


Agent项目PaiFlow能让大家学到什么?企业级AI Agent工作流平台实战教程
大家好,我是二哥呀。
PaiFlow,中文名我们叫他派派工作流,叠字听起来是不是蛮亲切的?😄
亲切就对了。这是一个企业级的 AI Agent 工作流编排平台,支持用户通过可视化方式编排大模型节点、工具节点和流程逻辑等。面试题交付部分包括架构设计、工作流引擎、Docker 容器、插件服务(MCP 前身)、Redis&MinIO&MySQL、微服务、Agent&Skills、设计模式、SSE、并发编程、SpringAI、大模型&Prompt、LangGraph4J 等(大家求职面试的重中之重)。
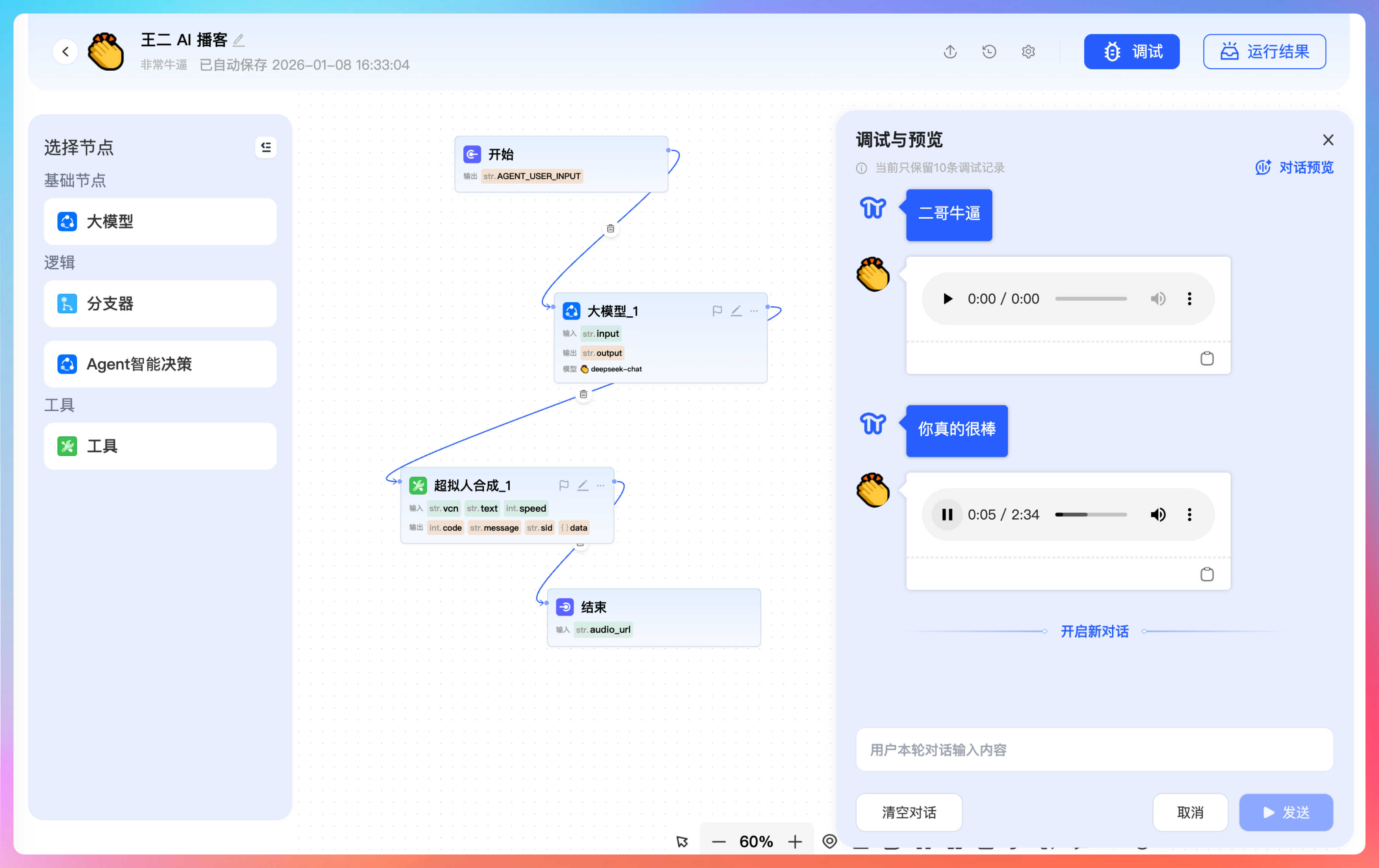
为了让大家能尽快上手,第一期我们主要交付这个工作流——用户输入一段主题,大模型会将其转换为播客风格的文本,再经过 TTS 将其转换为音频内容,主要包括四个节点:输入→LLM→超拟人音频合成→输出。
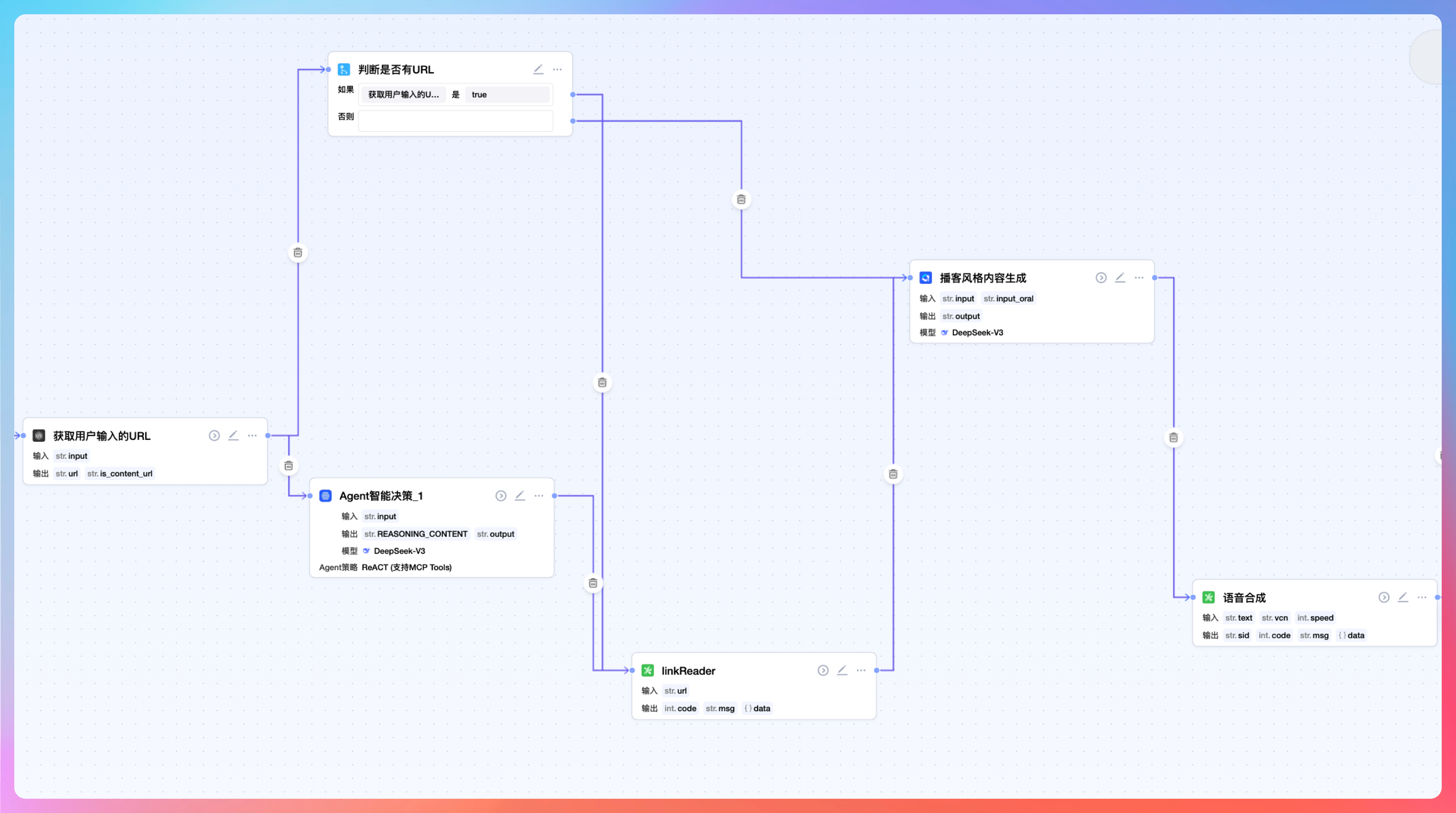
第二期,我们会在此基础上实现更复杂的流程编排(OCR 识别、代码分支、RAG 知识库、Agent 智能决策、MCP 等等【代码已经实现,第一期交付完就开始更新】),毕竟二哥的目标是对标 dify、coze 和 n8n 这些知名产品。
AI 时代,大家都在被时代洪流裹挟着前进,不得停息。从 2025 年 9 月份立项 PaiFlow,我就开始不停的肝教程,每天所有的空闲时间都扑在这个项目上,但依然到 2026 年 1 月份整体的教程才趋于完善,足足五个月啊。
为了让大家在求职/晋升的时候有更多的话语权,我只能加速冲刺。我能保证的是,目前交付的教程和源码,足够大家在 AI 时代拿下一个大 offer,就像派聪明RAG上架时一样。相信你看完这篇内容也会笃定这一点。
希望第二期,大家能多给我们一点时间撰写教程,星球里其实已经有 Spring Boot+React 前后端分离的技术派、微服务 PmHub、RAG 派聪明、轮子 MYDB 等系列项目,足够大家求职的时候(日常实习/暑期实习/春招/秋招/社招)拿到满意的 offer。
当然了,每个人都有欲望,大家想要更多的优质项目。其实我也迫切地想,假如一年能上他 10 个实战项目(真想克隆几个自己,狠狠肝教程😄),相信大家也会学到更多的同时,更加倾尽全力地推荐二哥给学弟学妹们(嘿嘿)。
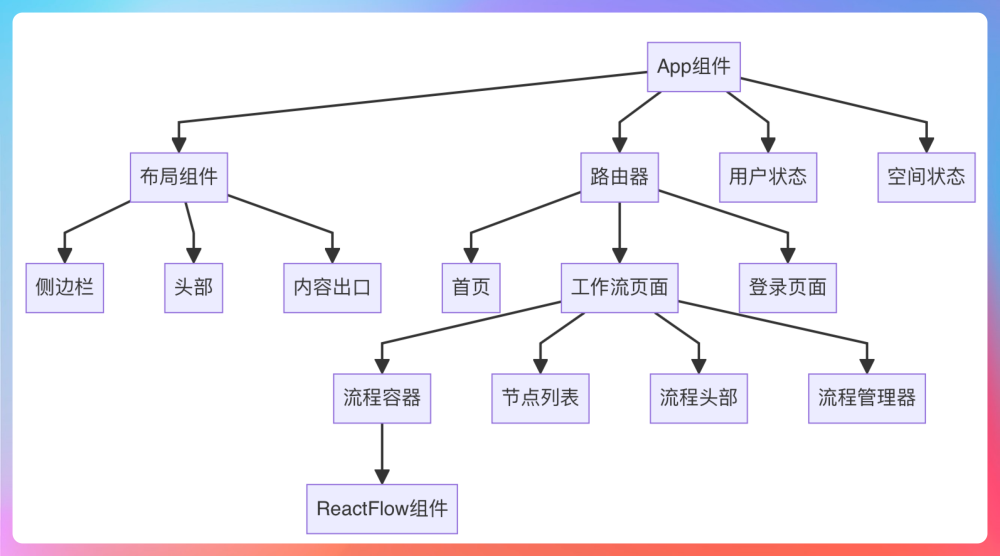
一、PaiFlow的架构
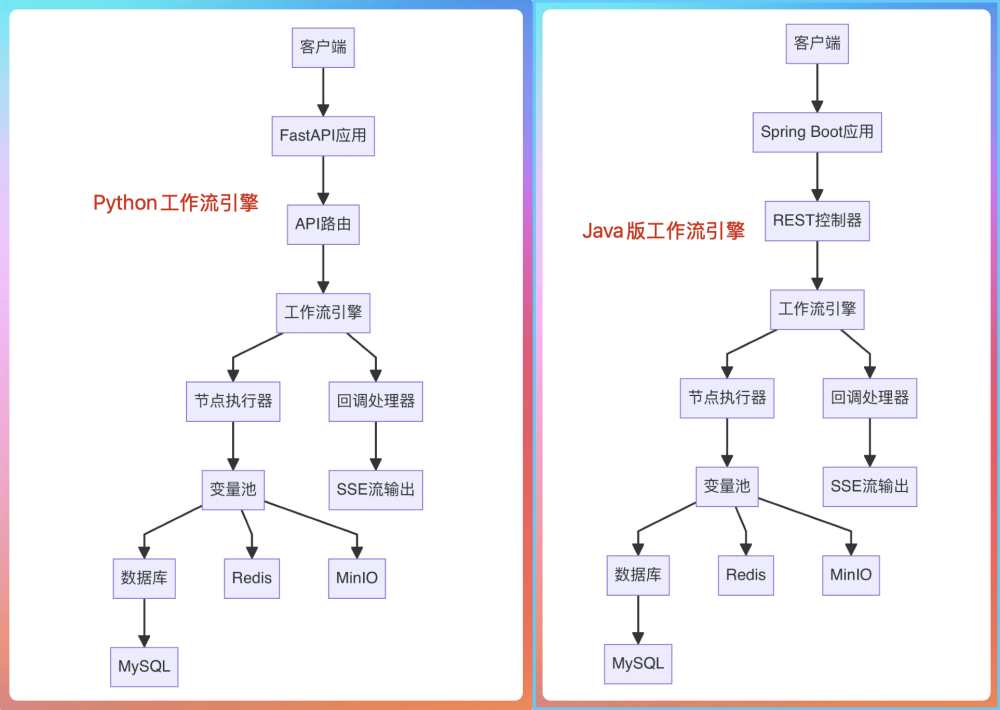
整体来看,PaiFlow 的架构可以拆成四层:前端表达层、控制台中枢层、工作流执行层,以及底层基础设施层。
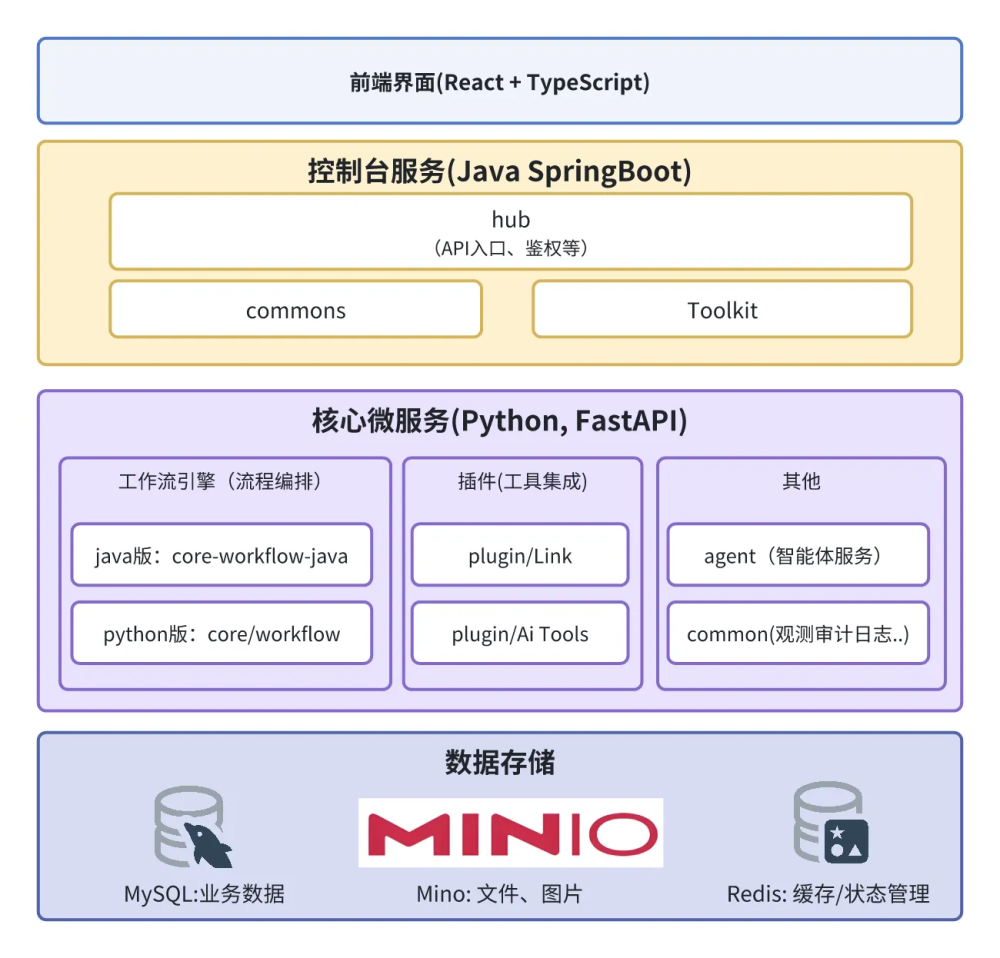
前端使用 React + TypeScript 实现,承担用户和后端交互的职责。用户可以编排工作流、配置节点参数、执行工作流、查看运行状态和日志等。当用户点击【发送】按钮时,前端会把整个工作流转化成一份结构化的 DSL 发送给 hub 中枢,并等待 hub 给出响应(异步流式)。
tips:在低代码平台中,DSL(Domain-Specific Language)被用于以声明式或可视化的方式定义用户界面和交互行为。
