


用Qoder集成qwen3-tts+MinIO完成超拟人音频节点开发
大家好,我是二哥呀。
关于超拟人音频节点,我首先想到的解决方案是 qwen3-tts-flash——阿里百炼平台上提供的一种语音合成服务,提供了多种拟人音色,还支持英语、汉语,以及方言。
输入参数也很简单,必须参数仅需一个要合成音频的文本 text;一个音色 voice,可选 Cherry(阳光积极、亲切自然小姐姐)、Serena(温柔小姐姐)、Ethan(标准普通话,带部分北方口音。阳光、温暖、活力、朝气)等等;还有一个 language_type,默认是自适应。

返回参数是一个 URL,有效期是 24 小时,后续我们可以在本地安装 MinIO,将音频保存到 MinIO 服务中。
整体的思路不复杂,接下来我们通过拆分任务,让 Qoder 来实现它:
- 定义超拟人音频节点的输入/输出参数结构,包括 text、voice、languageType
- 使用 Qoder CLI 创建全新的 AudioTTS 节点基础模板,让节点具备标准的 initConfig、schema、executor 结构
- 为音频节点加入完整的配置表单,包括文本输入框、音色选择器、语言类型下拉框
- 在工作流引擎中实现 AudioTTS 节点的执行逻辑,调用阿里百炼 qwen3-tts-flash,将生成的音频 URL 返回给下一节点
- 增加 URL 结果的合法性校验,并支持后续扩展为自动上传至 MinIO 的能力
- 将音频节点纳入“输入节点 → 音频节点 → 输出节点”的完整链路,验证整个工作流的可执行性
一、为超拟人音频合成节点配置参数
直接告诉 Qoder 我们的需求:
