


✅插件节点执行器:PaiFlow工具节点实现原理
PaiFlow 里的工具节点,说白了就是把外部工具的能力接到工作流里来用。Python 版本是通过 core/plugin 下的 aitools/link 微服务来完成的,工作流执行的时候会拿着 toolId 去调 aitools 微服务/或者 link 微服务,然后路由到具体的工具实现。
aitools 是内置的插件,link 是外部的插件。
比如说我们买了一部手机,会自带相机/计算机等内置的工具,它们相当于 aitools,可直接开箱即用;link 就相当于 app store,或者应用商店,外部的微信/支付宝/抖音这些工具需要先通过应用商店进行管理(增删改查),然后才能使用。
对于 PaiFlow 来说,内置了四个插件,它们是通过 aitools 来提供服务的。

它们在 Python 版的 aitools 中一一对应这些,ocr_llm 是 OCR 工具的实现,image_understanding 是图片理解工具的实现,image_generator 是图片生成工具的实现,speech_synthesis 是超拟人合成工具的实现。
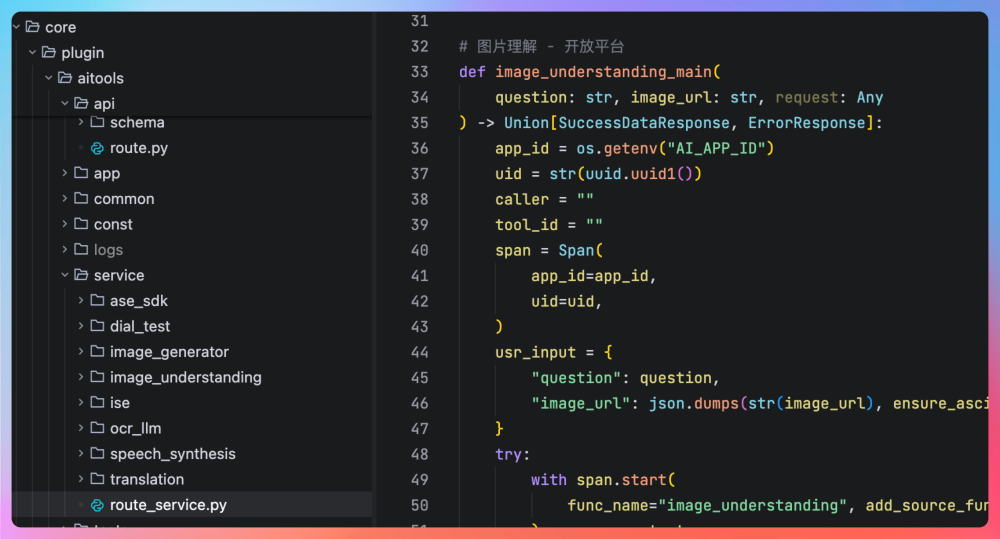
Java 版的工作流我们暂时只实现了超拟人合成节点的内置(第二期我们可以陆续实现图片生成/图片理解/OCR 等内置插件),放在了 plugins/tts 目录下,支持阿里通义千问的 tts(Text-to-Speech)和讯飞的 tts。
当然了,对于工作流来说,每个工具都是一个预设好的独立功能模块,背后不管怎么实现,最终都可以通过 REST API 被调用。因此,这些内置工具也可以通过 link 的形式来实现。当然了,我们还可以通过 link 接入更多第三方的插件。