后端采用的是微服务构架,Hub 负责业务管理和系统控制,包括用户鉴权、大模型和插件的统一管理、流程元数据的维护,以及工作流的执行调度等等。你可以把 Hub 理解成 PaiFlow 的“大脑皮层”。它负责判断谁可以执行哪一条流程、在什么条件下执行、执行时需要哪些资源。
想要更深层次学习微服务的球友,可以去学习一下:PmHub 项目
所有“执行相关”的事情,都会被 Hub 下发给专门的工作流引擎。
工作流引擎是 PaiFlow 最核心,也是最复杂的部分,既有 Python 版本,也有 Java 版本。主要负责 DSL 的解析与校验、节点的调度与执行顺序控制、上下文和参数的管理、链路的拓扑解析,以及执行过程中状态的变更和事件推送。也是第一期教程交付的重点。
你启动 Python 版工作流引擎,hub 就会自动将工作流的执行请求发送到 core 模块下的 workflow、aitools 和 link 服务;你启动的是 Java 版工作流引擎,hub 就会自动将工作流的执行请求发送到 core-workflow-java 模块下,并等待返回。
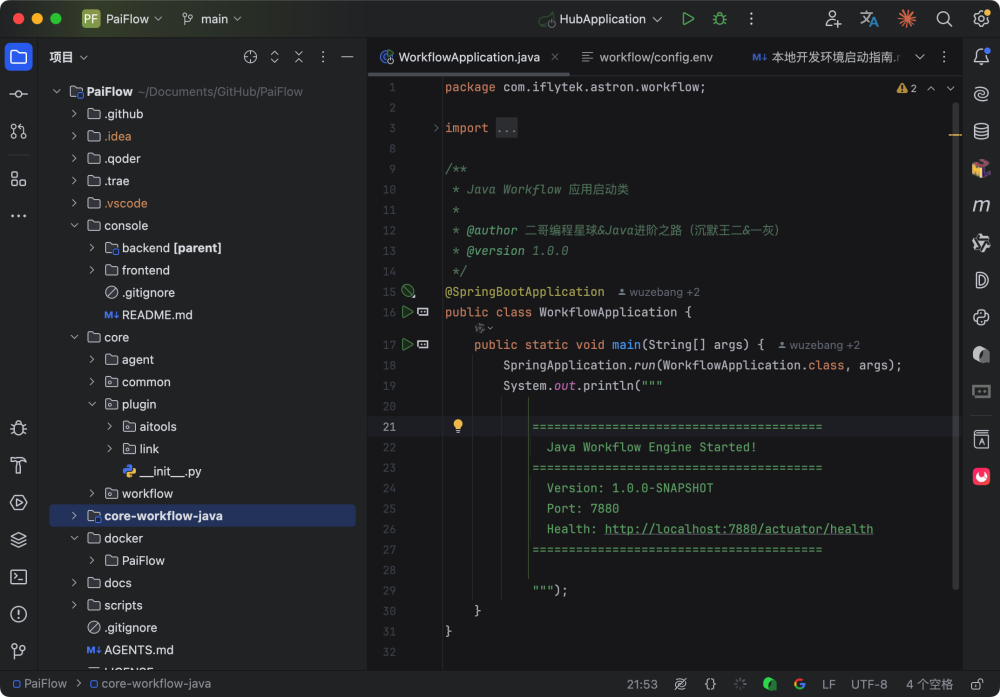
hub 不关心工作流最终由谁执行,它只负责调度和路由;真正的执行能力,是可以被替换、演进甚至并行存在的。后面我们打算再出一个 Go 版本的工作流引擎,和 Go 版的派聪明呼应起来,给学 go 的球友再增加一个选项。
基础设施层我们用到了 MySQL(持久化流程元数据和执行状态)、Redis(缓存上下文、运行状态、事件路由)和 MinIO(存储音频文件)等。
这里必须要感谢一下科大讯飞的 astron-agent 项目,2025 年 9 月份和他们有一次合作,动手尝试把这个项目跑起来编排了一个 AI 播客,感觉和当前的 Agent 市场需求非常契合,再加上球友们的诉求比较强烈(除了派聪明 RAG 项目外,迫切需要另外一个 AI 实战项目),于是我就萌生了一个大胆的想法,自己做个吧!
于是折腾了一个多月,项目也有了雏形,可以实现输入节点→LLM 节点→超拟人音频合成节点→输出节点这个工作流。项目名暂定为 PaiAgent,和 PaiFlow 算是同期进行,教程完稿后也会一并上架给大家(敬请期待)。
先上 PaiFlow 而不是 PaiAgent 主要考虑到:
一,前端我不擅长,但我又想呈现给大家一个比较漂亮的前端体验。用户体验这一趴必须要重视,因为大家对一个项目有没有印象,第一眼看到后的感觉很重要。技术派之所有这么长的生命周期,就是因为他的配色和页面布局,在 2023 年推出的时候足够震撼。
二,星球里有一部分球友迫切想要 Python 版的实战项目(毕竟 Java 和 Go 的项目咱都有了)。既然球友们有诉求,咱就必须要满足。后面还想尝试把前端的教程也搞起来,这样就齐活了,哈哈,野心咱必须有。
于是我就想,不如在 astron-agent 的前端交互基础上,新增一版 Java 版的工作流引擎,再加上我们精心为大家准备的 20 多万字教程,能更快交付给大家,能让大家把握住春招/暑期实习/年后跳槽这个窗口期。
好好好,非常好。就这么干。
这一干不要紧,前后花了三个多月时间,难度远超我的想象,从 9 月份开始, 一直到 12 月中旬代码部分才告一段落,然后我又开始马不停蹄的肝教程,熬夜又成了家常便饭,上次肝派聪明 RAG 的教程,最后熬感冒了,咳嗽了俩月才好。
但派聪明 RAG 上架后,大家如潮水般的好评,又让我觉得这一切的付出都是值得的,星球也快速增长到了 11000+ 人。大家斩获满意的 offer,我收获名望和财富,哈哈哈。不错不错,真不错。
