


老王就看了一眼我的简历,就开始上压力了:“你不知道现在是 AI 时代吗?简历上连个 Agent 项目都没有,你是怎么敢投 AI 岗的?”
“王哥,你能不能瞪大眼睛仔细瞧瞧。”我直接反击。
老王是真没想到,我敢回怼,立马怂了。
“压力你一下嘛,看你急的。”老王态度 180 度大转弯啊,“简历写得真不错,这恐怕是这一个月来,我见过写得最漂亮的简历了。”
PS:面试的时候一定要自信,已经上战场了,就没有退路可言。面试考察的除了实力,就是你对这份工作的热情,对自己的认可。
宁可盲目的自信,也不要畏畏缩缩的自卑~尤其是面对压力的时候,一定要不卑不亢。😄
content
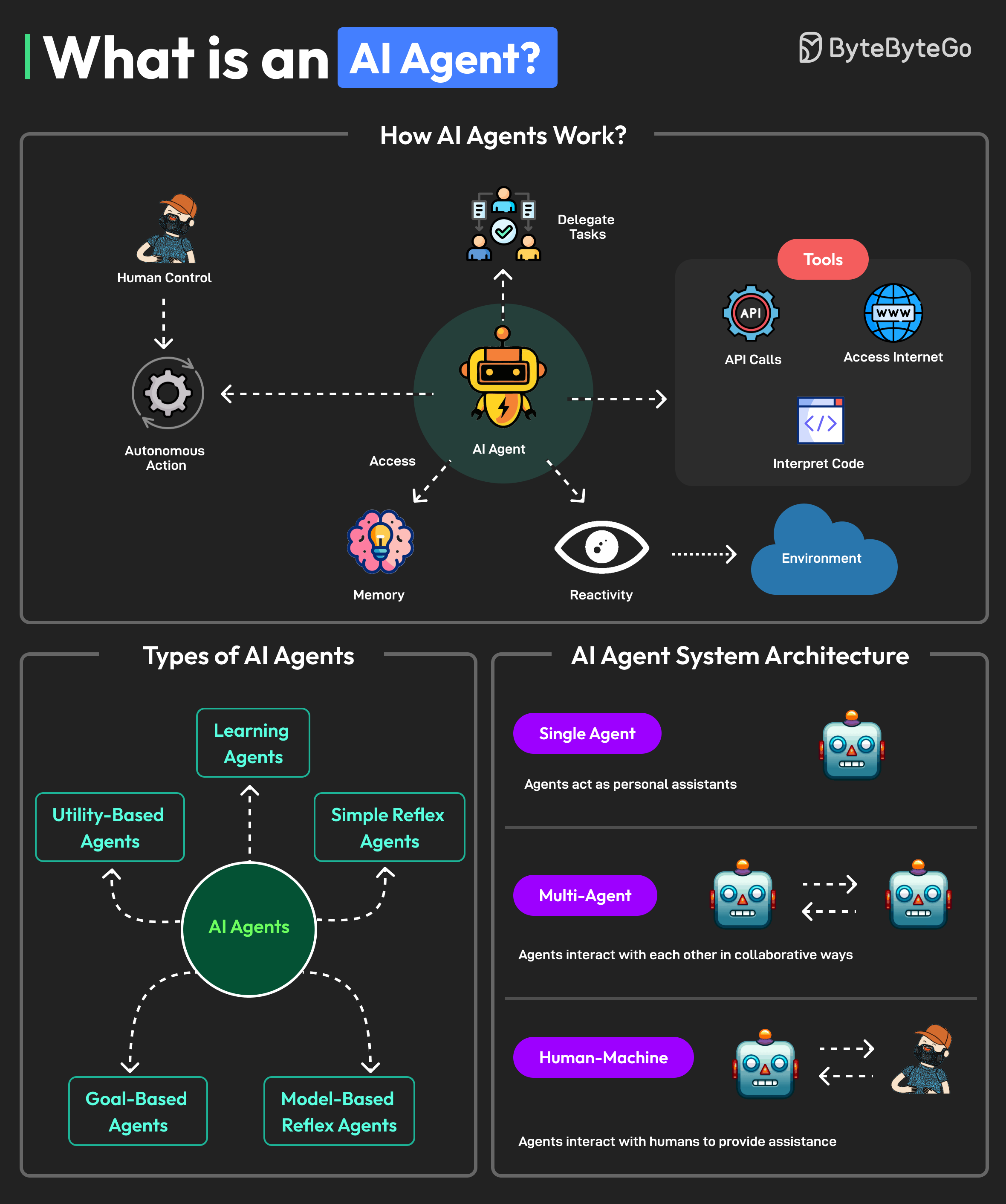
01、PaiAgent 项目的背景介绍下?
老王开始了他的第一问:“介绍一下 PaiAgent 的背景吧?”
我说:“PaiAgent 是我 Vibe Coding 出来的一个 dify 工作流编排 Agent。我想通过实际的项目,把 AI 发展过程中的核心技术栈应用实操起来,真正能达到一个 AI 应用开发工程师的水平。”

“后端技术栈用到了 Spring AI,用到了 LangGraph4J,这些都是 Java 领域最热门的 AI 应用开发框架。”
同时,我又串联了 Skill、ReAct、MCP、Function Calling 这些热门概念,让自己在做的过程中去理解技术的底层原理。
双引擎是 PaiAgent 的一个亮点。简单场景用我自己写的 DAG 引擎——里面用 Kahn 算法做拓扑排序,DFS 做循环检测,跑简单的线性工作流足够。
