


Redis/MinIO/MySQL/PostgreSQL面试题预测与解析
1. 工作流数据是存在哪里的?为什么选择 PostgreSQL?
考察点:数据库选型
参考答案:
Python 版工作流引擎的数据存在 PostgreSQL 里,包括流程定义、执行记录、节点状态、变量快照这些。
追问 1:为什么选 PostgreSQL:
第一,JSON 支持好:工作流 DSL 是 JSON 格式,PostgreSQL 有 jsonb 类型,可以直接存储和查询
-- 查询包含某个节点类型的工作流
SELECT * FROM workflow WHERE dsl::jsonb @> '{"nodeType": "LLM"}';
第二,支持向量扩展,后续做 RAG 可以用 pgvector。
-- 向量相似度搜索
SELECT * FROM documents ORDER BY embedding query_vector LIMIT 10;
表结构示例:
CREATE TABLE workflow (
id BIGSERIAL PRIMARY KEY,
name VARCHAR(100),
dsl JSONB, -- 工作流定义
status VARCHAR(20),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
参考答案版本 2:
主要有两个考虑。
第一是 JSON 支持更好。工作流的数据结构天然是嵌套的,节点定义、边的连接关系、节点参数配置,都是复杂的 JSON 结构。PostgreSQL 的 JSONB 类型是真正的二进制存储,可以建索引、可以做部分更新、查询性能也好。MySQL 的 JSON 类型相对弱一些,底层还是 TEXT。工作流引擎经常要查询"某个节点的配置"或者"输出里包含某个字段的执行记录",JSONB 的查询能力在这种场景下很有用。
第二是 Python 生态的适配。工作流引擎是 Python 写的,用 SQLAlchemy 做 ORM。SQLAlchemy 对 PostgreSQL 的支持是最完整的,很多高级特性比如数组类型、JSONB 操作、UPSERT 语法,都有原生支持。
2. Redis 在项目中是怎么用的?缓存了哪些数据?
考察点:缓存设计
参考答案:
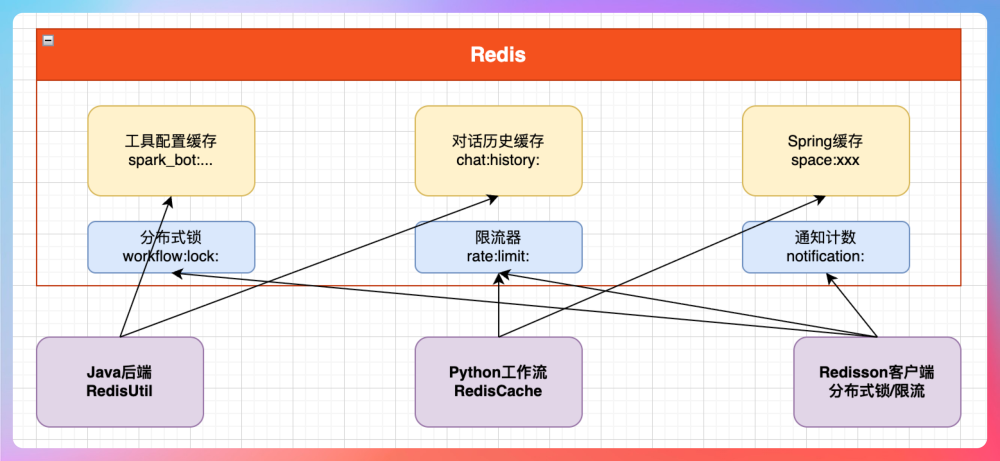
第一个用途是节点间的数据传递。并行分支场景下,多个节点可能跑在不同的线程甚至不同的进程里,变量池在内存里没法共享。我们把需要跨节点传递的数据写到 Redis,用 workflow_id + node_id 作为 key,下游节点从 Redis 里读。执行完之后设个过期时间自动清理,不用手动删。
第二个用途是分布式锁。并行分支的时候,多个上游节点同时完成,可能同时去更新下游节点的状态。为了避免重复执行,需要加锁。单机环境用 synchronized 就行,但如果工作流引擎是多实例部署的,就得用 Redis 的分布式锁。
第三个用途是会话缓存。用户登录之后的 session 信息、token 信息存在 Redis 里。这样后端服务可以无状态部署。token 刷新、强制下线这些操作也方便,改一下 Redis 里的数据就行。
第四个用途是热点数据缓存。工具的 Schema 信息查询频率很高,每次执行插件节点都要查一次。这些数据变化不频繁但访问量大,适合放 Redis。第一次查数据库,然后缓存到 Redis,后续直接读缓存。
第五个用途是限流计数。调用第三方 API 一般都有频率限制,比如每秒最多 10 次。我们用 Redis 的 INCR 命令做计数,key 是 tool_id + 当前秒的时间戳,每次调用前检查计数有没有超限。超限就等一下或者返回错误。这种滑动窗口的限流用 Redis 实现很方便。
有一点要注意的是缓存和数据库的一致性。我们用的是 Cache Aside 模式:读的时候先查缓存,没有再查数据库然后写缓存;写的时候先更新数据库,再删除缓存。用删除不用更新,可以避免并发写导致的数据不一致。
参考答案版本 2
第一,缓存插件的认证信息,避免频繁查询数据库。插件配置很少变化,但每次工作流执行都要读取,通过缓存将数据库查询从每秒几十次次降到几乎为零。
public class RedisService {
private static final String CONFIG_KEY_PREFIX = "spark_bot:tool_config:";
