


大家好,我是二哥呀。
很多同学在进入互联网行业时,都会倾向于选择北上深杭等一线城市,因为这里的机会更多,资源交易更频繁,也就更公平。
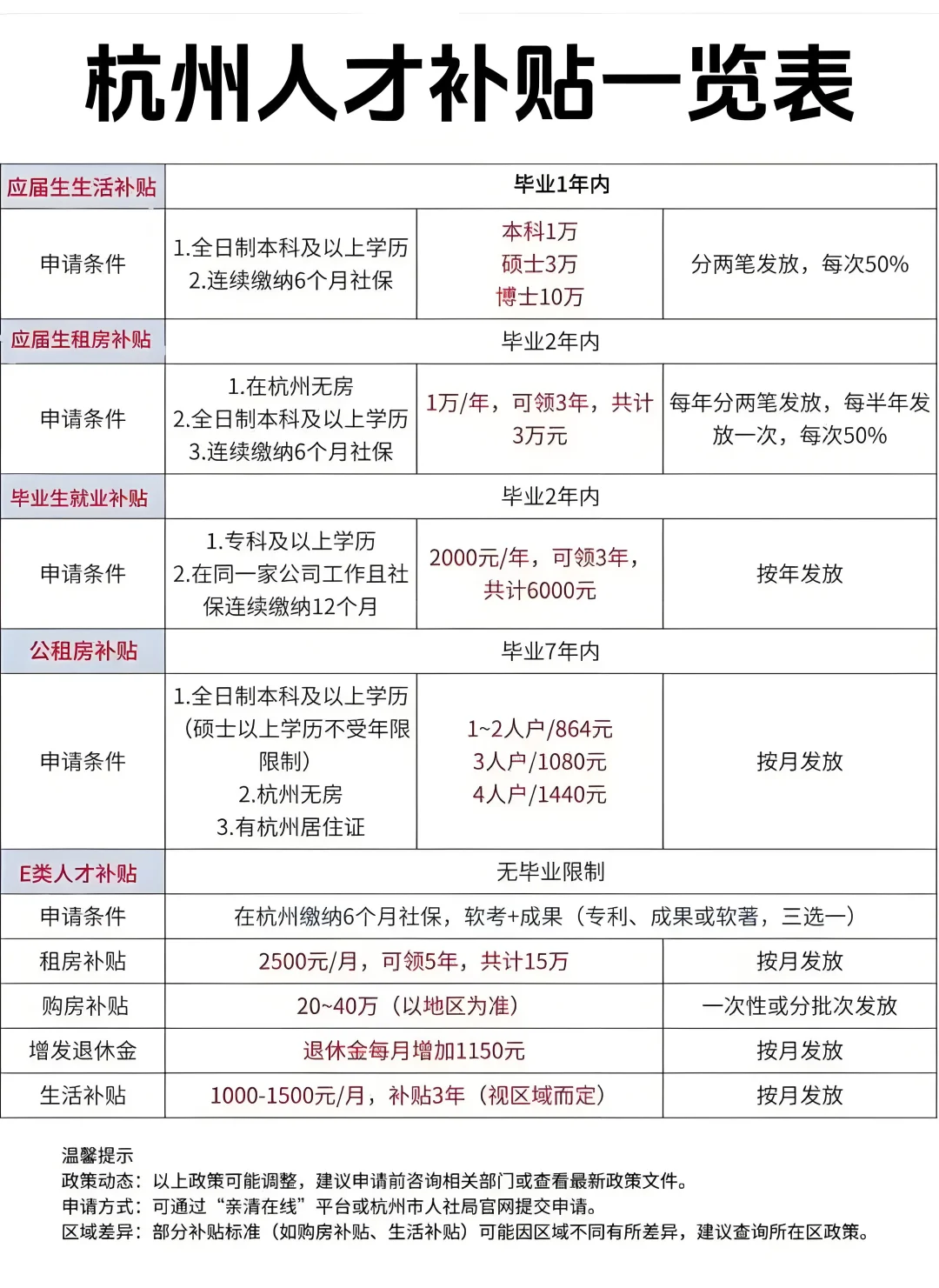
选择杭州,不仅是因为阿里系的公司都在这里,还有一个很重要的因素就是,应届生可以享受杭州的政策红利。
就像球友在选择 offer 的时候讲到的:杭州租房没那么贵,还有房补;可能也没那么敬业;还有人才补贴。

