


✅Agent&Skills面试题预测,最新AI八股,最新Agent八股
1. 什么是 AI Agent?和普通的 LLM 调用有什么区别?
考察点:Agent 概念
参考答案:
普通的 LLM 调用就是"一问一答":你给它一个问题,它给你一个回答,完事。
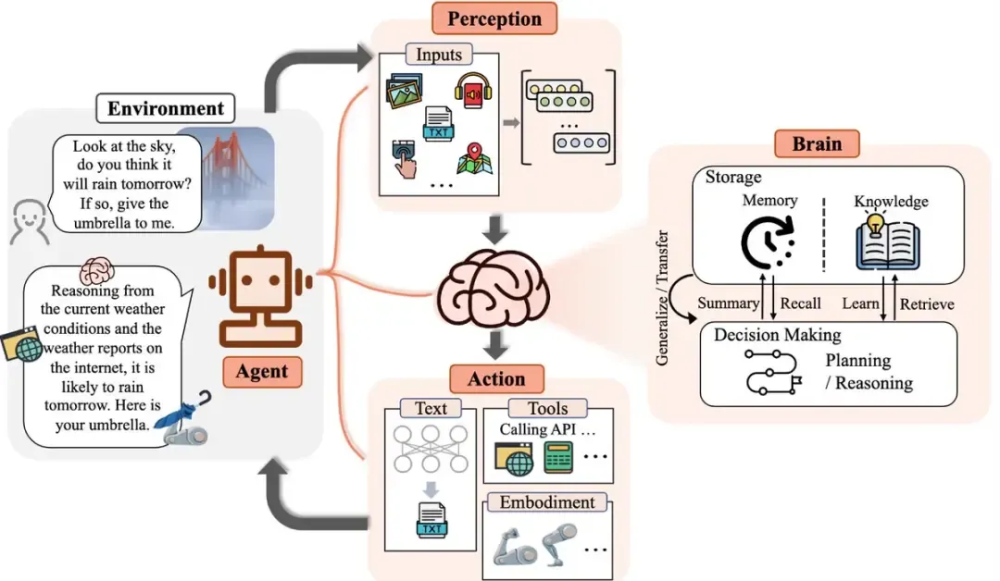
AI Agent 是让大模型能够"自主行动":它不只是回答问题,还能规划任务、使用工具、循环思考,直到完成目标。
核心区别:
| 特性 | 普通 LLM 调用 | AI Agent |
|---|---|---|
| 交互方式 | 单轮问答 | 多轮自主循环 |
| 工具使用 | 不能 | 可以调用 API、搜索、执行代码 |
| 规划能力 | 没有 | 能分解任务、制定计划 |
| 记忆 | 只有当前上下文 | 可以有长期记忆 |
举个例子:
普通 LLM:
用户:今天北京天气怎么样? LLM:抱歉,我无法获取实时天气信息。
AI Agent:
用户:今天北京天气怎么样?
