


用Qoder+SSE实现工作流实时推送
大家好,我是二哥呀。
前面我们已经完成了 LLM 节点和超拟人音频节点的开发,意味着从输入→LLM 节点→超拟人音频节点→输出节点的,一整套 AI 播客的工作流已经雏形可见了。
接下来,我们就需要把四个节点编排起来,来看看实际的效果。
一、AI 播客完整工作流验证
先来看输出节点,它的输出引用超拟人音频节点的 audioUrl,呈现给用户的就是原生的 {{output}},前端页面我们会渲染成一个音频播放器,这一步没问题。
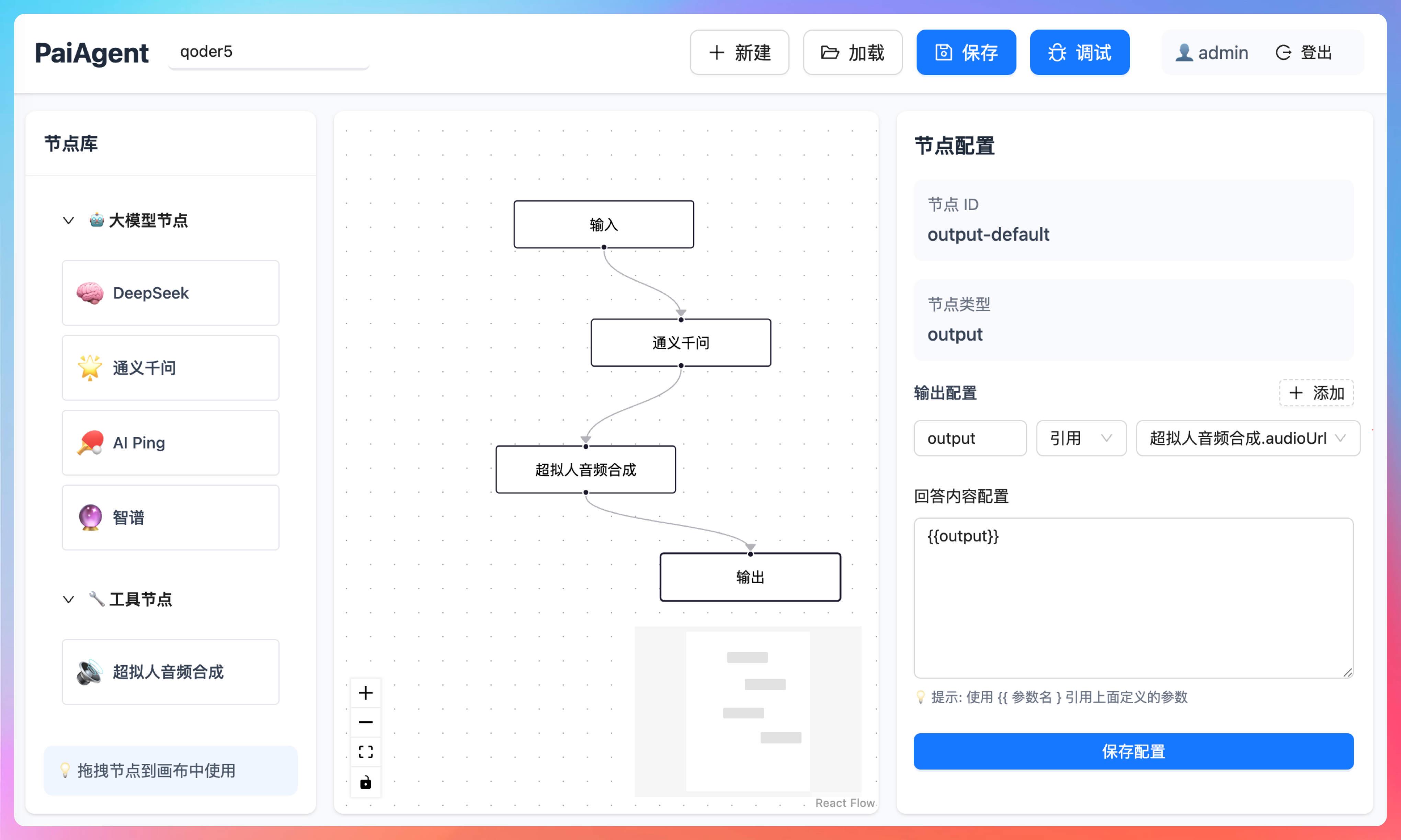
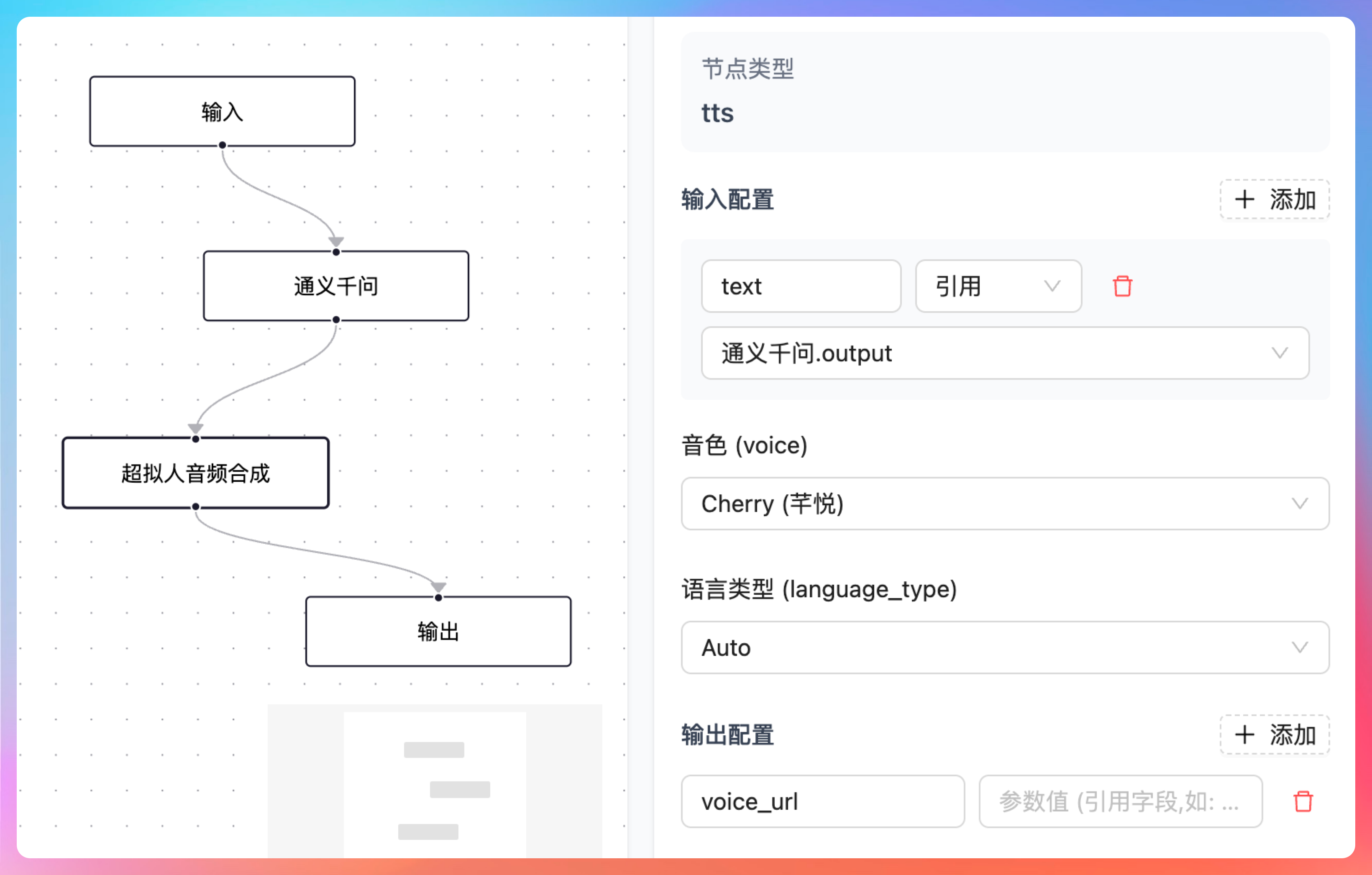
输出节点的前一个节点是超拟人音频合成节点,它的输出就是 