就比如说在杭州无房,全日制本科及以上学历,连续缴纳社保 6 个月的同学,每年可以领取 1 万的租房补贴,连续可领三年。
下面的表格讲得比较清楚,大家可以仔细看一下。如果打算选择杭州作为 base 地,就可以把这个表格收藏起来,落地后一一去兑现下。
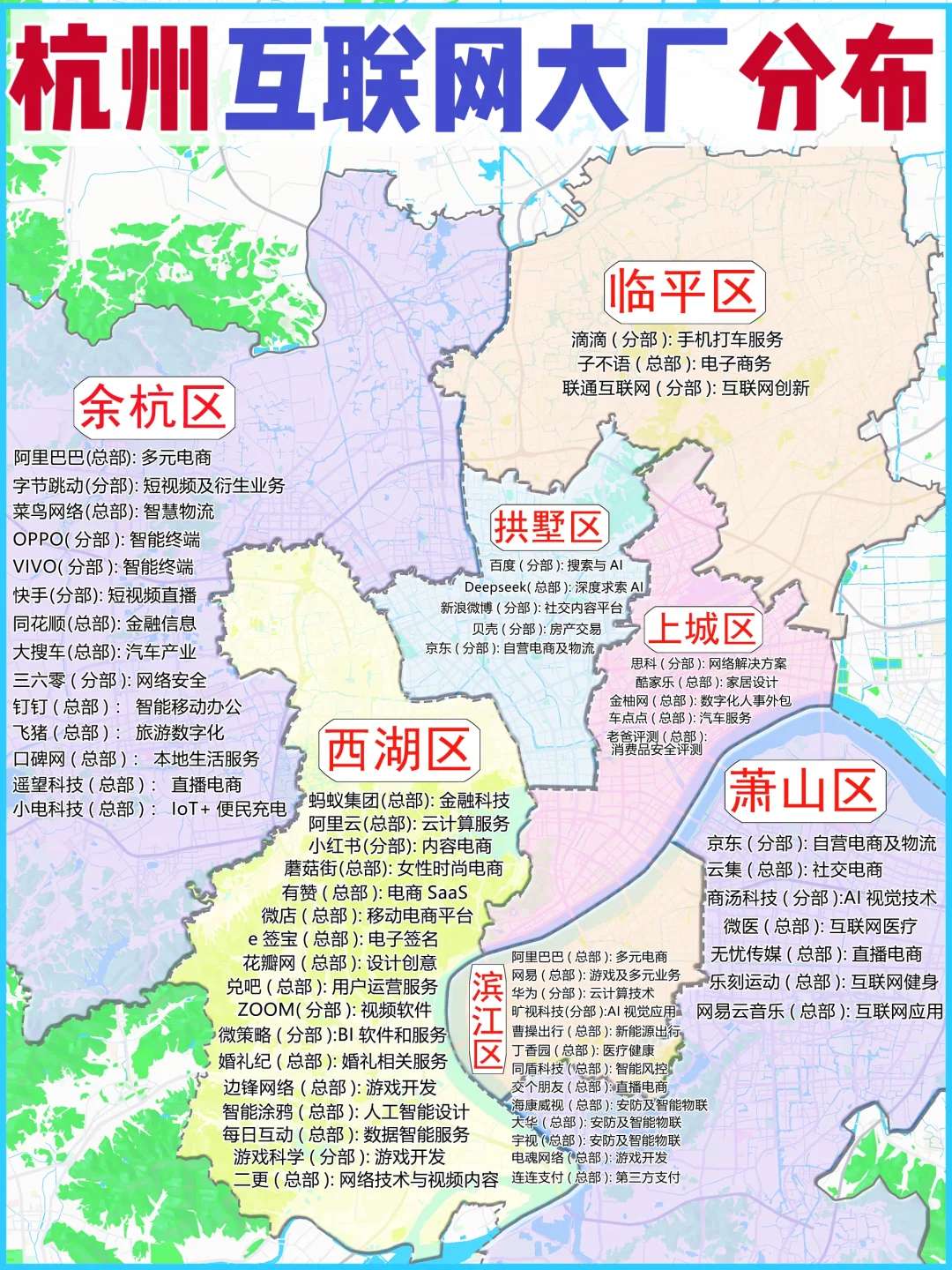
那可能有同学会问,杭州除了阿里系,还有哪些互联网公司可以选呢?