复杂场景,比如说带条件分支、循环、状态回溯的,可以切到 LangGraph4j 引擎。
LLM 这块我统一走的 Spring AI 框架。对接了多家顶级国内模型:DeepSeek、通义千问、智谱 GLM。
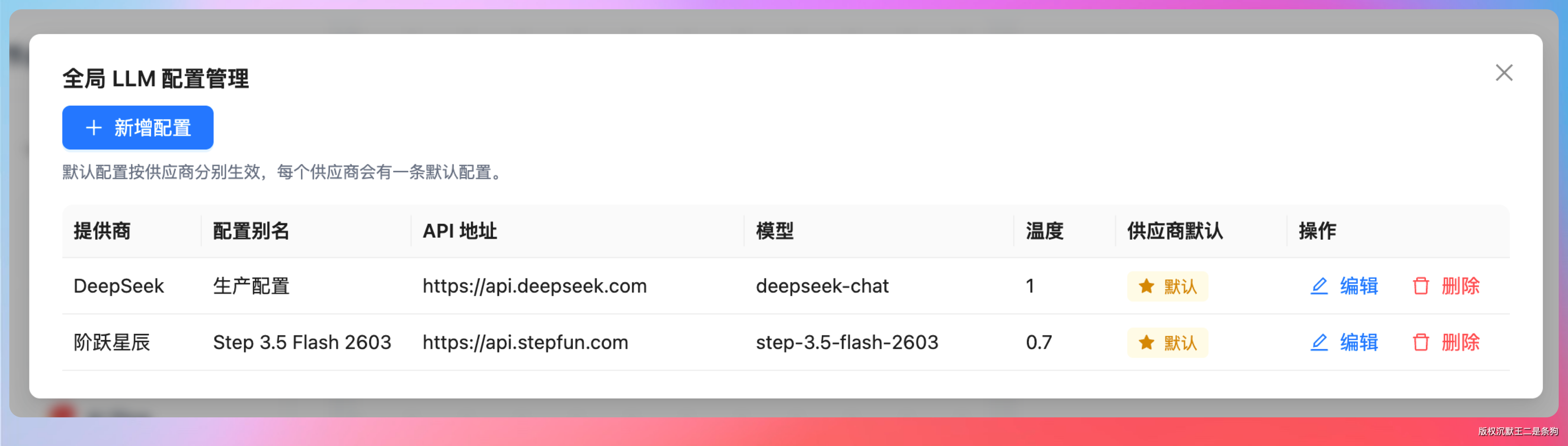
切换模型不需要改代码,切换一下全局的 LLM 配置就行。
像火爆全网的 Skill,我也做了应用。
在我看来,每个 Skill 就是一个目录,核心文件是 SKILL.md,可以用 YAML Frontmatter 定义名称和描述,Markdown 写执行规则。
然后在项目启动时扫描 classpath,把 Skill 对象缓存 Redis 中。加载机制也完全符合三级渐进式——第一级只加载名字和描述,第二级加载完整内容,第三级按需加载 reference 目录。
这样 LLM 在决策的时候,也可以省去非必要的上下文。
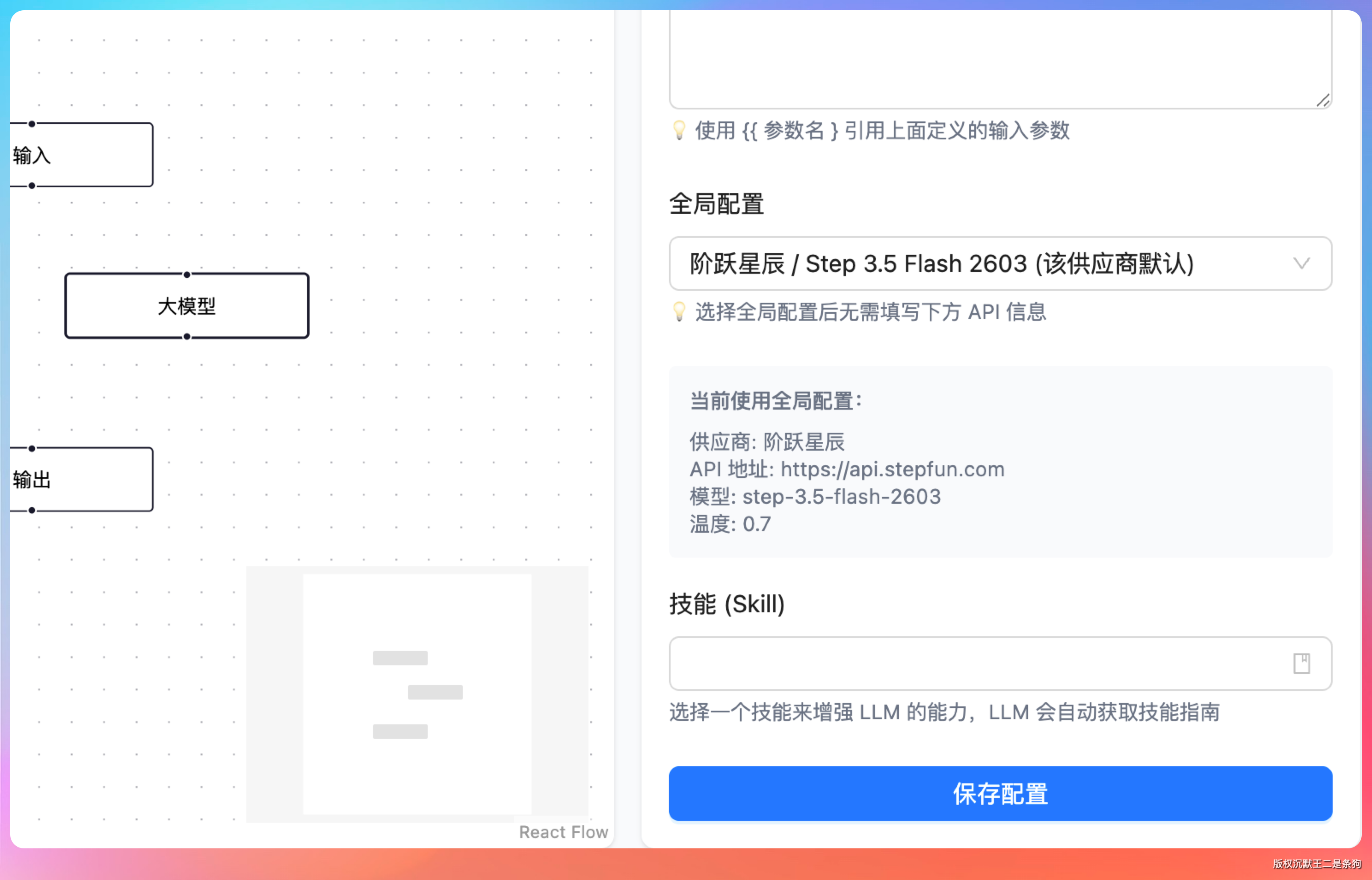
比如说我有这样一个 AI 播客工作流,用户只需要输入一段文字,LLM 节点就能够根据 Prompt 把输入转成符合播客的脚本,然后再通过 TTS 节点转成音频,最后通过 SSE 推送给用户。
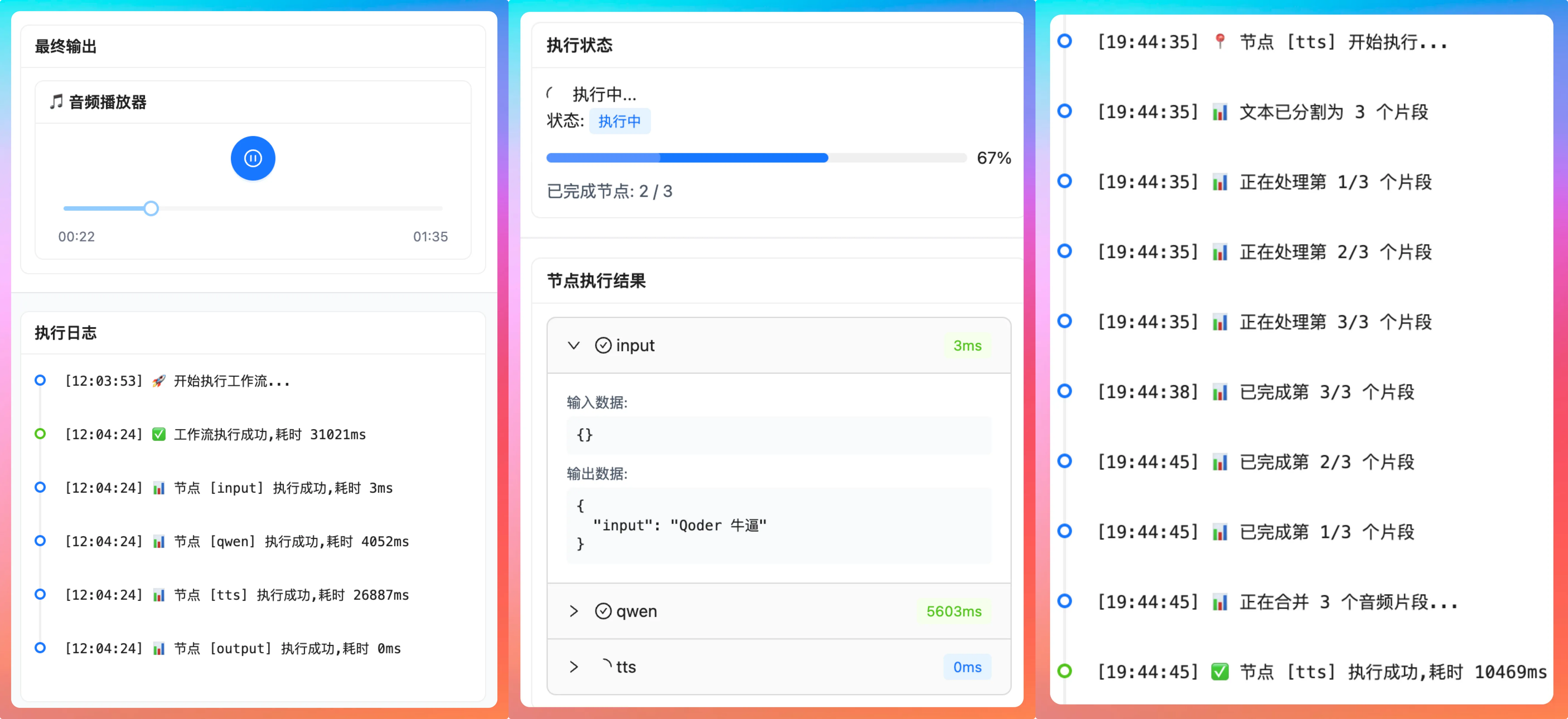
代码在 GitHub 上也是完全开源的,已经有 300 star 了,这让我感觉非常有成就感。
02、派聪明 RAG 的流程讲一下?
