


企业级AI Agent工作流编排项目的工作流引擎是如何设计和完成的?
在完成 DSL 的生成和解析之后,真正困难的才刚刚开始。DSL 只是描述了“流程长什么样子”,但一个工作流引擎的真正价值,不在于能不能把流程画出来,而在于:这个流程如何被一步一步、安全可控地执行。
工作流在执行过程中,往往伴随着输入参数的初始化、上下文的传递、状态的流转、异常的处理、以及执行结果的回传等。我画了一张图,可以清晰地概括出工作流的执行机制。
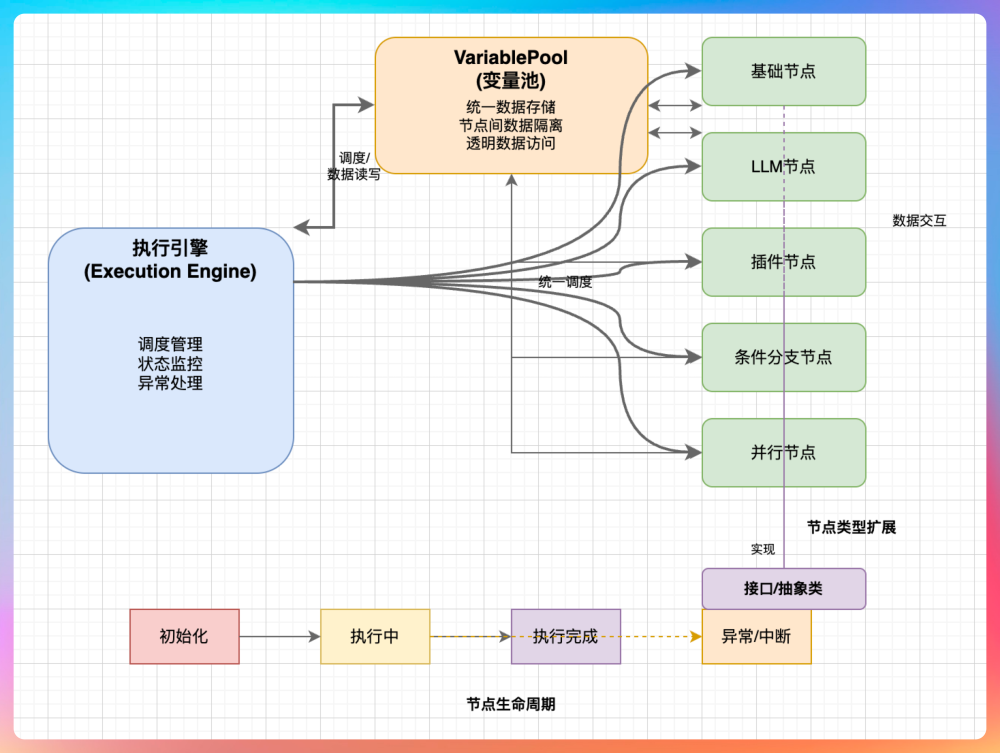
首先,执行引擎要将复杂的流程拆解为可独立执行的最小单元。每一个节点都应该是一个完整、自治的执行单元,节点之间不直接相互调用。这种设计可以避免流程复杂后出现强耦合的问题。
其次,提供统一且透明的数据传递能力。节点之间的数据依赖通过 VariablePool 进行管理,节点只关心“我需要哪些输入数据”和“我输出了什么数据”,而不关心这些数据来自哪个节点、在什么顺序下产生。
第三,节点的执行状态可管理。在执行过程中,每个节点都会经历初始化、执行中、执行完成等多个状态,这些状态不仅用于流程推进,也用于异常处理、中断执行等。
最后,也是最重要的一点,为未来的节点扩展预留足够的扩展空间。无论是新增 LLM 节点、插件节点,还是引入更复杂的控制节点(如条件分支、并行节点),都不应该影响现有的执行逻辑。因此,节点执行机制必须以接口和抽象类为核心,确保新节点只关注自身业务实现,而无需侵入执行引擎本身。
从整体上看,节点执行机制的组件架构可以分为四层。
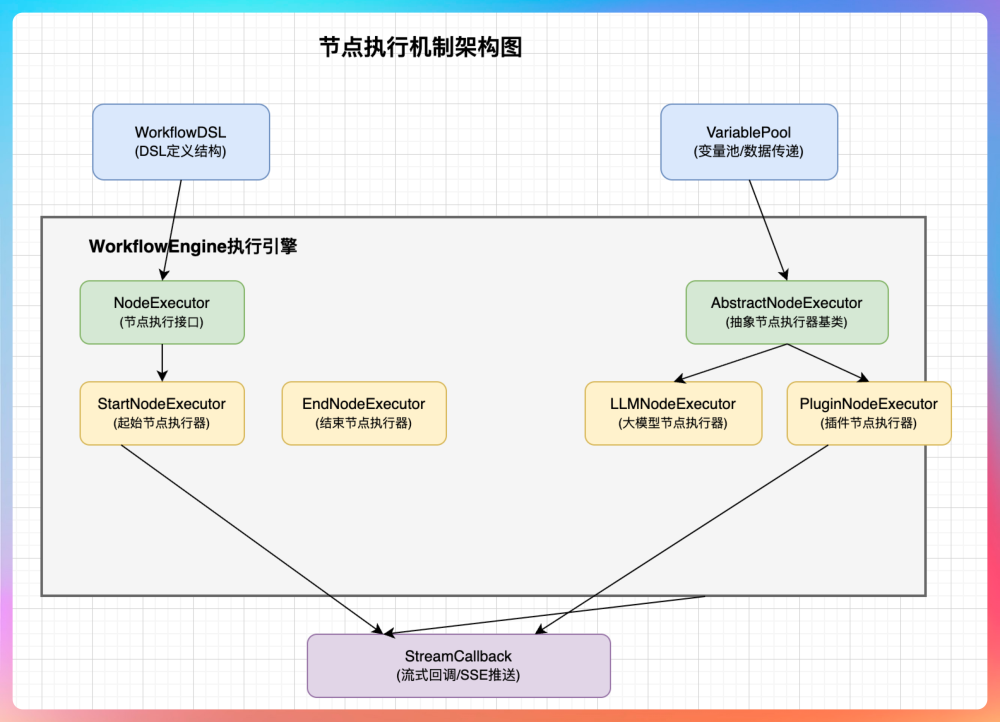
