


PaiFlow架构设计面试题预测:Agent项目是如何设计的
1. 请介绍一下 PaiFlow 这个项目是做什么的?解决了什么问题?
考察点:项目理解、业务价值表达
参考答案:
面试官您好,PaiFlow 是一个 AI 工作流编排平台,简单说就是让用户通过"拖拖拽拽"的方式,把多个 AI 能力串起来,自动完成一些复杂的任务。
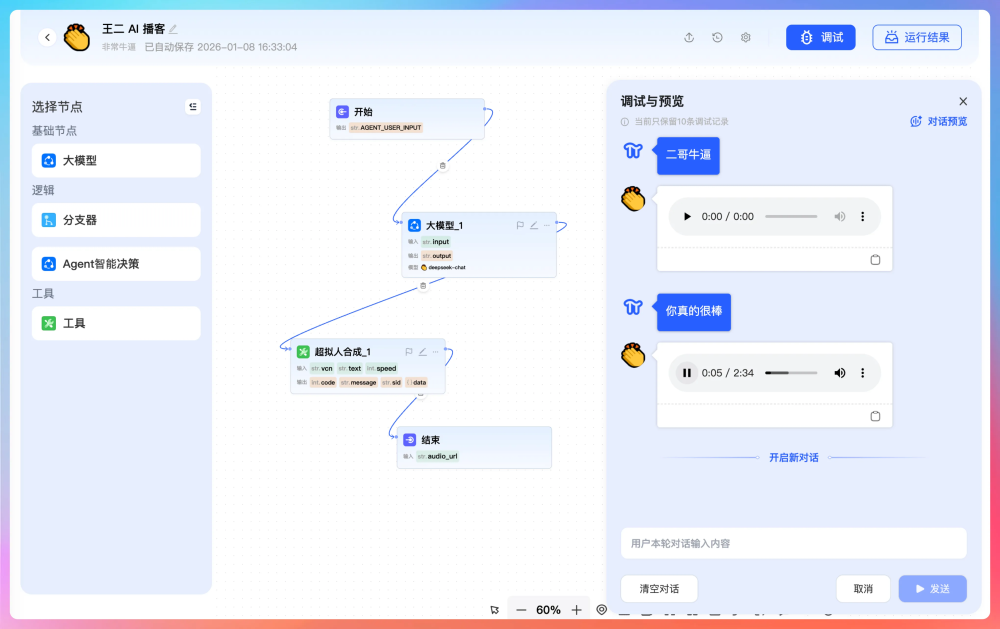
举个具体例子:我们有个"AI 播客生成"的场景。用户只需要输入一段文字,系统会自动调用大模型把它改写成适合口播的风格,然后再调用语音合成服务生成音频。以前这个过程需要人工一步步操作,现在配置好工作流后,一键就能完成。
它解决的核心问题是:降低 AI 应用的开发门槛。业务人员不需要写代码,只要在可视化界面上编排节点,就能快速搭建 AI 应用。
参考答案版本 2
PaiFlow 是一个企业级的 AI 工作流编排平台,能让用户通过可视化拖拽的方式,把大模型、语音合成、各种插件工具串成一条自动化流水线,不用写代码就能构建自己的 AI 应用。类似 n8n、扣子、dify 等平台。
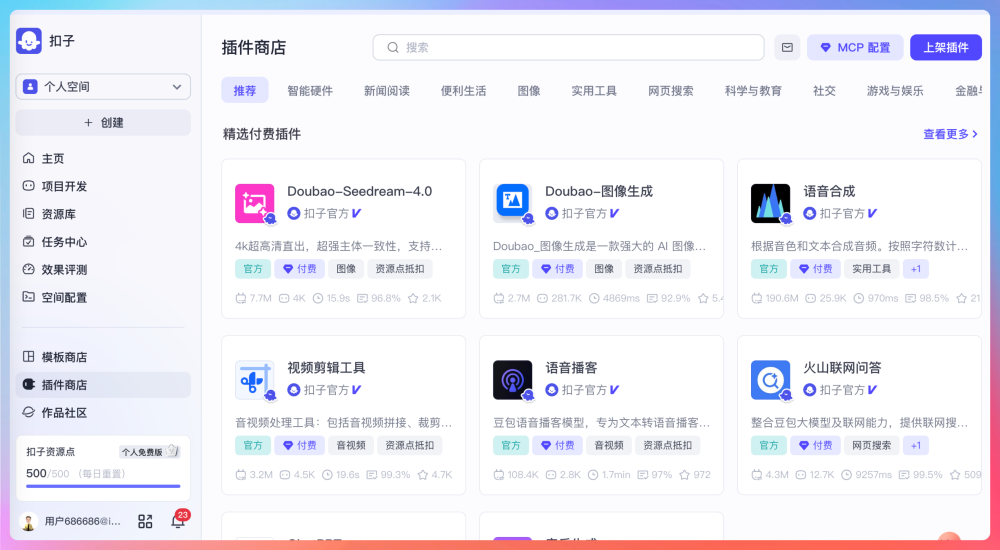
比如我有一篇技术文章,想把它变成播客节目。传统的做法要自己改稿、找工具合成语音、处理存储。而在 PaiFlow 里,画一个流程图,把"大模型改写"和"语音合成"两个节点连起来,输入原文,系统就能自动跑完整个流程,直接输出能播放的音频。
这个项目真正有意思的地方在于架构设计。我们采用了多语言微服务架构,前端 React 负责可视化编排,Spring Boot 做业务中台处理工作流编排,工作流执行可以用 Python 的 FastAPI + 自研引擎,也可以用 Java 版的 SpringAI +LangGraph4J 版本。
我们实现了一套基于 D...
已加入星球,可直接知识星球授权登录
二哥编程星球目前包含:
企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

8人已点赞
热门评论
58 条评论
回复