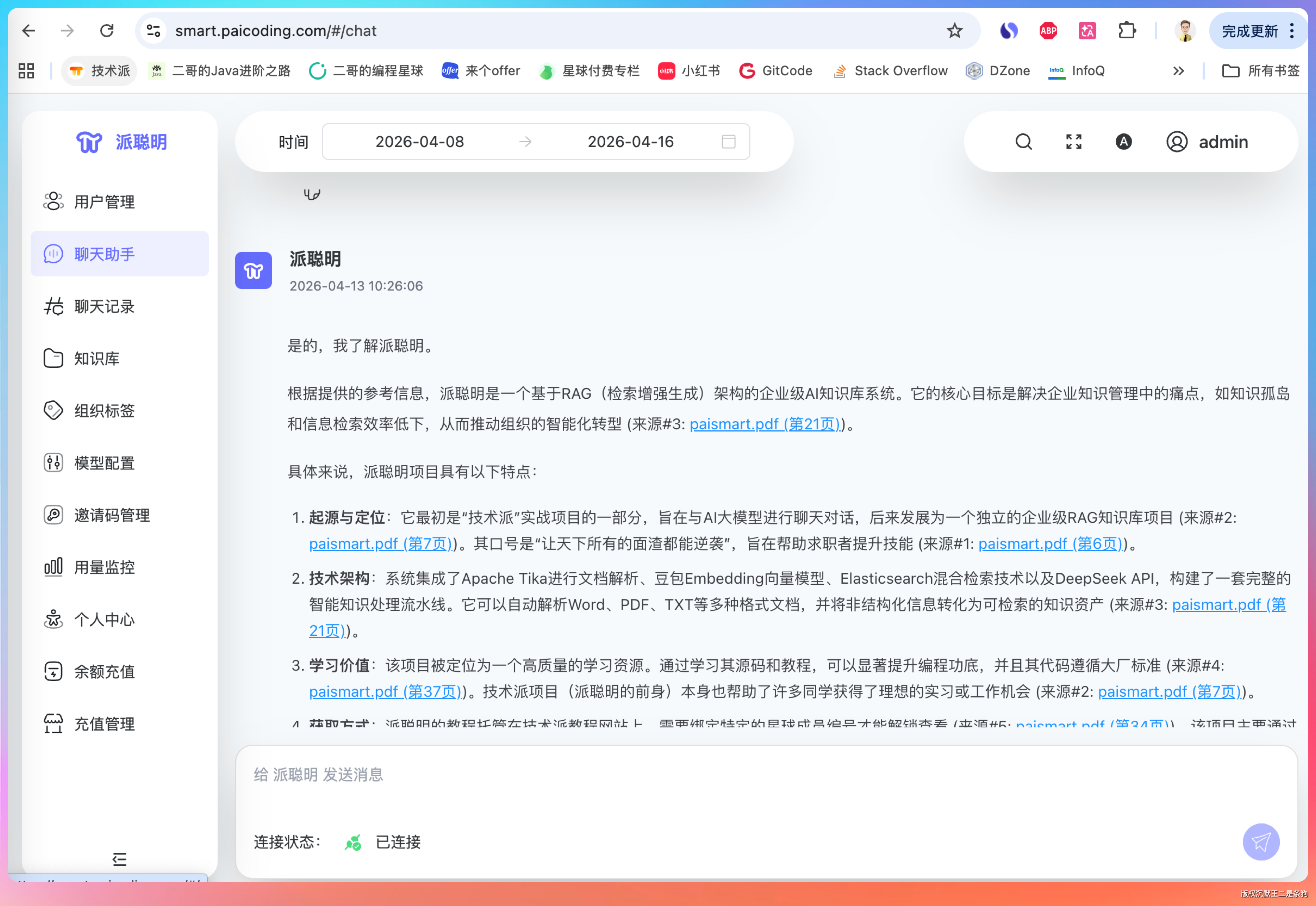
老王继续追问:“聊聊派聪明 RAG,流程讲一下?”
派聪明是一个企业级的 AI 知识库管理系统 。它的核心功能是对用户上传的私有文档(比如 Word、PDF、txt 等),进行语义解析和向量处理,然后存储到 ElasticSearch 中以供后续的关键词检索和语义检索。
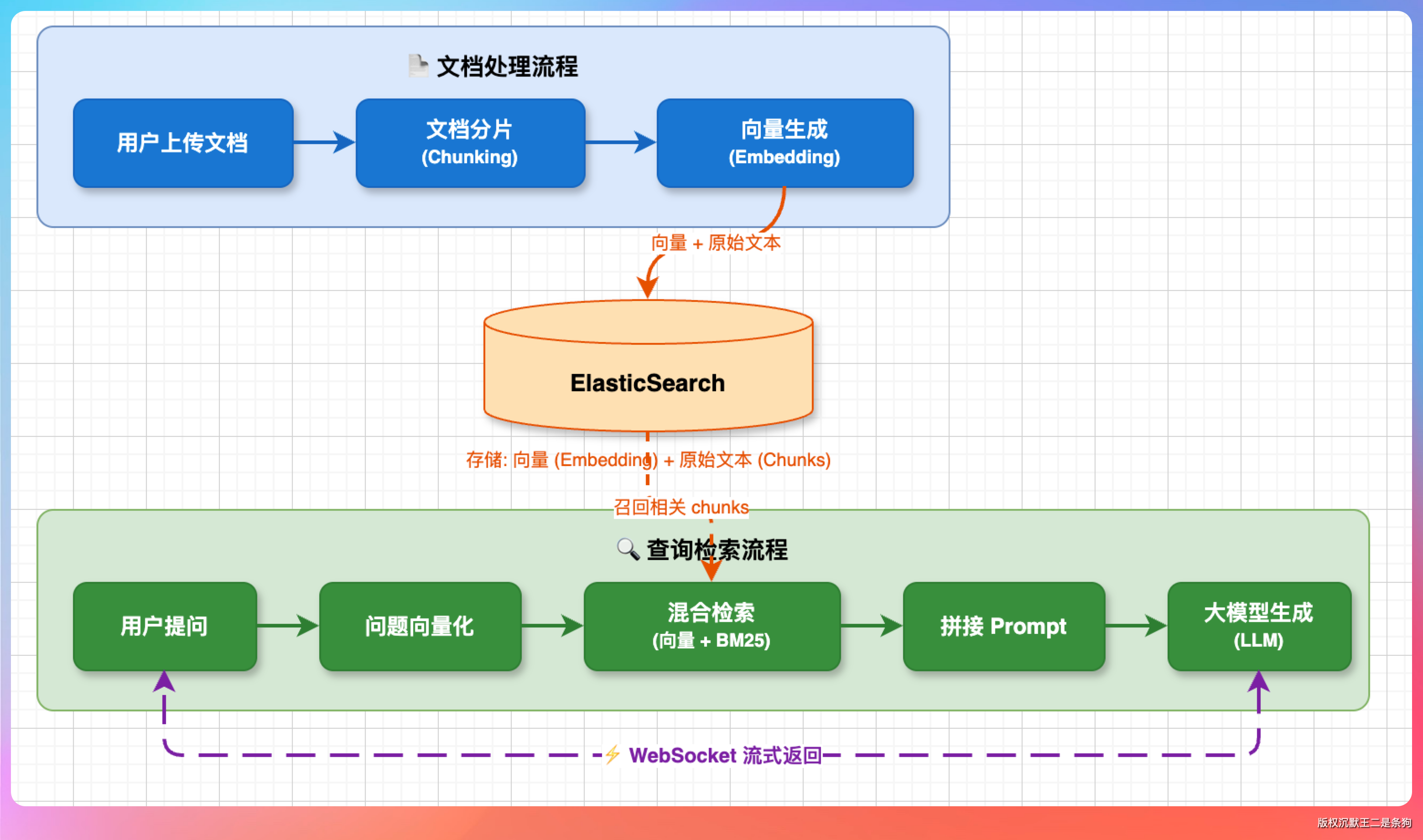
派聪明的整体流程是这样的:用户上传文档后,系统会先对文档进行分片处理,把长文档切成若干个 chunk,每个 chunk 生成对应的向量(embedding),然后和原始文本一起存入 ElasticSearch。
用户提问时,系统对问题向量化,在 ES 中执行混合检索(向量检索 + BM25 关键词检索),把召回的相关 chunk 拼接进 prompt,交给大模型生成答案,最后通过 WebSock 流式返回给前端。
两个比较值得说的难点:
第一个是分片策略。文档分片不是随便切的,切太短会丢失上下文,切太长会超出 embedding 模型的 token 限制,而且会稀释语义。
派聪明采用的是固定大小分片加上 overlap(重叠),保证相邻 chunk 之间有一定内容重叠,避免关键信息刚好落在切割边界上。
第二个是对话上下文管理。多轮对话时需要把历史记录带入 prompt,但上下文越来越长会超出大模型的 context window。如何在保留足够上下文的前提下控制 token 数,是 RAG 项目里很实际的工程问题。
03、lora 的原理和 qlora 的原理讲一下,qlora 怎么优化显存?
老王话锋一转:“LoRA 的原理讲一下?QLoRA 怎么优化显存?”