参考下图。
接下来给大家分享一个球友在面试阿里健康时的面经,他用的是派聪明 RAG 项目,完整题目我放到了下面这个帖子里。
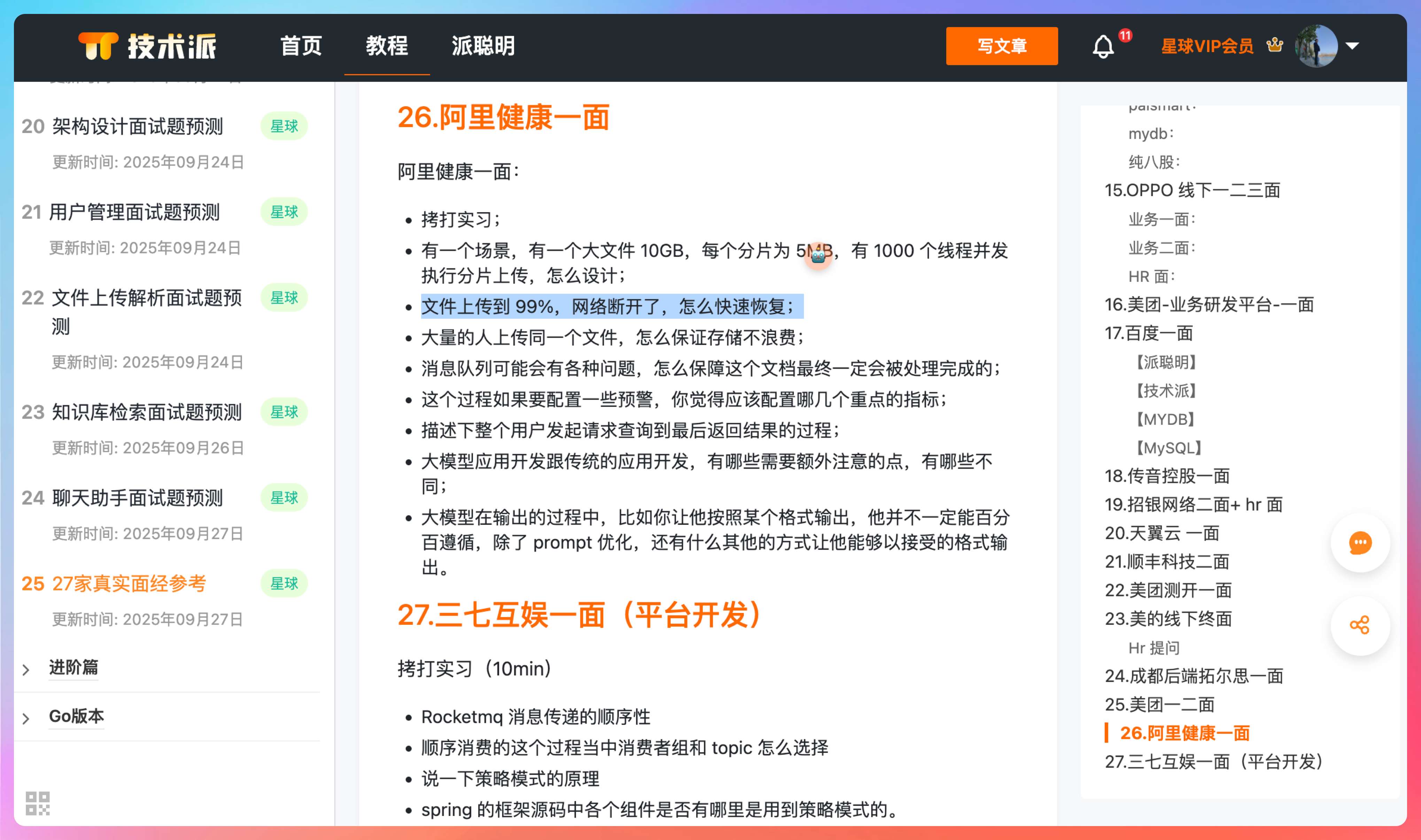
01、有一个场景,有一个大文件 10GB,每个分片为 5MB,有 1000 个线程并发执行分片上传,怎么设计
答:
整体的思路可以分为三步。
1、前端负责“分片” :将 10GB 大文件切分为 2000 个 5MB 的独立分片。
2、在后端引入 Redis,利用其 bitmap 记录所有分片的上传状态。
3、当 Redis 确认所有分片都已到达后,由 Kafka 触发一个后台合并任务,将分片合并成完整文件,全程不阻塞上传请求。
在派聪明项目中,我们是这样实现分片上传的。
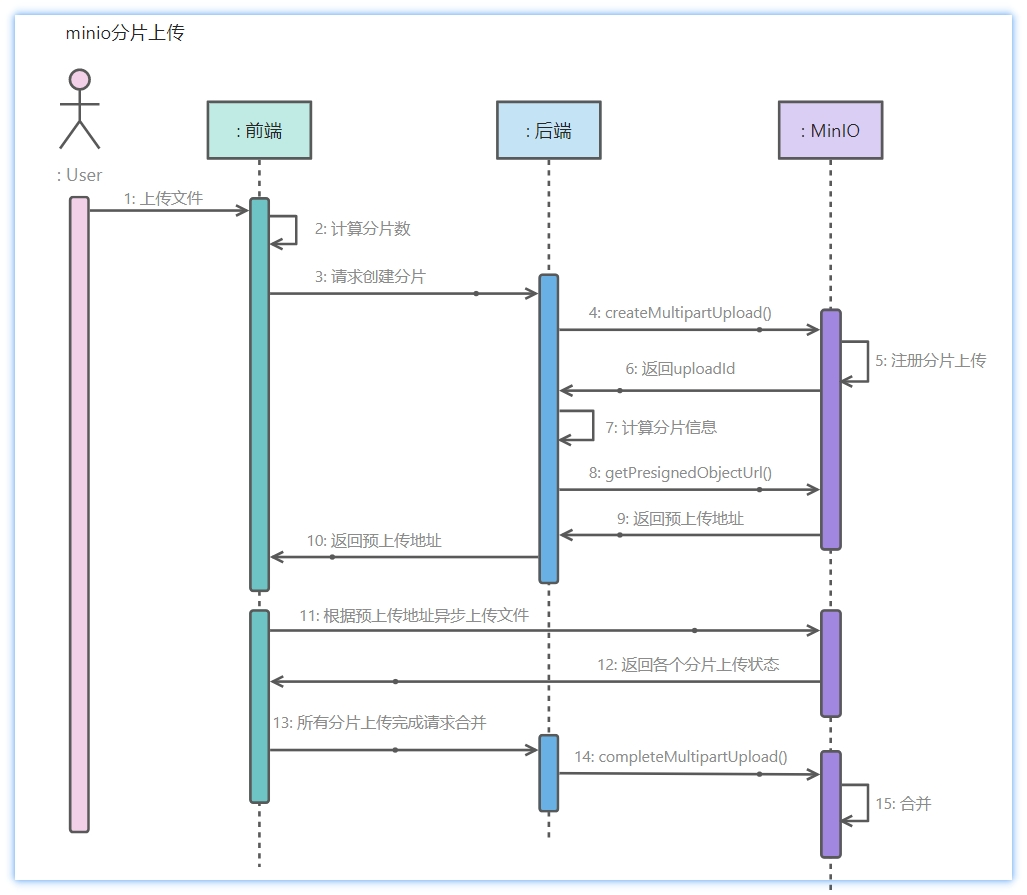
第一步,在上传开始前,前端需要根据文件名、大小、最后修改时间等信息,通过哈希算法(如 SHA-256)为这个 10GB 的文件生成一个唯一的 fileId 。这个 fileId 将贯穿整个上传流程。
前端将文件切成 2000 个分片,并为每个分片从 1 到 2000 编号。然后向后端发送分片上传请求。