最上层是 WorkflowDSL,它负责描述“流程是什么样的”,不关心“流程如何执行”。DSL 只定义节点、连线和输入输出规则,本身不参与任何执行逻辑。
中间层是 WorkflowEngine,也就是执行中枢,负责执行链路的调度、节点关系的依赖,以及执行状态的控制。
节点的具体执行能力,则由 **NodeExecutor **来承担。通过统一的 NodeExecutor 接口和 AbstractNodeExecutor 抽象基类,不同类型的节点(如 LLM 节点、插件节点、起始节点、结束节点)可以被统一的方式调度,同时又保留各自的差异。这种设计使得新增节点类型时,只需扩展执行器,而无需修改执行引擎本身。
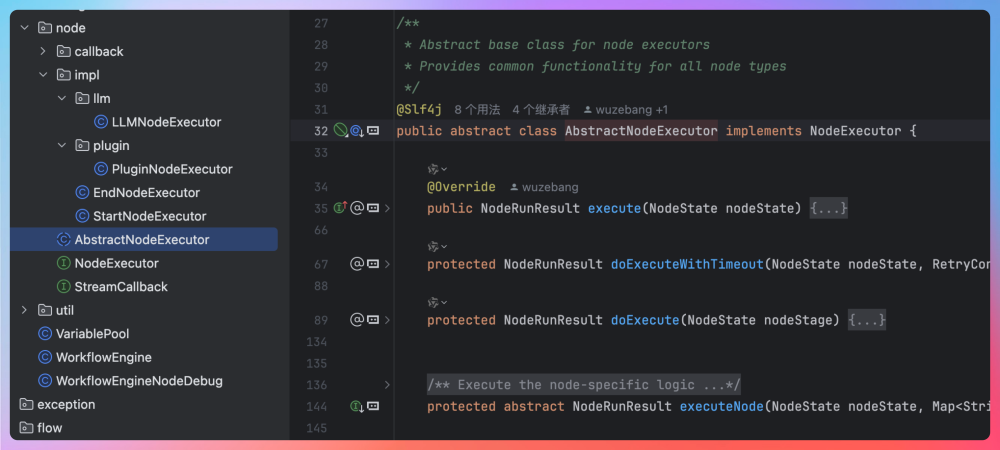
所有节点都必须实现统一的 NodeExecutor 接口,用于约束节点的执行入口和生命周期。在接口之上,引入 AbstractNodeExecutor 作为抽象基类,统一承载节点执行过程中的通用逻辑。例如执行前的上下文准备、执行状态的变更、异常捕获以及执行结果的回传等。
通过模板方法模式,节点的业务差异,则由子类实现。不同类型的节点,如起始节点、LLM 节点、插件节点,本质上只是“执行策略”的不同体现。
贯穿整个执行过程的数据流转,则由 VariablePool 统一管理。所有节点的输入和输出,都围绕 VariablePool 展开。
private void initializeStartNodeInputs(Node startNode, VariablePool variablePool, Map inputs) {
for (Map.Entry entry : inputs.entrySet()) {