Agent:(思考)我需要查天气 → (调用天气 API)→ (得到结果)
Agent:今天北京晴,气温 25°C,适合户外活动。
我们的 PaiFlow 本质上就是一个"可配置的 Agent",用户通过编排节点来定义 Agent 的行为逻辑。
参考答案版本 2:
普通的 LLM 调用,说白了就是"一问一答"。你给它一段 prompt,它返回一段文本,完事。它像一个很聪明的"应答机器"——你问什么它答什么,但它不会主动去做任何事情,也不会跟外部世界交互。比如你问它"今天北京天气怎么样",它只能根据训练数据瞎猜,因为它没法真的去查天气 API。
AI Agent 不一样,它不只是能说,还能"做"。
打个比方,普通 LLM 像是一个被关在屋子里的聪明人,你递纸条进去问问题,他写纸条回答你,但他出不来、也看不到外面的世界。而 AI Agent 像是一个有手有脚的助理,你跟他说"帮我订一张明天去上海的机票",他会自己去查航班、比较价格、帮你下单、付款,最后告诉你"搞定了"。
从技术上说,Agent 比普通 LLM 多了几个核心能力:
第一是工具调用。Agent 能使用外部工具,比如搜索引擎、数据库、API。LLM 本身只会生成文本,但 Agent 框架会解析 LLM 的输出,识别出"它想调用某个工具",然后真的去调用,把结果再喂回给 LLM。这就是 Function Calling 或者 Tool Use。
第二是规划能力。面对一个复杂任务,Agent 会把它拆解成多个步骤,然后一步步执行。比如生成播客,它会规划:先理解用户给的主题 → 生成对话脚本 → 调用 TTS 合成语音 → 拼接音频。这个过程不是一次 LLM 调用能完成的,需要多轮交互和决策。
第三是记忆。普通 LLM 调用是无状态的,上一轮对话说了什么,下一轮它就忘了(除非你把历史都塞进 prompt)。Agent 可以有短期记忆(当前任务的上下文)和长期记忆(跨任务的知识积累),这让它能处理更复杂的场景。
第四是自主循环。Agent 不是"调一次就结束",它会根据执行结果来决定下一步做什么。调用工具失败了,可能会换个方式重试;发现信息不够,可能会去搜索更多资料。这种"感知-决策-行动"的循环,是 Agent 的核心特征。
回到 PaiFlow,我们的工作流引擎其实就是一种 Agent 的实现方式。用户通过可视化界面编排一个工作流,里面有 LLM 节点、工具节点、条件分支,这本质上就是在定义一个 Agent 的"行为逻辑"。工作流引擎负责调度执行,就相当于 Agent 的"大脑"在驱动整个流程。
比如播客生成这个场景:用户输入一个主题,工作流先调 LLM 节点生成脚本,再调 TTS 工具节点合成语音,中间还有条件判断(内容是否合规)。这整个流程就是一个 Agent 在工作——它理解了用户意图,规划了执行步骤,调用了外部工具,最终完成了任务。