{
"fileId": "unique-hash-of-the-10gb-file",
"chunkNumber": 123, // 当前是第 123 个分片
"totalChunks": 2000, // 总分片数
"chunkData": "[5MB 的二进制数据]"
}
第二步,当后端接收到分片上传请求后,直接将这个分片存入 MinIO 的临时文件目录。
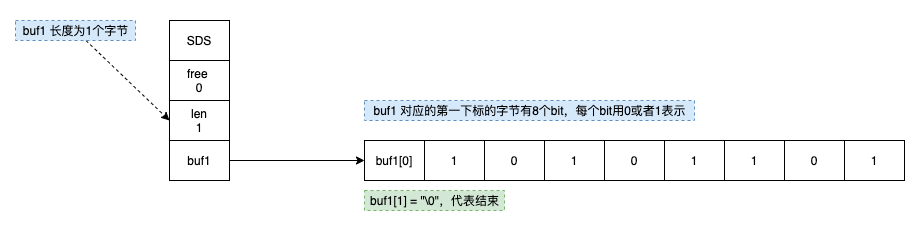
为了提高性能,我们使用 Redis 的 bitmap 来存储分片状态。
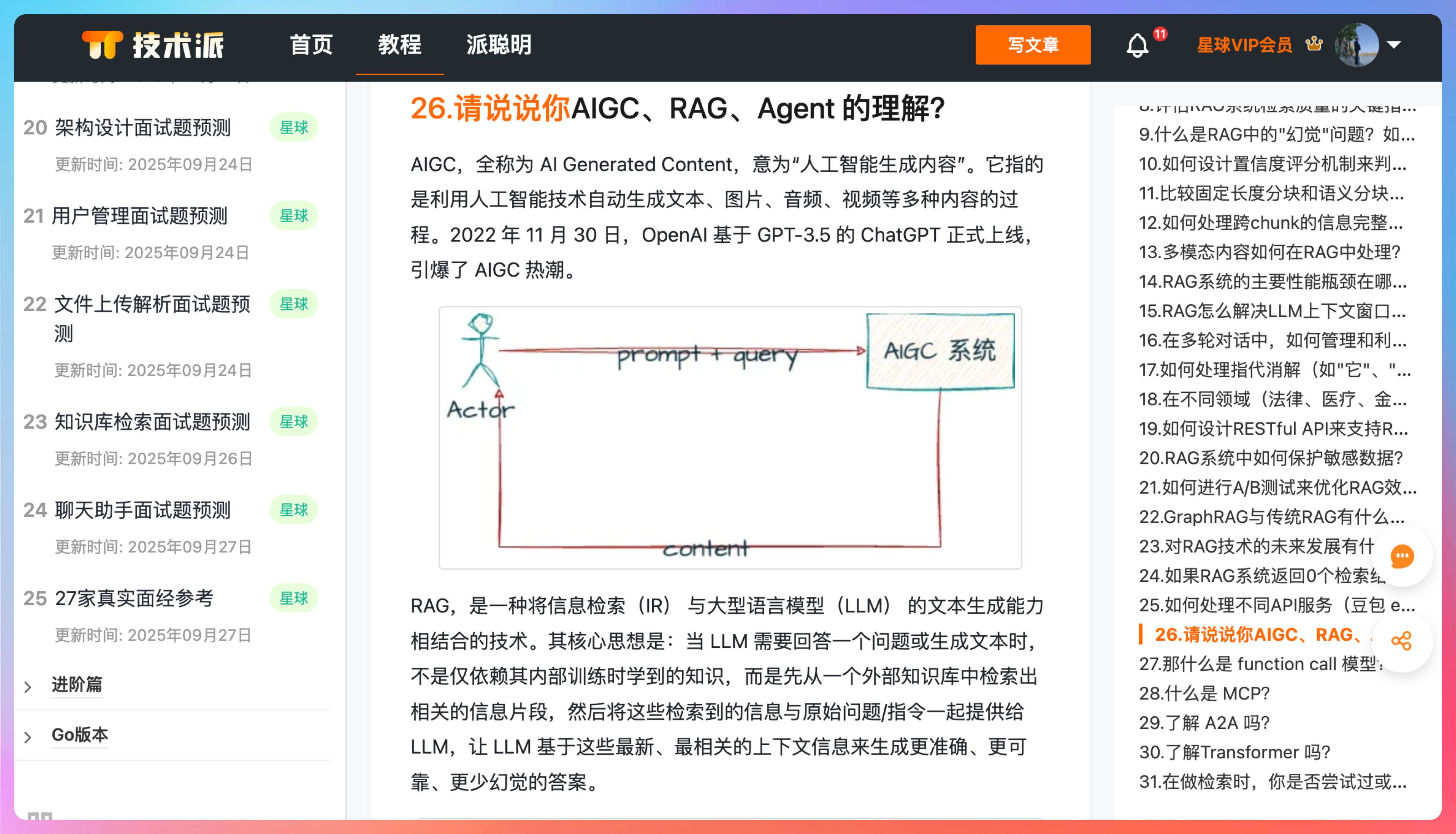
当第一个分片到达时,后端发现 Redis 中没有对应的记录,就会创建一个 bitmap ,键为 upload:status:{fileId} ,长度为 totalChunks (2000)。
每当一个分片成功保存后,就执行 SETBIT 命令保存状态。犹豫这个操作是原子性的,并且时间复杂度为 O(1),即使 1000 个线程同时操作,也能完美处理。
