


Agent 终于能看图了!GLM-5V 让 PaiCLI 在图像识别上有了一双眼睛。
大家好,我是二哥呀。
PaiCLI 已经非常强大了,有 ReAct、Multi-Agent、MCP、Skill、Function Calling,基本上 Claude Code 有的功能都覆盖到了。
今天这篇,我们给 PaiCLI 再追加一个能力:图片输入。听起来简单,但真正做起来涉及到的东西很多。
这个功能的核心前提是多模态模型。单纯的文本模型是看不了图的,比如说 GLM-5.1,于是我们追加了 GLM-5V 模型的 endpoint。
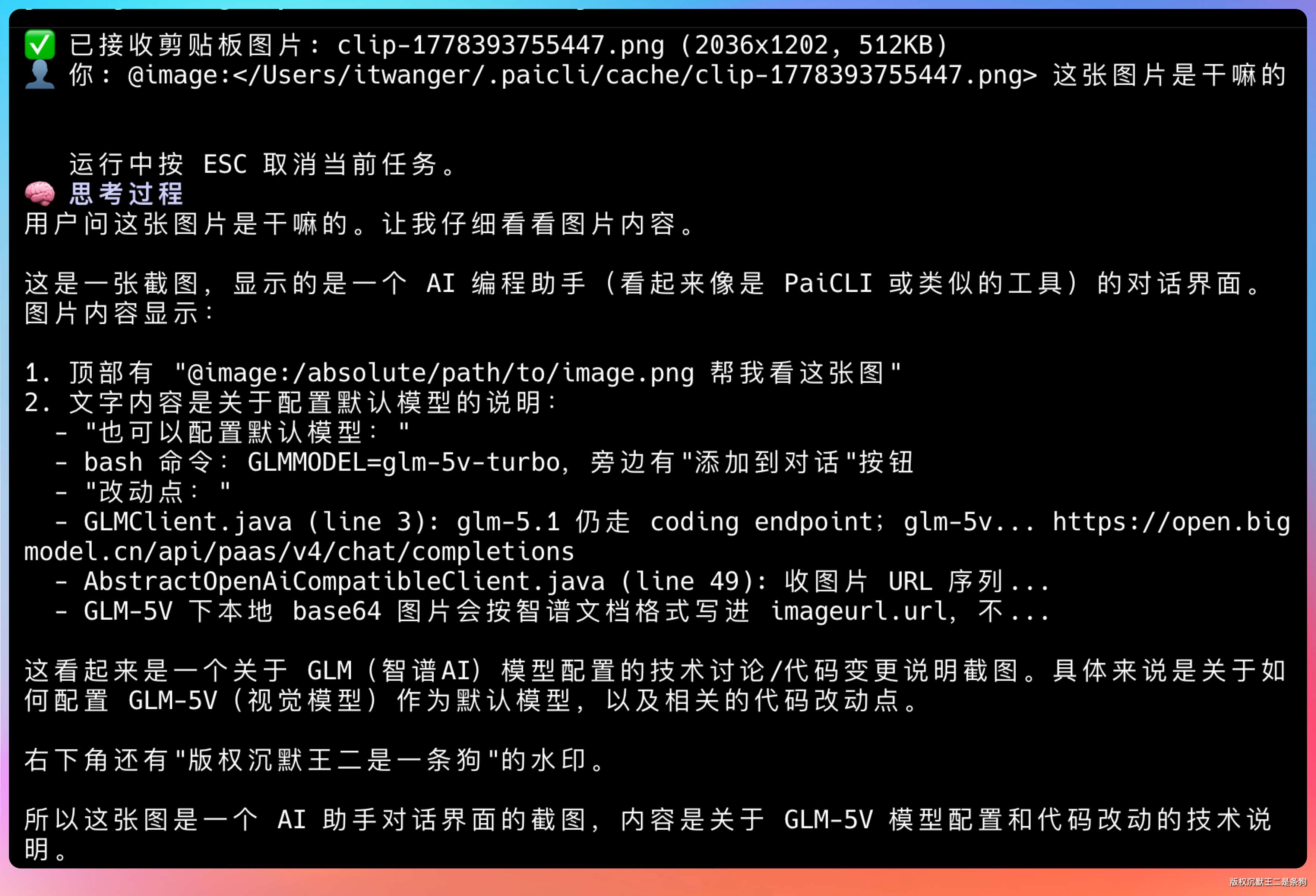
来看看效果,把技术派的首页复制粘贴进去。
能准确识别出这些信息。
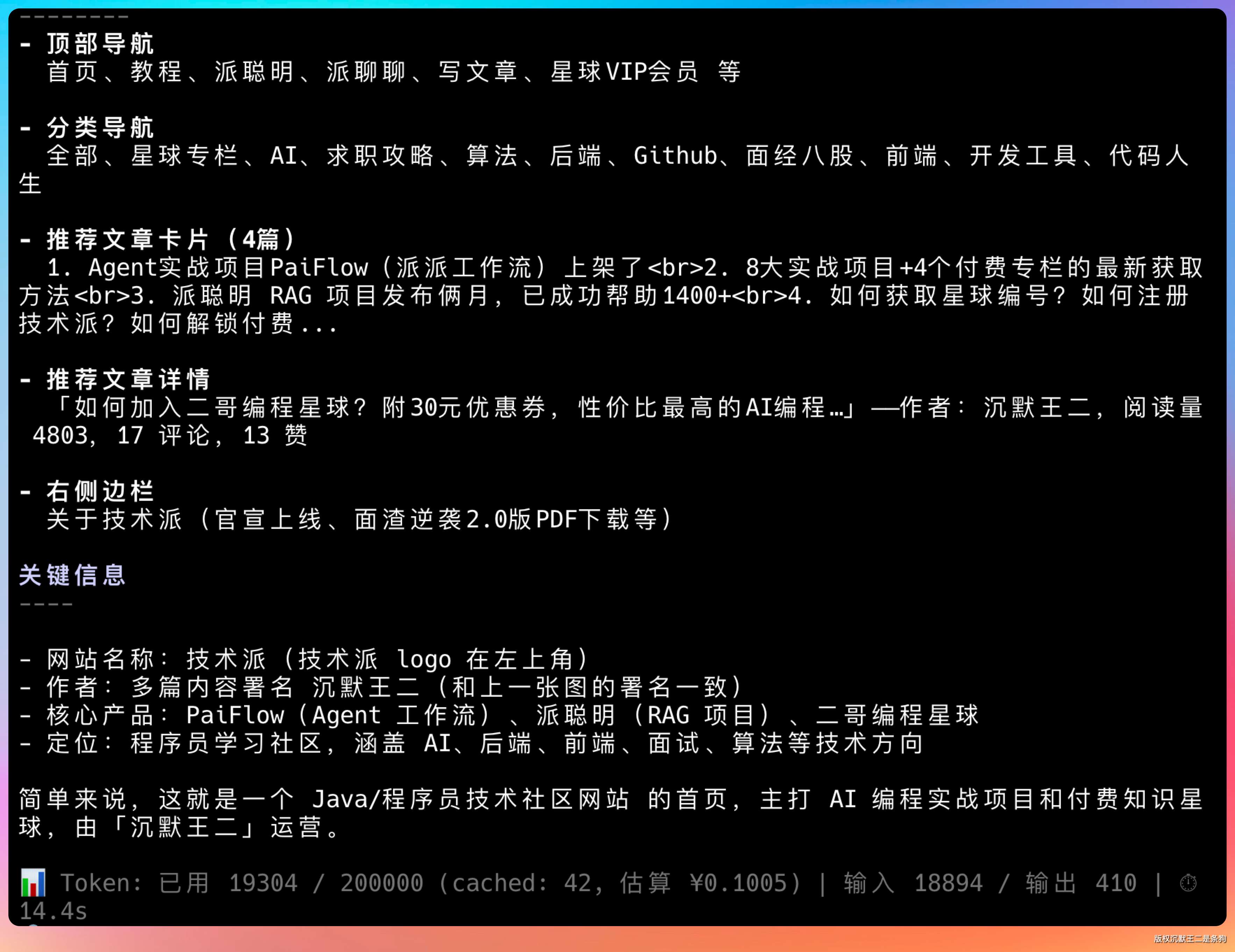
- 网站名称:技术派(技术派 logo 在左上角)
- 作者:多篇内容署名 沉默王二(和上一张图的署名一致)
- 核心产品:PaiFlow(Agent 工作流)、派聪明(RAG 项目)
01、为什么 GLM-5.1 看不了图