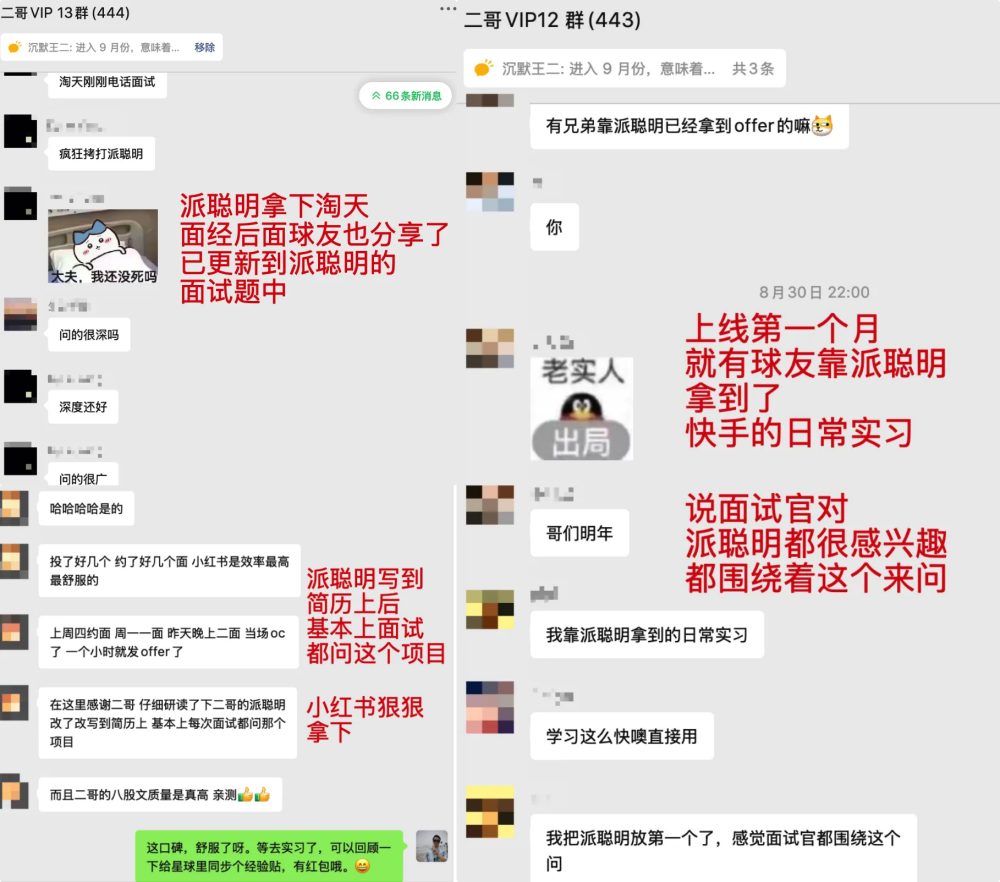
贴一点派聪明的证据
我相信,派派工作流这个项目一定能不负众望(成语没用错吧,用错就搞笑了)!看一眼 PaiFlow 写到简历上的部分内容吧,都是 AI 时代强需求的技能点,所向披靡没问题👍。

用星球嘉宾一灰的原话就是,派派工作流涉及的东西很多,深度广度都很大:设计模式、数据结构、架构思想、工程能力、AI 技术栈,全都涉及了,随便一个都可以聊很久聊很深(让面试官和 HR 对你刮目相看,一眼就相中你)。
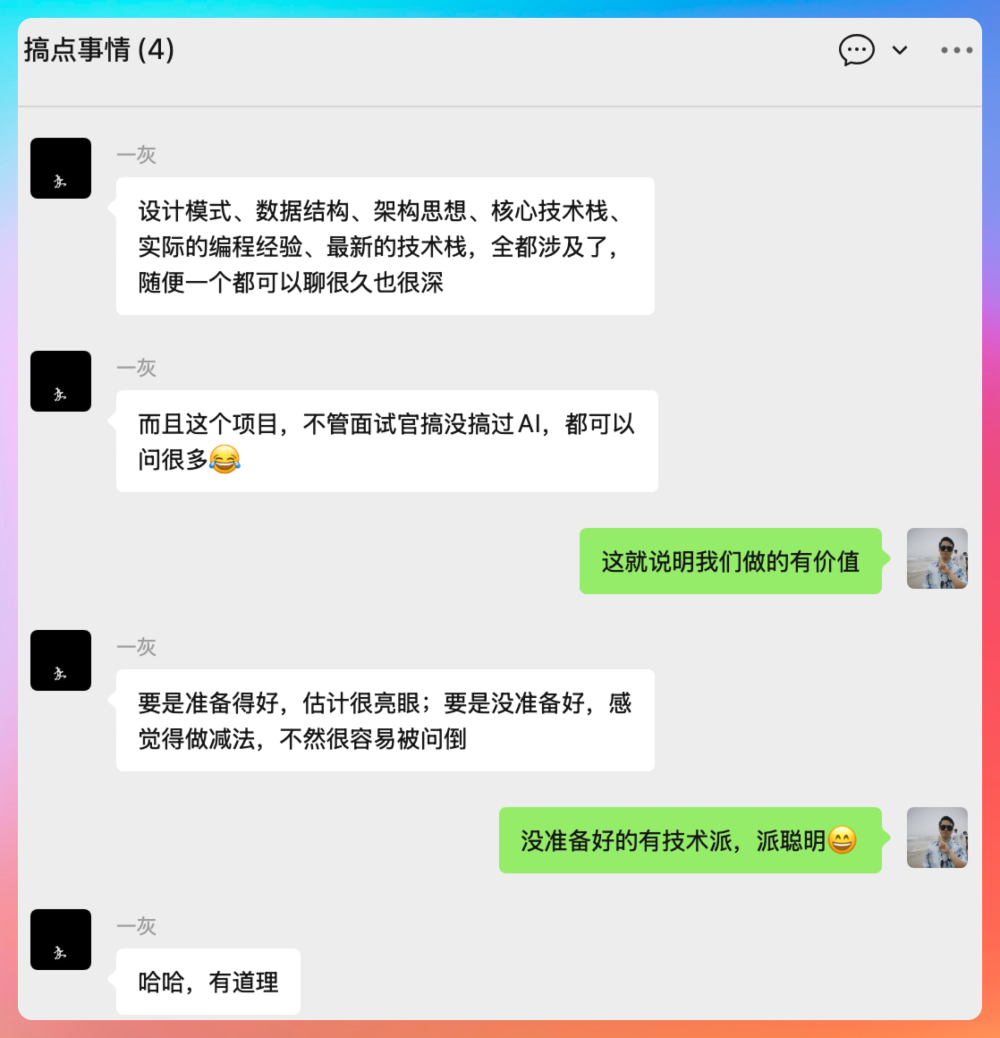
并且这个项目,不管面试官搞没搞过AI,都可以问很多。强烈推荐有实力的球友挑战一下自己(我相信球友们一个比一个有实力),如果能够吃透我们的教程和源码,那基本上不管是社招党跳槽,还是学生党秋招/春招/日常实习/暑期实习,都很无敌。
目前来星球的,从我修改过的简历来看,学历都很硬(五湖四海皆有,这也再次印证二哥的口碑刚刚的),所以我相信大家一定有能力掌握这个项目,并且战无不胜!我们开冲吧!

二、Python和Java双工作流引擎
第一期我们重点交付的是工作流引擎部分。所以我们重点介绍一下这部分。两套引擎解决的是同一个问题:把一条 DSL 描述的工作流,按照既定顺序执行完,并且把过程完整地记录下来,并实时返回给前端。
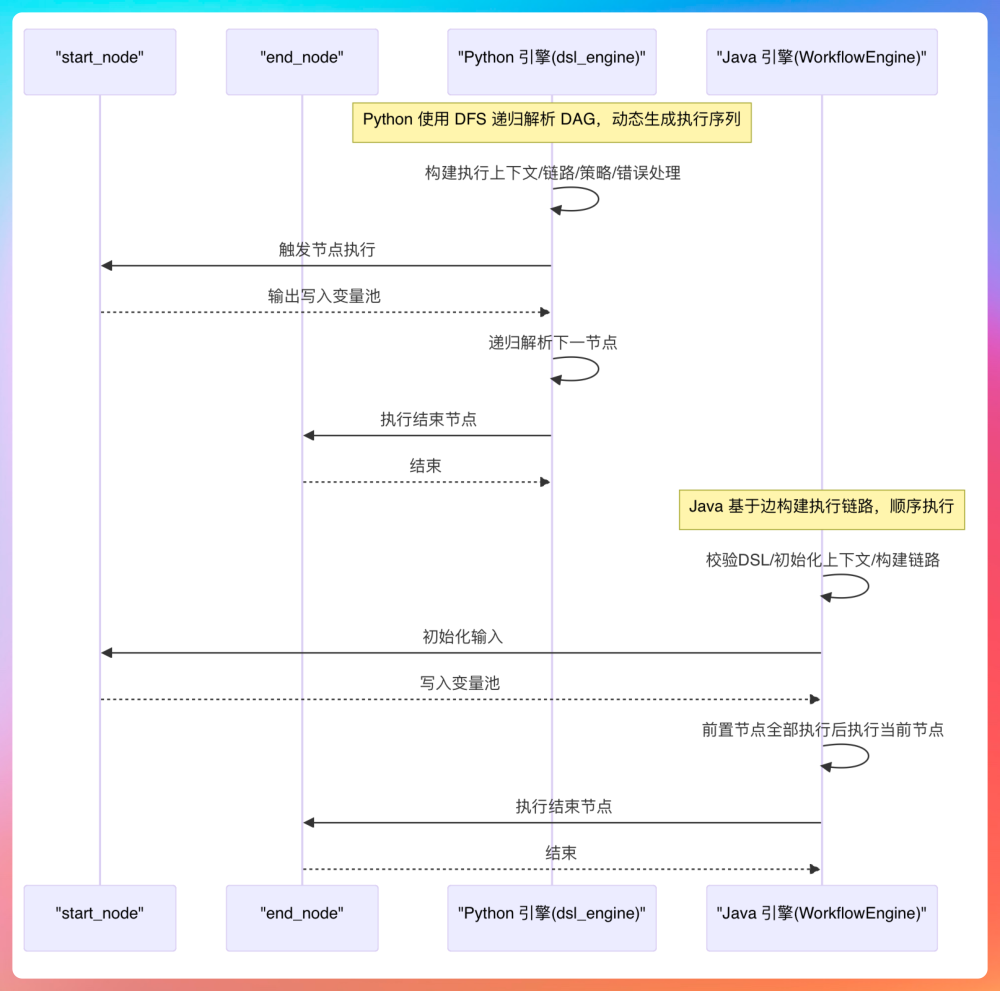
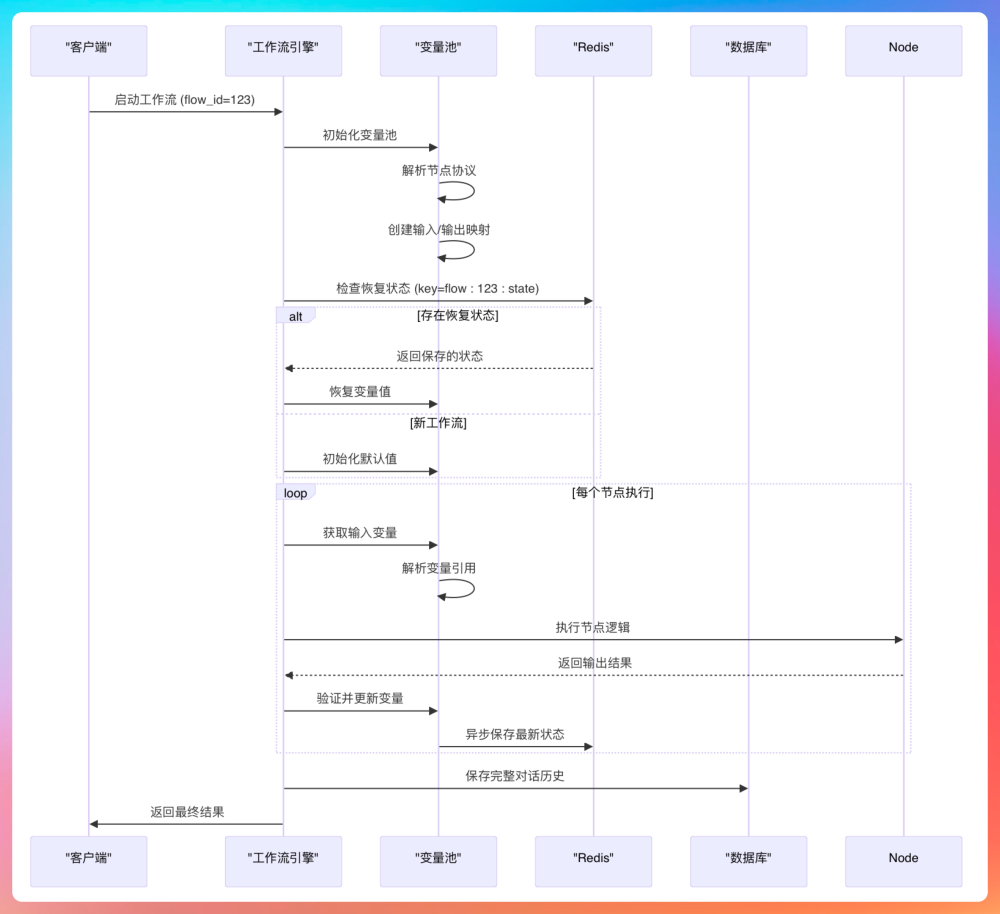
Python 版的工作流引擎是基于 FastAPI 框架构建的,采用的异步编程模型。依赖包括 Uvicorn、Pydantic、SQLAlchemy 等。Python 版的执行链路如下图所示,你可以很直观地看到一条工作流是如何被解析、节点是如何被依次调度、执行结果又是如何通过 SSE 实时回传给前端的。
Java 版的工作流引擎是基于 JDK 21+Spring Boot 3.5+SpringAI 1.1+LangGraph4J 构建的(目前最稳定的版本组合),采用多线程并发模型。持久层框架为 MyBatis-Plus 3.5, HTTP 客户端为 Okhttp 4.12,JSON 序列化和反序列化为 Fastjson2 2.0。
Java 版本重点关注:工作流如何被解析成 DSL、节点之间的依赖关系如何被调度、执行过程中的上下文和变量如何传递、执行状态如何被持久化和回传、执行失败时系统如何感知、处理和恢复。
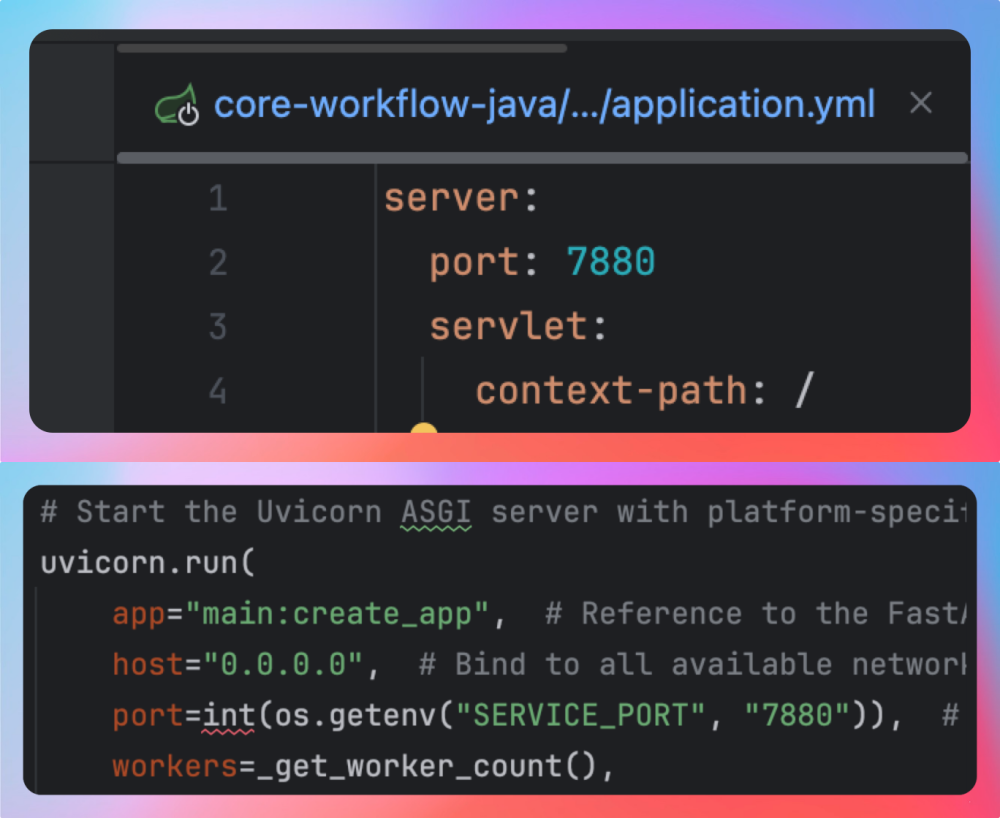
我们把 Python 版的入口 port 和 Java 版的入口 port 改成了一个,都是 7880。这样的好处是,不用刻意去改配置就可以切换到另外一个版本发起工作流调用,hub 微服务向下是无感知的,对新手比较友好。
接下来,我们把视角聚焦到 Java 版的工作流引擎实现上。
三、Java版工作流引擎介绍
01、core-workflow-java
core-workflow-java 是一个标准的 Spring Boot 微服务工程,外部请求从 Controller 进来,工作流的调度逻辑放在了 engine 包。整体的目录结构如下所示:
core-workflow-java/
├── src/main/java/com/iflytek/astron/workflow/