public Map getToolConfig(String toolId, String version, String appId) {
String key = CONFIG_KEY_PREFIX + toolId + ":" + version;
// 例如:spark_bot:tool_config:tool@8b2262bef821000:V1.0
// 1. 先查 Redis
Map config = (Map) redisTemplate.opsForValue().get(key);
if (config == null) {
// 2. Redis 没有,查数据库
config = getToolConfigFromDatabase(toolId, version, appId);
if (config != null) {
// 3. 回写 Redis,TTL = 3600秒(1小时)
setToolConfig(toolId, version, config, 3600);
}
}
return config;
}
}
第二,Python 版的工作流引擎中使用了 Redis 的 List 来缓存对话历史。
class RedisCache(BaseCacheService):
def __init__(self, addr: str, password: str, expiration_time: int = 60 * 60):
if model == RedisModel.CLUSTER:
self._client = self.init_redis_cluster(addr, password)
else:
self._client = self.init_redis(addr, password)
self.expiration_time = expiration_time # 默认 3600 秒
# 存储对话历史(使用 List)
def lpush(self, key: str, value: str) -> None:
"""
Left push to list (LPUSH command)
"""
self._client.lpush(key, value)
self._client.expire(key, self.expiration_time)
Java 版使用了 guava 来缓存。
public class LlmChatHistory {
// Key: "{chatId}:{nodeId}"
// Value: 最多保存10条历史记录的队列
private static final LoadingCache> chatHistoryCache =
CacheBuilder.newBuilder()
.maximumSize(10000) // 最大缓存10000个会话
.expireAfterWrite(30, TimeUnit.MINUTES) // 30分钟后过期
.build(CacheLoader.from(LlmChatHistory::createChatHistoryQueue));
// 数据结构
public record ChatItem(
String chatId,
String nodeId,
List userInputs, // 用户输入
List llmThinking, // LLM推理过程
List llmResponses // LLM回复
) {}
// 添加消息
public static void addMessage(String chatId, String nodeId, MsgTypeEnum role, String content) {
String key = chatId + ":" + nodeId;
// 例如:workflow_12345:node-llm::001
ChatMessage message = new ChatMessage(role, content);
ConcurrentLinkedQueue queue = chatHistoryCache.getUnchecked(key);
ChatItem currentItem = getCurrent...企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

3人已点赞
热门评论
12 条评论
回复