


如何将技术派写到简历上?提供超过 200 种写法,附30道高频面试题,覆盖 web项目的方方面面
大家好呀,我是技术派的导演二哥呀。
之前有球友反馈自己的项目经历太少,不好写简历,影响找工作,不知道你有没有这样的困惑?
如果有,那这篇文章将完美解决你的痛点。
一共三大块。
第一块,技术派在面试中都会遇到哪些问题,并且该如何回答,有完美的模板套路。
第二块,校招生在写简历的时候,应该怎么写,可以直接抄,但尽量自己稍微动动脑子优化一下。
第三块,社招党在把技术派写到简历的时候,应该怎么写,有哪些考察的点需要注意。
如果你还没有加入二哥的编程星球,那么可以扫下面这个优惠券加入,不贵,但真的能帮你拿到心仪的 offer。

扫码加入知识星球即可解锁。
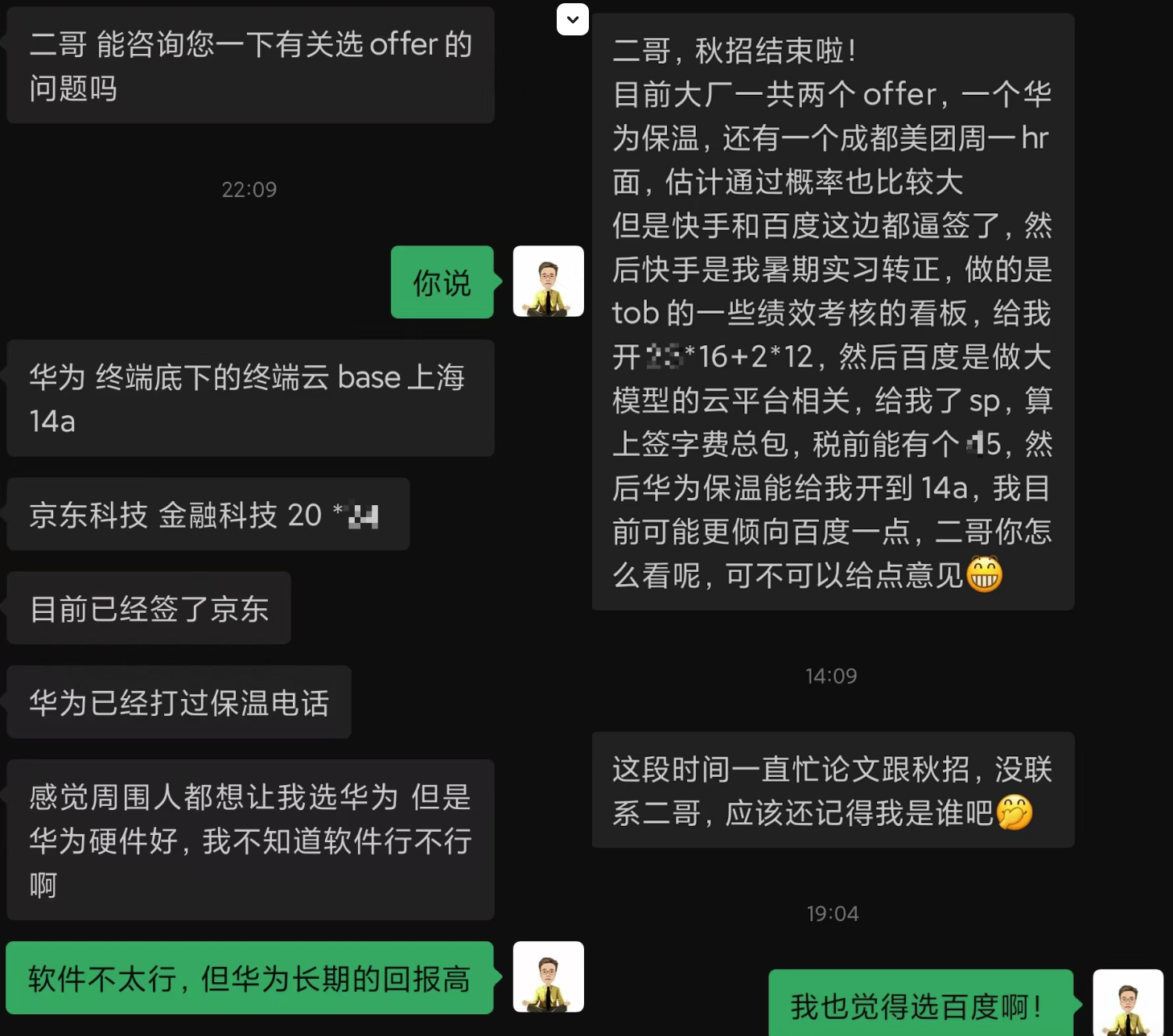
补充一些 25 届同学的 offer 截图,这些都是星球里的球友,他们的成功经历也是星球的成功(我骄傲了吗?嗯,骄傲了🤣)。
华为和京东、快手、百度、华为:
滴滴和百度、字节sp、美团、腾讯和京东、蚂蚁金服:

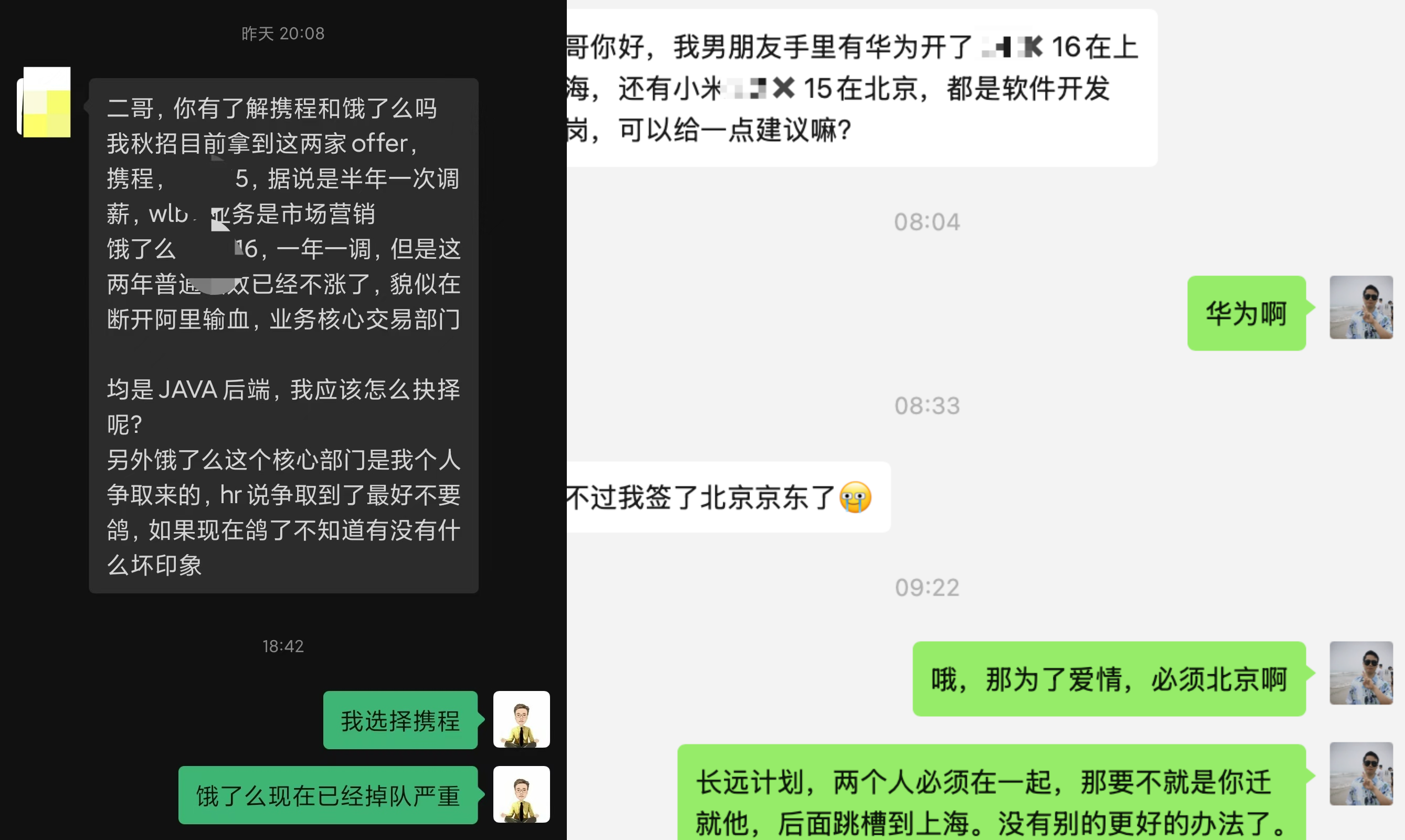
携程和饿了么、男朋友华为小米,自己京东:
太多太多,我就不一一列了。
记住一点,早就是优势,大家可以看一下这位球友的心路历程,是真的后悔没有早一点入,享受更多的优惠和更早的服务。
好,我们来进入重点。
1.1 核心面试点