我们要为超拟人音频节点添加基本配置,当选中超拟人音频节点时,右侧的节点配置中,第一个参数为 API key,第二个参数为模型名称,默认值为 qwen3-tts-flash;删除之前遗留的提示词、温度等配置项,这两个暂时不需要。
确认一下,没问题。
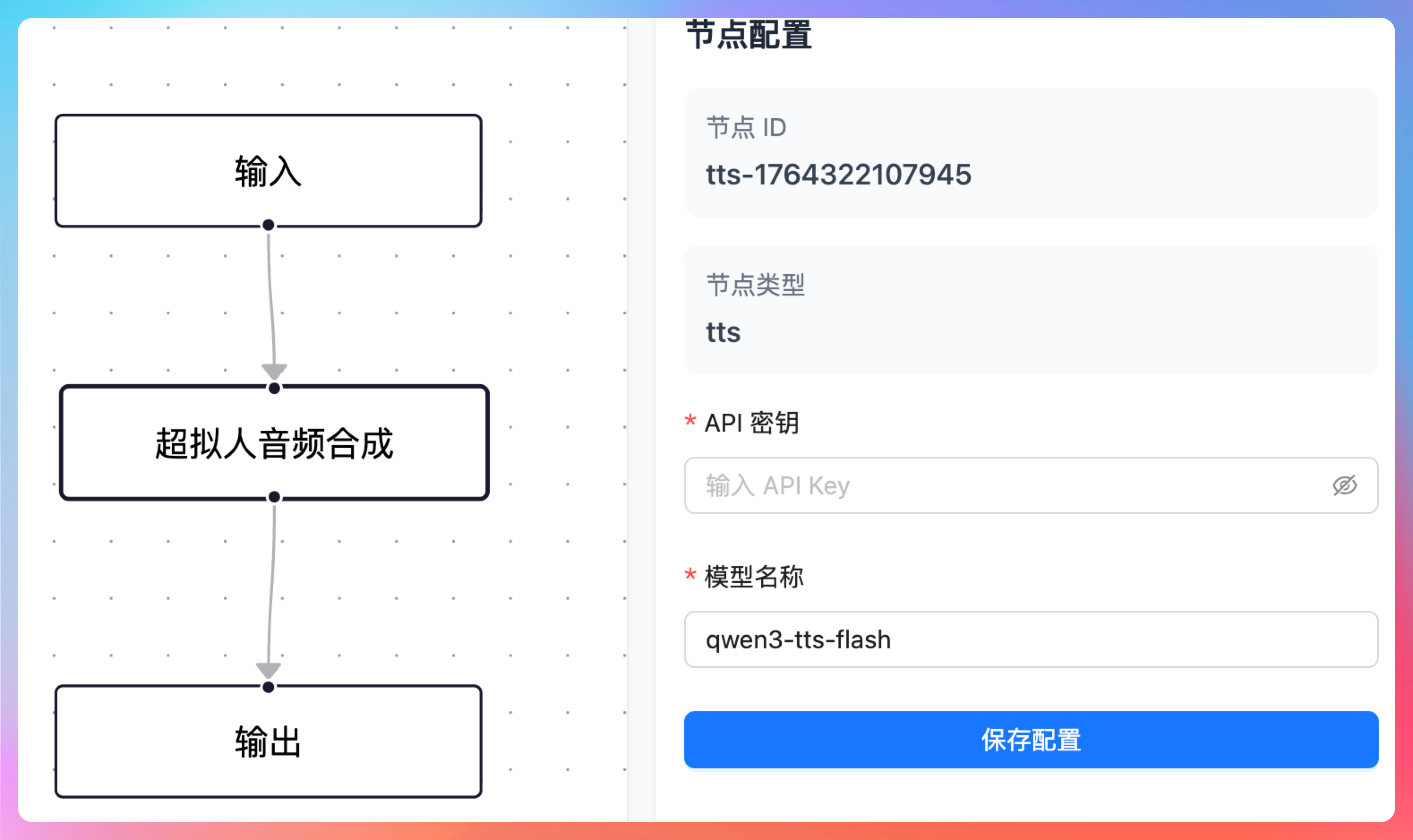
这里的 API key 仍然是上一节我们在阿里百炼平台上申请的,直接填过来就行。
接着,我们需要为超拟人音频合成节点增加三个输入参数:第一个参数为 text,类型可以是输入/引用,输入的时候是文本框,引用的时候可以选择上一个工作流节点的输出,比如说输入节点的用户输入;第二个参数为 voice,用于指定音色,可选参数有 Cherry、Serena、Ethan;第三个参数为language_type,可选参数为 Auto。