│ ├── WorkflowApplication.java # Spring Boot启动类
│ ├── controller/ # REST API控制器层
│ │ ├── WorkflowController.java # 工作流执行API
│ │ ├── WorkflowDebugController.java # 调试API
│ │ └── WorkflowFrontendController.java # 前端兼容API
│ ├── engine/ # 工作流引擎核心层
│ │ ├── WorkflowEngine.java # 工作流执行引擎
│ │ ├── VariablePool.java # 变量池管理
│ │ ├── constants/ # 枚举常量定义
│ │ ├── context/ # 上下文管理
│ │ ├── domain/ # 领域模型
│ │ ├── integration/ # 外部系统集成
│ │ ├── node/ # 节点执行器
│ │ └── util/ # 工具类
│ ├── exception/ # 异常处理层
│ ├── flow/ # 工作流服务层
│ └── config/ # 配置类
└── src/main/resources/
└── application.yml # 应用配置文件
02、核心组件
入口是 WorkflowApplication,负责启动 Spring Boot,并指定包扫描范围。
@SpringBootApplication
@ComponentScan(basePackages = "com.iflytek.astron")
public class WorkflowApplication {
public static void main(String[] args) {
SpringApplication.run(WorkflowApplication.class, args);
}
}
工作流相关的外部调用通过 Controller 层进入,WorkflowController:标准的工作流执行接口,WorkflowDebugController:调试和测试接口,WorkflowFrontendController:前端兼容接口。
engine 包负责工作流的运行时逻辑,其中WorkflowEngine 负责调度和执行链路,VariablePool 是变量池,管理节点间的数据传递;NodeExecutor 是节点执行器,提供节点执行的标准接口;Callback 用于实现状态推送机制。
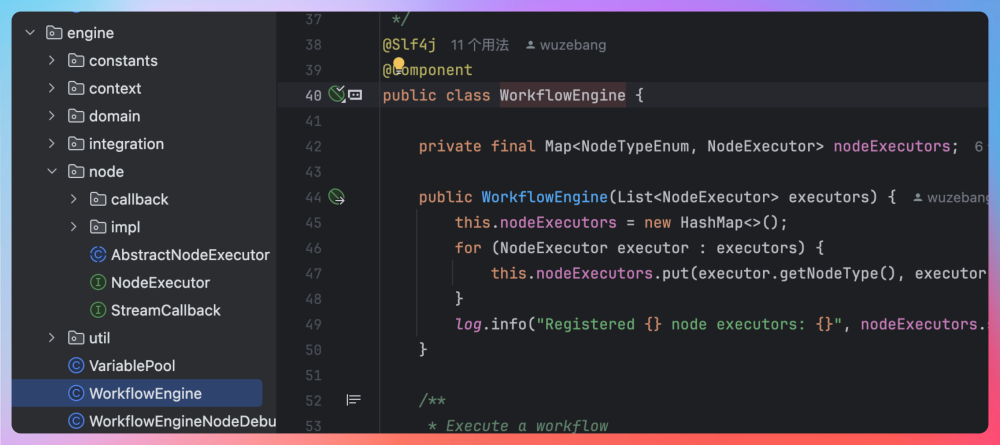
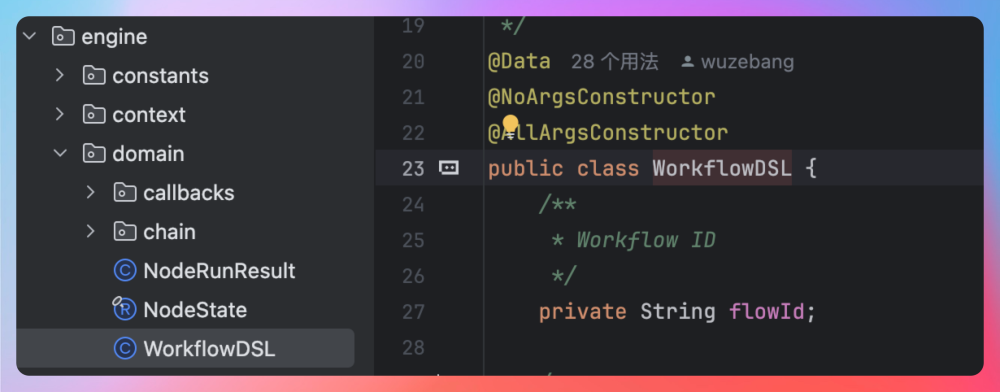
domain 包定义工作流的数据结构,其中 WorkflowDSL 表示 DSL定义;Node 表示节点;Edge 表示边;NodeData 表示节点数据和配置,包含 nodeType、nodeParam、inputs、outputs 等。
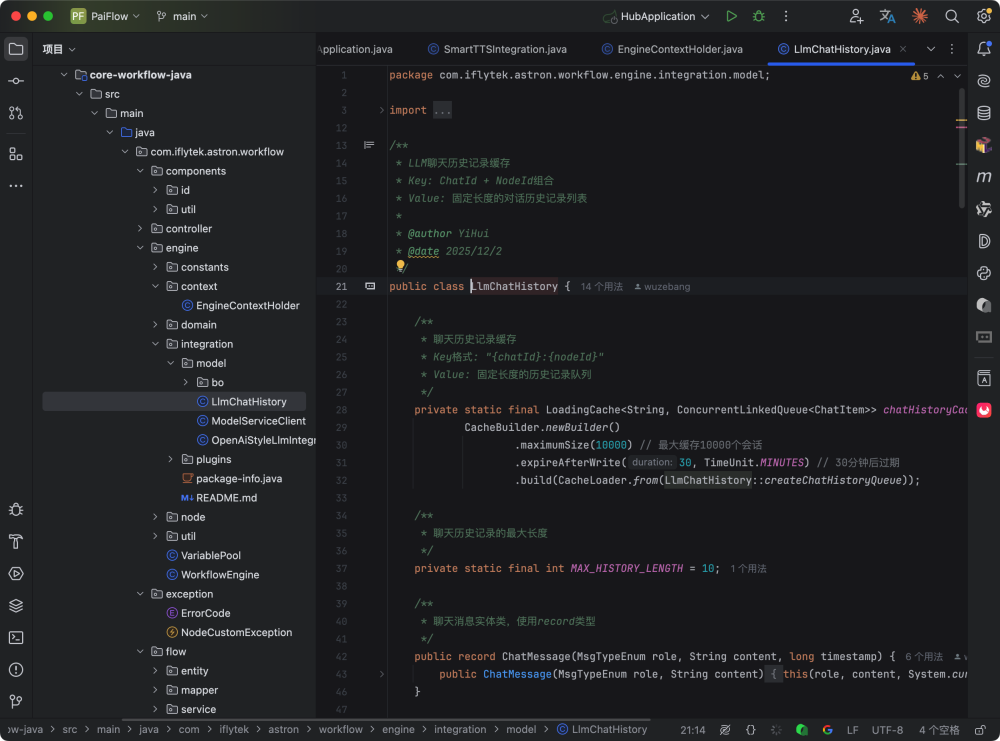
integration 包负责和外部系统交互,例如 LLM 节点集成、Plugin 插件集成、TTS 语音合成、聊天历史记录等。
四、Java版工作流引擎架构设计
在真正动手实现 Java 版工作流引擎之前,我们得先想清楚一个问题:工作流引擎是什么,到底让它来干嘛?