- 其他考点1:https://t.zsxq.com/3yPsJ
- 考点 2:https://t.zsxq.com/eLDQ7
- 技术派拿到阿里云暑期实习的总结https://t.zsxq.com/KFCaf
- 消息丢失是怎么解决的?重复消费是怎么解决的?:https://t.zsxq.com/fm6uF
考点 0:项目介绍
技术派是一个基于 Spring Boot、MyBatis-Plus、MySQL、Redis、ElasticSearch、MongoDB、Docker、RabbitMQ 等技术栈实现的社区系统。
这个系统旨在为创作者提供一个可以发布文章和教程,并赚取佣金的社区平台,同时又兼顾一些社交属性,比如说用户可以通过阅读、点赞、收藏、评论的形式和作者互动。
与此同时,为了紧跟时代潮流,该系统还为用户提供了一套基于 OpenAI、讯飞星火等多家大模型的派聪明 AI 助手,帮助用户在工作和学习中大幅提效。
项目立意说一下,是否上线,上线考虑过用户数吗?
由于平常热爱技术分享,于是就萌生一个大胆的想法,做一个比 CSDN、掘金、知乎更厉害的内容社区,起名叫技术派。
技术派里面用到的都是互联网当下最流行的技术架构,骨架是通过 Spring Boot+Mybatis-Plus 搭建的,并且是前后端分离的,admin 端用的是 React + TypeScript,其中还用到了数据库 MySQL、缓存中间件 Redis、搜索引擎 ElasticSearch、nosql 数据库 