换句话说,超拟人音频合成工具可以是 aitools,也可以是 link,看我们想要怎么去实现。
在 PaiFlow 中,如果想集成第三方工具,有两个入口。第一个入口是点工具这里的【+】号。
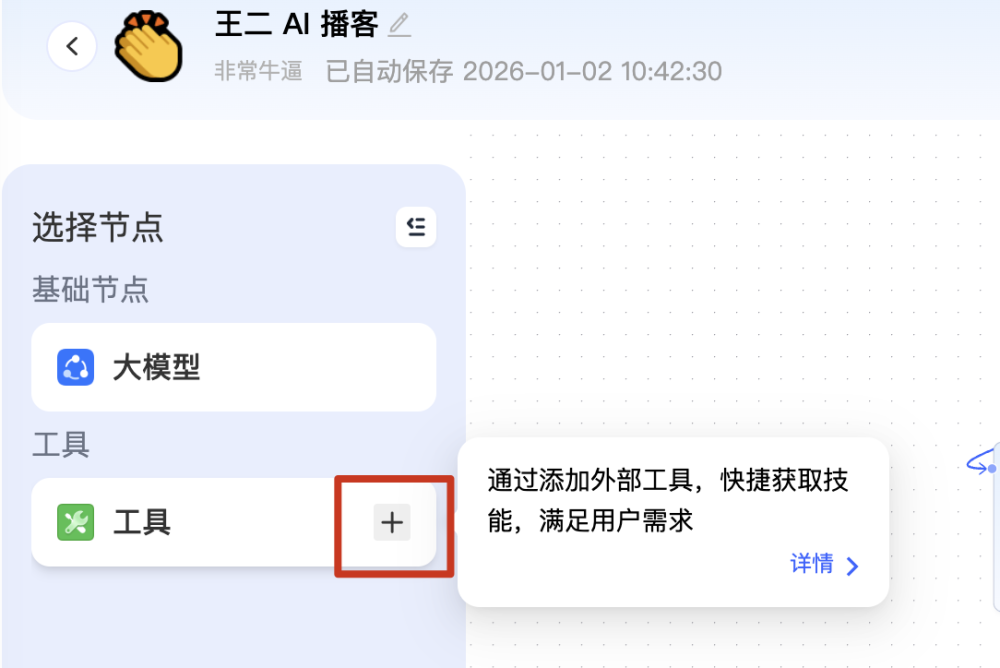
然后进入【新建工具】页,通过填写基本信息、插件信息、验证信息新建一个工具,这种适合你在编排工作流的时候,临时起意想调用一个工具。
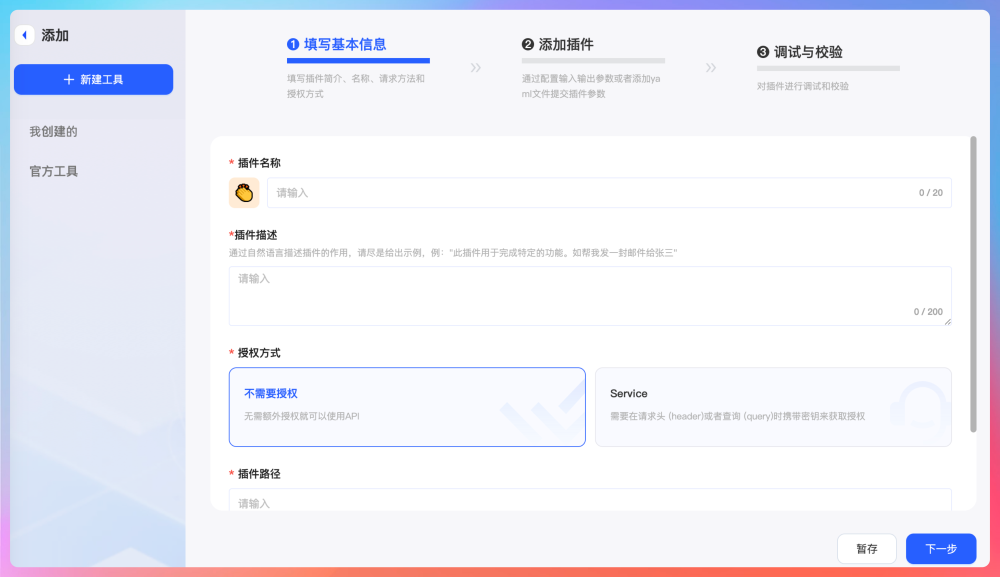
还有一种入口是在资源管理这里点击【新建插件】,适合我们提前规划好某个工具,然后在编排工作流的时候直接使用。

仍然是先把一个工具的基本信息填好,再选择请求方法和授权方式,最后做调试校验。工具本身就是一个可被描述、可被验证、可被复用的外部能力。
PaiFlow 除了 Python 版本的 aitools/link 微服务, 同样也实现了 Java 版本。插件节点的执行器由 PluginNodeExecutor 类来完成。
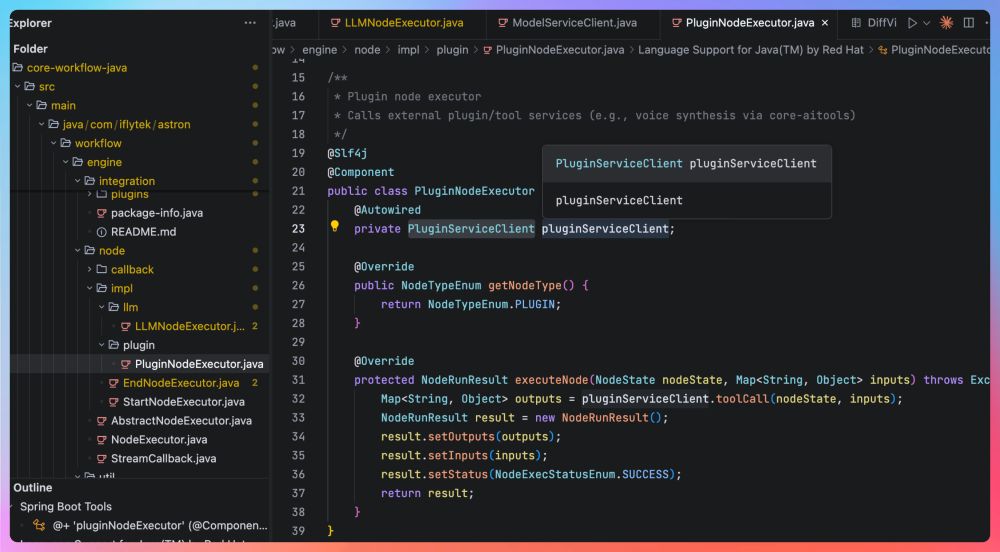
为了兼容 Python 版本的 aitools/link,我们在 PluginNodeExecutor 中注入了 PluginServiceClient,由它来负责具体插件的路由。
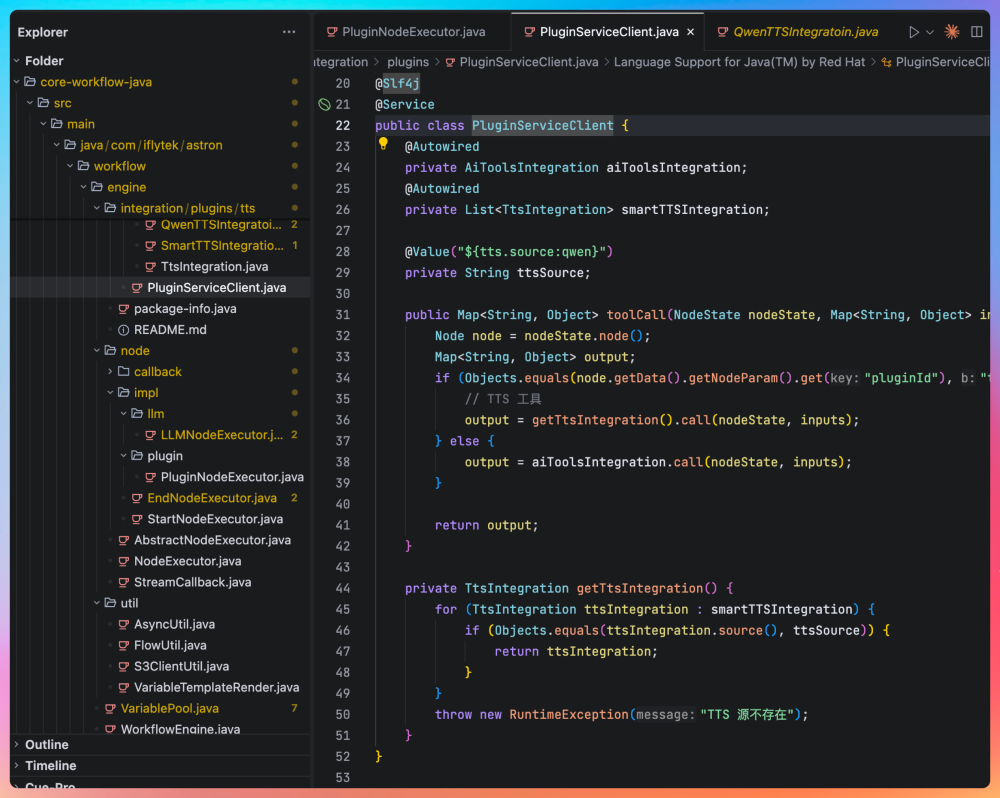
