


✅SSE面试题预测:SSE 与WebSocket区别详解
1. 什么是 SSE(Server-Sent Events)?和 WebSocket 有什么区别?
考察点:协议理解
参考答案:
SSE 是一种服务器向客户端单向推送数据的技术,基于 HTTP 协议。和 WebSocket 的主要区别:
| 对比项 | SSE | WebSocket |
|---|---|---|
| 通信方向 | 单向(服务端→客户端) | 双向 |
| 协议 | HTTP | 独立的 WebSocket 协议 |
| 连接 | 普通 HTTP 连接 | 需要协议升级握手 |
| 数据格式 | 纯文本 | 文本或二进制 |
| 断线重连 | 浏览器自动重连 | 需要自己实现 |
| 兼容性 | 几乎所有浏览器 | 部分老浏览器不支持 |
我们选择 SSE 的原因有三个,第一个是场景匹配:大模型输出是服务端单向推给前端,不需要双向通信;第二个是简单:不需要额外的协议,nginx 也好配置。
SSE 的数据格式:
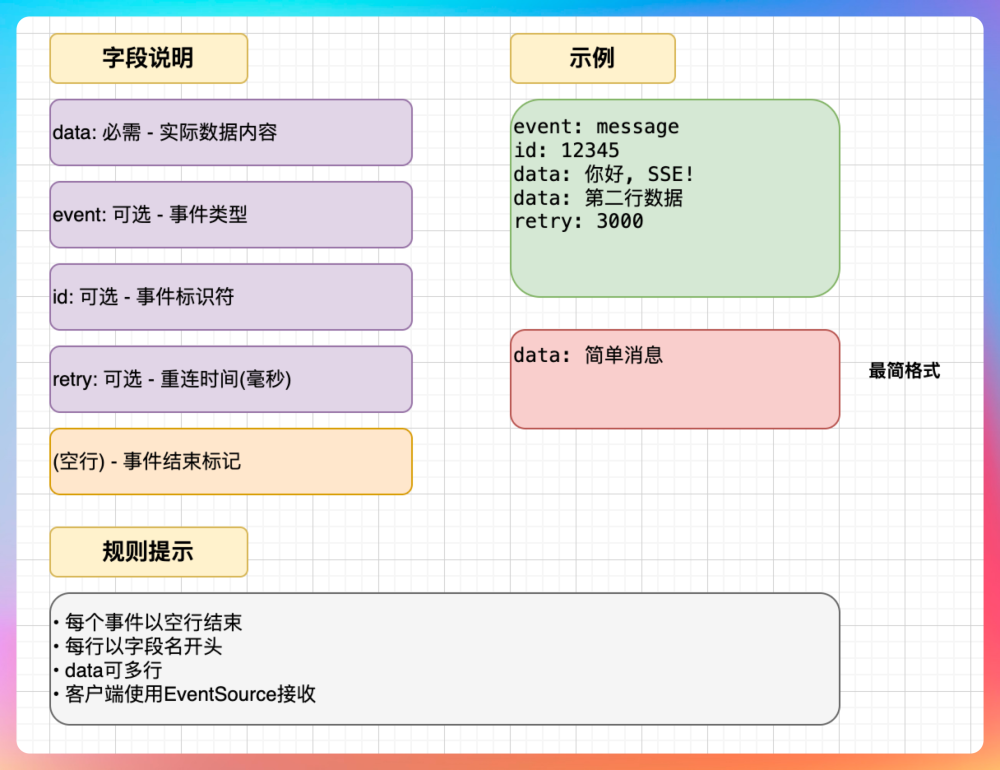
2. 你是怎么用 Spring Boot 实现 SSE 接口的?