MongoDB、容器化技术 Docker、消息中间件 RabbitMQ、权限安全框架 SpringSecurity、日志框架 Logback、 接口文档 Knife4j、及时消息通信 WebSocket 等技术栈,并且对接了当前最火热的 AI 大模型 OpenAI 和讯飞星火 API,项目支持一键启动和部署,这个过程让我的技术得到了极大的提升。
最近还对接了微信支付和支付宝支付,以及文章付费阅读的功能,感觉有一个属于自己的实战项目可以不断地迭代,锤炼自己的技术,这个过程还是蛮有意思的。
我们的技术派已经上线,域名是 paicoding.com,你也可以参考其他球友的,比如说编程汇,比如说http://user.vauni.top/、http://paicoding.nat300.top/、http://serendipityspace.top/、https://codewander.online/
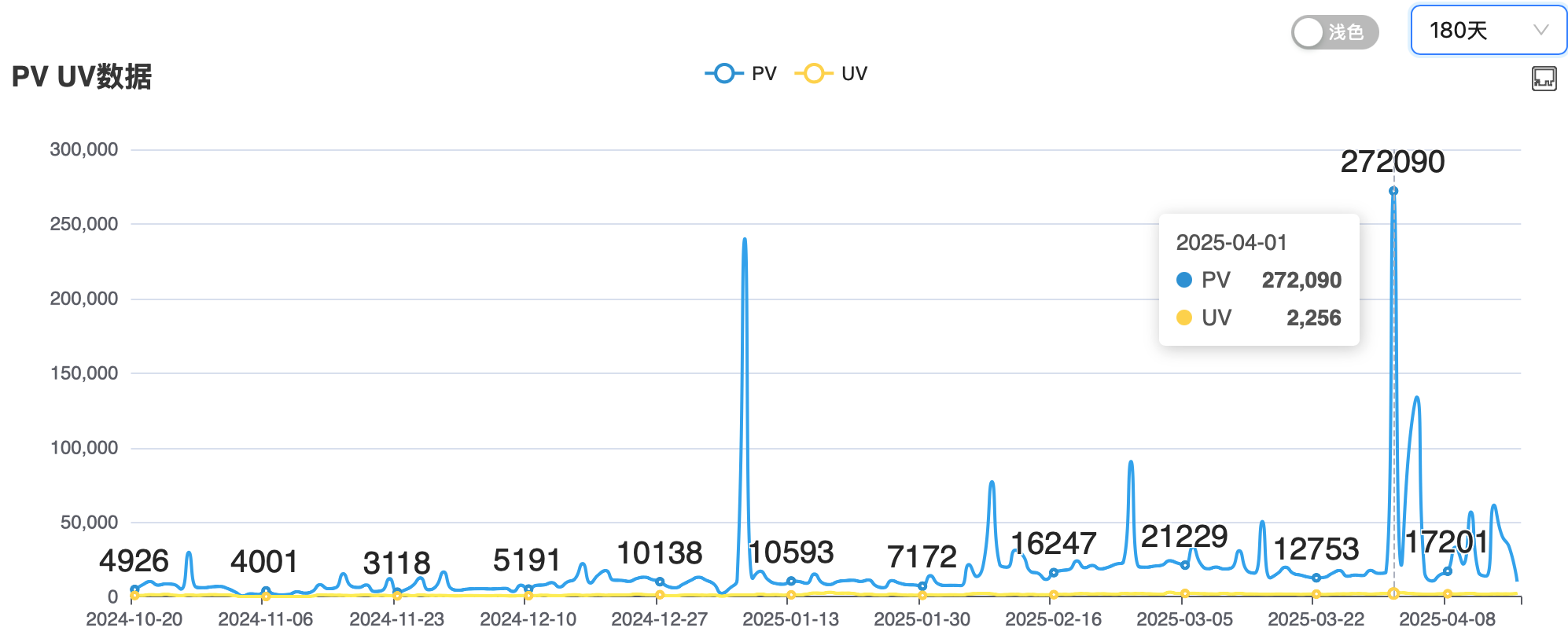
目前注册用户 10000+,PV 最高达 27 万,平均也有日访问量也有 10000+。
在项目中主要负责什么?
技术派是和三个宿友做的,我主要负责后端的接口开发,一名宿友负责前端,还有一名宿友负责 admin 端。
技术派是一个前后端分离的单体项目(主要用到的技术栈看上一个问题),本来二期是想做微服务改造的,后来我就想,不如直接再做一个新的业务吧,项目管理、OA 审批属于很多公司都会商用的项目,于是就又一起做了这个 PmHub,同样是我们三个人,我还是负责项目搭建、后端接口开发。