如果插件的 id 是硬编码的 tool@8b2262bef821000,就调用内置的 tts 工具,内置的 tts 工具又可以根据 ttsSource 来决定是调用讯飞的 tts 还是 阿里千问的 tts;否则就通过 AiToolsIntegration 来调用 Python 版或者 Java 版的插件服务,由 application.yml 文件里配置的 aitools-url 来决定。
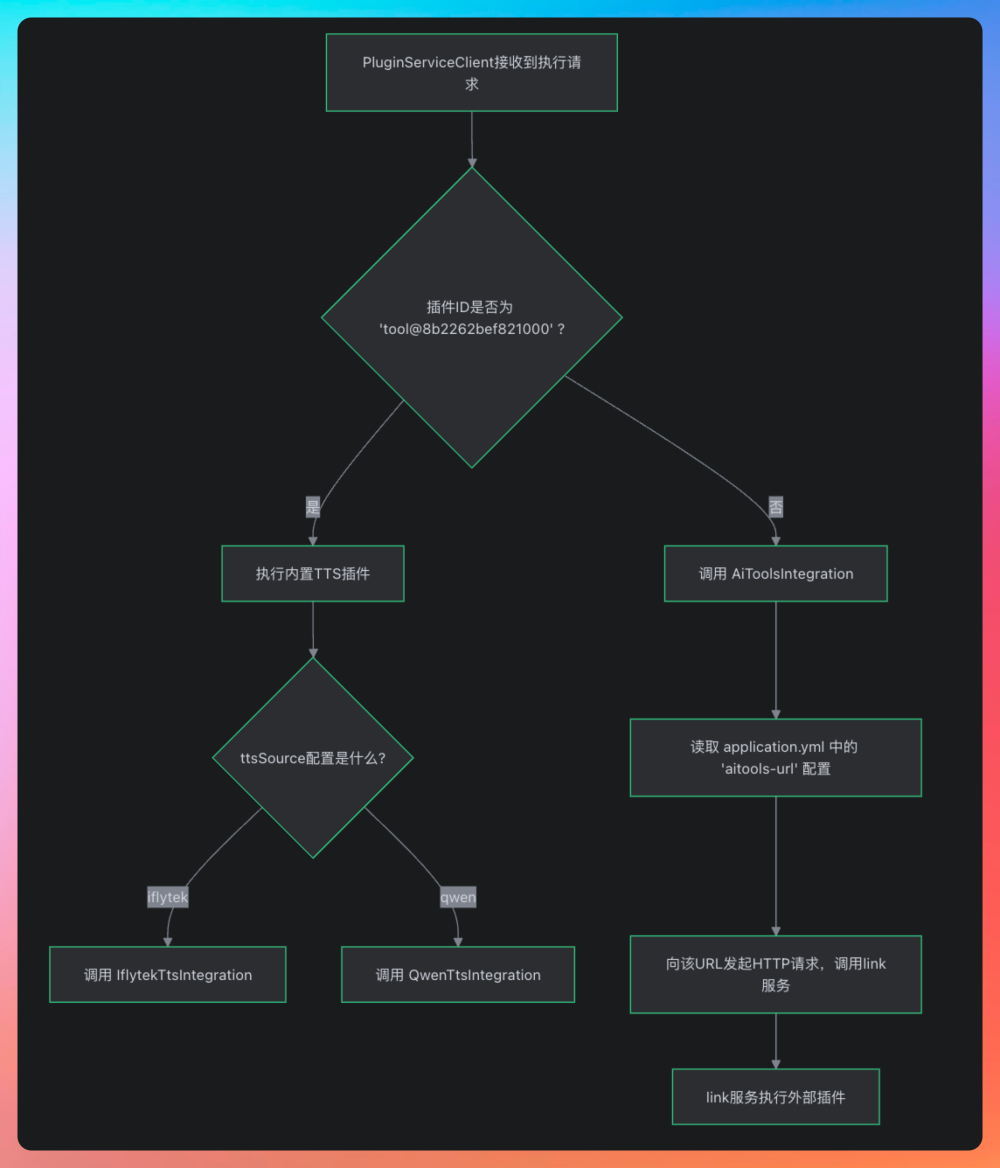
就目前的 AI 应用开发来说,多语言技术栈已经成为趋势,Python 干得好的地方就用 Python 来干,Java 干得好的地方就由 Java 来干。
PaiFlow 整体就是这样一个架构,hub 作为管理端适合 Java;工作流引擎上先实现了 Python 版本,后实现了 Java 版本,也是为了应对现在的开发趋势。第二期有可能还会追加 Go 语言的技术栈进来,比如说现在很火的一个方向——机器人流程自动化(RPA)就挺适合用 Go 语言来实现。
好,理清楚后,本篇我们重点来讲讲插件节点执行器,插件扩展我们后面会细讲。
1.插件节点执行器的整体设计
PluginNodeExecutor 负责把执行请求交给路由层 PluginServiceClient,PluginServiceClient 再根据插件 ID 或工具类型,把请求分发到对应的集成实现里。
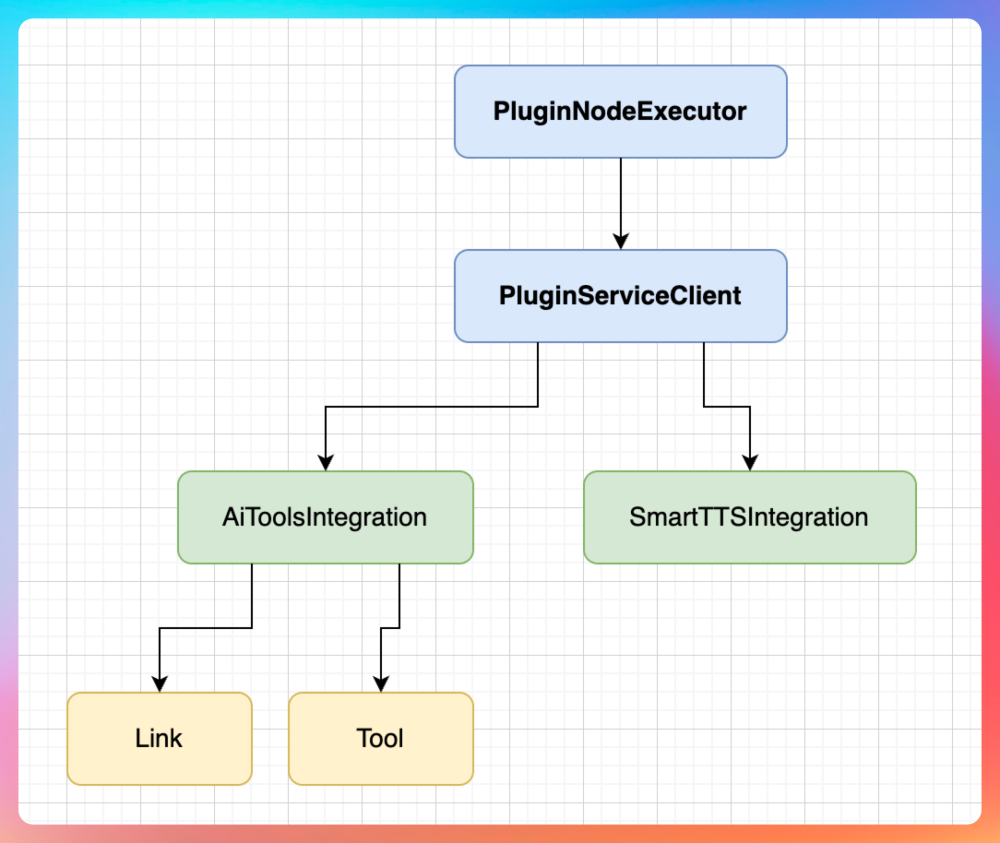
这里我们把集成实现按职责进行了拆分。遇到 TTS 语音合成场景,就走 SmartTTSIntegration,专门处理文本转语音这条链路。遇到通用工具调用,就走 AiToolsIntegration,通过 Python 版或者 Java 版的 aitools 或 link 服务去完成最终的插件执行。