考察点:SseEmitter 使用
参考答案:
Spring Boot 提供了 SseEmitter 类来实现 SSE。基本用法:
@GetMapping(value = "/stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public SseEmitter stream() {
SseEmitter emitter = new SseEmitter(60000L); // 60秒超时
// 异步执行,发送数据
executor.execute(() -> {
try {
for (int i = 0; i {
log.info("SSE connection completed");
cleanup(request.getSessionId());
});
// 超时回调
emitter.onTimeout(() -> {
log.warn("SSE connection timeout");
emitter.complete();
});
// 异常回调
emitter.onError(e -> {
log.error("SSE error", e);
cleanup(request.getSessionId());
});
第四,有些代理服务器会断开长时间没数据的连接,所以要定期发心跳,每 15 秒发一个注释消息(comment 不会被前端 onmessage 接收),保持连接活跃。
ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1);
scheduler.scheduleAtFixedRate(() -> {
try {
emitter.send(SseEmitter.event().comment("heartbeat"));
} catch (IOException e) {
scheduler.shutdown();
}
}, 15, 15, TimeUnit.SECONDS);
在 PaiFlow 里,Hub 服务接收前端请求,通过 HTTP 调用 Workflow 引擎,Workflow 引擎返回的也是 SSE 流。Hub 层做的事情是:从 Workflow 读一个 chunk,立刻转发给前端一个 chunk,实现端到端的流式体验。
// 转发上游的 SSE 流
webClient.post()
.uri(workflowUrl)
.bodyValue(request)
.retrieve()
.bodyToFlux(String.class)
.subscribe(
chunk -> emitter.send(chunk),
error -> emitter.completeWithError(error),
() -> emitter.complete()
);
3. SseEmitter 的超时时间怎么设置?如果连接断开了怎么处理?
考察点:超时处理、异常处理
参考答案:
我们设置的是 5 分钟,因为有些工作流执行时间比较长。
// 构造时设置,单位毫秒
SseEmitter emitter = new SseEmitter(60000L); // 60秒
// 或者设置为 0 表示不超时(不推荐,会占用连接)
SseEmitter emitter = new SseEmitter(0L);
连接断开处理:
SseEmitter emitter = new SseEmitter(300000L);
// 客户端断开连接时的回调
emitter.onCompletion(() -> {
log.info("SSE 连接正常结束");
// 清理资源
});
// 超时回调
emitter.onTimeout(() -> {
log.warn("SSE 连接超时");
emitter.complete();
});
// 错误回调
emitter.onError(ex -> {
log.error("SSE 连接异常", ex);
// 停止工作流执行
});
在发送数据时也要做异常处理:
try {
emitter.send(data);
} catch (IOException e) {
// 客户端已断开,停止发送
log.warn("客户端已断开连接");
}
参考答案版本 2:
我们做 LLM 流式输出,生成一篇长文章可能要两三分钟,但也不能设太长。我们一般设 5 到 10 分钟,既能覆盖大部分正常请求,又不会让异常连接占用太久资源。
连接断开有几种情况,每种都要处理。
第一种是正常完成,数据发完了,服务端主动调用 emitter.complete() 关闭连接。这时候会触发 onCompletion 回调。
第二种是超时,超过了设置的时间还没完成,会触发 onTimeout 回调。这时候应该主动关闭连接,清理资源。
第三种是客户端主动断开,这是最常见的情况——用户刷新页面、关闭浏览器标签页、或者网络波动。这时候再往 emitter 里发数据会抛 IOException,会触发 onError 回调。
处理这些情况的思路是:三个回调都要注册,都要做资源清理。
emitter.onCompletion(() -> cleanupResources(sessionId));
emitter.onTimeout(() -> cleanupResources(sessionId));
emitter.onError(e -> cleanupResources(sessionId));
但光注册回调还不够,还有一个关键问题:异步线程可能还在往 emitter 里发数据,这时候连接已经断了,会报错。
所以我会用一个 AtomicBoolean 标记位来记录连接状态。三个回调里都把它设成 false,发送数据之前先检查这个标记,如果已经断开了就不发了,直接停止后续逻辑。
AtomicBoolean connected = new AtomicBoolean(true);
// 回调里标记断开
emitter.onError(e -> {
connected.set(false);
cleanupResources(sessionId);
});
// 发送前检查
if (connected.get()) {
emitter.send(data);
}
还有一点很重要:客户端断开后,要通知上游停止工作。
// 用原子变量标记连接状态
AtomicBoolean connected = new AtomicBoolean(true);
emitter.onCompletion(() -> {
connected.set(false);
cleanupResources(sessionId);
});
emitter.onTimeout(() -> {
connected.set(false);