大模型全参数微调的成本太高——一个几十亿甚至几百亿参数的模型,全量微调需要的显存、算力、存储都是天文数字,普通团队根本玩不起。
LoRA 的核心思路是低秩分解。
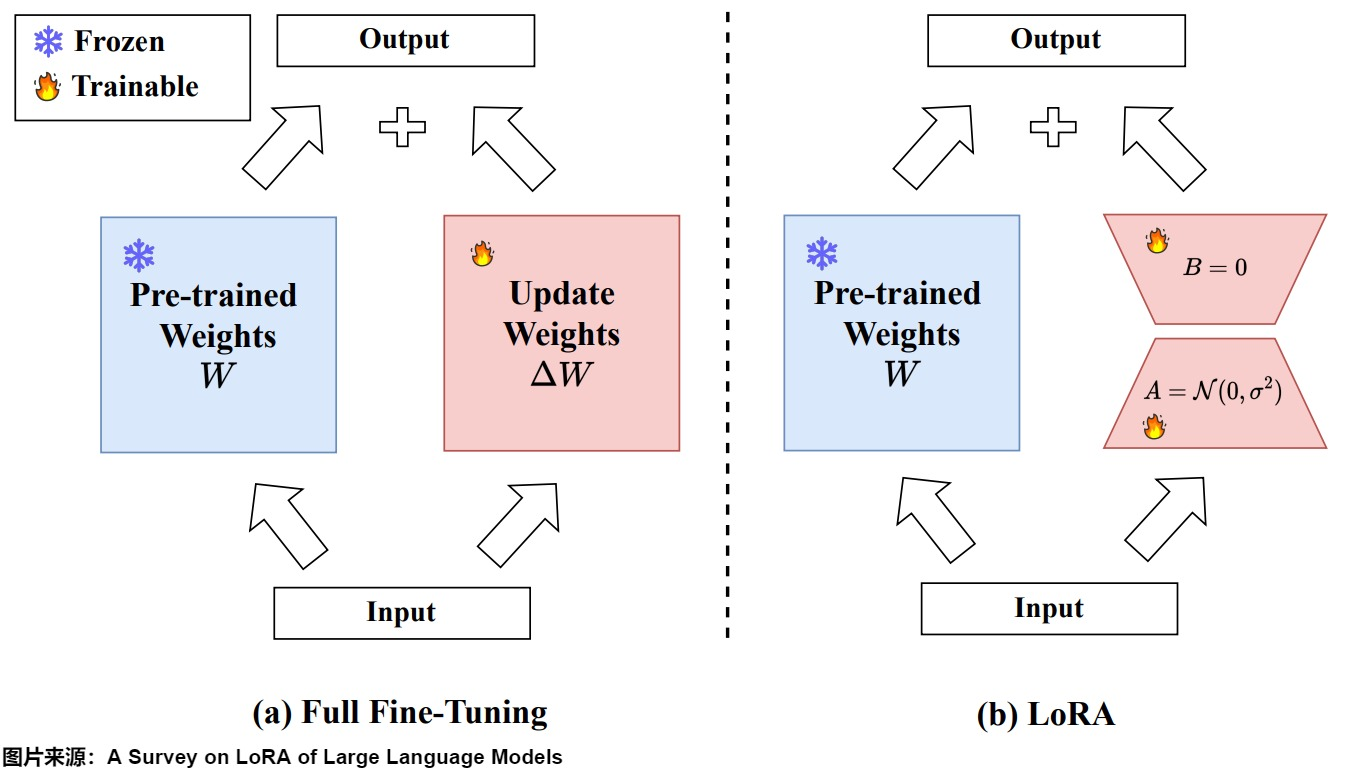
打个比方。
大模型的权重矩阵是一本 10 万页的百科全书,全量微调等于把这 10 万页全部重新印刷一遍。
LoRA 的思路是:不改原书,在原书上做注解。这个注解是两个很小的矩阵 B 和 A,原始权重 W 完全不动,训练的时候只更新 B 和 A。推理时把注解的内容“叠加”到原书上:h = Wx + BAx。
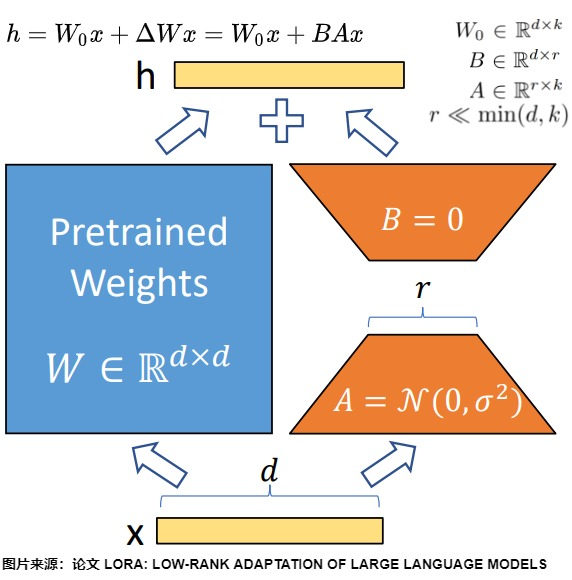
原始矩阵可能有几百万个参数,B 和 A 加起来可能只有几千个。
参数量少了几个数量级,但效果能达到全量微调的 99%。
这就是所谓的“低秩分解”——用两个小矩阵的乘积,去近似一个大矩阵的变化量。秩 r 一般取 8 到 64,r 越大注解越厚,模拟能力越强,但训练成本也越高。
老王追问:“QLoRA 呢?”
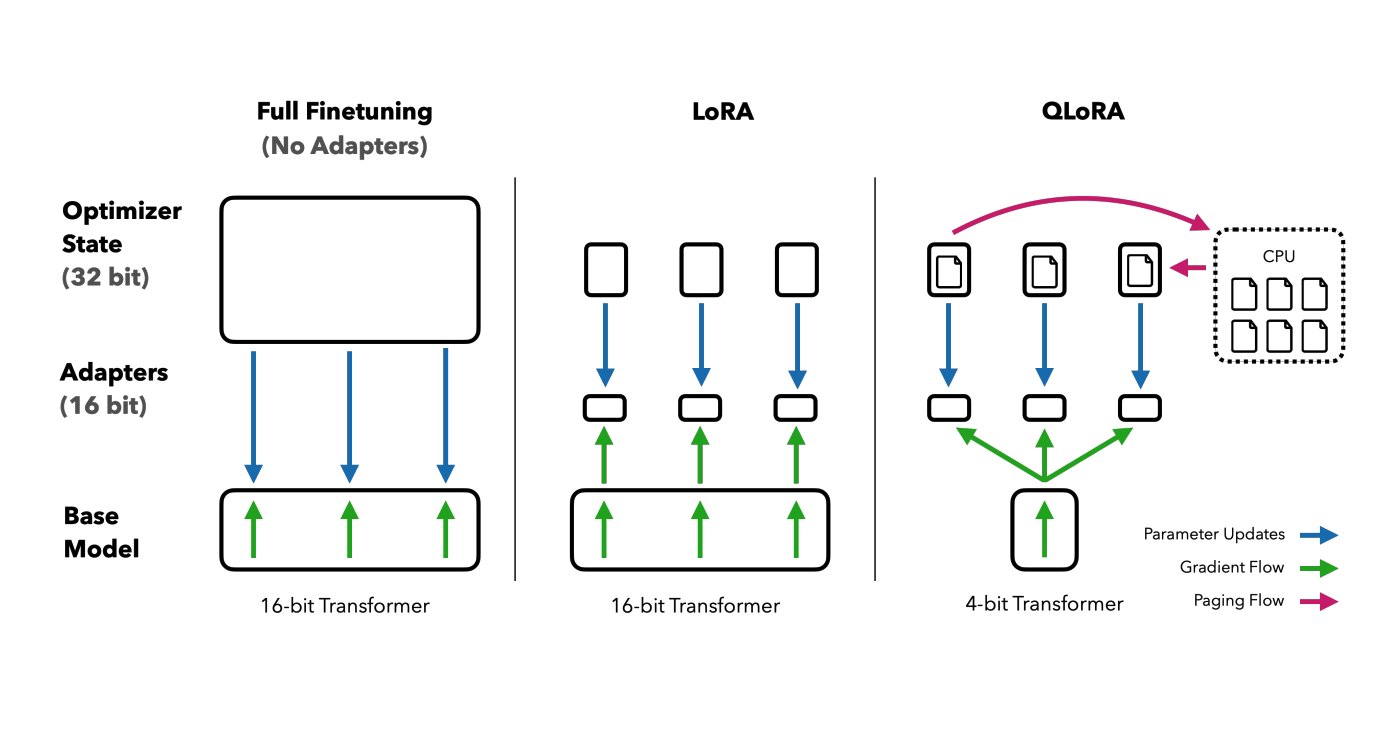
LoRA 解决了“参数多”的问题,但模型本身还是要完整加载到显存里。一个 65B 的模型,光加载权重就要 130GB 显存——普通显卡根本装不下。
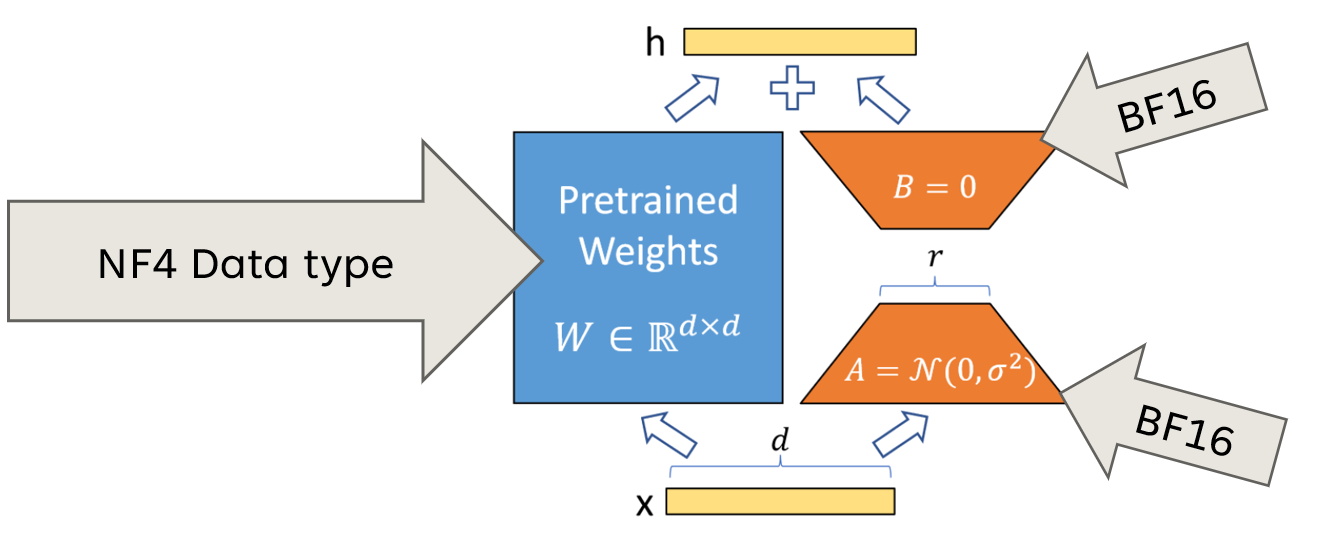
QLoRA 要做的事事:压缩体积。
第一,把模型权重从 16 位压缩到 4 位。
正常模型每个参数用 16 位浮点数存储(2 字节),QLoRA 用一种叫 NF4(4-bit NormalFloat)的格式压到 4 位(0.5 字节)。因为模型权重的分布接近正态分布(钟形曲线),NF4 是专门按照这个分布设计的——在权重密集的区间分配更多量化值,稀疏区间少分一点,精度损失很小。
第二,双重量化——压缩参数。 压缩过程中需要记一些“压缩参数”(量化常数),这些参数本身也占显存。QLoRA 把这些参数也压缩了一遍。
第三,显存不够就借内存。 训练时优化器(Adam)要记录每个参数的历史梯度信息,这部分占的显存比模型本身还多。QLoRA 在显存快满的时候,自动把这些信息临时挪到内存里,用的时候再搬回来——类似操作系统的虚拟内存机制。
04、演示 PaiAgent 项目的实现细节,尤其是 Skill 的实现?