2.PluginNodeExecutor类的说明
PluginNodeExecutor 继承了 AbstractNodeExecutor ,并实现了 executeNode() 这个方法。它不负责具体执行哪个插件,也不关心是内置的 TTS 插件还是其他的第三方工具,它只做两件事:告诉执行引擎自己是 PLUGIN 插件节点执行器,然后把执行请求交给真正干活的 PluginServiceClient。
@Slf4j
@Component
public class PluginNodeExecutor extends AbstractNodeExecutor {
@Autowired
private PluginServiceClient pluginServiceClient;
@Override
public NodeTypeEnum getNodeType() {
return NodeTypeEnum.PLUGIN;
}
}
节点生命周期管理、上下文处理、异常兜底、回调这些通用逻辑都由 AbstractNodeExecutor 兜着。executeNode 方法拿到 nodeState 和 inputs 后,直接调用 pluginServiceClient.toolCall(nodeState, inputs) 拿到 outputs。
@Override
protected NodeRunResult executeNode(NodeState nodeState, Map inputs) throws Exception {
Map outputs = pluginServiceClient.toolCall(nodeState, inputs);
NodeRunResult result = new NodeRunResult();
result.setOutputs(outputs);
result.setInputs(inputs);
result.setStatus(NodeExecStatusEnum.SUCCESS);
return result;
}
也就是说,插件节点到底怎么执行,参数怎么传递,调用链路怎么走,成功失败怎么处理,这些都不管,执行器只负责发起调用并拿结果。
3.PluginServiceClient类的说明
PluginServiceClient 是插件服务的统一入口,负责根据插件类型路由到具体的实现类:
@Slf4j
@Service
public class PluginServiceClient {
@Autowired
private AiToolsIntegration aiToolsIntegration;
@Autowired
private SmartTTSIntegration smartTTSIntegration;
public Map toolCall(NodeState nodeState, Map inputs) throws Exception {
Node node = nodeState.node();
Map output;
if (Objects.equals(node.getData().getNodeParam().get("pluginId"), "tool@8b2262bef821000")) {