PmHub 是一个微服务项目,主要用到了 Spring Cloud、Nacos、Gateway、Seata、Sentinel 等技术栈。
具体开发的功能有哪些?
1、整体前后端分离骨架的搭建,后端用的 Spring Boot+MyBatis-Plus+Redis+RabbitMQ,Admin 管理端用的 React,用户端用的 Thymeleaf。
2、使用 JWT + Session + Filter + AOP 完成用户登录和权限校验,支持微信扫码登录
3、作者使用 Markdown 发布教程、文章,图片会自动上传至 OSS 并使用 CDN 分发,用户可以点赞、收藏、评论,并且使用 RabbitMQ 进行异步消息处理
4、对接deepseek、讯飞星火、智谱 AI、字节豆包、阿里通义、OpenAI 等多家大模型,完成派聪明 AI 助手功能的开发,使用了策略模式和工厂模式,新增模型时非常简单,并通过 WebSocket 和 Stream 流实现及时通信和消息一点一点输出的效果
5、使用 Redis 实现作者白名单和用户活跃榜单,并且对热点数据进行缓存,为了提高缓存效率减轻 Redis 压力,还增加了本地缓存 Caffeine 作为二级缓存
6、借助 xxl-job 实现文章定时发布,ES 实现快速高效的文章查询等等。
遇到过最深刻的问题,怎么解决的?