老王说:“回到项目上,Skill 的实现,能再深入讲讲代码层面吗?”
每个 Skill 本质上就是一个目录,核心文件是 SKILL.md,用 YAML Frontmatter 定义名称和描述,Markdown 写执行规则。
项目启动时 SkillRegistry 会扫描所有 Skill 目录,把元信息缓存起来。
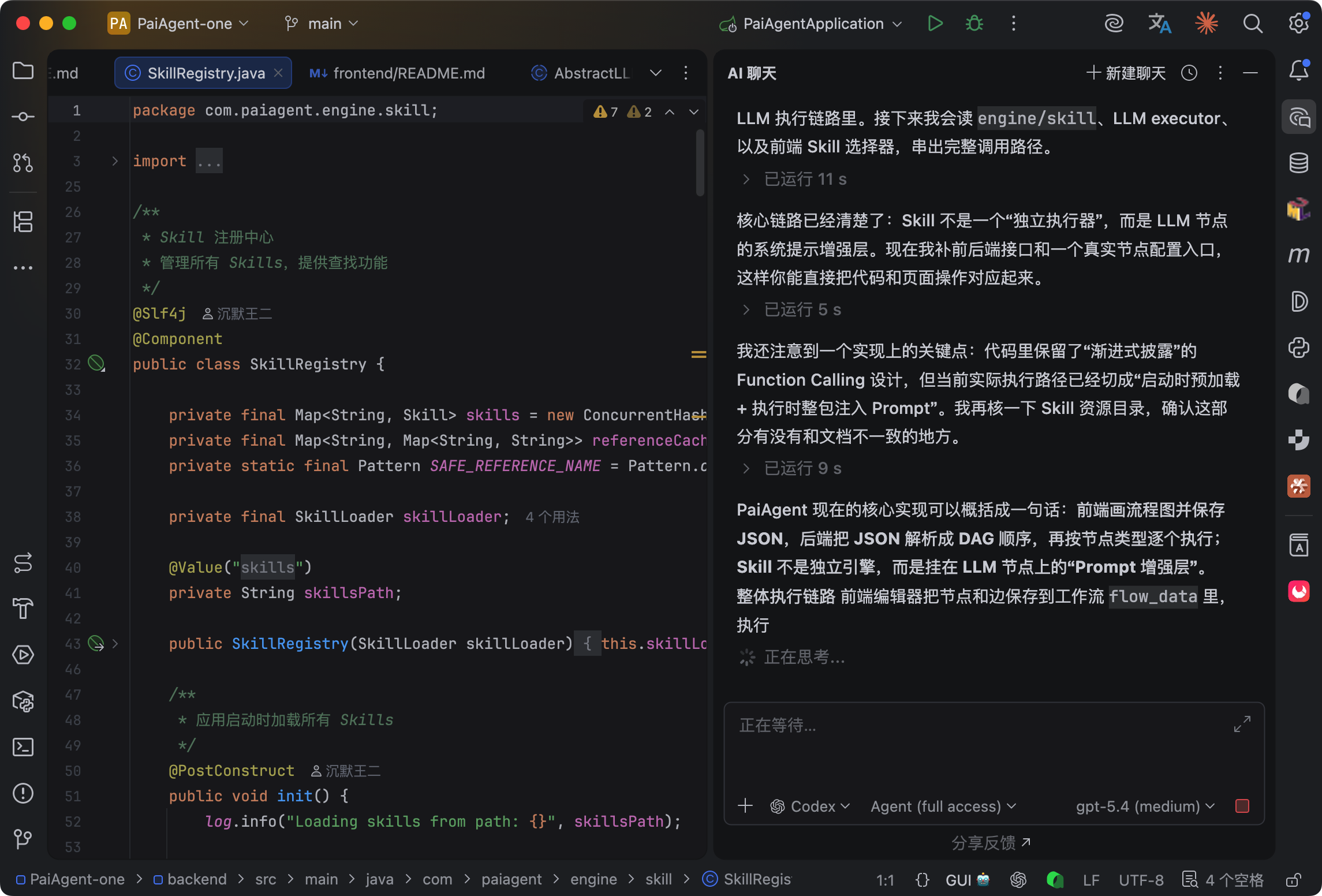
关键设计是三级渐进加载:第一级只加载名字和描述,给 LLM 做决策用——“我有哪些 Skill 可以选”;第二级加载 SKILL.md 的完整内容;第三级按需加载 reference 目录下的参考文件。这样 LLM 在选 Skill 的时候不用把所有内容都塞进 context,省 token。
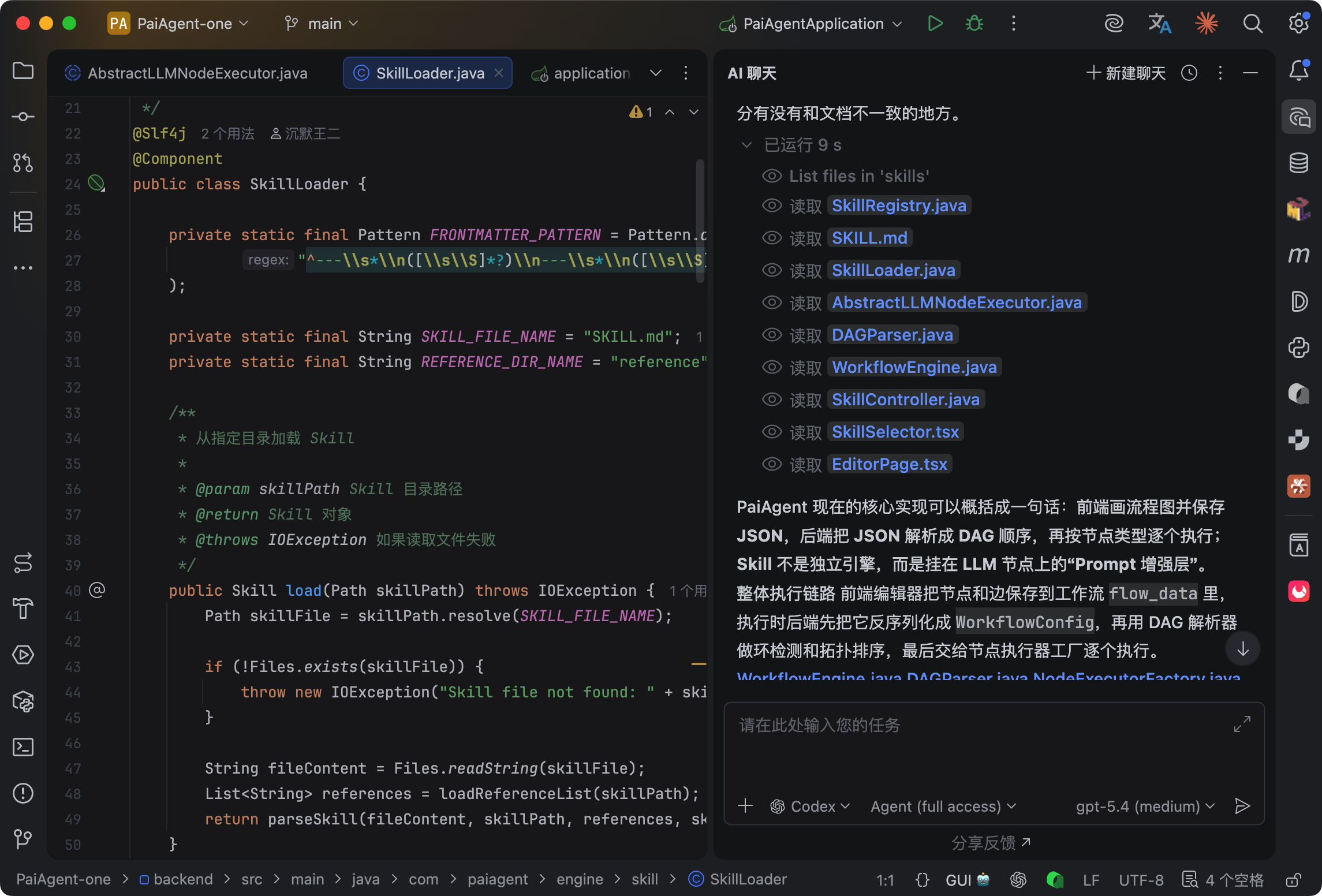
工作流执行到某个 LLM 节点时,如果配置了 skillName,就从 SkillRegistry 拿到对应的 Skill,把内容拼成系统提示词塞进去。
05、讲一下你对 AI 辅助开发的实践经验?