variablePool.set(startNode.getId(), entry.getKey(), entry.getValue());
if (log.isDebugEnabled()) {
log.debug("Initialized start node input: {}.{} = {}", startNode.getId(), entry.getKey(), entry.getValue());
}
}
}
之所以采用这样的设计,原因在于工作流执行并不是线性的调用链,而是一个可能存在分支、回退、并行与中断的执行过程。
节点在执行时只需要声明自己依赖哪些输入变量,以及会产出哪些输出变量。通过 {nodeId}.{outputName} 这种明确的引用格式,节点不仅可以访问前置节点的执行结果,还可以避免直接持有对象引用带来的耦合问题。
VariablePool 的第一层以节点 ID 作为命名空间,用于区分不同节点的输出数据;第二层以输出变量名作为 Key,存储节点执行过程中产生的具体结果值。
在 DSL 层面,节点的输入输出通过 inputs 和 outputs 进行声明。当 WorkflowEngine 决定执行某一个节点时,会首先进入输入构建阶段。在这一阶段,引擎会根据 DSL 中的输入定义,逐一解析每一个输入字段:
如果输入值是一个字面量,则直接作为静态参数注入;
如果输入值是形如 {nodeId}.{outputName} 的引用表达式,则会从 VariablePool 中查找对应节点的输出结果;
如果输入字段声明了 schema 约束,则在注入前完成必要的类型校验与结构校验。
