


求职派的表结构围绕三条业务线展开:用户体系、采集流水线、全局配置。
本篇内容第一版的作者:星球嘉宾灰灰。二哥做了二期的优化和迭代。
完整的 Schema 文件在 resources/db/changelog/ 目录下,Liquibase 管理,按时间顺序叠加。
01、用户体系
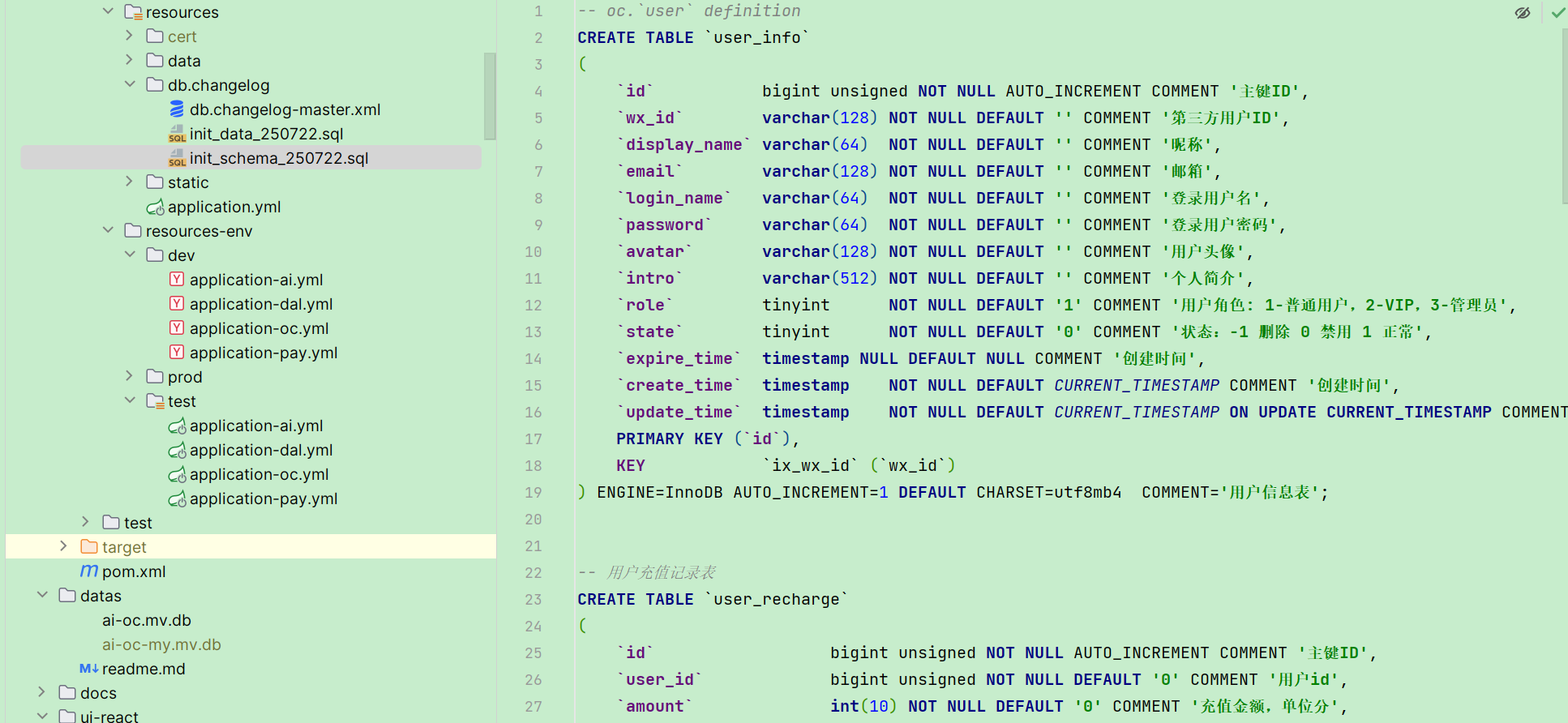
用户信息表
存储用户基本信息。微信 ID 同时用于登录识别和 MCP 接口鉴权。
支持多通道登录——除了微信,还预留了钉钉和飞书的用户 ID 字段,为后续 IM 通道扩展做准备。
角色分三级:1-普通用户、2-VIP、3-管理员。VIP 有过期时间,到期自动降级。

充值记录表
记录每笔充值的完整生命周期。从创建订单到微信回调,每个阶段都有对应字段。
支付状态四阶段:0-未支付、1-支付中、2-成功、3-失败。
预支付 ID 有十分钟有效期,过期未支付的订单会被定时任务自动标记为失败。
二期新增了优惠券字段(coupon_code、promotion_amount),支持减免和折扣两种优惠方式。