遇到最深刻的一个问题是,如何解决高并发情况下,大量用户同时访问同一篇热点文章,在缓存未命中的情况下,大量请求会同时访问数据库,对 DB 造成极大的请求压力,很容易将我们的 MySQL 打宕机,进而影响整个服务,这个时候该怎么办?
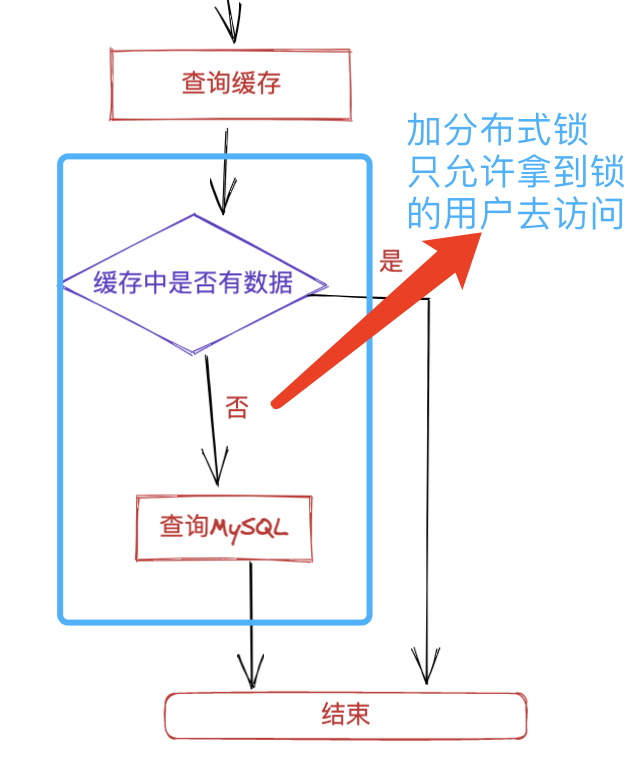
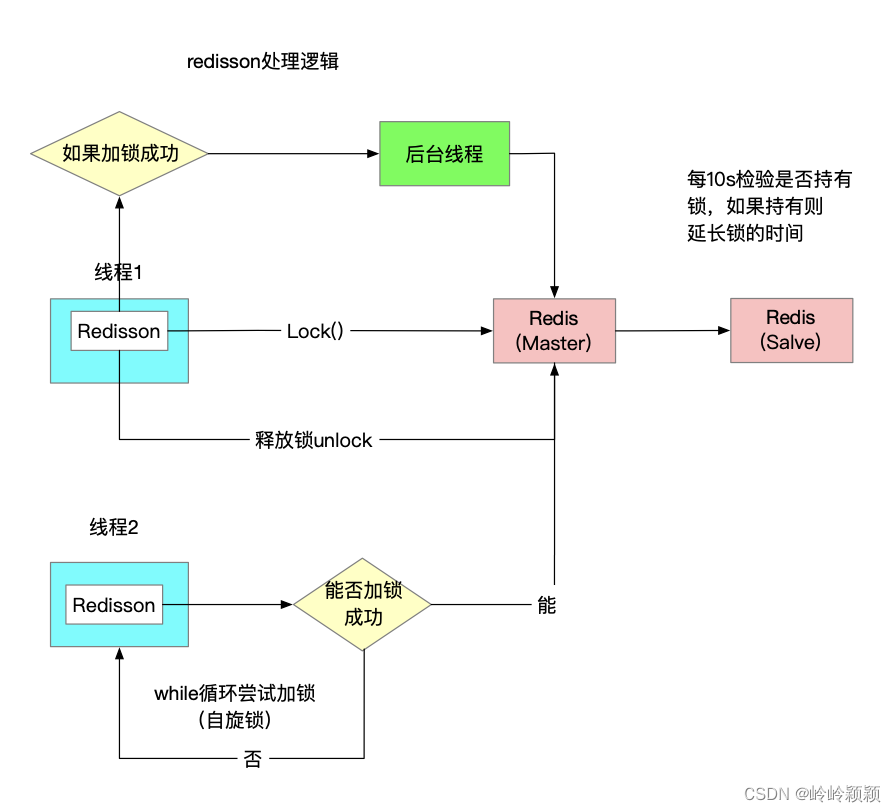
一开始尝试通过 Redis 的 setIfAbsent(key,value,time)手动释放锁,但遇到了锁不能及时释放的问题、误释放别人的锁,以及过期时间的设置是否合理等问题。
最后还是通过引入 Redission 的看门狗算法进行解决,这样就可以一劳永逸了,不过手动尝试的方式的确也让我对看门狗算法有了一个更深入更直接的了解,它的内部实现也是按照我之前手动的逻辑实现的,起一个定时任务,每 10 秒检查一下锁是否释放,如果没有释放就延长至 30 秒。
项目中有哪些亮点?