在派派工作流的预期场景下,工作流引擎要在一个请求的生命周期内,完成以下几件事:
根据 DSL 动态构建执行链路
数据能在多个节点之间正确传递
支持同步 / 异步 / 失败等分支的不同执行路径
能把状态实时推送给前端,让用户看到工作流当前的执行状态
基于这些目标,我们的工作流引擎架构是这样设计的。顶层为 API 层,对外提供 REST、调试、前端兼容三种接口。中间是服务编排执行层,负责解析 DSL、验证并调度任务,并将 DSL 存入 MySQL,方便持久化、调试和回放。
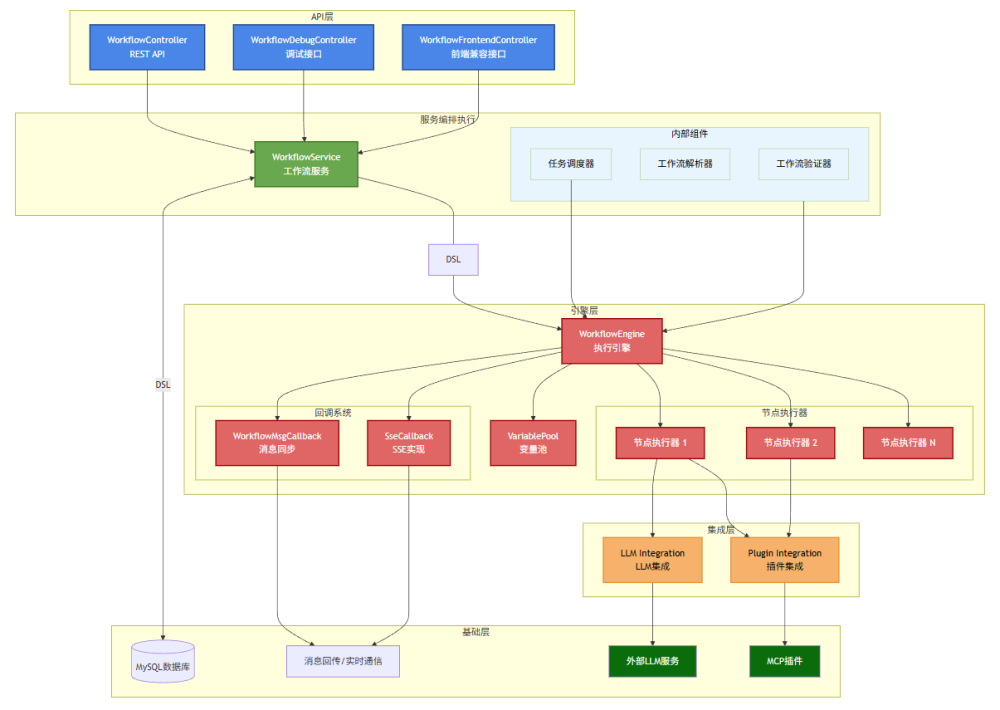
再往下是引擎层,负责推进流程,维护变量池,驱动一系列可插拔的节点执行器。不同的节点执行器负责处理不同类型的节点,比如 LLM 节点、TTS 节点。如果还需要外部交互,比如集成第三方的插件服务,包括 MCP 插件,会放在集成层完成。
为了让前端能实时看到执行过程,系统还设计了回调链路,通过消息同步和 SSE,把节点状态和输出实时回传。底层的基础设施主要包括 MySQL、Redis、MinIO、消息队列等。
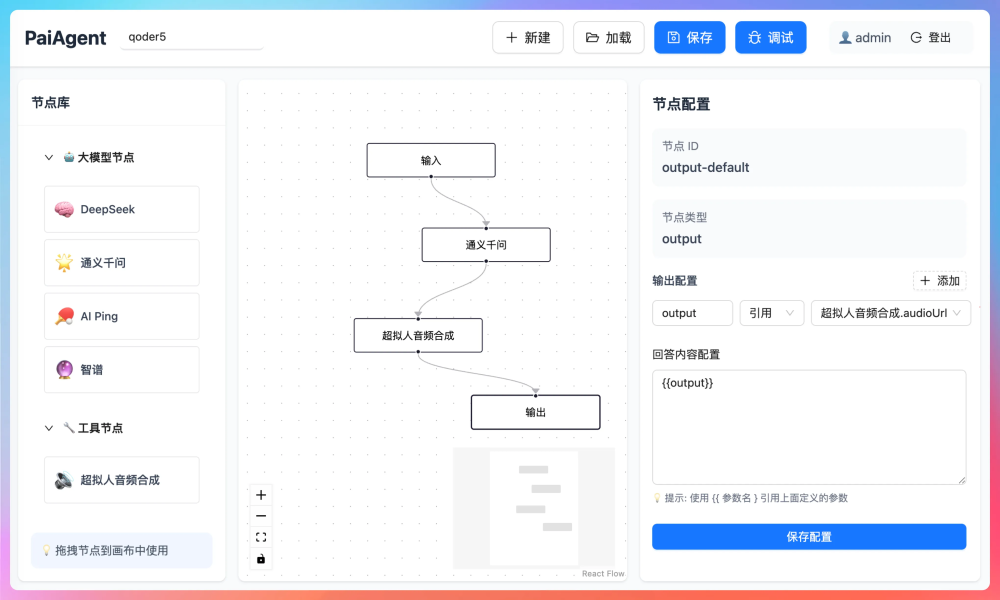
01、WorkflowEngine
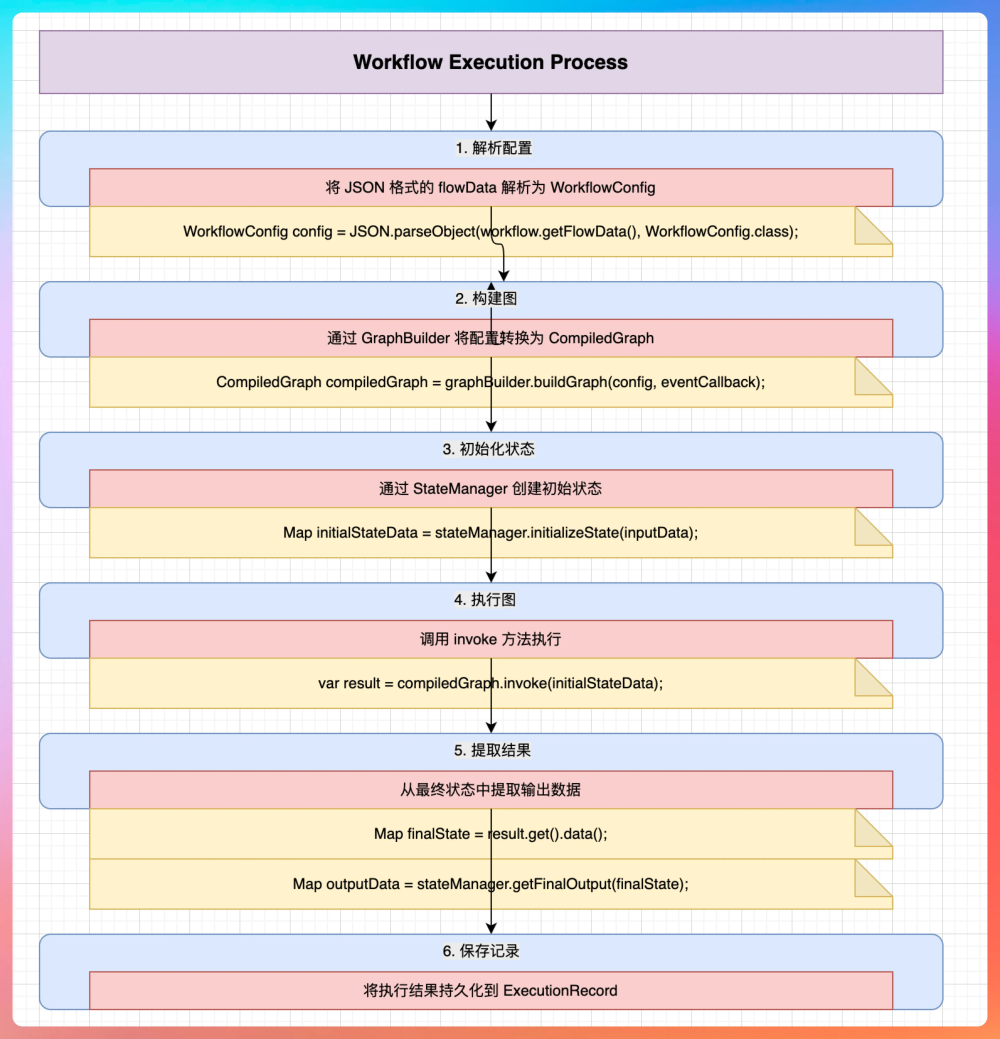
WorkflowEngine是整个引擎的核心组件,负责解析 DSL(JSON 格式的工作流)、构建执行链路(根据节点和边的关系构建)、按照依赖关系驱动节点执行、并在关键阶段触发回调,把执行过程中的状态和输出推送出去。
核心方法为 excute:
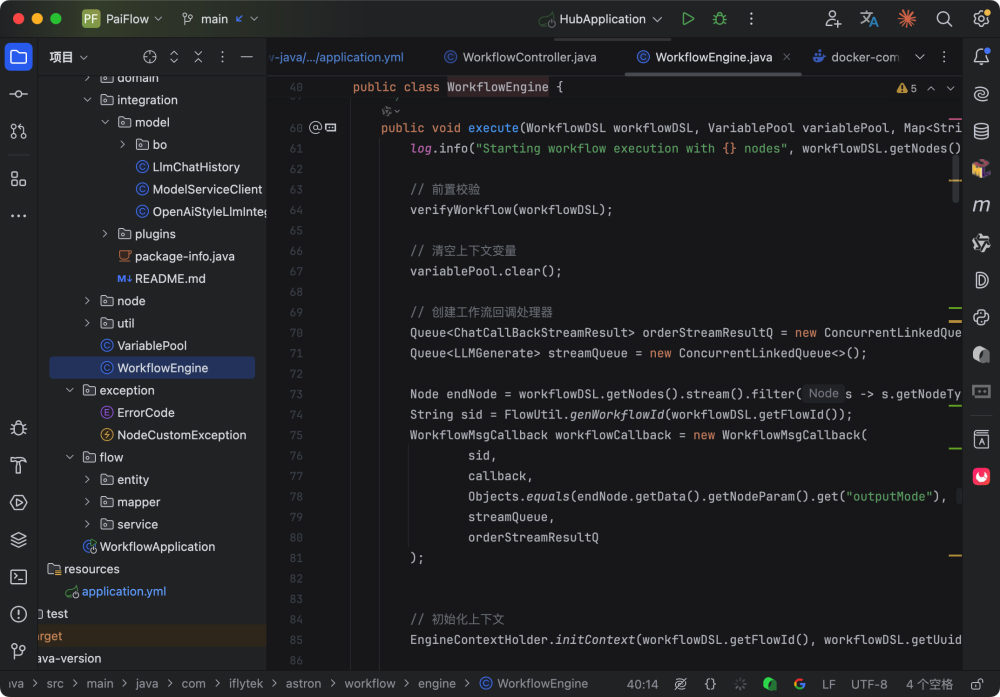
一开始先做前置校验,确保 DSL 结构是完整的、节点和边是对得上的,避免执行到一半才发现流程本身有问题。校验通过后会清空变量池,保证这次执行用的是干净的上下文。
接下来会准备好这次执行需要的关键对象,比如生成 sid,用于标识一次工作流执行;创建回调处理器,用来承接消息回传;再初始化引擎上下文,把 flowId、uuid 这些执行信息放进去,后面日志、回调和链路追踪都会用到。
上下文准备好之后,引擎开始构建节点执行链路。链路构建完成,会初始化起始节点的输入,把外部传入的 inputs 映射到工作流的起点,保证第一步能拿到正确的参数。进入执行阶段后,引擎会按照依赖关系驱动节点执行。
每个节点跑完会把输出写回变量池,同时触发对应的回调事件,把节点状态变化和输出内容实时推送出去。过程中如果遇到异常,引擎会根据 DSL 的定义决定是否走失败分支,并通过 executeFailedCondition 把异常路径也跑通,保证流程能按预期结束。
除了 execute 之外,WorkflowEngine 里还有几个关键方法(后面讲工作流引擎还会细讲):
buildNodeExecuteChain:根据 DSL 的节点和边构建可执行的链路
initializeStartNodeInputs:初始化起始节点输入,把外部 inputs 填到变量池
executeNode:执行当前节点,并推进后续节点
workflowCallback.onXxx:在执行关键阶段触发回调,实现消息回传与实时通信
executeFailedCondition:处理异常时的失败分支执行路径
02、NodeExecutor
NodeExecutor是节点执行器接口,execute 负责节点的执行逻辑,getNodeType 用来声明节点执行器类型,比如说 LLM 节点执行器、TTS 节点执行器。
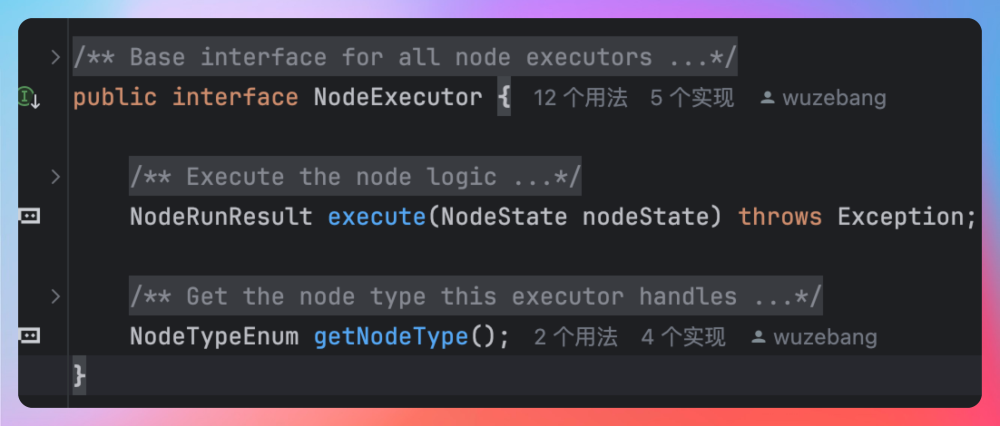
NodeState 封装了节点执行时所需的关键信息,该对象是一个 record 类,包含三个重要参数:
/**
* node之间执行时传递的状态信息
*/
public record NodeState(Node node, VariablePool variablePool, WorkflowMsgCallback callback) {
}
node:当前要执行的节点
variablePool:变量池,用于存储和获取节点间传递的数据
callback:回调接口,用来把执行过程里的状态变化、输出内容实时传递出去
AbstractNodeExecutor是所有节点执行器的抽象基类,它实现了 NodeExecutor 接口的 execute 方法,提供了通用的执行逻辑,包括节点执行次数管理、重试机制支持、超时控制机制、输入参数解析、输出结果存储、回调通知机制等。
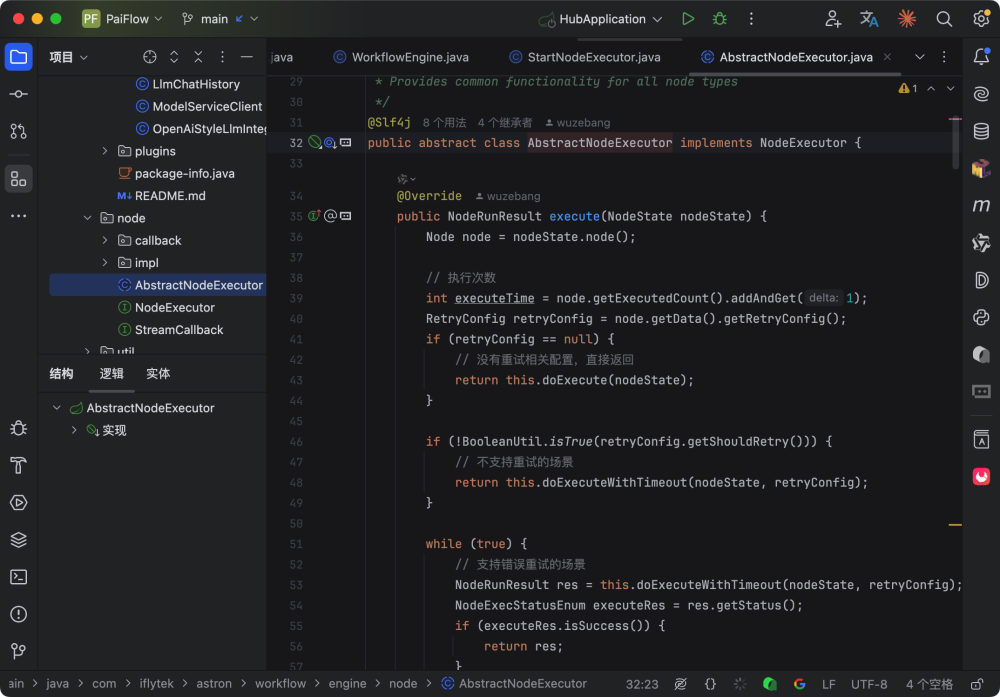
抽象方法 executeNode 可由具体的节点执行器实现,比如说 StartNodeExecutor 为起始节点执行器,负责初始化工作流的输入参数;LLMNodeExecutor 为大语言模型节点执行器,负责调用 LLM 服务;PluginNodeExecutor 为插件节点执行器,负责调用外部插件服务(如语音 TTS、文生图等);EndNodeExecutor 为结束节点执行器,负责格式化最终输出。
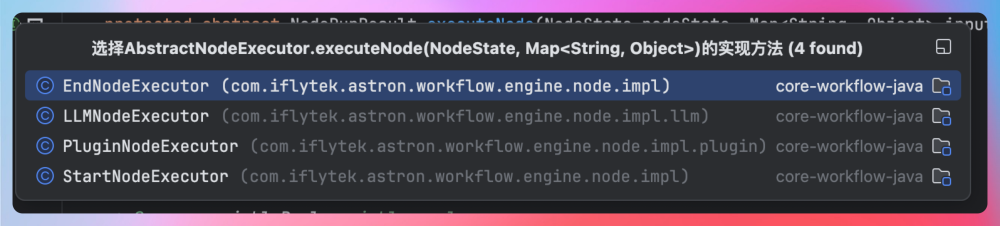
从设计模式的角度来看,NodeExecutor用到了策略模式+工厂模式+责任链模式,其中策略模式是核心,它将不同节点(如LLM、插件)的执行逻辑封装成可独立替换的策略;工厂模式根据节点类型创建对应的执行器实例,实现解耦;而责任链模式则体现在宏观上,工作流引擎将执行上下文按预定顺序在不同的节点执行器之间传递,共同完成整个流程。
03、VariablePool
VariablePool负责管理工作流执行过程中,节点之间的数据存储与引用(一个 Node 引用其他 Node 的输出,靠的就是变量池)。
变量池支持复杂的数据结构存储和检索、提供了嵌套的属性访问(如data.voice_url或data[0].voice_url)、能够自动进行数据类型转换,并且是线程安全的,支持并发执行。
04、StreamCallback
StreamCallback接口负责实时推送工作流的执行状态,其实现类有 SseStreamCallback,基于 SSE 的回调实现,用于向 Web 客户端推送实时消息;还有 WorkflowStreamCallback,Node 执行器的回调包装器,用于处理 Node 执行后的消息回显。
大模型调用最大的问题是慢。用户点一下按钮,等 10 秒才出结果。PaiFlow 的解法是全链路流式,每收到一个 token 就往前端推一次:
// LLM 节点执行时的回调
LlmResVo llmOutput = modelServiceClient.chatCompletion(req, chatResponse -> {
// 每收到一个 token 就往前端推一次
nodeState.callback().onNodeProcess(
0,
node.getId(),
chatResponse.getResult().getOutput().getText(),
chatResponse.getResult().getOutput().getMetadata().get("reasoningContent")
