


✅macOS用户如何在本地跑起来PaiFlow Agent项目?
本文会带大家在本地把 PaiFlow 全链路跑起来,完整走一遍从启动依赖到执行工作流的全过程。
我会写得尽量简单,为了让第一次折腾本地环境的同学不至于被一堆 MySQL、MinIO、Redis、Java 项目结构搞到心态爆炸。
默认大家已经把前面基础环境装好了(没装好也别慌,回头补一步就行)。
1.初始化
你可以用脚本一键初始化,也可以手动建库建表,两种方式随你选。
1.1 脚本初始化数据库(推荐)
项目里已经准备好了本地专用的初始化脚本:scripts/init-local-mysql.sh。作用很简单粗暴:自动创建五个模块的数据库,并把基础数据全部塞进去。你只需要输入一次 MySQL 密码,其余的交给脚本搞定。
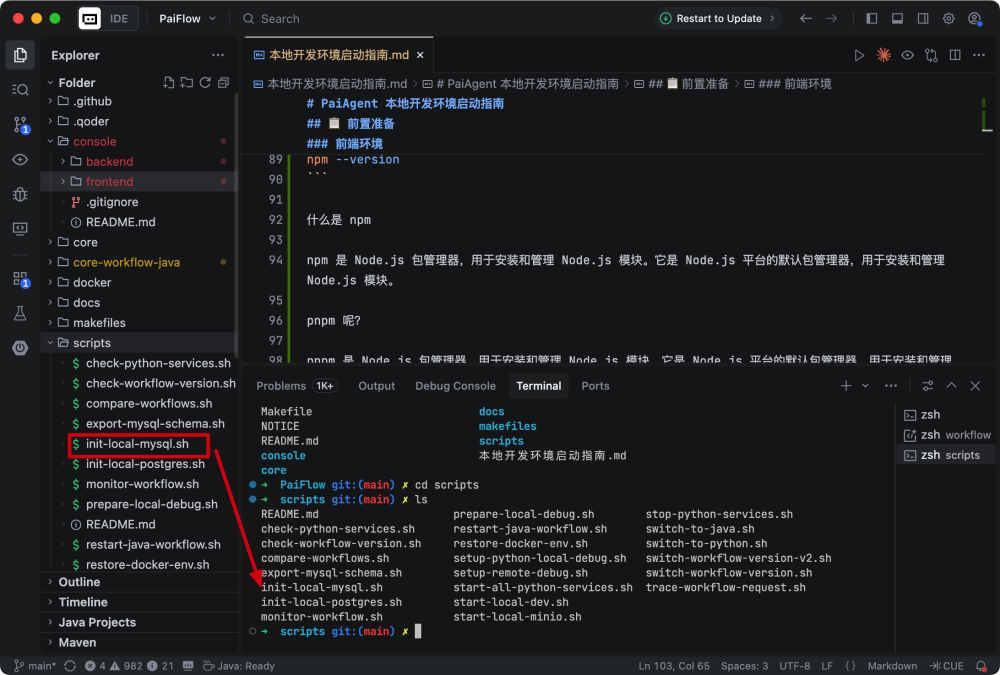
cd scripts
./init-local-mysql.sh
如果你是第一次跑,它会让你输入一次密码,然后自动跑完下面这些动作:
检查 MySQL 是否可用
创建五个库:paiflow-console / paiflow-link / paiflow-workflow / paiflow-agent / paiflow-tenant
执行建表 SQL
导入初始化数据
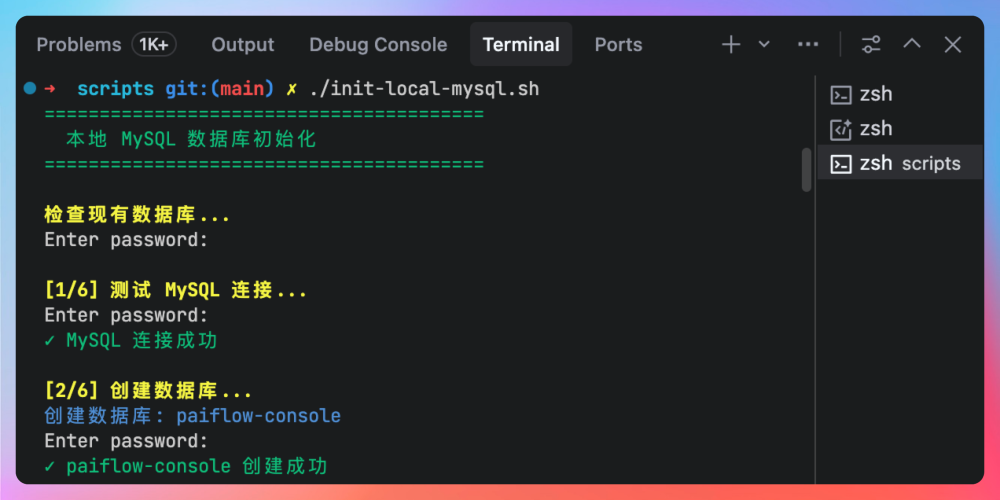
正常情况下,你会看到脚本一行行地打印“创建成功”“初始化完成”等字样,那就说明没问题了。
你可能会疑惑:脚本是不是每次都要跑?
不用。
初始化脚本只需要执行一次——你可以把它理解成“项目第一次开机”。如果你之前已经创建了数据库,想要重新初始化,那么只需要在交互界面键入 1 就可以了。
1.2 手动初始化数据库
如果你比较偏爱可视化工具,Navicat、DBeaver、Sequel Pro,这些都随便选一个,都能完成初始化。手动方式本质上就是两步:建库 → 导入 SQL。
step1: 创建数据库
无论你用哪个图形化工具,最终都要把下面这五个库创建出来:
create database paiflow-console; create database paiflow-link; create database paiflow-workflow; create database paiflow-agent; create database paiflow-tenant;
step2: 导入初始数据
初始化的sql数据,可以在 docker/astronAgent/mysql 下获取
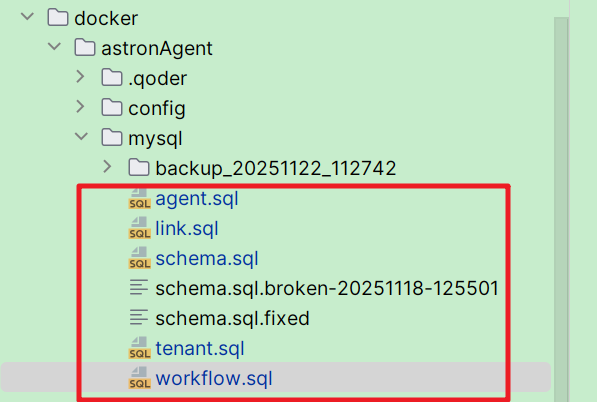
注进去之后你会看到几个关键文件:
schema.sql → 对应 paiflow-console(hub 的主库)
workflow.sql → 对应 paiflow-workflow(Java workflow + Python workflow 共用)
link.sql → 对应 paiflow-link(plugin/link 的库)
agent.sql → 对应 paiflow-agent(Python ...
企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

1人已点赞
热门评论
6 条评论
回复