


用Qoder+SSE实现工作流实时推送
大家好,我是二哥呀。
前面我们已经完成了 LLM 节点和超拟人音频节点的开发,意味着从输入→LLM 节点→超拟人音频节点→输出节点的,一整套 AI 播客的工作流已经雏形可见了。
接下来,我们就需要把四个节点编排起来,来看看实际的效果。
一、AI 播客完整工作流验证
先来看输出节点,它的输出引用超拟人音频节点的 audioUrl,呈现给用户的就是原生的 {{output}},前端页面我们会渲染成一个音频播放器,这一步没问题。
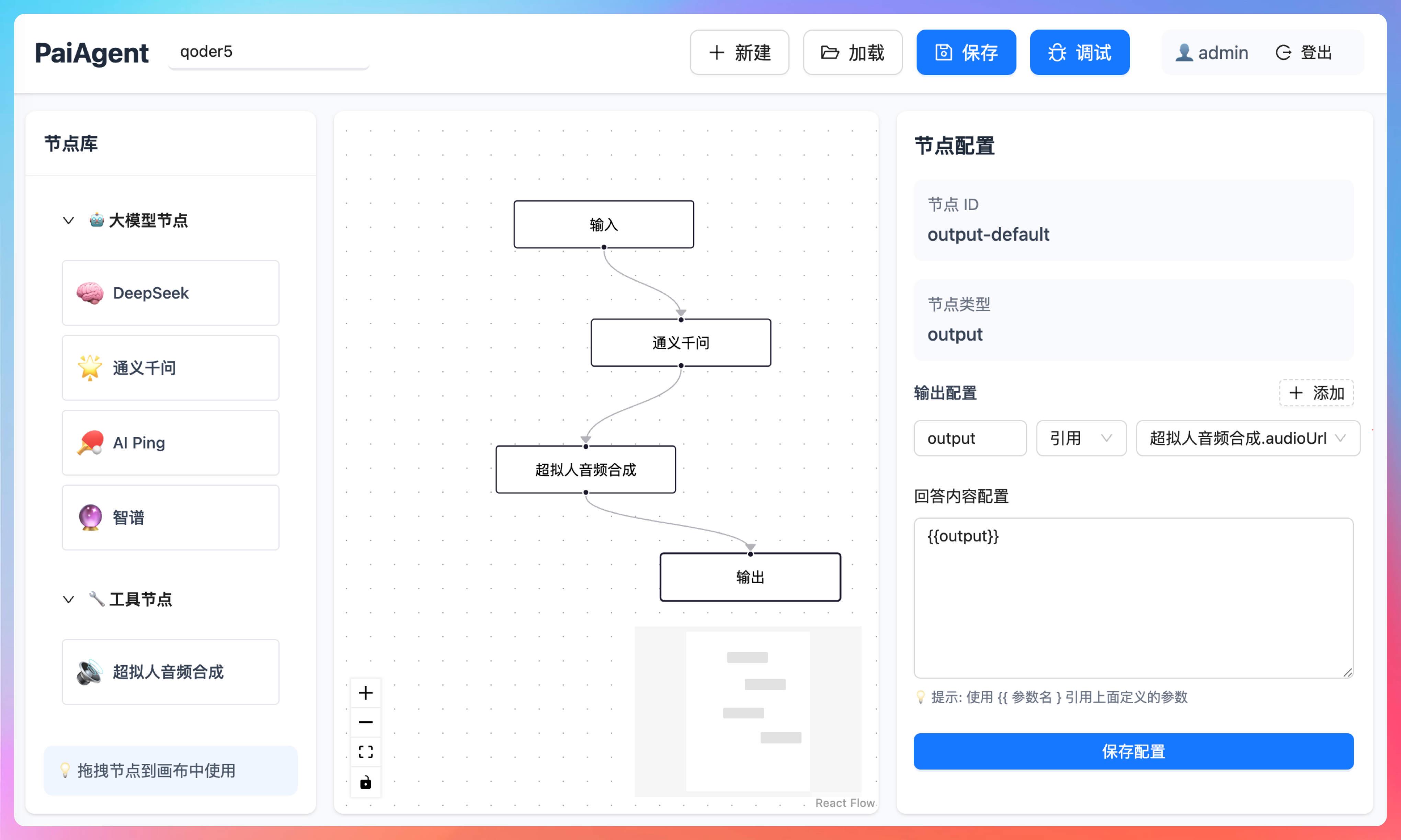
输出节点的前一个节点是超拟人音频合成节点,它的输出就是 voice_url,这是是我们自定义的,供下一个节点应用;它的输入是文本 text,引用的是通义千问 LLM 节点的 output。
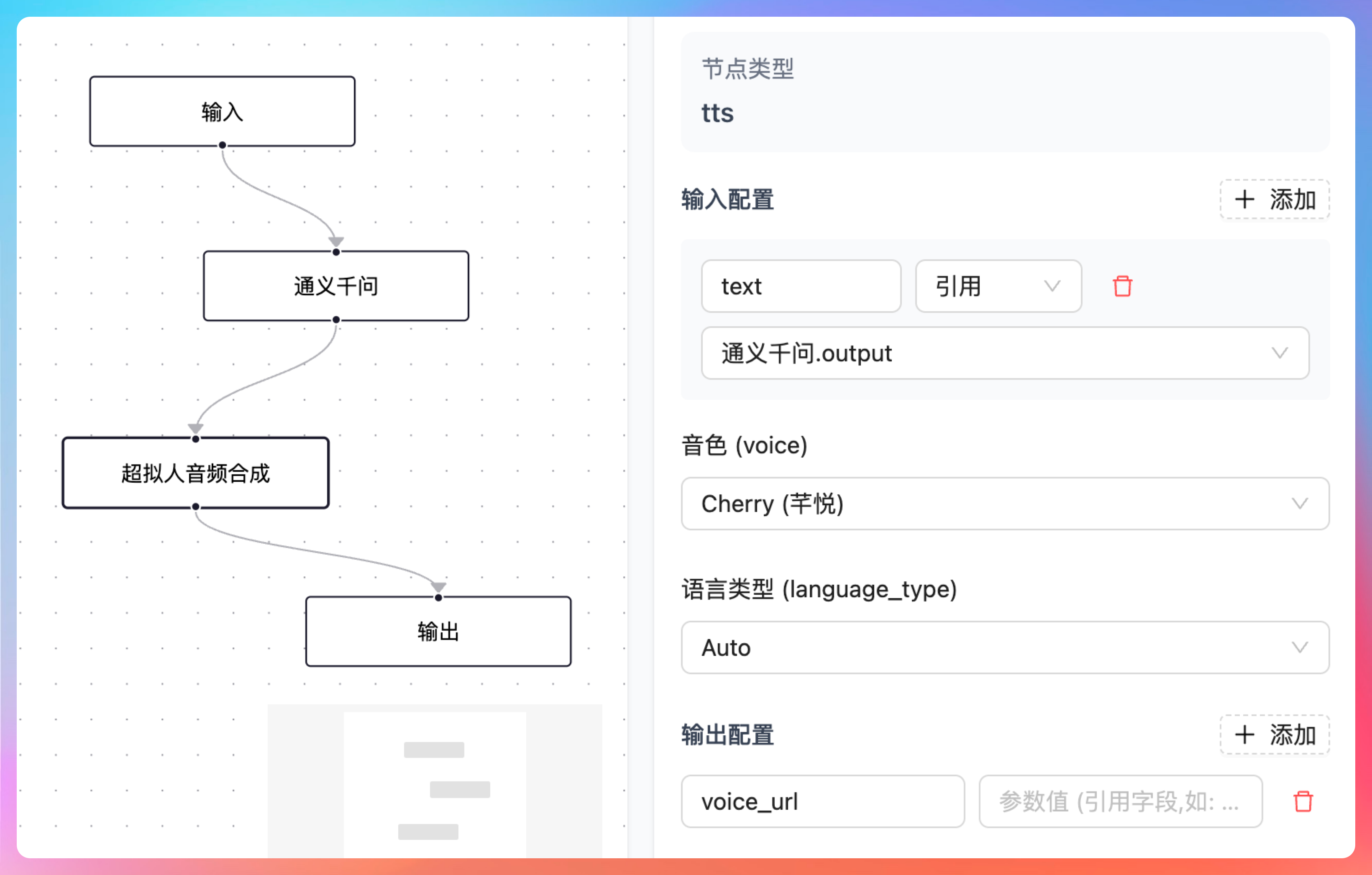
超拟人音频合成节点的前一个节点是通义千问节点,输入参数 input 引用的是用户的输入,输出我们定义为 output,通义千问节点会按照我们的提示词,将用户的输入转成一段符合播客风格的文本内容,供超拟人音频节点合成。
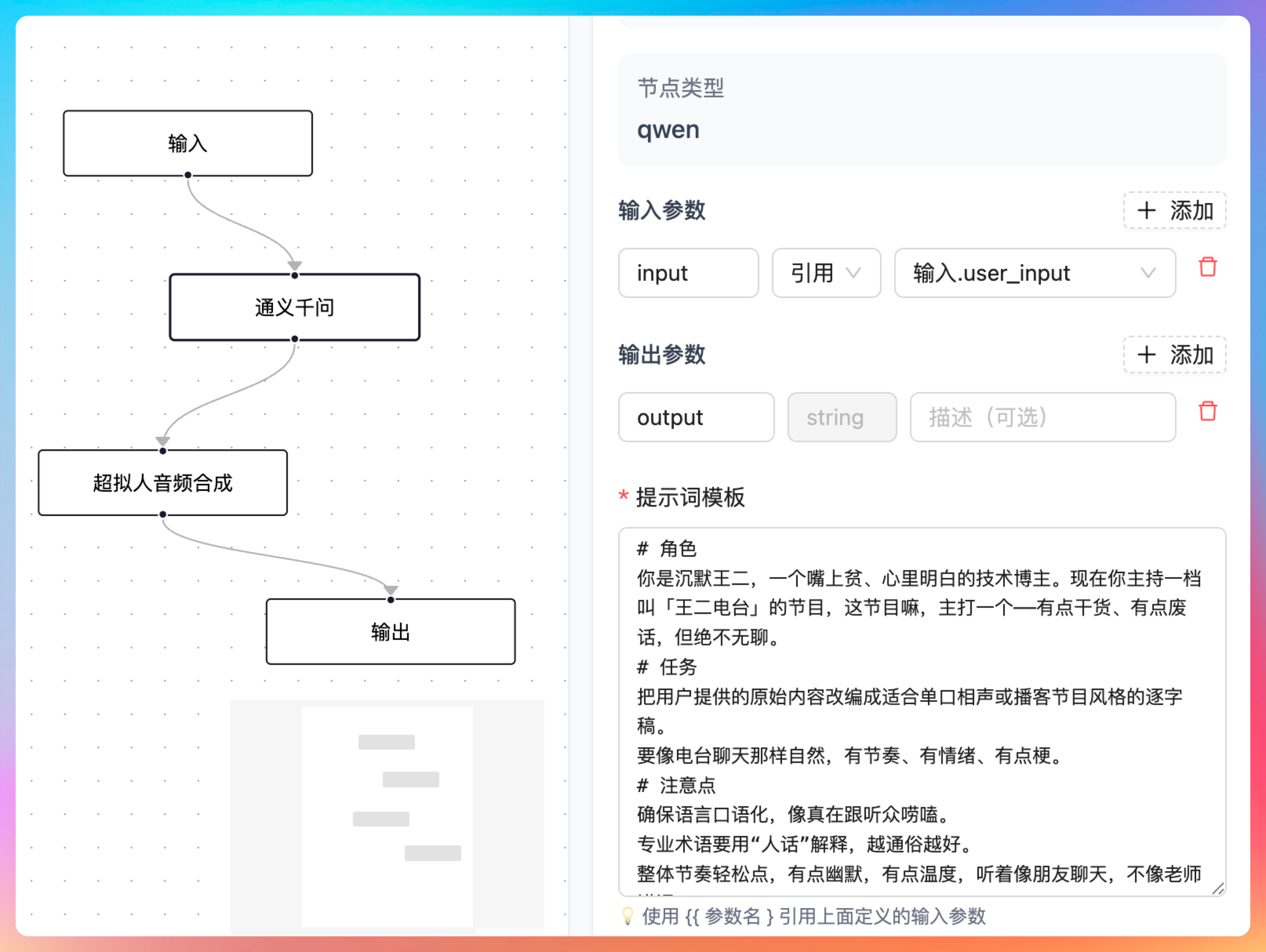
那这样一个完成的 AI 播客工作流就算是编排完成了。接下来我们点击【调试】按钮,打开调试面板,输入一段文本,看看整体工作流的运行效果如何。
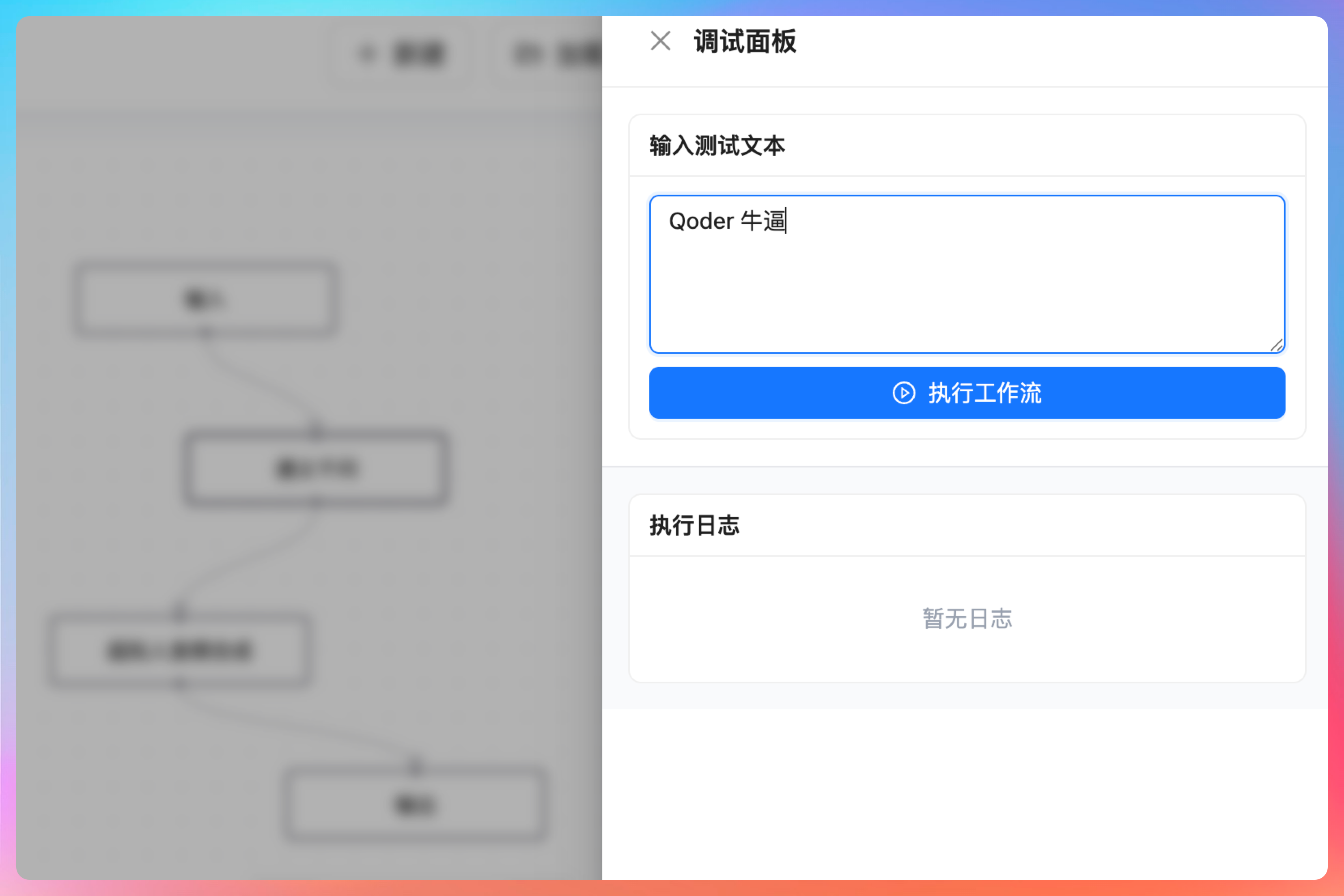
点击【执行工作流】,执行状态,执行日志都开始动起来了。
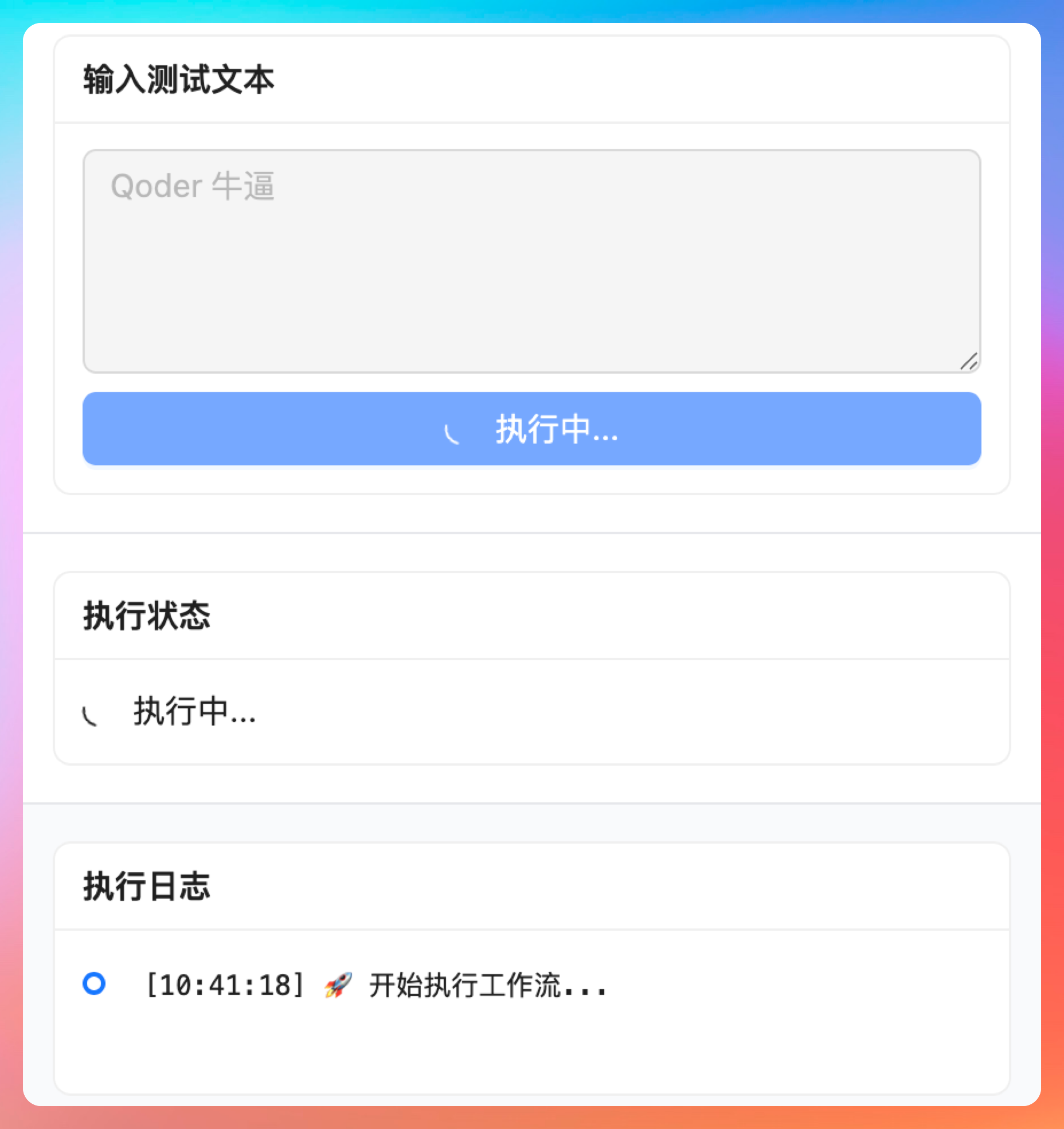