所以简单总结:LLM 是大脑,Agent 是有手有脚、能干活的完整个体。PaiFlow 做的事情,就是让用户能方便地"组装"出这样一个能干活的 Agent。
参考答案版本3
Chat时代,模型的失败成本很低,说错一句话,用户追问或者纠正就好了,但到了Agent时代,出错的代价就翻着倍的涨。
Agent接管的是整个过程,会自动拆任务、选工具,在你不盯着的时候一直运行,一旦出错,就把事搞砸了。
企业需要一个真正能干活的Agent,自动化流程、研发协作、运营执行、分析决策这些场景。
就像企业的一个数字员工,是操作系统级别的自动执行层,是连接模型、工具和真实世界的核心。
2. ReAct 范式是什么?你在 AgentNode 中是怎么实现的?
考察点:ReAct 模式
参考答案:
ReAct 是 "Reasoning + Acting" 的缩写,是一种让大模型能够"边思考边行动"的范式。
核心循环:
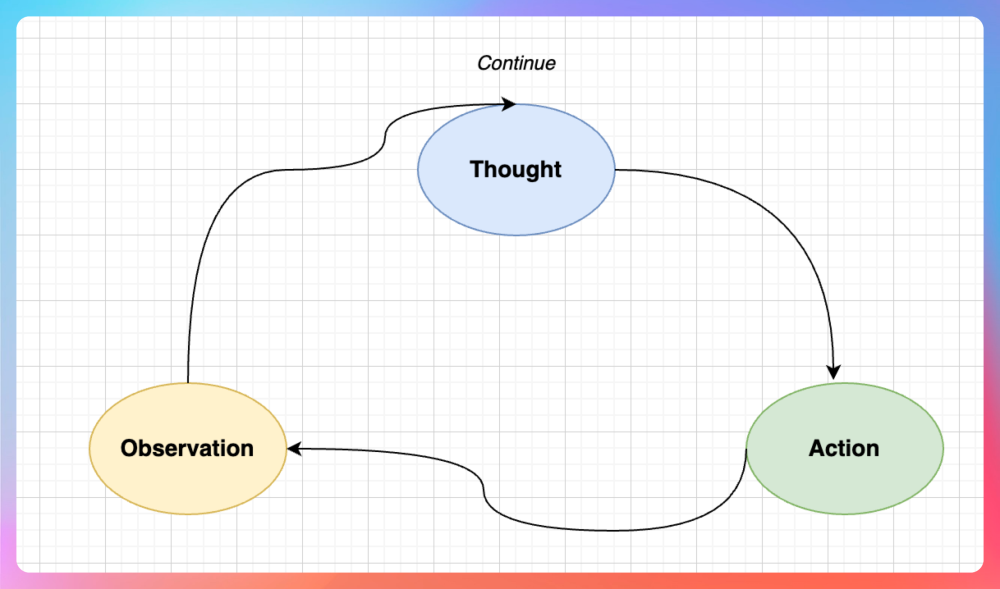
举例:
问题:帮我查一下特斯拉的股价,然后算一下买100股要多少钱
Thought: 我需要先查特斯拉的当前股价
Action: 调用股票API查询 TSLA
Observation: 特斯拉当前股价 $250
Thought: 股价是250美元,100股就是250×100
Action: 计算 250 * 100
Observation: 25000
Thought: 我已经得到了答案
Final Answer: 买100股特斯拉需要25000美元
在 AgentNode 中的实现:
public class AgentNodeExecutor extends AbstractNodeExecutor {
@Override
protected NodeRunResult executeNode(NodeState state, Map inputs) {
// 1. 把工具描述和用户问题发给大模型
String toolDescription = getToolDescription(pluginId);
String prompt = buildReActPrompt(toolDescription, userQuestion);
// 2. 大模型决定调用哪个工具、传什么参数
LlmResponse response = llm.call(prompt);
ToolCall toolCall = parseToolCall(response);
// 3. 执行工具调用
Object result = linkClient.execute(toolCall.toolId, toolCall.params);
// 4. 把结果返回给大模型,生成最终答案
String finalAnswer = llm.call(buildObservationPrompt(result));
return NodeRunResult.success(finalAnswer);
}
}
参考答案版本 2:
