


LangGraph4J面试预测题库:Java自研与LangChain4J区别解析
这部分我们原本放在第二期实现,但考虑到球友们想提前拿去面试,所以我们在 PaiAgent 项目中实现了,放在了:https://github.com/itwanger/PaiAgent/tree/LangGraph4J
1. 请介绍一下 LangGraph4J 是什么?它和 LangChain4J 有什么区别?
考察点:对 LangGraph4J 框架的基本理解
参考答案:
LangGraph4J 是 LangGraph(Python版本)的 Java 实现,是一个用于构建有状态、多角色 AI Agent 应用的图编排框架。
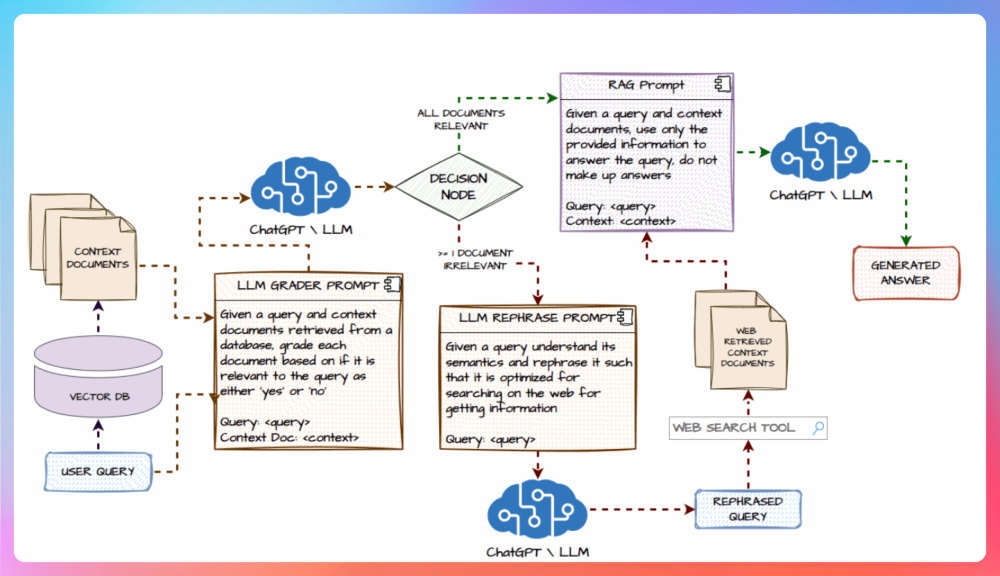
与 LangChain4J 的区别是:
LangChain4J 专注于 LLM 调用链、Prompt 模板、RAG 等基础能力的封装,是"链式"编排
LangGraph4J 专注于复杂 Agent 工作流的"图式"编排,支持状态机、条件分支、循环、检查点等高级特性
LangGraph4J 可以看作是 LangChain4J 的上层编排框架,用于构建更复杂的 Agent 应用场景。
参考答案版本 2:
LangGraph4J 是 LangGraph 的 Java 实现,它是一个用于构建有状态、可循环的多步骤 LLM 应用的编排框架。而 LangChain4J 更偏向于一个 LLM 应用的工具链和组件库。
| 维度 | LangChain4J | LangGraph4J |
|---|---|---|
| 定位 | 组件库 / 工具链 | 工作流编排框架 |
| 核心抽象 | Chain(链式调用) | StateGraph(状态图) |
| 适用场景 | 单次 LLM 调用、RAG | 复杂 Agent、多轮决策 |
LangChain4J 的 Chain 本质是线性的,A → B → C 顺序执行。LangGraph4J 支持循环和条件分支,比如:
// LangGraph4J 的条件路由
graph.addConditionalEdges(
"agent",
routingFunction, // 根据状态决定下一步
Map.of(
"continue", "tool",
"end", END
)
);
这在实现 ReAct Agent(思考→行动→观察→再思考)时非常关键。
LangGraph4J 的核心是 StateGraph,每个节点都能读写共享状态,而 LangChain4J 没有内置的状态持久化机制,需要自己维护上下文。
public class AgentState {
private List messages;
private String nextAction;
// getters/setters
}
StateGraph graph = new StateGraph<>(AgentState.class);
参考答案版本 3
LangGraph4J 是 LangGraph 的 Java 实现版本,它是一个专门用来构建有状态、可循环的多步骤 LLM 应用的编排框架。如果打个比方的话,LangChain4J 更像是一套乐高积木,提供了各种现成的组件让你去调用大模型;而 LangGraph4J 则是搭积木的图纸和流水线,它关注的是怎么把这些组件按照一定的逻辑编排起来。
两者最核心的区别体现在三个方面。第一是流程控制能力,LangChain4J 的 Chain 本质上是线性的,就是 A 调用完调用 B,B 调用完调用 C,顺序执行。
但 LangGraph4J 支持循环和条件分支,比如实现一个 ReAct Agent,它需要"思考→行动→观察→再思考"这样的循环,LangGraph4J 通过条件边可以根据当前状态动态决定下一步走哪个节点:
graph.addConditionalEdges(
"agent",
state -> state.needsTool() ? "tool" : END,
Map.of("tool", "tool_node", END, END)
);
第二是状态管理,LangGraph4J 的核心抽象是 StateGraph,需要先定义一个状态类,里面包含消息历史、中间结果这些字段,然后每个节点执行的时候都能读取和修改这个共享状态:
public class AgentState {
