


用 SQLite + Embedding 给 Agent 加上 RAG,从此秒懂项目源码
大家好,我是二哥呀。
这一期我们来给 Agent 装上 RAG,让 Agent 可以直接读我们的代码库。
举个具体场景,我问“MemoryManager 是怎么压缩上下文的”。没有 RAG 的 Agent 只能凭训练数据瞎猜,猜得对算运气好。
装了 RAG 之后,Agent 会先去代码库里捞 ContextCompressor.compressIfNeeded,看 Map-Reduce 的实现,再基于这段真实代码的回答。
整个 RAG 的架构示意图如下所示。
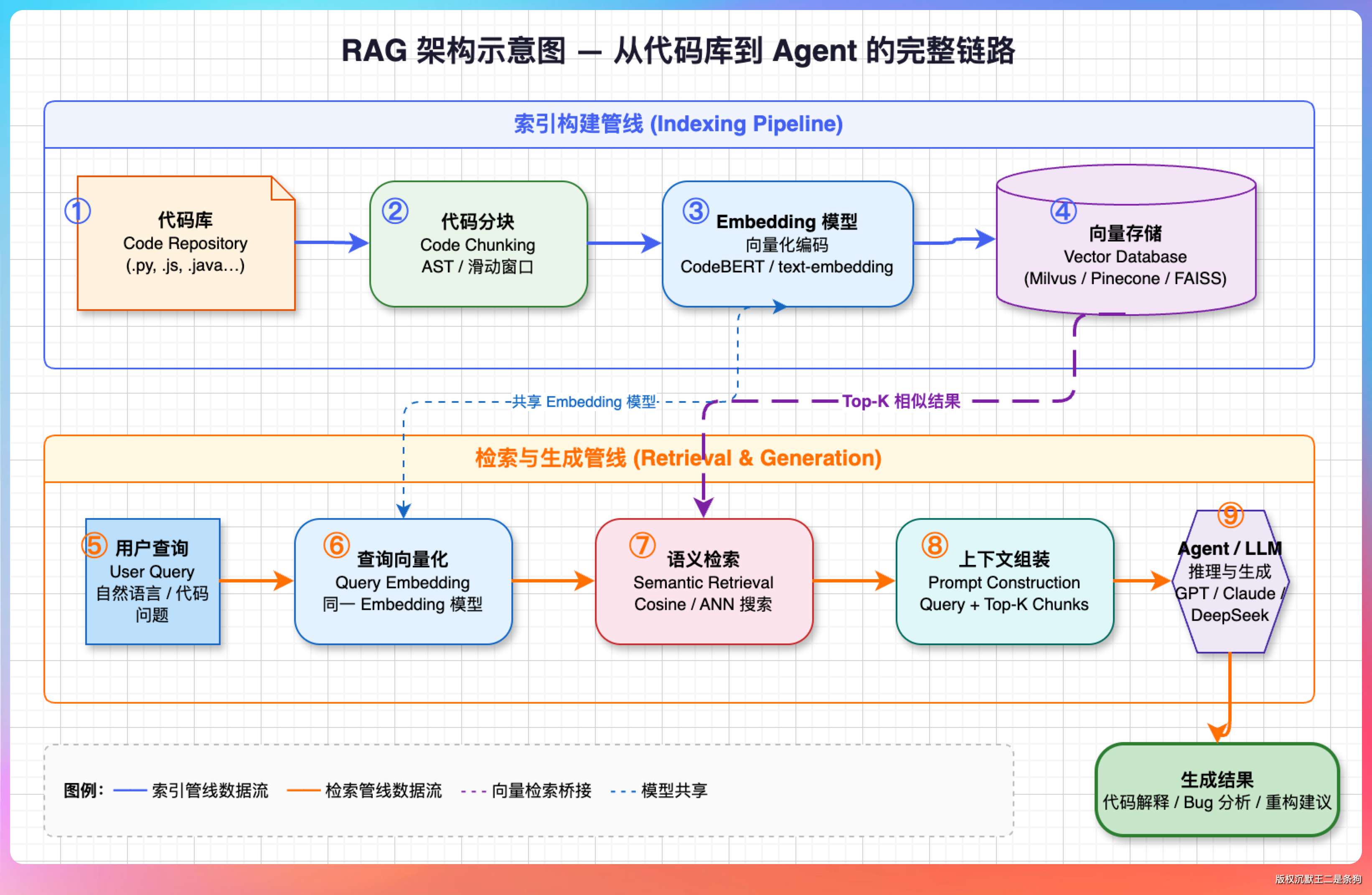
01、RAG 的整体设计
RAG 大家应该不陌生了,一句话讲清楚。
把知识库向量化然后持久化到向量数据库,查询的时候,按照语义相似度找出最相关的片段,再连同问题一起塞给 LLM。
落到代码场景,有三个问题绕不开。
第一个是怎么切。代码不像文档,按字数硬切会切出了很多噪音。最稳妥的办法是按结构特征切——文件级、类级、方法级,检索时按粒度匹配。
第二个是存到哪。生产环境通常上 Milvus、Pinecone 、ElasticSearch 这种专用向量库。但我们是个 CLI 工具,这些都太重量级了。
所以我这里选择了 SQLite。
第三个是怎么样才能搜得准。纯向量检索对自然语言友好,对代码标识符却不一定。
所以我们这里做了混合检索——语义打底、关键词加权、再按 chunk 类型加分。method 块比 file 块优先级高,因为用户问“怎么实现的”,给方法体比给整个文件有用得多。
举个例子,搜“处理用户登录的地方”,它能定位到 LoginService.authenticate。
整个 RAG 模块拆成 10 个类,下面一块...
已加入星球,可直接知识星球授权登录
二哥编程星球目前包含:
企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

真诚点赞 诚不我欺
回复