第一,技术派的模块划分非常清晰,paicoding-api 定义了模块间通信的契约,包括 DTO、VO 以及通用的枚举和实体,确保模块间的低耦合。paicoding-core 是我们的核心工具和组件库,沉淀了大量可复用的功能,比如我们自研的缓存组件、搜索服务、推荐引擎等。paicoding-service 是业务逻辑的核心实现层,负责处理所有的业务逻辑和数据库操作。paicoding-web 作为整个应用的入口,负责处理 HTTP 请求、用户认证、权限校验、全局异常处理等。
这种清晰的模块划分,使得我们的项目结构非常规整,易于维护和二次开发,也为团队协作提供了便利。
第二,在技术选型上,我们紧跟业界前沿,选择了一系列在大型互联网公司(比如阿里,你面哪家说哪家)得到广泛验证的成熟技术:
MySQL 作为主业务数据库。Redis 用于缓存热点数据,减轻 MySQL 压力,并实现了热门文章排行榜等功能。Elasticsearch 提供了强大的全文检索能力,保证用户可以快速、准确地找到所需内容。我们还通过 Canal 实现了 MySQL 和 ES 之间的数据准实时同步。MongoDB 用于存储一些非结构化的数据,发挥其灵活的文档模型优势。
我们还引入了 RabbitMQ 消息队列,将耗时的操作(如发送邮件、系统通知等)异步,提升系统的响应速度和吞吐量。
为了紧跟 AI 时代浪潮,我们还集成了派聪明 AI 助手,基于大语言模型为用户提供智能问答服务。通过策略模式可以无缝切换阿里通义千问、DeepSeek 等多家模型。
另外,我们使用 Docker 为项目提供了完整的容器化部署方案,配合 Nginx 进行反向代理和负载均衡,实现了项目的一键部署和弹性伸缩。
“技术派”拥有一套完整的社区业务闭环,涵盖了从用户注册登录、文章发布、教程学习、搜索查询、评论互动到后台管理的全流程。
在工程实践上,我们同样追求卓越:项目支持 dev 、 test 、 pre 、 prod 四种环境,通过 Maven Profile 可以一键切换。它沉淀了大量在真实开发场景中总结出的最佳实践,比如缓存一致性方案、数据库与搜索引擎的同步策略、异步任务处理等,这些都是非常有价值的实战经验。
通过这个项目,我不仅深入掌握了上述提到的各项技术,更重要的是,我学会了如何从一个系统性的、工程化的角度去思考和解决问题,这正是一个优秀的工程师所需要具备的核心素养。
项目中有哪些难点,如何解决?