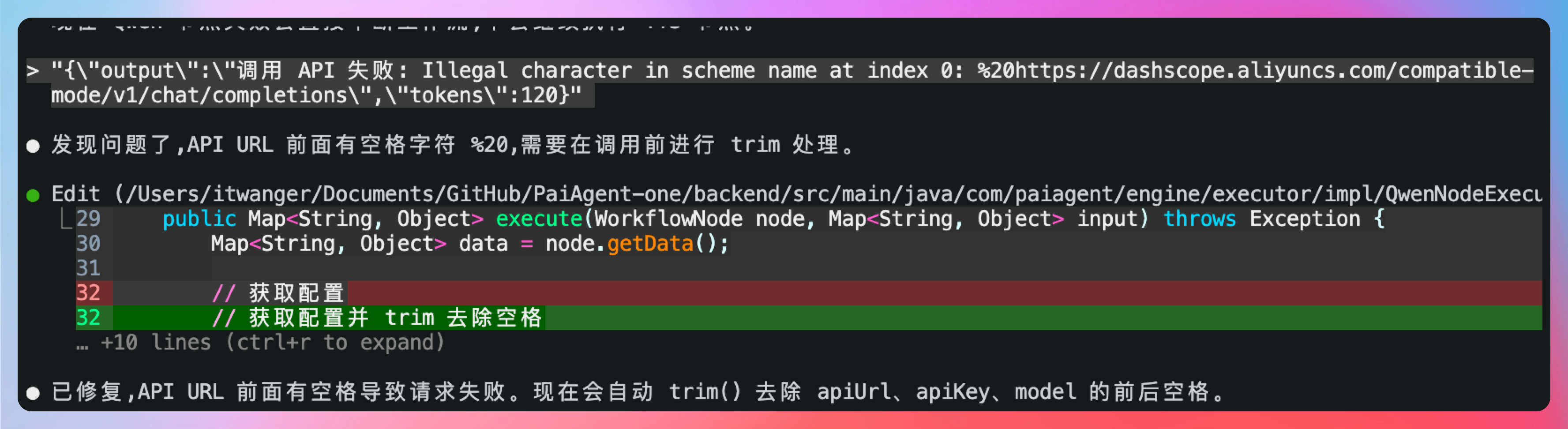
很遗憾,出现 bug 了,千问 LLM 和 qwen3-tts API 调用都失败了,但节点状态竟然是运行成功的状态,并且 qwen 这里执行失败,就应该立马停止,不应该再继续执行 tts,对吧?
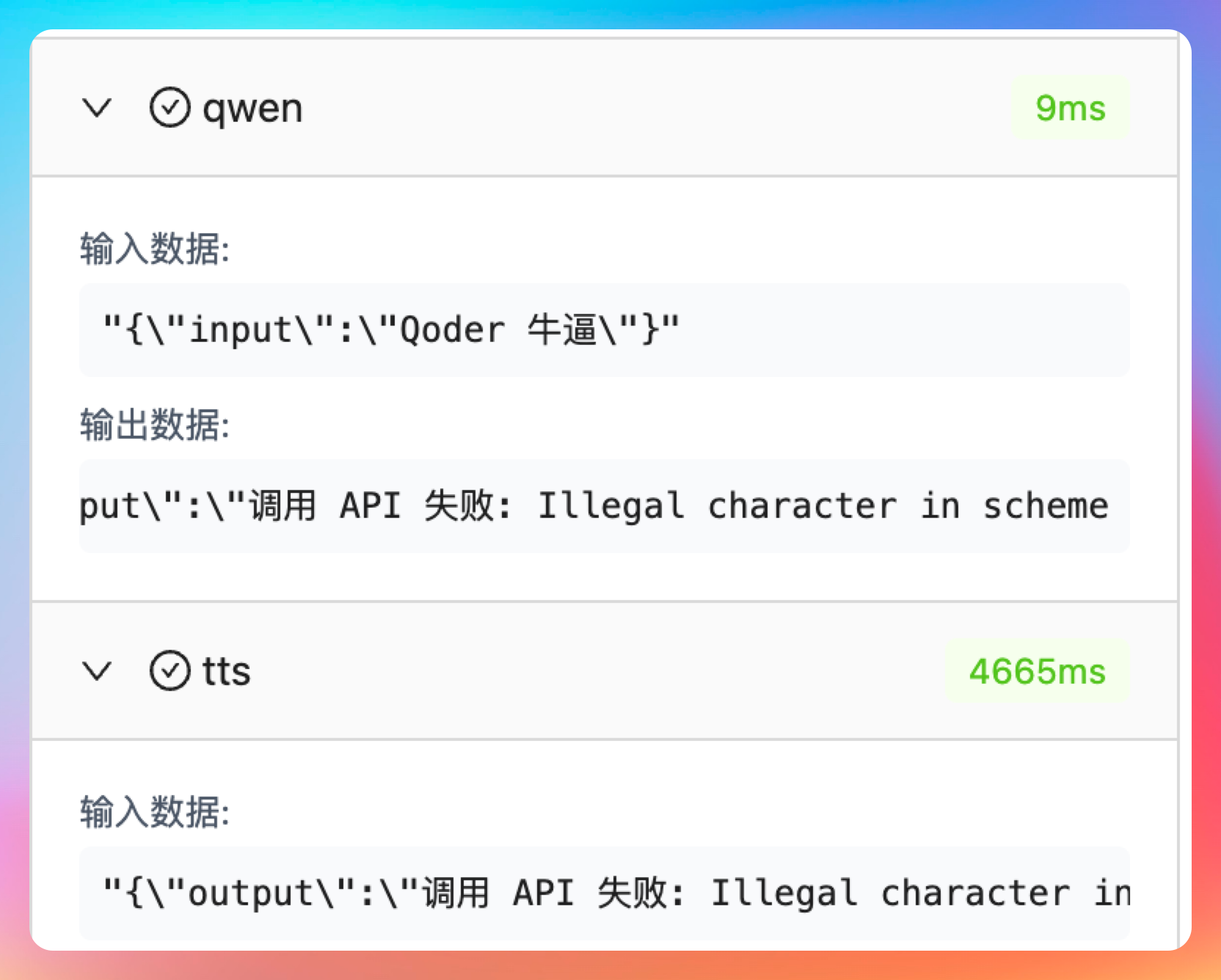
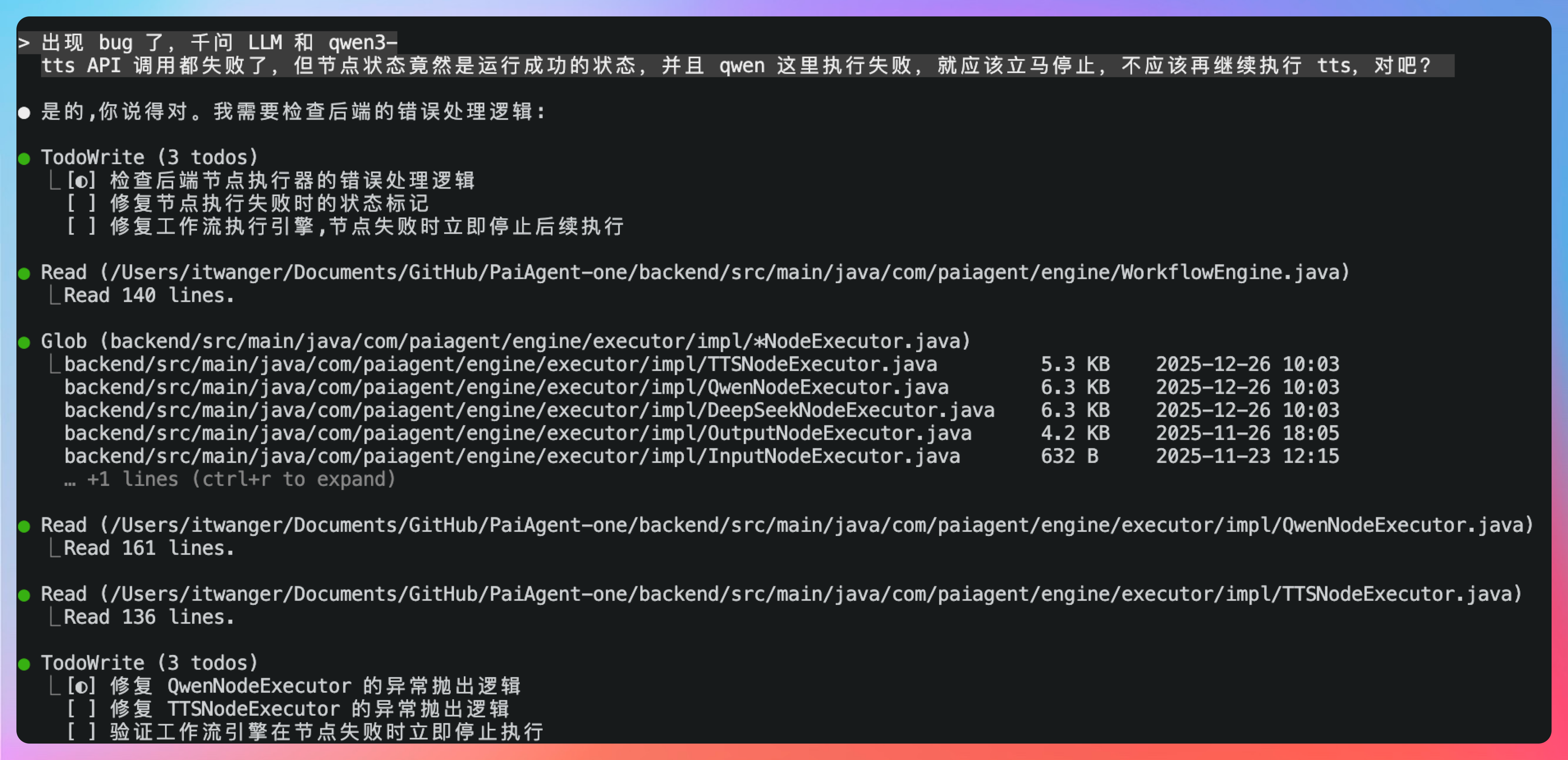
我们把问题直接扔给 Qoder CLI,让它修复。对于 Vibe Coding 来说,发现错误、调教 AI 是至关重要的能力,我们需要指出哪里出错了,应该如何修复,延后再验证,再继续测试,直到最终满足我们的预期效果。
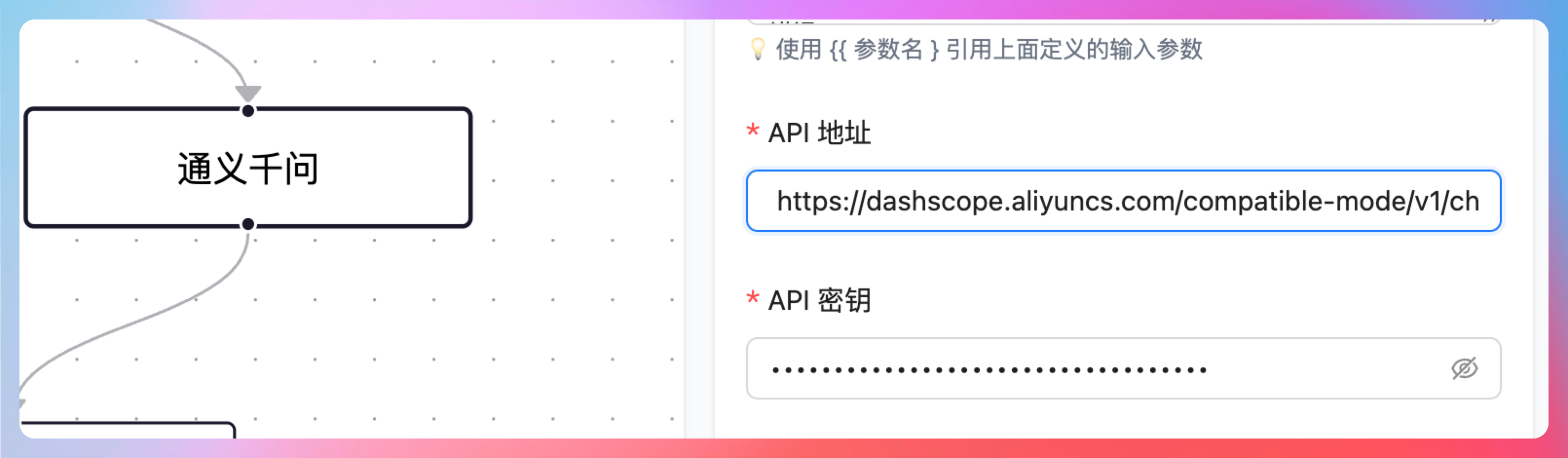
错误其实很明显,我已经看到了 调用 API 失败: Illegal character in scheme name at index 0: %20https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions\"也就是我们填写 API 地址的时候,多了一个空格。😄
Vibe Coding 时代,这种工程素养是非常重要的,否则 AI 改了,但可能改错了,我们没有发现,最终就是耗费大量的时间,拉扯,你会觉得 AI 很傻,AI 会觉得你很菜。
掐起架来了。
第一是我们填写的时候注意,第二是程序帮我们规避到这种问题。
来看看 Qoder CLI 的表现吧。

- QwenNodeExecutor: 移除了 try-catch 吞掉异常的逻辑,API 调用失败时会直接抛出异常
- TTSNodeExecutor: 已有正确的异常抛出机制(第31、41、62行)
