


PaiFlow架构设计面试题预测:Agent项目是如何设计的
1. 请介绍一下 PaiFlow 这个项目是做什么的?解决了什么问题?
考察点:项目理解、业务价值表达
参考答案:
面试官您好,PaiFlow 是一个 AI 工作流编排平台,简单说就是让用户通过"拖拖拽拽"的方式,把多个 AI 能力串起来,自动完成一些复杂的任务。
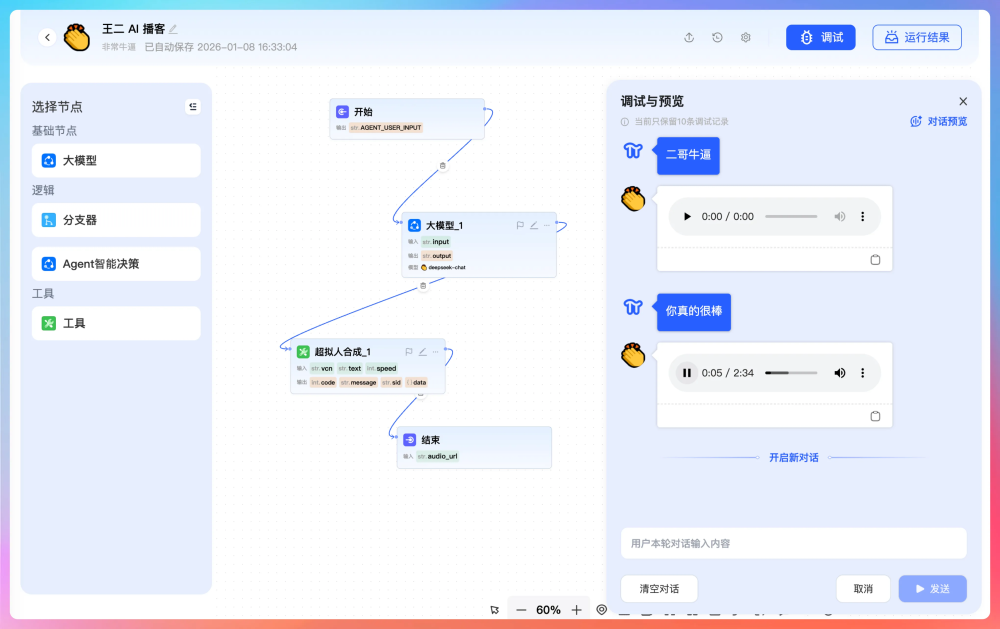
举个具体例子:我们有个"AI 播客生成"的场景。用户只需要输入一段文字,系统会自动调用大模型把它改写成适合口播的风格,然后再调用语音合成服务生成音频。以前这个过程需要人工一步步操作,现在配置好工作流后,一键就能完成。
它解决的核心问题是:降低 AI 应用的开发门槛。业务人员不需要写代码,只要在可视化界面上编排节点,就能快速搭建 AI 应用。
参考答案版本 2
PaiFlow 是一个企业级的 AI 工作流编排平台,能让用户通过可视化拖拽的方式,把大模型、语音合成、各种插件工具串成一条自动化流水线,不用写代码就能构建自己的 AI 应用。类似 n8n、扣子、dify 等平台。
比如我有一篇技术文章,想把它变成播客节目。传统的做法要自己改稿、找工具合成语音、处理存储。而在 PaiFlow 里,画一个流程图,把"大模型改写"和"语音合成"两个节点连起来,输入原文,系统就能自动跑完整个流程,直接输出能播放的音频。
这个项目真正有意思的地方在于架构设计。我们采用了多语言微服务架构,前端 React 负责可视化编排,Spring Boot 做业务中台处理工作流编排,工作流执行可以用 Python 的 FastAPI + 自研引擎,也可以用 Java 版的 SpringAI +LangGraph4J 版本。
我们实现了一套基于 DAG 的执行引擎,支持条件分支、并行执行、循环节点。每个节点执行完会把输出写到变量池中,下游节点通过变量引用的方式可以拿到上游的节点数据。执行状态会持久化到数据库,如果中间某个节点失败了,支持从断点重试,不用整个流程重跑。
另一个技术挑战是插件体系的设计。我们的工作流不只是调大模型,还要能调各种外部工具,比如语音合成、图片生成、RPA 操作等。我们基于 MCP 协议做了一套插件机制,外部工具只要按照标准的 Schema 注册进来,就能作为节点被编排。
另外,我们全链路接入了 OpenTelemetry。一个工作流跑下来可能调了三四个服务,如果出问题了,通过 TraceID 能把整条链路的日志、耗时、错误信息全部串起来看,定位问题很快。
部署这块我们做了 Docker Compose 一键启动,十几个服务的依赖关系、环境变量、网络配置全部封装好了,首次部署稍微花点时间,但所有依赖下载完成也差不多 30 分钟左右。
2. 能说一下 PaiFlow 的整体架构吗?各个服务之间是怎么协作的?