);
});
五、Java版工作流引擎的技术选型
Java 版工作流引擎是基于 JDK 21 + Spring Boot 3.x + SpringAI 1.x 构建的,我们在追求新的路上有所克制(因为等你实际参加工作了,可能还是 JDK 8 😄),但有些球友希望新,所以我们也在积极跟进,JDK 从技术派的 8 升级到派聪明 RAG 的 17,再到 PaiFlow 的 21。
SpringAI 之所以没有升级到 2.0,是因为立项的时候还没有这个版本;并且 Spring Boot 和 SpringAI 的版本要兼容,要使用 SpringAI 2.0,Spring Boot 就要升级到 4.x。实际上,SpringAI 新版有很多 bug,做校招派的时候就碰到了很多,后面我们也会讲。
除此之外,Java 版工作流引擎并没有引入复杂或较重的框架,而是尽量保持克制,只保留那些确实需要的组件:
JDK21 + Maven 3.8+
SpringBoot 3.5.4:项目基础框架
SpringAI 1.1.2: LLM 交互框架
LangGraph4J:Agent 编排框架
MybaitsPlus: ORM 框架
Minio: 文件存储
Redis: 分布式缓存
Guava: 本地缓存
OkHttp: 负责发起 http 请求和接收响应
Fastjson2 2.0.51:JSON 库
Mockito:Mock 框架
Docker & Docker Compose:容器
Jinja2 3.1.4:模板引擎(Prompt 渲染)
MCP 协议
FastAPI 0.111.1:Python 版异步 Web 框架
gRPC:跨平台的开源高性能远程过程调用框架
Spring AI 在这里的作用,主要是为了统一不同大模型的调用方式。无论底层接的是讯飞、智谱、百炼还是 DeepSeek,在 NodeExecutor 的视角里,调用模型和调用一个普通外部服务没有本质区别。
在实际使用中,工作流节点往往会产生中间产物,比如音频文件、图片、临时结果等。这些内容如果直接随上下文流转,不仅会增加内存压力,也不利于跨节点共享。因此 Java 版工作流引擎选择通过 MinIO 来统一管理这类文件数据,节点之间只传递引用信息,而非文件本身。
最后,无论是模型调用、插件节点,还是第三方系统集成,都绕不开 HTTP 通信。Java 版工作流引擎统一使用 OkHttp 作为底层 HTTP 客户端,并在其之上做了轻量封装,使得节点只需要关心请求语义,而不需要处理连接池、超时、重试等细节。
六、PaiFlow 能让大家学到什么
总结一下,😄
派派工作流(PaiFlow)是一个类似 Dify、Coze、n8n 的可视化流程编排平台,是一个面向企业级的 AI Agent 应用平台,支持大模型节点、工具节点、控制节点(条件/并行/循环)在同一画布中编排,后端采用了 Java + Python 双引擎,支持 Docker 容器化一键部署。
通过这个 AI Agent 实战项目,大家能学到:
01、微服务架构能力
整个系统按照业务领域和技术栈进行了拆分, Console Hub 负责前端和工作流引擎的交互,以及模型和工具的配置;工作流引擎则采用了 Python 和 Java 的双版本并行设计,Python 用来快速验证 MVP(Minimum Viable Product,即最小化可行产品),Java 负责生产环境部署;AI 插件服务也实现了 Python 和 Java 的双版本,能兼容 OpenAI 的 SDK 接入。
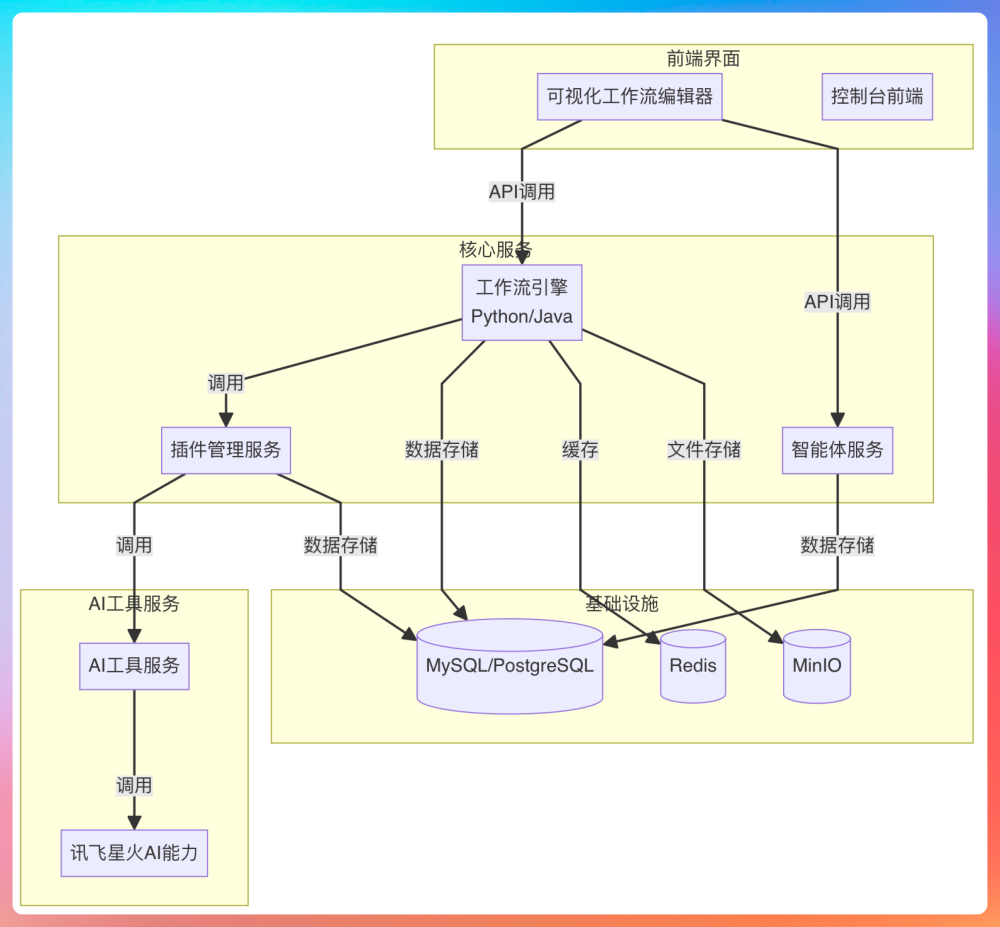
不同语言的服务之间则通过 REST API 协议通信,部分实时场景使用了 SSE 进行推送,确保用户可以在页面上实时看到每个节点的执行进度。而服务之间的解耦,则采用了事件驱动方式,通过消息传递完成不同节点之间的数据流动与状态联动。
工作流引擎模块,Python 版以 FastAPI 为基础,提供参考级实现,负责快速验证;Java 版本则采用 Spring Boot 3.2 + SpringAI 1.1 +LangGraph4J+ Java 21 的虚拟线程方案,支持全量监控、资源隔离、性能调优,主要面向企业级落地。两个版本都支持通过 Nginx 反向代理进行动态切换。
面试话术:在派派工作流项目中,我负责设计并实现了多语言微服务架构。针对 Workflow 引擎,我先用 Python FastAPI 快速验证 MVP,然后用 Spring Boot+SpringAI+LangGraph4J 重构了 Java 版本,两个版本在切换时完全不受影响,谁启动,Console Hub 就会将前端请求转发到启动的版本上。
02、前端工程能力
打算做全栈,或者前端的球友,可以多花一点时间在 console/frontend 上。
前端通过 React Flow 实现了一套复杂的 Canvas 应用开发,类似 Figma 或者 Draw.io,可通过拖拽实现可视化的流程编排。节点类型支持大模型、MCP 插件、条件判断等,并支持边的动态路径计算,实现失败分支和成功分支的自动跳转。同时还接入了 dagre 算法,在用户连线后自动重新布局。
在状态管理上,采用了 Recoil 管理全局 DSL 状态,而画布相关的交互状态则交由 Zustand 接管,两者职责分离、互不干扰。为了让用户实时了解每个节点的运行情况,还接入了 SSE 实现服务端推送,前端根据消息流自动高亮节点状态,从灰色变成蓝色,再到绿色或红色,整个流程一目了然。生成式节点还支持内容的流式展示,用户体验非常友好。
面试话术:在派派工作流项目中,我主导开发了可视化的 Workflow 编排,最大的挑战在于节点配置和画布状态的双向同步。我用了 Recoil 的 Atom Effects 做状态持久化,节点执行过程通过 SSE 推送流式渲染,颜色编码从灰到蓝再到绿或红,实现了类似 Airflow 的实时追踪体验。
03、LangGraph4J+SpringAI+JDK21+Spring Boot3.5 新特性
派派工作流使用 Java 21 和 Spring Boot 3.5 来重构工作流引擎,就顺带使用了 Project Loom 的虚拟线程机制来替代传统的线程池,进行节点的并发执行。
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
executor.submit(() -> executeNode(node, variablePool, callback));
}
以往处理 100 个并发节点时,需要创建 100 个系统线程,内存开销大,还得手动调优线程池参数。切换到虚拟线程后,通过 Executors.newVirtualThreadPerTaskExecutor() 就可以构建执行器,每个节点执行逻辑都能无痛地挂载在轻量线程上,整体内存占用直接从 500MB 降到了 50MB。这是我第一次在生产环境上落地 Project Loom,用起来感觉非常爽。
数据结构层也做了优化,很多 DTO 结构,如节点运行结果 NodeRunResult,都改成了 Java 14 引入的 Record 类型,不仅代码简洁、语义清晰,也省掉了对 Lombok 的依赖。