GLM-5.1 是一个纯文本大语言模型。它的输入只能是文本。
文本经过 Tokenizer 切成 token 序列,送进 Transformer 做注意力计算,输出也是 token 序列再解码回文本。整个推理过程中,模型的“感官”只有一个,就是文本。
GLM-5V 多了一个关键组件:Vision Encoder。
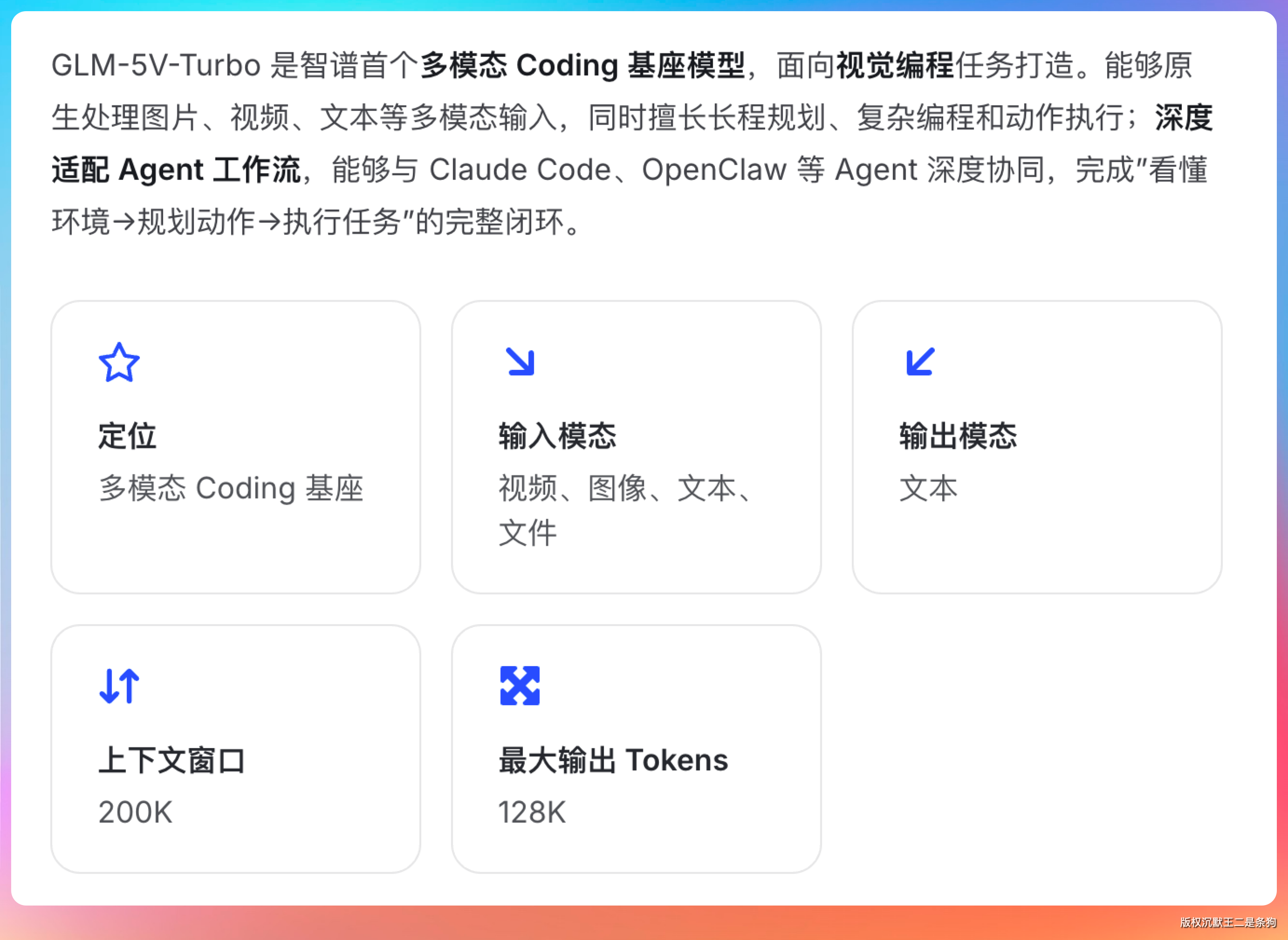
这个 Vision Encoder 通常是一个预训练好的 ViT(Vision Transformer),它的工作是把一张图片转换成一组“视觉 token”。