- WorkflowEngine: 第92行的 throw e 确保节点失败时立即停止后续节点执行
OK,这正是我们想要的。接着,我们继续让它修复多余空格的问题,直接 trim 掉,没问题。
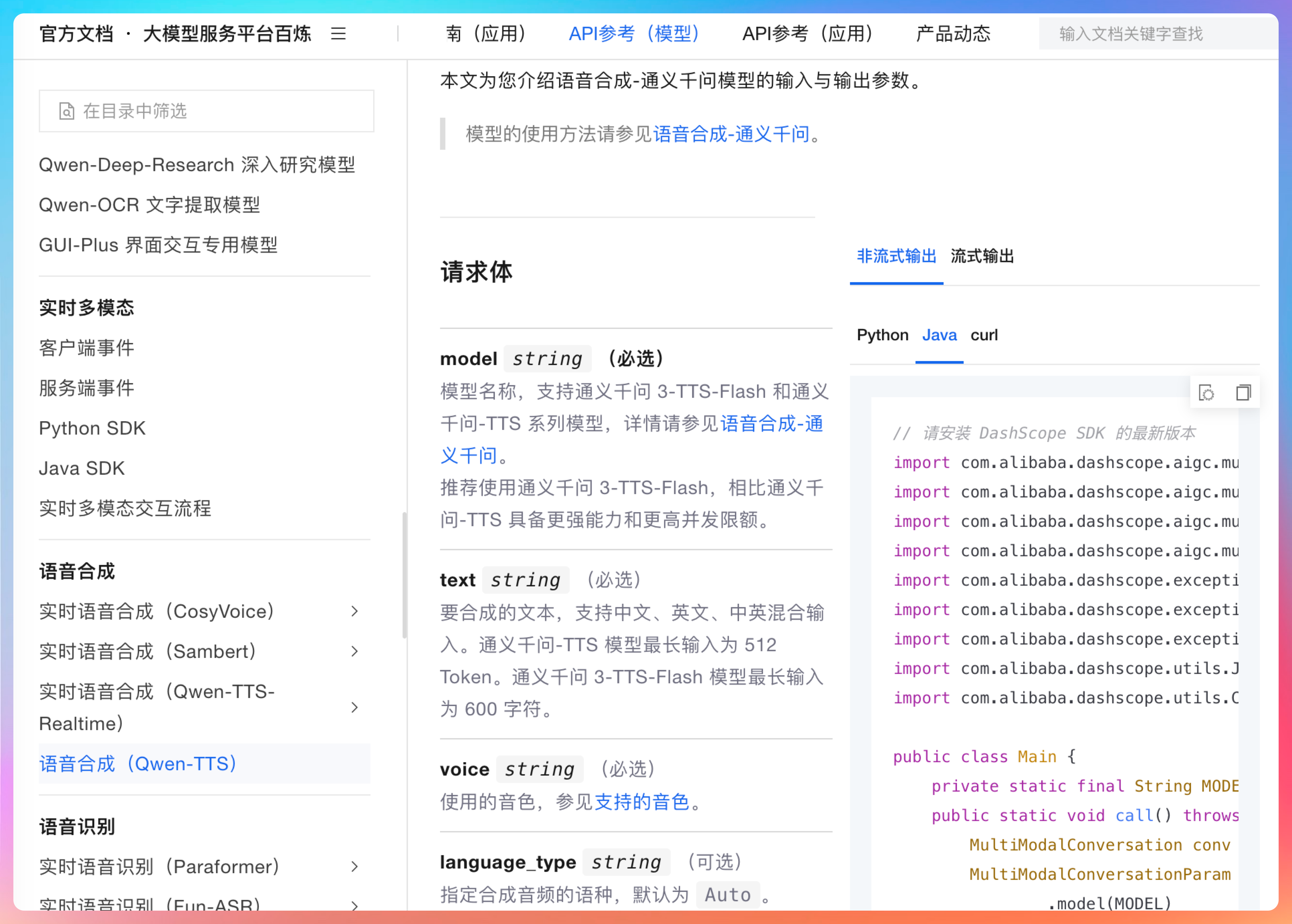
再次测试,我们发现了另外一个问题,qwen 返回正常的文本,但 tts 执行失败了,从错误信息来看,似乎阿里百炼 TTS API 对输入文本的长度有限制,这一点我们可以访问阿里百炼 TTS 的官方 API 确认一下。

的确,通义千问3-TTS-Flash模型最长输入为600字符。这就对了,实际上,在日常的开发当中,我们一定要多去看官方的 doc,因为 AI Coding 是没办法做到非常准确的,一是我们在提示词中无法给他准确的信息,二是官方的 doc 也会更新,所以这种刨根问底的态度是非常关键的。
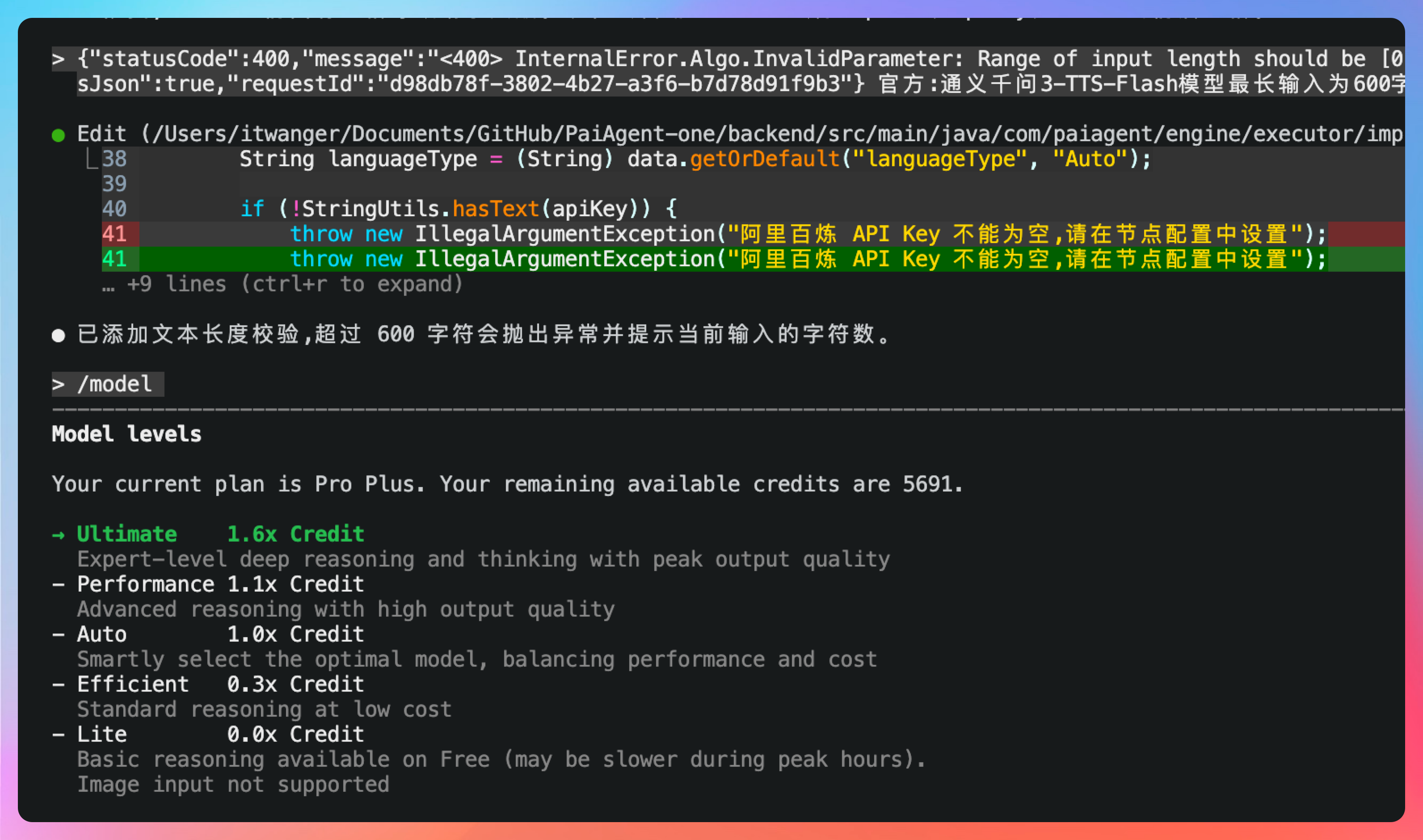
好,我们把错误直接扔给 Qoder CLI。但感觉这次反馈并不符合我们的预期(我们希望他能自动分块,然后按块去调用千问 TTS 的 API),那这个时候怎么办呢?可以键入 /model选择一个更高质量的模型,比如说先调整到 Performance 来试试,如果不满意,可以再调高至 Ultimate。
如果还不满意,就不让它猜我们的意图了,直接告诉 Qoder CLI 我们想要的(可以依赖 AI,但也要有自己的技术功底做支撑,否则 AI 和你都会感觉束手无策):需要切割文本,然后多次调用 tts API,分别把音频文件保存到 MinIO 后,再合并成一个返回回来。
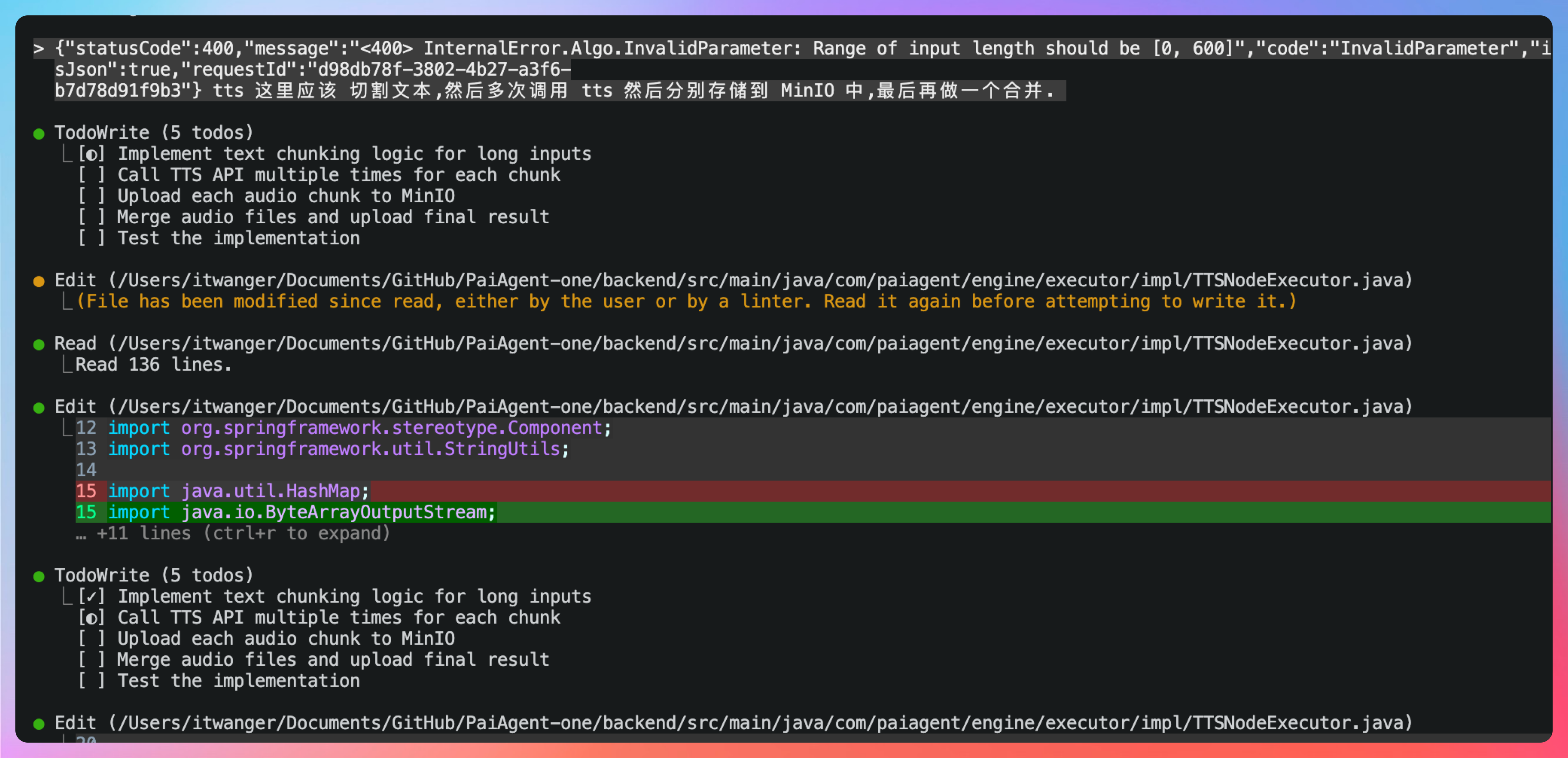