确认一下是没问题的,但是我们应该把它放到输入配置项里。
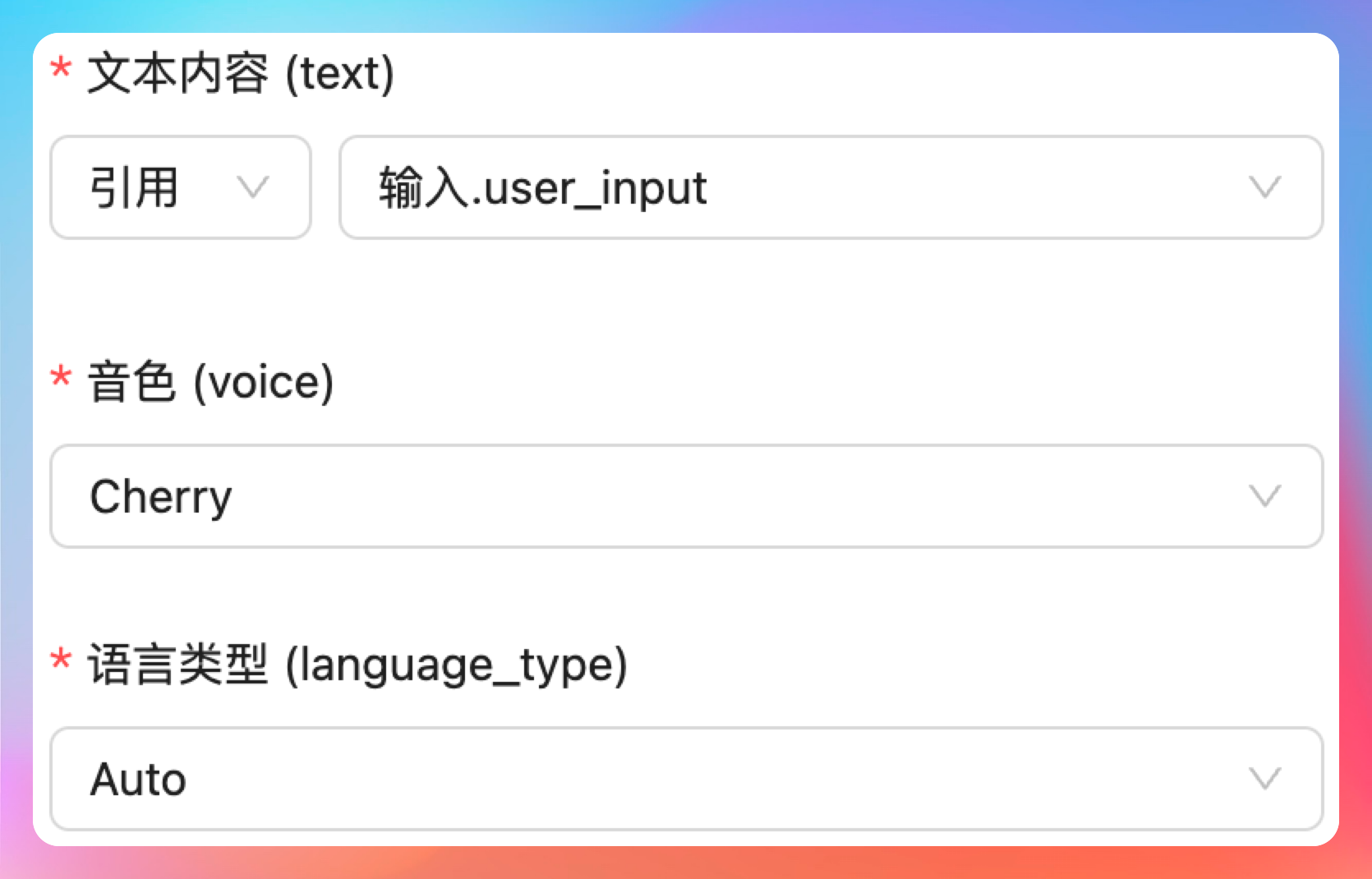
最好是把这三项和基本信息配置区分开,就放到节点配置的输入配置中,我还要增加一个输出配置项,里面包括一个 voice_url
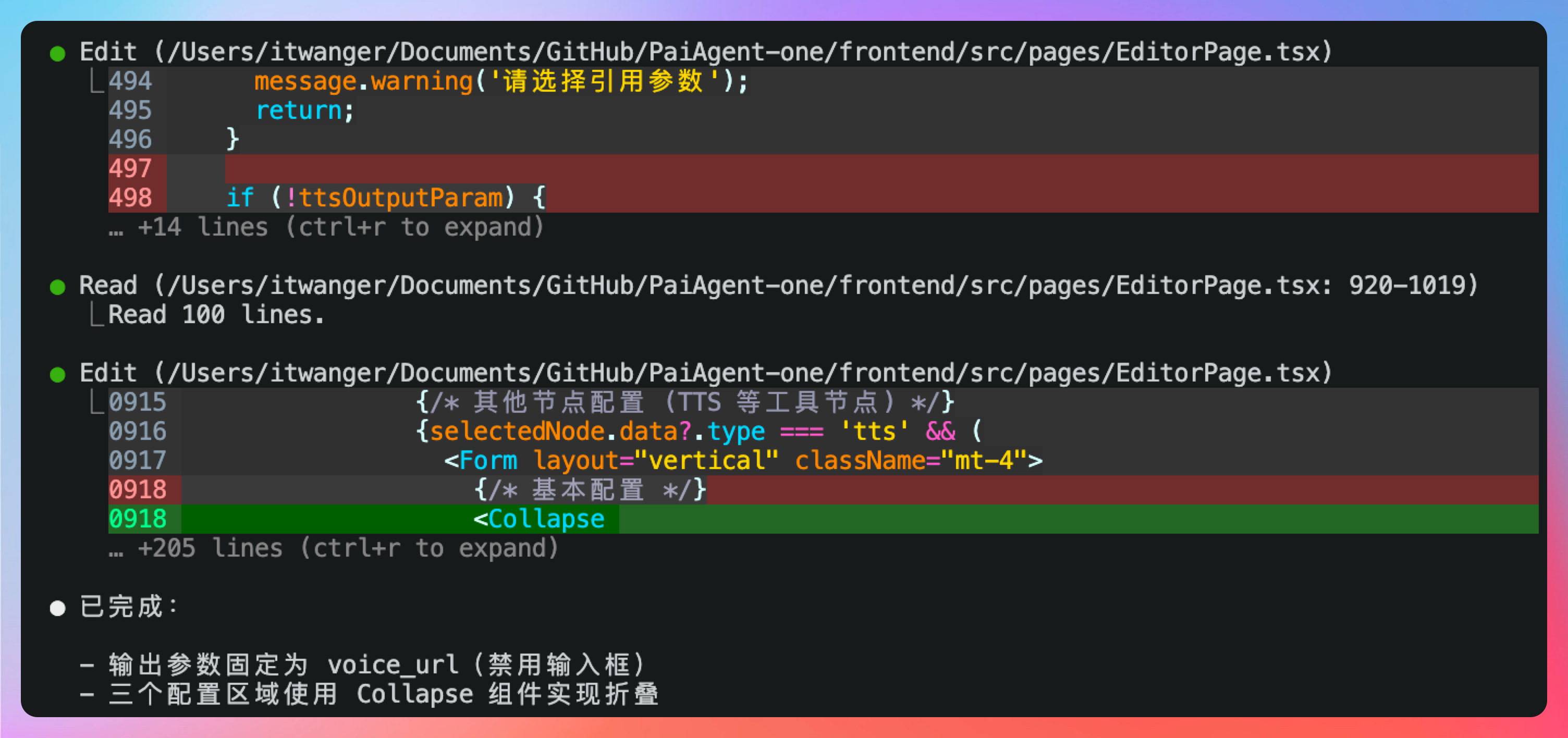
前端的所有配置项目我们都搞定了,并且新的工作流输入 → 超拟人音频合成 → 输出我们也配置完成了。
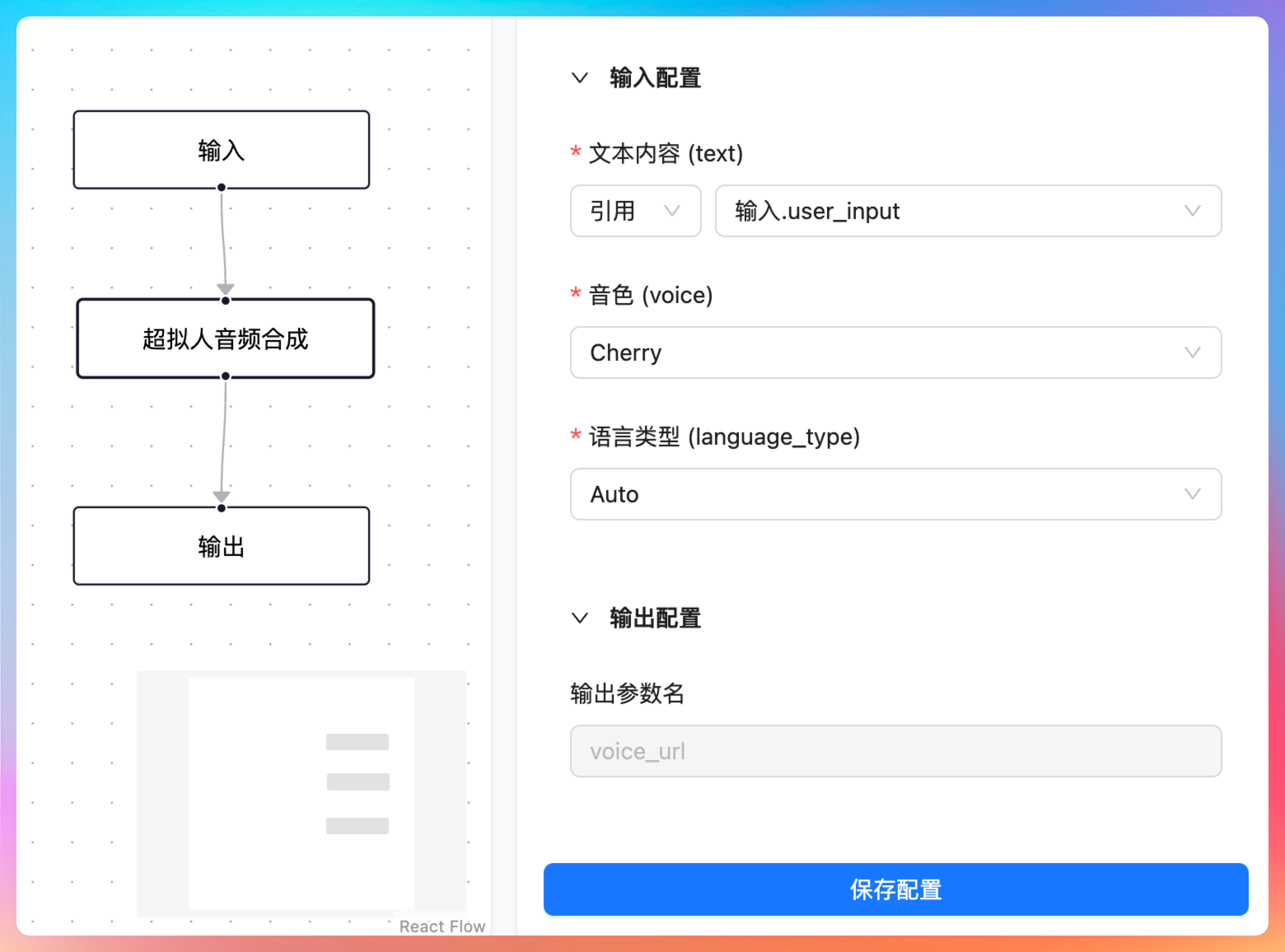
二、在工作流引擎中实现 AudioTTS 节点的执行逻辑
我们来测试一下工作流,按理说我们还没有在工作流引擎当中实现 AudioTTS 节点的执行逻辑呢,但目前测试的结果是 OK 的。