在节点执行完成后,输出结果同样会被统一处理。NodeExecutor 只需返回执行结果,WorkflowEngine 会根据 outputs 定义,将结果写入 VariablePool 中对应的节点命名空间下,供后续节点使用。
执行过程中产生的结果和状态变化,会通过 StreamCallback 进行实时回传,用于前端展示、日志追踪等。
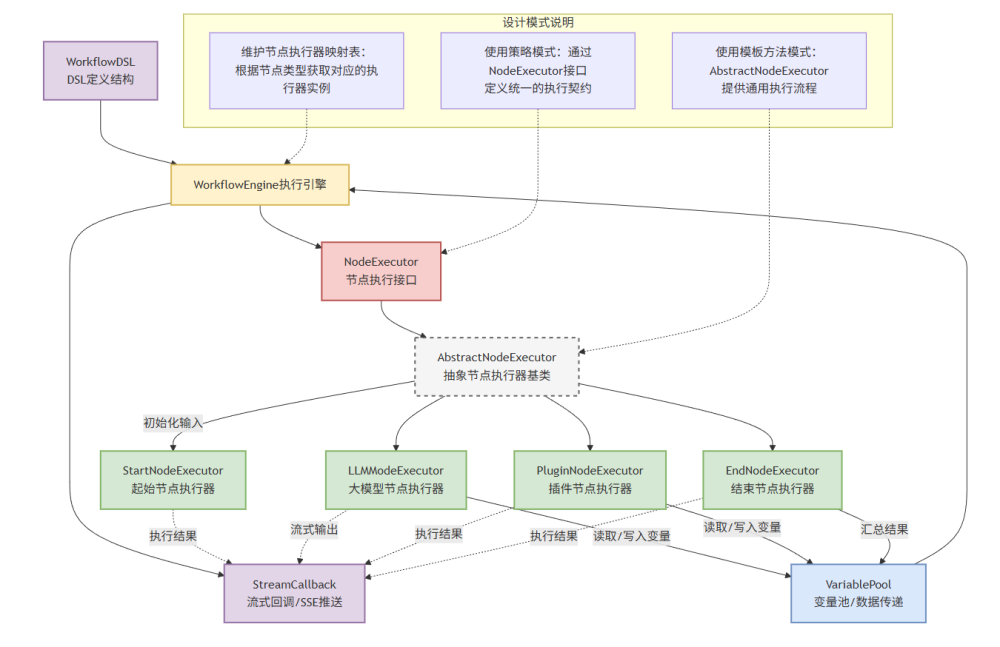
节点只需要在合适的时机触发回调,至于结果如何被展示、记录或推送给外部系统,则完全由回调方法决定。
1.执行引擎WorkflowEngine
在 PaiFlow 中,工作流的执行入口由执行引擎 WorkflowEngine 的 execute 方法统一驱动。包括执行前的校验、上下文初始化、执行链构建、节点调度、状态回传,以及最终的资源回收等。
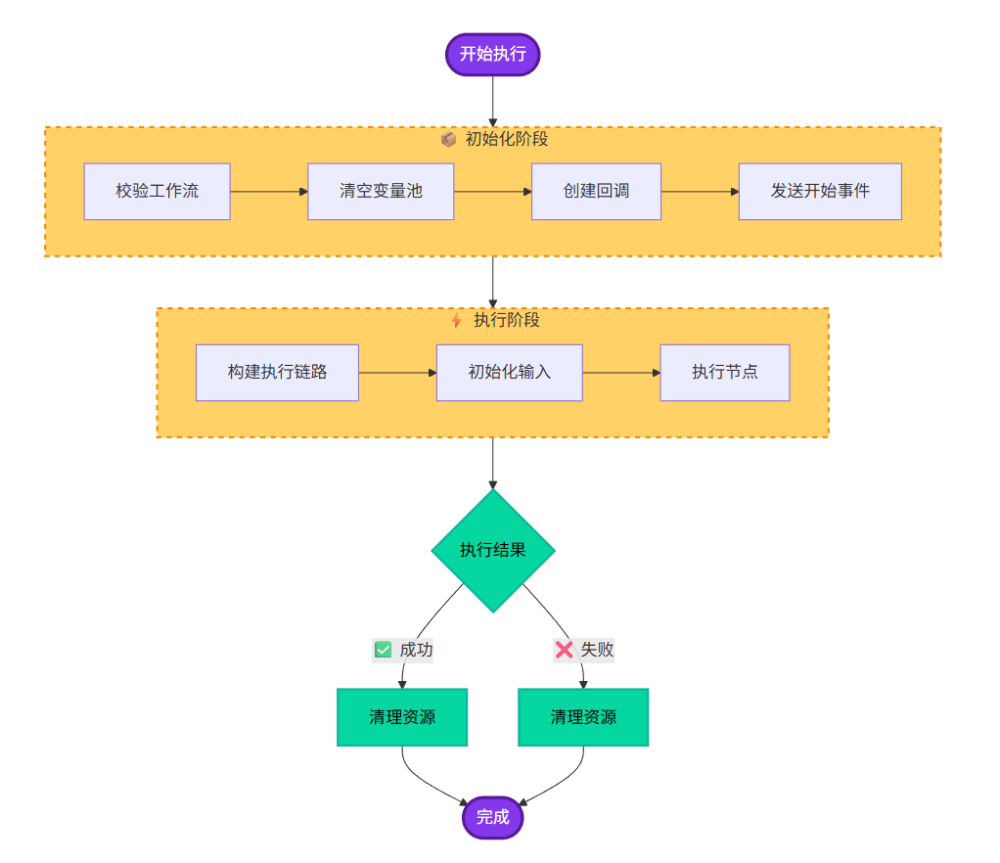
从生命周期的角度来看,一次完整的工作流执行,大致可以分为三个阶段:
第一阶段,是执行前准备。包括 DSL 的合法校验、上下文的初始化。
第二阶段,是工作流执行。执行引擎会从起始节点开始,按照节点之间的依赖关系,逐步推进节点执行。Java 版的节点执行器会返回不同的状态码,例如,当节点返回成功状态时,引擎会继续调度下一个节点;当节点返回可重试状态时,引擎会根据配置决定是否进行重试;当节点返回中断或失败状态时,引擎则会中止当前执行链路,或者进入失败分支处理逻辑。
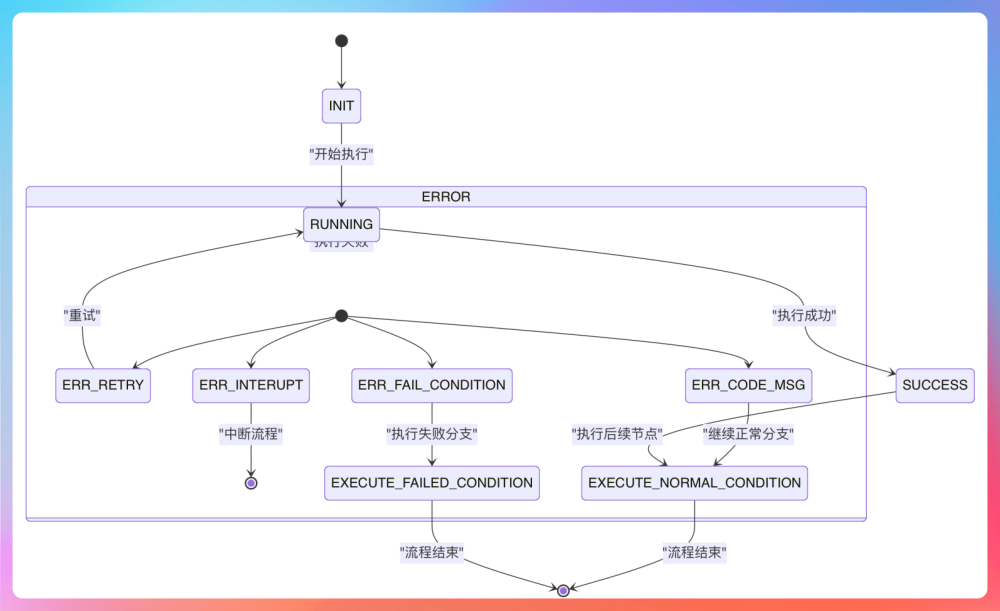
为了保证并发执行场景下的状态一致性,Java 版工作流引擎通过 EngineContextHolder 在整个工作流执行过程中传递和访问执行上下文信息。
内部封装的TransmittableThreadLocal能确保每个工作流执行过程中都有独立的上下文环境。假如没有 EngineContextHolder,工作流在执行的过程中需要一直传递 callback。
WorkflowEngine.execute(dsl, inputs, callback)
-> LlmNodeExecutor.execute(node, variablePool, callback)
-> ModelServiceClient.chat(request, callback)
-> SomeInternalHelper.prepareData(data, callback)
-> callback.onMessage(...) // 终于,发送了一条消息
为什么不用 ThreadLocal 呢?因为标准的 ThreadLocal 在线程池环境下无法正常工作。当一个任务被提交到线程池时,执行该任务的子线程不会继承提交任务的父线程的 ThreadLocal 值。 TransmittableThreadLocal (TTL) 通过自动将上下文从父线程拷贝到子线程解决了这个问题。
// 主线程设置上下文
EngineContextHolder.initContext(flowId, chatId, callback);
// 异步线程执行(线程池中的线程)
AsyncUtil.execute(() -> {
// ❌ 获取不到上下文!普通 ThreadLocal 无法跨线程传递
EngineContext ctx = EngineContextHolder.get(); // null!