OK,第一件事:将超过 600 字符的文本按标点符号智能分段;第二个件事:多次调用: 对每个分段调用 TTS API;第三件事:下载所有音频片段并合并为单个 WAV 文件;第四件事:将合并后的音频上传到 MinIO。
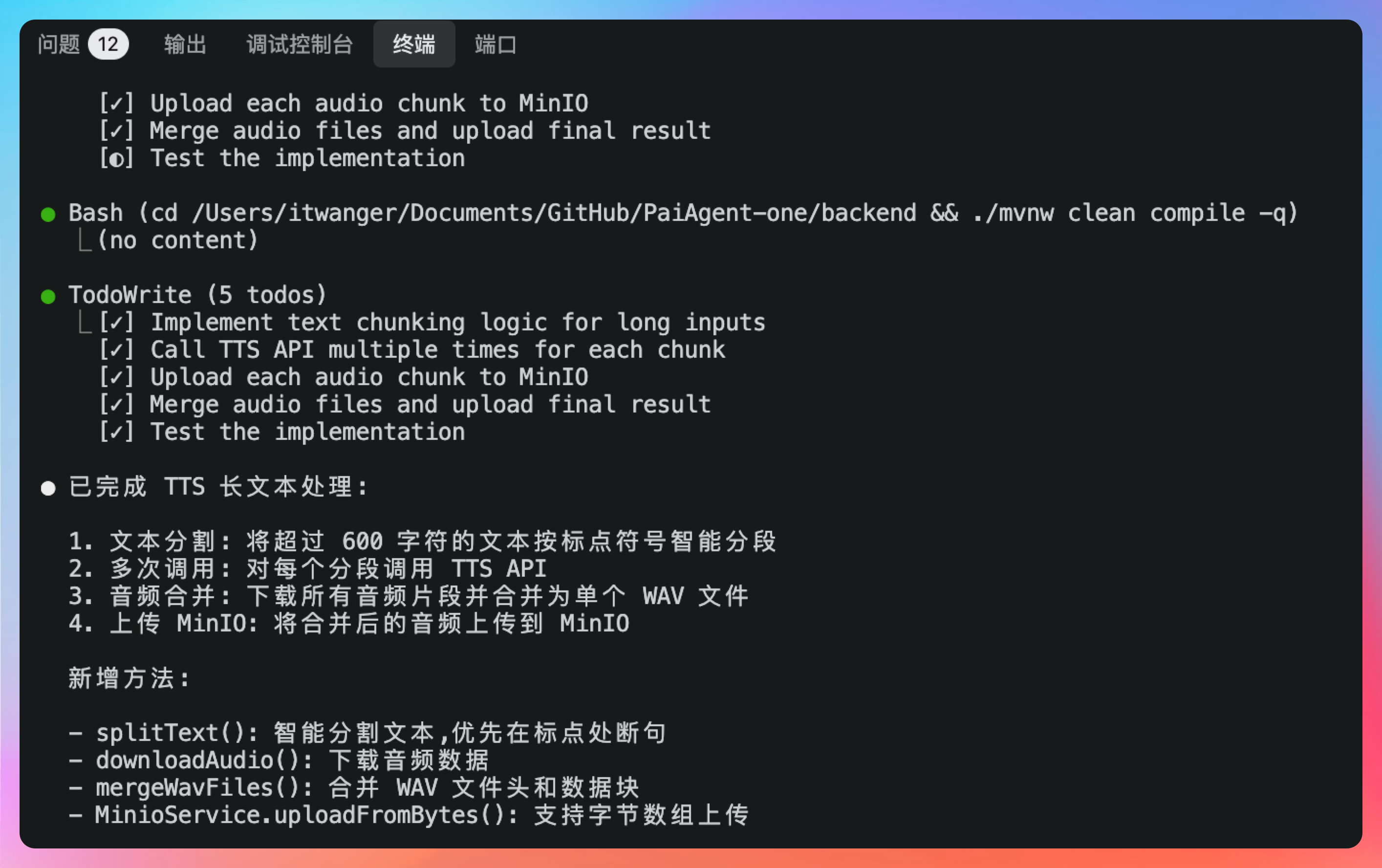
确认一下代码,整体上没什么问题。但其实还有一个更好的方案,我们以后再试,先看看目前的方案是否可以正常工作。
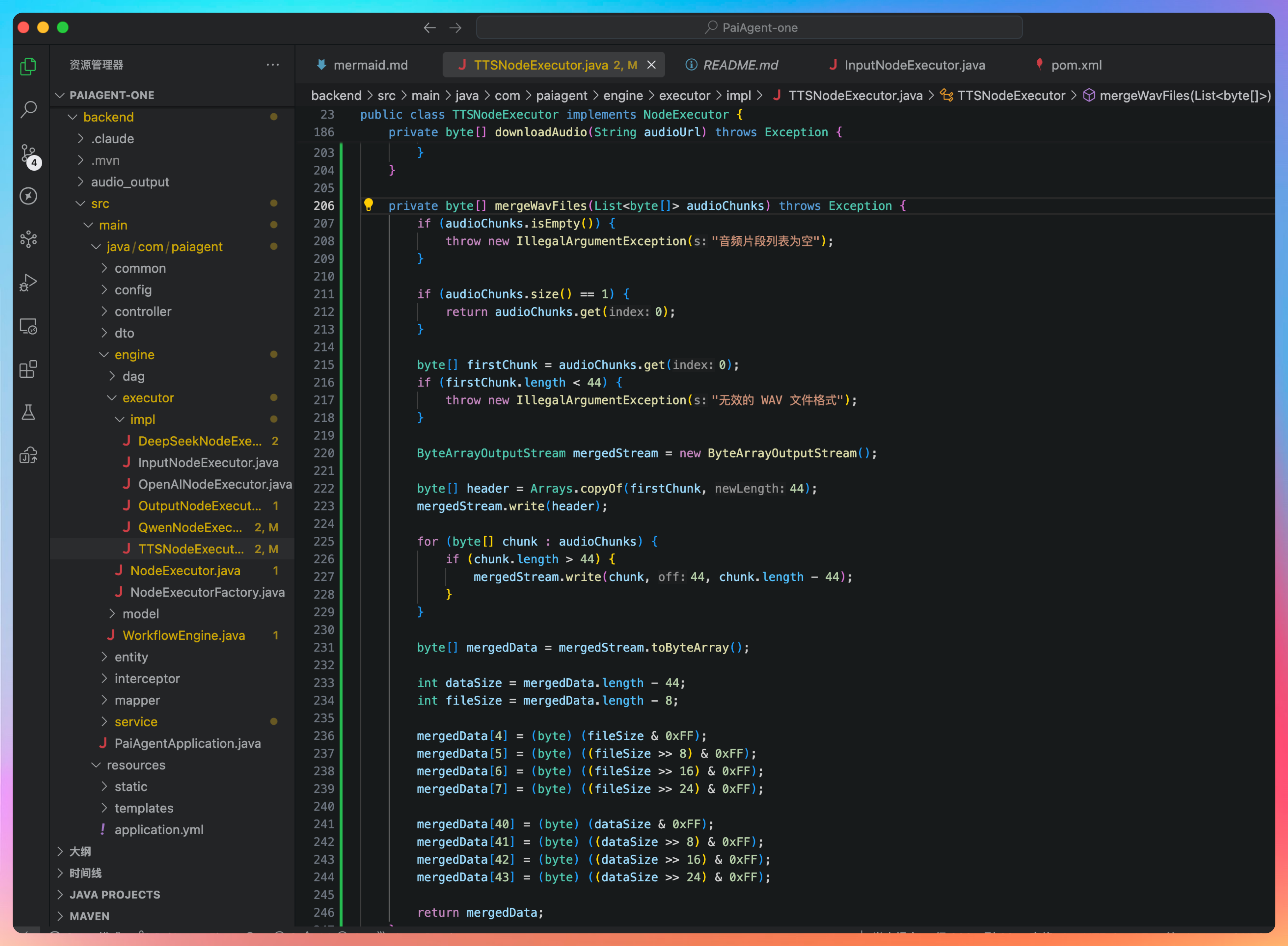
OK,确实搞定了,可以正常执行,多个音频文件和合并成了一个。
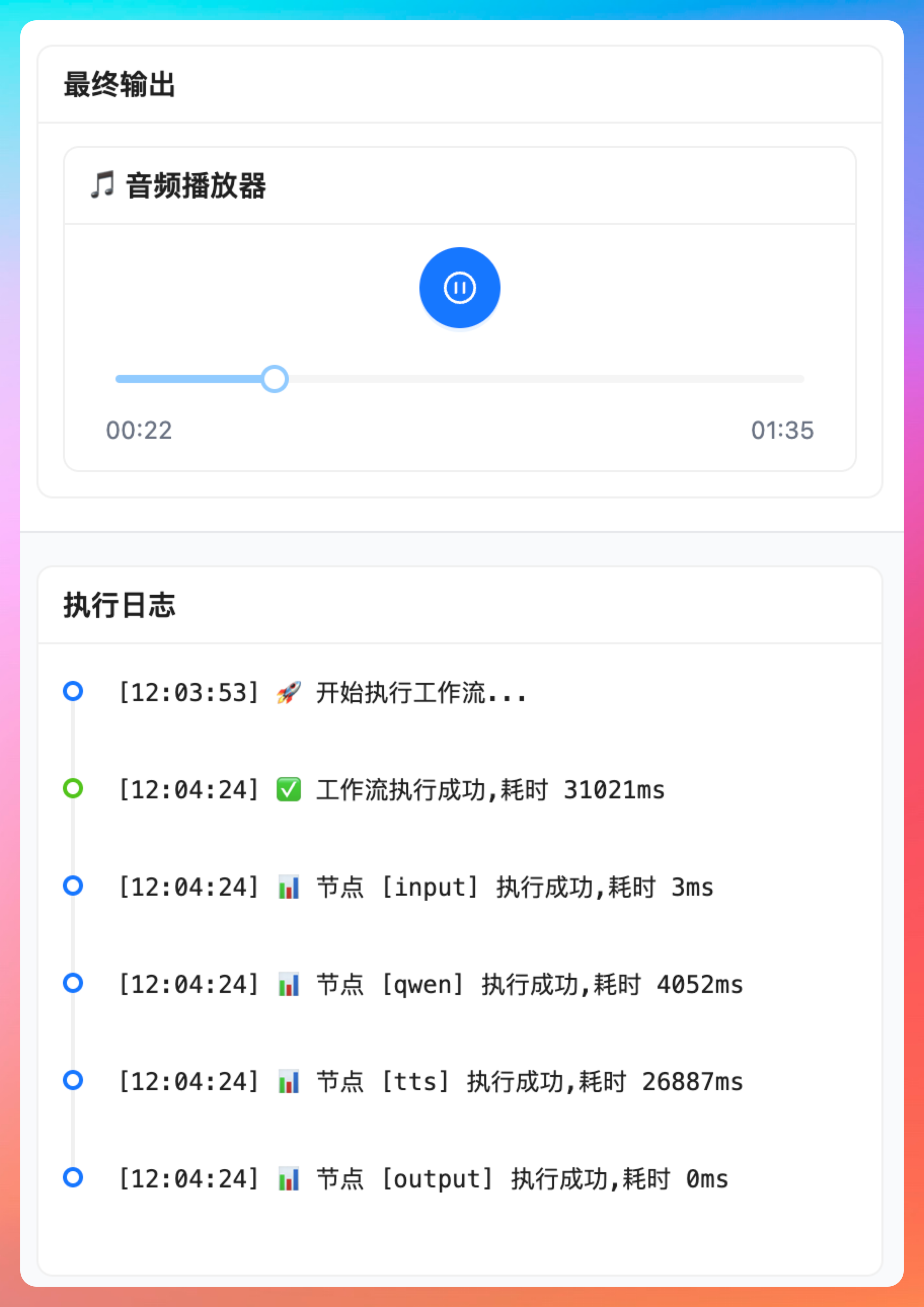
从后台的日志上,确实能看得出来,文本被切割成了 3 个片段。
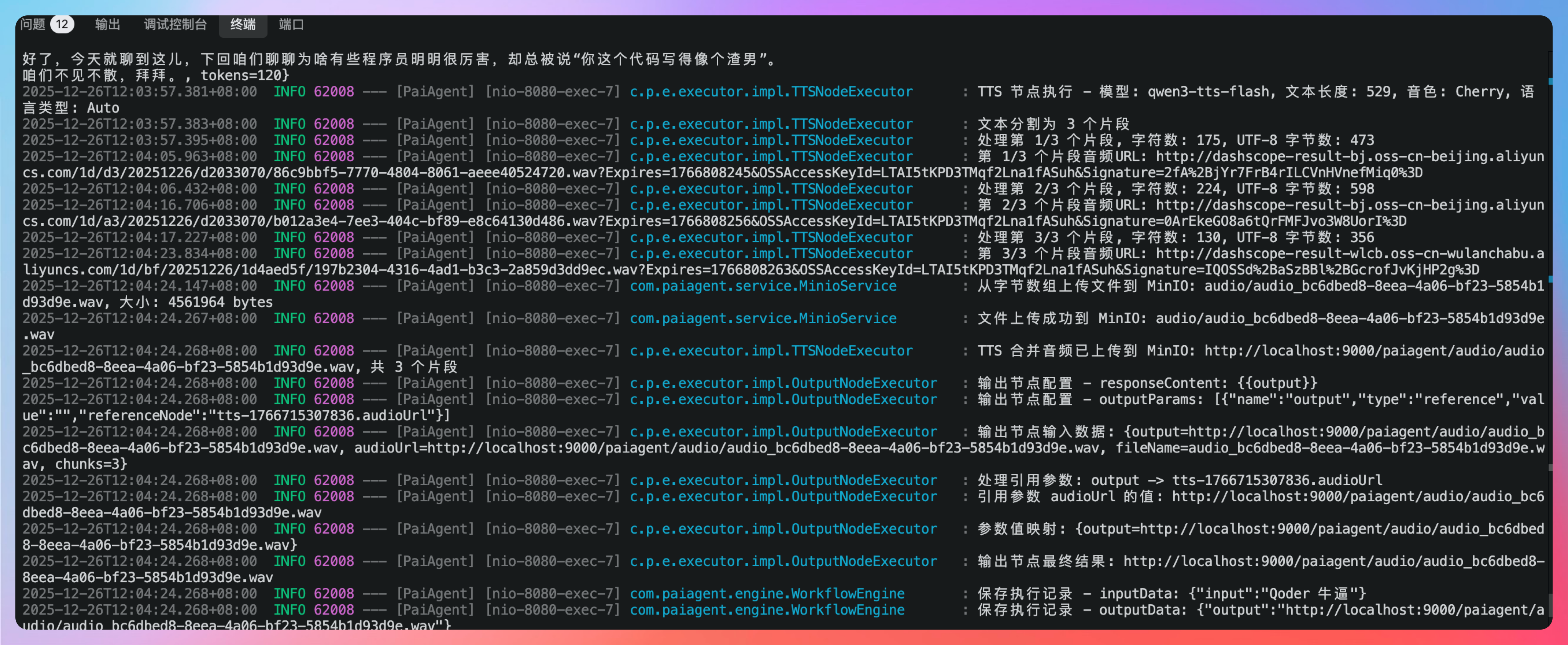
但有一个细节需要提醒大家,前面看官方 doc 的时候,有说:“通义千问3-TTS-Flash模型最长输入为600字符。”
但实际测试下来,明显感觉不太对劲,这里的 600 字符更像是 600 字节,因为我们总的文本长度为 529,但仍然会提示:
{"statusCode":400,"message":"<400> InternalError.Algo.InvalidParameter: Range of input length should be [0, 600]","code":"InvalidParameter","isJson":true,"requestId":"d98db78f-3802-4b27-a3f6-b7d78d91f9b3"}
类似的错误,当我按照字节去切割为 473、598、356 的时候,最终 API 调用成功了。😄