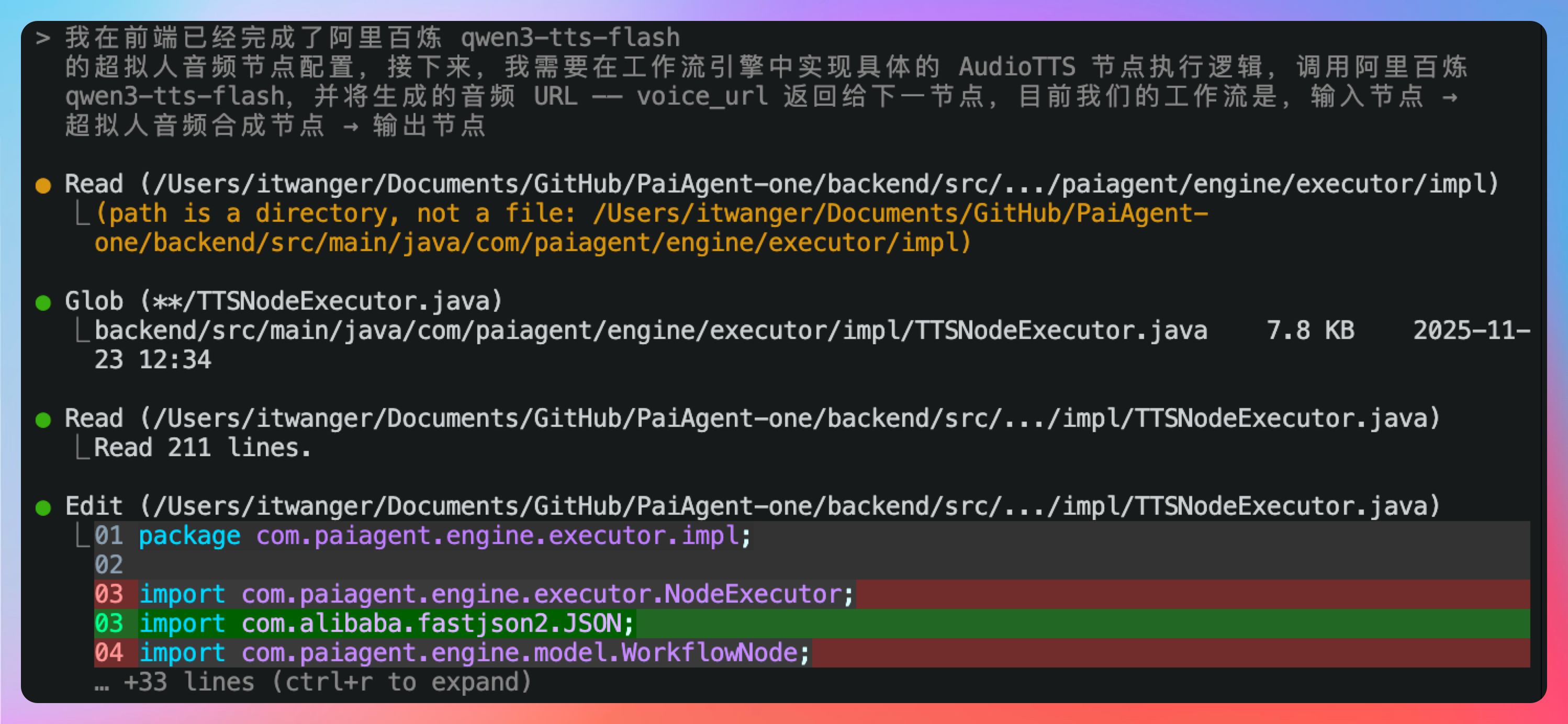
那这个时候,我们就应该抱着怀疑的态度去检查一下源码,发现 TTSNodeExecutor 提供了一个简单的模拟实现。
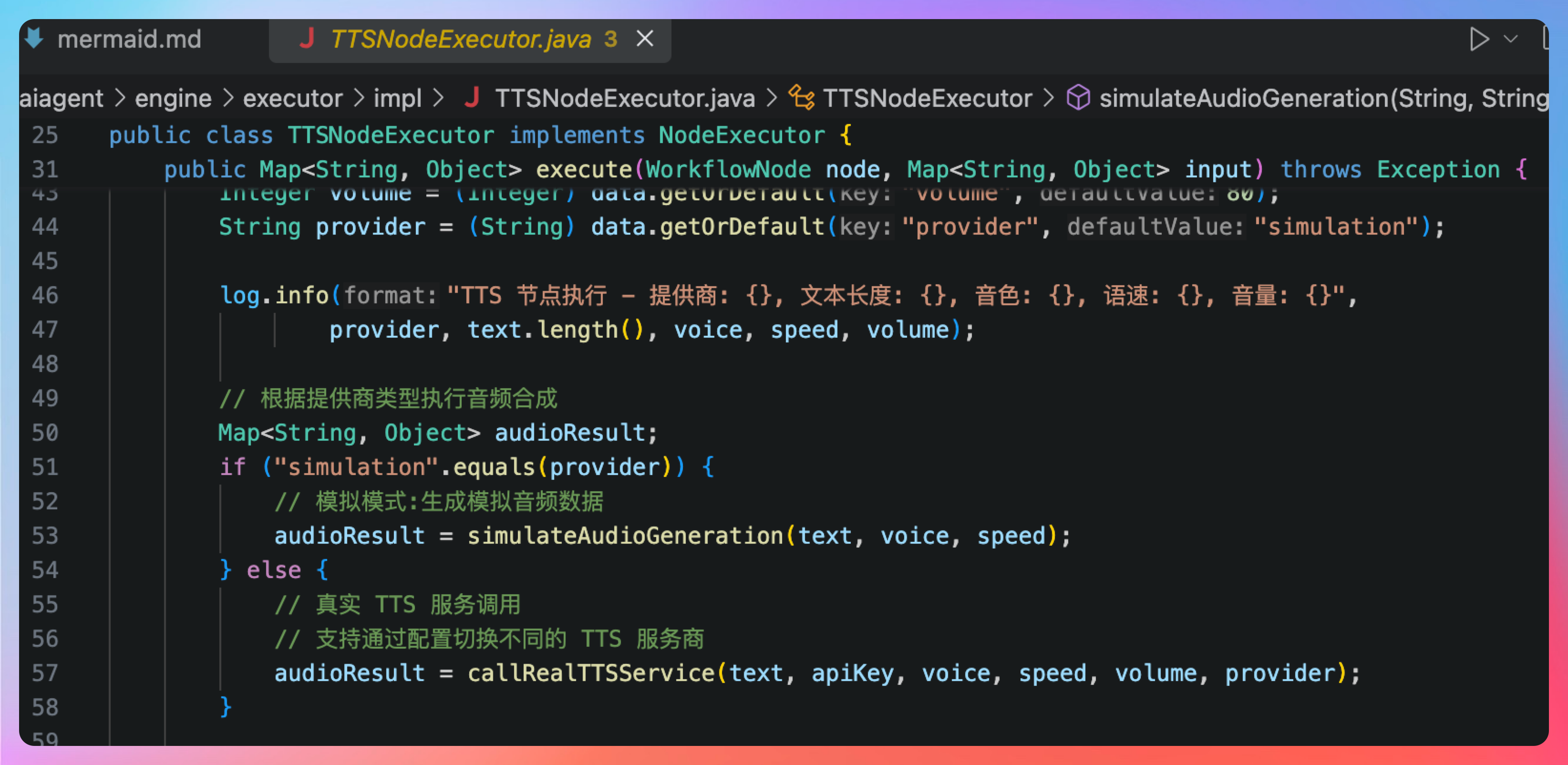
那接下来,我们就要对接真正的阿里音频合成服务。
我在前端已经完成了阿里百炼 qwen3-tts-flash 的超拟人音频节点配置,接下来,我需要在工作流引擎中实现具体的 AudioTTS 节点执行逻辑,调用阿里百炼 qwen3-tts-flash,并将生成的音频 URL —— voice_url 返回给下一节点,目前我们的工作流是,输入节点 → 超拟人音频合成节点 → 输出节点
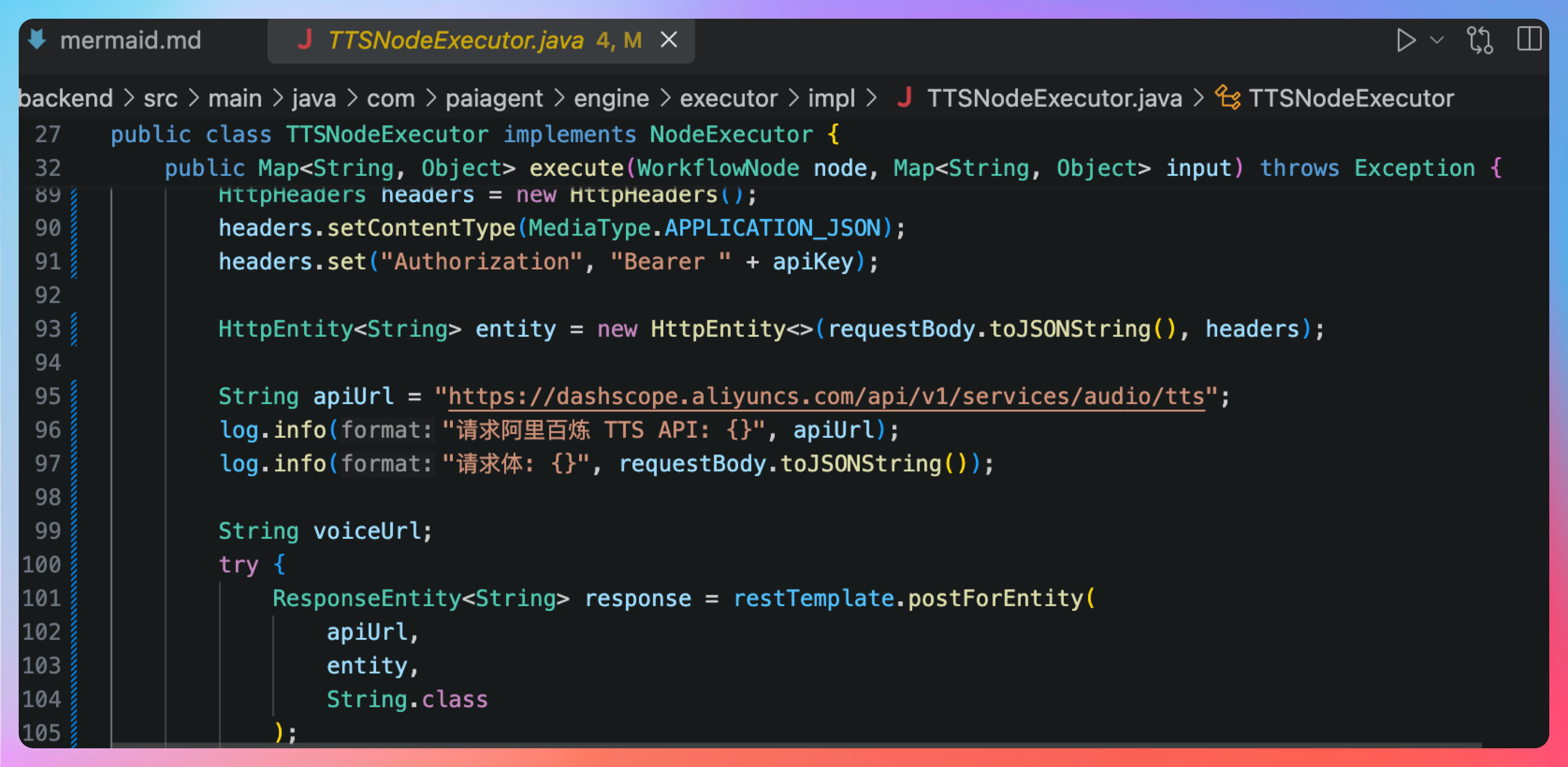
看一眼代码,大体上没什么问题。