ReAct 全称是 Reasoning + Acting,是 2022 年 Google 和普林斯顿提出的一个 Agent 设计范式。核心思想是让 LLM 交替进行"思考"和"行动",而不是想完再做或者做完再想。
或者:ReAct 范式是一种让大语言模型以交互方式解决复杂任务的设计模式。它将**思维链(Chain of Thought, CoT)与特定任务的操作(Action)**相结合,使 Agent 能够像人类一样思考、执行并观察结果。
传统的 LLM 调用是"一锤子买卖"——给它一个问题,它一口气输出答案。但复杂任务不是这样的,需要边想边做。比如用户问"沉默王二是谁,他有哪些作品",LLM 得先想"我需要查沉默王二是谁",然后调用搜索引擎,拿到结果后再想"他是一个技术博主,GitHub 上星标 16000+的二哥的 Java 进阶之路作者,他是一名原创博主,在业界很有名",最后输出建议。

这个思考-行动-观察-再思考的循环,就是 ReAct。
DeepSeek 在 2024 年至 2026 年期间对 **ReAct **范式的普及和优化做出了重要贡献:2025 年初发布的 DeepSeek-R1 系列模型,通过大规模强化学习(RL)显著增强了模型的自主推理(Thinking)能力。
DeepSeek-V3.2 等版本中,DeepSeek 专门针对“Agentic”任务(即 Agent 场景)进行了优化,使其在调用外部工具(Action)和自我检查(Reasoning)方面的表现达到了行业领先水平。
class AgentNode(BaseNode):
instruction: Instruction # 包含 reasoning、answer、query 三个模板
maxLoopCount: int = Field(...) # 最大循环次数
plugin: AgentNodePlugin # 包含 tools、knowledge 等工具
在我们的 AgentNode 里,instruction 里有三部分:reasoning(推理指令)、answer(回答指令)、query(查询指令)。这就是 ReAct 的核心——我们通过 prompt 告诉 LLM "先推理你需要做什么,然后决定调用哪个工具,最后根据结果给出答案"。
maxLoopCount 控制最大循环次数,防止 Agent 陷入死循环。因为 ReAct 是个迭代过程,LLM 可能会反复"思考-行动"好几轮,我们需要设个上限。
在流式响应处理里,可以看到我们分别提取了 content(最终回答)、reasoning_content(推理过程)和 tool_calls(工具调用):
content = choices[0].get("delta", {}).get("content", "")
reasoning_content = choices[0].get("delta", {}).get("reasoning_content", "")