这就是前面我一再强调的,一定要去看官方 doc,一是指引 AI,二是抱着怀疑的态度,去质疑 AI,去质疑官方 doc。
很多时候,新手容易犯的错误就是,明明我是对的,为什么错了。代码是不会说谎的,错了就是错了,肯定是你哪里错了。只有这样的心态,你才不容易被程序逼疯。
。。。。。。
二、集成 SSE 完成节点的实时执行反馈
调通整个工作流后,我们还有一个需求要解决。现在的执行状态,是等所有节点都跑完之后,前端一次性展示结果。
这种方式在功能上是没问题的,但从用户体验上来说,状态流转应该是一个动态过程:
- LLM 节点开始执行 → 执行中 → 执行完成
- 接着切换到 TTS 节点 → 执行中 → 执行完成
- 最后到结束节点,整体流程结束
也就是说,**工作流的执行状态,本质上是一个随时间不断演进的过程,而不是一个一次性结果。**带着这个问题,我们直接把需求丢给了 Qoder CLI:
现在有个问题,我发现,执行状态、节点执行结果都是等所有节点都执行完后才显示出来的,实际上这应该是一个动态的过程,llm 节点开始执行的时候执行状态就切到 llm 节点开始执行、执行中、执行结束,然后到 tts 的开始执行、执行中、执行结束,最后到结束节点,这应该是实时响应的。前后端需要联调起来。
面对这个问题,Qoder 并没有一上来就写代码,而是先拆解问题,给出了一套非常工程化的解决步骤。
- 分析当前的工作流架构
- 设计实时更新的方案
- 通过 WebSocket 或者 SSE 来实现实时更新
- 更新工作流引擎以出发状态更新事件
- 前端监听状态变更
- 更新前端 DebugDrawer 的页面,以展示实时更新的效果
- 联调前后端的实时更新
非常严谨,如果让我来实现这个功能,基本上也是这个节奏,哈哈。
