


DSL与执行链路构建:派派工作流PaiFlow Agent工作流编排项目
1. DSL是什么?
DSL(Domain Specific Language)是整个流程编排的核心数据结构,PaiFlow 的 DSL 是怎么设计的呢?
简单来说,PaiFlow 的 DSL 是一个 JSON 对象 ,它完整地描述了一个工作流的“图”结构,包括所有的节点定义、它们之间的连接关系,以及节点之间的数据依赖关系。
启动前端后,我们可以通过拖拉拽的方式,编排一个工作流,比如下面这样,就是一个典型的 LLM + TTS 工具节点的流程:
这个工作流对应的数据结构是什么样子呢?类似下面这样。
{
"nodes": [
{
"id": "start-node-1",
"type": "startNode",
"position": { "x": 100, "y": 100 },
"data": { "title": "开始" }
},
{
"id": "llm-node-2",
"type": "llmNode",
"position": { "x": 300, "y": 100 },
"data": {
"title": "调用大模型",
"model": "deepseek-v2",
"prompt": "请帮我总结一下:{{input.text}}"
}
},
{
"id": "end-node-3",
"type": "endNode",
"position": { "x": 500, "y": 100 },
"data": { "title": "结束" }
}
],
"edges": [
{
"id": "edge-1-2",
"source": "start-node-1",
"target": "llm-node-2",
"sourceHandle": "output",
"targetHandle": "input"
},
{
"id": "edge-2-3",
"source": "llm-node-2",
"target": "end-node-3",
"sourceHandle": "output",
"targetHandle": "input"
}
],
"viewport": {
"x": 0,
"y": 0,
"zoom": 1
}
}
这一长串 JSON 就是工作流的 DSL。基本组成包括:
节点(Node):执行某个具体动作的单元,比如调用模型、发起请求、合成音频等。
边(Edge):连接节点与节点,表示数据的流向。
并且我们做出了以下约束:
根对象必须包含 nodes 和 edges 两个核心数组,分别表示所有节点和所有边;
每个节点都必须有唯一的 ID,不能重复;
每条边所引用的源节点和目标节点都必须存在于节点集合中;
流程中必须包含且仅包含一个起始节点(node-start 类型);
必须包含至少一个结束节点(node-end类型);
数据流一定是从起始节点出发,串联所有节点,最后到结束节点。
工作流引擎在执行前会先做 DSL 校验,不符合约束的流程一律不执行。
对于节点(Node)来说,有几个属性是必须的:
id: 唯一标识,用于区分不同的node
name: 给用户展示的节点名;
type: 节点类型(比如是 llm、插件、开始节点、结束节点等等);
inputs: 输入参数;
outputs: 执行后的输出结果。
当然了,不同类型的节点,业务侧对它的要求是不一样的,所以我们还得考虑更多维度,比如大模型节点可以指定调用哪个模型?温度参数是多少?
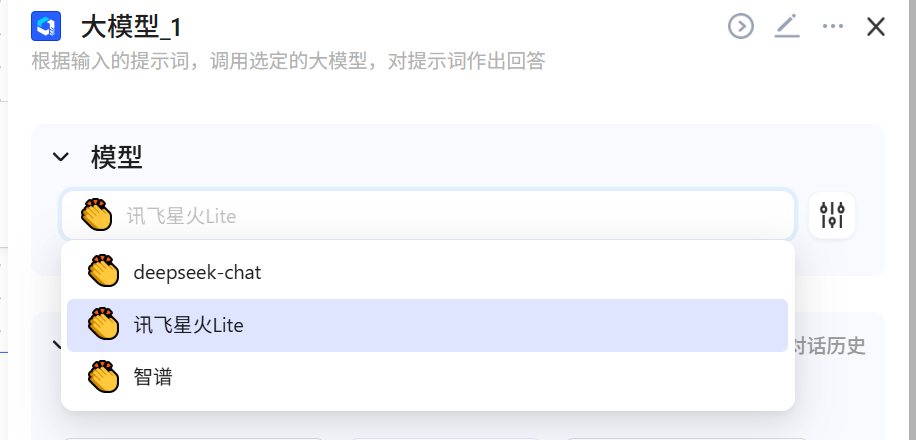
再比如说插件节点(Plugin Node),除了插件类型,还得有插件唯一标识、插件的 Schema 等信息。
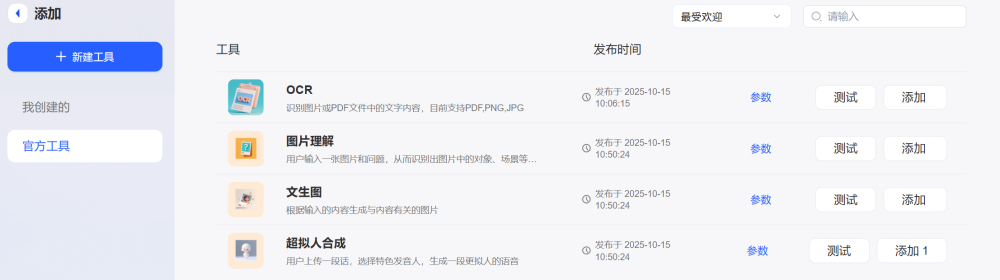
这些是内置插件
还有节点的异常处理策略,是否支持重试?走不走异常分支?要不要终止流程?