老王问:“讲一下你对 AI 辅助开发的实践经验?”
先说 OpenAI 的 Codex,这货量大管饱,代码质量也高。
近一个月吧,我所有的项目开发都交给它了,包括技术派、派聪明 RAG、PaiFlow Agent、PaiAgent 工作流、PaiSwitch(一个类似 CC Switch 的项目)、派简历。
可以在 IntelliJ IDEA 装一个 Codex 插件,日常开发一些后端代码的时候非常方便。
Codex 还有个杀手锏:配合 Chrome Devtools MCP 可以进行网页测试。有些页面上的 bug 很难用语言描述清楚,让 Codex 直接操作浏览器调试,比你自己折腾半天强多了。
再说 A 厂 的 Claude。
讲真,Claude 在文本方面的表现无可替代,解决一些 bug 的时候,那也是真神。
有时候,一些线上的 bug 我描述不清楚,Codex 经常也是胡言乱语,但 Claude 这玩意就好像装了监控,真的能 get 到我真正的诉求。
另外,不得不提的就是 Claude Code。这就是目前最强的 Agent 工具。
国内的模型配上 Claude Code,战斗力直接翻倍。比如 GLM-5.1,在 Claude Code 的助阵下,能力就很强。
我之前用这套组合完成了一个简历 Agent 项目。
Claude Code 最大的优势在于端到端能力:从拆解需求、生成规范、编写代码到执行测试,一条龙搞定。
复杂任务、多文件重构、自主调试,这些场景 Claude Code 是目前的天花板。
06、觉得当前的 agent 达到预期了吗?对 agent 的预期是什么?
老王追问:“觉得当前的 Agent 达到预期了吗?”
说实话,没有,差得还远。
我理想中的 Agent 是能自主完成一个完整的功能开发:理解需求 → 设计方案 → 写代码 → 跑测试 → 修 bug→ 提 PR,全程不用我插手。
但现在的 Agent,包括 Claude Code,还是需要人在旁边盯着。
哪怕是 Qoder 的专家团模式。
不过 Agent 的进步速度是真快。
明年这个时候,Agent 给我们的感觉应嘎就完全不同了,尤其是 OpenClaw、爱马仕 Agent 带给大家的震撼。
07、项目中 AI 贡献的代码占比有多少?
老王问:“AI 贡献的代码占比有多少?”
PaiAgent 大概 95%。
派聪明 RAG 的 AI 代码占比比较低,大概 10%。当时做这个项目的时候,AI 辅助开发的工具还不太成熟,很多东西只能靠我自己写。
08、怎么进行多模态的知识检索?
老王问:“怎么进行多模态的知识检索?”
传统 RAG 只能处理文本,遇到图片、表格、PDF 里的图表就抓瞎。
派聪明最开始也是这样——用户上传的技术文档里经常有架构图、时序图、流程图,Tika 完全没办法处理。
// 文档处理流程:解析 -> 分块 -> 向量化 -> 存储
public void vectorizeFile(MultipartFile file, String userId, String orgTag, boolean isPublic) {