voice_url,这是是我们自定义的,供下一个节点应用;它的输入是文本 text,引用的是通义千问 LLM 节点的 output。
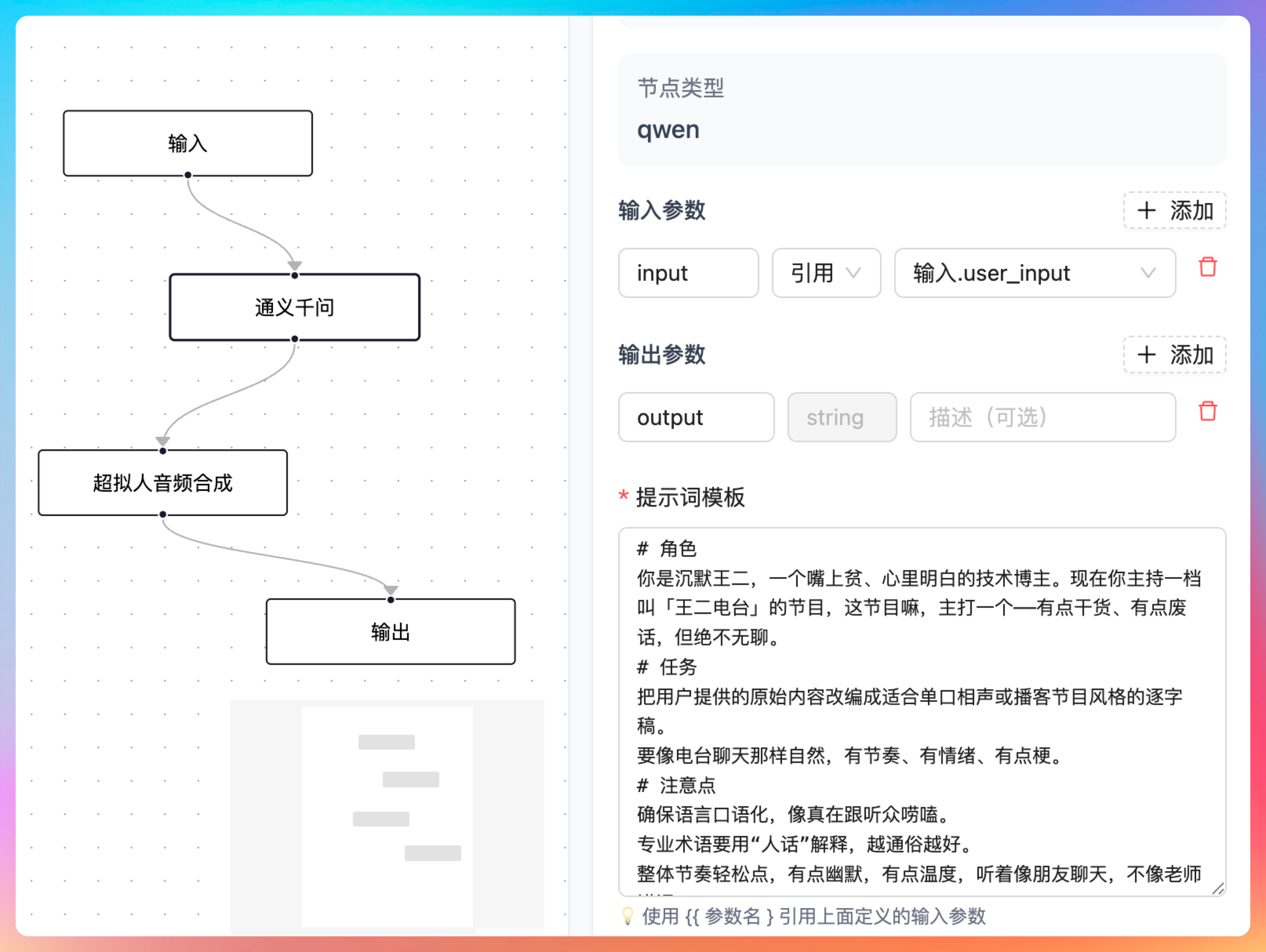
超拟人音频合成节点的前一个节点是通义千问节点,输入参数 input 引用的是用户的输入,输出我们定义为 