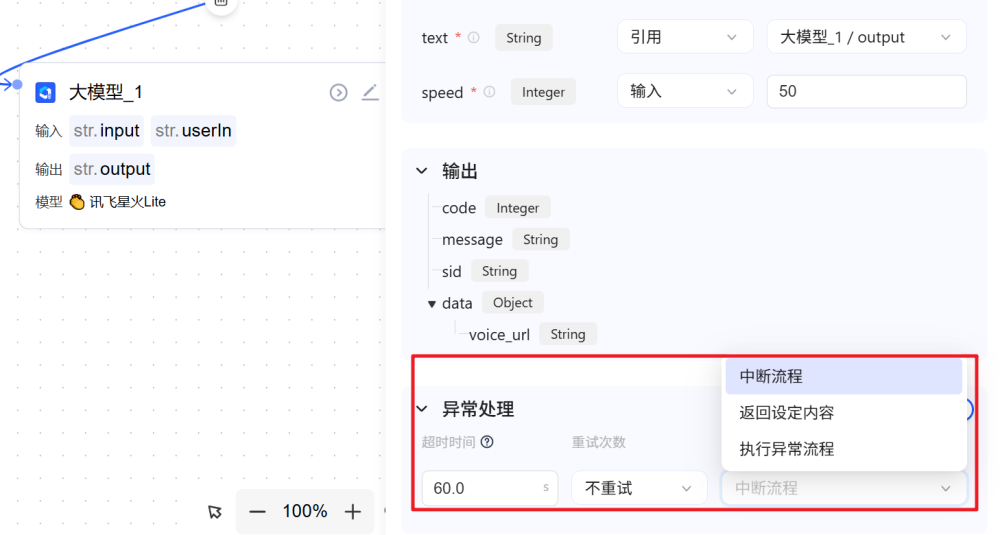
所有这些字段,都要在 Node 节点中有所体现。
除了 Node,整个工作流能不能跑通,还得靠节点之间的连接关系,也就是 Edge(边)。每一条边至少包含以下几个字段:
source:源节点 ID
target:目标节点 ID
type:边的类型(比如普通边、异常边、条件边)
condition:条件表达式(如果支持条件分支)
下面这个 Edge 代表流程从 node-1 到 node-2。如果 type = "error",表示异常边;如果带上 condition,那就是条件边,只有条件为 true 的时候,流程才会往目标节点走。
{ "source": "node-1", "target": "node-2", "type": "normal" }
PaiFlow 的 DSL 存储在 workflow.flow 表中,直接就是 JSON 格式的字符串。比如下面这个“多模型协作工作流”,在数据库里是这样的记录。
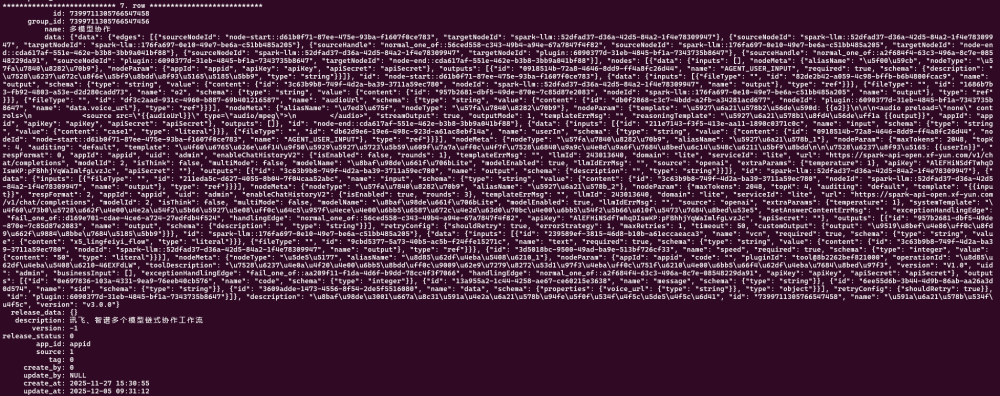
可以看到节点和边存在 data 字段中;外层还带有工作流的 id、name、description、version 等元信息。
我把 JSON 整理了下,大家可以重点关注一下 edges 和 nodes:
{
"data": {
"edges": [
{
"sourceNodeId": "node-start::d61b0f71-87ee-475e-93ba-f1607f0ce783",
"targetNodeId": "spark-llm::52dfad37-d36a-42d5-84a2-1f4e78309947"
},
{
"sourceNodeId": "spark-llm::52dfad37-d36a-42d5-84a2-1f4e78309947",
"targetNodeId": "spark-llm::176fa697-0e10-49e7-be6a-c51bb485a205"
},
{
"sourceHandle": "normal_one_of::56ced558-c343-49b4-a94e-67a7847f4f82",
"sourceNodeId": "spark-llm::176fa697-0e10-49e7-be6a-c51bb485a205",
"targetNodeId": "node-end::cda617af-551e-462e-b3b8-3bb9a041bf88"
},
{
"sourceNodeId": "spark-llm::52dfad37-d36a-42d5-84a2-1f4e78309947",
"targetNodeId": "plugin::6090377d-31eb-4845-bf1a-7343735b8647"
},
{
"sourceHandle": "normal_one_of::a2f684f4-63c3-496a-8c7e-08548229da91",
"sourceNodeId": "plugin::6090377d-31eb-4845-bf1a-7343735b8647",