Qoder 这次选择了 SSE。原因很简单,整个执行过程是典型的服务端主动推送、单向流式更新场景,不需要复杂的双向通信,SSE 足够轻量,也更容易和现有 HTTP 体系集成。
01、SSE 接口源码分析
在实现层面,整体改动可以分为两部分。后端侧,引入事件执行模型 ExecutionEvent,用来统一描述工作流和节点的状态变化。在 ExecutionController 中新增一个 SSE 接口 executeWorkflowStream,将这些事件以流的形式持续推送给前端。
@Operation(summary = "实时执行工作流(SSE)")
@GetMapping(value = "/{id}/execute/stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public SseEmitter executeWorkflowStream(@PathVariable Long id, @RequestParam String inputData) {
SseEmitter emitter = new SseEmitter(300000L);
String emitterId = id + "_" + System.currentTimeMillis();
emitters.put(emitterId, emitter);
emitter.onCompletion(() -> emitters.remove(emitterId));
emitter.onTimeout(() -> emitters.remove(emitterId));
emitter.onError((e) -> emitters.remove(emitterId));
Consumer eventCallback = event -> {
try {
emitter.send(SseEmitter.event()
.name(event.getEventType())
.data(event));
} catch (IOException e) {
log.error("发送 SSE 事件失败", e);
emitters.remove(emitterId);
}
};
new Thread(() -> {
try {
Workflow workflow = workflowService.getById(id);
if (workflow == null) {
emitter.send(SseEmitter.event()
.name("ERROR")
.data(ExecutionEvent.workflowComplete("FAILED", "工作流不存在", 0)));
emitter.complete();
return;
}
workflowEngine.executeWithCallback(workflow, inputData, eventCallback);
emitter.complete();
} catch (Exception e) {
log.error("工作流执行失败", e);
try {
emitter.send(SseEmitter.event()
.name("ERROR")
.data(ExecutionEvent.workflowComplete("FAILED", e.getMessage(), 0)));
} catch (IOException ex) {
log.error("发送错误事件失败", ex);
}