优惠券表
二期新增。
scope 字段控制优惠券的使用范围:999 表示全场通用,666 表示指定用户(具体用户列表存在 extra 的 JSON 里),0-3 对应四种会员等级。
优惠券有数量限制(coupon_count)和时间窗口(start_time/end_time),用完或过期自动失效。
02、采集流水线
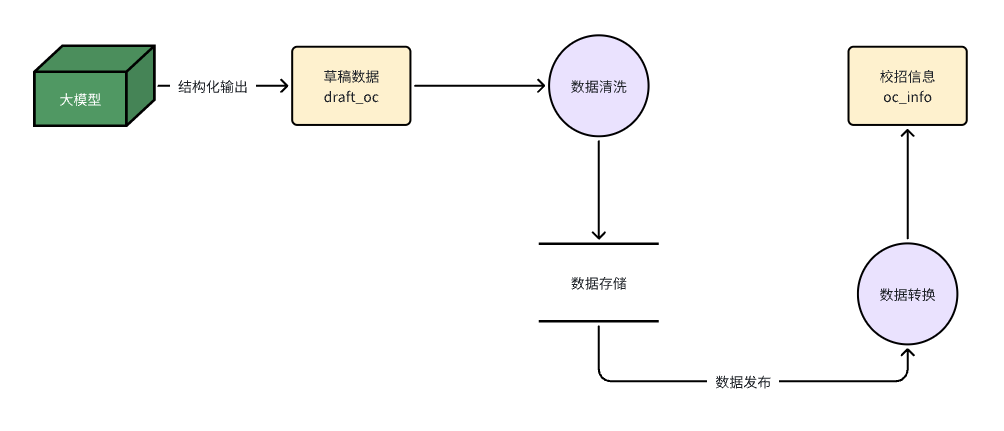
采集流水线涉及四张表,数据从任务表出发,经过草稿表清洗,最终进入正式的职位信息表。
采集任务表
用户提交的采集任务先进这张表排队。type 字段标识数据输入类型:1-HTML、2-纯文本、3-HTTP 链接、4-Excel、5-CSV、6-图片。

state 跟踪处理状态,cnt 记录重试次数,失败的任务可以重置状态后重新跑。result 字段用 JSON 存储处理结果,记录新增和更新的草稿 ID 列表。
二期新增了 source_id 关联采集源,支持同一来源的周期性采集。
采集源表
二期新增。把可复用的采集来源抽象成独立资产,记录每次执行的统计数据——最近成功时间、连续失败次数、新增/更新/无变化的数量。
source_hash 字段做内容指纹,同一来源重复提交时自动识别并跳过。version 字段支持来源版本管理,内容更新后自动触发重新采集。
草稿表
大模型的输出不能完全信任,所以采集结果先进草稿表,人工审核后再发布到正式库。

to_process 字段标记是否待处理,方便后台管理页筛选。state 有三个值:-1-删除、0-草稿、1-已发布。
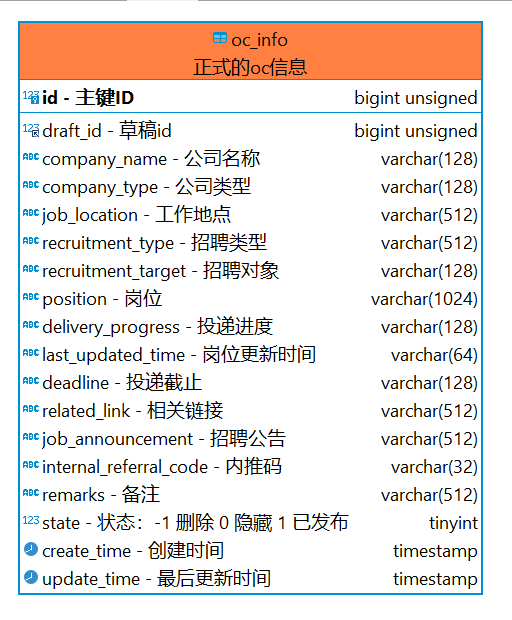
字段覆盖了校招信息的完整维度:公司名称、类型、行业、地点、岗位、薪资、学历要求、投递截止日期、内推码等。
职位信息表
正式库,数据模型和草稿表基本一致,多了一个 draft_id 字段关联源草稿。这张表里的数据都经过了人工审核,可以直接展示给用户。
03、全局配置
全局字典表
简单的 KV 模型,按 app 字段隔离不同业务域(server、site、gather、user、oc、recharge)。scope 区分私有和公有配置,前端只能拿到公有的。
项目启动时会自动把所有枚举定义导入字典表,对应的初始化 SQL 在 resources/db/changelog/init_data_250722.sql。

预置数据涵盖了公司类型、招聘类型、岗位投递状态、支持的大模型列表等全部业务枚举。

环境配置表
二期新增。和字典表的区别是:字典表存业务枚举值,环境配置表存系统级参数(数据库连接、LLM 供应商 API Key、功能开关等)。
config_key 支持嵌套路径格式(如 agent.ai.providers.zhipu.apiKey),config_type 区分 string/int/boolean/json 四种类型,priority 字段控制覆盖优先级。
目前主要用于管理多个 LLM 供应商的配置:智谱、硅基流动、DeepSeek、Step 等。
04、表间关联
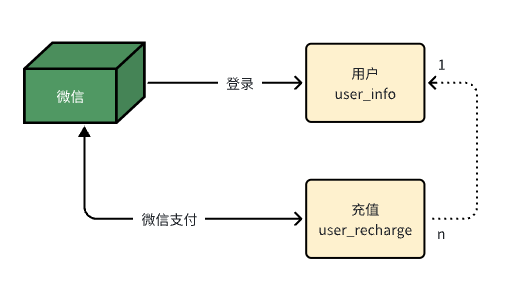
表之间没有用物理外键,全部是业务层面的逻辑关联。主要有两条关联线。
第一条是用户线:用户表和充值记录表通过 user_id 关联。
第二条是采集线:采集源 → 采集任务 → 草稿 → 正式职位信息,四张表串成一条数据流水线。每张表都保留了 source_id 和 source_task_id,可以追溯任意一条职位信息的完整采集来源。
整体设计遵循一个原则:状态字段全局统一(-1 删除、0 禁用/草稿、1 正常/已发布),时间戳成对出现(create_time + update_time),减少跨表理解成本。

回复