低于 system/developer 级别的安全和权限约束,但会作为项目约定持续影响 Agent 的行为;
- 第二,它通常比较稳定,有利于 Prompt Cache 复用前缀计算,从而降低长对话 Agent Loop 的成本。

热门评论
4 条评论
回复