public record NodeState(Node node, VariablePool variablePool, WorkflowMsgCallback callback) {
}
在框架层面,派派工作流集成了 Spring Boot 3 的 Micrometer Observation API,配合 Prometheus 做了分布式链路追踪,所有节点的执行耗时、错误信息都能实时收集和展示,调试效率得到了大幅提升。
面试话术:这次重构让我在实践中真正掌握了 Java 的新特性,也深入理解了虚拟线程,同时也提升了我对 Spring Boot 3 在可观测性方面的能力认知。
我们项目最初是用 Python FastAPI 配合 LangChain 实现的工作流引擎,后来客户说他们需要 Java 版本,于是我们就用 Spring AI 重构了一个新的版本,我这里说一下 SpringAI 的优势:
①、Spring AI 提供了多模型的统一抽象层,通过 ChatClient 和 ChatModel 接口,可以无缝切换 DeepSeek、OpenAI、通义千问等各种大模型。同时它的 Prompt Template 和结构化输出机制让提示词工程变得可复用、可测试。
②、SpringAI 基于 Reactor 的 Flux 流式处理让我们实现了真正的异步响应,大幅降低了首字延迟,用户体验非常流畅。我们还集成了 Spring Retry 和熔断器机制,能够优雅地处理 LLM API 的超时和限流问题,确保服务可用性达到 99.9% 以上。
③、强类型的 ChatResponse 和 Message 让我们能在编译期就捕获错误,重构起来特别安心。而且开箱即用地集成了 Spring Security 做权限控制、Spring Cache 做响应缓存、Spring Cloud 支持分布式部署。运维方面,Spring Boot Actuator 提供了完整的健康检查、优雅停机和 Prometheus 指标监控,对 DevOps 非常友好。
④、LangGraph4J 是 LangGraph 的 Java 实现,它是一个用于构建有状态、可循环的多步骤 LLM 应用的编排框架。而 LangChain4J 更偏向于一个 LLM 应用的工具链和组件库。
04、Workflow 引擎核心机制
在 PaiFlow 的工作流引擎上,我们的思路是“DSL 驱动 + 节点执行器解耦 + 变量池隔离”,整个执行过程始于前端生成的 JSON DSL,它描述了一张图:节点和边,准确说,是一个 DAG。系统会先解析这份定义,把它转换成内存中的工作流对象,并构建好所有节点之间的链路依赖。
{
"nodes": [
{
"id": "node-type::unique-id",
"data": {
"inputs": [],
"nodeMeta": {
"nodeType": "节点类型",
"aliasName": "节点别名"
},
"nodeParam": {},
"outputs": [],
"retryConfig": {}
}
}
],
"edges": [
{
"sourceNodeId": "源节点ID",
"targetNodeId": "目标节点ID",
"sourceHandle": "连接句柄"
}
]
}
在执行层面,我们通过策略模式将节点分发给不同的执行器处理。执行器有一个统一的基类 AbstractNodeExecutor,它封装了所有公共能力,比如超时控制、重试机制。如果要新增别的类型节点?可以直接写一个 XXNodeExecutor 扔进工厂里就完事。
再说变量池,这是流程之间通信的关键组件。我们搞了一个 VariablePool,所有节点执行时的输入输出都会写进来。为了提升可读性和灵活性,我们还内置了 Jinja2 模板引擎,可以通过双框号 {{start.input}} 这样直接拿到上游结果做引用类型参数。这点在串联上下文的时候特别有用,比如可以把用户输入的原样传递给 LLM 的提示词里,或者动态生成提示词。
这套设计其实参考了 Camunda、Activiti 这类 BPMN 流程引擎,但我们不追求那种繁琐的 XML 配置,而是采用轻量的 JSON+注解驱动实现。
面试话术:我实现了一套基于 DSL 的 Workflow 引擎,支持 DAG 拓扑排序、节点并发执行和异常分支路由。难点主要在变量池作用域隔离、循环节点状态管理上。通过策略 + 工厂模式解耦节点类型,新加节点只需实现 NodeExecutor 接口,符合开闭原则。
为什么你们不用 LangGraph(PaiAgent 项目用了)?
我深入研究过 LangGraph 框架,但在PaiFlow中我们依然坚持了自研,第一,LangGraph主要针对的是 Agent节点,我们支持了超 15+ 种节点(知识库/RPA/数据库/问答/MCP 等等);第二,LangGraph的核心是StateGraph状态机管理,它通过节点(Node)和边(Edge)定义Agent 的推理流程,这些我们也都实现了;第三,自研引擎的经验让我能理解LangGraph源码级细节,这对程序员的工程能力提升至关重要。

05、消息推送机制
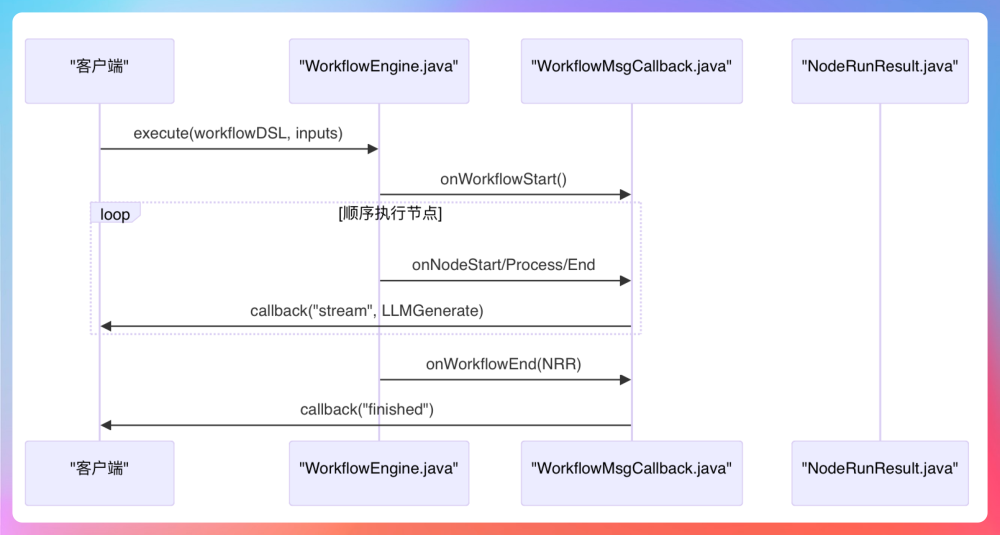
在整个工作流引擎的交互链路里,我们实现了一个基于 SSE 的实时推送机制,用于将节点执行状态和 LLM 输出内容第一时间同步给前端。这种机制的好处是轻量、简单,不需要客户端维护连接状态,也不用引入 WebSocket 那套双向握手和心跳机制。
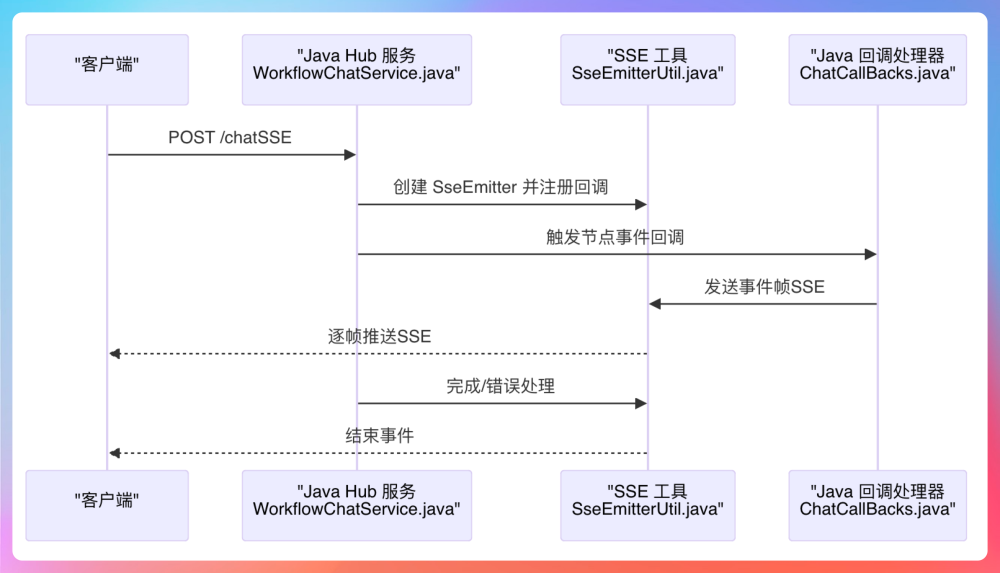
具体来说,Controller 层用 Spring 提供的 SseEmitter 对象,设置了一个 10 分钟的超时连接,在请求进来后立刻返回一个挂起的流。后面用了一个异步线程来执行工作流逻辑,避免阻塞主线程。在这个线程中,注入了一个自定义的 SseStreamCallback 回调,它实现了 StreamCallback 接口,会在工作流执行的不同阶段往前端推消息。
这个回调里面用的是 ConcurrentLinkedQueue 作为异步消息缓冲区,对执行链路和推送链路进行了解耦:Workflow 引擎不断往队列里丢消息,SSE 推送线程则从队列里消费数据并写入前端流。我们定义了四类事件:onWorkflowStart 表示工作流启动,onNodeProcess 会在 LLM 流式生成过程中逐 token 推送内容,onNodeEnd 标记节点结束,最后 onWorkflowEnd 表示整个流程收尾。
通过这套机制,用户在前端几乎是“边跑边看结果”,体验非常丝滑。
面试话术:为了实时展示 LLM 节点的生成过程,我实现了基于 SSE 的消息推送机制。通过 ConcurrentLinkedQueue 解耦生产者(Workflow 引擎)与消费者(SSE 推送线程),避免阻塞主线程。
06、LLM 集成与 Tool Calling
我们不仅把 LLM 集成了进来,还让它能实时生成流式结果、还能用 Tool Calling 自动调用插件工具。同时兼容了 OpenAI 的接口规范,也支持了 DeepSeek、通义千问等国产模型,统一用的是 Spring AI 1.1.2 提供的标准化封装,基本实现了一套接口打通多个模型的目标。