tool_calls = choices[0].get("delta", {}).get("tool_calls", [])
这就是 ReAct 循环的输出——LLM 会先输出推理内容("我需要查天气"),然后输出工具调用(调用天气 API),最后输出最终答案。
所以总结一下:ReAct 是让 AI 边想边做的范式,在我们项目中体现为 AgentNode 的多轮循环执行。AgentNode 负责"想"和"决策",而 PluginNode 负责执行具体的工具调用。
3. 什么是 RAG(检索增强生成)?为什么需要 RAG?
考察点:RAG 理解
参考答案:
RAG = Retrieval Augmented Generation,检索增强生成。
核心思路:大模型的知识是训练时固定的,可能过时或者不全。RAG 就是在调用大模型前,先从知识库里检索相关内容,塞到 Prompt 里,让大模型"看着资料回答"。
为什么需要 RAG?
知识更新:大模型不知道最新的信息,但知识库可以随时更新
私有数据:公司内部文档、产品手册,大模型没见过
减少幻觉:有了参考资料,大模型不容易编造
可解释:可以告诉用户"这个答案来自 XX 文档"
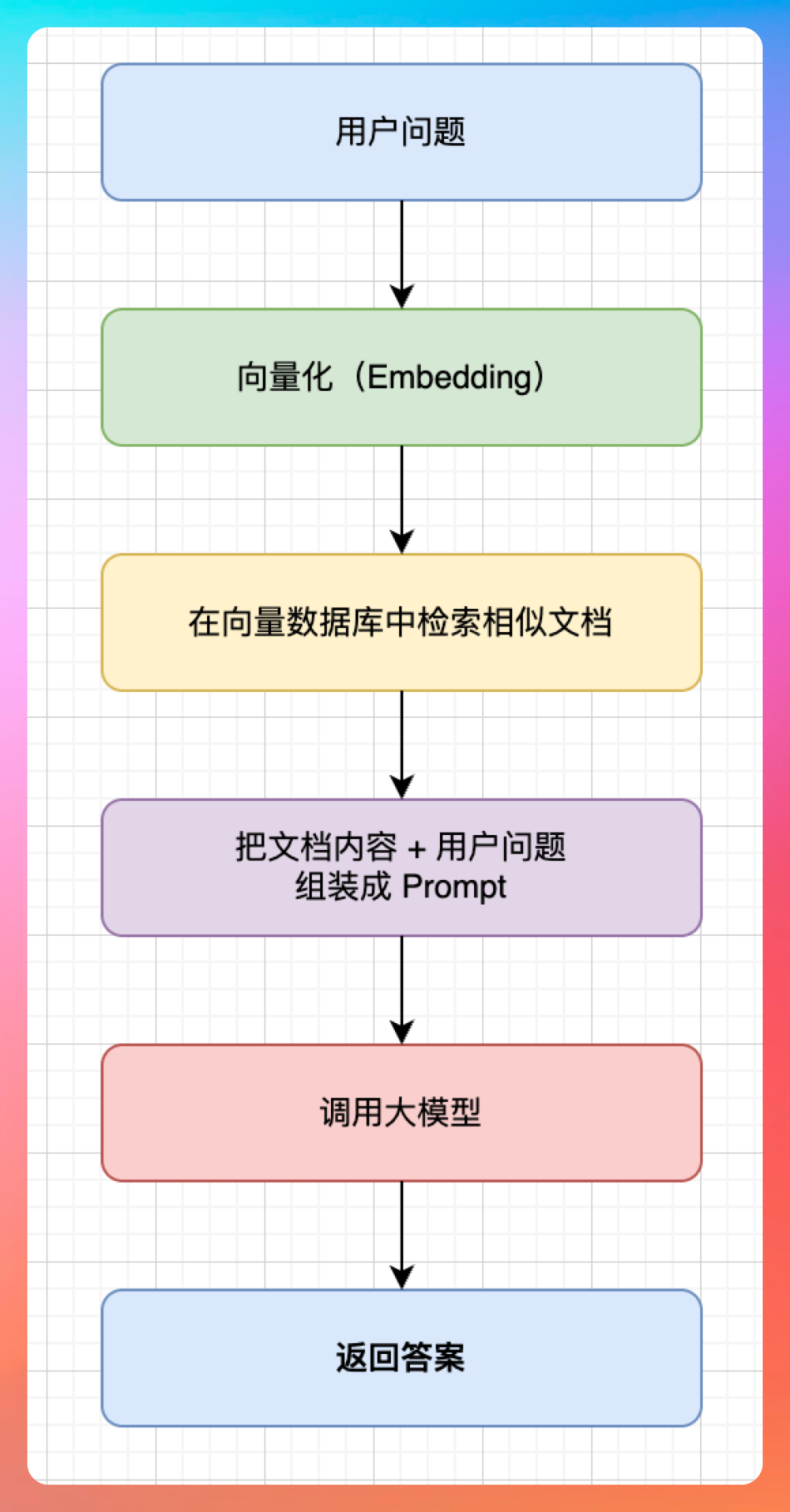
RAG 流程:
Prompt 模板:
根据以下文档回答用户问题,如果文档中没有相关信息,请回答"我不知道"。
参考文档: {{检索到的文档内容}}
用户问题:{{用户问题}}
参考答案版本 2
RAG 这个概念,用大白话说就是:让 AI 在回答问题之前,先去查资料。
为什么需要这个?因为 LLM 有几个天生的"痛点"。
第一是知识截止日期。LLM 的知识是训练时灌进去的,训练完就定格了。你问它"2026 年诺贝尔奖得主是谁",如果它是 2025 年训练的,它就不知道,只能瞎猜。
第二是幻觉问题。LLM 本质上是"生成"文本,不是"检索"事实。它会非常自信地编造不存在的东西——一本不存在的书、一个虚假的法律条文、一个错误的 API 用法。用户问它公司内部的规章制度,它可能编一套看起来很像但完全是假的东西出来。
第三是领域知识缺失。通用 LLM 对公开知识了解很多,但对企业内部知识一无所知——公司内部的产品文档、内部流程、客户数据,它都没见过,自然答不好。
RAG 的流程大概是这样的:
用户问一个问题 → 系统先把问题转成向量(Embedding)→ 去知识库里检索最相关的文档片段 → 把这些片段塞进 prompt 里 → LLM 基于这些"参考资料"生成回答
打个比方,普通 LLM 像一个博学但记忆可能出错的人,你问他问题他全凭脑子里的印象回答。RAG 就像让他先去图书馆查资料,拿着资料再回答你——答案更准确,还能告诉你"这个信息来自《XXX手册》第三章"。
在 PaiFlow 里,我们有 Knowledge 节点专门做这个事。
class Knowledge(BaseModel):
...企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

15人已点赞
热门评论
8 条评论
回复