String chatId = ctx.getChatId(); // NullPointerException!
});
// 主线程设置
EngineContextHolder.initContext(flowId, chatId, callback);
// 异步线程(TTL 自动复制上下文)
AsyncUtil.execute(() -> {
// ✅ 可以正常获取!
String chatId = EngineContextHolder.get().getChatId();
String sid = EngineContextHolder.get().getSid();
});
具体来说,EngineContext 内部封装了工作流执行所需的关键信息,包括但不限于:流程ID、会话ID、回调处理器和用于全链路追踪的唯一标识符等。这些信息在工作流执行的生命周期内始终保持一致,并作为引擎调度和回调的基础数据供上下文使用。
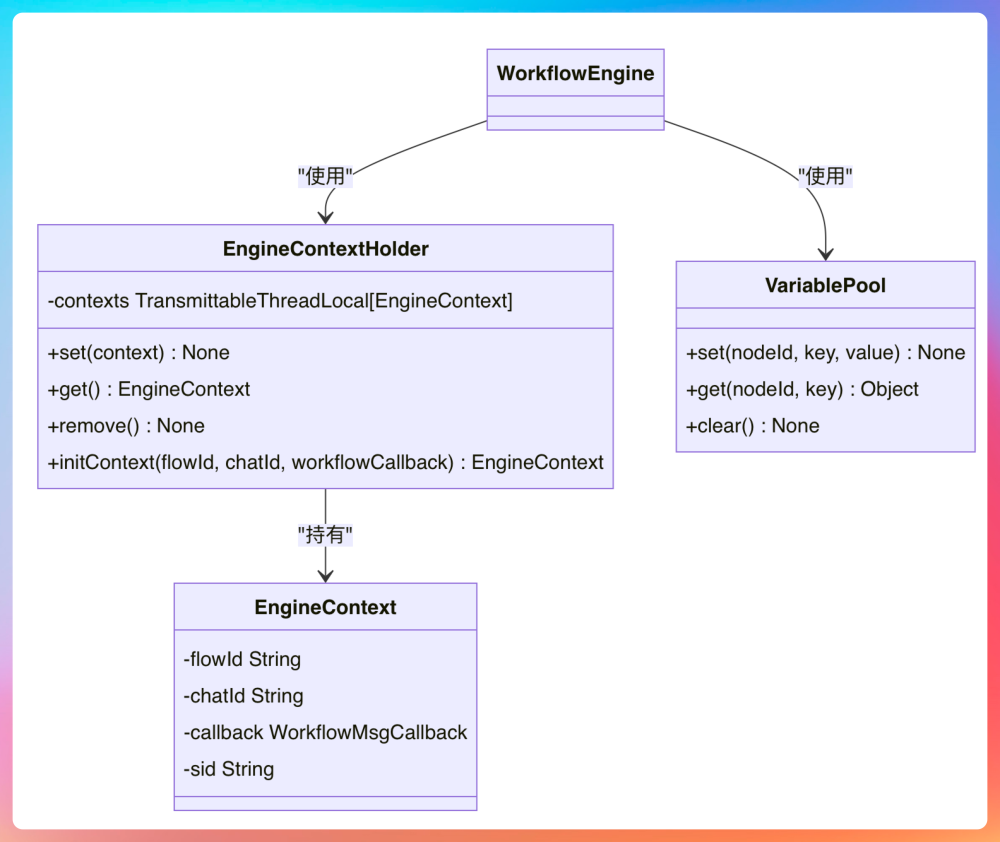
在通知机制上,Java 版工作流引擎采用了观察者模式来解耦执行逻辑与回调逻辑。在WorkflowEngine中,引擎通过WorkflowMsgCallback类实现了StreamCallback接口,当节点开始执行或者执行完成时,引擎会主动触发对应的回调方法,(如onWorkflowStart、onWorkflowEnd)以确保客户端能够实时收到工作流的执行状态。
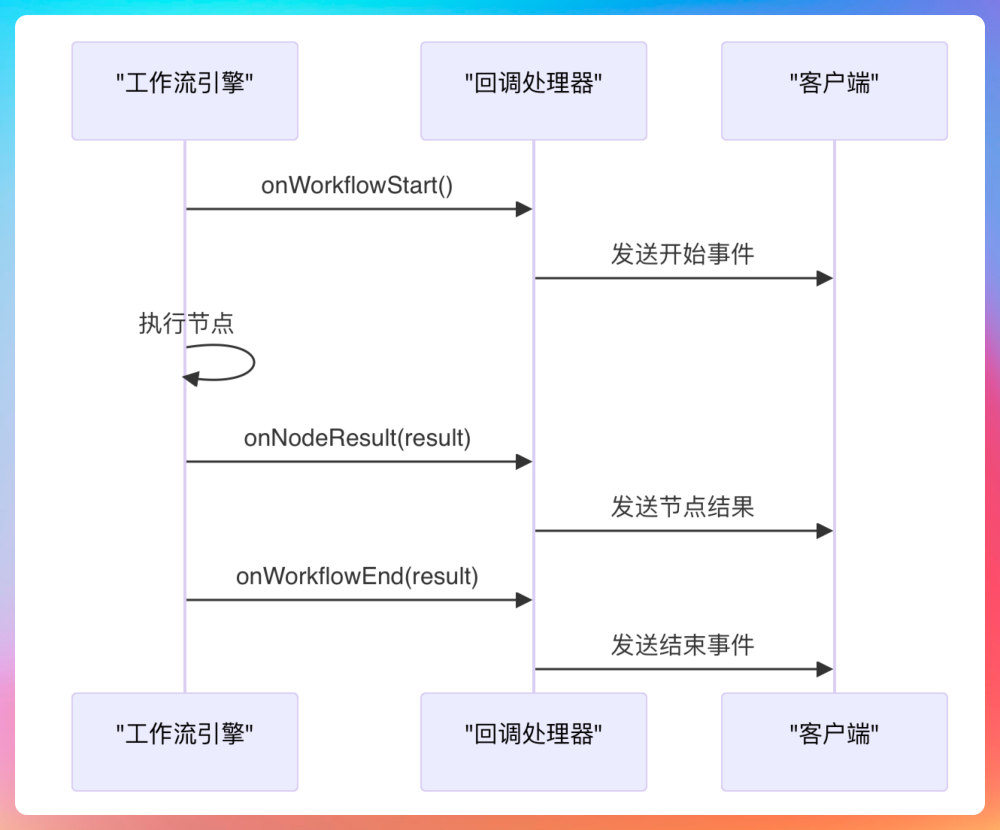