// 1. 文档解析和分块
List<String> chunks = fileParsingService.parseAndChunk(file);
// 2. 批量向量化
List<float[]> vectors = embeddingClient.batchEmbedding(chunks);
// 3. 构建文档对象
List<EsDocument> documents = buildDocuments(chunks, vectors, metadata);
// 4. 批量存储
elasticsearchService.bulkIndex(documents);
}
视频音频 RAG 的核心思路是先把它们转成文本或者其他可向量化的表示,再走传统 RAG 的流程。
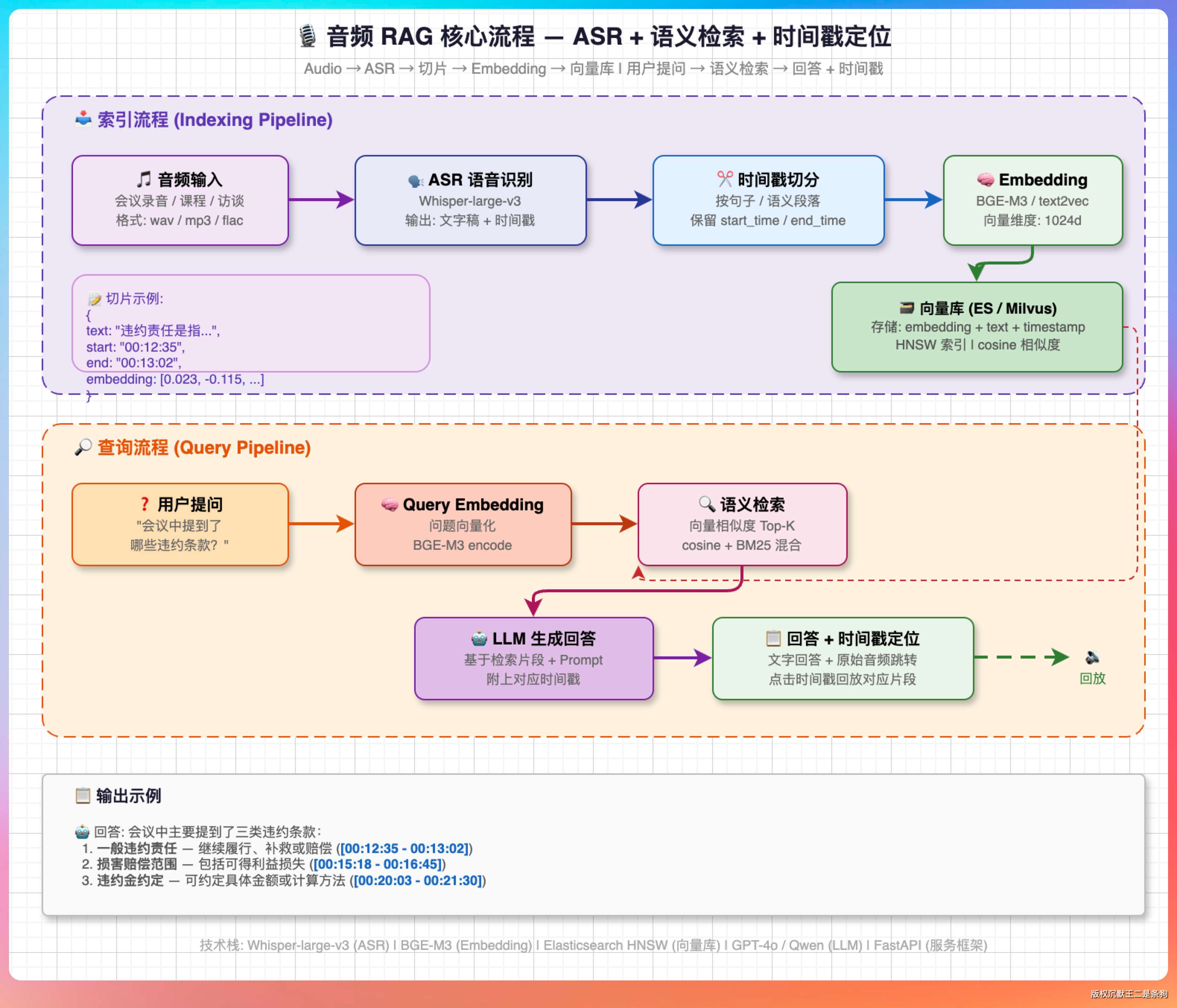
核心流程是这样的:把音频通过 ASR(自动语音识别)转成文字稿,文字稿按时间戳切分成片段,每个片段做 Embedding 向量化存到向量库里。
用户提问的时候做语义检索,找到最相关的文字片段,然后基于这些片段生成回答,同时返回对应的时间戳。
视频场景如果不需要画面信息也可以用这个方案,把视频里的音轨提取出来做 ASR 就行。
如果视频里的画面信息很重要,比如教学视频里的板书、商品视频里的展示、监控视频里的事件,那纯 ASR 就不够了,需要把画面信息也利用起来。
核心流程是这样的:把视频按一定频率抽帧(比如每秒抽一帧或每个关键帧抽一张),用多模态 Embedding 模型把每一帧图像转成向量,存到向量库里。用户提问的时候用同一个多模态 Embedding 模型把问题向量化(多模态模型可以同时处理文本和图像),做语义检索找到最相关的视频帧,然后基于这些帧的时间戳定位到视频片段。
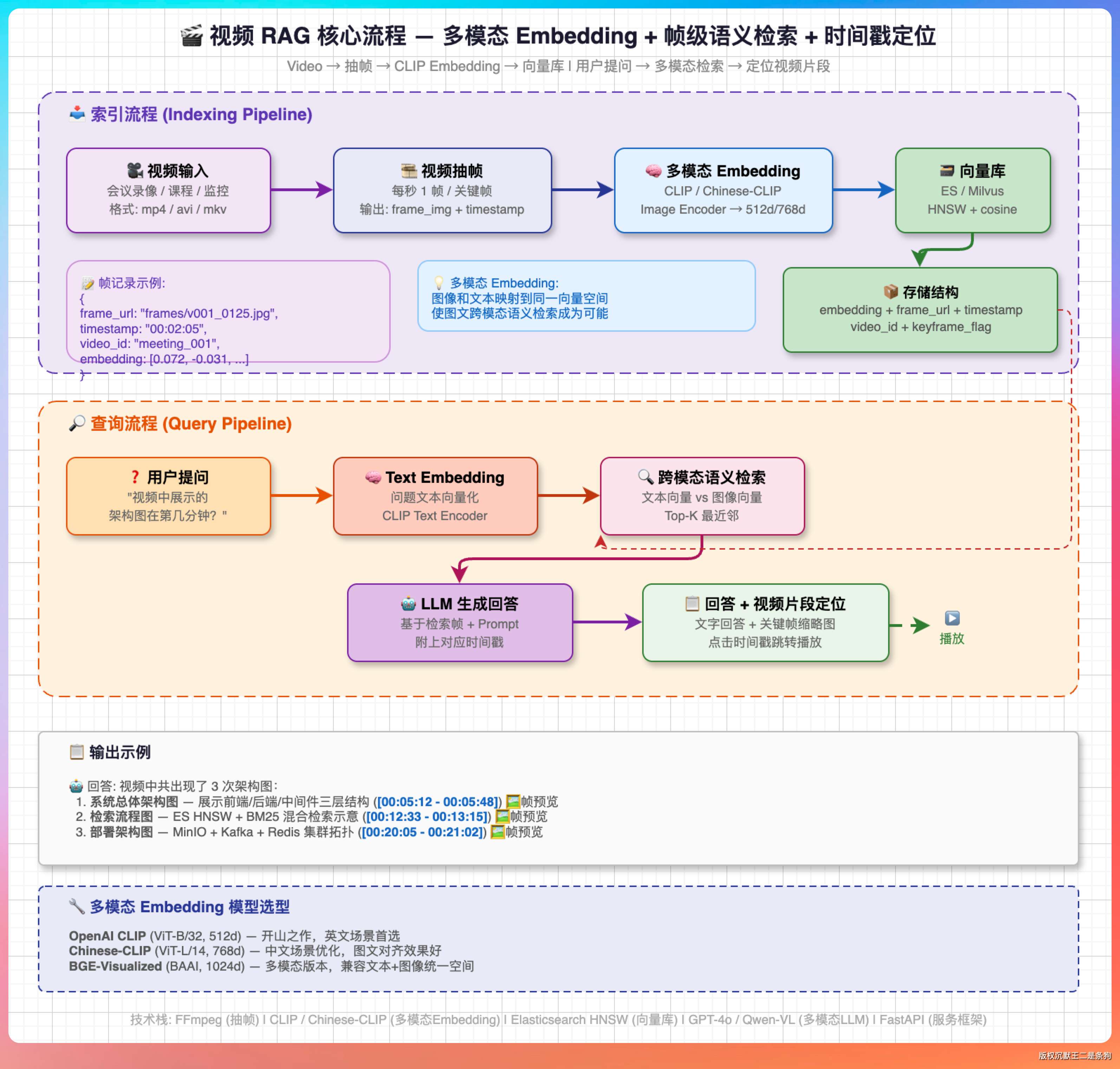
多模态 Embedding 模型的选择主要是 CLIP 系列。OpenAI 的 CLIP 是开山之作,中文场景下可以用 Chinese-CLIP 或者 BGE-M3 的多模态版本。
09、A2A 与 MCP 区别说一下?
老王问:“A2A 与 MCP 区别说一下?”
MCP 解决的是一个 Agent 怎么调用工具,定位“AI 的 USB 接口”。
Agent 通过 MCP Client 连 MCP Server,Server 暴露 tools、resources、prompts 三种能力。
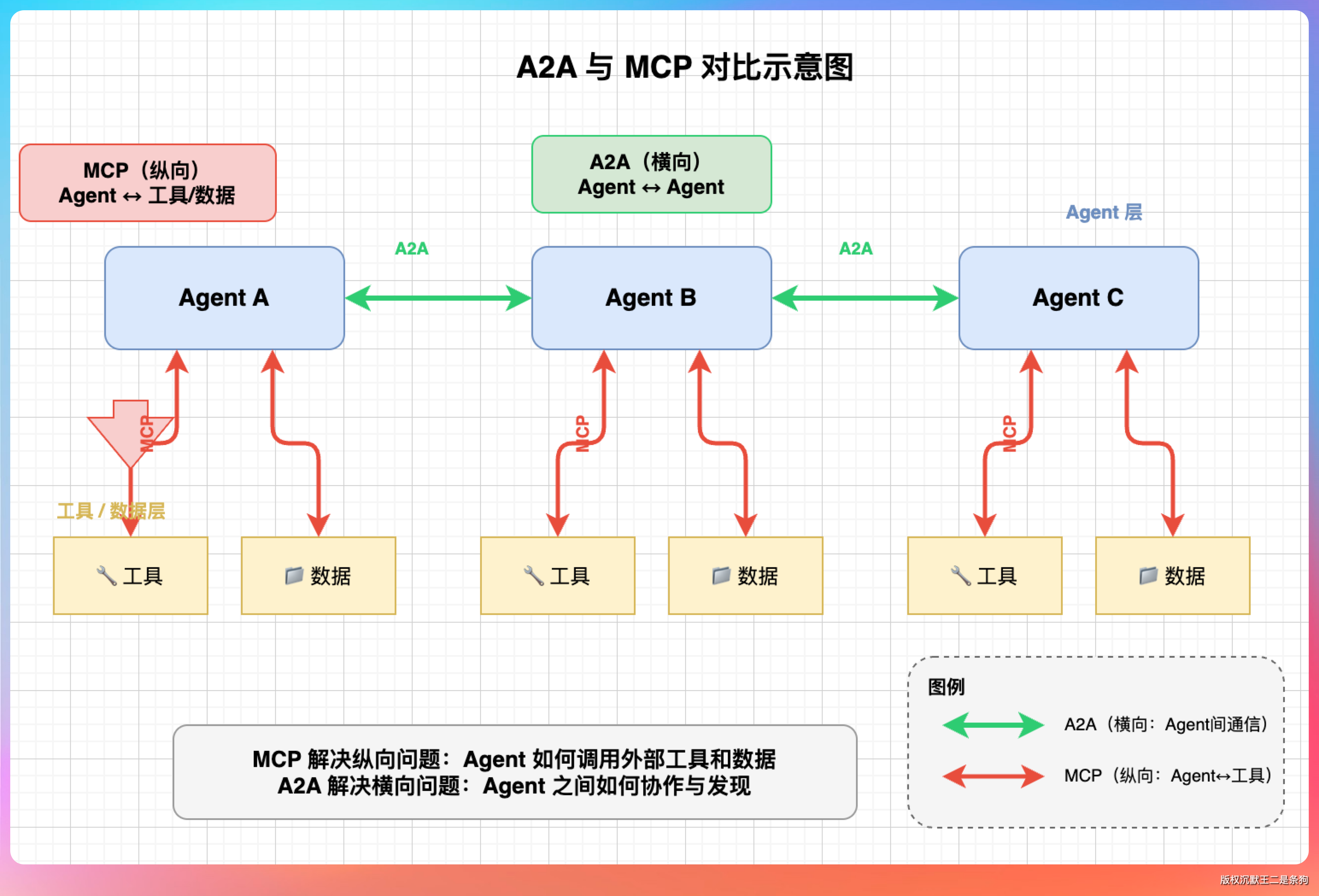
A2A 解决的是多个 Agent 怎么协作。每个 Agent 发布一个 Agent Card(JSON 格式)描述能力,其他 Agent 通过 Agent Card 发现并调用它。
举个例子:一个库存 Agent 用 MCP 连自己的数据库查库存,同时用 A2A 和供应商的订货 Agent 通信,库存不够就自动下单。MCP 管“我怎么用工具”,A2A 管“我怎么找别人帮忙”。
10、RAG 遇到较长较多的上下文怎么解决?