cleanupResources(sessionId);
});
emitter.onError(e -> {
connected.set(false);
cleanupResources(sessionId);
});
// 异步发送数据时,先检查连接状态
CompletableFuture.runAsync(() -> {
try {
workflowService.executeStream(request, chunk -> {
// 发送前检查连接是否还在
if (!connected.get()) {
throw new ClientDisconnectedException("客户端已断开");
}
try {
emitter.send(SseEmitter.event()
.id(String.valueOf(System.currentTimeMillis()))
.name("message")
.data(chunk, MediaType.APPLICATION_JSON));
} catch (IOException e) {
connected.set(false);
throw new ClientDisconnectedException("发送失败", e);
}
});
// 正常完成
if (connected.get()) {
emitter.complete();
}
} catch (ClientDisconnectedException e) {
log.info("客户端断开,停止生成: {}", sessionId);
// 关键:通知上游停止工作
workflowService.cancelExecution(sessionId);
} catch (Exception e) {
if (connected.get()) {
emitter.completeWithError(e);
}
}
});
比如用户问了一个问题,LLM 正在生成回答,用户突然关掉页面不想要了。如果不做处理,LLM 还会傻傻地继续生成,白白消耗算力。检测到客户端断开后,我会调用工作流引擎的取消接口,让它停止当前任务。
最后说一下心跳保活。
有些代理服务器或者负载均衡器,如果一段时间没有数据传输,会认为连接已经死了,主动断开。LLM 生成比较慢的时候,可能十几秒才出一个字,这段时间连接可能被中间件掐掉。
解决办法是定期发心跳。SSE 协议支持发送注释消息,客户端的 onmessage 不会收到,但能保持连接活跃。我一般每 15 到 20 秒发一次心跳,确保连接不会被中间件误杀。
// 创建心跳定时任务
ScheduledExecutorService scheduler = Executors.newSingleThreadScheduledExecutor();
ScheduledFuture heartbeat = scheduler.scheduleAtFixedRate(() -> {
if (connected.get()) {
try {
// 发送注释消息作为心跳,客户端不会收到
emitter.send(SseEmitter.event().comment("heartbeat"));
} catch (IOException e) {
connected.set(false);
}
}
}, 15, 15, TimeUnit.SECONDS); // 每15秒发一次
// 连接关闭时取消心跳任务
emitter.onCompletion(() -> {
heartbeat.cancel(true);
connected.set(false);
cleanupResources(sessionId);
});
4. 你说"首字响应延迟优化至 200ms 以内",是怎么做到的?
考察点:性能优化
参考答案:
首字响应延迟是指从用户发送请求到看到第一个字的时间。优化的关键是减少各环节的等待时间。
具体做的优化:
1. 流式调用大模型 API,不等大模型全部生成完,而是用流式接口,生成一点返回一点:
chatModel.stream(prompt).subscribe(response -> {
// 有数据就立即推送
callback.onNodeProcess(token);
});
2. 减少节点调度开销,节点执行前的参数解析、日志记录这些操作尽量轻。
3. 连接复用,用 OkHttp 的连接池,避免每次都重新建立 TCP 连接和 SSL 握手。
4. 异步化非关键路径,比如日志落库、metrics 上报这些不影响主流程的操作,异步执行。
测量方式是在关键节点打时间戳:
long start = System.currentTimeMillis();
// 第一个 token 到达
long firstTokenTime = System.currentTimeMillis() - start;
log.info("首字延迟: {}ms", firstTokenTime);
参考答案版本 2:
首字响应延迟,英文叫 Time to First Token(TTFT),就是用户发出问题到看到第一个字的时间。这个指标对用户体验特别重要,哪怕后面生成得再快,如果开头要等两三秒,用户就会觉得"卡"。
我们最初测下来首字延迟大概在 800ms 到 1 秒左右,优化后稳定在 200ms 以内。主要从几个方面入手。
第一,分析延迟瓶颈在哪。首先要知道时间花在哪了。我们在链路上打了埋点,拆解出每个环节的耗时:
用户请求 → 前端处理(~20ms) → 网络传输(~30ms) → Hub接收处理(~50ms)
→ 调用Workflow(~100ms) → Workflow启动执行(~200ms) → 调用LLM(~400ms) → 首字返回
发现大头在三个地方:Hub 到 Workflow 的 HTTP 调用、Workflow 内部启动、LLM 服务响应。
第二,HTTP 连接池复用。每次请求都新建 TCP 连接很慢,三次握手就要几十毫秒。我们用连接池复用已有连接。Hub 调用 Workflow 用的是 WebClient,配置了连接池:
@Configuration
public class WebClientConfig {
@Bean
public WebClient workflowWebClient() {
// 配置连接池
ConnectionProvider provider = ConnectionProvider.builder("workflow-pool")
.maxConnections(100) ...企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

5人已点赞
热门评论
29 条评论
回复