考察点:系统架构、服务间调用关系
参考答案:
PaiFlow 是一个典型的多语言微服务架构,整体分为四层:前端展示层、业务中台层、工作流执行层、还有插件能力层。
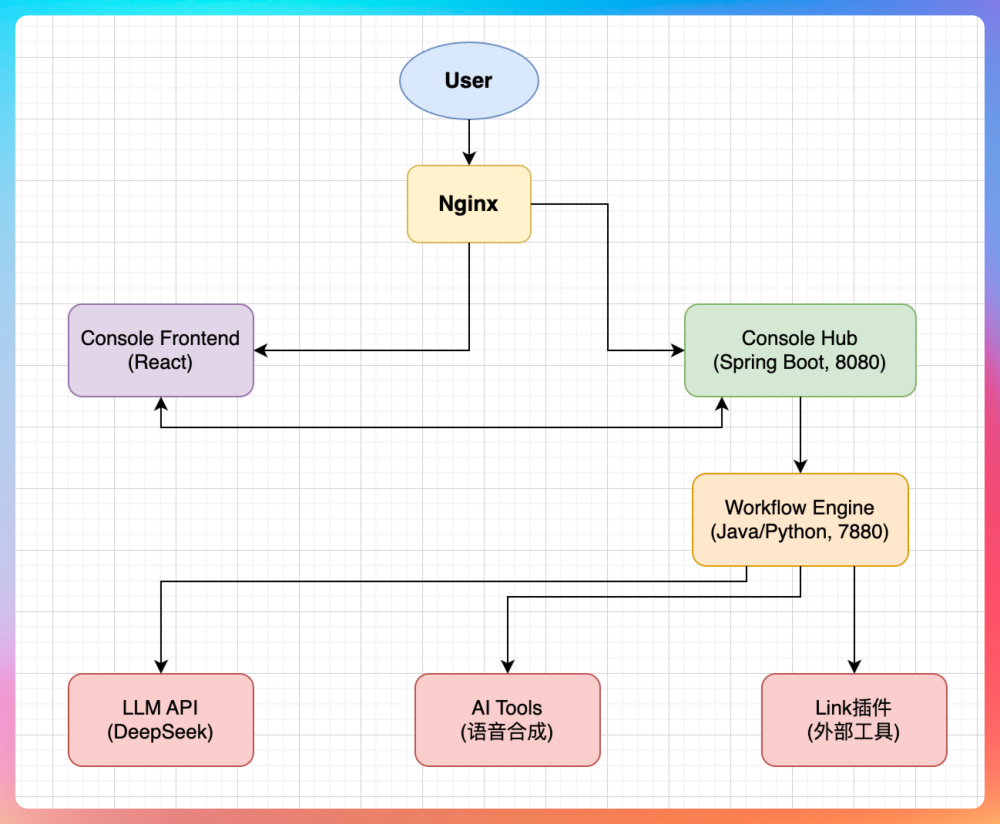
前端是 React 写的,核心是一个基于 React Flow 的可视化流程编辑器,用户在这里拖节点、连线、配参数。前端通过 Nginx 反向代理统一暴露在 80 端口,所有 API 请求都走 Nginx 转发到后端服务。
业务中台是 Java 21 + Spring Boot 3.5 写的,我们内部叫 Console Hub,跑在 8080 端口。这一层负责的是"业务逻辑"而不是"执行逻辑",比如用户登录认证、工作流的 CRUD、权限控制、工具市场管理这些。用户在前端保存一个工作流,实际上是 Hub 把流程定义存到 MySQL 里;用户点击运行,Hub 会把请求转发给下游的工作流引擎。
工作流引擎有两个版本,一个是 Python 版,一个是 Java 版,都跑在 7880 端口,当然只能同时启动一个。它拿到 Hub 传过来的流程定义和输入参数,按照 DAG 的拓扑顺序一个节点一个节点地执行。比如先跑"大模型改写"节点,拿到输出后再跑"语音合成"节点。Python 版的执行状态会实时写到 PostgreSQL,Java 版是写到 MySQL,如果中间挂了可以断点续跑。Redis 用来做节点间的分布式锁,以及部分高频数据的缓存,比如说第三方插件的权限等。
插件层也是有两个版本,一个是 Python,一个是 Java,Python 版的 Tools 服务跑在 18668 端口,Java 版和工作流引擎共用一个端口。工作流引擎执行到插件节点时,会通过 HTTP 调用这些插件服务,拿到结果后继续往下跑。
拿 AI 播客这个工作流来说,用户在前端点击"运行工作流",请求先到 Nginx,Nginx 转发到 Hub,Hub 做完鉴权后把请求丢给 Workflow Engine。Engine 开始执行,第一个节点是开始节点,第二个节点是 LLM 节点,它调用 DeepSeek 或者其他模型的 API 把原文改写成播客稿;第二个节点是语音合成,Engine 调用插件服务生成音频,音频文件存到 MinIO;最后 Engine 把结果返回给 Hub,Hub 再返回给前端,用户就能听到生成的播客了。
为什么要这样拆服务?一是让每个语言干自己擅长的事。Java 在企业级场景下生态成熟,Spring Security 做认证授权、MyBatis 做数据持久化。
但 Python 在 AI 领域的生态更多,调大模型、处理流式响应、对接各种 AI SDK 都很顺手,而且 FastAPI 的异步性能很强,适合做执行引擎这种 IO 密集型的活。
但作为一名 ...
企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

9人已点赞
热门评论
59 条评论
回复