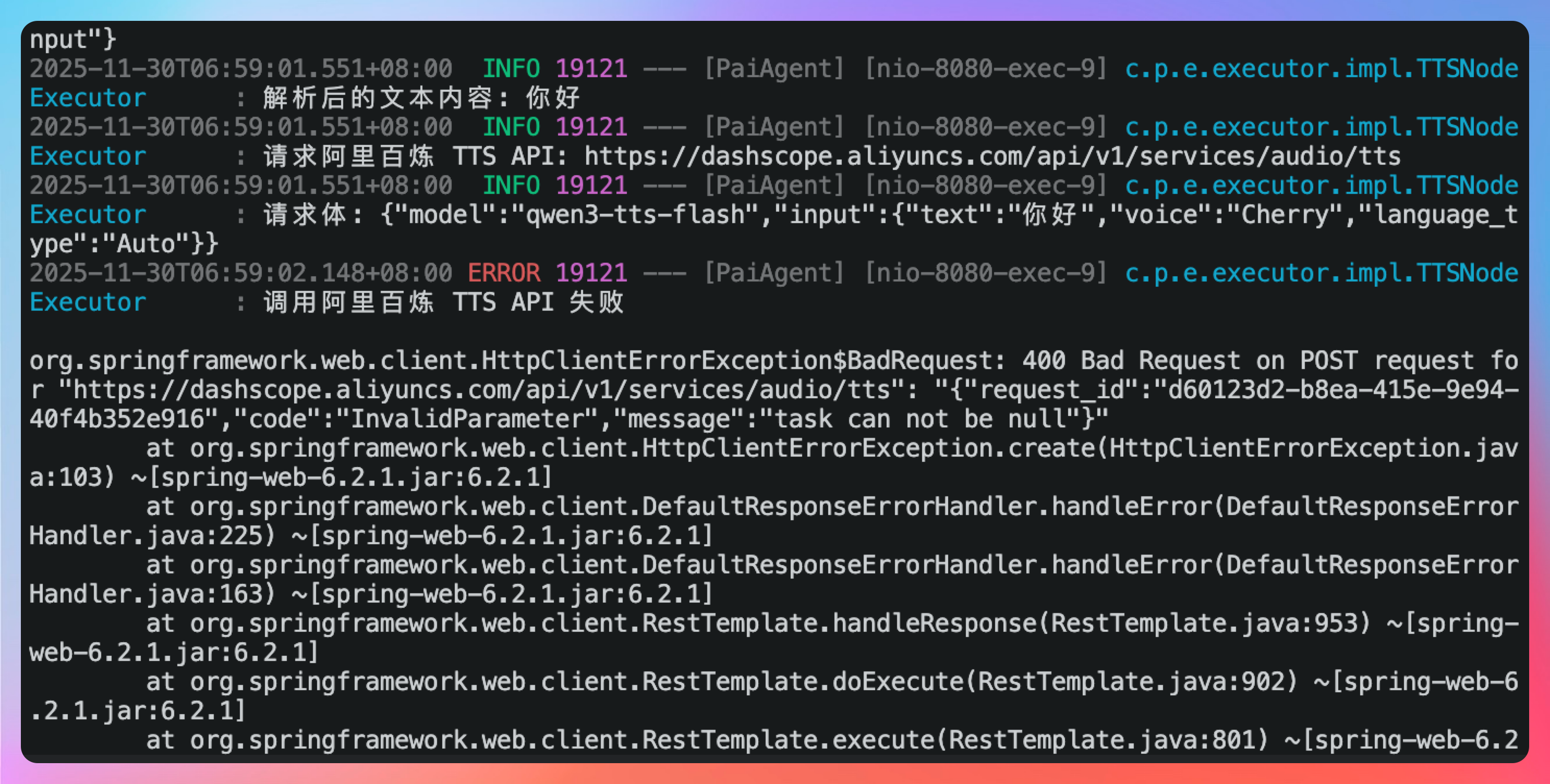
重启后端服务再来测试一下。很遗憾失败了,后端报错了,提示“task can not be null”。
我们直接把错误扔给 Qoder CLI 来看看反馈。
需要联网检查,我们直接放行。这次修改了参数的请求格式。
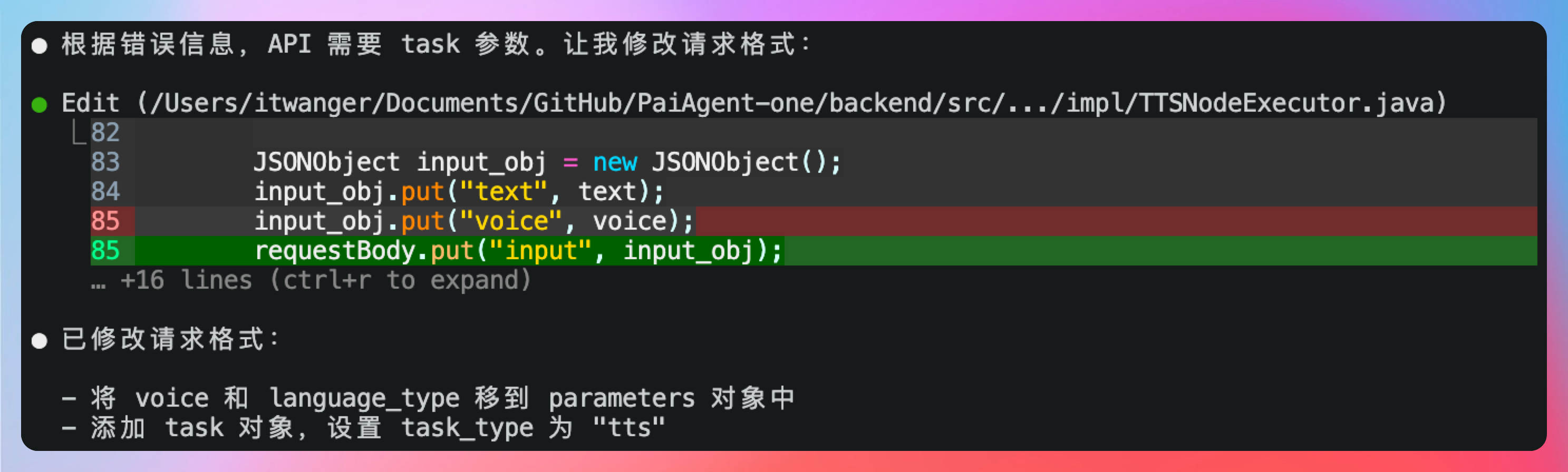
再来测试一下,发现仍然失败,还是原来的问题。
2025-11-30T07:06:00.908+08:00 ERROR 20334 --- [PaiAgent] [nio-8080-exec-7] c.p.e.executor.impl.TTSNodeExecutor : 调用阿里百炼 TTS API 失败