output,通义千问节点会按照我们的提示词,将用户的输入转成一段符合播客风格的文本内容,供超拟人音频节点合成。
那这样一个完成的 AI 播客工作流就算是编排完成了。接下来我们点击【调试】按钮,打开调试面板,输入一段文本,看看整体工作流的运行效果如何。
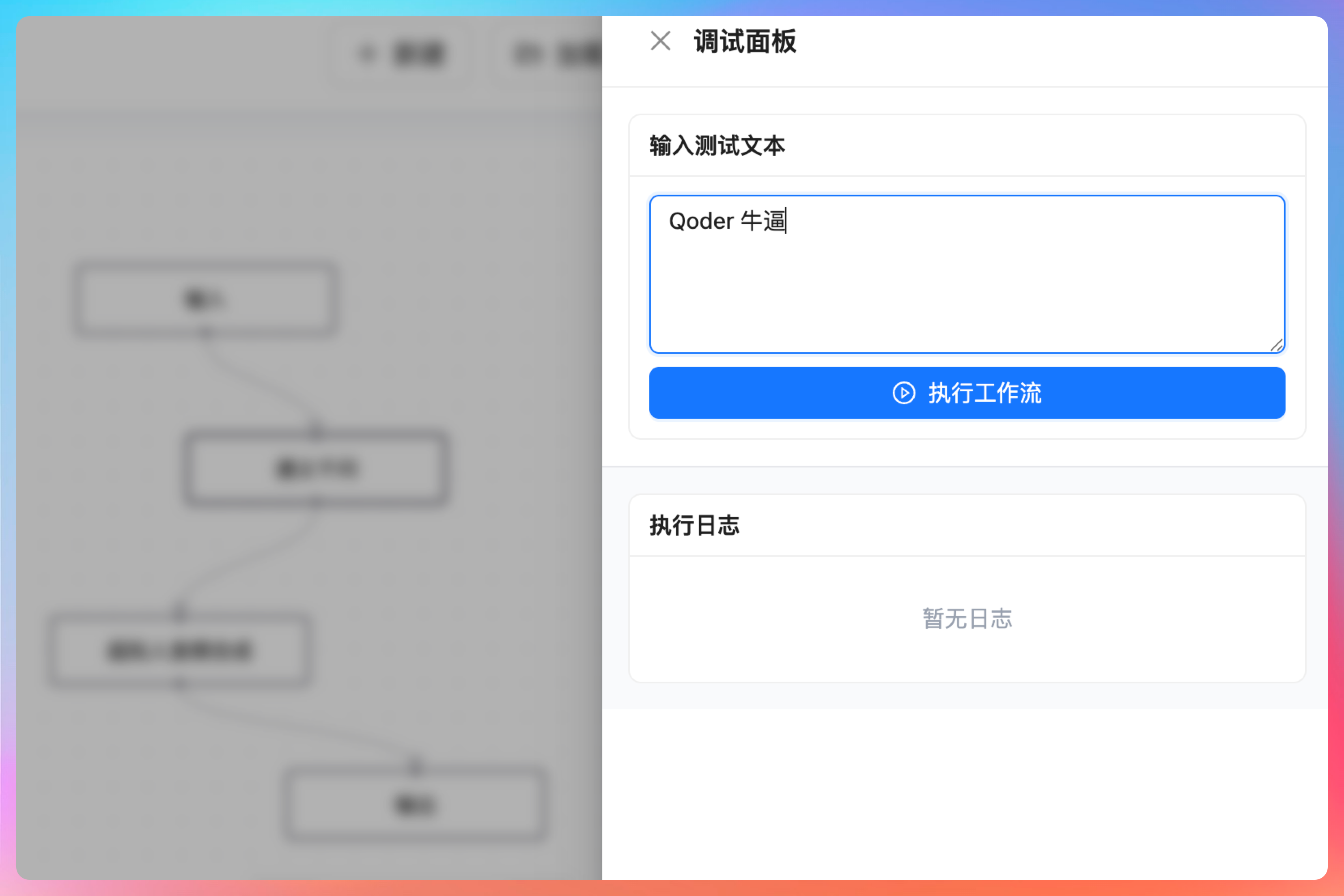
点击【执行工作流...
1人已点赞

回复