String redisKey = "upload:" + userId + ":" + fileMd5;
redisTemplate.opsForValue().setBit(redisKey, chunkIndex, true);
logger.debug("分片已标记为已上传 => fileMd5: {}, chunkIndex: {}, userId: {}", fileMd5, chunkIndex, userId);
第三步,如果 BITCOUNT 的结果不等于 totalChunks,说明还未上传完毕,直接给前端返回 200 OK ,表示“这个分片我收到了”。
否则就说明这是最后一个到达的分片。这个时候就向 Kafka 发送一条消息。
{
"fileId": "unique-hash-of-the-10gb-file",
"fileName": "original_filename.ext",
"totalChunks": 2000,
"storagePath": "/path/to/final/storage"
}
第四步,Kafka 的消费者订阅文件合并主题,根据文件 id 和分片数,按顺序(从 1 到 2000)读取 MinIO 临时目录下的所有分片文件,然后合并成一个完整的 10GB 文件。
02、文件上传到 99%,网络断开了,怎么快速恢复?
答:
在恢复上传前,前端需要和服务器进行一次“握手”,问清楚“已经收到了哪些分片?”,然后只传服务器没有的分片。
具体的步骤是。
第一步:网络恢复后,前端不会立即开始上传。会先找到正在上传文件的 id,然后向后端发起一个新的 GET 请求 ,比如 GET /upload/status/{fileId} 问清楚服务端哪些分片已经上传过了。
第二步,服务端收到请求后,直接去 Redis 查询分片的状态,找出所有值为 0 的位。这些就是“丢失的”或“未上传的”分片。
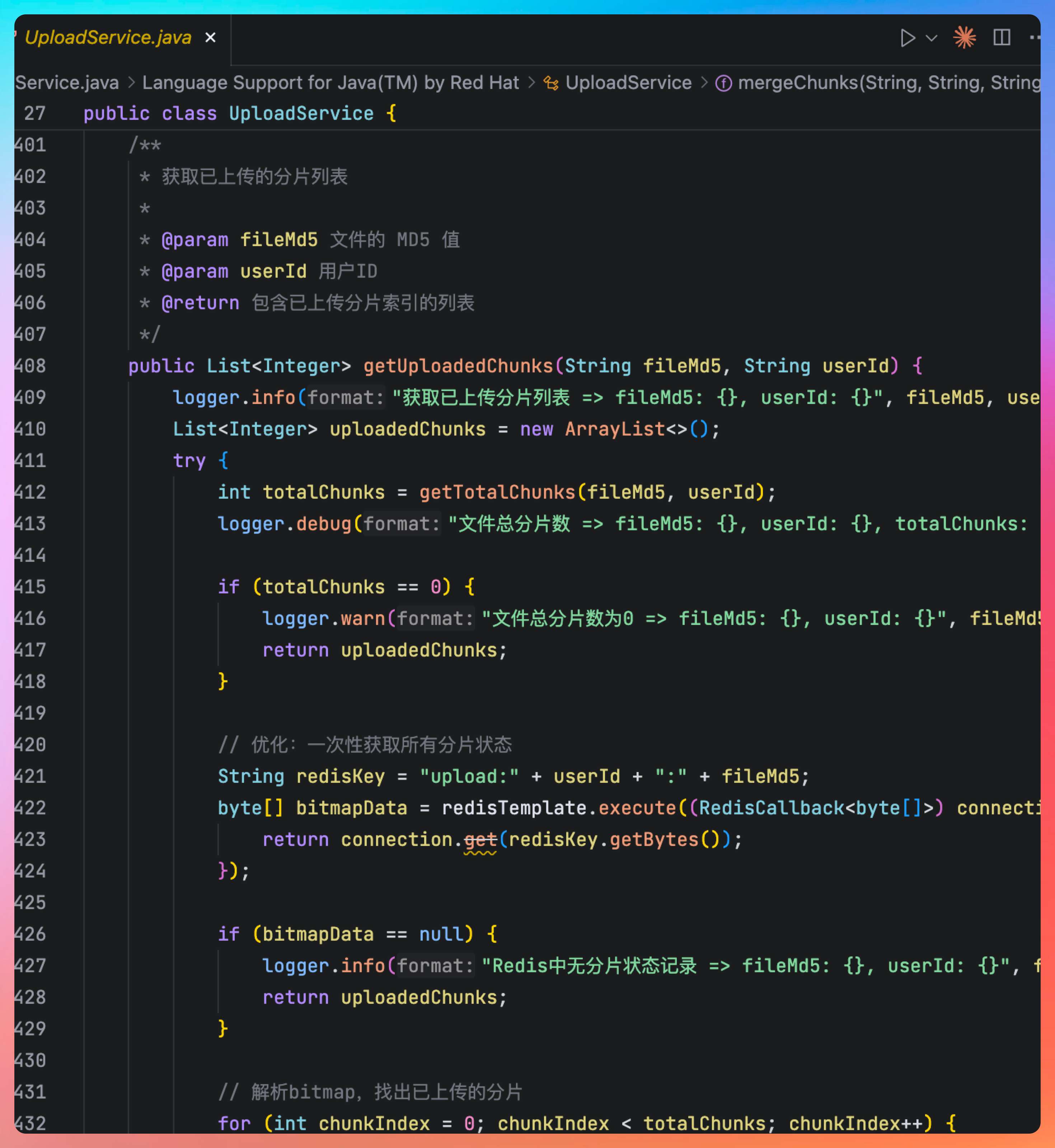
然后将分片的索引返回给前端。
{
"fileId": "unique-hash-of-the-10gb-file",
"status": "incomplete",
"missingChunks": [50, 123, 456, 1998, 1999] // 告诉客户端,这些分片我没有
}
第三步,前端收到分片列表后,重新上传这些分片。