在技术派这个项目当中,遇到了蛮多有挑战的任务。
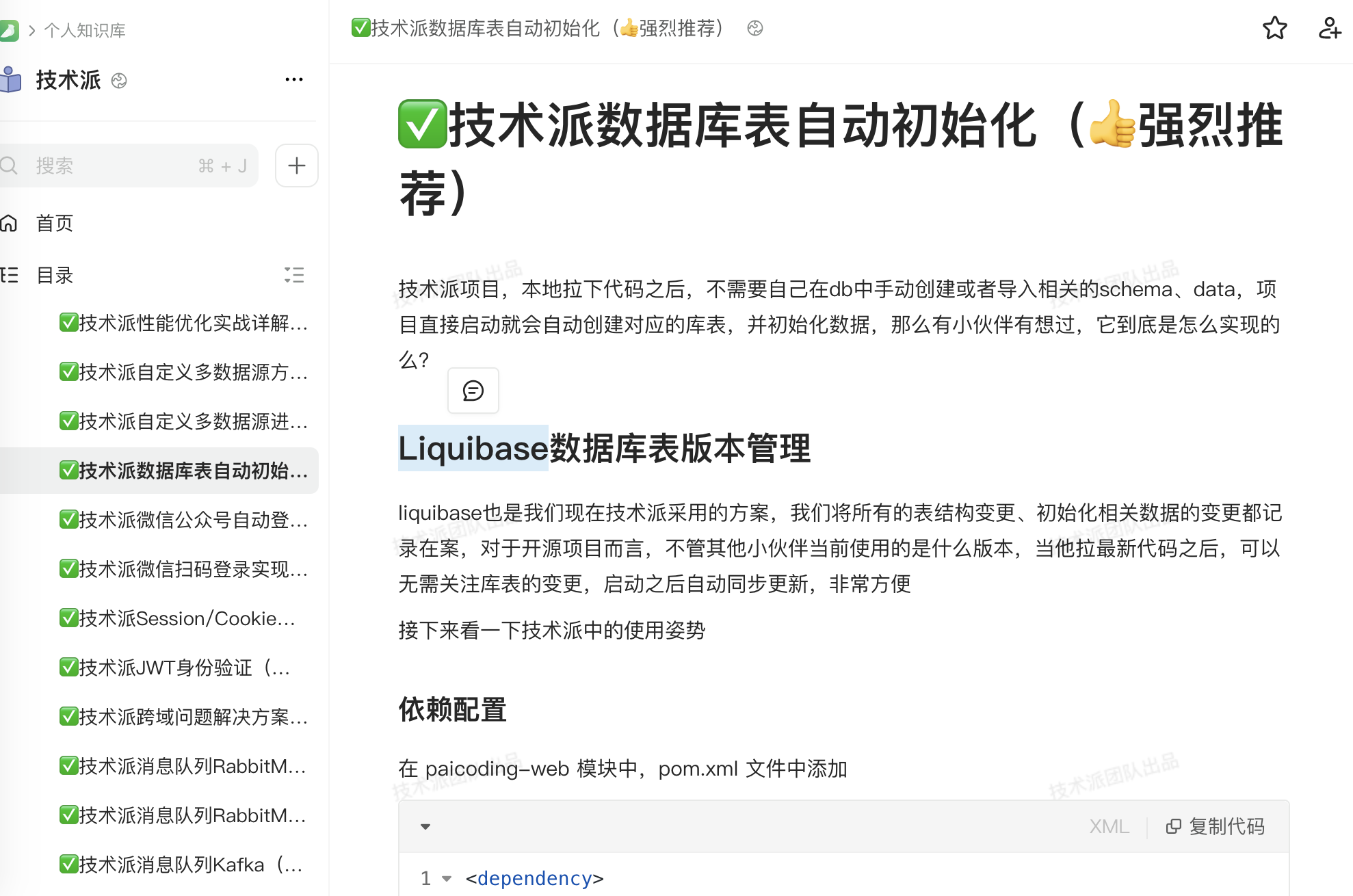
比如说 MySQL 的库表自动初始化,用户在启动项目前不需要手动导入 SQL 文件,只需要在 application.yml 中配置好 MySQL 的用户名和密码,run 以下 main 类,就自动完成了。这个是通过 Liquibase 实现的。
再比如说技术派是一个前后端分离项目,admin 端请求后...
企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

53人已点赞
热门评论
60 条评论
回复