org.springframework.web.client.HttpClientErrorException$BadRequest: 400 Bad Request on POST request for "https://dashscope.aliyuncs.com/api/v1/services/audio/tts": "{"request_id":"a6bf0828-f7bf-4be9-bab0-1c65592ba007","code":"InvalidParameter","message":"task can not be null"}"
at org.springframework.web.client.HttpClientErrorException.create(HttpClientErrorException.java:103) ~[spring-web-6.2.1.jar:6.2.1]
那这时候,我们就需要去官网看看具体的 API 调用方式了。发现官网用的是 DashScope SDK,和 Qoder 原来自研的不太一样。
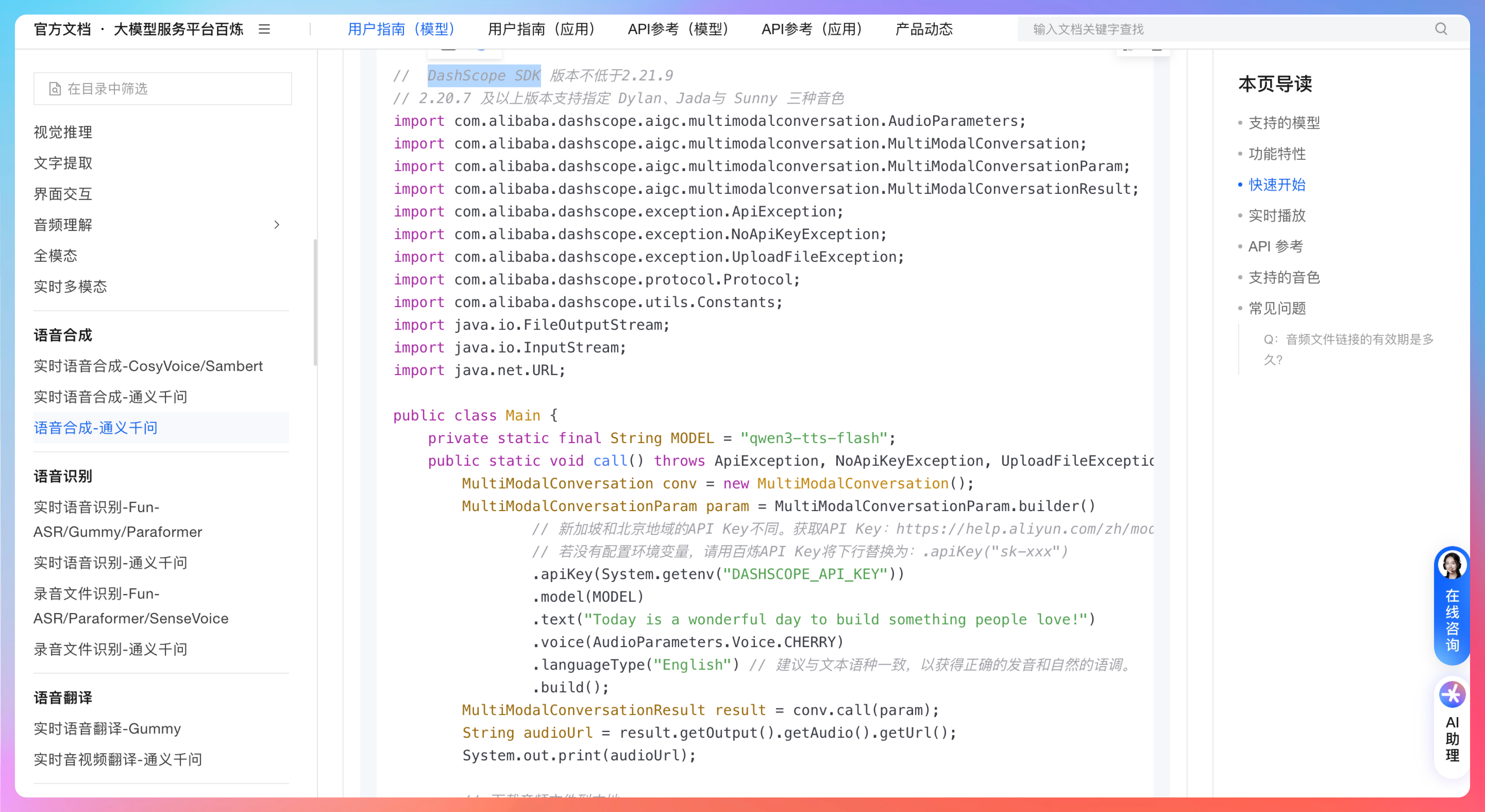
那我们直接切换一下。
嗯,再次执行,发现仍然出现了 task can not be null 的错误,所以我希望切换到 DashScope SDK 的方式实现,并且官方的请求发起是这样的 Constants.baseHttpApiUrl = "https://dashscope.aliyuncs.com/api/v1";
MultiModalConversation conv = new MultiModalConversation();
MultiModal...4人已点赞
回复