这种设计使得工作流引擎天然支持流式 Hook,非常适合用于后端主动向前端实时推送消息。在前端,用户会看到工作流正在以动态的流水形式一步步往后推进,非常友好。
从更宏观的角度来看,这一整套设计,正好对应了典型的 C4 架构:用户在前端发起交互请求、Hub 负责系统业务、工作流引擎负责执行与状态管理、MySQL、Redis、MinIO 等基础设施负责数据的持久化。
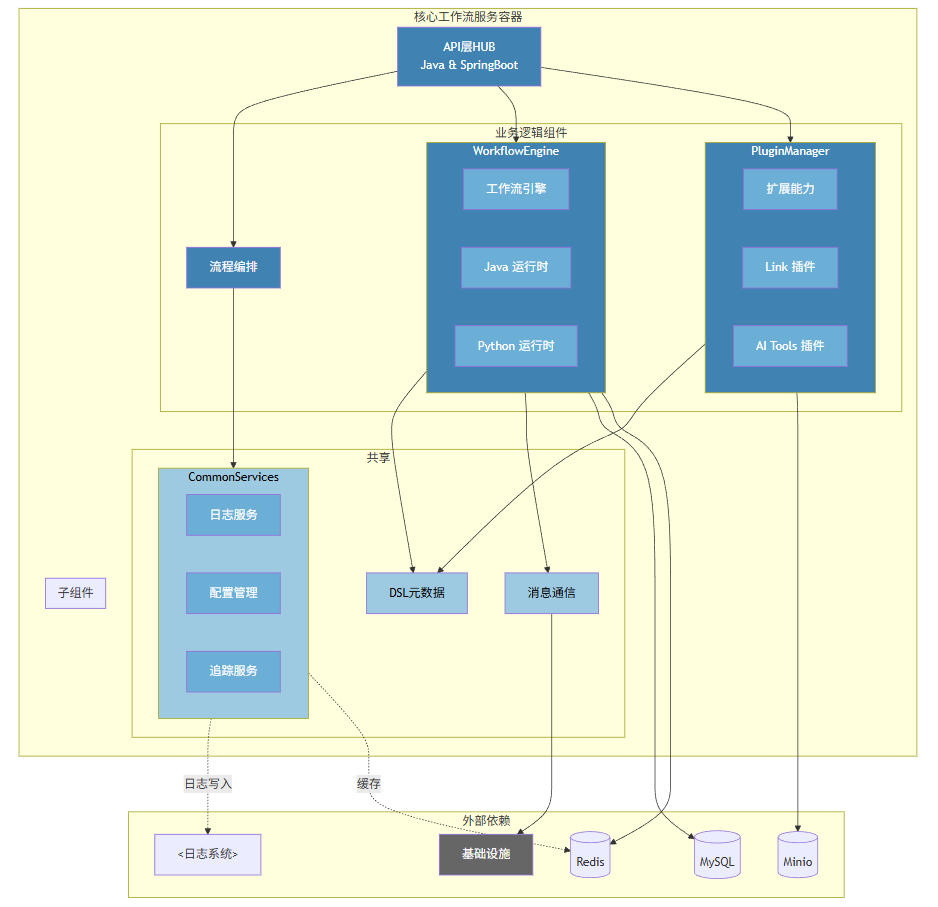
第三阶段,是收尾处理。无论流程是否正常结束,还是异常中断,执行引擎都需要完成状态回传、消息消费以及上下文清理。
public void execute(WorkflowDSL workflowDSL, VariablePool variablePool, Map inputs, StreamCallback callback) throws Exception {
log.info("Starting workflow execution with {} nodes", workflowDSL.getNodes().size());
// 前置校验
verifyWorkflow(workflowDSL);
// 清空上下文变量
variablePool.clear();
// 创建工作流回调处理器
Queue orderStreamResultQ = new ConcurrentLinkedQueue<>();
Queue streamQueue = new ConcurrentLinkedQueue<>();
Node endNode = workflowDSL.getNodes().stream().filter(s -> s.getNodeType() == NodeTypeEnum.END).findFirst().get();
String sid = FlowUtil.genWorkflowId(workflowDSL.getFlowId());
WorkflowStreamCallback workflowCallback = new WorkflowStreamCallback(
sid,
callback,
Objects.equals(endNode.getData().getNodeParam().get("outputMode"), 1) ? EndNodeOutputModeEnum.VARIABLE_MODE : EndNodeOutputModeEnum.DIRECT_MODE,
streamQueue,
orderStreamResultQ
);
// 初始化上下文
EngineContextHolder.initContext(workflowDSL.getFlowId(), workflowDSL.getUuid(), workflowCallback);
// 发送工作流开始事件
workflowCallback.onSparkflowStart();
try {
// 构建从起始节点开始的执行链...企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

19人已点赞
热门评论
46 条评论
回复