老王问:“RAG 检索回来几十个 chunk,上下文太长怎么办?”
“第一层,检索前置过滤。”
“搜索阶段用小粒度 chunk(256 token)做高精度召回,召回 30 条候选。然后用重排模型(Reranker)对这 30 条打分,只取 Top-5 到 Top-8 最相关的喂给模型。”
“这里有个技巧叫‘分层召回’:第一轮用向量检索快速缩小范围,第二轮用关键词匹配精确定位,第三轮用 Reranker 做最终排序。”
“第二层,context window 预算管理——给 token 定额度。”
“我的分配策略是:系统提示词占 20%,检索结果占 50%,对话历史占 30%。比如 8K 的 context window,系统提示词 1.6K,检索结果 4K,历史对话 2.4K。”
“超出预算的旧消息直接砍掉会丢失信息,我用的方法是渐进式摘要。最近三轮对话保留原文,再往前的对话压缩成 200 token 的摘要。”
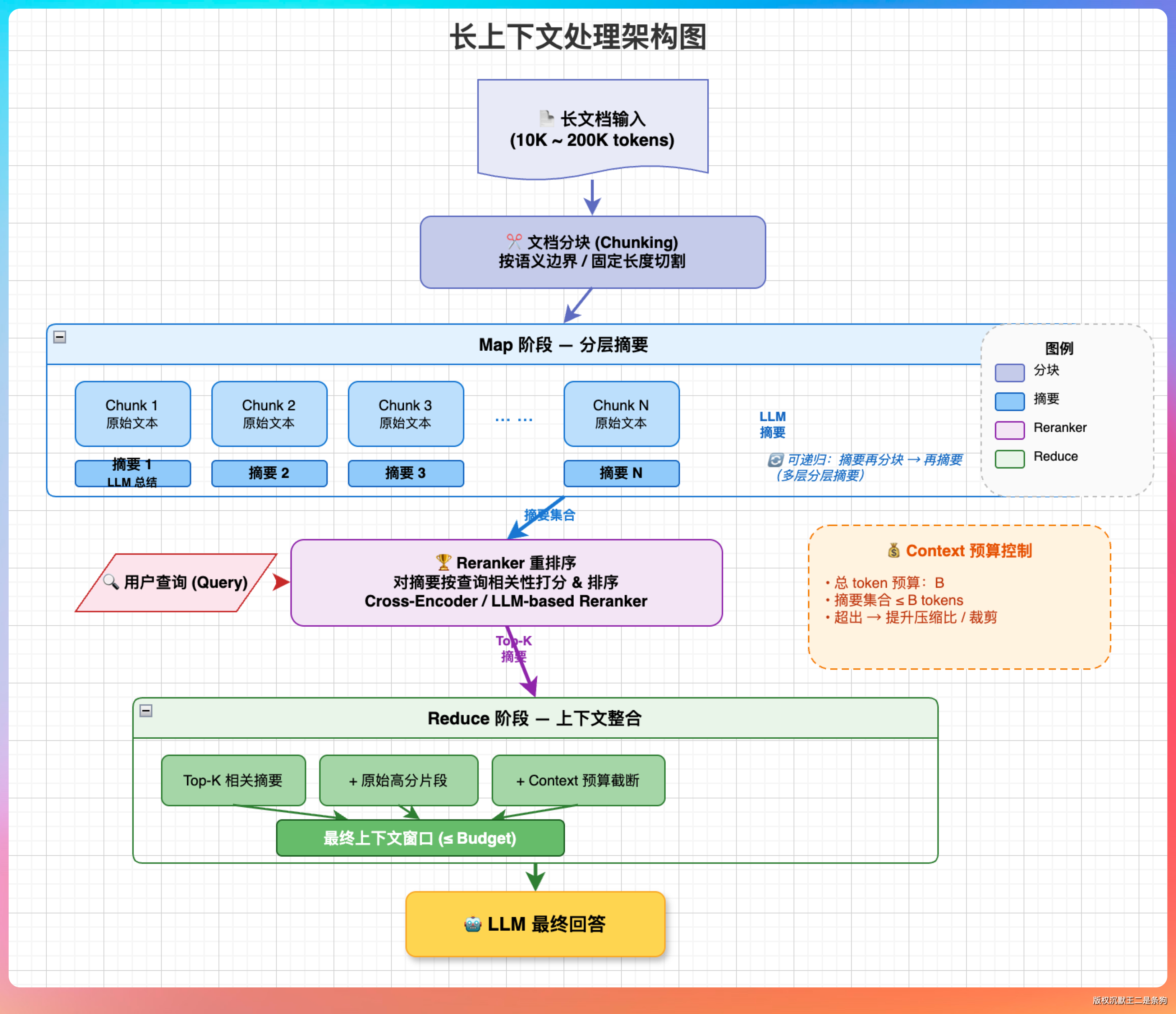
“第三层,长文档的特殊处理。”
“如果是整本书、长篇报告这种,单条就超过 8K token。”
“方案一是 Map-Reduce:把长文档切分成多个 chunk,每个 chunk 单独问模型,然后把多个回答再合并。缺点是丢失跨 chunk 的关联信息。”
“方案二是 RAG + 递归摘要:先对长文档做分层摘要——每 5 个 chunk 生成一个中间摘要,每 5 个中间摘要再生成一个高层摘要。检索时先匹配高层摘要,定位到相关章节,再深入匹配原始 chunk。”
“方案三是用支持长上下文的模型。最新的 Claude Code 已经支持 1M 上下文了。”
ending
Agent 开发| PaiAgent/PaiFlow 2026-03 ~ 至今
项目简介:基于 LangGraph4j + Spring AI 的企业级 AI 工作流平台,支持通过可视化拖拽界面编排多种大模型和工具节点,使用状态图引擎执行复杂 AI 任务。
技术栈:Java 21、Spring Boot 3.4、Spring AI 1.0、LangGraph4j 1.8、React 18、ReactFlow
- 基于 LangGraph4j StateGraph 构建工作流引擎,实现 GraphBuilder 节点注册和边连接、NodeAdapter 适配器桥接现有执行器、StateManager 管理节点间状态传递。
- 设计 ChatClientFactory 动态工厂,运行时根据节点配置动态创建 OpenAI 兼容的 ChatClient,实现 OpenAI、DeepSeek、通义千问等多厂商 LLM 无缝切换。
- 使用模板方法模式重构 5 个 LLM 节点执行器,抽象 AbstractLLMNodeExecutor 基类,子类仅需实现 getNodeType(),代码量从 800+ 行精简至每个 10 行。
- 实现 Skill 预置知识包机制,支持 SkillRegistry 自动加载、Reference 缓存、全量/渐进式两种注入模式。
派聪明 RAG 知识库 AI 应用开发 2026-01 ~ 2026-02
项目描述:派聪明是一个基于私有知识库的企业级智能对话平台,允许用户上传文档构建专属知识空间,并通过自然语言交互方式查询和获取知识。它结合了大语言模型和向量检索技术,能够让用户能够通过对话的形式与自己的知识库进行高效交互。
技术栈:SpringBoot、MySQL、Redis、Apache Tika、Ollama、Elasticsearch、MinIO、Kafka、Spring Security、WebSocket、Linux、Shell
核心职责:
- 利用 Elasticsearch + IK 分词器对知识库文档进行索引和向量检索,支持 Word、PDF 和 TXT 等多种文本类型;并集成阿里 Embedding 模型进行文本到向量的转换,支持 2048 维;再结合 ES 的 KNN 向量召回、关键词过滤和 BM25 重排序实现「关键词+语义」 的双引擎搜索。
- 编写 shell 脚本,一键启动 Kafka 的 KRaft 模式,自动处理 cluster ID 的冲突问题,包括清理日志、生成集群 ID、格式化存储目录、启动 Kafka 服务器等。
- 基于 WebSocket 实现长连接(用户可主动停止),并结合 DeepSeek 大模型的 Stream API 实现流式响应返回,只要 LLM 有新的内容生成,前端就能实时接收并呈现出“打字机”式的逐字生成。
- 引入 MCP 协议对本地文件操作、PDF 生成及数据库查询等能力进行 Server 端封装,实现了 Agent 与工具生态的解耦。

回复