Prompt 层我们也做了模板工程,支持 Jinja2 语法渲染变量,比如 VariableTemplateRender.render() 这一层就可以自动把上下游节点的输入注入到 Prompt 中。System Prompt 和 User Prompt 分开管理,多轮对话的上下文通过 LlmChatHistory.getHistory() 统一封装,避免了 prompt 泄漏或混乱。
在流式生成这块,我们通过一个回调函数处理 LLM 节点的 token 流,每生成一个 token 就通过 SSE 推给前端。代码里大概是这样写的:
LlmResVo llmOutput = modelServiceClient.chatCompletion(req, chatResponse -> {
nodeState.callback().onNodeProcess(
0, node.getId(),
chatResponse.getResult().getOutput().getText(),
chatResponse.getResult().getOutput().getMetadata().get("reasoningContent")
);
});
Tool Calling 的实现也很硬核。我们是通过 MCP 协议来让 PluginNode 直接调用已注册的插件,插件存放在 MySQL 的 tools_schema 表里,支持热更新。
面试话术:派派工作流不仅集成了多家 LLM 大模型,还支持流式响应和 Tool Calling。比如用户输入一个文本,节点会触发大模型生成内容,并且在生成过程中每个 token 都会实时通过 SSE 推送到前端。工作流执行过程中,如果识别到外部工具(比如语音合成),就会自动通过 MCP 协议调用讯飞/阿里 TTS 语音合成插件。
07、TTS 语音合成集成+MinIO
我们在播客生成流程中接入了讯飞星火的超拟人语音合成+阿里的 TTS。它的核心能力是把文本转成语音,支持多音色、多情感。生成的音频文件我们统一存储到了 MinIO。
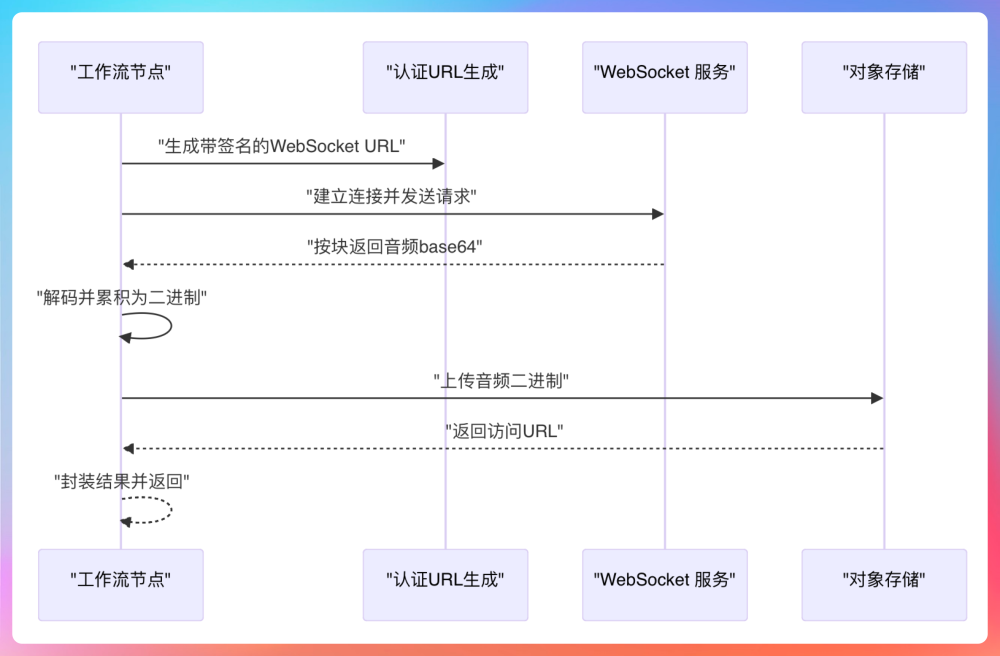
SDK 既可以在 Java 版的工作流引擎里调用,也可以通过 Python 版的 aitools 服务访问。首先能够让大家掌握如何集成第三方 AI SDK,其次是跨语言的调用流程;其次是音频处理的基础知识,比如格式转换;最后是对象存储的使用,比如 MinIO 的上传、权限控制和预签名机制。
面试话术:我这边做了两种 TTS 服务,一种是阿里的 TTS,一个是讯飞的超拟人音频合成,他们都可以无缝接入到工作流中;Python 版是用 FastAPI 封装的 SDK,Java 版工作流引擎是直接通过 HTTP 请求调用语音服务,合成结果存在 MinIO 中,前端再用预签名 URL 播放。
08、使用 MCP 协议实现插件系统
通过 MCP 协议,我们实现了一个低耦合、高扩展的插件系统。整个工具注册系统基于 tools_schema 表来存储所有工具的元数据信息,接口定义采用 JSON Schema 描述,统一存储在 open_api_schema 字段中。
Workflow 引擎可以根据 Schema 结构自动完成参数校验、请求封装与响应处理,不再需要为每个插件单独写调用逻辑。这种设计思路和 GPTs 插件市场的架构比较类似。
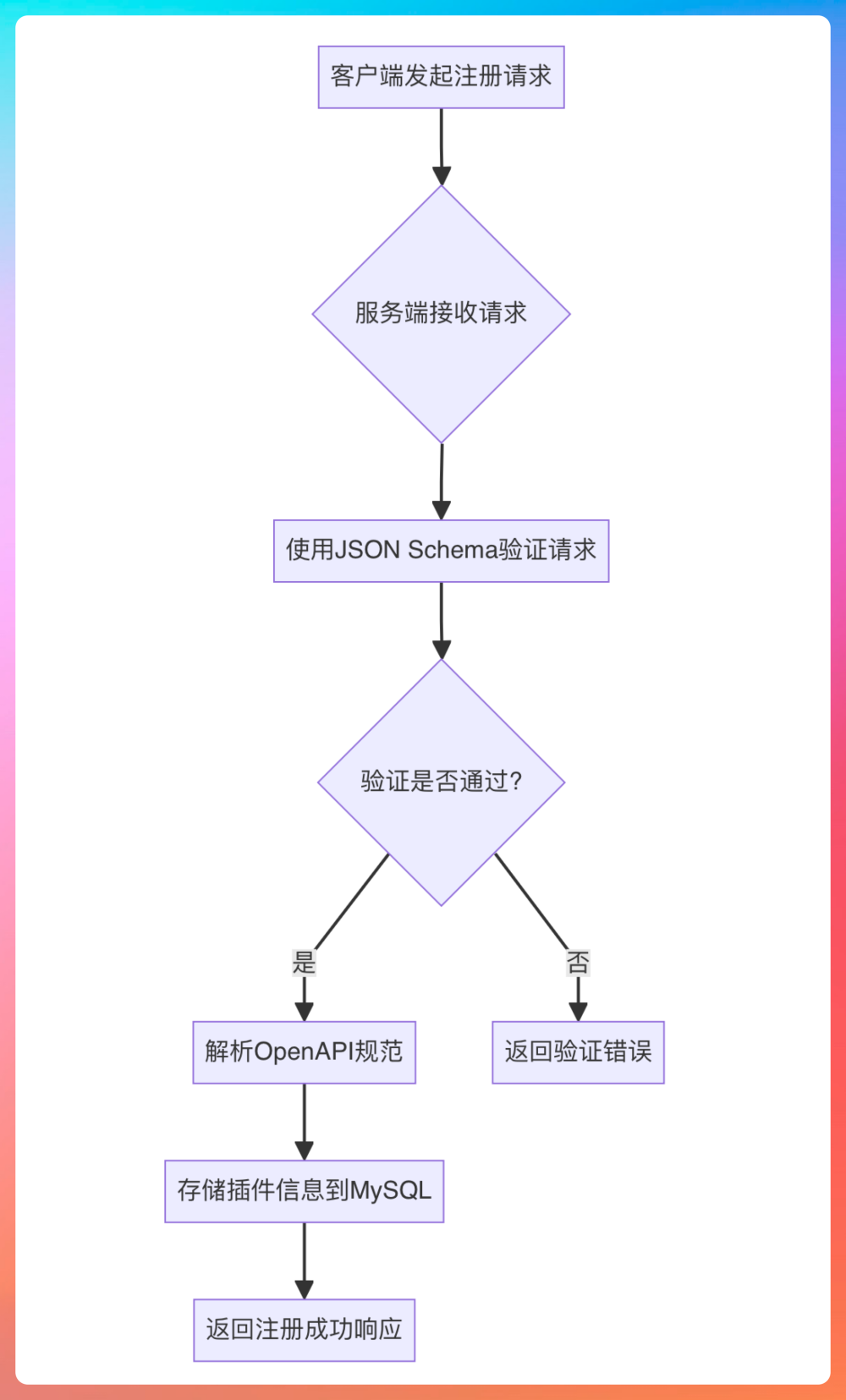
面试话术:我设计了一个基于 MCP 协议的工具注册系统。每个工具通过 JSON Schema 定义接口,Workflow 引擎在运行时自动加载并调用插件。
09、Docker 容器化部署
整个项目采用了多阶段构建的方式优化 Docker 镜像体积。第一阶段基于 maven:3.9-eclipse-temurin-21 镜像进行构建,执行 mvn clean package -DskipTests 完成编译打包;随后进入第二阶段运行环境,基于轻量的 eclipse-temurin:21-jre 镜像,仅将编译好的 jar 包复制进去,极大缩小了最终镜像的体积,控制在 200MB 左右。
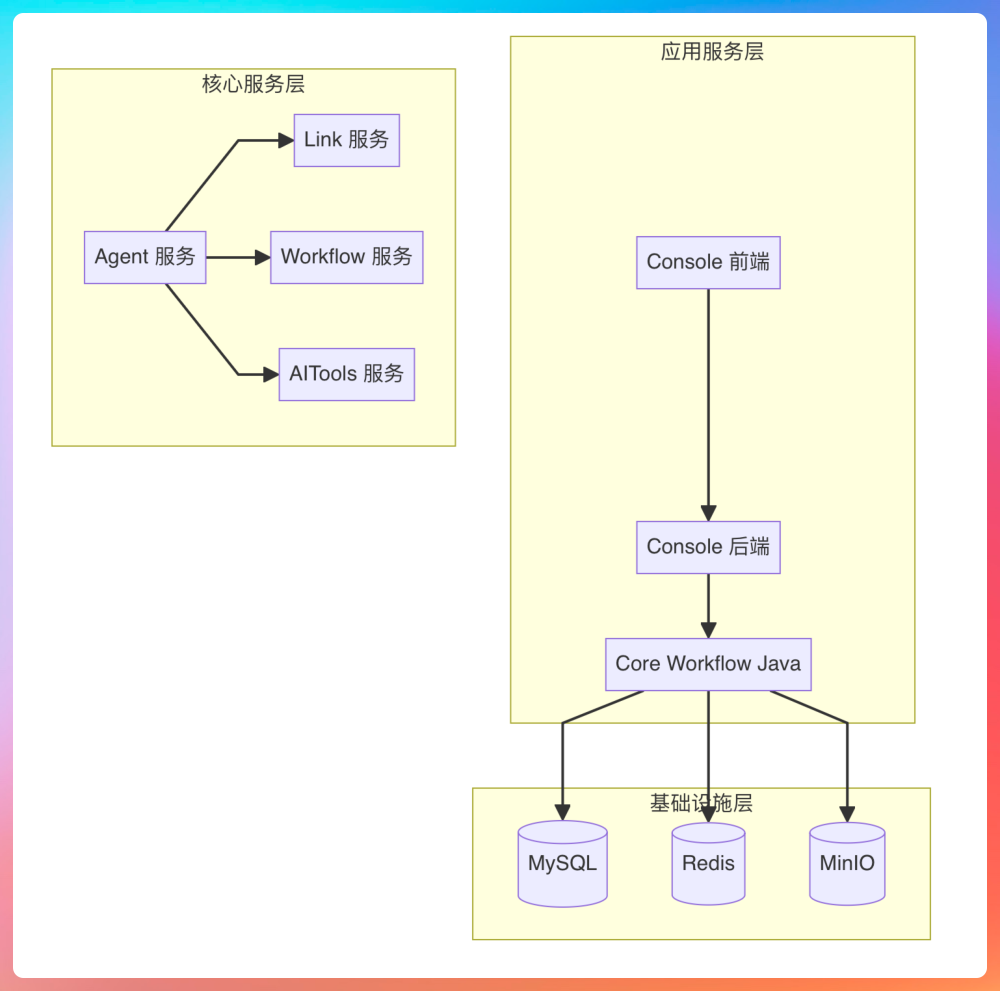
在服务编排层面,使用 Docker Compose 管理和启动整个系统,包括 console-hub、core-workflow、postgres、mysql、redis、minio、nginx 等共计 9 个服务。通过 depends_on 机制管理服务间的启动顺序,同时为核心服务配置了 healthcheck,确保服务在完全就绪后才被依赖组件访问,避免了冷启动过程中出现 502 报错的情况。Nginx 暴露在宿主机的 80 端口,提供前端访问入口,内部服务之间则通过 Docker 的 overlay 网络通信。
面试话术:我使用 Docker Compose 编排了 9 个模块的微服务系统,通过健康检查机制确保各服务按需启动。Java 应用采用多阶段构建,最终镜像仅 200MB。为避免 Nginx 报 502 错误,我还添加了 healthcheck 来解决这个问题。
10、分布式追踪
在分布式追踪方面,我们通过 OpenTelemetry 对整个 Workflow 引擎进行了埋点,覆盖了工作流的开始、结束,以及每个节点的执行阶段。系统支持跨服务链路追踪,能够完整记录从前端 Console Hub 到核心 Workflow 模块,再到 AI Tools 服务的调用路径,并通过 Jaeger 和 Zipkin 实现可视化分析。一旦工作流执行出现性能瓶颈,可以根据 Trace ID 精确回溯每个节点的耗时,快速定位问题。
日志方面,Java 模块采用 Logback 配合 SLF4J,Python 模块则使用 Loguru 实现统一日志记录格式。所有日志输出均为结构化 JSON,方便在日志平台中检索与聚合分析。
指标体系则是基于 Spring Boot Actuator 构建,采集了 JVM 内存、线程池状态、HTTP 请求响应等核心指标,并通过 Prometheus exporter 暴露给监控系统。结合 Grafana 可以实现实时仪表盘监控,也便于后续设置告警规则。
面试话术:我集成了 OpenTelemetry 以实现分布式追踪能力。当某个工作流执行卡顿时,就可以通过 traceId 精确追踪,也让我第一次体会到 DevOps 中 observability 的核心价值。
七、paiflow有哪些亮点?
八、ending
在我看来,派派工作流对大家的价值,不只是是拿到一个称心如意的 offer,更是提前让你进入高级工程师的思维区间。
所以如果你问我,派派工作流到底牛逼在哪。我会说,它不仅能保证你百分百上岸,还能极大概率把你从简历筛选的杂音里捞出来。毕竟 AI 的落地业务场景,一个是 RAG,我们派聪明实现了,另外一个就是工作流的 Agent 编排。
这是为什么星球的口碑一直刚刚的原因了,确实对大家的求职有帮助🤔。
14人已点赞
热门评论
25 条评论
回复