private List messages;
private String nextAction;
}
StateGraph graph = new StateGraph<>(AgentState.class);
graph.addNode("agent", agentNode);
graph.addNode("tool", toolNode);
graph.addEdge(START, "agent");
而 LangChain4J 没有内置的状态管理机制,如果要做多轮对话或者复杂的上下文传递,得自己去维护。
第三是适用场景,如果只是做一个简单的问答、RAG 检索增强这类单次调用的场景,LangChain4J 完全够用。但如果要构建一个能够自主决策、多步骤执行、需要循环判断的 Agent 系统,LangGraph4J 是更合适的选择。这也是为什么很多企业级 AI 工作流平台会选择图引擎来做编排,本质上和 LangGraph4J 的设计理念是一致的。
2. 请解释 LangGraph4J 中 StateGraph 和 CompiledGraph 的区别?
考察点:对核心类的理解
参考答案:
StateGraph:是图的构建器,用于定义节点(Node)、边(Edge)、入口和出口,是图的"设计态"
CompiledGraph:是 StateGraph 编译后的产物,是图的"运行态",只有编译后才能执行(invoke)
StateGraph 相当于 Java 源代码,CompiledGraph 相当于编译后的字节码。在项目中的体现(GraphBuilder.java:59):
var compiled = graph.compile();
参考答案版本 2
StateGraph 和 CompiledGraph 的关系,可以类比成 Java 正则表达式里的 Pattern.compile()。StateGraph 是图的"定义阶段",我们需要在这个阶段声明有哪些节点、节点之间怎么连接、什么条件走什么分支,它是可变的,我们可以不断往里面添加东西。
而 CompiledGraph 是调用 compile() 方法之后得到的"可执行图",它是不可变的,专门用来执行的。
从使用流程来看,我们先创建一个 StateGraph,然后往里面添加节点和边:
StateGraph graph = new StateGraph<>(AgentState.class);
graph.addNode("agent", agentNode);
graph.addNode("tool", toolNode);
graph.addEdge(START, "agent");
graph.addConditionalEdges("agent", routingFunc, Map.of("continue", "tool", "end", END));
graph.addEdge("tool", "agent");
这时候图还不能运行,必须调用 compile() 方法把它编译成 CompiledGraph:
CompiledGraph AgentState app = graph.compile();
编译这一步会做几件事情:验证图的结构是否合法,比如有没有孤立节点、有没有死循环风险;把节点和边的定义转换成内部的执行结构;如果配置了 checkpointer,还会初始化状态持久化的相关逻辑。
拿到 CompiledGraph 之后,就可以通过 invoke() 或者 stream() 方法来执行它了:
AgentState result = app.invoke(initialState);
// 或者流式执行
app.stream(initialState).forEach(state -> System.out.println(state));
这样设计的好处是职责分离,StateGraph 负责"构建",CompiledGraph 负责"执行",而且 CompiledGraph 是线程安全的,可以被多个请求并发调用,不需要每次都重新构建图。
这个模式在框架设计中非常常见,比如 Spring 的 BeanDefinition 和 Bean 实例、MyBatis 的 Configuration 和 SqlSession,都是类似的思路。
3. 请解释 AgentState 在 LangGraph4J 中的作用?