// TTS 工具
output = smartTTSIntegration.call(nodeState, inputs);
} else {
output = aiToolsIntegration.call(nodeState, inputs);
}
return output;
}
}
目前支持两种插件类型:
SmartTTSIntegration:专门用于语音合成的服务
AiToolsIntegration:通用的AI工具集成,可以调用各种外部工具
4.SmartTTSIntegration类的说明
SmartTTSIntegration 是一个内置插件,通过调用讯飞星火大模型的语音合成(TTS)服务,将文本转化为高质量的音频文件。
封装了讯飞星火 TTS 服务通信的所有细节,包括复杂的鉴权签名和 WebSocket 实时通信。对应的节点配置如下所示,输入参数有 vcn 也就是发音人的音色,text 也就是引用的文本,由大模型生成,speed 也就是语速,默认 50 为正常值。
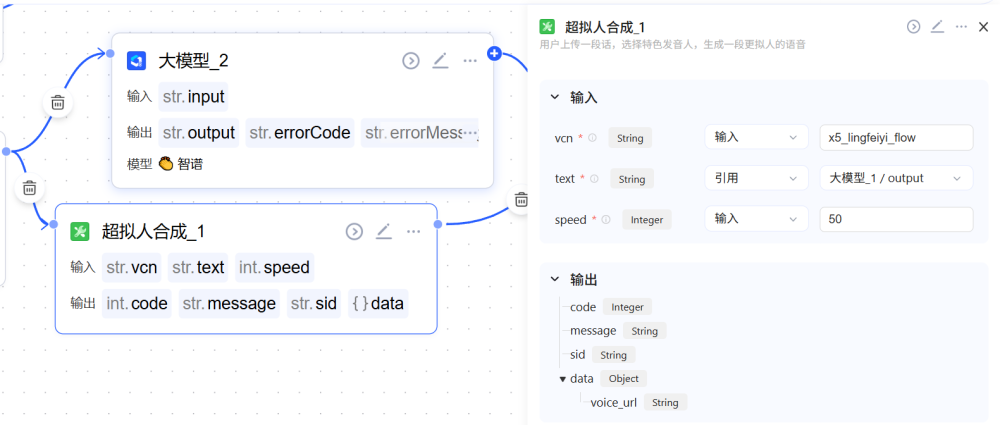
输出参数有状态码 code、描述 message、sid 唯一编码、data.voice_url 也就是音频的下载地址等。对应的节点配置如下所示:
{
"data": {
"inputs": [
{
"id": "239589ef-3815-46d8-b10b-a61eccaeaca3",
"name...企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

8人已点赞
热门评论
9 条评论
回复