emitter.complete();
}
}).start();
return emitter;
}
这个接口返回的不是普通的 JSON,而是一个 SseEmitter。它代表的是一条可以持续向客户端发送事件的长连接。只要这个 emitter 不关闭,服务端就可以不断往前端推送执行状态,而前端不需要反复轮询。
在方法一开始,就创建了一个 SseEmitter,并且显式设置了超时时间。这里设置的是 300 秒,目的是给一次完整工作流执行预留足够的时间窗口,避免流程还没跑完,连接就被服务端提前回收。
接着,通过 workflowId + 时间戳生成一个 emitterId,并把 emitter 放进一个 Map 里统一管理。这一层设计很关键,它解决的是两个问题:一是支持同一个工作流被多次触发执行;二是当连接异常、超时或完成时,能够准确地清理对应的 emitter,避免资源泄漏。
紧接着,为 emitter 注册了三个回调:onCompletion、onTimeout 和 onError。这三个回调的处理逻辑非常统一,都是在连接生命周期结束时,把 emitter 从管理容器中移除。
真正把“实时”串起来的,是接下来的 eventCallback。这里定义了一个 Consumer,用来接收 WorkflowEngine 在执行过程中抛出的 ExecutionEvent。每当有新的执行事件产生,就通过 emitter.send 将事件推送给前端。
注意这里发送的不只是字符串,而是一个带有 eventType 的 SSE 事件。这意味着前端可以根据不同的事件类型,区分是工作流开始、节点开始、节点成功、节点失败,还是流程结束。
接下来这段 new Thread,是整个流程真正启动的地方。之所...
2人已点赞
回复