


本篇记录的是求职派早期围绕“岗位信息采集展示”的应用架构演进,可用于理解职位数据、任务池和后台业务。
求职派的核心能力是岗位信息采集。
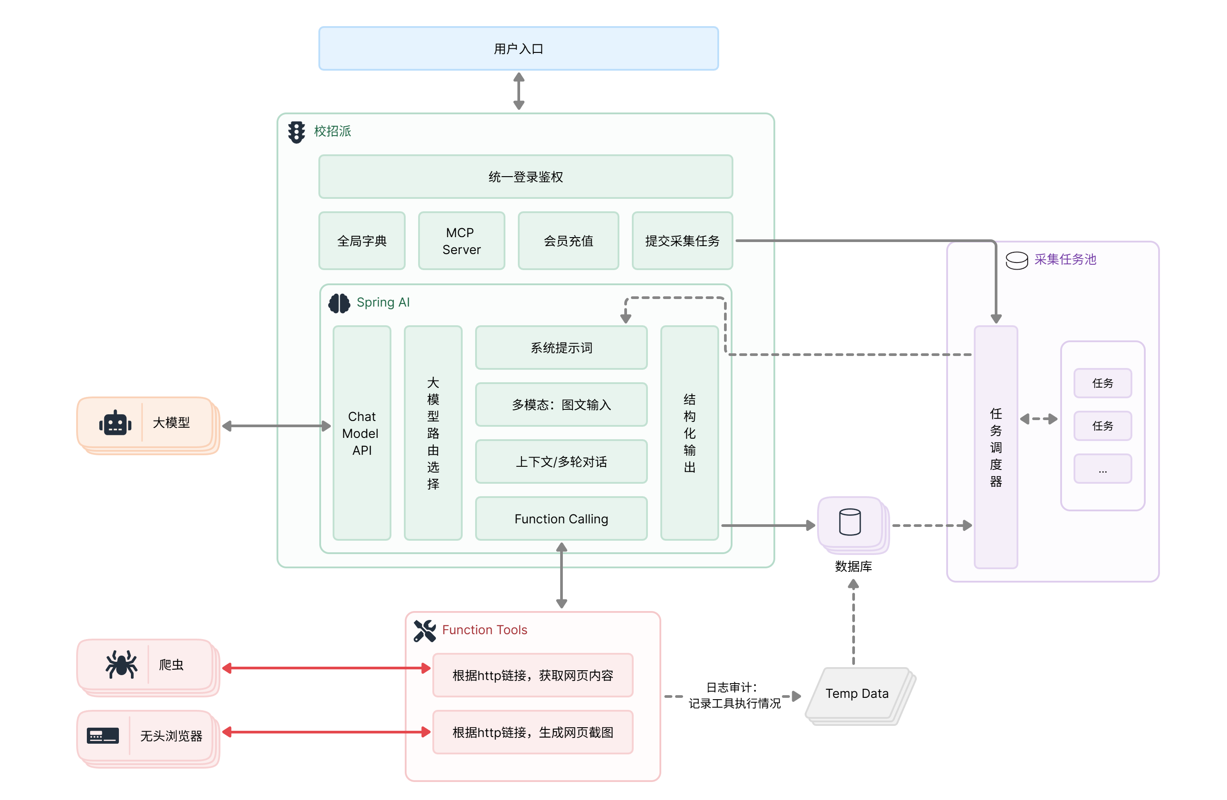
用户提交数据源——可能是一段文本、一个网页链接、一份 Excel 文件,甚至一张截图——系统调大模型把里面的岗位信息提取出来,清洗、校验、入库。
01、集成 AI 能力
求职派本质上是一个 Spring Web 应用,去掉 AI 能力也能跑。
但,如果没有AI,谁学啊,是吧,哈哈
AI 在求职派里的定位是数据采集引擎。
用户提交需要采集的目标数据源,通过系统内部维护的系统提示词,调用大模型提取岗位信息,然后把结构化的结果存入数据库。
对外是“提交任务 → 得到结果”,对内是“构造 Prompt → 调大模型 → 解析返回”。
基于 Spring AI 接入大模型,是整个架构的第一趴。后面所有的能力——多模态、多轮对话、工具调用——都是在这个基础上一层层往上添加的。
02、多模态支持
采集的数据源形式很多。有纯文本、有 HTML 网页、有 CSV 和 Excel 文件,还有图片格式(比如用户截了一张招聘信息的图)。
纯文本调文本模型没问题,图片就需要视觉模型了。


回复