考察点:对状态管理机制的理解
参考答案:
AgentState 是 LangGraph4J 中用于在节点之间传递状态的核心数据结构,本质上是一个 Map
主要作用:
跨节点数据传递:节点A的输出可以通过 AgentState 传递给节点B
全局上下文共享:存储整个工作流执行过程中的共享数据
状态持久化基础:配合 CheckpointSaver 实现断点续传
在 PaiAgent 中,我们通过 StateManager 来管理 AgentState 的初始化、更新和提取。
参考答案版本 2
AgentState 是 LangGraph4J 中用来承载整个工作流执行状态的核心对象,你可以把它理解成一个"全局上下文",它贯穿图执行的全过程,每个节点都可以读取它、修改它,然后把修改后的状态传给下一个节点。
它主要解决三个问题(和前面我们提到的变量池是一个道理)。首先是节点间的数据传递,比如 Agent 节点调用大模型生成了一个回复,Tool 节点需要拿到这个回复去解析里面的工具调用指令,这个数据就是通过 AgentState 传递的。其次是上下文的积累,比如多轮对话场景,需要把历史消息都存下来,每次调用大模型的时候带上完整的对话历史,这些消息就存在 AgentState 的 messages 字段里。最后是作为条件路由的决策依据,比如要判断是继续调用工具还是结束流程,这个判断逻辑就是根据 AgentState 里的某些字段来决定的。
AgentState 就是一个普通的 Java 类,然后在创建图的时候把类型传进去:
public class AgentState {
private List messages = new ArrayList<>();
private String nextAction;
private Map toolResults;
// getters and setters
}
StateGraph graph = new StateGraph<>(AgentState.class);
每个节点本质上是一个函数,接收当前状态,返回更新后的状态:
graph.addNode("agent", state -> {
List messages = state.getMessages();
AIMessage response = llm.call(messages);
state.getMessages().add(response);
state.setNextAction(parseAction(response));
return state;
});
有一点需要注意,LangGraph4J 推荐使用不可变更新的方式来修改状态(深拷贝),就是每次返回一个新的状态对象而不是直接修改原对象,这样在配合 Checkpointer 做状态持久化和回放的时候会更可靠。
4. 你在项目中是如何使用适配器模式将现有的 NodeExecutor 适配为 LangGraph 的 AsyncNodeAction 的?
考察点:适配器模式的实际应用
参考答案:
PaiAgent 中设计了 NodeAdapter 组件,核心思路是:
问题:现有系统已有完善的 NodeExecutor 体系,但 LangGraph4J 要求节点必须实现 AsyncNodeAction
解决方案:NodeAdapter 作为适配器,将 NodeExecutor 包装为 AsyncNodeAction
核心实现(NodeAdapter.java:39-112):
public AsyncNodeAction adaptNode(WorkflowNode node, Consumer eventCallback) {
return (AgentState state) -> {
// 1. 从 AgentState 提取输入
Map currentInput = (Map) state.data().get("currentInput");
// 2. 调用原有的 NodeExecutor 执行
NodeExecutor executor = executorFactory.getExecutor(node.getType());
Map output = executor.execute(node, currentInput, eventCallback);
// 3. 更新状态并返回
Map newStateData = new HashMap<>(state.data());
newStateData.put("currentInput", output);
return CompletableFuture.completedFuture(newStateData);
};
}
这样既复用了现有代码,又满足了 LangGraph4J 的接口要求。
参考答案版本 2
在我们项目中,原本已经有一套 NodeExecutor 的接口体系,每种节点类型比如 OpenAI、DeepSeek、TTS 都有对应的执行器实现。后来引入 LangGraph4J 做工作流编排的时候,发现它期望的节点是 AsyncNodeAction 这种函数式接口,接收一个 State 返回一个 State。
这两套接口不兼容,但我们又不想把原有的执行器全部重写一遍,所以就用适配器模式来做桥接。
原有的 NodeExecutor 接口大概长这样:
public interface NodeExecutor {
Map execute(WorkflowNode node, Map input);
}
而 LangGraph4J 期望的节点动作是这样的:
// LangGraph4J 的节点本质上是 Function
graph.addNode("agent", state -> {
// 处理逻辑
return updatedState;
});
于是我写了一个适配器类,把 NodeExecutor 包装成 LangGraph4J 能识别的形式:
public class NodeExecutorAdapter implements Function {
private final NodeExecutor executor;
private final WorkflowNode nodeConfig;
public NodeExecutorAdapter(NodeExecutor executor, WorkflowNode nodeConfig) {
this.executor = executor;
this.nodeConfig = nodeConfig;
}
@Override
public AgentState apply(AgentState state) {
// 从 AgentState 中提取 NodeExecutor 需要的输入
Map input = state.getCurrentInput();
// 调用原有的执行器
Map outp...企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

5人已点赞
热门评论
6 条评论
回复