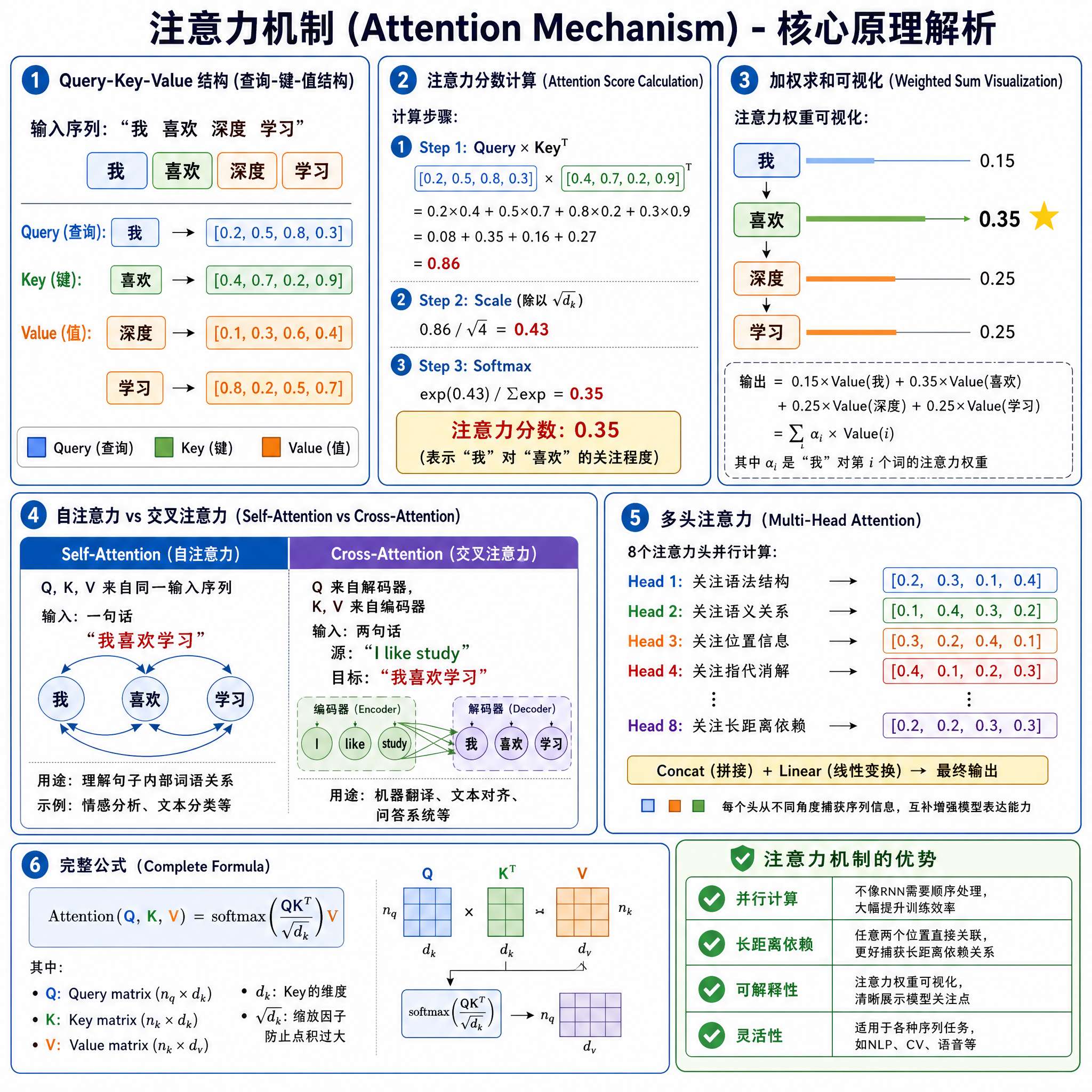
具体流程是这样的:
第一步,把图片切成固定大小的 patch(通常是 14x14 或 16x16 像素一个 patch)。一张 224x224 的图会被切成 16x16=256 ...
已加入星球,可直接知识星球授权登录
二哥编程星球目前包含:
企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

真诚点赞 诚不我欺
1 条评论
回复