"targetNodeId": "node-end::cda617af-551e-462e-b3b8-3bb9a041bf88"
}
],
"nodes": [
{
"data": {
"inputs": [],
"nodeMeta": {
"aliasName": "开始",
"nodeType": "基础节点"
},
"nodeParam": {
"appId": "appid",
"apiKey": "apiKey",
"apiSecret": "apiSecret"
},
"outputs": [
{
"id": "0918514b-72a8-4646-8dd9-ff4a8fc26d44",
"name": "AGENT_USER_INPUT",
"required": true,
"schema": {
"description": "用户本轮对话输入内容",
"type": "string"
}
}
]
},
"id": "node-start::d61b0f71-87ee-475e-93ba-f1607f0ce783"
},
{
"data": {
"inputs": [
{
"fileType": "",
"id": "82de2b42-a059-4c98-bffb-b6b4800fcac9",
"name": "output",
"schema": {
"type": "string",
"value": {
"content": {
"id": "3c63b9b8-749f-4d2a-ba39-3711a59ec780",
"nodeId": "spark-llm::52dfad37-d36a-42d5-84a2-1f4e78309947",
"name": "output"
},
"type": "ref"
}
}
},
{
"fileType": "",
"id": "1686b7b3-fb92-4803-a53e-d2d280cadd73",
"name": "o2",
"schema": {
"type": "string",
"value": {
"content": {
"id": "957b2681-dbf5-49de-870e-7c85d87e2083",
"nodeId": "spark-llm::176fa697-0e10-49e7-be6a-c51bb485a205",
"name": "output"
},
"type": "ref"
}
}
},
{
"fileType": "",
"id": "df3c2aad-931c-4960-b887-69b401216587",
"name": "audioUrl",
"schema": {
"type": "string",
"value": {
"content": {
"id": "db0f2868-c3c7-4bdd-a2fb-a34281acd677",
"nodeId": "plugin::6090377d-31eb-4845-bf1a-7343735b8647",
"name": "data.voice_url"
},
"t...企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

23人已点赞
热门评论
25 条评论
回复