在派聪明中,针对单个分片的上传失败,比如说因为网络抖动或者服务端临时出错导致的上传失败,前端是有内置重试机制的。也就是说,如果某个分片上传失败了,前端不会直接放弃,而是会自动重试几次,当然了,我们设置了最多三次,每次间隔逐渐拉长。
而且我们的后端接口做了幂等设计,哪怕同一个分片被重复上传多次,后端也能识别出来,不会存重复数据或者状态混乱。
更多的面试题目在这个帖子里:https://paicoding.com/column/10/19,包括各种 AI 八股,只不过我们会和项目真实结合起来。
希望能在秋招下半场,大家都能狠狠捡漏,我在这里等着大家的喜报。
冲!
ending
一个人可以走得很快,但一群人才能走得更远。二哥的编程星球已经有 10300 多名球友加入了(马上涨价),如果你也需要一个优质的学习环境,戳链接 🔗 加入我们吧。这是一个 简历精修 + 编程项目实战(RAG 派聪明 Java 版/Go 版本、技术派、微服务 PmHub)+ Java 面试指南的私密圈子,你可以阅读星球专栏、向二哥提问、帮你制定学习计划、和球友一起打卡成长。
最后,把二哥的座右铭送给大家:没有什么使我停留——除了目的,纵然岸旁有玫瑰、有绿荫、有宁静的港湾,我是不系之舟。共勉 💪。

回复